
A VPN-Encrypted Traffic Identification Method Based on Ensemble Learning



Abstract
:1. Introduction
1.1. Background
1.2. Related Works
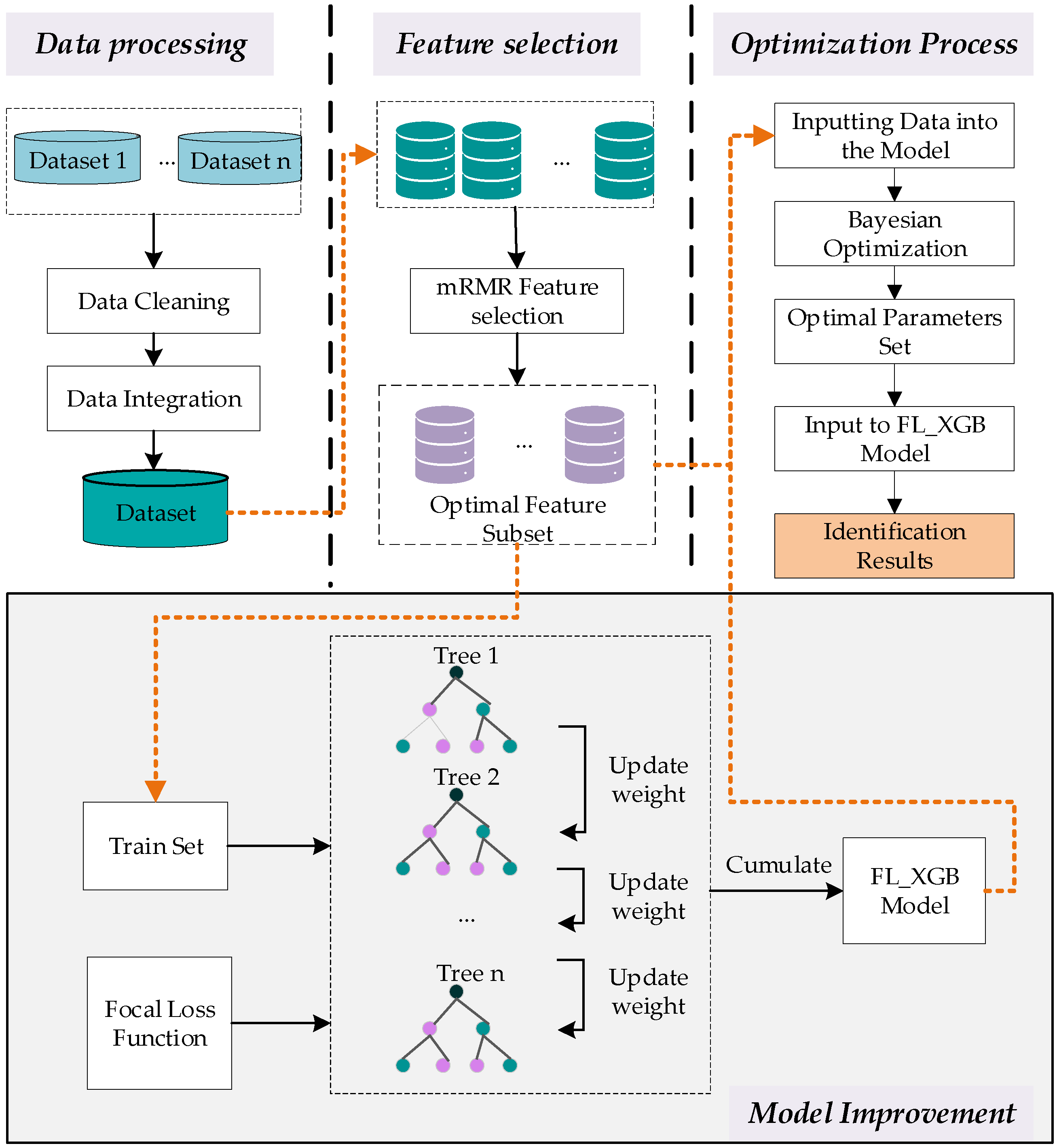
2. Methodology
2.1. Time-Related mRMR Feature Selection
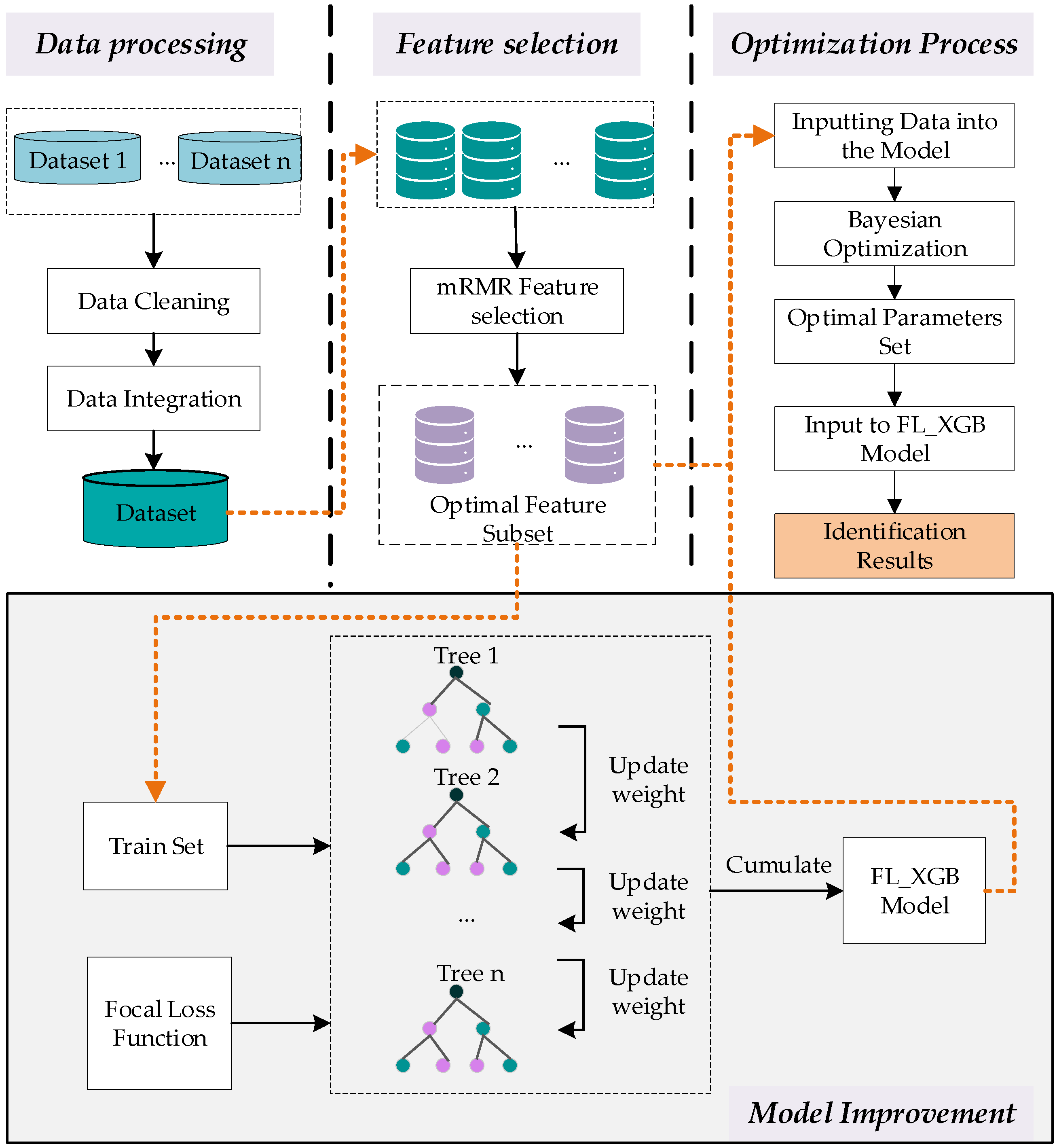
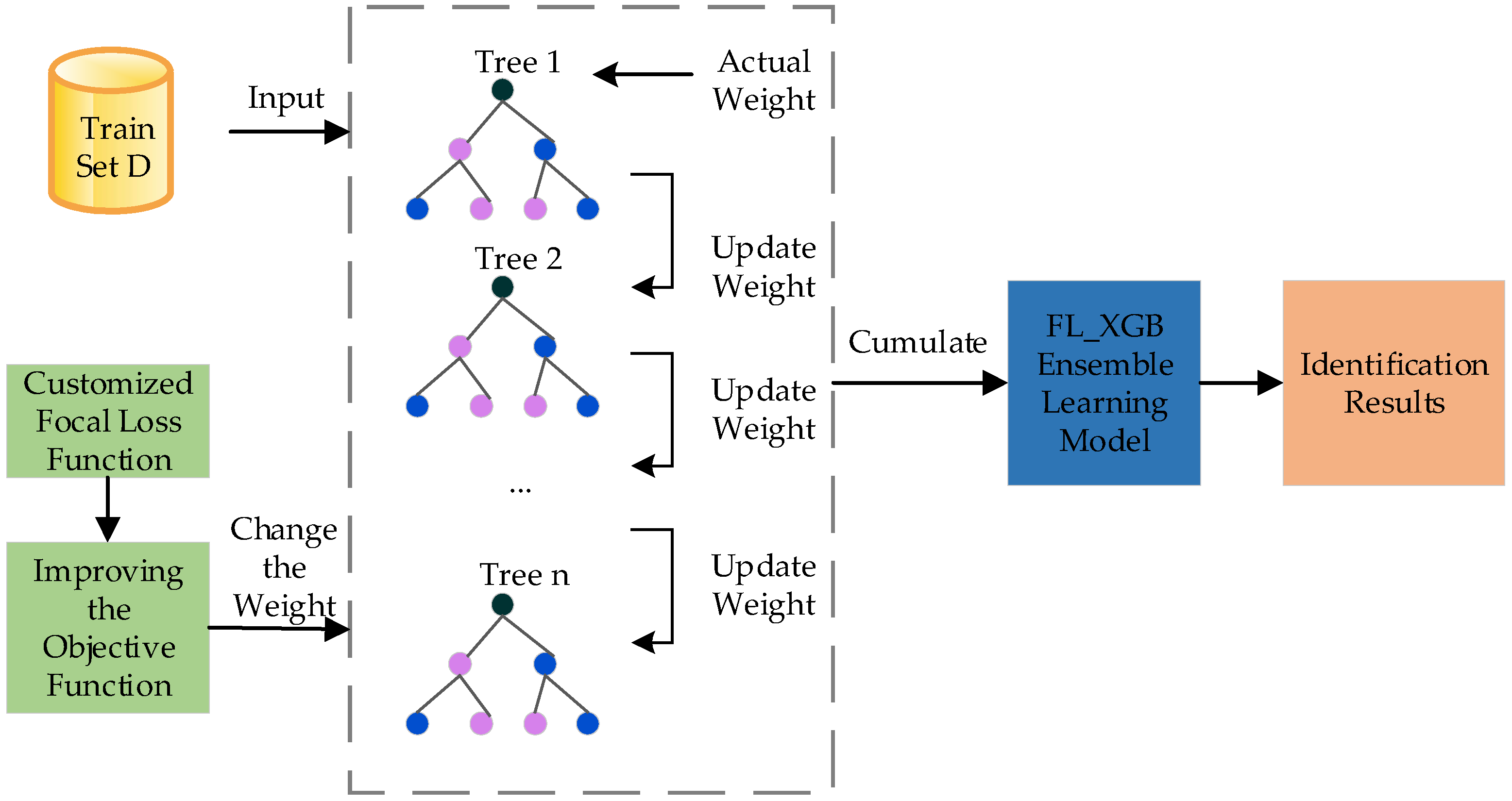
2.2. VPN-Encrypted Traffic FL-XGB Identification Model
2.2.1. Overview of the Basic Xgboost Model
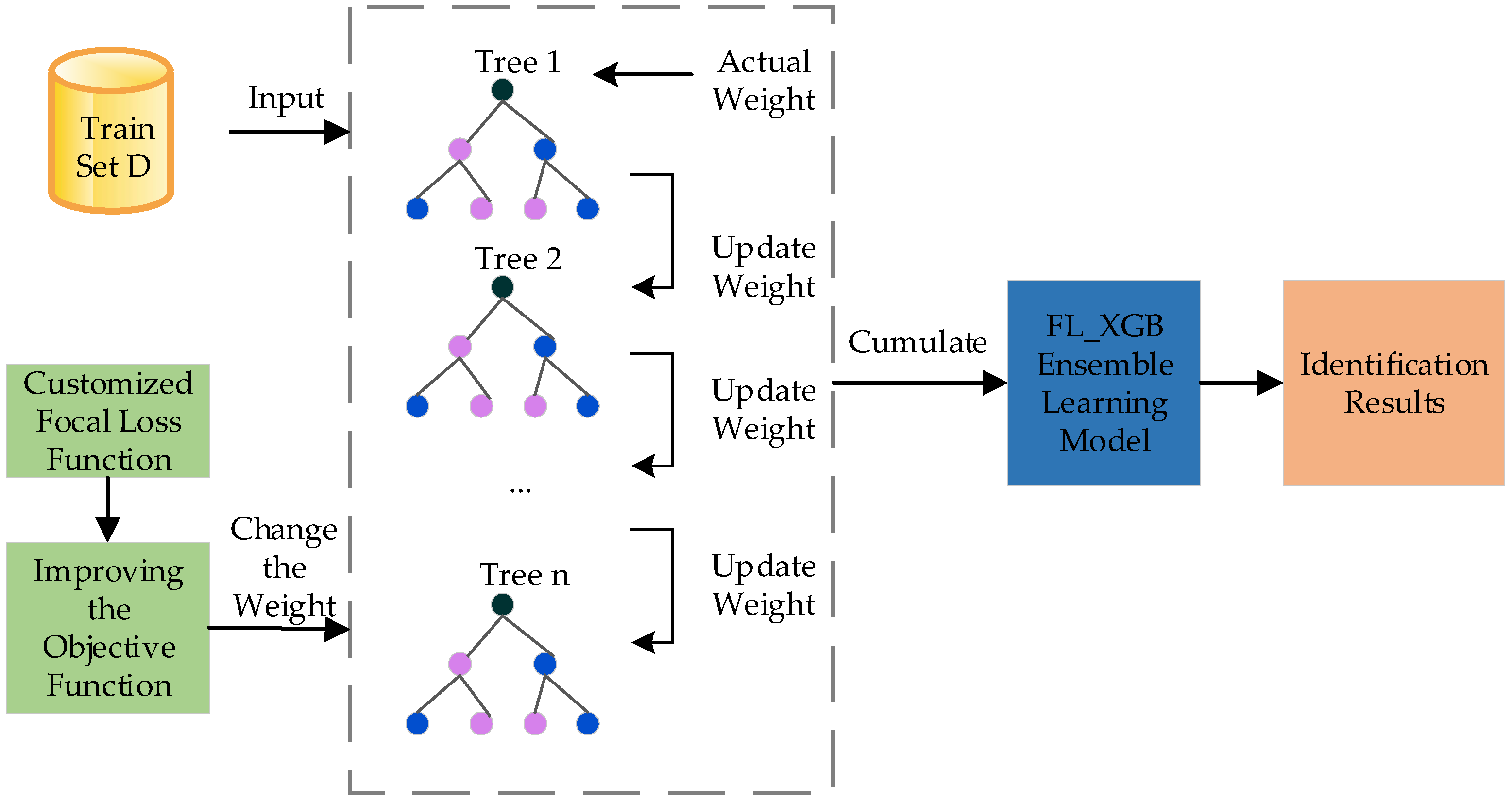
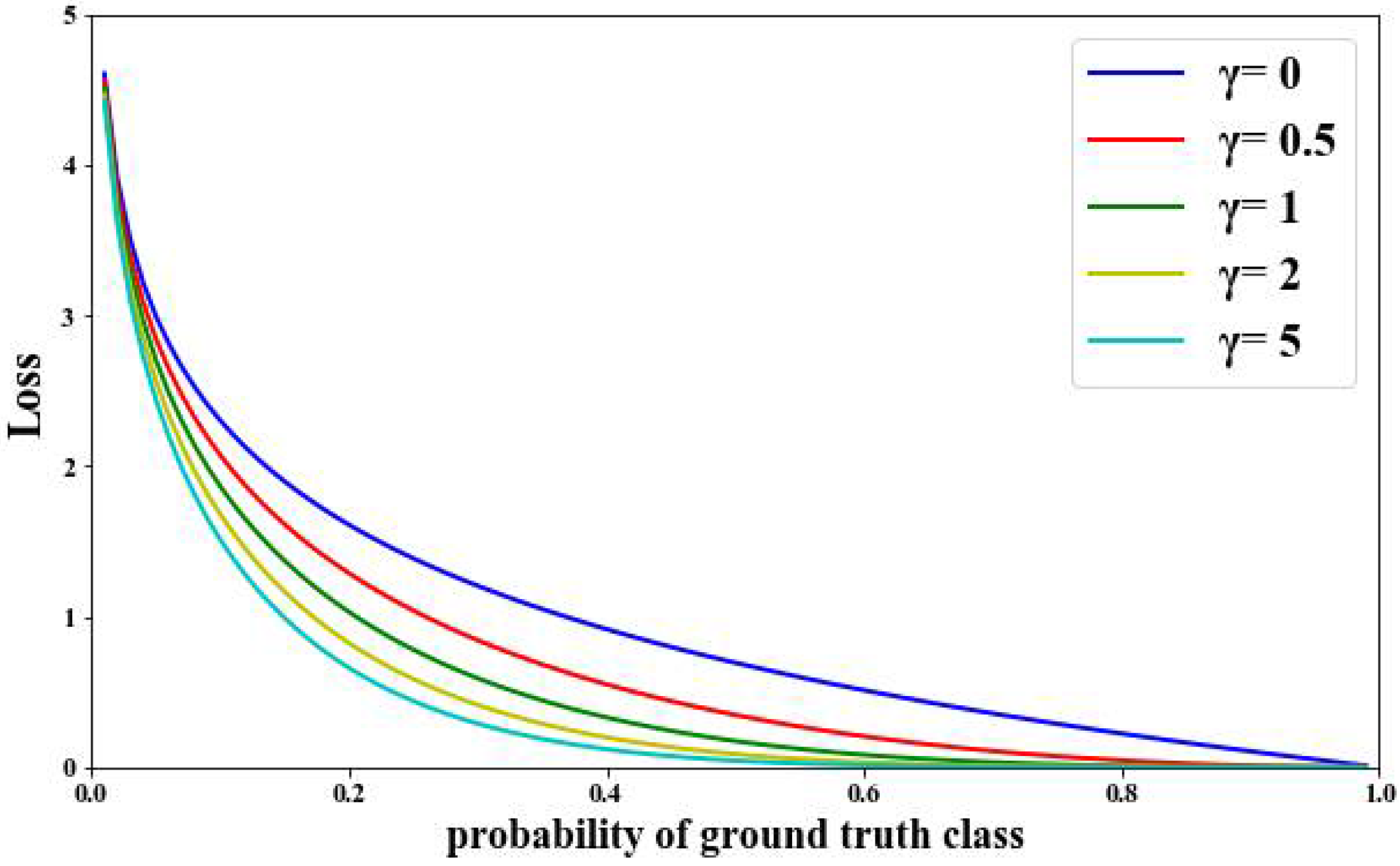
2.2.2. FL-XGB-VPN-Encrypted Traffic Identification Model
| Algorithm 1: FL-XGB-VPN-Encrypted Traffic Identification Algorithm |
| Input: Train Set |
| Output: Index value of Accuracy, Precision, Recall and F1-Score |
| Begin 1. For t = 1 to n do 2. If t = 1: 3. Then, initialize sample class label identification values . 4. Based on the , Input actual class label Y and predicted value , calculate . 5. according to and training 6. Strong Learner 7. Use training sample obtains identification values 8. End for 9. The train set is fed into , i.e., the FL-XGB model, to obtain the values of each index. End |
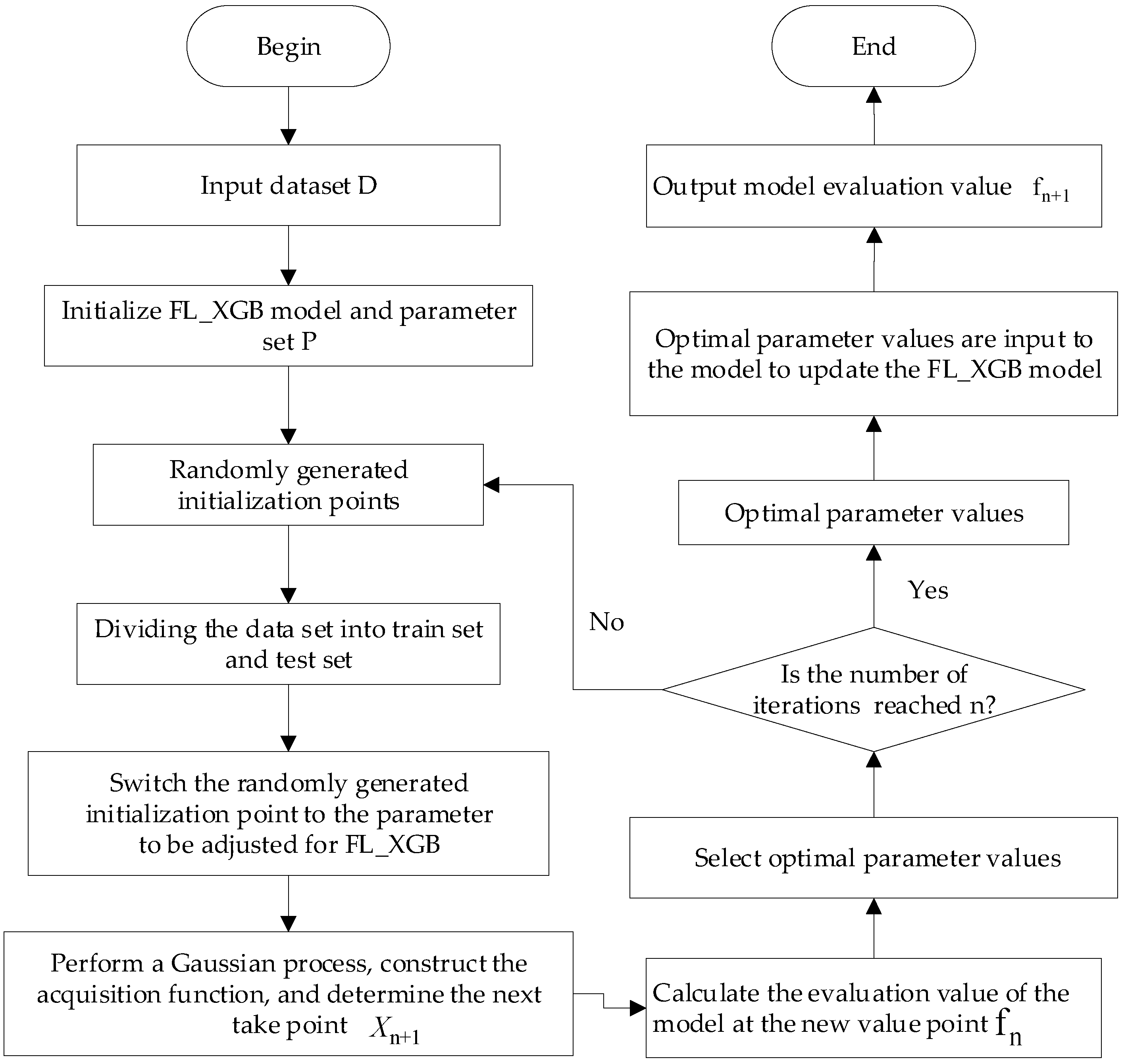
2.3. Optimization of FL-XGB-VPN-Encrypted Traffic Identification Model
- (1)
- Initialize the FL-XGB model, and choose the FL-XGB model as the training target. The objective function is the average evaluation value of the identification model. The set of input parameters and the range of parameter values and the objective function . Randomly set 6 parameters to be optimized, and determine the number of iterations of the algorithm n = 6;
- (2)
- Update the mean and variance of the prior based on the current training data , and calculate the value of the acquisition function based on the mean and variance of ;
- (3)
- Determination of the next parameter taking point according to the extreme value of the acquisition function;
- (4)
- Calculate the model evaluation value using the new parameter values in the FL-XGB model;
- (5)
- Find the optimal parameter value by the model evaluation value in step (4);
- (6)
- Determine whether the number of iterations reaches n;
- (7)
- When the maximum number of set iterations is reached, the parameter optimization process stops. Output a combination of parameter values with the highest evaluation value;
- (8)
- Otherwise, continue with step 2 Bayesian optimization parameters until the termination condition is met;
- (9)
- The optimal combination of parameters obtained in step (7) is input into the FL-XGB model to obtain the optimal identification model. The final identification result of the output model, i.e., the evaluation value. The final identification result of the model, i.e., the evaluation value , is output.
3. Example Analysis
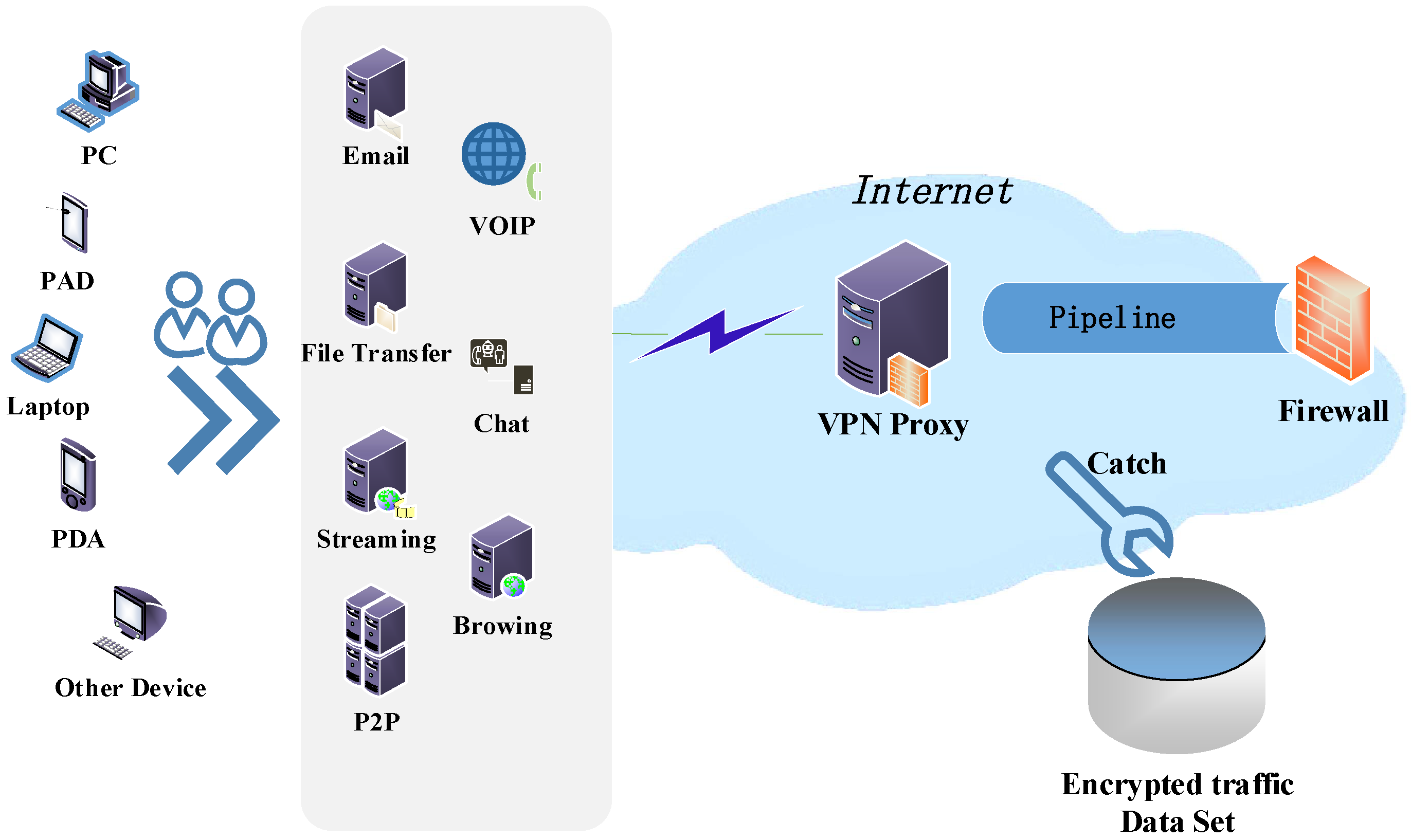
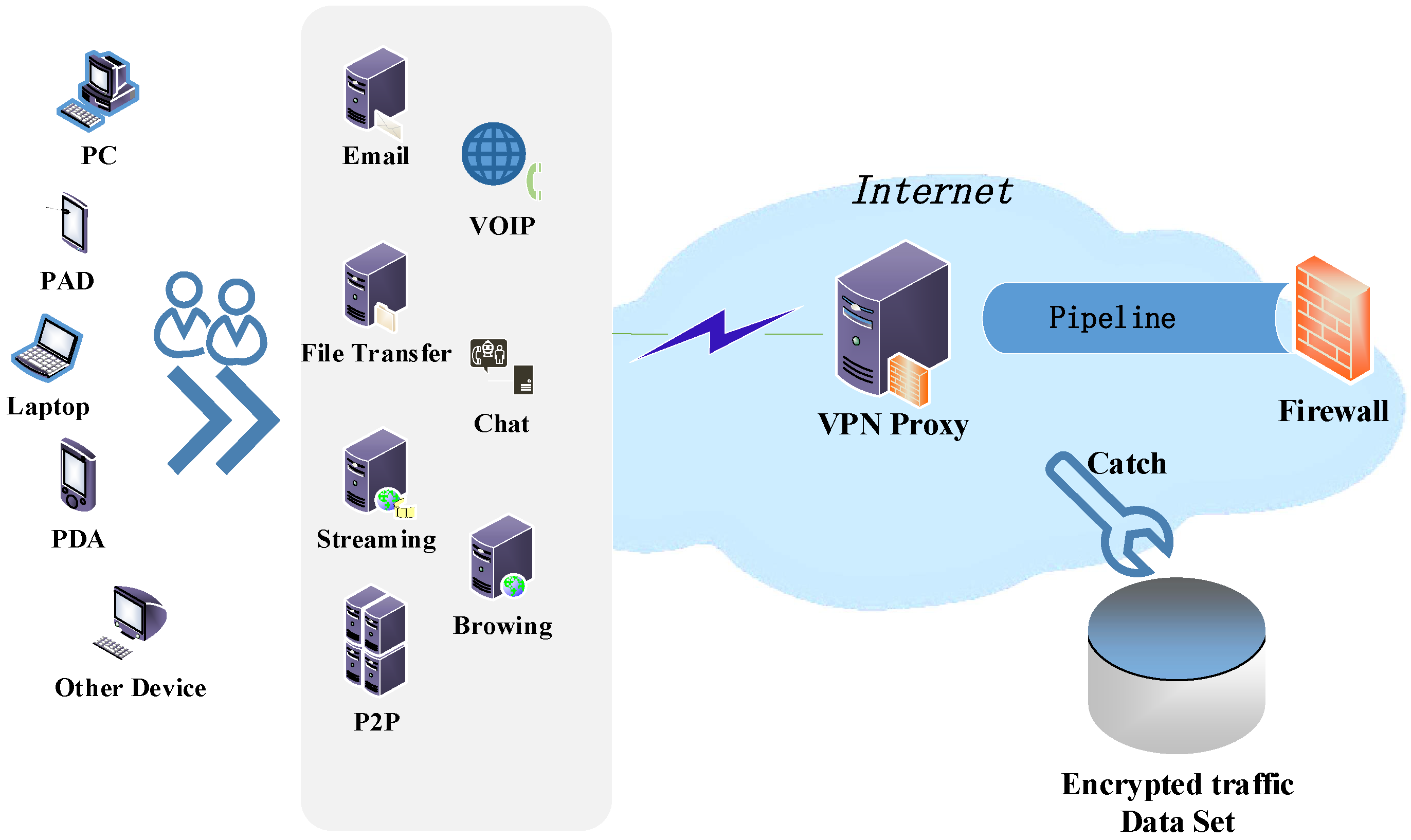
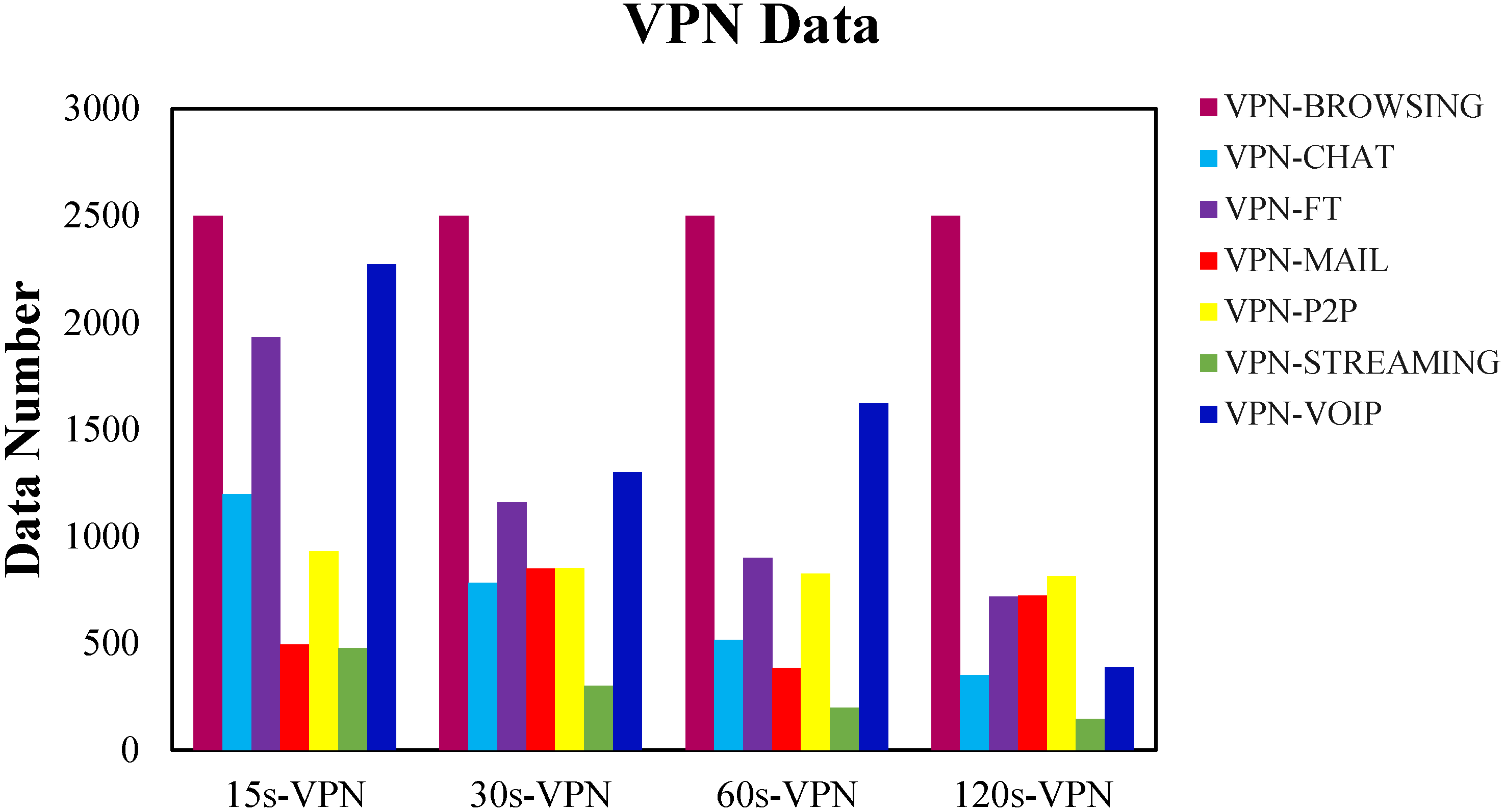
3.1. Data Sources
3.2. Experimental Analysis and Verification
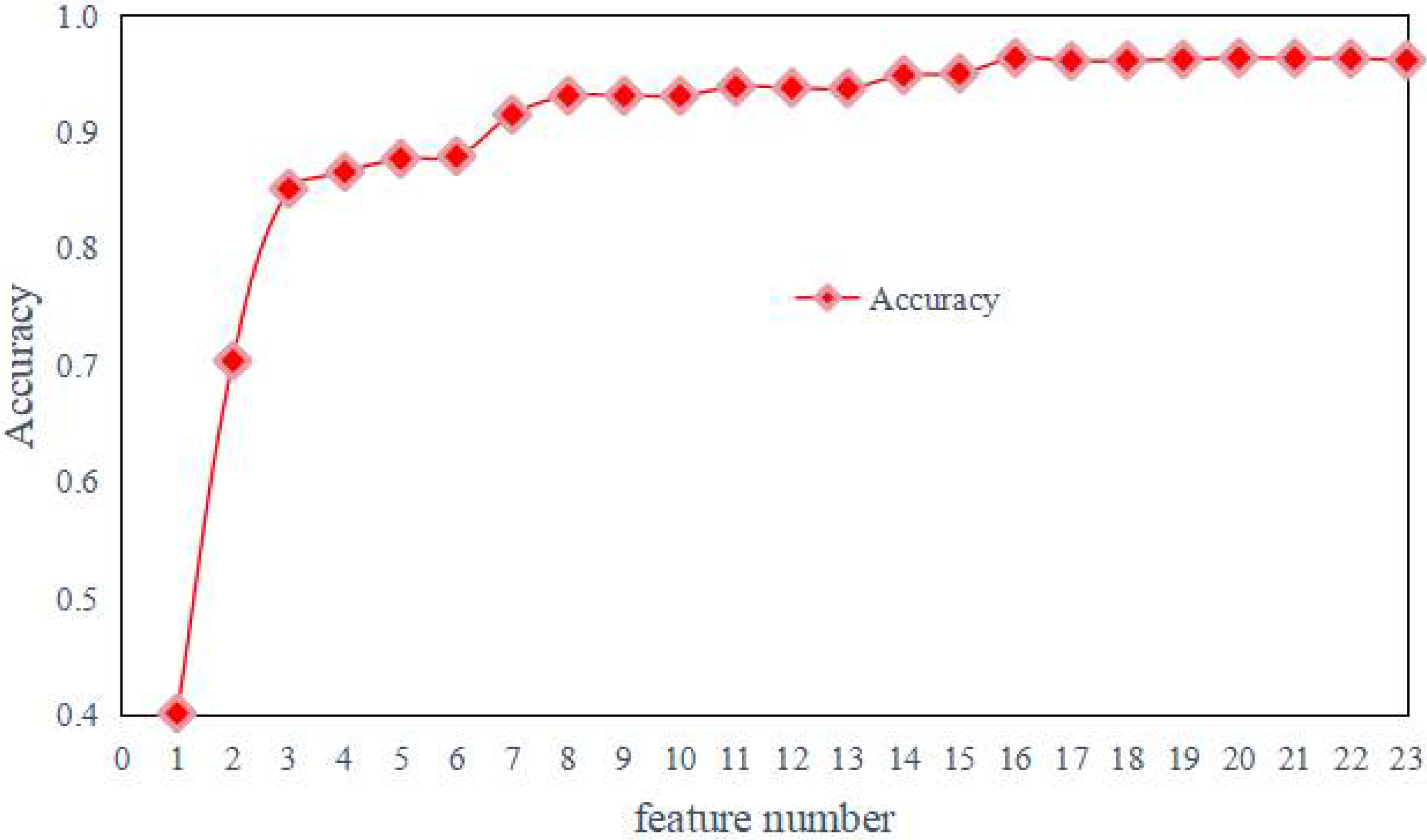
3.2.1. Time-Related mRMR Feature Selection
3.2.2. Construction and Optimization of FL-XGB-VPN-Encrypted Traffic Identification Model
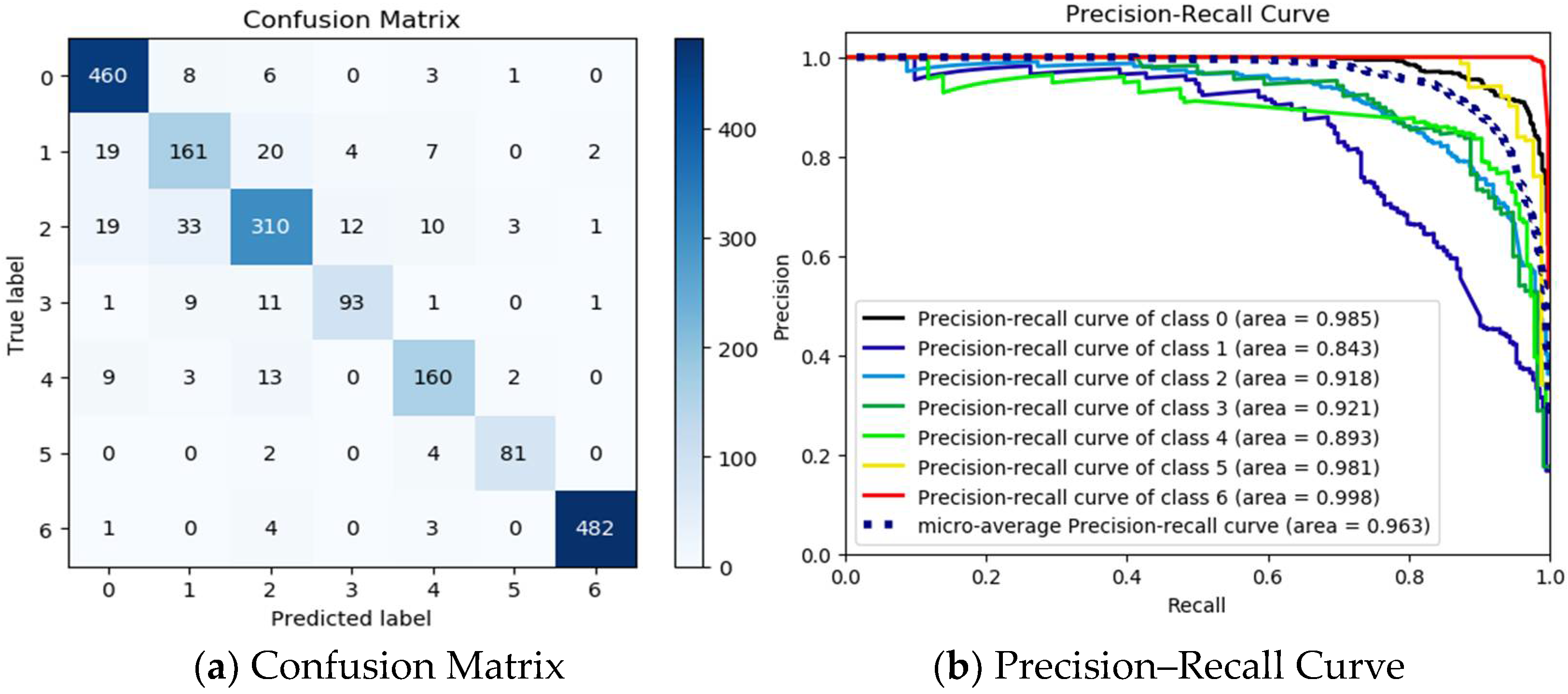
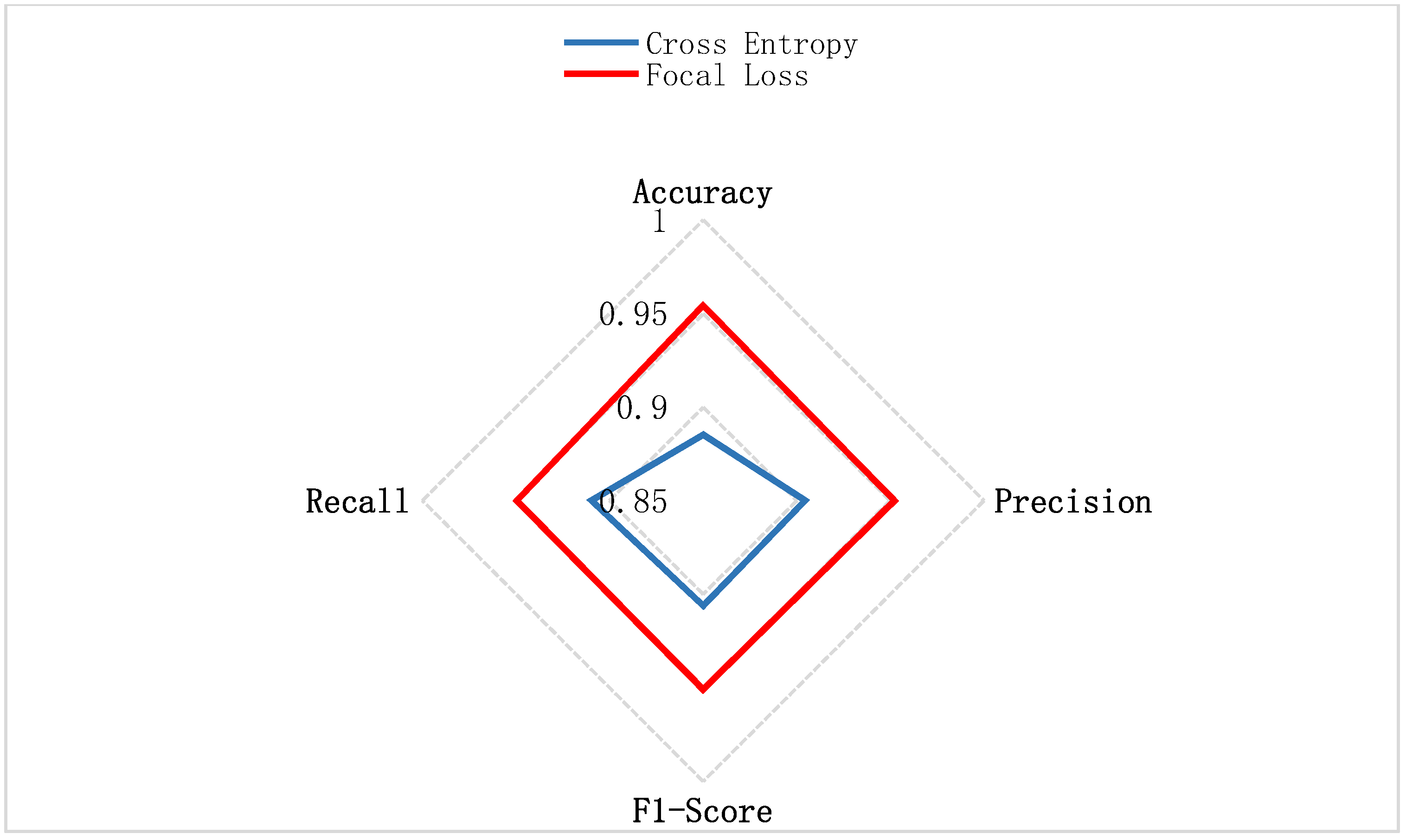
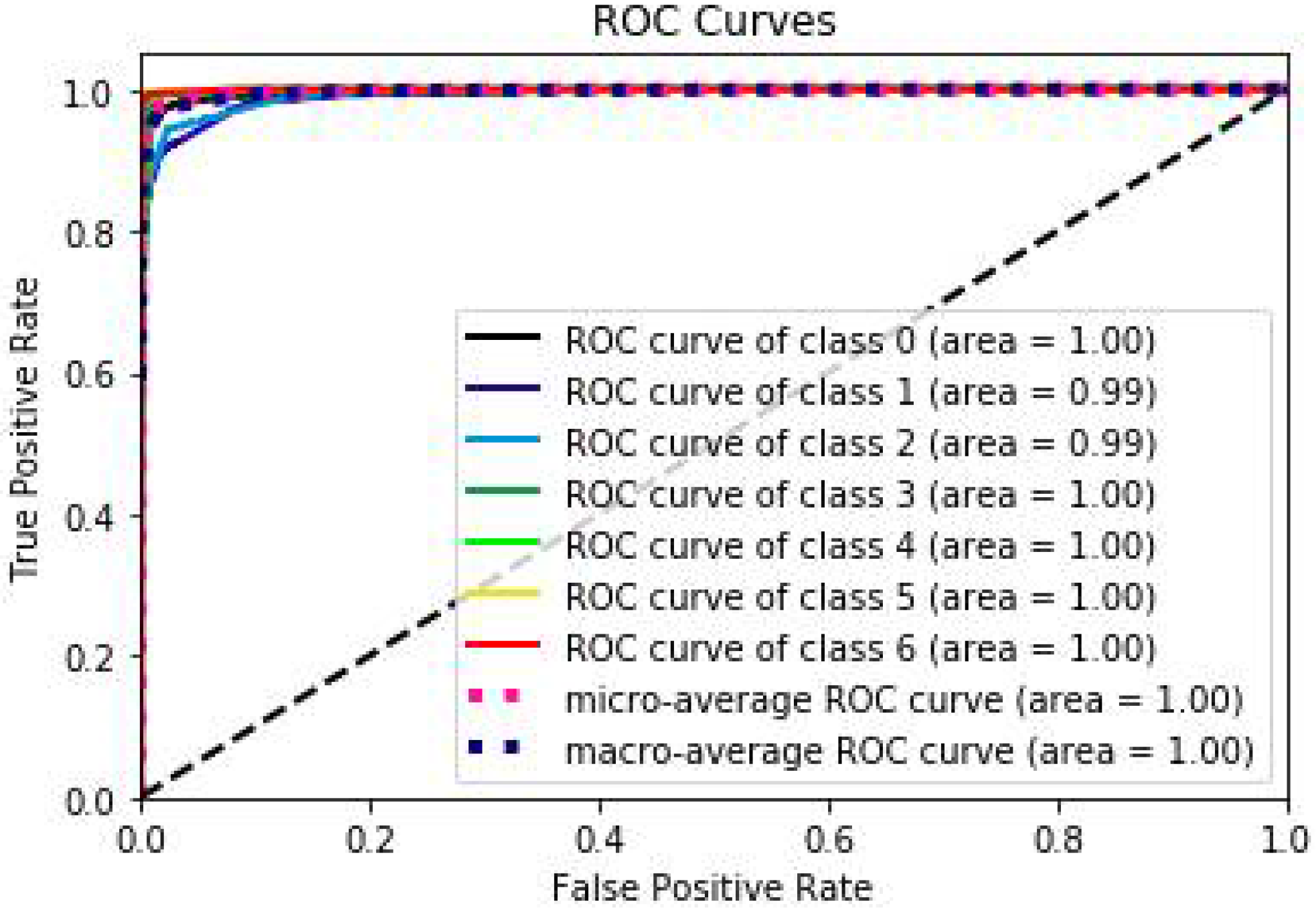
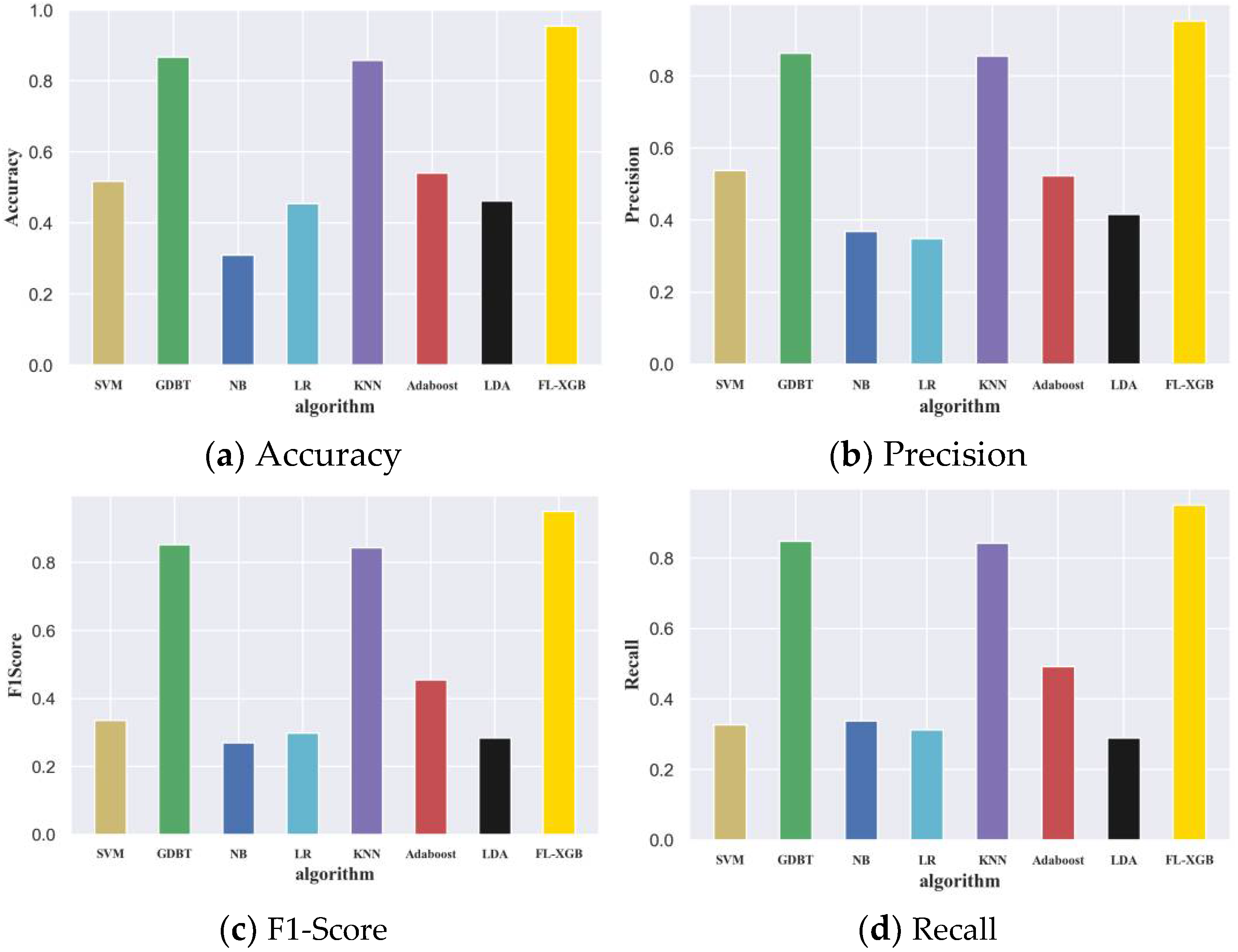
3.2.3. Performance Analysis and Comparison of FL-XGB-Encrypted Traffic Identification Model
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shao, B.; Li, X.; Bian, G. A Survey of Research Hotspots and Frontier Trends of Recommendation Systems from the Perspective of Knowledge Graph. Expert Syst. Appl. 2020, 165, 113764. [Google Scholar] [CrossRef]
- Nisar, K.; Jimson, E.R.; Hijazi, M.H.A.; Welch, I.; Hassan, R.; Aman, A.H.M.; Sodhro, A.H.; Pirbhulal, S.; Khan, S. A Survey on the Architecture, Application, and Security of Software Defined Networking. Internet Things 2020, 12, 100289. [Google Scholar] [CrossRef]
- Gualtieri, L.; Rauch, E.; Vidoni, R. Emerging research fields in safety and ergonomics in industrial collaborative robotics: A systematic literature review. Robot. Comput.-Ensemble Manuf. 2020, 67, 101998. [Google Scholar] [CrossRef]
- Fuentes-García, M.; Camacho, J.; Maciá-Fernández, G. Present and Future of Network Security Monitoring. IEEE Access 2021, 9, 112744–112760. [Google Scholar] [CrossRef]
- Sengupta, S.; Chowdhary, A.; Sabur, A.; Alshamrani, A.; Huang, D.; Kambhampati, S. A survey of moving target defenses for network security. IEEE Commun. Surv. Tutor. 2020, 22, 1909–1941. [Google Scholar] [CrossRef] [Green Version]
- Tahaei, H.; Afifi, F.; Asemi, A.; Zaki, F.; Anuar, N.B. The rise of traffic classification in IoT networks: A survey. J. Netw. Comput. Appl. 2020, 154, 102538. [Google Scholar] [CrossRef]
- Pacheco, F.; Exposito, E.; Gineste, M.; Baudoin, C.; Aguilar, J. Towards the deployment of machine learning solutions in network traffic classification: A systematic survey. IEEE Commun. Surv. Tutor. 2018, 21, 1988–2014. [Google Scholar] [CrossRef] [Green Version]
- Masdari, M.; Khezri, H. A survey and taxonomy of the fuzzy signature-based Intrusion Detection Systems. Appl. Soft Comput. 2020, 92, 106301. [Google Scholar] [CrossRef]
- Khatouni, A.S.; Heywood, N.Z. How much training data is enough to move a ML-based classifier to a different network? Procedia Comput. Sci. 2019, 155, 378–385. [Google Scholar] [CrossRef]
- Juma, M.; Monem, A.A.; Shaalan, K. Hybrid end-to-end VPN security approach for smart IoT objects. J. Netw. Comput. Appl. 2020, 158, 102598. [Google Scholar] [CrossRef]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A. Toward effective mobile encrypted traffic classification through deep learning. Neurocomputing 2020, 409, 306–315. [Google Scholar] [CrossRef]
- Bu, Z.; Zhou, B.; Cheng, P.; Zhang, K.; Ling, Z.-H. Encrypted Network Traffic Classification Using Deep and Parallel Network-in-Network Models. IEEE Access 2020, 8, 132950–132959. [Google Scholar] [CrossRef]
- Cao, Z.; Xiong, G.; Zhao, Y.; Li, Z.; Guo, L. A Survey on Encrypted Traffic Classification; International Conference on Applications and Techniques in Information Security; Springer: Berlin/Heidelberg, Germany, 2014; pp. 73–81. [Google Scholar]
- Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescape, A. Mobile encrypted traffic classification using deep learning: Experimental evaluation, lessons learned, and challenges. IEEE Trans. Netw. Serv. Manag. 2019, 16, 445–458. [Google Scholar] [CrossRef]
- Rezaei, S.; Liu, X. Deep learning for encrypted traffic classification: An overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef] [Green Version]
- Handa, A.; Sharma, A.; Shukla, S.K. Machine learning in cybersecurity: A review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1306. [Google Scholar] [CrossRef]
- Ribeiro, V.H.A.; Reynoso-Meza, G. Ensemble learning by means of a multi-objective optimization design approach for dealing with imbalanced data sets. Expert Syst. Appl. 2020, 147, 113232. [Google Scholar] [CrossRef]
- Meng, F.; Cheng, W.; Wang, J. Semi-supervised Software Defect Prediction Model Based on Tri-training. KSII Trans. Internet Inf. Syst. (TIIS) 2021, 15, 4028–4042. [Google Scholar] [CrossRef]
- Xibin, D.; Zhiwen, Y.; Wenming, C.; Yifan, S.; Qianli, M. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Paxson, V. Empirically derived analytic models of wide-area TCP connections. IEEE/ACM Trans. Netw. 1994, 2, 316–336. [Google Scholar] [CrossRef] [Green Version]
- Sen, S.; Spatscheck, O.; Wang, D. Accurate, scalable in-network identification of p2p traffic using application signatures. In Proceedings of the 13th International Conference on World Wide Web, New York, NY, USA, 17 May 2004; pp. 512–521. [Google Scholar]
- Lotfollahi, M.; Siavoshani, M.J.; Zade, R.S.H.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef] [Green Version]
- Dutt, I.; Borah, S.; Maitra, I.K. Multiple Immune-based Approaches for Network Traffic Analysis. Procedia Comput. Sci. 2020, 167, 2111–2123. [Google Scholar] [CrossRef]
- Yao, Z.; Ge, J.; Wu, Y.; Lin, X.; He, R.; Ma, Y. Encrypted traffic classification based on Gaussian mixture models and Hidden Markov Models. J. Netw. Comput. Appl. 2020, 166, 102711. [Google Scholar] [CrossRef]
- Chang, L.; Zigang, C.; Gang, X.; Gaopeng, G.; Siu-Ming, Y.; Longtao, H. MaMPF: Encrypted Traffic Classification Based on Multi-Attribute Markov Probability Fingerprints. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–10. [Google Scholar]
- Gijon, C.; Toril, M.; Solera, M.; Luna-Ramirez, S.; Jimenez, L.R. Encrypted Traffic Classification Based on Unsupervised Learning in Cellular Radio Access Networks. IEEE Access 2020, 8, 167252–167263. [Google Scholar] [CrossRef]
- Draper-Gil, G.; Habibi Lashkari, A.; Mamun, M.S.; Ghorbani, A.A. Characterization of encrypted and VPN traffic using time-related. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy, 19–21 February 2016; pp. 407–414. Available online: https://www.unb.ca/cic/datasets/vpn.html (accessed on 1 June 2022).
- Raikar, M.M.; Meena, M.S.; Mulla, M.M.; Shetti, N.S.; Karanandi, M. Data Traffic Classification in Software Defined Networks (SDN) using supervised-learning. Procedia Comput. Sci. 2020, 171, 2750–2759. [Google Scholar] [CrossRef]
- Dias, K.; Pongelupe, M.A.; Caminhas, W.M.; de Errico, L. An innovative approach for real-time network traffic classification. Comput. Netw. 2019, 158, 143–157. [Google Scholar] [CrossRef]
- Shekhawat, A.S.; Di Troia, F.; Stamp, M. Feature analysis of encrypted malicious traffic. Expert Syst. Appl. 2019, 125, 130–141. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Alonso-Betanzos, A. Ensembles for feature selection: A review and future trends. Inf. Fusion 2019, 52, 1–12. [Google Scholar] [CrossRef]
- Takeda, K.; Kabashima, Y. Multi-Label Feature Selection Algorithm Based on Information Entropy. J. Comput. Res. Dev. 2013, 50, 1177–1184. [Google Scholar]
- Berk, R.A. Classification and Regression Trees (CART). In Statistical Learning from a Regression Perspective; Springer Series in Statistics; Springer: New York, NY, USA, 2008. [Google Scholar]
- Lashkari, A.H.; Gil, G.D.; Mamun, M.; Ghorbani, A.A. Characterization of Tor Traffic using Time based Features. In Proceedings of the International Conference on Information Systems Security & Privacy, Porto, Portugal, 1 January 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traffic | Content |
|---|---|
| Browsing | Firefox and Chrome |
| SMPTS, POP3S and IMAPS | |
| Chat | ICQ, AIM, Skype, Facebook and Hangouts |
| Streaming | Vimero and Youtube |
| File Transfer | Skype, FTPS and SFTP |
| VoIP | Facebook, Skype, and Hangouts |
| P2P | Utorrent and Transmission |
| Feature | Description |
|---|---|
| Duration | The duration of the flow. |
| FIAT | Forward Inter Arrival Time, the time between two packets sent forward direction (mean, min, max, std). |
| BIAT | Backward Inter Arrival Time, the time between two packets sent backward (mean, min, max, std). |
| Flow-IAT | Flow Inter Arrival Time, is the time between two packets sent in either direction (mean, min, max, std). |
| Active | The amount of time a flow was active before going idle (mean, min, max, std). |
| Idle | The amount of time a flow was idle before becoming active (mean, min, max, std). |
| FB-psec | Flow Bytes per second. |
| FP-psec | Flow packets per second. |
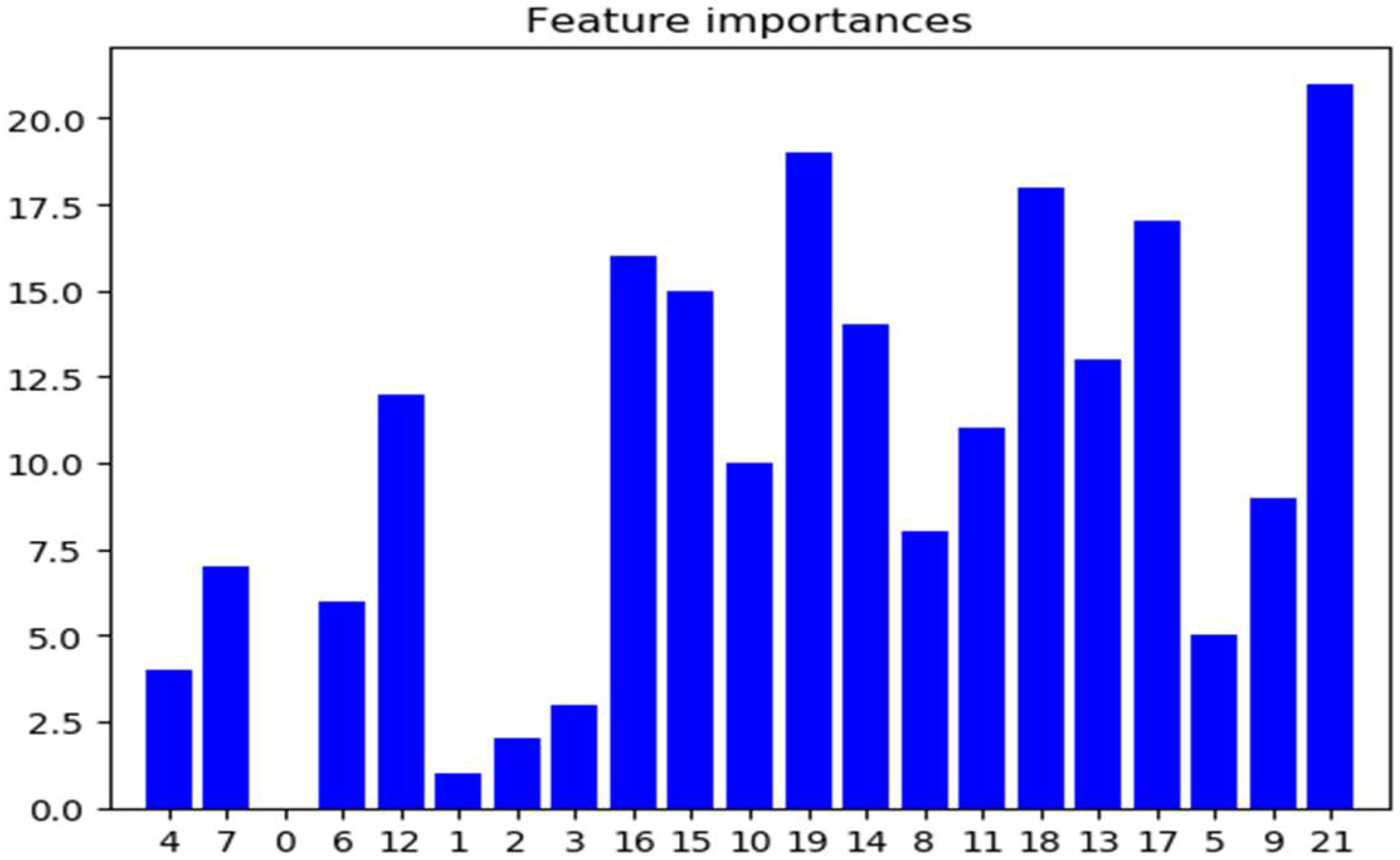
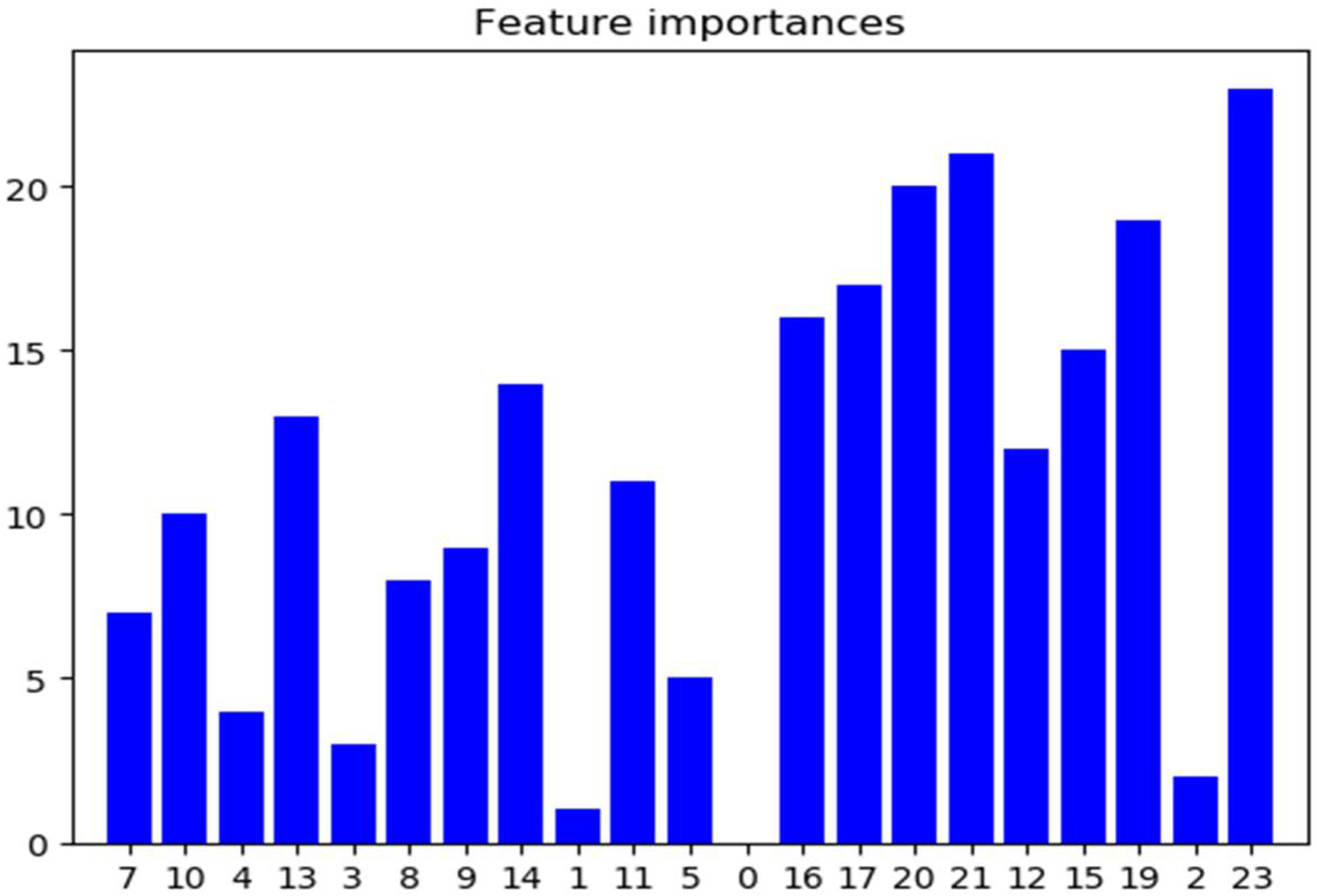
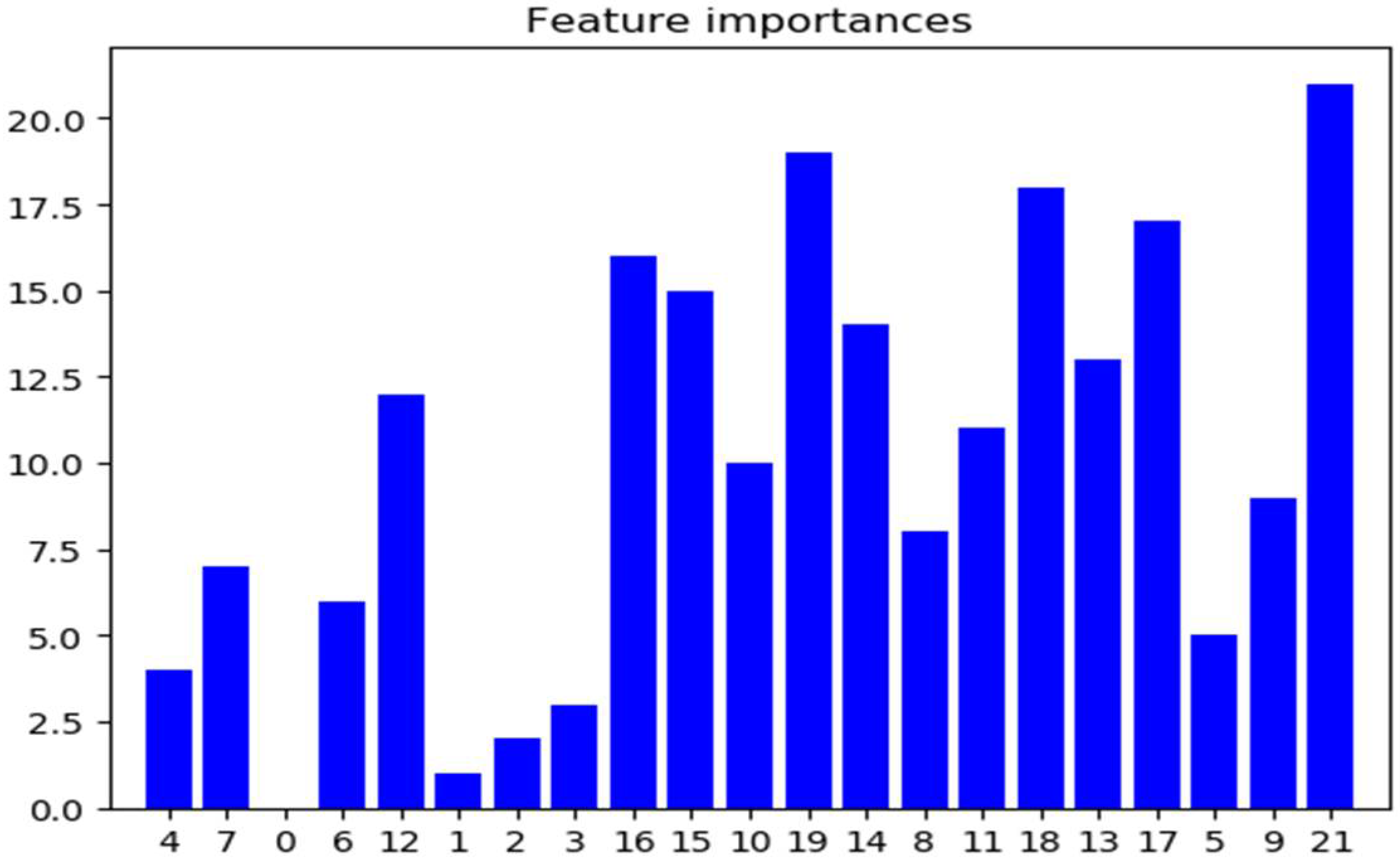
| Feature Number | Feature Name | Importance Ordering |
|---|---|---|
| 0 | duration NUMERIC | 18 |
| 1 | total_fiat NUMERIC | 23 |
| 2 | total_biat NUMERIC | 15 |
| 3 | min_fiat NUMERIC | 16 |
| 4 | min_biat NUMERIC | 14 |
| 5 | max_fiat NUMERIC | 21 |
| 6 | max_biat NUMERIC | 3 |
| 7 | mean_fiat NUMERIC | 19 |
| 8 | mean_biat NUMERIC | 20 |
| 9 | flowPktsPerSecond NUMERIC | 8 |
| 10 | flowBytesPerSecond NUMERIC | 2 |
| 11 | min_flowiat NUMERIC | 11 |
| 12 | max_flowiat NUMERIC | 7 |
| 13 | mean_flowiat NUMERIC | 17 |
| 14 | std_flowiat NUMERIC | 22 |
| 15 | min_active NUMERIC | 5 |
| 16 | mean_active NUMERIC | 9 |
| 17 | max_active NUMERIC | 12 |
| 18 | std_active NUMERIC | 13 |
| 19 | min_idle NUMERIC | 4 |
| 20 | mean_idle NUMERIC | 6 |
| 21 | max_idle NUMERIC | 10 |
| 22 | std_idle NUMERIC | 1 |
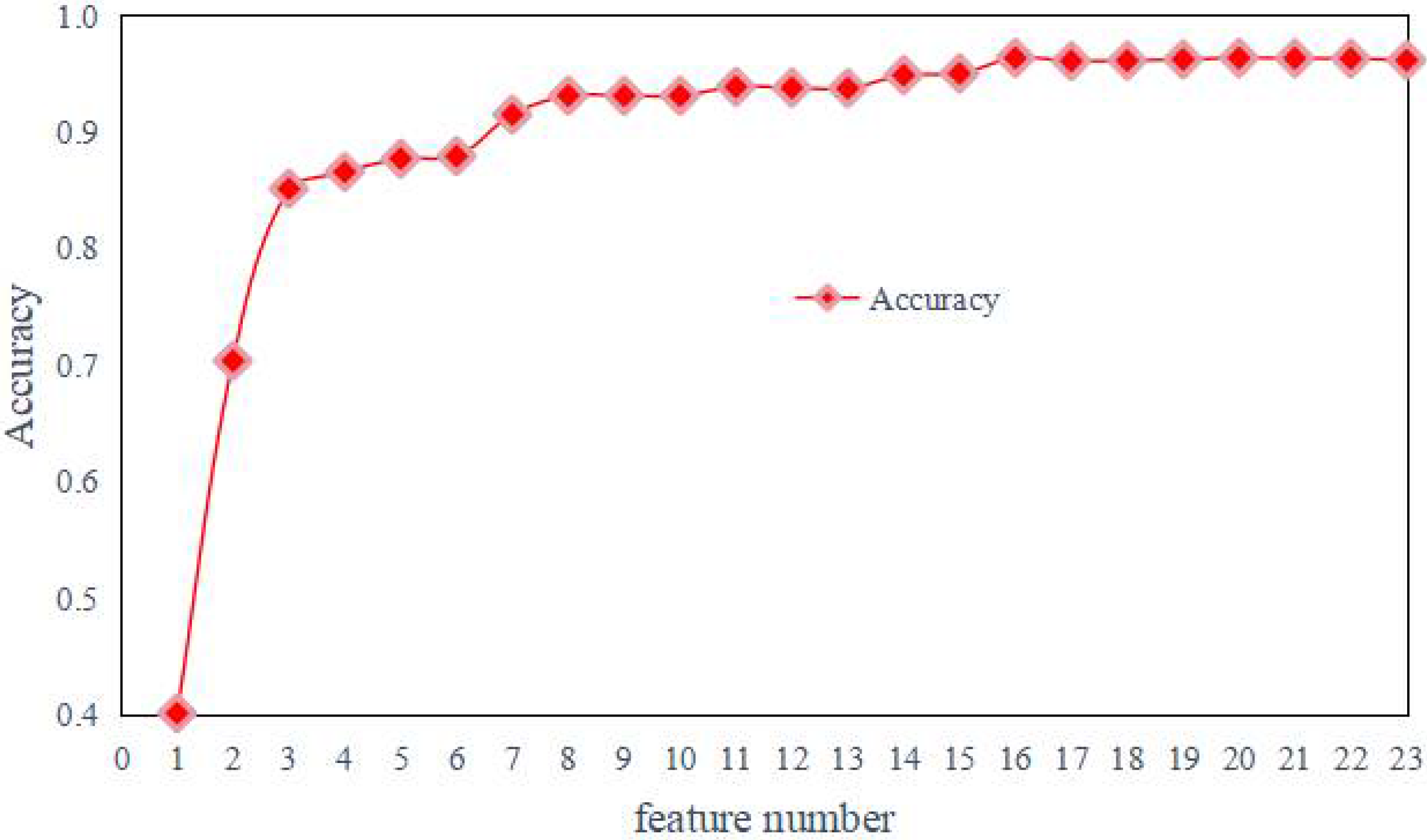
| The Number of Features | Accuracy | Removed Feature Number | Removed Feature Name |
|---|---|---|---|
| 23 | 0.9617 | Non | Non |
| 22 | 0.9630 | 1 | total_fiat NUMERIC |
| 21 | 0.9633 | 14 | std_flowiat NUMERIC |
| 20 | 0.9636 | 5 | max_fiat NUMERIC |
| 19 | 0.9623 | 8 | mean_biat NUMERIC |
| 18 | 0.9614 | 7 | mean_fiat NUMERIC |
| 17 | 0.9610 | 0 | duration NUMERIC |
| 16 | 0.9636 | 13 | mean_flowiat NUMERIC |
| 15 | 0.9503 | 3 | min_fiat NUMERIC |
| 14 | 0.9488 | 2 | total_biat NUMERIC |
| 13 | 0.9376 | 4 | min_biat NUMERIC |
| 12 | 0.9380 | 18 | std_active NUMERIC |
| 11 | 0.9388 | 17 | max_active NUMERIC |
| 10 | 0.9312 | 11 | min_flowiat NUMERIC |
| 9 | 0.9312 | 21 | max_idle NUMERIC |
| 8 | 0.9313 | 16 | mean_active NUMERIC |
| 7 | 0.9150 | 9 | flowPktsPerSecond NUMERIC |
| 6 | 0.8794 | 12 | max_flowiat NUMERIC |
| 5 | 0.8772 | 20 | mean_idle NUMERIC |
| 4 | 0.8658 | 15 | min_active NUMERIC |
| 3 | 0.8514 | 19 | min_idle NUMERIC |
| 2 | 0.7038 | 6 | max_biat NUMERIC |
| 1 | 0.4016 | 10 | flowBytesPerSecond NUMERIC |
| 0 | 0 | 22 | std_idle NUMERIC |
| Cross Entropy | ||
|---|---|---|
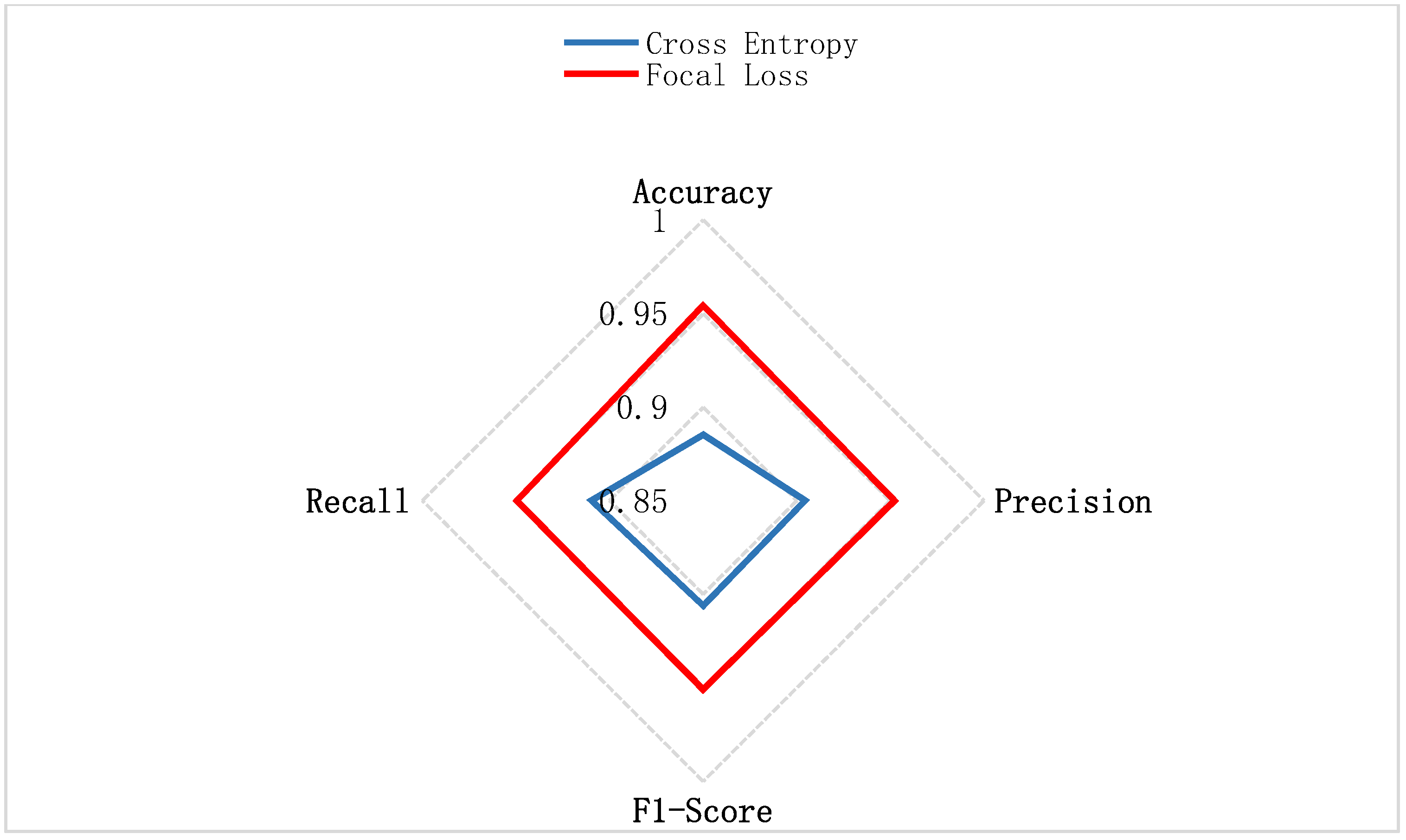
| Accuracy | 0.8852 | 0.9543 |
| Precision | 0.9045 | 0.9522 |
| F1-Score | 0.9062 | 0.9509 |
| Recall | 0.9097 | 0.9496 |
| Parameter Name | Value Ranges |
|---|---|
| Max_depth | (1, 15) |
| Eta | (0, 1) |
| Min_child_weight | (0.1, 20) |
| Gamma | (0, 20) |
| Subsample | (0, 1) |
| colsample_bytree | (0, 1) |
| Parameter Name | Value |
|---|---|
| Max_depth | 10 |
| Eta | 0.3 |
| Min_child_weight | 4 |
| Gamma | 7.7 |
| Subsample | 0.5 |
| colsample_bytree | 0.2 |
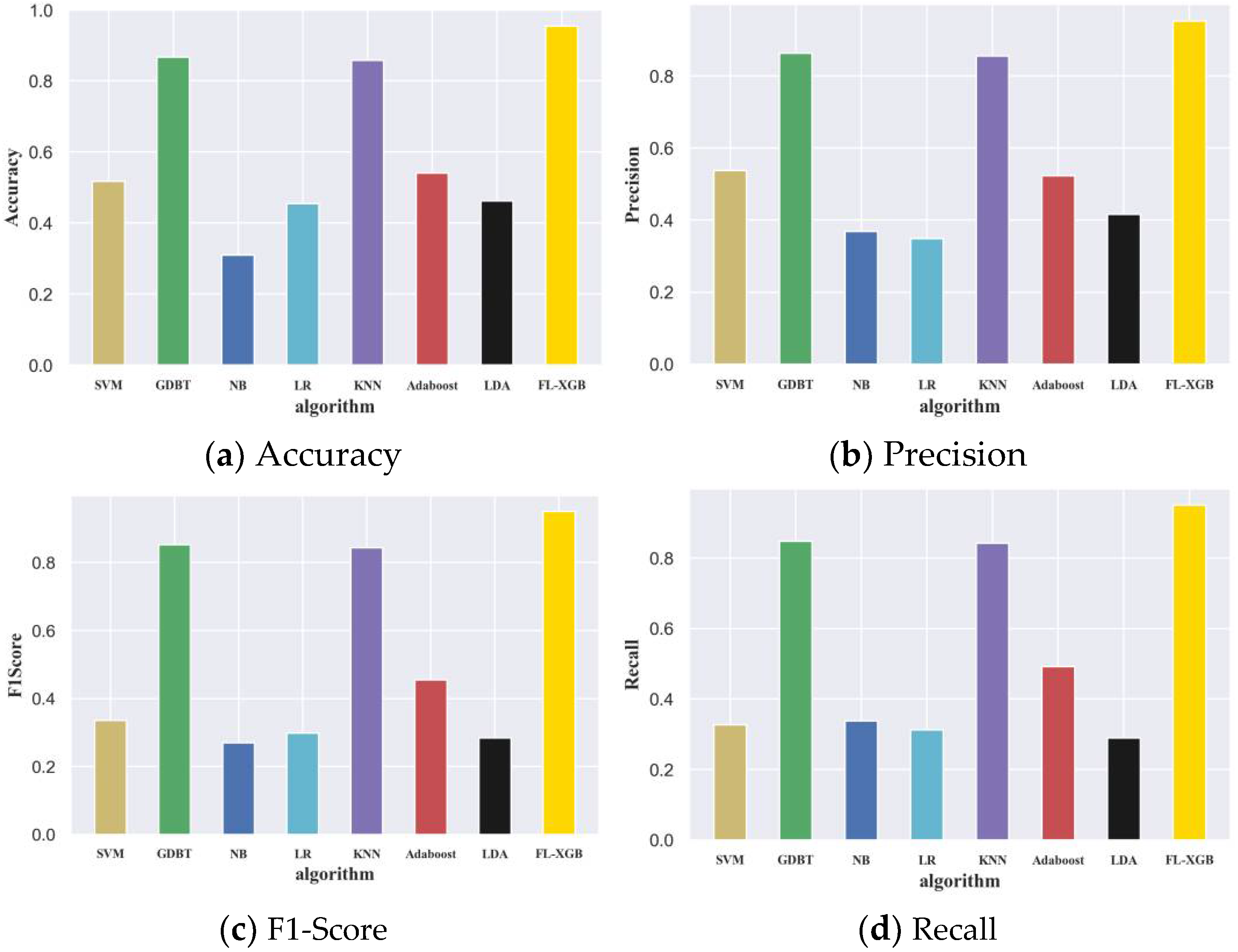
| Algorithm | ACC | Precision | F1-Score | Recall |
|---|---|---|---|---|
| SVM | 0.5169 | 0.5374 | 0.3361 | 0.3271 |
| GDBT | 0.8666 | 0.8626 | 0.8521 | 0.8475 |
| NB | 0.3093 | 0.3685 | 0.2691 | 0.3379 |
| LR | 0.4548 | 0.3489 | 0.2977 | 0.3126 |
| KNN | 0.8575 | 0.8553 | 0.8433 | 0.8416 |
| Adaboost | 0.5408 | 0.5224 | 0.4545 | 0.4913 |
| LDA | 0.4623 | 0.4153 | 0.2841 | 0.2892 |
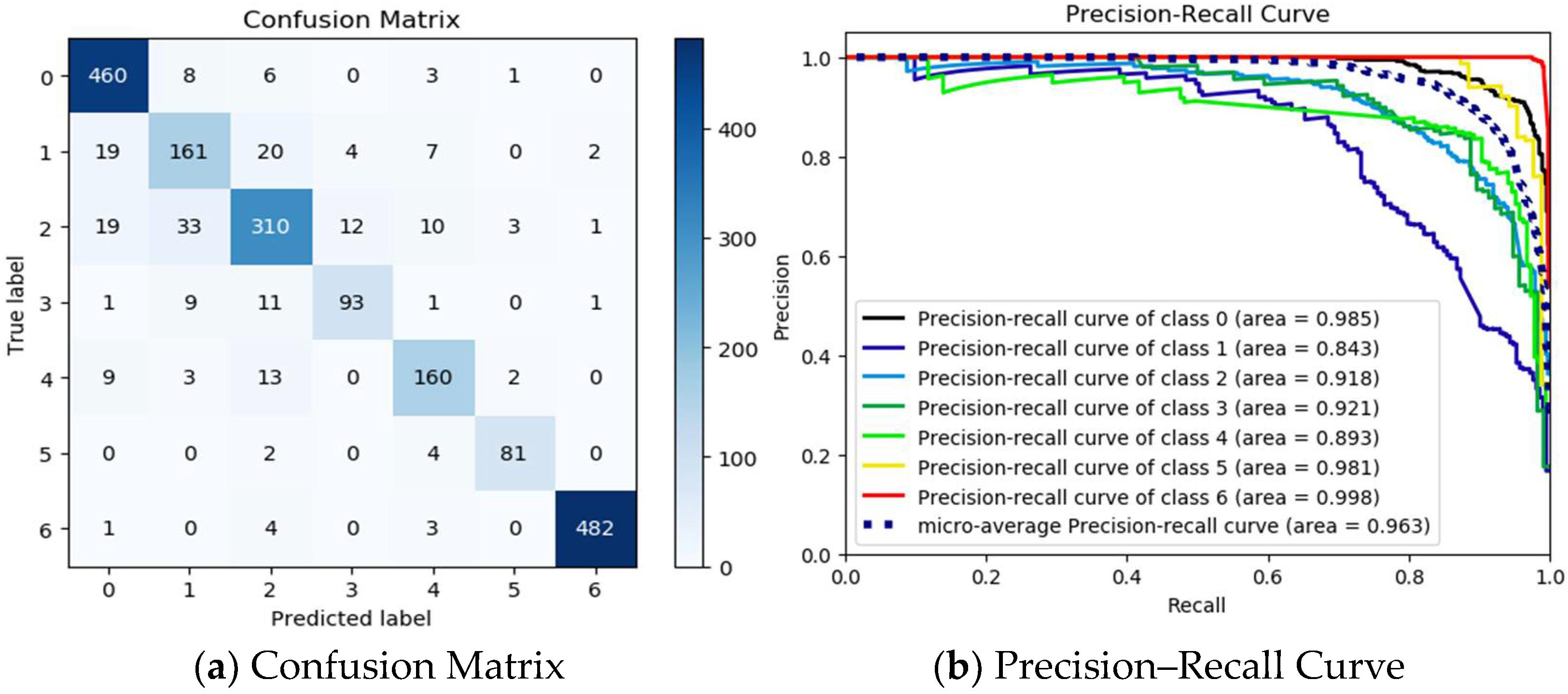
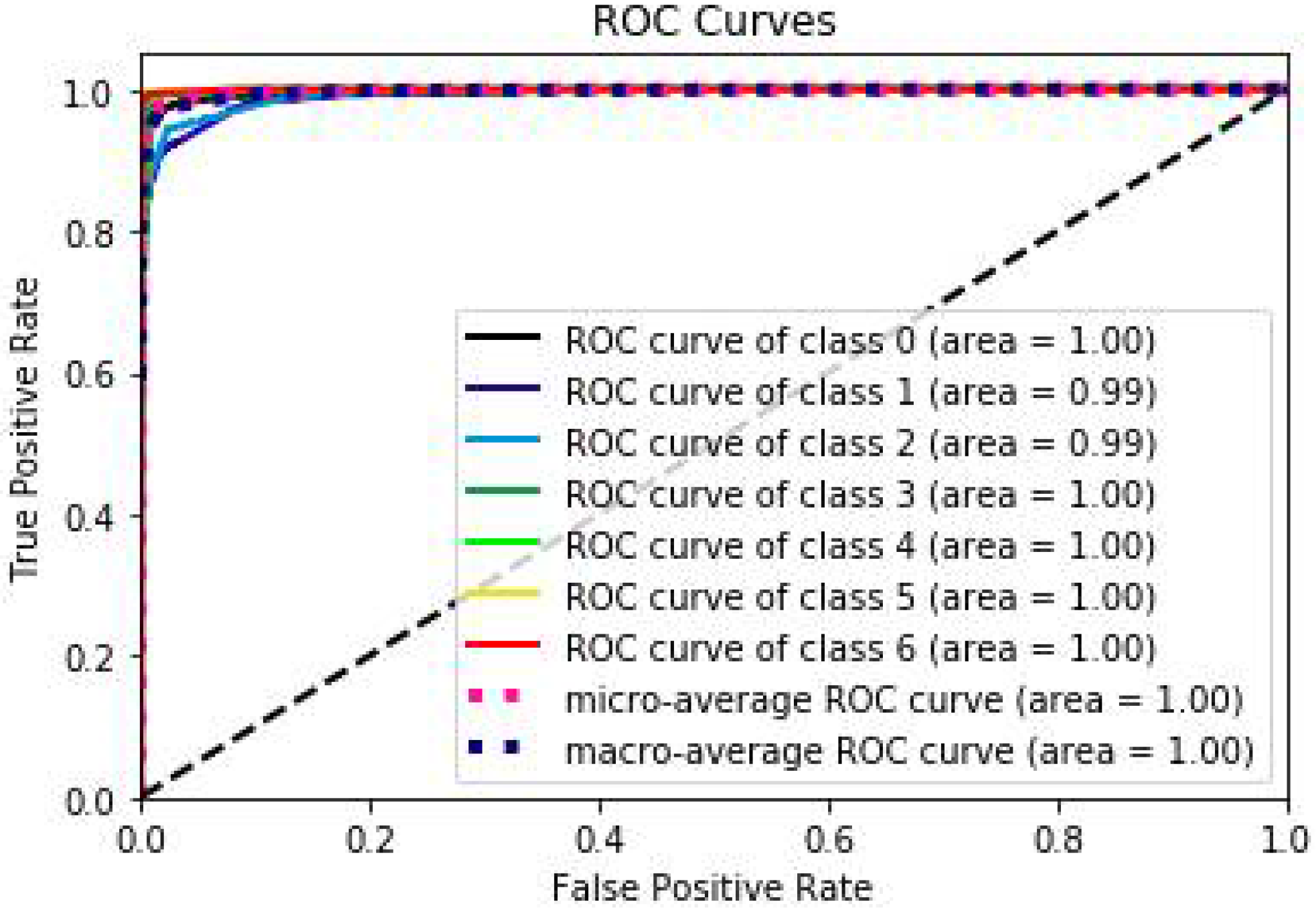
| FL-XGB | 0.9743 | 0.9722 | 0.9703 | 0.9796 |
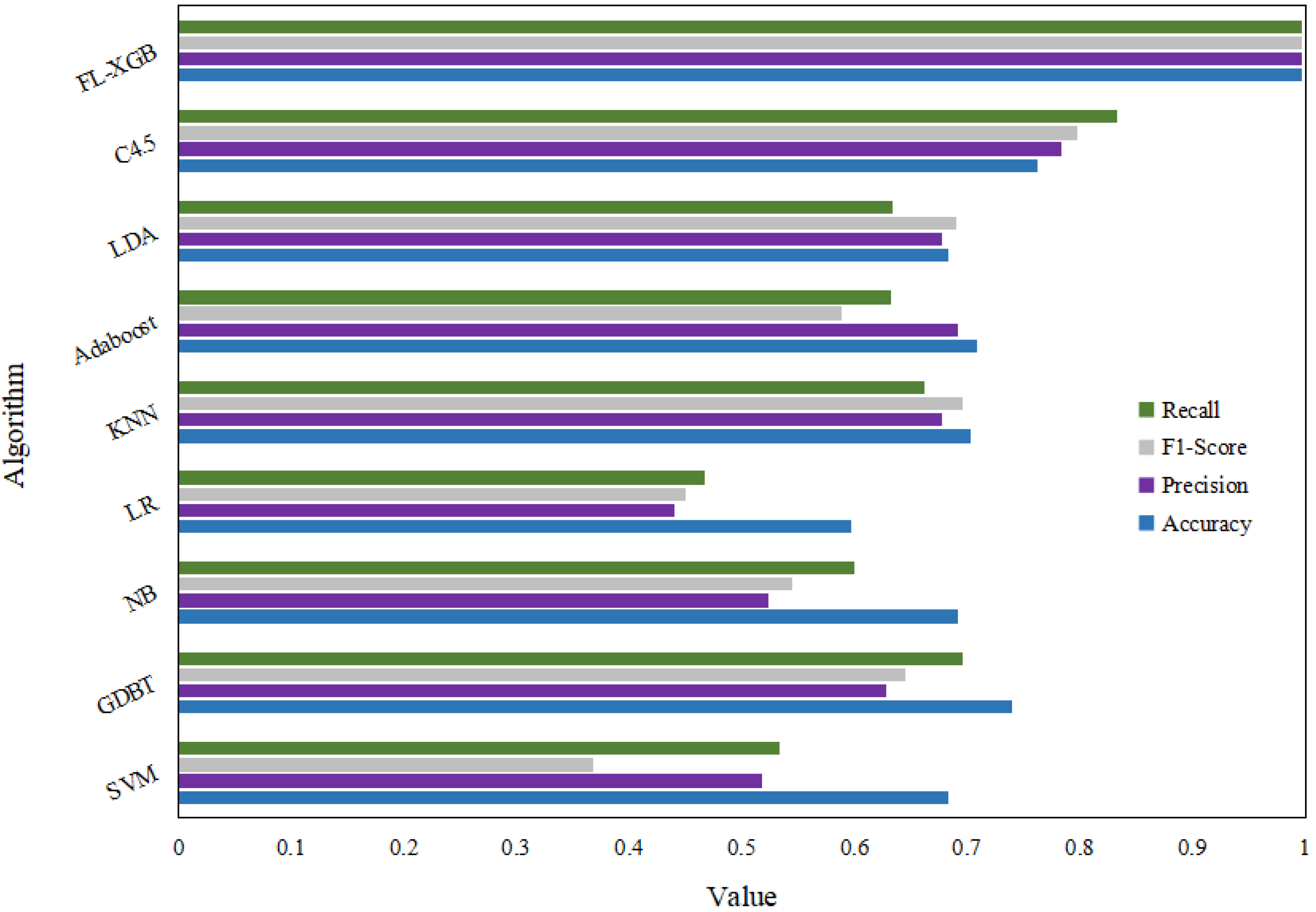
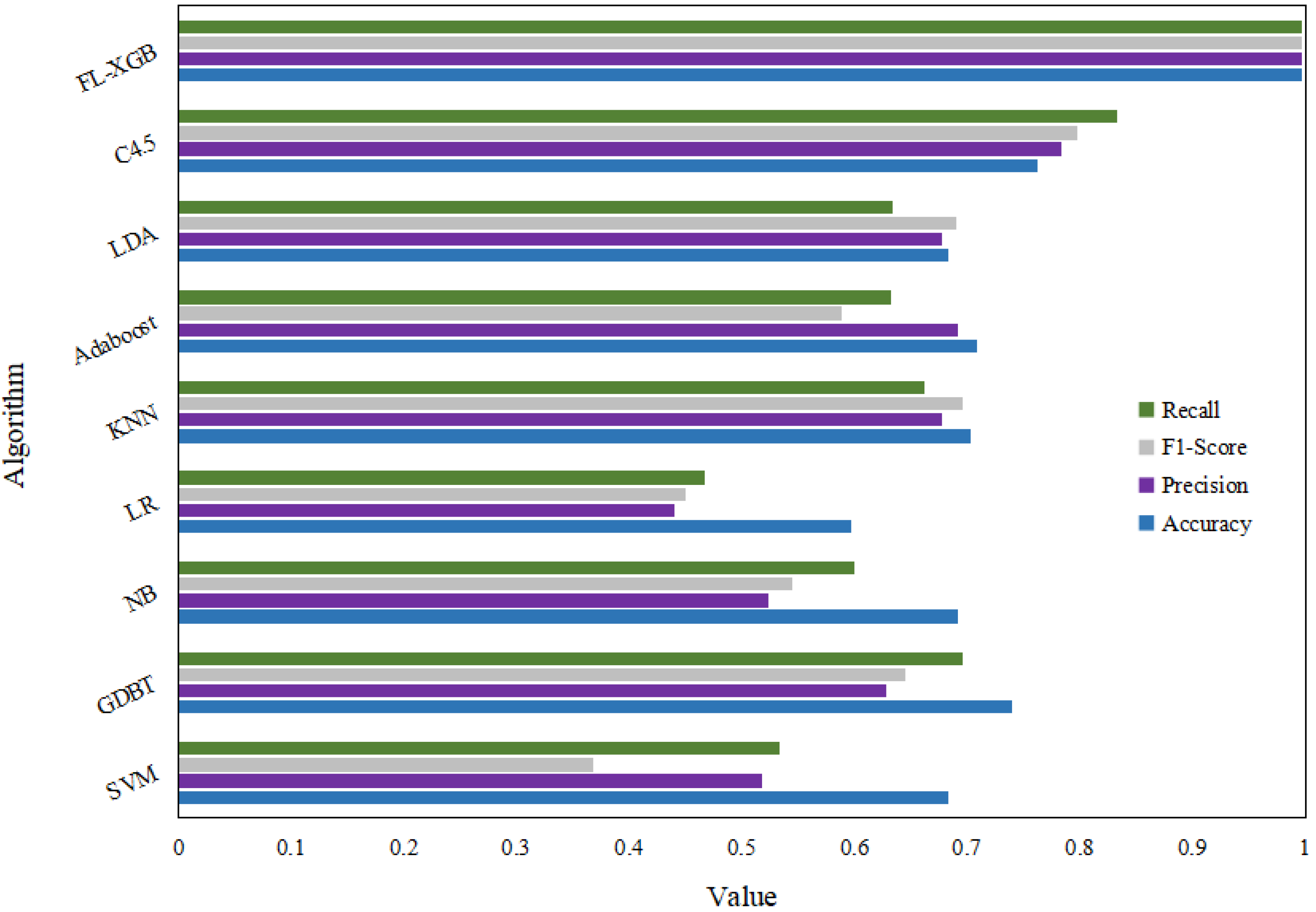
| Algorithm | Accuracy | Precision | F1-Score | Recall |
|---|---|---|---|---|
| SVM | 0.6824 | 0.5169 | 0.3671 | 0.5333 |
| GDBT | 0.739 | 0.6278 | 0.644 | 0.6949 |
| NB | 0.6911 | 0.5228 | 0.5441 | 0.6001 |
| LR | 0.5966 | 0.4398 | 0.4498 | 0.4667 |
| KNN | 0.7023 | 0.6775 | 0.6962 | 0.6618 |
| Adaboost | 0.7079 | 0.6911 | 0.5884 | 0.6321 |
| LDA | 0.6824 | 0.6778 | 0.69 | 0.6333 |
| C4.5 | 0.762 | 0.7827 | 0.7969 | 0.8333 |
| FL-XGB | 0.996 | 0.9959 | 0.9963 | 0.9967 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, J.; Yuan, X.-L.; Cui, Y.; Fan, J.-C.; Chen, C.-L. A VPN-Encrypted Traffic Identification Method Based on Ensemble Learning. Appl. Sci. 2022, 12, 6434. https://doi.org/10.3390/app12136434
Cao J, Yuan X-L, Cui Y, Fan J-C, Chen C-L. A VPN-Encrypted Traffic Identification Method Based on Ensemble Learning. Applied Sciences. 2022; 12(13):6434. https://doi.org/10.3390/app12136434
Chicago/Turabian StyleCao, Jie, Xing-Liang Yuan, Ying Cui, Jia-Cheng Fan, and Chin-Ling Chen. 2022. "A VPN-Encrypted Traffic Identification Method Based on Ensemble Learning" Applied Sciences 12, no. 13: 6434. https://doi.org/10.3390/app12136434
APA StyleCao, J., Yuan, X.-L., Cui, Y., Fan, J.-C., & Chen, C.-L. (2022). A VPN-Encrypted Traffic Identification Method Based on Ensemble Learning. Applied Sciences, 12(13), 6434. https://doi.org/10.3390/app12136434