
Medical Gesture Recognition Method Based on Improved Lightweight Network


Abstract
:1. Introduction
2. Related Works
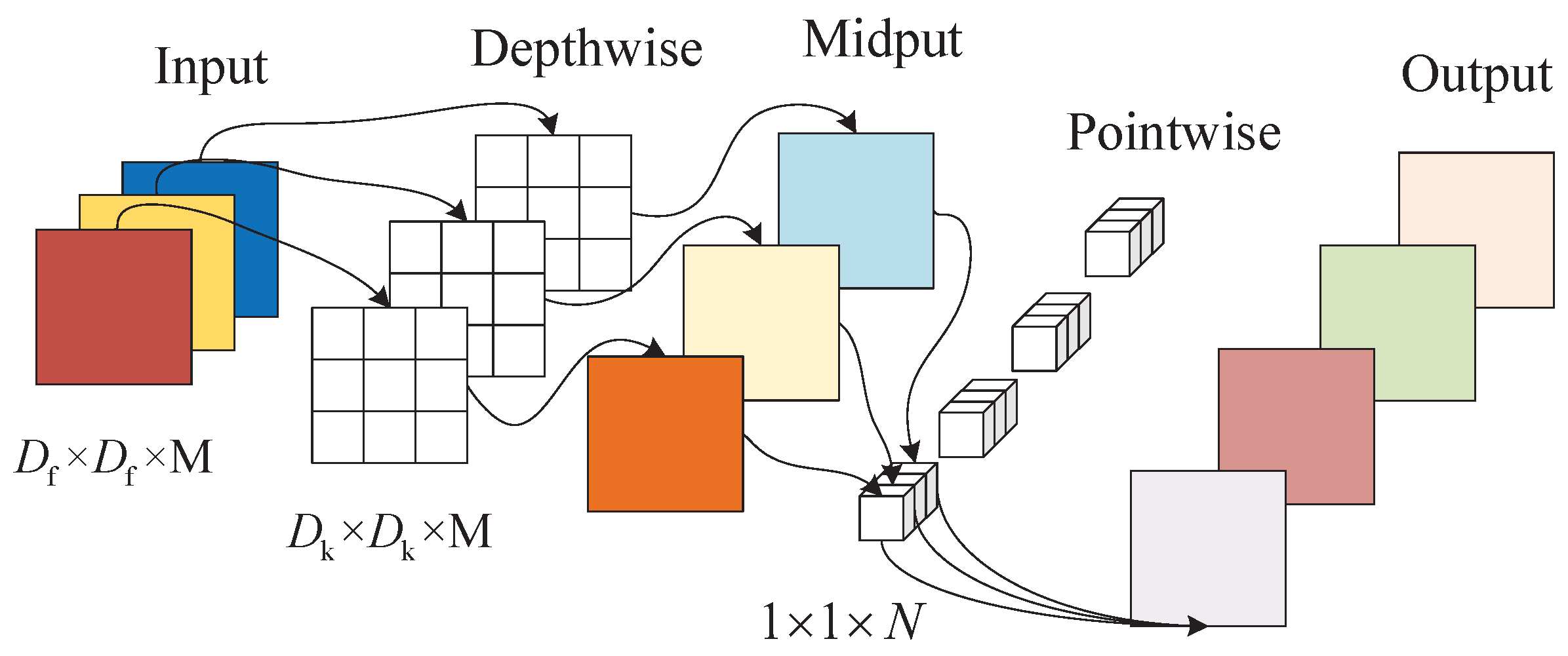
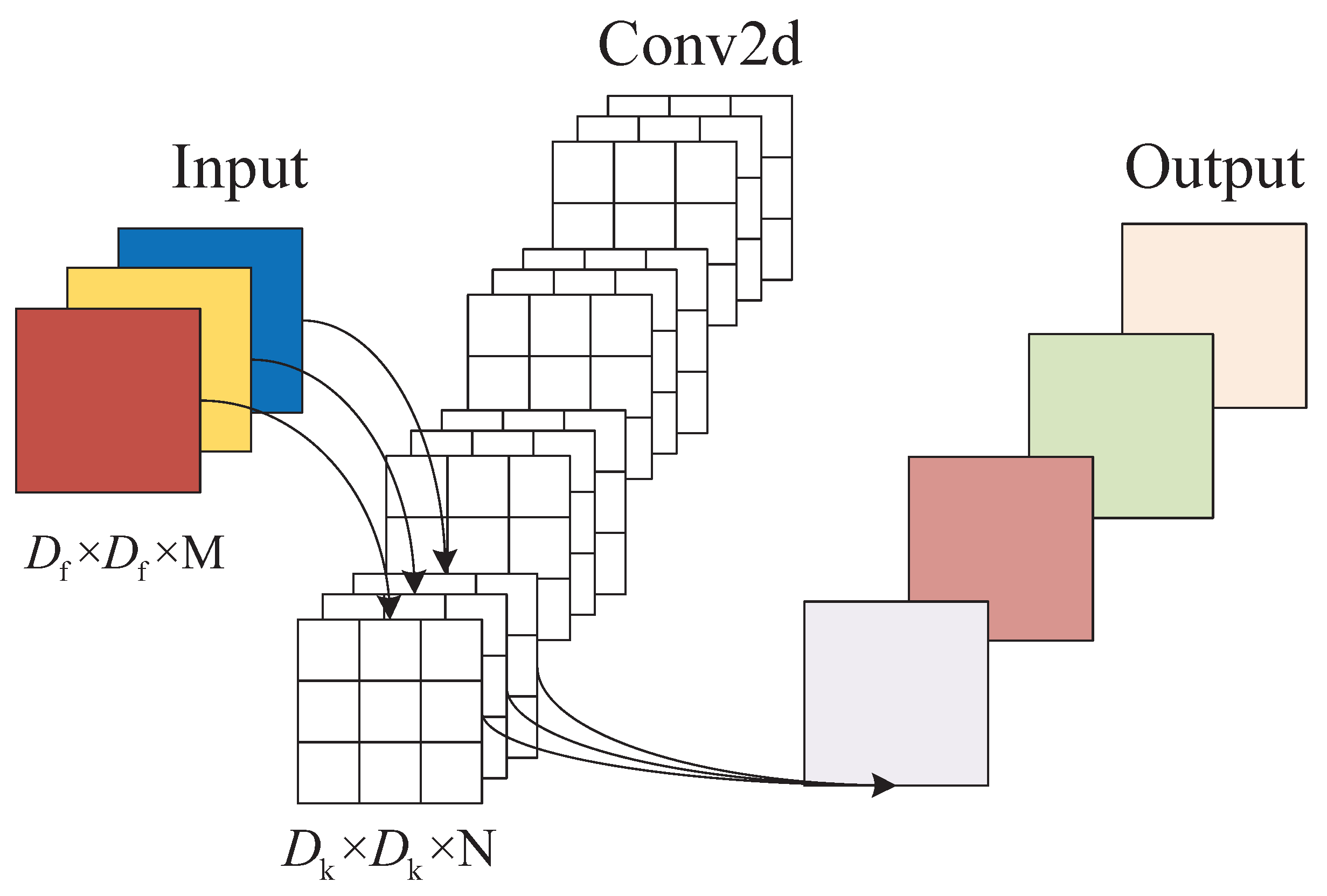
3. Model
3.1. Efficient Channel Attention Module
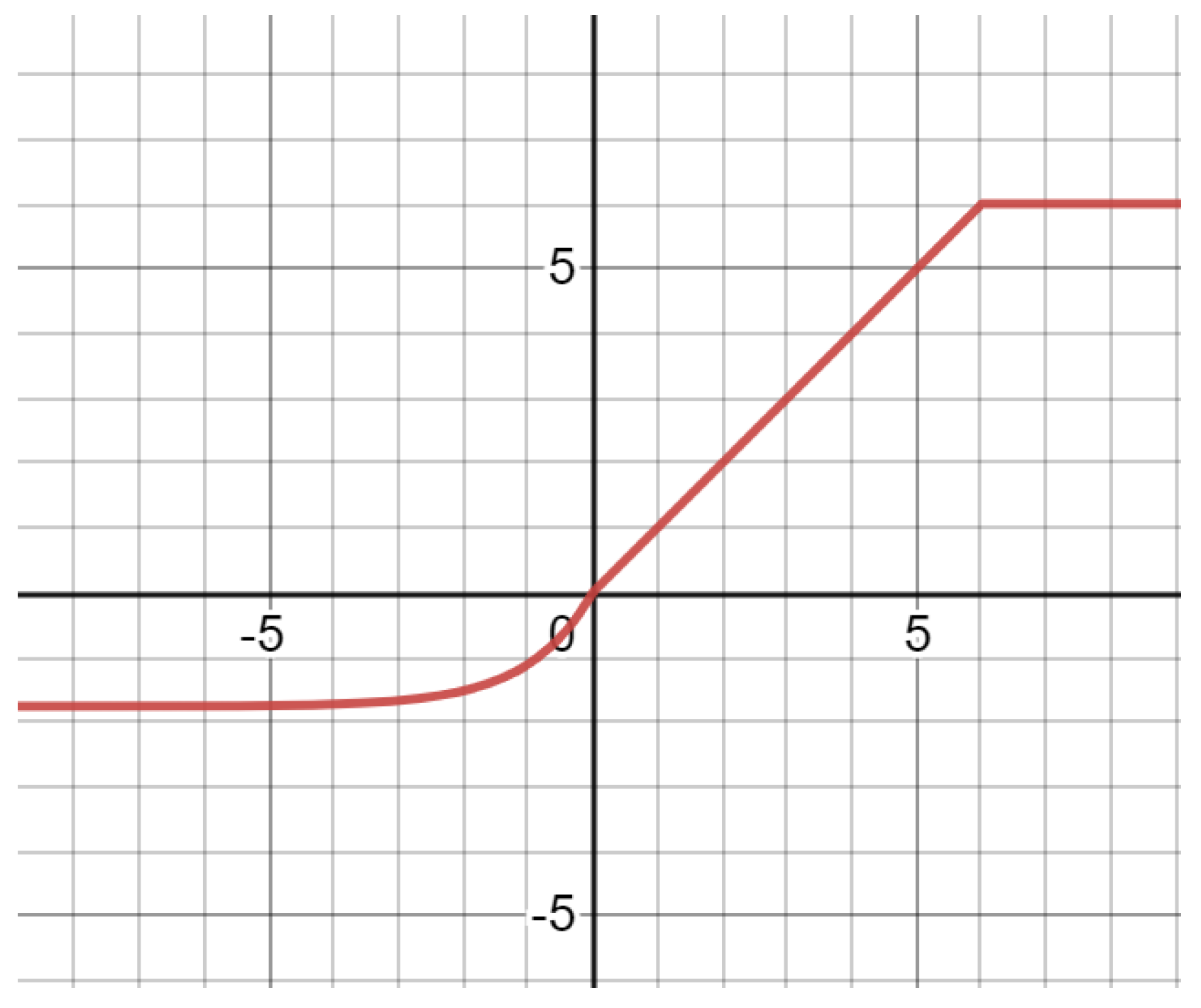
3.2. Improved R6-SELU Activation Function
- Parameters have non-zero output in both positive and negative half axes;
- The positive half axis inherits the characteristics of fast convergence and small precision loss of ReLU6 activation function;
- The negative half axis inherits the SELU activation function, non-linear correction of negative-valued characteristic information, smooth convergence, and enhances the model’s expression ability.
3.3. Setting Hyper-Parameters
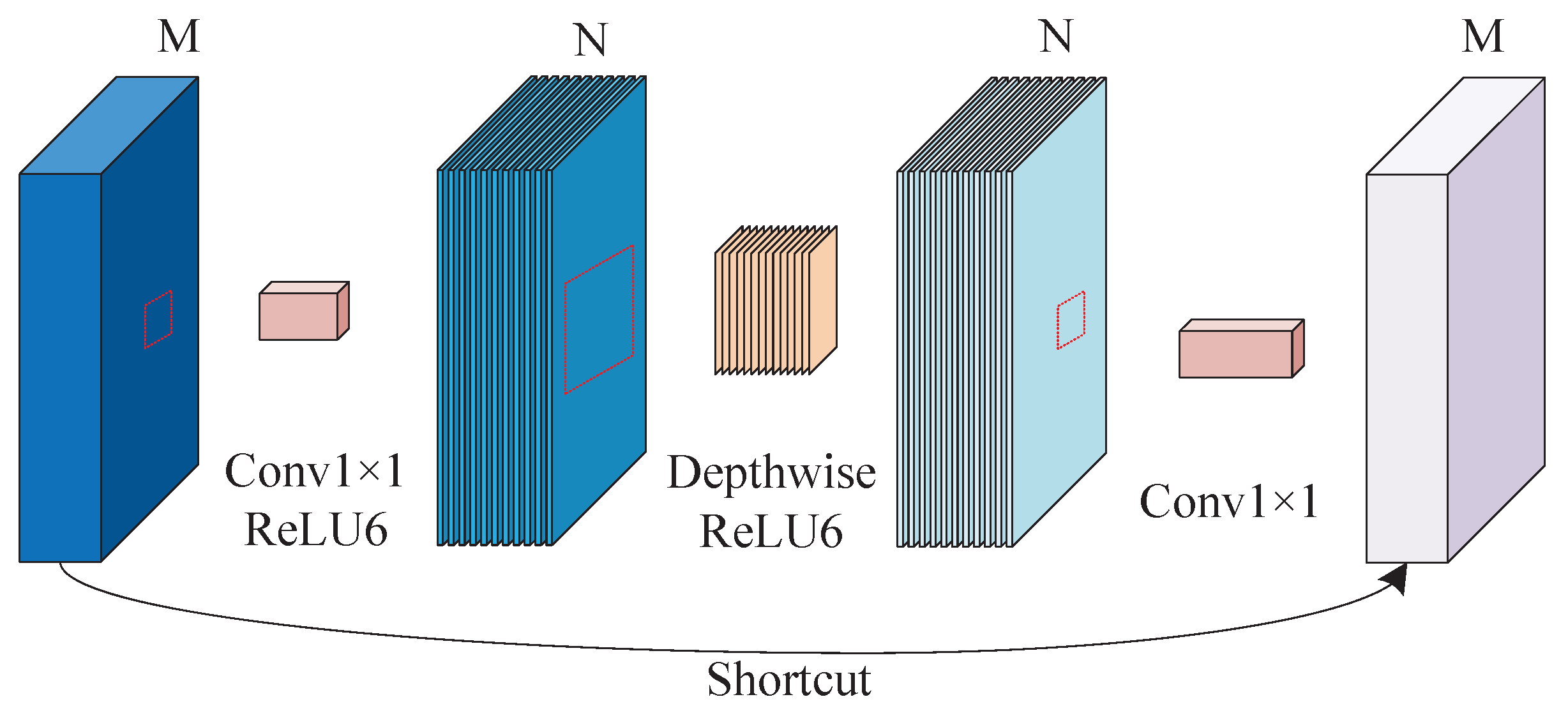
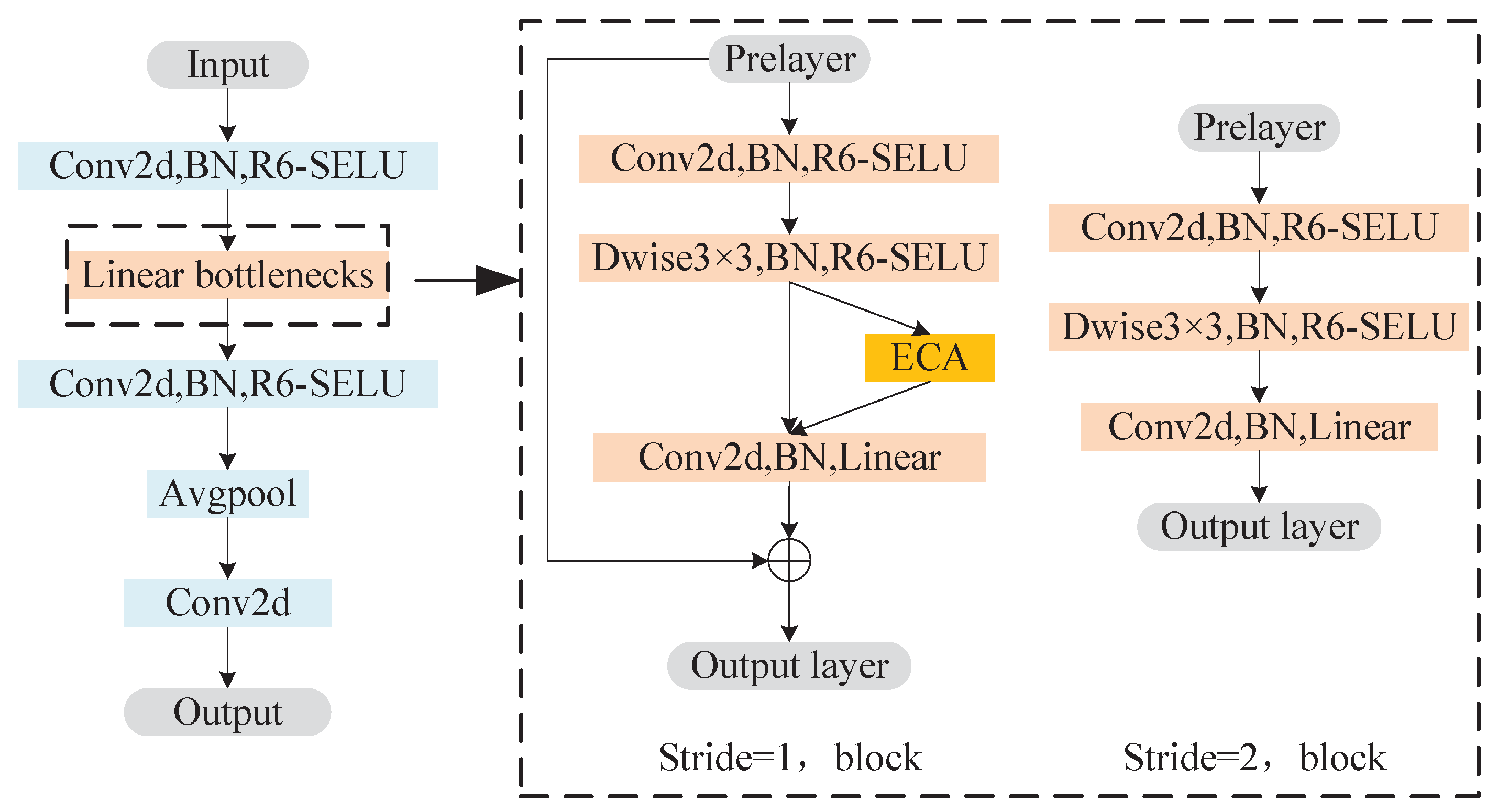
3.4. Establishment of the E-MobileNetv2 Model
4. Experiment
4.1. Experimental Environment and Parameter Setting
4.2. Data Sources and Pre-Processing
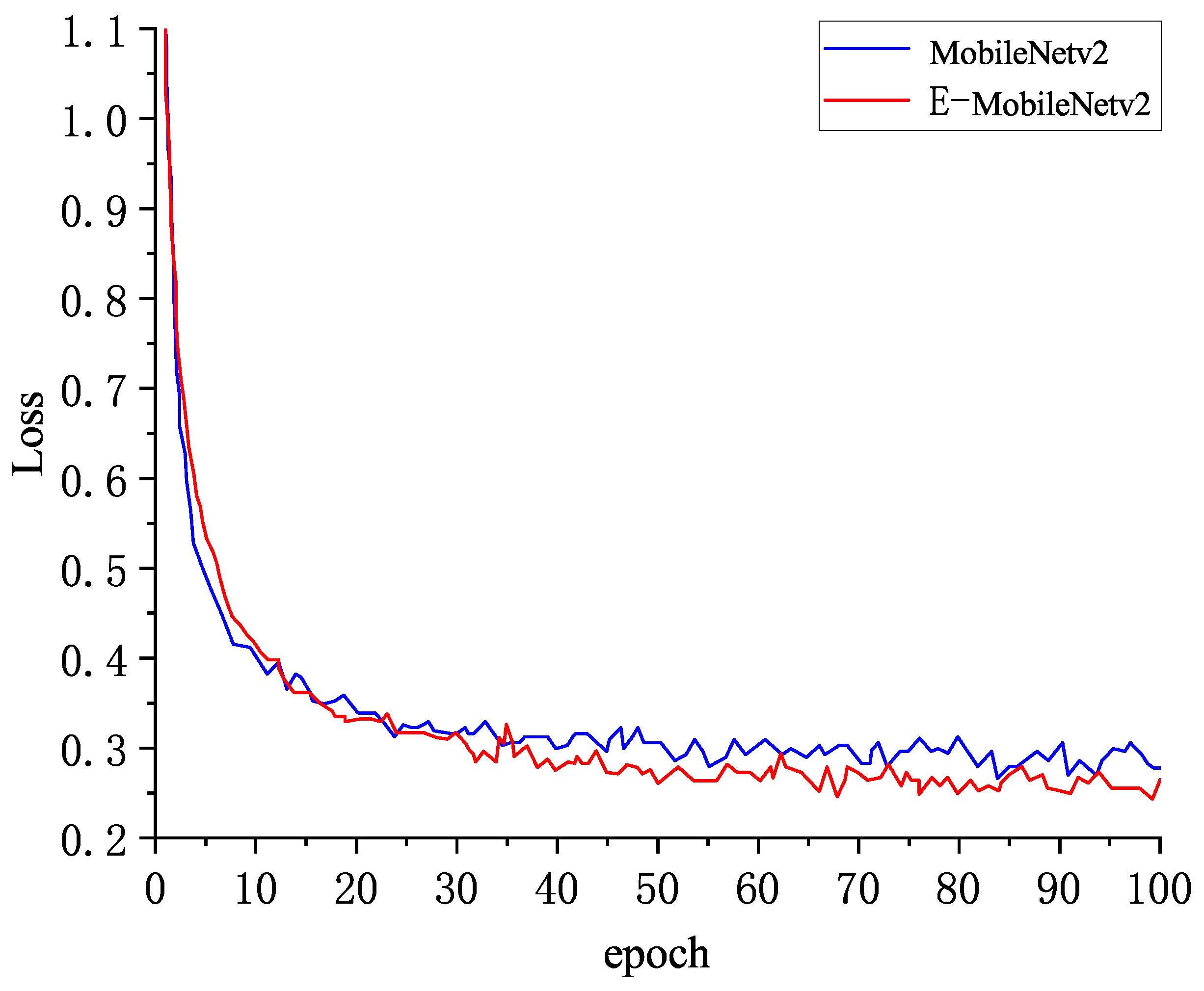
4.3. Experimental Results and Analysis
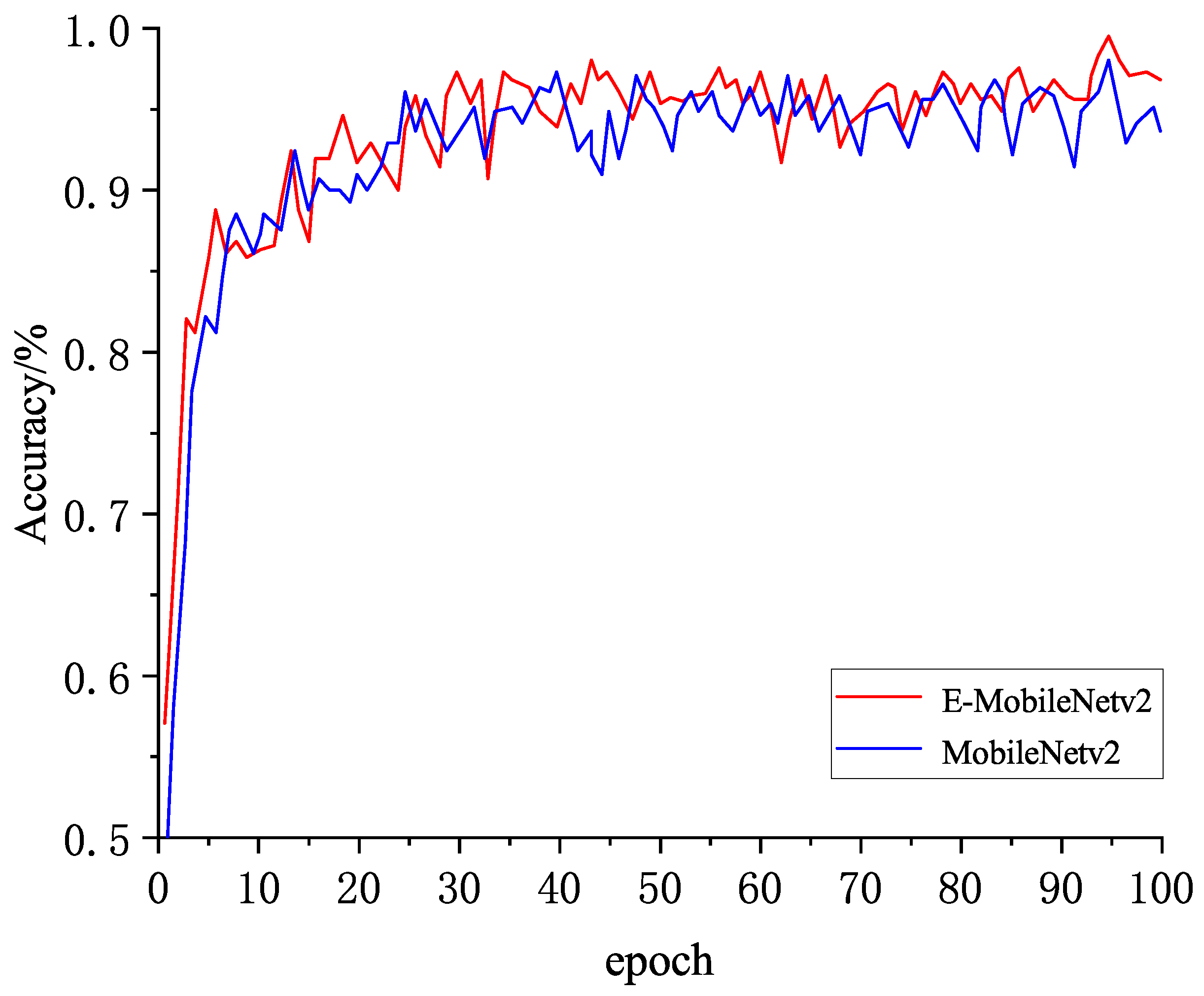
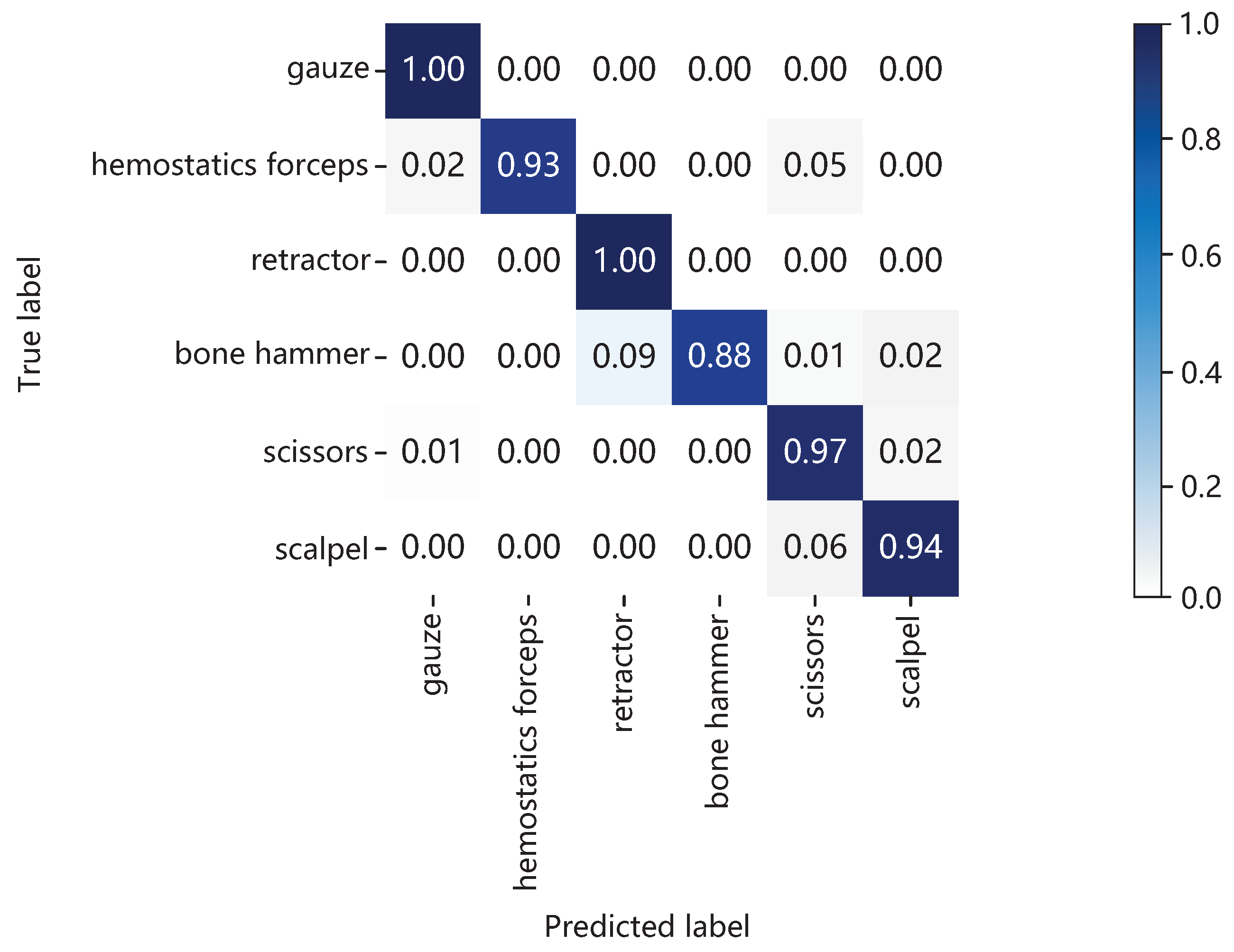
4.3.1. Ablation Experiment
4.3.2. Comparative Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mišeikis, J.; Caroni, P.; Duchamp, P.; Gasser, A.; Marko, R.; Mišeikienė, N.; Zwilling, F.; De Castelbajac, C.; Eicher, L.; Früh, M.; et al. Lio-a personal robot assistant for human-robot interaction and care applications. IEEE Robot. Autom. Lett. 2020, 5, 5339–5346. [Google Scholar] [CrossRef] [PubMed]
- Zahedi, E.; Khosravian, F.; Wang, W.; Armand, M.; Dargahi, J.; Zadeh, M. Towards skill transfer via learning-based guidance in human-robot interaction: An application to orthopaedic surgical drilling skill. J. Intell. Robot. Syst. 2020, 98, 667–678. [Google Scholar] [CrossRef]
- Bai, L.; Yang, J.; Chen, X.; Sun, Y.; Li, X. Medical robotics in bone fracture reduction surgery: A review. Sensors 2019, 19, 3593. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fukui, S.; Kawai, T.; Nishizawa, Y.; Nishikawa, A.; Nakamura, T.; Iwamoto, N.; Horise, Y.; Masamune, K. Locally operated assistant manipulators with selectable connection system for robotically assisted laparoscopic solo surgery. Int. J. Comput. Assist. Radiol. Surg. 2021, 16, 683–693. [Google Scholar] [CrossRef] [PubMed]
- Ji, P.; Song, A.; Xiong, P.; Yi, P.; Xu, X.; Li, H. Egocentric-vision based hand posture control system for reconnaissance robots. J. Intell. Robot. Syst. 2017, 87, 583–599. [Google Scholar] [CrossRef]
- Feng, Z.; Wu, J.; Ni, T. Research and Application of Multifeature Gesture Recognition in Human-Computer Interaction Based on Virtual Reality Technology. Wirel. Commun. Mob. Comput. 2021, 2021, 3603693. [Google Scholar] [CrossRef]
- Li, J.; Ray, S.; Rajanna, V.; Hammond, T. Evaluating the Performance of Machine Learning Algorithms in Gaze Gesture Recognition Systems. IEEE Access 2021, 10, 1020–1035. [Google Scholar] [CrossRef]
- Huang, D.Y.; Hu, W.C.; Chang, S.H. Gabor filter-based hand-pose angle estimation for hand gesture recognition under varying illumination. Expert Syst. Appl. 2011, 38, 6031–6042. [Google Scholar] [CrossRef]
- Tarvekar, M.P. Hand gesture recognition system for touch-less car interface using multiclass support vector machine. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; pp. 1929–1932. [Google Scholar]
- Rahim, M.A.; Miah, A.S.M.; Sayeed, A.; Shin, J. Hand Gesture Recognition Based on Optimal Segmentation in Human-Computer Interaction. In Proceedings of the 2020 3rd IEEE International Conference on Knowledge Innovation and Invention (ICKII), Kaohsiung, Taiwan, 21–23 August 2020; pp. 163–166. [Google Scholar]
- Guo, X.; Xu, W.; Tang, W.Q.; Wen, C. Research on optimization of static gesture recognition based on convolution neural network. In Proceedings of the 2019 4th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Hohhot, China, 25–27 October 2019; pp. 398–3982. [Google Scholar]
- Da Silva, I.J.; Perico, D.H.; Homem, T.P.D.; da Costa Bianchi, R.A. Deep Reinforcement Learning for a Humanoid Robot Soccer Player. J. Intell. Robot. Syst. 2021, 102, 69. [Google Scholar] [CrossRef]
- Oyedotun, O.K.; Khashman, A. Deep learning in vision-based static hand gesture recognition. Neural Comput. Appl. 2017, 28, 3941–3951. [Google Scholar] [CrossRef]
- Fang, W.; Ding, Y.; Zhang, F.; Sheng, J. Gesture recognition based on CNN and DCGAN for calculation and text output. IEEE Access 2019, 7, 28230–28237. [Google Scholar] [CrossRef]
- Molchanov, P.; Gupta, S.; Kim, K.; Pulli, K. Multi-sensor system for driver’s hand-gesture recognition. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 1, pp. 1–8. [Google Scholar]
- ElBadawy, M.; Elons, A.; Shedeed, H.A.; Tolba, M. Arabic sign language recognition with 3d convolutional neural networks. In Proceedings of the 2017 Eighth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 66–71. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Koller, O.; Ney, H.; Bowden, R. Deep hand: How to train a cnn on 1 million hand images when your data is continuous and weakly labelled. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3793–3802. [Google Scholar]
- Jahandad; Sam, S.M.; Kamardin, K.; Sjarif, N.N.A.; Mohamed, N. Offline signature verification using deep learning convolutional neural network (CNN) architectures GoogLeNet inception-v1 and inception-v3. Procedia Comput. Sci. 2019, 161, 475–483. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, A. Self-Selection Salient Region-Based Scene Recognition Using Slight-Weight Convolutional Neural Network. J. Intell. Robot. Syst. 2021, 102, 58. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Sun, K.; Li, M.; Liu, D.; Wang, J. Igcv3: Interleaved low-rank group convolutions for efficient deep neural networks. arXiv 2018, arXiv:1806.00178. [Google Scholar]
- Xiang, Q.; Wang, X.; Li, R.; Zhang, G.; Lai, J.; Hu, Q. Fruit image classification based on Mobilenetv2 with transfer learning technique. In Proceedings of the 3rd International Conference on Computer Science and Application Engineering, Sanya, China, 22–24 October 2019; pp. 1–7. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. In Advances in Neural Information Processing Systems 30; Curran Associates Inc.: Hook, NY, USA, 2017. [Google Scholar]

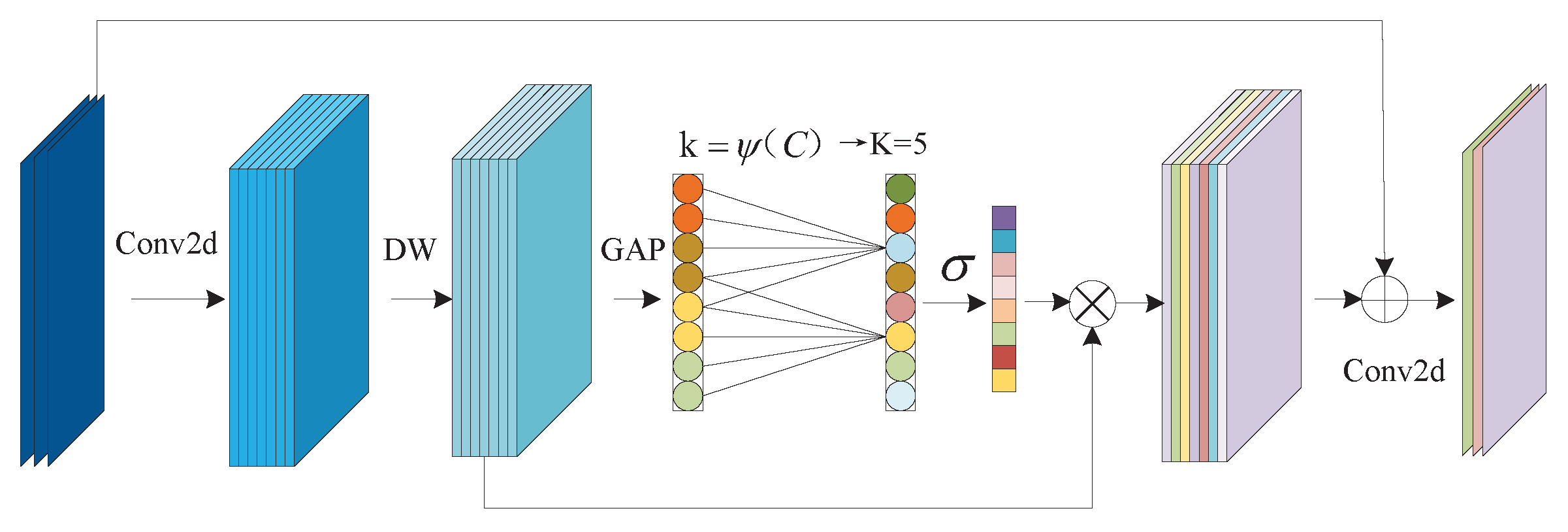



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acc/% | Mult-Adds/M | Param/M | |
|---|---|---|---|
| 1 | 70.60% | 569 | 4.2 |
| 0.75 | 68.40% | 325 | 2.6 |
| 0.5 | 63.70% | 149 | 1.3 |
| 0.25 | 50.60% | 41 | 0.5 |
| Input | Operator | t | c | n | s |
|---|---|---|---|---|---|
| 224 × 224 × 3 | Conv2d | - | 32 | 1 | 2 |
| 112 × 112 × 32 | Bottleneck_1 | 1 | 16 | 1 | 1 |
| 112 × 112 × 16 | Bottleneck | 6 | 24 | 2 | 2 |
| 56 × 56 × 24 | Bottleneck | 6 | 32 | 3 | 2 |
| 28 × 28 × 32 | Bottleneck | 6 | 64 | 6 | 2 |
| 14 × 14 × 64 | Bottleneck_1 | 6 | 96 | 3 | 1 |
| 14 × 14 × 96 | Bottleneck | 6 | 160 | 3 | 2 |
| 7 × 7 × 160 | Bottleneck_1 | 6 | 320 | 1 | 1 |
| 7 × 7 × 320 | Conv2d 1 × 1 | - | 1280 | 1 | 1 |
| 7 × 7 × 1280 | Avgpool 7 × 7 | - | - | 1 | - |
| 1 × 1 × 1280 | Conv2d 1 × 1 | - | 6 | - | - |
| Method | ECA | R6-SELU | Hyper-Parameters | mAp/% | Param/M |
|---|---|---|---|---|---|
| Mobilenetv2 | - | - | - | 93.65 | 3.34 |
| ✓ | - | - | 95.84 | 3.4 | |
| - | ✓ | - | 94.79 | 3.34 | |
| - | - | ✓ | 91.13 | 1.6 | |
| E-Mobilenetv2 | ✓ | ✓ | ✓ | 96.82 | 2.17 |
| Method | mAp/% | Param/M | /ms | |
|---|---|---|---|---|
| Gesture_II | Jester | |||
| EfficientNetb0 | 93.44 | 81.2 | 4.1 | 67.35 |
| ShuffleNetv2 | 91.31 | 78.6 | 3.5 | 57.26 |
| ResNet101 | 96.67 | 87.1 | 44.6 | 221.67 |
| GoogLeNet | 94.17 | 82.3 | 10.35 | 82.32 |
| MobileNetv2 | 93.65 | 82.4 | 3.34 | 45.74 |
| E-MobileNetv2 | 96.82 | 85.4 | 2.17 | 39.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; He, M.; Wang, X.; Ma, J.; Song, H. Medical Gesture Recognition Method Based on Improved Lightweight Network. Appl. Sci. 2022, 12, 6414. https://doi.org/10.3390/app12136414
Wang W, He M, Wang X, Ma J, Song H. Medical Gesture Recognition Method Based on Improved Lightweight Network. Applied Sciences. 2022; 12(13):6414. https://doi.org/10.3390/app12136414
Chicago/Turabian StyleWang, Wenjie, Mengling He, Xiaohua Wang, Jianwei Ma, and Huajian Song. 2022. "Medical Gesture Recognition Method Based on Improved Lightweight Network" Applied Sciences 12, no. 13: 6414. https://doi.org/10.3390/app12136414
APA StyleWang, W., He, M., Wang, X., Ma, J., & Song, H. (2022). Medical Gesture Recognition Method Based on Improved Lightweight Network. Applied Sciences, 12(13), 6414. https://doi.org/10.3390/app12136414