
Game-Theory-Based Task Offloading and Resource Scheduling in Cloud-Edge Collaborative Systems

Abstract
:1. Introduction
- (1)
- To address the utility maximization problem, this paper proposes a joint resource allocation and task offloading scheme based on game theory for Cloud-Edge collaboration, including computational resource allocation and task offloading strategy optimization.
- (2)
- The joint task offloading and resource allocation problem is described as mixed-integer nonlinear programming that combines task offloading decisions and resource allocation for offloading users to maximize system utility.
- (3)
- For the joint task offloading and resource allocation problem, an improved particle swarm optimization algorithm based on game theory is proposed to obtain the task offloading strategy, which achieves the Nash equilibrium of the multi-user computational offloading game.
- (4)
- Other resource allocations and computational offloading schemes are used as comparison schemes for the GTPSO algorithm, and simulation experiments are conducted under different parameters. The results show that the proposed offloading scheme in this paper significantly improves the offloading utility of users.
2. Related Work
3. Problem Description
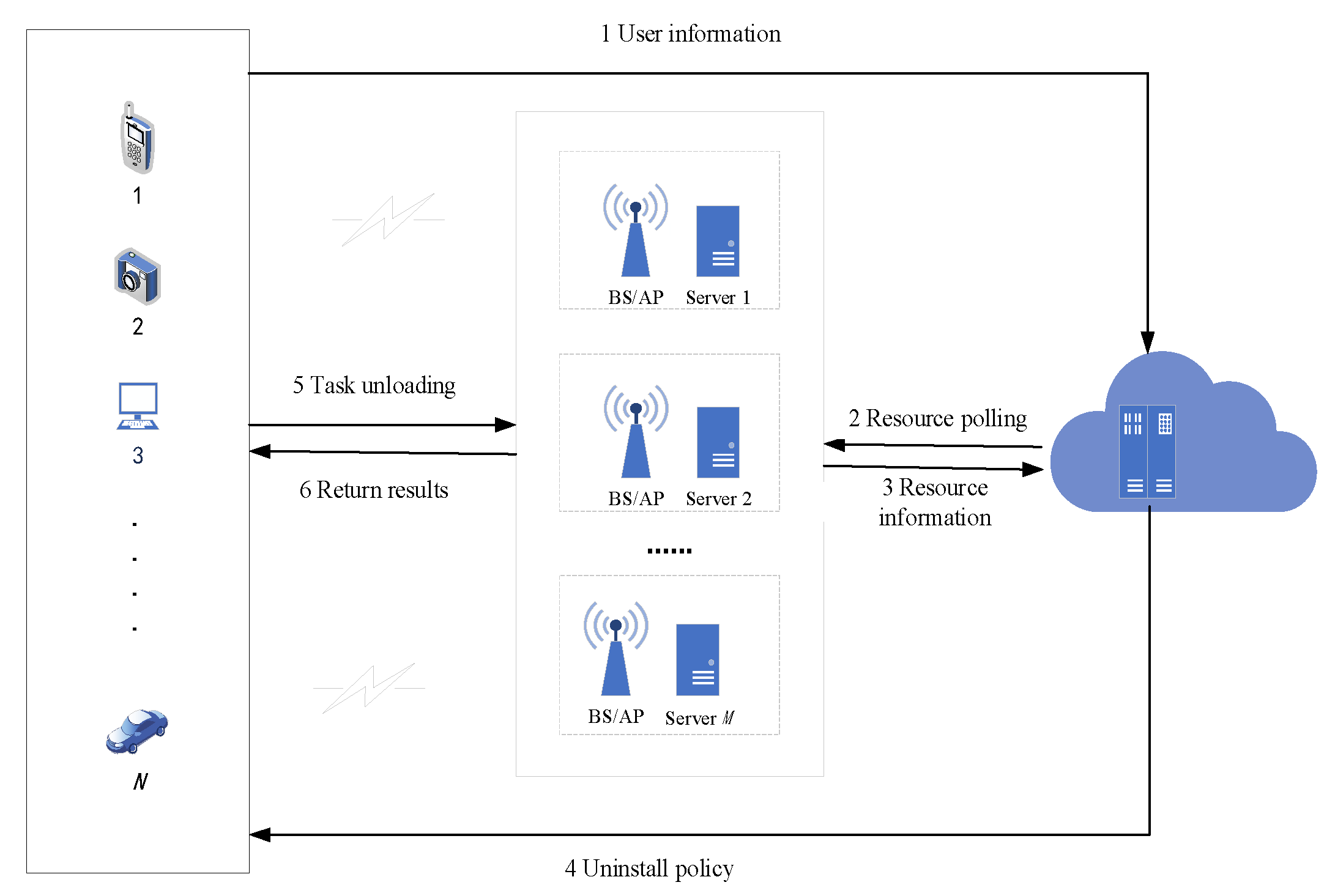
3.1. System Model
3.2. Computational Models
3.2.1. Local Computing
3.2.2. Edge Computing
3.3. Optimization Goals
4. Computing Resource Allocation
| Algorithm 1: MEC computing resource allocation scheme |
| 1: Initialization: very small tolerance , , |
| 2: While do |
| 3: |
| 4: into (20). |
| 5: If , update |
| , update |
| 6: end while |
| 7: The optimal computation resource allocation scheme can be derived by substituting |
| into (20). |
| 8: Output: |
5. Task Unloading Strategy
5.1. Multi-User Task Offloading Game
- (1)
- The offload policy for mobile user is updated from local processing to edge server processing . We can obtain
- (2)
- The offload policy for mobile user n is updated from offload to edge server processing to local processing . We can obtain
- (3)
- The offload policy for mobile user n is updated by edge server to edge server for processing. We can obtainCombining the above cases, we can obtain that the change in the potential function always satisfies Equation (23) for changes in the user offloading decision. Therefore, the game is a potential game that can reach Nash equilibrium within a finite number of improvements, further proving that there exists a set of offloading policies making the utility function of rational mobile users optimal in this paper’s complex network of multi-user multi-edge servers under the Cloud-Edge collaborative architecture. □
5.2. GTPSO Algorithm
5.2.1. Pre-Processing Offload Strategy
- Particle encoding
- 2.
- Fitness function
- 3.
- Algorithm Process
- (1)
- User set , MEC server set , task set .
- (2)
- Algorithm control parameters: maximum number of iterations , velocity boundary , position boundary , initial inertia factor and penalty factor .
- (1)
- The position vector of each particle and the velocity vector .
- (2)
- The fitness function value is initialized and updated as the iteration progresses.
- (3)
- Initialize the individual optimal solution and the global optimal solution of the particle, set the current position of the particle as the individual optimal solution and set the position of the particle with the smallest fitness value as the global optimal solution .
- (1)
- Let the number of iterations .
- (2)
- While .
- (3)
- Update the velocity; each dimension in particle k independently goes to update the velocity . If . Then, when , let , and when , let . The updated formula of particle velocity is:where and are learning factors and , and and are random numbers from 0~1.
- (4)
- Update the position. Particle updates the position independently based on the velocity information. If the value of is greater than , then let . The particle updated position equation is:
- (5)
- Update inertia weights. The fixed inertia weight values easily lead the algorithm to fall into partial optimality. Consider changing the fixed inertia weights in the standard PSO algorithm to a dynamic adjustment strategy to avoid falling into partial optimality and to obtain a better solution to the problem. To ensure that the algorithm starts with a global search in large steps, a large value is initially assigned to w. As the number of iterations increases, w gradually decreases; therefore, the solution of the problem can be traded off between the local optimum and the global optimum. The weights are calculated as in Equation (29):
- (6)
- Update the particle optimal allocation and global optimal allocation. All particles are calculated according to Equation (26) after iteration, and if the updated fitness function value is smaller than the current value, the particle’s individual optimal allocation and global optimal solution are updated.
- (7)
- Update the number of iterations, .Output: Optimal allocation vector and minimum delay .
5.2.2. Policy Update Process
- (1)
- Resource allocation optimization: The user uses Algorithm 1 to optimize resource allocation according to the current offload policy and calculates the corresponding utility values for different offload policies.
- (2)
- Policy update competitions: Based on the optimized computational resources, calculate the utility of each user with different uninstallation policies. The users who can improve their utility compete for the policy update opportunity in a distributed form, and the user with the largest utility improvement updates the uninstallation policy, whereas other users keep the original uninstallation policy and wait for the next round of decision updates. Using the finite improvement property of the potential game, only one user with the maximum utility improvement is allowed to update the uninstallation strategy in each iteration. The iteration terminates when the Nash equilibrium is reached and when all users have no incentive to change their uninstallation strategies. The uninstallation policy that maximizes the utility of the system is obtained.
| Algorithm 2: GTPSO |
| 1: Input: user set , , , ; |
| , , , , |
| 2: For each particle |
| 3: Initialize position , , |
| 4: End For |
| 5: Iteration = 1 |
| 6: DO |
| 7: Update the by (27) and by (28) |
| 8: Update the by (29) |
| 9: Evaluate particle k |
| 10: If ) |
| 11: |
| 12: End if |
| 13: If |
| 14: |
| 15: End if |
| 16: |
| 17: WHILE maximum iterations or optimal solution are not changed |
| 18: Output: Pre task offloading strategy |
| 19: ←+1 |
| 20: while do |
| 21: set = 1 |
| 22: while do |
| 23: calculate by (8) |
| 24: calculate and by algorithm 1 and (9), respectively |
| 25: compute the best response |
| 26: |
| 27: end while |
| 28: for each user do |
| 29: if user wins in the iteration, |
| 30: then update |
| 31: else |
| 32: end for |
| 33: + 1 |
| 34: end while |
| 35: Output: Optimal computation resource allocation and offloading strategy |
6. Experimental Results and Analysis
6.1. Experimental Setup
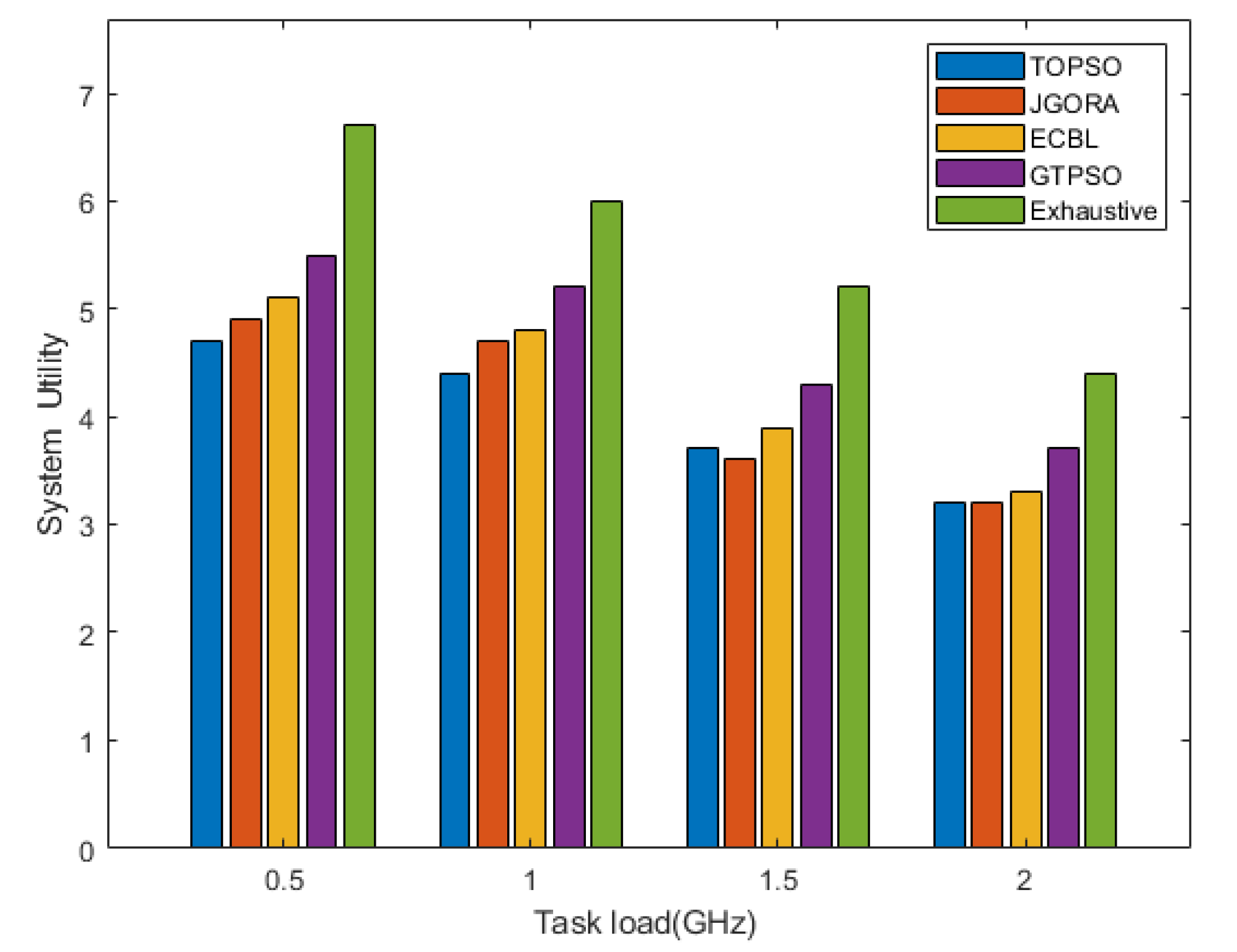
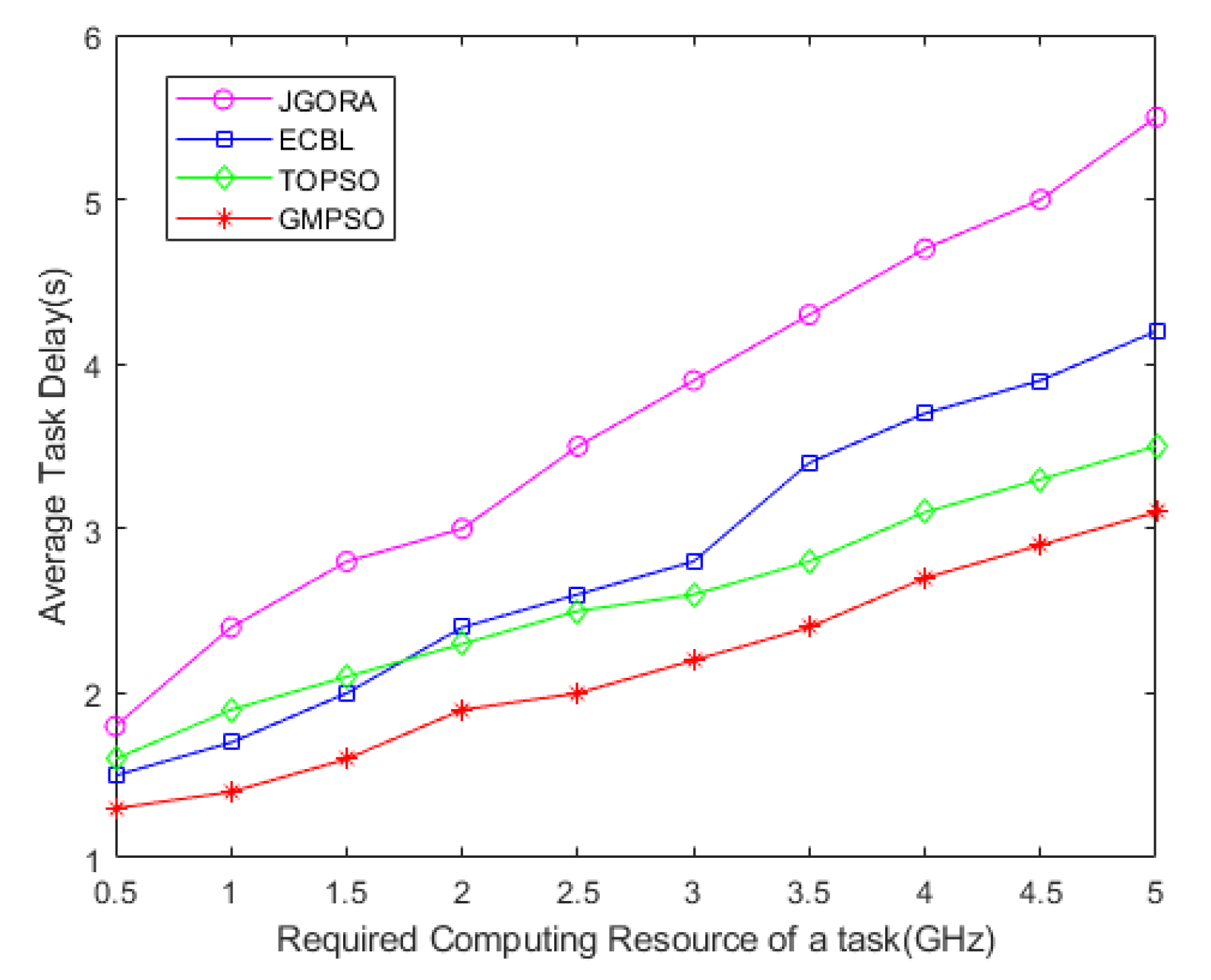
- Exhaustive: This is a brute-force method that finds the optimal offloading scheduling solution via an exhaustive search of over possible decisions. Since the computational complexity of this method is very high, its performance is only evaluated in a small network setting.
- Task offloading by the particle swarm optimization algorithm (TOPSO): Using the particle swarm optimization algorithm in [34] for task offloading and introducing the cloud center for offloading scheduling, the TOPSO scheme does not consider the resource allocation scheme.
- Joint Greedy Offloading and Resource Allocation (JGORA): All tasks are offloaded [35], and each offloaded user greedily selects the subchannel with the highest channel gain until all users are admitted or until all subchannels are occupied. The JGORA scheme does not account for the cloud computing processing model.
- ECBL: The literature [20] proposes an improved artificial bee colony algorithm to find the optimal allocation scheme. The ECBL scheme considers the cloud-side collaborative system but does not consider the task local processing scheme.
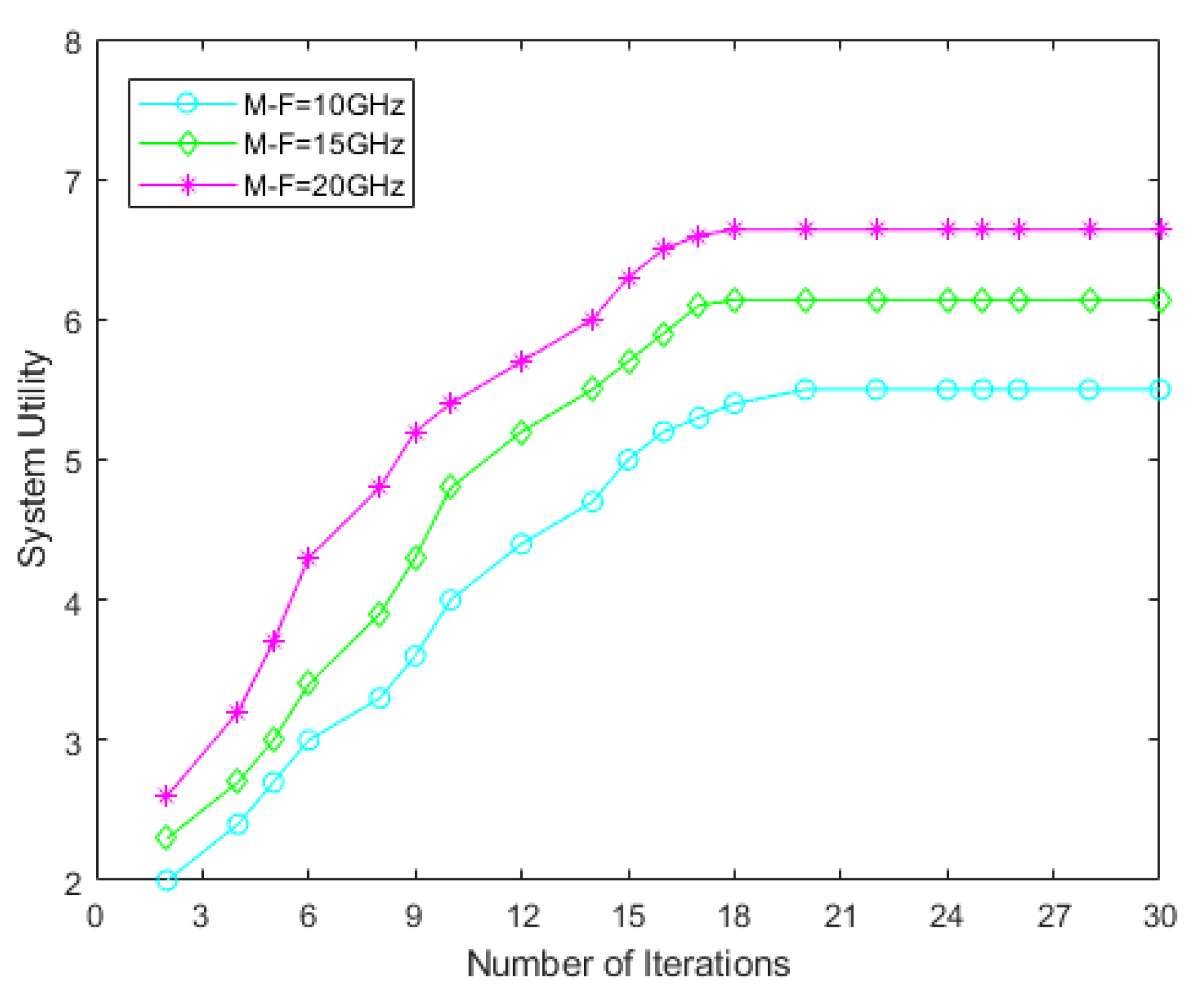
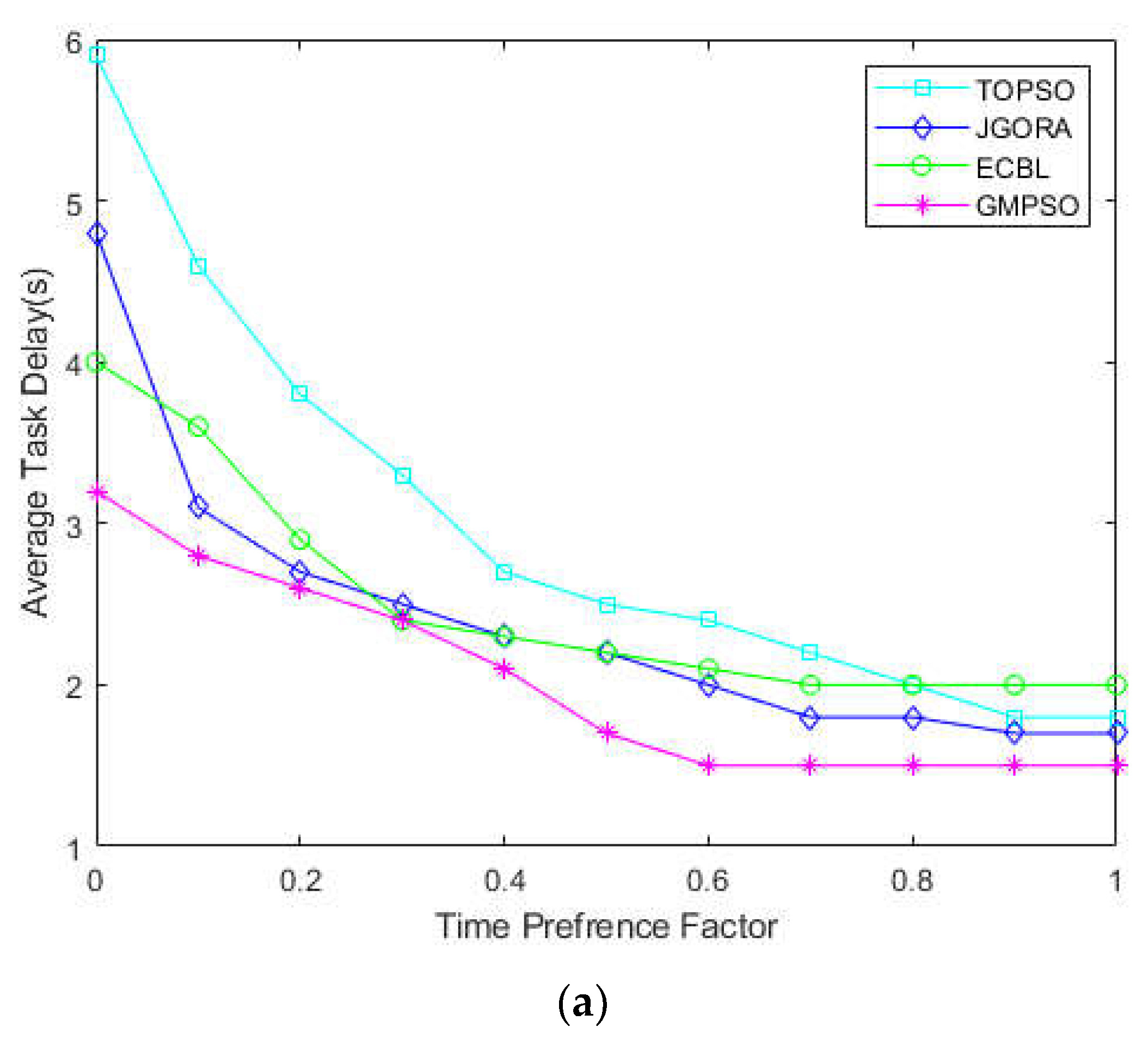
Performance Evaluation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, B.; Xu, X.; Qi, L.; Ni, Q.; Dou, W. Task scheduling with precedence and placement constraints for resource utilization improvement in multi-user MEC environment. J. Syst. Archit. 2021, 114, 101970. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. Internet Things J. IEEE 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Tran, T.X.; Hajisami, A.; Pandey, P.; Pompili, D. Collaborative Mobile Edge Computing in 5G Networks: New Paradigms, Scenarios, and Challenges. IEEE Commun. Mag. 2016, 55, 54–61. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Mao, Y.; Zhang, J.; Letaief, K.B. Delay-Optimal Computation Task Scheduling for Mobile-Edge Computing Systems. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016. [Google Scholar]
- Yang, L.; Cao, J.; Cheng, H.; Ji, Y. Multi-User Computation Partitioning for Latency Sensitive Mobile Cloud Applications. IEEE Trans. Comput. 2015, 64, 2253–2266. [Google Scholar] [CrossRef]
- Zhang, K.Y.; Gui, X.L.; Ren, D.; Li, J.; Wu, J.; Ren, D.S. Survey on computation offloading and content caching in mobile edge networks. Ruan Jian Xue Bao/J. Softw. 2019, 30, 2491–2516. Available online: http://www.jos.org.cn/1000-9825/5861.htm (accessed on 1 May 2021). (In Chinese).
- Alam, M.G.R.; Hassan, M.M.; Uddin, M.Z.; Almogren, A.; Fortino, G. Autonomic computation offloading in mobile edge for IoT applications. Future Gener. Comput. Syst. 2018, 90, 149–157. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Ji, H.; Li, X. Joint Computation Offloading and Service Caching for MEC in Multi-access Networks. In Proceedings of the 2019 IEEE 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Istanbul, Turkey, 8–11 September 2019. [Google Scholar]
- Wang, X.; Chen, X.; Wu, W. Towards truthful auction mechanisms for task assignment in mobile device clouds. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- You, C.; Huang, K.; Chae, H.; Kim, B. Energy-efficient resource allocation for mobile-edge computation offloading. IEEE Trans. Wirel. Commun. 2016, 16, 1397–1411. [Google Scholar] [CrossRef]
- Zhan, Y.; Guo, S.; Li, P.; Zhang, J. A Deep Reinforcement Learning Based Offloading Game in Edge Computing. IEEE Trans. Comput. 2020, 69, 883–893. [Google Scholar] [CrossRef]
- Tang, M.; Wong, V. Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing Systems. IEEE Trans. Comput. 2020, 21, 1985–1997. [Google Scholar] [CrossRef]
- Huang, D.; Wang, P.; Niyato, D. A Dynamic Offloading Algorithm for Mobile Computing. IEEE Trans. Wirel. Commun. 2012, 11, 1991–1995. [Google Scholar] [CrossRef]
- Dinh, T.Q.; Tang, J.; La, Q.D.; Quek, T.Q. Offloading in Mobile Edge Computing: Task Allocation and Computational Frequency Scaling. IEEE Trans. Commun. 2017, 65, 3571–3584. [Google Scholar]
- Cao, X.; Wang, F.; Xu, J.; Zhang, R.; Cui, S. Joint Computation and Communication Cooperation for Mobile Edge Computing. In Proceedings of the 2018 16th International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt), Shanghai, China, 7–11 May 2018. [Google Scholar]
- You, C.; Huang, K. Multiuser Resource Allocation for Mobile-Edge Computation Offloading. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016. [Google Scholar]
- Chen, M.; Hao, Y. Task Offloading for Mobile Edge Computing in Software Defined Ultra-Dense Network. IEEE J. Sel. Areas Commun. 2018, 36, 587–597. [Google Scholar] [CrossRef]
- Guo, X.; Singh, R.; Zhao, T.; Niu, Z. An index based task assignment policy for achieving optimal power-delay tradeoff in edge cloud systems. In Proceedings of the ICC 2016—2016 IEEE International Conference on Communications, Kuala Lumpur, Malaysia, 22–27 May 2016. [Google Scholar]
- Qiu, X.; Liu, L.; Chen, W.; Hong, Z.; Zheng, Z. Online Deep Reinforcement Learning for Computation Offloading in Blockchain-Empowered Mobile Edge Computing. IEEE Trans. Veh. Technol. 2019, 68, 8050–8062. [Google Scholar] [CrossRef]
- Wang, W.; Bai, Y.; Wang, S. Task Offloading Strategy in Cloud Collaborative Edge Computing. In Artificial Intelligence and Security. ICAIS 2020. Communications in Computer and Information Science; Springer: Singapore, 2020. [Google Scholar]
- Chen, Y.; Li, Z.; Yang, B.; Nai, K.; Li, K. A Stackelberg game approach to multiple resources allocation and pricing in mobile edge computing. Future Gener. Comput. Syst. 2020, 108, 273–287. [Google Scholar] [CrossRef]
- Ma, S.; Guo, S.; Wang, K.; Jia, W.; Guo, M. A cyclic game for service-oriented resource allocation in edge computing. IEEE Trans. Serv. Comput. 2020, 13, 723–734. [Google Scholar] [CrossRef]
- Gu, Y.; Chang, Z.; Pan, M.; Song, L.; Han, Z. Joint radio and computational resource allocation in IoT fog computing. IEEE Trans. Veh. Technol. 2018, 67, 7475–7484. [Google Scholar] [CrossRef]
- Chen, X. Decentralized Computation Offloading Game for Mobile Cloud Computing. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 974–983. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient Multi-User Computation Offloading for Mobile-Edge Cloud Computing. IEEE/ACM Trans. Netw. 2016, 24, 2795–2808. [Google Scholar] [CrossRef] [Green Version]
- Long, L.; Liu, Z.; Zhou, Y.; Liu, L.; Shi, J.; Sun, Q. Delay Optimized Computation Offloading and Resource Allocation for Mobile Edge Computing. In Proceedings of the IEEE 90th Vehicular Technology Conference (VTC2019-Fall), Honolulu, HI, USA, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Hu, J.; Li, K.; Liu, C.; Li, K. Game-Based Task Offloading of Multiple Mobile Devices with QoS in Mobile Edge Computing Systems of Limited Computation Capacity. ACM Trans. Embed. Comput. Syst. 2020, 19, 1–21. [Google Scholar] [CrossRef]
- Eshraghi, N.; Liang, B. Joint offloading decision and resource allocation with uncertain task computing requirement. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April 2019–2 May 2019. [Google Scholar]
- Poularakis, K.; Llorca, J.; Tulino, A.M.; Taylor, I.; Tassiulas, L. Joint service placement and request routing in multi-cell mobile edge computing networks. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April 2019–2 May 2019. [Google Scholar]
- Chen, L.; Wu, J.; Zhang, J.; Dai, H.N.; Long, X.; Yao, M. Dependency-Aware Computation Offloading for Mobile Edge Computing with Edge-Cloud Cooperation. IEEE Trans. Cloud Comput. 2020, 1. [Google Scholar] [CrossRef]
- Shami, T.M.; El-Saleh, A.A.; Alswaitti, M.; Al-Tashi, Q.; Summakieh, M.A.; Mirjalili, S. Particle Swarm Optimization: A Comprehensive Survey. IEEE Access 2022, 10, 10031–10061. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Joint Task Offloading and Resource Allocation for Multi-Server Mobile-Edge Computing Networks. IEEE Trans. Veh. Technol. 2018, 68, 856–868. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Li, Q.; Gong, Y.; Zhang, K. Computation Offloading and Resource Allocation for Cloud Assisted Mobile Edge Computing in Vehicular Networks. IEEE Trans. Veh. Technol. 2019, 68, 7944–7956. [Google Scholar] [CrossRef]
- Cao, S.; Tao, X.; Hou, Y.; Cui, Q. An energy-optimal offloading algorithm of mobile computing based on HetNets. In Proceedings of the IEEE International Conference on Connected Vehicles & Expo, Shenzhen, China, 19–23 October 2015. [Google Scholar]
- Sardellitti, S.; Scutari, G.; Barbarossa, S. Joint optimization of radio and computational resources for multicell mobile cloud computing. In Proceedings of the 2014 IEEE 15th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Toronto, ON, Canada, 22–25 June 2014; pp. 354–358. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Parameter | Numerical Value |
|---|---|
| Cloud center CPU frequency | 20 GHz |
| Edge server CPU frequency | 10 GHz |
| User CPU frequency | 1 GHz |
| 1 us/bit | |
| 20 MHz | |
| 20 dBm | |
| 0.6~0.8 | |
| −100 dBm | |
| cycle/J | |
| cycle/J | |
| 0.8 |
| Scheme | Time |
|---|---|
| TOPSO | 0.2 |
| JGORA | 2.5 |
| ECBL | 0.7 |
| GTPSO | 0.4 |
| Exhaustive | 36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Hu, Z.; Deng, Y.; Hu, L. Game-Theory-Based Task Offloading and Resource Scheduling in Cloud-Edge Collaborative Systems. Appl. Sci. 2022, 12, 6154. https://doi.org/10.3390/app12126154
Wang S, Hu Z, Deng Y, Hu L. Game-Theory-Based Task Offloading and Resource Scheduling in Cloud-Edge Collaborative Systems. Applied Sciences. 2022; 12(12):6154. https://doi.org/10.3390/app12126154
Chicago/Turabian StyleWang, Suzhen, Zhongbo Hu, Yongchen Deng, and Lisha Hu. 2022. "Game-Theory-Based Task Offloading and Resource Scheduling in Cloud-Edge Collaborative Systems" Applied Sciences 12, no. 12: 6154. https://doi.org/10.3390/app12126154
APA StyleWang, S., Hu, Z., Deng, Y., & Hu, L. (2022). Game-Theory-Based Task Offloading and Resource Scheduling in Cloud-Edge Collaborative Systems. Applied Sciences, 12(12), 6154. https://doi.org/10.3390/app12126154