
A Survey of Big Data Archives in Time-Domain Astronomy




{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Big Data in Astronomical Domain
The Four Vs of Big Data
- (i)
- Volume: The quantity of data is known as the volume. The data are described in terms of terabytes, petabytes, and even exabytes. Consequently, the collection, cleaning, curation, integration, storage, processing, indexing, search, sharing, transfer, mining, analysis, and visualization of large amounts of data are complicated by the quantity of data [10]. There are too many data for current technology to handle them effectively. There is an avalanche of data in astronomy generated by a number of earth- and space-based broad astronomical observations.
- (ii)
- Variety: Variety is an indicator of data complexity. Structured, semi-structured, unstructured, and mixed data are all types of data [17]. Images, spectra, time series, and simulations constitute a large amount of astronomical data. Catalogs and databases contain the vast majority of information. This complicates data integration from different telescopes and projects because the data are stored in different formats. The high dimensionality problem is exacerbated because each piece of data has thousands or more features.
- (iii)
- Velocity: The term “velocity” represents the rate of creation, communication, and analysis of data. For ten years, The Rubin Observatory Legacy Survey of Space and Time (LSST) [18] generated one Sloan Digital Sky Survey (SDSS) [15] of data volume one night [19]. It is necessary to analyze data in a bundle, stream, near-instantaneous, or instantaneous setting. The LSST expects to discover a thousand additional supernova explosions every night for the next ten years. Scientists have a significant challenge in determining how to mine, correctly identify, and target supernova prospects in ten years.
- (iv)
- Value: Discovering new and unusual astronomical objects and events is a challenge that has inspired and exhilarated scientists. Therefore, spotting a new pattern or law in the data distribution is valuable. The term “value” refers to the enormous value of the data [10].
3. Time-Domain Astronomy
Science Project and Virtual Observatory in the Era of Big Data in Astronomy
4. Astronomical Data Mining
- Data Collection: All actions necessary to gather the desired data in digital form were included in data collection. As a part of the research process, data collection methods include acquiring fresh observations, querying existing databases, and completing data mergers (data fusion). An enormous cross-matching dataset can introduce confusing matches, discrepancies in the point spread function (object resolution) inside or between data sets, adequate processing time, and data transit needs. A few arcseconds of astrometric tolerance are typically utilized when each database item lacks exact identification [48]. If the researcher chooses a method of collecting data based on a legitimate premise, he or she must weigh the method’s strengths and weaknesses when analyzing their results. In qualitative research, it is critical that participants be recruited in a transparent manner [49].
- Processing of data: Data preprocessing, such as sample cuts in database searches, may be required during the data collection process. It is essential to use caution when preprocessing data because the input data can significantly affect many data mining approaches. For a specific algorithm, preprocessing can be divided into two types: procedures that make it meaningful for reading and processes that alter the data in some manner [48]. Data preprocessing includes the preparation and transformation of data so that it may be used in the mining process. Data preprocessing attempts to minimize data size, identify the relationships between data, normalize data, remove outliers, and extract characteristics from the data. Numerous methods have been proposed, such as cleaning, integration, transformation, and reduction of data sets [50].
- Selection of Attributes: Some properties of an object are not necessary for its proper functioning. To maximize performance, it is possible to use all the qualities of the object. Several low-density habitats and gaps have been created because of this. It is difficult to extract new ideas from data. As a result, dimension reduction is essential for retaining as much information as possible while using fewer attributes. Several algorithms are hampered by the presence of unnecessary, redundant, or otherwise unimportant features [48]. Filters and wrappers are prominent phrases used to describe the nature of the metric used to evaluate the value of attributes in a categorization. The accuracy estimates produced by the real target learning method are used by wrappers to evaluate attributes. Filters, on the other hand, work independently of any learning process and use generic properties of the data to evaluate attributes [51].
- Use of Machine Learning Algorithms: Machine learning algorithms are usually classified into supervised, semi-supervised, and unsupervised methods. Semi-supervised approaches use two sets of objects for which the target property, such as classification, is known with confidence. The algorithm was trained on these objects and then applied to others without the target characteristics. The test set included these additional items. In most astronomy cases, a photometric sample of objects can predict qualities that ordinarily require a spectroscopic sample. The parameter space spanned by the input attributes must span the time for which the algorithm is employed. This may appear restricted initially, but may often be overcome by merging data sets [48]. The research, development, and validation of algorithms for web service-based (possibly grid-based or peer-to-peer) classification and mining of distributed data are required. A combined text-numeric data mining algorithm may be the most effective, and thus has to be explored for these algorithms to be successful [45].
5. Scientific Archives Services
- (i)
- SIMBAD (Set of Identification, Measurements, and Bibliography for Astronomical Data): SIMBAD [53,54] is the principal database for astronomical object identification and bibliography. e Centre de Donn´ees astronomiques de Strasbourg (CDS) developed and maintained the SIMBAD. Many astronomical objects are included in the database, bibliography, and selected observational measurements. Priority is given to catalogs and tables that span a wide range of wavelengths and serve large-scale research efforts. Meanwhile, systematic scanning of the bibliography provides an overview of current astronomical studies, including their diversity and broader trends. The World Wide Web (WWW) interface for Simbad is available at: http://simbad.u-strasbg.fr/Simbad (accessed on 1 June 2022).
- (ii)
- SMOKA (Subaru-Mitaka-Okayama-Kiso-Archive): Multiple telescope data can be found in the SMOKA [55] science archive system. More than 20 million astronomical images are currently stored on the server, totaling more than 150 gigabytes. Additionally, the search interface can be used to perform searches based on various search restrictions and flexible image transport system (FITS)-Header keyword values for specific data sets. Data from telescopes and observatories from Subaru (Subaru), OAO (Okayama), Kiso (Kiso) and MITSuME (MITSuME) instruments and reduction tools can be accessed via the search interface.
- (iii)
- IRSA (NASA/IPAC Infrared Science Archive): Several National Aeronautics and Space Act (NASA) [56] programs are supported by the Infrared Processing and Analysis Center (IPAC) [57], including Spitzer, the (NEO)WISE and 2MASS satellites, and the IRAS. IPAC also manages NASA’s data archives. The IRSA also provides access to data from ESA missions, including Herschel and Planck, in collaboration with NASA. IRTF and SOFIA data will soon be archived at IRSA. IPAC’s non-NASA or non-infrared initiatives, such as the Palomar Transient Factory (PTF), Zwicky Transient Facility (ZTF), and Vera C. Rubin Observatory (VCRO), benefit from IPAC’s archiving technology (formerly known as LSST) [58]. One petabyte of data from more than 15 projects can be found at IRSA. More than 100 billion astronomical measurements can be accessed through IRSA, including all-sky coverage.
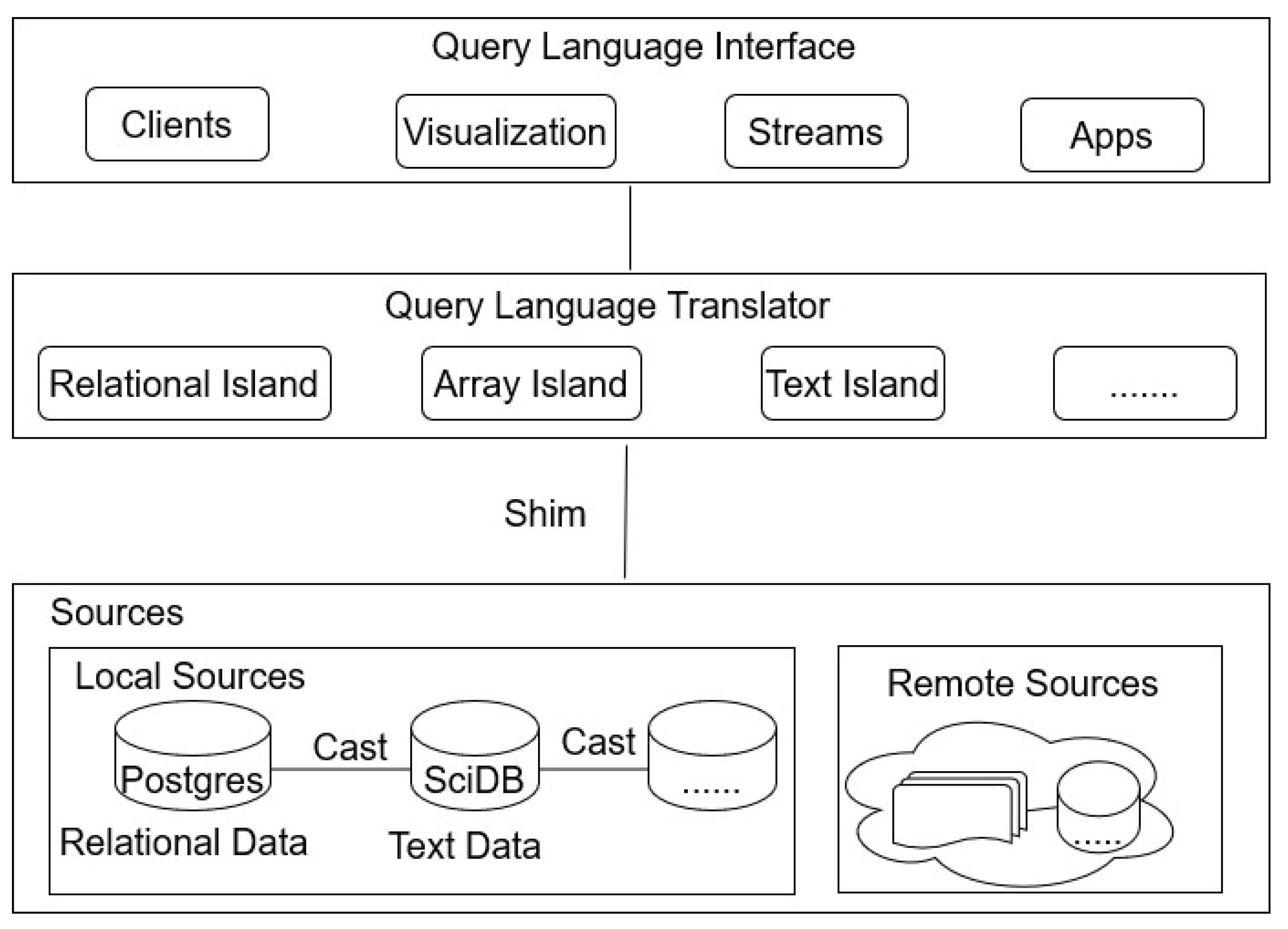
6. Polystores
6.1. Existing Architecture of a Polystore Database System
6.2. Major BigDAWG Components
7. Challenge of the Future Management in Astronomical Data Archives
8. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- SAS. Big Data. 2022. Available online: https://www.sas.com/en_us/insights/big-data/what-is-big-data.html (accessed on 25 May 2022).
- Segal, T. Big Data. 2022. Available online: https://www.investopedia.com/terms/b/big-data.asp (accessed on 25 May 2022).
- Tillett, B. RDA and the semantic web, linked data environment. Ital. J. Libr. 2013, 4, 139–146. [Google Scholar]
- Heath, T.; Bizer, C. Linked data: Evolving the web into a global data space. Synth. Lect. Semant. Web Theory Technol. 2011, 1, 1–136. [Google Scholar] [CrossRef]
- Eibeck, A.; Zhang, S.; Lim, M.Q.; Kraft, M. A Simple and Effective Approach to Unsupervised Instance Matching and Its Application to Linked Data of Power Plants; University of Cambridge: Cambridge, UK, 2022. [Google Scholar]
- Portal, L. What Is Linked Open Data? 2022. Available online: https://landportal.org/developers/what-is-linked-open-data (accessed on 26 May 2022).
- Monaco, D.; Pellegrino, M.A.; Scarano, V.; Vicidomini, L. Linked open data in authoring virtual exhibitions. J. Cult. Herit. 2022, 53, 127–142. [Google Scholar] [CrossRef]
- Beno, M.; Figl, K.; Umbrich, J.; Polleres, A. Open data hopes and fears: Determining the barriers of open data. In Proceedings of the 2017 Conference for E-Democracy and Open Government (CeDEM), Krems, Austria, 17–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 69–81. [Google Scholar]
- Department of Public Expenditure. What Is Open Data? 2021. Available online: https://data.gov.ie/edpelearning/en/module1/#/id/co-01 (accessed on 26 May 2022).
- Zhang, Y.; Zhao, Y. Astronomy in the big data era. Data Sci. J. 2015, 14, 11. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Y. Data Mining in Astronomy. 2008. Available online: https://spie.org/news/1283-data-mining-in-astronomy?SSO=1 (accessed on 28 May 2022).
- Bose, R.; Mann, R.G.; Prina-Ricotti, D. Astrodas: Sharing assertions across astronomy catalogues through distributed annotation. In Proceedings of the International Provenance and Annotation Workshop, Chicago, IL, USA, 3–5 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 193–202. [Google Scholar]
- Zakir, J.; Seymour, T.; Berg, K. Big Data Analytics. Issues Inf. Syst. 2015, 16, 81–90. [Google Scholar]
- Chathuranga, K. Big Data in Astronomy. 2018. Available online: https://doi.org/10.13140/RG.2.2.31794.96962 (accessed on 30 May 2022).
- York, D.G.; Adelman, J.; Anderson, J.E., Jr.; Anderson, S.F.; Annis, J.; Bahcall, N.A.; Bakken, J.; Barkhouser, R.; Bastian, S.; Berman, E.; et al. The sloan digital sky survey: Technical summary. Astron. J. 2000, 120, 1579. [Google Scholar] [CrossRef]
- Bryant, A.; Raja, U. In the realm of Big Data. First Monday 2014, 19, 1–22. [Google Scholar] [CrossRef]
- Jena, M.; Behera, R.K.; Dehuri, S. Hybrid decision tree for machine learning: A big data perspective. In Advances in Machine Learning for Big Data Analysis; Springer: Berlin/Heidelberg, Germany, 2022; pp. 223–239. [Google Scholar]
- Schmidt, S.; Malz, A.; Soo, J.; Almosallam, I.; Brescia, M.; Cavuoti, S.; Cohen-Tanugi, J.; Connolly, A.; DeRose, J.; Freeman, P.; et al. Evaluation of probabilistic photometric redshift estimation approaches for The Rubin Observatory Legacy Survey of Space and Time (LSST). Mon. Not. R. Astron. Soc. 2020, 499, 1587–1606. [Google Scholar] [CrossRef]
- Robertson, B.E.; Banerji, M.; Brough, S.; Davies, R.L.; Ferguson, H.C.; Hausen, R.; Kaviraj, S.; Newman, J.A.; Schmidt, S.J.; Tyson, J.A.; et al. Galaxy formation and evolution science in the era of the Large Synoptic Survey Telescope. Nat. Rev. Phys. 2019, 1, 450–462. [Google Scholar] [CrossRef]
- Poudel, M.; Sarode, R.P.; Shrestha, S.; Chu, W.; Bhalla, S. Development of a polystore data management system for an evolving big scientific data archive. In Heterogeneous Data Management, Polystores, and Analytics for Healthcare; Springer: Berlin/Heidelberg, Germany, 2019; pp. 167–182. [Google Scholar]
- Harvard University. Time Domain Astronomy. 2021. Available online: https://www.cfa.harvard.edu/research/topic/time-domain-astronomy (accessed on 24 May 2022).
- Unsöld, A.; Baschek, B. The New Cosmos: An Introduction to Astronomy and Astrophysics; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- California Institute of Technology. Time Domain Astronomy. 2021. Available online: https://www.growth.caltech.edu/tda.html (accessed on 24 May 2022).
- Vaughan, S. Random time series in astronomy. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2013, 371, 20110549. [Google Scholar] [CrossRef]
- Isadora Nun, P.P. Feature Analysis for Time Series. 2021. Available online: https://isadoranun.github.io/tsfeat/FeaturesDocumentation.html (accessed on 9 June 2022).
- Kasliwal, M.; Cannella, C.; Bagdasaryan, A.; Hung, T.; Feindt, U.; Singer, L.; Coughlin, M.; Fremling, C.; Walters, R.; Duev, D.; et al. The growth marshal: A dynamic science portal for time-domain astronomy. Publ. Astron. Soc. Pac. 2019, 131, 038003. [Google Scholar] [CrossRef]
- Janesick, J.R.; Elliott, T.; Collins, S.; Blouke, M.M.; Freeman, J. Scientific charge-coupled devices. Opt. Eng. 1987, 26, 268692. [Google Scholar] [CrossRef]
- Szalay, A.; Gray, J. Science in an exponential world. Nature 2006, 440, 413–414. [Google Scholar] [CrossRef] [PubMed]
- Science Projects. Blink Comparator. 2021. Available online: https://science-projects.org/portfolios/blink-comparator/ (accessed on 9 June 2022).
- Smithsonian Institution. Blink Comparator. 2022. Available online: https://airandspace.si.edu/multimedia-gallery/11363hjpg (accessed on 9 June 2022).
- Sheehan, W. Planets & Perception: Telescopic Views and Interpretations, 1609–1909; University of Arizona Press: Tucson, AZ, USA, 1988. [Google Scholar]
- Ragagnin, A.; Dolag, K.; Biffi, V.; Bel, M.C.; Hammer, N.J.; Krukau, A.; Petkova, D.S.M.; Steinborn, D. An online theoretical virtual observatory for hydrodynamical, cosmological simulations. arXiv 2016, arXiv:1612.06380v1. [Google Scholar]
- Law, N.M.; Kulkarni, S.R.; Dekany, R.G.; Ofek, E.O.; Quimby, R.M.; Nugent, P.E.; Surace, J.; Grillmair, C.C.; Bloom, J.S.; Kasliwal, M.M.; et al. The Palomar Transient Factory: System overview, performance, and first results. Publ. Astron. Soc. Pac. 2009, 121, 1395. [Google Scholar] [CrossRef]
- Stritzinger, M.; Leibundgut, B.; Walch, S.; Contardo, G. Constraints on the progenitor systems of type Ia supernovae. Astron. Astrophys. 2006, 450, 241–251. [Google Scholar] [CrossRef]
- Shrestha, S.; Poudel, M.; Wu, Y.; Chu, W.; Bhalla, S.; Kupfer, T.; Kulkarni, S. PDSPTF: Polystore database system for scalability and access to PTF time-domain astronomy data archives. In Heterogeneous Data Management, Polystores, and Analytics for Healthcare; Springer: Berlin/Heidelberg, Germany, 2018; pp. 78–92. [Google Scholar]
- Bebek, C.; Coles, R.; Denes, P.; Dion, F.; Emes, J.; Frost, R.; Groom, D.; Groulx, R.; Haque, S.; Holland, S.; et al. CCD research and development at Lawrence Berkeley National Laboratory. In High Energy, Optical, and Infrared Detectors for Astronomy V; International Society for Optics and Photonics: Amsterdam, The Netherlands, 2012; Volume 8453, p. 845305. [Google Scholar]
- Grillmair, C.; Laher, R.; Surace, J.; Mattingly, S.; Hacopians, E.; Jackson, E.; van Eyken, J.; McCollum, B.; Groom, S.; Mi, W.; et al. An overview of the palomar transient factory pipeline and archive at the infrared processing and analysis center. Astron. Data Anal. Softw. Syst. XIX 2010, 434, 28. [Google Scholar]
- Kulkarni, S. The intermediate palomar transient factory (iptf) begins. Astron. Telegr. 2013, 4807, 1. [Google Scholar]
- Cao, Y.; Nugent, P.E.; Kasliwal, M.M. Intermediate palomar transient factory: Realtime image subtraction pipeline. Publ. Astron. Soc. Pac. 2016, 128, 114502. [Google Scholar] [CrossRef][Green Version]
- Bellm, E. The Zwicky transient facility. In The Third Hot-Wiring the Transient Universe Workshop; IOP Publishing: Bristol, UK, 2014; Volume 27. [Google Scholar]
- Bellm, E.C.; Kulkarni, S.R.; Graham, M.J.; Dekany, R.; Smith, R.M.; Riddle, R.; Masci, F.J.; Helou, G.; Prince, T.A.; Adams, S.M.; et al. The Zwicky Transient Facility: System overview, performance, and first results. Publ. Astron. Soc. Pac. 2018, 131, 018002. [Google Scholar] [CrossRef]
- Masci, F.J.; Laher, R.R.; Rusholme, B.; Shupe, D.L.; Groom, S.; Surace, J.; Jackson, E.; Monkewitz, S.; Beck, R.; Flynn, D.; et al. The zwicky transient facility: Data processing, products, and archive. Publ. Astron. Soc. Pac. 2018, 131, 018003. [Google Scholar] [CrossRef]
- Raiteri, C.M.; Carnerero, M.I.; Balmaverde, B.; Bellm, E.C.; Clarkson, W.; D’Ammando, F.; Paolillo, M.; Richards, G.T.; Villata, M.; Yoachim, P.; et al. Blazar Variability with the Vera C. Rubin Legacy Survey of Space and Time. Astrophys. J. Suppl. Ser. 2021, 258, 3. [Google Scholar] [CrossRef]
- Xi, S. Large Synoptic Survey Telescope. 2022. Available online: https://www.americanscientist.org/article/large-synoptic-survey-telescope (accessed on 10 June 2022).
- Borne, K.D. Scientific data mining in astronomy. In Next Generation of Data Mining; Chapman and Hall/CRC: Boca Raton, FL, USA, 2008; pp. 115–138. [Google Scholar]
- Frawley, W.J.; Piatetsky-Shapiro, G.; Matheus, C.J. Knowledge discovery in databases: An overview. AI Mag. 1992, 13, 57. [Google Scholar]
- Fayyad, U.M. Data Mining and Knowledge Discovery in Databases: Applications in Astronomy and Planetary Science; Technical Report; American Association for Artificial Intelligence: Menlo Park, CA, USA, 1996. [Google Scholar]
- Brunner, N.M.B.R.J. Data Mining and Machine Learning in Astronomy. 2010. Available online: https://ned.ipac.caltech.edu/level5/March11/Ball/Ball2.html (accessed on 25 May 2022).
- Kairuz, T.; Crump, K.; O’Brien, A. Tools for data collection and analysis. Pharm. J. 2007, 278, 371–377. [Google Scholar]
- Alasadi, S.A.; Bhaya, W.S. Review of data preprocessing techniques in data mining. J. Eng. Appl. Sci. 2017, 12, 4102–4107. [Google Scholar]
- Hall, M.A.; Holmes, G. Benchmarking attribute selection techniques for discrete class data mining. IEEE Trans. Knowl. Data Eng. 2003, 15, 1437–1447. [Google Scholar] [CrossRef]
- Werner, M.W.; Roellig, T.; Low, F.; Rieke, G.H.; Rieke, M.; Hoffmann, W.; Young, E.; Houck, J.; Brandl, B.; Fazio, G.; et al. The Spitzer space telescope mission. Astrophys. J. Suppl. Ser. 2004, 154, 1. [Google Scholar] [CrossRef]
- Shaw, R.A.; Hill, F.; Bell, D.J. Astronomical Data Analysis Software and Systems XVI; ACM: New York, NY, USA, 2007; Volume 376. [Google Scholar]
- Wenger, M.; Ochsenbein, F.; Egret, D.; Dubois, P.; Bonnarel, F.; Borde, S.; Genova, F.; Jasniewicz, G.; Laloë, S.; Lesteven, S.; et al. The SIMBAD astronomical database-The CDS reference database for astronomical objects. Astron. Astrophys. Suppl. Ser. 2000, 143, 9–22. [Google Scholar] [CrossRef]
- SMOKA Science Archive. 2022. Available online: https://smoka.nao.ac.jp/ (accessed on 26 May 2022).
- Kurtz, M.J.; Eichhorn, G.; Accomazzi, A.; Grant, C.S.; Murray, S.S.; Watson, J.M. The NASA astrophysics data system: Overview. Astron. Astrophys. Suppl. Ser. 2000, 143, 41–59. [Google Scholar] [CrossRef]
- Laher, R.R.; Surace, J.; Grillmair, C.J.; Ofek, E.O.; Levitan, D.; Sesar, B.; van Eyken, J.C.; Law, N.M.; Helou, G.; Hamam, N.; et al. IPAC image processing and data archiving for the Palomar Transient Factory. Publ. Astron. Soc. Pac. 2014, 126, 674. [Google Scholar] [CrossRef][Green Version]
- Science & Data Center for Astrophysics & Planetary Sciences. Available online: https://www.ipac.caltech.edu/ (accessed on 25 May 2022).
- Bondiombouy, C.; Valduriez, P. Query Processing in Multistore Systems: An Overview; Inria: Le Chesnay, France, 2016. [Google Scholar]
- Xia, Y.; Yu, X.; Butrovich, M.; Pavlo, A.; Devadas, S. Litmus: Towards a Practical Database Management System with Verifiable ACID Properties and Transaction Correctness. In Proceedings of the 2022 International Conference on Management of Data, Philadelphia, PA, USA, 12–17 June 2022. [Google Scholar]
- Han, R.; John, L.K.; Zhan, J. Benchmarking big data systems: A review. IEEE Trans. Serv. Comput. 2017, 11, 580–597. [Google Scholar] [CrossRef]
- Gadepally, V.; Chen, P.; Duggan, J.; Elmore, A.; Haynes, B.; Kepner, J.; Madden, S.; Mattson, T.; Stonebraker, M. The BigDAWG polystore system and architecture. In Proceedings of the 2016 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 13–15 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Patidar, R.G.; Shrestha, S.; Bhalla, S. Polystore Data Management Systems for Managing Scientific Data-sets in Big Data Archives. In Proceedings of the International Conference on Big Data Analytics, Seattle, WA, USA, 10–13 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 217–227. [Google Scholar]
- Massachusetts Institute of Technology. BigDAWG—Introduction and Overview. 2022. Available online: https://bigdawg-documentation.readthedocs.io/en/latest/intro.htm (accessed on 25 May 2022).
- Duggan, J.; Elmore, A.J.; Stonebraker, M.; Balazinska, M.; Howe, B.; Kepner, J.; Madden, S.; Maier, D.; Mattson, T.; Zdonik, S. The bigdawg polystore system. ACM SIGMOD Rec. 2015, 44, 11–16. [Google Scholar] [CrossRef]
- Shrestha, S.; Bhalla, S. A Survey on the Evolution of Models of Data Integration. Int. J. Knowl. Based Comput. Syst. 2020, 8, 11–16. [Google Scholar]
- Poudel, M.; Shrestha, S.; Sarode, R.P.; Chu, W.; Bhalla, S. Query Languages for Polystore Databases for Large Scientific Data Archives. In Proceedings of the 2019 9th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 10–11 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 185–190. [Google Scholar]
- Oracle. Data Warehousing Concepts. 1999. Available online: https://docs.oracle.com/cd/A84870_01/doc/server.816/a76994/concept.htm (accessed on 29 May 2022).
- Stonebraker, M.; Çetintemel, U. “One size fits all” an idea whose time has come and gone. In Making Databases Work: The Pragmatic Wisdom of Michael Stonebraker; ACM: New York, NY, USA, 2018; pp. 441–462. [Google Scholar]
- Kranas, P.; Kolev, B.; Levchenko, O.; Pacitti, E.; Valduriez, P.; Jiménez-Peris, R.; Patiño-Martinez, M. Parallel query processing in a polystore. Distrib. Parallel Databases 2021, 39, 939–977. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poudel, M.; Sarode, R.P.; Watanobe, Y.; Mozgovoy, M.; Bhalla, S. A Survey of Big Data Archives in Time-Domain Astronomy. Appl. Sci. 2022, 12, 6202. https://doi.org/10.3390/app12126202
Poudel M, Sarode RP, Watanobe Y, Mozgovoy M, Bhalla S. A Survey of Big Data Archives in Time-Domain Astronomy. Applied Sciences. 2022; 12(12):6202. https://doi.org/10.3390/app12126202
Chicago/Turabian StylePoudel, Manoj, Rashmi P. Sarode, Yutaka Watanobe, Maxim Mozgovoy, and Subhash Bhalla. 2022. "A Survey of Big Data Archives in Time-Domain Astronomy" Applied Sciences 12, no. 12: 6202. https://doi.org/10.3390/app12126202
APA StylePoudel, M., Sarode, R. P., Watanobe, Y., Mozgovoy, M., & Bhalla, S. (2022). A Survey of Big Data Archives in Time-Domain Astronomy. Applied Sciences, 12(12), 6202. https://doi.org/10.3390/app12126202