
Machine Learning-Powered Rainfall-Based Landslide Predictions in Hong Kong—An Exploratory Study

Abstract
:1. Introduction
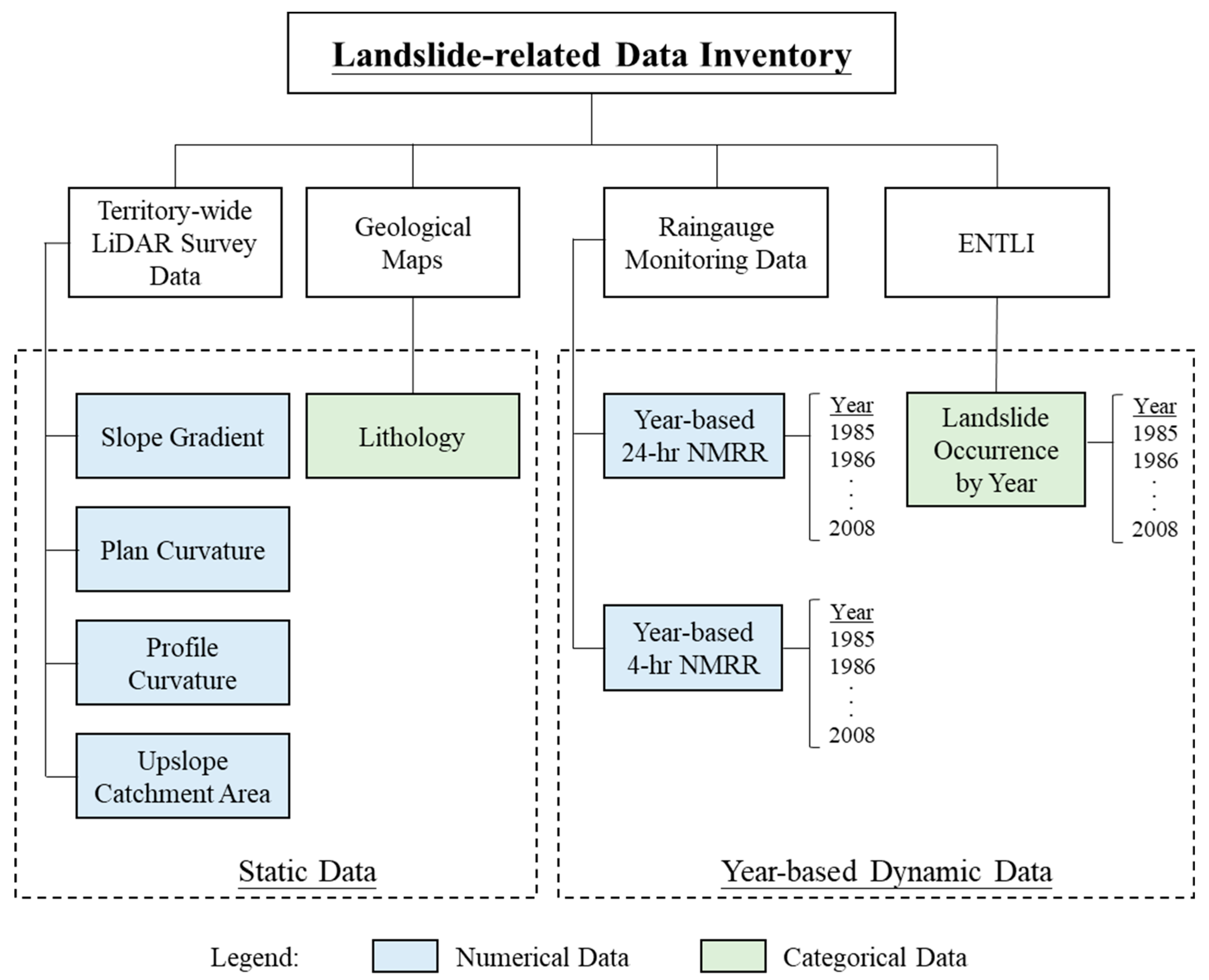
2. Landslide-Related Data Inventory in Hong Kong
2.1. Enhanced Natural Terrain Landslide Inventory (ENTLI)
2.2. Rainfall
2.3. Airborne Light Detection and Ranging (LiDAR) Survey
2.4. Geological Map
3. The Pilot Study—ML-Powered Natural Terrain Landslide Susceptibility Analysis
3.1. Background
- (1)
- Conventional statistical approach: Evans & King (1998) [9] undertook the first landslide susceptibility analysis for the whole natural terrain of Hong Kong. The historical landslides observed from aerial photographs, together with the slope angle and lithology, were considered. The result provided five susceptibility classes differentiated by one order of magnitude in terms of landslide frequency (0.1 to 1 no. of landslide/km2/year). Subsequently, in cognizance of the rainfall’s effects on the landslides, Ko & Lo (2016) [2] proposed an updated, higher-resolution, and territory-wide natural terrain landslide susceptibility model by considering rainfall intensity as an additional conditioning factor. Year-based rainfall intensities were adopted. An enhanced resolution of the landslide and terrain data were also used. This updated landslide susceptibility model achieved an overall four to five orders of magnitude in terms of landslide density (no./km2).
- (2)
- Machine learning (ML)-based approach: Dai & Lee (2002) [10] adopted the logistic multiple regression method to categorize the relative landslide susceptibility of the natural terrain on an outlying island of Hong Kong. Recently, Ng et al. (2021) [11] carried out a territory-wide spatiotemporal modelling of rainfall-induced natural terrain landslides with ML and deep learning algorithms considering storm-based data. Both of these studies adopted grid-based analysis, which is by far the most commonly adopted mapping unit for statistically-based landslide susceptibility analysis [12]. Wang et al. (2021a) [13] performed an AI-based territory-wide landslide susceptibility analysis of Hong Kong with an object-based method. Object units of 30 m × 30 m formed of 2 m × 2 m grids were considered. These ML-based studies have proven to be powerful in learning the association between landslide occurrences and the set of conditioning factors in a mathematical manner.
- (a)
- Data sampling commonly used in previous studies to deal with an imbalanced dataset is not adopted. This helps improve the resolution of the landslide susceptibility maps (see more details in Section 3.3);
- (b)
- A new feature selection framework has been proposed in this study for identifying features with physical significance to landslide occurrences in the ML model development (see more details in Section 3.5) to ensure domain knowledge on landslide characteristics, which is often lacking in previous studies, is duly considered for the development of physically meaningful ML models.
3.2. The Study Area
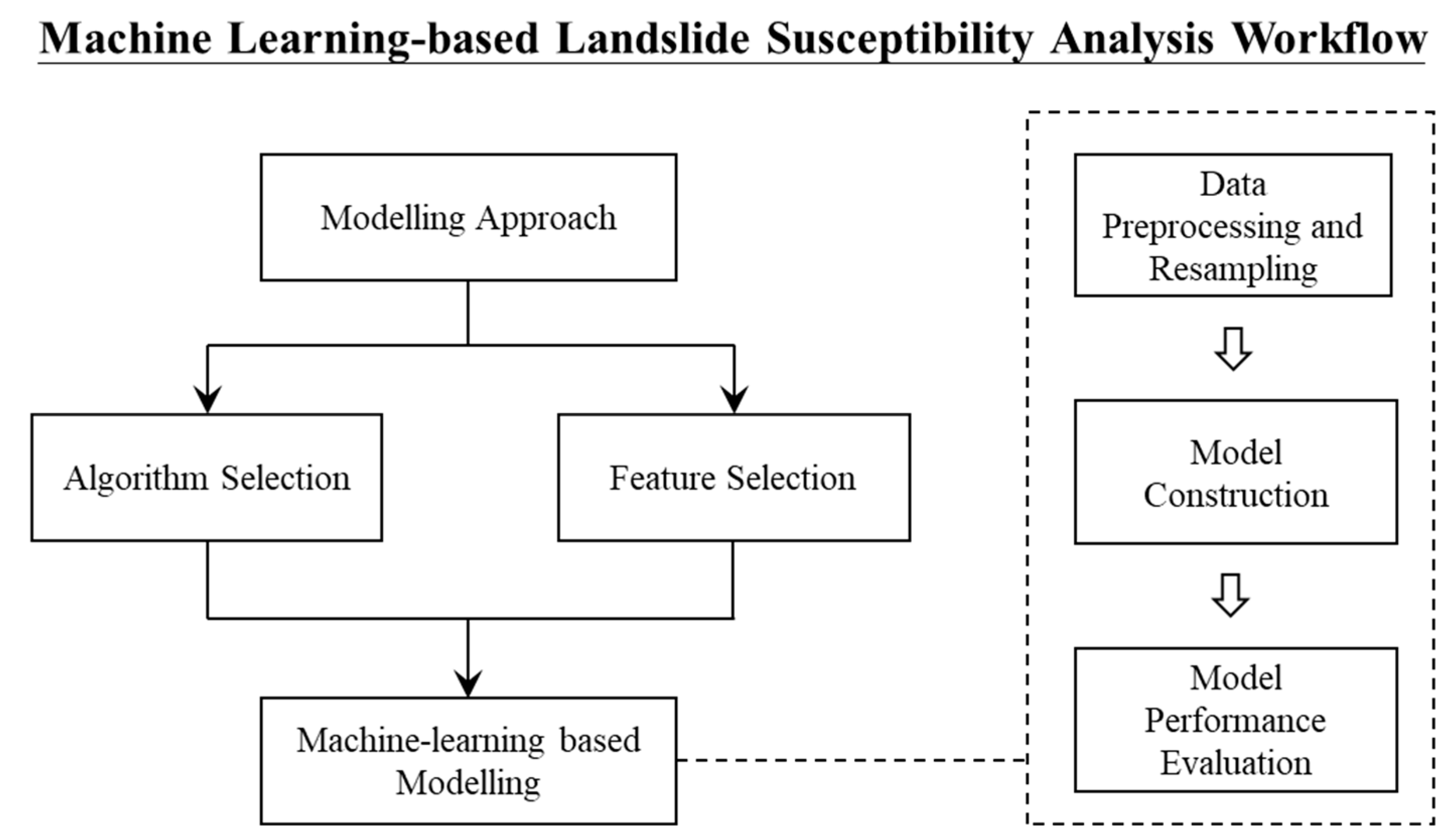
3.3. The Modelling Approach
3.4. Algorithm Selection
- Interpretability of the algorithms: how easy is it to explain the results from the input data, or to understand the patterns that models use to link to the training datasets (Ma et al., 2021). This factor is essential for detecting bias and debugging the models. The model predictions should also be explainable using our professional knowledge (domain knowledge) on landslides.
- Balance between bias and variances: whether the algorithm can form a predictive model that is generalized enough to give consistent yet accurate forward predictions. Algorithms which are prone to overfitting should be avoided as a result.
- Suitability for handling correlated features: the ability of an algorithm to handle correlated features provides additional flexibility in the selection of features and is thus preferable.
- Computational efficiency: the time and computational effort spent on the study.
3.5. Feature Selection
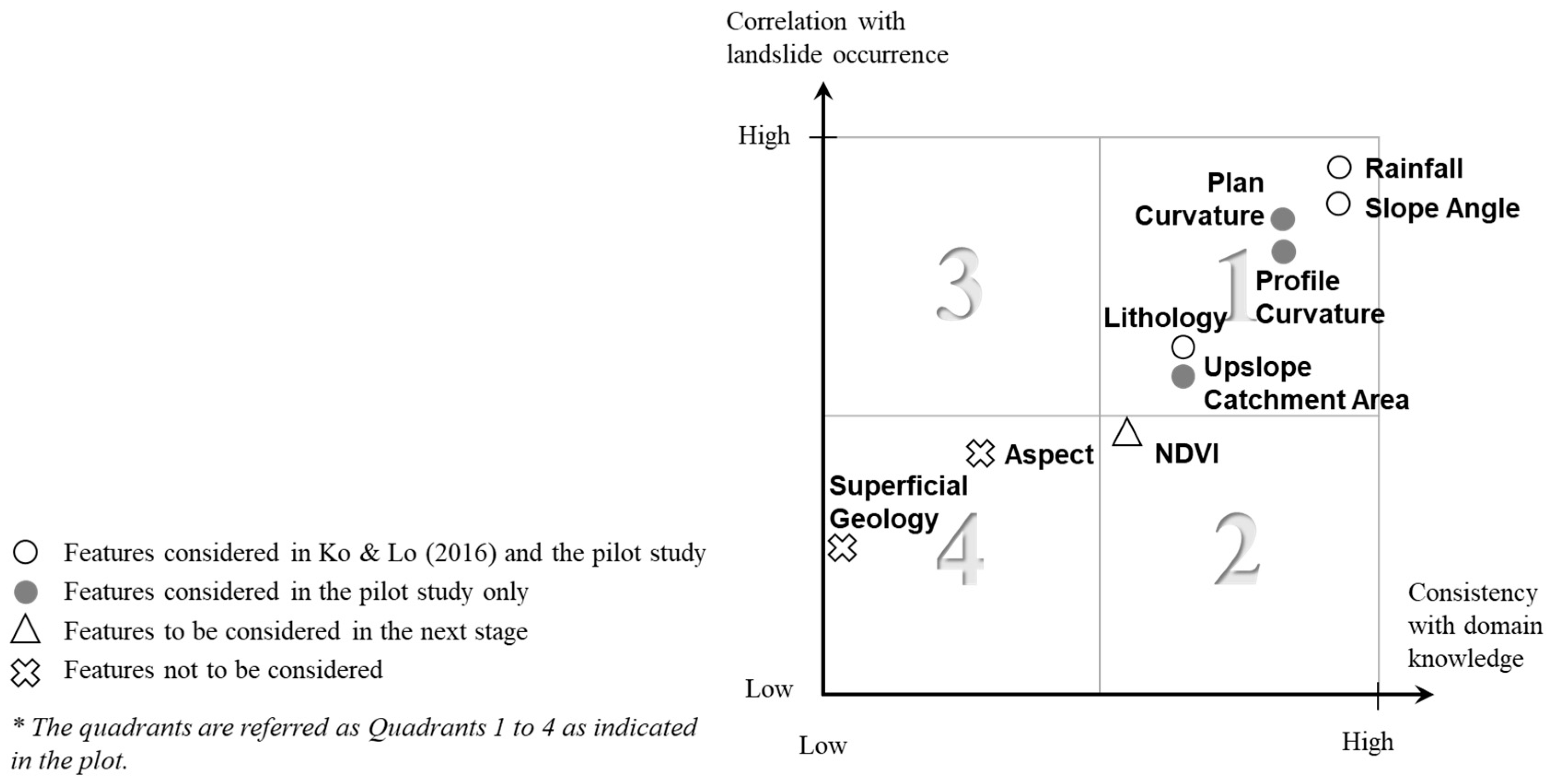
3.5.1. The Feature Selection Framework
- Criterion (i): the quality of feature datasets;
- Criterion (ii): the statistical correlation between a feature and the landslide occurrence;
- Criterion (iii): the consistency of the above correlation with the domain knowledge on landslide susceptibility.
3.5.2. The Selection Outcome
3.5.3. Landslide Data
3.6. The Machine Learning-Based Modelling
3.6.1. Preprocessing and Resampling of Data
3.6.2. Model Construction
- Shuffling of the input dataset in a random manner.
- Splitting of the shuffled dataset into nine groups in a stratified manner.
- From (2), the selection of seven groups of the split data as a training dataset to fit the model.
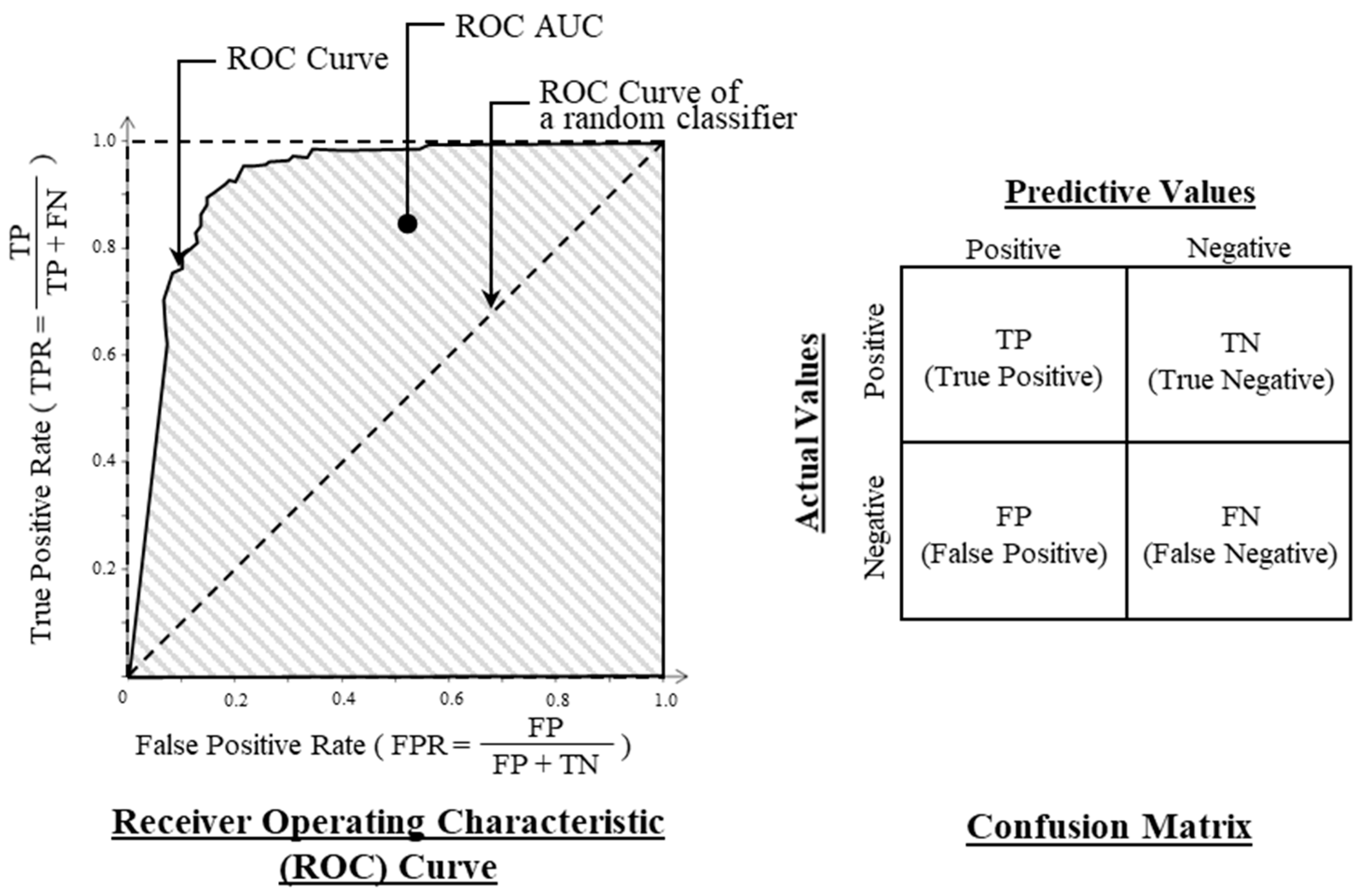
- An evaluation of the trained model with the validation dataset (i.e., the remaining two groups of split data) based on the area under the receiver operating characteristic (ROC) curve.
- Repetition of (3) and (4) five times.
3.6.3. Model Performance Evaluation
- (a)
- Evaluation Metrics
- The ROC AUC based on the training data of all cases are over 94%, indicating that the machine learning models fit the training data very well.
- The ROC AUC based on the two sets of testing data are over 86%. The highest ROC AUCs based on TD1 and TD2 were up to 91.5% and 97.3%, respectively, for individual XGBoost models. The ROC AUC based on TD1 is obviously lower than that based on TD2 for all of the cases as the former served as a more stringent test of the models’ ability to make forward predictions. All in all, the ROC AUC values that were achieved reveal that all of the ML models are able to make fairly accurate predictions.
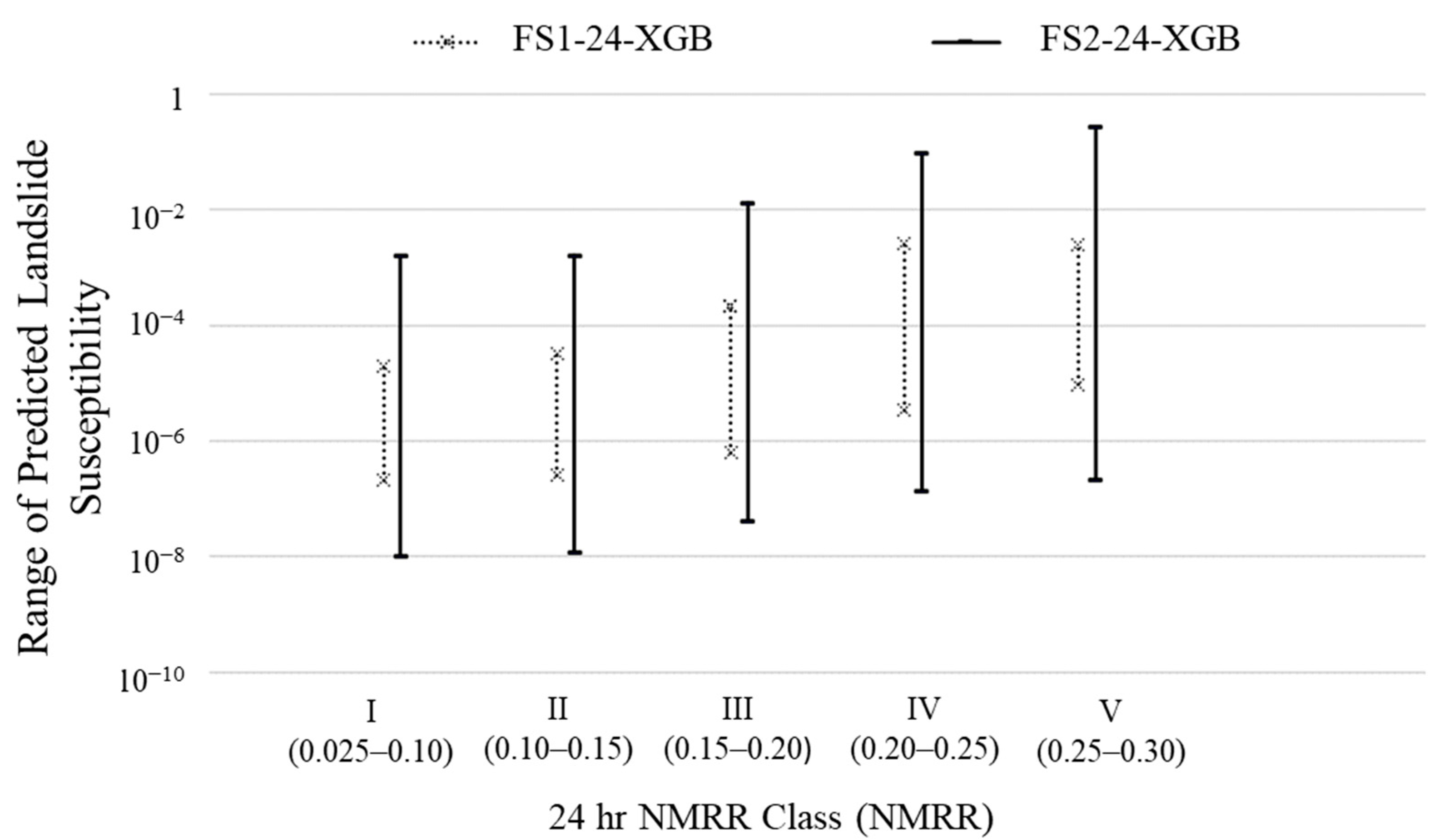
- With reference to the ROC AUC based on the testing data, the XGBoost and Random Forest models perform better than the Decision Tree models. The introduction of additional features (i.e., FS2) improved the performance of the ML models; the effect is more obvious when the models were tested with TD2. On the other hand, the durations of NMRR seemed to have no significant effect on the models’ performances.
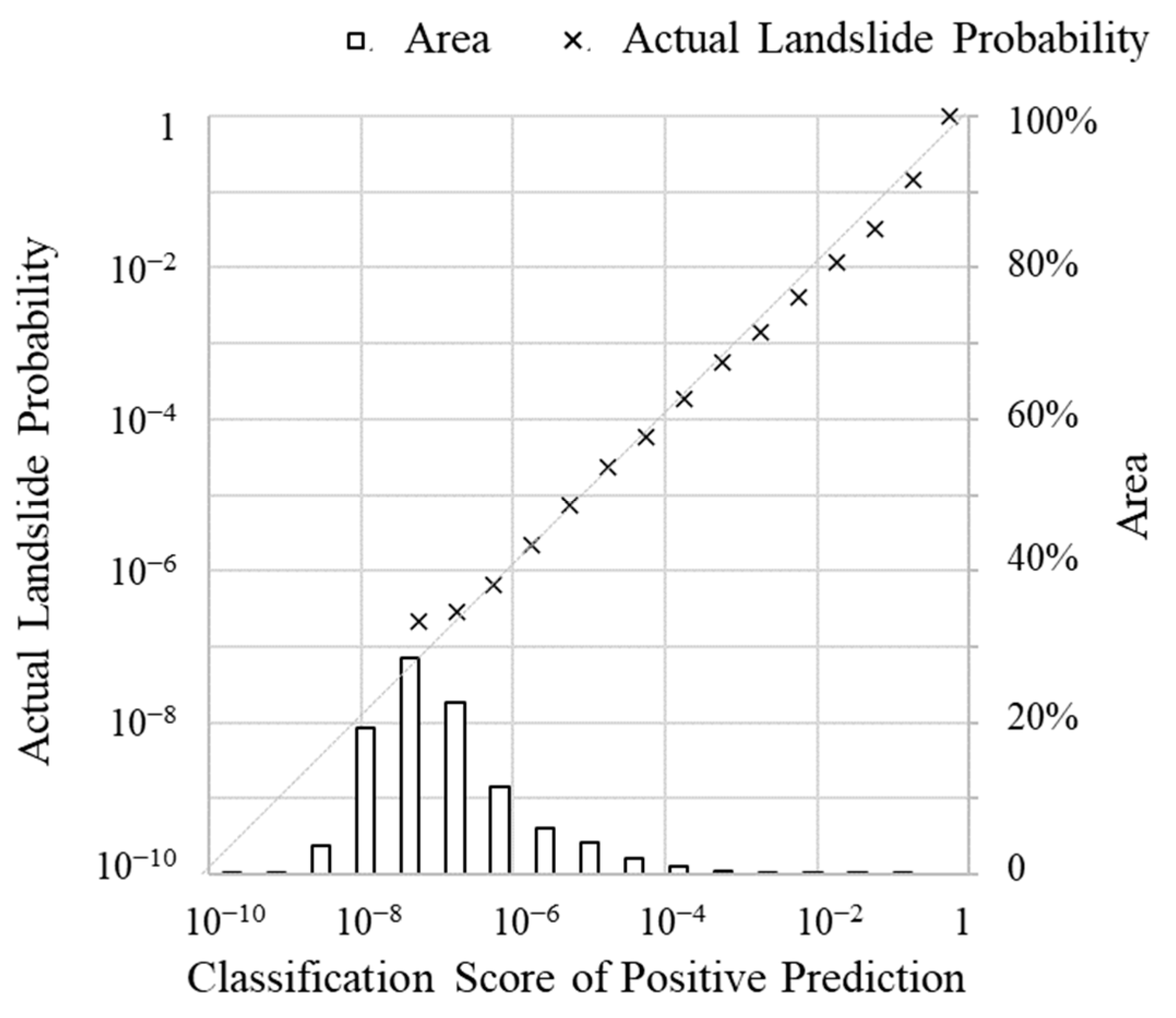
- (b) Susceptibility Map
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cheung, R.W.M. Landslide risk management in Hong Kong. Landslides 2021, 18, 3457–3473. [Google Scholar] [CrossRef]
- Ko, F.W.Y.; Lo, F.L.C. Rainfall-based landslide susceptibility analysis for natural terrain in Hong Kong-A direct stock-taking approach. Eng. Geol. 2016, 215, 95–107. [Google Scholar] [CrossRef]
- Kong, V.W.W.; Kwan, J.S.H.; Pun, W.K. Hong Kong’s landslip warning system—40 years of progress. Landslides 2020, 17, 1453–1463. [Google Scholar] [CrossRef]
- Li, H.W.M.; Li, R.H.L.; Wong, C.C.J.; Lo, F.L.C. ML-Powered Natural Terrain Landslide Susceptibility Analysis–A Pilot Study. 2022; not yet published. [Google Scholar]
- Wong, H.N. Digital technology in geotechnical engineering. In Proceedings of the Hong Kong Institution of Engineers Geotechnical Division Annual Seminar 2007, Hong Kong, China, 15 May 2017; pp. 157–168. [Google Scholar]
- Ng, K.C.; Chiu, K.M. Airborne LiDAR survey in Hong Kong-Application to natural terrain hazard study. In Proceedings of the 28th Annual Seminar 2008, Hong Kong, China, 27–29 March 2008; Geotechnical Division, The Hong Kong Institution of Engineer: Hong Kong, China; pp. 219–224. [Google Scholar]
- Hong Kong Geological Survey. Available online: https://www.cedd.gov.hk/eng/publications/geo/hong-kong-geological-survey/index.html (accessed on 10 April 2022).
- Wong, H.N.; Shum, W.W.L.; Ko, F.W.Y. Assessment of Natural Terrain Landslide Risk on the Planned Development in Ling Pei, Lantau; Geotechnical Engineering Office: Hong Kong, China, 2004. [Google Scholar]
- Evans, N.C.; King, J.P. The Natural Terrain Landslide Study-Debris Avalanche Susceptibility (TN 1/98); Geotechnical Engineering Office: Hong Kong, China, 1998. [Google Scholar]
- Dai, F.C.; Lee, C.F. Terrain-based mapping of landslide susceptibility using a geographical information system: A case study. Can. Geotech. J. 2001, 38, 911–923. [Google Scholar] [CrossRef]
- Ng, C.W.W.; Yang, B.; Liu, Z.Q.; Kwan, J.S.H.; Chen, L. Spatiotemporal modelling of rainfall-induced landslides using machine learning. Landslides 2021, 18, 2499–2514. [Google Scholar] [CrossRef]
- Reichenbach, P.; Rossi, M.; Malamud, B.D.; Mihri, M.; Guzzetti, F. A review of statistically-based landslide susceptibility models. Earth-Sci. Rev. 2018, 180, 60–91. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Lau, H.; He, J.; Cheung, R.W.M. AI-powered landslide susceptibility assessment in Hong Kong. Eng. Geol. 2021, 288, 106103. [Google Scholar] [CrossRef]
- Tehrani, F.S.; Calvello, M.; Liu, Z.Q.; Zhang, L.; Lacasse, S. Machine learning and landslide studies: Recent advances and applications. 2021; not yet published. [Google Scholar]
- Ma, Z.; Mei, G.; Piccialli, F. Machine Learning for Landslides Prevention: A Survey. Neural Comput. Appl. 2021, 33, 10881–10907. [Google Scholar] [CrossRef]
- Liu, Z.Q.; Gilbert, G.; Cepeda, J.M.; Lysdahl, A.O.K.; Piciullo, L.; Hefre, H.; Lacasse, S. Modelling of shallow landslides with machine learning algorithms. Geosci. Front. 2021, 12, 385–393. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Yin, K.; Luo, H.; Li, J. Landslide identification using machine learning. Geosci. Front. 2020, 12, 351–364. [Google Scholar] [CrossRef]
- Xiao, T.; Zhang, L. Storm-based forecasting of man-made slope failures using machine learning. In Proceedings of the 20th International Conference on Soil Mechanics and Geotechnical Engineering, Sydney, Australia, 1–5 May 2022. [Google Scholar]
- Merghadi, A.; Yunus, A.P.; Dou, J.; Whiteley, J.; Pham, B.T.; Bui, D.T.; Avtar, R.; Abderrahmane, B. Machine learning methods for landslide susceptibility studies: A comparative overview of algorithm performance. Earth-Sci. Rev. 2020, 207, 103225. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Tree, 1st ed.; Wadsworth: New York, NY, USA, 1984. [Google Scholar]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 4–32. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Ho, H.Y.; Roberts, K.J. Guidelines for Natural Terrain Hazard Studies (GEO Report No. 138), 2nd ed.; Geotechnical Engineering Office, Civil Engineering and Development Department: Hong Kong, China, 2016. [Google Scholar]
- Ko, F.W.Y. Correlation between Rainfall and Natural Terrain Landside Occurrence in Hong Kong (GEO Report No. 168); Geotechnical Engineering Office: Hong Kong, China, 2005. [Google Scholar]
- Marc, O.; Gosset, M.; Saito, H.; Uchida, T.; Malet, J.-P. Spatial patterns of storm-induced landslides and their relation to rainfall anomaly maps. Geophys. Res. Lett. 2019, 46, 11167–11177. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evans & King (1998) [9] | Dai & Lee (2002) [10] | Ko & Lo (2016) [2] | Ng et al. (2021) [11] | Wang et al. (2021a) [13] | The Current Pilot Study | |
|---|---|---|---|---|---|---|
| Modelling Approach |
|
|
|
|
|
|
| Resampling Ratio | Not Applicable | 1:1 | Not Applicable | 1:1 | 1:2 | Not Applicable |
| Features |
|
|
|
|
|
|
| Machine Learning Algorithm | Not Applicable | Logistic Regression | Not Applicable |
|
|
|
| Susceptibility Resolution Achieved |
|
|
|
|
|
|
| ML Algorithms | Brief Descriptions |
|---|---|
| Decision Tree | It is known as one of the most commonly used algorithms in studies of a similar nature. It works by recursive partitioning of data (i.e., splitting of tree) based on splitting criteria that yields the maximum information gain as assessed based on Gini impurity value. Despite this, it is a less robust algorithm and sensitive to the predictive data. It has been adopted for its computational efficiency and high interpretability to facilitate an understanding of the other two tree-based algorithms. |
| Random forest | It is a tree-based ensemble learning algorithm, of which performance is greatly enhanced in terms of robustness and generalizability compared with Decision Tree. Random Forest adopts the bagging method which lowers variance and avoids overfitting of the models by injecting randomness into the model though feature selection. The collection of independent tree-structured predictors formed from different subsets of randomly selected features are combined giving the majority vote cast as the final prediction for classification problems. |
| XGBoost | It is also a tree-based ensemble learning algorithm. XGBoost adopts a scalable gradient tree boosting (GTB) system in which outputs from many weak tree-based learners are ensembled in a stage-wise manner. A weak learner learns from the errors of the previous learner and improves the model at each stage under this method. While Gradient Boosting has recently become popular, it is less routinely used in landslide susceptibility studies, but it improves the accuracies of ML models according to Merghadi et al. (2020). In fact, the performance of XGBoost is widely recognized in several ML and data mining challenges. |
| Feature | Selected Feature | FS1 | FS2 |
|---|---|---|---|
| Rainfall | ✓ | ✓ | ✓ |
| Lithology | ✓ | ✓ | ✓ |
| Slope gradient | ✓ | ✓ | ✓ |
| Plan curvature | ✓ | - | ✓ |
| Profile curvature | ✓ | - | ✓ |
| Aspect | ✗ | - | - |
| Upslope catchment area | ✓ | - | ✓ |
| Normalized vegetation density index (NDVI) | ✗ | - | - |
| Superficial geology | ✗ | - | - |
| Feature | Description | Criterion (i) | Criterion (ii) | Criterion (iii) |
|---|---|---|---|---|
| Rainfall |
|
|
|
|
| Slope Gradient |
|
|
|
|
| Plan Curvature |
|
|
|
|
| Profile Curvature |
|
|
|
|
| Upslope Catchment Area |
|
|
|
|
| Lithology |
|
|
|
|
| Feature | Description | Criterion (i) | Criterion (ii) | Criterion (iii) |
|---|---|---|---|---|
| Normalized Difference Vegetation Index (NDVI) |
|
|
|
|
| Superficial Geology |
|
|
|
|
| Aspect |
|
|
|
|
| Feature Set | Rainfall | Machine Learning Algorithm | ||
|---|---|---|---|---|
| Decision Tree | Random Forest | XGBoost | ||
| FS1 | 24 h-NMRR | FS1-24-DT | FS1-24-RF | FS1-24-XGB |
| 4 h-NMRR | FS1-4-DT | FS1-4-RF | FS1-4-XGB | |
| 4 h- & 24 h-NMRR | FS1-4&24-DT | FS1-4&24-RF | FS1-4&24-XGB | |
| FS2 | 24 h-NMRR | FS2-24-DT | FS2-24-RF | FS2-24-XGB |
| 4 h-NMRR | FS2-4-DT | FS2-4-RF | FS2-4-XGB | |
| 4 h- & 24 h-NMRR | FS2-4&24-DT | FS2-4&24-RF | FS2-4&24-XGB | |
| Evaluation Data | Feature Set & NMRR Duration | Decision Tree | Random Forest | XGBoost |
|---|---|---|---|---|
| Training Data | FS1-24 | 0.9571 | 0.9881 | 0.9660 |
| FS1-4 | 0.9426 | 0.9905 | 0.9559 | |
| FS1-4&24 | 0.9601 | 0.9965 | 0.9748 | |
| FS2-24 | 0.9674 | 0.9965 | 0.9808 | |
| FS2-4 | 0.9480 | 0.9931 | 0.9720 | |
| FS2-4&24 | 0.9599 | 0.9999 | 0.9769 | |
| Testing Data 1 (TD1) | FS1-24 | 0.8770 | 0.8836 | 0.8867 |
| FS1-4 | 0.8709 | 0.8740 | 0.8873 | |
| FS1-4&24 | 0.8717 | 0.8742 | 0.8602 | |
| FS2-24 | 0.8764 | 0.9083 | 0.9149 | |
| FS2-4 | 0.8744 | 0.8970 | 0.9130 | |
| FS2-4&24 | 0.8795 | 0.9042 | 0.9132 | |
| Testing Data 2 (TD2) | FS1-24 | 0.9499 | 0.9593 | 0.9627 |
| FS1-4 | 0.9444 | 0.9654 | 0.9695 | |
| FS1-4&24 | 0.9481 | 0.9563 | 0.9602 | |
| FS2-24 | 0.9443 | 0.9670 | 0.9732 | |
| FS2-4 | 0.9437 | 0.9603 | 0.9685 | |
| FS2-4&24 | 0.9518 | 0.9729 | 0.9734 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.W.M.; Lo, F.L.C.; Wong, T.K.C.; Cheung, R.W.M. Machine Learning-Powered Rainfall-Based Landslide Predictions in Hong Kong—An Exploratory Study. Appl. Sci. 2022, 12, 6017. https://doi.org/10.3390/app12126017
Li HWM, Lo FLC, Wong TKC, Cheung RWM. Machine Learning-Powered Rainfall-Based Landslide Predictions in Hong Kong—An Exploratory Study. Applied Sciences. 2022; 12(12):6017. https://doi.org/10.3390/app12126017
Chicago/Turabian StyleLi, Helen Wai Ming, Frankie Leung Chak Lo, Thomas Kwok Chi Wong, and Raymond Wai Man Cheung. 2022. "Machine Learning-Powered Rainfall-Based Landslide Predictions in Hong Kong—An Exploratory Study" Applied Sciences 12, no. 12: 6017. https://doi.org/10.3390/app12126017
APA StyleLi, H. W. M., Lo, F. L. C., Wong, T. K. C., & Cheung, R. W. M. (2022). Machine Learning-Powered Rainfall-Based Landslide Predictions in Hong Kong—An Exploratory Study. Applied Sciences, 12(12), 6017. https://doi.org/10.3390/app12126017