
Hyperparameter Tuning with High Performance Computing Machine Learning for Imbalanced Alzheimer’s Disease Data



Abstract
:1. Introduction
2. Materials and Methods
2.1. High-Performance Computing Structure
2.2. R Pseudocode for Parallel SVM Hyperparameter Tuning
2.3. 10 Times Repeated Fivefold Cross-Validation
2.4. Performance Measurement
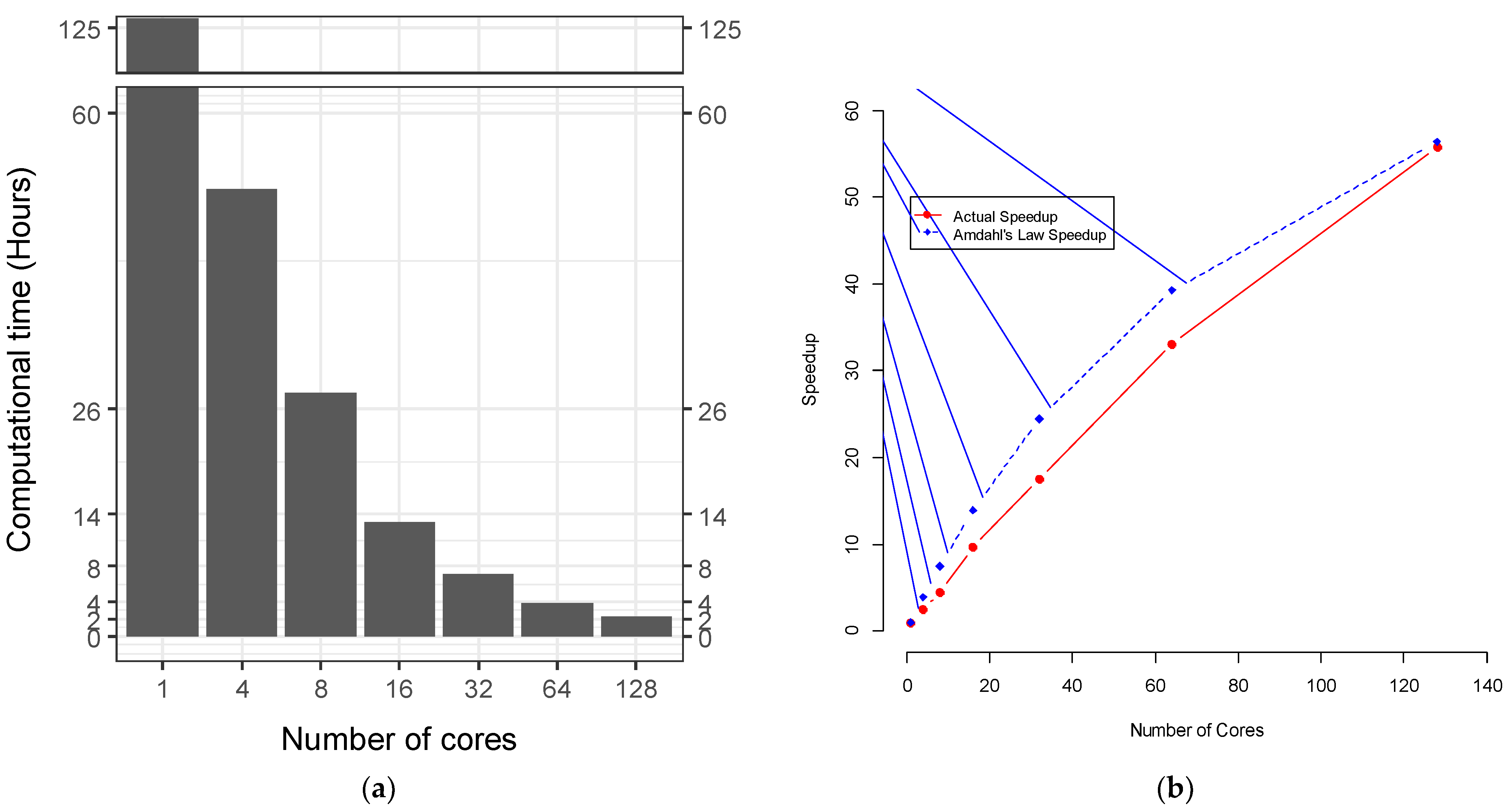
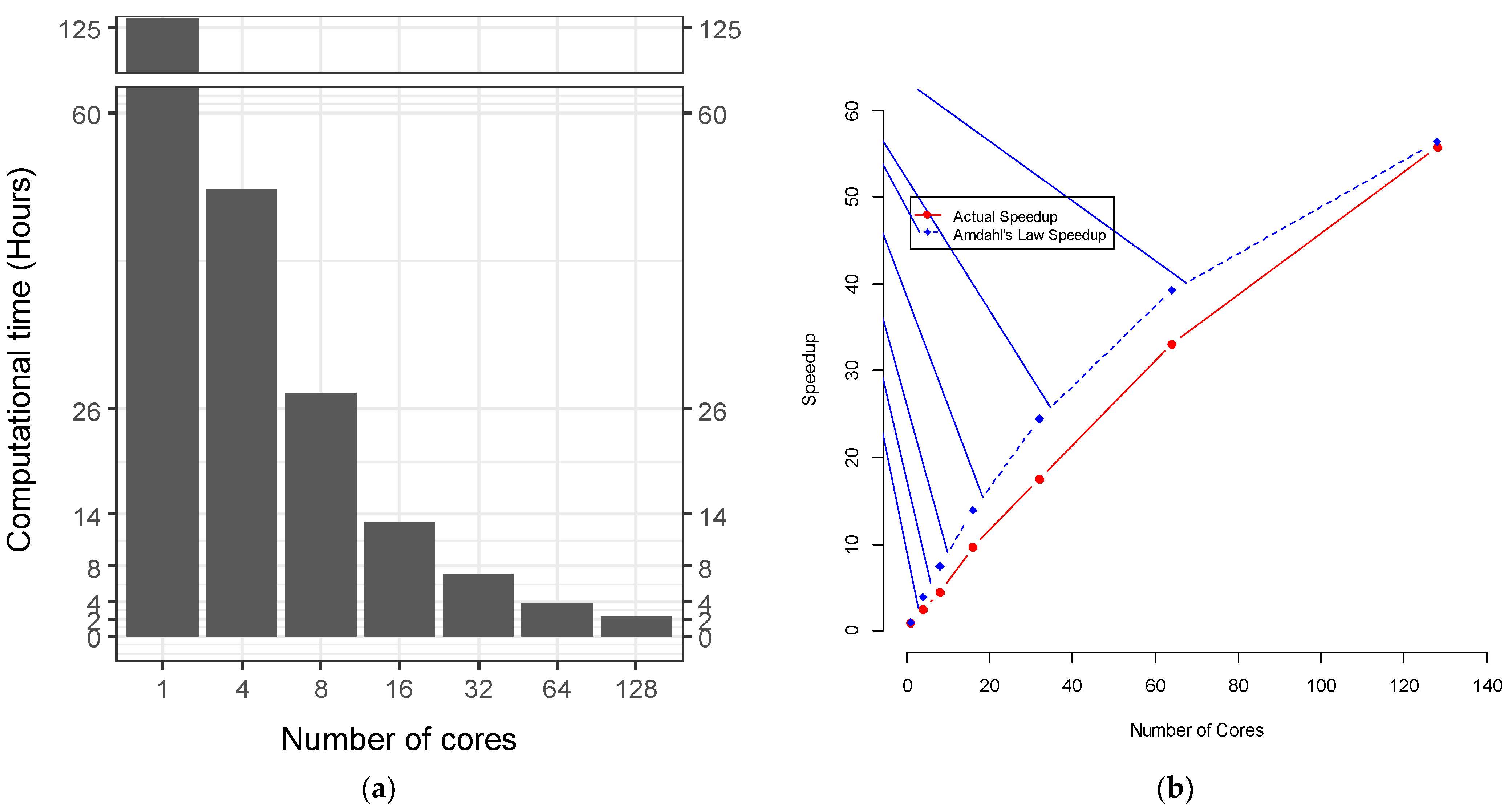
3. Results
4. Discussion
4.1. Handling Imbalanced Data
4.2. Memory Optimization
4.3. Multinode Parallel
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, F.; Petersen, M.; Johnson, L.; Hall, J.; O’Bryant, S.E. Accelerating Hyperparameter Tuning in Machine Learning for Alzheimer’s Disease With High Performance Computing. Front Artif Intell 2021, 4, 798962. [Google Scholar] [CrossRef] [PubMed]
- Alzheimer’s Association. Alzheimer’s Disease Facts and Figures. Available online: https://www.alz.org/alzheimers-dementia/facts-figures (accessed on 21 March 2022).
- Hudomiet, P.; Hurd, M.D.; Rohwedder, S. Dementia Prevalence in the United States in 2000 and 2012: Estimates Based on a Nationally Representative Study. J. Gerontol. B Psychol. Sci. Soc. Sci. 2018, 73, S10–S19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Iram, S.; Vialatte, F.-B.; Qamar, M.I. Chapter 1—Early Diagnosis of Neurodegenerative Diseases from Gait Discrimination to Neural Synchronization. In Applied Computing in Medicine and Health; Al-Jumeily, D., Hussain, A., Mallucci, C., Oliver, C., Eds.; Morgan Kaufmann: Boston, MA, USA, 2016; pp. 1–26. [Google Scholar]
- Hall, J.R.; Johnson, L.A.; Zhang, F.; Petersen, M.; Toga, A.W.; Shi, Y.; Mason, D.; Rissman, R.A.; Yaffe, K.; O’Bryant, S.E.; et al. Using Fractional Anisotropy Imaging to Detect Mild Cognitive Impairment and Alzheimer’s Disease among Mexican Americans and Non-Hispanic Whites: A HABLE Study. Dement. Geriatr. Cogn. Disord. 2021, 50, 266–273. [Google Scholar] [CrossRef]
- Hall, J.R.; Wiechmann, A.R.; Johnson, L.A.; Edwards, M.L.; O’Bryant, S.E. Levels of alpha-2 Macroglobulin in cognitively normal Mexican- Americans with Subjective Cognitive Decline: A HABLE Study. Curr. Neurobiol. 2019, 10, 22–25. [Google Scholar] [PubMed]
- Johnson, L.A.; Edwards, M.; Gamboa, A.; Hall, J.; Robinson, M.; O’Bryant, S.E. Depression, inflammation, and memory loss among Mexican Americans: Analysis of the HABLE cohort. Int. Psychogeriatr. 2017, 29, 1693–1699. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- King, K.S.; Vintimilla, R.M.; Braskie, M.N.; Wei, K.; Hall, J.R.; Borzage, M.; Johnson, L.A.; Yaffe, K.; Toga, A.W.; O’Bryant, S.E.; et al. Vascular risk profile and white matter hyperintensity volume among Mexican Americans and non-Hispanic Whites: The HABLE study. Alzheimer’s Dement. 2022, 14, e12263. [Google Scholar] [CrossRef] [PubMed]
- O’Bryant, S.E.; Zhang, F.; Petersen, M.; Hall, J.R.; Johnson, L.A.; Yaffe, K.; Braskie, M.; Vig, R.; Toga, A.W.; Rissman, R.A.; et al. Proteomic Profiles of Neurodegeneration Among Mexican Americans and Non-Hispanic Whites in the HABS-HD Study. J Alzheimer’s Dis. 2022, 86, 1243–1254. [Google Scholar] [CrossRef] [PubMed]
- O’Bryant, S.E.; Johnson, L.A.; Barber, R.C.; Braskie, M.N.; Christian, B.; Hall, J.R.; Hazra, N.; King, K.; Kothapalli, D.; Large, S.; et al. The Health & Aging Brain among Latino Elders (HABLE) study methods and participant characteristics. Alzheimer’s Dement. 2021, 13, e12202. [Google Scholar] [CrossRef] [PubMed]
- O’Bryant, S.E.; Zhang, F.; Petersen, M.; Hall, J.; Johnson, L.A.; Yaffe, K.; Braskie, M.; Rissman, R.A.; Vig, R.; Toga, A.W.; et al. Neurodegeneration from the AT(N) framework is different among Mexican Americans compared to non-Hispanic Whites: A Health & Aging Brain among Latino Elders (HABLE) Study. Alzheimer’s Dement. 2022, 14, e12267. [Google Scholar] [CrossRef]
- Vintimilla, R.; Hall, J.; Johnson, L.; O’Bryant, S. The relationship of CRP and cognition in cognitively normal older Mexican Americans: A cross-sectional study of the HABLE cohort. Medicine 2019, 98, e15605. [Google Scholar] [CrossRef] [PubMed]
- Vintimilla, R.; Reyes, M.; Johnson, L.; Hall, J.; O’Bryant, S. Cardiovascular risk factors in Mexico and the United States: A comparative cross-sectional study between the HABLE and MHAS participants. Gac. Med. Mex. 2020, 156, 17–21. [Google Scholar] [CrossRef] [PubMed]
- O’Bryant, S.E.; Petersen, M.; Hall, J.; Johnson, L.; Team, H.-H.S. Metabolic Factors Are Related to Brain Amyloid Among Mexican Americans: A HABS-HD Study. J. Alzheimer’s Dis. 2022, 86, 1745–1750. [Google Scholar] [CrossRef] [PubMed]
- Kong, J.; Kowalczyk, W.; Nguyen, D.A.; Bäck, T.; Menzel, S. Hyperparameter Optimisation for Improving Classification under Class Imbalance. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 3072–3078. [Google Scholar]
- Guido, R.; Groccia, M.C.; Conforti, D. A hyper-parameter tuning approach for cost-sensitive support vector machine classifiers. Soft Comput. 2022. [Google Scholar] [CrossRef]
- Hancock, J.; Khoshgoftaar, T.M. Impact of Hyperparameter Tuning in Classifying Highly Imbalanced Big Data. In Proceedings of the 2021 IEEE 22nd International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 10–12 August 2021; pp. 348–354. [Google Scholar]
- Liu, Y.; Li, X.; Chen, X.; Wang, X.; Li, H.; Ali, R. High-Performance Machine Learning for Large-Scale Data Classification considering Class Imbalance. J. Sci. Program. 2020, 2020, 16. [Google Scholar] [CrossRef]
- Guo, J.; Nomura, A.; Barton, R.; Zhang, H.; Matsuoka, S. Machine Learning Predictions for Underestimation of Job Runtime on HPC System; Springer: Cham, Switzerland, 2018; pp. 179–198. [Google Scholar]
- Zhang, F.; Petersen, M.; Johnson, L.; Hall, J.; O’Bryant, S.E. Recursive Support Vector Machine Biomarker Selection for Alzheimer’s Disease. J Alzheimer’s Dis 2021, 79, 1691–1700. [Google Scholar] [CrossRef] [PubMed]
- O’Bryant, S.; Petersen, M.; Hall, J.; Johnson, L.; Yaffe, K.; Braskie, M.; Toga, A.W.; Rissman, R.A.; Rissman, for the HABLE study team. Characterizing plasma NfL in a community-dwelling multi-ethnic cohort: Results from the HABLE study. Alzheimers Dement 2022, 18, 240–250. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Practical Guide to Support Vector Classification; National Taiwan University: Taipei, Taiwan, 2003. [Google Scholar]
- Bischl, B.; Lang, M.; Kotthoff, L.; Schiffner, J.; Richter, J.; Studerus, E.; Casalicchio, G.; Jones, Z.M. mlr: Machine learning in R. JMLR 2016, 17, 5938–5942. [Google Scholar]
- Alzheimer’s Association. Mild Cognitive Impairment (MCI). Available online: https://www.alz.org/alzheimers-dementia/what-is-dementia/related_conditions/mild-cognitive-impairment (accessed on 16 June 2022).
- Kane, M.; Emerson, J.W.; Weston, S. Scalable Strategies for Computing with Massive Data. J. Stat. Softw. 2013, 55, 1–19. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| CPU | 2× AMD EPYC 7763 64-Core Processor (“Milan”) |
| Total cores per node | 128 cores on two sockets (64 cores/socket) |
| Clock rate | 2.45 GHz (Boost up to 3.5 GHz) |
| RAM | 256 GB (3200 MT/s) DDR4 |
| Local storage | 144 GB /tmp partition on a 288 GB SSD |
| Variable Name | Description | Average Value | Standard Deviation |
|---|---|---|---|
| CRP | C-reactive protein (CRP) | 41,567,738 | 67,325,201 |
| FABP3 | Fatty acid-binding proteins (FABPs) | 4953.23 | 2611.45 |
| GLP_1 | Glucagon-like peptide-1 (GLP-1) | 1.07 | 2.09 |
| Glucagon | Glucagon | 49.46 | 49.98 |
| IL_6 | Human interleukin-6 (IL-6) | 1.85 | 19.63 |
| Insulin | Insulin | 233.35 | 287.24 |
| PPY | Pancreatic polypeptide (PPY) | 400.87 | 491.56 |
| PYY | Peptide YY (PYY), also known as peptide tyrosine tyrosine | 35.46 | 38.33 |
| sICAM_1 | Intercellular adhesion molecule 1 (ICAM-1/CD54) | 2,354,989 | 2,759,979 |
| sVCAM_1 | Vascular cell adhesion molecule 1 (VCAM-1/CD106) | 3,681,600 | 4,361,946 |
| TNF_alpha | Human tumor necrosis factor alpha (TNF-alpha) | 3.57 | 15.14 |
| Ab40 | Aβ40 is a 40-amino acid proteolytic | 244.08 | 78.38 |
| Ab42 | Aβ42 is a 42-amino acid proteolytic | 11.7 | 3.71 |
| Tau | Tau | 2.38 | 1.17 |
| NFL | Neurofilament light | 18.47 | 14.08 |
| IL_10 | Human interleukin-10 | 0.42 | 0.64 |
| HOMA_IR | Homeostatic model assessment for insulin resistance | 1.9 | 2.92 |
| Actual | ||
|---|---|---|
| Predicted | ADMCI | NC |
| ADMCI | 0 | 0 |
| NC | 75 | 265 |
| Precision/PPV | NaN% | |
| Accuracy | 77.94% | |
| Sensitivity | 0.00% | |
| Specificity | 100.00% | |
| NPV | 77.94% | |
| AUC | 59.21% | |
| PPV12 | NaN% | |
| NPV12 | 88.00% |
| Actual | ||
|---|---|---|
| Predicted | ADMCI | NC |
| ADMCI | 53 | 130 |
| NC | 22 | 135 |
| Precision/PPV | 28.96% | |
| Accuracy | 55.29% | |
| Sensitivity | 70.67% | |
| Specificity | 50.94% | |
| NPV | 85.99% | |
| AUC | 64.73% | |
| PPV12 | 16.42% | |
| NPV12 | 92.72% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Petersen, M.; Johnson, L.; Hall, J.; O’Bryant, S.E. Hyperparameter Tuning with High Performance Computing Machine Learning for Imbalanced Alzheimer’s Disease Data. Appl. Sci. 2022, 12, 6670. https://doi.org/10.3390/app12136670
Zhang F, Petersen M, Johnson L, Hall J, O’Bryant SE. Hyperparameter Tuning with High Performance Computing Machine Learning for Imbalanced Alzheimer’s Disease Data. Applied Sciences. 2022; 12(13):6670. https://doi.org/10.3390/app12136670
Chicago/Turabian StyleZhang, Fan, Melissa Petersen, Leigh Johnson, James Hall, and Sid E. O’Bryant. 2022. "Hyperparameter Tuning with High Performance Computing Machine Learning for Imbalanced Alzheimer’s Disease Data" Applied Sciences 12, no. 13: 6670. https://doi.org/10.3390/app12136670
APA StyleZhang, F., Petersen, M., Johnson, L., Hall, J., & O’Bryant, S. E. (2022). Hyperparameter Tuning with High Performance Computing Machine Learning for Imbalanced Alzheimer’s Disease Data. Applied Sciences, 12(13), 6670. https://doi.org/10.3390/app12136670