
MLMD—A Malware-Detecting Antivirus Tool Based on the XGBoost Machine Learning Algorithm

 , , , , , and
, , , , , and
Abstract
:1. Introduction
- Analysis of the success of particular machine learning algorithms, such as extreme gradient boosting (XGBoost), extreme random trees (ET), and others, in their application in the field of malware detection;
- Exploration of the potential of combining static and dynamic analysis of malware samples through Dependency Walker for static analysis and Cuckoo Sandbox for dynamic analysis in machine learning applications for malware detection;
- Automation of malware analysis and classification using a newly designed solution in the form of a software tool;
- Comparison of the proposed software tool with the published theoretical works, as well as with the solutions used in practice, included in the VirusTotal service.
2. Theoretical Background
2.1. Malware Analysis
- Static analysis—analysis of a program without executing it. Basic static analysis looks for static information, such as strings, network addresses, called functions, and executable file header information. Advanced static analysis applies reverse engineering techniques using various special tools [7].
- Dynamic analysis—analysis of a program during execution. It is performed in a secure virtual environment, in which the activities of the executed program are observed; these are then used to deduce the purpose of the program [8]. In a secure environment, registry changes, network activity, function calls, disk file modifications, and so on are observed.
2.2. Malware Detection
- Signature-based detection—the most commonly used malware detection method [9]. Signatures are unique sequences of bytes obtained by malware analysis. These signatures are used to identify a particular piece of malware [8]. Security programs contain a database of signatures of known malware. Whenever a new file is checked, this file is analysed and compared with the database [9]. If the analysed file contains a signature listed in the database, it is highly probable that the file is malicious.
- Behaviour-based detection—during the detection, the behaviour of the program and its activities are examined. Attempts to perform abnormal or unauthorised action could indicate the program is malicious or at least suspicious. Examples of abnormal actions include modifying other files, adding new users to the system, and stopping system security software, to name a few [9].
- Heuristic detection—this means looking for certain features indicating malicious behaviour by using rules and algorithms, either by looking for commands and instructions typical of malware or by monitoring its behaviour and activities during execution, or even—frequently—by a combination of the two [10]. Each activity is then rated in terms of risk, and—if a set threshold is surpassed—preventive action is taken [11].
2.3. Detection Using Machine Learning
2.4. Reference Works
3. Design Methods
- Data acquisition and processing into a suitable form to train the machine learning models;
- Training the models on the training data and finding the best hyperparameters for the particular model;
- Evaluating the models using test data and comparing them.
3.1. Experimental Hardware Environment
- Processor: Intel(R) Core(TM) i5-9500 CPU @ 3.00GHz;
- Memory: 16 GB DDR4;
- Hard drive: Samsung SSD 860 PRO 512GB, Samsung SSD 970 EVO Plus 500GB;
- GPU: NVIDIA GeForce RTX 3060 12 GB.
3.2. Obtaining the Training Samples
3.3. Static Analysis of the Samples
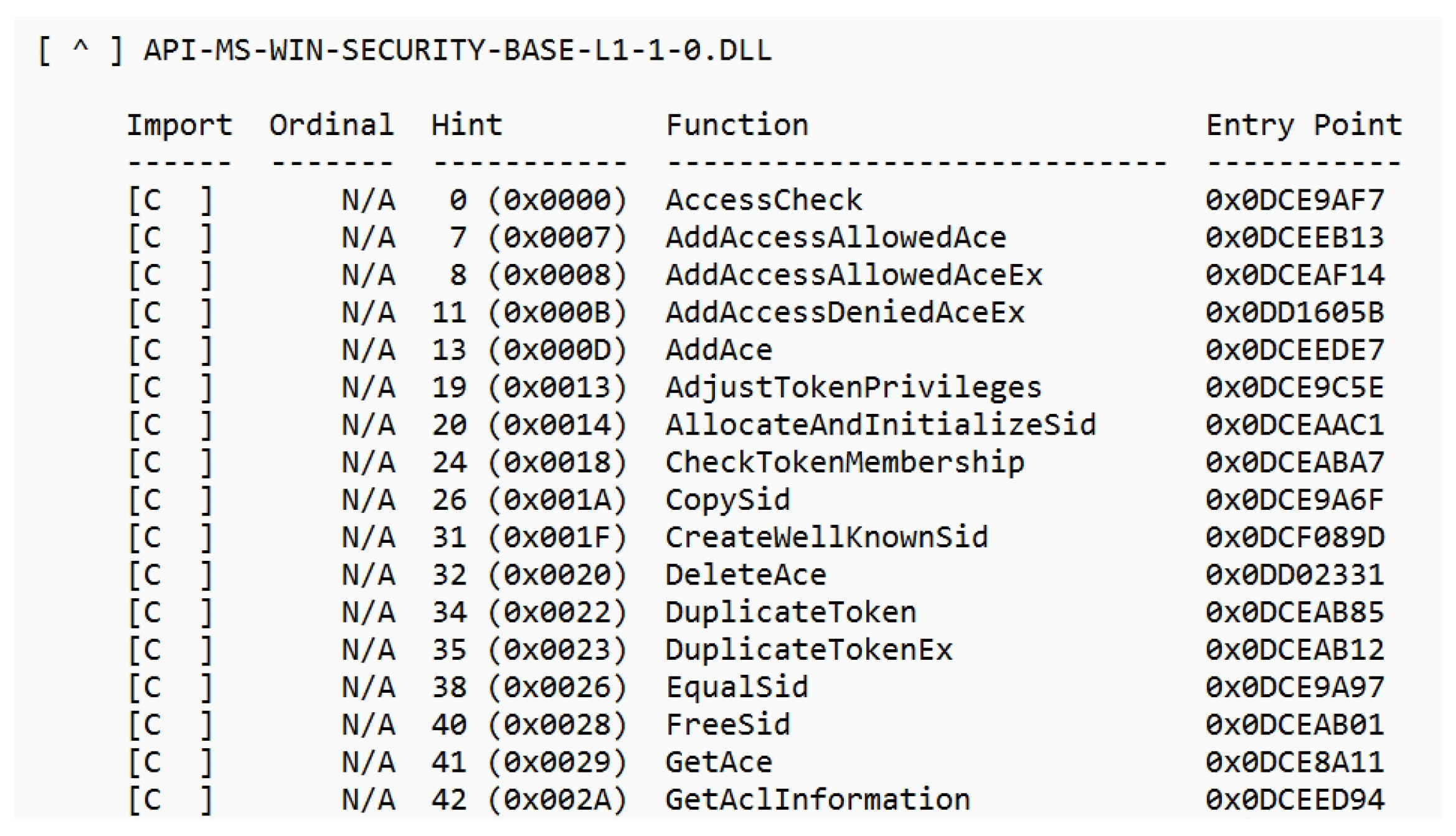
3.3.1. Dependency Walker
3.3.2. Processing the Output and Creating the Dataset
3.4. Dynamic Analysis of the Samples
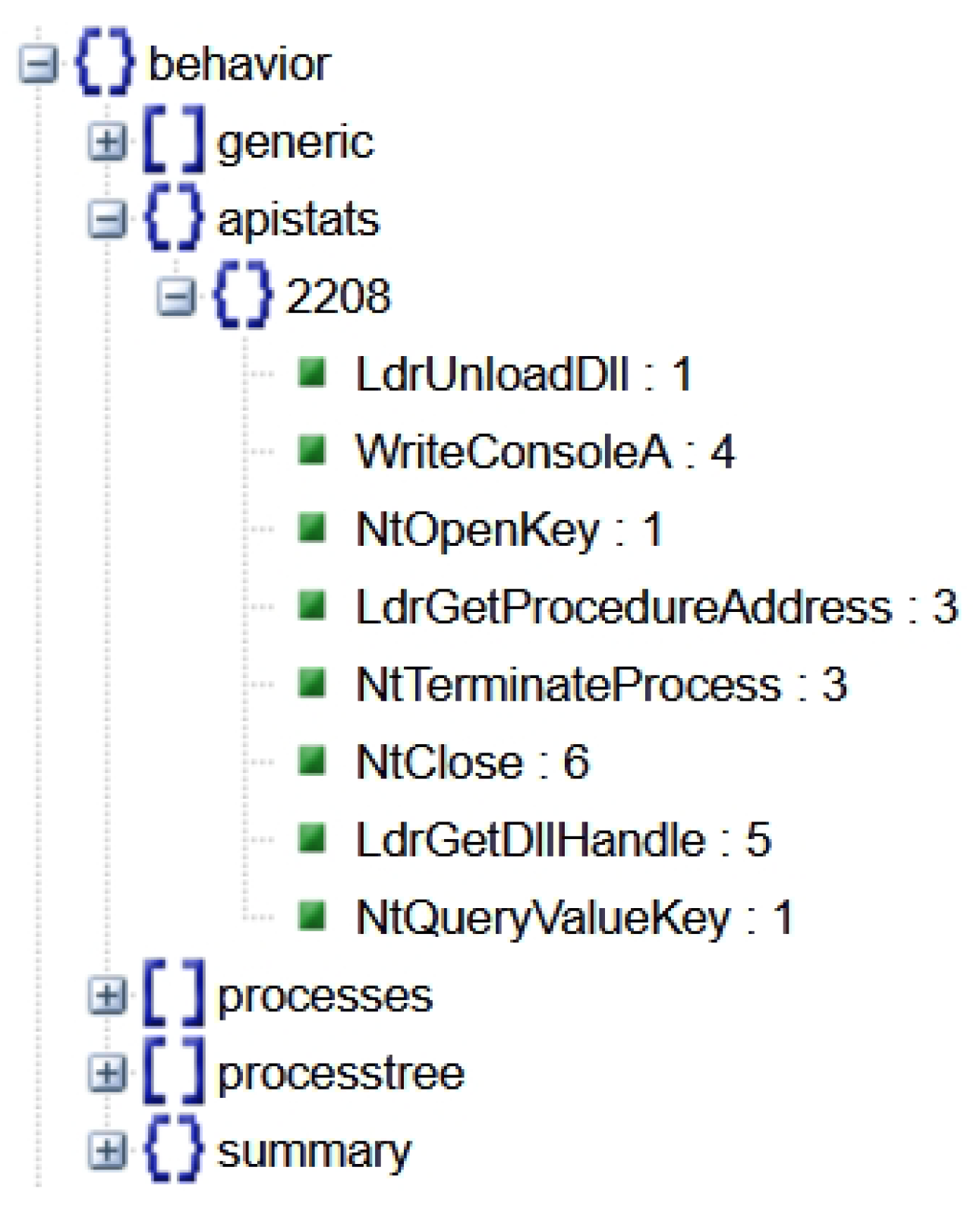
3.4.1. Cuckoo Sandbox
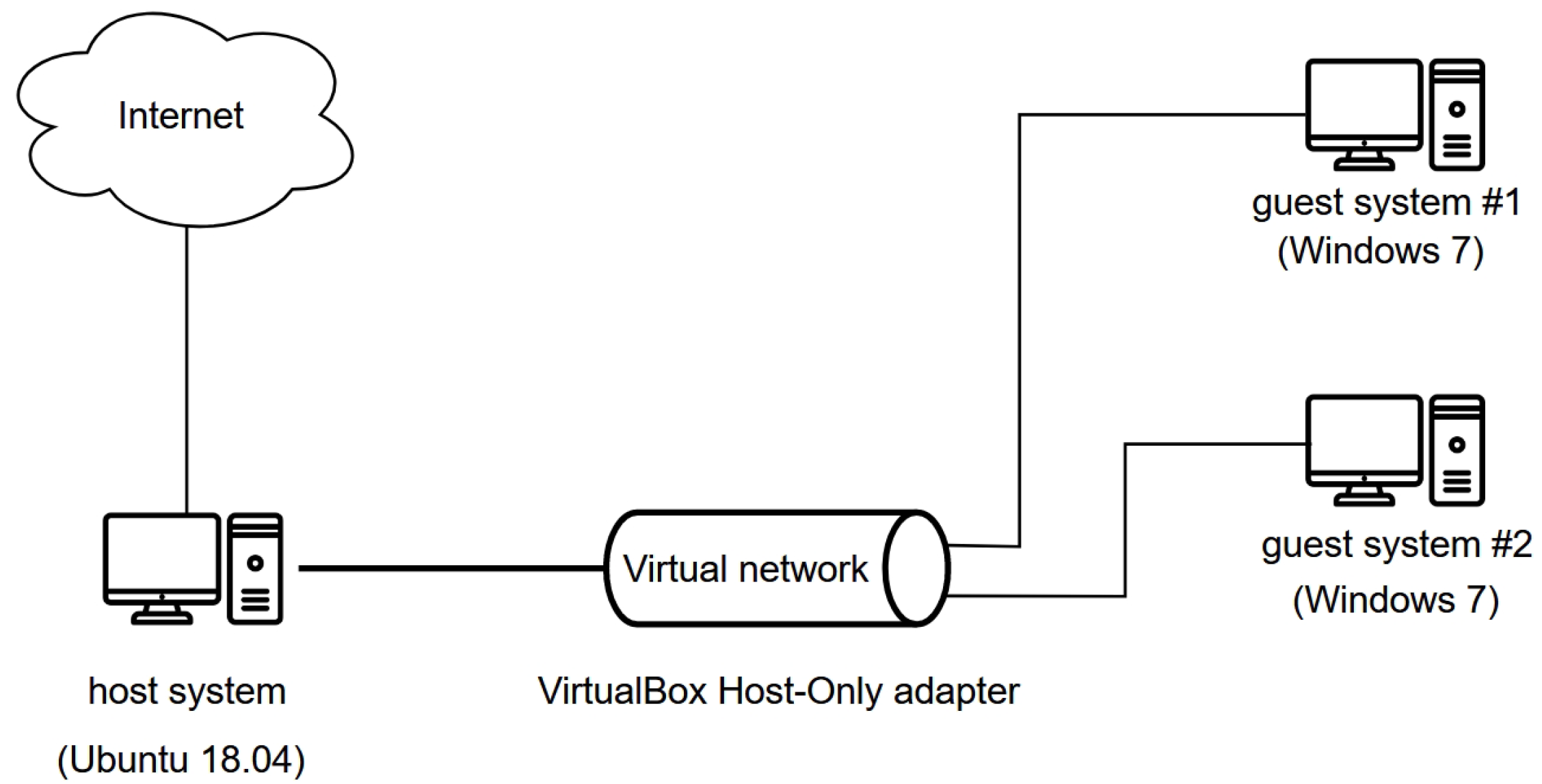
3.4.2. Dynamic Analysis Test Environment
- A host system running Ubuntu 18.04 LTS. This operating system contains Python version 2.7, an installation prerequisite of the Cuckoo Sandbox tool. This system contains the aforementioned central management software that manages the dynamic analysis, accessible through port 8090 of the localhost server, using a REST API.
- A guest system running Windows 7—in our case, two virtual machines created using the VMCloak tool. On these, we performed the dynamic analysis of the samples. We stored the clean, post-installation state of these systems as an environment snapshot. After the analysis, this environment snapshot was automatically restored, as the execution of the malicious samples may have disrupted the environment. Since the operating system inherently contains security mechanisms that could prevent malicious activity from being performed during dynamic analysis, the Windows Defender, Windows Firewall, and Windows Update security mechanisms were disabled on both guest systems. The virtual machines could access the Internet using the VirtualBox host-only adapter.
3.4.3. Obtaining and Processing the Output, Creating the Dataset
- A method to submit a file for analysis (submit_file), returning the assigned ID;
- A method to submit a URL for analysis (submit_url), also returning the assigned ID;
- A method to find out the analysis status (get_status), returning the status of the analysis with the given ID;
- A method to retrieve the final analysis report (save_report) in JSON format.
3.5. Training and Testing Classification Models
- Extremely randomized trees (ET for short), implemented using the ExtraTreesClassifier class of the Scikit-learn package;
- Extreme gradient boosting (XGBoost for short), implemented using the XGBClassifier class from the xgboost package.
3.6. Evaluation of the Models
3.6.1. Evaluation Metrics
- True negative (TN)—the number of correctly identified benign samples;
- True positive (TP)—the number of correctly identified malicious samples;
- False positive (FP)—the number of incorrectly identified malicious samples;
- False negative (FN)—the number of incorrectly identified benign samples.
Classification Accuracy
Precision
Sensitivity (aka Recall)
Specificity
F1 Score
Area under the Curve
3.6.2. Extremely Randomized Trees
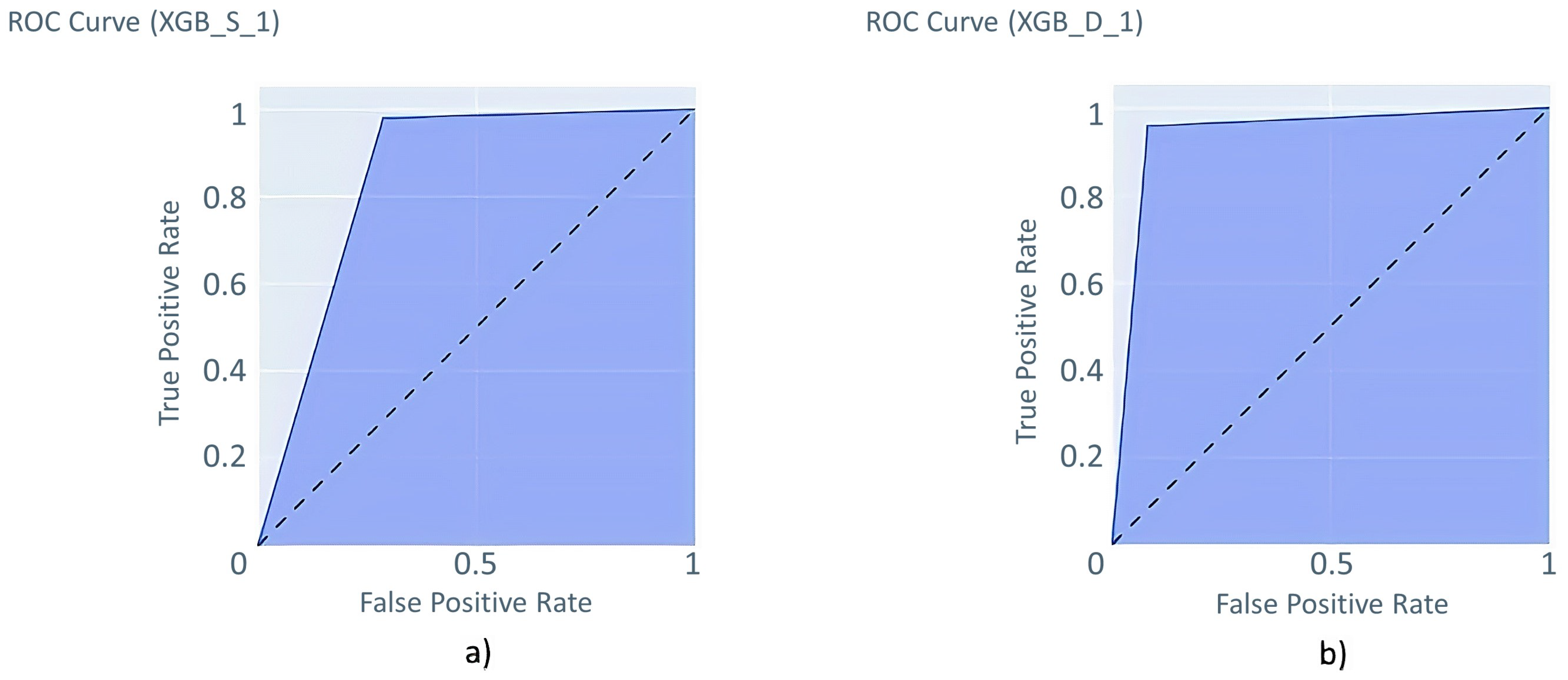
3.6.3. Extreme Gradient Boosting
3.7. Choosing the Best Model
3.8. The Program and Its User Interface
- Scanning of multiple files in a folder or the whole system;
- Quarantining malicious executable files;
- Scheduled scanning according to user-specified conditions.
- A screen to select a file or to enter a URL to be scanned or to scan the entire system;
- A screen showing an overview of scheduled one-time or repeated scans of files and folders;
- A screen showing an overview of already completed scans;
- A screen showing quarantined files;
- A screen to view and change program settings.
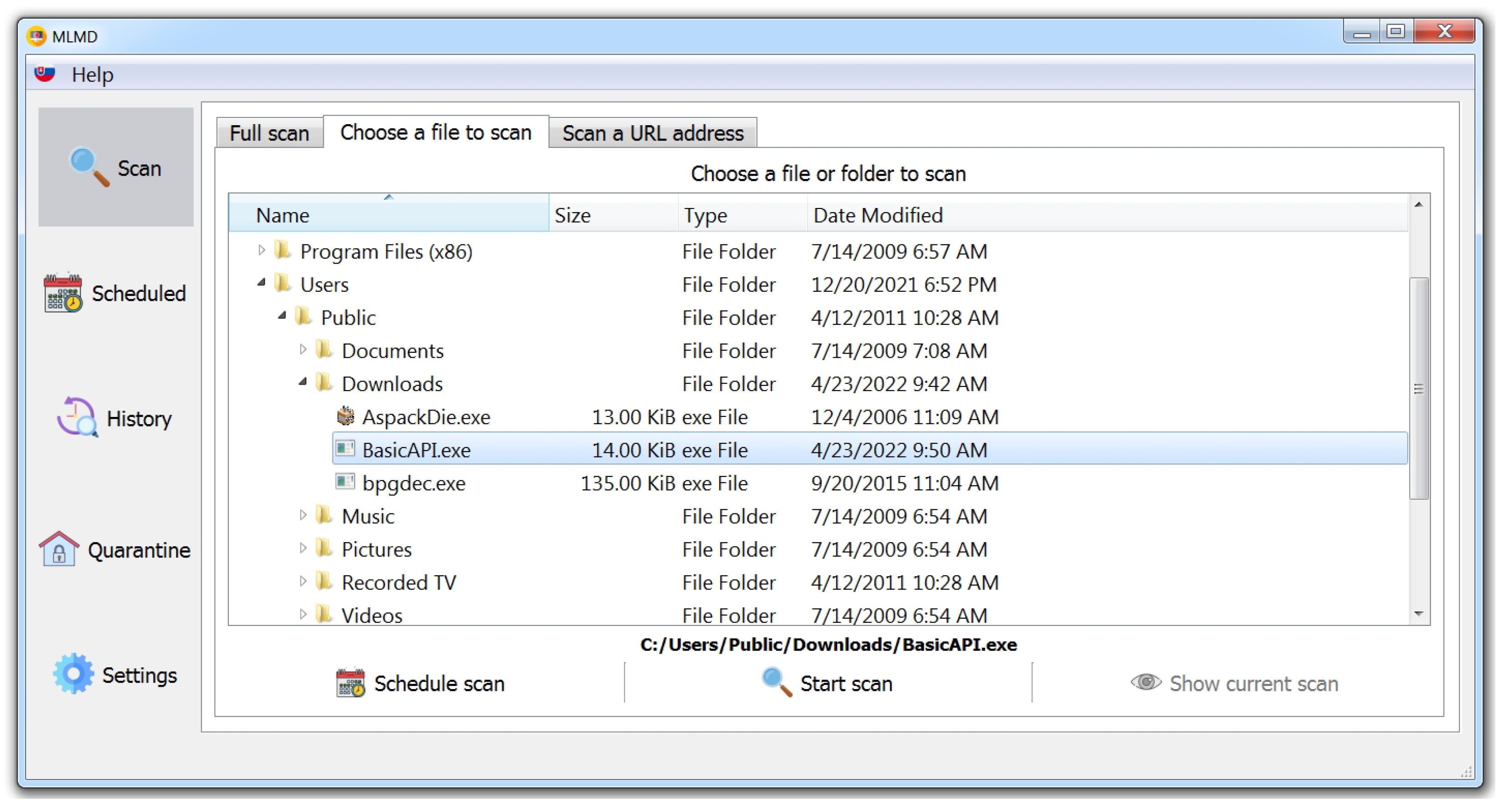
3.8.1. Scanning a File
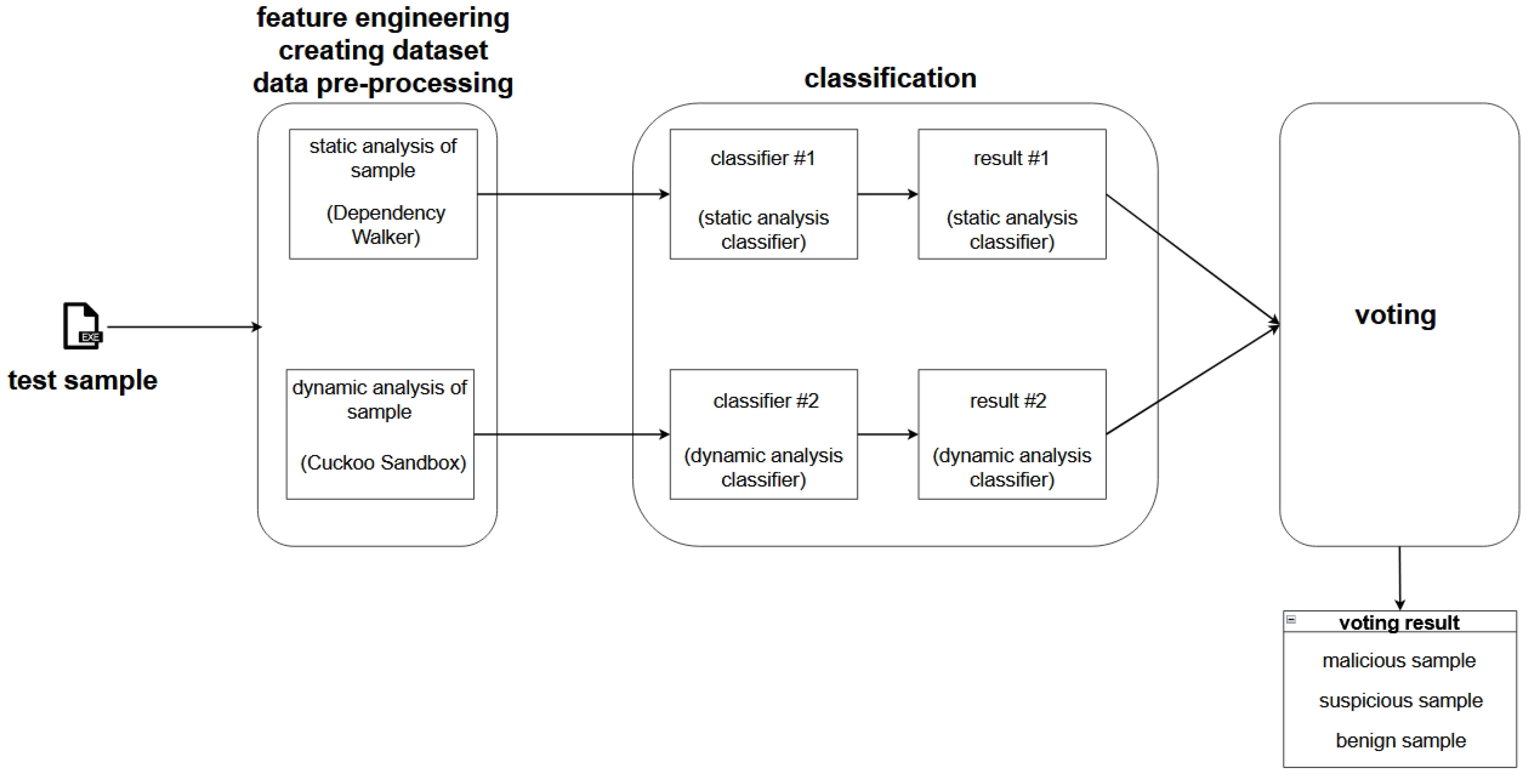
- Static analysis using Dependency Walker and dynamic analysis using Cuckoo Sandbox, resulting in two analysis outputs. From these, the features are extracted and the dataset is created (as in the case of the training data).
- Loading the two machine learning classifiers trained on the training data, separately, for the dataset obtained by static analysis and for the dataset obtained by dynamic analysis.
- Classification itself.
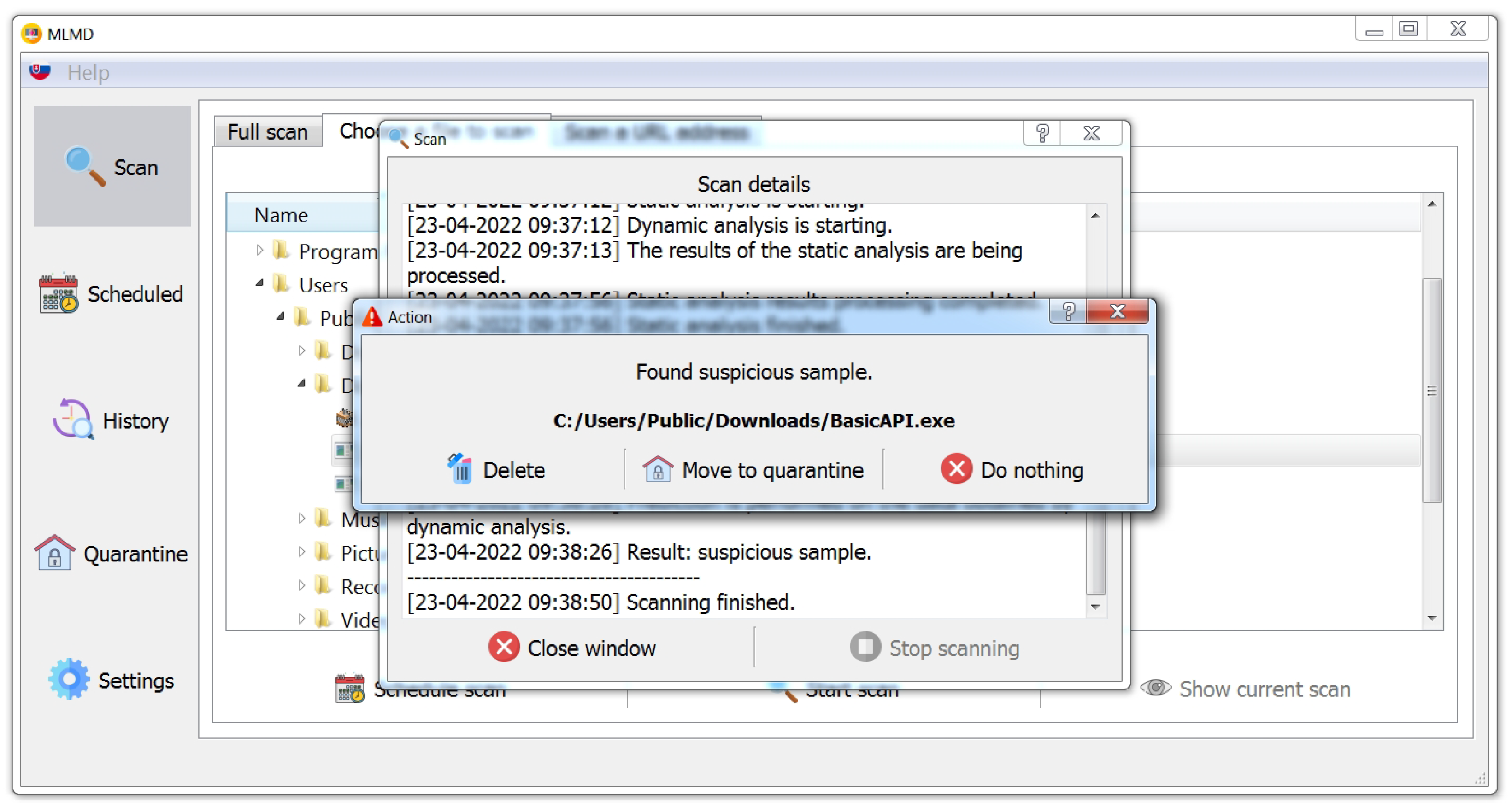
- Combining the obtained results (voting) to decide on the malicious, suspicious, or benign nature of the test sample.
Obtaining the Final Result—Malicious/Benign Nature
3.8.2. Scanning a Web Address
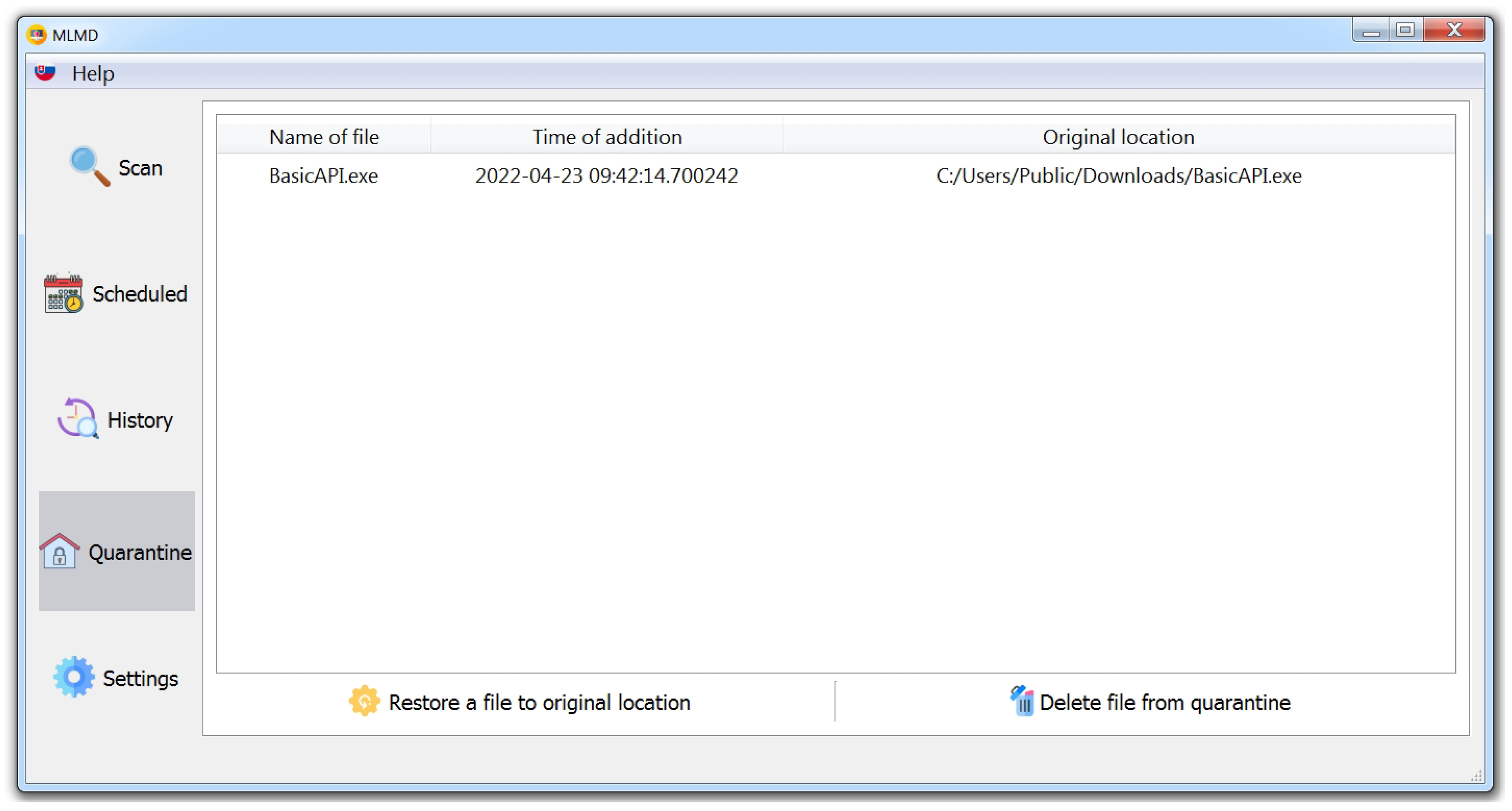
3.8.3. Quarantine
- Opening the original file in read binary mode;
- Opening a new file in write binary mode in the Quarantine folder;
- Reading the original file line by line and transforming (encoding) it using the base64io library;
- Writing each transformed line to the new file;
- Deleting the original file.
4. Evaluation
- Existing studies, mentioned at the beginning hereof;
- The free VirusTotal tool.
4.1. Comparison with Existing Studies
4.2. Comparison of MLMD and VirusTotal
4.2.1. Test Samples
- Malicious—both classification models classified the sample as malicious;
- Suspicious—one classification model classified the sample as malicious, the other as benign;
- Benign—both classification models classified the sample as benign.
- The number of systems that detected the sample as malicious;
- The number of systems that detected the sample as benign.
4.2.2. Comparison of Classifications
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | Artificial neural network |
| API | Application programming interface |
| AUC | Area under the curve |
| BP | Back-propagation |
| CPU | Central processing unit |
| DT | Decision tree |
| ET | Extremely randomized trees |
| FN | False negative |
| FP | False positive |
| GB | Gigabyte |
| GDB | Gradient boost |
| GDBT | Gradient boost decision tree |
| HV | Hard voting |
| HTTP | Hypertext Transfer Protocol |
| ID | Identifier |
| JSON | JavaScript Object Notation |
| KNN | k-nearest neighbors |
| LDA | Linear discriminant analysis |
| LR | Logistic regression |
| MLMD | Machine Learning Malware Detector |
| MLP | Multilayer perceptron |
| NB | Naïve Bayes |
| PRC | Precision-recall curve |
| REST | Representational state transfer |
| RF | Random forest |
| ROC | Receiver operating characteristic curve |
| SSD | Solid-state drive |
| SVC | Support vector classification |
| SVM | Support vector machine |
| TN | True negative |
| TP | True positive |
| URL | Uniform resource locator |
| XGBoost | Extreme gradient boosting |
References
- Monnappa, K. Learning Malware Analysis, 1st ed.; Packt Publishing: Birmingham, UK, 2018; Chapter 1; ISBN 978-178-839-250-1. [Google Scholar]
- 2020 State of Malware Report. Available online: https://www.malwarebytes.com/resources/files/2020/02/2020_state-of-malware-report.pdf (accessed on 28 March 2022).
- Elisan, C. Malware, Rootkits & Botnets A Beginner’s Guide, 1st ed.; McGraw-Hill Education: New York, NY, USA, 2012; Chapter 1; ISBN 978-007-179-206-6. [Google Scholar]
- Ławrynowicz, A.; Tresp, V. Introducing Machine Learning. In Perspectives on Ontology Learning; Microsoft Press: Redmond, WA, USA, 2014; pp. 35–50. [Google Scholar]
- Deep Instinct Website. Available online: https://www.deepinstinct.com (accessed on 10 June 2022).
- Mohanta, A.; Saldanha, A. Malware Analysis and Detection Engineering: A Comprehensive Approach to Detect and Analyze Modern Malware, 1st ed.; Apress: New York, NY, USA, 2020; ISBN 978-148-426-192-7. [Google Scholar]
- Fedak, A.; Stulrajter, J. Fundamentals of static malware analysis: Principles, methods, and tools. Sci. Mil. 2014, 15, 45–53. [Google Scholar]
- Hisham, S.G. Behavior-based features model for malware detection. J. Comput. Virol. Hacking Tech. 2015, 12, 59–67. [Google Scholar]
- Damodaran, A.; Troia, F.D.; Visaggio, C.A.; Austin, T.H.; Stamp, M. A comparison of static, dynamic, and hybrid analysis for malware detection. J. Comput. Virol. Hacking Tech. 2017, 13, 1–12. [Google Scholar] [CrossRef]
- Cisar, P.; Joksimovic, D. Heuristic scanning and sandbox approach in malware detection. Archibald Reiss Days 2019, 9, 299–308. [Google Scholar]
- Advanced Heuristics to Detect Zero-Day Attacks. Available online: https://hackernoon.com/advanced-heuristics-to-detect-zero-day-attacks-8e3335lt (accessed on 28 March 2022).
- Gibert, D.; Mateu, C.; Planes, J. The rise of machine learning for detection and classification of malware: Research developments, trends and challenges. J. Netw. Comput. Appl. 2020, 153, 102526. [Google Scholar] [CrossRef]
- Senanayake, J.; Kalutarage, H.; Al-Kadri, M.O. Android Mobile Malware Detection Using Machine Learning: A Systematic Review. Electronics 2021, 10, 1606. [Google Scholar] [CrossRef]
- Schultz, G.M.; Eskin, E.; Zadok, F.; Stolfo, J.S. Data Mining Methods for Detection of New Malicious Executables. In Proceedings of the IEEE Computer Society Symposium on Research in Security and Privacy, Oakland, CA, USA, 13–16 May 2001; pp. 38–49. [Google Scholar]
- Bai, J.; Wang, J.; Zou, G. A Malware Detection Scheme Based on Mining Format Information. Sci. World J. 2014, 2014, 260905. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Kuppusamy, K.S.; Aghila, G. A learning model to detect maliciousness of portable executable using integrated feature set. J. King Saud Univ.—Comput. Inf. Sci. 2019, 31, 252–265. [Google Scholar] [CrossRef]
- Bragen, R.S. Malware Detection Through Opcode Sequence Analysis Using Machine Learning. Master’s Thesis, Gjøvik University College, Gjøvik, Norway, 2015. [Google Scholar]
- Chowdhury, M.; Rahman, A.; Islam, M. Protecting data from malware threats using machine learning technique. In Proceedings of the 2017 12th IEEE Conference on Industrial Electronics and Applications (ICIEA), Siem Reap, Cambodia, 18–20 June 2017; pp. 1691–1694. [Google Scholar]
- Moser, A.; Kruegel, C.; Kirda, E. Limits of Static Analysis for Malware Detection. In Proceedings of the Twenty-Third Annual Computer Security Applications Conference (ACSAC 2007), Miami Beach, FL, USA, 10–14 December 2007; pp. 421–430. [Google Scholar]
- Shijo, P.V.; Salim, A. Integrated Static and Dynamic Analysis for Malware Detection. Procedia Comput. Sci. 2015, 46, 804–811. [Google Scholar] [CrossRef] [Green Version]
- Firdausi, I.; Lim, C.; Erwin, A.; Nugroho, A.S. Analysis of machine learning techniques used in behavior-based malware detec. In Proceedings of the 2010 Second International Conference on Advances in Computing, Control, and Telecommunication Technologies, Jakarta, Indonesia, 2–3 December 2010; pp. 201–203. [Google Scholar]
- Mosli, R.; Yuan, B.; Li, R.; Pan, Y. A Behavior-Based Approach for Malware Detection. In Proceedings of the 13th IFIP International Conference on Digital Forensics (DigitalForensics), Orlando, FL, USA, 30 January–1 February 2017; pp. 187–201. [Google Scholar]
- Kumar, R.; Geetha, S. Malware classification using XGboost-Gradient Boosted Decision Tree. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 536–549. [Google Scholar] [CrossRef]
- Dhamija, H.; Dhamija, A.K. Malware Detection using Machine Learning Classification Algorithms. Int. J. Comput. Intell. Res. 2021, 17, 1–7. [Google Scholar]
- Shhadata, I.; Bataineh, B.; Hayajneh, A.; Al-Sharif, Z.A. The Use of Machine Learning Techniques to Advance the Detection and Classification of Unknown Malware. Procedia Comput. Sci. 2020, 170, 917–922. [Google Scholar] [CrossRef]
- VirusShare Malware Repository. Available online: https://virusshare.com/ (accessed on 29 March 2022).
- The Portable Freeware Collection. Available online: https://www.portablefreeware.com/ (accessed on 29 March 2022).
- Portable Software Repository. Available online: https://portableapps.com/ (accessed on 29 March 2022).
- Dependency Walker Website. Available online: https://www.dependencywalker.com/ (accessed on 29 March 2022).
- Cuckoo Sandbox Website. Available online: https://cuckoosandbox.org/ (accessed on 29 March 2022).
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar]
- Sutorčík, K. Detection of Malware Samples Using Machine Learning Algorithms and Methods of Dynamic Analysis (In Orig Lang: Využitie Algoritmov StrojovéHo UčEnia na Detekciu MalvéRovýCh Vzoriek Pomocou MetóD Dynamickej Analýzy). Master’s Thesis, Technická Univerzita v Košiciach, Košice, Slovakia, 2021. [Google Scholar]
- Špakovský, E. Detection of Malware Samples Using Machine Learning Algorithms and Methods of Static Analysis (In Orig Lang: Využitie Algoritmov StrojovéHo UčEnia na Detekciu MalvéRovýCh Vzoriek Pomocou MetóD Statickej Analýzy). Master’s Thesis, Technická Univerzita v Košiciach, Košice, Slovakia, 2021. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Analysis Type | Dataset Size (Malicious/Clean) | Algorithms Compared | Best Accuracy (%) | Best Sensitivity (%) |
|---|---|---|---|---|---|
| Schultz et al. [14] | static | 3265/1001 | RIPPER, NB, Multi-NB | 97.11 | 97.43 |
| Bai et al. [15] | static | 10,521/8592 | J48, RF | 95.1–99.1 | 91.3–99.1 |
| Kumar et al. [16] | static | 2722/2488 | RF, DT, LR, NB, LDA, KNN | 98.78 | 99.0 |
| Bragen [17] | static | 992/771 | RF, NB, KNN, SVM, J48, ANN | 95.58 | 96.77 |
| Chowdhury et al. [18] | static | 41,265/10,920 | NB, J48, RF, SVM, ANN | 97.7 | 91 |
| Shijo, Salim [20] | static | 997/490 | SVM, RF | 95.88 | 95.9 |
| Shijo, Salim [20] | dynamic | 997/490 | SVM, RF | 97.16 | 97.2 |
| Shijo, Salim [20] | combined | 997/490 | SVM, RF | 98.71 | 98.7 |
| Firdausi et al. [21] | dynamic | 220/250 | NB, SVM, MLP, KNN, J48 | 96.8 | 95.9 |
| Mosli et al. [22] | dynamic | 3130/1157 | KNN, SVM, RF | 91.4 | 91.1 |
| Kumar, Geetha [23] | Ember dataset | 300 K/300 K | Gaussian NB, KNN, Linear SVC, DT, AdaBoost, RF, Extra Trees, GB, XGBoost | 98.5 | 0.89–0.99 |
| Dhamija, Dhamija [24] | open data source | 4060/2709 | NB, DT, RF, GB, XGBoost | 99.95 | - |
| Shhadat et al. [25] | open data source | 984/172 | KNN, SVM, Bernoulli NB, RF, DT, LR, HV | 98.2 | 92 |
| Class | Count |
|---|---|
| Malicious | 2747 |
| Benign | 837 |
| Total | 3584 |
| Class | Count |
|---|---|
| Malicious | 2937 |
| Benign | 828 |
| Total | 3765 |
| Hyperparameter | Value |
|---|---|
| criterion | gini; entropy |
| n_estimators | 10; 50; 100; 150; 200; 300 |
| min_samples_split | 2; 3; 4; 5 |
| min_samples_leaf | 1; 2; 3; 5 |
| max_features | auto; sqrt; log2; None |
| class_weight | balanced; balanced_subsample; None |
| max_depth | 3; 5; 8; None |
| Hyperparameter | Value |
|---|---|
| n_estimators | 10; 50; 100; 150; 200; 250; 300 |
| max_depth | 3; 5; 7; 9; 11 |
| learning_rate | 0.001; 0.01; 0.1; 0.2; 0.3 |
| colsample_bytree | 0.3; 0.7; 1 |
| subsample | 0.5; 1 |
| scale_pos_weight | 0.3 |
| gamma | 0; 1; 2; 3 |
| Parameters | Classification Accuracy (%) | Sensitivity (%) | Specificity (%) | ROC AUC | F1 |
|---|---|---|---|---|---|
| ET_S_1 | |||||
| ET_S_2 | |||||
| ET_S_3 | |||||
| ET_S_4 | |||||
| ET_S_5 |
| Parameters | Classification Accuracy (%) | Sensitivity (%) | Specificity (%) | ROC AUC | F1 |
|---|---|---|---|---|---|
| ET_D_1 | |||||
| ET_D_2 | |||||
| ET_D_3 | |||||
| ET_D_4 | |||||
| ET_D_5 |
| Parameters | Classification Accuracy (%) | Sensitivity (%) | Specificity (%) | ROC AUC | F1 |
|---|---|---|---|---|---|
| XGB_S_1 | |||||
| XGB_S_2 | |||||
| XGB_S_3 | |||||
| XGB_S_4 | |||||
| XGB_S_5 |
| Parameters | Classification Accuracy (%) | Sensitivity (%) | Specificity (%) | ROC AUC | F1 |
|---|---|---|---|---|---|
| XGB_D_1 | |||||
| XGB_D_2 | |||||
| XGB_D_3 | |||||
| XGB_D_4 | |||||
| XGB_D_5 |
| Algorithm | Classification Accuracy (%) | Sensitivity (%) | Specificity (%) | ROC AUC |
|---|---|---|---|---|
| XGB | ||||
| ET | ||||
| RF | ||||
| DT | ||||
| SVM (poly) | ||||
| SVM (rbf) | ||||
| SVM (linear) | ||||
| NB |
| Algorithm | Classification Accuracy (%) | Sensitivity (%) | Specificity (%) | ROC AUC |
|---|---|---|---|---|
| XGB | ||||
| ET | ||||
| RFC | ||||
| DT | ||||
| SVM (linear) | ||||
| SVM (poly) | ||||
| SVM (rbf) | ||||
| NB |
| Model | n_estimators | max_depth | learning_rate | colsample_bytree | subsample | scale_pos_weight | gamma |
|---|---|---|---|---|---|---|---|
| XGB_S_1 | 300 | 11 | 0.01 | 0.7 | 1 | 0.3 | 1 |
| XGB_D_1 | 300 | 11 | 0.01 | 0.3 | 1 | 0.3 | 0 |
| Result (Static Analysis) | Result (Dynamic Analysis) | Final Result |
|---|---|---|
| malicious (1) | malicious (1) | malicious |
| malicious (1) | benign (0) | suspicious |
| benign (0) | malicious (1) | suspicious |
| benign (0) | benign (0) | benign |
| Maliciousness Score (0 = min., 10 = max.) | Final Result |
|---|---|
| 0 ≤ score < 4 | secure |
| 4 ≥ score < 7 | suspicious |
| 7 ≥ score ≤ 10 | very suspicious |
| Work | Analysis Type | Dataset Size (Malicious/Clean) | Best Algorithm | Accuracy (%) | Sensitivity (%) |
|---|---|---|---|---|---|
| Schultz a kol. [14] | static | 3265/1001 | RF | 97.11 | 97.43 |
| Bai a kol. [15] | static | 10,521/8592 | J48 | 95.1–99.1 | 91.3–99.1 |
| Kumar a kol. [16] | static | 2722/2488 | RF | 98.78 | 99.0 |
| Bragen [17] | static | 992/771 | RF | 95.58 | 96.77 |
| Chowdhury a kol. [18] | static | 41,265/10,920 | ANN | 97.7 | 91 |
| Shijo a Salim [20] | static | 997/490 | SVM | 95.88 | 95.9 |
| This study | static | 2747/837 | XGBoost | 91.92 | 98.25 |
| This study | dynamic | 2937/828 | XGBoost | 96.48 | 98.51 |
| Shijo a Salim [20] | dynamic | 997/490 | SVM | 97.16 | 97.2 |
| Shijo a Salim [20] | combined | 997/490 | SVM | 98.71 | 98.7 |
| Firdausi a kol. [21] | dynamic | 220/250 | J48 | 96.8 | 95.9 |
| Mosli a kol. [22] | dynamic | 3130/1157 | RF | 91.4 | 91.1 |
| Kumar and Geetha [23] | Ember dataset | 300 K/300 K | Gaussian NB, KNN, Linear SVC, DT, AdaBoost, RF, Extra Trees, GB, XGBoost | 98.5 | 0.89–0.99 |
| Dhamija and Dhamija [24] | Open data source | 4060/2709 | NB, DT, RF, GB, XGBoost | 99.95 | - |
| Shhadat et al. [25] | Open data source | 984/172 | KNN, SVM, Bernoulli NB, RF, DT, LR, HV | 98.2 | 92 |
| Class | Count |
|---|---|
| Malicious | 70 |
| Benign | 35 |
| Total | 105 |
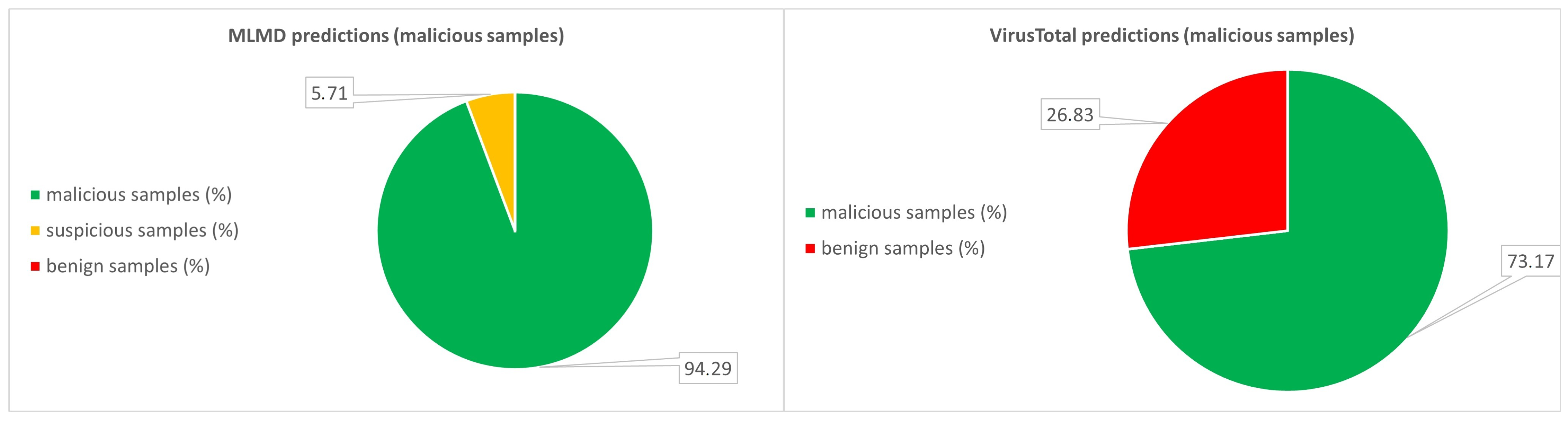
| MLMD | VirusTotal | |
|---|---|---|
| All samples | 70 | 70 |
| Malicious samples (%) | 94.29 | 71.17 |
| Suspicious samples (%) | 5.71 | - |
| Benign samples (%) | 0 | 26.83 |
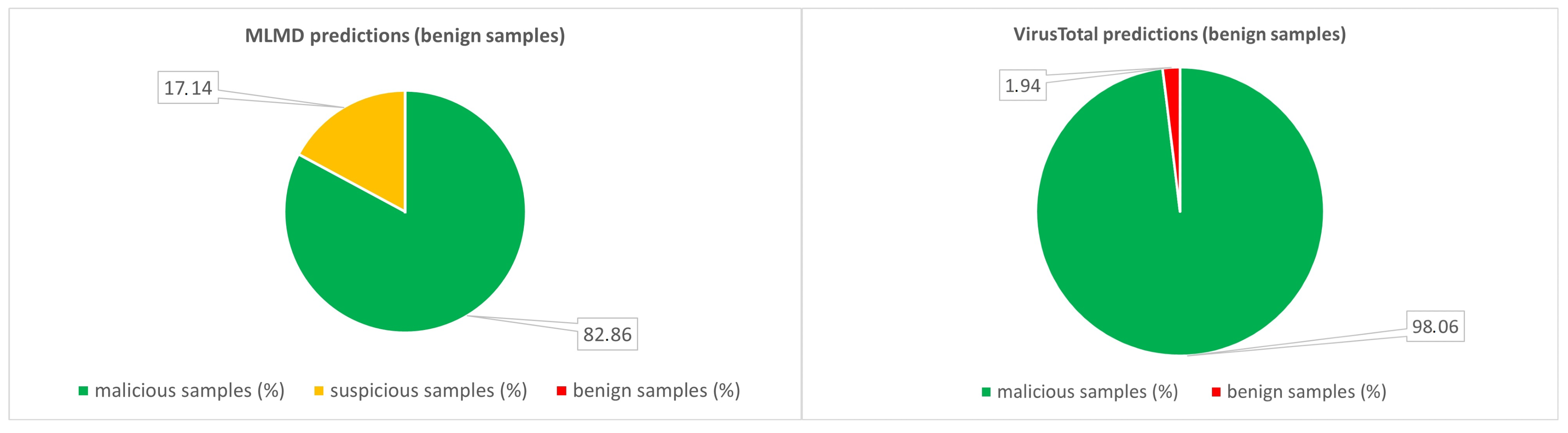
| MLMD | VirusTotal | |
|---|---|---|
| All samples | 35 | 35 |
| Malicious samples (%) | 0 | 1.94 |
| Suspicious samples (%) | 17.14 | - |
| Benign samples (%) | 82.86 | 98.06 |
| Tool | Count |
|---|---|
| VirusTotal | 8 |
| MLMD | 2 |
| Tool | Count |
|---|---|
| VirusTotal | 0 |
| MLMD | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Palša, J.; Ádám, N.; Hurtuk, J.; Chovancová, E.; Madoš, B.; Chovanec, M.; Kocan, S. MLMD—A Malware-Detecting Antivirus Tool Based on the XGBoost Machine Learning Algorithm. Appl. Sci. 2022, 12, 6672. https://doi.org/10.3390/app12136672
Palša J, Ádám N, Hurtuk J, Chovancová E, Madoš B, Chovanec M, Kocan S. MLMD—A Malware-Detecting Antivirus Tool Based on the XGBoost Machine Learning Algorithm. Applied Sciences. 2022; 12(13):6672. https://doi.org/10.3390/app12136672
Chicago/Turabian StylePalša, Jakub, Norbert Ádám, Ján Hurtuk, Eva Chovancová, Branislav Madoš, Martin Chovanec, and Stanislav Kocan. 2022. "MLMD—A Malware-Detecting Antivirus Tool Based on the XGBoost Machine Learning Algorithm" Applied Sciences 12, no. 13: 6672. https://doi.org/10.3390/app12136672
APA StylePalša, J., Ádám, N., Hurtuk, J., Chovancová, E., Madoš, B., Chovanec, M., & Kocan, S. (2022). MLMD—A Malware-Detecting Antivirus Tool Based on the XGBoost Machine Learning Algorithm. Applied Sciences, 12(13), 6672. https://doi.org/10.3390/app12136672