
Wind Turbine Fault Diagnosis by the Approach of SCADA Alarms Analysis

Abstract
:Featured Application
Abstract
1. Introduction
- We segment alarms into alarm lists by an information alarm and represent alarm lists by vectors to simplify alarms;
- We extract the feature vector from alarm vectors as a unique signature representing an occurring fault;
- We define the weights of alarms to establish the coupling correspondence between alarms and faults.
2. Background
2.1. SCADA Alarms
2.2. Maintenance Log
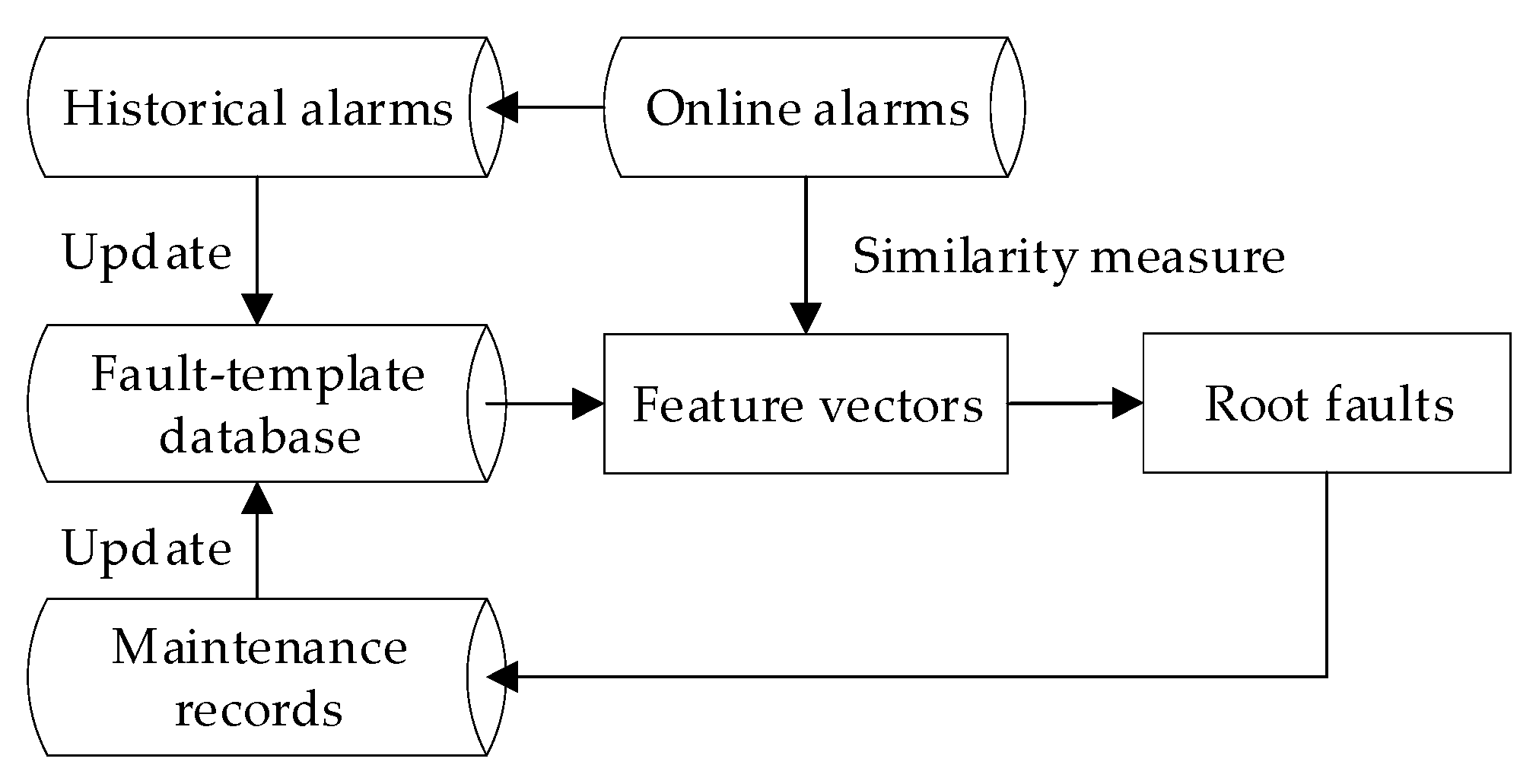
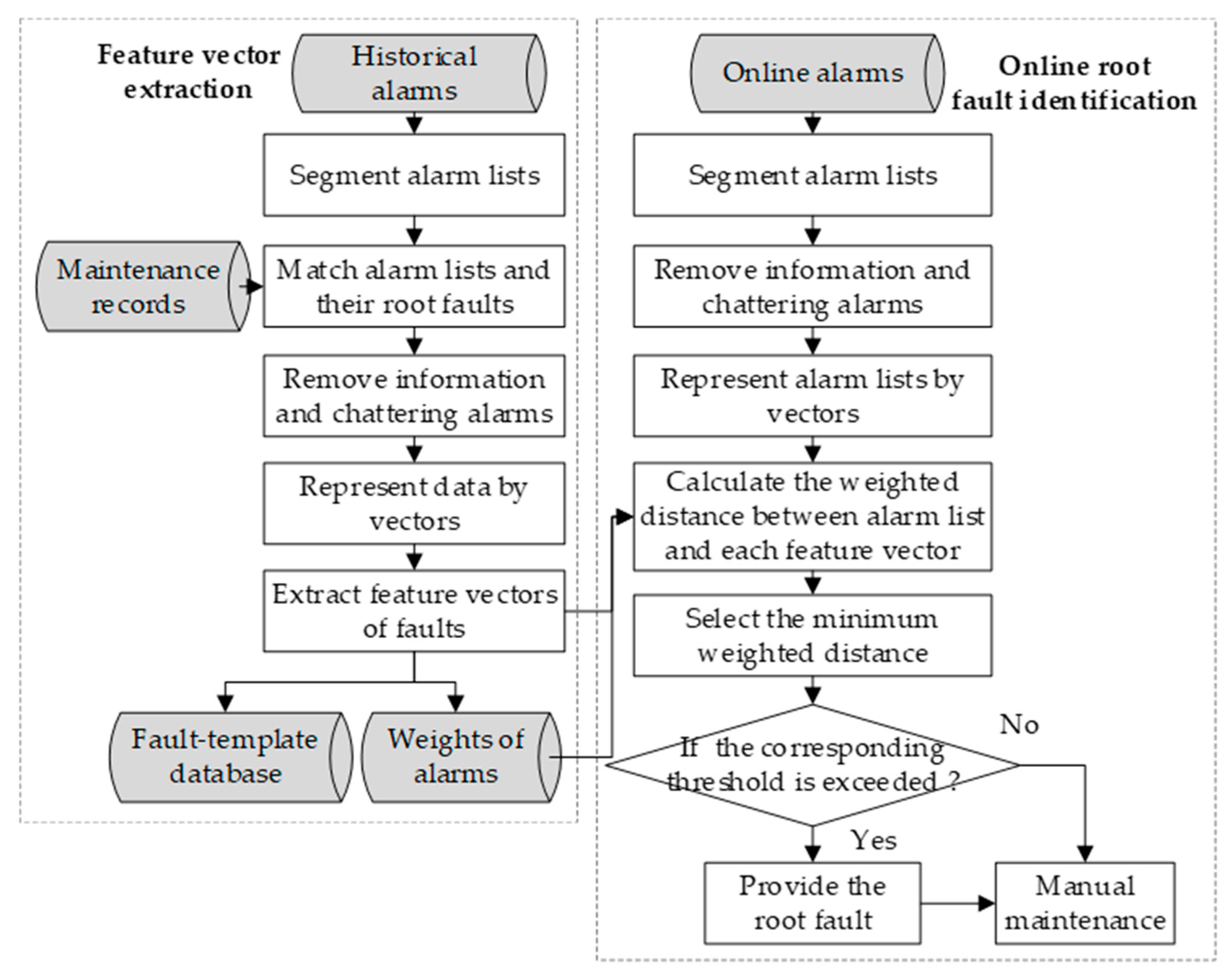
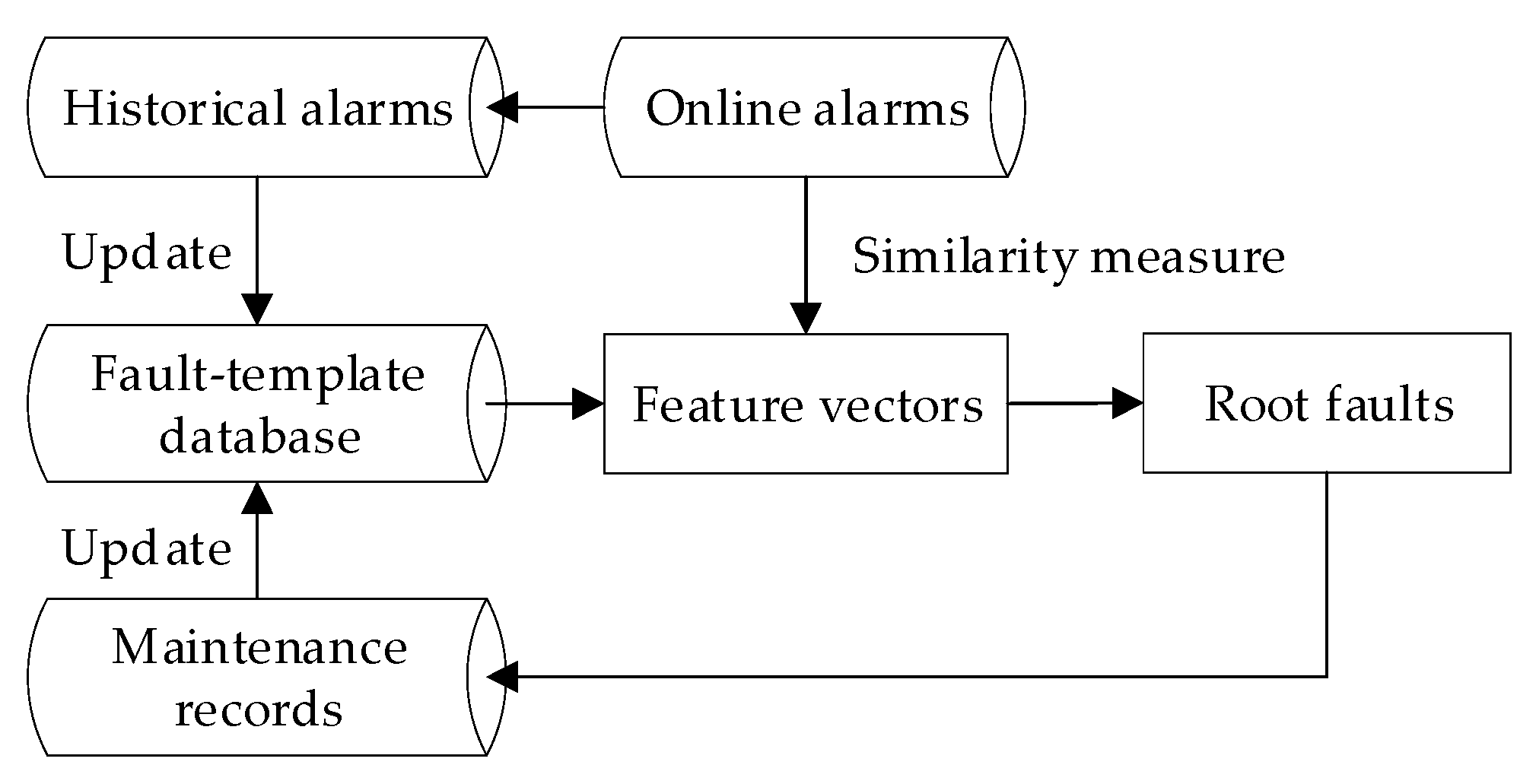
3. Online Root Fault Identification Method
3.1. Feature Vector Extraction
3.1.1. Segmenting Alarm Lists
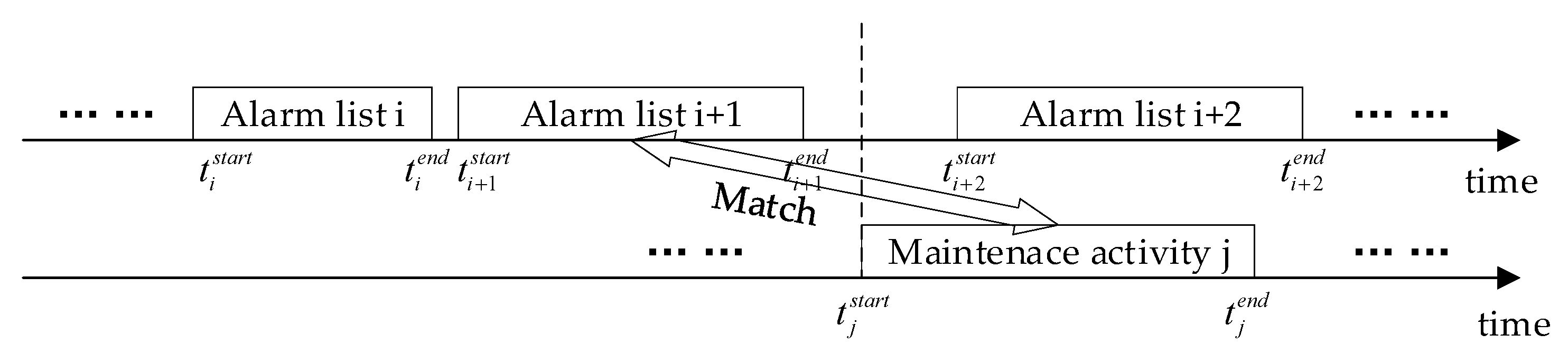
3.1.2. Matching Alarm Lists and Their Root Faults
3.1.3. Removing Information and Chattering Alarms
3.1.4. Representing Data by Vectors
3.1.5. Feature Vector Extraction
3.1.6. Weights of Alarms
- Alarm type
- 2.
- The significance of an alarm
- 3.
- The specificity of an alarm
3.2. Online Root Fault Diagnosis
3.2.1. Weighted Distance Calculation
- Distance measure
- 2.
- Weighted distance
3.2.2. Root Fault Label
4. Results and Discussion
4.1. Data Description
4.2. Case Study: Pitch–Motor Driver Fault
- T309 is a fault alarm, thus ;
- ;
- ;
- .
- The same process of steps 1–4 is repeated to achieve:;;;.
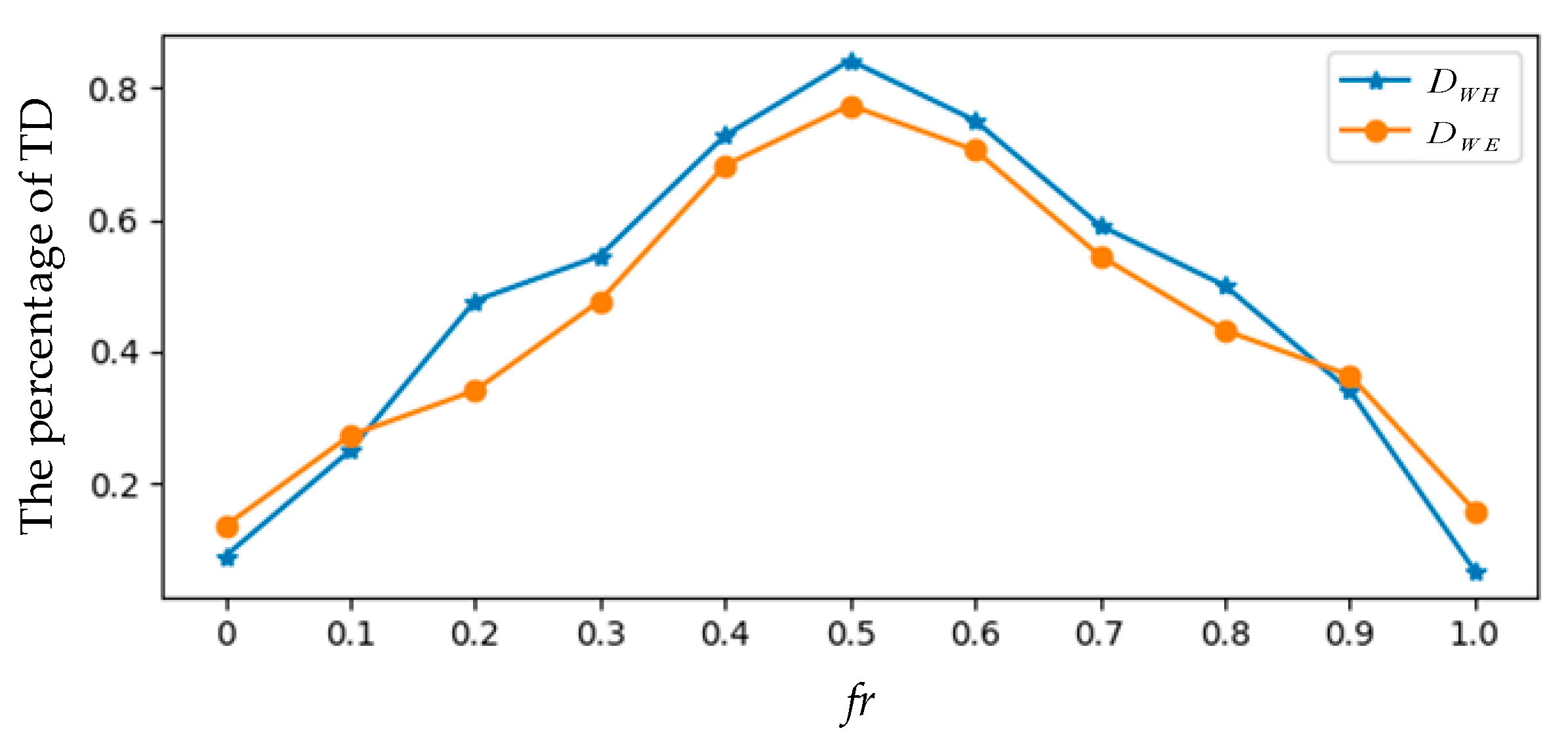
4.3. Performance Evaluation
- True detections (TD): the labeled root fault of an alarm list is the same as the actual fault;
- False detections (FD): the labeled root fault of an alarm list is different from the actual fault;
- Misdetection (MD): an alarm list is not assigned with a fault.
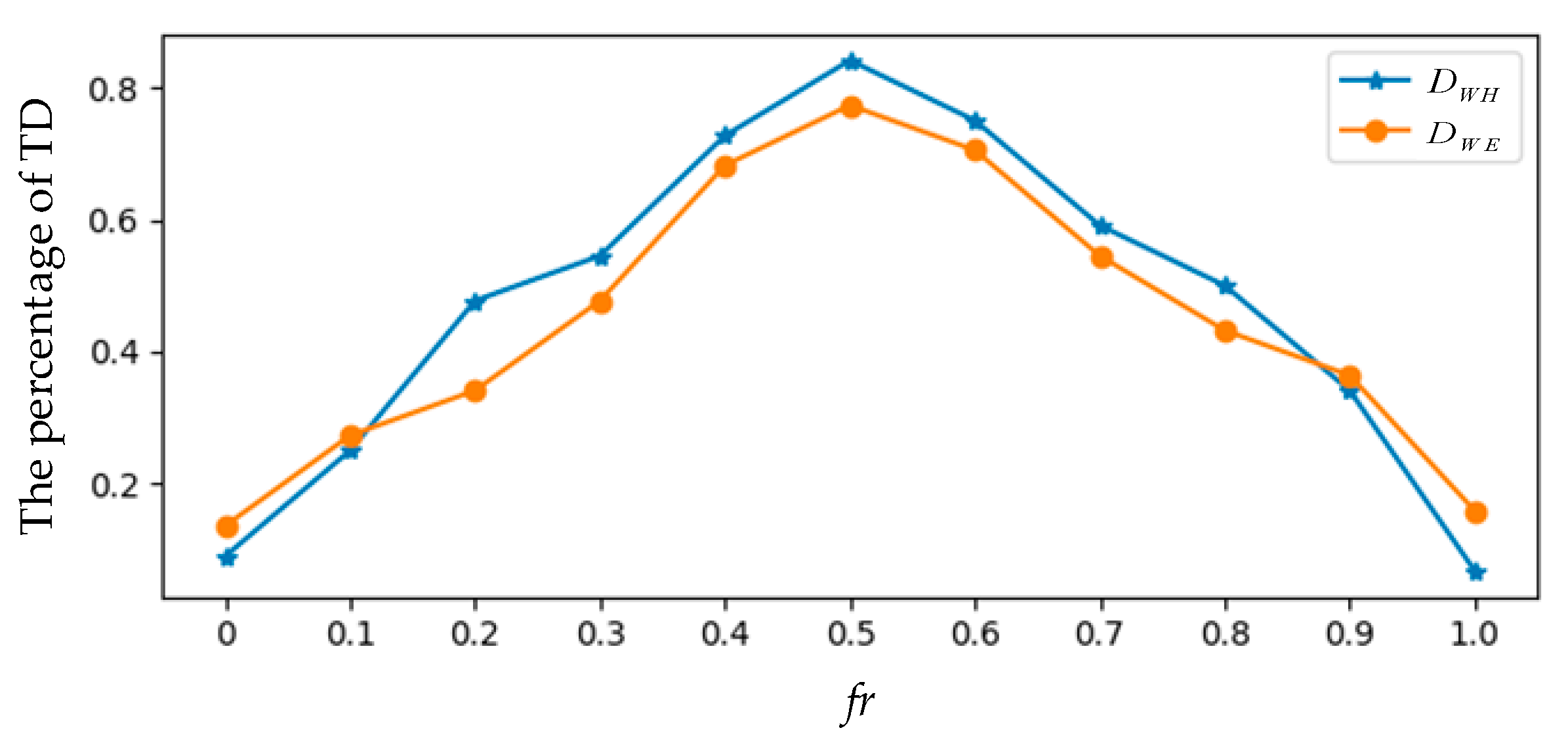
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, W.; Tavner, P.J.; Crabtree, C.J.; Feng, Y.; Qiu, Y. Wind turbine condition monitoring: Technical and commercial challenges. Wind Energy 2014, 17, 673–693. [Google Scholar] [CrossRef] [Green Version]
- Martin, R.; Lazakis, I.; Barbouchi, S.; Johanning, L. Sensitivity analysis of offshore wind farm operation and maintenance cost and availability. Renew. Energy 2016, 85, 1226–1236. [Google Scholar] [CrossRef] [Green Version]
- Stetco, A.; Dinmohammadi, F.; Zhao, X.; Robu, V.; Flynn, D.; Barnes, M.; Keane, J.; Nenadic, G. Machine learning methods for wind turbine condition monitoring: A review. Renew. Energy 2019, 133, 620–635. [Google Scholar] [CrossRef]
- Tautz-Weinert, J.; Watson, S.J. Using SCADA data for wind turbine condition monitoring—A review. IET Renew. Power Gener. 2017, 11, 382–394. [Google Scholar] [CrossRef] [Green Version]
- Wei, L.; Qian, Z.; Zareipour, H. Wind turbine pitch system condition monitoring and fault detection based on optimized relevance vector machine regression. IEEE Trans. Sustain. Energy 2019, 11, 2326–2336. [Google Scholar] [CrossRef]
- International Society of Automation (ISA). Management of Alarm Systems for the Process Industries; International Society of Automation: Research Triangle Park, NC, USA, 2009. [Google Scholar]
- Naghoosi, E.; Izadi, I.; Chen, T. Estimation of alarm chattering. J. Process. Control. 2011, 21, 1243–1249. [Google Scholar] [CrossRef]
- Folmer, J.; Vogel-Heuser, B. Computing dependent industrial alarms for alarm flood reduction. In Proceedings of the 9th IEEE International Multi-Conference on Systems, Sygnals & Devices (IFFE), Chemnitz, Germany, 10 May 2012; pp. 1–6. [Google Scholar]
- Qiu, Y.; Feng, Y.; Tavner, P.; Richardson, P.; Erdos, F.G.; Chen, B. Wind turbine SCADA alarm analysis for improving reliability. Wind Energy 2012, 15, 951–966. [Google Scholar] [CrossRef]
- Chen, B.; Qiu, Y.N.; Feng, Y.; Tavner, P.J.; Song, W.W. Wind turbine SCADA alarm pattern recognition. In Proceedings of the IET Conference on Renewable Power Generation (RPG 2011), Edinburgh, UK, 6–8 September 2011; pp. 1–6. [Google Scholar]
- Tong, C.; Guo, P. Data mining with improved Apriori algorithm on wind generator alarm data. In Proceedings of the 25th Chinese Control and Decision Conference, Guiyang, China, 25–27 May 2013; pp. 1936–1941. [Google Scholar]
- Leahy, K.; Gallagher, C.; O’Donovan, P.; O’Sullivan, D.T.J. Cluster analysis of wind turbine alarms for characterising and classifying stoppages. IET Renew. Power Gener. 2018, 12, 1146–1154. [Google Scholar] [CrossRef] [Green Version]
- Costa, R.; Cachulo, N.; Cortez, P. An intelligent alarm management system for large-scale telecommunication companies. In Proceedings of the 14th Portuguese Conference on Artificial Intelligence (EPIA’09), Aveiro, Portugal, 12–15 October 2009; pp. 386–399. [Google Scholar]
- Alserhani, F.; Akhlaq, M.; Awan, I.; Cullen, A.; Mirchandani, P. MARS: Multi-stage Attack Recognition System. In Proceedings of the 24th IEEE International Conference on Advanced Information Networking and Applications, Perth, Australia, 20–23 April 2010; pp. 753–759. [Google Scholar]
- Chen, Y.; Lee, J. Autonomous mining for alarm correlation patterns based on time-shift similarity clustering in manufacturing system. In Proceedings of the IEEE Conference on Prognostics and Health Management (PHM’11), Denver, CO, USA, 20–23 June 2011; pp. 1–8. [Google Scholar]
- Salah, S.; Maciá-Fernández, G.; Díaz-Verdejo, J.E. A model-based survey of alert correlation techniques. Comput. Netw. 2013, 57, 1289–1317. [Google Scholar] [CrossRef]
- Ahmed, K.; Izadi, I.; Chen, T.; Joe, D.; Burton, T. Similarity analysis of industrial alarm flood data. IEEE Trans. Autom. Sci. Eng. 2013, 10, 452–457. [Google Scholar] [CrossRef]
- Lai, S.; Yang, F.; Chen, T. Online pattern matching and prediction of incoming alarm floods. J. Process. Control 2017, 56, 69–78. [Google Scholar] [CrossRef]
- Charbonnier, S.; Bouchair, N.; Gayet, P. Fault template extraction to assist operators during industrial alarm floods. Eng. Appl. Artif. Intell. 2016, 50, 32–44. [Google Scholar] [CrossRef]
- Charbonnier, S.; Bouchair, N.; Gayet, P. A weighted dissimilarity index to isolate faults during alarm floods. Control. Eng. Pract. 2015, 45, 110–122. [Google Scholar] [CrossRef]
- Wang, J.; Yang, F.; Chen, T.; Shah, S.L. An overview of industrial alarm systems: Main causes for alarm overloading, research status, and open problems. IEEE Trans. Autom. Sci. Eng. 2015, 13, 1045–1061. [Google Scholar] [CrossRef]
- Wang, J.; Chen, T. An online method to remove chattering and repeating alarms based on alarm durations and intervals. Comput. Chem. Eng. 2014, 67, 43–52. [Google Scholar] [CrossRef]
- Singh, M.K.; Singh, N.; Singh, A.K. Speaker’s voice characteristics and similarity measurement using Euclidean distances. In Proceedings of the 2019 International Conference on Signal Processing and Communication (ICSC), Noida, India, 7–9 March 2019; pp. 317–322. [Google Scholar]
- Lee, K.; Kim, J.; Kwon, K.H.; Han, Y.; Kim, S. DDoS attack detection method using cluster analysis. Expert Syst. Appl. 2008, 34, 1659–1665. [Google Scholar] [CrossRef]
- Qiu, Y.; Feng, Y.; Infield, D. Fault diagnosis of wind turbine with SCADA alarms based multidimensional information processing method. Renew. Energy 2020, 145, 1923–1931. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Turbine Number | Time | Type | Code | Flag | Description |
|---|---|---|---|---|---|
| P01 | 2017/5/22 16:30:05 | information | I2 | start | The wind turbine is started |
| P01 | 2017/5/22 17:38:18 | warning | A264 | start | The first measuring point temperature of the generator stator is high |
| P01 | 2017/5/22 17:38:37 | warning | A264 | end | The first measuring point temperature of the generator stator is high |
| P01 | 2017/5/22 17:38:51 | fault | T21 | start | The communication of the pitch system is an error |
| P01 | 2017/5/22 17:38:52 | information | I2 | end | The wind turbine is started |
| P01 | 2017/5/23 00:15:20 | fault | T21 | end | The communication of the pitch system is an error |
| Turbine Number | Start Time | End Time | Subcomponents | Types of Faults | Solutions | Downtime/h |
|---|---|---|---|---|---|---|
| 1 | 2016/12/21 17:34:00 | 2016/12/25 12:45:00 | Pitch system | Slip ring is damaged | Replace the slip ring | 91.18 |
| Faults | The Total Number of Alarm Lists (Feature Vector Extraction/Test) | |
|---|---|---|
| 1 | Pitch–motor driver fault | 10(5/5) |
| 2 | Pitch–system communication fault | 7(4/3) |
| 3 | Hub speed encoder fault | 8(4/4) |
| 4 | High temperature of generator stator | 10(5/5) |
| 5 | Wind vane fault | 46(23/23) |
| 6 | Vibration sensor fault | 9(5/4) |
| Faults | The Total Number of Alarm Lists | The Occurrence Number | ||
|---|---|---|---|---|
| T309 | T724 | |||
| 1 | Pitch–motor driver fault | 5 | 4 | 5 |
| 2 | Pitch–system communication fault | 4 | 1 | 2 |
| 3 | Hub speed encoder fault | 4 | 0 | 0 |
| 4 | High temperature of generator stator | 5 | 0 | 0 |
| 5 | Wind vane fault | 23 | 2 | 3 |
| 6 | Vibration sensor fault | 5 | 0 | 0 |
| Test Set One | Test Set Two | |||
|---|---|---|---|---|
| The percentage of TD | 77.3% | 84.1% | - | - |
| The percentage of FD | 6.8% | 4.5% | 12.0% | 9.3% |
| The percentage of MD | 15.9% | 11.4% | 88.0% | 90.7% |
| Test Set One | |
|---|---|
| The percentage of TD | 81.8% |
| The percentage of FD | 18.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, L.; Qian, Z.; Pei, Y.; Wang, J. Wind Turbine Fault Diagnosis by the Approach of SCADA Alarms Analysis. Appl. Sci. 2022, 12, 69. https://doi.org/10.3390/app12010069
Wei L, Qian Z, Pei Y, Wang J. Wind Turbine Fault Diagnosis by the Approach of SCADA Alarms Analysis. Applied Sciences. 2022; 12(1):69. https://doi.org/10.3390/app12010069
Chicago/Turabian StyleWei, Lu, Zheng Qian, Yan Pei, and Jingyue Wang. 2022. "Wind Turbine Fault Diagnosis by the Approach of SCADA Alarms Analysis" Applied Sciences 12, no. 1: 69. https://doi.org/10.3390/app12010069
APA StyleWei, L., Qian, Z., Pei, Y., & Wang, J. (2022). Wind Turbine Fault Diagnosis by the Approach of SCADA Alarms Analysis. Applied Sciences, 12(1), 69. https://doi.org/10.3390/app12010069