
An Evolutionary Computation Approach for Twitter Bot Detection





Abstract
:Featured Application
Abstract
1. Introduction
- (i)
- describing and analyzing the main features that can be associated with user accounts on Twitter to understand the types of property that may help to discriminate between human profiles and bot profiles;
- (ii)
- proposing a novel approach based on genetic algorithms and genetic programming to detect bot profiles on Twitter, and presenting two classification models that exhibit good qualitative performance and generalization capabilities, while ensuring interpretability of predictions;
- (iii)
- providing a way to compute how much our models are confident with a given prediction.
- RQ1: is it possible to obtain interpretable models with good generalization capabilities for Twitter bot detection?
- RQ2: can we trust predictions of ML models based on Twitter bot detection?
2. Related Work
3. Data Preparation
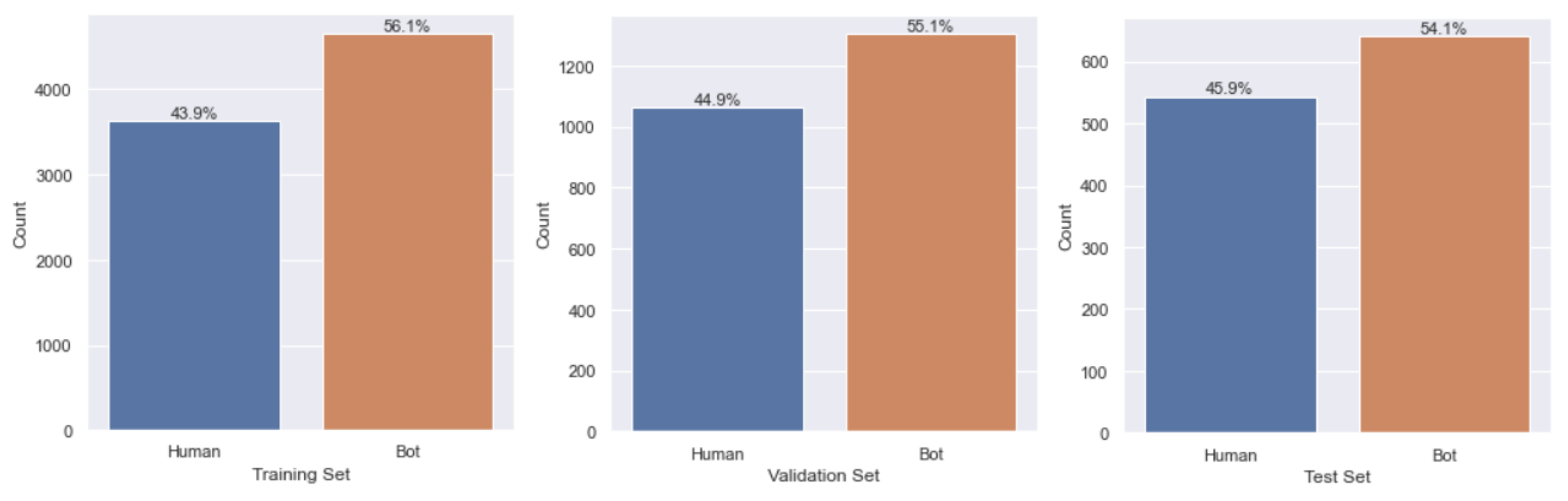
3.1. Data Description
3.2. Feature Extraction
- id: unique numerical identifier of the user account;
- screen_name: unique string composed of letters, digits, and underscores, which identifies the username of the Twitter account;
- name: name visualized for the user account;
- description: optional field indicating the description visualized for the user account;
- URL: optional field indicating an URL for the user account;
- location: optional attribute indicating a location for the user account;
- created_at: timestamp indicating the user account creation time;
- statuses_count: total number of tweets (including retweets) published by the user during the entire account lifetime;
- followers_count: total number of followers of the user account;
- friends_count: total number of followings of the user account;
- favourites_count: total number of posts that the user has marked as favorites;
- listed_count: total number of public lists that the user is a member of.
- we first perform lowering of text and trimming. Then, we extract the hashtags and the mentioned users that are eventually contained in the current tweet. We also count the number of URLs and we check whether the tweet is an authentic published tweet or a retweet;
- we perform tokenization of the text using a Tweet Tokenizer, and part-of-speech tagging after proper punctuation, URLs, and digits removal;
- we use a Word Net Lemmatizer to lemmatize the tagged tokens of the previous step in this pipeline;
- we filter lemmatized tokens by excluding stop words and single-character words;
- we return the list of tokenized tweets obtained by following this pipeline.
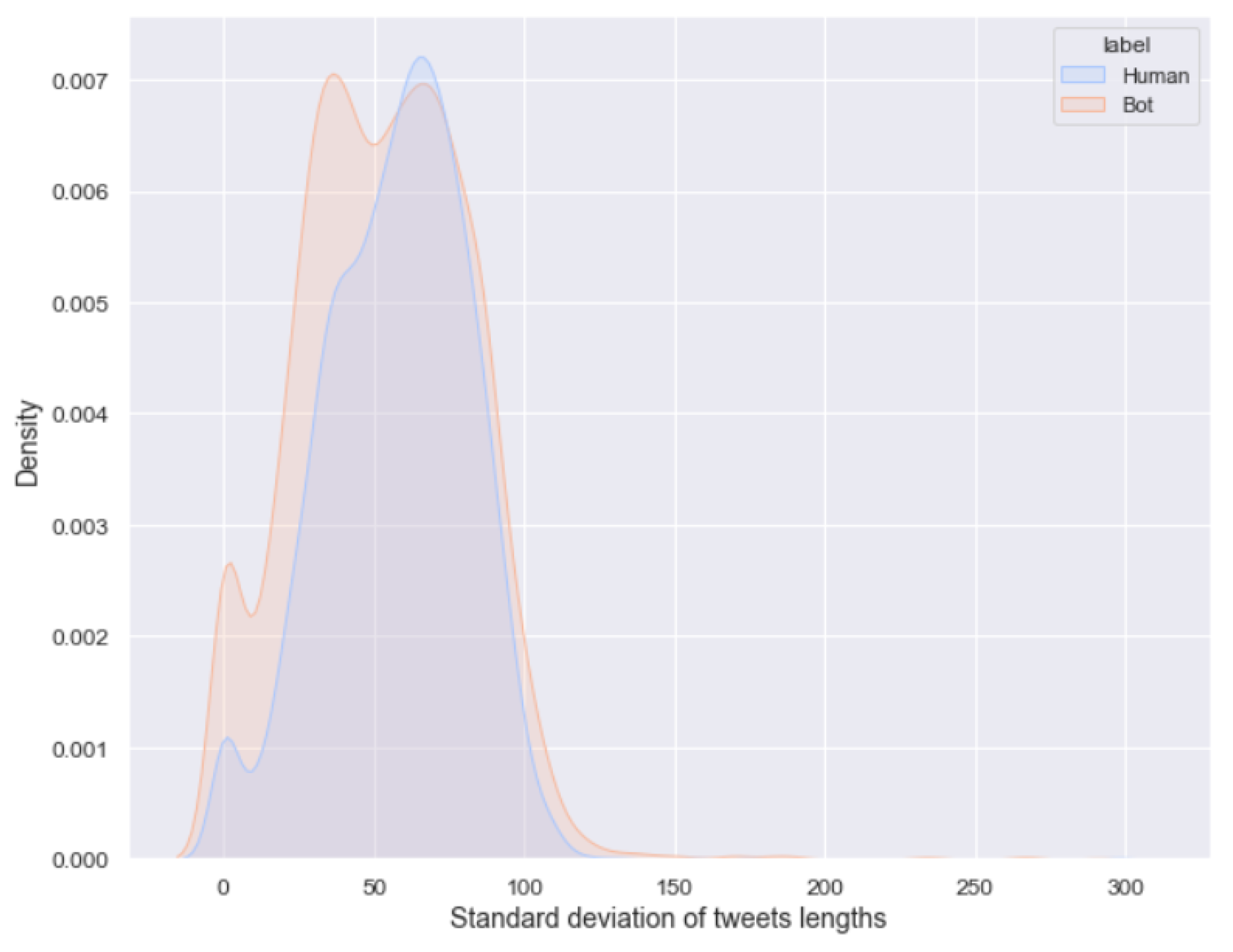
- Statistical measures over tweet lengths: a set of characteristics derived by applying statistical measures, namely, mean, median, maximum minimum range, and standard deviation, to an array containing the lengths, in terms of the number of characters, of the original tweets. In particular, the standard deviation of the lengths of tweets enables us to say whether the user tends to publish tweets of approximately the same length (e.g, identical tweets, which are common among certain types of bot accounts) or tends to vary a lot the size of the published posts. Figure 2 shows that bot profiles are more likely to exhibit a lower standard deviation of tweet lengths than humans, which means that bot profiles are more likely to publish tweets with approximately the same length and presumably the same type of content;
- Frequency over the content of collected tweets and retweets: a set of features that measure the frequency of appearances of retweets, URLs, mentioned users, and hashtags, over the sample of tweets and retweets retrieved via Twitter API for a given user account u. Each feature of this category is computed using the following formula:where , , , is the set of tokenized tweets for user u and is the set of tokenized retweets for user u while is a function that counts the number of times a word of category c appears in the input list of tokenized posts (tweets and retweets), including duplicates. Therefore, we are describing the mean number of hashtags, mentioned users, and URLs, for each retrieved tweet and retweet. Similarly, the frequency of retweets is calculated as follows.One intuitive reason that may justify the derivation of features such as, for example, the frequency of retweets and URLs, can be explained by observing the general trend of a significant percentage of bot profiles that avoid publishing self-made tweets and prefer to retweet specific content several times and post several URLs that usually redirect to spam, phishing, or, in general, undesirable web pages. Moreover, several bot profiles that, for example, promote political campaigns, are used to expose a high frequency of mentioned users, since they usually include the target politician’s screen name in their tweets. Figure 3 confirms that bot profiles are more likely to exhibit a higher frequency of retweets than humans. Additionally, the frequency of words used to write tweets by a given user u is calculated as follows:In this way, we are describing the mean number of words (tokens that are not hashtags nor mentioned users) for each published tweet, including duplicates. Since this measure should account for the writing behavior of user u, we decide to exclude from the computation of this property the words contained in retweets, which are tweets that have not been written by u and thus they present a potentially different writing behavior;
- Statistical measures over raw counts: set of features derived by applying statistical measures, namely, mean, median, max, min, and standard deviation, to three arrays containing, respectively, the raw counts of the distinct words, hashtags, and mentioned users. Raw counts can be extracted from tokenized published tweets set and tokenized retweets set of a given user u. These measures are computed considering distinct hashtags and mentioned users that appear in both tweets and retweets of user u. We consider distinct words that appear only in published tweets at least three times, and thus when computing these statistical measures on the raw counts of distinct words, we exclude words that appear in retweets of user u. As a matter of fact, these types of measures over raw word counts aim to capture the writing behavior of a given user u. Quite to the contrary, when computing these statistical measures over the raw counts of hashtags and mentioned users, we consider those that are contained in retweets and tweets as well, since it can be arguably verified that a hashtag or a mentioned user that appears in a retweet of user u gains additional exposure even though the user u has posted it through a retweet. These measures can be useful because they can estimate, for example, how the frequency of words varies within the sample of tweets collected for the user u. In particular, a low standard deviation of raw word counts is expected if user u has a uniform behavior when writing posts. In contrast, this value is high if few words are over-used, while many others are less sponsored. For these reasons, these types of measures can help to discriminate between bot profiles and human profiles by analyzing their writing behavior;
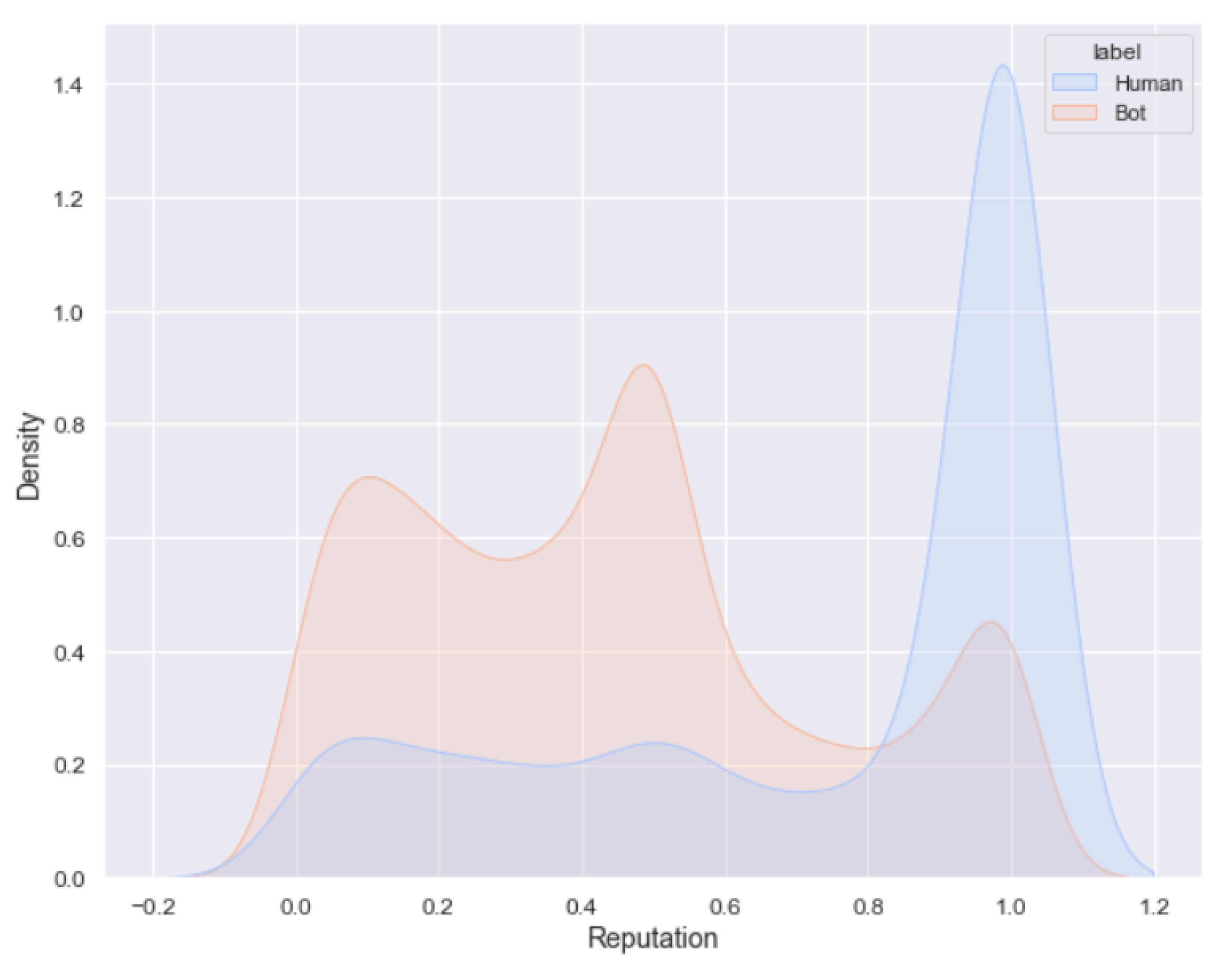
- Reputation: this feature is computed by analyzing the number of followers of a given user u compared to the number of followings, or friends, of the same user:This property exhibits a high value when the user u has a large number of followers and a few followings, such as celebrities and politicians. Quite the opposite, bot accounts that usually have a large number of followings and a few followers are likely to exhibit a low reputation value. Figure 4 shows that high reputation values are easily observable in human accounts, while lower reputation values are more likely to belong to bot accounts;
- Growth rate: a set of features that can be computed by dividing each user metadata numerical property by the number of years of activity of a given user u on the Twitter platform. In particular, each growth rate is computed as follows:where , friends, favourites, listed, . Therefore, we describe the mean number of followers, followings, favorites, lists, and tweets, that a given user u gains or produces in a year of activity on Twitter;
- Tweets similarity: a feature that measures the mean similarity computed between each pair of distinct published tweets contained in the tokenized tweets sample for a given user u. This property is derived using the following formula:whereis a symmetric similarity score, defined as the Sørensen–Dice coefficient [52,53], that is used to estimate the similarity between two discrete sets of tokens that, in our case, consist of the tokens contained in a sample of Twitter posts published by the user u. This computation of the similarity score takes into account the distinct tokens of the involved pair of tweets and thus each tokenized tweet is treated as a set where duplicates are removed. The mean similarity score is high when tweets are very similar to each other in terms of content. This may be expected for those, perhaps not so sophisticated bot profiles, that are used to publish almost identical tweets;
- Screen name length: a feature that incorporates the length as the number of characters of the screen name of a given user u;
- URL flag: a boolean flag that holds if the URL field in the account of a given user u is empty, and otherwise.
3.3. Feature Selection and Scaling
4. Proposed Approach
4.1. Problem Statement
- It exhibits good classification performance on unseen observations;
- It can be interpreted by simply looking at the types of operations that it performs internally to do the prediction.
4.2. Evolutionary Methods Overview
- Fitness evaluation: fitness function is evaluated for each individual in the current population. This step can be easily parallelized in real implementations;
- Selection: a selection algorithm is used to select among individuals in the current population, the ones that exhibit the best fitness according to the criterion implemented by the selection algorithm itself;
- Crossover: a crossover algorithm is performed among selected individuals to produce new individuals by merging the data structures of pairs of individuals;
- Mutation: a random mutation is applied to each individual according to a fixed probability threshold and a new generation begins.
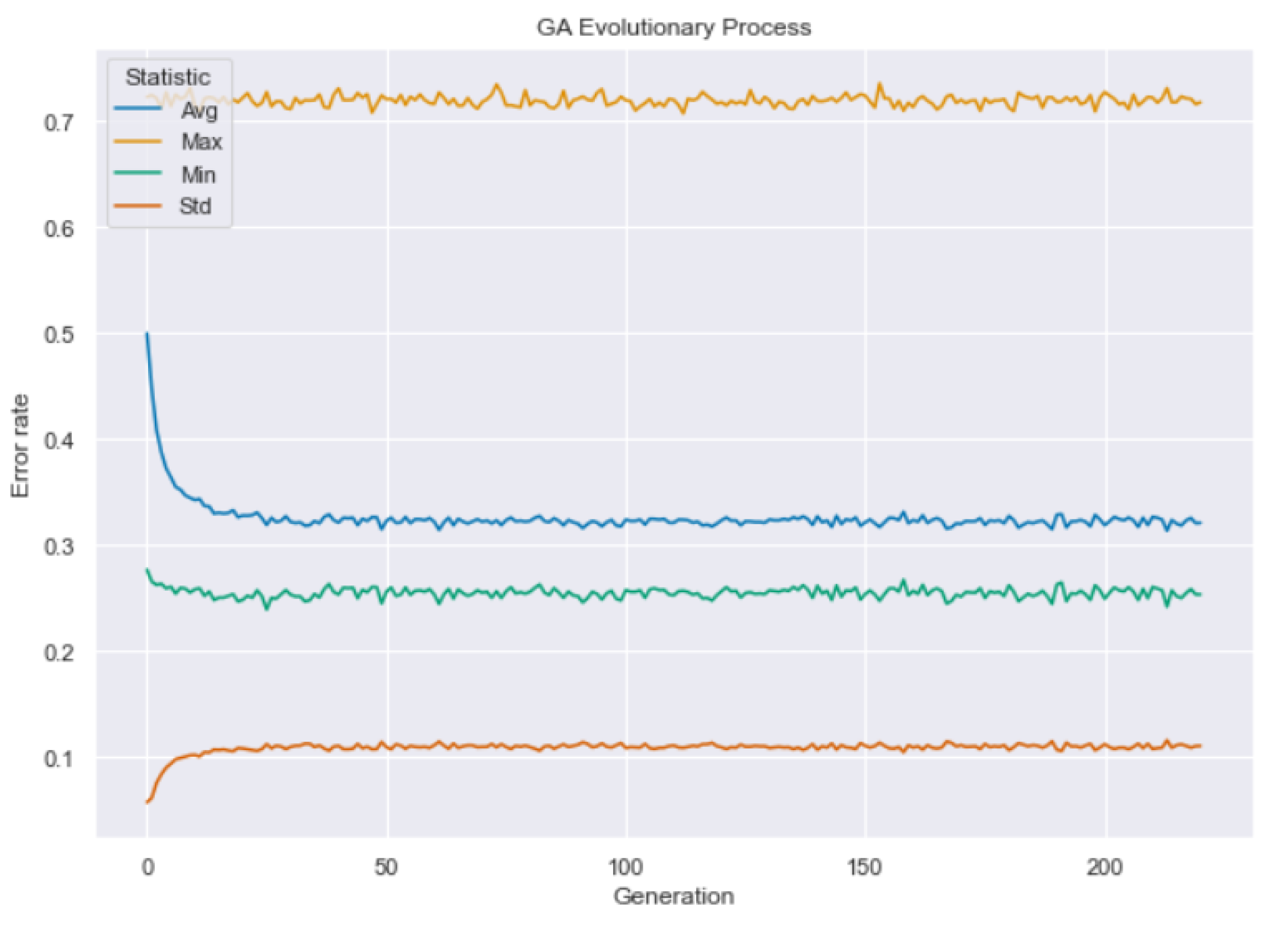
4.3. Genetic Algorithm
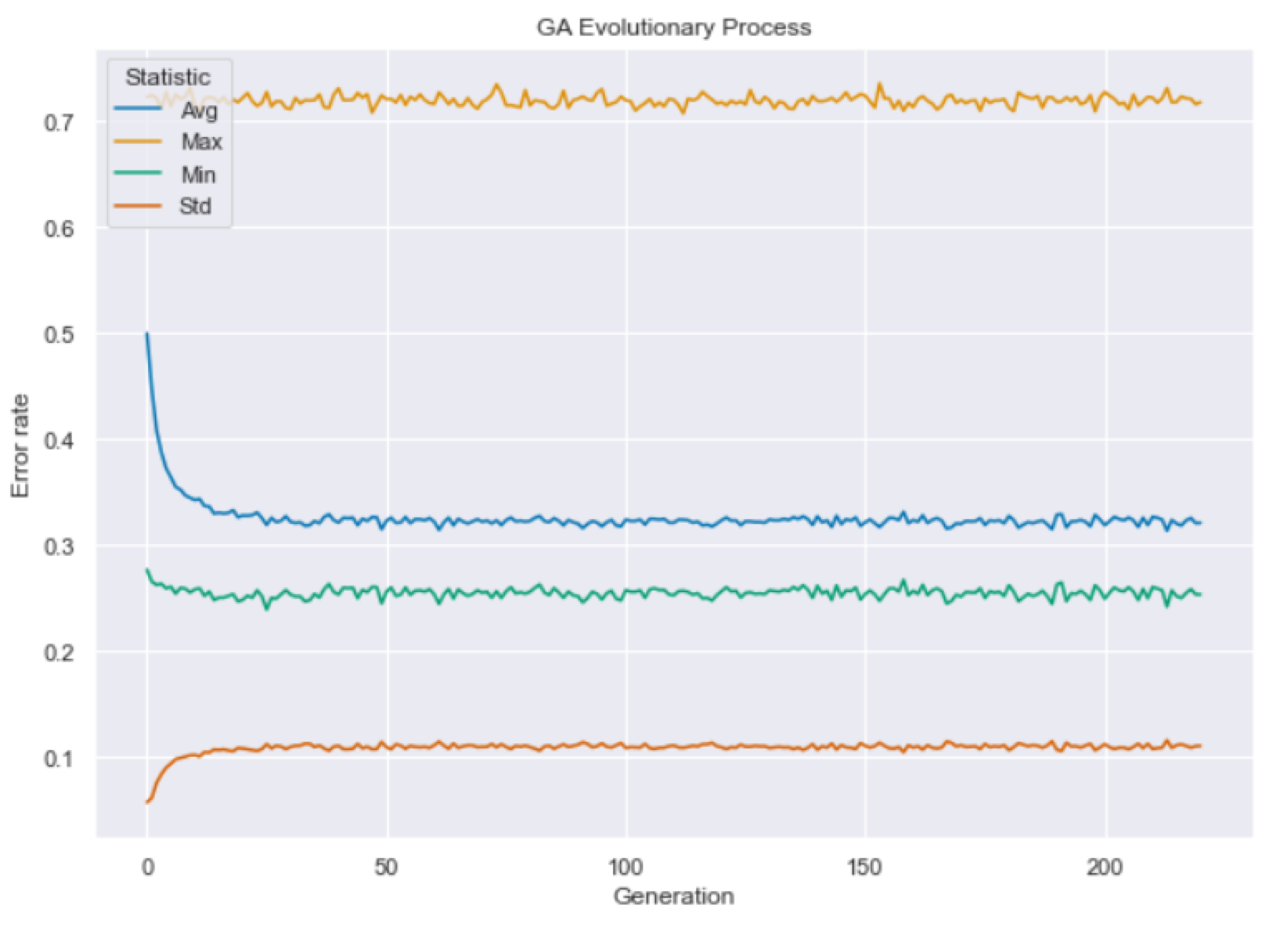
- we generate an initial population of 100,000 individuals using a standard normal distribution for each component of each individual, and we set the evolution to last 220 generations with a hall of fame equal to 100;
- we choose the tournament selection algorithm to perform the selection with the tournament size equal to seven and the number of individuals to select equal to the size of the population;
- we choose two points crossover with crossover probability equal to 0.5;
- we choose Gaussian mutation with zero mean, standard deviation of 300, and an independent probability of 0.15 for performing mutation step with mutation probability equal to 0.3.
Model Description
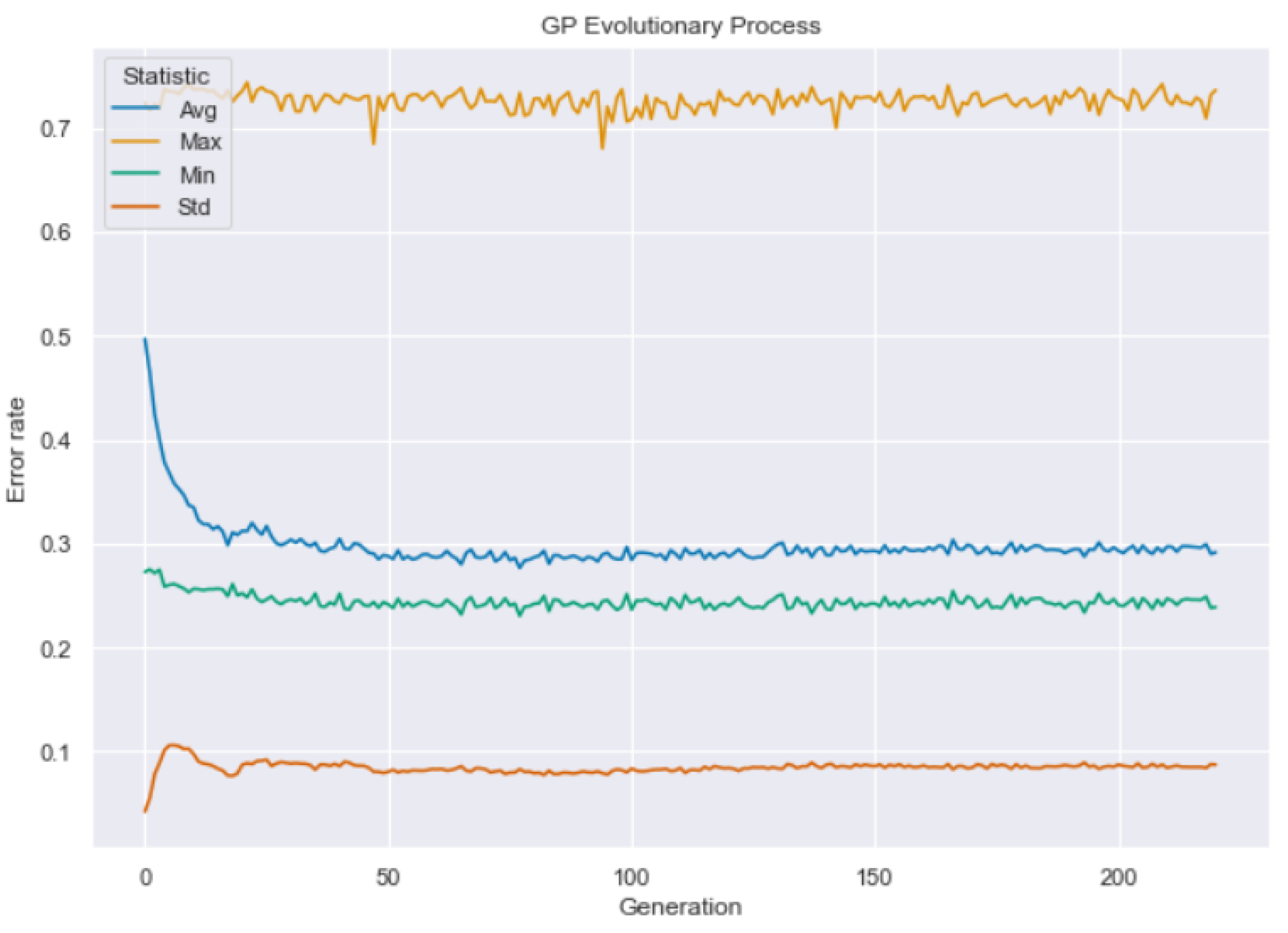
4.4. Genetic Programming
- in the fitness function, we weight 0.60 for the randomized mean squared error and 0.40 for the anti-reciprocal of the number of nodes;
- we generate an initial population of 80,000 individuals using a ramped grow algorithm for each individual with the depth set to be between three and seven. We set the evolution to last 220 generations with a hall of fame equal to 100;
- we choose the tournament selection algorithm to perform the selection with the tournament size equal to eight and the number of individuals to select equal to the size of the population;
- we choose one point crossover for performing crossover step with crossover probability equal to 0.5;
- as regards the mutation step, we choose uniform mutation combined with ramped grow for the construction of the tree that is muting the individual. The generated tree depth is set to be between two and four. Mutation probability is equal to 0.3;
- we set a bloat control that limits the max depth that can be reached by an individual to seven.
Model Description
5. Experimental Phase
- accuracy;
- F1 score;
- Matthews correlation coefficient (MCC) [59].
- Yang et al. [36] have the best method with respect to accuracy and F1 score, while Kudugunta et al. [44] have the best method with respect to MCC, and it matches Yang’s model as regards accuracy. However, both methods are based on complex models with low interpretability and, for this reason, it is also extremely difficult to know how much these models are confident when doing a specific prediction and why a specific prediction has been done;
- the top performing method is the only one that leverages meta-data information without accounting for tweets. This may pose a security problem on diverse data with different distributions since prediction does not take into account tweets content and, for this reason, bot accounts can publish any kind of content while ensuring that their meta-data properties are similar to the ones of a legit human profile (e.g., by increasing the number of followers with fake accounts);
- GA and GP models are the third best models with respect to accuracy and MCC and they are the second best models with respect to F1 score, on a par with Lee et al. [37]. This shows that our models are capable of exposing good detection capabilities that are close to the best existing models while ensuring high interpretability of predictions.
6. Discussion
- RQ1: is it possible to obtain interpretable models with good generalization capabilities? It is possible to obtain models with good detection accuracy and a low number of components. A simple model has clearly more chance of being interpretable, but it is not trivial to ensure that interpretable models are able to exhibit good qualitative performance at the same time. In this work, we demonstrated that with evolutionary algorithms it is possible to discover interpretable models with good detection accuracy. However, we believe that using additional types of features that better encode anomalous behavior of Twitter profiles would enable us to learn more effective models that can be interpretable at the same time.
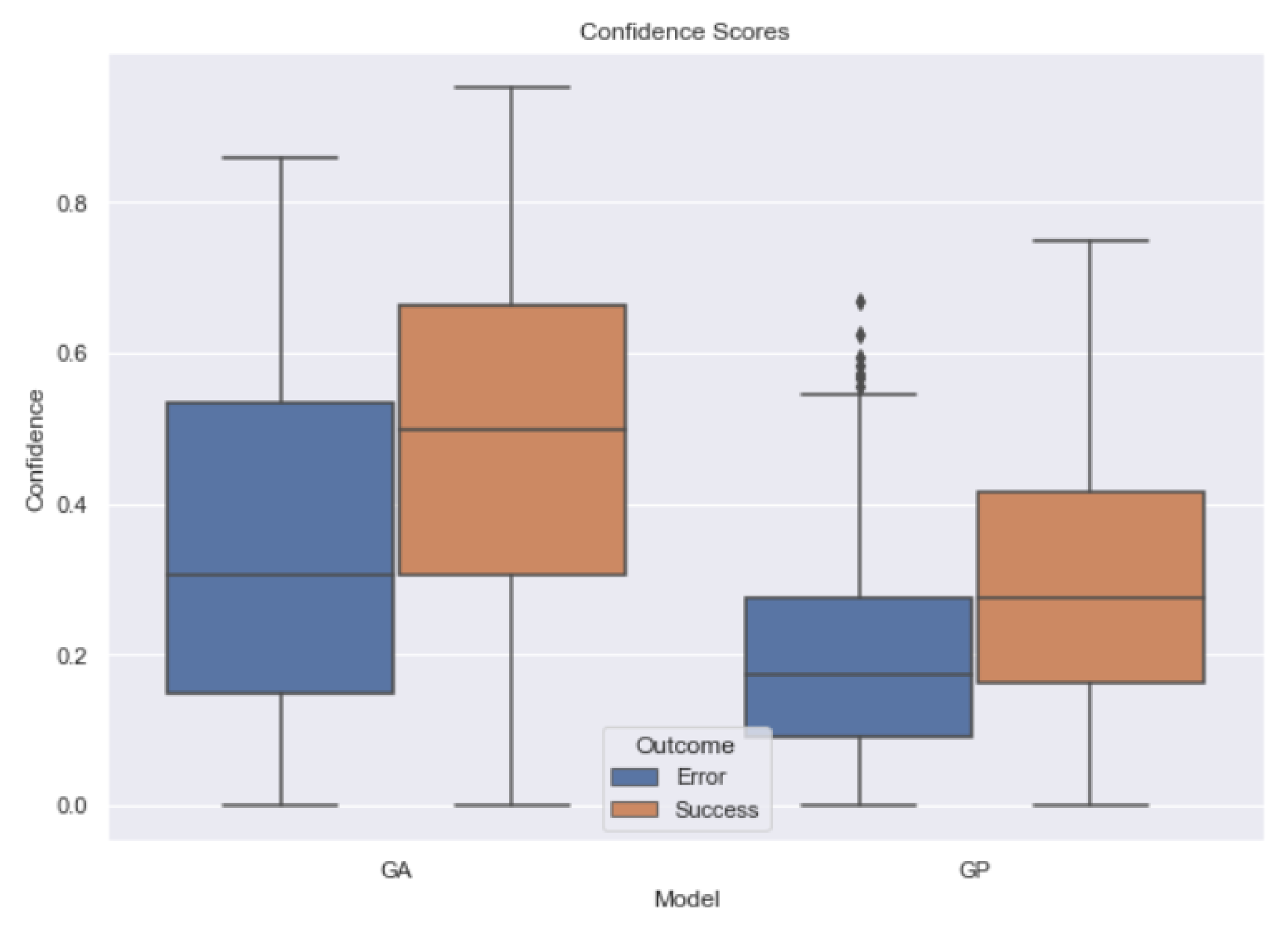
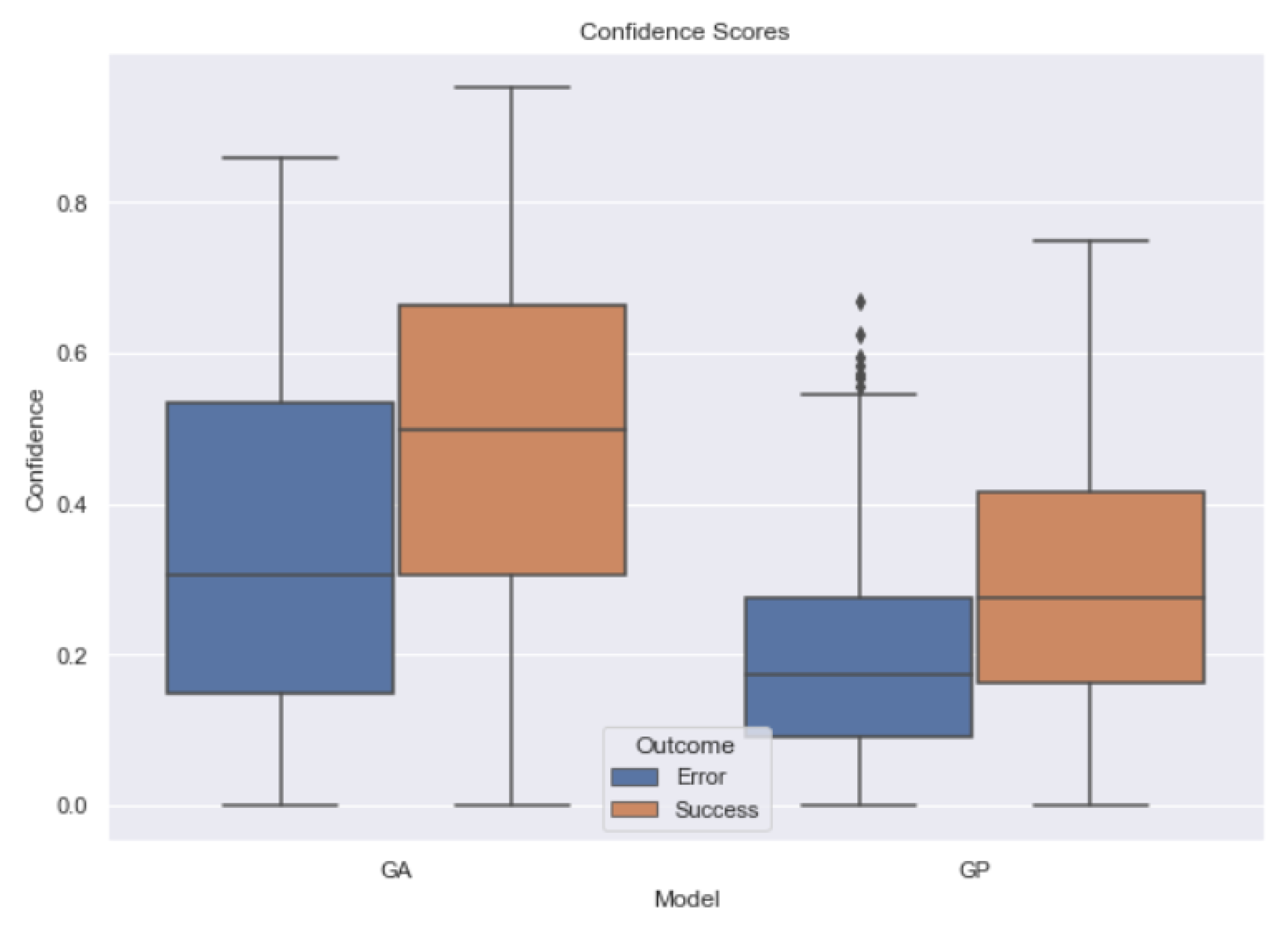
- RQ2: can we trust the predictions of ML models based on Twitter bot detection? It is not trivial to define a measure of reliability for an ML model. In this work, we defined a confidence score and we checked whether this measure is high when the model performs a correct prediction, based on the data available. The results are encouraging and, therefore, the possibility of using other consistent datasets as benchmarks would increase the probability of defining a trustworthy confidence score that allows us to know whether we can trust a given prediction.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| API | Application Programming Interface |
| OSN | Online Social Networks |
| SVM | Support Vector Machine |
| CNN | Convolutional Neural Network |
| GCNN | Graph Convolutional Neural Network |
| GAN | Generative Adversarial Network |
| GA | Genetic Algorithms |
| GP | Genetic Programming |
| MCC | Matthews Correlation Coefficient |
References
- Ahn, G.J.; Shehab, M.; Squicciarini, A. Security and Privacy in Social Networks. IEEE Internet Comput. 2011, 15, 10–12. [Google Scholar] [CrossRef]
- Ji, Y.; He, Y.; Jiang, X.; Cao, J.; Li, Q. Combating the evasion mechanisms of social bots. Comput. Secur. 2016, 58, 230–249. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, R.; Zhang, Y.; Yan, G. On the impact of social botnets for spam distribution and digital-influence manipulation. In Proceedings of the 2013 IEEE Conference on Communications and Network Security (CNS), National Harbor, MD, USA, 14–16 October 2013; pp. 46–54. [Google Scholar] [CrossRef]
- Boshmaf, Y.; Muslukhov, I.; Beznosov, K.; Ripeanu, M. Design and analysis of a social botnet. Comput. Netw. 2013, 57, 556–578. [Google Scholar] [CrossRef] [Green Version]
- Cresci, S. A decade of social bot detection. Commun. ACM 2020, 63, 72–83. [Google Scholar] [CrossRef]
- Feng, S.; Wan, H.; Wang, N.; Li, J.; Luo, M. TwiBot-20: A Comprehensive Twitter Bot Detection Benchmark. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, 1–5 November 2021. [Google Scholar] [CrossRef]
- Becchetti, L.; Castillo, C.; Donato, D.; Leonardi, S.; Baeza-Yates, R.; EITO-BRUN, R. Link-Based Characterization and Detection of Web Spam. In Proceedings of the Adversarial Information Retrieval on the Web 2006 (AIRWEB’06), Seattle, WA, USA, 10 August 2006. [Google Scholar]
- Gyöngyi, Z.; Garcia-Molina, H.; Pedersen, J. Combating Web Spam with TrustRank. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004. [Google Scholar]
- Thomas, K.; Grier, C.; Ma, J.; Paxson, V.; Song, D. Design and Evaluation of a Real-Time URL Spam Filtering Service. In Proceedings of the 2011 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 22–25 May 2011; pp. 447–462. [Google Scholar] [CrossRef] [Green Version]
- Benczúr, A.; Csalogány, K.; Sarlós, T. Link-based similarity search to fight Web spam. In Proceedings of the Adversarial Information Retrieval on the Web 2006 (AIRWEB’06), Seattle, WA, USA, 10 August 2006. [Google Scholar]
- Bratko, A.; Cormack, G.; Filipic, B.; Lynam, T.; Zupan, B. Spam Filtering Using Statistical Data Compression Models. J. Mach. Learn. Res. 2006, 6, 2673–2698. [Google Scholar]
- Grier, C.; Thomas, K.; Paxson, V.; Zhang, C.M. @spam: The underground on 140 characters or less. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010. [Google Scholar]
- Gao, H.; Chen, Y.; Lee, K.; Palsetia, D.; Choudhary, A. Towards Online Spam Filtering in Social Networks; Northwestern University: Evanston, IL, USA, 2012. [Google Scholar]
- Jindal, N.; Liu, B. Opinion Spam and Analysis. In Proceedings of the 2008 International Conference on Web Search and Data Mining, Palo Alto, CA, USA, 11–12 February 2008. [Google Scholar] [CrossRef] [Green Version]
- Ott, M.; Choi, Y.; Cardie, C.; Hancock, J. Finding Deceptive Opinion Spam by Any Stretch of the Imagination. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Portland, Oregon, 19–24 June 2011; pp. 309–319. [Google Scholar]
- Lee, S.; Kim, J. WarningBird: A Near Real-Time Detection System for Suspicious URLs in Twitter Stream. IEEE Trans. Dependable Secur. Comput. 2013, 10, 183–195. [Google Scholar] [CrossRef]
- Chu, Z.; Gianvecchio, S.; Wang, H.; Jajodia, S. Detecting Automation of Twitter Accounts: Are You a Human, Bot, or Cyborg? IEEE Trans. Dependable Secur. Comput. 2012, 9, 811–824. [Google Scholar] [CrossRef]
- Perdana, R.; Muliawati, T.; Harianto, R. Bot Spammer Detection in Twitter Using Tweet Similarity and Time Interval Entropy. J. Comput. Inf. Sci. 2015, 8, 20–26. [Google Scholar] [CrossRef] [Green Version]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. DNA-Inspired Online Behavioral Modeling and Its Application to Spambot Detection. IEEE Intell. Syst. 2016, 31, 58–64. [Google Scholar] [CrossRef] [Green Version]
- Beskow, D.; Carley, K. Its All in a Name: Detecting and Labeling Bots by Their Name. Comput. Math. Organ. Theory 2019, 25. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, F.; Abulaish, M. A generic statistical approach for spam detection in Online Social Networks. Comput. Commun. 2013, 36, 1120–1129. [Google Scholar] [CrossRef]
- Chavoshi, N.; Hamooni, H.; Mueen, A. DeBot: Twitter Bot Detection via Warped Correlation. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016. [Google Scholar] [CrossRef]
- Miller, Z.; Dickinson, B.; Deitrick, W.; Hu, W.; Wang, A. Twitter spammer detection using data stream clustering. Inf. Sci. 2014, 260, 64–73. [Google Scholar] [CrossRef]
- Ackermann, M.; Lammersen, C.; Märtens, M.; Raupach, C.; Sohler, C.; Swierkot, K. StreamKM++: A Clustering Algorithms for Data Streams. Acm J. Exp. Algorithmics 2010, 17, 173–187. [Google Scholar] [CrossRef]
- Cao, F.; Ester, M.; Qian, W.; Zhou, A. Density-Based Clustering over an Evolving Data Stream with Noise. In Proceedings of the 2006 SIAM International Conference on Data Mining (SDM), Bethesda, MD, USA, 20–22 April 2006; pp. 328–339. [Google Scholar] [CrossRef] [Green Version]
- Wang, A.H. Don’t follow me: Spam detection in Twitter. In Proceedings of the 2010 International Conference on Security and Cryptography (SECRYPT), Athens, Greece, 26–28 July 2010; pp. 1–10. [Google Scholar]
- Stringhini, G.; Kruegel, C.; Vigna, G. Detecting spammers on social networks. In Proceedings of the 26th Annual Computer Security Applications Conference, Austin, TX, USA, 6–10 December 2010; pp. 1–9. [Google Scholar] [CrossRef]
- Cao, Q.; Yang, X.; Yu, J.; Palow, C. Uncovering Large Groups of Active Malicious Accounts in Online Social Networks. In Proceedings of the ACM Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 477–488. [Google Scholar] [CrossRef] [Green Version]
- Yardi, S.; Romero, D.; Schoenebeck, G.; Boyd, D. Detecting Spam in a Twitter Network. First Monday 2010, 15. [Google Scholar] [CrossRef]
- Ghosh, S.; Viswanath, B.; Kooti, F.; Sharma, N.; Korlam, G.; Benevenuto, F.; Ganguly, N.; Gummadi, K.P. Understanding and Combating Link Farming in the Twitter Social Network. In Proceedings of the 21st World Wide Web Conference, Lyon, France, 16–20 April 2012. [Google Scholar] [CrossRef] [Green Version]
- Ferrara, E. Disinformation and Social Bot Operations in the Run Up to the 2017 French Presidential Election. First Monday 2017, 22. [Google Scholar] [CrossRef] [Green Version]
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The Rise of Social Bots. Commun. ACM 2014, 59, 96–104. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Harkreader, R.; Gu, G. Empirical Evaluation and New Design for Fighting Evolving Twitter Spammers. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1280–1293. [Google Scholar] [CrossRef]
- Benevenuto, F.; Magno, G.; Rodrigues, T.; Almeida, V. Detecting spammers on Twitter. In Proceedings of the Seventh Annual Collaboration, Electronic Messaging, AntiAbuse and Spam Conference, Redmond, WA, USA, 13–14 July 2010. [Google Scholar]
- McCord, M.; Chuah, M. Spam Detection on Twitter Using Traditional Classifiers. In Autonomic and Trusted Computing; Calero, J.M.A., Yang, L.T., Mármol, F.G., García Villalba, L.J., Li, A.X., Wang, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 175–186. [Google Scholar]
- Yang, K.C.; Varol, O.; Hui, P.M.; Menczer, F. Scalable and Generalizable Social Bot Detection through Data Selection. AAAI Tech. Track Appl. 2020, 34, 1096–1103. [Google Scholar] [CrossRef]
- Lee, K.; Eoff, B.; Caverlee, J. Seven Months with the Devils: A Long-Term Study of Content Polluters on Twitter. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Davis, C.A.; Varol, O.; Ferrara, E.; Flammini, A.; Menczer, F. BotOrNot. In Proceedings of the 25th International Conference Companion on World Wide Web, Montreal, QC, Canada, 11–15 April 2016. [Google Scholar] [CrossRef] [Green Version]
- Alsaleh, M.; Alarifi, A.; Al-Salman, A.M.; Alfayez, M.; Almuhaysin, A. TSD: Detecting Sybil Accounts in Twitter. In Proceedings of the 2014 13th International Conference on Machine Learning and Applications, Detroit, MI, USA, 3–6 December 2014; pp. 463–469. [Google Scholar] [CrossRef]
- Ren, Y.; Ji, D. Neural networks for deceptive opinion spam detection: An empirical study. Inf. Sci. 2017, 385–386, 213–224. [Google Scholar] [CrossRef]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2267–2273. [Google Scholar]
- Zhang, W.; Du, Y.; Yoshida, T.; Wang, Q. DRI-RCNN: An approach to deceptive review identification using recurrent convolutional neural network. Inf. Process. Manag. 2018, 54, 576–592. [Google Scholar] [CrossRef]
- Alhosseini, S.; Bin Tareaf, R.; Najafi, P.; Meinel, C. Detect Me If You Can: Spam Bot Detection Using Inductive Representation Learning. In Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 148–153. [Google Scholar] [CrossRef]
- Kudugunta, S.; Ferrara, E. Deep neural networks for bot detection. Inf. Sci. 2018, 467, 312–322. [Google Scholar] [CrossRef] [Green Version]
- Wei, F.; Nguyen, U.T. Twitter Bot Detection Using Bidirectional Long Short-Term Memory Neural Networks and Word Embeddings. In Proceedings of the 2019 First IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Los Angeles, CA, USA, 12–14 December 2019; pp. 101–109. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Pan, Q.; Wang, S.; Yang, T.; Cambria, E. A Generative Model for Category Text Generation. Inf. Sci. 2018, 450, 301–315. [Google Scholar] [CrossRef]
- Stanton, G.; Irissappane, A.A. GANs for Semi-Supervised Opinion Spam Detection. arXiv 2019, arXiv:abs/1903.08289. [Google Scholar]
- Yang, K.; Varol, O.; Davis, C.A.; Ferrara, E.; Flammini, A.; Menczer, F. Arming the public with artificial intelligence to counter social bots. Hum. Behav. Emerg. Technol. 2019, 1, 48–61. [Google Scholar] [CrossRef] [Green Version]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. The Paradigm-Shift of Social Spambots. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017. [Google Scholar] [CrossRef] [Green Version]
- Varol, O.; Ferrara, E.; Davis, C.A.; Menczer, F.; Flammini, A. Online Human-Bot Interactions: Detection, Estimation, and Characterization. arXiv 2017, arXiv:cs.SI/1703.03107. [Google Scholar]
- Gilani, Z.; Farahbakhsh, R.; Tyson, G.; Wang, L.; Crowcroft, J. Of Bots and Humans (on Twitter). In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Sydney, Australia, 31 July–3 August 2017. [Google Scholar]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Sørensen, T.; Sørensen, T.; Biering-Sørensen, T.; Sørensen, T.; Sorensen, J.T. A method of establishing group of equal amplitude in plant sociobiology based on similarity of species content and its application to analyses of the vegetation on Danish commons. K. Dan. Vidensk. Selsk. 1948, 5, 1–34. [Google Scholar]
- Yeo, I.K.; Johnson, R. A new family of power transformations to improve normality or symmetry. Biometrika 2000, 87, 954–959. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Koza, J.R. Genetic Programming: On the Programming of Computers by Means of Natural Selection (Complex Adaptive Systems); MIT Press: Cambridge, MA, USA, 1993. [Google Scholar]
- Fogel, D. Evolutionary Computation: Toward a New Philosophy of Machine Intelligence, 3rd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Fortin, F.A.; De Rainville, F.M.; Gardner, M.A.; Parizeau, M.; Gagné, C. DEAP: Evolutionary Algorithms Made Easy. J. Mach. Learn. Res. 2012, 13, 2171–2175. [Google Scholar]
- Matthews, B. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta (BBA) Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Feature Name |
|---|---|
| reputation | |
| listed growth rate | |
| favorites growth rate | |
| friends growth rate | |
| followers growth rate | |
| statuses growth rate | |
| screen name length | |
| frequency of words | |
| frequency of hashtags | |
| frequency of mentioned users | |
| frequency of retweets | |
| frequency of URLs | |
| words raw counts standard dev. | |
| hashtags raw counts standard dev. | |
| mentioned users raw counts standard dev. | |
| tweets similarities mean | |
| tweets lengths standard dev. |
| ID | Name | Learned Weight | Favored Category |
|---|---|---|---|
| reputation | 1.65 | Human | |
| listed growth rate | 1.50 | Human | |
| favorites growth rate | 0.13 | Human | |
| friends growth rate | 0.54 | Bot | |
| followers growth rate | 1.67 | Human | |
| statuses growth rate | 1.32 | Bot | |
| screen name length | 0.03 | Human | |
| frequency of words | 0.37 | Bot | |
| frequency of hashtags | 0.71 | Bot | |
| frequency of mentioned users | 0.61 | Bot | |
| frequency of retweets | 0.93 | Bot | |
| frequency of URLs | 1.74 | Bot | |
| words raw counts standard dev. | 1.66 | Bot | |
| hashtags raw counts standard dev. | 0.13 | Bot | |
| mentioned users raw counts standard dev. | 0.68 | Human | |
| tweets similarities mean | 0.40 | Bot | |
| tweets lengths standard dev. | 0.77 | Human |
| Component ID | Component Formula | Favored Category |
|---|---|---|
| Human | ||
| Human | ||
| Human | ||
| Bot | ||
| Bot | ||
| Bot |
| Component ID | Component Description |
|---|---|
| Combination of listed growth rate and reputation | |
| Weighted followers growth rate | |
| Weighted mentioned users raw counts standard deviation | |
| Weighted frequency of hashtags | |
| Mean between frequency of retweets and frequency of URLs | |
| Words raw counts standard deviation weighted by screen name length |
| GA | GP | Yang et al. [36] | Kudugunta et al. [44] | Wei et al. [45] | Cresci et al. [19] | Botometer [38] | Alhosseini et al. [43] | Miller et al. [23] | Lee at al. [37] | |
|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 0.76 | 0.76 | 0.82 | 0.82 | 0.71 | 0.48 | 0.56 | 0.68 | 0.48 | 0.75 |
| F1 score | 0.78 | 0.78 | 0.85 | 0.75 | 0.75 | 0.11 | 0.49 | 0.73 | 0.63 | 0.78 |
| MCC | 0.51 | 0.52 | 0.66 | 0.67 | 0.42 | 0.08 | 0.16 | 0.35 | −0.14 | 0.49 |
| GA | GP | Yang et al. [36] | Kudugunta et al. [44] | Wei et al. [45] | Cresci et al. [19] | Botometer [38] | Alhosseini et al. [43] | Miller et al. [23] | Lee at al. [37] | |
|---|---|---|---|---|---|---|---|---|---|---|
| Meta-data | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Tweets | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Neighbors | ✓ | ✓ |
| GA | GP | ||
|---|---|---|---|
| Accuracy | Mean | 0.7511 | 0.7660 |
| Std dev. | 0.0045 | 0.0070 | |
| F1 score | Mean | 0.7789 | 0.7884 |
| Std dev. | 0.0032 | 0.0067 | |
| MCC | Mean | 0.4974 | 0.5278 |
| Std dev. | 0.0092 | 0.0140 | |
| Seed | Max Depth | MSE Weight | Size Weight | Size | Accuracy | F1 | MCC |
|---|---|---|---|---|---|---|---|
| 1 | 16 | 0.95 | 0.05 | 97 | 0.7796 | 0.7945 | 0.5409 |
| 2 | 14 | 0.90 | 0.10 | 116 | 0.7701 | 0.7943 | 0.5357 |
| 3 | 12 | 0.85 | 0.15 | 54 | 0.7667 | 0.7896 | 0.5289 |
| 4 | 11 | 0.80 | 0.20 | 70 | 0.7650 | 0.7891 | 0.5254 |
| 5 | 10 | 0.75 | 0.25 | 64 | 0.7642 | 0.7859 | 0.5240 |
| 6 | 9 | 0.70 | 0.30 | 65 | 0.7796 | 0.7920 | 0.5414 |
| 7 | 8 | 0.65 | 0.25 | 65 | 0.7701 | 0.7930 | 0.5357 |
| 8 | 7 | 0.60 | 0.40 | 44 | 0.7557 | 0.7758 | 0.5075 |
| 9 | 6 | 0.50 | 0.50 | 26 | 0.7616 | 0.7797 | 0.5200 |
| 10 | 5 | 0.40 | 0.60 | 27 | 0.7608 | 0.7874 | 0.5168 |
| 11 | 4 | 0.30 | 0.70 | 16 | 0.7430 | 0.7686 | 0.4809 |
| 12 | 4 | 0.20 | 0.80 | 14 | 0.7557 | 0.7772 | 0.5071 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rovito, L.; Bonin, L.; Manzoni, L.; De Lorenzo, A. An Evolutionary Computation Approach for Twitter Bot Detection. Appl. Sci. 2022, 12, 5915. https://doi.org/10.3390/app12125915
Rovito L, Bonin L, Manzoni L, De Lorenzo A. An Evolutionary Computation Approach for Twitter Bot Detection. Applied Sciences. 2022; 12(12):5915. https://doi.org/10.3390/app12125915
Chicago/Turabian StyleRovito, Luigi, Lorenzo Bonin, Luca Manzoni, and Andrea De Lorenzo. 2022. "An Evolutionary Computation Approach for Twitter Bot Detection" Applied Sciences 12, no. 12: 5915. https://doi.org/10.3390/app12125915
APA StyleRovito, L., Bonin, L., Manzoni, L., & De Lorenzo, A. (2022). An Evolutionary Computation Approach for Twitter Bot Detection. Applied Sciences, 12(12), 5915. https://doi.org/10.3390/app12125915