1. Introduction
In the modern theory of portfolio selection, investor preferences are defined in terms of profit and risk. The return of a portfolio is a combination of the returns of the weighted assets that compose it. The risk of a portfolio is a function of the correlation between the assets that compose it. It is therefore important to diversify your portfolio so as not to suffer from large fluctuations in the asset prices due to the reoccurrence of shocks in the financial sphere and the increase in geopolitical and macroeconomic uncertainties. These fluctuations in assets prices are also linked to the general health of the sector in which one invests. It is well known that, for example, the technology, telecommunications and cryptocurrency markets are marked by strong fluctuations. Diversification therefore obeys the famous adage in portfolio management which says: “you must not put all your eggs in one basket”. Thus, according to the modern portfolio theory developed by Markowitz [
1], the ultimate goal of portfolio managers is to combine a set of assets with maximum profit for a given level of risk or alternatively, with minimum risk for a given level of profit. This is the efficient portfolio.
Indeed, the frantic search for diversification and the creation in 2009 of new digital financial assets based on the highly secure “distributed ledger technology” (DLT) and cryptography, have led portfolio managers and many financial institutions to successfully integrate this new class of crypto-assets into the financial world. Cryptocurrencies or virtual currencies (VC) are the main components of crypto-assets defined as a type of unregulated or decentralised digital currency, created and generally controlled by its developers, used and accepted by members of a virtual community. Therefore, it is easy to become a cryptocurrency market player as long as one has some basic knowledge about their functionality. VCs have many unusual characteristics compared to other financial instruments such as lack of centralised control, (pseudo-) anonymity, difficulties of estimating their value, their hybrid characteristics combining aspects of traditional financial instruments with those of intangible assets, and the rapid evolution of technology which underpins them. Those erratic characteristics have contributed to their popularity and the rapid growth of their total market capitalisation which was estimated to 2.37 trillion US dollars in May 2021 (
https://coinmarketcap.com/all/views/all/, accessed on 20 May 2021) with Bitcoin, the oldest and most traded and valuable cryptocurrency representing 44% and other altcoins (alternative coin to Bitcoin) share the rest. The abovementioned facts and the potential shown by cryptocurrency to become a cheap alternative to conventional currencies can justify the interests of investors, portfolio managers, financial institutions and researchers on the opportunities offered by the cryptocurrencies markets.
A good portfolio is one that gives a maximum return for a given level of risk or one that gives the minimum risk for a given level of return. Thus, a good portfolio must combine different assets satisfying a set of given restriction in order to achieve that goal. Hence, this situation requires mathematical modelling for portfolio selection and optimization. In practice, the portfolio selection (or allocation) and optimisation problems must take into account real characteristics of the assets that compose it, such as correlation and dependencies that may exist between assets, market risks, quantity constraint which imposes a limit on the number of assets in the portfolio, weigh allocation constraints limiting the proportion of each asset in the portfolio and transaction cost. This leads to a complex optimization problem.
Markowitz’s model [
2] was the first to formalise an analytical response to the asset allocation and selection problem. Indeed, Markowitz considers the particular case of investors with risk preferences adjusting to quadratic utility functions. The analytical solution to this problem gives all the portfolios that form the “so-called efficient frontier”, which represents the optimal returns to be achieved for each level of risk. In order to overcome the shortcomings of the Markowitz approach, alternative approaches have been developed. Bares et al. [
3] discuss portfolio optimization within the framework of the expected utility approach using iso-elastic utility functions. Javed et al. [
4], Khan et al. [
5] as well as Jurczenko et al. [
6] proposed the analysis based on moments of higher orders. Hunjra et al. [
7], Krokhmal et al. [
8] as well as Agrawal and Naik [
9] construct optimal portfolios using alternative risk measures. All these methods have shown their performance compared to the results given through classical analysis. This confirms the interest in dealing with issue of portfolio selection outside the Gaussian framework.
One of the approaches aimed at relaxing the Gaussian framework imposed by the mean-variance approach concerns the modelling of the asymmetric nature of the dependency structure of the portfolio [
10]. One of the solutions is that of copula functions, vine copula specification based on sequential method (also based on maximum spanning tree algorithm and maximum likelihood estimation of the pair-copula parameters) used to solve the joint probability modelling problem. The use of copula functions in the context of the asset allocation problem is still relevant today. Mba et al. [
11], use GARCH-differential evolution t-copula method in order to optimize and analyse cryptocurrency portfolio risk and return within the framework of a multi-period setting type approach. More recently, Boako et al. [
12] integrated copula functions into a GARCH modelling to analyse the structural interdependencies among seventeen cryptocurrency prices and to optimise the portfolio Value-at-Risk (VaR). In the same wake Mba and Mwambi [
13] used a two state Markov-switching technique combined with R-vine copula and GARCH (MSCOGARCH) to model heavy tail dependencies and structural breaks within the states of Markov switching with the aim of achieving a maximum return with a minimum conditional value-at-risk of a portfolio of top ten virtual currencies (in term of market capitalisation).
The results obtained in the aforementioned works on the selection, allocation and optimization of crypto-asset portfolios present some shortcomings, namely:
These portfolios have a very low VaR or Conditional VaR and high return (above 50%) which is not in line with the crypto-market dynamics which is unregulated, highly volatile and permanently subjected to extreme events.
In addition, these portfolios are only made up of the best performing crypto assets, which are strongly and positively correlated between themselves and in particular with Bitcoin and, therefore, cannot constitute a diversified portfolio.
The fundamental objective of this paper is to improve the work of Mba [
11,
13] and Boako et al. [
12] on the optimization and selection of cryptocurrency portfolios in order to address the aforementioned shortcomings. The issue of non diversification is addressed by applying a machine learning technique known as K-means algorithm, reinforce with hierarchical clustering which groups similar assets into a cluster exhibiting a certain level of dissimilarity with other clusters. In fact, the technique will be applied to the top hundred cryptocurrencies consisting of different class of cryptoassets such as: coins, token, stablecoins, decentralised finance token (DeFi) and non fungible token (NFT). To overcome the issue of underestimation of the risk and overestimation of the returns, we preprocess the input data for the optimisation of CVaR and expected returns as follows: inverse transformation of the copula output using the quantile of the skew student-t distribution which constitutes the marginal in the copula fitting.
The novelty of our integrated approach is the combination of the machine learning technique (clustering and hierarchical algorithm), econometric model (GJR-GARCH), differential evolution algorithm and vine copula model in the selection and optimisation of a cryptoasset portfolio. Our results highlight the fact that, the top ten or twenty cryptocurrencies cannot constitute a diversify portfolio since they are highly and positively correlated. Another take away of our findings is that stablecoin such as True-USD is negatively correlated to the other cryptoassets in the portfolio and could therefore be safe haven for crypto-investors when market experiences extreme events.
The roadmap of the contributions of this work is organised as follows. First, in
Section 2, a non-exhaustive literature review on the application of copula in the portfolio optimisatio is presented; a survey of different risk measures that can be useful in cryptocurrency portfolio optimization problems is also discussed.
Section 3 is devoted to the methodology that was used to achieve the objective of this paper. In
Section 4, we implement the methodology and present the empirical results. In the last section, we summarise the main results obtained in the previous section and we will also point out their weaknesses and strengths.
2. Methodology
This section presents the theoretical framework of the paper. We introduce the objective and the methods used to present our results.
2.1. Machine Learning: K-Means Clustering
Definition 1. K-means is an unsupervised algorithm for non-hierarchical clustering. It allows the observations of the data set to be grouped into distinct clusters. Thus, similar data will be found in the same cluster. In addition, an observation can only be found in one cluster at a time (membership exclusivity). The same observation cannot therefore belong to two different clusters.
K-means is an iterative algorithm that minimizes the sum of the distances between each observation and the centroid. The initial choice of number K of the centroids determines the final result. Admitting a cloud of a set of points (data or observations), K-means changes the points of each cluster until the sum can no longer decrease. The result is a set of compact and clearly separated clusters, provided the researcher chooses the right K value for the number of clusters.
The convergence of the K-means Algorithm 1 can be one of the following conditions:
A pre-set number of iterations, in this case K-means will perform the iterations and stop regardless of the shape of compound clusters.
Stabilization of cluster centers (centroids no longer move or change during iterations).
| Algorithm 1: K-means Algorithm |
Input: Output: Randomly choose points (K rows of the data matrix). These points are the centers of the clusters (called centroid). Assign a cluster to each point (or observation), randomly. Calculate the centroid of each cluster (i.e. the vector of the means of the different variables) For each point calculate its Euclidean distance with the centroids of each of the clusters Assign the closest cluster to the object Calculate the sum of the intra-cluster variability Repeat steps 3 to 5, until an equilibrium is reached, that is convergence: no more change in clusters, or stabilization of the sum of the intra-cluster variability.
|
2.2. Vine-Copula
This subsection describes the characteristics necessary for a function to be a copula, as well as some of their properties. Before mentioning them, some preliminary definitions and results are useful. In fact, here is the idea behind the copula approach.
Let
be a vector of
n random variables for which we want to construct the joint distribution function. Let assume that,
are random variables with the following marginal distributions
, such as
(the probability that the measure of
be less than
). Then the joint distribution function is given by
Definition 2. An n dimensional () copula is a function satisfying the following properties:
- 1.
C is non-decreasing that is for all
- 2.
C possess one dimensional uniform margins on , that is:
for all . is an invariant non-decreasing transformation of the marginal.
We can now show the link between copulae and random variables. Copulas are of interest in statistics thanks to the theorem proposed by Sklar [
14].
Theorem 1. Assume is an n dimensional joint distribution function with marginal distribution function . Then, there exists a copula C such that for all If are continue, then C is unique. Otherwise C is non-unique on .
In addition, if are distribution function on I and if C is a copula, then the function is a joint distribution function on .
The canonical representation of the copula density function is given as
To obtain the density of the
n-dimension distribution
F, the following relation is used
where
is the density of the marginal distribution
.
Copula functions constitute an advantageous statistical tool for constructing and simulating multivariate distributions. The literature devoted to the copula approach provides us with different types of density functions which can be summarized in two categories of families: the family of elliptical copulas and that of Archimedean copulas.
Table 1 and
Table 2 show different properties of popular copulas functions.
In practical applications, modelling using copula with a large set of high-dimensional variables, such as in this paper (a set of eight cryptocurrencies), has some limitations. These limitations can be parameters restriction and the selection of the appropriate copula function. Joe [
15] proposed an alternative which is the use of vine-copulas method for high-dimensional data. Thus vine copulas, described by Bedford and Cooke [
16,
17] are flexible graphical models to describe multivariate copulas constructed using a cascade of bivariate copulas or pair-copulas. In this paper we will use C (canonical) and R (regular) vine copula specification.
2.3. GARCH-Copula Differential Evolution (DE): (GJR-GARCH-DE-C-Vine-Copula)
In many works, the copula approach is directly applied to returns of financial assets. Nevertheless, we recognize the stylised facts related to the fat tail distributions and the phenomenon of volatility clustering observed in financial time series data. Given this fact, it is useful to introduce GARCH models in order to filter these distributions. Then, the copula model can be used to model the dependency structure between the standardised innovations considered here as iid observations.
Here, we opt for GJR-GARCH(1,1) because it accounts for the leverage effect that creates asymmetry in the dynamics of the variance of the financial returns. More details on this model can be found in the works of Glosten et al. [
18]. We recall that if a
n-dimensional vector of time series variables (returns)
is assumed to follow a GARCH-Copula modelling type, by construction the joint distribution function is given in the following form
where
C is the
n-dimensional copula,
are the conditional marginal distribution functions relative to
, whose dynamics are described by the intercept
which corresponds to the conditional mean and by an error term
, which can be constant or time dependent as in a GJR-GARCH(1,1) specification
where
is the conditional variance of the series
, given the prior information to time
t, and
are iid random variables characterising the standardised innovation, considered as white noise with zero mean and variance equals 1 (
).
if
, otherwise
and
is the term related to the leverage effect.
The differential evolution initiated by Storn and Price [
19] is a nonlinear optimization algorithm that has been extremely successful since its conception and was originally created to solve continuous problems. The algorithm is inspired from evolutionary biology operations which follow the following steps: initialisation, mutation, recombination and selection on a given population to minimise an objective function through successive generations. The algorithm uses alteration and selection operator to transform progressively a population of candidate solution.
Consider a population
of size
n and the objective function
to be optimised. The optimisation process is as follows [
20,
21]:
2.4. Efficient Portfolio and Optimisation
An efficient portfolio is a portfolio whose expected return
is maximum for a given level of risk, or whose risk is minimal for a given return. Efficient portfolios are on the “efficient frontier” of the set of portfolios in the plane
. The first question an investor asks himself is obviously to know: Which efficient portfolio offers the lowest level of risk? Our aim, therefore, is to determine this efficient frontier or at least to find a function which allows to determine the optimal portfolio for a target level of return
. This problem can be formulated as below:
where
is a
n vector column of 1.
In this paper, we chose the conditional value at risk (CVaR) as risk measure and follow Rockafellar and Uryasev [
22] optimisation approach for problem (
7).
Let
denote a loss function characterise par the decision (weight) vector
and the return (random) vector
R. The probability that the loss function
never exceeds the threshold
is given by
and the value at risk for a certain level of confidence
, is given by:
and the formula of the conditional value at risk by
Since it depends by construction on the function
which itself depends on
, the optimization of CVaR can sometimes be difficult to approach. Without having recourse to an analytical representation of VaR, Rockafellar and Uryasev [
22] formulate the following auxiliary function
and demonstrate that
The advantage of using the auxiliary function is twofold: Firstly it is jointly convex with respect to and , provided that the loss function is also convex with respect to . Secondly we do not have to choose a value for beforehand, which can be difficult in practice. This is naturally derived during the optimization process based on the chosen confidence level.
Rockafellar and Uryasev [
22] finally show that minimizing
with respect to
is equivalent to minimizing
with respect to
, that is
Since
is convex by definition, (
10) is therefore a convex optimization problem.
The optimal value of the conditional value at risk optimization problem (
10) of a crypto-asset portfolio, can be found by solving the following convex optimization problem:
subject to
2.5. Snapshot of the Methodology
The nine steps below are followed for the analysis on the CVaR:
- step 1
Compute log-returns of the top 100 cryptoassets.
- step 2
portfolio selection
Machine learning: K-means and hierarchical clustering deployment in order to group assets that appear to be reasonably similar versus those that share large dissimilarities.
- step 3
Extract Standardized Residuals from AR-GJR-GARCH(1,1) with Student-t innovations to convert the log returns into an IID series.
- step 4
Use the residuals from Step 3 and standardise them with the deviations obtained in Step 3.
- step 5
Convert these residuals to student-t marginals for the estimation of copula. These steps are repeated for all the cryptocurrencies to obtain a multivariate matrix of uniform marginals.
- step 6
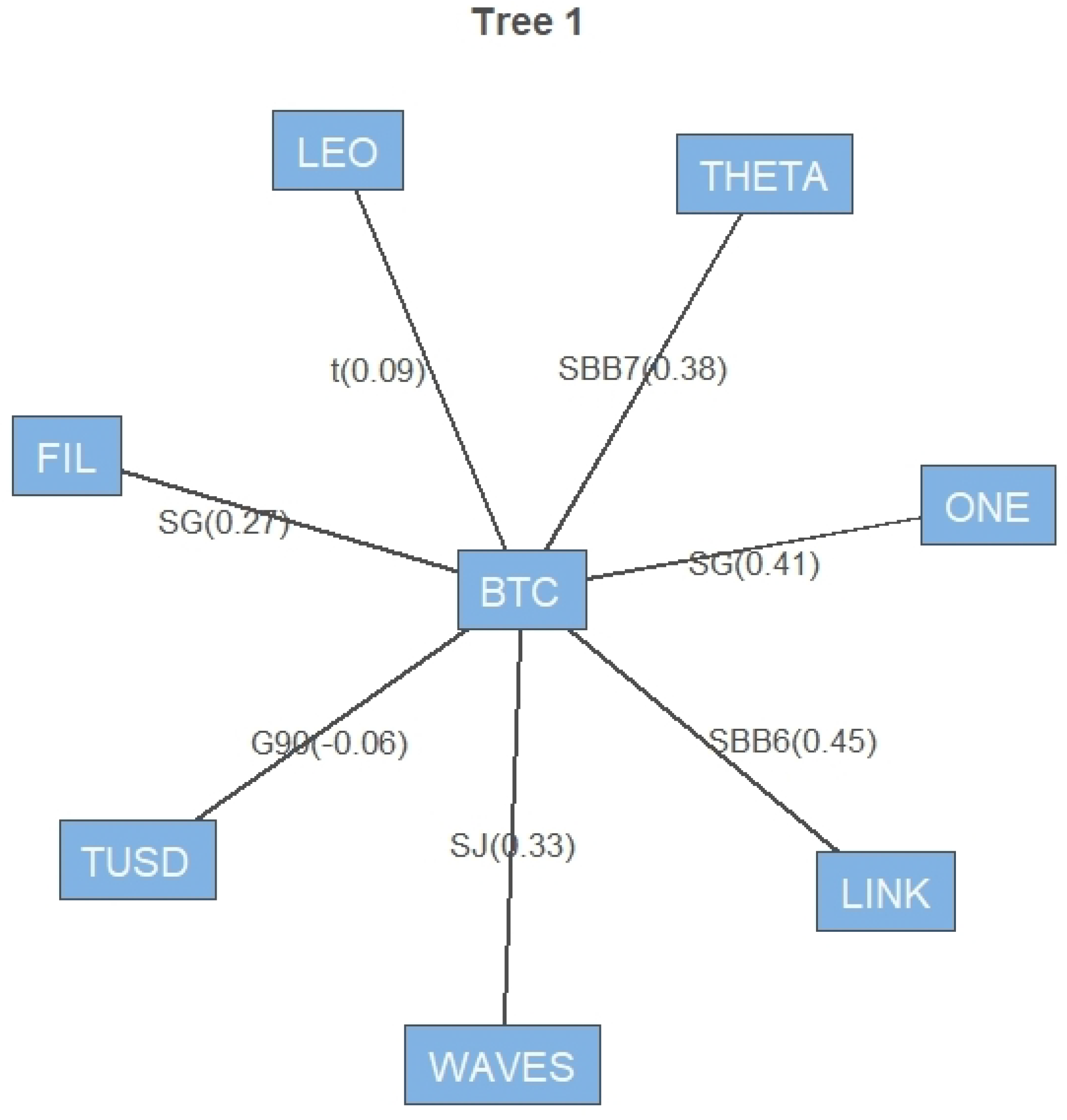
Fitting C-vine. to multivariate data obtained in step 5 and Benchmark Gauss R-vines using sequential estimation with restricted pair copula family set of first 14 copulas.
- step 7
Step 6 is repeated with R-vine.
- step 8
Inverse transform of the C-vine copula output using skew student-t distribution (marginal in the copula fitting).
- step 9
Use outputs from step 8 to generate a series of simulated monthly portfolio returns to predict 5% CVaR.
4. Conclusions
The goal sought through this paper was to develop a method that could allow a crypto-investor or manager to select a diversified portfolio of cryptocurrencies and to estimate the risk and profitability of the portfolio. Our approach to diversification combined similarity and tail dependence structure through K-means algorithm and Vine copula respectively, thus, achieving wealth/weights allocation which is not concentrated only on few assets.
During this study, we first tried to illustrate a method that relies on the K-means algorithm and which made it possible to select a diversified portfolio of eight cryptocurrencies. Subsequently, we opted for a GARCH-C-Vine copula approach combined with the differential evolution algorithm for co-dependence analysis in order to estimate the return and CVaR of the selected portfolio. The method also makes it possible to determine an accurate and reliable result in a very short computing time, which facilitates its implementation in practice. Our results show:
consistency with the risky characteristics of the cryptocurrency market-unregulated, anonymity of the transaction and highly volatile.
that stablecoin such as True-USD is negatively correlated to the other cryptoassets in the portfolio and could therefore be safe haven for crypto-investors during market turmoil.
On the other hand our findings are in line with previous studies exhibiting stablecoins as potential diversifiers.
Contrary to the previous studies which focused mainly on the top twenty, we build our portfolio from a pool of hundred cryptocurrencies to take advantage of possible dissimilarity that may exists among them. The top twenty cryptocurrencies considered in previous studies appear to be be highly correlated, so that a diversified cryptocurrency portfolio cannot be formed from these top twenty.
Several extensions of this work can be considered later. For example, it would be interesting to consider the use of diversification measures such as Diversification ratio or Entropy. The higher these measures, the well diversified a portfolio will be. We could also consider a diversification approach through risk contribution with risk measures being either CVaR or any other coherent risk measures such as spectral risk measure or distortion risk measure. One could also consider a possibility of a multi-period horizon for the portfolio optimisation with rebalancing with additional constraints such as transaction costs.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}