
The Amalgamation of the Object Detection and Semantic Segmentation for Steel Surface Defect Detection


Abstract
:1. Introduction
2. Related Work
2.1. Traditional Methods
2.2. Deep Learning Methods
2.3. Segmentation Methods
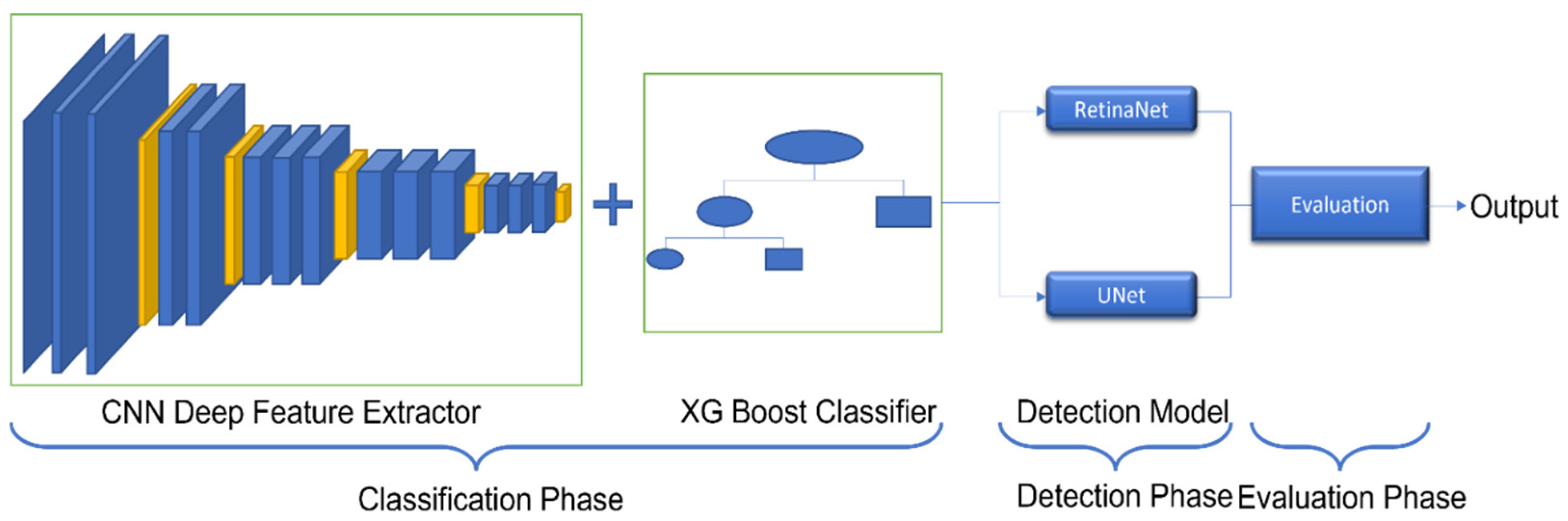
3. The Hierarchical Steel Surface Detection Methodology
3.1. Defect Image Classification
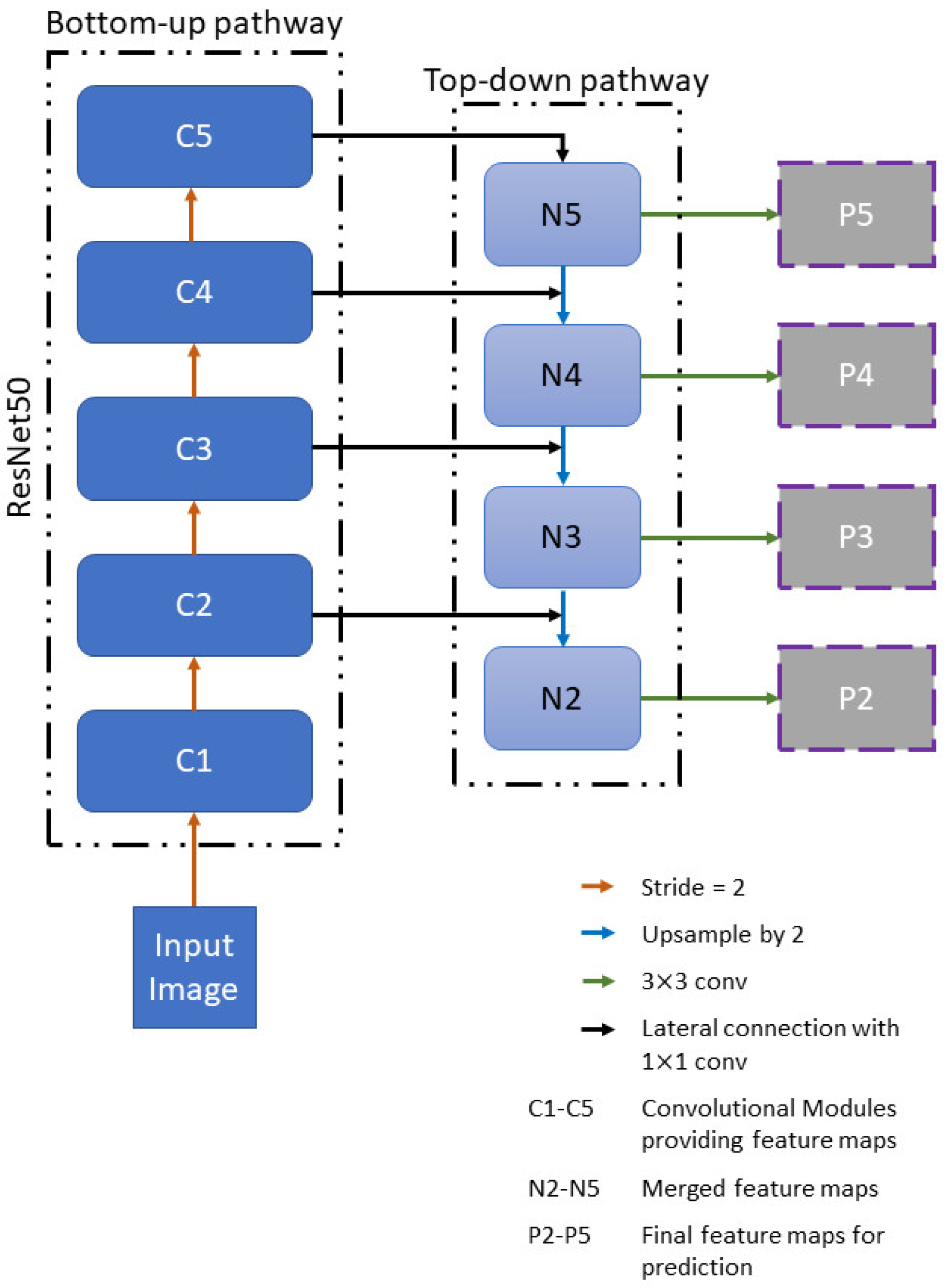
3.2. Object Detection for the Pitted Surface, Inclusion, Patches, Rolled-In Scale and Crazing Defects Detection
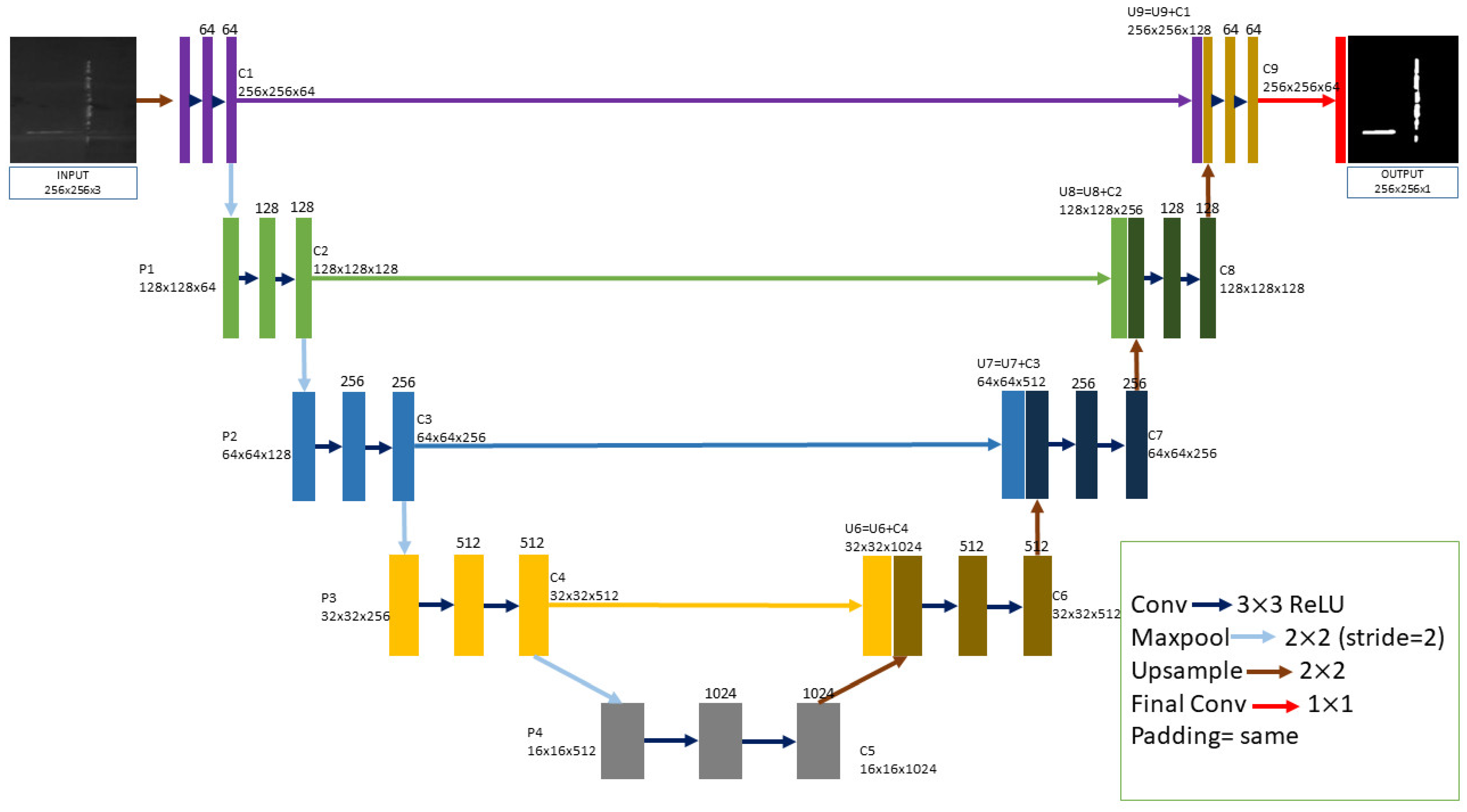
3.3. Image Segmentation for the Scratch Defect Detection
4. Experimental Results
4.1. Implementation Details
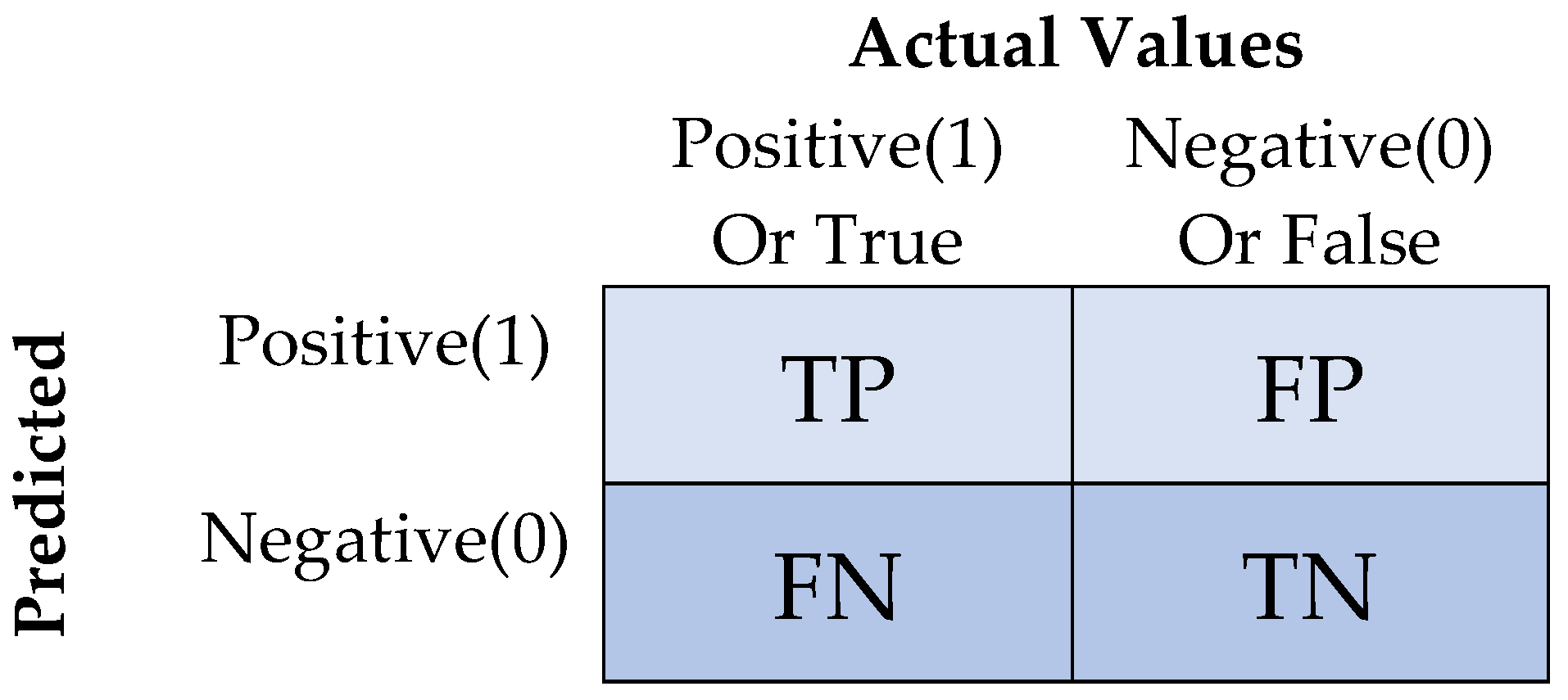
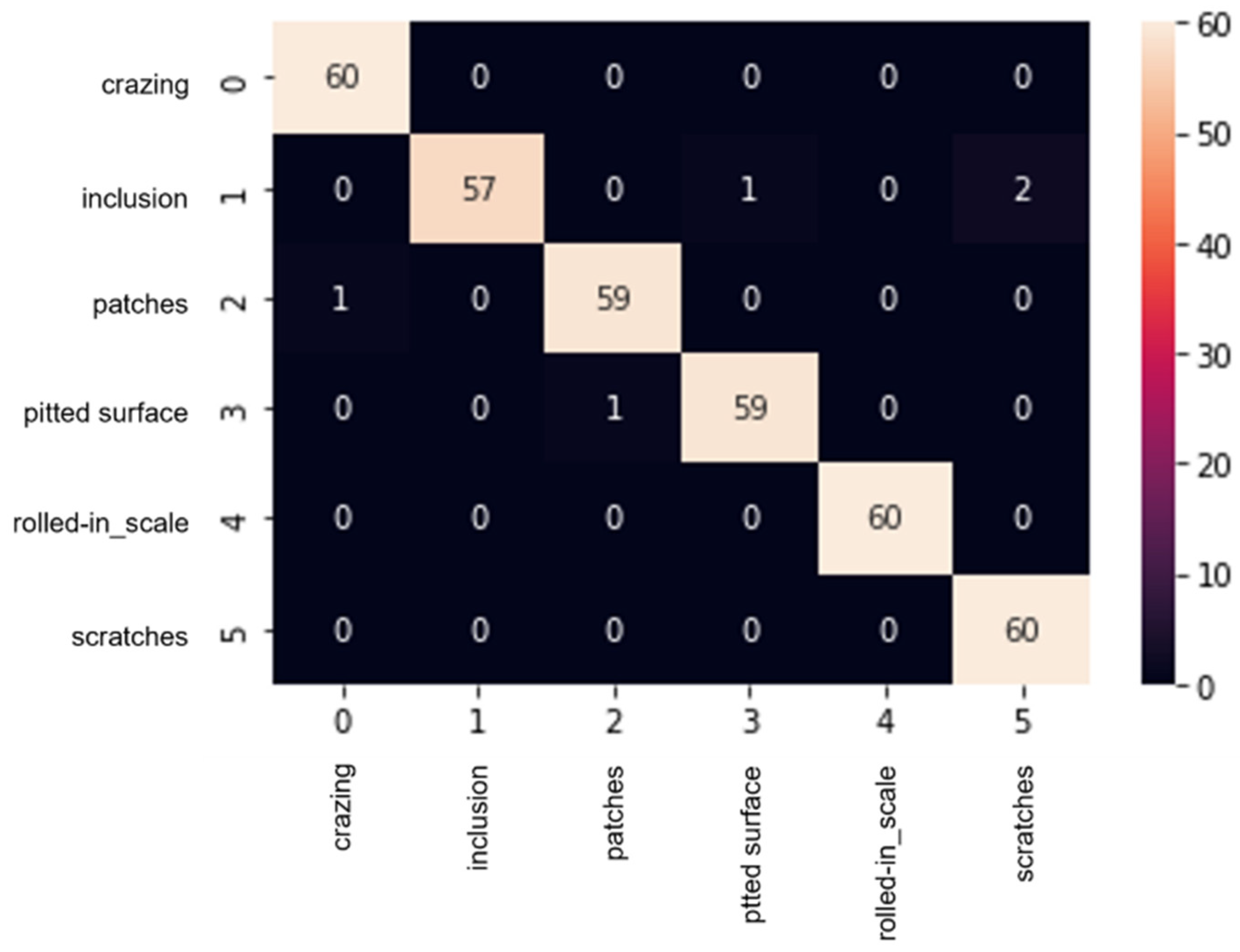
4.2. Evaluation of the Defect Image Classification and Defect Detection
4.3. Comparison of Average Precision with Traditional Methods
4.4. Comparison of Average Precision with Deep Learning Methods
4.5. Detection Results
5. Analysis and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| NEU | Northeastern University |
| mAP | Mean average precision |
| AI | Artificial intelligence |
| HOG | Histogram of oriented gradient |
| LBP | Local binary pattern |
| EDDN | End-to-end defect detection network |
| SSD | Single shot multibox detector |
| CNN | Convolutional neural network |
| VGG | Visual geometry group |
| DDN | Defect detection network |
| ResNet | Residual neural network |
| Faster-RCNN | Region-based convolutional neural network |
| YOLO | You Only Look Once |
| FCN | Fully convolutional network |
| IoU | Intersection over union |
| PFF | Pyramid feature fusion |
| GCA | Global context attention |
| DAN | Dual attention network |
| TAS-Net | Triple attention semantic segmentation network |
| TLU-Net | Transfer learning-based UNet |
| GT | Groundtruth |
| XGBoost | Extreme gradient boosting |
| ML | Machine learning |
| FPN | Feature pyramid network |
| ReLU | Rectified linear unit |
| DSSD | Deconvolutional single shot detector |
| CM | Confusion matrix |
| AP | Average precision |
| SVM | Support vector machine |
| NNC | Neighbor classifier |
| mIoU | MeanIoU |
References
- Dai, W.; Li, D.; Tang, D.; Jiang, Q.; Wang, D.; Wang, H.; Peng, Y. Deep learning assisted vision inspection of resistance spot welds. J. Manuf. Process 2021, 62, 262–274. [Google Scholar] [CrossRef]
- Saif, Y.; Yusof, Y.; Latif, K.; Kadir, A.Z.A.; Ahmad, M.B.I.; Adam, A.; Hatem, N. Development of a smart system based on STEP-NC for machine vision inspection with IoT environmental. Int. J. Adv. Manuf. 2022, 118, 4055–4072. [Google Scholar] [CrossRef]
- Muresan, M.P.; Cireap, D.G.; Giosan, I. Automatic vision inspection solution for the manufacturing process of automotive components through plastic injection molding. In Proceedings of the 16th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2020. [Google Scholar]
- Wang, J.; Fu, P.; Gaob, R.X. Machine vision intelligence for product defect inspection based on deep learning and Hough transform. J. Manuf. Syst. 2019, 51, 52–60. [Google Scholar] [CrossRef]
- Moru, D.K.; Borro, D. A machine vision algorithm for quality control inspection of gears. Int. J. Adv. Manuf. 2020, 106, 105–123. [Google Scholar] [CrossRef]
- Win., M.; Bushroa, A.R.; Hassan, M.A.; Hilman, N.M.; Ide-Ektessabi, A. A contrast adjustment thresholding method for surface defect detection based on mesoscopy. IEEE Trans. Ind. Inform. 2015, 11, 642–649. [Google Scholar] [CrossRef]
- Chetverikov, D. Structural defects: General approach and application to textile inspection. In Proceedings of the 15th International Conference on Pattern Recognition (ICPR), Barcelona, Spain, 3–7 September 2000. [Google Scholar]
- Chondronasios, A.; Popov, I.; Jordanov, I. Feature selection for surface defect classification of extruded aluminum profiles. Int. J. Adv. Manuf. Technol. 2016, 83, 33–41. [Google Scholar] [CrossRef]
- Shumin, D.; Zhoufeng, L.; Chunlei, L. AdaBoost learning for fabric defect detection based on HOG and SVM. In Proceedings of the 2011 International Conference on Multimedia Technology (ICMT), Hangzhou, China, 26–28 July 2011. [Google Scholar]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]
- Tsanakas, J.A.; Chrysostomou, D.; Botsaris, P.N.; Gasteratos, A. Fault diagnosis of photovoltaic modules through image processing and Canny edge detection on field thermographic measurements. Int. J. Sustain. Energy 2015, 34, 351–372. [Google Scholar] [CrossRef]
- Tastimur, C.; Yetis, H.; Karakös, M.; Akin, E. Rail defect detection and classification with real time image processing technique. Int. J. Comput. Sci. Softw. Eng. 2016, 5, 283–290. [Google Scholar]
- Mak, K.L.; Peng, P.; Yiu, K.F.C. Fabric defect detection using morphological filters. Image Vis. Comput. 2009, 27, 1585–1592. [Google Scholar] [CrossRef]
- Bai, X.; Fang, Y.; Lin, W.; Wang, L.; Ju, B. Saliency-Based Defect Detection in Industrial Images by Using Phase Spectrum. IEEE Trans. Ind. Inform. 2014, 10, 2135–2145. [Google Scholar] [CrossRef]
- Hu, G.H. Automated defect detection in textured surfaces using optimal elliptical Gabor filters. Optik 2015, 126, 1331–1340. [Google Scholar] [CrossRef]
- Borwankar, R.; Ludwig, R. An Optical Surface Inspection and Automatic Classification Technique Using the Rotated Wavelet Transform. IEEE Trans. Instrum. Meas. 2018, 67, 690–697. [Google Scholar] [CrossRef]
- Mandelbrot, B.B. The Fractal Geometry of Nature; WH Freeman: New York, NY, USA, 1982; Volume 1. [Google Scholar]
- Kindermann, R. Markov random fields and their applications. Am. Math. Soc. 1980, 97, 3923–3931. [Google Scholar]
- Hajimowlana, S.H.; Muscedere, R.; Jullien, G.A.; Roberts, J.W. 1D autoregressive modeling for defect detection in web inspection systems. In Proceedings of the 1998 Midwest Symposium on Circuits and Systems (Cat. No. 98CB36268) (MWSCAS), Notre Dame, IN, USA, 9–12 August 1998. [Google Scholar]
- Lv, X.; Duan, F.; Jiang, J.J.; Fu, X.; Gan, L. Deep Metallic Surface Defect Detection: The New Benchmark and Detection Network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fadli, V.F.; Herlistiono, I.O. Steel Surface Defect Detection using Deep Learning. Int. J. Innov. Sci. Res. Technol. 2020, 5, 244–250. [Google Scholar] [CrossRef]
- Liu, Y.; Geng, J.; Su, Z.; Zhang, W.; Li, J. Real-time classification of steel strip surface defects based on deep CNNs. In Proceedings of the 2018 Chinese Intelligent Systems Conference (CISC), Wenzhou, China, 4 October 2018. [Google Scholar]
- Andrei-Alexandru, T.; Henrietta, D.E. Low cost defect detection using a deep convolutional neural network. In Proceedings of the IEEE International Conference on Automation, Quality and Testing, Robotics (AQTR), Cluj-Napoca, Romania, 21–23 May 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference of Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans. Instrum. Meas. 2020, 69, 1493–1504. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, K.; Wang, X.; Ji, L. Application of multi-scale feature fusion and deep learning in detection of steel strip surface defect. In Proceedings of the IEEE International Conference on Artificial Intelligence and Advance Manufacturing (AIAM), Dublin, Ireland, 16–18 October 2019. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montréal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: New York, NY, USA, 2015. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the Eu. Conf. on Comp. Vis. (ECCV), Amsterdam, The Netherlands, 17 September 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Le, J.; Su, Z.; Geng, J.; Yin, Y. Real-time detection of steel strip surface defects based on improved YOLO detection network. IFAC-PapersOnLine 2018, 51, 76–81. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhang, J.; Kang, X.; Ni, H.; Ren, F. Surface defect detection of steel strips based on classification priority YOLOv3-dense network. Ironmak. Steelmak. 2021, 48, 547–558. [Google Scholar] [CrossRef]
- Youkachen, S.; Ruchanurucks, M.; Phatrapomnant, T.; Kaneko, H. Defect Segmentation of Hot-rolled Steel Strip Surface by using Convolutional Auto-Encoder and Conventional Image processing. In Proceedings of the 10th International Conference on Information and Communication Technology for Embedded System (IC-ICTES), Bangkok, Thailand, 25–27 March 2019. [Google Scholar]
- Wu, H.; Lv, Q. Hot-Rolled Steel Strip Surface Inspection Based on Transfer Learning Model. J. Sens. 2021, 2021, 8. [Google Scholar] [CrossRef]
- Enshaei, N.; Ahmad, S.; Naderkhani, F. Automated detection of textured-surface defects using UNet-based semantic segmentation network. In Proceedings of the IEEE International Conference on Prognostics and Health Management (ICPHM), Detroit, MI, USA, 8–10 June 2020. [Google Scholar]
- Neven, R.; Goedemé, T. A Multi-Branch U-Net for Steel Surface Defect Type and Severity Segmentation. Metals 2021, 11, 870. [Google Scholar] [CrossRef]
- Huang, Z.; Wu, J.; Xie, F. Automatic surface defect segmentation for hot-rolled steel strip using depth-wise separable U-shape network. Mater. Lett. 2021, 301, 130271. [Google Scholar] [CrossRef]
- Wang, K.; Wang, Y.; Zhou, L.; Wang, Z.; Zhang, G. A New Method of Surface Defect Semantic Segmentation of Steel Ball Based on Pre-Trained U-Net Model. In Proceedings of the IEEE International Conference on Computer Science, Electronic Information Engineering and Intelligent Control Technlogy (CEI), Fuzhou, China, 24–26 September 2021. [Google Scholar]
- Dong, H.; Song, K.; He, Y.; Xu, J.; Yan, Y.; Meng, Q. PGA-Net: Pyramid Feature Fusion and Global Context Attention Network for Automated Surface Defect Detection. IEEE Trans. Ind. Inf. 2020, 16, 7448–7458. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L. Dual attention deep learning network for automatic steel surface defect segmentation. Comput.-Aided Civ. Infrastruct. Eng. 2021. [Google Scholar] [CrossRef]
- Liu, T.; He, Z. TAS2-Net: Triple Attention Semantic Segmentation Network for Small Surface Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 5004512. [Google Scholar] [CrossRef]
- Damacharla, P.; Rao, M.V.A.; Ringenberg, J.; Javaid, A.Y. IEEE TLU-Net: A Deep Learning Approach for Automatic Steel Surface Defect Detection. In Proceedings of the International Conference on Applied Artificial Intelligence (ICAPAI), Halden, Norway, 19–21 May 2021. [Google Scholar]
- Ali, A.A.; Chramcov, B.; Jasek, R.; Katta, R.; Krayem, S.; Kadi, M.; Silhavy, R.; Silhavy, P.; Prokopova, Z. Detection of Steel Surface Defects Using U-Net with Pre-trained Encoder. In Software Engineering Application in Informatics; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’16), San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intelligence 2020, 42, 318–327. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar]
- Padilla, R.; Netto, S.L.; DaSilva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extractor | VGG16 | VGG19 | ResNet50 |
|---|---|---|---|
| Accuracy | 98.6 | 97.2 | 92.2 |
| Average Precision | |
|---|---|
| Pitted Surface | 0.8504 |
| Inclusion | 0.7117 |
| Patches | 0.8987 |
| Rolled-in Scale | 0.6794 |
| Crazing | 0.6928 |
| Scratches | 0.7942 |
| Defects | HOG + NNC [20] | HOG + SVM [20] | LBP + NNC [20] | LBP + SVM [20] | Proposed Method |
|---|---|---|---|---|---|
| Pitted Surface | 0.438 | 0.328 | 0.446 | 0.515 | 0.8504 |
| Inclusion | 0.576 | 0.580 | 0.412 | 0.378 | 0.7117 |
| Patches | 0.612 | 0.630 | 0.538 | 0.601 | 0.8987 |
| Rolled-in Scale | 0.358 | 0.330 | 0.237 | 0.330 | 0.6794 |
| Crazing | 0.400 | 0.412 | 0.321 | 0.335 | 0.6928 |
| Scratches | 0.474 | 0.463 | 0.326 | 0.432 | 0.7942 |
| Defects | SSD [20] | Faster-RCNN [20] | YOLO-V2 [20] | YOLO-V3 [20] | EDDN [20] | Xception [21] | Proposed Method |
|---|---|---|---|---|---|---|---|
| Pitted Surface | 0.839 | 0.815 | 0.454 | 0.239 | 0.851 | 0.75 | 0.8504 |
| Inclusion | 0.796 | 0.794 | 0.592 | 0.580 | 0.763 | 0.50 | 0.7117 |
| Patches | 0.839 | 0.853 | 0.774 | 0.772 | 0.863 | 0.67 | 0.8987 |
| Rolled-in Scale | 0.621 | 0.545 | 0.246 | 0.335 | 0.581 | N/A | 0.6794 |
| Crazing | 0.411 | 0.374 | 0.211 | 0.221 | 0.417 | N/A | 0.6928 |
| Scratches | 0.836 | 0.882 | 0.739 | 0.570 | 0.856 | 0.93 | 0.7942 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, M.; Lim, J.; Lee, H. The Amalgamation of the Object Detection and Semantic Segmentation for Steel Surface Defect Detection. Appl. Sci. 2022, 12, 6004. https://doi.org/10.3390/app12126004
Sharma M, Lim J, Lee H. The Amalgamation of the Object Detection and Semantic Segmentation for Steel Surface Defect Detection. Applied Sciences. 2022; 12(12):6004. https://doi.org/10.3390/app12126004
Chicago/Turabian StyleSharma, Mansi, Jongtae Lim, and Hansung Lee. 2022. "The Amalgamation of the Object Detection and Semantic Segmentation for Steel Surface Defect Detection" Applied Sciences 12, no. 12: 6004. https://doi.org/10.3390/app12126004
APA StyleSharma, M., Lim, J., & Lee, H. (2022). The Amalgamation of the Object Detection and Semantic Segmentation for Steel Surface Defect Detection. Applied Sciences, 12(12), 6004. https://doi.org/10.3390/app12126004