1. Introduction
Genetic programming (GP) [
1] is a method for evolving programs, usually represented as trees, through operations that mimic the Darwinian process of natural selection. Among the most successful methods of GP, there is the
geometric semantic GP (GSGP) [
2]. In its inception, GSGP was only an object of theoretical interest because of the geometric properties it induced on the fitness landscape. Subsequently, an efficient implementation of the geometric semantic genetic operators [
3,
4] allowed for the application of GSGP in many different fields (e.g., [
5]).
To implement and execute GSGP in an efficient manner, it is necessary to store all the information regarding the entire evolutionary process. In particular, all the populations need to be efficiently stored. Thus, it is natural to ask how this information can be used to improve the search process.
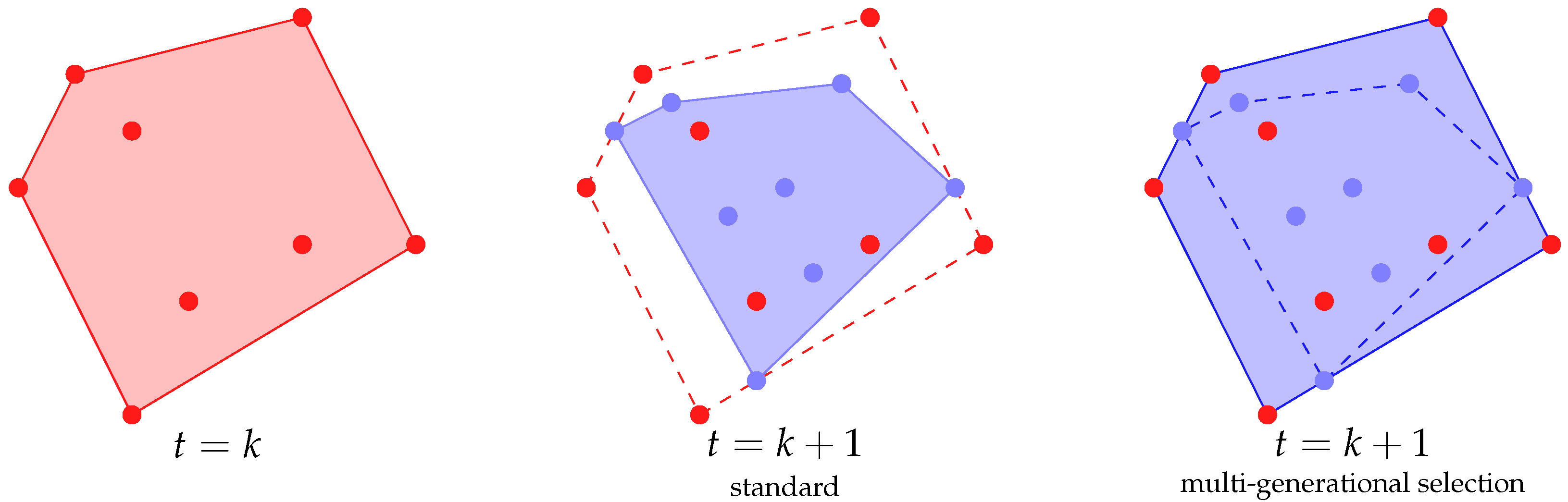
In this paper, we propose a method to use this additional “free” information by allowing the selection process to select individuals from the “old” populations. In particular, we present two ways for performing this multi-generational selection:
By selecting uniformly among the last k generations;
By selecting among all the generations with a decreasing probability (i.e., with a geometric distribution).
We compare the performance of two methods over six real-world datasets, showing that the ability to look back at the evolutionary history of GSGP is actually beneficial in the evolutionary process.
The paper is structured as follows:
Section 2 explores the existing works concerning the use of old generations (or
memory) to improve the performance of evolutionary computation algorithms.
Section 3.2 recalls the basic notions of GSGP and introduces multi-generational selection. In
Section 4, the experimental settings are presented, while
Section 5 discusses and analyzes the results.
Section 6 provides a summary of this work and directions for future research.
2. Related Works
When considering an evolutionary algorithm (EA) as a dynamic system, the idea of selecting individuals from older populations may be regarded as the ability of the system to directly exploit its memory, or equivalently the sequence of its past states. Under this perspective, approaches that enhanced genetic algorithms (GA) with memory started to appear in the literature in the mid-90s.
As far as we know, Louis and Li [
6] were the first to propose the use of a
long-term memory to store the best solutions found so far by a GA, eventually reintegrating them into the population in a later stage. Their experimental investigation of the traveling salesman problem (TSP) showed that GA obtained a better performance when its population was seeded with sub-optimal solutions found in previous instances rather than initializing it at random. Wiering [
7] experimented with a combination of GA and local search, where memory plays an analogous role in Tabu Search: if a local optimum has been found before, then it gets the lowest possible fitness to maximize the probability that the corresponding individual is replaced in the next generation. Later, Yang [
8] compared two variants of the random immigrants scheme based on memory and elitism to enhance the performance of GA over dynamic fitness landscapes. In these hybrid schemes, the best individual retained either by memory or elitism from old populations was used as a basis to evolve new immigrants through mutation, thus increasing the diversity of the population and its adaptability against a dynamic environment. Still, concerning dynamic optimization problems, Cao and Luo [
9] considered two retrieving strategies which selected the two best individuals from the associative memory of a GA. In particular, the environmental information associated with these two individuals was evaluated by either a survivability or diversity criterion. Similar to the methods proposed in this paper, Castelli et al. [
10,
11] proposed the reinsertion of old genetic material in GAs. In particular, the authors proposed a method to boost the GA optimization ability by replacing a fraction of the worst individuals with the best ones from an older population.
From the point of view of GP, the reinsertion of genetic material from old populations usually occurs in the related literature under the name of
concept and knowledge reuse. This is indeed a proper term since GP evolves programs that can be used, in turn, for learning concepts and functions, as in symbolic regression [
12]. Séront [
13] set forth a method to retrieve concepts evolved by GP based on a library that saved the trees of the best individuals. This method stood on the reasonable assumption that highly fit individuals embed useful concepts in their syntactic trees for solving a particular optimization problem. The results showed that the use of a concept library to create the initial population is beneficial for GP, as compared to the random initialization. Jaskowski et al. [
14] explored a different direction where a method for reusing knowledge embedded by GP was used among a group of learners that worked in parallel on a visual learning task. Therefore, in this case, the reuse of GP subprograms does not come from old populations but is rather shared among different current populations at the same time. Pei et al. [
15] investigated the issue of class imbalance in GP-based classifiers and proposed a method to mitigate it by using previously evolved GP trees to initialize the population in later runs. The experimental results indicated that such a mechanism allows the training time to be reduced and increases the accuracy of multi-classifier systems based on GP. More recently, Bi et al. [
16] proposed a new method to improve GP learning performance over image classification problems. Such a method is based on knowledge transfer among multiple populations, similarly to the aforementioned approach of [
14].
One of the main issues of the methods proposed in the above papers is that (a part of) the evolutionary history is needed to properly exploit older populations, thus increasing the space necessary for those methods to work. It is also interesting to notice that an increase in the population’s size (under a certain limit) is also useful for GSGP [
17]. Thus, as proposed in this paper, it is fundamental to explore the trade-off between population size and performance and whether this trade-off can be removed or mitigated by using part of the existing evolutionary history.
The principle of exploiting memory in evolutionary algorithms is also considered under a different guise in the area of machine learning. This is the case, for instance, of the
conservation machine learning approach proposed by Sipper and Moore [
18,
19]. There, the authors explore the idea of reusing ML models learned in different ways (e.g., multiple runs, ensemble methods, etc.) and apply it to the case of random forests. The results showed that their method improves the performance over some classification tasks through ensemble cultivation.
Finally, to the best of our knowledge, in the specific area of GSGP, there is no work directly addressing the reuse of old genetic material or individuals from past populations. Nevertheless, there have been several attempts aimed at improving the performance of the basic GSGP algorithm over regression problems. One of the most relevant approaches considers the integration of
local search in the evolutionary process of GSGP [
20,
21].
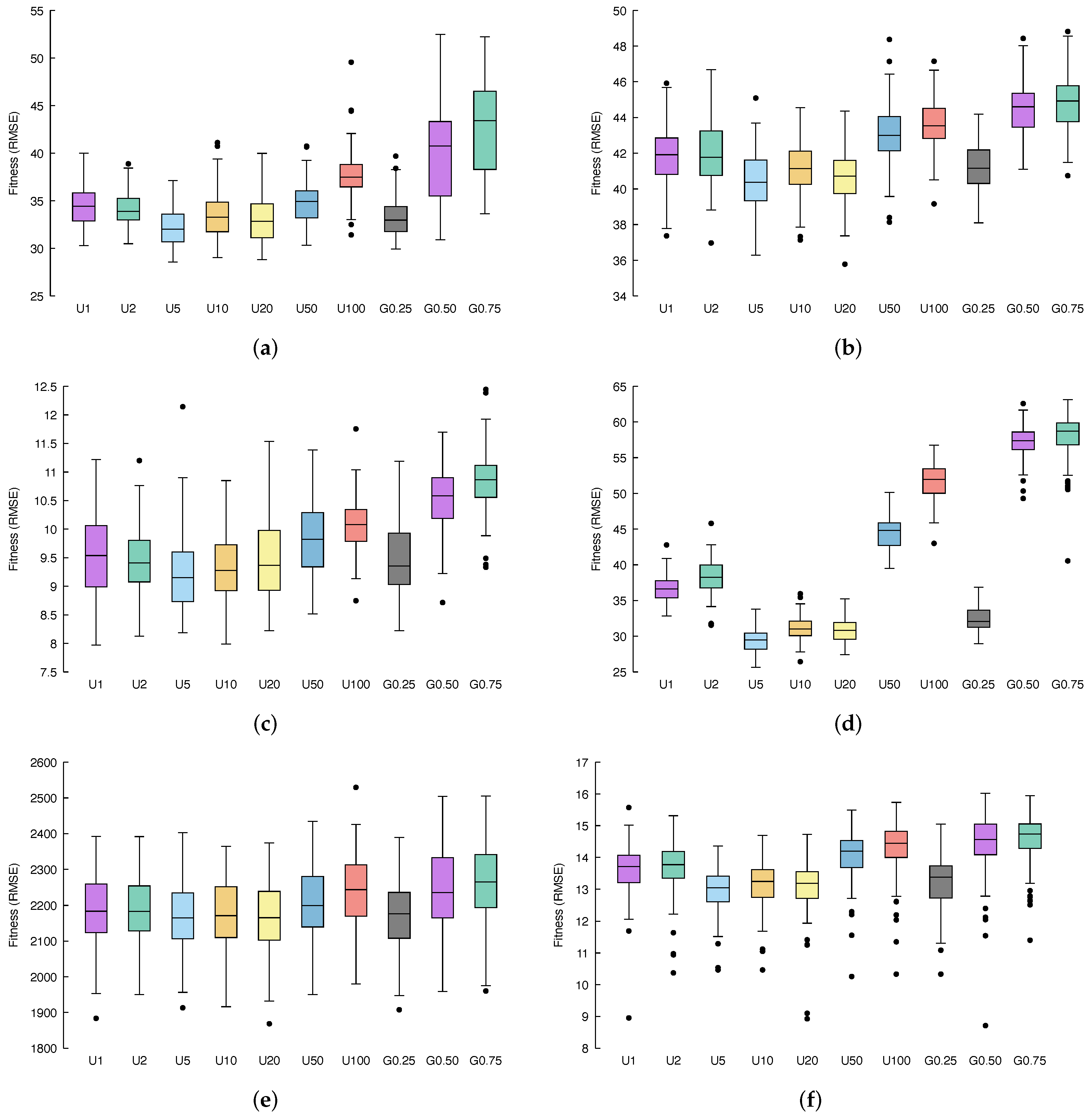
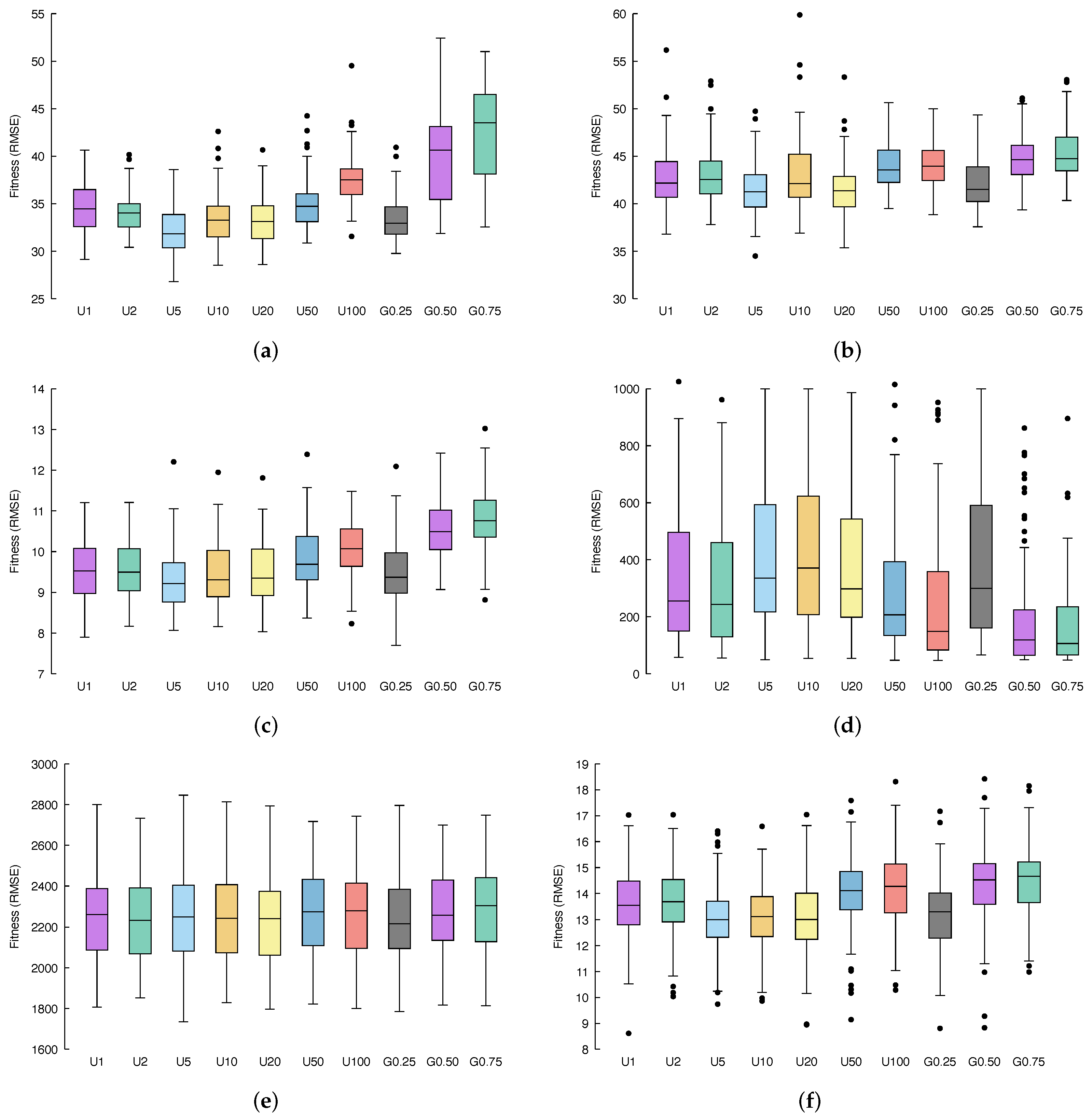
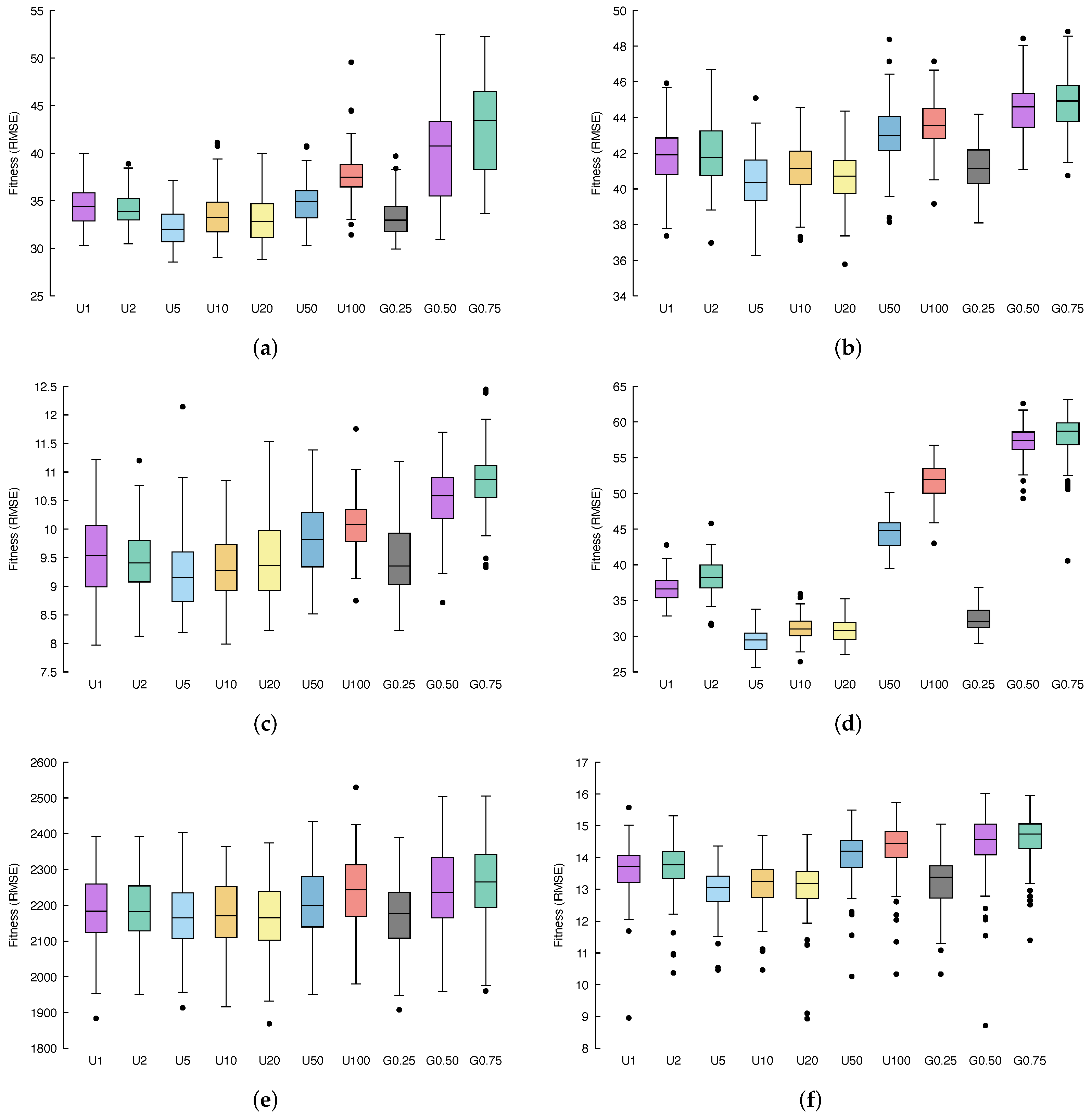
5. Results and Discussion
Figure 3 and
Figure 4 show, via box-plots, the distribution of the fitness, calculated over 100 independent runs, achieved by the different configurations, discussed in
Section 4.2, compared to classical GSGP, which is denoted here as U1 whereas, as explained before, it considers only the previous generation from which to select parents, exactly as in GSGP.
Table 3 stores the fitness values obtained by selecting the ancestors with uniform multi-generational selection for both the training and testing set among all the considered benchmark problems. Similarly,
Table 4 stores the geometric multi-generational selection method’s fitness values.
Table 5 reports a statistical significance assessment of the achieved result, displaying the
p-values obtained under the hypothesis that the median fitness resulting from the considered technique is equal to the one obtained with standard GSGP. This means that, if the resulting
p-values are zero, the fitness obtained is statistically significantly better or significantly worse with respect to the one achieved by GSGP, and to understand which case we are dealing with, the results contained in
Table 3 and
Table 4 must be compared. Finally,
Table 3 and
Table 4 display the fitness values obtained by selecting parents using a uniform distribution and geometric distribution, respectively.
Concerning the
air dataset (
Figure 3a and
Figure 4a), it is possible to see that, if we consider a uniform distribution for the multi-generational selection, the best performance is obtained by selecting ancestors from the 5 previous generations (
Table 3); on the other hand, with a geometric distribution, better results are achieved with
(
Table 4). Both of these methods meaningfully outperform standard GSGP, as confirmed by the statistical results of
Table 5. For what concerns the other variations of the proposed methods, combining information provided by fitness distribution shown in the box plots with the corresponding
p-values, it is possible to conclude that: U2, U10 and U20 also outperform GSGP with statistical significance, U50 leads to results similar to GSGP, while U100, G0.50 and G0.75 results are substantially less performing with respect to GSGP.
Considering the %F dataset (
Figure 3b and
Figure 4b), a similar behavior as the one observed for the previous benchmark problem appears. Again, U5 and G0.25 represent the two best candidates and outperform GSGP together with U2, U10, and U20. Here, U50, U100, G0.50, and G0.75 lead to worse fitness values compared to classical GSGP.
Moving to the
conc dataset, (
Figure 3c and
Figure 4c provide us with more evidence that U5 and G0.25 are a significant improvement of the standard GSGP. Moreover, it is still the case that U2, U10 and U20 slightly outperform GSGP, while U50, U100, G0.50 and G0.75 bring poor fitness values.
Taking into account the %PPB dataset (
Figure 3d and
Figure 4d), it is clear that all models are affected by overfitting, and a lower error in the training set entails a bigger error in the test set.
Applying our methods to the LD50 dataset (
Figure 3e and
Figure 4e), we can once more recognize that U5 and G0.25 represent the best improvement in GSGP. Further, it is important to highlight that for this dataset, while U2, U10, U20, U50, U100, G0.50, and G0.75 are indeed less well performing than the standard GSGP, none of these methods result in actually poor fitness values; instead, each of them reaches performance very similar to that obtained by GSGP.
Finally, the
yac dataset (
Figure 3f and
Figure 4f) is the last confirmation of the behavior we have been observing so far. Once more, U5 and G0.25 are a significant improvement of the standard GSGP, U2, U10 and U20 outperform GSGP, whereas U50, U100, G0.50 and G0.75 result in poor fitness values.
All in all, experiments performed revealed that U5 and G0.25 provide us with a meaningful improvement of the standard GSGP.
Regarding results obtained with uniform multi-generational selection, a number k of previous generations equal to 10 and 20 (and 5, as aforementioned) leads to statistically significant improvement in the fitness. This confirms our intuition: selecting ancestors also from previous generations (that, anyway, are not too far away) led to better results as a more wide set of genotypes is considered for recombination, and good characteristics of an individual that may have been lost during generation can be retrieved, thus decreasing the likelihood of being stuck in local minima. On the other hand, considering only 2 previous generations results in fitness values comparable with GSGP. This is reasonable considering that individuals of two subsequent generations do not differ too much. Thus, selecting ancestors from a generation or from the directly previous one does not remarkably affect the quality of the offspring generated. On the other hand, U50 and U100 lead to significantly worse performance in terms of fitness. This is because ancestors are selected from generations too far back, where individuals were not yet improved by the genetic process.
Considering the results achieved by geometric multi-generational selection, while, as stated above, setting led to a significant upgrade of the fitness value; for the other choice of parameters, i.e., and , the obtained results were worse with regards to standard GSGP.
These results are interesting for a particular reason: the expected value of the geometric distributions with , , and are 3, 1, and , respectively (i.e., ). Thus, we would expect G0.25, G0.50, and G0.75 to behave similarly to U4, U2, and between U1 and U2, respectively. In the first case, it appears to be correct, while in the second one, this happens only in some of the datasets. However, the behaviour of G0.75 is quite different from what was expected. Since the motivation cannot be traced back to the expected value of the distribution, it could be due to the fact that while it is expected that most of the individuals will be from the previous generation, only a limited number of them can be from older ones, damaging the search process. However, this is only a conjecture, and we expect to investigate this unexpected behaviour in later works together with the effect of using other distributions in the multi-generational selection.









{kind=link}
{kind=link}
{kind=link}
{kind=link}