
Evaluating Human versus Machine Learning Performance in a LegalTech Problem

 ,
,  , , , , and
, , , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Research Questions
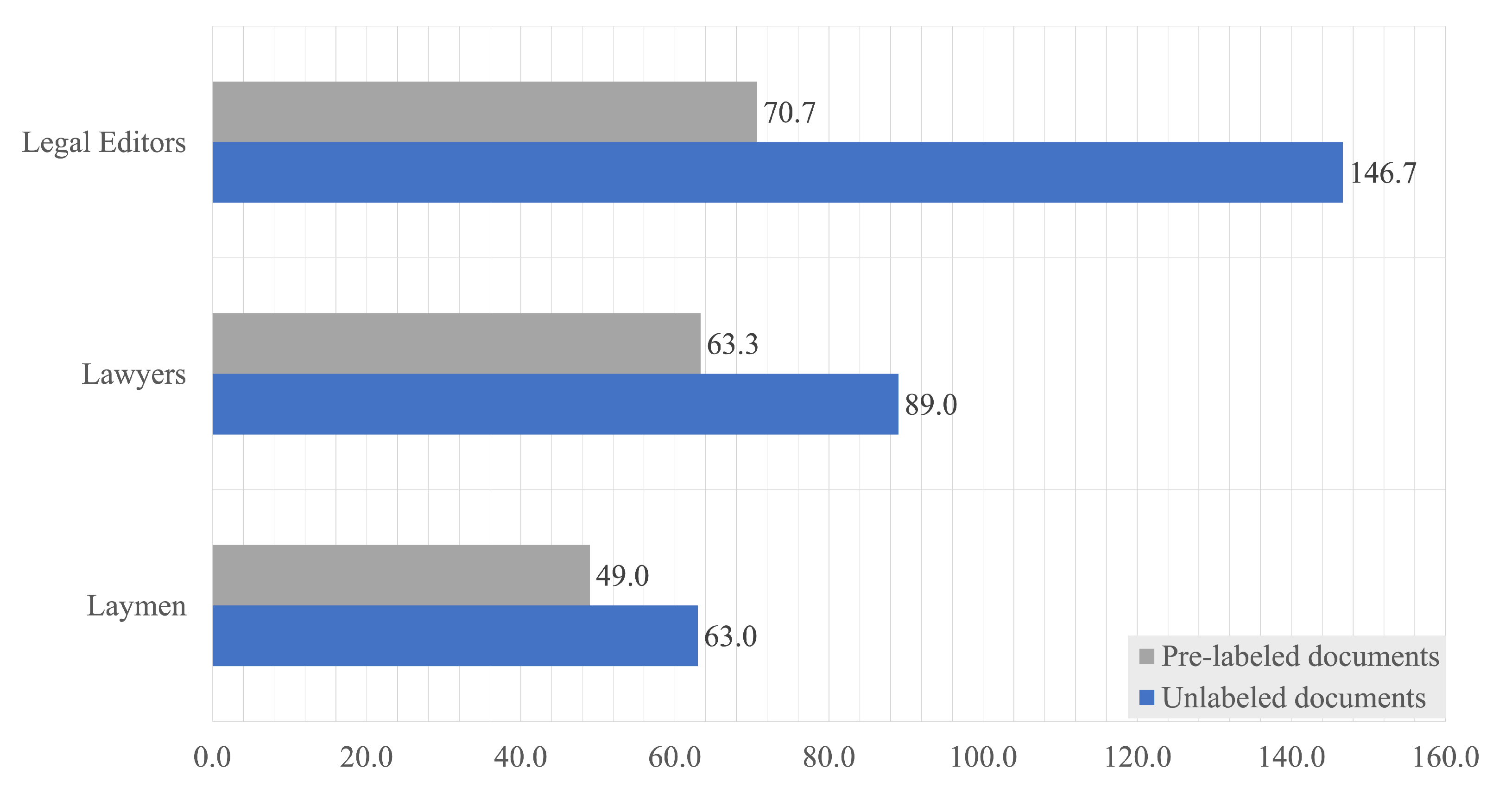
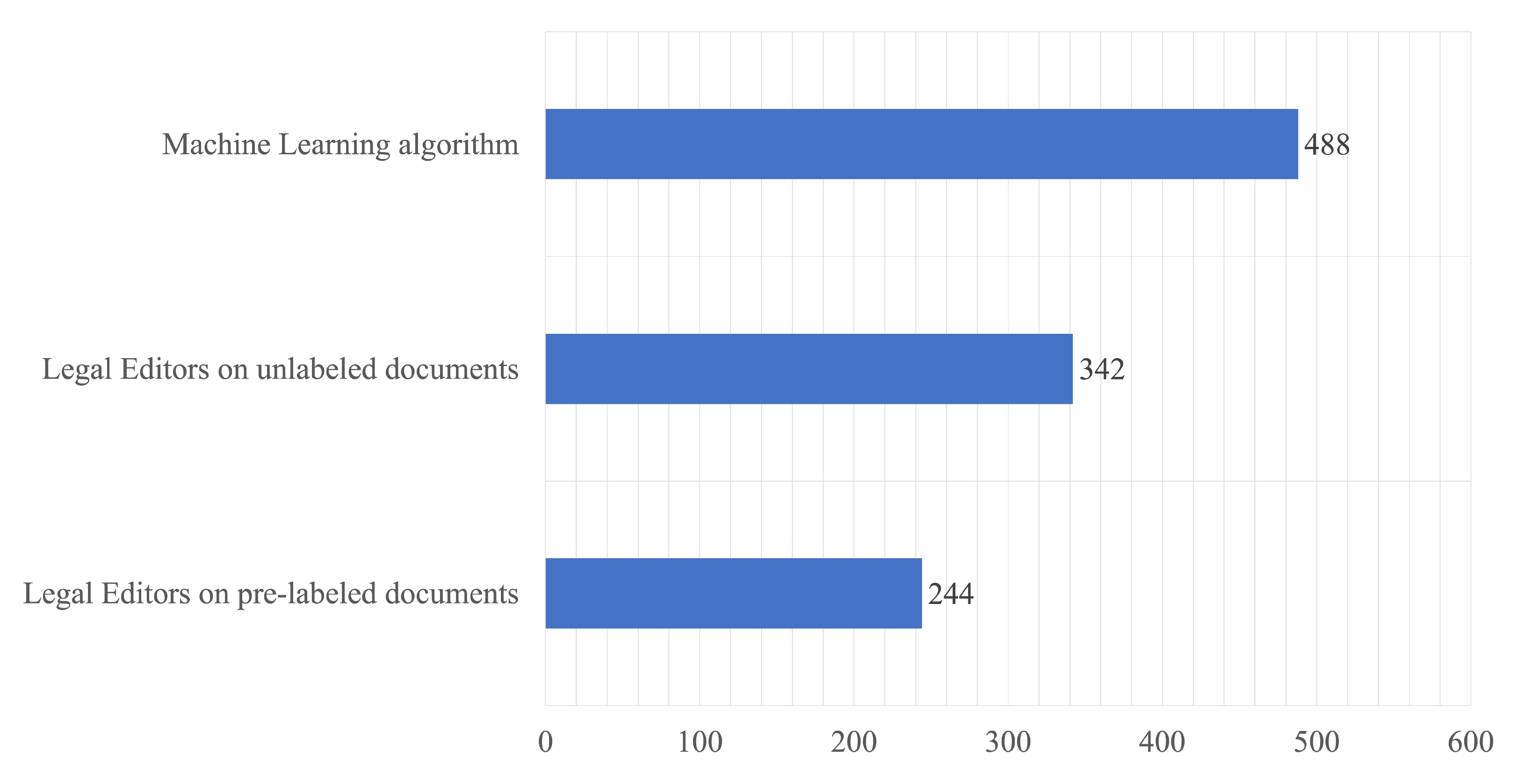
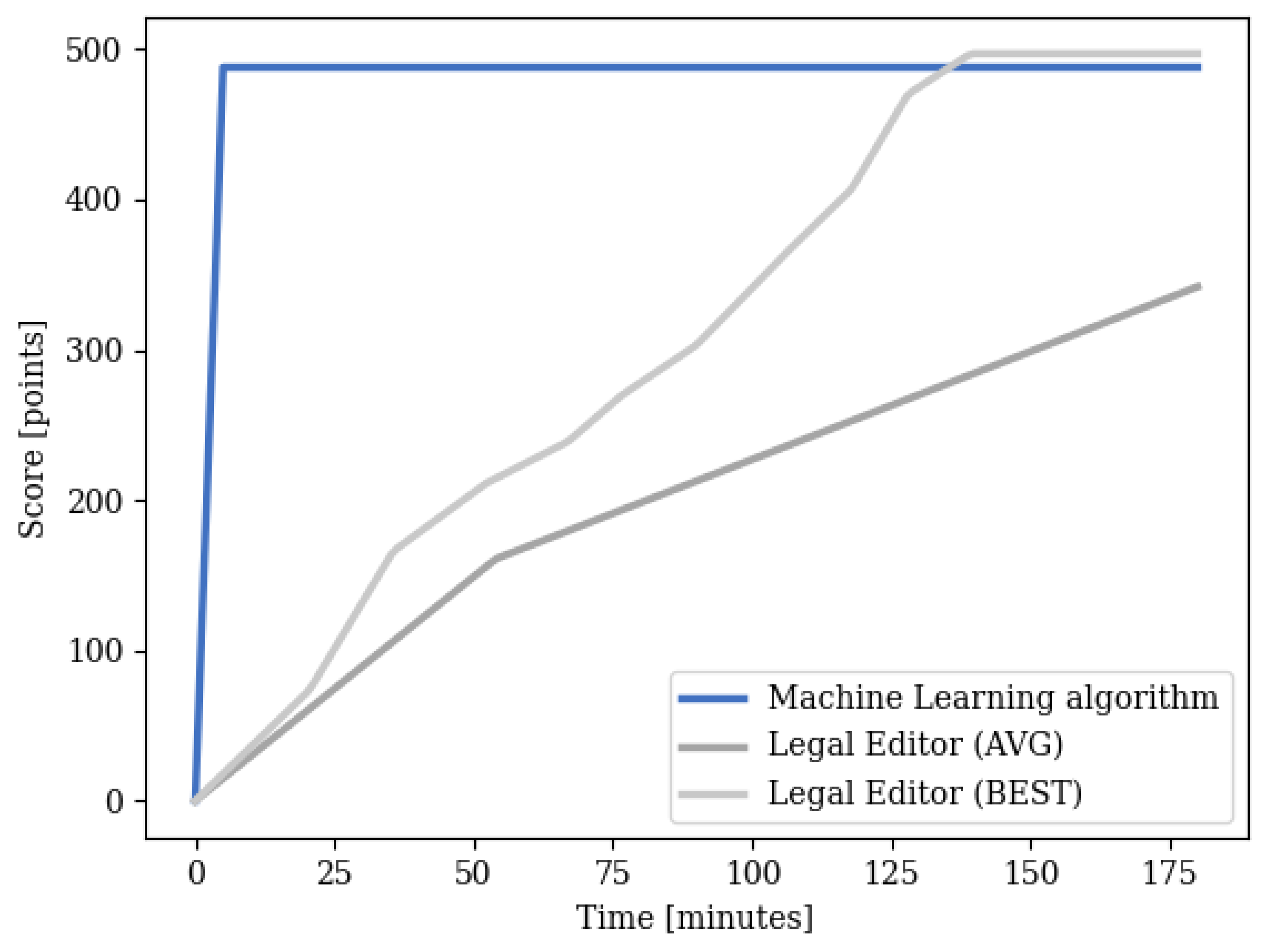
- How much time would the human categorizers need to label the whole dataset (about 170,000 documents)? How could this work be accelerated by the assistance of the computer?
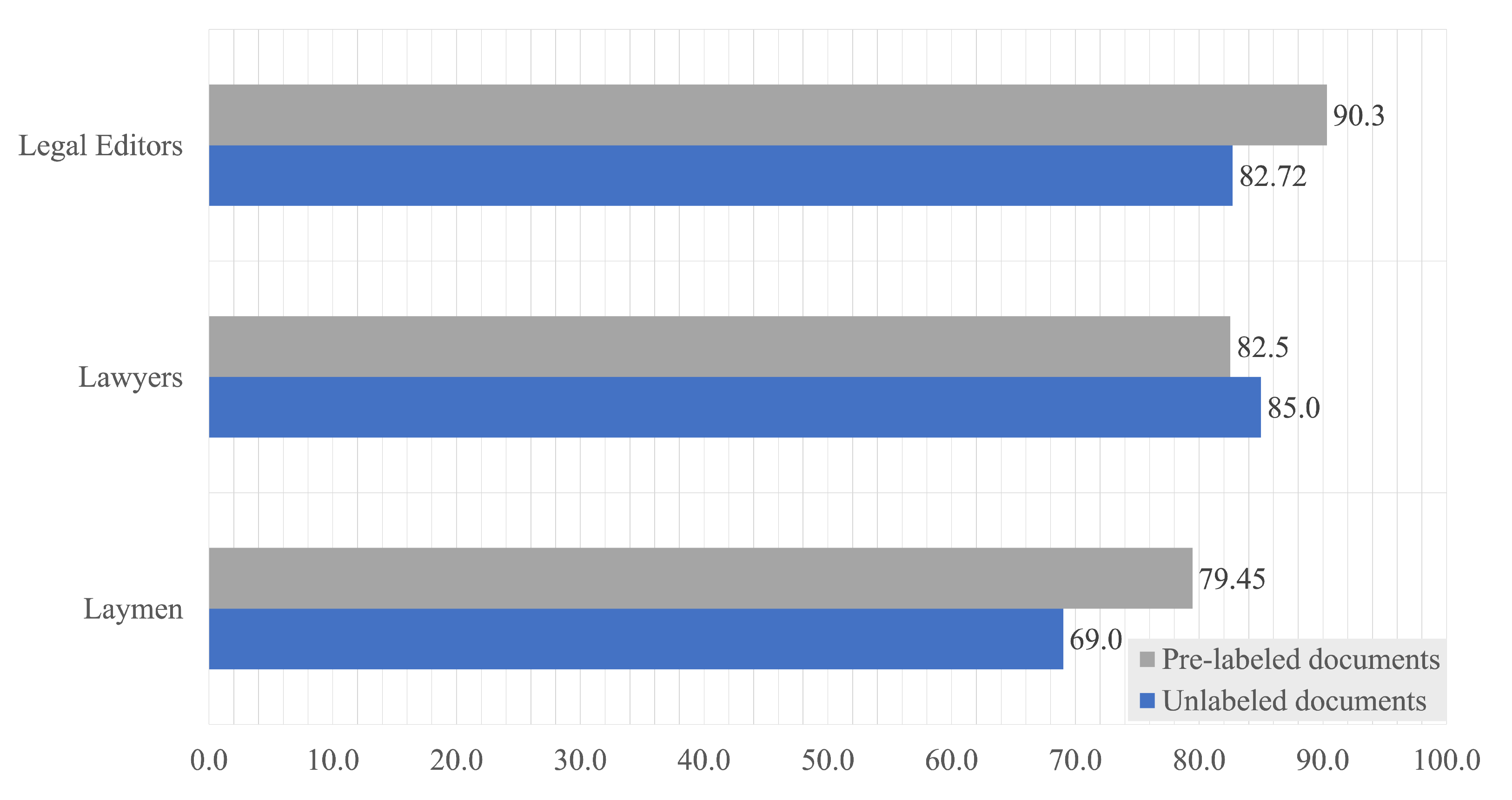
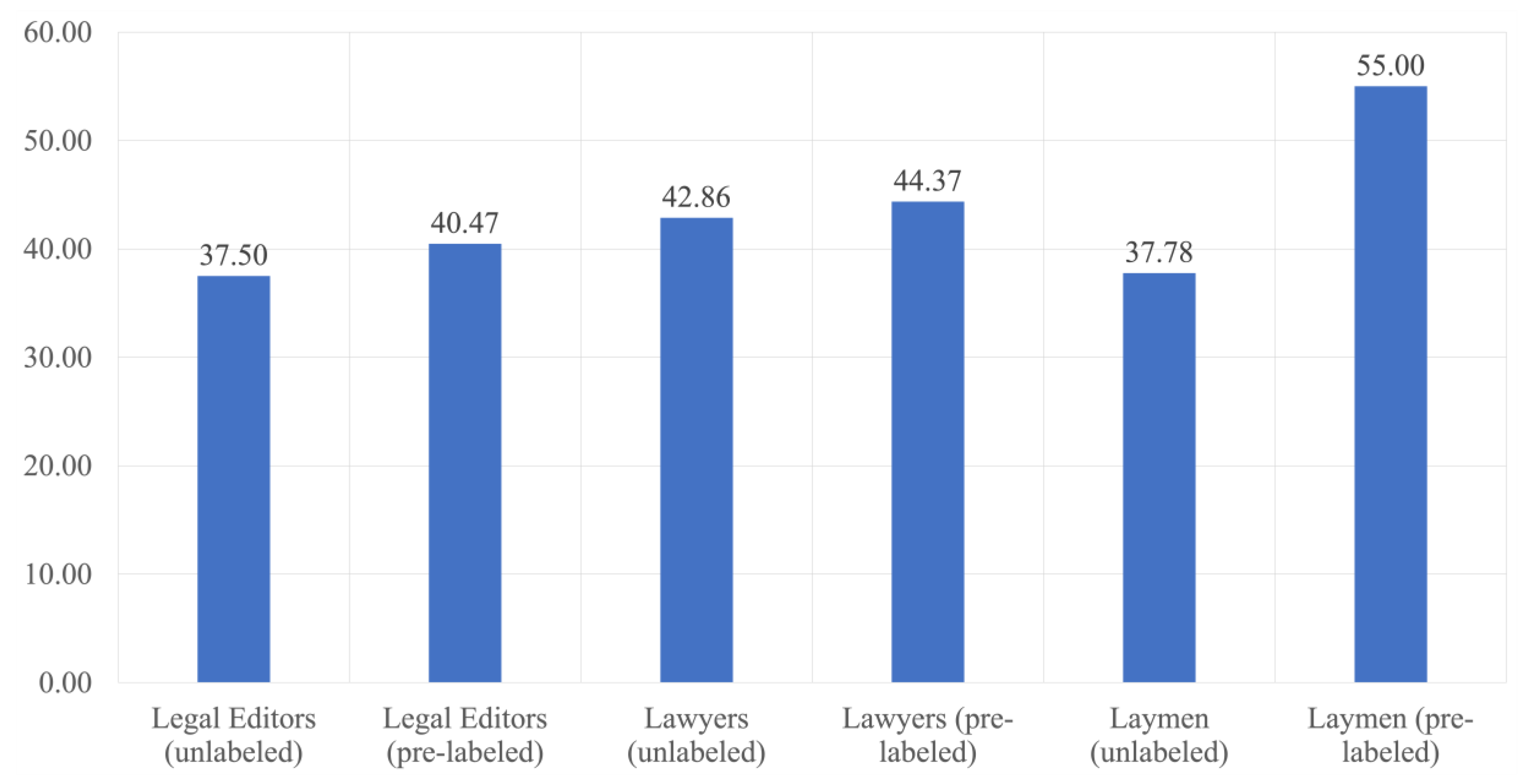
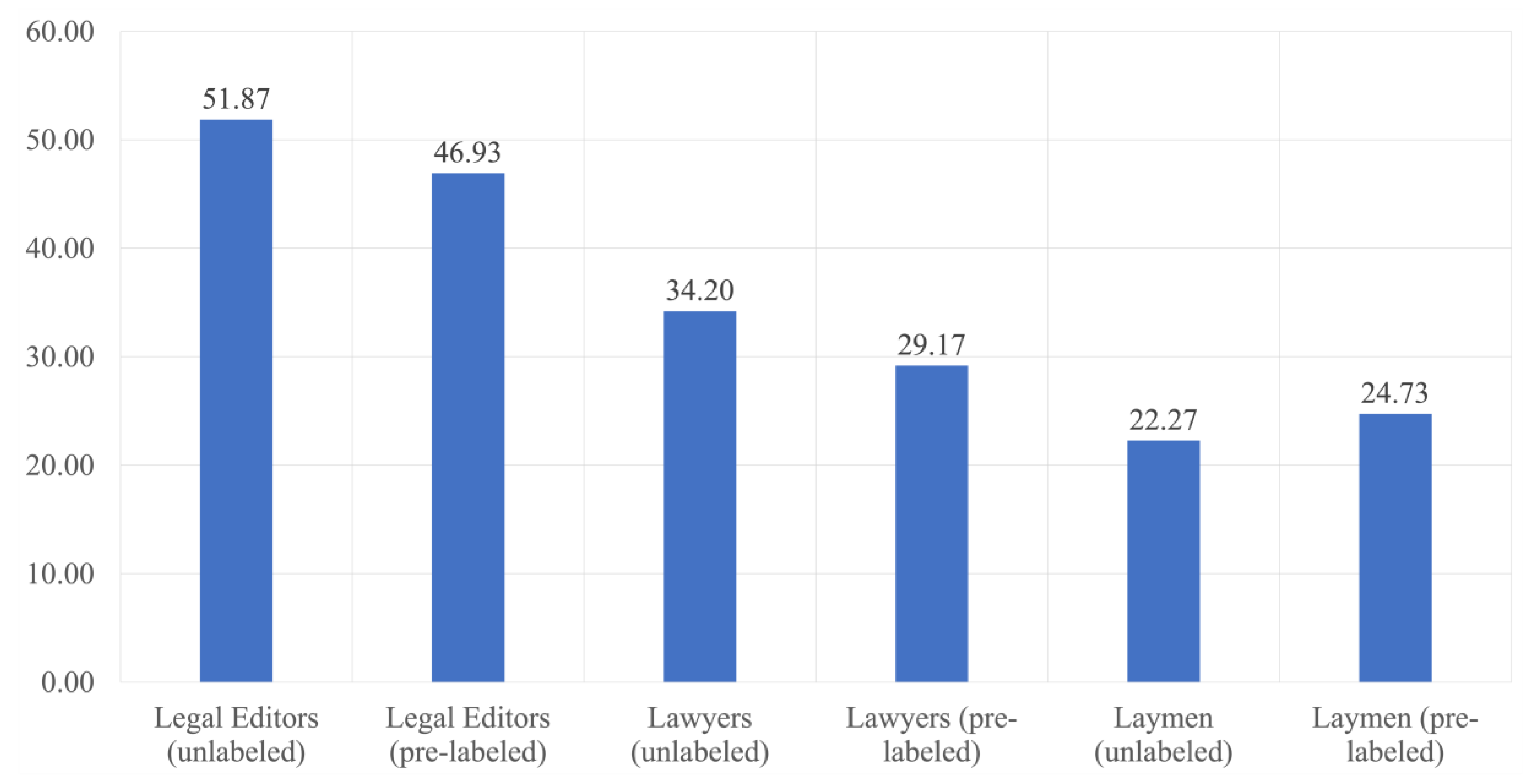
- How much information would a human expert find with or without the aid of the machine learning classifier?
- Are machine learning algorithms more reliable than humans for classifying legal documents?
- Can machine learning algorithms hide the differences between the performance of legal experts and laymen or non-expert lawyers?
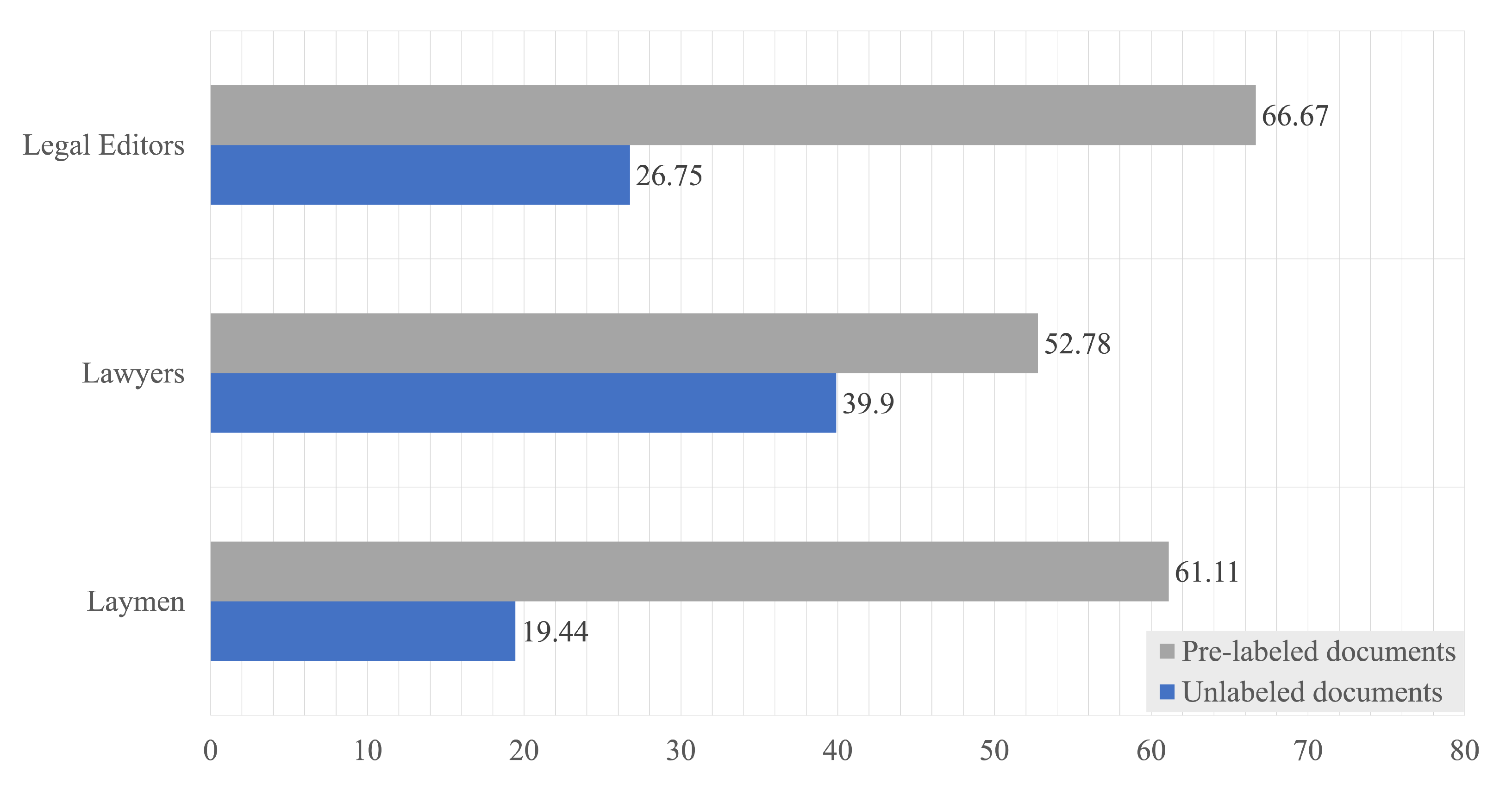
- How much is the inter-annotator agreement between legal experts on a specific task?
2.2. Study Design
- Laymen: Never received formal legal training in their life, so they were not a student of any law university and had not received any law-related training. They only met law in their everyday life.
- Lawyers: At least fourth-grade law students or people with law degrees.
- Legal editors: Legal database editors employed by Wolters Kluwer Hungary, whose task is to categorize legal documents and manually enrich them with other metadata.
2.3. Evaluation Metrics
2.4. Machine Learning-Based Classification
3. Results
3.1. Throughput
3.2. Accuracy
3.3. Performance
3.4. Inter-Annotator Agreement
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Parikh, V.; Mathur, V.; Metha, P.; Mittal, N.; Majumder, P. LawSum: A weakly supervised approach for Indian Legal Document Summarization. arXiv 2021, arXiv:2110.01188. [Google Scholar]
- Heller, J.; Arredondo, P. AI in Legal Research: How AI Is Provideing Everyone Acces to Information and Leveling the Playing Field for Firms of All Sizes. In AI for Lawyers: How Artificial Intelligence Is Adding Value, Amplifying Expertise, and Transforming Carriers; Waisberg, N., Hudek, A., Eds.; Wiley: Hoboken, NJ, USA, 2021. [Google Scholar]
- Walters, E.; Asjes, J. Fastcase and the Visual Understanding of Judicial Precedents. In Legal Informatics; Katz, D.M., Dolin, R., Bommarito, M.J., Eds.; Cambridge University Press: Cambridge, UK, 2021; pp. 357–406. [Google Scholar]
- Blair, D.C.; Maron, M.E. An evaluation of retrieval effectiveness for a full-text document-retrieval system. Commun. ACM 1985, 28, 289–299. [Google Scholar] [CrossRef]
- Roitblat, H.L.; Kershaw, A.; Oot, P. Document categorization in legal electronic discovery: Computer classification vs. manual review. J. Am. Soc. Inf. Sci. Technol. 2010, 61, 70–80. [Google Scholar] [CrossRef]
- Park, S.H.; Lee, D.G.; Park, J.S.; Kim, J.W. A Survey of Research on Data Analytics-Based Legal Tech. Sustainability 2021, 13, 8085. [Google Scholar] [CrossRef]
- Chalkidis, I.; Kampas, D. Deep learning in law: Early adaptation and legal word embeddings trained on large corpora. Artif. Intell. Law 2018, 27, 171–198. [Google Scholar] [CrossRef]
- Li, G.; Wang, Z.; Ma, Y. Combining Domain Knowledge Extraction With Graph Long Short-Term Memory for Learning Classification of Chinese Legal Documents. IEEE Access 2019, 7, 139616–139627. [Google Scholar] [CrossRef]
- Thammaboosadee, S.; Watanapa, B.; Chan, J.H.; Silparcha, U. A Two-Stage Classifier That Identifies Charge and Punishment under Criminal Law of Civil Law System. IEICE Trans. Inf. Syst. 2014, E97.D, 864–875. [Google Scholar] [CrossRef] [Green Version]
- Ashley, K.D.; Brüninghaus, S. Automatically classifying case texts and predicting outcomes. Artif. Intell. Law 2009, 17, 125–165. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, P.; Ma, J. An Ontology Driven Knowledge Block Summarization Approach for Chinese Judgment Document Classification. IEEE Access 2018, 6, 71327–71338. [Google Scholar] [CrossRef]
- de Maat, E.; Krabben, K.; Winkels, R. Machine Learning Versus Knowledge Based Classification of Legal Texts. In Proceedings of the 2010 Conference on Legal Knowledge and Information Systems: JURIX 2010: The Twenty-Third Annual Conference, Amsterdam, The Netherland, 12 August 2010; IOS Press: Amsterdam, The Netherland, 2010; pp. 87–96. [Google Scholar]
- Barnett, T.; Godjevac, S.; Renders, J.M.; Privault, C.; Schneider, J.; Wickstrom, R. Machine learning classification for document review. In DESI III: The ICAIL Workshop on Globaal E-Discovery/E-Disclosure; Citeseer: Princeton, NJ, USA, 2009. [Google Scholar]
- Borko, H. Measuring the reliability of subject classification by men and machines. Am. Doc. 1964, 15, 268–273. [Google Scholar] [CrossRef]
- van Rijsbergen, C. Information Retrieval, 2nd ed.; Butterworths: London, UK, 1979. [Google Scholar]
- Tonta, Y. A study of indexing consistency between Library of Congress and British Library catalogers. Libr. Resour. Tech. Serv. 1991, 35, 177–185. [Google Scholar]
- Voorhees, E.M. Variations in relevance judgments and the measurement of retrieval effectiveness. Inf. Process. Manag. 2000, 36, 697–716. [Google Scholar] [CrossRef]
- Fang, Y.; Tian, X.; Wu, H.; Gu, S.; Wang, Z.; Wang, F.; Li, J.; Weng, Y. Few-Shot Learning for Chinese Legal Controversial Issues Classification. IEEE Access 2020, 8, 75022–75034. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Brueckner, R.; Schulter, B. Social signal classification using deep BLSTM recurrent neural networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4823–4827. [Google Scholar]
- Rahman, L.; Mohammed, N.; Azad, A. A new LSTM model by introducing biological cell state. In Proceedings of the 2016 3rd International Conference on Electrical Engineering and Information Communication Technology (ICEEICT), Dhaka, Bangladesh, 22–24 September 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Agrawal, R.; de Alfaro, L.; Polychronopoulos, V. Learning From Graph Neighborhoods Using LSTMs. arXiv 2016, arXiv:1611.06882. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Wiley Interscience: Berlin, Germany, 1998. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene Selection for Cancer Classification Using Support Vector Machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Goh, Y.C.; Cai, X.Q.; Theseira, W.; Ko, G.; Khor, K.A. Evaluating human versus machine learning performance in classifying research abstracts. Scientometrics 2020, 125, 1197–1212. [Google Scholar] [CrossRef]
- Schumacher, J.; Zazworka, N.; Shull, F.; Seaman, C.; Shaw, M. Building Empirical Support for Automated Code Smell Detection. In Proceedings of the 2010 ACM-IEEE International Symposium on Empirical Software Engineering and Measurement, ESEM ’10, Bozen, Italy, 16–17 September 2010; Association for Computing Machinery: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Simundic, A.M.; Nikolac, N.; Ivankovic, V.; Ferenec-Ruzic, D.; Magdic, B.; Kvaternik, M.; Topic, E. Comparison of visual vs. automated detection of lipemic, icteric and hemolyzed specimens: Can we rely on a human eye? Clin. Chem. Lab. Med. 2009, 47, 1361–1365. [Google Scholar] [CrossRef]
- Weismayer, C.; Pezenka, I.; Gan, C.H.K. Aspect-Based Sentiment Detection: Comparing Human Versus Automated Classifications of TripAdvisor Reviews. In Information and Communication Technologies in Tourism 2018; Stangl, B., Pesonen, J., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 365–380. [Google Scholar]
- Nasiri, S.; Khosravani, M.R. Machine learning in predicting mechanical behavior of additively manufactured parts. J. Mater. Res. Technol. 2021, 14, 1137–1153. [Google Scholar] [CrossRef]
- Chen, H.; Wu, L.; Chen, J.; Lu, W.; Ding, J. A comparative study of automated legal text classification using random forests and deep learning. Inf. Process. Manag. 2022, 59, 102798. [Google Scholar] [CrossRef]
- Khosravani, M.R.; Nasiri, S. Injection molding manufacturing process: Review of case-based reasoning applications. J. Intell. Manuf. 2020, 31, 847–864. [Google Scholar] [CrossRef]
- Niewiadomski, P.; Stachowiak, A.; Pawlak, N. Knowledge on IT tools based on AI maturity–Industry 4.0 perspective. Procedia Manuf. 2019, 39, 574–582. [Google Scholar] [CrossRef]
- Farkas, R.; Szarvas, G.; Kocsor, A. Named entity recognition for Hungarian using various machine learning algorithms. Acta Cybern. 2006, 17, 633–646. [Google Scholar]
- Firestone, C. Performance vs. competence in human–machine comparisons. Proc. Natl. Acad. Sci. USA 2020, 117, 26562–26571. [Google Scholar] [CrossRef] [PubMed]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1998; pp. 137–142. [Google Scholar]
- Boutell, M.R.; Luo, J.; Shen, X.; Brown, C.M. Learning multi-label scene classification. Pattern Recognit. 2004, 37, 1757–1771. [Google Scholar] [CrossRef] [Green Version]
- Ghaddar, B.; Naoum-Sawaya, J. High dimensional data classification and feature selection using support vector machines. Eur. J. Oper. Res. 2018, 265, 993–1004. [Google Scholar] [CrossRef]
- Khor, K.; Ko, G.; Walter, T. Applying machine learning to compare research grant programs. In Proceedings of the STI 2018 Conference Proceedings, Leiden, The Netherlands, 12–14 September 2018; Centre for Science and Technology Studies (CWTS): Leiden, The Netherlands, 2018; pp. 816–824. [Google Scholar]
- Csányi, G.; Orosz, T. Comparison of data augmentation methods for legal document classification. Acta Tech. Jaurinensis 2021. [Google Scholar] [CrossRef]
- Orosz, T.; CsÁnyi, G.; Nagy, D. Mesterséges Intelligenciát alkalmazó szövegbányászati eszközök készítése a distiller keretrendszer segítségével–Jogi szövegek automatikus feldolgozása: Development of Artificial Intelligence-based Text Mining Tools with the distiller-framework–in case of Legal Documents. Energetika-Elektrotechnika–Számítástechnika és Oktatás Multi-konferencia 2021, XXI, 62–69. [Google Scholar]
- Orosz, T.; Gadó, K.; Katona, M.; Rassõlkin, A. Automatic Tolerance Analysis of Permanent Magnet Machines with Encapsuled FEM Models Using Digital-Twin-Distiller. Processes 2021, 9, 2077. [Google Scholar] [CrossRef]
- Luhn, H.P. A statistical approach to mechanized encoding and searching of literary information. IBM J. Res. Dev. 1957, 1, 309–317. [Google Scholar] [CrossRef]
- Jones, K.S. A statistical interpretation of term specificity and its application in retrieval. J. Doc. 1972. [Google Scholar]
- Orosz, T.; Csányi, G.M.; Vági, R.; Nagy, D.; Üveges, I.; Vadász, J.P.; Megyeri, A. Building a Production-ready Multi-label Classifier for LegalDocuments with Digital-Twin-Distiller. Appl. Sci. 2021. submitted. [Google Scholar]
- Krippendorff, K. Computing Krippendorff’rs Alpha-Reliability. Computer Science, Annenberg. 2011. Available online: https://repository.upenn.edu/asc_papers/43/ (accessed on 23 October 2021).
- Artstein, R. Inter-annotator Agreement. In Handbook of Linguistic Annotation; Ide, N., Pustejovsky, J., Eds.; Springer: Dordrecht, The Netherlands, 2017; pp. 297–313. [Google Scholar] [CrossRef]
- Glen, S. Krippendorff’s Alpha Reliability Estimate: Simple Definition. Available online: https://www.statisticshowto.com/krippendorffs-alpha/ (accessed on 23 October 2021).
- Krippendorff, K. Reliability in Content Analysis. Hum. Commun. Res. 2004, 30, 411–433. [Google Scholar] [CrossRef]
- Hayes, A.F.; Krippendorff, K. Answering the Call for a Standard Reliability Measure for Coding Data. Commun. Methods Meas. 2007, 1, 77–89. [Google Scholar] [CrossRef]
- Passonneau, R. Measuring agreement on set-valued items (MASI) for semantic and pragmatic annotation. In Proceedings of the Fifth International Conference on Language Resources and Evaluation, LREC 2006, Genoa, Italy, 22–28 May 2006. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Orosz, T.; Vági, R.; Csányi, G.M.; Nagy, D.; Üveges, I.; Vadász, J.P.; Megyeri, A. Evaluating Human versus Machine Learning Performance in a LegalTech Problem. Appl. Sci. 2022, 12, 297. https://doi.org/10.3390/app12010297
Orosz T, Vági R, Csányi GM, Nagy D, Üveges I, Vadász JP, Megyeri A. Evaluating Human versus Machine Learning Performance in a LegalTech Problem. Applied Sciences. 2022; 12(1):297. https://doi.org/10.3390/app12010297
Chicago/Turabian StyleOrosz, Tamás, Renátó Vági, Gergely Márk Csányi, Dániel Nagy, István Üveges, János Pál Vadász, and Andrea Megyeri. 2022. "Evaluating Human versus Machine Learning Performance in a LegalTech Problem" Applied Sciences 12, no. 1: 297. https://doi.org/10.3390/app12010297
APA StyleOrosz, T., Vági, R., Csányi, G. M., Nagy, D., Üveges, I., Vadász, J. P., & Megyeri, A. (2022). Evaluating Human versus Machine Learning Performance in a LegalTech Problem. Applied Sciences, 12(1), 297. https://doi.org/10.3390/app12010297