
Automatic Construction of Fine-Grained Paraphrase Corpora System Using Language Inference Model

Abstract
:1. Introduction
- We defined a set of fine-grained sentence-level paraphrase relations based on similar relations at the word and phrase level.
- We developed a method utilising the language inference model to automatically assign fine-grained labels to sentence pairs in existing paraphrase and language inference corpora.
- We demonstrated that models trained with fine-grained data are able to generate paraphrases with specified directions.
- Compared with Quora Question Pair (QQP), MRPC tolerates more semantic divergence in its positive class, which contains more directional paraphrases than equivalent ones.
- Compared with the Stanford Natural Language Inference (SNLI), Multi-Genre Natural Language Inference (MNLI) contains more diversified sentence pairs in all three classes.
2. Related Work
- Authorities said a young man injured Richard Miller.
- Richard Miller was hurt by a young man.
- Premise: A soccer game with multiple males playing.
- Hypothesis: Some men are playing a sport.
3. Auto Relabelling Methods
3.1. Fine-Grained Paraphrase Relations
3.2. Observations from Language Inference Datasets
- The “entailment” label contains forward entailment (⊏ ) and equivalent (≡) pairs. This conforms to the definition of “entailment” class. The first two rows in Table 4 show sample “entailment” pairs from MNLI. The first pair is an example of forward entailment while the second one is an example of bidirectional entailment.
- The “neutral” class contains reverse entailment pairs, alternate pairs, independent pairs and pairs of other relations. It seems to be the result that “neutral” is designed as a catch-all class. There are also cases where event and entity coreference could make the distinction between “neutral” and “contradiction” ambiguous. The last three rows in Table 4 shows three sample “neutral” pairs from MNLI.
3.3. Auto Relabel Rules
- If is “contradiction” and is “contradiction”, is of negation or contradiction relation and is labelled as 0.
- If is “entailment” and is “neutral”, is a ⊏ relation and is labelled as 1.
- If is “neutral” and is “entailment”, is a ⊐ relation and is labelled as 2.
- If ) is “entailment“ and is “entailment”, is of equivalent or bidirectional entailment relation (≡) and is labelled as 3.
- If is “neutral” and is “neutral”, the sentence pair could be of alternation or independence relation. We label it as 4.
4. Automatic Relabelling with Fine-Grained Paraphrase Relations
4.1. Three-Label Language Inference Classifiers and Initial Data Cleansing
4.2. Summary Statistics of Fine-Grained Labels
5. Fine-Grained Label Correctness and Accuracy Investigation
5.1. Original Label vs. Fine-Grained Label
5.2. String Property Analysis
- Yesterday I went to the park.
- Yesterday I went to Victoria Park.
6. Generation Experiment
6.1. Experiment Models
6.2. Generator Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dolan, W.B.; Brockett, C. Automatically constructing a corpus of sentential paraphrases. In Proceedings of the Third International Workshop on Paraphrasing (IWP2005), Jeju Island, Korea, 14 October 2005. [Google Scholar]
- De Beaugrande, R.A.; Dressler, W.U. Introduction to Text Linguistics; Longman: London, UK, 1981; Volume 1. [Google Scholar]
- Shinyama, Y.; Sekine, S.; Sudo, K.; Grishman, R. Automatic paraphrase acquisition from news articles. In Proceedings of the HLT, San Diego, CA, USA, 2002; Volume 2, p. 1. [Google Scholar]
- Barzilay, R.; Lee, L. Learning to paraphrase: An unsupervised approach using multiple-sequence alignment. arXiv 2003, arXiv:cs/0304006. [Google Scholar]
- Bhagat, R.; Hovy, E. What is a paraphrase? Comput. Linguist. 2013, 39, 463–472. [Google Scholar] [CrossRef]
- Qiu, L.; Kan, M.Y.; Chua, T.S. Paraphrase recognition via dissimilarity significance classification. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006; pp. 18–26. [Google Scholar]
- Radev, D.R.; Hovy, E.; McKeown, K. Introduction to the special issue on summarization. Comput. Linguist. 2002, 28, 399–408. [Google Scholar] [CrossRef]
- Elhadad, N.; Sutaria, K. Mining a lexicon of technical terms and lay equivalents. In Proceedings of the Biological, Translational, and Clinical Language Processing, Prague, Czech Republic, 29 June 2007; pp. 49–56. [Google Scholar]
- Tomuro, N. Interrogative reformulation patterns and acquisition of question paraphrases. In Proceedings of the Second International Workshop on Paraphrasing, Sapporo, Japan, 11 July 2003; pp. 33–40. [Google Scholar]
- Rus, V.; McCarthy, P.M.; Graesser, A.C.; McNamara, D.S. Identification of sentence-to-sentence relations using a textual entailer. Res. Lang. Comput. 2009, 7, 209–229. [Google Scholar] [CrossRef]
- Vila, M.; Martí, M.A.; Rodríguez, H. Is this a paraphrase? What kind? Paraphrase boundaries and typology. Open J. Mod. Linguist. 2014, 4, 205. [Google Scholar] [CrossRef] [Green Version]
- Iyer, S.; Dandekar, N.; Csernai, K. First Quora Dataset Release: Question Pairs. 2017. Available online: https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs (accessed on 20 November 2021).
- Cer, D.; Diab, M.; Agirre, E.; Lopez-Gazpio, I.; Specia, L. Semeval-2017 task 1: Semantic textual similarity-multilingual and cross-lingual focused evaluation. arXiv 2017, arXiv:1708.00055. [Google Scholar]
- Pavlick, E.; Rastogi, P.; Ganitkevitch, J.; Van Durme, B.; Callison-Burch, C. PPDB 2.0: Better paraphrase ranking, fine-grained entailment relations, word embeddings, and style classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; pp. 425–430. [Google Scholar]
- Bhagat, R.; Pantel, P.; Hovy, E. LEDIR: An unsupervised algorithm for learning directionality of inference rules. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 161–170. [Google Scholar]
- Pavlick, E.; Bos, J.; Nissim, M.; Beller, C.; Van Durme, B.; Callison-Burch, C. Adding semantics to data-driven paraphrasing. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 1512–1522. [Google Scholar]
- MacCartney, B. Natural Language Inference. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. [Google Scholar]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. arXiv 2015, arXiv:1508.05326. [Google Scholar]
- Williams, A.; Nangia, N.; Bowman, S.R. A broad-coverage challenge corpus for sentence understanding through inference. arXiv 2017, arXiv:1704.05426. [Google Scholar]
- Sukthanker, R.; Poria, S.; Cambria, E.; Thirunavukarasu, R. Anaphora and coreference resolution: A review. Inf. Fusion 2020, 59, 139–162. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lin, C.Y.; Och, F.J. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04), Barcelona, Spain, 21–26 July 2004; pp. 605–612. [Google Scholar]
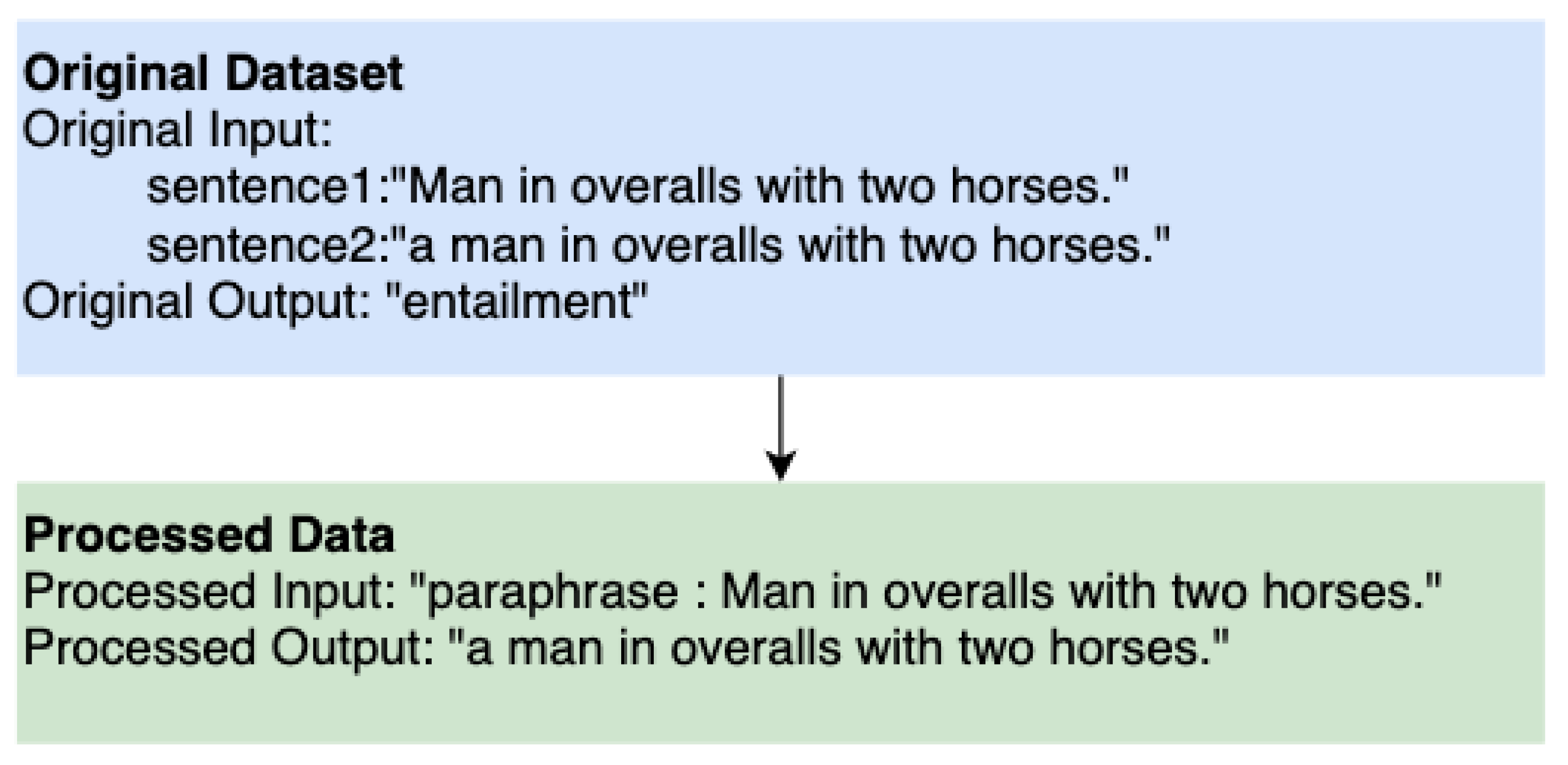
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv 2019, arXiv:1910.10683. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]

{kind=link}
| Sentence 1 | Sentence 2 | |
|---|---|---|
| 1 | Amrozi accused his brother, whom he called “the witness”, of deliberately distorting his evidence. | Referring to him as only “the witness”, Amrozi accused his brother of deliberately distorting his evidence. |
| 2 | PeopleSoft also said its board had officially rejected Oracle’s offer. | Thursday morning, PeopleSoft’s board rejected the Oracle takeover offer. |
| Symbol | Name | Example |
|---|---|---|
| forward entailment | ||
| reverse entailment. | ||
| equivalence | ||
| alternation | ||
| negation | ||
| cover | non-ape | |
| independence |
| Relation | First | Second |
|---|---|---|
| ⊏ | A young child is riding a horse. | A child is riding a horse. |
| ⊐ | Three men are playing guitars. | Three men are on stage playing guitars. |
| ≡ | The man cut down a tree with an axe. | A man chops down a tree with an axe. |
| | | The report also claims that there will be up to 9.3 million visitors to hot spots this year, up again from the meagre 2.5 million in 2002. | There will be 9.3 million visitors to hot spots in 2003, up from 2.5 million in 2002, Gartner said. |
| Relation | Premise | Hypothesis |
|---|---|---|
| ⊏ | Finally, the FDA will conduct workshops, issue guidance manuals and videotapes and hold teleconferences to aid small entities in complying with the rule. | The FDA is set to conduct workshops. |
| ≡ | Postal Service were to reduce delivery frequency. | The postal service could deliver less frequently. |
| ⊐ | A smiling costumed woman is holding an umbrella. | A happy woman in a fairy costume holds an umbrella. |
| # | He went down on his knees, examining it minutely, even going so far as to smell it. | It smelled like eggs. |
| | | The company once assembled, Poirot rose from his seat with the air of a popular lecturer, and bowed politely to his audience. | Poirot rose from his seat, bowed and started addressing the audience. |
| Data Set | Label Type | Label Examples |
|---|---|---|
| MRPC | discrete | [0, 1] |
| QQP | discrete | [0, 1] |
| STSB | continuous | [0, 5.0] |
| SNLI | discrete | [“contradiction”, “neutral”, “entailment”] |
| MNLI | discrete | [“contradiction”, “neutral”, “entailment”] |
| RoBERTa | Roberta-Large |
|---|---|
| Maximum Input Token | {256} |
| Learning Rate | {1 , 1 , 1 } |
| Batch sizes | {8, 16} |
| Classifier | SNLI | MNLI Matched | MNLI Mismached |
|---|---|---|---|
| SNLI-RoBERTa | 89.65% | 77.04% | 76.99% |
| MNLI-RoBERTa | 87.55% | 89.46% | 89.15% |
| Relation Combination | MRPC | QQP | STSB | SNLI | MNLI |
|---|---|---|---|---|---|
| Entailment–Entailment | 9.00% | 14.00% | 9.00% | 2.30% | 7.10% |
| Entailment–Neutral | 15.50% | 10.80% | 10.00% | 28.70% | 18.70% |
| Entailment–Contradiction | 0.30% | 0.6% | 0.40% | 0.30% | 0.70% |
| Neutral–Entailment | 16.50% | 10.30% | 10.60% | 3.20% | 3.80% |
| Neutral–Neutral | 35.60% | 27.40% | 8.50% | 27.60% | 25.20% |
| Neutral–Contradiction | 4.60% | 8.30% | 5.30% | 3.10% | 6.40% |
| Contradiction–Entailment | 0.20% | 0.50% | 0.50% | 0.26% | 0.70% |
| Contradiction–Neutral | 4.30% | 7.70% | 5.70% | 4.30% | 17.00% |
| Contradiction–Contradiction | 14.00% | 20.30% | 40.00% | 30.20% | 20.40% |
| Fine-Grained Class | MRPC | QQP | STSB | SNLI | MNLI |
|---|---|---|---|---|---|
| 0 (∧) | 197 | 46,156 | 1389 | 117,614 | 52,185 |
| 1 (⊏) | 400 | 29,413 | 450 | 127,093 | 59,126 |
| 2 (⊐) | 427 | 27,982 | 479 | 14,152 | 11,942 |
| 3 (≡) | 233 | 38,160 | 406 | 10,389 | 22,395 |
| 4 (|or#) | 846 | 42,102 | 688 | 86,263 | 63,501 |
| Fine-Grained Class Label | ||||||
|---|---|---|---|---|---|---|
| Metrics | Data Sets | 0 (∧) | 1 (⊏) | 2 (⊐) | 3 (≡) | 4 (|or#) |
| Average Similarity Score | STS-B | 1.19 | 3.69 | 3.71 | 4.62 | 3.06 |
| Positive Paraphrase Percent | MRPC | 39.6% | 81% | 82.0% | 99.1% | 49.9% |
| QQP | 6.4% | 52.6% | 56.7% | 86.2% | 20.8% | |
| (a) Paraphrase Datasets | |||||
| Data | 0 | 1 | All | ||
| QQP | −0.4 | 0 | −0.3 | ||
| MRPC | −0.1 | 0 | 0 | ||
| (b) Language Inference Datasets | |||||
| Data | Contradiction | Neutral | Entailment | All | |
| MNLI | 12.3 | 11.1 | 12.5 | 12 | |
| SNLI | 5.8 | 5 | 6.6 | 5.8 | |
| (c) Fine-grained Labelled Datasets | |||||
| Data | Negation (∧) | Entailment (⊏) | Elaboration (⊐) | Equivalence (≡) | Independence (#) |
| QQP | 0 | 3.3 | −3.6 | 0 | 1 |
| MRPC | 0 | 3.1 | −3 | 0 | 0.1 |
| MNLI | 10 | 16 | 2.4 | 4.3 | 13.1 |
| SNLI | 5.6 | 7.3 | −1 | 0.8 | 6 |
| (a) Paraphrase Datasets | |||||
| Data | Negative | Positive | |||
| QQP | 45.26 | 64.65 | |||
| MRPC | 59.22 | 71.28 | |||
| (b) Language Inference Datasets | |||||
| Data | Contradiction | Neutral | Entailment | ||
| MNLI | 35.59 | 32.8 | 44.48 | ||
| SNLI | 33.47 | 38.35 | 45.16 | ||
| (c) Fine-grained Labelled Datasets | |||||
| Data | Negation (∧) | Entailment (⊏) | Elaboration (⊐) | Equivalence (≡) | Independence (#) |
| QQP | 47.79 | 60.09 | 58.98 | 69.17 | 37.64 |
| MRPC | 61.08 | 71.72 | 71.69 | 75.92 | 61.78 |
| MNLI | 37.02 | 40.01 | 47.2 | 53.97 | 29.58 |
| SNLI | 34.57 | 43.79 | 58.83 | 62.09 | 33.18 |
| Data | Class 1 (⊏) | Class 2 (⊐) | Class 3 (≡) | |||
|---|---|---|---|---|---|---|
| Train | Test and Val. | Train | Test and Val. | Train | Test and Val. | |
| MNLI | 86,950 | 2253 | 22,983 | 551 | 41,787 | 1117 |
| SNLI | 164,285 | 3183 | 21,679 | 387 | 18,251 | 311 |
| QQP | 47,710 | 5440 | 45,688 | 5055 | 76,806 | 8373 |
| Data | Training Time | Epoch | Train Loss | Dev Loss |
|---|---|---|---|---|
| MNLI 1 (⊏) | 116 min | 2 | 0.140 | 0.139 |
| MNLI 2 (⊐) | 62 min | 4 | 0.195 | 0.214 |
| MNLI 3 (≡) | 87 min | 3 | 0.09 | 0.106 |
| SNLI 1 (⊏) | 248 min | 2 | 0.08 | 0.08 |
| SNLI 2 (⊐) | 49 min | 3 | 0.164 | 0.161 |
| SNLI 3 (≡) | 20 min | 2 | 0.108 | 0.09 |
| QQP 1 (⊏) | 116 min | 3 | 0.07 | 0.07 |
| QQP 2 (⊐) | 221 min | 5 | 0.146 | 0.178 |
| QQP 3 (≡) | 148 min | 3 | 0.05 | 0.06 |
| Data | Input Sentence | Target Sentence | Generated Sentence |
|---|---|---|---|
| MNLI 1 (⊏) | 26.3 | 11.6 | 13.8 |
| MNLI 2 (⊐) | 10.3 | 12.3 | 12.6 |
| MNLI 3 (≡) | 11.8 | 10.7 | 10.9 |
| SNLI 1 (⊏) | 15.8 | 7.4 | 10.1 |
| SNLI 2 (⊐) | 10 | 11.6 | 12.3 |
| SNLI 3 (≡) | 11.3 | 10.4 | 11.3 |
| QQP 1 (⊏) | 13.1 | 9.8 | 9.9 |
| QQP 2 (⊐) | 10 | 13.4 | 12.3 |
| QQP 3 (≡) | 9.9 | 9.9 | 9.6 |
| Data | Entailment (⊏) | Elaboration (⊐) | Equavalence (≡) |
|---|---|---|---|
| MNLI | 1.41 | −0.79 | 0.2 |
| SNLI | 1.61 | −0.3 | 0.09 |
| QQP | 0.71 | −0.59 | 0.12 |
| Data Sets | Refined Labels | Precision | Recall | F1 Score |
|---|---|---|---|---|
| QQP | 1 (⊏) | 61.80% | 79.95% | 68.76% |
| 2 (⊐) | 72.69% | 58.03% | 63.82% | |
| 3 (≡) | 79.5% | 81.23% | 79.96% | |
| SNLI | 1 (⊏) | 53.92% | 80.78% | 62.52% |
| 2 (⊐) | 92.74% | 73.85% | 81.57% | |
| 3 (≡) | 90.15% | 90.24% | 89.87% | |
| MNLI | 1 (⊏) | 49.26% | 82.07% | 59.05% |
| 2 (⊐) | 69.76% | 53.96% | 53.96% | |
| 3 (≡) | 71.03% | 77.80% | 73.40% |
| Datasets | Generator Class | Class 0 Percent | Class 1 Percent | Class 2 Percent | Class 3 Percent | Class 4 Percent |
|---|---|---|---|---|---|---|
| QQP | 1 (⊏) | 0% | 84.8% | 0% | 14.7% | 0.4% |
| 2 (⊐) | 0.6% | 0.4% | 82.6% | 16.0% | 0.4% | |
| 3 (≡) | 0% | 1.8% | 0.4% | 97.7% | 0.2% | |
| SNLI | 1 (⊏) | 0.1% | 97.5% | 0% | 2.3% | 0% |
| 2 (⊐) | 1.1% | 0.2% | 90.3% | 8.2% | 0.1% | |
| 3 (≡) | 0% | 4.4% | 0.3% | 95.2% | 0% | |
| MNLI | 1 (⊏) | 0.4% | 88.8% | 0% | 10.5% | 0.3% |
| 2 (⊐) | 2.7% | 0.7% | 80.2% | 15.9% | 0.4% | |
| 3 (≡) | 0% | 4.0% | 0.7% | 94.9% | 0.3% |
| Datasets | Sentence Relations | Source Text | Generated Text |
|---|---|---|---|
| Forward Entailment | What are the three places that anyone should visit at least once in their life, and why? | What are the places that anyone should visit at least once in their life? | |
| QQP | Reverse Entailment | What is a conspiracy theory that turned out to be real? | What is the most plausible conspiracy theory that turned out to be real? |
| Equivalence | What are some ways to become an entrepreneur? | How can I become an entrepreneur? | |
| Forward Entailment | In front of the church tower is a Statue of St. Francis Xavier, its right arm broken off during a storm. | St. Francis Xavier’s arm was broken off during a storm. | |
| MNLI | Reverse Entailment | The woman was Nema. | Nema was the woman who was a nurse. |
| Equivalence | What they owe us is an admission that their professed faith in term limits was phony in the first place. | They owe us an admission that their professed faith in term limits was phony in the first place. | |
| Forward Entailment | A man wearing a white helmet is rock climbing. | A man is rock climbing. | |
| SNLI | Reverse Entailment | Four dogs in a grassy area. | Four dogs are playing in a grassy area. |
| Equivalence | Three men in a foreign country sorting limes. | Three men sort limes in a foreign country. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Hu, X.; Chung, V. Automatic Construction of Fine-Grained Paraphrase Corpora System Using Language Inference Model. Appl. Sci. 2022, 12, 499. https://doi.org/10.3390/app12010499
Zhou Y, Hu X, Chung V. Automatic Construction of Fine-Grained Paraphrase Corpora System Using Language Inference Model. Applied Sciences. 2022; 12(1):499. https://doi.org/10.3390/app12010499
Chicago/Turabian StyleZhou, Ying, Xiaokang Hu, and Vera Chung. 2022. "Automatic Construction of Fine-Grained Paraphrase Corpora System Using Language Inference Model" Applied Sciences 12, no. 1: 499. https://doi.org/10.3390/app12010499
APA StyleZhou, Y., Hu, X., & Chung, V. (2022). Automatic Construction of Fine-Grained Paraphrase Corpora System Using Language Inference Model. Applied Sciences, 12(1), 499. https://doi.org/10.3390/app12010499