
An Intelligent Manufacturing Approach Based on a Novel Deep Learning Method for Automatic Machine and Working Status Recognition





Abstract
:1. Introduction
2. Literature Review
2.1. Object Detection
2.1.1. Traditional Object Detection Methods
2.1.2. Deep Learning-Based Detection Methods
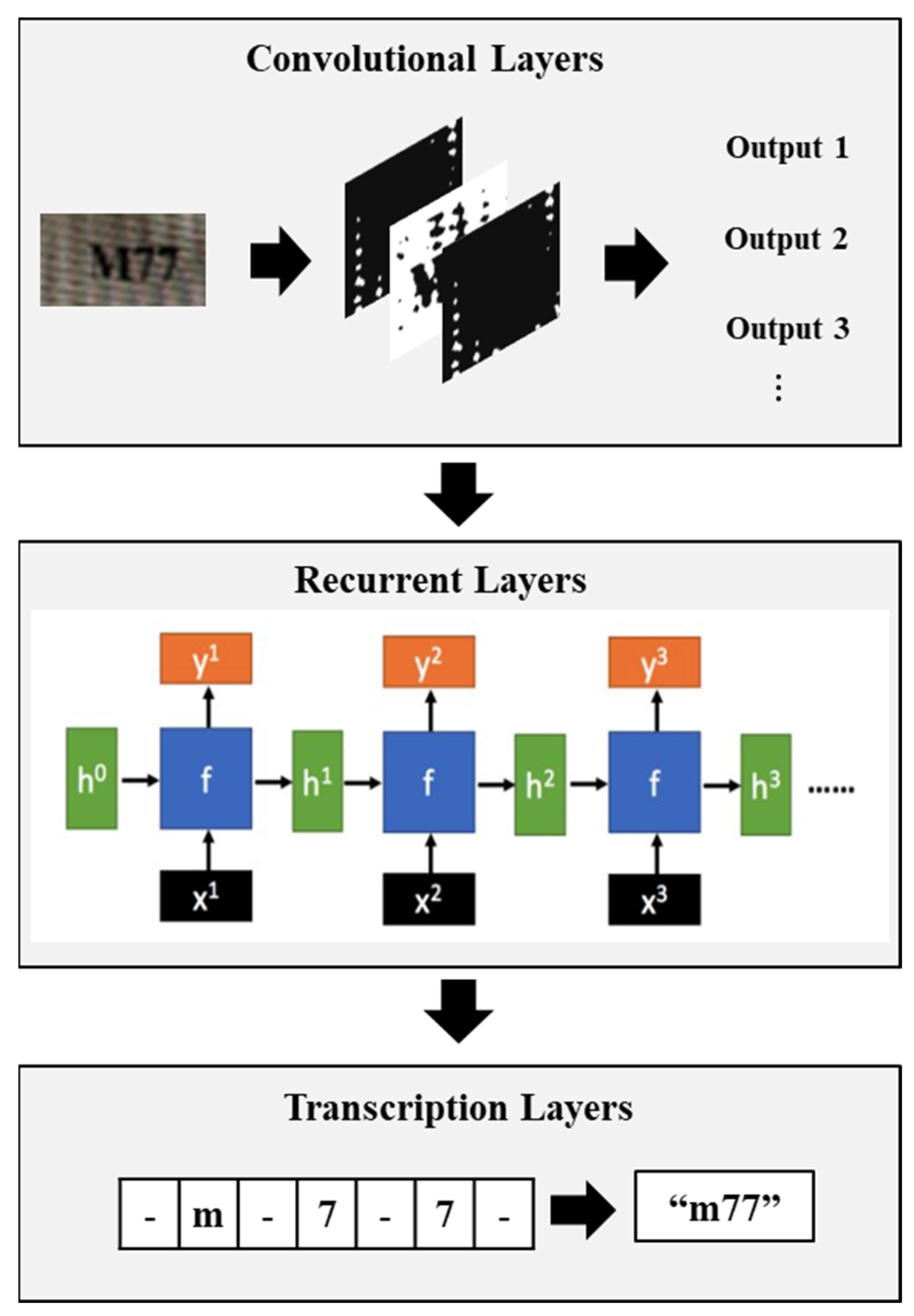
2.2. Scene Text Recognition
2.2.1. Text Detection
2.2.2. Text Recognition
3. Methodology
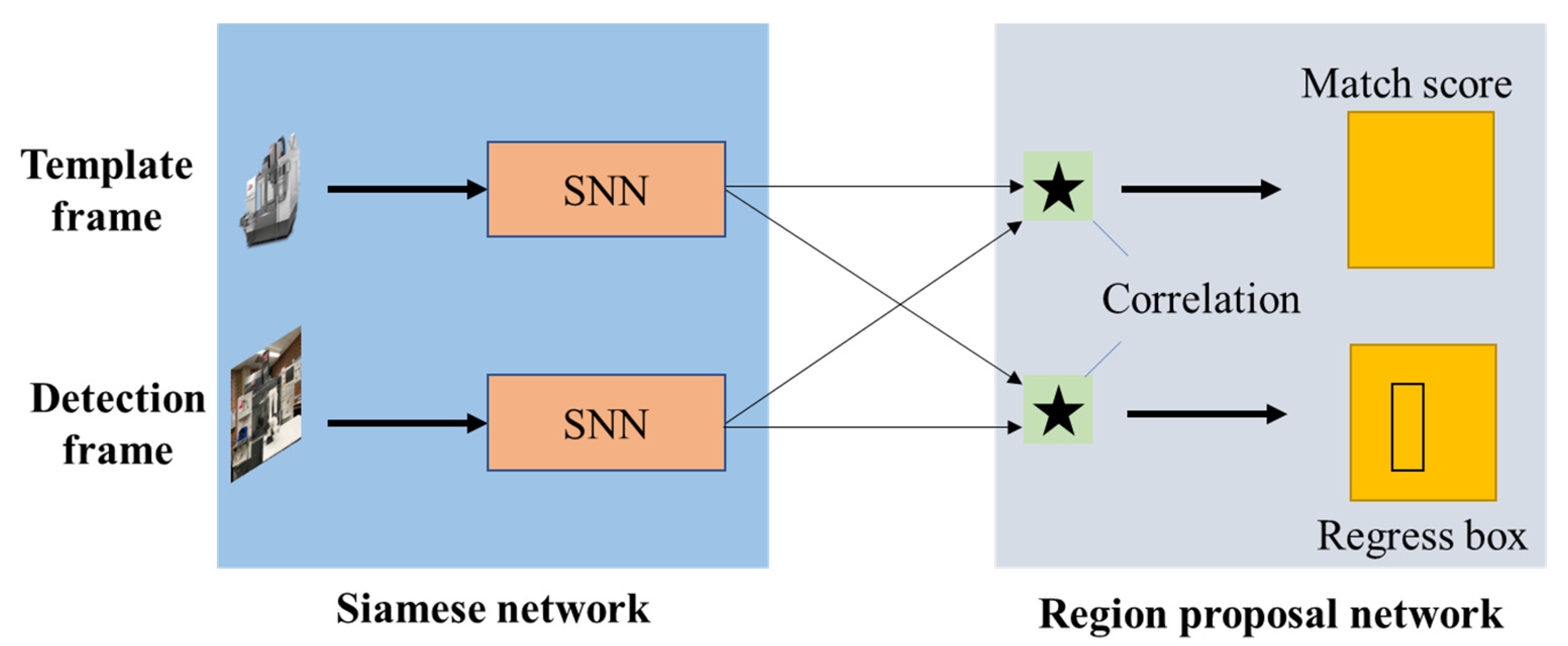
3.1. Siamese Region Proposal Network (Siameserpn) Architecture
3.1.1. Siamese Neural Network
3.1.2. Region Proposal Network
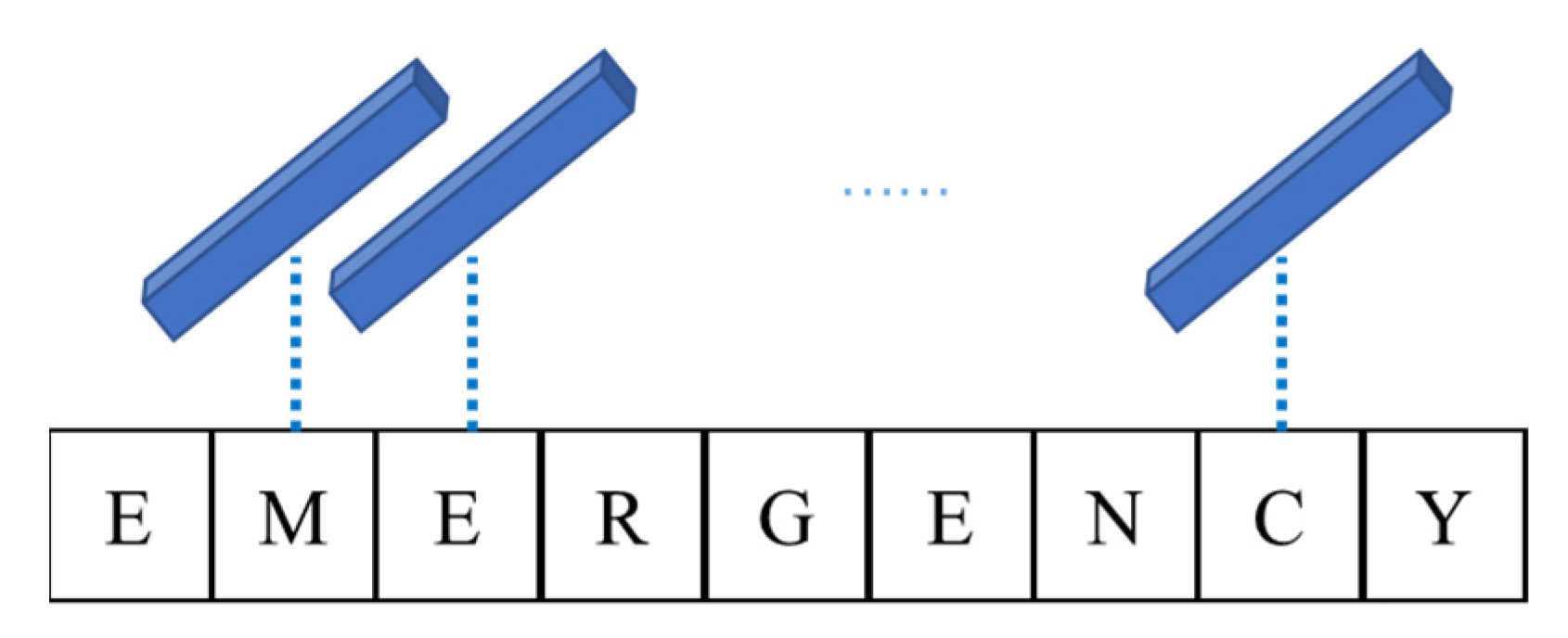
3.2. Working Status Recognition
Value(i, j) = 1, pixel(i, j) > P
(0 < i < width, 0 < j < height)
Horizontal [j] = 1, pixelRow[j] < Q
(0 < j < height)
3.3. Data Augmentation
3.4. Transfer Learning
4. Experiments and Results
4.1. Robot System Structure
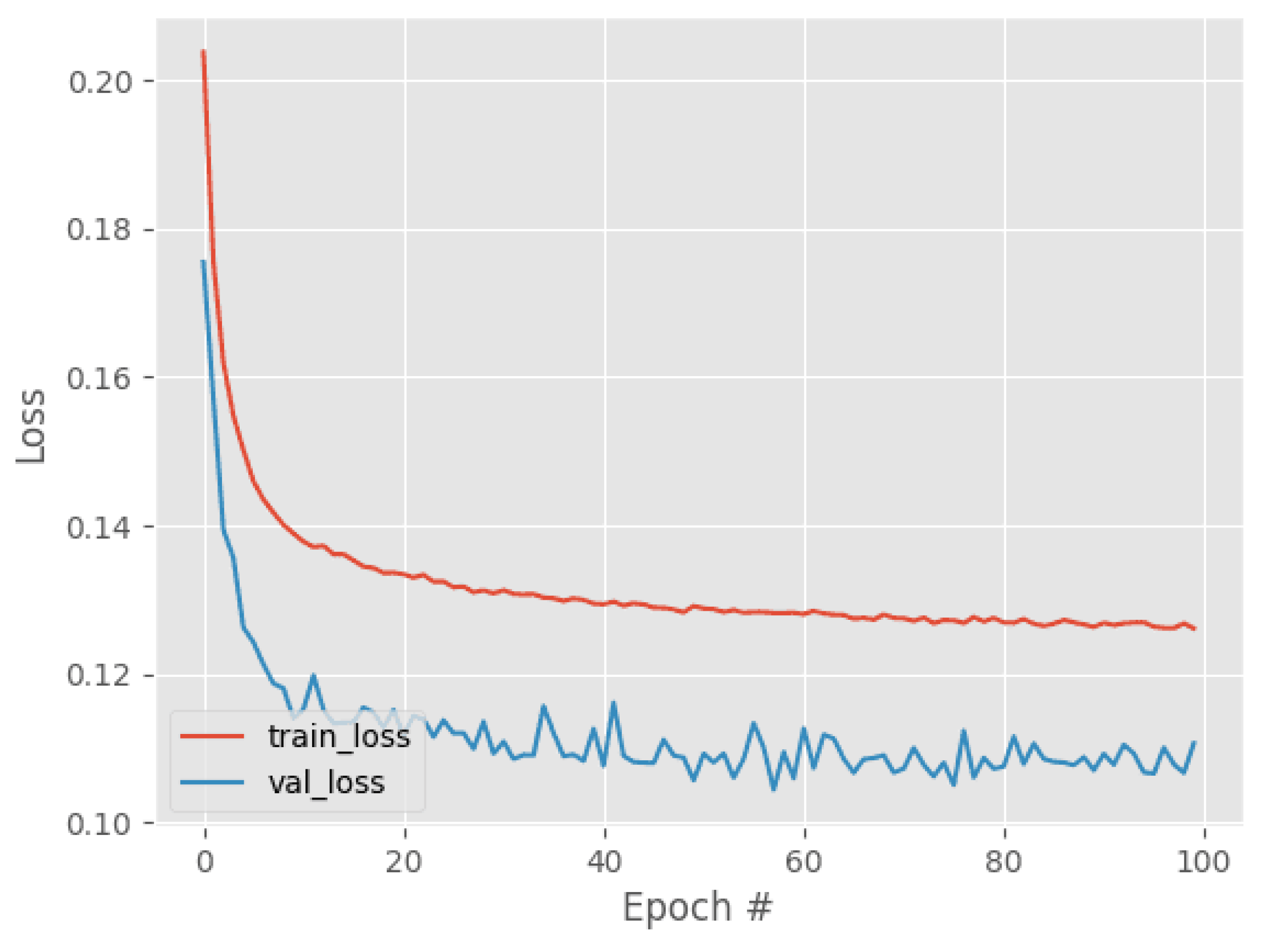
4.2. Training Details
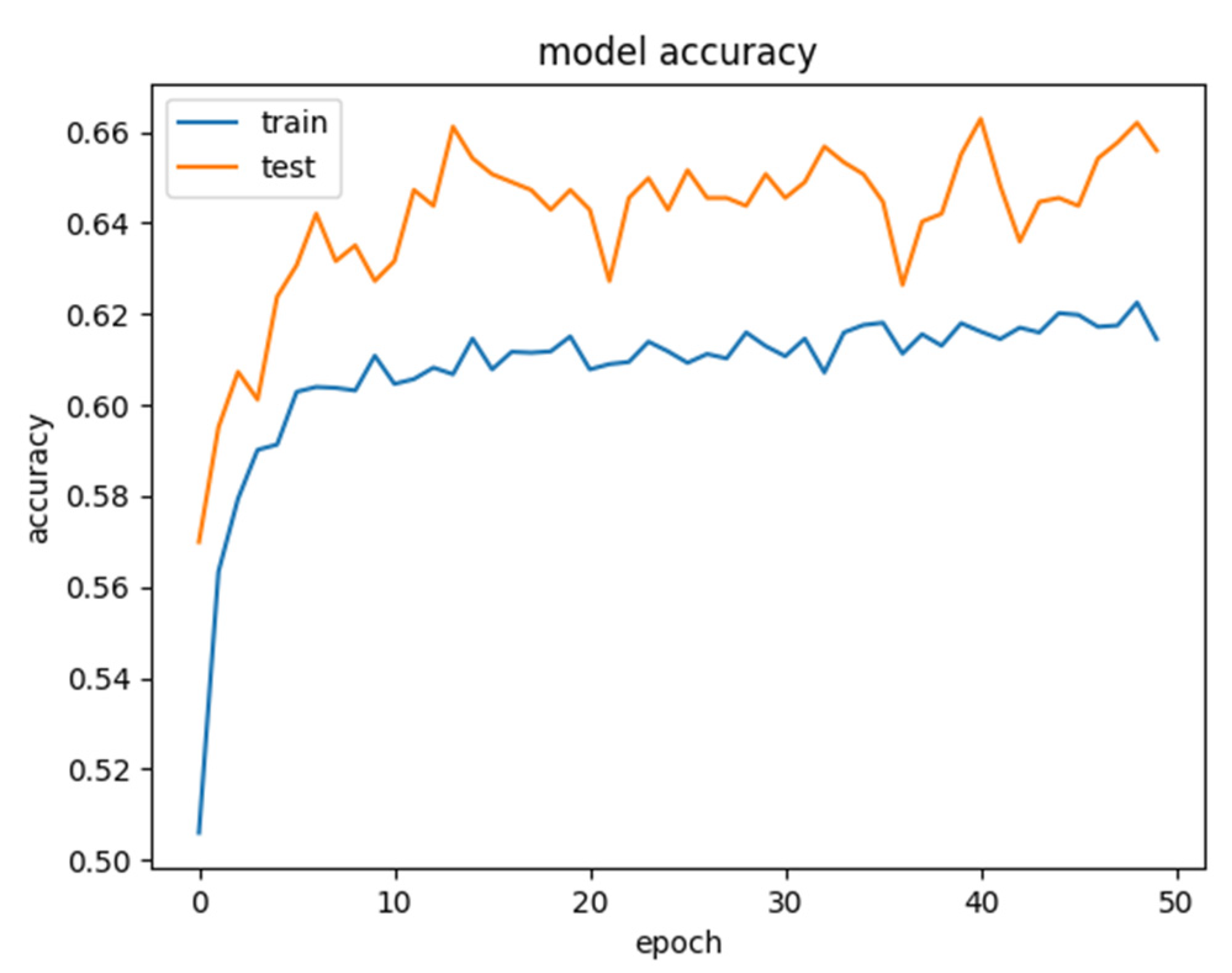
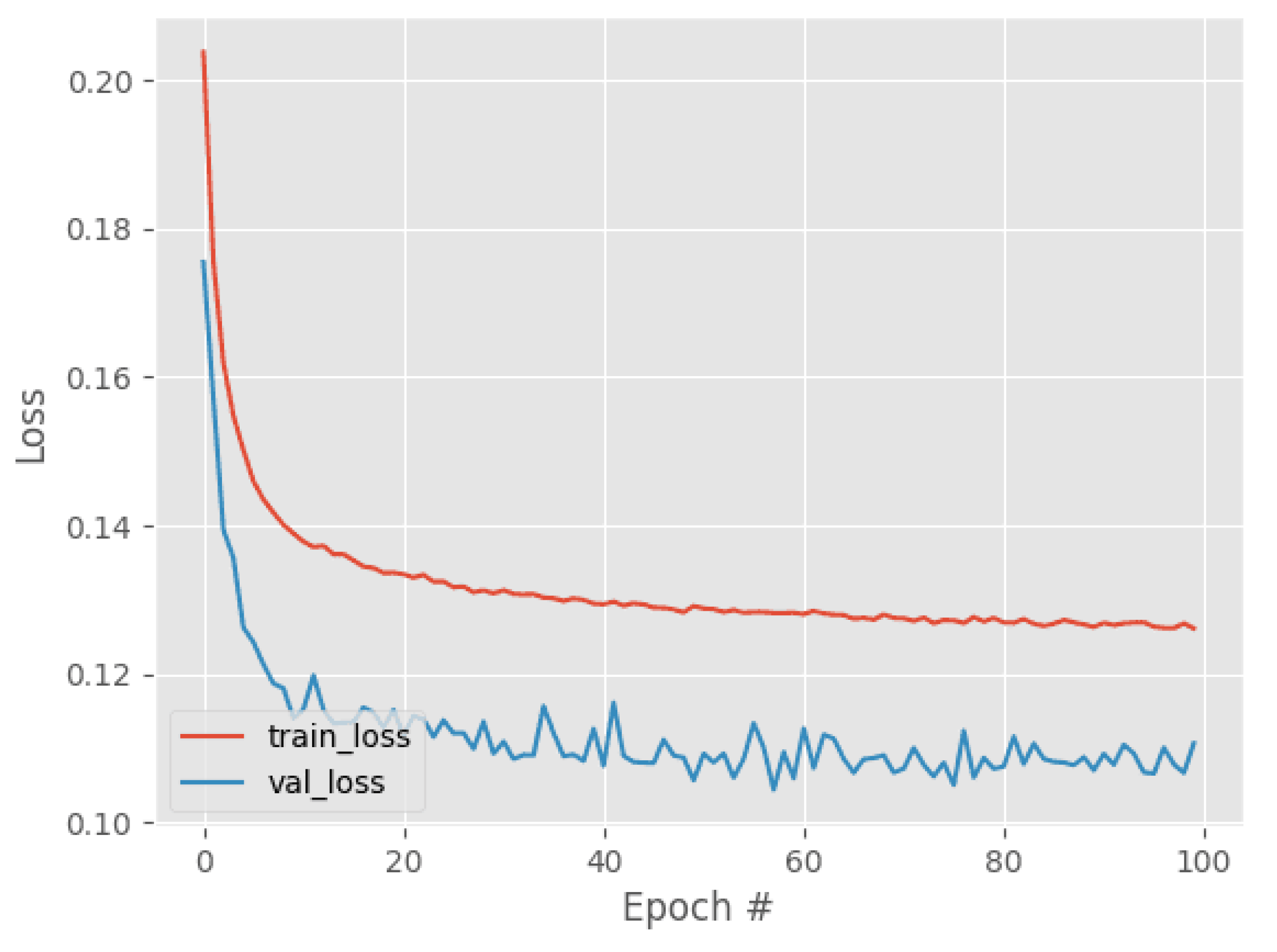
4.3. Evaluation
4.4. Results
5. Discussion and Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Martinez, P.; Al-Hussein, M.; Ahmad, R. Intelligent vision-based online inspection system of screw-fastening operations in light-gauge steel frame manufacturing. Int. J. Adv. Manuf. Technol. 2020, 109, 645–657. [Google Scholar] [CrossRef]
- Wang, T.-M.; Tao, Y.; Liu, H. Current Researches and Future Development Trend of Intelligent Robot: A Review. Int. J. Autom. Comput. 2018, 15, 525–546. [Google Scholar] [CrossRef]
- Khansari-Zadeh, S.M.; Billard, A. Learning Stable Nonlinear Dynamical Systems with Gaussian Mixture Models. IEEE Trans. Robot. 2011, 27, 943–957. [Google Scholar] [CrossRef] [Green Version]
- Schmitz, A.; Maiolino, P.; Maggiali, M.; Natale, L.; Cannata, G.; Metta, G. Methods and Technologies for the Implementation of Large-Scale Robot Tactile Sensors. IEEE Trans. Robot. 2011, 27, 389–400. [Google Scholar] [CrossRef]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2017, 37, 421–436. [Google Scholar] [CrossRef]
- Finn, C.; Levine, S. Deep visual foresight for planning robot motion. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2786–2793. [Google Scholar]
- Jia, F.; Ma, Y.; Ahmad, R. Vision-Based Associative Robotic Recognition of Working Status in Autonomous Manufacturing Environment. Procedia CIRP 2021, 104, 1535–1540. [Google Scholar] [CrossRef]
- Shen, X.; Xie, F.; Liu, X.-J.; Ahmad, R. An NC Code Based Machining Movement Simulation Method for a Parallel Robotic Machine; Huang, Y., Wu, H., Liu, H., Yin, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10463, pp. 3–13. [Google Scholar]
- Martinez, P.; Ahmad, R.; Al-Hussein, M. Real-time visual detection and correction of automatic screw operations in dimpled light-gauge steel framing with pre-drilled pilot holes. Procedia Manuf. 2019, 34, 798–803. [Google Scholar] [CrossRef]
- Matheson, E.; Minto, R.; Zampieri, E.G.G.; Faccio, M.; Rosati, G. Human–Robot Collaboration in Manufacturing Applications: A Review. Robotics 2019, 8, 100. [Google Scholar] [CrossRef] [Green Version]
- Jia, F.; Tzintzun, J.; Ahmad, R. An Improved Robot Path Planning Algorithm for a Novel Self-Adapting Intelligent Machine Tending Robotic System; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 86. [Google Scholar]
- Khosravani, M.R.; Nasiri, S.; Reinicke, T. Intelligent knowledge-based system to improve injection molding process. J. Ind. Inf. Integr. 2022, 25, 100275. [Google Scholar] [CrossRef]
- Ying, L.; Li, M.; Yang, J. Agglomeration and driving factors of regional innovation space based on intelligent manufacturing and green economy. Environ. Technol. Innov. 2021, 22, 101398. [Google Scholar] [CrossRef]
- Xu, L.; Li, G.; Song, P.; Shao, W. Vision-Based Intelligent Perceiving and Planning System of a 7-DoF Collaborative Robot. Comput. Intell. Neurosci. 2021, 2021, 5810371. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, I.; Din, S.; Jeon, G.; Piccialli, F.; Fortino, G. Towards Collaborative Robotics in Top View Surveillance: A Framework for Multiple Object Tracking by Detection Using Deep Learning. IEEE/CAA J. Autom. Sin. 2020, 8, 1253–1270. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, L.; Fürsterling, A.; Durocher, H.J.; Mouridsen, J.; Zhang, X. Learning-based object detection and localization for a mobile robot manipulator in SME production. Robot. Comput. Manuf. 2021, 73, 102229. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Leal-Taixé, L.; Canton-Ferrer, C.; Schindler, K. Learning by Tracking: Siamese CNN for Robust Target Association. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lin, H.; Yang, P.; Zhang, F. Review of Scene Text Detection and Recognition. Arch. Comput. Methods Eng. 2020, 27, 433–454. [Google Scholar] [CrossRef]
- Zhu, Y.; Yao, C.; Bai, X. Scene text detection and recognition. Front. Comput. Sci. 2016, 10, 19–36. [Google Scholar] [CrossRef]
- Brisinello, M.; Grbic, R.; Vranjes, M.; Vranjes, D. Review on Text Detection Methods on Scene Images. In Proceedings of the 2019 International Symposium ELMAR, Zadar, Croatia, 23–25 September 2019. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading Text in the Wild with Convolutional Neural Networks. Int. J. Comput. Vis. 2016, 116, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Jin, L.; Zhang, S.; Feng, Z. DeepText: A Unified Framework for Text Proposal Generation and Text Detection in Natural Images. arXiv 2016, arXiv:1605.07314. [Google Scholar]
- He, W.; Zhang, X.-Y.; Yin, F.; Liu, C.-L. Deep Direct Regression for Multi-oriented Scene Text Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 745–753. [Google Scholar]
- Su, B.; Lu, S. Accurate Scene Text Recognition Based on Recurrent Neural Network. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2015; Volume 9003, pp. 35–48. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.-Y.; Osindero, S. Recursive Recurrent Nets with Attention Modeling for OCR in the Wild. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2231–2239. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X.; Wang, X.; Liu, W. TextBoxes: A fast text detector with a single deep neural network. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4161–4167. [Google Scholar]
- Hradiš, M.; Kotera, J.; Zemčík, P.; Šroubek, F. Convolutional Neural Networks for Direct Text Deblurring. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 6.1–6.13. [Google Scholar]
- Mahajan, S.; Rani, R. Text detection and localization in scene images: A broad review. Artif. Intell. Rev. 2021, 54, 4317–4377. [Google Scholar] [CrossRef]
- Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. Unconstrained online handwriting recognition with recurrent neural networks. In Advances in Neural Information Processing System; MIT Press: Cambridge, MA, USA, 2008; pp. 1–8. [Google Scholar]
- Dieleman, S.; Willett, K.W.; Dambre, J. Rotation-invariant convolutional neural networks for galaxy morphology prediction. Mon. Not. R. Astron. Soc. 2015, 450, 1441–1459. [Google Scholar] [CrossRef]
- Zheng, Y.; Mamledesai, H.; Imam, H.; Ahmad, R. A Novel Deep Learning-based Automatic Damage Detection and Localization Method for Remanufacturing/Repair. Comput. Des. Appl. 2021, 18, 1359–1372. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Necula, M.; Câmpean, E.; Morar, L. Defining the Characteristics Needed for the Cobots Design Used for the Supply of Cnc Machines. Acta Tech. Napoc. 2022, 65, 171–178. [Google Scholar]
- Al-Hussaini, S.; Thakar, S.; Kim, H.; Rajendran, P.; Shah, B.C.; Marvel, J.A.; Gupta, S.K. Human-Supervised Semi-Autonomous Mobile Manipulators for Safely and Efficiently Executing Machine Tending Tasks. arXiv 2020, arXiv:2010.04899. [Google Scholar]
- Annem, V.; Rajendran, P.; Thakar, S.; Gupta, S.K. Towards Remote Teleoperation of a Semi-Autonomous Mobile Manipulator System in Machine Tending Tasks. In Proceedings of the ASME 2019 14th International Manufacturing Science and Engineering Conference, Erie, PA, USA, 10–14 June 2019. [Google Scholar]
- Long, S.; He, X.; Yao, C. Scene Text Detection and Recognition: The Deep Learning Era. Int. J. Comput. Vis. 2020, 129, 161–184. [Google Scholar] [CrossRef]
- Wojna, Z.; Gorban, A.N.; Lee, D.-S.; Murphy, K.; Yu, Q.; Li, Y.; Ibarz, J. Attention-Based Extraction of Structured Information from Street View Imagery. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 844–850. [Google Scholar]
- Nadeem, M.S.; Hussain, S.; Kurugollu, F. Textual Deblurring using Convolutional Neural Network. TechRxiv 2021. [Google Scholar] [CrossRef]
- Wu, C.; Du, H.; Wu, Q.; Zhang, S. Image Text Deblurring Method Based on Generative Adversarial Network. Electronics 2020, 9, 220. [Google Scholar] [CrossRef] [Green Version]
- Amanlou, A.; Suratgar, A.A.; Tavoosi, J.; Mohammadzadeh, A.; Mosavi, A. Single-Image Reflection Removal Using Deep Learning: A Systematic Review. IEEE Access 2022, 10, 29937–29953. [Google Scholar] [CrossRef]
- Li, C.; Yang, Y.; He, K.; Lin, S.; Hopcroft, J.E. Single Image Reflection Removal Through Cascaded Refinement. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 3562–3571. [Google Scholar]
- Li, Y.; Liu, M.; Yi, Y.; Li, Q.; Ren, D.; Zuo, W. Two-Stage Single Image Reflection Removal with Reflection-Aware Guidance. arXiv 2020, arXiv:2012.00945. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Weight | 25 kg |
| Maximum Payload | 5 kg |
| Max Reach | 1096 mm |
| Voltage | DC48 V |
| Maximum Speed of TCP | 3 m/s |
| Communication | TCP/IP, WIFI |
| Power | 150 W |
| Axes | 6 |
| Method | Accuracy |
|---|---|
| Faster-RCNN | 0.67 |
| SSD | 0.54 |
| YOLO | 0.53 |
| The Proposed Method (this paper) | 0.78 |
| Method | Accuracy |
|---|---|
| RNN | 78.2% |
| The Proposed Method (this paper) | 85.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, F.; Jebelli, A.; Ma, Y.; Ahmad, R. An Intelligent Manufacturing Approach Based on a Novel Deep Learning Method for Automatic Machine and Working Status Recognition. Appl. Sci. 2022, 12, 5697. https://doi.org/10.3390/app12115697
Jia F, Jebelli A, Ma Y, Ahmad R. An Intelligent Manufacturing Approach Based on a Novel Deep Learning Method for Automatic Machine and Working Status Recognition. Applied Sciences. 2022; 12(11):5697. https://doi.org/10.3390/app12115697
Chicago/Turabian StyleJia, Feiyu, Ali Jebelli, Yongsheng Ma, and Rafiq Ahmad. 2022. "An Intelligent Manufacturing Approach Based on a Novel Deep Learning Method for Automatic Machine and Working Status Recognition" Applied Sciences 12, no. 11: 5697. https://doi.org/10.3390/app12115697
APA StyleJia, F., Jebelli, A., Ma, Y., & Ahmad, R. (2022). An Intelligent Manufacturing Approach Based on a Novel Deep Learning Method for Automatic Machine and Working Status Recognition. Applied Sciences, 12(11), 5697. https://doi.org/10.3390/app12115697