
Online Forecasting and Anomaly Detection Based on the ARIMA Model



Abstract
:1. Introduction
2. Materials and Methods
2.1. Classical ARIMA Model
2.2. Online Algorithms Based on the ARIMA Model
2.2.1. Online Gradient Descent
- Noise components are randomly and independently distributed with zero expectations and satisfy the following conditions: and for every t.
- The loss function must satisfy a Lipschitz condition [19].
- Autoregressive weight coefficients satisfy . This assumption is necessary to restrict the decision set [12], but it is not necessary or sufficient for stability. In fact, the absolute values of autoregressive weight coefficients can be bounded to any other real number.
- Moving average weight coefficients satisfy for some .
- The signal is bounded by the constant. Without the loss of generality, we assume that for every t.
| Algorithm 1 Online Gradient Descent. |
| Input Hyperparameters , learning rate ; Set For t from 1 to do: Predict ; Get and ; Set ; Update End for |
2.2.2. Full Refitting
| Algorithm 2 Full refitting. |
| Input Hyperparameters , learning rate ; Set randomly For t from to do: Set Predict End for * is the notation of any suitable optimization algorithm using “warm start” technology |
2.2.3. Window Refitting
| Algorithm 3 Window refitting. |
| Input Hyperparameters , learning rate , window width W; Set randomly For t from to do: Set Predict End for * is the notation of any suitable optimization algorithm using “warm start” technology |
2.3. Performance Metric for the Forecasting Problem
2.4. Anomaly Detection Algorithms
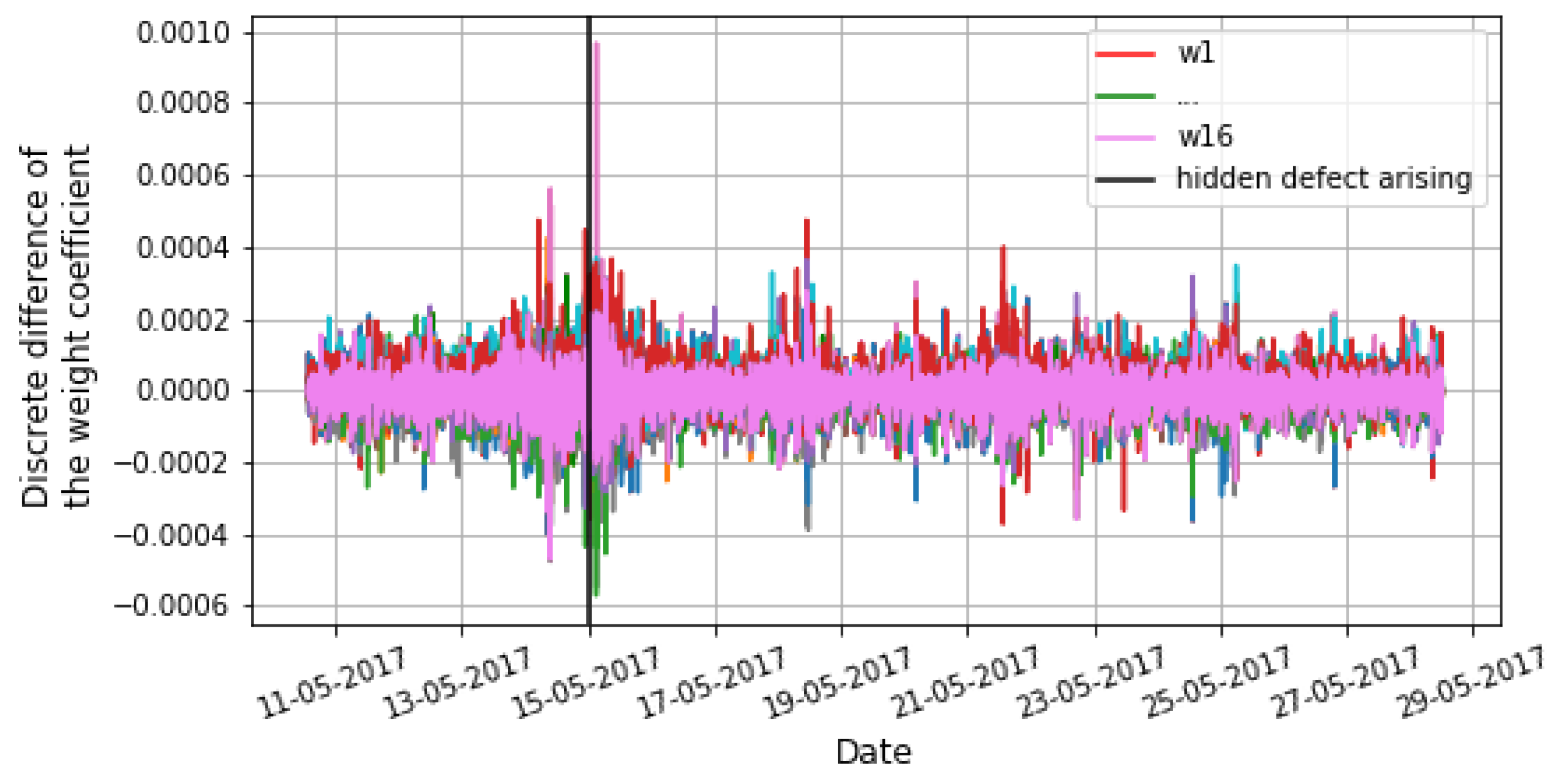
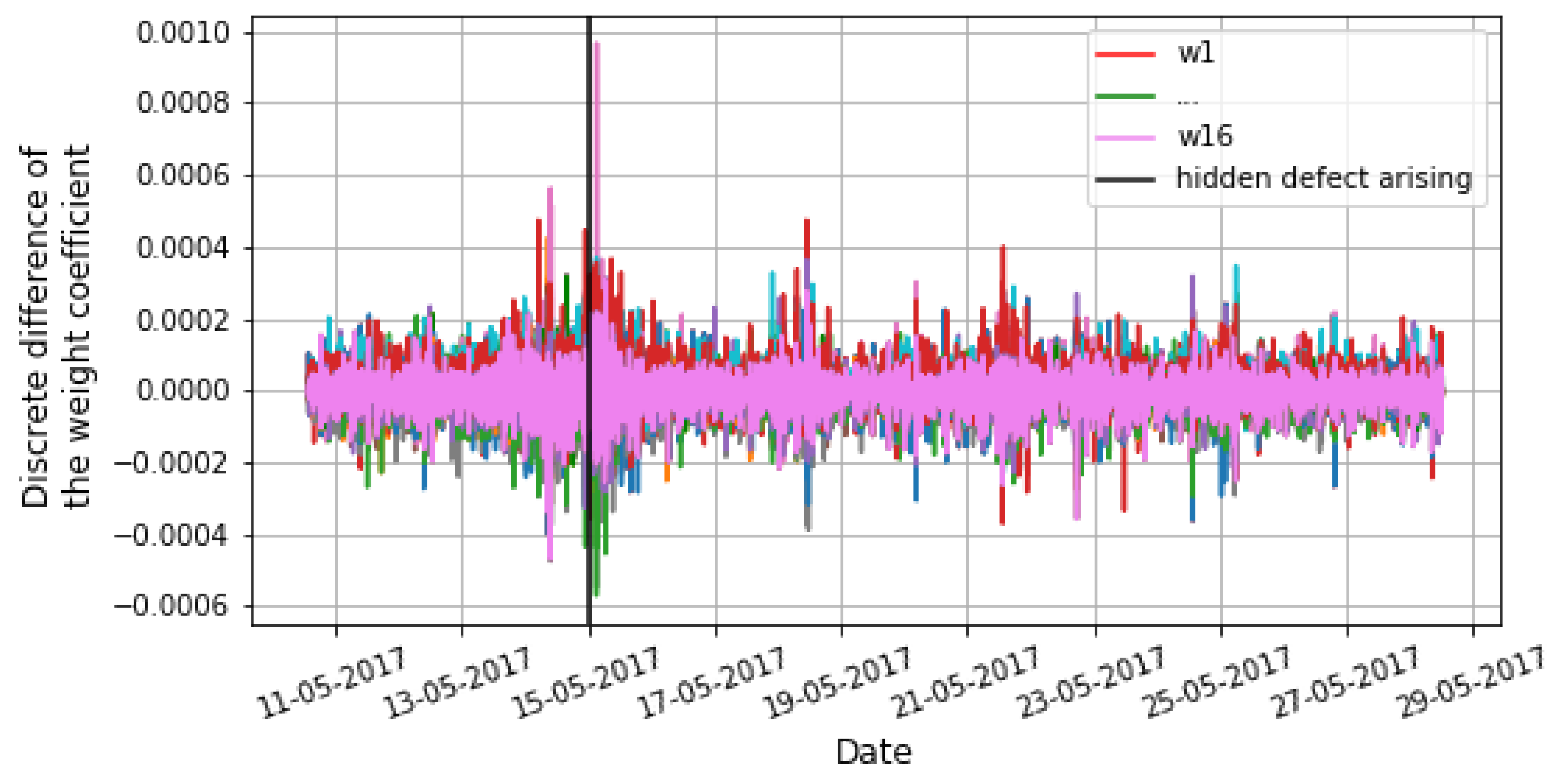
2.4.1. Novel Anomaly Detection Algorithm Based on OGD Algorithm
- The optimal values of the weight coefficients are unknown initially.
- The state of a considered system may gradually change over time. This will lead to a shift in the optimal values of the weight coefficients. This, in turn, can lead to a high false-positive rate in an anomaly detection algorithm.
| Algorithm 4 ARIMA Anomaly detection. |
| Input Hyperparameters , learning rate , threshold , empty list r; Set For t from 1 to do: Predict ; Get and ; Set ; Update Update For w from 1 to do: If then Add value t to r ALERT End for End for |
- Metric based on Euclidean normwhere S is the number of all weight coefficients of the ARIMA models for the considered system, t is the time moment, is a discrete difference in one specific weight coefficient, is the width of the window (requiring separate tuning, can be an equally timed physical process), is a function for computing the mean of a metric in a particular window , is a function for computing the standard deviation of a metric in a particular window , and is the threshold of the metric.
- Using a metric based on the maximum absolute values
- Metric based on the mean of max/std
- Complex metric
2.4.2. One Point Prediction
| Algorithm 5 One-point prediction. |
| Input Hyperparameters , learning rate , threshold , emply list r; Set For t from to do: Predict If then Add value t to r ALERT End for * is the notation of any suitable optimization algorithm |
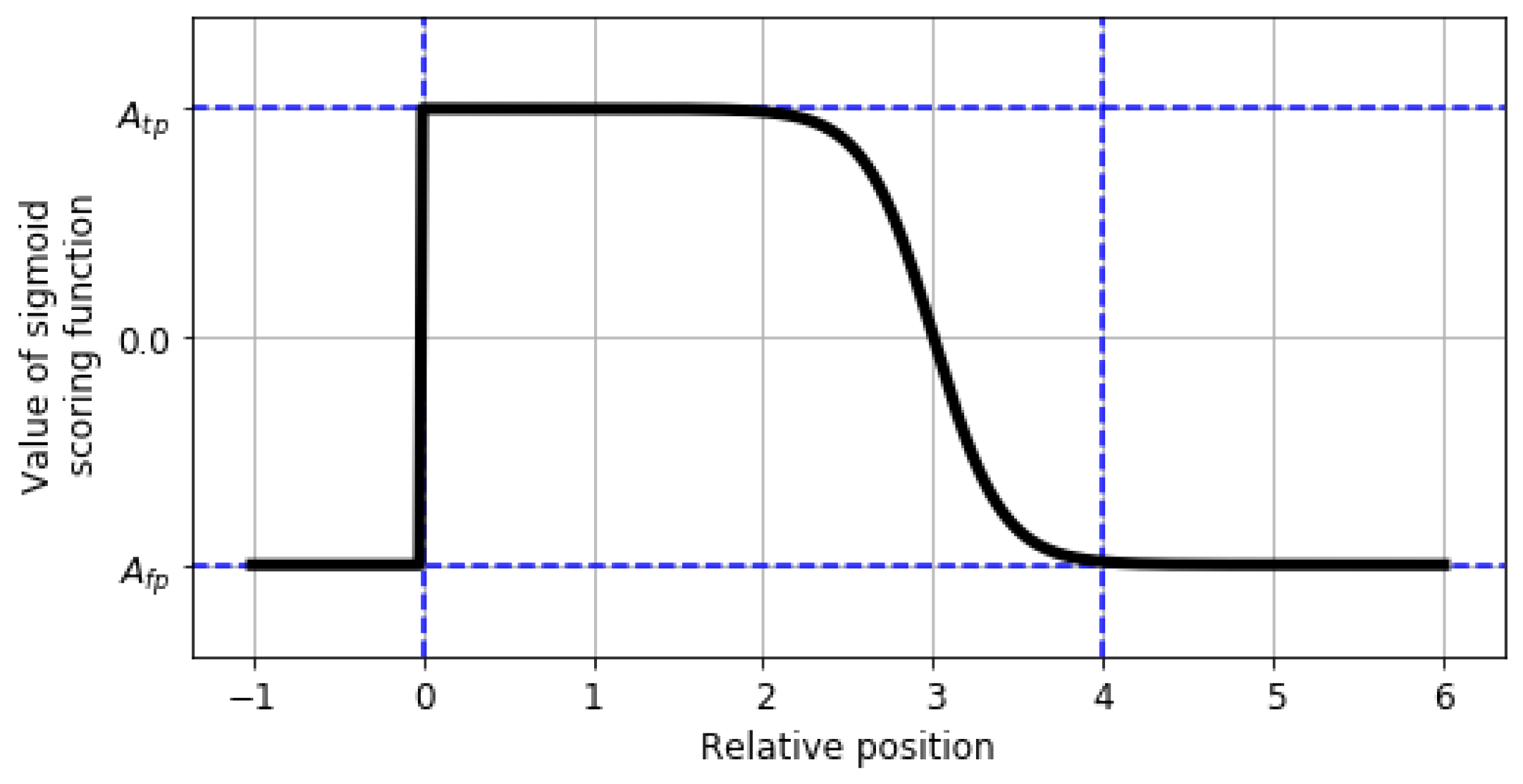
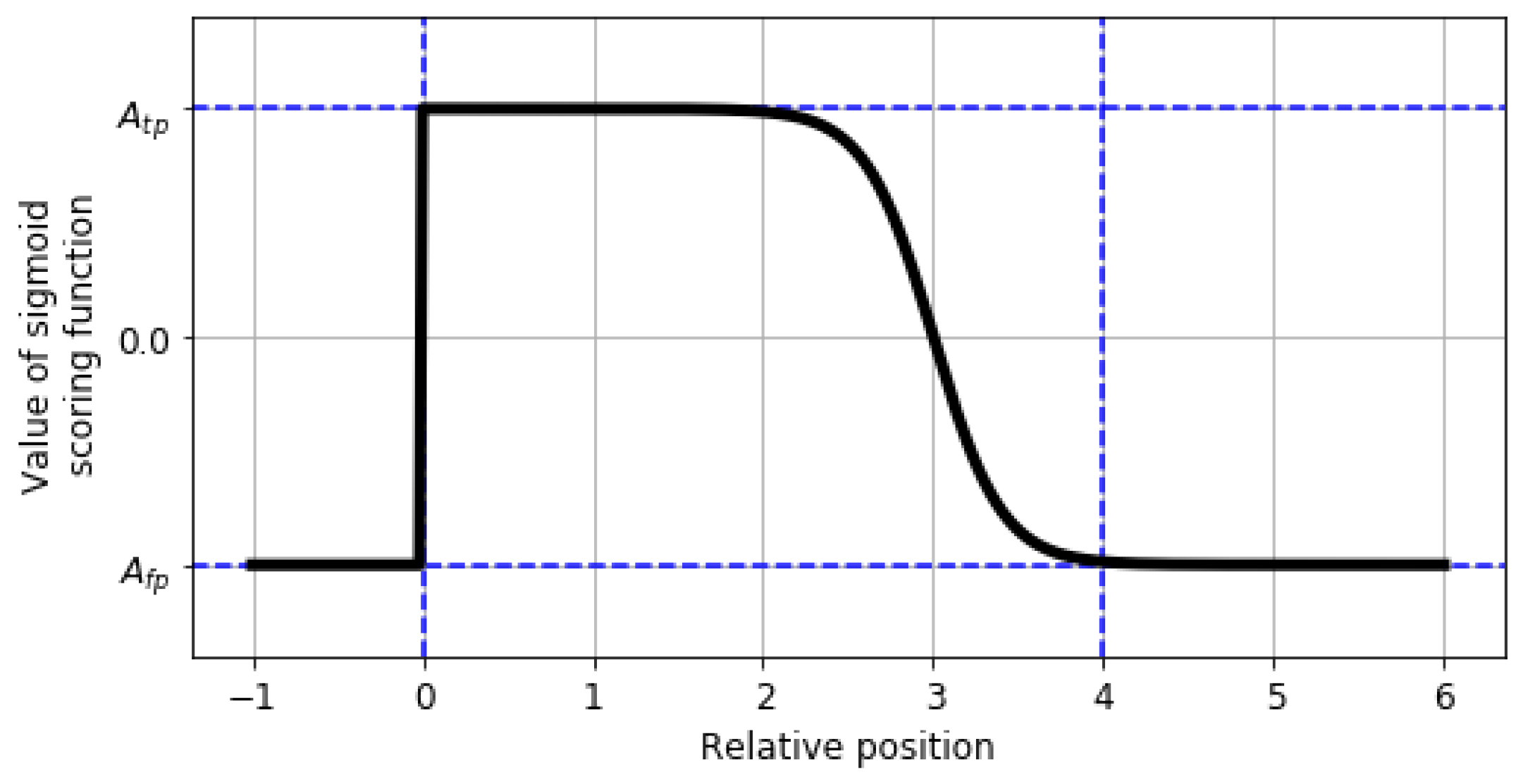
2.5. Performance Metric for Anomaly Detection Problem
- the anomaly window;
- the application profiles;
- the scoring function.
2.6. Python Library
3. Results
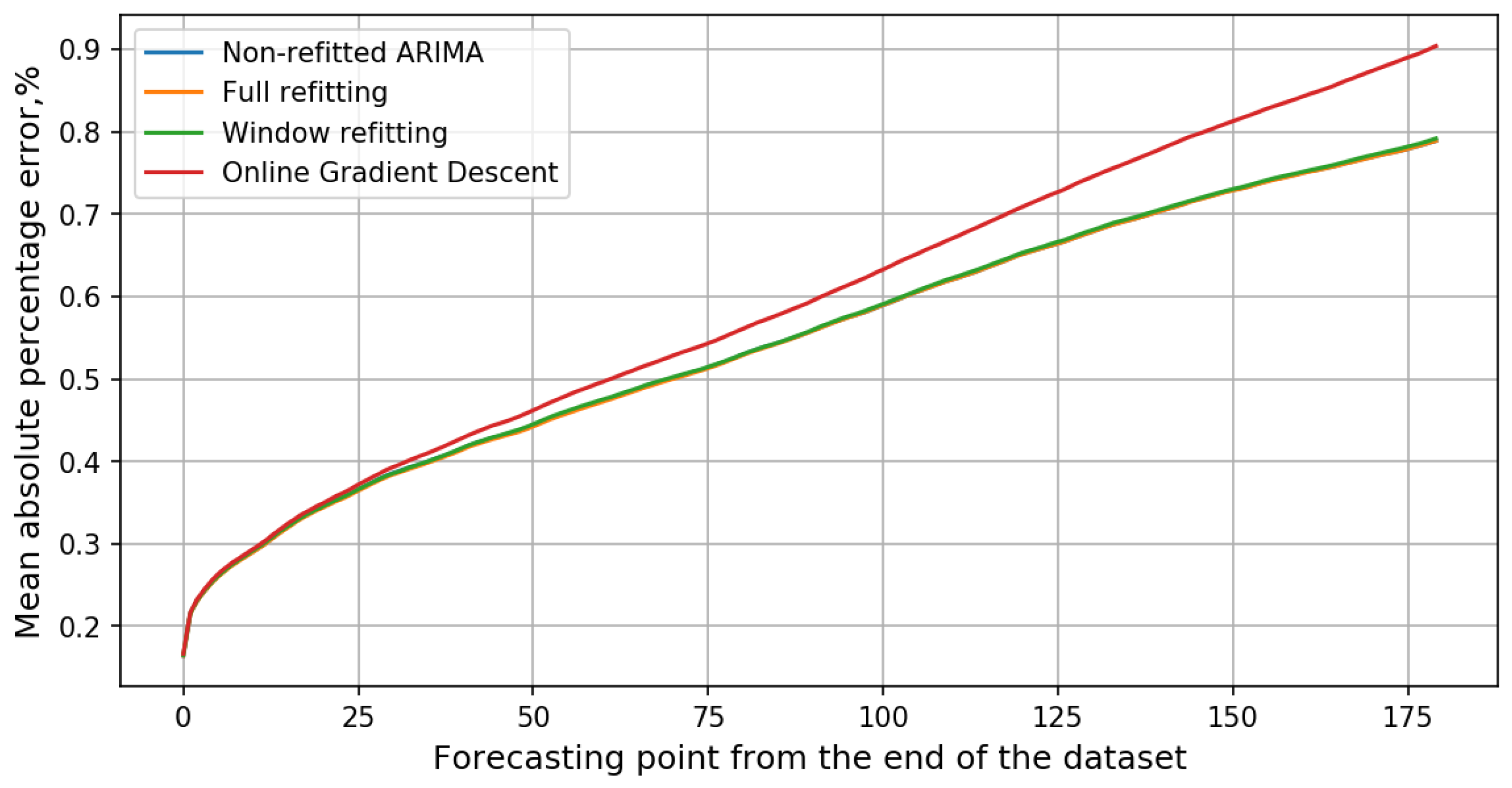
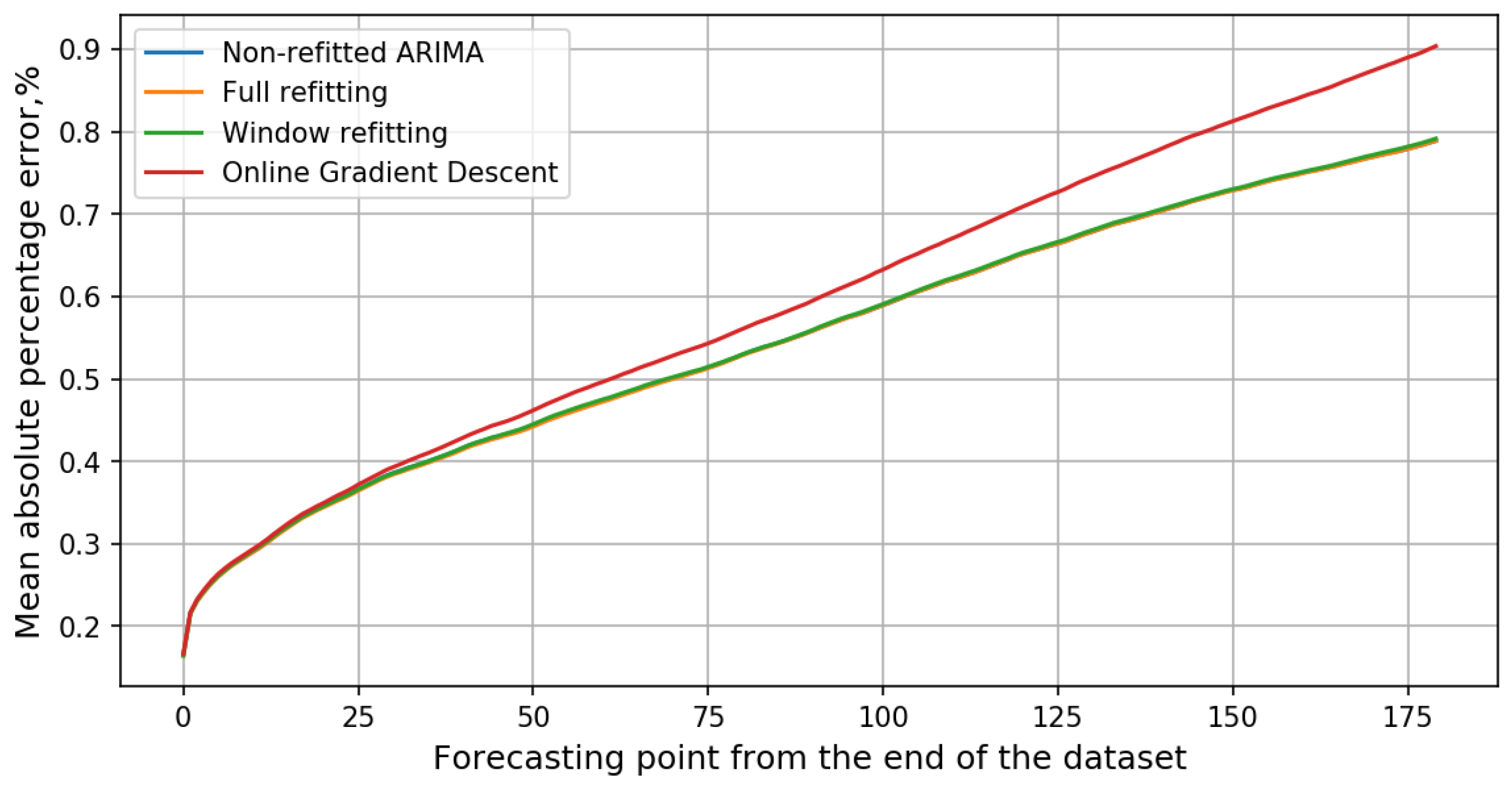
3.1. Forecasting by Online Algorithms
3.2. Anomaly Detection
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmad, S.; Purdy, S. Real-time anomaly detection for streaming analytics. arXiv 2016, arXiv:1607.02480. [Google Scholar]
- Aminikhanghahi, S.; Cook, D.J. A survey of methods for time series change point detection. Knowl. Inf. Syst. 2017, 51, 339–367. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dobre, I.; Alexandru, A.A. Modelling unemployment rate using Box-Jenkins procedure. J. Appl. Quant. Methods 2008, 3, 156–166. [Google Scholar]
- Rahman, M.; Islam, A.H.M.S.; Nadvi, S.Y.M.; Rahman, R.M. Comparative study of ANFIS and ARIMA model for weather forecasting in Dhaka. In Proceedings of the 2013 International Conference on Informatics, Electronics and Vision (ICIEV), Dhaka, Bangladesh, 17–18 May 2013. [Google Scholar] [CrossRef]
- Asteriou, D.; Hall, S.G. Applied Econometrics; Macmillan International Higher Education: London, UK, 2015. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Brockwell, P.J.; Davis, R.A.; Calder, M.V. Introduction to Time Series and Forecasting; Springer: New York, NY, USA, 2002; Volume 2. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications: With R Examples; Springer: New York, NY, USA, 2017. [Google Scholar]
- Lavin, A.; Ahmad, S. Evaluating Real-Time Anomaly Detection Algorithms—The Numenta Anomaly Benchmark. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, F.; Suri-Payer, F.; Gulenko, A.; Wallschlager, M.; Acker, A.; Kao, O. Unsupervised Anomaly Event Detection for Cloud Monitoring Using Online Arima. In Proceedings of the 2018 IEEE/ACM International Conference on Utility and Cloud Computing Companion (UCC Companion), Zurich, Switzerland, 17–20 December 2018. [Google Scholar] [CrossRef]
- Zinkevich, M. Online convex programming and generalized infinitesimal gradient ascent. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 928–936. [Google Scholar]
- Anava, O.; Hazan, E.; Mannor, S.; Shamir, O. Online Learning for Time Series Prediction. arXiv 2013, arXiv:1302.6927v1. [Google Scholar]
- Chen, Q.; Guan, T.; Yun, L.; Li, R.; Recknagel, F. Online forecasting chlorophyll a concentrations by an auto-regressive integrated moving average model: Feasibilities and potentials. Harmful Algae 2015, 43, 58–65. [Google Scholar] [CrossRef]
- Leithon, J.; Lim, T.J.; Sun, S. Renewable energy management in cellular networks: An online strategy based on ARIMA forecasting and a Markov chain model. In Proceedings of the 2016 IEEE Wireless Communications and Networking Conference, Doha, Qatar, 3–6 April 2016. [Google Scholar] [CrossRef]
- Yao, L.; Su, L.; Li, Q.; Li, Y.; Ma, F.; Gao, J.; Zhang, A. Online Truth Discovery on Time Series Data. In Proceedings of the 2018 SIAM International Conference on Data Mining; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2018; pp. 162–170. [Google Scholar] [CrossRef] [Green Version]
- Anava, O.; Hazan, E.; Zeevi, A. Online time series prediction with missing data. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2191–2199. [Google Scholar]
- Giraud, C.; Roueff, F.; Sanchez-Perez, A. Aggregation of predictors for nonstationary sub-linear processes and online adaptive forecasting of time varying autoregressive processes. Ann. Stat. 2015, 43, 2412–2450. [Google Scholar] [CrossRef]
- Enqvist, P. A convex optimization approach to n, m (ARMA) model design from covariance and cepstral data. SIAM J. Control Optim. 2004, 43, 1011–1036. [Google Scholar] [CrossRef]
- Vasiliev, F. Optimization Methods. Second Book; Factorial Press: Moscow, Russia, 2017. [Google Scholar]
- USSR State Committee for Product Quality and Standards Management; Ministry of Automotive and Agricultural Engineering of the USSR; USSR Academy of Sciences; Ministry of Higher and Secondary Education of the RSFSR; State Commission of the Council of Ministers of the USSR for food purchases. Technical Diagnostics. Terms and Definitions. GOST 20911-89; Interstate Standard: Moscow, Russia, 1991. [Google Scholar]
- Yaacob, A.H.; Tan, I.K.; Chien, S.F.; Tan, H.K. ARIMA Based Network Anomaly Detection. In Proceedings of the 2010 Second International Conference on Communication Software and Networks, Bangalore, India, 5–9 January 2010. [Google Scholar] [CrossRef]
- Krishnamurthy, B.; Sen, S.; Zhang, Y.; Chen, Y. Sketch-based change detection: Methods, evaluation, and applications. In Proceedings of the 3rd ACM SIGCOMM Conference on Internet Measurement, Miami Beach, FL, USA, 27–29 October 2003; pp. 234–247. [Google Scholar]
- Ishimtsev, V.; Nazarov, I.; Bernstein, A.; Burnaev, E. Conformal k-NN Anomaly Detector for Univariate Data Streams. arXiv 2017, arXiv:1706.03412v1. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Metric | ||||
|---|---|---|---|---|
| Standard | 1.0 | −0.11 | 1.0 | −1.0 |
| LowFP | 1.0 | −0.22 | 1.0 | −1.0 |
| LowFN | 1.0 | −0.11 | 1.0 | −2.0 |
| Algorithm | MAPE, % | Training | |||
|---|---|---|---|---|---|
| 1 Point | 30 Points | 60 Points | 180 Points | Time Ratio | |
| Non-refitted ARIMA | 0.1642 | 0.3828 | 0.4713 | 0.7886 | 0.00 |
| Full refitting | 0.1644 | 0.3808 | 0.4698 | 0.7887 | 205.24 |
| Window refitting | 0.165 | 0.3823 | 0.4725 | 0.7914 | 16.04 |
| Online gradient descent | 0.1667 | 0.3895 | 0.4936 | 0.9036 | 1.00 |
| Detector | Standard Profile | Reward Low FP | Reward Low FN |
|---|---|---|---|
| Perfect | 100.0 | 100.0 | 100.0 |
| Numenta HTM | 70.5–69.7 | 62.6–61.7 | 75.2–74.2 |
| CAD OSE | 69.9 | 67.0 | 73.2 |
| ARIMA AD algorithm with complex metric * | 65.03 | 48.11 | 71.23 |
| earthgecko Skyline | 58.2 | 46.2 | 63.9 |
| KNN CAD | 58.0 | 43.4 | 64.8 |
| One point prediction * | 56.76 | 25.61 | 67.44 |
| Relative Entropy | 54.6 | 47.6 | 58.8 |
| ARIMA AD algorithm with mean of max/std metric * | 53.66 | 34.20 | 60.48 |
| ARIMA AD algorithm with max of absolute value metric * | 51.11 | 29.05 | 59.07 |
| Random Cut Forest | 51.7 | 38.4 | 59.7 |
| Twitter ADVec v1.0.0 | 47.1 | 33.6 | 53.5 |
| Windowed Gaussian | 39.6 | 20.9 | 47.4 |
| Etsy Skyline | 35.7 | 27.1 | 44.5 |
| ARIMA AD algorithm with Euclidean norm metric * | 18.57 | 13.75 | 21.00 |
| Bayesian Changepoint | 17.7 | 3.2 | 32.2 |
| EXPoSE | 16.4 | 3.2 | 26.9 |
| Random | 11.0 | 1.2 | 19.5 |
| Null | 0.0 | 0.0 | 0.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kozitsin, V.; Katser, I.; Lakontsev, D. Online Forecasting and Anomaly Detection Based on the ARIMA Model. Appl. Sci. 2021, 11, 3194. https://doi.org/10.3390/app11073194
Kozitsin V, Katser I, Lakontsev D. Online Forecasting and Anomaly Detection Based on the ARIMA Model. Applied Sciences. 2021; 11(7):3194. https://doi.org/10.3390/app11073194
Chicago/Turabian StyleKozitsin, Viacheslav, Iurii Katser, and Dmitry Lakontsev. 2021. "Online Forecasting and Anomaly Detection Based on the ARIMA Model" Applied Sciences 11, no. 7: 3194. https://doi.org/10.3390/app11073194
APA StyleKozitsin, V., Katser, I., & Lakontsev, D. (2021). Online Forecasting and Anomaly Detection Based on the ARIMA Model. Applied Sciences, 11(7), 3194. https://doi.org/10.3390/app11073194