
An Approach for Selecting the Most Explanatory Features for Facial Expression Recognition

 ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Feature Extraction Methods
3.1.1. Local Features
- Gabor wavelet filters (GW): This technique has previously been applied successfully for facial expression recognition [18,30]. In our work, landmark points were selected. For each point, a patch sized was used to compute the feature vector. Four scales and eight orientations were used to calculate the Gabor kernels, where . This selection generated a vector of () elements.
- Local binary patterns (LBP): this system has been widely used as a robust illumination-invariant feature descriptor [19,27,36,37]. This operator generates a binary number by comparing neighboring pixel values with the center pixel value. The uniform LBP and rotation-invariant uniform LBP [38] were also used in the experiment. These methods generated a vector that was the same size as the image ().
- Histograms of oriented gradients (HOG): This concept has also been successfully applied in facial expression recognition [19,39]. The basic idea of HOG features is that the local object’s appearance and shape can often be well-characterized by the distribution of local intensity gradients or edge directions, even without precise knowledge of the corresponding gradient or edge positions. The orientation analysis is robust to changes in illumination, as the histogram possesses translational invariance. The associated vector size was .
- Local phase quantization (LPQ): The LPQ feature [18,40] is a blur-robust image descriptor. The LPQ descriptor is based on the intensity of low-frequency phase components with respect to a centrally symmetric blur. Therefore, LPQ employs the phase information obtained from the short-term Fourier transform, which is locally computed on a window around each pixel of the image. The vector size was .
3.1.2. Geometric Features
3.1.3. Pre-Trained Deep Models
3.2. Expression Classification
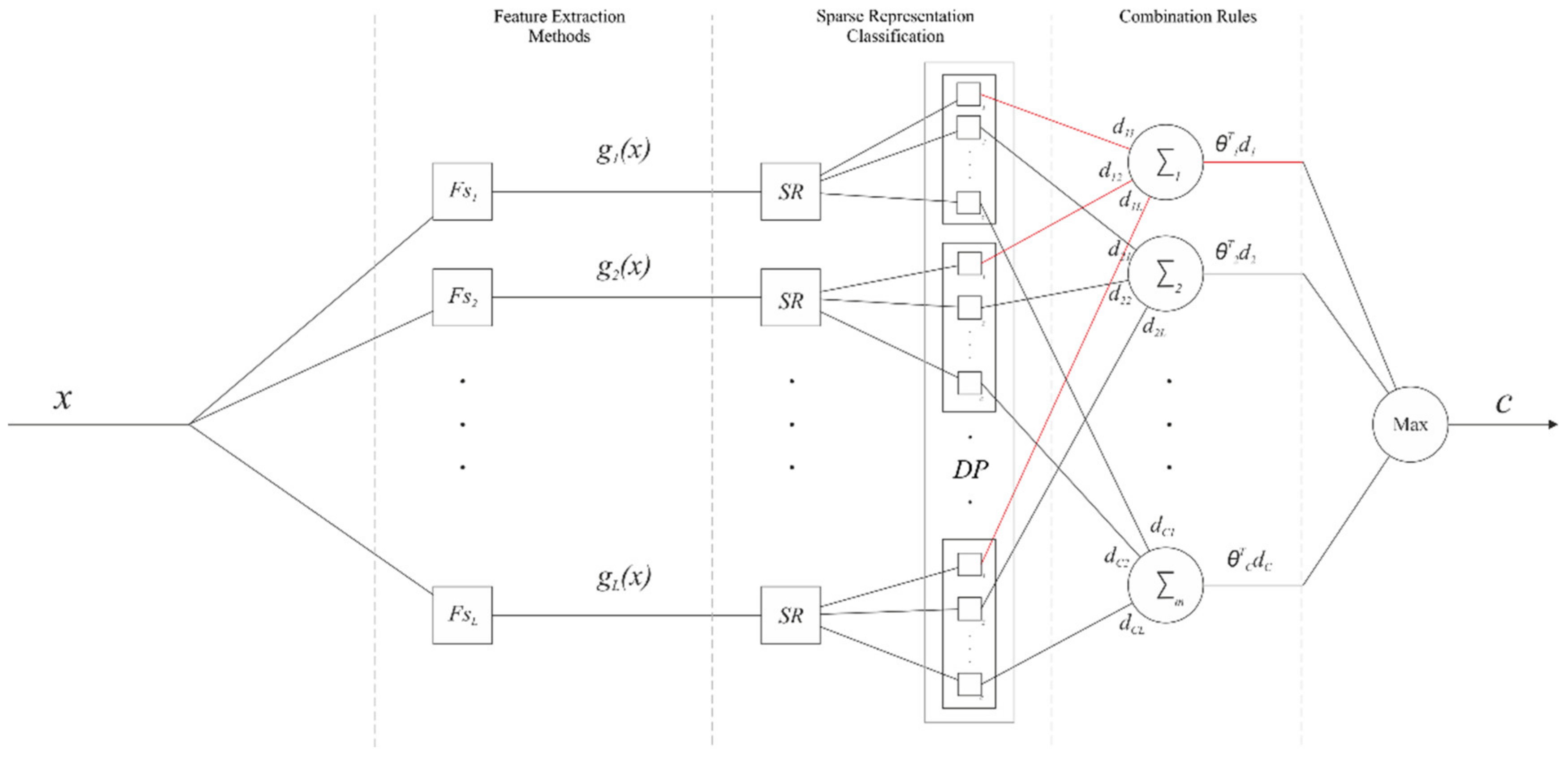
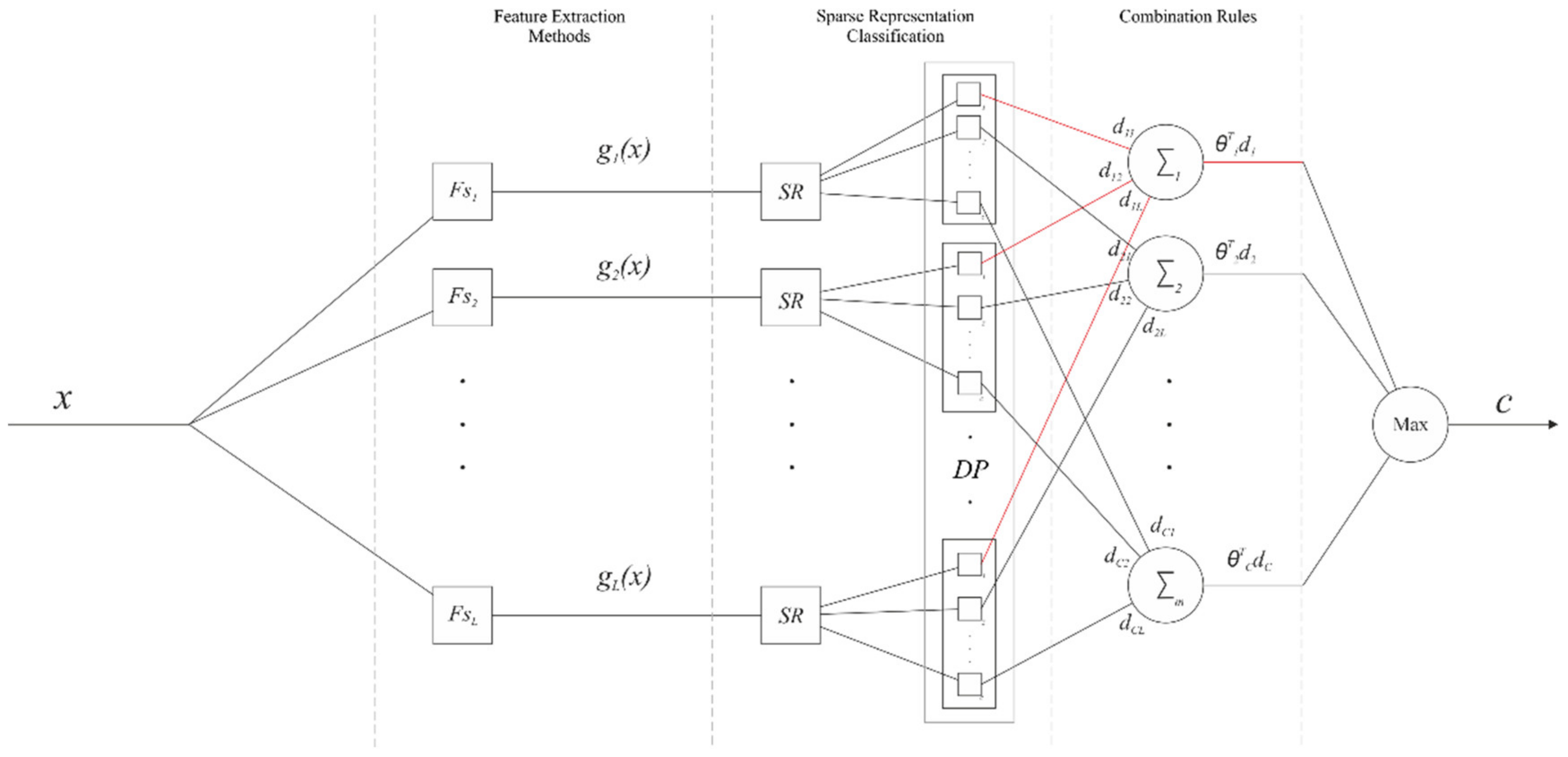
3.3. Proposed Combination Framework
| Algorithm 1. Sparse representation fusion classification (SRFC). , with , are the dictionaries for each feature space; , with and , are the feature extraction methods | |
| 1: Calculate sparse representation: | |
| For | |
| (5) | |
| 2: Calculate the vote of each representation to each class: | |
| For and | |
| (6) | |
| where selects the entries of corresponding to the class , and represents the residual test sample with the linear combination . To obtain the vote for each class, the softmax function is applied to the inverse of the normalization of : | |
| (7) | |
| where refers to the column as a vector and represents the decision profile. | |
| 3: Trained combination rules: | |
| (8) | |
| The weights are estimated for the decision profile for class . | |
| 4: Classification: | |
| (9) | |
| 5: Return | |
| The estimated class for the signal |
4. Experiments
4.1. Data Set
- CK+ data set: This includes 593 image sequences from 123 subjects. From the 593 sequences, we selected 325 sequences of 118 subjects, each of which met the criteria for one of the seven expressions [54]. The selected 325 sequences consisted of 45 angry, 18 contempt, 58 disgust, 25 fear, 69 happy, 28 sadness, and 82 surprise sequences [54]. In the neutral face scenario, we selected the first frame of the sequence of 33 randomly selected subjects.
- BU-3DFE data set: This is known as the most challenging and difficult data set, mainly due to the presence of a variety of ethnic/racial ancestries and expression intensities [43]. A total of 700 expressive face images (1 intensity × 6 expressions × 100 subjects) and 100 neutral face images (each of which was of one subject) [43] were used.
- JAFFE data set: This contains 10 female subjects and 213 facial expression images [55]. The number of images corresponding to each of the seven categories of expression (neutrality, happiness, sadness, surprise, anger, disgust, and fear) was almost always the same. Each actor repeated the same expression several times (i.e., two, three, or four times).


4.2. Protocol
4.3. Metrics
4.4. Experimental Environment
5. Results and Discussion
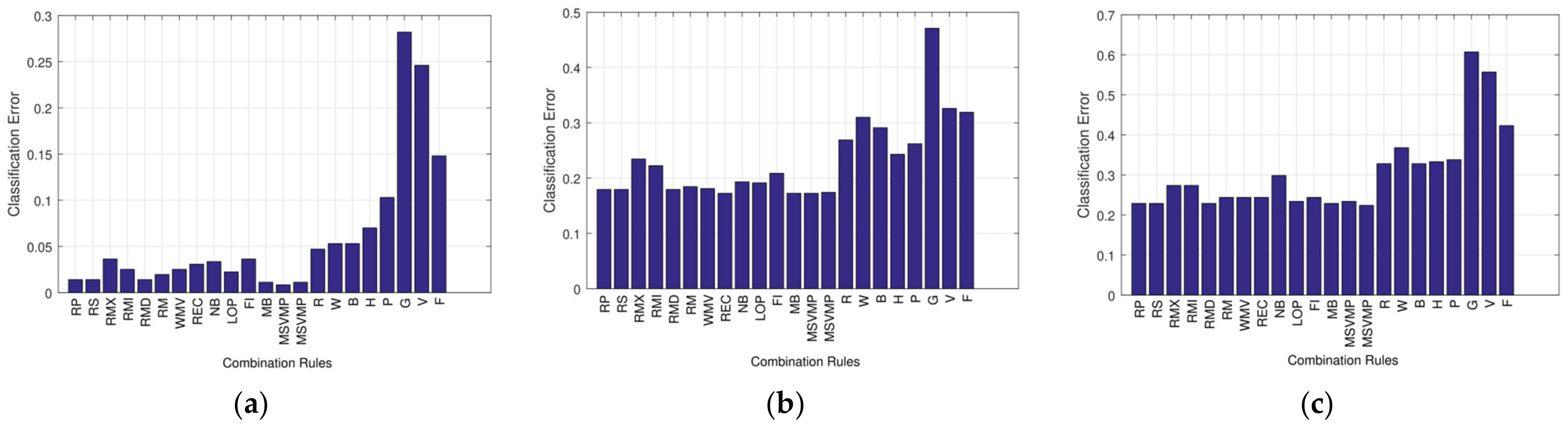
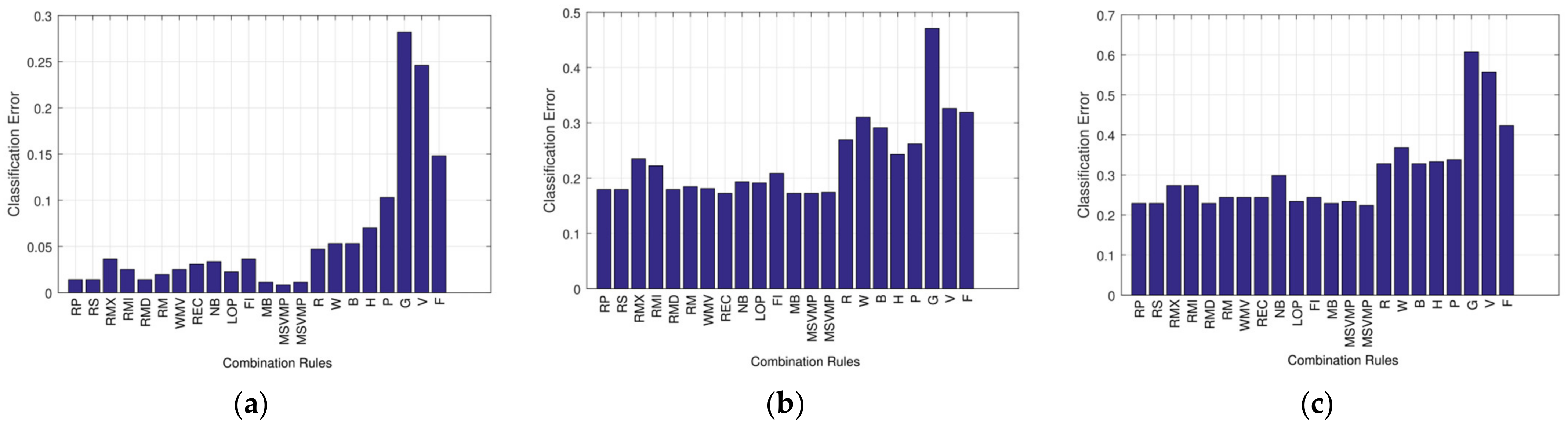
5.1. Statistical Analysis of the Combination Rule
5.2. Multiple vs. Individual Classification Methods
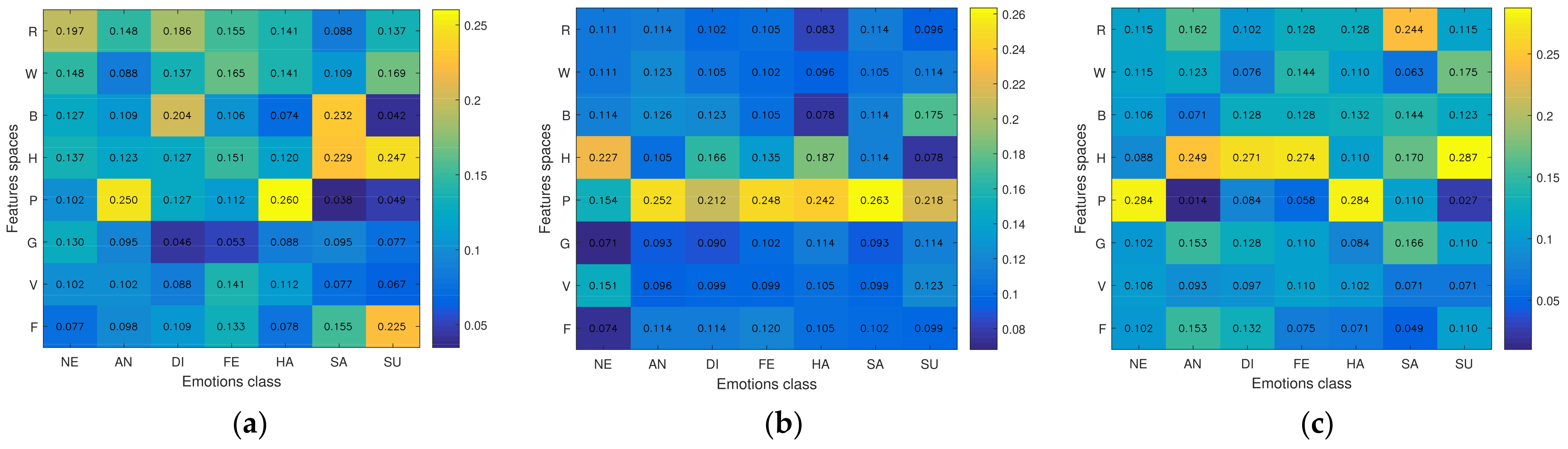
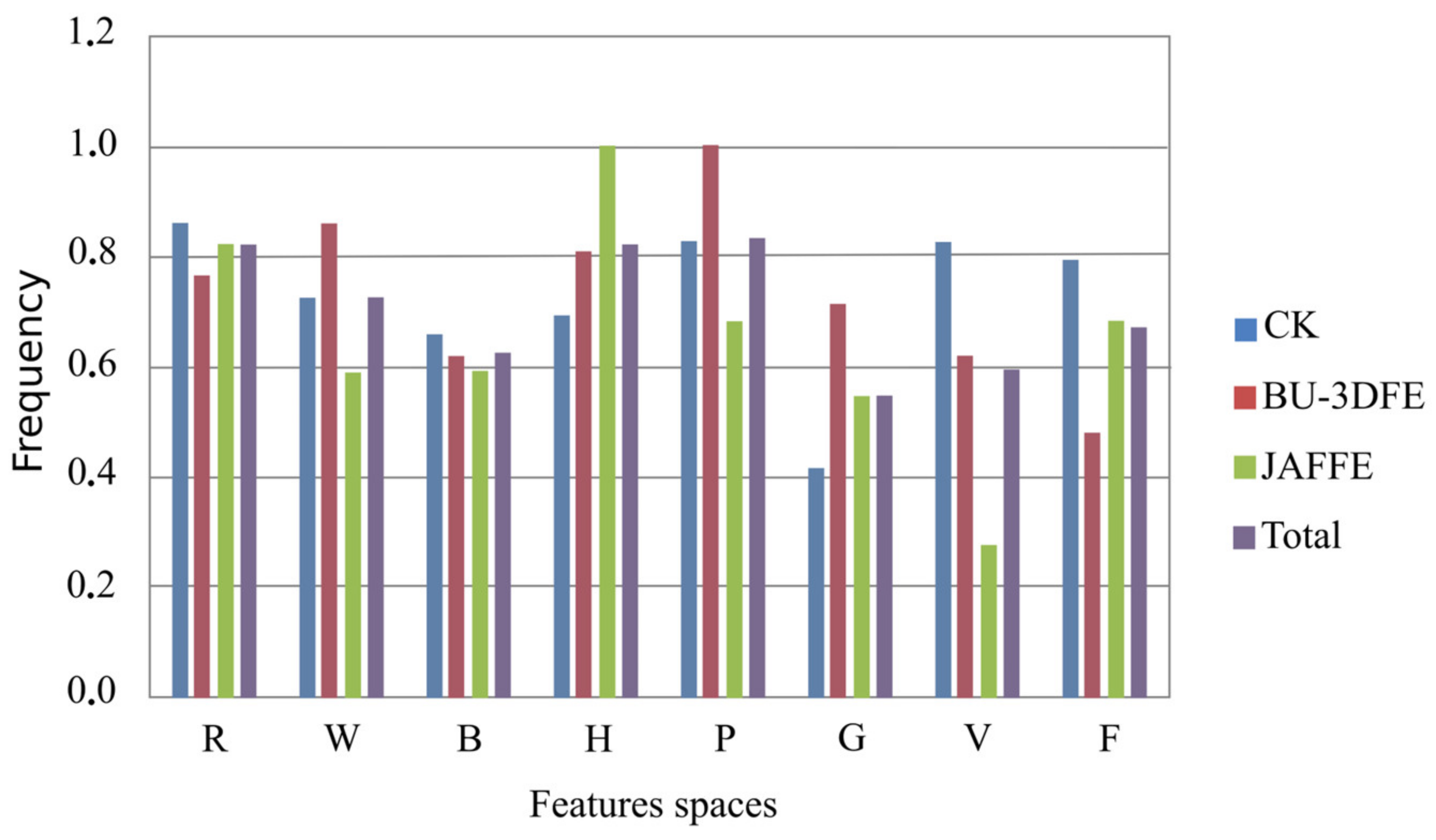
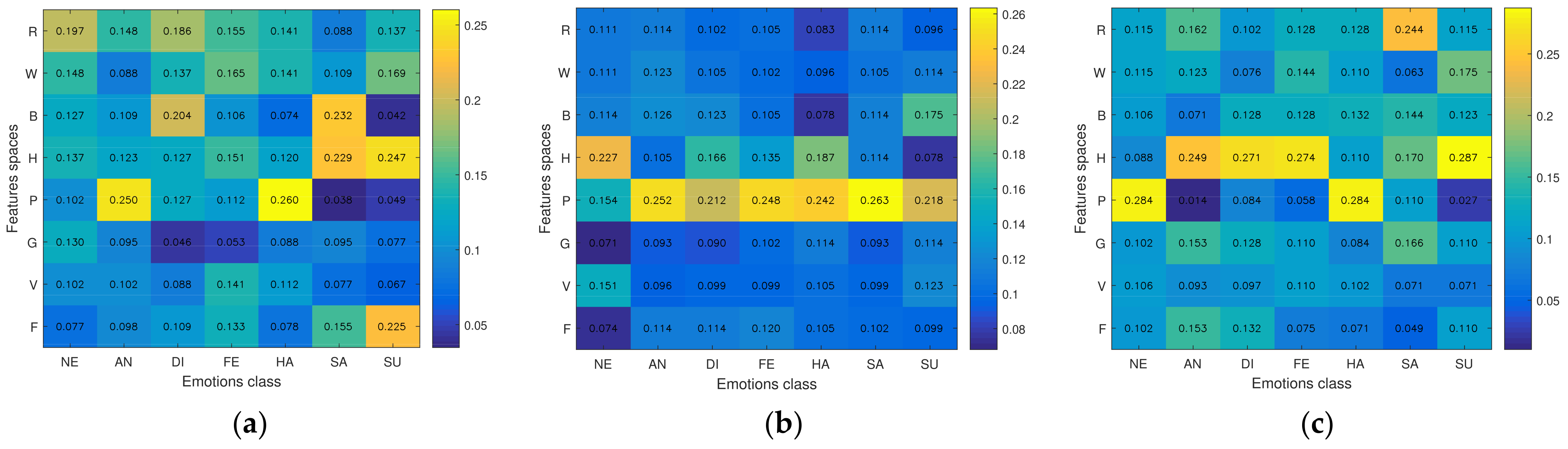
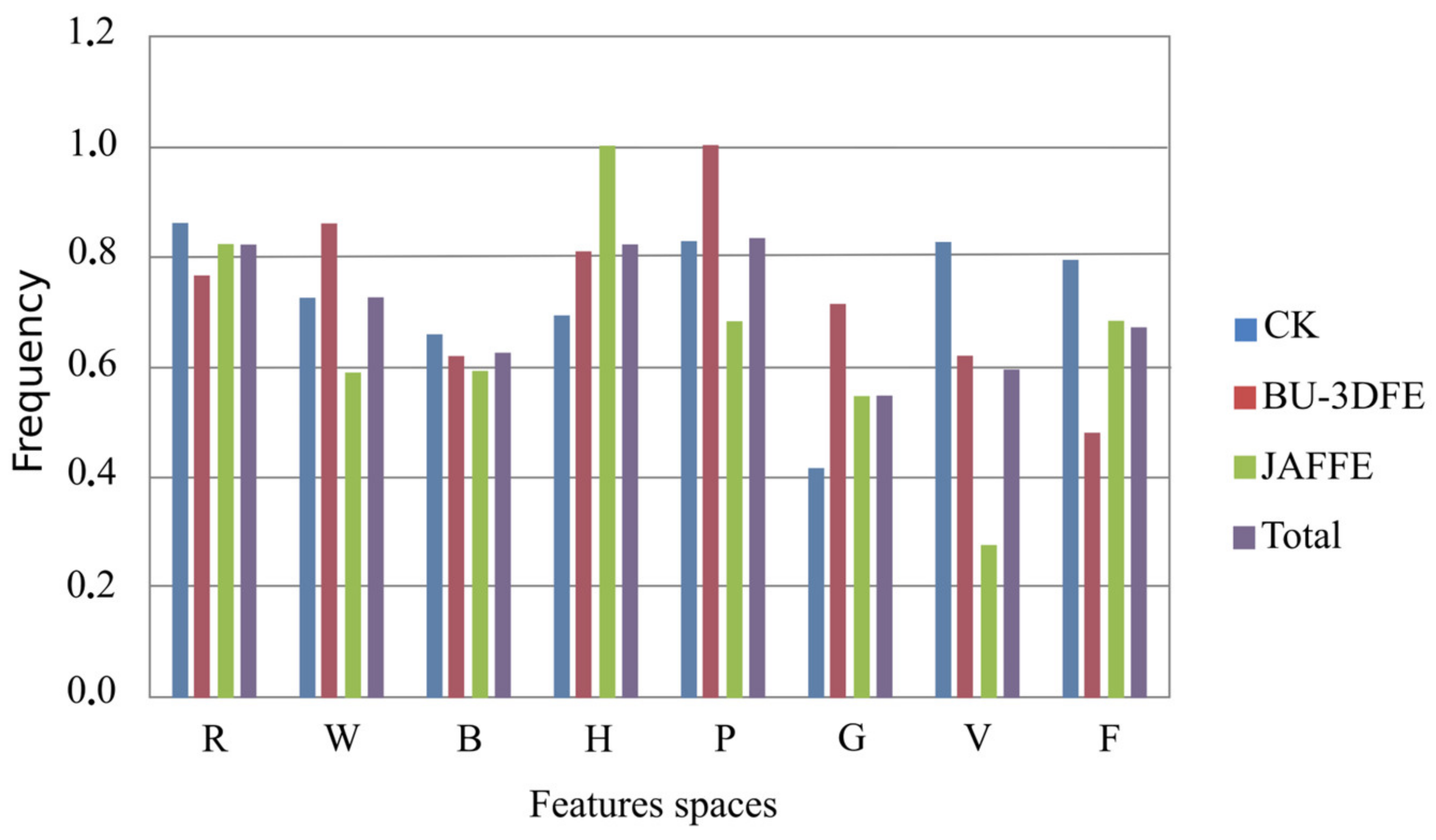
5.3. Analysis of the Influence of the Feature Methods
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, X.; He, Z.; Zhao, L.; Dai, Z.; Yang, Q. A Cascade Attention Based Facial Expression Recognition Network by Fusing Multi-Scale Spatio-Temporal Features. Sensors 2022, 22, 1350. [Google Scholar] [CrossRef] [PubMed]
- Bonnard, J.; Dapogny, A.; Dhombres, F.; Bailly, K. Privileged Attribution Constrained Deep Networks for Facial Expression Recognition. arXiv 2022, arXiv:2203.12905. [Google Scholar]
- Adadii, A.; Mohammed, B. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef] [Green Version]
- Petrović, N.; Moyà-Alcover, G.; Jaume-i-Capó, A.; González-Hidalgo, M. Sickle-cell disease diagnosis support selecting the most appropriate machine learning method: Towards a general and interpretable approach for cell morphology analysis from microscopy images. Comput. Biol. Med. 2020, 126, 104027. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Letham, B.; Rudin, C.; McCormick, T.H.; Madigan, D. Interpretable classifiers using rules and bayesian analysis: Building a better stroke prediction model. Ann. Appl. Stat. 2015, 9, 1350–1371. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Weitz, K.; Hassan, T.; Schmid, U.; Garbas, J.-U. Deep-learned faces of pain and emotions: Elucidating the differences of facial expressions with the help of explainable AI methods Tief erlernte Gesichter von Schmerz und Emotionen: Aufklärung der Unterschiede von Gesichtsausdrücken mithilfe erklärbarer K. tm-Technisches Mess. 2019, 86, 404–412. [Google Scholar] [CrossRef]
- Gund, M.; Bharadwaj, A.R.; Nwogu, I. Interpretable emotion classification using temporal convolutional models. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6367–6374. [Google Scholar] [CrossRef]
- Burg, K.T. Explaining Dnn Based Facial Expression Classifications. Bachelor’s Thesis, Utrecht University, Utrecht, The Netherlands, 2021. Volume 7. [Google Scholar]
- Wang, X.; He, J.; Jin, Z.; Yang, M.; Wang, Y.; Qu, H. M2Lens: Visualizing and Explaining Multimodal Models for Sentiment Analysis. IEEE Trans. Vis. Comput. Graph. 2021, 28, 802–812. [Google Scholar] [CrossRef]
- Lian, Z.; Li, Y.; Tao, J.H.; Huang, J.; Niu, M.Y. Expression Analysis Based on Face Regions in Read-world Conditions. Int. J. Autom. Comput. 2020, 17, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint fine-tuning in deep neural networks for facial expression recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2983–2991. [Google Scholar]
- Deramgozin, M.; Jovanovic, S.; Rabah, H.; Ramzan, N. A Hybrid Explainable AI Framework Applied to Global and Local Facial Expression Recognition. In Proceedings of the 2021 IEEE International Conference on Imaging Systems and Techniques (IST), Kaohsiung, Taiwan, 24–26 August 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Ying, Z.-L.; Wang, Z.-W.; Huang, M.-W. Facial expression recognition based on fusion of sparse representation. In Advanced Intelligent Computing Theories and Applications. With Aspects of Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2010; pp. 457–464. [Google Scholar]
- Li, L.; Ying, Z.; Yang, T. Facial expression recognition by fusion of gabor texture features and local phase quantization. In Proceedings of the 2014 12th International Conference on Signal Processing (ICSP), Hangzhou, China, 19–23 October 2014; pp. 1781–1784. [Google Scholar]
- Ouyang, Y.; Sang, N.; Huang, R. Accurate and robust facial expressions recognition by fusing multiple sparse representation based classifiers. Neurocomputing 2015, 149, 71–78. [Google Scholar] [CrossRef]
- Kittler, J.; Hatef, M.; Duin, R.P.W.; Matas, J. On combining classifiers. Pattern Anal. Mach. Intell. IEEE Trans. 1998, 20, 226–239. [Google Scholar] [CrossRef] [Green Version]
- Ptucha, R.; Savakis, A. Fusion of static and temporal predictors for unconstrained facial expression recognition. In Proceedings of the 2012 19th IEEE International Conference on Image Processing (ICIP), Orlando, FL, USA, 30 September–3 October 2012; pp. 2597–2600. [Google Scholar]
- Ji, Y.; Idrissi, K. Automatic facial expression recognition based on spatiotemporal descriptors. Pattern Recognit. Lett. 2012, 33, 1373–1380. [Google Scholar] [CrossRef]
- Tsalakanidou, F.; Malassiotis, S. Real-time 2D+ 3D facial action and expression recognition. Pattern Recognit. 2010, 43, 1763–1775. [Google Scholar] [CrossRef]
- Olshausen, B.A.; Field, D.J. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef] [Green Version]
- Olshausen, B.A.; Field, D.J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381, 607–609. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. Pattern Anal. Mach. Intell. IEEE Trans. 2009, 31, 210–227. [Google Scholar] [CrossRef] [Green Version]
- Weifeng, L.; Caifeng, S.; Yanjiang, W. Facial expression analysis using a sparse representation based space model. In Proceedings of the 2012 IEEE 11th International Conference on Signal Processing (ICSP), Beijing, China, 21–25 October 2012; Volume 3, pp. 1659–1662. [Google Scholar]
- Zhen, W.; Zilu, Y. Facial expression recognition based on local phase quantization and sparse representation. In Proceedings of the 2012 Eighth International Conference on Natural Computation (ICNC), Chongqing, China, 29–31 May 2012; pp. 222–225. [Google Scholar]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Zhang, S.; Li, L.; Zhao, Z. Facial expression recognition based on Gabor wavelets and sparse representation. In Proceedings of the 2012 IEEE 11th International Conference on Signal Processing (ICSP), Beijing, China, 21–25 October 2012; Volume 2, pp. 816–819. [Google Scholar]
- Ptucha, R.; Savakis, A. Manifold based sparse representation for facial understanding in natural images. Image Vis. Comput. 2013, 31, 365–378. [Google Scholar] [CrossRef]
- Zhong, L.; Liu, Q.; Yang, P.; Liu, B.; Huang, J.; Metaxas, D.N. Learning active facial patches for expression analysis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2562–2569. [Google Scholar]
- Baltrušaitis, T.; Robinson, P.; Morency, L.-P. OpenFace: An open source facial behavior analysis toolkit. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Placid, NY, USA, 7–10 March 2016. [Google Scholar]
- Happy, S.L.; Routray, A. Automatic Facial Expression Recognition Using Features of Salient Facial Patches. Affect. Comput. IEEE Trans. 2015, 6, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the BMVC, Swansea, UK, 7–10 September 2015; Volume 1, p. 6. [Google Scholar]
- Liu, P.; Han, S.; Meng, Z.; Tong, Y. Facial expression recognition via a boosted deep belief network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1805–1812. [Google Scholar]
- Liu, Z.; Song, X.; Tang, Z. A novel SRC fusion method using hierarchical multi-scale LBP and greedy search strategy. Neurocomputing 2015, 151, 1455–1467. [Google Scholar] [CrossRef]
- Huang, M.-W.; Wang, Z.; Ying, Z.-L. A new method for facial expression recognition based on sparse representation plus LBP. In Proceedings of the 2010 3rd International Congress on Image and Signal Processing (CISP), Yantai, China, 16–18 October 2010; Volume 4, pp. 1750–1754. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition CVPR 2005, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Ojansivu, V.; Heikkilä, J. Blur Insensitive Texture Classification Using Local Phase Quantization. In Image and Signal Processing; Springer: Berlin/Heidelberg, Germany, 2008; ISBN 978-3-540-69904-0. [Google Scholar]
- Yuan, X.-T.; Liu, X.; Yan, S. Visual classification with multitask joint sparse representation. Image Process. IEEE Trans. 2012, 21, 4349–4360. [Google Scholar] [CrossRef]
- Yin, L.; Chen, X.; Sun, Y.; Worm, T.; Reale, M. A high-resolution 3d dynamic facial expression database. In Proceedings of the 2008 8th IEEE International Conference on Automatic Face and Gesture Recognition, FG 2008, Amsterdam, The Netherlands, 17–19 September 2008; pp. 1–6. [Google Scholar] [CrossRef]
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D facial expression database for facial behavior research. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition, FGR 2006, Southampton, UK, 10–12 April 2006; pp. 211–216. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Wang, R.; Chen, X. Deeply learning deformable facial action parts model for dynamic expression analysis. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 143–157. [Google Scholar]
- Marrero Fernandez, P.D.; Guerrero Pena, F.A.; Ing Ren, T.; Cunha, A. FERAtt: Facial Expression Recognition with Attention Net. arXiv 2019, arXiv:1902.03284. [Google Scholar]
- Manresa-Yee, C.; Ramis, S. Assessing Gender Bias in Predictive Algorithms Using EXplainable AI; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar] [CrossRef]
- Wang, Z.; Qinami, K.; Karakozis, I.C.; Genova, K.; Nair, P.; Hata, K.; Russakovsky, O. Towards fairness in visual recognition: Effective strategies for bias mitigation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8916–8925. [Google Scholar] [CrossRef]
- Xu, T.; White, J.; Kalkan, S.; Gunes, H. Investigating Bias and Fairness in Facial Expression Recognition. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Donoho, D.L. For most large underdetermined systems of linear equations the minimal ?1-norm solution is also the sparsest solution. Commun. Pure Appl. Math. 2006, 59, 797–829. [Google Scholar] [CrossRef]
- Kuncheva, L.I.; Bezdek, J.C.; Duin, R.P.W. Decision templates for multiple classifier fusion: An experimental comparison. Pattern Recognit. 2001, 34, 299–314. [Google Scholar] [CrossRef]
- Jacobs, R.A. Methods for combining experts’ probability assessments. Neural Comput. 1995, 7, 867–888. [Google Scholar] [CrossRef]
- Jordan, M.I.; Jacobs, R.A. Hierarchical mixtures of experts and the EM algorithm. Neural Comput. 1994, 6, 181–214. [Google Scholar] [CrossRef] [Green Version]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The Extended Cohn-Kanade Dataset (CK+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with gabor wavelets. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar]
- Zeng, Z.; Pantic, M.; Roisman, G.; Huang, T.S. A survey of affect recognition methods: Audio, visual, and spontaneous expressions. Pattern Anal. Mach. Intell. IEEE Trans. 2009, 31, 39–58. [Google Scholar] [CrossRef]
- Li, X.; Hong, X.; Moilanen, A.; Huang, X.; Pfister, T.; Zhao, G.; Pietikäinen, M. Reading Hidden Emotions: Spontaneous Micro-expression Spotting and Recognition. arXiv 2015, arXiv:1511.00423. [Google Scholar]
- Ouyang, Y.; Sang, N.; Huang, R. Robust automatic facial expression detection method based on sparse representation plus LBP map. Opt. J. Light Electron. Opt. 2013, 124, 6827–6833. [Google Scholar] [CrossRef]
- Kuncheva, L.I.; Rodríguez, J.J. A weighted voting framework for classifiers ensembles. Knowl. Inf. Syst. 2014, 38, 259–275. [Google Scholar] [CrossRef]
- Zavaschi, T.H.H.; Britto, A.S.; Oliveira, L.E.S.; Koerich, A.L. Fusion of feature sets and classifiers for facial expression recognition. Expert Syst. Appl. 2013, 40, 646–655. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Huang, X.; Zhao, G.; Zheng, W.; Pietikäinen, M. Spatiotemporal local monogenic binary patterns for facial expression recognition. Signal Process. Lett. IEEE 2012, 19, 243–246. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Zhao, Y.; Ji, Q. Simultaneous facial feature tracking and facial expression recognition. Image Process. IEEE Trans. 2013, 22, 2559–2573. [Google Scholar]
- Lee, S.H.; Plataniotis, K.; Konstantinos, N.; Ro, Y.M. Intra-Class Variation Reduction Using Training Expression Images for Sparse Representation Based Facial Expression Recognition. Affect. Comput. IEEE Trans. 2014, 5, 340–351. [Google Scholar] [CrossRef]
- Ramis, S.; Buades, J.M.; Perales, F.J.; Manresa-Yee, C. A Novel Approach to Cross dataset studies in Facial Expression Recognition. Multimed. Tools Appl. 2022. [Google Scholar] [CrossRef]
- Littlewort, G.; Bartlett, M.S.; Fasel, I.; Susskind, J.; Movellan, J. Dynamics of facial expression extracted automatically from video. Image Vis. Comput. 2006, 24, 615–625. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measurement | Name | Distances Involved |
|---|---|---|
| Inner eyebrow displacement | ||
| Outer eyebrow displacement | ||
| Inner eyebrow corners dist. | ||
| Eyebrow from nose root dist. | ||
| Eye opening | ||
| Eye shape | ||
| Nose length | ||
| Nose width | ||
| Lower lip boundary length | ||
| Mouth corners dist. | ||
| Mouth opening | ||
| Mouth shape | ||
| Nose–mouth corners angle | ||
| Mouth corners to eye dist. | ||
| Mouth corners to nose dist. | ||
| Upper lip to nose dist. | ||
| Lower lip to nose dist. |
| Type | Feature | Vector Size |
|---|---|---|
| Local | GW | |
| Local | LBP | |
| Local | HOG | |
| Local | LPQ | |
| Local | RAW | |
| Geometric | GEO |
| Features | CSC | CHC | TC | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP | RS | RMX | RMI | RMD | RM | WMV | REC | NB | LOP | FI | MB | MP | ML | |
| R/B/P/V | 0.986 | 0.986 | 0.950 | 0.913 | 0.986 | 0.975 | 0.972 | 0.969 | 0.958 | 0.978 | 0.950 | 0.978 | 0.975 | 0.975 |
| R/P/V/F | 0.961 | 0.961 | 0.936 | 0.908 | 0.961 | 0.944 | 0.947 | 0.958 | 0.939 | 0.955 | 0.936 | 0.980 | 0.989 | 0.983 |
| R/W/B/P/V | 0.975 | 0.975 | 0.947 | 0.930 | 0.975 | 0.972 | 0.964 | 0.950 | 0.950 | 0.975 | 0.947 | 0.986 | 0.978 | 0.978 |
| R/W/B/V/F | 0.969 | 0.969 | 0.947 | 0.933 | 0.969 | 0.964 | 0.964 | 0.961 | 0.955 | 0.961 | 0.947 | 0.986 | 0.983 | 0.980 |
| R/W/H/P/F | 0.969 | 0.969 | 0.947 | 0.941 | 0.969 | 0.958 | 0.955 | 0.961 | 0.947 | 0.964 | 0.947 | 0.989 | 0.983 | 0.983 |
| R/W/P/G/F | 0.947 | 0.947 | 0.902 | 0.894 | 0.947 | 0.953 | 0.953 | 0.961 | 0.941 | 0.925 | 0.902 | 0.972 | 0.986 | 0.986 |
| R/B/H/V/F | 0.969 | 0.969 | 0.953 | 0.933 | 0.969 | 0.966 | 0.966 | 0.953 | 0.950 | 0.966 | 0.953 | 0.975 | 0.980 | 0.986 |
| R/H/P/V/F | 0.964 | 0.964 | 0.944 | 0.916 | 0.964 | 0.950 | 0.955 | 0.953 | 0.927 | 0.953 | 0.944 | 0.983 | 0.986 | 0.986 |
| R/P/G/V/F | 0.939 | 0.939 | 0.883 | 0.880 | 0.939 | 0.933 | 0.941 | 0.961 | 0.908 | 0.930 | 0.883 | 0.975 | 0.989 | 0.980 |
| W/B/H/P/V | 0.975 | 0.975 | 0.955 | 0.927 | 0.975 | 0.964 | 0.964 | 0.953 | 0.950 | 0.964 | 0.955 | 0.986 | 0.983 | 0.983 |
| W/B/H/V/F | 0.969 | 0.969 | 0.955 | 0.930 | 0.969 | 0.961 | 0.958 | 0.947 | 0.936 | 0.958 | 0.955 | 0.978 | 0.986 | 0.983 |
| R/W/B/H/P/V | 0.978 | 0.978 | 0.947 | 0.933 | 0.978 | 0.975 | 0.972 | 0.955 | 0.955 | 0.972 | 0.947 | 0.989 | 0.986 | 0.983 |
| R/W/B/H/P/F | 0.975 | 0.975 | 0.953 | 0.944 | 0.975 | 0.978 | 0.969 | 0.953 | 0.964 | 0.975 | 0.953 | 0.986 | 0.983 | 0.983 |
| R/W/B/H/V/F | 0.975 | 0.975 | 0.947 | 0.939 | 0.975 | 0.964 | 0.961 | 0.950 | 0.950 | 0.961 | 0.947 | 0.989 | 0.980 | 0.986 |
| R/W/B/P/G/V | 0.958 | 0.958 | 0.908 | 0.888 | 0.958 | 0.972 | 0.966 | 0.950 | 0.941 | 0.941 | 0.908 | 0.986 | 0.983 | 0.983 |
| R/W/B/P/V/F | 0.975 | 0.975 | 0.947 | 0.927 | 0.975 | 0.975 | 0.969 | 0.961 | 0.961 | 0.961 | 0.947 | 0.989 | 0.980 | 0.980 |
| R/W/H/P/G/V | 0.958 | 0.958 | 0.897 | 0.885 | 0.958 | 0.955 | 0.953 | 0.950 | 0.919 | 0.933 | 0.897 | 0.980 | 0.980 | 0.986 |
| R/W/H/P/G/F | 0.955 | 0.955 | 0.905 | 0.894 | 0.955 | 0.958 | 0.955 | 0.953 | 0.941 | 0.933 | 0.905 | 0.978 | 0.986 | 0.986 |
| R/W/H/P/V/F | 0.966 | 0.966 | 0.936 | 0.927 | 0.966 | 0.966 | 0.955 | 0.953 | 0.939 | 0.955 | 0.936 | 0.986 | 0.992 | 0.989 |
| R/B/H/P/V/F | 0.972 | 0.972 | 0.953 | 0.925 | 0.972 | 0.975 | 0.969 | 0.955 | 0.950 | 0.966 | 0.953 | 0.989 | 0.986 | 0.986 |
| R/B/H/G/V/F | 0.961 | 0.961 | 0.899 | 0.888 | 0.961 | 0.964 | 0.964 | 0.953 | 0.947 | 0.933 | 0.899 | 0.975 | 0.986 | 0.986 |
| R/H/P/G/V/F | 0.944 | 0.947 | 0.894 | 0.883 | 0.947 | 0.958 | 0.955 | 0.947 | 0.902 | 0.927 | 0.894 | 0.978 | 0.989 | 0.986 |
| W/B/H/P/V/F | 0.972 | 0.972 | 0.955 | 0.925 | 0.972 | 0.972 | 0.966 | 0.955 | 0.939 | 0.953 | 0.955 | 0.983 | 0.980 | 0.986 |
| R/W/B/H/P/G/F | 0.966 | 0.964 | 0.911 | 0.894 | 0.964 | 0.966 | 0.961 | 0.953 | 0.964 | 0.925 | 0.911 | 0.986 | 0.983 | 0.983 |
| R/W/B/H/P/V/F | 0.972 | 0.972 | 0.947 | 0.933 | 0.972 | 0.966 | 0.969 | 0.955 | 0.955 | 0.958 | 0.947 | 0.989 | 0.980 | 0.983 |
| R/W/B/P/G/V/F | 0.958 | 0.958 | 0.908 | 0.888 | 0.958 | 0.966 | 0.958 | 0.955 | 0.958 | 0.933 | 0.908 | 0.986 | 0.983 | 0.983 |
| R/W/H/P/G/V/F | 0.950 | 0.950 | 0.897 | 0.885 | 0.950 | 0.953 | 0.947 | 0.953 | 0.927 | 0.930 | 0.897 | 0.980 | 0.989 | 0.989 |
| W/B/H/P/G/V/F | 0.955 | 0.955 | 0.891 | 0.880 | 0.955 | 0.961 | 0.961 | 0.953 | 0.939 | 0.930 | 0.891 | 0.983 | 0.986 | 0.986 |
| Average | 0.946 | 0.946 | 0.910 | 0.902 | 0.946 | 0.941 | 0.946 | 0.948 | 0.929 | 0.940 | 0.910 | 0.966 | 0.971 | 0.971 |
| Features | CSC | CHC | TC | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP | RS | RMX | RMI | RMD | RM | WMV | REC | NB | LOP | FI | MB | MP | ML | |
| R/W/P/G | 0.774 | 0.778 | 0.724 | 0.697 | 0.778 | 0.772 | 0.783 | 0.781 | 0.771 | 0.771 | 0.724 | 0.807 | 0.824 | 0.826 |
| R/W/B/P/G | 0.807 | 0.807 | 0.741 | 0.709 | 0.807 | 0.781 | 0.798 | 0.802 | 0.779 | 0.788 | 0.741 | 0.807 | 0.828 | 0.826 |
| R/W/B/P/V | 0.802 | 0.800 | 0.752 | 0.767 | 0.800 | 0.790 | 0.797 | 0.795 | 0.778 | 0.797 | 0.752 | 0.822 | 0.816 | 0.817 |
| R/W/H/P/G | 0.788 | 0.791 | 0.729 | 0.714 | 0.791 | 0.805 | 0.805 | 0.809 | 0.779 | 0.784 | 0.729 | 0.809 | 0.826 | 0.824 |
| R/H/P/G/V | 0.784 | 0.784 | 0.724 | 0.714 | 0.784 | 0.779 | 0.791 | 0.790 | 0.778 | 0.776 | 0.724 | 0.803 | 0.824 | 0.819 |
| W/H/P/G/V | 0.778 | 0.778 | 0.719 | 0.698 | 0.778 | 0.779 | 0.788 | 0.800 | 0.784 | 0.781 | 0.719 | 0.795 | 0.822 | 0.819 |
| W/H/P/V/F | 0.795 | 0.798 | 0.734 | 0.748 | 0.798 | 0.798 | 0.793 | 0.797 | 0.781 | 0.783 | 0.734 | 0.822 | 0.814 | 0.810 |
| R/W/B/H/P/G | 0.809 | 0.807 | 0.743 | 0.712 | 0.807 | 0.802 | 0.800 | 0.819 | 0.783 | 0.798 | 0.743 | 0.819 | 0.828 | 0.822 |
| R/W/B/H/P/F | 0.817 | 0.816 | 0.745 | 0.752 | 0.816 | 0.810 | 0.807 | 0.817 | 0.795 | 0.809 | 0.745 | 0.821 | 0.822 | 0.824 |
| R/W/B/P/G/V | 0.798 | 0.800 | 0.741 | 0.721 | 0.800 | 0.788 | 0.795 | 0.795 | 0.783 | 0.783 | 0.741 | 0.814 | 0.826 | 0.826 |
| R/W/H/P/G/V | 0.800 | 0.800 | 0.728 | 0.721 | 0.800 | 0.798 | 0.809 | 0.814 | 0.791 | 0.790 | 0.728 | 0.816 | 0.826 | 0.824 |
| R/W/H/P/G/F | 0.803 | 0.803 | 0.728 | 0.722 | 0.803 | 0.798 | 0.807 | 0.828 | 0.784 | 0.793 | 0.728 | 0.816 | 0.812 | 0.807 |
| R/B/H/P/V/F | 0.807 | 0.807 | 0.764 | 0.767 | 0.807 | 0.803 | 0.810 | 0.814 | 0.802 | 0.800 | 0.764 | 0.822 | 0.810 | 0.810 |
| R/H/P/G/V/F | 0.810 | 0.809 | 0.722 | 0.724 | 0.809 | 0.786 | 0.803 | 0.812 | 0.779 | 0.776 | 0.722 | 0.817 | 0.822 | 0.824 |
| W/B/H/P/G/V | 0.800 | 0.798 | 0.741 | 0.707 | 0.798 | 0.795 | 0.795 | 0.807 | 0.790 | 0.784 | 0.741 | 0.809 | 0.822 | 0.821 |
| W/B/H/P/G/F | 0.803 | 0.803 | 0.726 | 0.710 | 0.803 | 0.805 | 0.807 | 0.819 | 0.790 | 0.790 | 0.726 | 0.812 | 0.822 | 0.822 |
| W/B/H/P/V/F | 0.805 | 0.803 | 0.750 | 0.759 | 0.803 | 0.805 | 0.809 | 0.809 | 0.790 | 0.786 | 0.750 | 0.828 | 0.814 | 0.814 |
| R/W/B/H/P/G/V | 0.802 | 0.800 | 0.743 | 0.722 | 0.800 | 0.791 | 0.802 | 0.816 | 0.790 | 0.786 | 0.790 | 0.821 | 0.822 | 0.819 |
| R/W/B/H/P/G/F | 0.821 | 0.821 | 0.741 | 0.722 | 0.821 | 0.816 | 0.819 | 0.812 | 0.795 | 0.798 | 0.791 | 0.828 | 0.826 | 0.822 |
| R/W/B/H/P/V/F | 0.802 | 0.803 | 0.750 | 0.760 | 0.803 | 0.812 | 0.816 | 0.817 | 0.798 | 0.795 | 0.791 | 0.824 | 0.816 | 0.816 |
| Average | 0.779 | 0.779 | 0.727 | 0.727 | 0.779 | 0.762 | 0.774 | 0.777 | 0.766 | 0.7740 | 0.729 | 0.789 | 0.794 | 0.794 |
| Features | CSC | CHC | TC | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP | RS | RMX | RMI | RMD | RM | WMV | REC | NB | LOP | FI | MB | MP | ML | |
| R/B/H | 0.746 | 0.746 | 0.726 | 0.706 | 0.746 | 0.701 | 0.711 | 0.706 | 0.692 | 0.761 | 0.726 | 0.751 | 0.726 | 0.741 |
| B/H/P | 0.746 | 0.746 | 0.706 | 0.667 | 0.746 | 0.726 | 0.706 | 0.692 | 0.701 | 0.766 | 0.706 | 0.716 | 0.736 | 0.736 |
| R/W/H/G | 0.751 | 0.746 | 0.647 | 0.622 | 0.746 | 0.721 | 0.731 | 0.736 | 0.597 | 0.731 | 0.647 | 0.761 | 0.736 | 0.736 |
| R/H/P/G | 0.771 | 0.766 | 0.672 | 0.612 | 0.766 | 0.701 | 0.721 | 0.711 | 0.597 | 0.716 | 0.672 | 0.731 | 0.736 | 0.736 |
| R/H/P/F | 0.716 | 0.716 | 0.697 | 0.687 | 0.716 | 0.726 | 0.711 | 0.697 | 0.627 | 0.736 | 0.697 | 0.746 | 0.766 | 0.761 |
| W/B/H/P | 0.721 | 0.721 | 0.682 | 0.682 | 0.721 | 0.687 | 0.706 | 0.751 | 0.647 | 0.751 | 0.682 | 0.721 | 0.761 | 0.756 |
| W/H/P/F | 0.746 | 0.746 | 0.647 | 0.677 | 0.746 | 0.726 | 0.706 | 0.726 | 0.642 | 0.736 | 0.647 | 0.721 | 0.761 | 0.776 |
| R/W/H/P/G | 0.751 | 0.751 | 0.647 | 0.622 | 0.751 | 0.716 | 0.731 | 0.736 | 0.612 | 0.741 | 0.647 | 0.761 | 0.746 | 0.746 |
| R/W/H/G/F | 0.766 | 0.761 | 0.642 | 0.617 | 0.761 | 0.716 | 0.726 | 0.726 | 0.562 | 0.721 | 0.642 | 0.741 | 0.692 | 0.687 |
| R/B/H/G/F | 0.761 | 0.756 | 0.677 | 0.617 | 0.756 | 0.731 | 0.716 | 0.701 | 0.582 | 0.711 | 0.677 | 0.716 | 0.721 | 0.726 |
| R/H/P/G/F | 0.766 | 0.766 | 0.667 | 0.617 | 0.766 | 0.721 | 0.721 | 0.706 | 0.587 | 0.701 | 0.667 | 0.736 | 0.751 | 0.751 |
| W/H/P/V/F | 0.741 | 0.746 | 0.652 | 0.637 | 0.746 | 0.716 | 0.731 | 0.716 | 0.587 | 0.726 | 0.652 | 0.716 | 0.766 | 0.756 |
| R/W/B/H/P/F | 0.741 | 0.741 | 0.692 | 0.682 | 0.741 | 0.726 | 0.721 | 0.726 | 0.637 | 0.731 | 0.692 | 0.731 | 0.746 | 0.761 |
| R/W/B/H/G/V | 0.731 | 0.731 | 0.652 | 0.612 | 0.731 | 0.716 | 0.721 | 0.721 | 0.522 | 0.697 | 0.652 | 0.771 | 0.726 | 0.731 |
| R/W/B/H/G/F | 0.761 | 0.761 | 0.657 | 0.622 | 0.761 | 0.726 | 0.731 | 0.721 | 0.587 | 0.716 | 0.657 | 0.746 | 0.716 | 0.726 |
| R/W/B/H/V/F | 0.761 | 0.756 | 0.692 | 0.637 | 0.756 | 0.716 | 0.731 | 0.731 | 0.572 | 0.721 | 0.692 | 0.741 | 0.697 | 0.692 |
| R/W/H/P/G/F | 0.766 | 0.766 | 0.642 | 0.622 | 0.766 | 0.726 | 0.741 | 0.736 | 0.582 | 0.716 | 0.642 | 0.741 | 0.736 | 0.736 |
| R/B/H/P/G/F | 0.766 | 0.771 | 0.677 | 0.622 | 0.771 | 0.741 | 0.726 | 0.706 | 0.607 | 0.706 | 0.677 | 0.731 | 0.746 | 0.736 |
| R/B/H/P/V/F | 0.761 | 0.761 | 0.687 | 0.647 | 0.761 | 0.746 | 0.751 | 0.731 | 0.602 | 0.746 | 0.687 | 0.736 | 0.721 | 0.711 |
| R/W/B/H/P/G/F | 0.771 | 0.771 | 0.657 | 0.627 | 0.771 | 0.731 | 0.731 | 0.726 | 0.597 | 0.721 | 0.756 | 0.746 | 0.756 | 0.756 |
| R/W/B/H/P/V/F | 0.761 | 0.761 | 0.692 | 0.647 | 0.761 | 0.726 | 0.726 | 0.731 | 0.592 | 0.721 | 0.726 | 0.731 | 0.721 | 0.721 |
| R/B/H/P/G/V/F | 0.761 | 0.761 | 0.657 | 0.597 | 0.761 | 0.746 | 0.751 | 0.736 | 0.562 | 0.711 | 0.741 | 0.726 | 0.736 | 0.731 |
| Average | 0.700 | 0.700 | 0.640 | 0.604 | 0.700 | 0.685 | 0.700 | 0.697 | 0.586 | 0.691 | 0.643 | 0.693 | 0.685 | 0.686 |
| Combined Schemes | Individual Schemes | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP (R/B/P/V) | RS (R/B/P/V) | RMX (R/B) | RMI (W/B) | RMD (R/B/P/V) | RM (R/W/B/P) | WMV (R/B/H/F) | REC (R/B/P/V) | NB (R/B/H/F) | LOP (R/W/B) | FI (R/B) | MB (R/W/H/P/F) | MSVMP (R/W/H/P/G/F) | MSVML (R/W/H/P/G/F) | R | B | H | W | P | G | V | F | |
| Acc. | 0.986 | 0.986 | 0.964 | 0.975 | 0.986 | 0.980 | 0.975 | 0.969 | 0.966 | 0.978 | 0.964 | 0.989 | 0.992 | 0.989 | 0.953 | 0.947 | 0.930 | 0.947 | 0.897 | 0.718 | 0.754 | 0.852 |
| F1 | 0.992 | 0.992 | 0.968 | 0.982 | 0.992 | 0.987 | 0.981 | 0.975 | 0.973 | 0.982 | 0.968 | 0.989 | 0.991 | 0.989 | 0.961 | 0.966 | 0.951 | 0.964 | 0.940 | 0.774 | 0.798 | 0.898 |
| Prec | 0.985 | 0.985 | 0.945 | 0.968 | 0.985 | 0.977 | 0.967 | 0.957 | 0.953 | 0.968 | 0.945 | 0.980 | 0.985 | 0.980 | 0.936 | 0.942 | 0.918 | 0.938 | 0.900 | 0.674 | 0.699 | 0.835 |
| Rec | 0.998 | 0.998 | 0.994 | 0.996 | 0.998 | 0.997 | 0.996 | 0.995 | 0.995 | 0.997 | 0.994 | 0.998 | 0.999 | 0.998 | 0.993 | 0.992 | 0.990 | 0.992 | 0.985 | 0.936 | 0.948 | 0.976 |
| Combined Schemes | Individual Schemes | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP (R/B/H/P/G/F) | RS (R/B/H/P/G/F) | RMX (H/P) | RMI (R/H/V) | RMD (R/B/H/P/G/F) | RM (R/W/B/H/P/G/F) | WMV (R/W/B/H/P/G/F) | REC (R/W/H/P/G/F) | NB (R/B/H/P/F) | LOP (R/W/B/H/P/F) | FI (R/W/B/H/P/G/F) | MB (W/B/H/P/V/F) | MSVMP (R/W/B/P/G) | MSVML (R/W/P/G) | R | B | H | W | P | G | V | F | |
| Acc. | 0.821 | 0.821 | 0.766 | 0.778 | 0.821 | 0.816 | 0.819 | 0.828 | 0.807 | 0.809 | 0.791 | 0.828 | 0.828 | 0.826 | 0.731 | 0.709 | 0.757 | 0.690 | 0.738 | 0.529 | 0.674 | 0.681 |
| F1 | 0.891 | 0.890 | 0.849 | 0.858 | 0.890 | 0.890 | 0.890 | 0.894 | 0.878 | 0.883 | 0.874 | 0.892 | 0.893 | 0.892 | 0.833 | 0.810 | 0.842 | 0.799 | 0.840 | 0.654 | 0.782 | 0.791 |
| Prec | 0.829 | 0.828 | 0.770 | 0.780 | 0.828 | 0.830 | 0.830 | 0.835 | 0.812 | 0.819 | 0.807 | 0.830 | 0.833 | 0.830 | 0.753 | 0.720 | 0.760 | 0.706 | 0.759 | 0.537 | 0.687 | 0.697 |
| Rec | 0.965 | 0.965 | 0.950 | 0.954 | 0.965 | 0.964 | 0.964 | 0.965 | 0.960 | 0.962 | 0.958 | 0.965 | 0.965 | 0.966 | 0.941 | 0.933 | 0.947 | 0.929 | 0.947 | 0.857 | 0.919 | 0.924 |
| Combined Schemes | Individual Schemes | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RP (R/H/P/G) | RS (R/B/H/P/G/F) | RMX (R/B) | RMI (R/H) | RMD (R/B/H/P/G/F) | RM (R/B/H/P/V) | WMV (R/B/H/G/V) | REC (R/W/H/P/G/V) | NB (B/H/P) | LOP (B/H/P) | FI (R/W/B/H/P/G/F) | MB (R/W/B/H/G/V) | MSVMP (R/H/P/F) | MSVML (W/H/P/F) | R | B | H | W | P | G | V | F | |
| Acc. | 0.771 | 0.771 | 0.726 | 0.726 | 0.771 | 0.756 | 0.756 | 0.756 | 0.701 | 0.766 | 0.756 | 0.771 | 0.766 | 0.776 | 0.672 | 0.672 | 0.667 | 0.632 | 0.662 | 0.393 | 0.443 | 0.577 |
| F1 | 0.871 | 0.870 | 0.838 | 0.830 | 0.870 | 0.867 | 0.850 | 0.848 | 0.803 | 0.859 | 0.860 | 0.856 | 0.844 | 0.859 | 0.787 | 0.785 | 0.787 | 0.733 | 0.793 | 0.541 | 0.578 | 0.701 |
| Prec | 0.809 | 0.807 | 0.764 | 0.750 | 0.807 | 0.804 | 0.776 | 0.768 | 0.707 | 0.788 | 0.794 | 0.779 | 0.762 | 0.784 | 0.689 | 0.694 | 0.695 | 0.629 | 0.699 | 0.416 | 0.462 | 0.583 |
| Rec | 0.959 | 0.958 | 0.944 | 0.942 | 0.958 | 0.957 | 0.950 | 0.951 | 0.934 | 0.955 | 0.953 | 0.954 | 0.950 | 0.956 | 0.927 | 0.924 | 0.926 | 0.898 | 0.932 | 0.804 | 0.809 | 0.889 |
| Method | Accuracy | F1-Measure |
|---|---|---|
| R/B/H/W/P/G/V/F | 0.523 | 0.726 |
| R/H/P/F | 0.517 | 0.703 |
| R/W/B/H/P/G/F | 0.527 | 0.722 |
| R/W/B/P/G | 0.547 | 0.721 |
| R | 0.433 | 0.635 |
| B | 0.368 | 0.494 |
| H | 0.488 | 0.626 |
| W | 0.353 | 0.594 |
| P | 0.463 | 0.592 |
| G | 0.378 | 0.582 |
| V | 0.189 | 0.332 |
| F | 0.468 | 0.720 |
| Feature | CK | BU-3DFE | JAFFE | Total |
|---|---|---|---|---|
| R | 0.86 | 0.76 | 0.82 | 0.82 |
| W | 0.72 | 0.86 | 0.59 | 0.73 |
| B | 0.66 | 0.62 | 0.59 | 0.40 |
| H | 0.69 | 0.81 | 1.00 | 0.82 |
| P | 0.83 | 1.00 | 0.68 | 0.83 |
| G | 0.42 | 0.71 | 0.54 | 0.55 |
| V | 0.83 | 0.62 | 0.28 | 0.59 |
| F | 0.79 | 0.48 | 0.68 | 0.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marrero-Fernandez, P.D.; Buades-Rubio, J.M.; Jaume-i-Capó, A.; Ing Ren, T. An Approach for Selecting the Most Explanatory Features for Facial Expression Recognition. Appl. Sci. 2022, 12, 5637. https://doi.org/10.3390/app12115637
Marrero-Fernandez PD, Buades-Rubio JM, Jaume-i-Capó A, Ing Ren T. An Approach for Selecting the Most Explanatory Features for Facial Expression Recognition. Applied Sciences. 2022; 12(11):5637. https://doi.org/10.3390/app12115637
Chicago/Turabian StyleMarrero-Fernandez, Pedro D., Jose M. Buades-Rubio, Antoni Jaume-i-Capó, and Tsang Ing Ren. 2022. "An Approach for Selecting the Most Explanatory Features for Facial Expression Recognition" Applied Sciences 12, no. 11: 5637. https://doi.org/10.3390/app12115637
APA StyleMarrero-Fernandez, P. D., Buades-Rubio, J. M., Jaume-i-Capó, A., & Ing Ren, T. (2022). An Approach for Selecting the Most Explanatory Features for Facial Expression Recognition. Applied Sciences, 12(11), 5637. https://doi.org/10.3390/app12115637