1. Introduction
Nowadays, as the data dimension and quantity increases, distributed local servers are essential in storing large-scale data. The distributed framework enables many equivalent local servers to seek the solution to the same class of problems, where specific servers may provide insight for other servers. This process is usually achieved by iteratively exchanging information between local servers, namely, in multi-round communication, to partially improve the way they accomplish their tasks. As increasing scenarios, such as financial [
1], medical [
2], and biomedical [
3] tasks, come into view, where they usually hold the sensitive and limited scale of datasets in a distributed manner, the distributed systems shall offer a relatively safe and efficient way to obtain a satisfying result.
There have been many works on distributed systems in the past decades, especially in classification [
4,
5] and regression [
6,
7,
8,
9]. However, the discussion about distributed generalized eigenvalue problem (GEP) is rare. GEP is known as another important type of learning task that involves (generalized) eigenvalue decomposition (GED), including Singular Value Decomposition (SVD) [
10], Principal Component Analysis (PCA) [
11], Canonical Correlation Analysis (CCA) [
12], etc. In optimization, such problems can be formulated in the following way:
where
is a symmetric matrix,
is a positive definite matrix, and
denotes the conjugate transpose matrix of
w. The optimization problem has an equivalent solution to
[
13], which pursues the maximum eigenvalue
of the symmetric data covariance
with an invertible matrix
B. In short, (
1) finds the generalized eigenvector
w corresponding to the largest eigenvalue of the data covariance. Then, we can build the relationship between GEP and GED. The Lagrangian for (
1) is given by:
where
is the Lagrange multiplier. By equating the derivation of Lagrangian to zero, we obtain the generalized eigenvalue decomposition as below:
where
denotes the generalized eigenvector of GEP with respect to the generalized eigenvalue
.
Since GEP plays a vital role in a large family of high-dimensional statistical models, distributed algorithms for GEP are desired. However, only some variant cases are discussed in the distributed manner. There are two common variants of GEP whose distributed algorithms are well studied. On the one hand, when the constraint of (
1) is linear, distributed linearly constrained minimum variance (LCMV) is widely used in signal processing [
14,
15] with the same objective function in beamforming. However, its algorithms cannot deal with quadratic constraints in GEP obviously. On the other hand, when
B in (
1) is an identity matrix, GEP turns to the ordinary eigenvalue problem (EP). Moreover, distributed algorithms for EP are numerous due to its good characteristics. Further in detail, when
A is symmetric, it is PCA, and it is SVD otherwise. For one-shot communication with efficiency, distributed PCA algorithms are given in [
16,
17,
18]. In addition, distributed SVD [
19] conducts distributed averaging over measurement vectors in one-shot communication. For iterative communication, a distributed sparse PCA [
20] is proposed based on the power method, which is numerically efficient for the large-scale data. In addition, distributed SVD methods in [
21,
22] utilize the distributed power method in both the centralized and decentralized way. However, the distributed algorithms mentioned above cannot be used in distributed GEP because, in distributed systems, the sum of the local covariance matrices of GEP does not equal to the global centered covariance matrix while it equals in EP. We call this phenomenon the divergence of data covariance, which has been neglected in the previous work. Thus, although these distributed algorithms above perform well in theory and practice, they cannot be directly applied to distributed GEP. Due to the distributed data storage method, some techniques, e.g., partial differential equations, used in non-linear systems [
23,
24] cannot be used in distributed GEP. In brief, there is not a general distributed algorithm for GEP formulated as in (
1).
To solve GEP in a distributed manner, in this paper, we propose a one-shot algorithm with high communication efficiency and bounded approximation error. To our best knowledge, it is the first sample-distributed algorithm for GEP. The key is to estimate the centered global covariance from local empirical data covariances. Generally, there are two types of distributed algorithms: multi-round communication and one-shot. Algorithms with multi-round communication are usually more accurate but suffer from the high communication cost and the privacy risk. One-shot algorithms overcome these shortcomings but require better design and approximation analysis. Thus, for the proposed algorithm, we investigate the upper bound of the approximation error, and show it is concerned with the eigenvalues of the empirical data covariance and the number of local servers.
To demonstrate the effectiveness of the proposed distributed algorithm in practice, we consider Fisher’s Discriminant Analysis (FDA) [
25] and CCA as specific applications of GEP. Among them, distributed FDA achieves remarkable performance in the learning task of binary classification. However, CCA is more special for its symmetric self-adjoint dilation [
26] of the empirical covariance matrix in the GEP form. When using the power method (PM), which is commonly used to solve GEP for computation efficiency, the iterations become inefficient due to the repeated non-zero generalized eigenvalues of the covariance matrix, namely, no eigengap (see Corollary 1 in [
27]). Note that such a problem only exists in sample-distributed CCA while not in feature-distributed ones [
28,
29]. To solve this problem in the sample-distributed setting, we reformulate the objective function of CCA and further propose the distributed multiple CCA algorithm for better convergence in the experiments.
The main contributions of the paper are summarized as follows:
The first one-shot distributed algorithm is specially designed for the Generalized Eigenvalue Problem (GEP) with communication efficiency.
The efficient reformulated distributed multiple CCA algorithm is established for better convergence under the distributed GEP framework and proven necessary in some cases.
The approximation error is bounded theoretically in relation to the eigenvalues of the empirical data covariance and the number of local servers.
The remainder of the paper is organized as follows.
Section 2 gives a general framework of the distributed GEP algorithm in one-shot communication and its extensional applications. In
Section 3, we analyze the approximation error of the proposed algorithm.
Section 4 puts forward the distributed multiple CCA algorithm with the power method as one detailed application. The performance of numerical experiments is shown in
Section 5. The conclusion is presented in
Section 6. Based on our former conference paper, we provide thoughtful discussion about our formulation, the whole process, and extensional applications of distributed GEP in
Section 2. We also complement the experiments both on synthetic and real-word datasets to illustrate the effectiveness of our proposed methods in
Section 5.
3. Approximation Error Analysis of Distributed GEP
In this section, we analyze the approximation error of DGEP in Algorithm 1, which is defined as the distance
between the centered ground truth
and the estimator
. Without loss of generality, the top
k subspace distance, measured by the sine of the angle
, is analyzed. Thus,
where
, norm
denotes
norm as default, and
denotes the top
k subspace distance. Our analysis is based on
theorem in [
33], which reveals how much the invariant subspace will be affected if the covariance matrix is slightly perturbed. We first define that the centered covariance before one-shot communication
and the approximation covariance in the center server
are represented by the detailed data matrix multiplication of
and
, respectively. The goal of Algorithm 1 is to learn a central orthonormal matrix
to estimate
, which is the top
k eigenspace of
and also the ground truth. Our main result is in the following.
Theorem 1. Given matrices with eigenvalues and in the central server with eigenvalues . For a given dimension k, where , let and have orthogonal columns satisfying and for . Assume , where and and . The approximation error is upper-bounded by: where are the maximum spectral radii of , respectively.
Proof of Theorem 1. From the
theorem in [
33], a direct conclusion is obtained as:
Considering Jensen’s Inequality for
, we have:
and only if
, the equality holds. That is,
. Then:
where
are the maximum spectral radii of
,
, respectively, for
. Hence, Theorem 1 is obtained. □
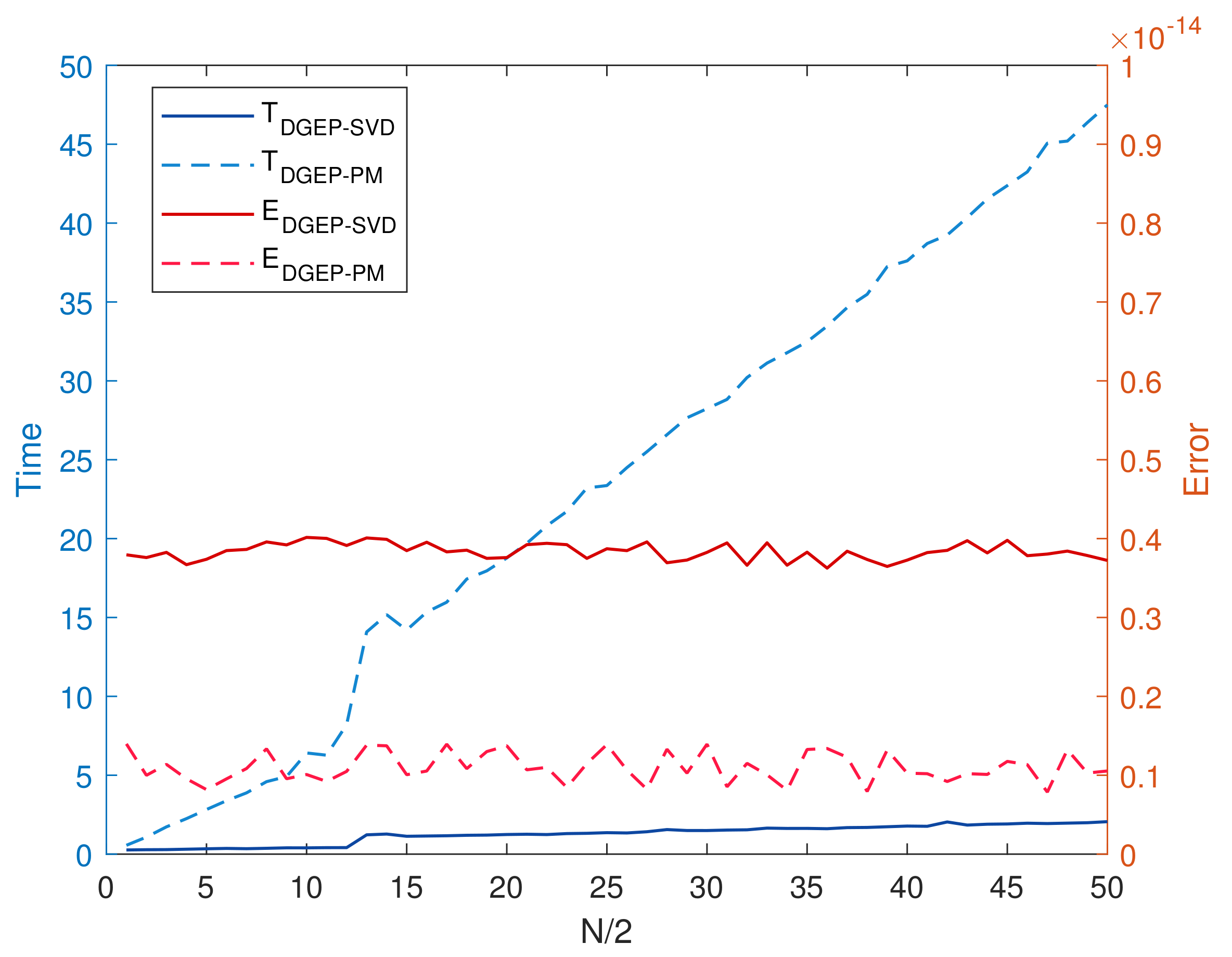
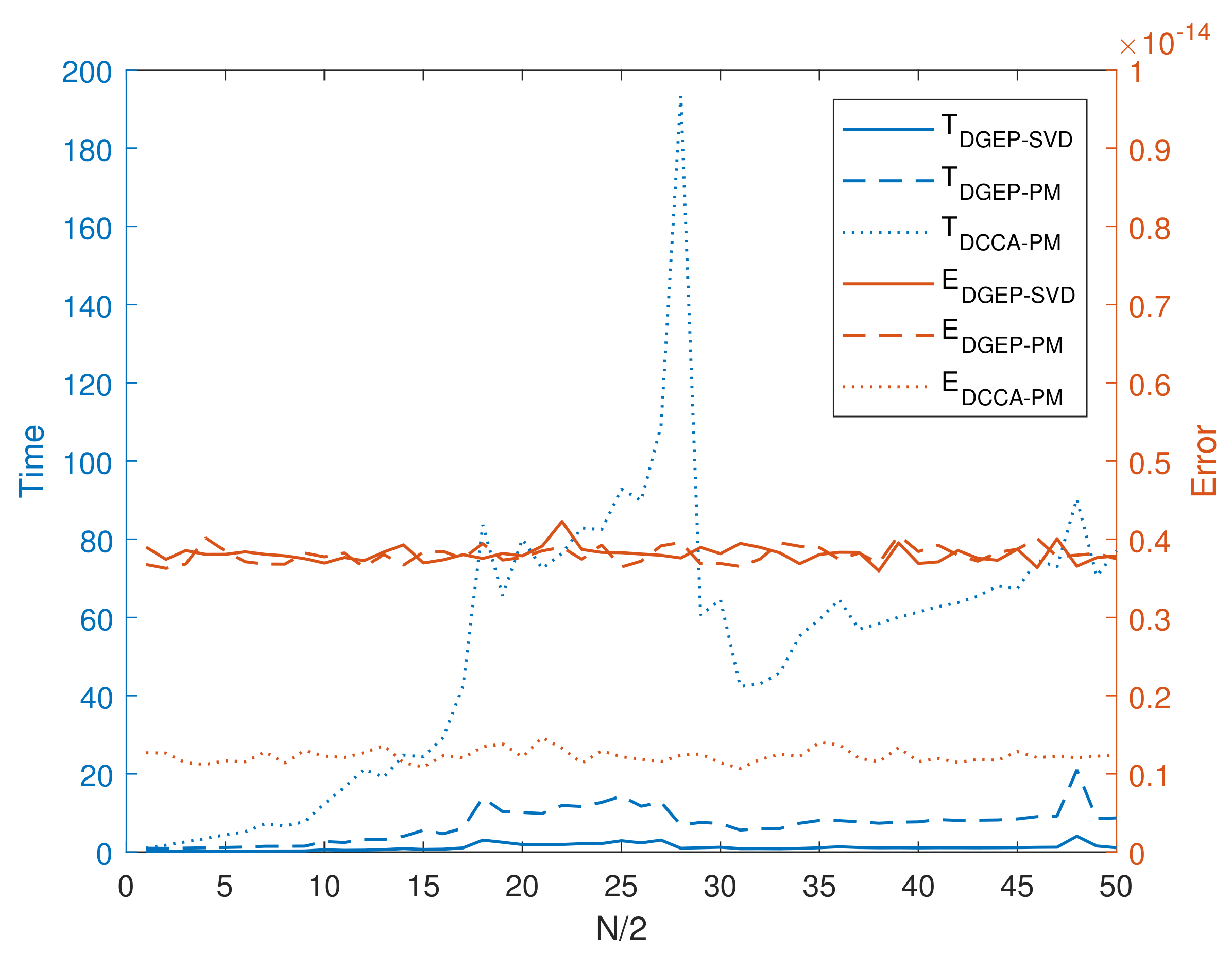
The upper bound of the approximation error of Algorithm 1 is concerned with the eigenvalues of the empirical data covariance, and the number of local servers. This accounts for the divergence of data covariance in one-shot communication. For the special case, such as distributed EP,
for any local server,
for any eigenvalue, and
. When the number of local servers
and the eigengap is
, the right side of (
6) approaches zero, satisfying the known conclusion.
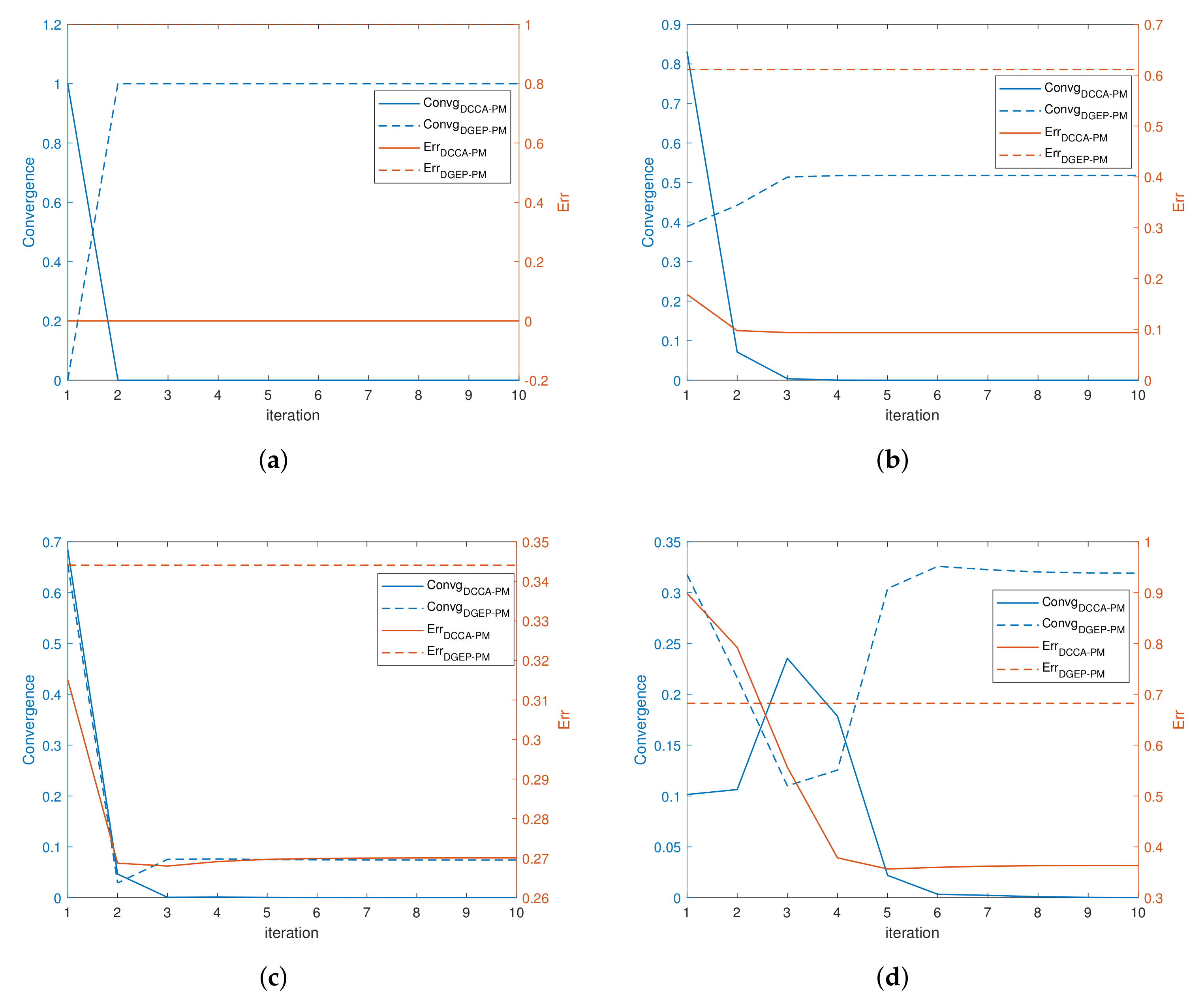
4. Distributed Canonical Correlation Analysis and Its Multiple Formulation
In this section, we investigate distributed CCA, which is a special instance of distributed GEP. In the classical setting, the CCA finds the linear combinations of two sets of random variables with maximal correlation. Furthermore, multiple CCA [
34] is the cornerstone of multi-view learning. However, if considering the original data from each view, Algorithm 1 encounters the theoretical barrier of convergence in solving the distributed CCA with the tool of the power method. So, we put forward a new algorithm based on Algorithm 1 when using the power method in this section.
We first provide the mathematical formulation of CCA. Given
d observations, denote
,
. The covariances
,
and
. Without loss of generality, its multiple version is formulated as below:
where
stands for identity matrix, and its number of columns is
k, denoting the number of canonical components and normally
. When
, it degrades to the standard CCA. Recall from the formulation of CCA, we obtain:
where
,
,
. This kind of self-adjoint structure keeps the symmetry of
A and
B. However, according to Theorem 2 in [
21], there must be an eigengap of
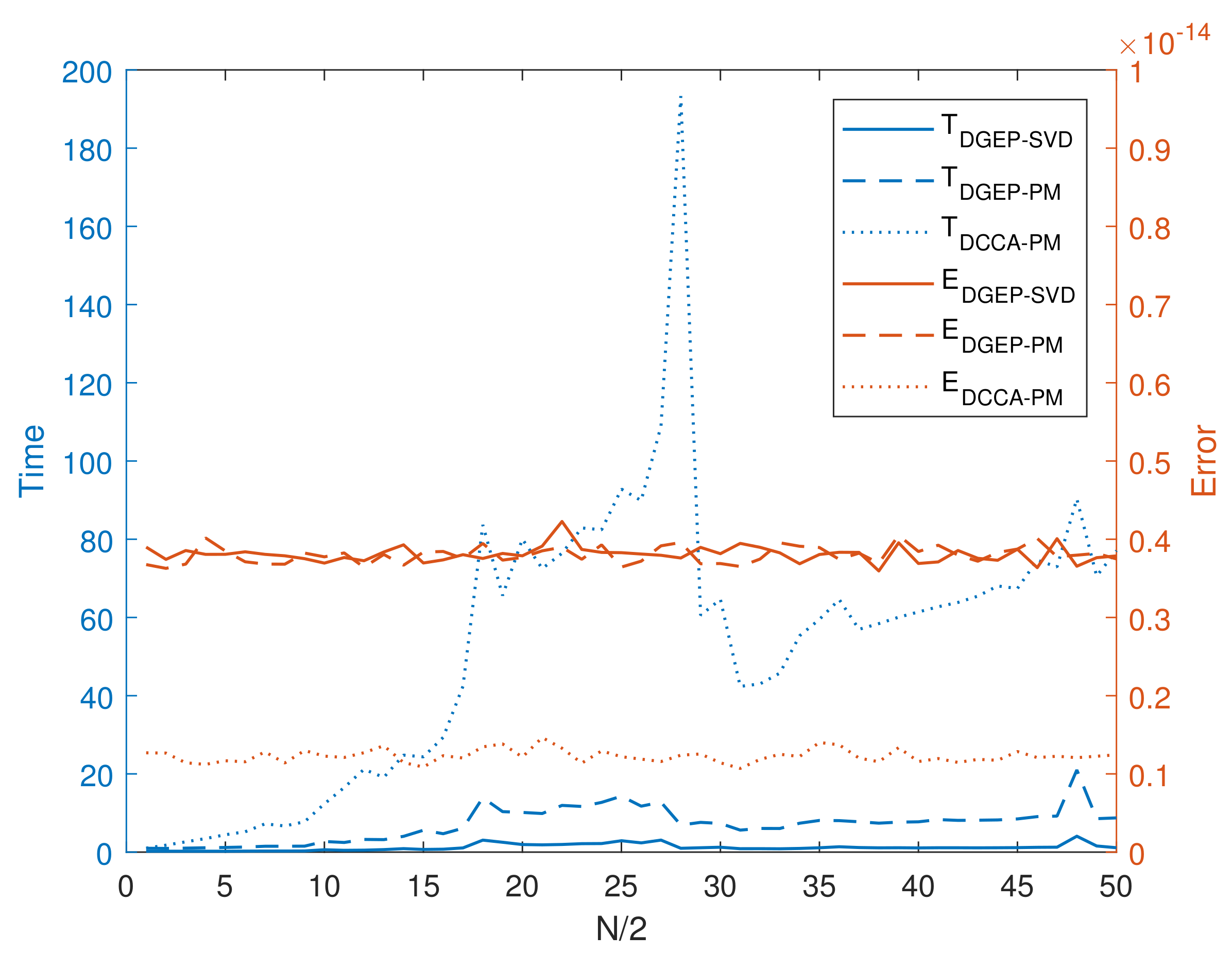
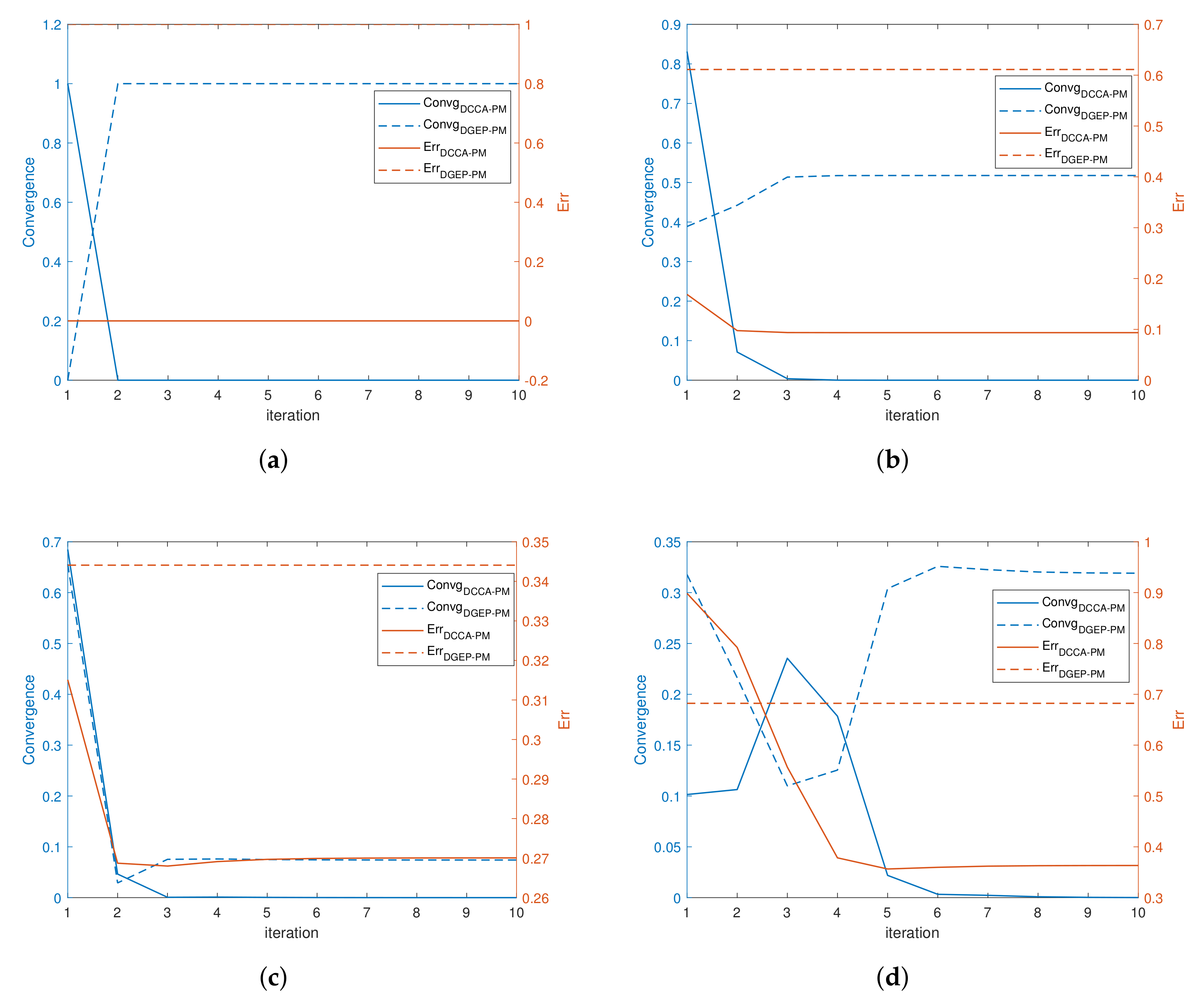
when using the power method. Hence, using Algorithm 1 in distributed CCA may not only increase the approximation error during communication but also result in a convergence barrier for no eigengap. We will also illustrate this barrier in further numerical experiments.
So, in this section, we reformulate CCA and put forward a one-shot distributed multiple CCA algorithm with the power method, which solves the inherent structure defect efficiently. The reformulated centered problem is shown as below:
where
and
are concatenations of original data from
N local servers.
is the asymmetric covariance of the centered problem. The distributed optimization problem is:
where the covariance
for CCA is also asymmetric, and
is an approximation of
in the distributed setting. Then, we derive the one-shot distributed algorithm for multiple CCA in the following.
Algorithm 3 shows the one-shot distributed multiple CCA algorithm which improves the performance by breaking the self-adjoint symmetric GEP structure. The power iterations in the central optimization are divided into two parts as computing the eigenspace of
and
. The process can be viewed as seeking the left and right singular vector of the approximated covariance
at the same time. QR factorization [
30] is used to become the orthonormal approximated eigenspace. The analysis of the approximated error of Algorithm 3 is similar as that in
Section 3. The convergence boils down to that of the power method in [
30].
| Algorithm 3 One-shot Distributed multiple CCA algorithm. |
- 1:
In the local servers, calculate local covariance matrix in i-th local server and broadcast and , respectively, to the central server. - 2:
In the central server, calculate the leading k eigenvectors of and as and , respectively, by the power method in parallel. - 3:
Return and .
|




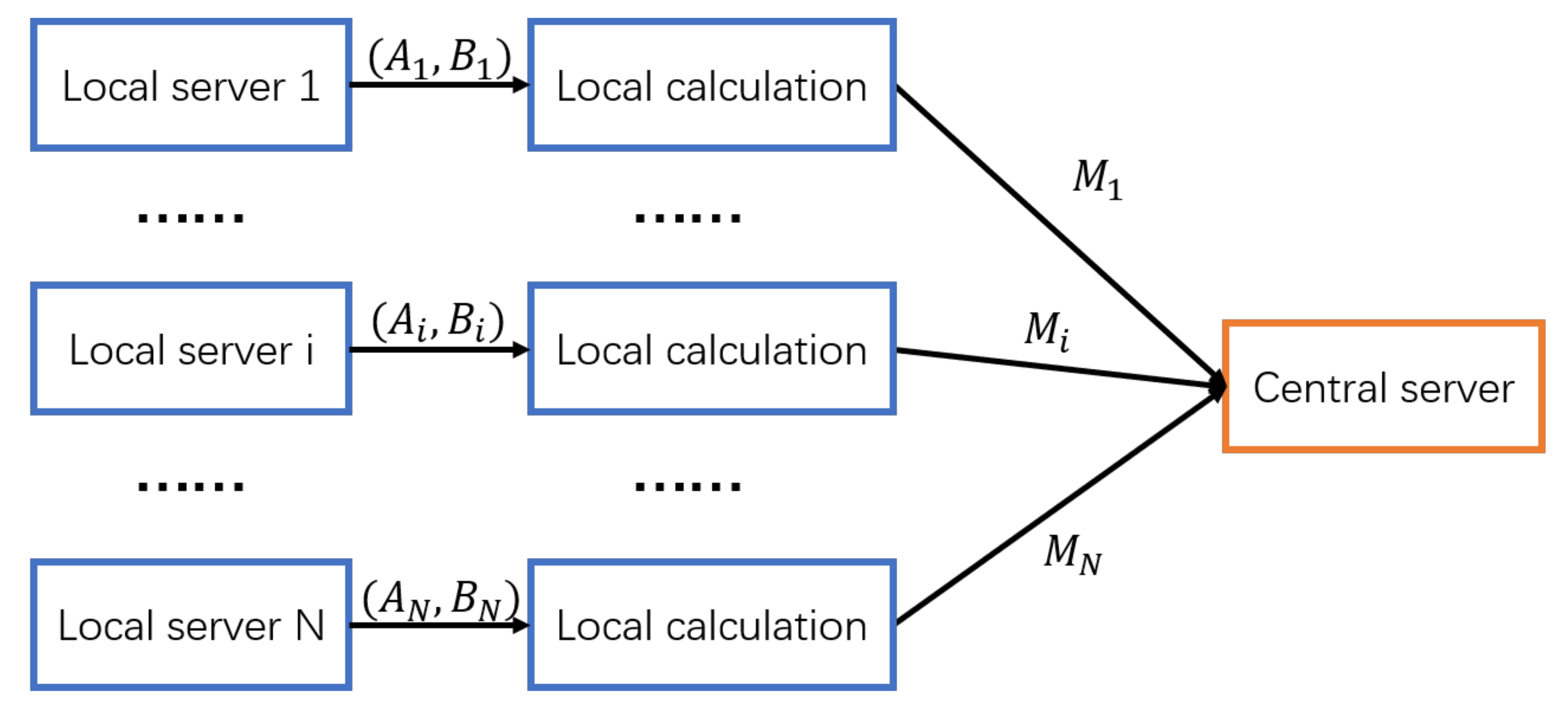
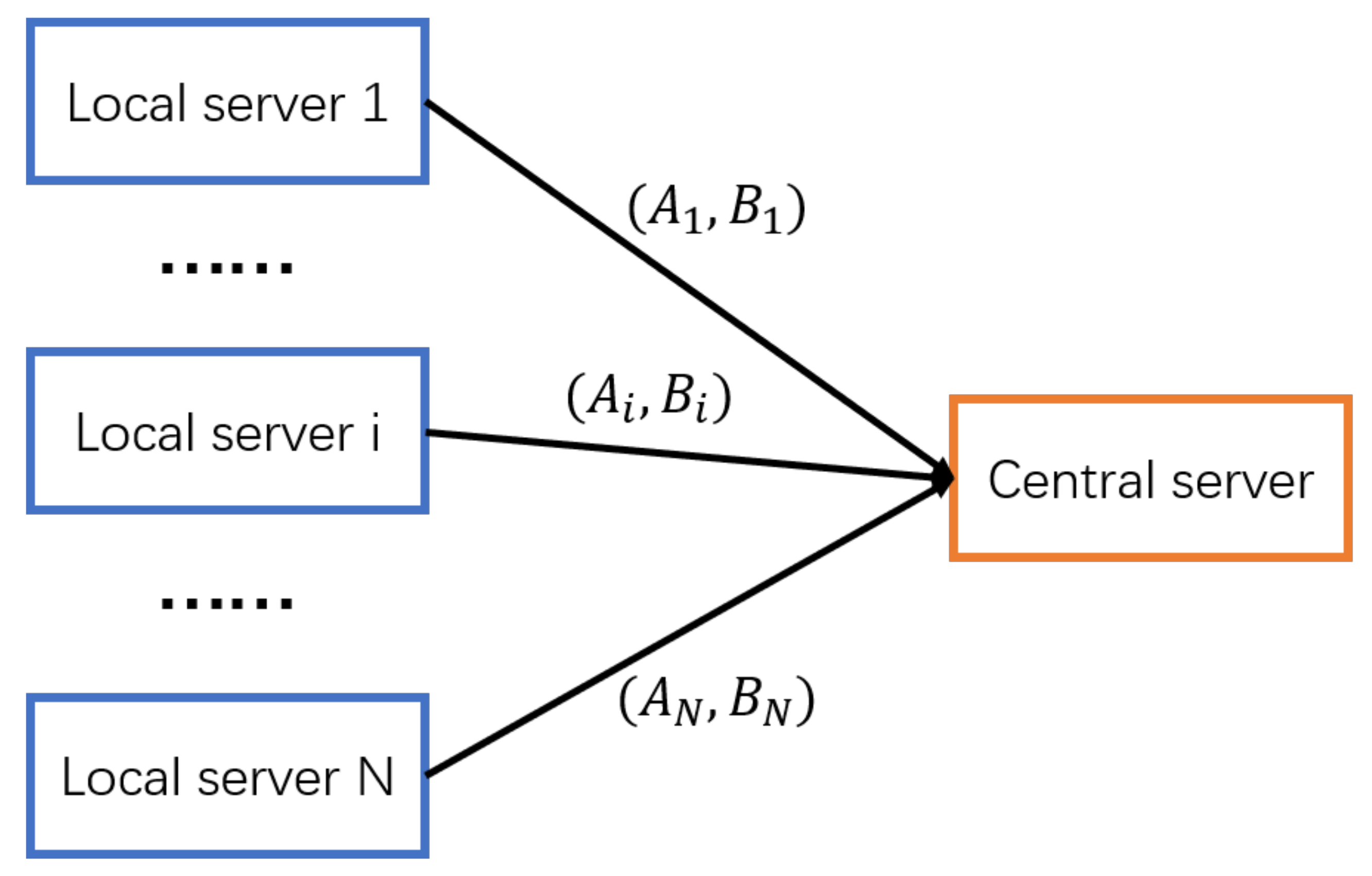

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}