1. Introduction
As the main equipment for underground transportation and loading in non-coal mines, the efficiency of LHD machines directly affects the productivity of mines. Traditionally, a LHD machine needs to be driven and controlled by professionals. Although this can achieve a good result, the working environment of an underground LHD machine is poor, and problems such as dust, noise, and vibration are common, which have a serious impact on the driver’s health. Therefore, the main development trend of underground unmanned technology has become making an LHD machine achieve autonomous walking and shovel loading [
1,
2,
3].
The maintenance and use cost of an actual LHD machine is high. Frequent field experiments consume a lot of human and material resources and affect the normal production process. With the development of simulation software, such as Bullet, Mujoco, Carla, V-rep, and the Unreal Engine, it is possible to more accurately simulate various situations from reality on a computer. The Unreal Engine is a game engine developed by Epic Games in 1998. Unreal Engine 4 was launched in 2014, and the source code is open source. UE4 has a complete set of development tools. It is widely used in automatic driving, military training, safety training, etc. Michalík [
4] developed a set of driving simulation platforms based on UE4, to analyze the driving safety of drivers, while Sim Centric and Torch Technologies have developed a VR system for tactical training in cooperation with military institutions. Carla, an automatic driving simulation platform, is another a secondary development based on UE4. Therefore, UE4 is very reliable and effective as a platform to build an autonomous walking simulation environment for an LHD machine.
The underground LHD machine is a special vehicle, which is essentially an articulated vehicle, that is, a vehicle composed of two or more car bodies connected by a hinge device. Its special structure creates a unique steering mode [
5]. The dynamic model of an articulated vehicle can be divided into two degrees of freedom [
6], three degrees of freedom [
7], four degrees of freedom [
8], and multiple degrees of freedom [
9,
10]. Theoretically, four degrees of freedom can meet the needs of driving force distribution control and autonomous driving control. Bai [
11], of Beijing University of science and technology, optimized a model based on the classical articulated vehicle kinematics model [
12] proposed by Corke et al., and regarded the articulated vehicle as a rigid body, ignoring the tire slip, and established a set of dynamic models suitable for a four-wheel independent drive articulated vehicle.
The research on LHD machine autonomous walking mainly focuses on the research of control algorithms, such as PID (proportion integral differential), LQR (linear quadratic regulator), SMC (sliding mode control), MPC (model predictive control), etc. Aslam [
13] et al., based on the SMC [
14] algorithm and inspired by the research of SSV (skid-steer vehicles) [
15,
16,
17,
18] based on FLC (fuzzy logic control), integrated FLC [
19,
20] with SMC to solve the jitter problem often encountered in traditional sliding module control. Jiang [
21], based on the PID algorithm and the reactive navigation technology of “along the wall”, designed an autonomous navigation bivariate PID controller to realize the autonomous navigation and driving of a LHD machine. Nayl [
22,
23] and others established a lateral control algorithm based on MPC control for a complete kinematic model of an articulated vehicle. Although the vehicle cannot reach the speed of manual operation, it can stably realize the autonomous walking of the LHD machine. Wu [
24] applied the QPSO (quantum-behaved particle swarm optimization) algorithm to the selection of LQR control weighting matrix parameters and proposed the LQR-QPSO algorithm, which greatly shortens the time for correcting the body attitude of an underground LHD machine in case of abnormal conditions. Benefiting from the rapid development of computer performance in recent years, machine learning has been widely used in the field of vehicle control [
25,
26,
27]. Kanarachos Stratis [
28,
29] used a feedforward neural network to track the trajectory of intelligent vehicles and achieved good experimental results. Shao et al. [
30,
31,
32,
33] proposed to use of the reinforcement learning method to adjust PID control parameters in real-time, and applied this to the autonomous walking of an articulated vehicle. Experiments showed that, under the support of reinforcement learning, a PID controller can effectively reduce vibration. Although these control algorithms can achieve good results, this depends on the artificially given route, and the use of a reinforcement learning algorithm will enable the LHD to explore a route by itself; so as to realize the real sense of autonomous walking.
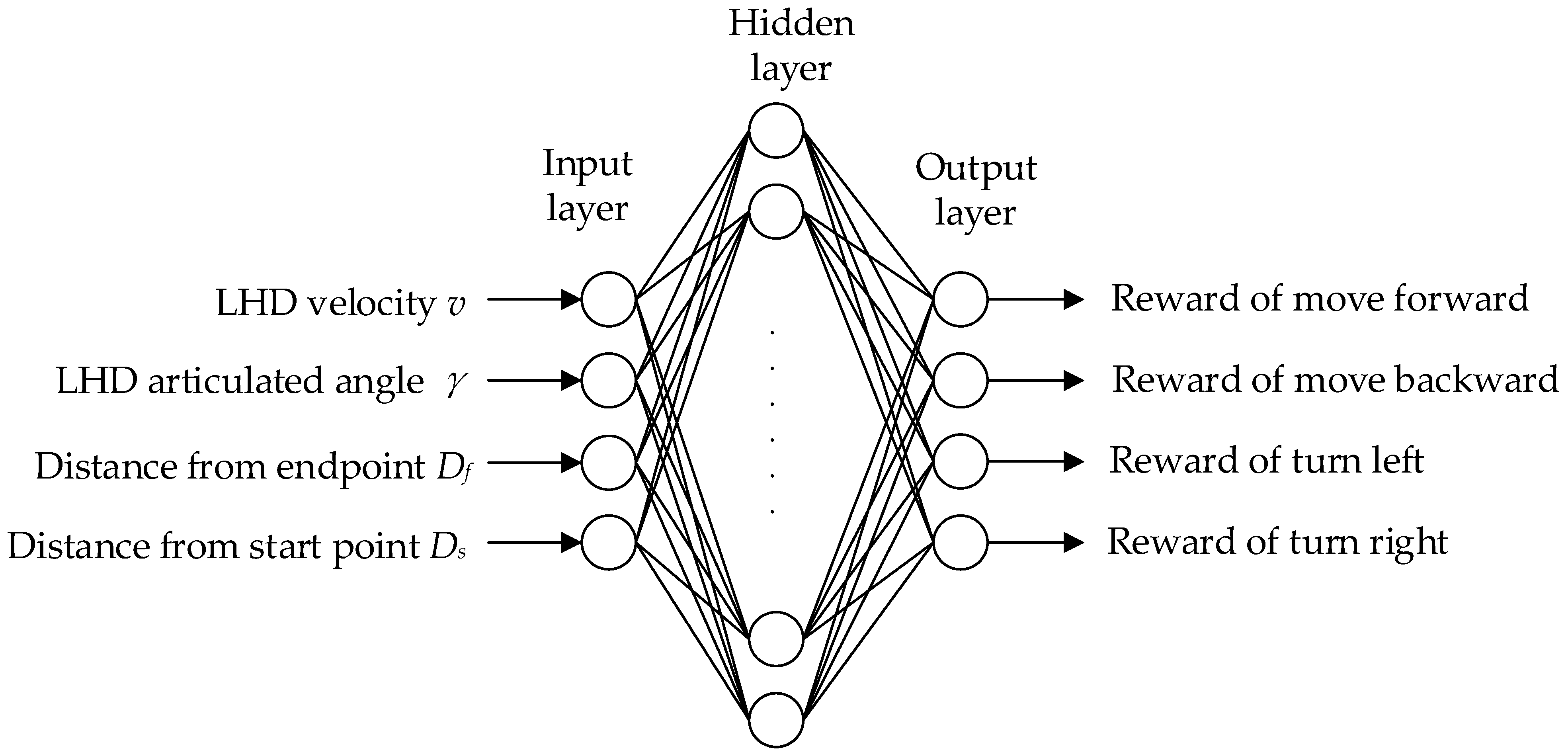
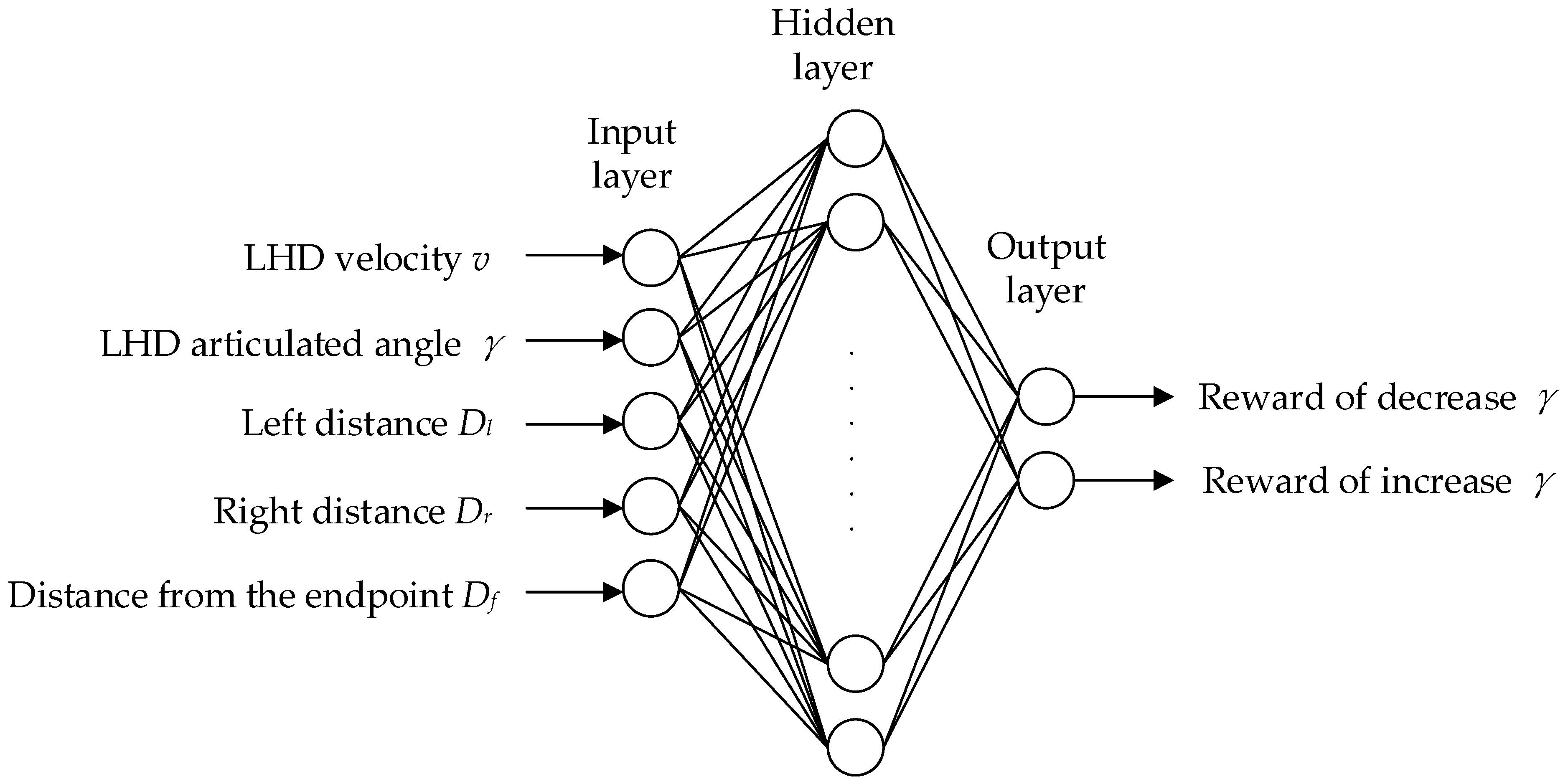
In the working scene of an LHD machine, the state space is mainly the vehicle speed, articulation angle, body surrounding environment information, etc. Through reinforcement learning, an LHD machine can independently learn walking control in a complex environment. However, relying solely on reinforcement learning will make the LHD machine explore many unnecessary situations and reduce the training efficiency. Therefore, this paper proposes a training network, Traditional Control Based DQN (TCB-DQN), which combines a traditional control algorithm and DQN reinforcement learning method to train an LHD machine in autonomous walking. Its main contributions are as follows:
- (1)
An underground simulation LHD machine operation environment was built in UE4, based on realistic standards. The simulation environment can output a variety of information about the LHD machine itself, such as speed, steering angle, etc., as well as interactive information regarding the LHD machine and the surrounding environment, such as the distance between the vehicle body and the edge of the tunnel, the distance between the vehicle and the starting and ending points, etc. In this environment, the autonomous walking of LHD can be studied efficiently.
- (2)
A new training framework TCB-DQN is proposed, which combines traditional relative navigation and a DQN neural network. The framework adopts a weak constraint strategy, to avoid frequent route correction of the LHD machine. Compared with the traditional control algorithm, TCB-DQN changes the LHD autonomous walking mode from passive acceptance to autonomous exploration. In addition, compared with the DQN algorithm training, TCB-DQN gives the LHD machine the ability to judge when to start exploration, avoiding the LHD machine exploring in unnecessary situations, greatly improving the training efficiency of the LHD machine, and enabling the LHD machine to still realize autonomous walking in a more complex environment.
The structure of this paper is as follows:
Section 2 introduces the construction process of the simulation environment; in
Section 3, the experimental design of different algorithms is carried out. In
Section 4 and
Section 5, the algorithm is tested and analyzed, and the corresponding summary is made.
2. Tunnel Model Construction
The construction of the underground simulation platform was mainly divided into tunnel modeling and LHD machine model construction. Due to the high-level physical simulation effect and realistic rendering effect of UE4, UE4 was used to build the simulation platform. Tunnel and LHD machine models preprocessed from other modeling software were imported into UE4 and given corresponding material and physical properties, so that the interaction between models can be realized and the collision effect between models can be truly simulated.
2.1. Tunnel Simulation Modeling
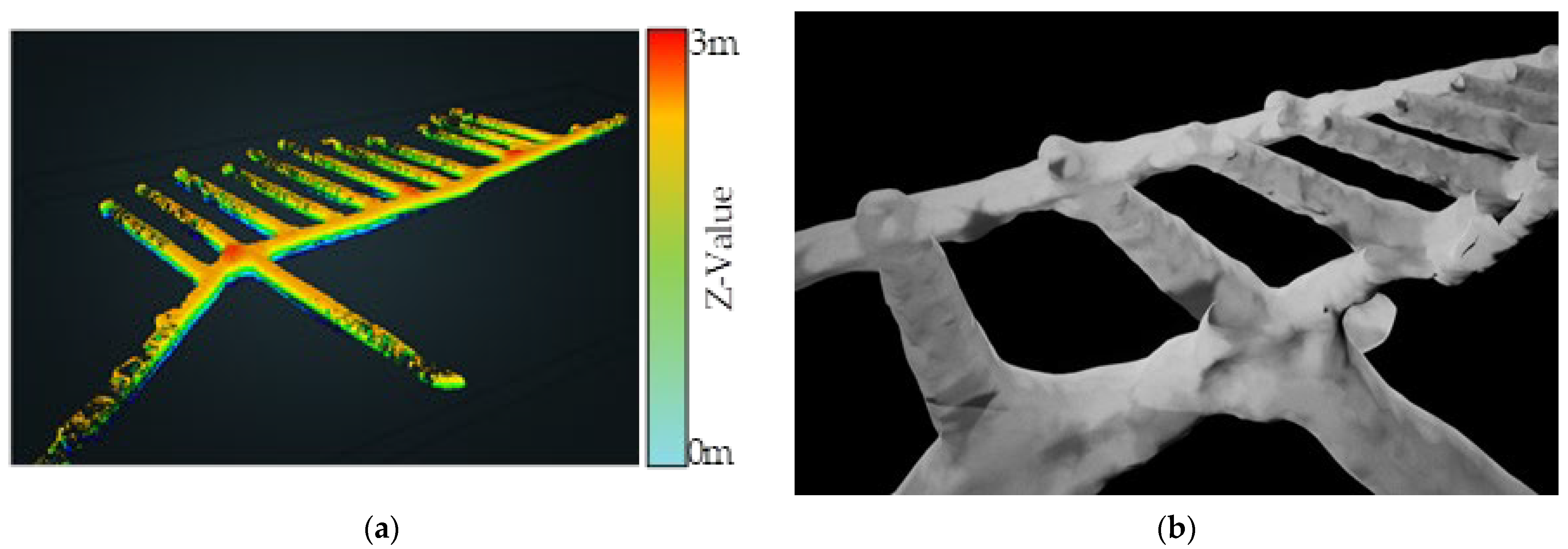
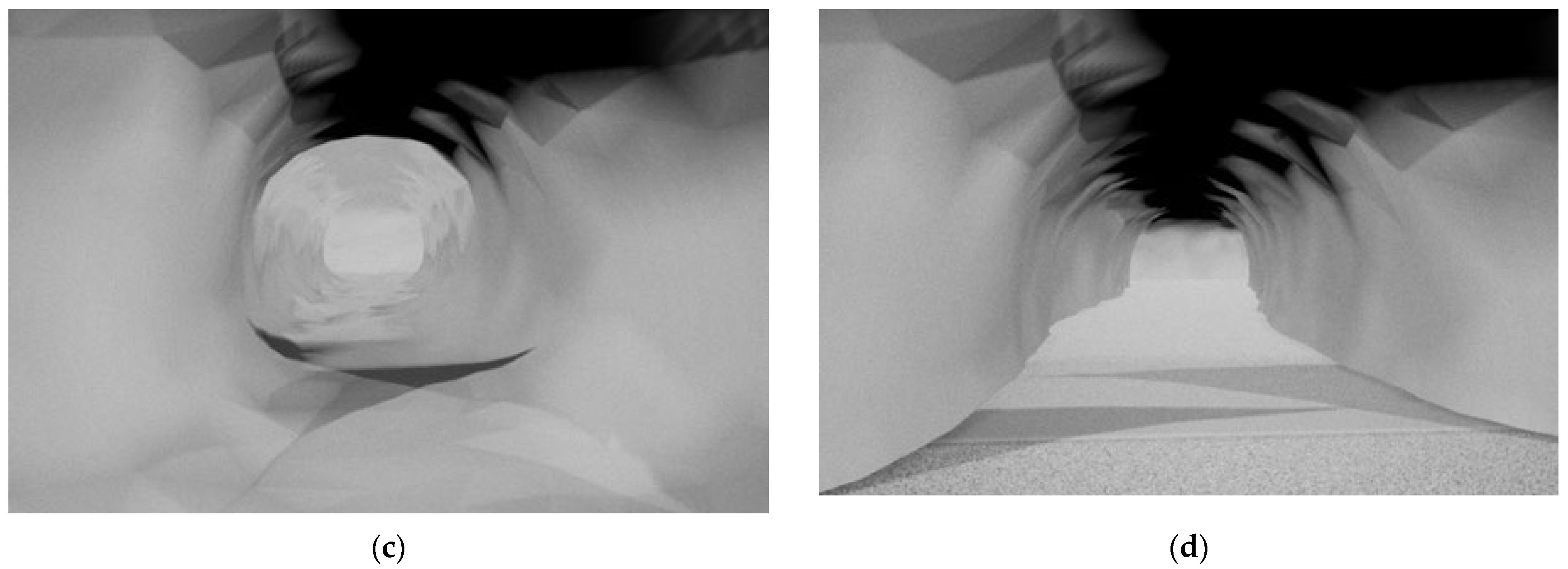
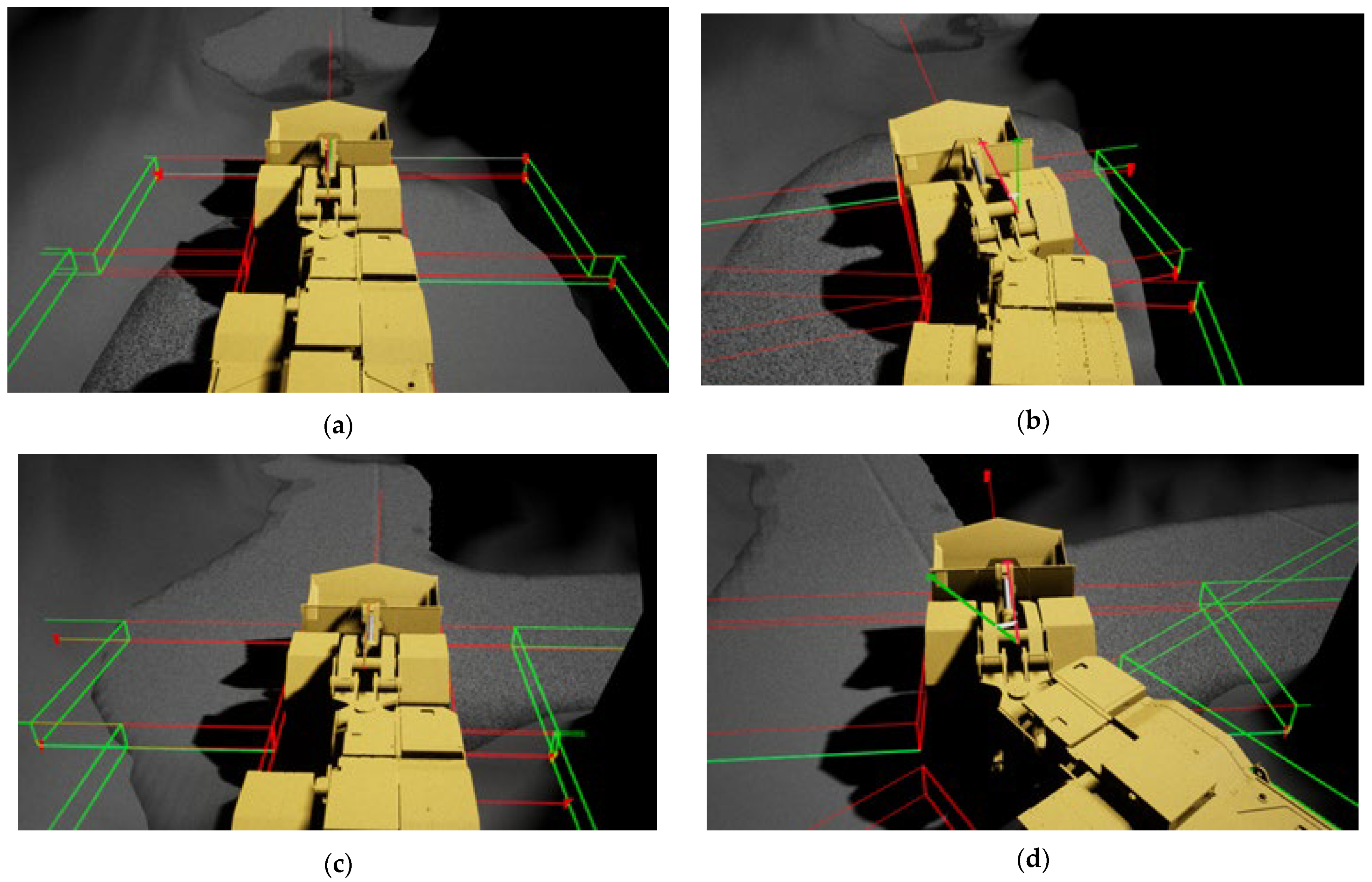
The original 3D tunnel model was constructed using a ZEB-Horizon 3D laser scanner developed by GeoSLAM, which scanned and reconstructed the data in a real tunnel. The reconstructed point cloud data after scanning is shown in
Figure 1a; after it was imported into UE4, the tunnel model was saved in the assets in the format of a static mesh, as shown in
Figure 1b. The internal state of the initial tunnel is shown in
Figure 1c; it can be seen that the ground of the tunnel model is extremely rough, which is too different from the flat ground in an actual transportation tunnel, which is related to factors such as ponding in the tunnel and stacking of obstacles during data collection. Therefore, the floor of the tunnel ground was flattened in UE4, and the final tunnel is shown in
Figure 1d.
2.2. LHD Machine Simulation Modeling
The body of the LHD machine model is composed of front and rear parts, and the middle is connected by a hinge device. The bucket is divided into six Z-type reverse bars and eight forward, bars according to the structural characteristics. Based on the model of the LHD machine made in Qingdao Zhonghong, this paper selected six Z-type reverse bars as the structural characteristics to build the model. The main components of the LHD machine are the front body, the rear body, and the bucket. The bucket is connected to the front body by the tilting oil cylinder and piston, the lifting oil cylinder, piston, the swing arm, rocker arm, and connecting rod. To achieve steering of the LHD machine, two symmetrical steering pistons need to be set at the connection between the front body and the rear body.
UE4 has two methods to realize object displacement and rotation: physical simulation, and coordinate transformation. Using the physical simulation method requires turning on the simulated physics of the static mesh in advance and add constraints in different directions, it requires a high accuracy and no overlap between the various components, otherwise unpredictable errors will occur. Pure physical simulation is usually used when the model structure is not complex or there are few connections between models. For a complex body model, such as the LHD machine model, the use of pure physical simulation will not only increase the consumption of computer resources but also lead to various abnormalities.
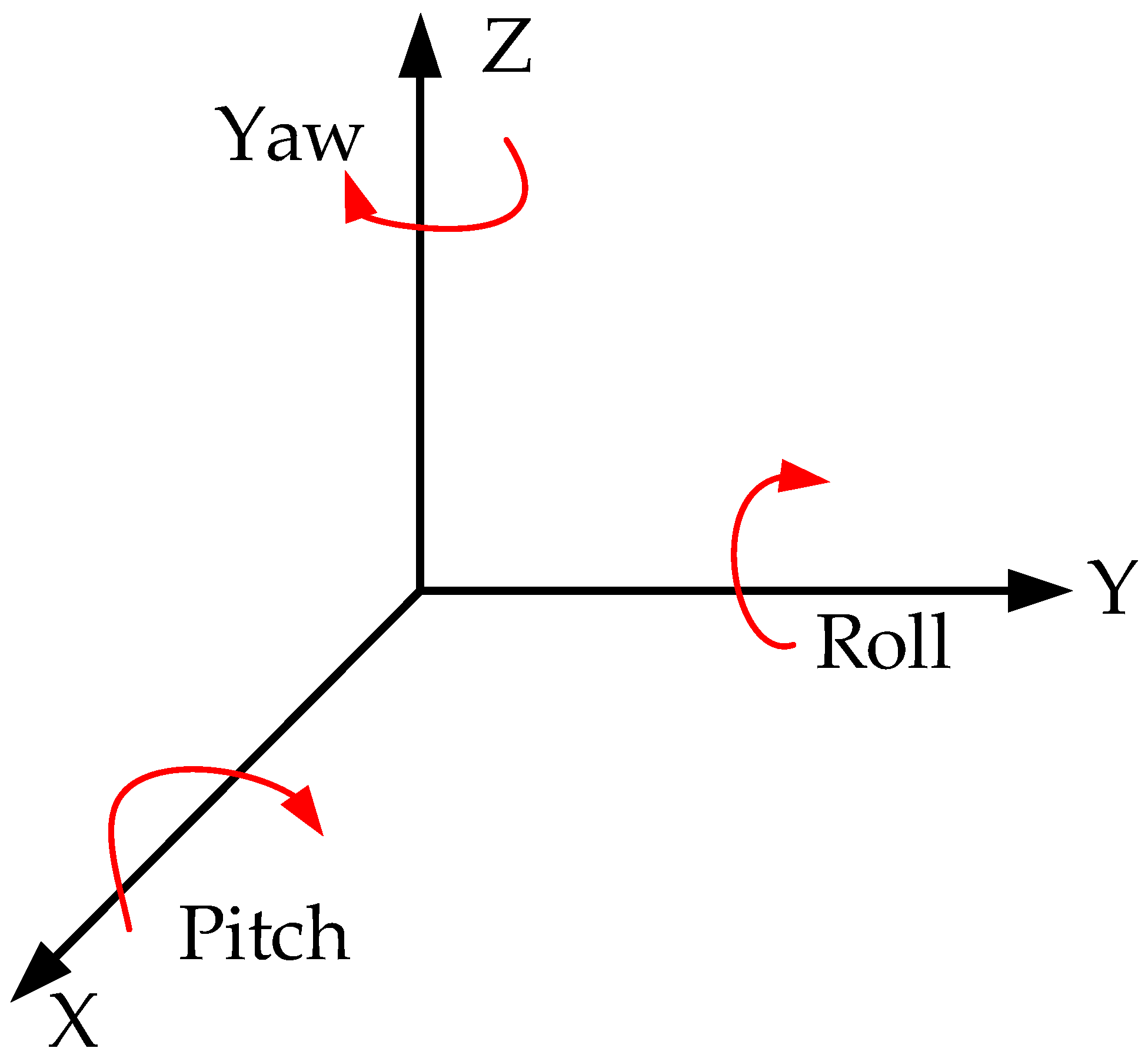
For the movement simulation of the LHD machine, only the acceleration and deceleration control needs to be realized, and the overall coordinate transformation of the LHD machine can be realized through a physical formula, which can accurately simulate the walking of the LHD machine. Note that UE4 adopts a left-hand coordinate system instead of a right-hand coordinate system, as shown in
Figure 2.
The movement of the LHD machine can be regarded as the movement of object coordinates in three-dimensional space, and the motion simulation of object coordinates is based on the translation and rotation transformation of the coordinate system. The translation transformation process can be simply represented by Equation (1):
The rotation matrix can be derived from the following matrix, which rotates
degrees around the
Z-axis
is
Similarly, rotates
degrees around the
X-axis
and rotates
degrees around the
Y-axis
are
Therefore, the final rotation matrix of the coordinate system after three rotations of the object is:
Matrix is the rotation matrix after the object rotates around the Z, Y, and X axes, in turn. According to the above method, the rotation matrix of the object according to other rotation orders can be solved. To avoid the problem of Gimbal lock, the quaternion method is introduced to correct it.
Referring to the dynamic model of a four-wheel independent drive articulated vehicle by Bai [
11], as shown in the Equation (6), a set of dynamic models based on the articulated angle was established in the UE4 blueprint, and the turning radius and steering center of the front frame and rear frame were calculated in real-time using the articulated angle. When the simulation LHD machine has power input (i.e., the user operates the LHD machine through the key), the LHD machine will move along the track circle. The dynamic parameters of the simulated LHD machine are shown in
Table 1.
Through the above description of the motion state of the space object and the mechanical model of the LHD machine in UE4, a blueprint was used to establish the function for calculating the object rotation matrix, and the simulation control of the LHD machine was realized through a matrix operation. The movement of the simulation LHD machine was realized by calling the set scene position and set scene rotation in the UE4 blue diagram every frame. For the construction of radar, the built-in function module BoxTraceByChannel can monitor whether there are objects within the specified range and feed the monitoring information, including the distance between the emission point and the object, to complete the simulation of the radar function.
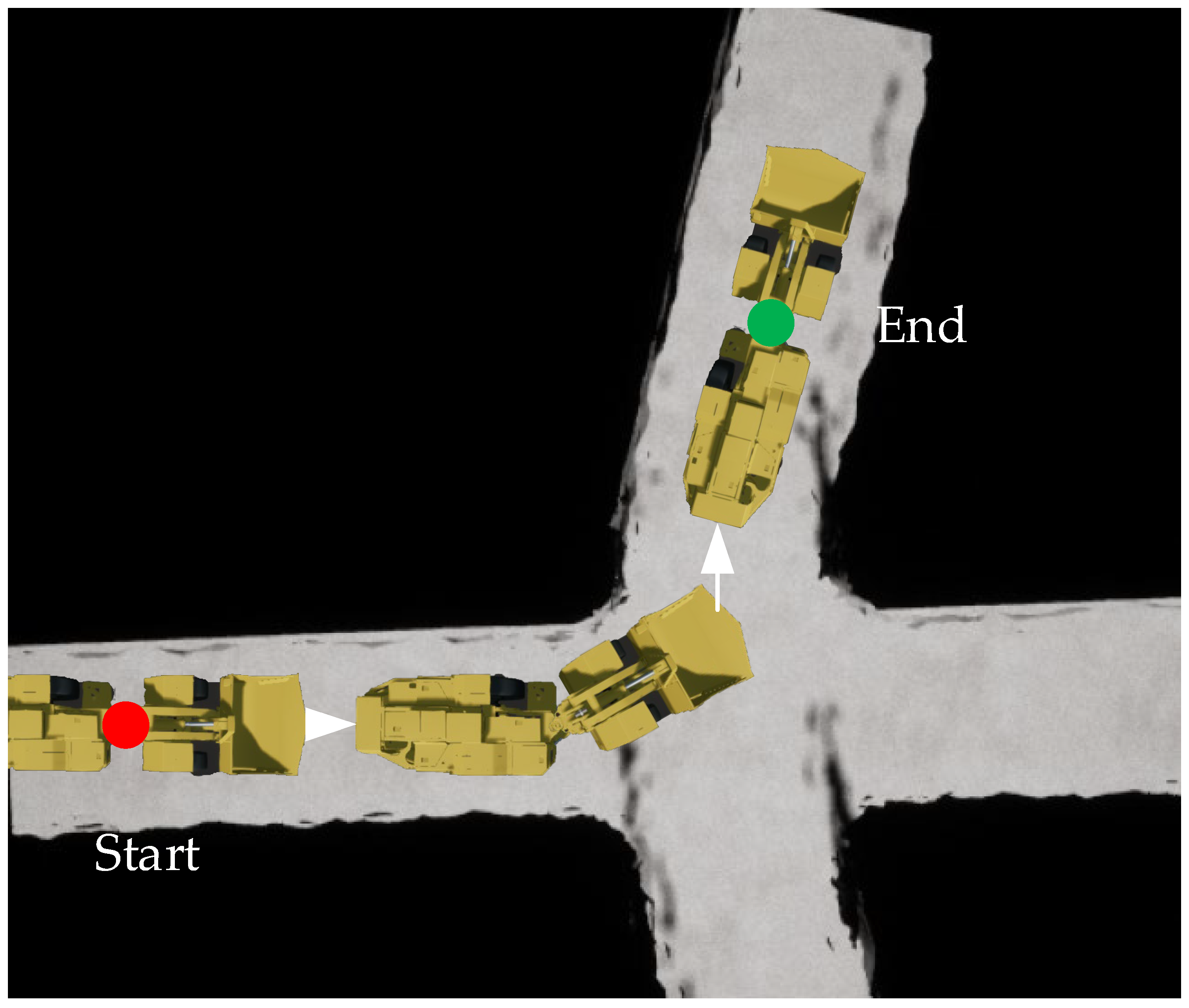
2.3. Interaction Design
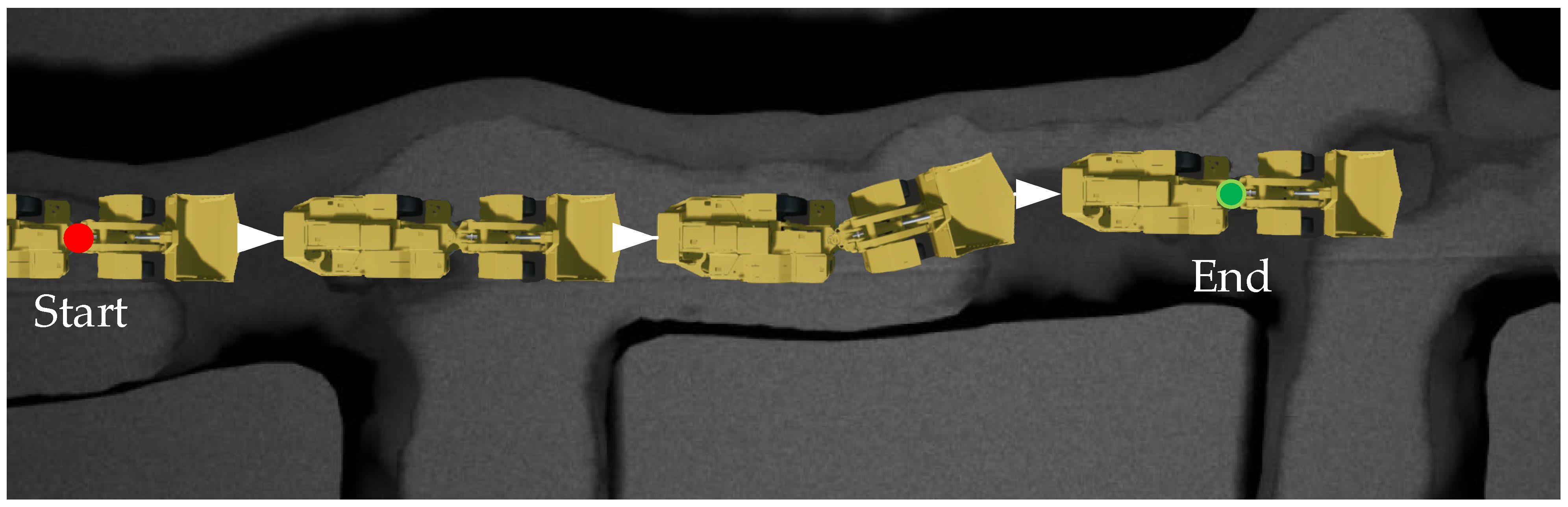
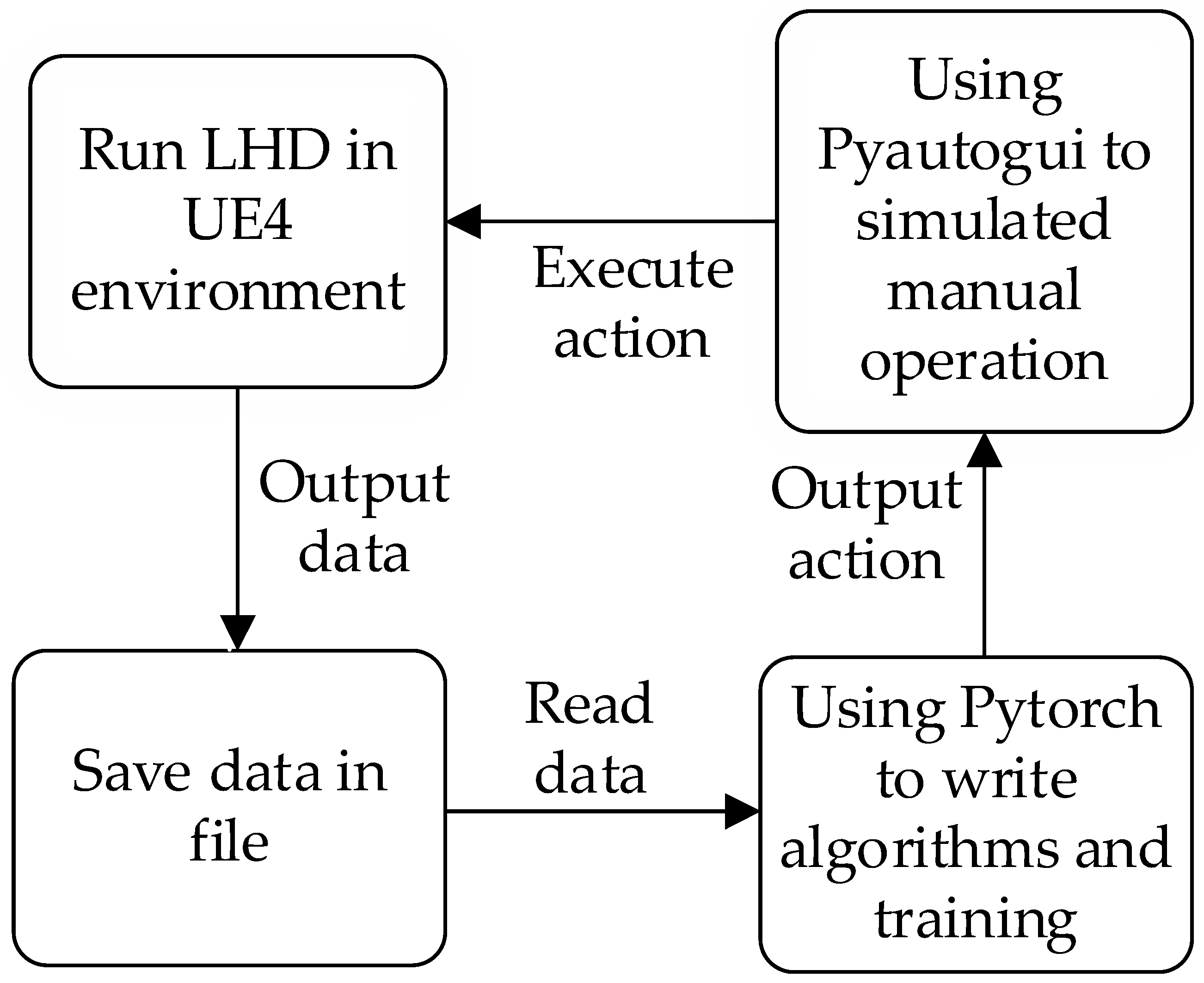
The underground simulation platform developed based on UE4 is an independent process and cannot directly interact with Python files using a third-party library. The reinforcement learning algorithms are based on Python’s Pytorch library. To realize the interaction between our algorithm and UE4 simulation components, UE4 is regarded as a black box, and Pyautoigui transmits operation instructions to the simulation platform, to realize the operation of the LHD machine, the current state information of the LHD machine is obtained, and saving through the SaveStringToFile function in UE4 C++ library. Other operations such as calculating reward functions and selecting action instructions are implemented in Python. The main flow of interactions is shown in
Figure 3.
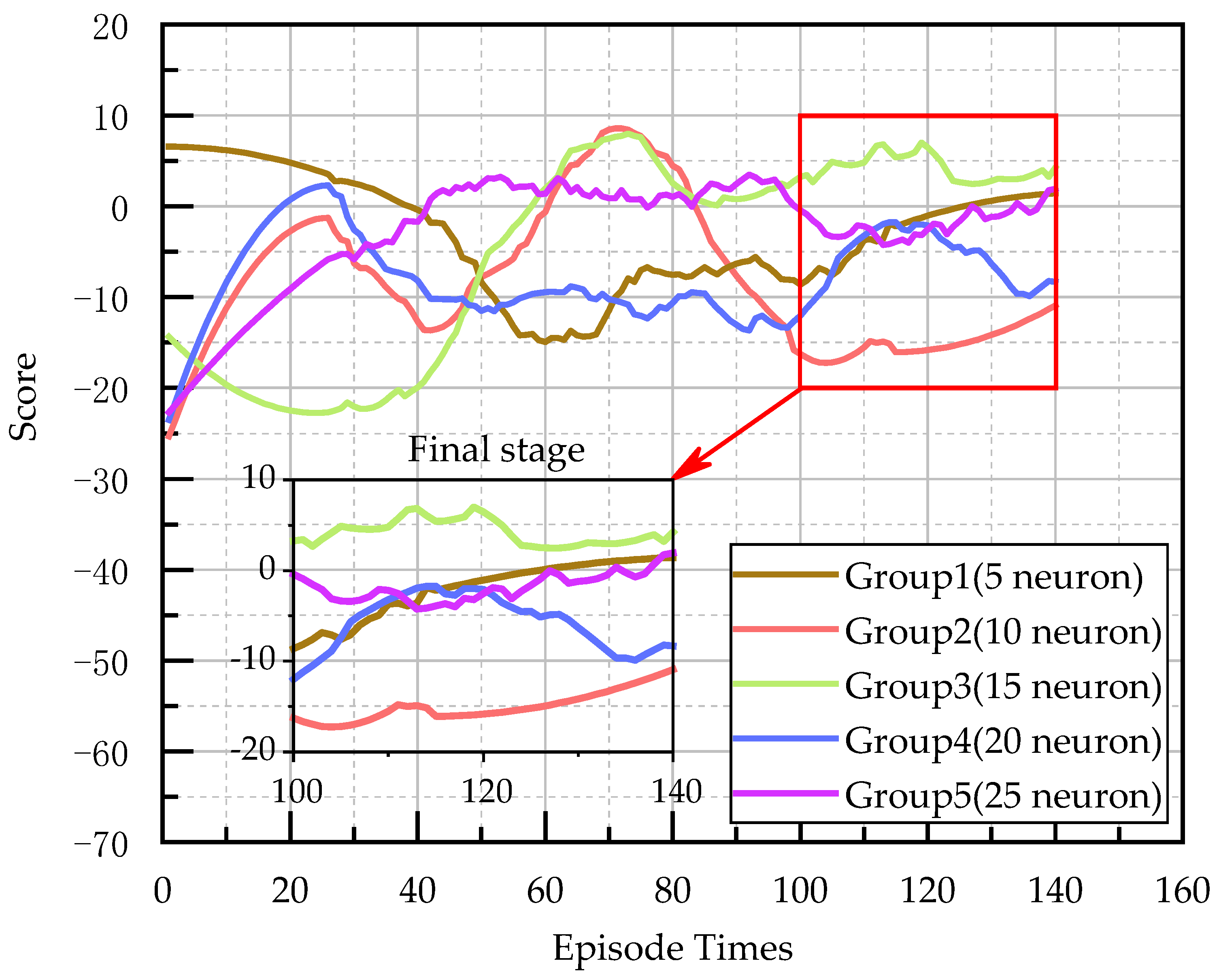
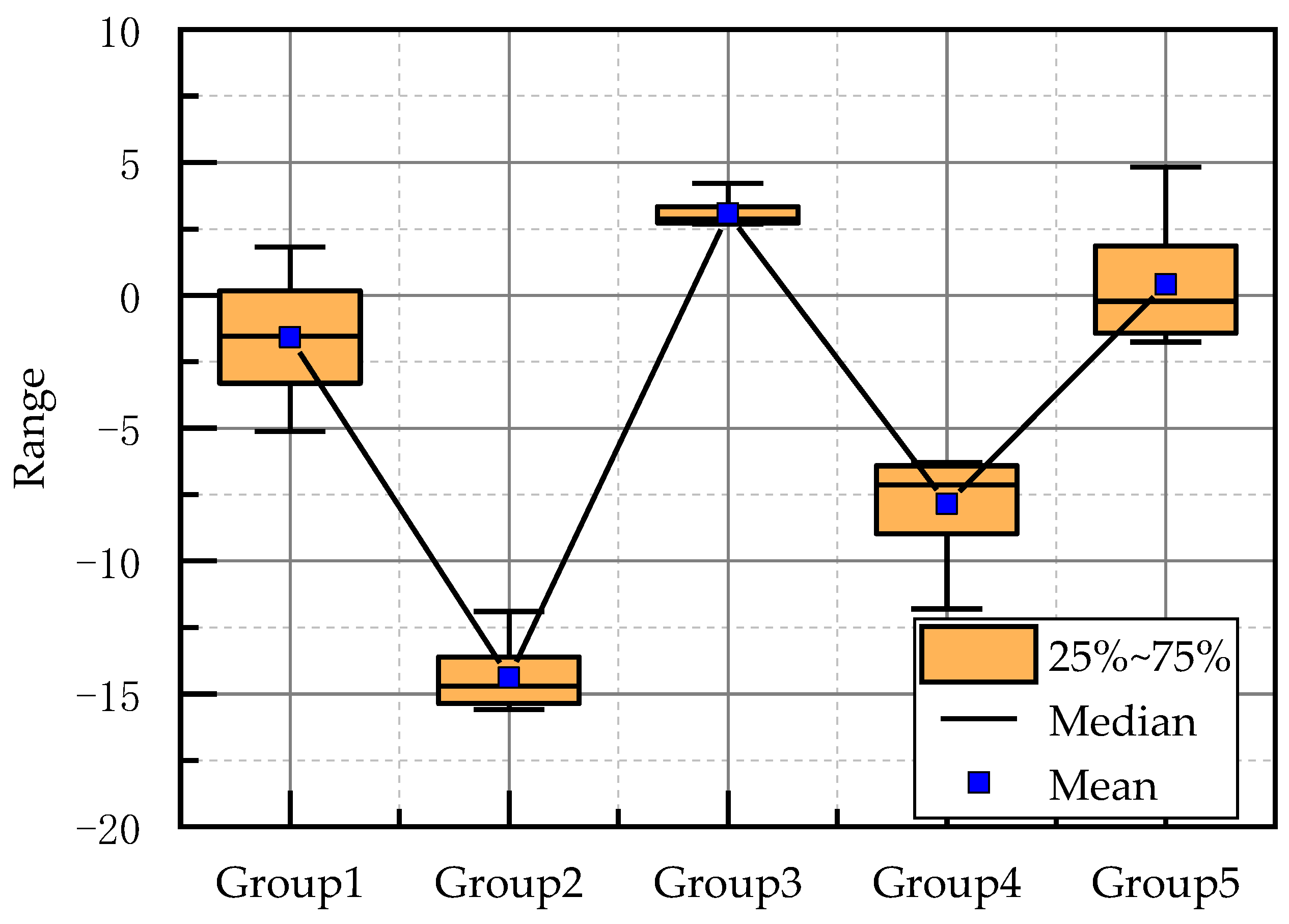
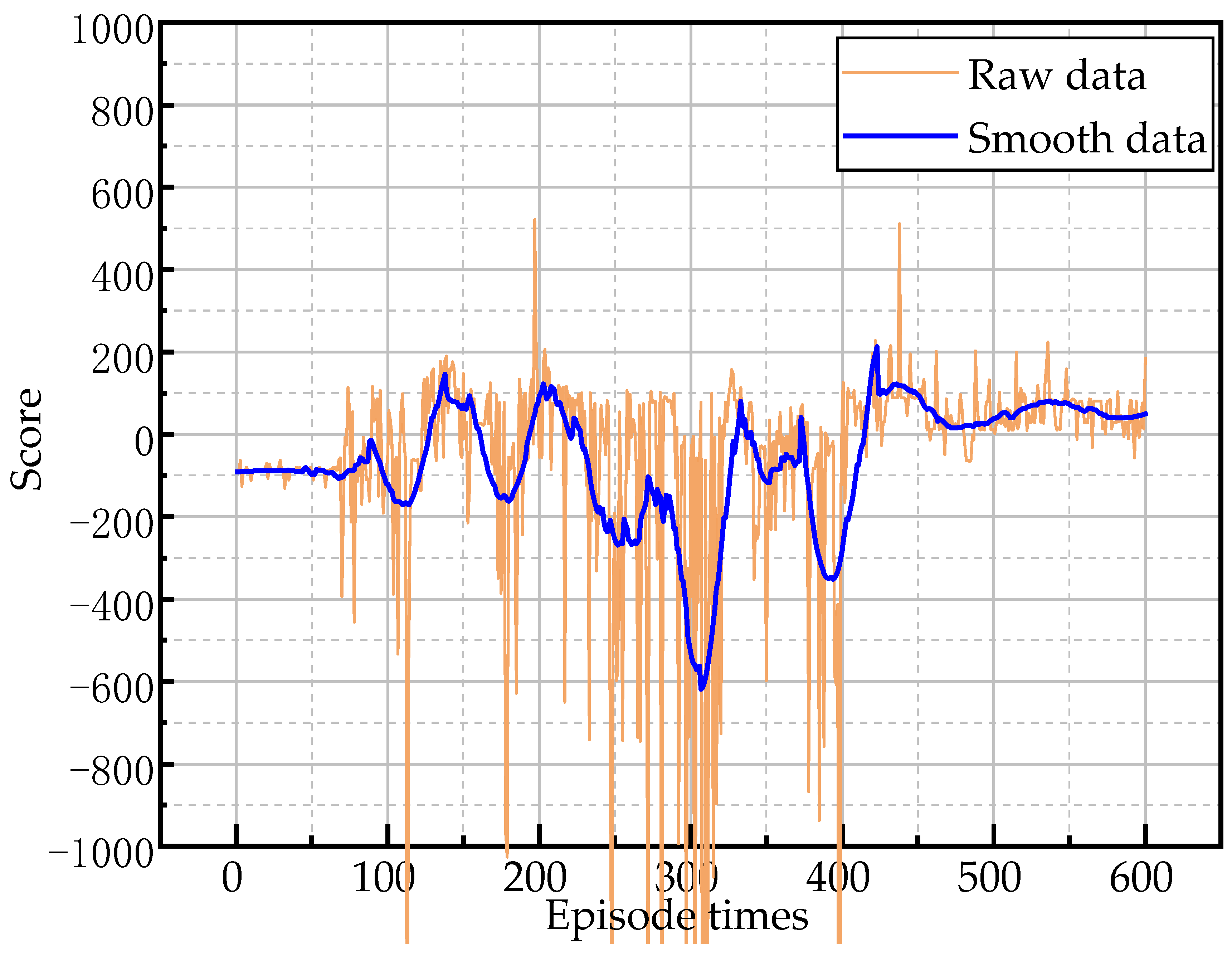
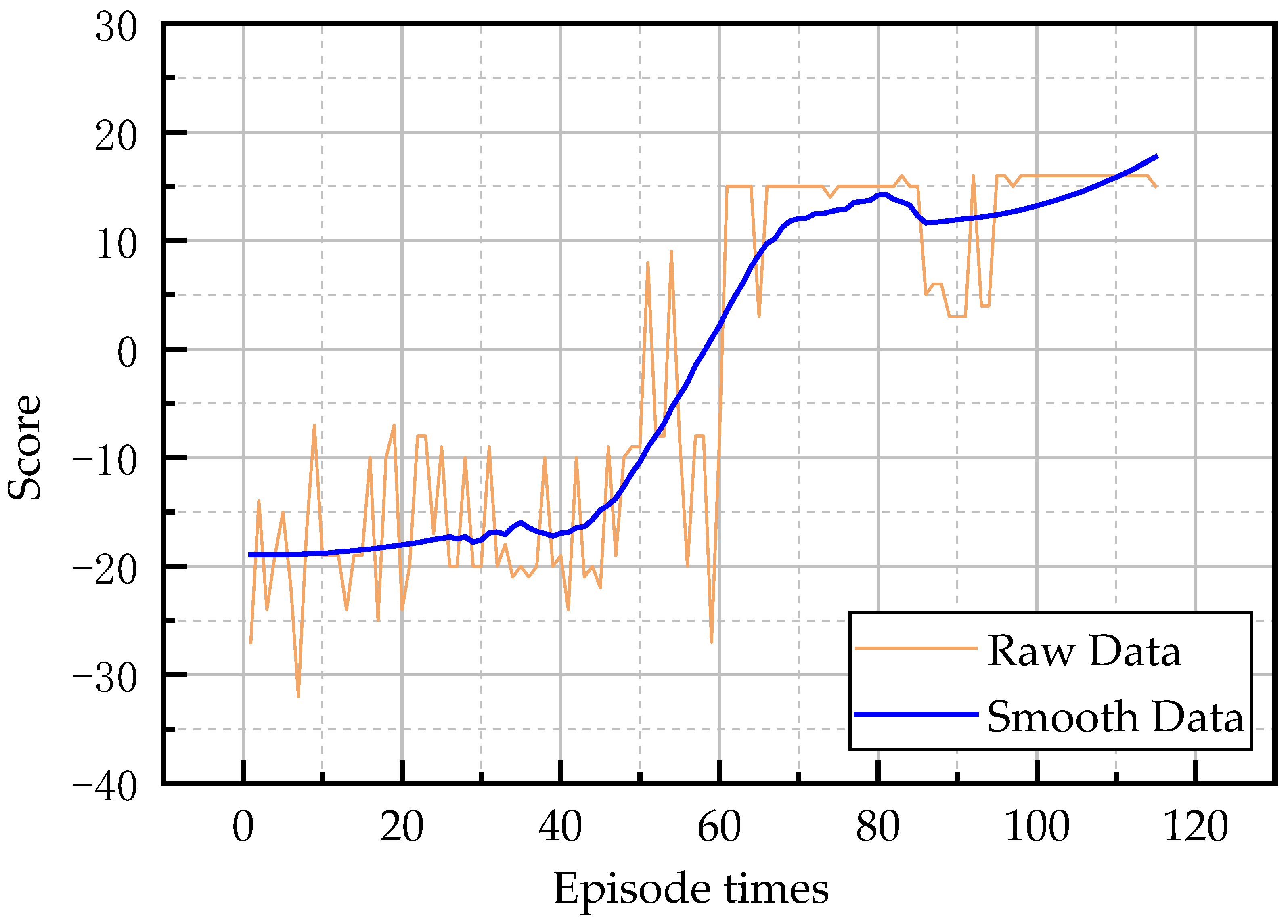
5. Conclusions and Discussion
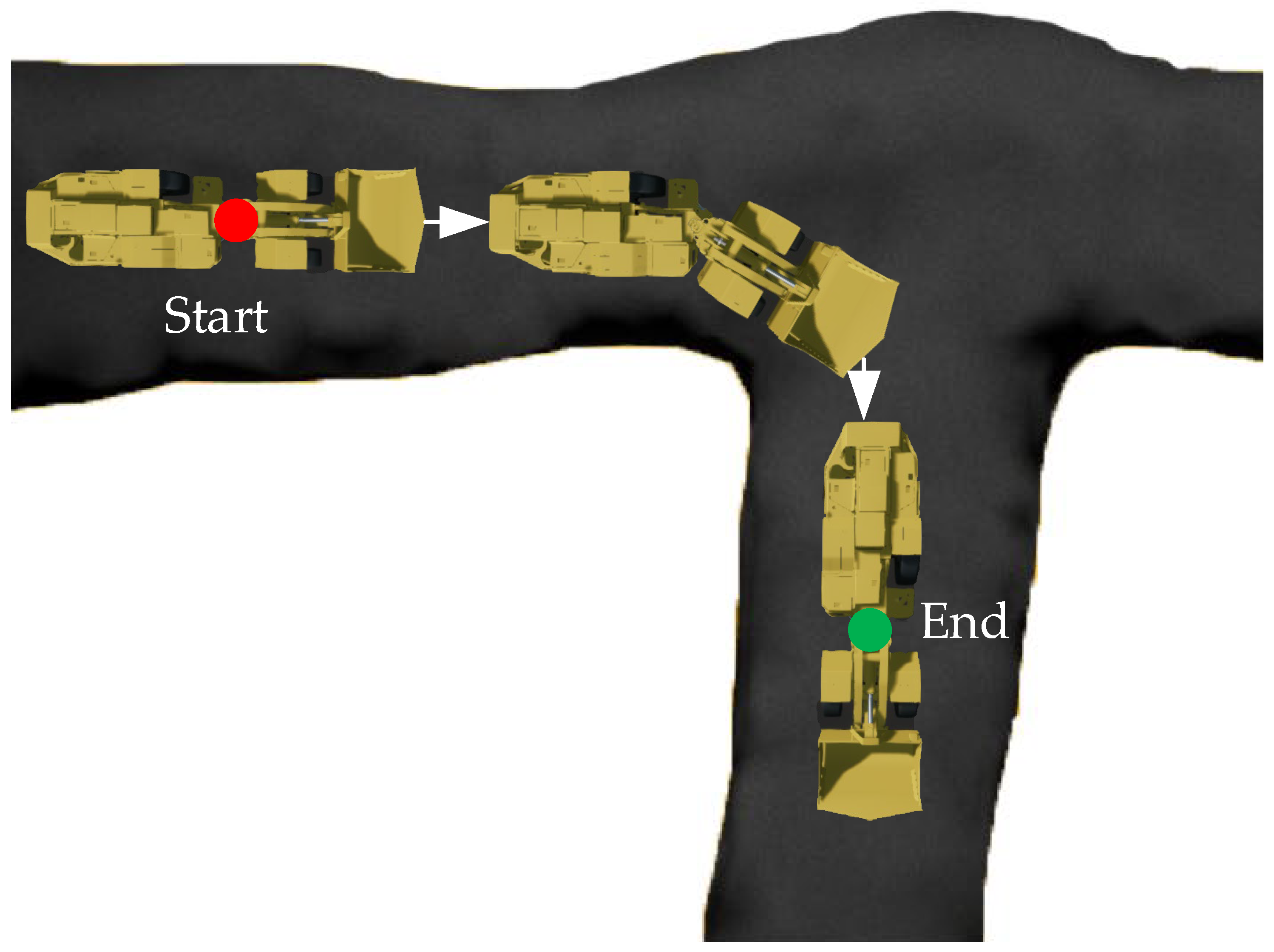
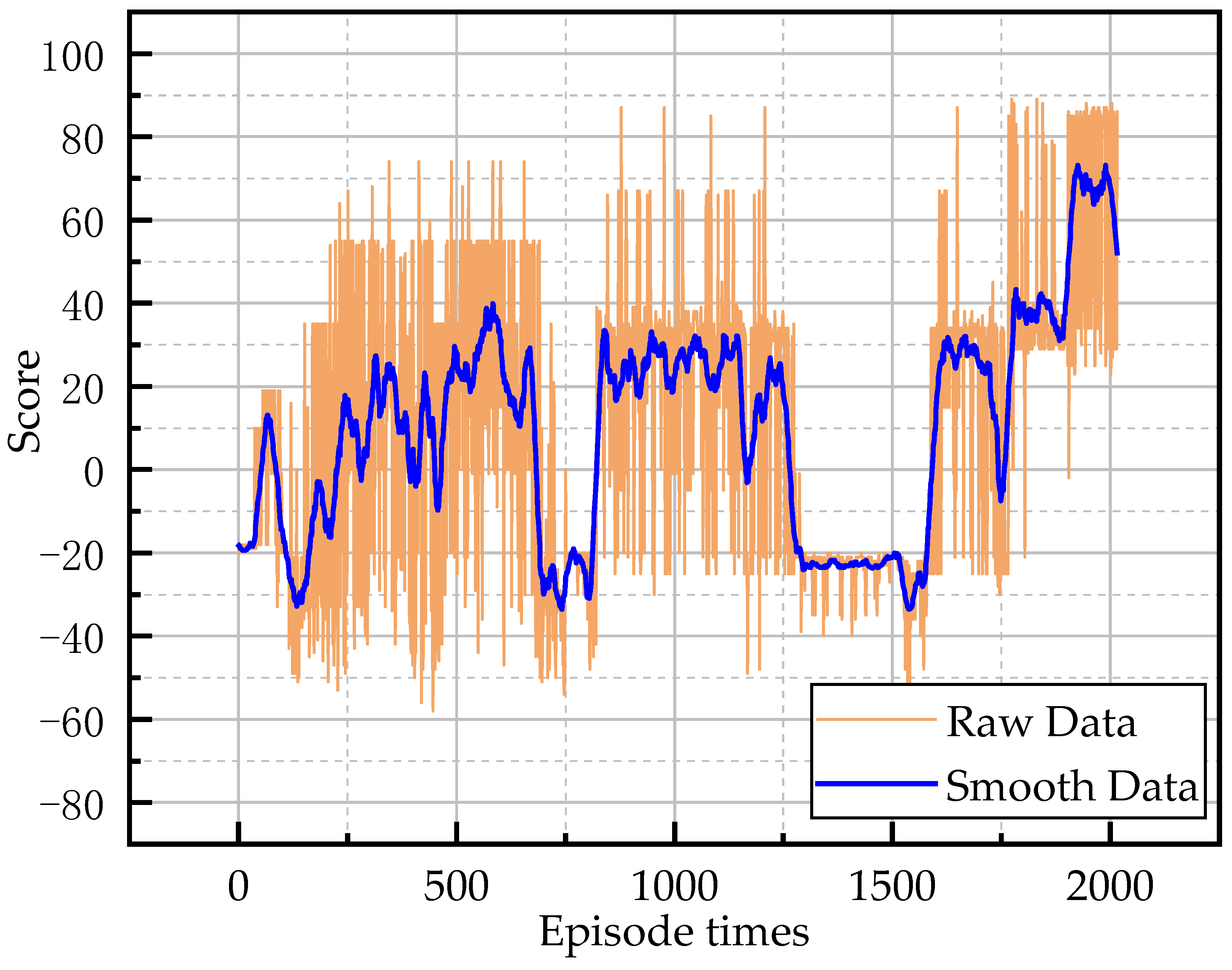
This paper aimed to realize the autonomous walking of an underground LHD machine in a tunnel, and built an underground working scenario based on a real tunnel and LHD machine in UE4. In this scenario, the feasibility of reinforcement learning in the autonomous walking control of the LHD machine was verified, and the experimental effect of the DQN algorithm in multi-state reinforcement learning training was further verified. In the experiment, inspired by reflective navigation and the DQN algorithm, a new training framework TCB-DQN was proposed, which combines the traditional control algorithm and DQN algorithm. This algorithm could realize the autonomous walking of the LHD machine faster and better. The experiments showed that TCB-DQN could avoid unnecessary exploration of the LHD machine in reinforcement learning training, and shortened the training time by 77% compared with the pure DQN algorithm. Finally, the robustness of the TCB-DQN algorithm was verified in a complex tunnel. The experiments showed that even if the training environment was changed to a more complex tunnel, a feasible LHD machine control method could still be obtained by using the TCB-DQN algorithm. The innovations of this paper are as follows:
- (1)
It was proven that the reinforcement learning algorithm is feasible for realizing the autonomous walking of a LHD machine in a definite scene.
In previous studies, research on the walking of a LHD machine often focused on the control algorithm. The advantage of a control algorithm is that it is relatively stable. Around a prepared standard, the LHD machine can move to the greatest extent according to this standard. However, the prepared standard is also formulated with the participation of people, which inevitably leads to some biases. According to the preferences of different makers, the standards may be different. The use of the reinforcement learning method can endow the LHD machine itself with the capability for exploration of the environment, without giving standards in advance. After repeated training in large quantities, it can often achieve better results.
- (2)
A TCB-DQN algorithm that integrates the traditional control algorithm and DQN was proposed.
Combining the advantages of the traditional control algorithm and DQN, a TCB-DQN algorithm was designed. Using this algorithm can greatly reduce the unnecessary exploration behavior of a simulated LHD machine; thus, it can greatly reduce the time of using the algorithm to train the simulated LHD machine, and use DQN to explore the best driving mode at key positions. Experiments showed that TCB-DQN can achieve an effect similar to, or even surpassing, manual operation.
- (3)
Autonomous walking of the simulated LHD machine in the simulation environment was realized, and this laid the foundation for parallel driving of the LHD machine.
To make a LHD machine unmanned, starting with the walking of the LHD machine, how to realize the autonomous walking of the LHD machine simply and efficiently must be considered. The most direct method is to install lidar and various mechanical sensors on a real LHD machine. However, the transformation of a LHD machine is a difficult problem, and the LHD machine and various equipment are easily damaged in the training process. Therefore, modeling of the real scenario and the LHD machine is carried out, Training the LHD machine in the virtual environment can complete the training effect that cannot be achieved in the real scenario in a short time. After the training is successful, the results will be transferred to the real LHD machine controller, which can realize the autonomous walking of the LHD machine, with the advantages of low cost and high efficiency.
Tunnels are often sprayed with concrete, which makes the tunnel wall appear full of folds. In the process of modeling, to make the tunnel look more real, the tunnel wall model is artificially adjusted. The folds and bulges on the tunnel wall should have a collision volume, but it is often found that some folds and bulges lose collision volume in the simulation environment, resulting in the occurrence of formwork penetration; this is because the collision box does not perfectly cover the tunnel model. In future research, the number convex hulls can be adjusted to make the tunnel model collision more real; but at the same time, the problem of computer resource allocation should be considered to balance quality and performance.
Reinforcement learning has been mainly divided into two parts: one is value-based, and the other is policy-based. The former provides a deterministic action at each step, and the latter provides the probability of different actions being selected at each step. They have their advantages and are developing in the direction of gradual integration. In the experiment, solely a value-based DQN algorithm was used in reinforcement learning. In future work, other algorithms of reinforcement learning can be used to train the LHD machine, which may achieve better results.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}