
Food Risk Entropy Model Based on Federated Learning


Abstract
:1. Introduction
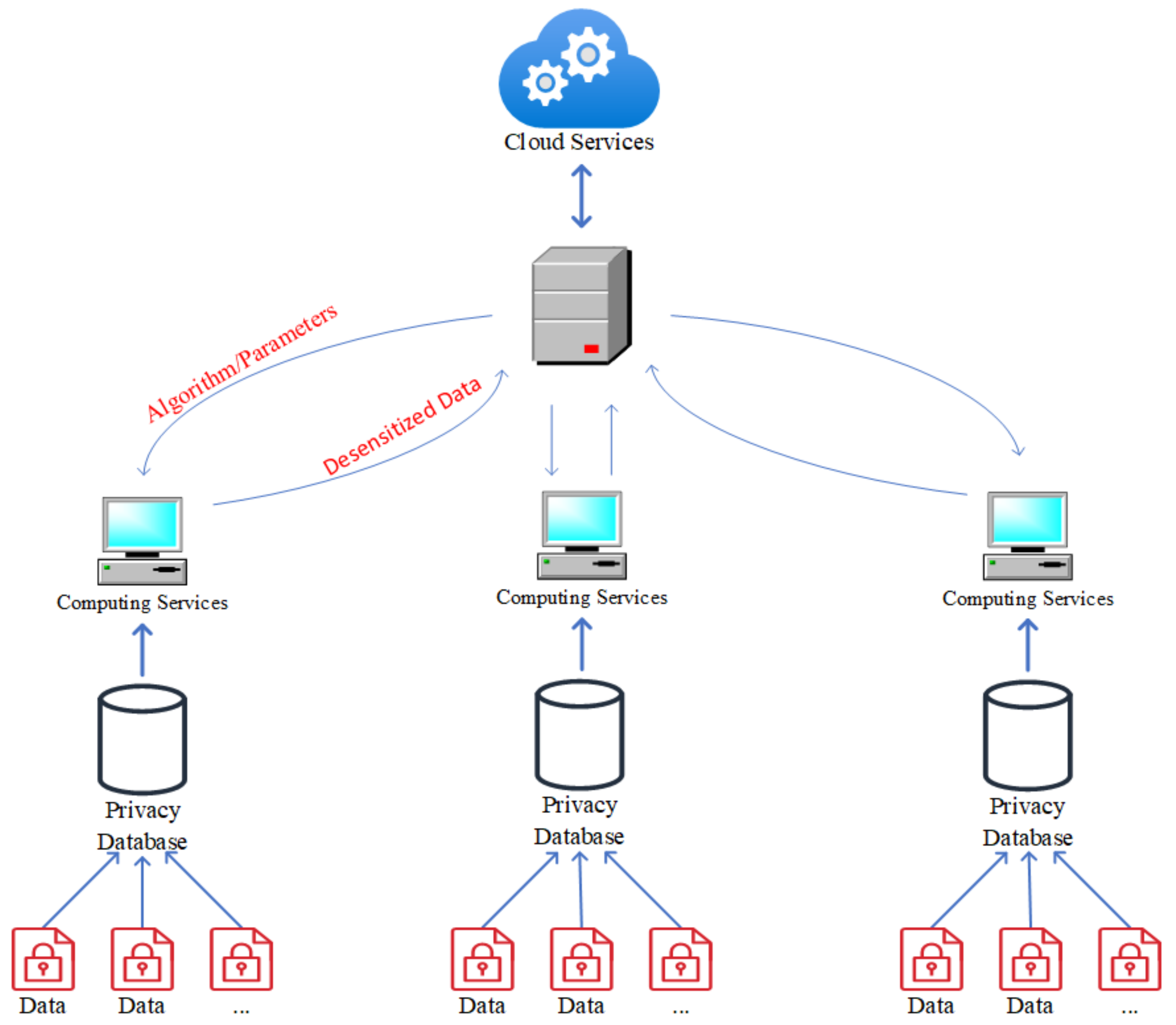
- Data Silos: From the Figure 1, we can see that the data among various departments are private and cannot be exchanged. Hence, this has caused isolated data to form between different departments and regions. The isolated data has the significant impact on the macroscopic evaluation in food safety. The current work reflect only one aspect of risk in the area of food safety, while it is not comprehensive. Due to the protection of sampling data, the data is not fully used because that the isolation of data between various places.
- Quantitative Evaluation Metrics: The food testing institutions take sample at the national, provincial, and local levels, which is only a qualitative summary of pesticide residues in fruits and vegetables. There is no quantitative indicator to analyze the risk of pesticide residues of the sample. The pass rate and residue rate are common indicators for evaluating the risk of pesticide residues in food safety. In terms of the pass rate, pesticide residues are inevitable even if they pass the check. The accumulation of pesticides can also lead to risks. In terms of the residue rate, it can only qualitatively indicate the presence or absence of pesticide residues in a sample, not quantitatively indicate the level of specific residues.
- 1
- The federated learning server sends the calculation method, parameters, and data format of risk entropy to the clients in each department. The data format is shown in Section 4.1 in Table 1.
- 2
- According to the standard data format, privacy data is statistically grouped by year, quarter, province, category, and product to represent the features.
- 3
- Selecting features of different dimensions to form the privacy data within the group (e.g., year is 2019 and quarters are 1 and 2).
- 4
- Risk entropy is calculated for the data within the group. The privacy data is calculated in the clients of each department, and the risk entropy is uploaded to the server for aggregation and macroscopic evaluation.
- 5
- Transferring the summarized risk entropy data to the clients of each department.
- 1
- We have designed a federated learning model to solve the data gap of various departments, which can maximize the use of data to optimize the model.
- 2
- We have designed a model for calculating the risk entropy of pesticide residues in fruits and vegetables, which can quantitatively to analyze the sampling data.
- 3
- We have developed a multi-dimensional data analyzing tool to calculate the risk entropy by selecting different dimensions and categories of data automatically.
- 4
- Our approach pioneers the latest models and provides novel insights. Notably, this paper can provide policymakers, environmental engineers, and agricultural technicians with important insights on soil pollution control and management strategies and technologies.
2. Related Work
2.1. Federated Learning
2.2. Food Security
3. The Quantitative Evaluation Method Based on Risk Entropy
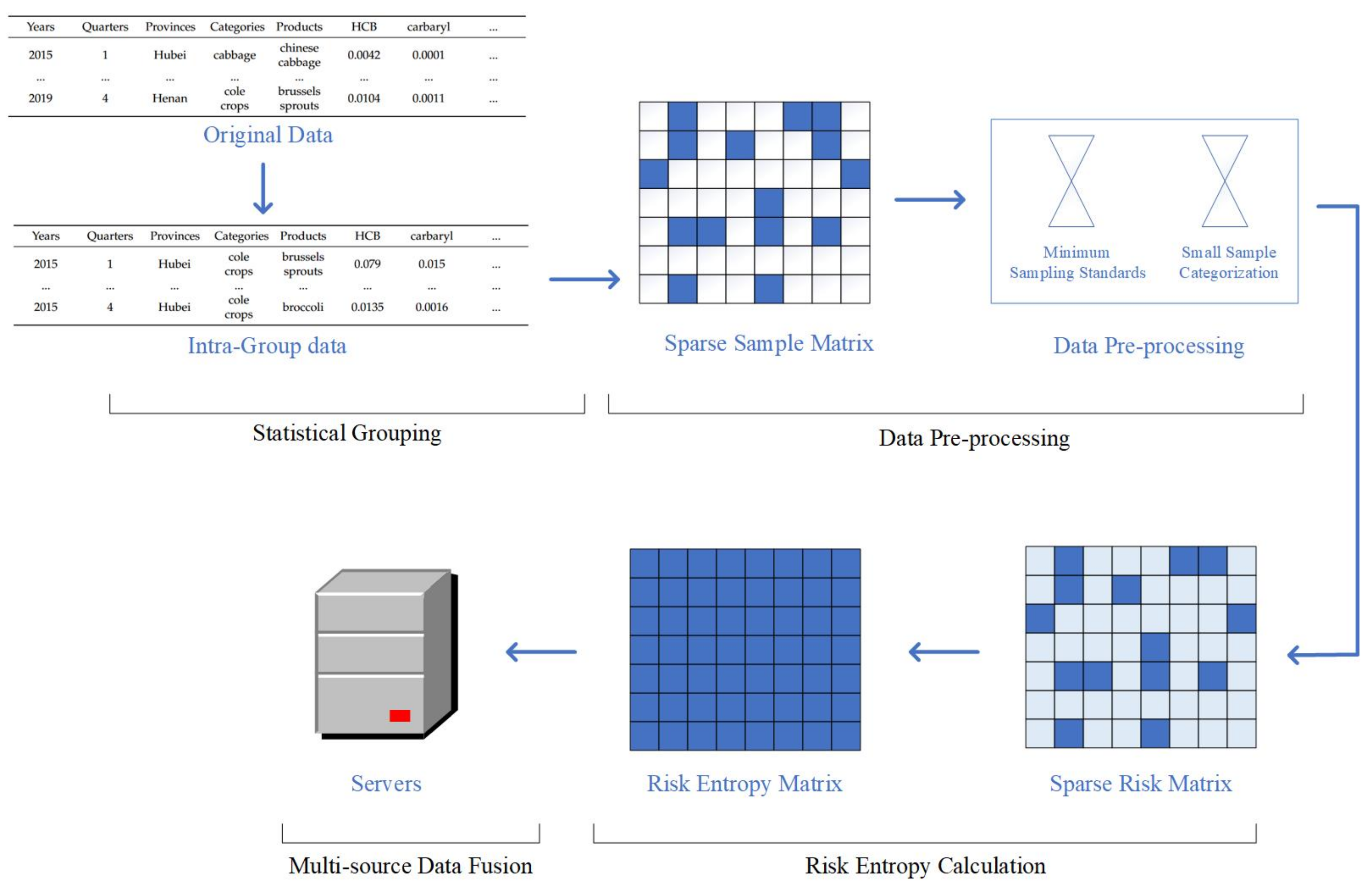
3.1. Workflow
3.2. Statistical Grouping
3.3. Data Pre-Processing
3.4. Risk Entropy Calculation
3.5. Multi-Departments Data Fusion
4. Experimental Setup
4.1. Dataset
4.2. Experimental Results
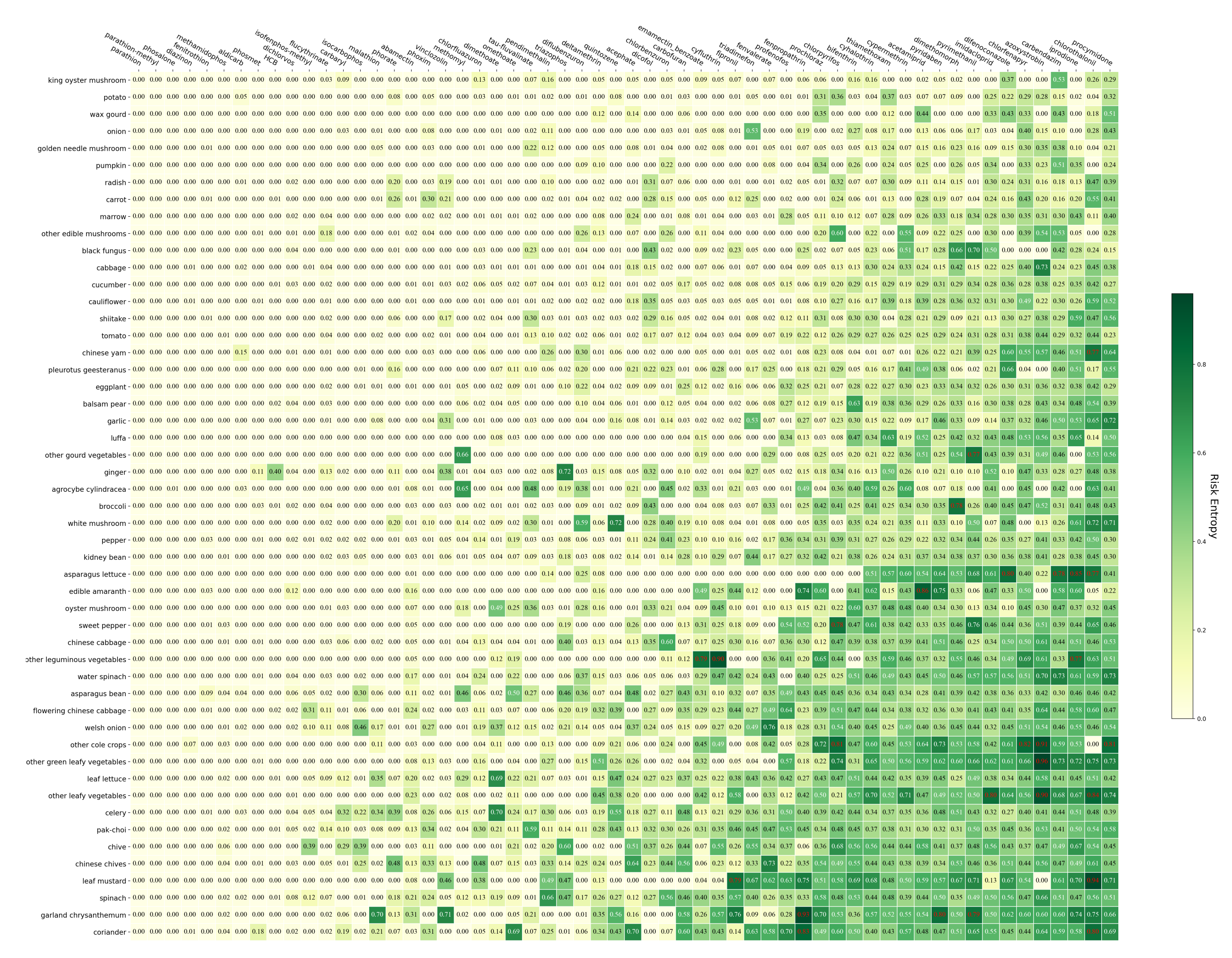
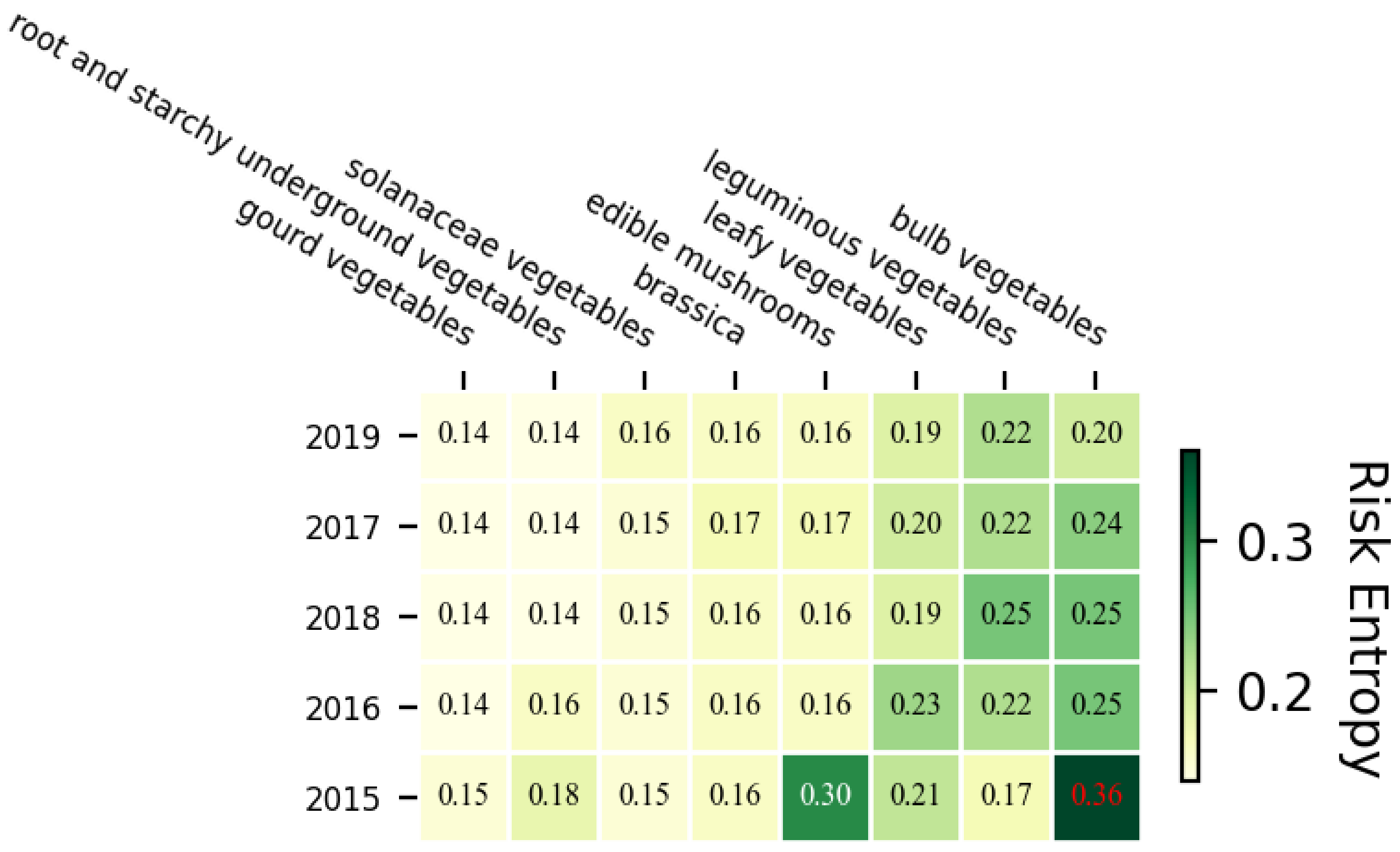
4.2.1. The Risk Entropy of Pesticide Residues
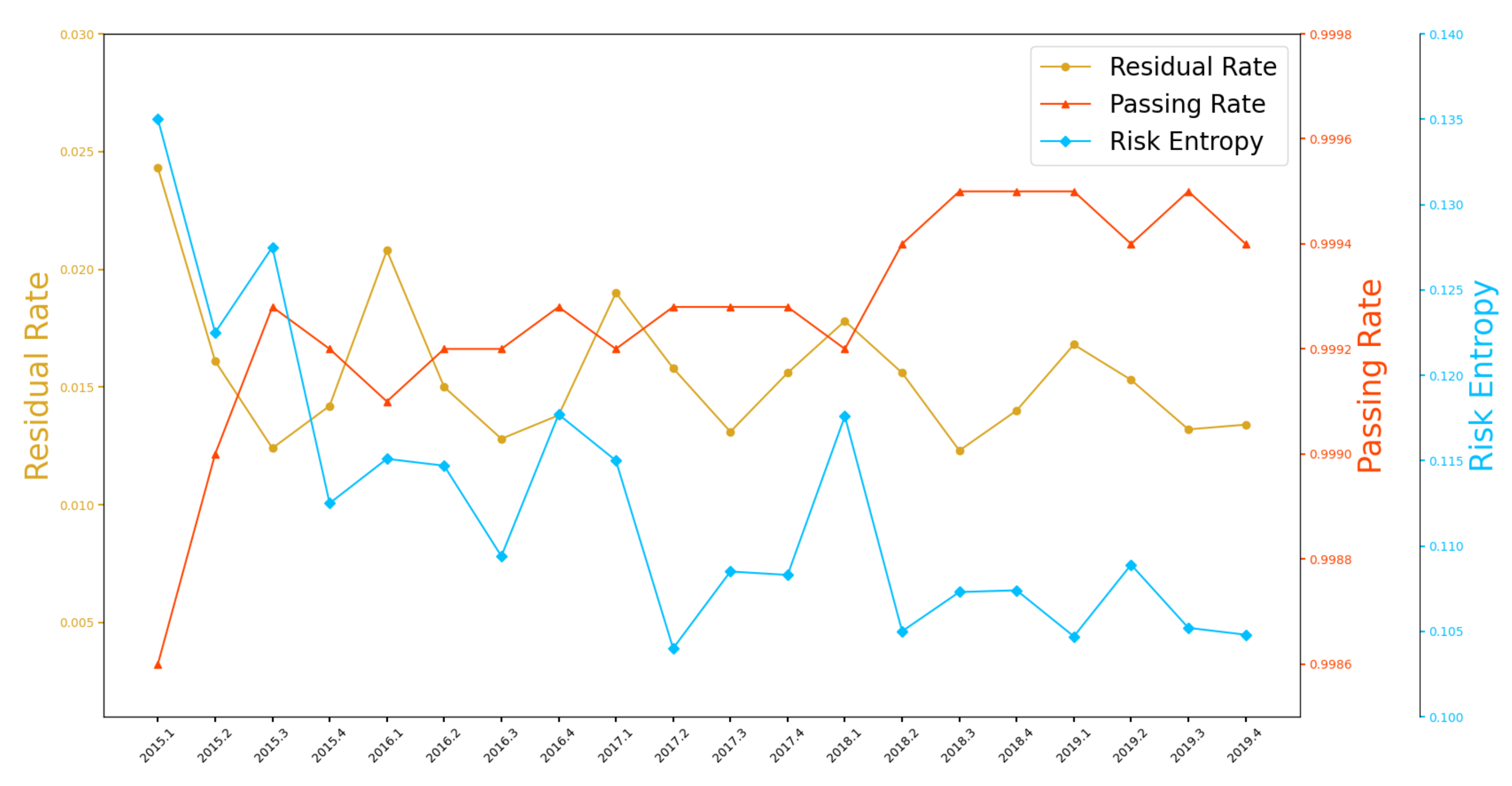
4.2.2. Overall Evaluation
4.2.3. The Multi-Dimensional Data Analysis Tool
5. Threats of Validity
6. Conclusions and Future Work
6.1. Conclusions
6.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Borchers, A.; Teuber, S.S.; Keen, C.L.; Gershwin, M.E. Food safety. Clin. Rev. Allergy Immunol. 2010, 39, 95–141. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Min, W.; Yang, J.; Liu, T.; Jiang, S.; Rui, Y. What If We Could Not See? Counterfactual Analysis for Egocentric Action Anticipation. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 1316–1322. [Google Scholar]
- Tirado, M.C.; Clarke, R.; Jaykus, L.; McQuatters-Gollop, A.; Frank, J. Climate change and food safety: A review. Food Res. Int. 2010, 43, 1745–1765. [Google Scholar] [CrossRef]
- Ehuwa, O.; Jaiswal, A.K.; Jaiswal, S. Salmonella, food safety and food handling practices. Foods 2021, 10, 907. [Google Scholar] [CrossRef] [PubMed]
- Maurya, A.; Prasad, J.; Das, S.; Dwivedy, A.K. Essential oils and their application in food safety. Front. Sustain. Food Syst. 2021, 5, 133. [Google Scholar] [CrossRef]
- Cheng, W.; Tang, X.; Zhang, Y.; Wu, D.; Yang, W. Applications of metal-organic framework (MOF)-based sensors for food safety: Enhancing mechanisms and recent advances. Trends Food Sci. Technol. 2021, 112, 268–282. [Google Scholar] [CrossRef]
- Ataei, P.; Sadighi, H.; Izadi, N. Major challenges to achieving food security in rural, Iran. Rural. Soc. 2021, 30, 15–31. [Google Scholar] [CrossRef]
- Nordhagen, S. Food safety perspectives and practices of consumers and vendors in Nigeria: A review. Food Control 2022, 134, 108693. [Google Scholar] [CrossRef]
- Qin, G.; Niu, Z.; Yu, J.; Li, Z.; Ma, J.; Xiang, P. Soil heavy metal pollution and food safety in China: Effects, sources and removing technology. Chemosphere 2021, 267, 129205. [Google Scholar] [CrossRef]
- Wang, T.; Wang, S.; Cheng, Z.; Wei, J.; Yang, L.; Zhong, Z.; Hu, H.; Wang, Y.; Zhou, B.; Li, P. Emerging core–shell nanostructures for surface-enhanced Raman scattering (SERS) detection of pesticide residues. Chem. Eng. J. 2021, 424, 130323. [Google Scholar] [CrossRef]
- Oo, L.M.; Aung, N.Z. A simple and efficient method for automatic strawberry shape and size estimation and classification. Biosyst. Eng. 2018, 170, 96–107. [Google Scholar] [CrossRef]
- Sørensen, L.B.; Møller, P.; Flint, A.; Martens, M.; Raben, A. Effect of sensory perception of foods on appetite and food intake: A review of studies on humans. Int. J. Obes. 2003, 27, 1152–1166. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, B.; Pu, H.; Sun, D.W. Multifunctional cellulose based substrates for SERS smart sensing: Principles, applications and emerging trends for food safety detection. Trends Food Sci. Technol. 2021, 110, 304–320. [Google Scholar] [CrossRef]
- Tuglo, L.S.; Agordoh, P.D.; Tekpor, D.; Pan, Z.; Agbanyo, G.; Chu, M. Food safety knowledge, attitude, and hygiene practices of street-cooked food handlers in North Dayi District, Ghana. Environ. Health Prev. Med. 2021, 26, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Jacquet, F.; Butault, J.P.; Guichard, L. An economic analysis of the possibility of reducing pesticides in French field crops. Ecol. Econ. 2011, 70, 1638–1648. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Tao, Y. Food safety inspection using “from presence to classification” object-detection model. Pattern Recognit. 2001, 34, 2331–2338. [Google Scholar] [CrossRef]
- Harris, M. Comment on Vayda’s review of good to eat: Riddles of food and culture. Hum. Ecol. 1987, 15, 511–517. [Google Scholar] [CrossRef]
- Henson, S.; Caswell, J. Food safety regulation: An overview of contemporary issues. Food Policy 1999, 24, 589–603. [Google Scholar] [CrossRef] [Green Version]
- Rahman, M.; Hoque, M.S.; Bhowmik, S.; Ferdousi, S.; Kabiraz, M.P.; van Brakel, M.L. Monitoring of pesticide residues from fish feed, fish and vegetables in Bangladesh by GC-MS using the QuEChERS method. Heliyon 2021, 7, e06390. [Google Scholar] [CrossRef]
- Darko, G.; Acquaah, S.O. Levels of organochlorine pesticides residues in meat. Int. J. Environ. Sci. Technol. 2007, 4, 521–524. [Google Scholar] [CrossRef] [Green Version]
- Masud, T. Determination of pesticides residues in selected varieties of mango. Pak. J. Nutr. 2002, 1, 41–42. [Google Scholar]
- Qin, G.; Chen, Y.; He, F.; Yang, B.; Zou, K.; Shen, N.; Zuo, B.; Liu, R.; Zhang, W.; Li, Y. Risk assessment of fungicide pesticide residues in vegetables and fruits in the mid-western region of China. J. Food Compos. Anal. 2021, 95, 103663. [Google Scholar] [CrossRef]
- Yitian Shao, Y.W. Pesticide Residues and Government Regulation in China—Evidence from Pesticide Residues in Fruits and Vegetables. Agric. Sci. Technol. 2021, 22, 42–49. [Google Scholar]
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated learning. Synth. Lect. Artif. Intell. Mach. Learn. 2019, 13, 1–207. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farhad, F.; Jin, S.; Quek, T.; Poor, H.V. Federated Learning with Differential Privacy: Algorithms and Performance Analysis. IEEE Trans. Inf. Forensics Secur. 2019, 15, 3454–3469. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Huang, A.; Luo, Y.; Huang, H.; Yang, Q. FedVision: An Online Visual Object Detection Platform Powered by Federated Learning. Proc. AAAI Conf. Artif. Intell. 2020, 34, 13172–13179. [Google Scholar] [CrossRef]
- Long, G.; Tan, Y.; Jiang, J.; Zhang, C. Federated learning for open banking. In Federated Learning; Springer: Berlin/Heidelberg, Germany, 2020; pp. 240–254. [Google Scholar]
- Brisimi, T.S.; Chen, R.; Mela, T.; Olshevsky, A.; Paschalidis, I.C.; Shi, W. Federated learning of predictive models from federated electronic health records. Int. J. Med. Inf. 2018, 112, 59–67. [Google Scholar] [CrossRef]
- Hou, Q.; Min, W.; Wang, J.; Hou, S.; Zheng, Y.; Jiang, S. FoodLogoDet-1500: A Dataset for Large-Scale Food Logo Detection via Multi-Scale Feature Decoupling Network. In Proceedings of the 29th ACM International Conference on Multimedia, Newark, NJ, USA, 27–30 June 2021; pp. 4670–4679. [Google Scholar]
- Liu, X.; Min, W.; Mei, S.; Wang, L.; Jiang, S. Plant disease recognition: A large-scale benchmark dataset and a visual region and loss reweighting approach. IEEE Trans. Image Process. 2021, 30, 2003–2015. [Google Scholar] [CrossRef]
- Min, W.; Liu, L.; Wang, Z.; Luo, Z.; Wei, X.; Wei, X.; Jiang, S. Isia food-500: A dataset for large-scale food recognition via stacked global-local attention network. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 393–401. [Google Scholar]
- Jiménez, A.R.; Jain, A.K.; Ceres, R.; Pons, J.L. Automatic fruit recognition: A survey and new results using range/attenuation images. Pattern Recognit. 1999, 32, 1719–1736. [Google Scholar] [CrossRef]
- Kate, K.; Negi, S.; Kalagnanam, J. Monitoring food safety violation reports from internet forums. In e-Health–For Continuity of Care; IOS Press: Amsterdam, The Netherlands, 2014; pp. 1090–1094. [Google Scholar]
- Tao, D.; Yang, P.; Feng, H. Utilization of text mining as a big data analysis tool for food science and nutrition. Compr. Rev. Food Sci. Food Saf. 2020, 19, 875–894. [Google Scholar] [CrossRef] [Green Version]
- Bouzembrak, Y.; Marvin, H.J. Impact of drivers of change, including climatic factors, on the occurrence of chemical food safety hazards in fruits and vegetables: A Bayesian Network approach. Food Control 2019, 97, 67–76. [Google Scholar] [CrossRef]
- Geng, Z.; Shang, D.; Han, Y.; Zhong, Y. Early warning modeling and analysis based on a deep radial basis function neural network integrating an analytic hierarchy process: A case study for food safety. Food Control 2019, 96, 329–342. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Years | Quarters | Provinces | Categories | Products | DR | … | DR |
|---|---|---|---|---|---|---|---|
| 2022 | 4 | Hubei | leafy vegetables | Chinese cabbage | 0.005 | … | 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Chen, Y.; Wang, Z.; Liu, J.; Huang, B. Food Risk Entropy Model Based on Federated Learning. Appl. Sci. 2022, 12, 5174. https://doi.org/10.3390/app12105174
Yu J, Chen Y, Wang Z, Liu J, Huang B. Food Risk Entropy Model Based on Federated Learning. Applied Sciences. 2022; 12(10):5174. https://doi.org/10.3390/app12105174
Chicago/Turabian StyleYu, Jiaojiao, Yizhou Chen, Zhenyu Wang, Jin Liu, and Bo Huang. 2022. "Food Risk Entropy Model Based on Federated Learning" Applied Sciences 12, no. 10: 5174. https://doi.org/10.3390/app12105174
APA StyleYu, J., Chen, Y., Wang, Z., Liu, J., & Huang, B. (2022). Food Risk Entropy Model Based on Federated Learning. Applied Sciences, 12(10), 5174. https://doi.org/10.3390/app12105174