
Clickbait Detection Using Deep Recurrent Neural Network

 ,
,  ,
,  , , and
, , and 
Abstract
:1. Introduction
1.1. Research Contributions
- A novel browser extension is proposed that analyzes links attached to clickbait while using less memory.
- The proposed ClickBaitSecurity is capable of efficiently distinguishing between legitimate and illegitimate links by accurately using an RNN.
- The novel proposed ClickBaitSecurity integrates the features of binary and domain rating check algorithms for a faster and more efficient search process.
1.2. Paper Organization
2. Problem Identification and Importance
- Educate naive users about threats that they might encounter on the Internet by creating more services.
- Publish a list of well-known fraudulent Internet resources in order to warn users.
- Protect users from suspicious links that appear in advertisements using intrusion detection/prevention tools.
3. Related Work
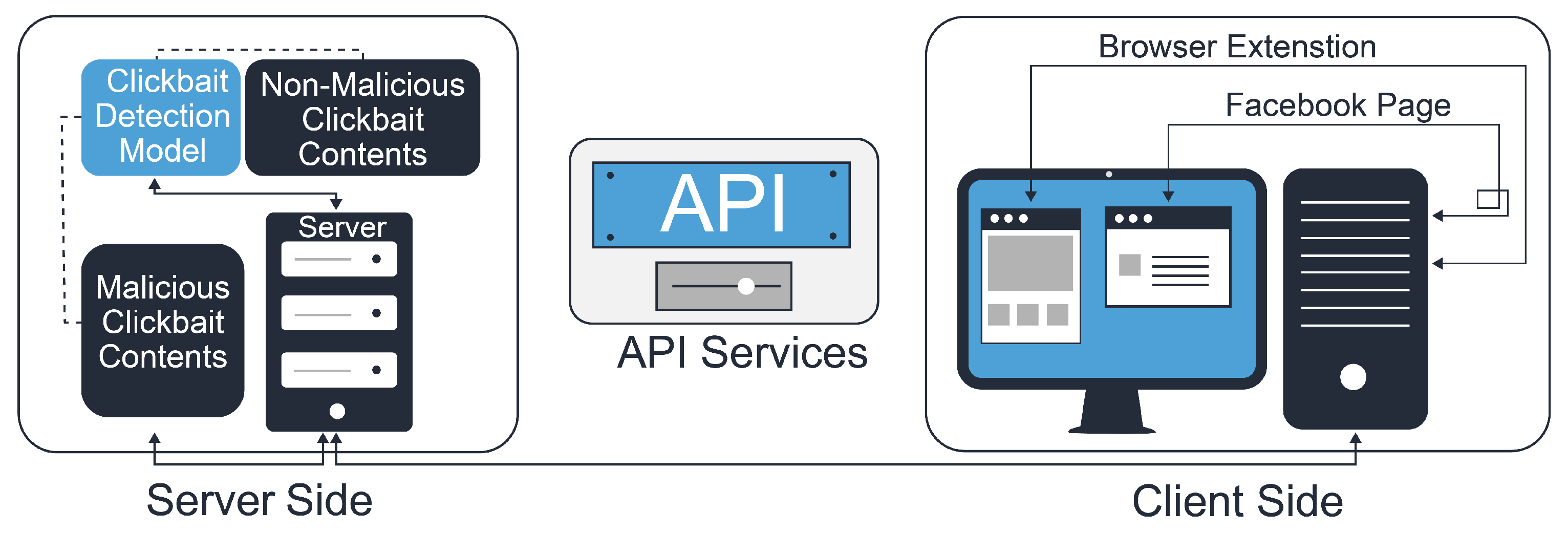
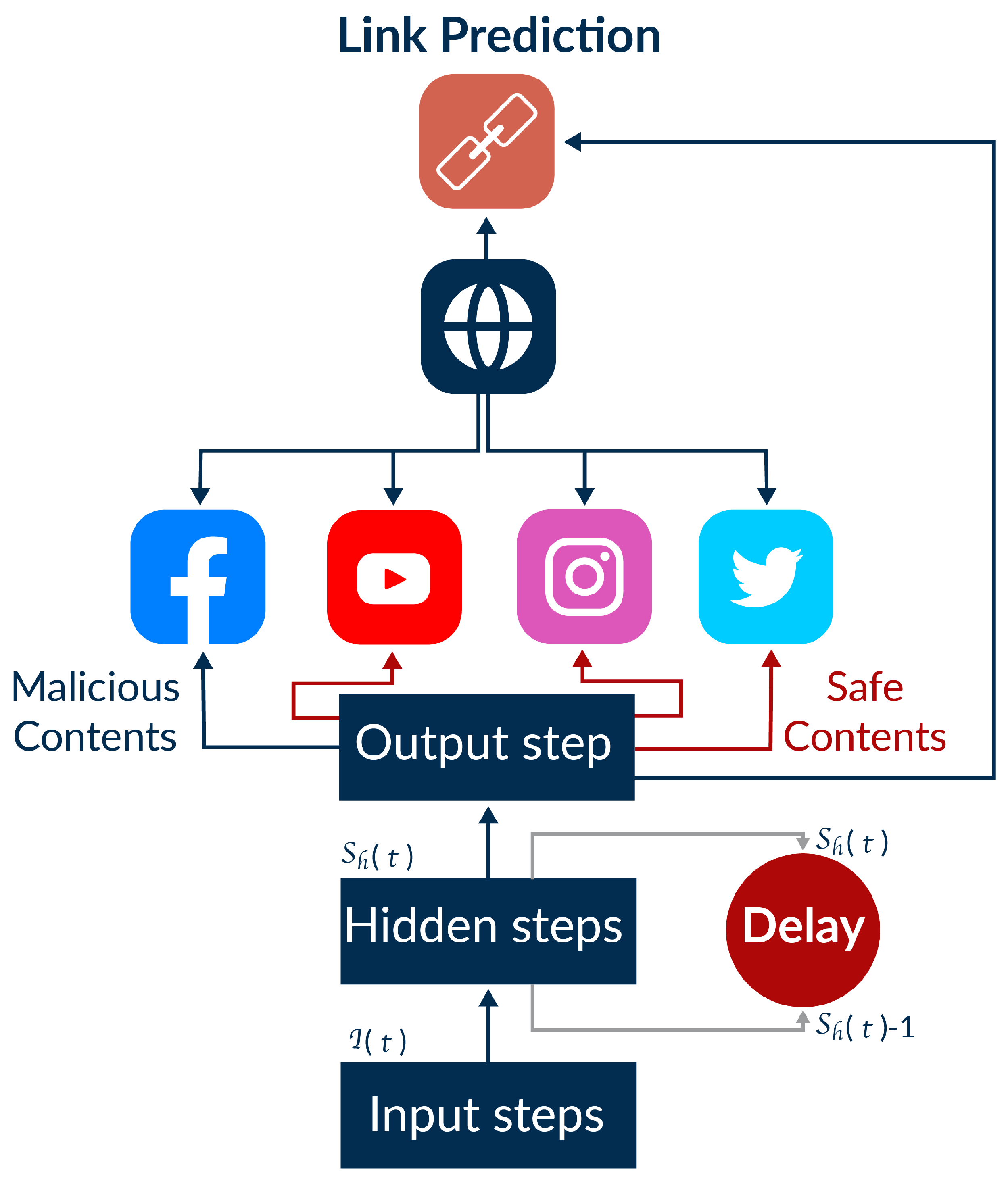
4. System Model
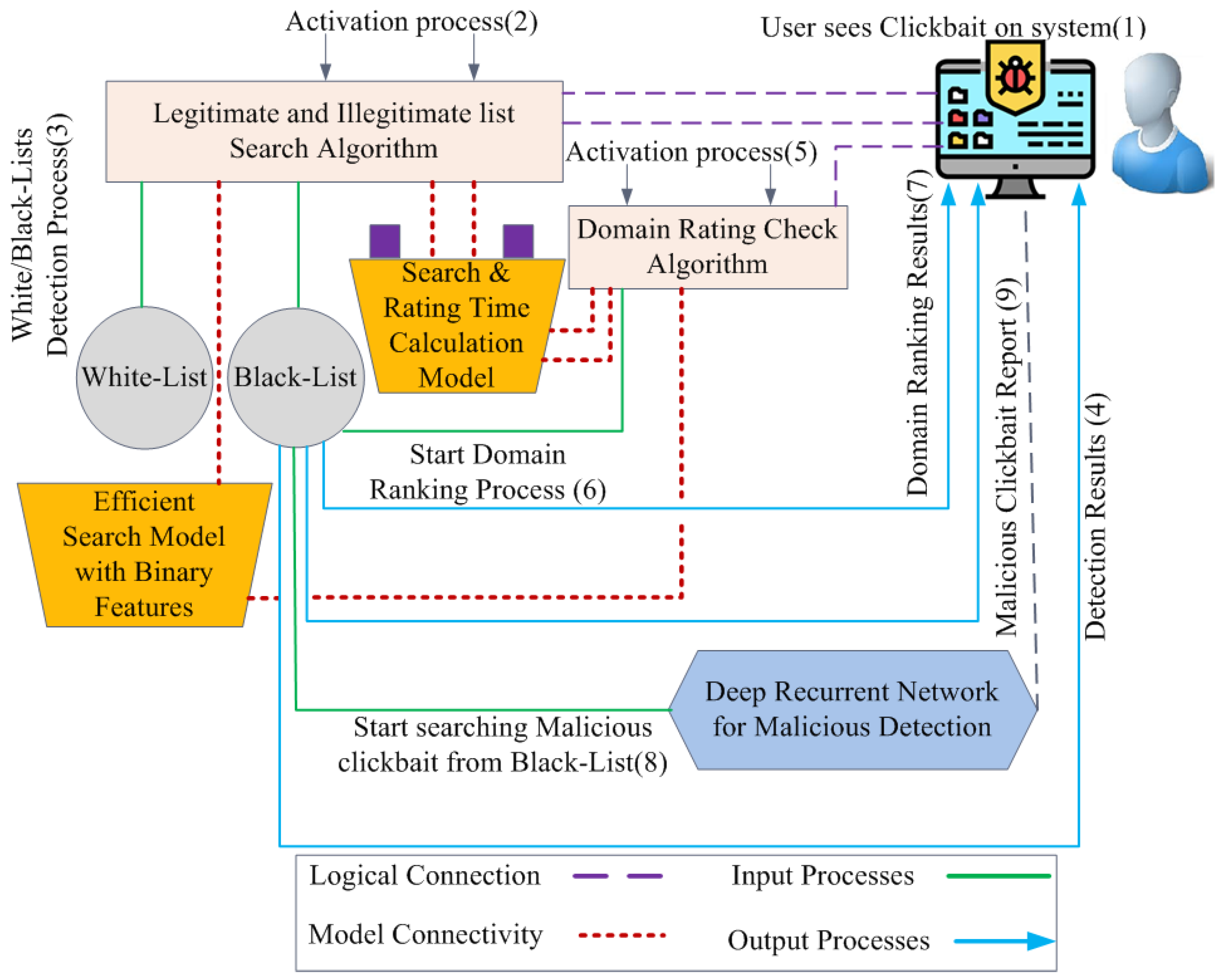
5. Proposed Extension Scanning Process
- Analysis and examination of legal websites;
- Examination of search process;
- Recurrent neural network for malicious content detection.
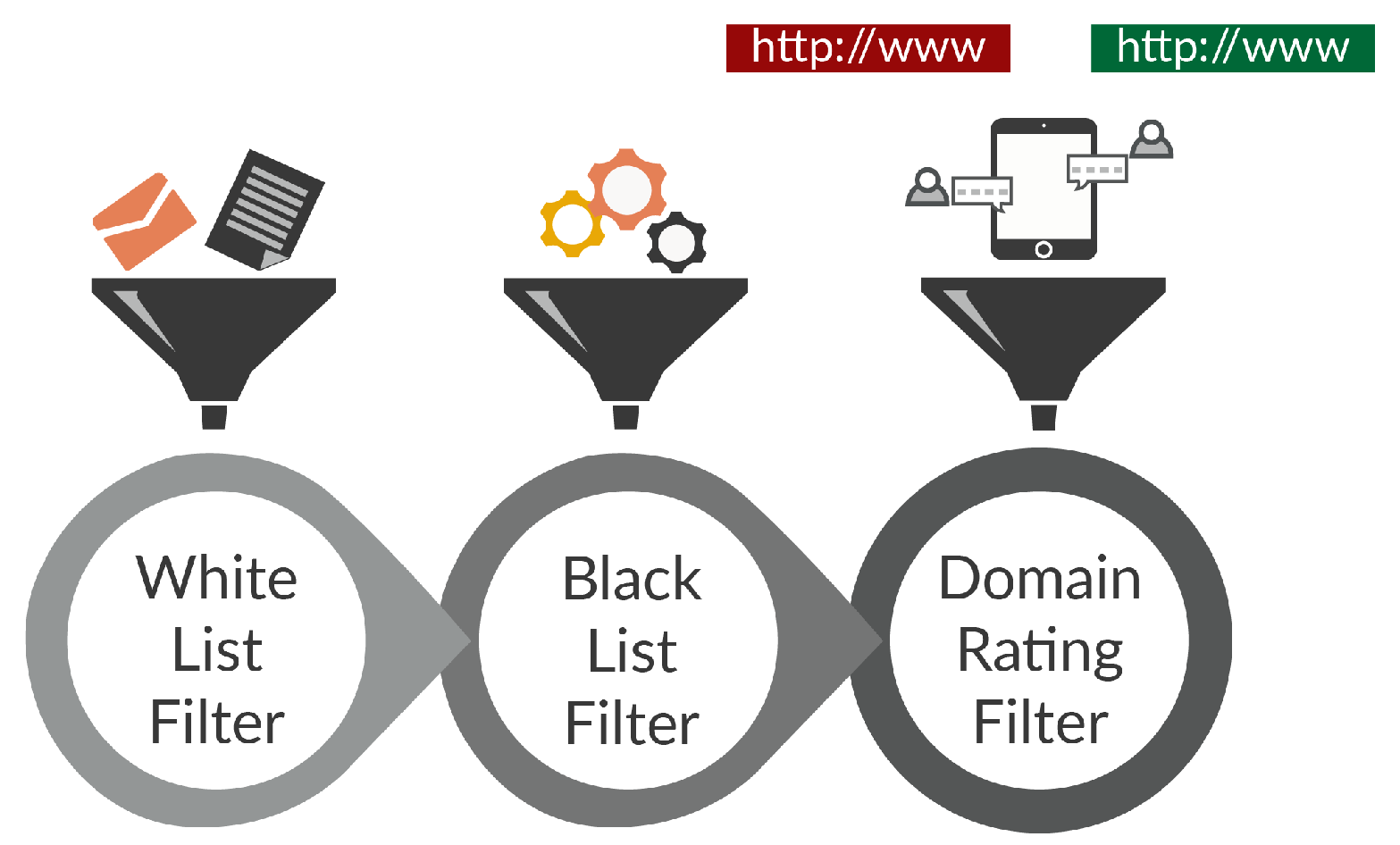
5.1. Analysis and Examination of Legal Websites
| Algorithm 1 Legitimate and illegitimate list search algorithm. |
| Input:, , in Output: or out
|
| Algorithm 2 Domain rating check algorithm |
| Input:
in Output: out
|
5.2. Examination of Search Process
6. Deep Recurrent Neural Network for Malicious Content Detection
7. Experimental Setup and Results
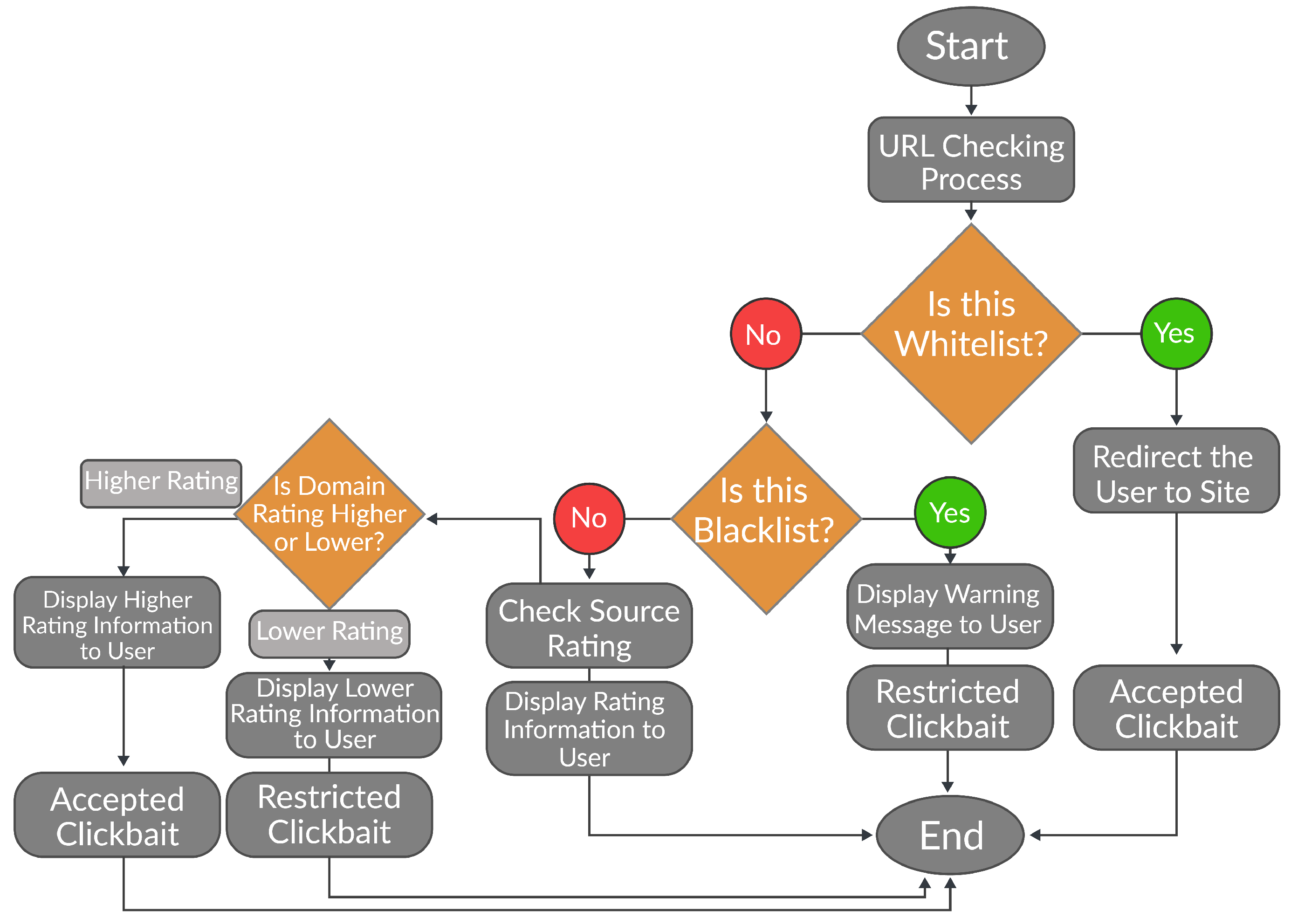
- Scenario 1: ClickBaitSecurity detects the link in a URL blacklist or whitelist and provides the obtained information to the user.
- Scenario 2: ClickBaitSecurity does not detect the link in or but finds its domain name in the domain list and, based on the domain rating of website , provides information to the user.
- Scenario 3: ClickBaitSecurity does not find information in any list and provides the user with a message asserting that it cannot analyze this web resource.
- Malicious and safe link detection;
- Accuracy.
7.1. Malicious and Safe Link Detection
7.2. Accuracy
8. Discussion of Results
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Razaque, A.; Rizvi, S.; Almiani, M.; Al Rahayfeh, A. State-of-art review of information diffusion models and their impact on social network vulnerabilities. J. King Saud-Univ.-Comput. Inf. Sci. 2019, 34, 1275–1294. [Google Scholar] [CrossRef]
- Pujahari, A.; Sisodia, D.S. Clickbait detection using multiple categorisation techniques. J. Inf. Sci. 2021, 47, 118–128. [Google Scholar] [CrossRef] [Green Version]
- Gomez-Mejia, G. “Fail, Clickbait, Cringe, Cancel, Woke”: Vernacular Criticisms of Digital Advertising in Social Media Platforms. In International Conference on Human–Computer Interaction; Springer: Cham, Switzerland, 2020; pp. 309–324. [Google Scholar]
- Razaque, A.; Alotaibi, B.; Alotaibi, M.; Amsaad, F.; Manasov, A.; Hariri, S.; Yergaliyeva, B.; Alotaibi, A. Blockchain-enabled Deep Recurrent Neural Network Model for Clickbait Detection. IEEE Access 2021. [Google Scholar] [CrossRef]
- Chawda, S.; Patil, A.; Singh, A.; Save, A. A Novel Approach for Clickbait Detection. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 1318–1321. [Google Scholar]
- Wang, W.; Feng, F.; He, X.; Zhang, H.; Chua, T.S. Clicks can be cheating: Counterfactual recommendation for mitigating clickbait issue. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 1288–1297. [Google Scholar]
- Zannettou, S.; Sirivianos, M.; Blackburn, J.; Kourtellis, N. The web of false information: Rumors, fake news, hoaxes, clickbait, and various other shenanigans. J. Data Inf. Qual. (JDIQ) 2019, 11, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Varshney, D.; Vishwakarma, D.K. A unified approach for detection of Clickbait videos on YouTube using cognitive evidences. Appl. Intell. 2021, 51, 4214–4235. [Google Scholar] [CrossRef]
- Razaque, A.; Al Ajlan, A.; Melaoune, N.; Alotaibi, M.; Alotaibi, B.; Dias, I.; Zhao, C. Avoidance of Cybersecurity Threats with the Deployment of a Web-Based Blockchain-Enabled Cybersecurity Awareness System. Appl. Sci. 2021, 11, 7880. [Google Scholar] [CrossRef]
- Baptista, J.P.; Gradim, A. Understanding fake news consumption: A review. Soc. Sci. 2020, 9, 185. [Google Scholar] [CrossRef]
- Zheng, H.T.; Chen, J.Y.; Yao, X.; Sangaiah, A.K.; Jiang, Y.; Zhao, C.Z. Clickbait convolutional neural network. Symmetry 2018, 10, 138. [Google Scholar] [CrossRef] [Green Version]
- Razaque, A.; Amsaad, F.; Halder, D.; Baza, M.; Aboshgifa, A.; Bhatia, S. Analysis of Sentimental Behaviour over Social Data Using Machine Learning Algorithms. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Springer: Cham, Switzerland, 2021; pp. 396–412. [Google Scholar]
- Munger, K.; Luca, M.; Nagler, J.; Tucker, J. The (null) effects of clickbait headlines on polarization, trust, and learning. Public Opin. Q. 2020, 84, 49–73. [Google Scholar] [CrossRef]
- Zeng, E.; Kohno, T.; Roesner, F. Bad news: Clickbait and deceptive ads on news and misinformation websites. In Workshop on Technology and Consumer Protection (ConPro); IEEE: New York, NY, USA, 2020. [Google Scholar]
- Horák, A.; Baisa, V.; Herman, O. Technological Approaches to Detecting Online Disinformation and Manipulation. In Challenging Online Propaganda and Disinformation in the 21st Century; Palgrave Macmillan: Cham, Switzerland, 2021; pp. 139–166. [Google Scholar]
- Kumi, S.; Lim, C.; Lee, S.G. Malicious URL Detection Based on Associative Classification. Entropy 2021, 23, 182. [Google Scholar] [CrossRef]
- Uçtu, G.; Alkan, M.; Dogru, İ.A.; Dorterler, M. A suggested testbed to evaluate multicast network and threat prevention performance of Next Generation Firewalls. Future Gener. Comput. Syst. 2021, 124, 56–67. [Google Scholar] [CrossRef]
- Jain, A.K.; Gupta, B.B. A novel approach to protect against phishing attacks at client side using auto-updated white-list. EURASIP J. Inf. Secur. 2016, 2016, 9. [Google Scholar] [CrossRef] [Green Version]
- Sahoo, S.R.; Gupta, B.B. Multiple features based approach for automatic fake news detection on social networks using deep learning. Appl. Soft Comput. 2021, 100, 106983. [Google Scholar] [CrossRef]
- Khan, M.A.; Kim, J. Toward developing efficient Conv-AE-based intrusion detection system using heterogeneous dataset. Electronics 2020, 9, 1771. [Google Scholar] [CrossRef]
- Arachchilage, N.A.G.; Hameed, M.A. Integrating self-efficacy into a gamified approach to thwart phishing attacks. arXiv 2017, arXiv:1706.07748. [Google Scholar]
- Mathur, A.; Vitak, J.; Narayanan, A.; Chetty, M. Characterizing the use of browser-based blocking extensions to prevent online tracking. In Proceedings of the Fourteenth Symposium on Usable Privacy and Security SOUPS, Baltimore, MD, USA, 12–14 August 2018; pp. 103–116. [Google Scholar]
- Kaur, S.; Kumar, P.; Kumaraguru, P. Detecting clickbaits using two-phase hybrid CNN-LSTM biterm model. Expert Syst. Appl. 2020, 151, 113350. [Google Scholar] [CrossRef]
- Siregar, B.; Habibie, I.; Nababan, E.B. Identification of Indonesian clickbait news headlines with long short-term memory recurrent neural network algorithm. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1882, p. 012129. [Google Scholar]
- Probierz, B.; Stefański, P.; Kozak, J. Rapid detection of fake news based on machine learning methods. Procedia Comput. Sci. 2021, 192, 2893–2902. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Clickbait Detection Protocol | Features/Characteristics | Deficiencies |
|---|---|---|---|
| [17] | A protocol that uses a firewall to block malicious advertising | The ability to restrict malicious advertisements and prevent clients from revealing sensitive information | Incapable of discovering the filed advertisement |
| [18] | Blacklist and whitelist detection technique | Blocking suspicious Internet resources and the given information about Internet resources is delicate | Lack of completeness (i.e., it is not capable of providing a complete list of Internet resources). Additionally, it is not superior in terms of accuracy |
| [19] | Constructing a set of rules to protect clients from malicious resources | The capacity to prevent unverified sources by checking suspicious title content and disabling execution of scripts | Following the suggested rules does not prevent most Internet fraud |
| [20] | An approach based on artificial intelligence | The ability to detect various cybersecurity attacks using machine learning and predefined signatures | Ineffective in detecting new attacks |
| [21] | A rule-based method to detect/prevent clickbait and phishing | Some of the provided filtering rules are able to prevent phishing and clickbait | Not all phishing activities are covered by the suggested rules |
| [22] | A browser-based extension method to detect clickbait | The ability to find and block active scripts that can communicate with clients to reveal personal information | Useful advertisements are also blocked |
| [23] | Clickbait detection based on deep learning | High performance in terms of accuracy to detect more clickbait on social media. Moreover, it is able to detect headlines that consist of suspicious clickbait on several social media platforms | It is computationally complex because it combines two deep learning architectures (i.e., LSTM and CNN) |
| [11] | A convolutional neural network-based approach | It combines both similarity and lure features and achieved good accuracy using an adequately sized dataset | The detection time is long, and this method is limited to media and news content |
| [24] | An approach that consists of multiple stages | The accuracy of this approach is high compared to existing techniques | Limited to headline classification and attribute similarity scoring (i.e., it is not designed to detect malicious clickbait) |
| ClickBaitSecurity | Clickbait detection using deep recurrent neural network | Clickbait and source rating analysis and multilayered clickbait identification and search process. This approach can efficiently and accurately detect malicious content. It outperforms existing approaches in terms of accuracy, CPU consumption, memory usage, and link detection | It has some marginal deficiencies inherited from blockchain technology |
| Method | Source Rating | Accuracy | Unverified Source Detection | False Positive Rate | False Negative Rate | Memory/CPU Consumption |
|---|---|---|---|---|---|---|
| [17] | No | Low | No | High | High | High |
| [18] | No | Low | Yes | Medium | High | Medium |
| [19] | No | Low | Yes | High | High | High |
| [20] | No | Medium | No | Medium | Medium | Medium |
| [21] | Yes | Low | No | Medium | Medium | Medium |
| [22] | No | Low | Yes | High | High | High |
| [23] | No | Low | Yes | High | High | High |
| [11] | No | Medium | No | Medium | Medium | High |
| [24] | No | Medium | No | Medium | Medium | High |
| ClickBaitSecurity | Yes | High | Yes | Low | Low | Low |
| Components | Description |
|---|---|
| Operating system | Windows 10 |
| Processor | Intel(R) Celeron(R) N4020 (1.1 GHz base frequency, up to 2.8 GHz burst) |
| RAM | GB DDR4-2400 MHz RAM (1 × 4 GB) |
| HARD Disk free space | GB DDR4-2400 MHz RAM (1 × 4 GB) |
| Development environment | IntelliJ IDE |
| Approach | Malicious Link Detection with 63 Conducted Tests | Malicious Link Detection 126 (Conducted Tests) | Safe Link Detection 63 (Conducted Tests) | Safe Link Detection 126 Conducted Tests | Accuracy [%] with 450 Examined Links | Accuracy [%] with 900 (Examined Links) | Accuracy [%] with 1800 (Examined Links) |
|---|---|---|---|---|---|---|---|
| ClickBaitSecurity | 9379 Links | 741 Links | 141 Links | 280 Links | 100% | 99.95% | 99.83% |
| CEM | 321 Links | 338 Links | 188 Links | 640 Links | 98.04% | 98.66% | 96.96% |
| C-LSTM | 334 Links | 389 Links | 189 Links | 621 Links | 98.66% | 98.25% | 97.39% |
| LASC | 346 Links | 465 Links | 218 Links | 685 Links | 98.25% | 98.04% | 97.31% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Razaque, A.; Alotaibi, B.; Alotaibi, M.; Hussain, S.; Alotaibi, A.; Jotsov, V. Clickbait Detection Using Deep Recurrent Neural Network. Appl. Sci. 2022, 12, 504. https://doi.org/10.3390/app12010504
Razaque A, Alotaibi B, Alotaibi M, Hussain S, Alotaibi A, Jotsov V. Clickbait Detection Using Deep Recurrent Neural Network. Applied Sciences. 2022; 12(1):504. https://doi.org/10.3390/app12010504
Chicago/Turabian StyleRazaque, Abdul, Bandar Alotaibi, Munif Alotaibi, Shujaat Hussain, Aziz Alotaibi, and Vladimir Jotsov. 2022. "Clickbait Detection Using Deep Recurrent Neural Network" Applied Sciences 12, no. 1: 504. https://doi.org/10.3390/app12010504
APA StyleRazaque, A., Alotaibi, B., Alotaibi, M., Hussain, S., Alotaibi, A., & Jotsov, V. (2022). Clickbait Detection Using Deep Recurrent Neural Network. Applied Sciences, 12(1), 504. https://doi.org/10.3390/app12010504