
Bot Datasets on Twitter: Analysis and Challenges

 ,
,  ,
,  and
and 
Abstract
1. Introduction
1.1. Contributions
- A comparison chart of the public and private databases analyzed from the literature.
- A recommendation for researchers of which database to use based on their needs.
- The identification of the distinct behaviors of automated accounts that appear across all bot datasets inside the databases analyzed.
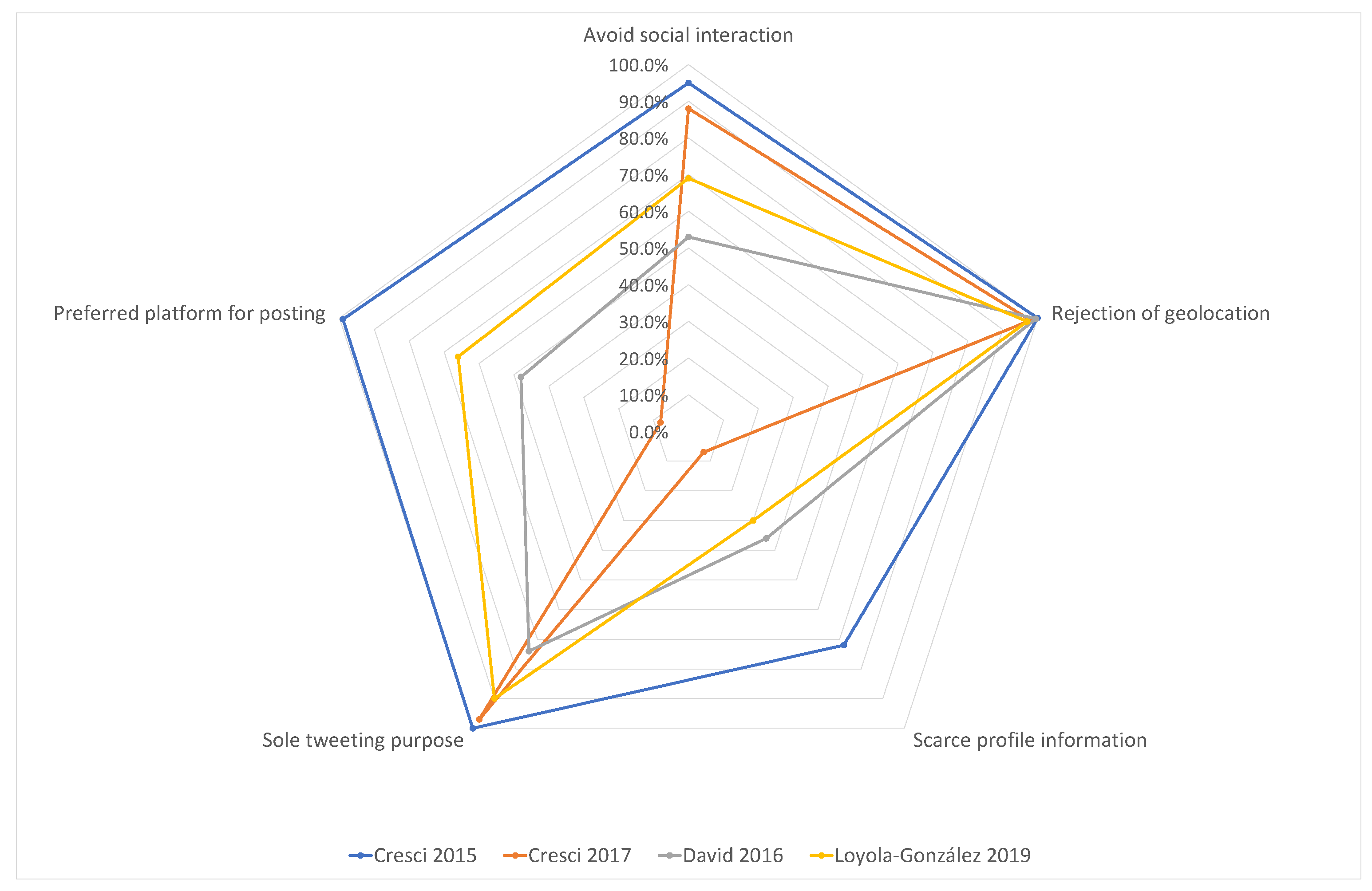
- The quantification of the presence of these behaviors in each database using a radar chart.
- A set of suggestions by way of good practices for future database creators and researchers of bot detection on Twitter.
1.2. Roadmap
2. Literature Review
2.1. Analysis of Twitter’s Social Structure
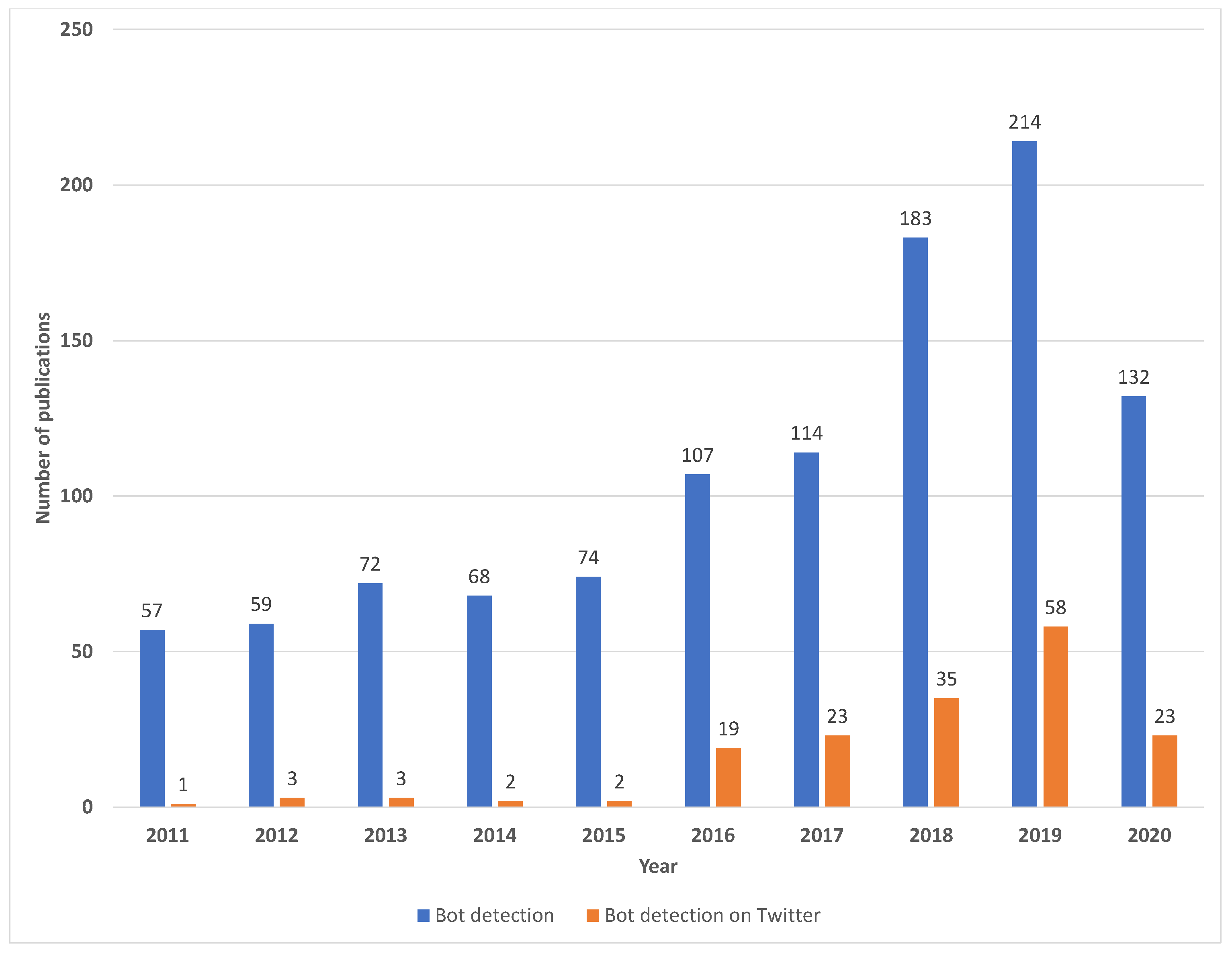
2.2. Bot Detection on Twitter
2.3. Bot Behavior Identification
3. Database Analysis
3.1. Materials and Methods
3.2. Cresci et al. Database (2015)
3.2.1. Representation
3.2.2. Analysis
3.2.3. Concluding Remarks
3.3. Cresci et al. Database (2017)
3.3.1. Representation
3.3.2. Analysis
3.3.3. Concluding Remarks
3.4. David et al. Database (2016)
3.4.1. Representation
3.4.2. Analysis
3.4.3. Concluding Remarks
3.5. Loyola-González et al. Database (2019)
3.5.1. Representation
3.5.2. Analysis
3.5.3. Concluding Remarks
3.6. Discussion
4. Bot Behaviors
4.1. Avoidance of Social Interaction
4.2. Rejection of Geolocation
4.3. Scarce Profile Information
4.4. Sole Tweeting Purpose
4.5. The Preferred Platform for Posting
5. Challenges
5.1. Corrupted Data
5.2. Accounts’ Metadata
5.3. Lack of Ground Truth Data
5.4. Outdated Collections
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Short Biography of Authors
 | Luis Daniel Samper-Escalante obtained a M.Sc. in Intelligent Systems in 2017 from the Tecnologico de Monterrey, where he is currently pursuing a PhD. in Computer Science. In 2017 he was honored with the Summa Cum Laude recognition as the highest GPA of all the generation when he finished his Master’s Degree. He has been publishing different articles since 2013 on National and International Conferences as well as Indexed and Refereed Journals. His research interests include Botnet Detection on Twitter, Wireless Sensor Networks, Swarm Intelligence, Graph Mining, and Provenance. |
 | Octavio Loyola-González received his PhD degree in Computer Science from the National Institute for Astrophysics, Optics, and Electronics, Mexico, in 2017. He has won several awards from different institutions due to his research work on applied projects; consequently, he is a Member of the National System of Researchers in Mexico (Rank1). He worked as a distinguished professor and researcher at Tecnologico de Monterrey, Campus Puebla, for undergraduate and graduate programs of Computer Sciences. Currently, he is responsible for running Machine Learning & Artificial Intelligence practice inside Altair Management Consultants Corp., where he is involved in the development and implementation using analytics and data mining in the Altair Compass department. He has outstanding experience in the fields of big data & pattern recognition, cloud computing, IoT, and analytical tools to apply them in sectors where he has worked for as Banking & Insurance, Retail, Oil&Gas, Agriculture, Cybersecurity, Biotechnology, and Dactyloscopy. From these applied projects, Dr. Loyola-González has published several books and papers in well-known journals, and he has several ongoing patents as manager and researcher in Altair Compass. |
 | Raúl Monroy obtained a a Ph.D. degree in Artificial Intelligence from Edinburgh University, in 1998, under the supervision of Prof. Alan Bundy. He has been in Computing at Tecnologico de Monterrey, Campus Estado de México, since 1985. In 2010, he was promoted to (full) Professor in Computer Science. Since 1998, he is a member of the CONACYT-SNI National Research System, rank three. Together with his students and members of his group, Machine Learning Models (GIEE–MAC), Prof. Monroy studies the discovery and application of novel model machine learning models, which he often applies to cybersecurity problems. At Tecnologico de Monterrey, he is also Head of the graduate programme in computing, at region CDMX. |
 | Miguel Angel Medina-Pérez received a Ph.D. in Computer Science from the National Institute of Astrophysics, Optics, and Electronics, Mexico, in 2014. He is currently a Research Professor with the Tecnologico de Monterrey, Campus Estado de Mexico, where he is also a member of the GIEE-ML (Machine Learning) Research Group. He has rank 1 in the Mexican Research System. His research interests include Pattern Recognition, Data Visualization, Explainable Artificial Intelligence, Fingerprint Recognition, and Palmprint Recognition. He has published tens of papers in referenced journals, such as “Information Fusion,” “IEEE Transactions on Affective Computing,” “Pattern Recognition,” “IEEE Transactions on Information Forensics and Security,” “Knowledge-Based Systems,” “Information Sciences,” and “Expert Systems with Applications.” He has extensive experience developing software to solve Pattern Recognition problems. A successful example is a fingerprint and palmprint recognition framework which has more than 1.3 million visits and 135 thousand downloads. |
References
- Ortiz-Ospina, E. The Rise of Social Media. Our World in Data. 18 September 2019. Available online: https://ourworldindata.org/rise-of-social-media (accessed on 6 October 2020).
- Orabi, M.; Mouheb, D.; Al Aghbari, Z.; Kamel, I. Detection of Bots in Social Media: A Systematic Review. Inf. Process. Manag. 2020, 57, 102250. [Google Scholar] [CrossRef]
- Rovetta, S.; Suchacka, G.; Masulli, F. Bot recognition in a Web store: An approach based on unsupervised learning. J. Netw. Comput. Appl. 2020, 157, 102577. [Google Scholar] [CrossRef]
- Asadi, M.; Jabraeil Jamali, M.A.; Parsa, S.; Majidnezhad, V. Detecting botnet by using particle swarm optimization algorithm based on voting system. Future Gener. Comput. Syst. 2020, 107, 95–111. [Google Scholar] [CrossRef]
- Porche, I.R. Cyberwarfare: An Introduction to Information-Age Conflict; Artech House: Boston, MA, USA, 2020; p. 380. [Google Scholar]
- Besel, C.; Echeverria, J.; Zhou, S. Full Cycle Analysis of a Large-Scale Botnet Attack on Twitter. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM’18), Barcelona, Spain, 30 August 2018; pp. 170–177. [Google Scholar] [CrossRef]
- Yang, K.C.; Varol, O.; Davis, C.A.; Ferrara, E.; Flammini, A.; Menczer, F. Arming the public with artificial intelligence to counter social bots. Hum. Behav. Emerg. Technol. 2019, 1, 48–61. [Google Scholar] [CrossRef]
- Latah, M. Detection of malicious social bots: A survey and a refined taxonomy. Expert Syst. Appl. 2020, 151, 113383. [Google Scholar] [CrossRef]
- Freitas, C.; Benevenuto, F.; Ghosh, S.; Veloso, A. Reverse Engineering Socialbot Infiltration Strategies in Twitter. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM’15), Paris, France, 25–28 August 2015; pp. 25–32. [Google Scholar] [CrossRef]
- Gyftopoulos, S.; Drosatos, G.; Stamatelatos, G.; Efraimidis, P.S. A Twitter-based approach of news media impartiality in multipartite political scenes. Soc. Netw. Anal. Min. 2020, 10, 36. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhao, J.; Sano, Y.; Levy, O.; Takayasu, H.; Takayasu, M.; Li, D.; Wu, J.; Havlin, S. Fake news propagates differently from real news even at early stages of spreading. EPJ Data Sci. 2020, 9, 7. [Google Scholar] [CrossRef]
- Cresci, S. A Decade of Social Bot Detection. Commun. ACM 2020, 63, 72–83. [Google Scholar] [CrossRef]
- Gorwa, R. Twitter Has a Serious Bot Problem, and Wikipedia Might Have the Solution. Quartz. 23 October 2017. Available online: https://qz.com/1108092/ (accessed on 19 August 2020).
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The Rise of Social Bots. Commun. ACM 2016, 59, 96–104. [Google Scholar] [CrossRef]
- Twitter Public Policy. Update on Twitter’s Review of the 2016 US Election. Twitter Incorporated. 2018. Available online: https://blog.twitter.com/official/en_us/topics/company/2018/2016-election-update.html (accessed on 15 October 2019).
- Shaban, H. Twitter Reveals Its Daily Active User Numbers for the First Time. The Washington Post. 8 February 2019. Available online: https://www.washingtonpost.com/technology/2019/02/07/twitter-reveals-its-daily-active-user-numbers-first-time/ (accessed on 11 March 2020).
- Twitter Investor Relations. Q4 and Fiscal Year 2018 Letter to Shareholders. Twitter Incorporated. 2019. Available online: https://s22.q4cdn.com/826641620/files/doc_financials/2018/q4/Q4-2018-Shareholder-Letter.pdf (accessed on 22 August 2019).
- Subrahmanian, V.S.; Azaria, A.; Durst, S.; Kagan, V.; Galstyan, A.; Lerman, K.; Zhu, L.; Ferrara, E.; Flammini, A.; Menczer, F. The DARPA Twitter Bot Challenge. Computer 2016, 49, 38–46. [Google Scholar] [CrossRef]
- Varol, O.; Ferrara, E.; Davis, C.; Menczer, F.; Flammini, A. Online Human-Bot Interactions: Detection, Estimation, and Characterization. In Proceedings of the 2017 Eleventh International AAAI Conference on Web and Social Media (ICWSM’17), Montréal, QC, Canada, 15–18 May 2017; pp. 280–289. [Google Scholar]
- Sysomos. An In-Depth Look at the Most Active Twitter User Data. Meltwater Social. 2009. Available online: https://sysomos.com/inside-twitter/most-active-twitter-user-data/ (accessed on 31 August 2020).
- Elsevier. Scopus. Elsevier B.V. 2020. Available online: https://www.scopus.com/ (accessed on 20 April 2021).
- Bessi, A.; Ferrara, E. Social bots distort the 2016 U.S. Presidential election online discussion. First Monday 2016, 21, 1–14. [Google Scholar] [CrossRef]
- Aljohani, N.; Fayoumi, A.; Hassan, S.U. Bot prediction on social networks of Twitter in altmetrics using deep graph convolutional networks. Soft Comput. 2020, 24, 11109–11120. [Google Scholar] [CrossRef]
- Pozzana, I.; Ferrara, E. Measuring Bot and Human Behavioral Dynamics. Front. Phys. 2020, 8, 125. [Google Scholar] [CrossRef]
- Echeverria, J.; Zhou, S. Discovery, Retrieval, and Analysis of the Star Wars Botnet in Twitter. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM’17), Sydney, Australia, 31 July–3 August 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Kwak, H.; Lee, C.; Park, H.; Moon, S. What is Twitter, a Social Network or a News Media? In Proceedings of the 2010 19th International Conference on World Wide Web (WWW’10), Raleigh, NC, USA, 26–30 April 2010; pp. 591–600. [Google Scholar] [CrossRef]
- Klymenko, O. Twitterverse: The birth of new words. Proc. Linguist. Soc. Am. 2019, 4, 1–12. [Google Scholar] [CrossRef][Green Version]
- Efstathiades, H.; Antoniades, D.; Pallis, G.; Dikaiakos, M.D.; Szlávik, Z.; Sips, R. Online social network evolution: Revisiting the Twitter graph. In Proceedings of the 2016 IEEE International Conference on Big Data (BigData’16), Washington, DC, USA, 5–8 December 2016; pp. 626–635. [Google Scholar] [CrossRef]
- Daher, L.A.; Zantout, R.; Elkabani, I.; Almustafa, K. Evolution of Hashtags on Twitter: A Case Study from Events Groups. In Proceedings of the 2018 5th International Symposium on Data Mining Applications (SDMA’18), Riyadh, Saudi Arabia, 21–22 March 2018; pp. 181–194. [Google Scholar] [CrossRef]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An Open Source Software for Exploring and Manipulating Networks. In Proceedings of the 2009 Third International AAAI Conference on Web and Social Media (ICWSM’09), San Jose, CA, USA, 17–20 May 2009; pp. 361–362. [Google Scholar]
- Motamedi, R.; Jamshidi, S.; Rejaie, R.; Willinger, W. Examining the evolution of the Twitter elite network. Soc. Netw. Anal. Min. 2019, 10, 1. [Google Scholar] [CrossRef]
- Roth, Y. Bot or Not? The Facts about Platform Manipulation on Twitter. Twitter Incorporated. 2020. Available online: https://blog.twitter.com/en_us/topics/company/2020/bot-or-not.html (accessed on 3 June 2020).
- Loyola-González, O.; Monroy, R.; Rodríguez, J.; Lopez Cuevas, A.; Mata Sánchez, J. Contrast Pattern-Based Classification for Bot Detection on Twitter. IEEE Access 2019, 7, 45800–45817. [Google Scholar] [CrossRef]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. Fame for sale: Efficient detection of fake Twitter followers. Decis. Support Syst. 2015, 80, 56–71. [Google Scholar] [CrossRef]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. The Paradigm-Shift of Social Spambots: Evidence, Theories, and Tools for the Arms Race. In Proceedings of the 2017 26th International Conference on World Wide Web Companion (WWW’17), Perth, Australia, 3–7 April 2017; pp. 963–972. [Google Scholar] [CrossRef]
- Kumar, G.; Rishiwal, V. Machine learning for prediction of malicious or spam users on social networks. Int. J. Sci. Technol. Res. 2020, 9, 926–932. [Google Scholar]
- Fazzolari, M.; Pratelli, M.; Martinelli, F.; Petrocchi, M. Emotions and Interests of Evolving Twitter Bots. In Proceedings of the 2020 IEEE Conference on Evolving and Adaptive Intelligent Systems (EAIS’20), Bari, Italy, 27–29 May 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Chu, Z.; Gianvecchio, S.; Wang, H.; Jajodia, S. Who is tweeting on Twitter: Human, bot, or cyborg? In Proceedings of the 2010 26th Annual Computer Security Applications Conference (ACSAC’10), Austin, TX, USA, 5–9 December 2010; pp. 21–30. [Google Scholar] [CrossRef]
- Krogh, A. What are artificial neural networks? Nat. Biotechnol. 2008, 26, 195–197. [Google Scholar] [CrossRef]
- David, I.; Siordia, O.S.; Moctezuma, D. Features combination for the detection of malicious Twitter accounts. In Proceedings of the 2016 IEEE International Autumn Meeting on Power, Electronics and Computing (ROPEC’16), Ixtapa, Mexico, 9–11 November 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Liu, L.; Özsu, M.T. Contrast Pattern Based Classification. In Encyclopedia of Database Systems; Springer: Boston, MA, USA, 2009; p. 494. [Google Scholar] [CrossRef]
- Echeverria, J.; De Cristofaro, E.; Kourtellis, N.; Leontiadis, I.; Stringhini, G.; Zhou, S. LOBO: Evaluation of Generalization Deficiencies in Twitter Bot Classifiers. In Proceedings of the 2018 34th Annual Computer Security Applications Conference (ACSAC’18), San Juan, PR, USA, 3–7 December 2018; pp. 137–146. [Google Scholar] [CrossRef]
- Abokhodair, N.; Yoo, D.; McDonald, D.W. Dissecting a Social Botnet: Growth, Content and Influence in Twitter. In Proceedings of the 2015 18th ACM Conference on Computer Supported Cooperative Work & Social Computing (CSCW’15), Vancouver, BC, Canada, 14–18 March 2015; pp. 839–851. [Google Scholar] [CrossRef]
- Mazza, M.; Cresci, S.; Avvenuti, M.; Quattrociocchi, W.; Tesconi, M. RTbust: Exploiting Temporal Patterns for Botnet Detection on Twitter. In Proceedings of the 2019 10th ACM Conference on Web Science (WebSci’19), Boston, MA, USA, 30 June–3 July 2019; pp. 183–192. [Google Scholar] [CrossRef]
- Priem, J.; Groth, P.; Taraborelli, D. The Altmetrics Collection. PLoS ONE 2012, 7, 1–2. [Google Scholar] [CrossRef]
- Oracle Corporation. Java SE. Oracle. 2019. Available online: https://www.oracle.com/technetwork/java/javase/overview/index.html (accessed on 11 February 2020).
- Jacomy, M.; Venturini, T.; Heymann, S.; Bastian, M. ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software. PLoS ONE 2014, 9, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Lavrakas, P. Percentage Frequency Distribution. In Encyclopedia of Survey Research Methods; SAGE Publications Incorporated: Thousand Oaks, CA, USA, 2008; pp. 577–578. [Google Scholar] [CrossRef]
- Scopus. What Is Field-weighted Citation Impact (FWCI)? Elsevier B.V. 2020. Available online: https://service.elsevier.com/app/answers/detail/a_id/14894/ (accessed on 20 March 2021).
- Singh, S. Simple Random Sampling. In Advanced Sampling Theory with Applications; Springer: Dordrecht, Netherlands, 2003; Chapter 2; pp. 71–136. [Google Scholar] [CrossRef]
- Hinkle, D.E.; Wiersma, W.; Jurs, S.G. Applied Statistics for the Behavioral Sciences; Houghton Mifflin Harcourt: Boston, MA, USA, 2003; p. 756. [Google Scholar]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures; Chapman & Hall/CRC: Boca Raton, FL, USA, 2007; p. 1776. [Google Scholar]
- Wolfram. Graph Measures & Metrics. Wolfram Research Incorporated. 2020. Available online: https://reference.wolfram.com/language/guide/GraphMeasures.html (accessed on 21 June 2020).
- Akrami, A.; Rostami, H.; Khosravi, M.R. Design of a reservoir for cloud-enabled echo state network with high clustering coefficient. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 64. [Google Scholar] [CrossRef]
- Grover, P.; Kar, A.K.; Dwivedi, Y.K.; Janssen, M. Polarization and acculturation in US Election 2016 outcomes - Can twitter analytics predict changes in voting preferences. Technol. Forecast. Soc. Chang. 2019, 145, 438–460. [Google Scholar] [CrossRef]
- Avvenuti, M.; Bellomo, S.; Cresci, S.; La Polla, M.N.; Tesconi, M. Hybrid Crowdsensing: A Novel Paradigm to Combine the Strengths of Opportunistic and Participatory Crowdsensing. In Proceedings of the 26th International Conference on World Wide Web Companion (WWW’17), Perth, Australia, 3–7 April 2017; pp. 1413–1421. [Google Scholar] [CrossRef]
- Yang, C.; Harkreader, R.; Gu, G. Empirical Evaluation and New Design for Fighting Evolving Twitter Spammers. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1280–1293. [Google Scholar] [CrossRef]
- BotsDeTwitter. @BotsPoliticosNo. WordPress. 2019. Available online: https://botsdetwitter.wordpress.com/ (accessed on 22 March 2020).
- Althaus, D. These Are The Four Candidates in Mexico’s Presidential Election. The Washington Post. 2018. Available online: https://www.washingtonpost.com/news/worldviews/wp/2018/06/29/these-are-the-four-candidates-in-mexicos-presidential-election/ (accessed on 10 April 2020).
- Wright, J.; Anise, O. Don’t @ Me: Hunting Twitter Bots at Scale. In Proceedings of the 2018 Black Hat USA (BlackHat’18), Mandalay Bay, LV, USA, 4–9 August 2018; pp. 1–43. [Google Scholar]
- Twitter Dev. Data Dictionary: The Set of Features That Can Be Extracted from the Twitter API Regarding a User’s Public Information. Twitter Incorporated. 2021. Available online: https://developer.twitter.com/en/docs/twitter-api/data-dictionary (accessed on 20 April 2021).
- Twitter Dev. Developer Agreement and Policy. Twitter Incorporated. 2020. Available online: https://developer.twitter.com/en/developer-terms/agreement-and-policy (accessed on 15 November 2020).
- Lingam, G.; Rout, R.R.; Somayajulu, D.; Das, S.K. Social Botnet Community Detection: A Novel Approach Based on Behavioral Similarity in Twitter Network Using Deep Learning. In Proceedings of the 2020 15th ACM Asia Conference on Computer and Communications Security (ACCS’20), Taipei, Taiwan, 5–9 October 2020; pp. 708–718. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Key Findings |
|---|---|
| favourites_count | 94% of bots gave no favorite since created, which is drastically different from humans, which have 20%. |
| friends_count | The average of bots’ followings is around 210, and several of them follow each other. |
| retweet_count | There is a retweeting behavior for a small group of bot accounts that could be the work of a botnet. |
| source | Almost all of the bots’ tweets come from the web, compared to the diversity of sources of humans’ tweets. |
| Feature | Key Findings |
|---|---|
| listed_count | Half of the social spambots do not appear on public lists compared to one-quarter of the genuine accounts. |
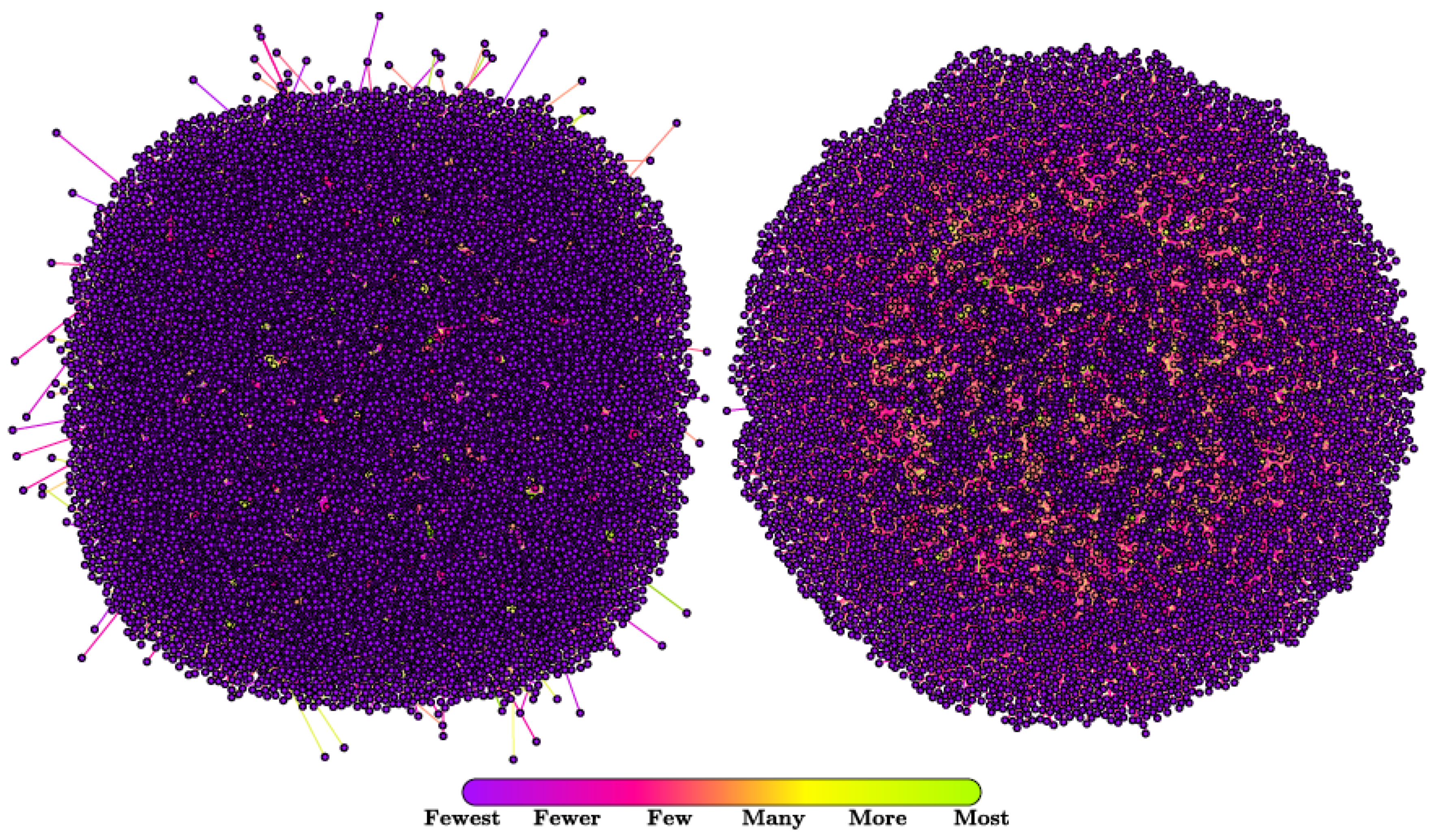
| location | Most of the bots are from Italy as they are retweeters of an Italian politician, contrary to genuine accounts that are scattered throughout the world. |
| statuses_count | More than 15% of bot accounts have a similar number of tweets with increments of 0.10% in their PFD [49]. |
| time_zone | The time zone of the bots is mostly from Europe, which agrees with their reported location. |
| num_urls | About 6% of bot tweets have at least one URL, compared to 15% of human tweets. |
| source | The genuine accounts usually utilize iPhone to tweet, while bot accounts diversify between many devices. |
| num_mentions | 97% of the bots’ tweets do not mention other users, different to humans with about 40%. |
| retweet_count | Three-quarters of the bots’ tweets have no retweets, while humans’ tweets have more than half. |
| Feature | Key Findings |
|---|---|
| lang | More than 90% of bot accounts set their default language to Spanish, while roughly 70% of human accounts did. |
| listed_count | Bot accounts are not present in public lists (about 64%) as much as human accounts are (roughly 76%). |
| location | Bot accounts are spread around the world when they should be in places near Spain or Argentina. |
| statuses_count | Bots tend to post more than 1000 tweets. In contrast, humans tend to have less than 100 tweets. |
| source | Humans tweet more from an iPhone device (35%) while bots prefer the TweetDeck platform (about 50%). |
| retweet_count | Bots have less tweets without a retweet (around one-fourth) compared to human tweets (about half). |
| type | Bots do more retweets (75%) than original content, which directly contrasts with human behavior (27%). |
| created_at | Almost 31% of bot tweets have same creation dates, compared to only 0.6% of human tweets. |
| Feature | Key Findings |
|---|---|
| lang | 92% of bots and humans set their language to English and all Mexican politicians picked Spanish. |
| listed_count | All politicians appear in more than 950 public lists, and bots have the lowest appearance in public lists. |
| location | Most of bots do not have a location (87%), which is higher than humans (27%) and politicians (0%). |
| source | Bot accounts prefers to use different applications (TweetAdder) than the other classes to tweet. |
| retweet_count | 97% of the tweets made by bots do not get retweeted, but for politicians it is only 10%. |
| num_mentions | Bots mention other users scarcely (11%) while humans (59%) and politicians (35%) do it more. |
| sunday_tweetdist | Politicians have a busier schedule, bots are half less active, and humans have the least. |
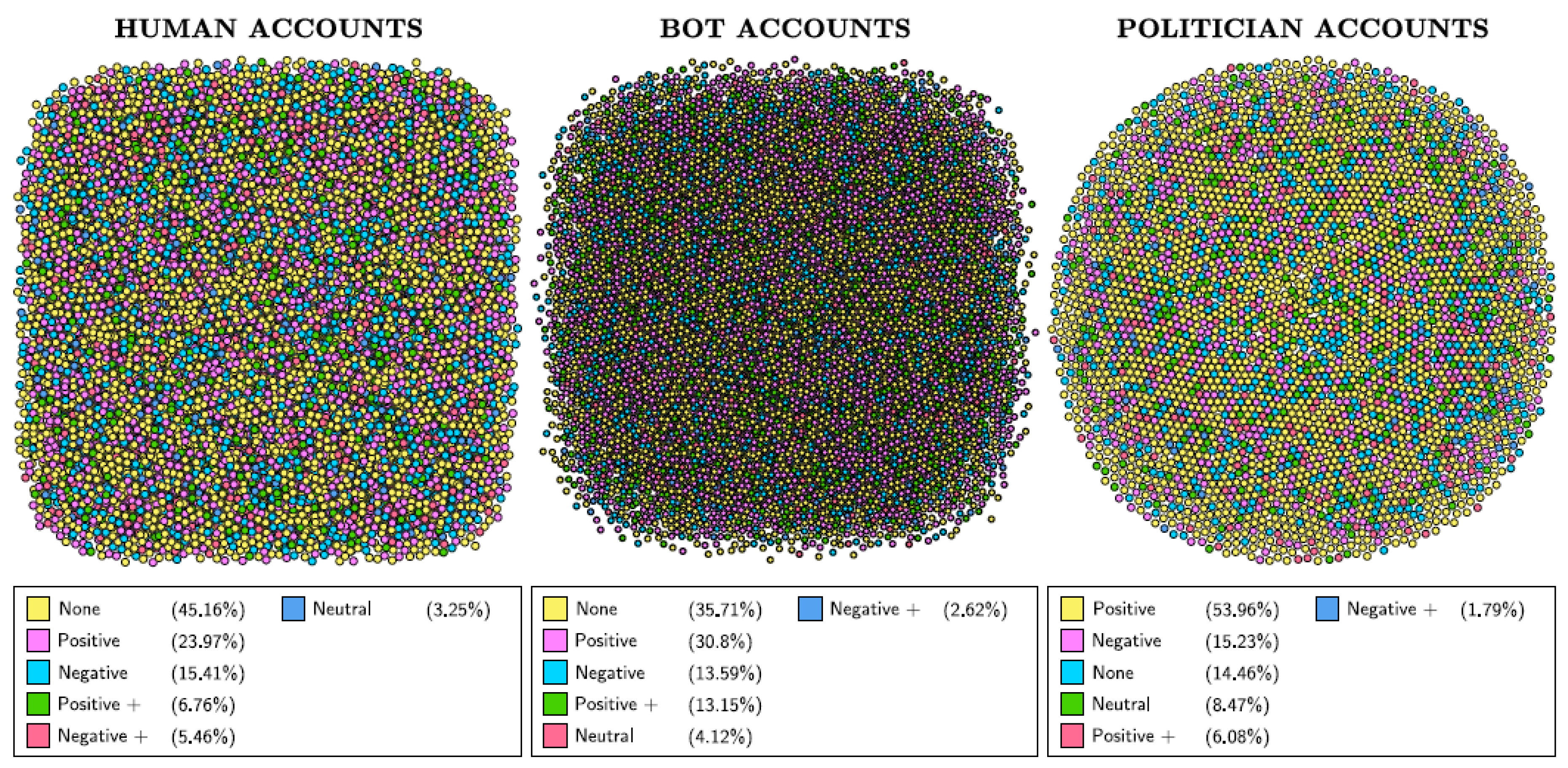
| sa_score_tag | Majority of bot and human tweets do not express a sentiment, while politician tweets are most positive. |
| Database | Advantages | Disadvantages |
|---|---|---|
| Cresci et al. [34] (2015) | Clear difference between classes, 5 distinct datasets, includes relationships, datasets are small and manageable. | Only has fake followers, some features have been deprecated, imbalance of classes, more than 4 years old. |
| Cresci et al. [35] (2017) | Popular for benchmarking, 9 distinct datasets, data easy to handle and interpret, introduces social spambots. | Classes are harder to separate, datasets’ size is very large, no relationships between nodes, imbalance of classes. |
| David et al. [40] (2016) | Only has Spanish-speaking accounts, the dataset is relatively small, bots’ type is not identified, significant features. | Not used much in the literature, only one dataset, no relationships between nodes, fewer features. |
| Loyola-González et al. [33] (2019) | Introduces a Mexican politician class, the dataset is not large thus more manageable, has a mixture of different types of bots, adds new features. | Bot and human classes are harder to separate, it only has one dataset, no relationships between nodes, has few politician accounts. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Samper-Escalante, L.D.; Loyola-González, O.; Monroy, R.; Medina-Pérez, M.A. Bot Datasets on Twitter: Analysis and Challenges. Appl. Sci. 2021, 11, 4105. https://doi.org/10.3390/app11094105
Samper-Escalante LD, Loyola-González O, Monroy R, Medina-Pérez MA. Bot Datasets on Twitter: Analysis and Challenges. Applied Sciences. 2021; 11(9):4105. https://doi.org/10.3390/app11094105
Chicago/Turabian StyleSamper-Escalante, Luis Daniel, Octavio Loyola-González, Raúl Monroy, and Miguel Angel Medina-Pérez. 2021. "Bot Datasets on Twitter: Analysis and Challenges" Applied Sciences 11, no. 9: 4105. https://doi.org/10.3390/app11094105
APA StyleSamper-Escalante, L. D., Loyola-González, O., Monroy, R., & Medina-Pérez, M. A. (2021). Bot Datasets on Twitter: Analysis and Challenges. Applied Sciences, 11(9), 4105. https://doi.org/10.3390/app11094105