1. Introduction
Globally, the number of mobile application users has increased dramatically. Besides that, many social networking sites have been developed allowing people to express their thoughts regarding controversial events or matters. This helps to increase the number of content creators who utilize social networking media such as Twitter, Facebook, and others. In addition, the users of these mobile applications can add reviews using different platforms such as Google Play and the App Store. These platforms allow users to be a part of content creators by posting comments regarding the content and quality of these applications. Due to the huge expansion of the content posted on these sites daily, institutions including government agents and private companies have exploited people’s expressions and opinions regarding the services or products that are provided online.
Sentiment analysis is the task of utilizing text mining, natural language processing (NLP), and computational linguistics approaches to systematically detect, analyze, and examine the users’ opinions appearing in subjective textual information. Sentiment analysis processes concentrate on detecting text containing opinions and deciding whether these opinions are positive, negative, or neutral comments [
1,
2]. Recently, sentiment analysis approaches have relied on inspecting opinions or emotions of diverse subjects, such as peoples’ opinions and impressions about movies, products, and daily affairs.
In the literature, several researchers have utilized supervised machine learning algorithms, especially classification methods, for sentiment analysis purposes, such as support vector machine (SVM) and naïve Bayes classifiers. Alomari [
3] showed that the SVM classifier with both TF-IDF and stemming outperformed the naïve Bayes classifier for Arabic tweets’ sentiment analysis. Similarly, Abuelenin et al. [
4] combined machine learning classifiers, ISRI Arabic stemmer, and the cosine similarity to propose a better-performing hybrid method. The experimental results in [
4] demonstrated that the ISRI Arabic stemmer with linear SVM can achieve higher accuracy compared to other stemmers, such as the Porter stemmer. In addition, Shoukry and Rafea [
5] used SVM and naïve Bayes classification algorithms for sentiment analysis. Unigram and bigram features were extracted to train the classifiers. The outcomes showed that SVM performed better than NB on the collected tweets using Twitter API.
On the other hand, deep neural networks (DNN) have been applied and shown a good performance compared to traditional machine learning in terms of detecting sentiments of short texts. A number of sentiment analysis studies have showed that convolution neural networks (CNN) and long–short-term memory networks (LSTM) [
6] outperform the traditional machine learning approaches to detect sentiment. In addition, combining LSTM with CNN [
7] showed promising results and surpassed the performance of the conventional machine learning models.
Several research works were conducted for Arabic sentiment analysis (ASA) that gained more interest recently, especially during the COVID-19 pandemic. According to [
8], there are three main approaches used for Arabic sentiment analysis, which are supervised, unsupervised, and hybrid methods. The research conducted obtained interesting outcomes, but at the same time, the results were more divergent because of the different types of methods used and Latin languages, where only a few research works were conducted for studying ASA, which focused on analyzing Arabic tweets. Therefore, more efforts are still needed to address the sentiment analysis of users’ reviews on mobile applications, especially the applications that provide governmental services in health, education, and other sectors. Recently, different mobile applications were developed in Saudi Arabia after the COVID-19 pandemic. According to the World Health Organization (WHO), Saudi Arabia actively participated in fighting COVID-19 nationally, regionally, and globally. Locally, the government has taken several urgent actions to fight COVID-19 in different sectors, such as health, education, security, Islamic affairs, and others. Several mobile applications were developed to provide online services. For instance, these healthcare applications, namely Tawakkalna, Tetaman, Tabaud, Sehhaty, Mawid, and Sehhah, were successfully launched and used by millions of users in Saudi Arabia during the COVID-19 pandemic. This study will review the most recent studies in this field and propose a sentiment classification approach for measuring user satisfaction toward governmental services’ mobile applications. This analysis will support the government officers to make better decisions regarding the improvements in the quality of the online services offered to citizens and residents. In addition, the paper will help the developers to improve any potential bugs or difficulties in these applications based on the users’ opinions and experiences.
The key contributions of this research paper can be summarized as follows:
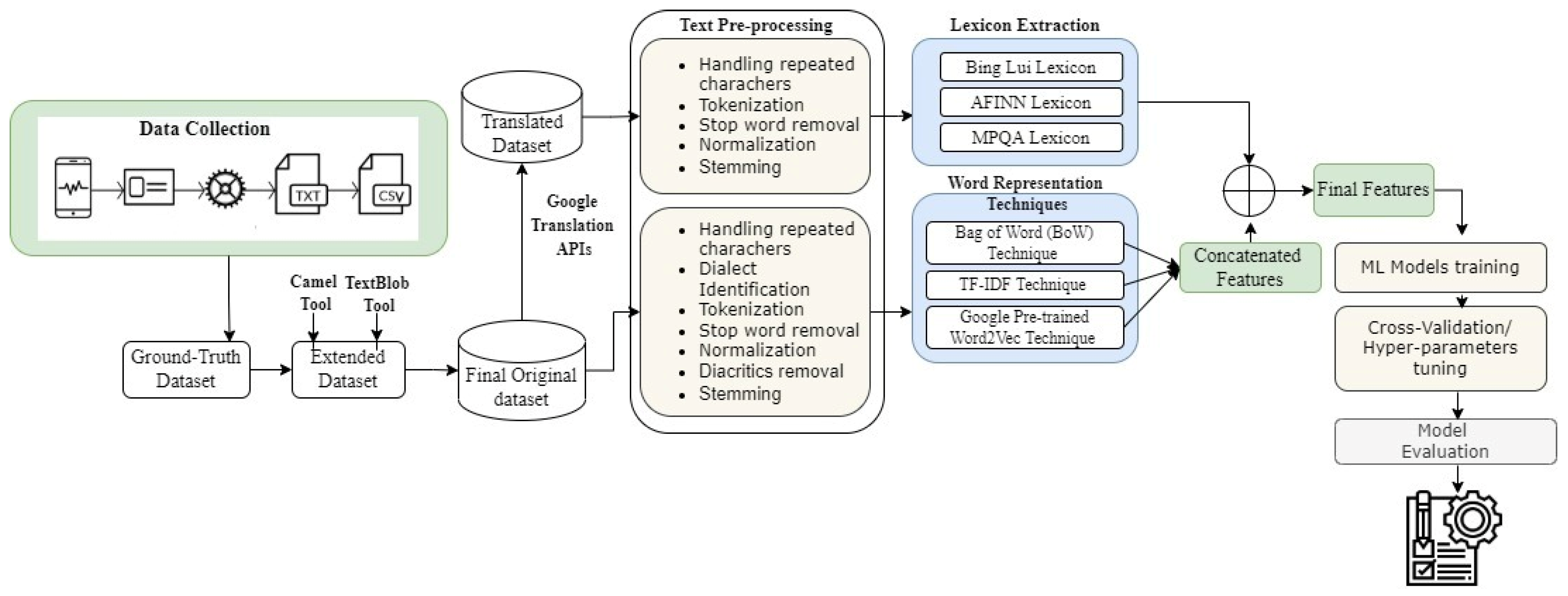
The original dataset finds the sentiment score for each review by running the Camel tool (
https://camel-tools.readthedocs.io/en/latest/api/sentiment.html) (accessed on 1 March 2022). However, the authors found that some reviews were labeled incorrectly. Thus, the dataset was enriched by several lexical dictionaries. In this study, the Arabic TextBlob lexical dictionary was integrated firstly for annotating the users’ reviews, and later the performance of the ML classifiers was compared with the original dataset labeled by the Camel tool.
Several feature engineering approaches, namely, Bing Liu lexicon, AFINN, and MPQA Subjectivity Lexicon, a bag of words (BoW), term frequency-inverse document frequency (TF-IDF), and the Google pre-trained Word2Vec, were integrated.
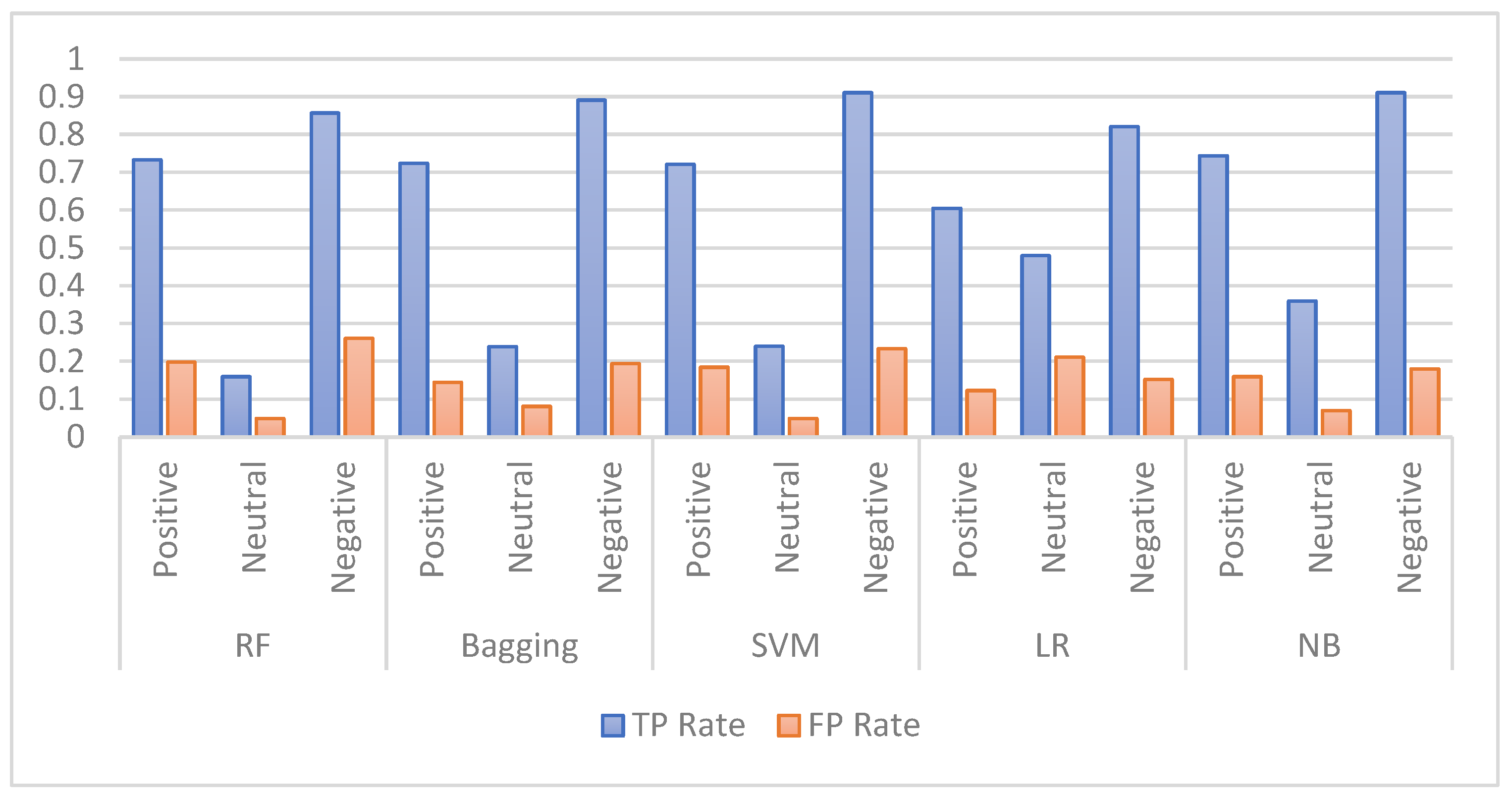
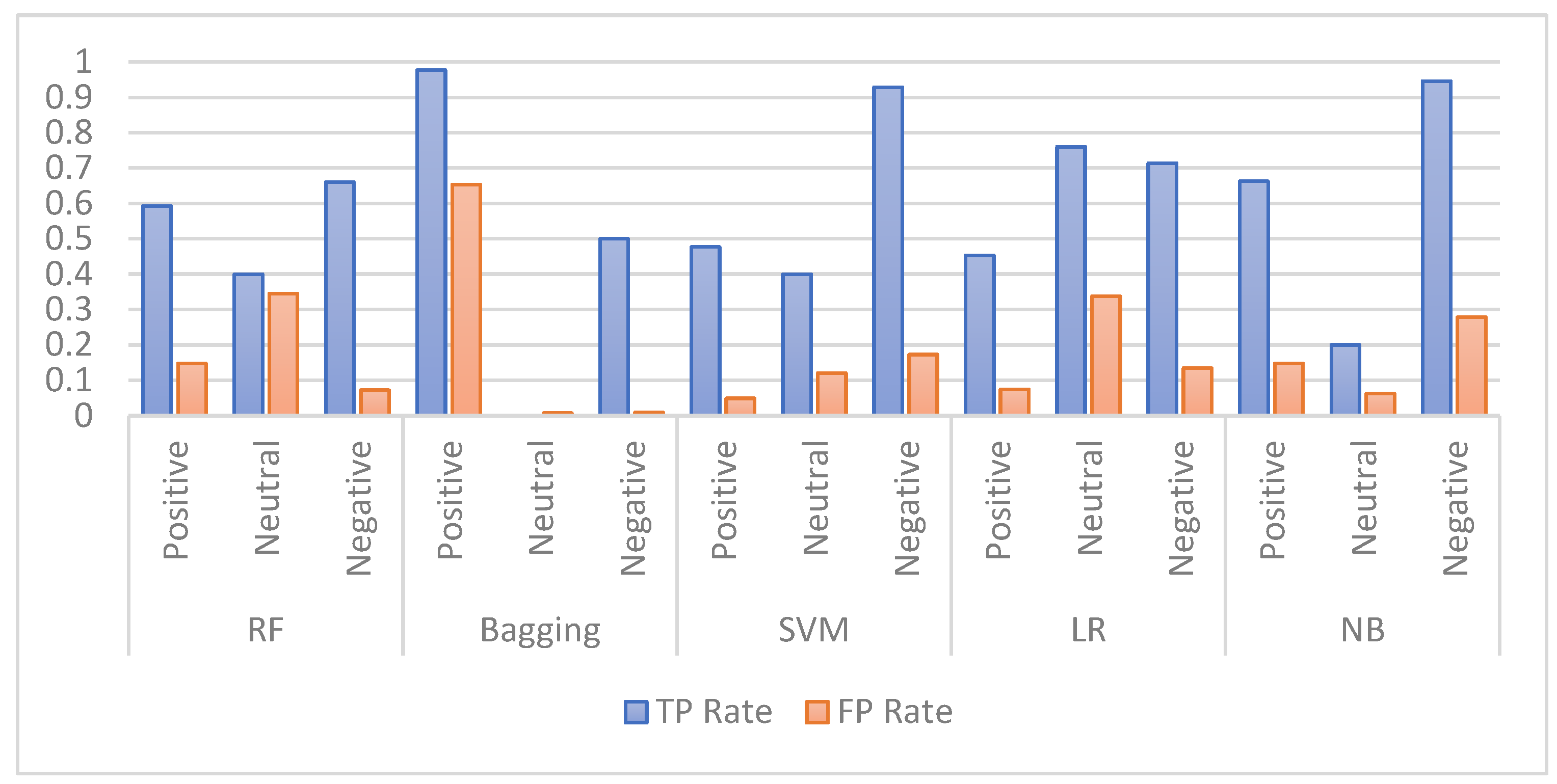
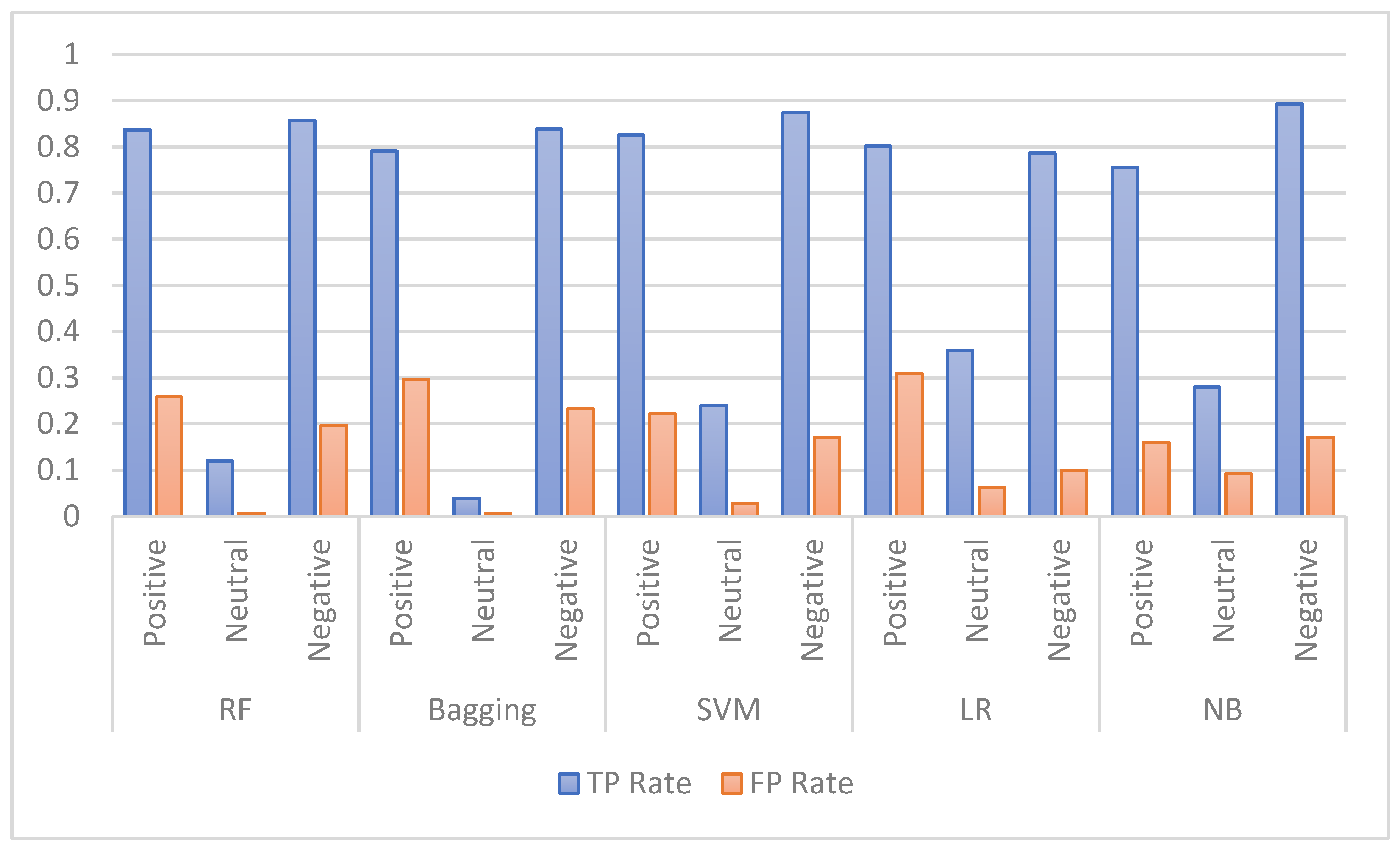
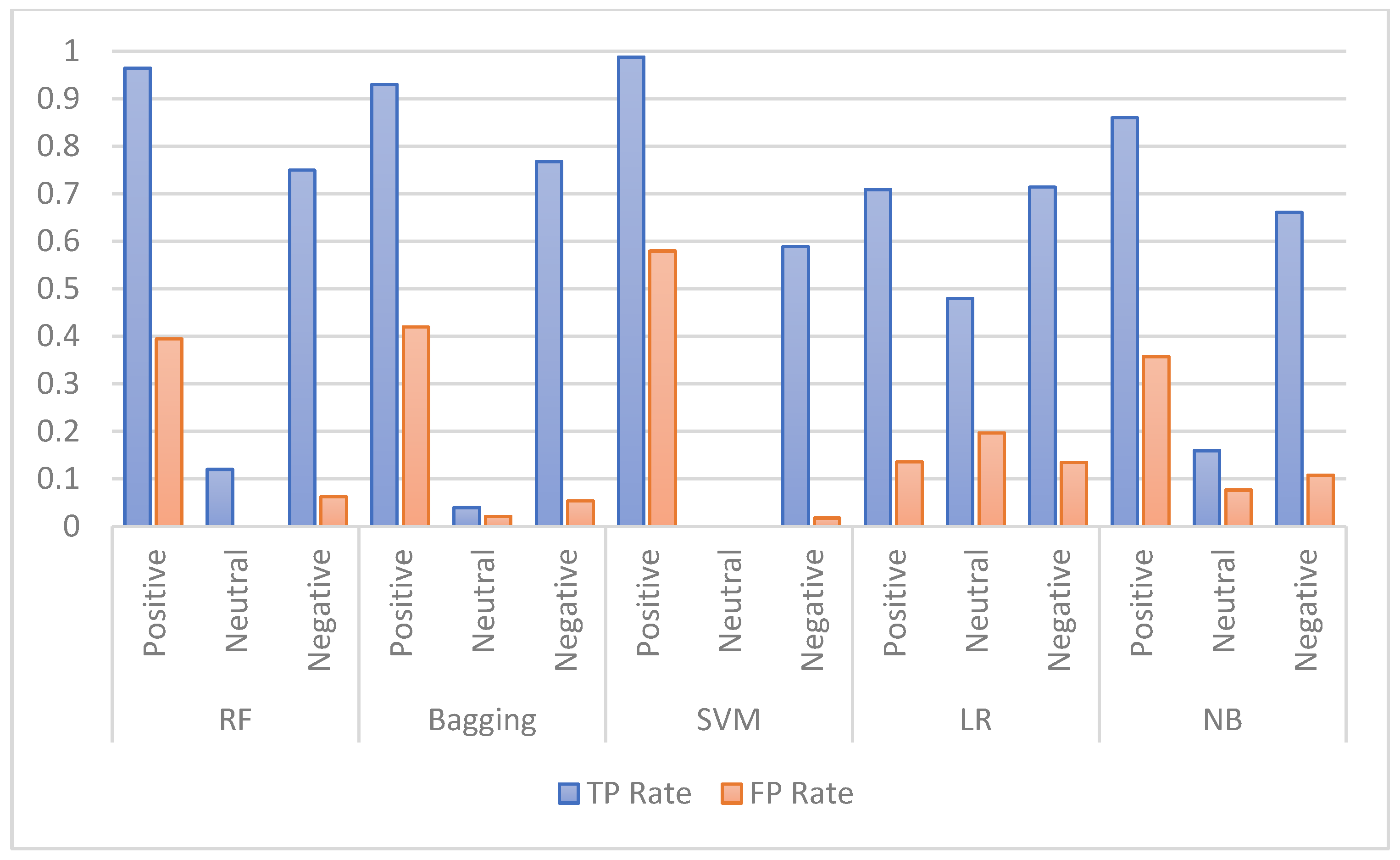
Several experiments were carried out in this study to compare the performance of the proposed feature extraction techniques using five ML models, including random forest (RF), bagging, support vector machine (SVM), logistic regression (LR), and naïve Bayes (NB).
The performance of the selected ML models was first investigated using an imbalanced dataset. Later, further experiments were performed using a balanced dataset. As balancing techniques, both under-sampling and oversampling were used. In this regard, the SMOTE technique was applied as a balancing technique on this dataset and obtained better enhancements.
The rest of the paper is organized as follows:
Section 2 presents the recent studies on Arabic sentiment analysis. The materials and methods are presented in
Section 3, which briefly describes the dataset along with the used preprocessing techniques. In addition, it explains the techniques and algorithms utilized in this research. In
Section 4, the results and discussions of the proposed approach are highlighted. Finally,
Section 5 concludes the whole paper.
2. Related Works
The Arabic language has special characteristics that add additional challenges when addressing the Arabic sentiment analysis. These challenges include morphological analysis, dialectal Arabic, Arabizi, and named entity recognition, in addition to the Arabic structure complexity and having different cultures [
8,
9]. This makes it necessary to conduct more research and propose new methods for enhancing the sentiment analysis in Arabic. More efforts were made to analyze data from Twitter for serval purposes, such as analyzing the users’ opinions about online learning during COVID-19. This section focuses on reviewing the existing studies that used machine leaching and deep learning for Arabic sentiment analysis. More focus will be given to the studies that were applied for addressing the sentiment analysis of the Saudi Arabia community.
According to [
10], there are many benefits to analyzing Arabic sentiment, such as showing valuable insights for different provided services [
11], recognizing the potential influencers in social media [
12], and email spam detection [
13]. There are three main strategies with different challenges for ASA, and these include preprocessing, feature generation, and selection and classification methods. Several studies proposed different methods for each of these strategies to enhance the performance of ASA. For instance, applying different preprocessing methods such as stemming, tokenization, and normalization can improve the performance of the sentiment analysis [
10]. In addition, the effect of stemming on the ASA problem was studied in [
14]. They used the Arabic root stemmer of Khoja and the light stemmer on two datasets and found that the latter performed better for sentiment classification.
Other studies highlighted the importance of data preprocessing for Arabic sentiment analysis. For instance, the authors of [
15] recommended that the preprocessing tools such as normalization, tokenization, and stop words’ removal should be utilized in all ASA studies to improve the performance of the analysis. Additionally, they recommended ending the preprocessing by applying stemming methods, although aggressive stemming was not recommended as it might change the Arabic words’ polarity.
It is worth mentioning that most of the research efforts on the Arabic language aimed to discuss the modern standard form. However, by browsing the social media websites, we can find that majority of the Arabic users used their dialects, which generates a huge amount of Arabic dialects texts [
16]. Different Arabic dialects were addressed, such as Saudi, Iraqi, Egyptian, Jordanian, Palestinian, and Algerian dialects [
16]. According to [
17], most of the studies focused on Jordanian (38%), Egyptian (23%), and Saudi (15%) dialects. For instance, Mustafa et al. [
18] applied automatic extraction of opinions on social media that are written in modern standard Arabic and Egyptian dialects, and they automatically analyzed sentiment into either positive or negative. Gamal et al. [
19] applied ML methods for analyzing the sentiment of Arabic dialects. They applied different classifiers using a labeled dataset and found that the classifiers obtained good results using different evaluation metrics.
To address the challenges of the Arabic language, Touahri and Mazroui [
20] created both stemmed and lemmatized versions of word lexicons for integrating the morphological notion. Then, a supervised model was constructed from a set of features. In addition, they semantically segmented the lexicon for reducing the vector’s size of the model and enhancing the execution time. In addition, Aloqaily et al. [
21] proposed lexicon-based and ML methods for sentiment analysis. They used the Arabic tweets dataset. The outcomes showed that ML methods, especially logistic model trees and SVM, outperformed the lexicon-based methods in predicting the subjectivity of tweets. The outcomes also showed the importance of applying feature selection for improving the performance of ASA.
Several studies were conducted on ASA in Saudi Arabia. For instance, Aljameel et al. [
22] developed a prediction model for people’s awareness of the precautionary procedures in Saudi Arabia. They used an Arabic COVID-19-related dataset that was generated from Twitter. Three predictive models were applied, which included SVM, K-NN, and naïve Bayes, with the N-gram feature extraction method. The experimental results showed that SVM with bigram in TF-IDF outperformed other methods, and obtained 85% of prediction accuracy. The applied method was recommended to help the decision-makers in the medical sectors to apply different procedures in each region in Saudi Arabia during the pandemic. In addition, the authors of [
23] studied the attitude of individuals in Saudi Arabia about online learning. They collected Arabic tweets posted in 2020 and applied sentiment analysis to this dataset. The results showed that people have maintained a neutral response toward online learning. The authors of [
24] also collected a dataset that includes 8144 tweets related to Qassim University in Saudi Arabia. They applied one-way analysis of variance (ANOVA) as a feature selection method for removing the irrelevant and redundant features for sentiment analysis of Arabic tweets. Then, the results showed that SVM and naïve Bayes achieved the best results with one-way ANOVA compared to other ML methods on the same dataset.
Deep learning was also applied to enhance the performance of Arabic sentiment analysis. Several studies utilized deep learning methods for this purpose; for instance, the authors of [
25] used an ensemble model that combined convolutional neural network (SNN) and long–short-term memory (LSTM) methods for analyzing the sentiment of Arabic tweets. The proposed model in [
25] achieved a 64.46% F1-score, which is considered higher than the applied deep learning methods on the same dataset. Moreover, the authors of [
26] proposed a feature ensemble model of surface (manually extracted) and deep (sentiment-specific word embedding) features. The models were applied on three Arabic tweets datasets. The results showed that the proposed ensemble of surface and deep features models obtained the highest performance for sentiment analysis. In addition, Mohammed and Kora [
27] proposed a corpus of 40,000 labeled Arabic tweets and applied 3 deep learning models for Arabic sentiment analysis, which were CNN, LSTM, and recurrent convolution neural network (RCNN). The results showed that LSTM outperformed CNN and RCNN with an average accuracy of 81.31%. Additionally, it was found that when data augmentation was applied to the corpus, the accuracy of LSTM increased by 8.3%. Another study on ASA [
28] applied the multilayer, bidirectional, long–short-term memory (BiLSTM) method, that used the pre-trained word-embedding vectors. The applied model showed a notable enhancement in the performance of sentiment analysis compared to other models. The authors of [
29] extracted Twitter data from different cities in Saudi Arabia. NLP and ML methods were used to analyze the sentiments of individuals during the COVID-19 pandemic. This research collected Arabic tweets, and then after manual annotation to classify the tweets into different sentiments, such as negative, positive, neutral, etc., they applied LSTM and naïve Bayes for classification. Similar to other studies, the results here showed that the LSTM model performed better than other models and obtained high accuracy. In [
30], the performance of ML-based models, as well as the performance of deep learning models such as CNN, LSTM, CNN-LSTM, and Bi-LSTM, was examined using a set of 17,155 tweets about e-learning systems. The authors adopted TextBlob, VADER (Valence Aware Dictionary for Sentiment Reasoning), and SentiWordNet to analyze the polarity and subjectivity score of tweets’ text. To ensure the quality of the dataset, the SMOTE technique was applied as a balancing technique for the dataset. The results showed that the TextBlob technique yielded the best accuracy of 94% when applied with the Bi-LSTM model. The performance of the CNN-LSTM model was also investigated in [
31]. Although the model was tested on three non-Arabic datasets, the results demonstrated that combining CNN and LSTM is a good idea and produces a stable performance against the three datasets.
Referring to the studies conducted in the literature, we can obviously find that most of the studies were conducted using tweet datasets. This is maybe because the researchers prefer to use short text datasets. However, little attention was given to analyzing the huge amount of users’ reviews for important mobile applications, such as governmental mobile apps. Therefore, this study investigates the analysis of sentiments for the Arabic dataset collected for six mobile apps available on the Google Play Store. The study also proposed a sentiment classification approach for measuring user satisfaction toward these governmental services’ mobile apps.
5. Conclusions
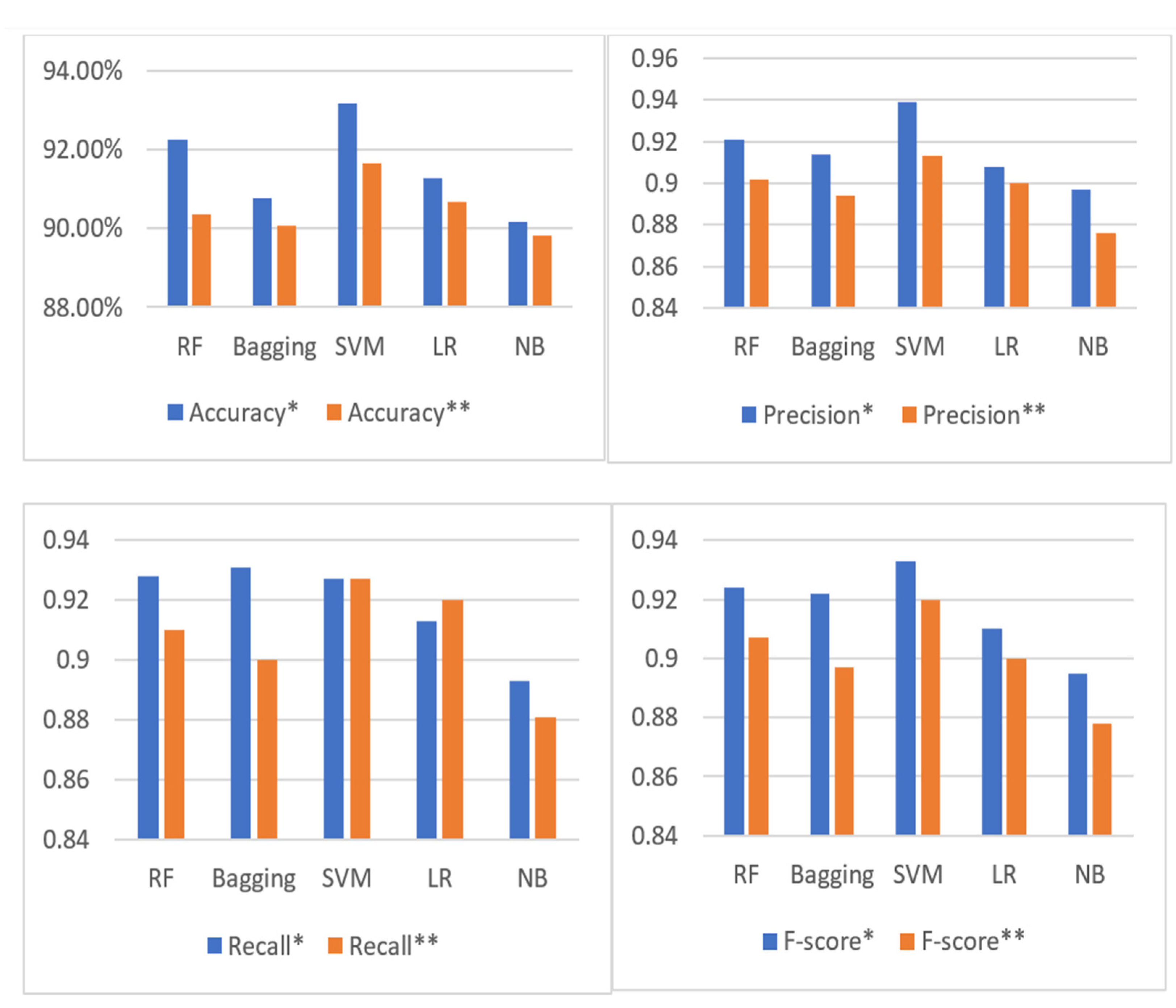
This paper presented the Arabic sentiment analysis on the reviews of six governmental mobile applications from Google Play and the App Store. Several ML models were applied to the AppsReview dataset, which includes 51k reviews. These ML methods were: RF, bagging, SVM, LR, and NB. In the conducted experiments, we evaluated the ML performance by integrating different feature extraction techniques, which were Bing Lui, AFINN, and MPQA lexicons. In addition, the performance of the ML models was investigated using an imbalanced and a balanced dataset. As balancing techniques, both under-sampling and oversampling were used. In this regard, the SMOTE technique was applied as an oversampling technique. The experimental results showed that when the features were extracted by BoW using the sentiments of the original Arb-AppsReview dataset, the NB classifier performed better than the other models (74.25% for accuracy). Then, when the TextBlob sentiment tool was applied to the Arb-AppsReview dataset, it was found that all classifiers performed better when the extracted features were concatenated. Among all the classifiers, SVM yielded the highest accuracy of 91.67%. Then, the findings showed that the highest accuracy score of 93.17% was achieved by SVM when it was integrated with the concatenated features and the features extracted by the proposed lexicons. Finally, the outcomes of the ML models using the SMOTE technique, the concatenated features, and all lexicons obtained the best results. For instance, SVM with these preprocessing methods obtained an accuracy of 94.38%, which overcame all other models. This study recommends applying the used feature engineering methods with the SMOTE oversampling technique to obtain better ASA results. Since the proposed model relies on the translation of reviews using google translation, the quality of the model might be affected by the quality of the translation. For future work, it is recommended to investigate the machine translation techniques to obtain high-quality translations that might increase the model performance. Additionally, it is recommended to explore the effect of applying different feature extraction and selection methods to the dataset used in this research and conduct more experiments that apply different combinations of deep learning methods on the Arb-AppsReview dataset to enhance the Arabic sentiment analysis.






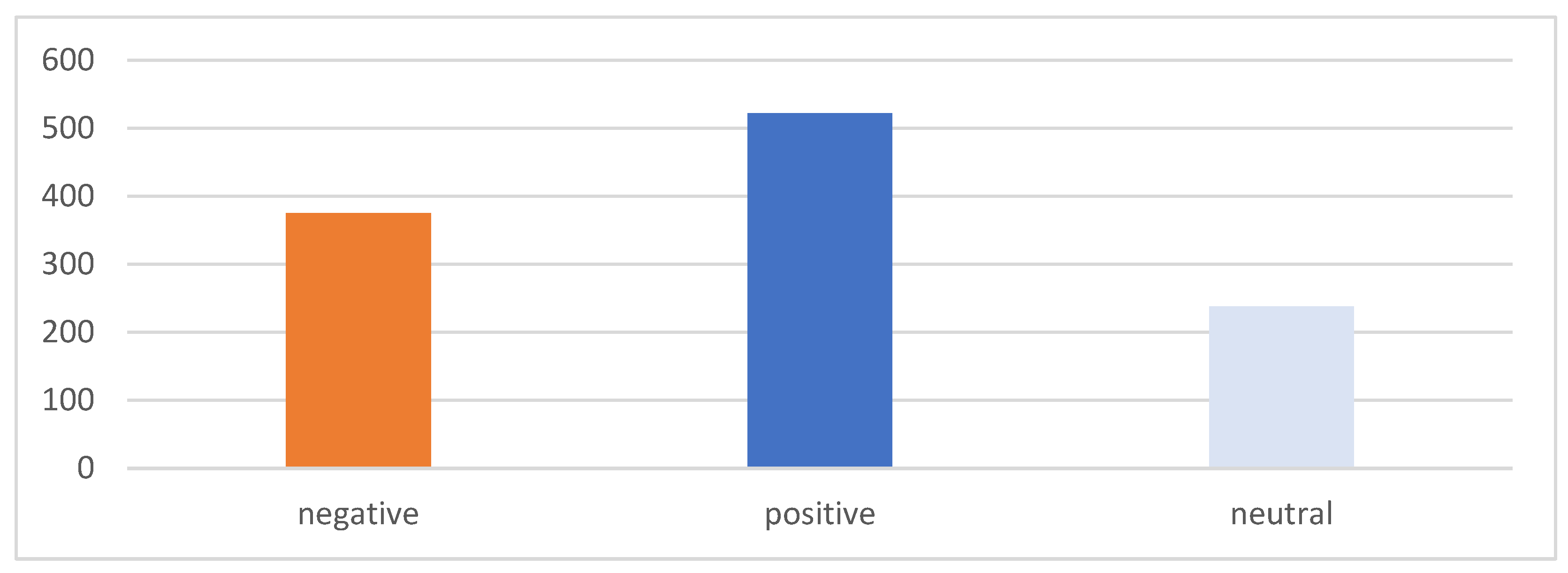




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}