1. Introduction
Traffic sign detection is the premise for driverless cars to understand traffic information, avoid traffic congestion and accidents, and ensure the safe and orderly driving of vehicles. It is also an essential submodule of driver assistance systems. Currently, CNNs are widely used for traffic sign detection [
1,
2,
3,
4], which relies heavily on a large number of accurate bounding box annotations and artificially balanced training classes. When the contextual information of the training and testing sets is distributed unevenly, a serious mistake will occur that fails to generalize. It is a great challenge to guarantee the accuracy and robustness of detection results when samples are limited because of the large variation in object scales, such as vehicle speed, and the inconsistencies in traffic signs due to regional differences.
Meta-YOLO draws inspiration from classical CNNs and few-shot techniques. We outline some of the salient works here to set the context.
Traffic Sign Detection by CNNs. In recent years, researchers have generally adopted a visual scheme based on deep CNNs (convolutional neural networks) to achieve the task of traffic signs detection. A one-stage detector is based on the regression method, which directly outputs the location and category of the bounding boxes densely in a single-shot, such as YOLOv1-v4 [
5,
6,
7,
8], SSD [
9] and RetinaNet [
10]. A two-stage detector is based on a region proposal, including R-CNN [
11], Fast R-CNN [
12], Faster R-CNN [
13] and Mask R-CNN [
14].
In view of the complex background and unbalanced sample distribution, Li et al. [
15], on the basis of a fully study of the relationship between different traffic signs with digital characters, designed an SE block that could automatically learn the importance of each channel from global information. This method simplifies the detection of a wide variety of numerical traffic signs to 10 digital categories, but it is difficult to distinguish similar false targets in complex real traffic scenes. Min et al. [
16] proposed an LW-RefineNet to segment the scene and obtain the information regarding the spatial positional at pixel level, and then the constraint model is constructed to establish the search regions. Experiments show that this method alleviates the mis-detection of small traffic signs. However, it is limited in scenarios where both sides of the road, and other scenarios (such as intersections), have ineffective detection. The above research shows that fully understanding and representing the real features of the extracted traffic signs is an effective solution to distinguish similar objects and filter false associations, which provides a basis for the design of the FDM module in this algorithm. Too small traffic signs are one of the main causes of mis-detection, and improving the multi-scale ability of detection algorithms is a common method to solve the challenge of small target detection. Cao et al. [
17] presented an improved Sparse R-CNN and constructed hierarchical residual-like connections within each single radix block, while a cross-channel attention mechanism was added in the RoI division process to fuse shallow feature information. However, due to its single attention mechanism, global correlation in RPN may suffer from spatial scale dislocation, and local correspondence between objects may be ignored. Wang et al. [
18] applied an inception and channel attention mechanism to a superclass detector and directly concatenated feature maps of different channels, which overcomes Cao et al.’s [
17] complex backbone problems. At the same time, there is a negative impact on robustness because the importance of the different feature channels is not considered. Although the traffic sign detection algorithm based on CNN has achieved remarkable results in real-time performance and accuracy, most methods require a good deal of labeled sample data, and, in fact, our dataset cannot exhaust all traffic scenes. Based on this consideration, we combined the meta-paradigm with CNN to promote the robustness to unseen classes’ tasks.
Few-shot object detection. Since the performance of large neural networks is limited by the size of the training set, a small number of samples within the training set can easily lead to overfitting of the network and failure to realize the potential of deep networks. Few-shot learning is a method of deep learning training and prediction with insufficient sample data. In few-shot tasks, models trained with small samples can easily fall into overfitting to small samples as well as underfitting to the target task.
Meta-learning has shown great potential in solving few-shot problems [
19,
20,
21,
22], and its unique implementation can improve the accuracy of target detection for the classification of novel categories. The main idea is to use meta-info accumulated from historical tasks as prior knowledge, and then learn a small number of target samples to quickly master new tasks. This method has strong adaptability and robustness to unseen scenarios. Meta-learning approaches used for few-shot detection are roughly divided into three groups: gradient-based [
23,
24], nearest-neighbor [
25,
26] and model-based [
27,
28]. Zhao et al. [
29] proposed a multi-scale few-shot detection model based on fine-tuning, which utilizes residual involution blocks to construct the all feature learning architecture as well as design PAM to aggregate from all feature levels. This method exploits shallow feature semantic information for object location in the first stage and is partly fine-tuned on a small balanced dataset in the second stage. However, Zhang et al. [
30] visualized the feature distribution of samples in the pre-training space, proving that fine-tuning has limited performance improvement in meta-learning and can easily increase the risk of base task overfitting. Therefore, in this work, we take meta-info to update the meta-learner to replace fine-tuning. Whang et al. [
31] proposed a general object detection system, which combines the feature-based domain attention mechanism with sequence and exception networks, and assigns network activation to different domains through SE adapter library learning, so as to automatically obtain the importance of each feature channel. The core idea of SENet is to learn the feature weight according to the loss, so that the weight of an effective feature map is large, and the weight of an ineffective feature map is small, so as to achieve better results. However, the general detection system ignores the problem of spatial dislocation, which leads to the poor performance in detecting traffic signs with small targets and a chaotic background. Han et al. [
32] improved the problem of training on base training to generate candidate proposals for novel classes and missing high IOU boxes in the RPN stage. A coarse-grained prototype matching network (meta-RPN) was proposed, which takes a non-linear classifier based on metric learning to replace the traditional linear target classifier, dealing with the similarity between anchor boxes and novel classes in query images, so as to improve the recall of the few novel class candidate boxes. A fine-grained prototype matching network (meta-classifier) was designed. The network has spatial feature alignment and foreground attention modules to deal with the similarity between noise and novel classes, so as to enhance the overall detection accuracy. However, within the meta optimizer lies the problem of prototype deviation. The reason for this problem is the use of an average-based method to roughly estimate the gradient when the labeled samples are limited in each category.
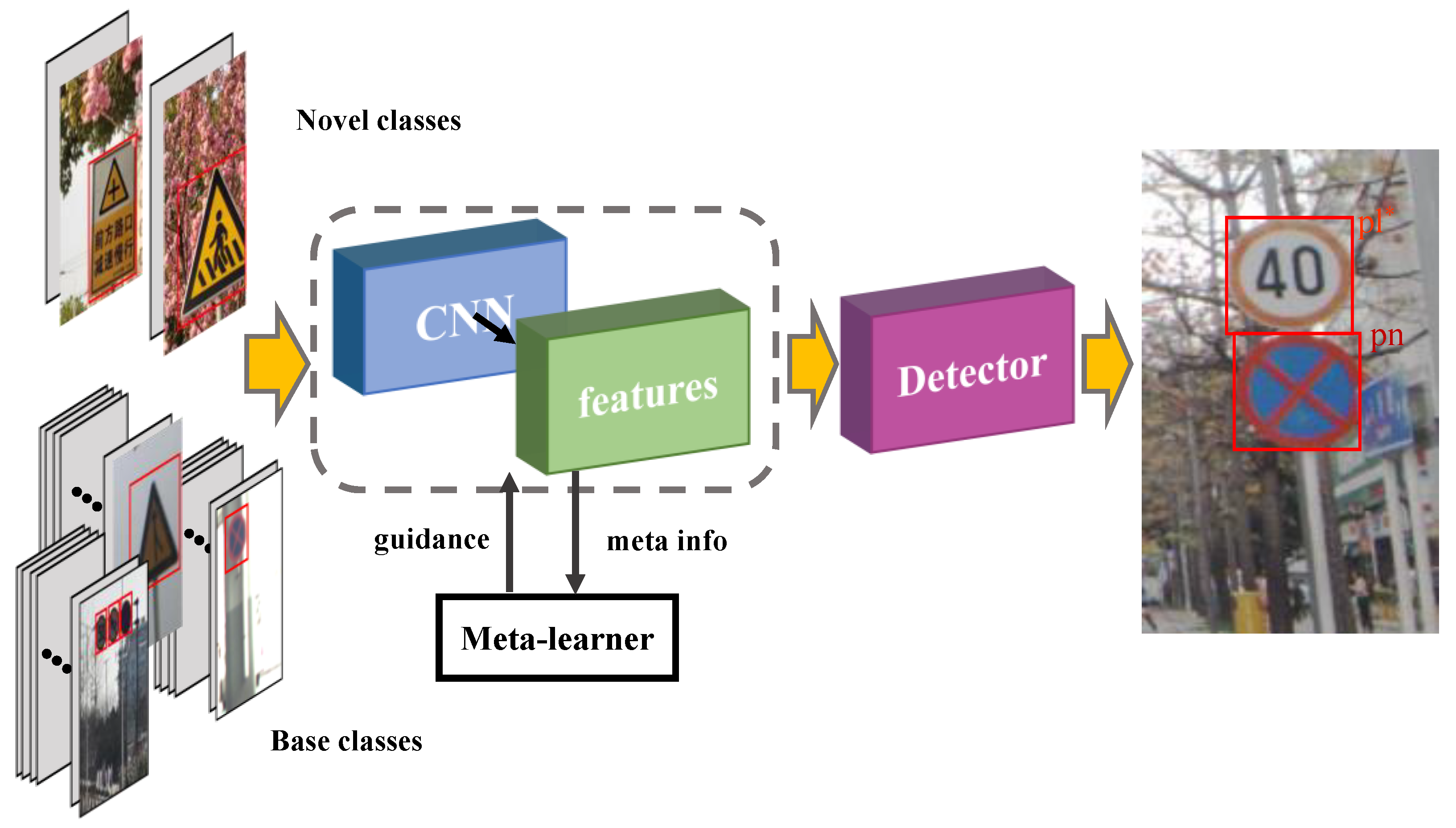
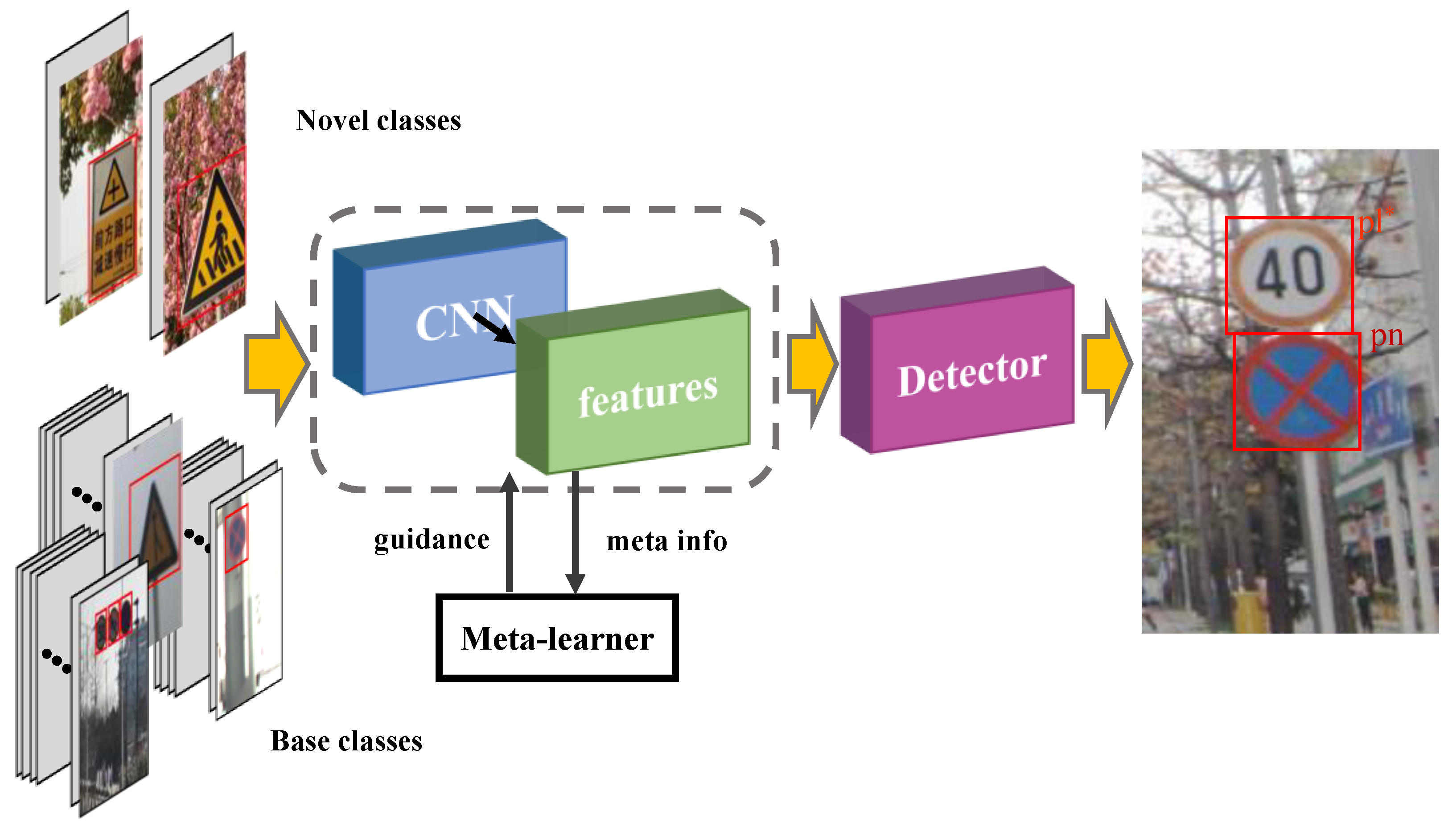
Given the above considerations, in this work, our aim is to address the challenging few-shot traffic sign detection problem, as shown in
Figure 1. Specifically, given the problem of unbalanced sample distribution, we aim to obtain a model that can detect both base and novel objects at test time. We believe that this eliminates the impact of distribution shifts between training and testing data, which is vital for improving the detection accuracy and generalization ability of the constructed model. Therefore, we use the method of Random Fourier Features and sample weighting to effectively remove the statistical correlation between relevant and irrelevant features.
Traffic sign detection is a key part of autonomous driving technology with good performance for both speed and accuracy. This requires a detector with the ability to detect unseen classes accurately in real time. Few-shot is a feasible approach to the above problem, which can detect new classes with only a small number of labeled samples needing to be trained. The current transfer learning is more effective for solving few-shot problems, but it needs to be trained on the source domain and then fine-tuned on the target domain with few samples, which is not suitable for dynamic environments and urgent tasks.
Meta-learning provides a new and feasible solution to the above few-shot problem. We designed a traffic sign detector that unifies the few-shot learning ability by two-stage meta-learner learning class features from base classes at the image-level and a multi-scale ability to predict novel classes in conformity with limited support examples.
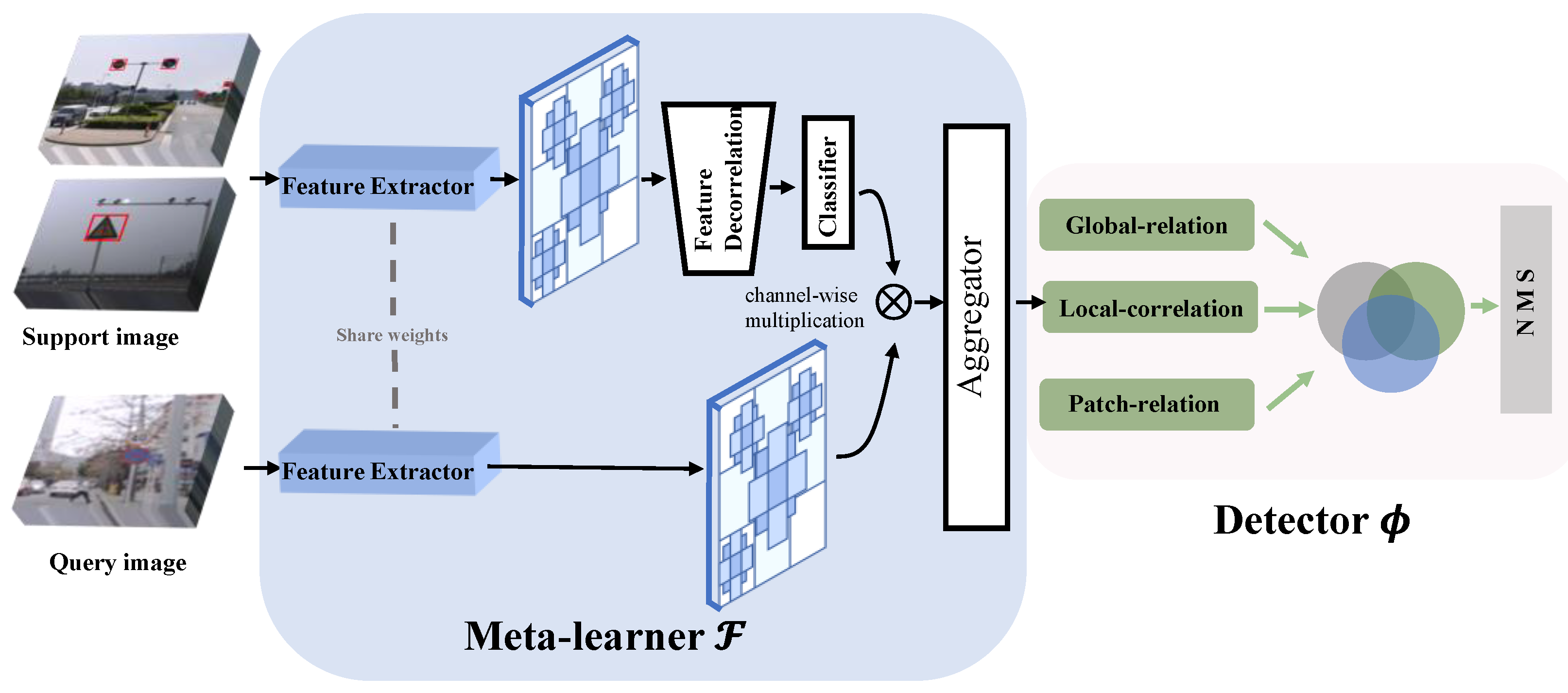
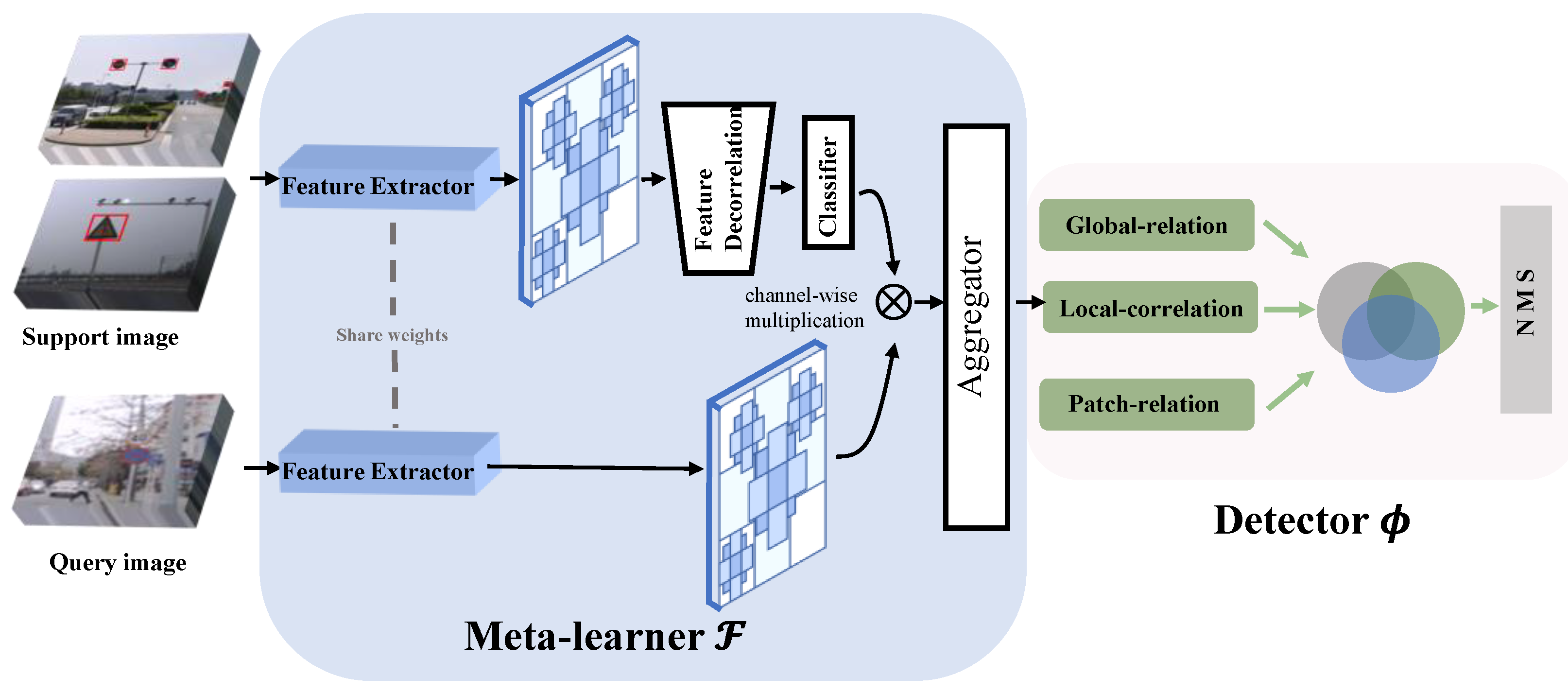
The proposed meta-learning FSD framework, shown in
Figure 2 contains a meta-learner model F and a detector model
. We extract query features and support features by utilizing the YOLOv4 backbone network, gaining the ability to quickly adjust parameters to be at the optimal level for new tasks with the meta-learner. Here, the learning process exists at two terms: the initialization term and adaptation term, shown in
Figure 3, improving a strong discriminative ability of a detector to distinguish different categories from the multi-relation detector module. Our framework boils down exactly to a typical meta-learning paradigm, encouraging the name Meta-YOLO.
Our contributions are as follows:
We present Meta-YOLO, a novel few-shot traffic sign detection framework that unifies image-level meta-info of object localization and classification into a one-stage module.
We design a feature decorrelation module (FDM) that gets rid of spurious correlations and, in turn, focuses more on the real connection between discriminative features and labels. This module can overcome the complex backgrounds’ interference in the detection process, thus enhancing the robustness of the system.
We introduce a three-head mechanism that allows the detector to jointly attend to information from the spatial position relationship of different levels. The application of this mechanism’s advance ability allows a detector to distinguish between different categories as well as to detect different scale targets.
The rest of this paper is organized as follows: in
Section 2 we discuss details of the feature decorrelation module, while the architecture and implementation details of our network are presented in
Section 3. We give experimental results in
Section 4 and conclusions in
Section 5.
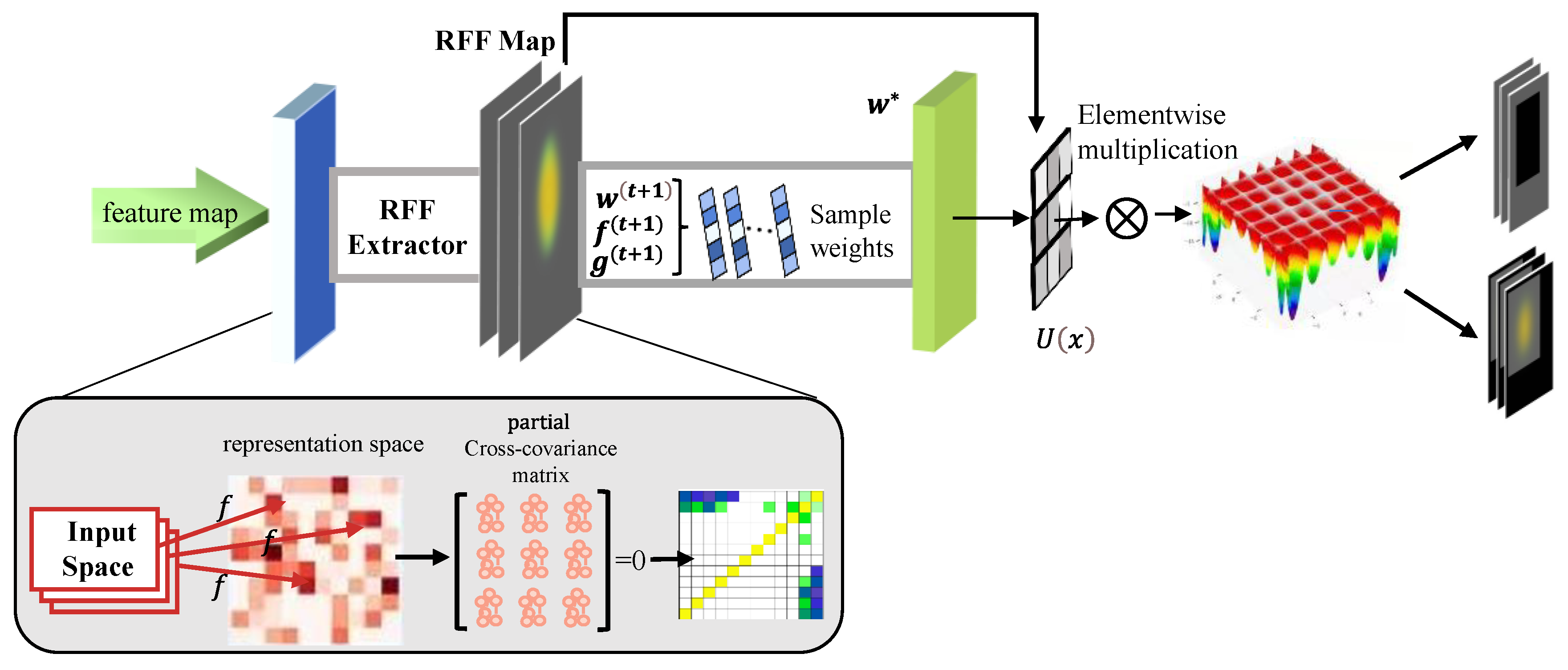
2. Sample Weighting for Decoupling Dependencies
This section mainly describes the construction method of the feature decorrelation module (FDM). Inspired by [
33,
34,
35,
36], we propose a method to perceive and decouple global correlations by iteratively saving and reloading the features and sampled weights of the model. The architecture of the feature decorrelation module is shown in
Figure 4.
Notations: denotes the space of input, denotes the space of outcome space, denotes the space of representation. , , are the dimensions of space , , , respectively. If we suppose that there are two different random variables M, N in the representation space (their sample information and label information are stored in , , respectively), and are Random Fourier Features mapping functions. : denotes the representation function and : denotes the prediction function.
If we suppose that most of the traffic signs are located in front of trees in support sets , then RFF will extract the features of traffic signs and trees, while mapping the original dimension features data extracted in the input space to the higher dimensional (-dimensional) representation space by the representation function ; therefore, the samples are linearly separable in this feature space. Since the datasets do not contain all the features of “trees”, we first multiply the difference between the predicted and ground truth with the weights of the features to obtain the optimization target. Then we iteratively change the weights of different features to obtain the features with the correct correlation to traffic signs.
2.1. RFF-Based Feature Decorrelation
According to [
33] the independence testing statistic
is defined as the Frobenius norm of the partial cross-covariance matrix, i.e.,
. Notice that
is always non-negative, and two variables
M,
N tend to be independent as
is equal to zero. Thus,
can effectively measure the independence between random variables. Actually, the Frobenius norm corresponds to the Hilbert–Schmidt norm in Euclidean space [
37], and, according to the Hilbert–Schmidt norm [
38], which needs the squared Hilbert–Schmidt norm of
to be zero, it can be used as a criterion to supervise feature decorrelation. Thus, based on the Frobenius norm, the partial cross-covariance matrix is as follows
where
Here
denotes the function space of Random Fourier Features. The results are calculated using the partial cross-covariance matrix for random variables
M and
N after weighting as follows
We set the weight optimization method as follows, and this optimization strategy can minimize the dependency between features.
The iterative equation is as follows
where
represents the cross-entropy loss function and
represents the time stamp.
2.2. Global Optimization
In practice, especially for deep learning tasks, it needs enormous storage and computational cost to learn sample weights globally. Moreover, SGD tends to fall into local minima and saddle points, and the noise from small batch sampling makes the loss oscillate back and forth; hence, global weights for all samples cannot be learned. In this section, supported by the findings in [
35], we propose a method to perceive and remove global correlations though iteratively saving and reloading the features and sampled weights of the model.
Our main idea is to maintain the upper bounds on the piecewise linearity of the sample features
and weights
while using them to determine the estimate of
in each optimization step. Then, the upper bound of piecewise linear function
can be determined by the following function [
35]
where
is a noise term and
K is a diagonal matrix with k terms of the Lipschitz constant. We point out that we adopt the k-value estimation method of C. Malherbe et al. [
36]. This approach makes the algorithm run faster by using a random search of
to check if the upper bound of the new point is better than the existing optimal point and, if so, update it to the new optimal value. Moreover, sample features
and weights
are updated at the end of each batch and represent the global information of the whole training dataset.
Although the local maximum region can be reached quickly using the above method, it cannot be moved to the optimal position rapidly. In the light of this problem, we introduce the classical confidence domain method of Powell et al. [
39] to fit the quadratic surface of the current optimal solution, and then the next iteration to the quadratic surface extreme value point at a certain distance from the current optimal solution.
3. Methodology
Our aim is to solve the problem of few-shot traffic sign detection. We first define the problem and task of FSD under meta-learning. Following recent work, we propose the solution: Meta-YOLO, which is implemented by integrating YOLOv4 into a meta- learning pipeline. The traffic sign detection framework proposed in this paper, works in a meta-learning process, composed of meta-learner and object detector.
3.1. Task Definition
Given two sets of categories, sets and which are mutually disjointed, ∩ = ∅; corresponding categories with a base dataset contains abundant annotated instances in each novel class instance, and a novel dataset contains very few samples in each novel class. We propose a distribution lies in the relevant task space and sample randomly from this distribution.
Simulating the meta-learning paradigm, meta-training tasks are comprised of support set and query set and meta-testing tasks are comprised of support set and query set to keep consistency.
Arbitrary target categories and datasets corresponding to it are randomly sampled from , a part of it as , another part as . Likewise, arbitrary target categories and datasets corresponding to it are randomly sampled from , a part of it as , another part as . N classes are randomly selected from , samples are randomly selected from corresponding to classes where K samples will be used as and samples as . The task is to find all the attributes from query support category and label them with tight bounding boxes.
Our goal is to build detection algorithms that work in a meta-learning process that allows a meta-learner to learn how to quickly adjust its parameters to the optimum for a new task in the presence of new classes with very few instances by training on a series of seen classes, thus teaching the detector to quickly detect unseen targets and output the predicted categories y and locations t. Among others, the meta-learner model should be trained on the distribution according to the principle that the training and testing processes should be consistent.
3.2. Network Description
We adopt the backbone of YOLOv4 (i.e., CSPDarknet53) to implement the feature extractor; support features share all learnable parameters with query feature following the philosophy [
40]. We filter out irrelevant information within the support image via FDM whose further details have been shown in
Section 2. Meta-YOLO is conceptually simple and aims to quickly and accurately detect unseen traffic signs. The framework is shown in
Figure 2, which is mainly composed of two parts: meta-learner model
and detection model
.
We set a learnable learning rate for all parameters so that the meta-learning system can learn good initialization as well as fast adaptation strategies. Given a query image, first the feature extractor generates its feature map and then adopts 1
1 convolution to make the feature map’s channel dimension compatible with the downstream modules. Unlike query feature, which retains image-level information, for support image it is necessary to extract the category features of the certain object instance. Therefore, we utilize Fourier features combined with sample weights to decouple dependencies and remove the irrelevant information present in the support set. The design of aggregator follows previous work [
41], reweighting the query features
according to the output of the support set class feature
. The support class features are combined with query features as in Equation (8) to obtain the detection results of the corresponding category.
where
represents channel-wise multiplication. The support set is utilized in a loop to construct a classifier for the sample class. The aggregator is then used to cascade the information matching to the query set with the feature relationships and categories corresponding to each image in the support set.
The detector we desire is with a powerful discriminative capacity to distinguish between different categories as well as to detect different scale targets. Based on this, three-heads, the global-relation head, the local-correlation head and patch-relation head, are constructed to learn a deep embedding for global matching, pixel-wise and depth-wise cross-correlation between support and query sets and a deep non-linear metric for patch matching, respectively.
Revisiting Yolov4 backbone. The proposed Meta-YOLO utilizes the successful YOLOv4 for FSD to detect traffic signs, shown in
Figure 2. YOLO [
5,
6,
7,
8] is the representative work of one-stage model; the core idea is to input the complete image into the network and regress the classes and coordinates of the bounding box in the output layer to achieve end-to-end training. YOLOv4 [
8] improves on YOLO v3 [
7] to sit at the faster end of the speed–accuracy trade-off. Its accuracy is already comparable to or even surpasses two-stage target detection algorithms while maintaining a very high speed. The YOLOv4 backbone uses CSPDarknet53 with the mish activation function to increase the network’s learning ability and gradient transmission efficiency; the network’s regularization process is upgraded and improved extensively by employing a better Dropblock. CSPDarknet53 is a backbone structure based on the Yolov3 backbone network Darknet53, which draws on the experience of CSPNet 2019. The use of this network structure enhances the learning capability of CNNs, enabling a light weight while sustaining accuracy, decreasing computational bottlenecks and lowering memory costs. This is of great significance to YOLO, which not only ensures the speed and accuracy of inference but also reduces the size of the model.
This work aims to address the problem of few-shot traffic sign detection under the blessing of meta-learning. Then we evaluate the feasibility of the framework by equipping it with an object detection architecture; to this end, relatively simple and efficient detectors should be selected, i.e., YOLOv4. Meta-YOLO extends the YOLOv4 framework by integrating meta-learning within an end-to-end convolutional neural network-based detection framework. This creative design not only enhances the image feature extraction capability, but also helps to improve the accuracy of one-stage classification on new categories; in fact, the FSD accuracy and speed are greatly improved.
Meta-learner: With only a few labeled instances, it is intractable to decide how to initialize parameters and learning rate as well as when to halt the learning process to shun overfitting. We need to maximize the generalization capability rather than data fitting to determine all the learning factors and eventually bring the model to the point where it can acquire learning in just a few iterations while speeding up learning so that the detector can learn and respond in a rapidly changing environment. Inspired by X. Yang et al. [
42] and B. Kang et al. [
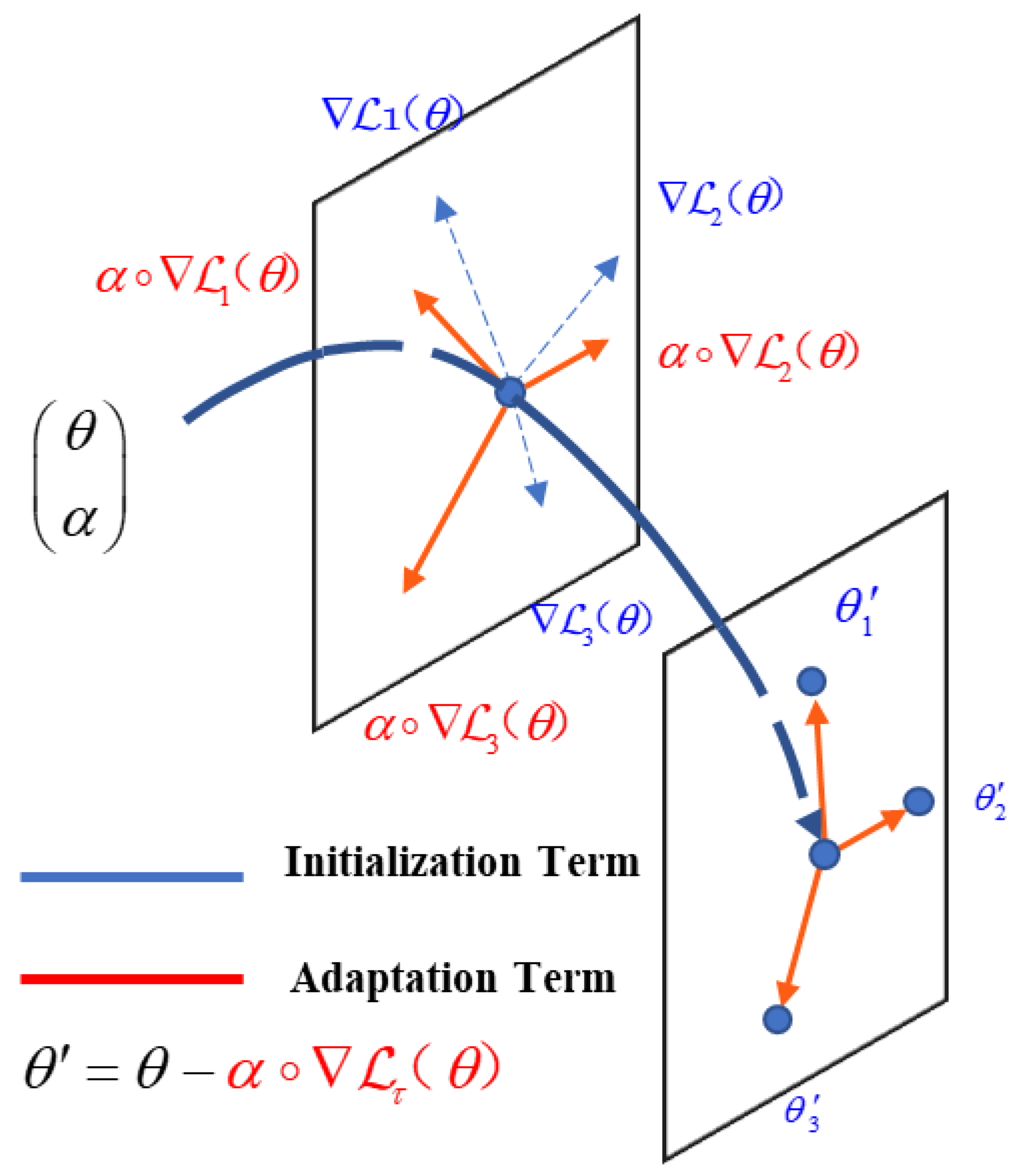
37], we introduce the following end-to-end meta-learner, which consists of two terms: initialization and adaptation, as shown in Algorithm 1.
where
and
are parameters of the meta-learner to be learned, and
stands for element-wise product.
is a vector whose direction corresponds to the update direction and whose length corresponds to the learning rate. With some loss function
,
is the gradient of
, where
consists of a conventional cross-entropy loss
for classification, a smoothed-L1 loss
for bounding box regression and a cross-entropy loss function for acquiring the relationship between different classes from class features, as shown in Equation (10).
Our method first initializes the learner parameters with then adjusts it to in just one phase at a time in direction and by adopting a learning rate implicitly implemented in .
With the above definition, the objective of meta-learning is
The meta-learner is updated iteratively from random initialization using gradient descent, as shown in
Figure 3.
Meta-learning generally occurs on batches of tasks where the detector
is trained on
and use
as a meta-info to update the meta-learner, which is then tested on
. The meta-learning process is repeated until the meta-learner is able to learn how to tune the detector to give it the best performance. The improved end-to-end two-stage meta-learner
, which learns not only the initialization of the learner but updates direction and learning rate of the learner, is equipped to have positive performance for a new task with scant instances.
| Algorithm 1: Meta-Learner for Meta-YOLO |
| Input: task distribution
meta-learning rate |
| Output: detector’s parameters
, detector’s learning rate |
| 1: Initialize ; |
| 2: While not end do |
| 3: Sample batch of tasks ; |
| 4: for all do |
| 5: ; |
| 6: ; |
| 7: ; |
| 8: end for |
| 9: ; |
| 10: end while |
4. Experiments
This section evaluates the effectiveness of Meta-YOLO on few-shot traffic sign detection both qualitatively and quantitatively by testing it with two challenge datasets and comparing with the baselines.
Section 4.1 gives a brief introduction to the datasets used in the experiment.
Section 4.2 presents the setup of the experiment. The experiment and comparisons of the three baselines and state-of-the-art methods are presented in
Section 4.3.
4.1. Datasets
Empirically, three standard TSD benchmark datasets are considered: (1) the GTSDB dataset [
43], (2) the TT100K dataset [
44] and (3) the MSTD [
45] dataset These datasets share a common characteristic in that they cover a variety of fine traffic sign categories, which fit the actual detection demands and the evaluation of our claim on the robustness of few-shot traffic sign detection. The main characteristics of the datasets used in the experiments are shown in
Table 1.
GTSDB The German traffic sign detection benchmark (GTSDB) is a single-image traffic sign detection dataset and is widely used to evaluate traffic sign detectors. This dataset consists of 900 images with 1206 traffic signs that are split into a training set of 600 images with 846 traffic signs and a testing set of 300 images with 360 traffic signs. The resolution of this dataset is 1360 × 800.
TT100K The TT100K dataset is composed of 100,000 images with 30,000 traffic sign instances, which are annotated with a sign type, a pixel map and a bounding box. It consists of 45 categories of a relatively large real-world traffic benchmark. The image resolution in this benchmark is 2048 × 2048 and covers large variations in lighting and weather. This dataset has unbalanced category distribution.
MTSD: The Mapillary Traffic Sign dataset covers multiple locations on six continents and consists of 52,453 high-resolution images with more than 80,000 annotated signs. This dataset includes 313 categories and has variations in weather, season, moment, camera and perspective.
4.2. Experimental Setup
We set an object detection benchmark for traffic sign detection processed in the following way. Out of TT100K’s 45 instance categories, we randomly selected nine classes as the novel ones, while keeping the other 36 as the base. During the initialization term of meta-learning, only the base class objects are considered. In the adaptation term, there are K-shot annotated bounding boxes for objects in each novel class and 3K annotated bounding boxes for objects in each base class for training, where K is set at 1, 2, 3, 5 and 10. We adopted the mean Average Precision (mAP) as the evaluation metric and a qualified prediction that ought to be more than 0.5 IoU with the ground truth. To design a few-shot learning setup, we considered three different novel/base class split settings, i.e., (“w1”, “w27”, “pd”, “ip”, “i6”/rest); (“ip”, “pg”, “w27”, “w1”, “i6”/rest) and (“w1”, “p7”, “w27”, “i6”, “pd”/rest).
Similarly, on the GTSDB dataset, we had 300 images from the validation set for evaluation, and the remaining images for training. Out of its 43 instance categories, we randomly selected 10 classes overlapped with TT100K as the novel ones while keeping the remaining 33 as the base. We also considered the proposed model learning on the 43 base classes from GTSDB and exploiting it to detect the two novel objects in TT100K. This setting features a cross-dataset problem that we called GTSDB to TT100K.
We took a similar approach to the MIST dataset as the previous two datasets. We selected 55 classes as the novel classes, while keeping the rest as base classes.
As for the computer platform settings, a standard PC was used for all the experiments, whose hardware and software configuration are listed as follows:
4.3. Performance
4.3.1. Comparison with Baseline
We compared our model with three competitive baselines. We constructed baselines as follows: YOLO-joint jointly trains the YOLOv4 detector on the base and novel classes, and uses the identical number of iterations as Meta-YOLO to train this baseline model. YOLO-based takes the same training strategy in Meta-YOLO. YOLO-ft applies the same training strategy of ours but trains the detector to fully converge.
TT100K The K-shot traffic sign detection is performed based on K = (1, 2, 3, 5, 10) across three novel/base class splits. As shown in the experimental evaluation results in
Table 2, our proposed model significantly outperforms the baseline. It reveals the generalization weakness of the one-stage detector YOLOv4 with a small number of labels in the training term. Comparing the performance results of the YOLO-joint and YOLO-based baselines shows that joint training biases the detection results toward the base class and nothing about the new class. Note that, YOLO-ft performs significantly better than the other two baselines, which proves the necessity of a two-stage strategy for a meta-learner. Furthermore, the attention maps are visualized in
Figure 5. The attention maps show that these highlighted regions are almost correlated with traffic sign instances, which indicates that the feature decorrelation module effectively removes irrelevant features and enhances the generalization of meta-learned representations.
GTSDB: We evaluated 10-shot/30-shot setups on the GTSDB [
4] benchmark and report the standard GTSDB metrics. The results on the novel classes are shown in
Table 3. In both cases, meta-YOLO outperforms the other baselines. The results show that the performance of the baselines in detecting new classes is extremely poor, which is caused by the unbalanced setting of the number of base classes and new classes, further revealing the vulnerability of YOLO to the generalization problem. In
Figure 6, some comparisons between YOLO-ft and Meta-YOLO are visualized when detecting novel class traffic signs; the results indicate our method is indeed effective.
GTSDB to TT100K: In this cross-dataset few-shot traffic sign detection setup, all the baselines are trained with 10-shot objects in novel classes on GTSDB, while they are evaluated on the TT100K test set. Distinct from the previous experiments that concentrate on evaluating cross-category model generalization, this setup goes further to manifest the cross-domain generalization ability. The mAP of YOLO-based and YOLO-ft achieve the detection performance of 20.1% and 32.6%, respectively. Instead, Meta-YOLO achieves 39.8%, while this performance is poorer than when using base classes in TT100K (which has a mAP of around 42%).
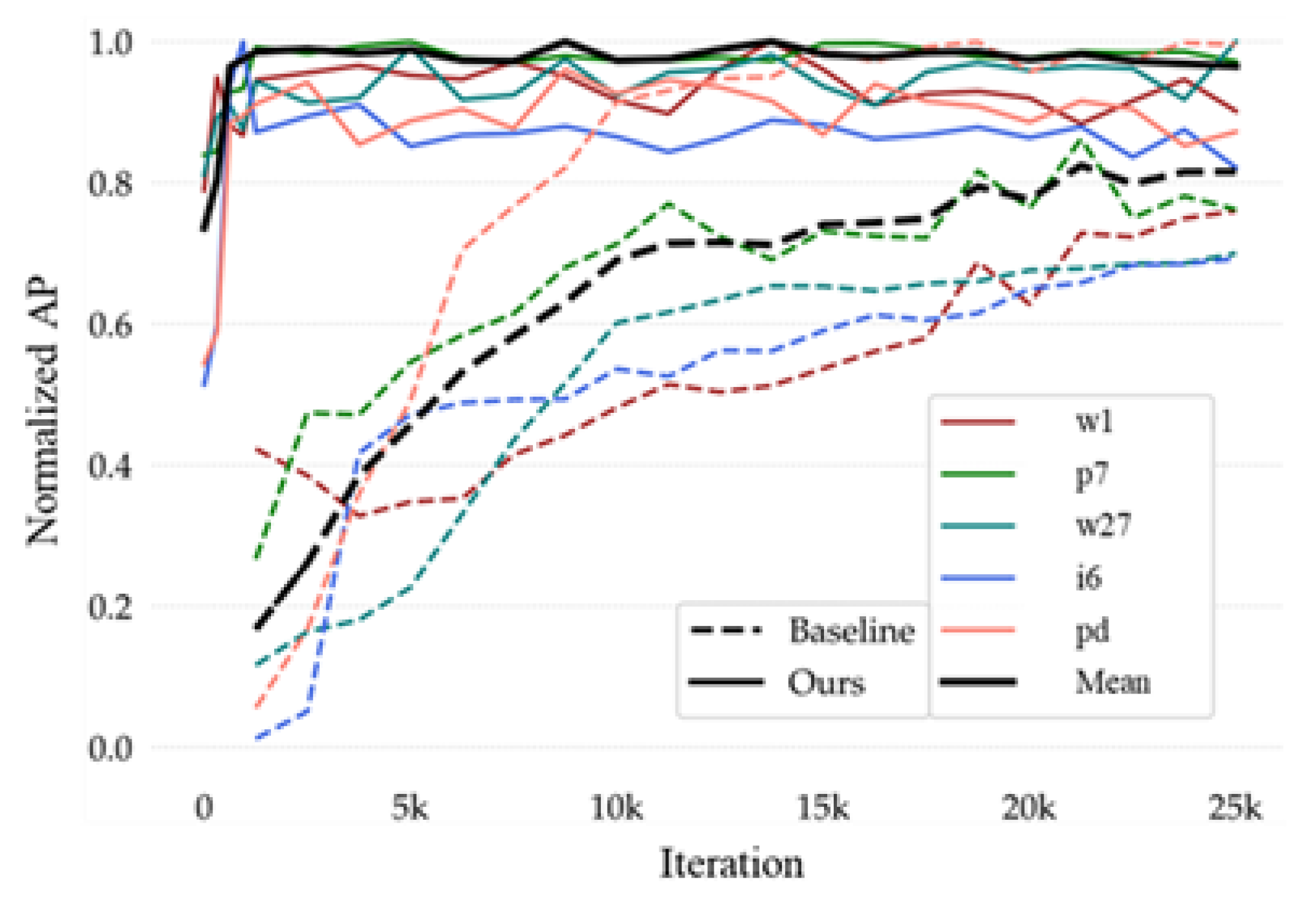
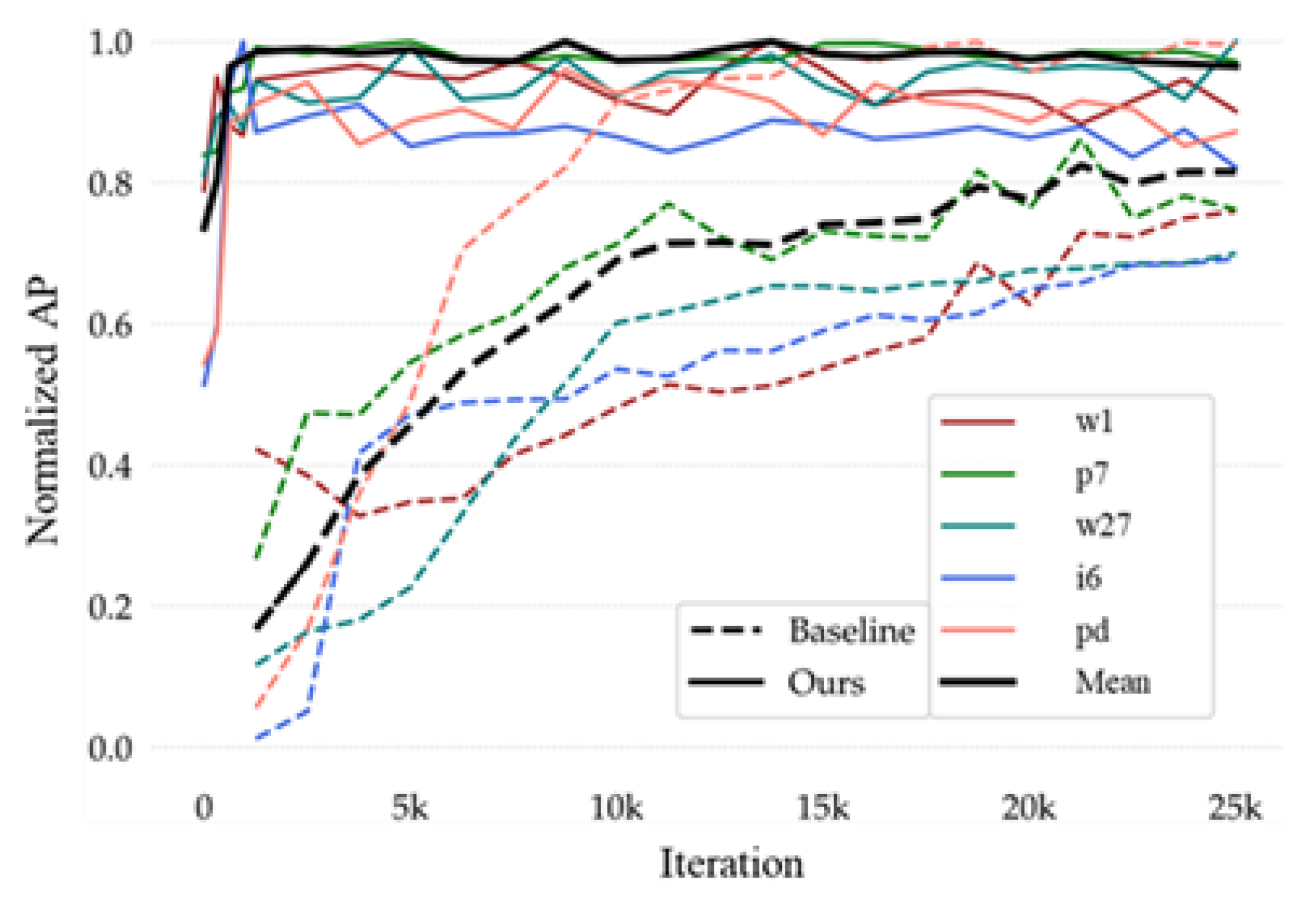
Adaptation speed. Our two-stage meta-learner model
is able to rapidly learn all parameters and directions during the adaptation term. We use the AP, obtained from Equations (13) and (14), to plot versus the number of training iterations to analyze the adaptation speed of the models. Here we select the TT100K base/novel split three to train under our method and the baseline, respectively, and its AP variations under different iterations as shown in
Figure 7. The results show that Meta-YOLO exhibits remarkable fast adaptation ability, shown in
Figure 7. It is noted that in the experiments shown in
Table 3, YOLO-based and YOLO-ft need 2.5K iterations for them to fully converge; however, ours only requires 0.1K iterations to converge to a higher accuracy.
where
is the number of positive samples,
is the recall of positive samples and
is the precision corresponding to the
.
4.3.2. Comparison with State-Of-The-Art Methods
In order to ensure the justness of the experiments, in this section, the meta-YOLO proposed by us is compared with state-of-the-art methods by Han et al. [
46], Min et al. [
16], Zhang et al. [
47] and Fan et al. [
48]. The experiments were performed based on K=10 across MIST datasets, and the results on mAP50, base and novel classes are shown in
Table 4. The results show that our method outperformed most algorithms. The performances of meta-YOLO were 46.2 and 51.7 on mAP50, which are the best for all methods. Fan et al. [
48] combined a two-way contrastive training strategy and attention RPN to construct an object detection frame that solved the problem of the poor generalization of few-shot. Although the attention RPN method mitigates the dependence on region proposals to some extent, its framework is still RPN and the detection backgrounds are complex traffic scenes, so its performance is worse than ours with scarce training samples. It is worth noting that the meta-DETR framework proposed by Zhang et al. [
47] is on a par with our model, and even better than ours in the novel class. We think this is mainly due to the semantic alignment mechanism (SAM) that, using a residual connection, aligns the high-level and low-level semantics and raises the function of regularization.
4.4. Ablation Studies
We constructed extensive ablation experiments to research how our proposed individual components contribute to the detection performance. The experiments used the TT100K base/novel split1 with 10-shot data on novel classes.
Effect of Feature Decorrelation Module (FDM). We introduced FDM into the model to utilize RFF to map non-linear indivisible features of raw space to a higher dimensional space, and transform these into linearly separable features, thereby obtaining the real features of the object. As shown in
Table 5 FDM is effective in hindering the reliance on category-specific features. Without FDM the method has a strong effect on the performance on novel classes, but is only slightly affected on base classes. With FDM included, the detection performance of the base and novel classes improves, which shows that the more generalizable representations are learned effectively.
Effect of meta-learner. Since Meta-YOLO is formally designed as a meta-learner, it is crucial to observe whether our method truly improves the performance. To verify our claim, we ablated the initialization term of the meta-learner to observe the object detection performances in the base and novel classes. As illustrated in
Table 6, our two-stage strategy significantly boosts the model generalization and learning capability.
Effect of three-head mechanism. We introduced a three-head mechanism with three different scale modules that complemented each other to predict objects within their respective specified ranges. As shown in
Table 6, the three-head mechanism achieves a significant improvement in the detection performance for base classes. With a limited number of base categories, it unavoidably has poor performance on novel classes.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}