
An Open Relation Extraction System for Web Text Information


Abstract
:1. Introduction
- AutomationThe open relation extraction system can execute automatically, and the algorithm only needs to go through the corpus once for triple tuples extraction. It should be based on an unsupervised extraction strategy and cannot be a predefined relation. In addition, the cost of manually constructing training samples is small, and only a tiny number of initialization seeds need to be labeled or a small number of extraction templates need to be defined.
- Non-homologous corpusThe goal of open-domain relation extraction is domain-independent and should not be limited to a particular domain. In addition, it is important to avoid using domain-dependent deep syntactic analysis tools, such as syntactic analysis.
- EfficiencyOpen information extraction systems handle large-scale corpora, and a high efficiency is required to ensure a rapid response. Prioritizing shallow syntactic features is also necessary.
- We propose a new open relation extraction system (ORES), a novel structure to train a neural relation classifier with few initial new relation instances by iteratively accumulating new instances and facts from unlabeled data with prior data knowledge of historical relations. We design three functional components of ORES to realize the mining of Web text information, automatic labeling, and extraction and output of new relation data.
- We design and combine two new encoders based on tBERT and K-BERT language models to better express features in textual information. Experiments show that combined cooperation is beneficial for improving model performance. Specifically, for the sample selector 1 of the data mining component, we introduce a topic model and design a new encoder based on tBERT, which improves the recall rate. For the example selector 2 of the relation extraction component, we design a new encoder based on K-BERT to inject external knowledge for further improvement in accuracy. We also conducted a fusion experiment to prove the effectiveness of the combination.
2. Related Work
2.1. Supervised RE
2.2. Bootstrapping Algorithm for RE
- Record and store each observation;
- Put all samples in black box;
- Randomly sample and record its observations;
- Put the sample back, and then randomly sample.
2.3. Distant Supervised RE
2.4. Few-Shot Learning for RE
3. Methodology
3.1. Few-Shot Relation Extraction Learning Framework
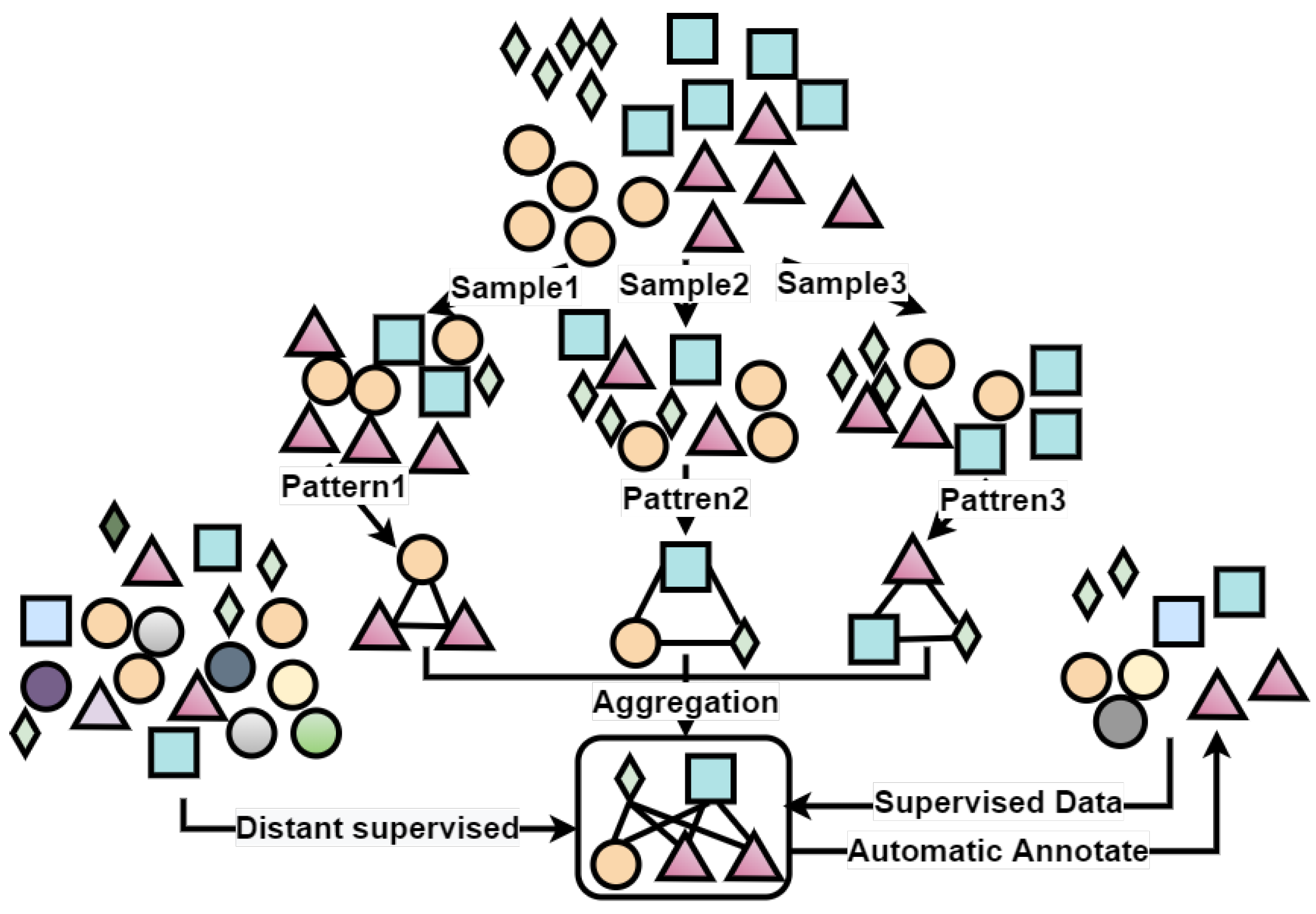
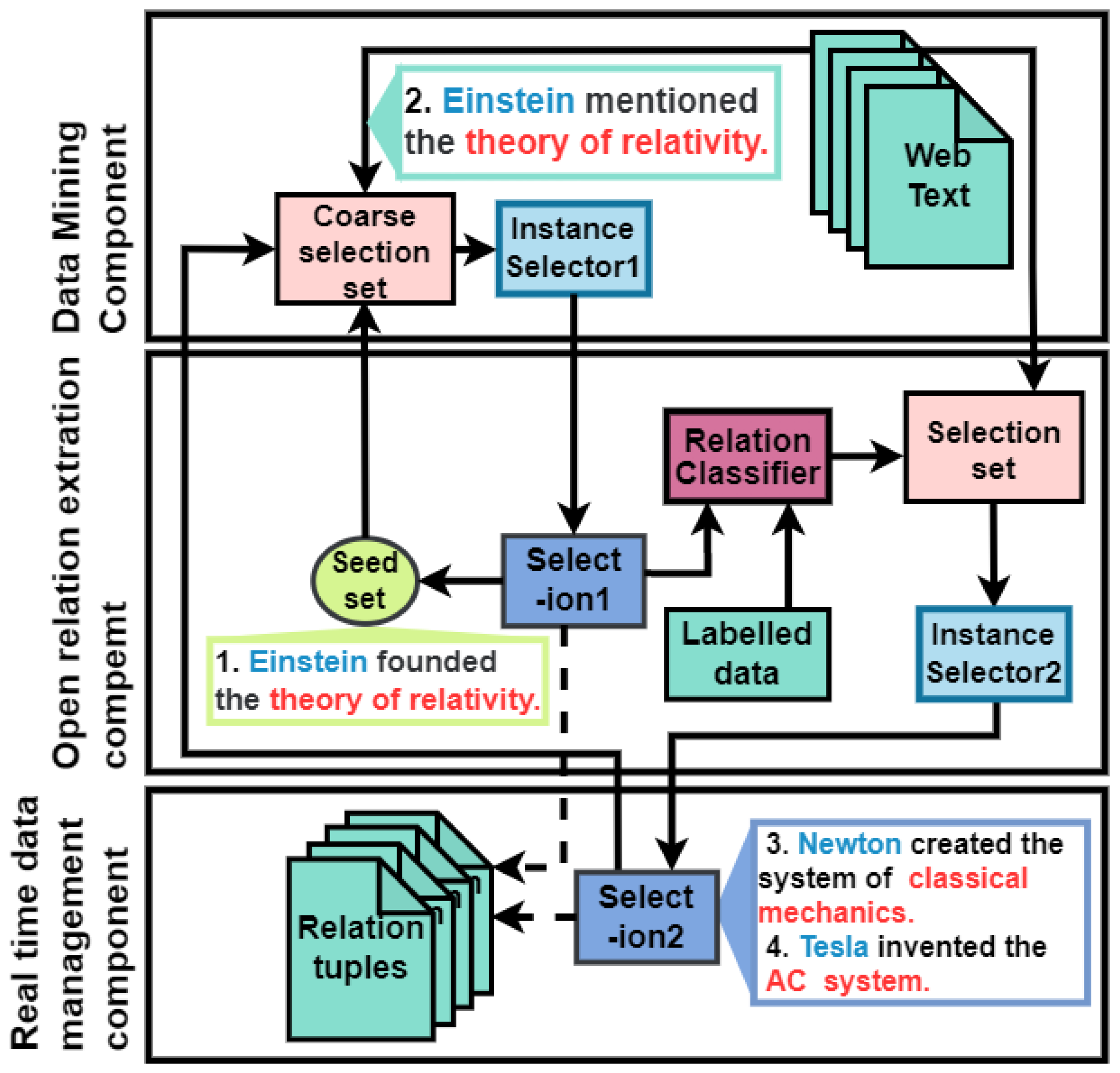
- Phase 1(a) Add sentences in the initial seed set to the coarse selection set. As shown in Figure 4: it put “Einstein founded the theory of relativity” into the coarse selection set from the seed set.(b) Using distant supervision, mine sentence pairs from Web text and add them to the coarse selection set and the selection set. At first, perform named-entity recognition, and extract the head and tail entities from the initial seed sentence X as entity pair .is the initial seed set, is the entity pair matching function, and X is the sentence in the initial seed set. Then mine all sentences containing entity pair in the Web text denoted as .is a rough selection, and is a Web text library.(c) Load sentences in the coarse selection set into instance selector 1. The tBERT encoder in instance selector 1 outputs the representation vectors of the embedding features of the sentence pair, denoted as em. The instance selector 1 through the Siamese network calculates the similarity of the two sentences and scores them. The similarity distance function is:where and are learnable parameters.(d) After the instance selector 1 filters out sentences that meet the threshold, add them to selection 1 and the seed set. The instance selector 1 and instance selector 2 are denoted as f, and the threshold is set to 0.5, marked as . Selection 1 is denoted as :where represents Web text.(e) Train a relation classifier with a small amount of labeled data and instances in selection 1 as input to identify sentences with a new relation r.
- Phase 2(a) Classifier g mines sentences in Web text that may belong to relation r. The confidence region of g is set to 0.9. When the input instance meets the threshold condition, it is filtered out and added to the selection set.is the sentence selection set. is the large-scale annotated relation set.(b) Filter the selection set again to enhance the performance of the classifier. Then, load the sentences in the selection set to the instance selector 2.(c) After sentences are loaded into the coarse selection set, one iteration is complete. To further improve the accuracy, the instance selector 2 adopts the K-BERT encoder. K-BERT is a language model that can inject external knowledge.
3.2. Instance Selector
3.3. Encoder
3.3.1. tBERT Encoder
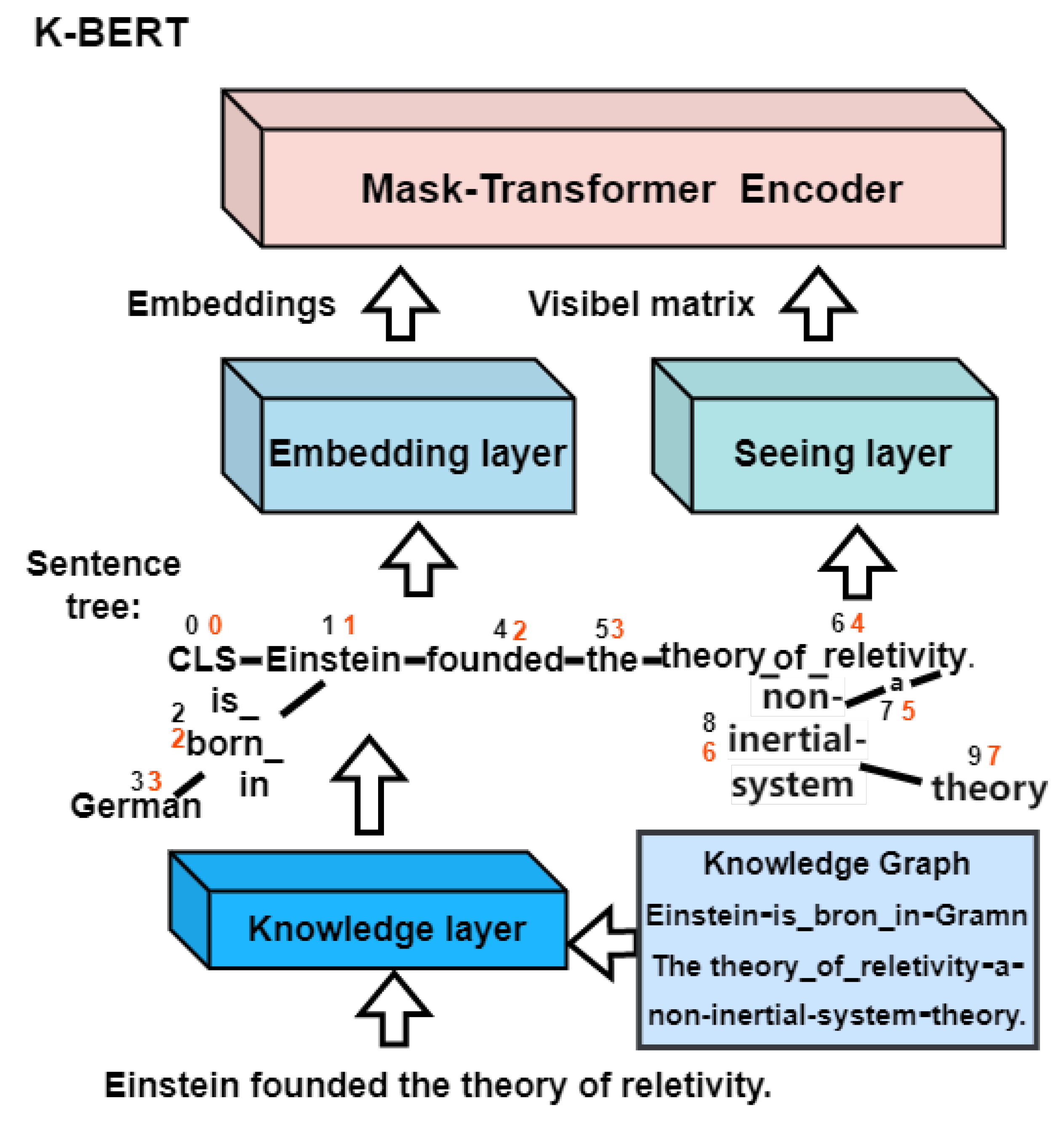
3.3.2. K-BERT Encoder
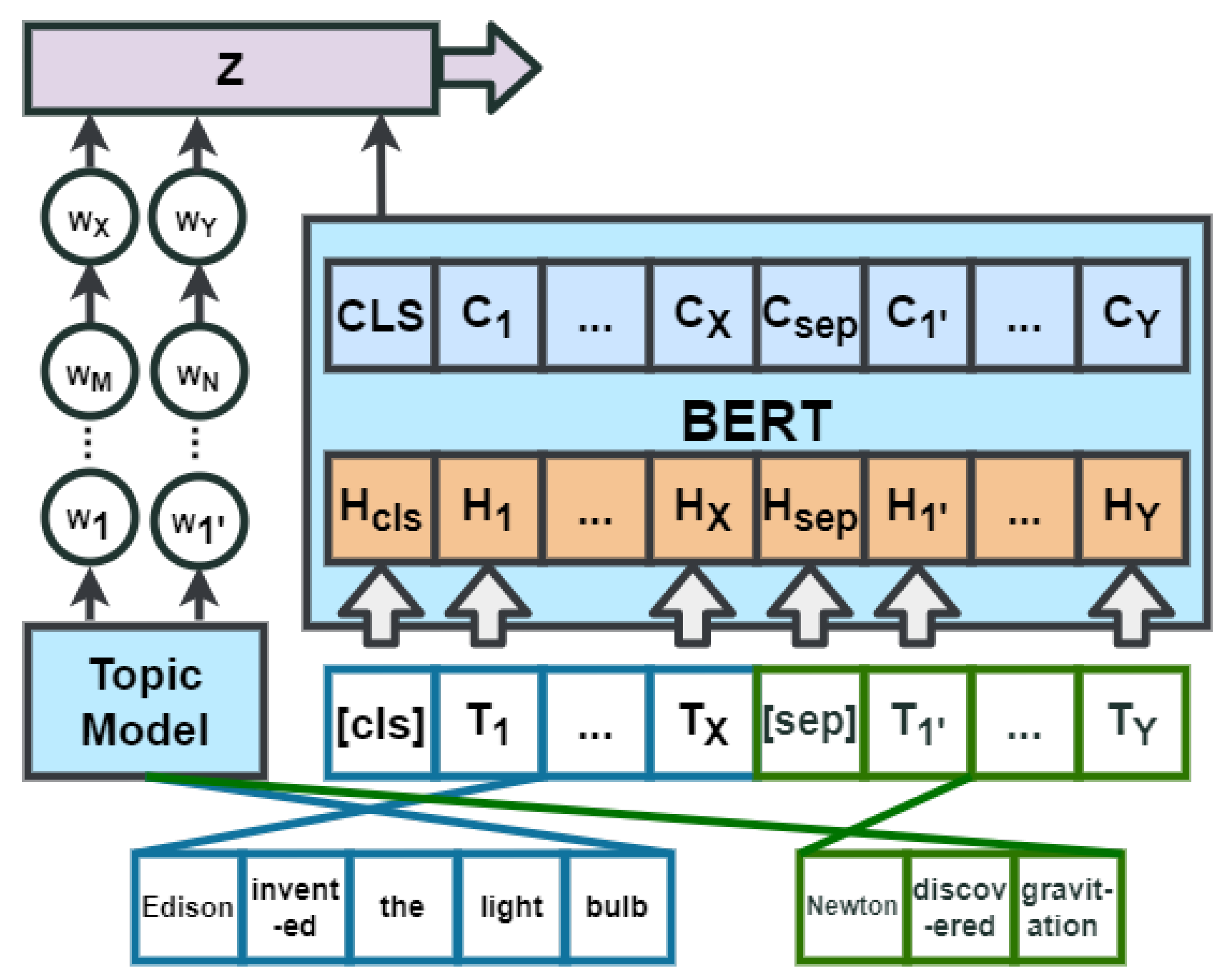
- Process 1:BERT can only process sentence input with sequence structure. The structural information will be lost if the sentence tree is tiled into a sequence. The visual matrix can convert the sentence tree into a sequence and save the structural information, and its principle is shown in Figure 7.The embedding representation includes three parts: token embedding, position embedding, and segment embedding. In the token embedding section, K-BERT flattens the tokens in the sentence tree into embedding sequences according to the hard position index. “[CLS](0) Einstein(1) is_born_in(2) German(3) founded(4) the_theory_of relativity(5) is_ proposed _by(6) Einstein(7)”. Obviously, tiling causes losses in sentence structure and readability. For example, the positional index of “is born in(2)” and “founded(2)” are both (2), and they all follow “Einstein(1)”. This information can be recovered by soft-position coding.As shown in Figure 7, “[CLS](0) Einstein(1) is born in(2) German(3) founded(2) the(3) theory of relativity(4) a(5) non-inertial-system(6) theory (7)”. In the soft-position embedding section, K-BERT restores the graph structure and readability of the sentence tree through soft-position encoding. K-BERT uses soft-position embedding to map the readable information of sentence trees. Nevertheless, only using soft positions is not enough because it will make the model misunderstand that found(2) follows German(3), which will also lead to knowledge noise. In order to solve this problem, we can convert the soft-position coding into a visible matrix through the process 2 seeing layer. The role of this last section segment embedding is to identify sentence 1 and sentence 2. For the sentence pair, it is marked with a sequence of segment tags, .
- Process 2:The seeing layer’s role is to limit the field of view of the knowledge referenced by the entities. It can avoid false references to knowledge and the noise caused by mutual interference between knowledge. The visible matrix M is defined as:where i and j are the hard-position index, and are co-branched, meaning that they are the same entity, and its distance is 0. On the contrary, its distance is negative infinity.
4. Experimental Results and Experiment Analysis
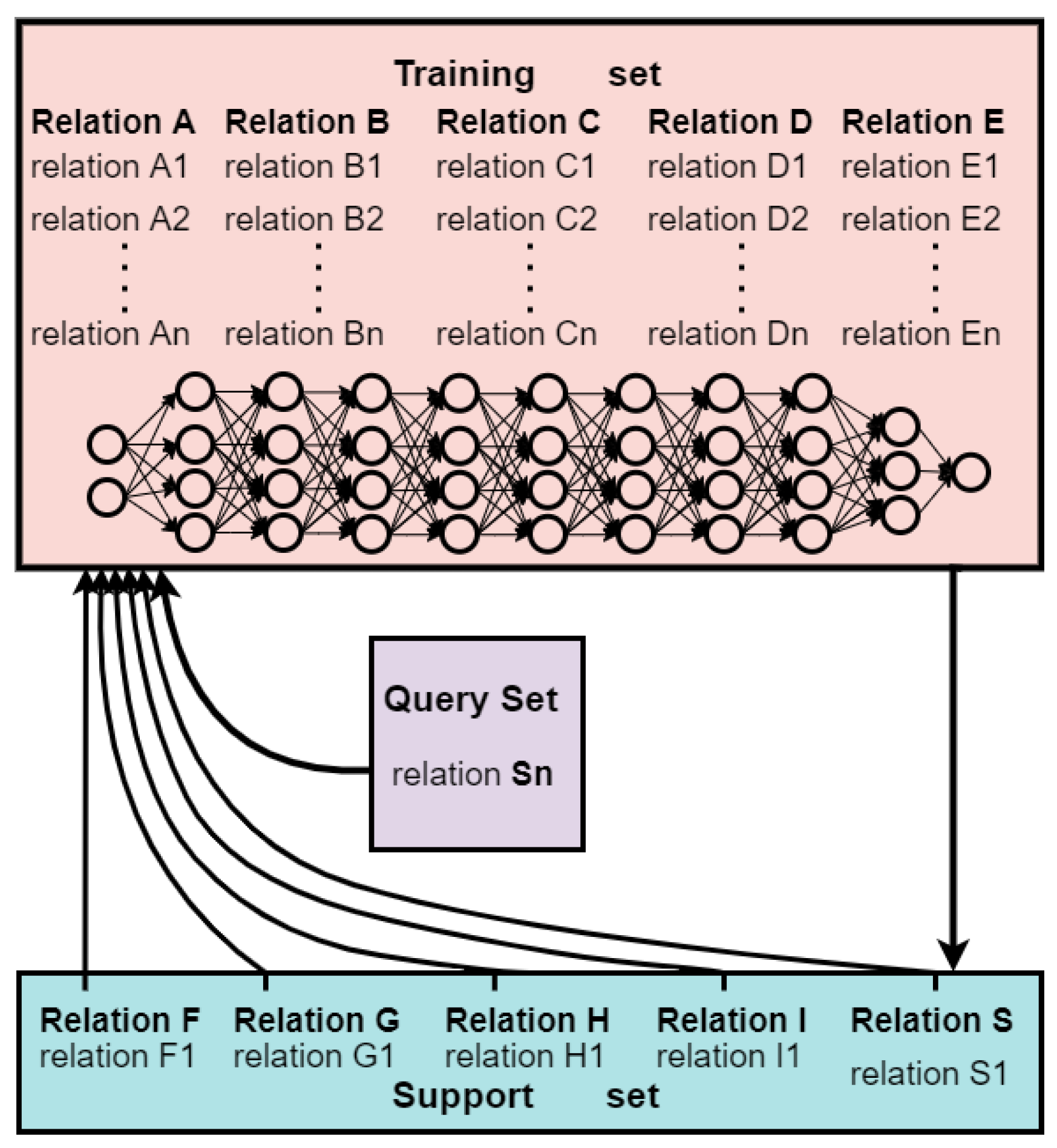
4.1. Datasets and Evaluation Settings
- Train the ORES model on the training set T1, namely, sample selector 1 and instance selector 2.
- Randomly sample a relation r and its K instances from the training set T2, the validation set, and the test set to form a query set Q. Moreover, randomly sample a sentence SR from Q. Its entity–pair relation is recorded as R.
- Input SR as a query sentence into the model and let the classifier judge whether SR and Sr, sampled from the validation set and the test set, are the same types of relationship in a binary classification manner. A new relation extraction classifier is obtained by evaluating and tuning the relation classifier.
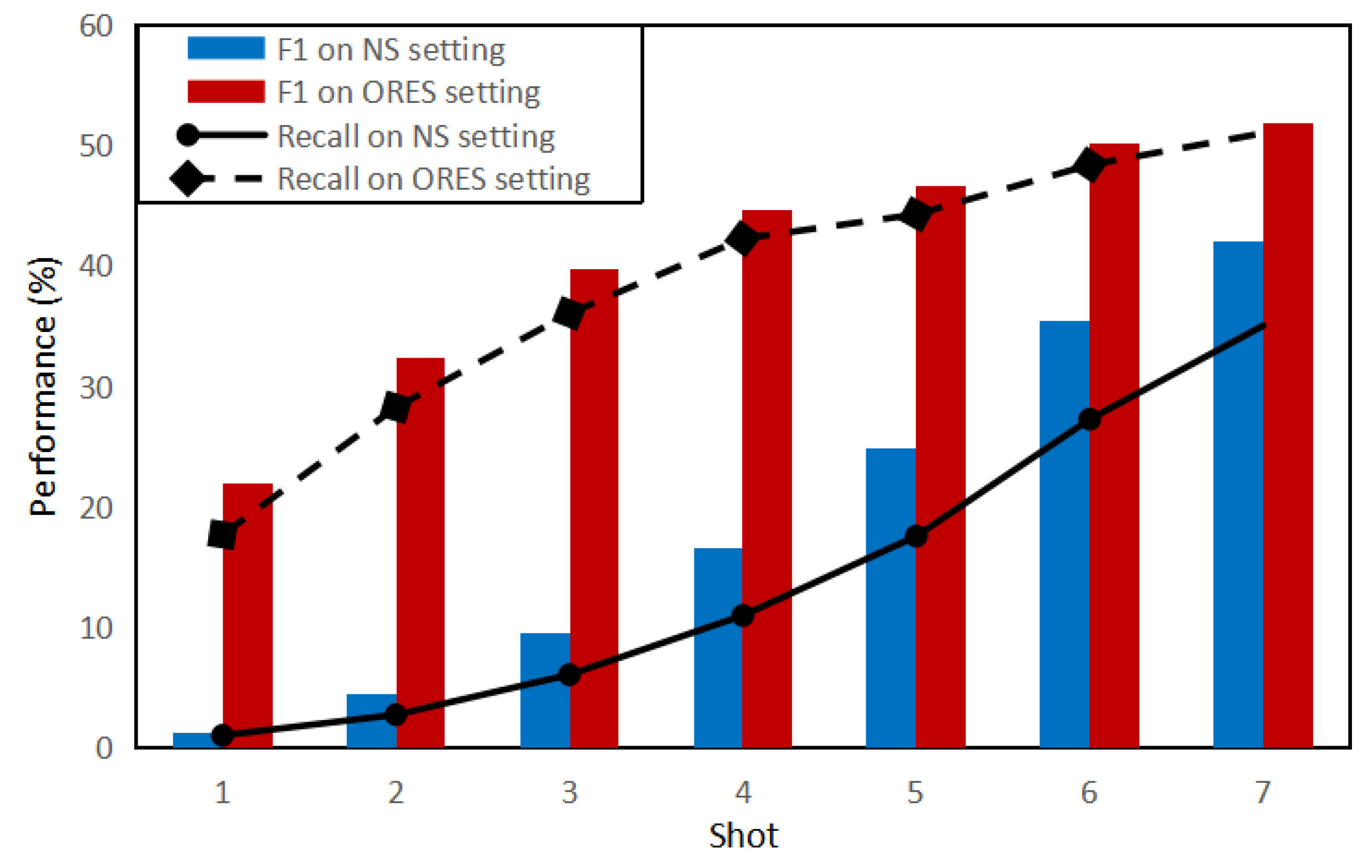
4.2. Experiments
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Feng, J.; Meng, Y.; Han, Q.; Wu, F.; Li, J. A Unified MRC Framework for Named Entity Recognition. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5849–5859. [Google Scholar]
- Grover, C.; Haddow, B.; Klein, E.; Matthews, M.; Neilsen, A.L.; Tobin, R.; Wang, X. Adapting a Relation Extraction Pipeline for the BioCreAtIvE II Tasks. 2007. Available online: https://www.research.ed.ac.uk/en/publications/adapting-a-relation-extraction-pipeline-for-the-biocreative-ii-ta (accessed on 5 May 2022).
- Miwa, M.; Sasaki, Y. Modeling Joint Entity and Relation Extraction with Table Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1858–1869. [Google Scholar]
- Yates, A.; Cafarella, M.; Banko, M.; Etzioni, O.; Broadhead, M.; Soderland, S. TextRunner: Open information extraction on the web. In Proceedings of the Human Language Technologies: The Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), Rochester, NY, USA, 22–27 April 2007; pp. 25–26. [Google Scholar]
- Mausam; Schmitz, M.; Bart, R.; Soderland, S.; Etzioni, O. Open language learning for information extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, 12–14 July 2012; pp. 523–534. [Google Scholar]
- Fader, A.; Soderland, S.; Etzioni, O. Identifying relations for open information extraction. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 1535–1545. [Google Scholar]
- Yahya, M.; Whang, S.; Gupta, R.; Halevy, Y.A. ReNoun: Fact Extraction for Nominal Attributes. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 325–335. [Google Scholar]
- Corro, D.L.; Gemulla, R. ClausIE: Clause-based open information extraction. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 355–366. [Google Scholar]
- Angeli, G.; Premkumar, J.J.M.; Manning, D.C. Leveraging Linguistic Structure For Open Domain Information Extraction. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1, pp. 344–354. [Google Scholar]
- Stanovsky, G.; Ficler, J.; Dagan, I.; Goldberg, Y. Getting More Out Of Syntax with PropS. arXiv 2016, arXiv:1603.01648. [Google Scholar]
- Cetto, M.; Niklaus, C.; Freitas, A.; Handschuh, S. Graphene: Semantically-Linked Propositions in Open Information Extraction. arXiv 2018, arXiv:1807.112. [Google Scholar]
- Gao, T.; Han, X.; Xie, R.; Liu, Z.; Lin, F.; Lin, L.; Sun, M. Neural Snowball for Few-Shot Relation Learning. Natl. Conf. Artif. Intell. 2020, 34, 7772–7779. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, J.R. An Introduction to the Bootstrap. In Technometrics; CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar]
- Bromley, J.; Guyon, I.; Lecun, Y.; Säckinger, E.; Shah, R.; Moore, C.; Säckinger, E.; Shah, R. Signature Verification Using a Siamese Time Delay Neural Network. In Advances in Neural Information Processing Systems; Morgan Kaufmann: Burlington, MA, USA, 1994; pp. 737–744. [Google Scholar]
- Xu, H.; Tianyu, G.; Yankai, L.; Hao, P.; Yaoliang, Y.; Chaojun, X.; Zhiyuan, L.; Peng, L.; Maosong, S.; Jie, Z. More Data, More Relations, More Context and More Openness: A Review and Outlook for Relation Extraction. arXiv 2020, arXiv:2004.03186. [Google Scholar]
- Zhong, Z.; Chen, D. A Frustratingly Easy Approach for Joint Entity and Relation Extraction. arXiv 2020, arXiv:2010.12812. [Google Scholar]
- Sun, A.; Grishman, R.; Sekine, S. Semi-supervised relation extraction with large-scale word clustering. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, ON, USA, 19–24 June 2011; pp. 521–529. [Google Scholar]
- Felsenstein, J. Confidence limits on phylogenies: An approach using the bootstrap. Evolution 1985, 39, 783–791. [Google Scholar] [CrossRef] [PubMed]
- Brin, S. Extracting Patterns and Relations from the World Wide Web. In Proceedings of the International Workshop on the World Wide Web and Databases, Valencia, Spain, 27–28 March 1998; pp. 172–183. [Google Scholar]
- Agichtein, E.; Gravano, L. Snowball: Extracting relations from large plain-text collections. In Proceedings of the Fifth ACM Conference on Digital Libraries, San Antonio, TX, USA, 2–7 June 2000; pp. 85–94. [Google Scholar]
- Qin, P.; Xu, W.; Wang, Y.W. Robust Distant Supervision Relation Extraction Via Deep Reinforcement Learning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 2137–2147. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural Relation Extraction With Selective Attention Over Instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 2124–2133. [Google Scholar]
- Ji, G.; Liu, K.; He, S.; Zhao, J. Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, Berlin, Germany, 7–12 August 2017; pp. 3060–3066. [Google Scholar]
- Jia, W.; Dai, D.; Xiao, X.; Wu, H. ARNOR: Attention Regularization based Noise Reduction for Distant Supervision Relation Classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1399–1408. [Google Scholar]
- Liang, C.; Yu, Y.; Jiang, H.; Er, S.; Wang, R.; Zhao, T.; Zhang, C. BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision. In Proceedings of the KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, 6–10 July 2020; pp. 1054–1064. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.; Ni, M.L. Generalizing from a Few Examples: A Survey on Few-shot Learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Chen, W.; Matusov, E.; Khadivi, S.; Peter, J.T. Guided Alignment Training for Topic-Aware Neural Machine Translation. arXiv 2016, arXiv:1607.01628. [Google Scholar]
- Peinelt, N.; Nguyen, D.; Liakata, M. tBERT: Topic Models and BERT Joining Forces for Semantic Similarity Detection. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7047–7055. [Google Scholar]
- Li, H.; Liu, B. Knowledge Extraction: A Few-shot Relation Learning Approach. In Proceedings of the 2022 International Conference on Machine Learning and Knowledge Engineering (MLKE), Guilin, China, 25–27 February 2022; pp. 261–265. [Google Scholar] [CrossRef]
- Nickel, M.; Murphy, K.; Tresp, V.; Gabrilovich, E. A Review of Relational Machine Learning for Knowledge Graphs. Proc. IEEE 2016, 104, 11–33. [Google Scholar] [CrossRef]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-Bert: Enabling Language Representation With Knowledge Graph. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, the Thirty-Second Innovative Applications of Artificial Intelligence Conference and the Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2901–2908. [Google Scholar]
- Han, X.; Zhu, H.; Yu, P.; Wang, Z.; Yao, Y.; Liu, Z.; Sun, M. FewRel: A Large-Scale Supervised Few-shot Relation Classification Dataset with State-of-the-Art Evaluation. arXiv 2018, arXiv:1810.10147. [Google Scholar]
- Batista, S.D.; Martins, B.; Silva, J.M. Semi-Supervised Bootstrapping of Relationship Extractors with Distributional Semantics. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| BREDS | 33.71 | 11.89 | 17.58 |
| Fine-tuning (CNN) | 46.90 | 9.08 | 15.22 |
| Distant Supervision (CNN) | 44.99 | 31.06 | 36.75 |
| Fine-tuning (BERT) | 50.85 | 16.66 | 25.10 |
| Distant Supervision (BERT) | 38.06 | 51.18 | 43.66 |
| Neural Snowball (BERT) | 56.87 | 40.43 | 47.26 |
| Our Topic Snowball (tBERT) | 54.84 | 69.25 | 53.13 |
| Our ORES (t-KBERT) | 55.69 | 69.78 | 61.94 |
| Model | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| BREDS | 28.29 | 17.02 | 21.25 |
| Fine-tuning (CNN) | 47.58 | 38.36 | 42.28 |
| Distant Supervision (CNN) | 42.48 | 48.64 | 45.35 |
| Fine-tuning (BERT) | 5.87 | 55.19 | 57.43 |
| Distant Supervision (BERT) | 38.45 | 76.12 | 51.09 |
| Neural Snowball (BERT) | 60.50 | 62.20 | 61.34 |
| Our Topic Snowball (tBERT) | 49.28 | 78.18 | 56.33 |
| Our ORES (t-KBERT) | 51.47 | 75.01 | 61.05 |
| Model | Precision (%) | Recall (%) | F1 (%) |
|---|---|---|---|
| BREDS | 25.24 | 17.96 | 20.99 |
| Fine-tuning (CNN) | 74.70 | 48.03 | 58.46 |
| Distant Supervision (CNN) | 43.70 | 54.76 | 48.60 |
| Fine-tuning (BERT) | 81.60 | 58.92 | 68.43 |
| Distant Supervision (BERT) | 35.48 | 80.33 | 49.22 |
| Neural Snowball (BERT) | 78.13 | 66.87 | 72.06 |
| Our Topic Snowball (tBERT) | 50.08 | 79.88 | 58.16 |
| Our ORES (t-KBERT) | 56.23 | 78.15 | 66.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Liu, B. An Open Relation Extraction System for Web Text Information. Appl. Sci. 2022, 12, 5718. https://doi.org/10.3390/app12115718
Li H, Liu B. An Open Relation Extraction System for Web Text Information. Applied Sciences. 2022; 12(11):5718. https://doi.org/10.3390/app12115718
Chicago/Turabian StyleLi, Huagang, and Bo Liu. 2022. "An Open Relation Extraction System for Web Text Information" Applied Sciences 12, no. 11: 5718. https://doi.org/10.3390/app12115718
APA StyleLi, H., & Liu, B. (2022). An Open Relation Extraction System for Web Text Information. Applied Sciences, 12(11), 5718. https://doi.org/10.3390/app12115718