
A Supervised Learning Method for Improving the Generalization of Speaker Verification Systems by Learning Metrics from a Mean Teacher



Abstract
:1. Introduction
- •
- We introduced a novel supervised training method utilizing the MT framework for the SV task of the open-set evaluation condition.
- •
- We analyzed the effectiveness of the proposed framework’s components through ablation and comparison experiments.
2. Related Work
3. Baseline
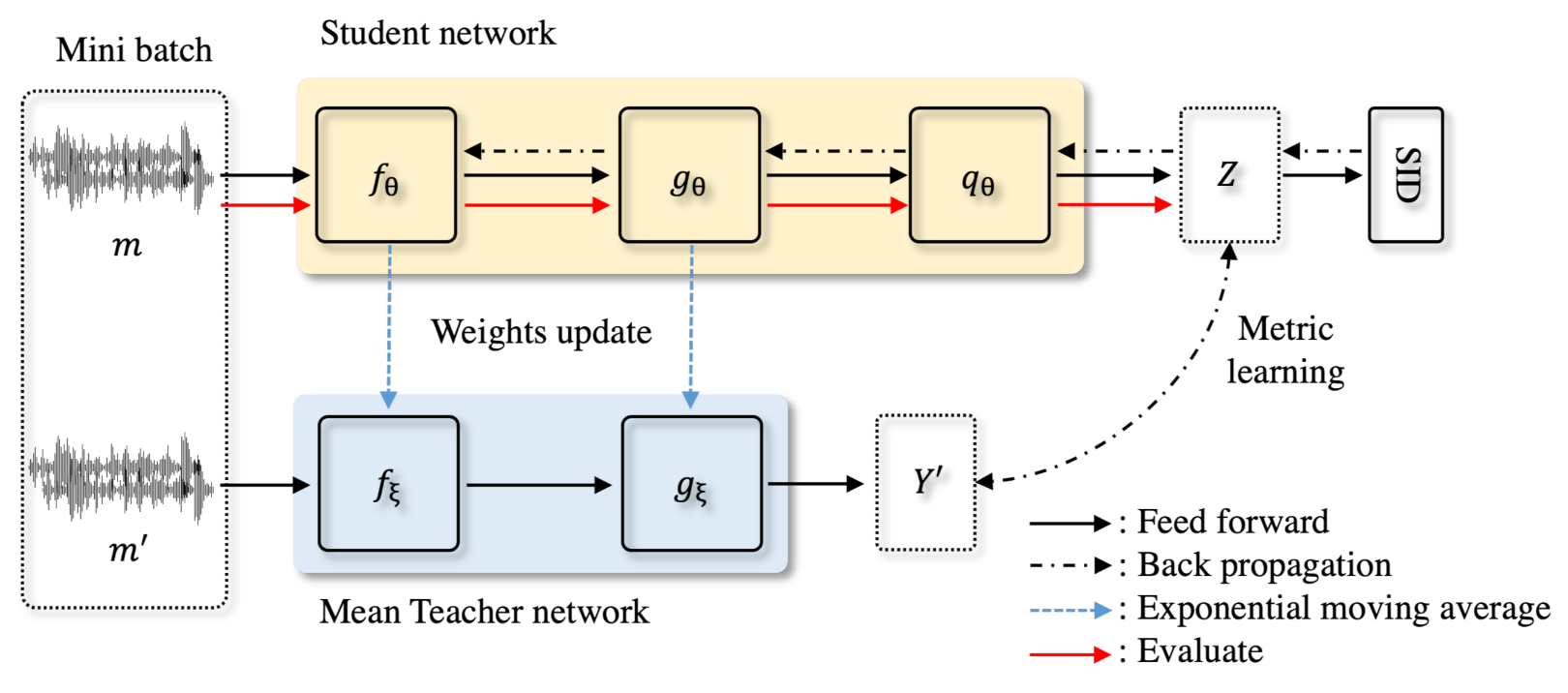
4. Proposed Method
4.1. Architecture
4.2. Model Update
5. Experiments and Result
5.1. Dataset
5.2. Experimental Configurations
5.3. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hansen, J.H.; Hasan, T. Speaker recognition by machines and humans: A tutorial review. IEEE Signal Process. Mag. 2015, 32, 74–99. [Google Scholar] [CrossRef]
- Bai, Z.; Zhang, X.L. Speaker recognition based on deep learning: An overview. Neural Netw. 2021, 140, 65–99. [Google Scholar] [CrossRef] [PubMed]
- Bendale, A.; Boult, T.E. Towards open set deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1563–1572. [Google Scholar]
- Polyak, B.T.; Juditsky, A.B. Acceleration of stochastic approximation by averaging. SIAM J. Control Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Freitag, M.; Al-Onaizan, Y.; Sankaran, B. Ensemble distillation for neural machine translation. arXiv 2017, arXiv:1702.01802. [Google Scholar]
- Chung, J.S.; Huh, J.; Mun, S.; Lee, M.; Heo, H.S.; Choe, S.; Ham, C.; Jung, S.; Lee, B.J.; Han, I. In Defence of Metric Learning for Speaker Recognition. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. VoxCeleb2: Deep Speaker Recognition. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Zisserman, A. Voxceleb: A large-scale speaker identification dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Variani, E.; Lei, X.; McDermott, E.; Moreno, I.L.; Gonzalez-Dominguez, J. Deep neural networks for small footprint text-dependent speaker verification. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4052–4056. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-vectors: Robust dnn embeddings for speaker recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5265–5274. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4080–4090. [Google Scholar]
- Wan, L.; Wang, Q.; Papir, A.; Moreno, I.L. Generalized end-to-end loss for speaker verification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4879–4883. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar] [CrossRef] [Green Version]
- Snyder, D.; Garcia-Romero, D.; Povey, D.; Khudanpur, S. Deep Neural Network Embeddings for Text-Independent Speaker Verification. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 999–1003. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sang, M.; Xia, W.; Hansen, J.H. Open-set Short Utterance Forensic Speaker Verification using Teacher-Student Network with Explicit Inductive Bias. arXiv 2020, arXiv:2009.09556. [Google Scholar]
- Tao, F.; Tur, G. Improving Embedding Extraction for Speaker Verification with Ladder Network. arXiv 2020, arXiv:2003.09125. [Google Scholar]
- Vogl, T.P.; Mangis, J.; Rigler, A.; Zink, W.; Alkon, D. Accelerating the convergence of the back-propagation method. Biol. Cybern. 1988, 59, 257–263. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech emotion recognition from spectrograms with deep convolutional neural network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Korea, 13–15 February 2017; pp. 1–5. [Google Scholar]
- Fu, S.W.; Tsao, Y.; Lu, X.; Kawai, H. Raw waveform-based speech enhancement by fully convolutional networks. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 006–012. [Google Scholar]
- Ravanelli, M.; Bengio, Y. Speaker recognition from raw waveform with sincnet. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 1021–1028. [Google Scholar]
- Jung, J.W.; Heo, H.S.; Kim, J.H.; Shim, H.J.; Yu, H.J. RawNet: Advanced end-to-end deep neural network using raw waveforms for text-independent speaker verification. arXiv 2019, arXiv:1904.08104. [Google Scholar]
- Jung, J.W.; Shim, H.J.; Kim, J.H.; Yu, H.J. α-feature map scaling for raw waveform speaker verification. J. Acoust. Soc. Korea 2020, 39, 441–446. [Google Scholar]
- Jung, J.W.; Kim, S.B.; Shim, H.J.; Kim, J.H.; Yu, H.J. Improved RawNet with Feature Map Scaling for Text-independent Speaker Verification using Raw Waveforms. arXiv 2020, arXiv:2004.00526. [Google Scholar]
- Okabe, K.; Koshinaka, T.; Shinoda, K. Attentive Statistics Pooling for Deep Speaker Embedding. arXiv 2018, arXiv:1803.10963. [Google Scholar]
- Samuli, L.; Timo, A. Temporal ensembling for semi-supervised learning. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; Volume 4, p. 6. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Kye, S.M.; Jung, Y.; Lee, H.B.; Hwang, S.J.; Kim, H.R. Meta-Learning for Short Utterance Speaker Recognition with Imbalance Length Pairs. arXiv 2020, arXiv:2004.02863. [Google Scholar]
- Snyder, D.; Chen, G.; Povey, D. Musan: A music, speech, and noise corpus. arXiv 2015, arXiv:1510.08484. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the Convergence of Adam and Beyond. In Proceedings of the International Conference on Learning Representations, Vancouver, Canada, 30 April–3 May 2018. [Google Scholar]
- You, Y.; Gitman, I.; Ginsburg, B. Large batch training of convolutional networks. arXiv 2017, arXiv:1708.03888. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, large minibatch sgd: Training imagenet in 1 h. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- Nagrani, A.; Chung, J.S.; Xie, W.; Zisserman, A. Voxceleb: Large-scale speaker verification in the wild. Comput. Speech Lang. 2020, 60, 101027. [Google Scholar] [CrossRef]
- Hong, Q.B.; Wu, C.H.; Wang, H.M.; Huang, C.L. Statistics Pooling Time Delay Neural Network Based on X-Vector for Speaker Verification. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6849–6853. [Google Scholar] [CrossRef]
- Zhou, J.; Jiang, T.; Li, Z.; Li, L.; Hong, Q. Deep Speaker Embedding Extraction with Channel-Wise Feature Responses and Additive Supervision Softmax Loss Function. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 2883–2887. [Google Scholar]
- Zhu, G.; Duan, Z. Y-vector: Multiscale waveform encoder for speaker embedding. In Proceedings of the Interspeech, Brno, Czechia, 30 August–3 September 2021. [Google Scholar]

{kind=link}
| Block | Block Structure | # Blocks | Output Shape |
|---|---|---|---|
| 1D-Conv | Conv(3, 3, 128) | 1 | L/3 × 128 |
| Res1 | BN and LeakyReLU | 2 | L/ × 128 |
| Conv(3, 1, 128) | |||
| BN and LeakyReLU | |||
| Conv(3, 1, 128) | |||
| Maxpool(3) | |||
| AFMS | |||
| Res2 | BN and LeakyReLU | 3 | L/ × 256 |
| Conv(3, 1, 256) | |||
| BN and LeakyReLU | |||
| Conv(3, 1, 256) | |||
| Maxpool(3) | |||
| AFMS | |||
| Res1 | BN and LeakyReLU | 3 | L/ × 512 |
| Conv(3, 1, 512) | |||
| BN and LeakyReLU | |||
| Conv(3, 1, 512) | |||
| Maxpool(3) | |||
| AFMS | |||
| Pooling | ASP | 1 | 1024 |
| Embedding | FC(512) | 1 | 512 |
| Block | Block Structure | Output |
|---|---|---|
| Encoder | RawNet2 | 512 |
| Converter | FC(512) | 512 |
| BN and LeakyReLU | ||
| FC(512) | ||
| Projector | FC(512) | 512 |
| BN and LeakyReLU | ||
| FC(512) |
| Model | Features | Loss | Vox1-O | Vox1-E | Vox1-H |
|---|---|---|---|---|---|
| EER (%) | EER (%) | EER (%) | |||
| ResNet-50 [9] | Spectrogram | Softmax+C | 3.95 | 4.42 | 7.33 |
| Thin ResNet-34 [42] | Softmax | 2.87 | 2.95 | 4.93 | |
| Stats-vector [43] | MFCC | Softmax | 3.29 | 3.39 | 5.94 |
| ResNet-34-SE [44] | AS-softmax | 3.10 | 3.38 | 5.93 | |
| RawNet2 [32] | Raw waveform | Softmax | 2.48 | 2.57 | 4.89 |
| Y-vector [45] | AM-softmax | 2.72 | 2.38 | 3.87 | |
| Our baseline | Softmax | 2.24 | 2.18 | 4.08 | |
| Our proposed | GE2E-H+Softmax | 1.98 | 1.88 | 3.81 |
| System | Consistency Loss | NP | BC | LT | Vox1-O | Vox1-E | Vox1-H |
|---|---|---|---|---|---|---|---|
| EER (%) | EER (%) | EER (%) | |||||
| #1 (Org_MT) | MSE | × | S | P | 4.98 | 4.86 | 8.61 |
| #2 | × | S | E | 3.56 | 3.15 | 5.61 | |
| #3 | × | D | E | 2.37 | 2.18 | 4.35 | |
| #4 | ✓ | D | E | 2.28 | 2.13 | 4.22 | |
| #5 | GE2E | ✓ | D | E | 2.27 | 2.21 | 4.3 |
| #6 | AP | ✓ | D | E | 2.18 | 2.05 | 4.11 |
| #7 (Proposed) | GE2E-H | ✓ | D | E | 1.98 | 1.88 | 3.81 |
| Batch Size | Baseline | Proposed Method | ||
|---|---|---|---|---|
| # Utterances per Speaker | ||||
| 4 | 6 | 8 | ||
| 200 | 2.24 | 2.1 | 2.23 | 3.04 |
| 800 | 2.36 | 2.12 | 2.07 | 2.19 |
| 1920 | 2.51 | 1.98 | 2.09 | 2.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-H.; Shim, H.-J.; Jung, J.-W.; Yu, H.-J. A Supervised Learning Method for Improving the Generalization of Speaker Verification Systems by Learning Metrics from a Mean Teacher. Appl. Sci. 2022, 12, 76. https://doi.org/10.3390/app12010076
Kim J-H, Shim H-J, Jung J-W, Yu H-J. A Supervised Learning Method for Improving the Generalization of Speaker Verification Systems by Learning Metrics from a Mean Teacher. Applied Sciences. 2022; 12(1):76. https://doi.org/10.3390/app12010076
Chicago/Turabian StyleKim, Ju-Ho, Hye-Jin Shim, Jee-Weon Jung, and Ha-Jin Yu. 2022. "A Supervised Learning Method for Improving the Generalization of Speaker Verification Systems by Learning Metrics from a Mean Teacher" Applied Sciences 12, no. 1: 76. https://doi.org/10.3390/app12010076
APA StyleKim, J.-H., Shim, H.-J., Jung, J.-W., & Yu, H.-J. (2022). A Supervised Learning Method for Improving the Generalization of Speaker Verification Systems by Learning Metrics from a Mean Teacher. Applied Sciences, 12(1), 76. https://doi.org/10.3390/app12010076