
GSV-NET: A Multi-Modal Deep Learning Network for 3D Point Cloud Classification


Abstract
:1. Introduction
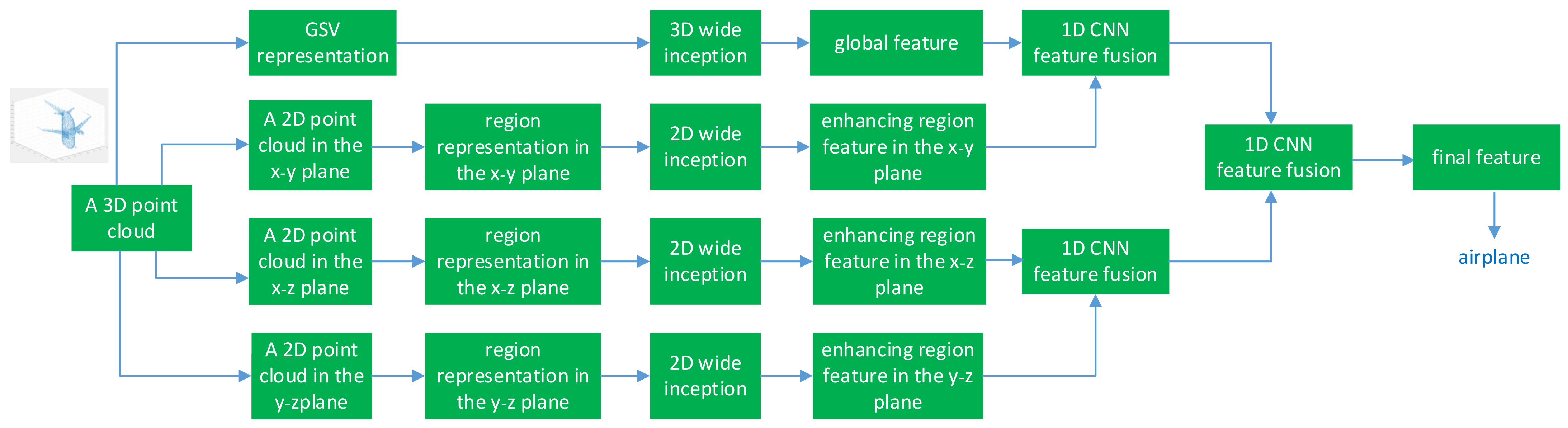
- We present a novel approach to extract the global point cloud feature using GSV representation and the 3D wide-inception architecture.
- After converting 3D point cloud regions into color representation, a 2D wide-inception network is employed to extract the regional feature of the 3D point cloud. In addition, we present the 1D convolution neural network (CNN) structure that fuses the extracted global and regional features. The GSV and ERR are novel to the best knowledge of the authors.
- Based on our numerical outcomes on challenging databases, the proposed approach is more accurate and efficient than the well-known methods.
2. Related Work
- Volumetric-based methods: These methods transform a point cloud into voxel and then use a 3D CNN to solve the shape-classification problem with the volumetric representation. Wu et al. [17] introduce a method: the deep belief network 3D ShapeNets, described by the distribution of the binary values on voxel grids for learning the distribution of points from different 3D objects. Maturana et al. [18] propose a volumetric occupation network (VoxNet) to obtain robust 3D shape classification. Although having promising results, these methods can not apply to big 3D data because the memory and the computation time increase cubically with voxel size. To handle the drawbacks, several authors propose a compact and hierarchical structure to reduce the memory and computational costs. Reference [19] introduces a 3D object recognition method, so-called OctNet, which implements 3D-CNN on the octants obtained by the 3D object surface. OctNet consumes less runtime and memory at higher points than a standard network based on dense input grids. OctNet divides a point cloud hierarchically using an octree structure, which describes the scenery with some octrees on a grid. Every voxel feature vector, cataloged by the uncomplicated arithmetic octree structure, is encoded efficiently utilizing a bit string description. Authors in [20] use 3D grids to describe the point cloud, represented by the 3D modified Fisher Vector, an input of CNN structure to produce the global description. Reference [21] offers a hybrid network PointGrid, which uses the grid description. PointGrid samples the points within each embedding volumetric grid-cell and uses 3D CNN to extract geometric details.
- Multiview-based methods: These approaches generate various 2D projections from the original 3D object, then obtain and fuse view-wise features for object recognition. The challenge is to integrate various view-wise features toward an overall description. Researchers in [22] firstly exploit the inter-relationships (view–view or region–region) across views by a leverage connection system, then integrate those views to obtain a discriminative 3D shape description. MHBN [23] adopts bilinear pooling to integrate local convolutional descriptors, then creates dense global features. MVCNN [24], only max-pooling multi-view descriptors toward global features, leads to information loss because max-pooling only holds the highest elements of a particular view.
- Raw point cloud-based methods: The initial point cloud is converted into voxel and views, respectively, in the two approaches mentioned above. Several researchers propose various methods to use the raw point cloud as input data without any transformation. Unlike the two approaches above, PointNet [25] employs a multilayer perceptron (MLP). This pioneering method leads a set of approaches that perform classification directly on the point cloud. PointNet converts the coordinates of the 3D point cloud to higher-dimensional descriptor space with the MLP. It also resolves the disorder obstacle and reduces the high-dimensional data by using max-pooling. Lastly, it employs the MLP to perform the recognition problem. PointNet++ [26] splits the point cloud toward various overlapping regions and uses PointNet to obtain the local descriptors in these regions. Local descriptors are continuously converted into global descriptors by repeated iterations to obtain the final descriptors. Motivated by the 2D SIFT [27], ref. [28] creates a PointSIFT module to describe data in many directions, and adjusts to the object proportion. An orientation-coding element is formed to represent eight essential orientations, and a multi-scale description is achieved by accumulating the multiple orientation coding elements. The PointSIFT network enhances presentation capacity by blending PointSIFT modules into several PointNet-based structures. PointCNN [29] first applies χ-transformation to resolve the obstacle of unordered and irregular structure in the point cloud, then uses the convolution approach for point cloud input.
- Graph-based methods: Graph Signal Processing (GSP) can handle unstructured or unordered data. GSP for preparing a 3D point cloud has been a popular field at current times, with many applications such as compression, painting, and data visualization [30,31,32,33]. GSP becomes essential because most data obtained can convert into a widespread graph. CNN introduces an effective architecture to exploit important patterns in regular structural data such as 2D images. Some approaches attempt to extend the concept of CNNs into widespread graphs, which are not straight because of the abnormal structure of these graphs. Defferrard et al. [34] define a recursive kernel of Chebyshev polynomials to introduce a quick localized convolution process, making it quickly learn while keeping sufficient complexity of deep learning. Bruna et al. [35] apply a graph convolution described in the graph spectral field. Graph-based methods implement a graph with an individual vertex for every point and edges within nearby points instead of converting point cloud toward voxels. A Graph-CNN structure in [36] uses the local architecture of the 3D point cloud data encoded in graphs to analyze 3D point cloud data. Graph-CNN requires neighbor data of every point at the best level for building a solid graph. In contrast, ref. [16] dismisses the uselessness by extracting a higher compact graph and making GSP on the Reeb graph.
3. Methodology
3.1. Global Point Cloud Feature Extraction with Gaussian Supervector Representation and 3D Wide Inception
3.1.1. Gaussian Supervector Representation
3.1.2. 3D Wide-Inception Architecture
3.2. Region Point Cloud Feature Extraction with 2D Wide Inception
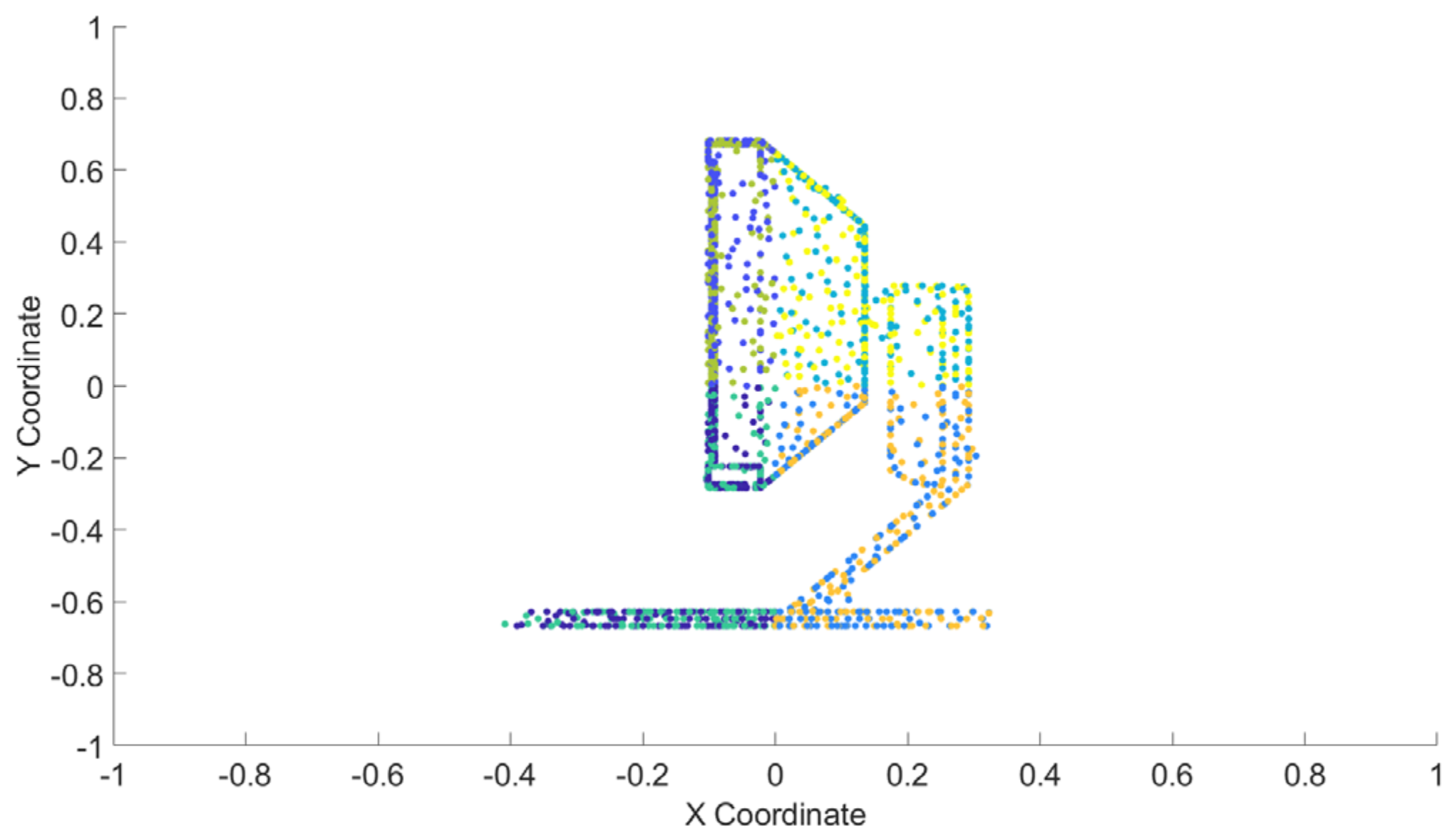
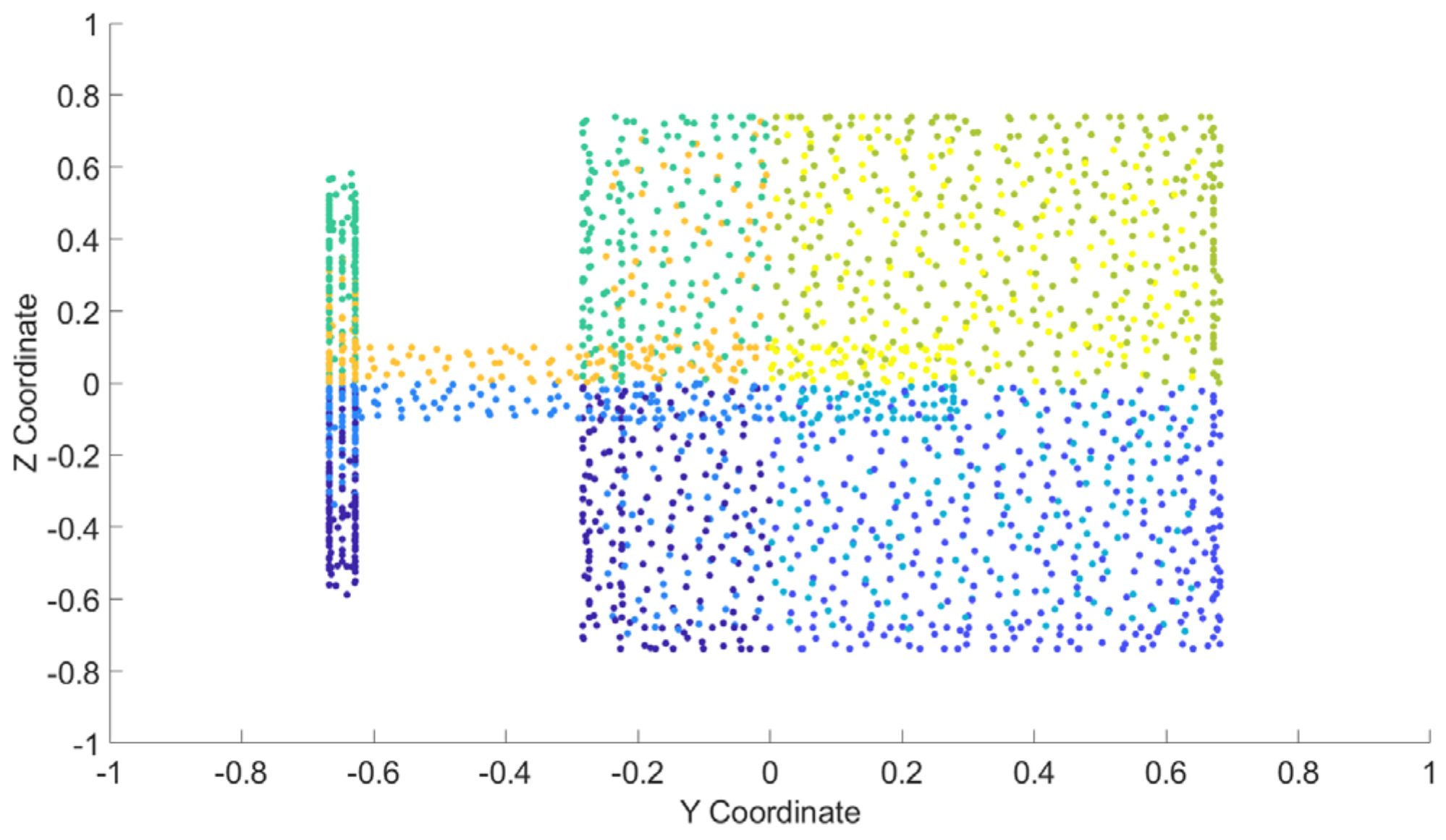
3.2.1. Enhancing Region Representation
3.2.2. 2D Wide-Inception Architecture
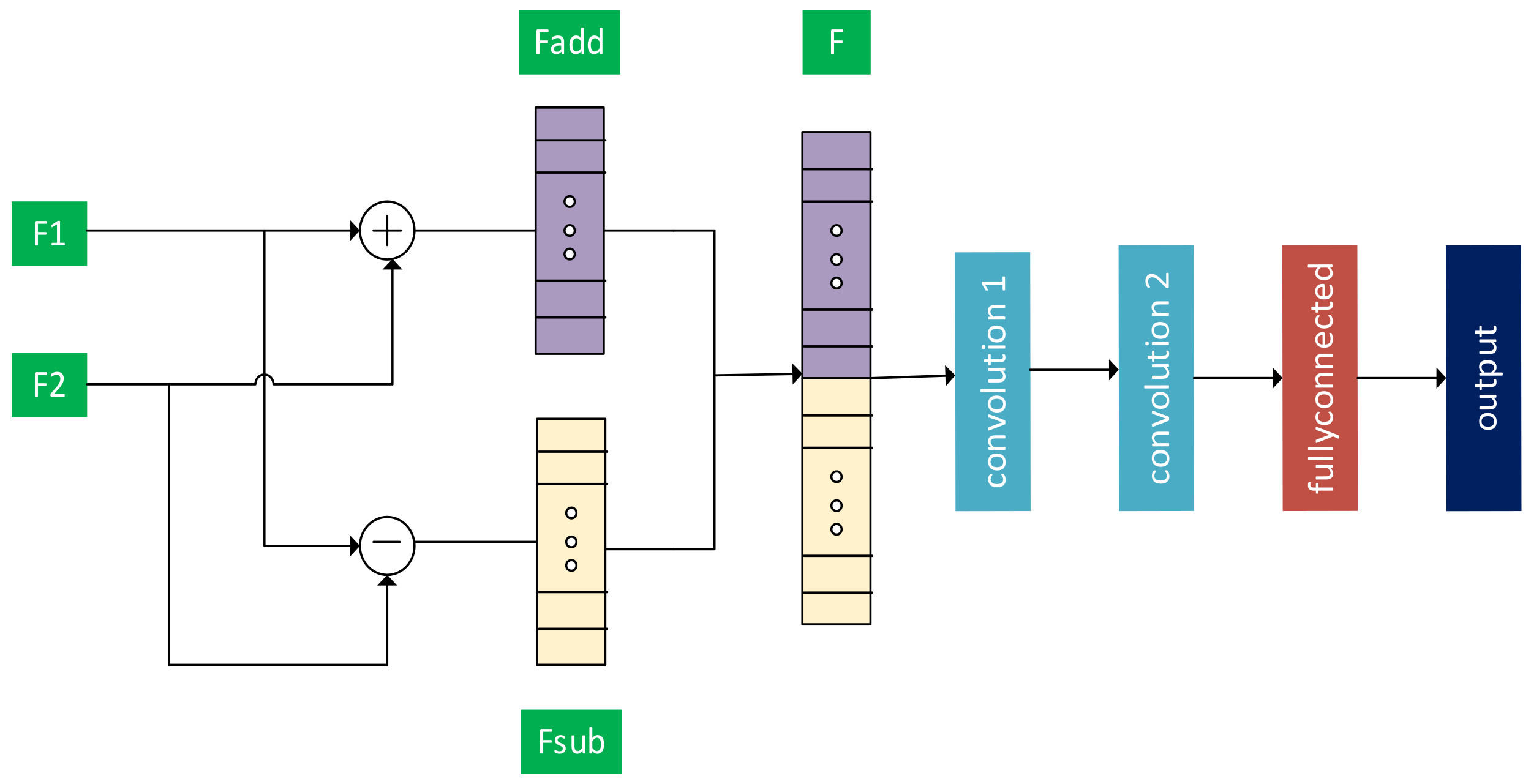
3.3. Feature Fusion with 1D CNN
4. Experiment
4.1. Datasets
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. The Comparison on ModelNet40 Dataset
4.5. The Comparison on Sydney Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 3DmFV | 3D Modified Fisher Vectors |
| CNN | Convolution Neural Network |
| EEM | Effective Encoding Method |
| ERR | Enhancing Region Representation |
| GCN | Graph Convolutional Networks |
| GSP | Graph Signal Processing |
| GSV | Gaussian Supervector |
| LiDAR | Light Detection and Ranging |
| MIFN | Multimodal Information Fusion Network |
| MLP | Multilayer Perceptron |
| MV | Multi-View |
| MVCNN | Multi-View Convolutional Neural Networks |
| PC | Point Cloud |
| PV | PANORAMA-View |
| SIFT | Scale Invariant Feature Transform |
| TCN | Transformation Correction Network |
References
- Liang, Z.; Guo, Y.; Feng, Y.; Chen, W.; Qiao, L.; Zhou, L.; Zhang, J.; Liu, H. Stereo matching using multi-level cost volume and multi-scale feature constancy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 300–315. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 4338–4364. [Google Scholar] [CrossRef]
- Guo, Y.; Sohel, F.; Bennamoun, M.; Lu, M.; Wan, J. Rotational projection statistics for 3D local surface description and object recognition. Int. J. Comput. Vis. 2013, 105, 63–86. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J. 3D object recognition in cluttered scenes with local surface features: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2270–2287. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Zhai, R.; Li, X.; Wang, Z.; Guo, S.; Hou, S.; Hou, Y.; Gao, F.; Song, J. Point cloud classification model based on a dual-input deep network framework. IEEE Access 2020, 8, 55991–55999. [Google Scholar] [CrossRef]
- Chen, B.; Shi, S.; Gong, W.; Zhang, Q.; Yang, J.; Du, L.; Sun, J.; Zhang, Z.; Song, S. Multispectral LiDAR point cloud classification: A two-step approach. Remote Sens. 2017, 9, 373. [Google Scholar] [CrossRef] [Green Version]
- Maes, W.; Huete, A.; Steppe, K. Optimizing the processing of UAVbased thermal imagery. Remote Sens. 2017, 9, 476. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Zhang, L.; Fang, T. A multiscale and hierarchical feature extraction method for terrestrial laser scanning point cloud classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2409–2425. [Google Scholar] [CrossRef]
- Xie, Y.; Tian, J.; Zhu, X.X. A review of point cloud semantic segmentation. arXiv 2019, arXiv:1908.08854. [Google Scholar]
- Griffiths, D.; Boehm, J. A review on deep learning techniques for 3D sensed data classification. Remote Sens. 2019, 11, 1499. [Google Scholar] [CrossRef] [Green Version]
- Vosselman, G.; Coenen, M.; Rottensteiner, F. Contextual segment-based classification of airborne laser scanner data. ISPRS J. Photogramm. Remote Sens. 2017, 128, 354–371. [Google Scholar] [CrossRef]
- Landrieu, L.; Raguet, H.; Vallet, B.; Mallet, C.; Weinmann, M. A structured regularization framework for spatially smoothing semantic labelings of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 132, 102–118. [Google Scholar] [CrossRef] [Green Version]
- Grilli, E.; Menna, F.; Remondino, F. A review of point clouds segmentation and classification algorithms. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 339–344. [Google Scholar] [CrossRef] [Green Version]
- Liang, Q.; Xiao, M.; Song, D. 3D shape recognition based on multi-modal information fusion. Multimed. Tools Appl. 2021, 80, 16173–16184. [Google Scholar] [CrossRef]
- Wang, W.; You, Y.; Liu, W.; Lu, C. Point cloud classification with deep normalized Reeb graph convolution. Image Vis. Comput. 2021, 106, 104092. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J.; Fisher, Y. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar] [CrossRef] [Green Version]
- Maturana, D.; Scherer, S. VoxNet: A 3D convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar] [CrossRef]
- Riegler, G.; Ulusoy, A.O.; Geiger, A. Octnet: Learning deep 3D representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar] [CrossRef] [Green Version]
- BYizhak, B.; Michael, L.; Anath, F. 3DmFV: Three-dimensional point cloud classification in real-time using convolutional neural networks. IEEE Robot. Autom. Lett. 2018, 25, 3145–3152. [Google Scholar] [CrossRef]
- Le, T.; Duan, Y. Pointgrid: A deep network for 3D shape understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9204–9214. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, L. Learning relationships for multi-view 3D object recognition. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 7 October–2 November 2019; pp. 7505–7514. [Google Scholar] [CrossRef]
- Yu, T.; Meng, J.; Yuan, J. Multi-view harmonized bilinear network for 3D object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 186–194. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3D shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Drui, F.; Franck, E.; Helluy, P.; Navoret, L. An analysis of overrelaxation in kinetic approximation. arXiv 2018, arXiv:1807.05695. [Google Scholar]
- Li, Y.Y.; Bu, R.; Sun, M.C.; Wu, W.; Di, X.H.; Chen, B.Q. PointCNN: Convolution on X-transformed points. Adv. Neural Inf. Process. Syst. 2018, 31, 828–838. [Google Scholar]
- Chen, S.; Tian, D.; Feng, C.; Vetro, A.; Kovacevic, J. Contour-enhanced resampling of 3D point clouds via graphs. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2941–2945. [Google Scholar] [CrossRef]
- Chen, S.; Tian, D.; Feng, C.; Vetro, A.; Kovačević, J. Fast resampling of 3d point clouds via graphs. arXiv 2017, arXiv:1702.06397. [Google Scholar]
- Lozes, F.; Elmoataz, A.; Lezoray, O. PDE-based graph signal processing for 3-D color point clouds: Opportunities for cultural heritage. IEEE Signal Process. Mag. 2015, 32, 103–111. [Google Scholar] [CrossRef]
- Thanou, D.; Chou, P.A.; Frossard, P. Graph-based compression of dynamic 3D point cloud sequences. IEEE Trans. Image Process. 2016, 25, 1765–1778. [Google Scholar] [CrossRef] [Green Version]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 4–9 December 2016; pp. 3844–3852. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; Lecun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Zhang, Y.; Rabbat, M. A graph-CNN for 3D point cloud classification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); Calgary, AB, Canada, 15–20 April 2018, IEEE: Piscataway, NJ, USA, 2018; pp. 6279–6283. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Smith, D.C.; Kornelson, K.A. A comparison of Fisher vectors and Gaussian Supervectors for document versus non-document image classification. In Applications of Digital Image Processing XXXVI.; International Society for Optics and Photonics: Bellingham, WA, USA, 2013; Volume 8856, p. 88560N. [Google Scholar]
- Zhou, X.; Zhuang, X.; Tang, H.; Hasegawa-Johnson, M.; Huang, T. Novel Gaussianized vector representation for improved natural scene categorization. Pattern Recognit. Lett. 2012, 31, 702–708. [Google Scholar] [CrossRef]
- Kang, G.X.; Liu, K.; Hou, B.B.; Zhang, N. 3D multi-view convolutional neural networks for lung nodule classification. PLoS ONE 2017, 12, e0188290. [Google Scholar] [CrossRef] [Green Version]
- Muhammad, W.; Aramvith, S. Multi-scale inception based super-resolution using deep learning approach. Electronics 2019, 8, 8920. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- He, K.; Sun, J. Convolutional neural networks at constrained time cost. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar] [CrossRef] [Green Version]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar]
- Lee, Y.; Kim, H.; Park, E.; Cui, X.; Kim, H. Wide-residual-inception networks for real-time object detection. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 758–764. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Kandel, I.; Castelli, M. Transfer learning with convolutional neural networks for diabetic retinopathy image classification. A review. Appl. Sci. 2020, 10, 2021. [Google Scholar] [CrossRef] [Green Version]
- Hoang, H.H.; Trinh, H.H. Improvement for Convolutional Neural Networks in Image Classification Using Long Skip Connection. Appl. Sci. 2021, 11, 2092. [Google Scholar] [CrossRef]
- Quadros, A.J. Representing 3D Shape in Sparse Range Images for Urban Object Classification. Ph.D. Thesis, The University of Sydney, Sydney, Australia, 2013; p. 204. Available online: http://www.acfr.usyd.edu.au/papers/SydneyUrbanObjectsDataset.shtml (accessed on 22 August 2021).
- Deuge, M.D.; Quadros, A.; Hung, C.; Douillard, B. Unsupervised feature learning for classification of outdoor 3D scans. Proceedings of Australasian Conference on Robotics and Automation, Sydney, Australia, 2–4 December 2013; p. 9. Available online: https://www.araa.asn.au/acra/acra2013/papers/pap133s1-file1.pdf (accessed on 22 August 2021).
- Luo, Z.; Li, J.; Xiao, Z.; Mou, Z.G.; Cai, X.; Wang, C. Learning high-level features by fusing multi-view representation of MLS point clouds for 3D object recognition in road environments. ISPRS J. Photogramm. Remote Sens. 2019, 150, 44–58. [Google Scholar] [CrossRef]
- Seo, K.; Chung, B.; Panchaseelan, H.P.; Kim, T.; Park, H.; Oh, B.; Chun, M.; Won, S.; Kim, D.; Beom, J.; et al. Forecasting the Walking Assistance Rehabilitation Level of Stroke Patients Using Artificial Intelligence. Diagnostics 2021, 11, 1096. [Google Scholar] [CrossRef]
- Ren, M.; Niu, L.; Fang, Y. 3D-A-Nets: 3D deep dense descriptor for volumetric shapes with adversarial networks. arXiv 2017, arXiv:1711.10108. [Google Scholar]
- Song, Y.; Gao, L.; Li, X.; Pan, Q.K. An effective encoding method based on local information for 3D point cloud classification. IEEE Access 2019, 7, 39369–39377. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, J.; Zheng, Q. 3D point cloud recognition based on a multi-view convolutional neural network. Sensors 2018, 18, 3681. [Google Scholar] [CrossRef] [Green Version]
- Han, X.F.; Sun, S.J.; Song, X.Y.; Xiao, G.Q. 3D point cloud descriptors in hand-crafted and deep learning age: State-of-the-art. arXiv 2018, arXiv:1802.02297. [Google Scholar]
- Munoz, D.; Bagnell, J.A.; Hebert, M. Co-inference for multi-modal scene analysis. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 668–681. [Google Scholar]
- Gupta, A. Deep Learning for Semantic Feature Extraction in Aerial Imagery and LiDAR Data. Ph.D. Thesis, University of Manchester, Manchester, UK, January 2020. Available online: https://www.research.manchester.ac.uk/portal/files/184627877/FULL_TEXT.PDF (accessed on 22 August 2021).
- Chao, M.; Yulan, G.; Yinjie, L.; Wei, A. Binary volumetric convolutional neural networks for 3-D object recognition. IEEE Trans. Instrum. Meas. 2019, 68, 38–48. [Google Scholar] [CrossRef]
- Wang, C.; Cheng, M.; Sohel, F.; Bennamoun, M.; Li, J. NormalNet: A voxel-based CNN for 3D object classification and retrieval. Neurocomputing 2019, 323, 139–147. [Google Scholar] [CrossRef]
- Sedaghat, N.; Zolfaghari, M.; Amiri, E.; Brox, T. Orientation-boosted voxel nets for 3D object recognition. In Proceedings of the 28th British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Yoo, I. Point Cloud Deep Learning. Available online: On-demand.gputechconf.com/gtc/2018/presentation/s8453-point-cloud-deep-learning.pdf (accessed on 22 August 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Liang et al. [15] | Wang et al. [16] | Wu et al. [17] | Maturana et al. [18] | Riegler et al. [19] | BYizhak et al. [20] | Le et al. [21] | Yang et al. [22] | Yu et al. [23] | Su et al. [24] | Qi et al. [25] | Qi et al. [26] | Li et al. [29] | Defferrard et al. [34] | Bruna et al. [35] | Zhang et al. [36] | GSV-NET | ||
| Format | Voxelization | X | X | X | ||||||||||||||
| Point cloud | X | X | X | X | X | X | X | |||||||||||
| Views | X | X | X | X | X | |||||||||||||
| Graph | X | X | X | X | ||||||||||||||
| Dataset | Computer data | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
| Real-world | X | X | X | X | ||||||||||||||
| Architecture | MLP | X | X | X | X | X | ||||||||||||
| 2D CNN | X | X | X | X | X | |||||||||||||
| 3D CNN | X | X | X | X | X | X | ||||||||||||
| Graph CNN | X | X | X | X | ||||||||||||||
| Model | Single | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | ||
| Multi-Modal | X | X | ||||||||||||||||
| Method | Data Format | ACC |
|---|---|---|
| VoxNet [18] | Voxelization | 83% |
| 3D ShapeNets [17] | Voxelization | 77.32% |
| 3D-A-Nets [53] | Voxelization | 90.5% |
| EEM [54] | Point Cloud | 90.5% |
| PointGCN [36] | Point Cloud | 89.5 |
| PointNet [25] | Point Cloud | 89.2% |
| PointNet++ [26] | Point Cloud | 90.7% |
| 3DmFV+VoxNet [20] | Point Cloud | 88.5% |
| 3DmFV-Net [20] | Point Cloud | 91.6% |
| MVCNN, metric,12× [24] | 12 views | 89.5% |
| MVCNN, 12× [24] | 12 views | 89.9% |
| MVCNN, metric,80× [24] | 80 views | 90.1% |
| MVCNN, 80× [24] | 80 views | 90.1% |
| TCN-MVCNN [55] | 12 views | 90.5% |
| Reeb graph convolution [16] | graph | 89.9% |
| MIFN, PC+MV [15] | Point Cloud + 12 views | 90.83% |
| MIFN, PC+MV+PV [15] | Point Cloud + 12 views + panorama-views | 91.86% |
| GSV-NET | Point Cloud + 3 views | 92.7% |
| Class Name | Methods | Methods | Methods | Methods | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PointNet++ | Ours | Class Name | PointNet++ | Ours | Class Name | PointNet++ | Ours | Class Name | PointNet++ | Ours | ||
| Precision | airplane | 1.00 | 1.00 | cup | 0.75 | 0.75 | laptop | 1.00 | 1.00 | sofa | 0.96 | 0.98 |
| bathtub | 0.92 | 0.84 | curtain | 0.85 | 0.95 | mantel | 0.96 | 0.97 | stairs | 0.95 | 0.80 | |
| bed | 0.96 | 0.99 | desk | 0.92 | 0.93 | monitor | 0.99 | 1.00 | stool | 0.80 | 0.95 | |
| bench | 0.80 | 0.90 | door | 0.80 | 0.85 | night_stand | 0.71 | 0.79 | table | 0.72 | 0.94 | |
| bookshelf | 0.97 | 0.97 | dresser | 0.73 | 0.87 | person | 0.90 | 0.90 | tent | 0.95 | 0.95 | |
| bottle | 0.93 | 0.96 | flower_pot | 0.35 | 0.20 | piano | 0.95 | 0.95 | toilet | 1.00 | 0.98 | |
| bowl | 0.95 | 1.00 | glass_box | 0.93 | 0.96 | plant | 0.79 | 0.83 | tv_stand | 0.70 | 0.88 | |
| car | 0.98 | 1.00 | guitar | 1.00 | 1.00 | radio | 0.85 | 0.85 | vase | 0.79 | 0.81 | |
| chair | 0.96 | 0.96 | keyboard | 1.00 | 1.00 | range_hood | 0.94 | 0.94 | wardrobe | 0.75 | 0.75 | |
| cone | 1.00 | 1.00 | lamp | 0.85 | 0.95 | sink | 0.85 | 0.80 | xbox | 0.80 | 0.90 | |
| Recall | airplane | 1.00 | 0.98 | cup | 0.60 | 0.65 | laptop | 0.91 | 1.00 | sofa | 0.98 | 1.00 |
| bathtub | 0.96 | 1.00 | curtain | 0.81 | 0.86 | mantel | 0.98 | 0.95 | stairs | 1.00 | 0.76 | |
| bed | 0.98 | 0.95 | desk | 0.75 | 0.89 | monitor | 0.96 | 0.98 | stool | 0.89 | 0.70 | |
| bench | 0.64 | 0.90 | door | 0.84 | 0.89 | night_stand | 0.78 | 0.86 | table | 0.83 | 0.91 | |
| bookshelf | 0.93 | 0.97 | dresser | 0.78 | 0.86 | person | 1.00 | 1.00 | tent | 0.83 | 0.76 | |
| bottle | 0.95 | 0.95 | flower_pot | 0.19 | 0.17 | piano | 0.97 | 0.97 | toilet | 0.99 | 1.00 | |
| bowl | 0.83 | 0.74 | glass_box | 0.99 | 0.98 | plant | 0.90 | 0.86 | tv_stand | 0.63 | 0.94 | |
| car | 1.00 | 1.00 | guitar | 1.00 | 1.00 | radio | 0.68 | 0.71 | vase | 0.83 | 0.87 | |
| chair | 0.95 | 0.98 | keyboard | 0.95 | 1.00 | range_hood | 0.99 | 0.99 | wardrobe | 0.63 | 0.94 | |
| cone | 0.95 | 0.95 | lamp | 1.00 | 0.86 | sink | 0.89 | 0.84 | xbox | 0.89 | 0.86 | |
| F1-score | airplane | 1.00 | 0.99 | cup | 0.67 | 0.70 | laptop | 0.95 | 1.00 | sofa | 0.97 | 0.99 |
| bathtub | 0.94 | 0.91 | curtain | 0.83 | 0.90 | mantel | 0.97 | 0.96 | stairs | 0.97 | 0.78 | |
| bed | 0.97 | 0.97 | desk | 0.83 | 0.91 | monitor | 0.98 | 0.99 | stool | 0.84 | 0.81 | |
| bench | 0.71 | 0.90 | door | 0.82 | 0.87 | night_stand | 0.74 | 0.82 | table | 0.77 | 0.93 | |
| bookshelf | 0.95 | 0.97 | dresser | 0.75 | 0.87 | person | 0.95 | 0.95 | tent | 0.88 | 0.84 | |
| bottle | 0.94 | 0.96 | flower_pot | 0.25 | 0.19 | piano | 0.96 | 0.96 | toilet | 1.00 | 0.99 | |
| bowl | 0.88 | 0.85 | glass_box | 0.96 | 0.97 | plant | 0.84 | 0.85 | tv_stand | 0.66 | 0.91 | |
| car | 0.99 | 1.00 | guitar | 1.00 | 1.00 | radio | 0.76 | 0.77 | vase | 0.81 | 0.84 | |
| chair | 0.96 | 0.97 | keyboard | 0.98 | 1.00 | range_hood | 0.96 | 0.96 | wardrobe | 0.68 | 0.83 | |
| cone | 0.98 | 0.98 | lamp | 0.92 | 0.90 | sink | 0.87 | 0.82 | xbox | 0.84 | 0.88 | |
| Class Name | Accuracy | Class Name | Accuracy | Class Name | Accuracy | Class Name | Accuracy | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| EEM | Ours | EEM | Ours | EEM | Ours | EEM | Ours | ||||
| airplane | 100 | 100 | cup | 65 | 75 | laptop | 100 | 100 | sofa | 98 | 98 |
| bathtub | 90 | 84 | curtain | 85 | 95 | mantel | 96 | 97 | stairs | 85 | 80 |
| bed | 99 | 99 | desk | 89 | 93 | monitor | 97 | 100 | stool | 85 | 95 |
| bench | 75 | 90 | door | 95 | 85 | night_stand | 81 | 79 | table | 77 | 94 |
| bookshelf | 97 | 97 | dresser | 81 | 87 | person | 80 | 90 | tent | 95 | 95 |
| bottle | 94 | 96 | flower_pot | 20 | 20 | piano | 87 | 95 | toilet | 99 | 98 |
| bowl | 100 | 100 | glass_box | 94 | 96 | plant | 79 | 83 | tv_stand | 88 | 88 |
| car | 96 | 100 | guitar | 100 | 100 | radio | 50 | 85 | vase | 78 | 81 |
| chair | 96 | 96 | keyboard | 95 | 100 | range_hood | 90 | 94 | wardrobe | 65 | 75 |
| cone | 90 | 100 | lamp | 75 | 95 | sink | 75 | 80 | xbox | 75 | 90 |
| Method | F1 Score |
|---|---|
| UFL + SVM [50] | 0.67 |
| BV-CNNs [59] | 0.755 |
| VoxNet [18] | 0.72 |
| NormalNet [60] | 0.74 |
| ORION [61] | 0.778 |
| JointNet [51] | 0.749 |
| 3DmFV-Net [20] | 0.76 |
| GSV-NET | 0.798 |
| class | 4wd | bldg | bus | car | ped | pill | pole | light | sig | tree | trc | trn | ute | van |
| num | 21 | 20 | 16 | 88 | 152 | 20 | 21 | 47 | 51 | 34 | 12 | 55 | 16 | 35 |
| GSV-NET | 0.29 | 0.75 | 0.38 | 0.85 | 0.99 | 0.85 | 0.81 | 0.87 | 0.69 | 0.82 | 0.25 | 0.82 | 0.31 | 0.69 |
| 3DmFV | 0.22 | 0.64 | 0.21 | 0.81 | 0.99 | 0.84 | 0.68 | 0.74 | 0.78 | 0.82 | 0.27 | 0.74 | 0.31 | 0.57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoang, L.; Lee, S.-H.; Lee, E.-J.; Kwon, K.-R. GSV-NET: A Multi-Modal Deep Learning Network for 3D Point Cloud Classification. Appl. Sci. 2022, 12, 483. https://doi.org/10.3390/app12010483
Hoang L, Lee S-H, Lee E-J, Kwon K-R. GSV-NET: A Multi-Modal Deep Learning Network for 3D Point Cloud Classification. Applied Sciences. 2022; 12(1):483. https://doi.org/10.3390/app12010483
Chicago/Turabian StyleHoang, Long, Suk-Hwan Lee, Eung-Joo Lee, and Ki-Ryong Kwon. 2022. "GSV-NET: A Multi-Modal Deep Learning Network for 3D Point Cloud Classification" Applied Sciences 12, no. 1: 483. https://doi.org/10.3390/app12010483
APA StyleHoang, L., Lee, S.-H., Lee, E.-J., & Kwon, K.-R. (2022). GSV-NET: A Multi-Modal Deep Learning Network for 3D Point Cloud Classification. Applied Sciences, 12(1), 483. https://doi.org/10.3390/app12010483