Performance Evaluation Metrics for Multi-Objective Evolutionary Algorithms in Search-Based Software Engineering: Systematic Literature Review




Abstract
1. Introduction
2. Related Work
3. Research Methodology
3.1. Research Questions
3.2. The Search Strategy
- IEEExplore
- Scopus
- Web of Science
- Science Direct
3.3. Study Selection
- The study must be related to the topic (SBSE) and must use multi-objective or many-objective methods.
- The study must be written in the English language.
- The study must be available online and in electronic format.
- Studies not related to SBSE;
- Thesis, tutorials, book chapters, editorials;
- Not written in the English language;
- Not available online.
3.4. Data Extraction Process
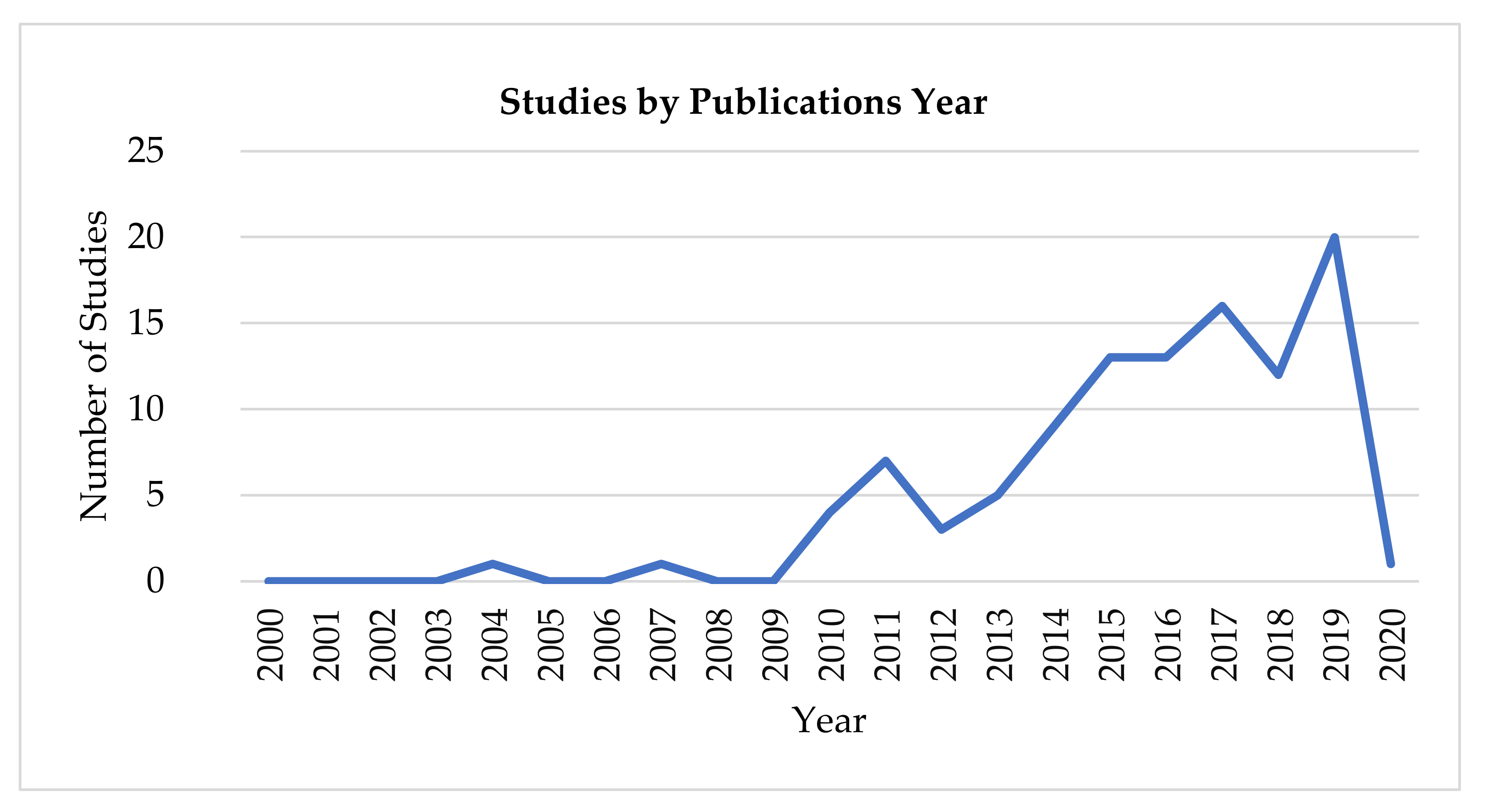
4. Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Harman, M.; Jones, B.F. Search-based software engineering. Inf. Softw. Technol. 2001, 43, 833–839. [Google Scholar] [CrossRef]
- Harman, M.; Mansouri, S.A.; Zhang, Y. Search-based software engineering: Trends, techniques and applications. ACM Comput. Surv. (CSUR) 2012, 45, 2379787. [Google Scholar] [CrossRef]
- Fleck, M.; Troya, J.; Kessentini, M.; Wimmer, M.; Alkhazi, B. Model transformation modularization as a many-objective optimization problem. IEEE Trans. Softw. Eng. 2017, 43, 1009–1032. [Google Scholar] [CrossRef]
- Harman, M. The Current State and Future of Search Based Software Engineering. In Proceedings of the Future of Software Engineering (FOSE’07), Minneapolis, MN, USA, 23–25 May 2007; pp. 342–357. [Google Scholar]
- Tian, Y.; Cheng, R.; Zhang, X.; Cheng, F.; Jin, Y. An indicator-based multiobjective evolutionary algorithm with reference point adaptation for better versatility. IEEE Trans. Evol. Comput. 2017, 22, 609–622. [Google Scholar] [CrossRef]
- Geng, J.; Ying, S.; Jia, X.; Zhang, T.; Liu, X.; Guo, L.; Xuan, J. Supporting Many-Objective Software Requirements Decision: An Exploratory Study on the Next Release Problem. IEEE Access 2018, 6, 60547–60558. [Google Scholar] [CrossRef]
- Gonsalves, T.; Itoh, K. Multi-Objective Optimization for Software Development Projects. In Proceedings of the International Multiconference of Engineers and Computer Scientist 2010, Hong Kong, China, 17–19 March 2010; Lecture Notes in Engineering and Computer Science. pp. 1–6. [Google Scholar]
- Okabe, T.; Jin, Y.; Sendhoff, B. A Critical Survey of Performance Indices for Multi-Objective Optimization. In Proceedings of the 2003 Congress on Evolutionary Computation, 2003 (CEC’03), Canberra, Australia, 8–12 December 2003; Volume 2, pp. 878–885. [Google Scholar]
- Ravber, M.; Mernik, M.; Črepinšek, M. The impact of quality indicators on the rating of multi-objective evolutionary algorithms. Appl. Softw. Comput. 2017, 55, 265–275. [Google Scholar] [CrossRef]
- Li, M.; Yang, S.; Liu, X. Diversity comparison of Pareto front approximations in many-objective optimization. IEEE Trans. Cybern. 2014, 44, 2568–2584. [Google Scholar] [CrossRef]
- Deb, K. Multi-Objective Optimization Using Evolutionary Algorithms; Wiley: Chichester, UK, 2001. [Google Scholar]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Jiang, S.; Ong, Y.S.; Zhang, J.; Feng, L. Consistencies and contradictions of performance metrics in multiobjective optimization. IEEE Trans. Cybern. 2014, 44, 2391–2404. [Google Scholar] [CrossRef]
- Riquelme, N.; von Lücken, C.; Baran, B. Performance Metrics in Multi-Objective Optimization. In Proceedings of the 2015 Latin American Computing Conference (CLEI), Arequipa, Peru, 19–23 October 2015; pp. 1–11. [Google Scholar]
- Yen, G.G.; He, Z. Performance metric ensemble for multiobjective evolutionary algorithms. IEEE Trans. Evol. Comput. 2013, 18, 131–144. [Google Scholar] [CrossRef]
- Cardona, J.G.F.; Coello, C.A.C. A Multi-Objective Evolutionary Hyper-Heuristic Based on Multiple Indicator-Based Density Estimators. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018; pp. 633–640. [Google Scholar]
- Chen, T.; Li, M.; Yao, X. How to Evaluate Solutions in Pareto-based Search-Based Software Engineering? A Critical Review and Methodological Guidance. arXiv 2020, arXiv:2002.09040. [Google Scholar]
- Ramirez, A.; Romero, J.R.; Ventura, S. A survey of many-objective optimisation in search-based software engineering. J. Syst. Softw. 2019, 149, 382–395. [Google Scholar] [CrossRef]
- Sayyad, A.S.; Ammar, H. Pareto-Optimal Search-Based Software Engineering (POSBSE): A literature survey. In Proceedings of the 2013 2nd International Workshop on Realizing Artificial Intelligence Synergies in Software Engineering (RAISE), San Francisco, CA, USA, 25–26 May 2013; pp. 21–27. [Google Scholar]
- Colanzi, T.E.; Vergilio, S.R.; Assunção, W.K.G.; Pozo, A. Search based software engineering: Review and analysis of the field in Brazil. J. Syst. Softw. 2013, 86, 970–984. [Google Scholar] [CrossRef]
- Assunção, W.K.; de Barros, M.O.; Colanzi, T.E.; Neto, A.C.D.; Paixão, M.H.; de Souza, J.T.; Vergilio, S.R. A mapping study of the Brazilian SBSE community. J. Softw. Eng. Res. Dev. 2014, 2, 3. [Google Scholar] [CrossRef]
- Rezende, A.V.; Silva, L.; Britto, A.; Amaral, R. Software project scheduling problem in the context of search-based software engineering: A systematic review. J. Syst. Softw. 2019, 155, 43–56. [Google Scholar] [CrossRef]
- Silva, R.A.; de Souza, S.D.R.S.; de Souza, P.S.L. A systematic review on search based mutation testing. Inf. Softw. Technol. 2017, 81, 19–35. [Google Scholar] [CrossRef]
- Khari, M.; Kumar, P. An extensive evaluation of search-based software testing: A review. Soft Comput. 2019, 23, 1933–1946. [Google Scholar] [CrossRef]
- McMinn, P. Search-Based Software Testing: Past, Present and Future. In Proceedings of the 2011 IEEE 4th Int. Conference Software Testing, Verification and Validation Workshops, Berlin, Germany, 21–25 March 2011; pp. 153–163. [Google Scholar]
- Herrejon, R.E.L.; Linsbauer, L.; Egyed, A. A systematic mapping study of search-based software engineering for software product lines. Inf. Softw. Technol. 2015, 61, 33–51. [Google Scholar] [CrossRef]
- Malhotra, R.; Khanna, M.; Raje, R.R. On the application of search-based techniques for software engineering predictive modeling: A systematic review and future directions. Swarm Evol. Comput. 2017, 32, 85–109. [Google Scholar] [CrossRef]
- Pitangueira, A.M.; Maciel, R.S.P.; Barros, M. Software requirements selection and prioritization using SBSE approaches: A systematic review and mapping of the literature. J. Syst. Softw. 2015, 103, 267–280. [Google Scholar] [CrossRef]
- Mariani, T.; Vergilio, S.R. A systematic review on search-based refactoring. Inf. Softw. Technol. 2017, 83, 14–34. [Google Scholar] [CrossRef]
- Afzal, W.; Torkar, R.; Feldt, R. A systematic review of search-based testing for non-functional system properties. Inf. Softw. Technol. 2009, 51, 957–976. [Google Scholar] [CrossRef]
- Souza, J.; Araújo, A.A.; Saraiva, R.; Soares, P.; Maia, C. A Preliminary Systematic Mapping Study of Human Competitiveness of SBSE. In Proceedings of the International Symposium on Search Based Software Engineering, Montpellier, France, 8–9 September 2018; pp. 131–146. [Google Scholar]
- Ramirez, A.; Romero, J.R.; Simons, C.L. A systematic review of interaction in search-based software engineering. IEEE Trans. Softw. Eng. 2018, 45, 760–781. [Google Scholar] [CrossRef]
- Peixoto, D.C.C.; Mateus, G.R.; Resende, R.F. Evaluation of the Search-Based Optimization Techniques to Schedule and Staff Software Projects: A Systematic Literature Review. Available online: https://homepages.dcc.ufmg.br/~cascini/cascini_paper_SBSE.pdf (accessed on 15 December 2019).
- Li, M.; Yao, X. Quality evaluation of solution sets in multiobjective optimisation: A survey. ACM Comput. Surv. (CSUR) 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Laszczyk, M.; Myszkowski, P.B. Survey of quality measures for multi-objective optimization. Construction of complemen-tary set of multi-objective quality measures. Swarm Evol. Comput. 2019, 48, 109–133. [Google Scholar] [CrossRef]
- Audet, C.; Bigeon, J.; Cartier, D.; le Digabel, S.; Salomon, L. Performance indicators in multiobjective optimization. Optim. Online 2018, 8, 546. [Google Scholar]
- Zitzler, E.; Thiele, L.; Laumanns, M.; Fonseca, C.M.; da Fonseca, V.G. Performance assessment of multiobjective optimizers: An analysis and review. IEEE Trans. Evol. Comput. 2003, 7, 117–132. [Google Scholar] [CrossRef]
- Wang, S.; Ali, S.; Yue, T.; Li, Y.; Liaaen, M. A Practical Guide to Select Quality Indicators for Assessing Pareto-Based Search Algorithms in Search-Based Software Engineering. In Proceedings of the 38th International Conference on Software Engi-neering, Austin, TX, USA, 14–16 May 2016; pp. 631–642. [Google Scholar]
- Liefooghe, A.; Derbel, B. A Correlation Analysis of Set Quality Indicator Values in Multiobjective Optimization. In Proceedings of the Genetic and Evolutionary Computation Conference 2016, Denver, CO, USA, 20–24 July 2016; pp. 581–588. [Google Scholar]
- Knowles, J.; Corne, D. On Metrics for Comparing Nondominated Sets. In Proceedings of the 2002 Congress on Evolutionary Computation, CEC’02, Honolulu, HI, USA, 12–17 May 2002; pp. 711–716. [Google Scholar]
- Kosar, T.; Bohra, S.; Mernik, M. A systematic mapping study driven by the margin of error. J. Syst. Softw. 2018, 144, 439–449. [Google Scholar] [CrossRef]
- Kitchenham, B.A.; Budgen, D.; Brereton, O.P. Using mapping studies as the basis for further research–A participant-observer case study. Inf. Softw. Technol. 2011, 53, 638–651. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, O.P.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic literature reviews in software en-gineering–a systematic literature review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Ferreira, T.N.; Vergilio, S.R.; de Souza, J.T. Incorporating user preferences in search-based software engineering: A systematic mapping study. Inf. Softw. Technol. 2017, 90, 55–69. [Google Scholar] [CrossRef]
- Saeed, A.; Hamid, S.H.A.; Mustafa, M.B. The experimental applications of search-based techniques for model-based testing: Taxonomy and systematic literature review. Appl. Soft Comput. 2016, 49, 1094–1117. [Google Scholar] [CrossRef]
- Herrejon, R.E.L.; Ferrer, J.; Chicano, F.; Egyed, A.; Alba, E. Comparative Analysis of Classical Multi-Objective Evolutionary Algorithms and Seeding Strategies for Pairwise Testing of Software Product Lines. In Proceedings of the 2014 IEEE Con-gress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 387–396. [Google Scholar]
- Praditwong, K.; Harman, M.; Yao, X. Software module clustering as a multi-objective search problem. IEEE Trans. Softw. Eng. 2010, 37, 264–282. [Google Scholar] [CrossRef]
- Khoshgoftaar, T.M.; Liu, Y.; Seliya, N. A multiobjective module-order model for software quality enhancement. IEEE Trans. Evol. Comput. 2004, 8, 593–608. [Google Scholar] [CrossRef]
- Khoshgoftaar, T.M.; Liu, Y. A multi-objective software quality classification model using genetic programming. IEEE Trans. Reliab. 2007, 56, 237–245. [Google Scholar] [CrossRef]
- Nguyen, M.L.; Hui, S.C.; Fong, A.C. Large-scale multiobjective static test generation for web-based testing with integer programming. IEEE Trans. Learn. Tech. 2012, 6, 46–59. [Google Scholar] [CrossRef]
- Paixao, M.; Harman, M.; Zhang, Y.; Yu, Y. An empirical study of cohesion and coupling: Balancing optimization and disruption. IEEE Trans. Evol. Comput. 2017, 22, 394–414. [Google Scholar] [CrossRef]
- Bushehrian, O. Dependable composition of transactional web services using fault-tolerance patterns and service scheduling. IET Softw. 2017, 11, 338–346. [Google Scholar] [CrossRef]
- Rathee, A.; Chhabra, J.K. A multi-objective search based approach to identify reusable software components. J. Comput. Lang. 2019, 52, 26–43. [Google Scholar] [CrossRef]
- Chhabra, J.K. Search-Based Object-Oriented Software Re-Structuring with Structural Coupling Strength. In Proceedings of the Procedia Computer Science, Bangalore, India, 21–23 August 2015; Volume 54, pp. 380–389. [Google Scholar]
- Kessentini, W.; Sahraoui, H.; Wimmer, M. Automated metamodel/model co-evolution: A search-based approach. Inf. Softw. Technol. 2019, 106, 49–67. [Google Scholar] [CrossRef]
- Chen, X.; Zhao, Y.; Wang, Q.; Yuan, Z. MULTI: Multi-objective effort-aware just-in-time software defect prediction. Inf. Softw. Technol. 2018, 93, 1–13. [Google Scholar] [CrossRef]
- Panichella, A.; Kifetew, F.M.; Tonella, P. A large scale empirical comparison of state-of-the-art search-based test case gener-ators. Inf. Softw. Technol. 2018, 104, 236–256. [Google Scholar] [CrossRef]
- Mohan, M.; Greer, D. Using a many-objective approach to investigate automated refactoring. Inf. Softw. Technol. 2019, 112, 83–101. [Google Scholar] [CrossRef]
- Kumari, A.C.; Srinivas, K. Hyper-heuristic approach for multi-objective software module clustering. J. Syst. Softw. 2016, 117, 384–401. [Google Scholar] [CrossRef]
- Arcuri, A. Test suite generation with the Many Independent Objective (MIO) algorithm. Inf. Softw. Technol. 2018, 104, 195–206. [Google Scholar] [CrossRef]
- Tawosi, V.; Jalili, S.; Hasheminejad, S.M.H. Automated software design using ant colony optimization with semantic network support. J. Syst. Softw. 2015, 109, 1–17. [Google Scholar] [CrossRef]
- Chhabra, J.K. Improving modular structure of software system using structural and lexical dependency. Inf. Softw. Technol. 2017, 82, 96–120. [Google Scholar]
- Chhabra, J.K. Preserving core components of object-oriented packages while maintaining structural quality. In Proceedings of the Procedia Computer Science, Kochi, India, 3–5 December 2014; Volume 46, pp. 833–840. [Google Scholar]
- Langdon, W.B.; Harman, M.; Jia, Y. Efficient multi-objective higher order mutation testing with genetic programming. J. Syst. Softw. 2010, 83, 2416–2430. [Google Scholar] [CrossRef]
- Jalali, N.S.; Izadkhah, H.; Lotfi, S. Multi-objective search-based software modularization: Structural and non-structural fea-tures. Soft Comput. 2019, 23, 11141–11165. [Google Scholar] [CrossRef]
- Khanna, M.; Chaudhary, A.; Toofani, A.; Pawar, A. Performance comparison of multi-objective algorithms for test case pri-oritization during web application testing. Arab. J. Sci. Eng. 2019, 44, 9599–9625. [Google Scholar] [CrossRef]
- Rathee, A.; Chhabra, J.K. Reusability in multimedia softwares using structural and lexical dependencies. Multimed. Tools Appl. 2019, 78, 20065–20086. [Google Scholar] [CrossRef]
- Mansoor, U.; Kessentini, M.; Wimmer, M.; Deb, K. Multi-view refactoring of class and activity diagrams using a mul-ti-objective evolutionary algorithm. Softw. Qual. J. 2017, 25, 473–501. [Google Scholar] [CrossRef]
- White, D.R.; Arcuri, A.; Clark, J.A. Evolutionary improvement of programs. IEEE Trans. Evol. Comput. 2011, 15, 515–538. [Google Scholar] [CrossRef]
- Sabbaghi, A.; Keyvanpour, M.R. A Novel Approach for Combinatorial Test Case Generation Using Multi Objective Optimization. In Proceedings of the 2017 7th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 26–27 October 2017; pp. 411–418. [Google Scholar]
- Whigham, P.A.; Owen, C. Multi-Objective Optimisation, Software Effort Estimation and Linear Models. In Proceedings of the Asia-Pacific Conference on Simulated Evolution and Learning, Dunedin, New Zealand, 15–18 December 2014; pp. 263–273. [Google Scholar]
- Hrubá, V.; Křena, B.; Letko, Z.; Pluháčková, H.; Vojnar, T. Multi-Objective Genetic Optimization for Noise-Based Testing of Concurrent Software. In Proceedings of the International Symposium on Search Based Software Engineering, Fortaleza, Brazil, 26–29 August 2014; pp. 107–122. [Google Scholar]
- Shuaishuai, Y.; Dong, F.; Li, B. Optimal Testing Resource Allocation for Modular Software Systems Based-On Mul-ti-Objective Evolutionary Algorithms with Effective Local Search Strategy. In Proceedings of the IEEE Workshop Memetic Computing (MC), Singapore, Singapore, 16–19 April 2013; pp. 1–8. [Google Scholar]
- Yano, T.; Martins, E.; de Sousa, F.L. A Multi-Objective Evolutionary Algorithm to Obtain Test Cases with Variable Lengths. In Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation, Dublin, Ireland, 12–16 July 2011; pp. 1875–1882. [Google Scholar]
- Panichella, A.; Kifetew, F.M.; Tonella, P. Automated test case generation as a many-objective optimisation problem with dynamic selection of the targets. IEEE Trans. Softw. Eng. 2017, 44, 122–158. [Google Scholar] [CrossRef]
- Yoo, S.; Harman, M.; Ur, S. GPGPU test suite minimisation: Search based software engineering performance improvement using graphics cards. Empir. Softw. Eng. 2013, 18, 550–593. [Google Scholar] [CrossRef]
- Ouni, A.; Kessentini, M.; Sahraoui, H.; Hamdi, M.S. The Use of Development History in Software Refactoring Using a Mul-ti-Objective Evolutionary Algorithm. In Proceedings of the 15th Annual Conference on Genetic and Evolutionary Compu-tation, Amsterdam, The Netherlands, 6–10 July 2013; pp. 1461–1468. [Google Scholar]
- Bibi, N.; Anwar, Z.; Ahsan, A. Comparison of Search-Based Software Engineering Algorithms for Resource Allocation Optimization. J. Intell. Syst. 2016, 25, 629–642. [Google Scholar] [CrossRef]
- Masoud, H.; Jalili, S. A clustering-based model for class responsibility assignment problem in object-oriented analysis. J. Syst. Softw. 2014, 93, 110–131. [Google Scholar] [CrossRef]
- Mukherjee, R.; Patnaik, K.S. Prioritizing JUnit Test Cases Without Coverage Information: An Optimization Heuristics Based Approach. IEEE Access 2019, 7, 78092–78107. [Google Scholar] [CrossRef]
- Shahbazi, A.; Miller, J. Black-box string test case generation through a multi-objective optimization. IEEE Trans. Softw. Eng. 2015, 42, 361–378. [Google Scholar] [CrossRef]
- Marchetto, A.; Islam, M.M.; Asghar, W.; Susi, A.; Scanniello, G. A multi-objective technique to prioritize test cases. IEEE Trans. Softw. Eng. 2015, 42, 918–940. [Google Scholar] [CrossRef]
- Yang, B.; Hu, Y.; Huang, C.Y. An architecture-based multi-objective optimization approach to testing resource allocation. IEEE Trans. Reliab. 2014, 64, 497–515. [Google Scholar] [CrossRef]
- Bian, Y.; Li, Z.; Zhao, R.; Gong, D. Epistasis based aco for regression test case prioritization. IEEE Trans. Emerg. Top. Comput. Intell. 2017, 1, 213–223. [Google Scholar] [CrossRef]
- Zheng, W.; Wu, X.; Cao, S.; Lin, J. MS-guided many-objective evolutionary optimisation for test suite minimisation. IET Softw. 2018, 12, 547–554. [Google Scholar] [CrossRef]
- Wang, Z.; Tang, K.; Yao, X. Multi-objective approaches to optimal testing resource allocation in modular software systems. IEEE Trans. Reliab. 2010, 59, 563–575. [Google Scholar] [CrossRef]
- Lu, H.; Wang, S.; Yue, T.; Nygård, J.F. Automated refactoring of ocl constraints with search. IEEE Trans. Softw. Eng. 2017, 45, 148–170. [Google Scholar] [CrossRef]
- Li, L.; Harman, M.; Wu, F.; Zhang, Y. The value of exact analysis in requirements selection. IEEE Trans. Softw. Eng. 2016, 43, 580–596. [Google Scholar] [CrossRef]
- Ni, C.; Chen, X.; Wu, F.; Shen, Y.; Gu, Q. An empirical study on pareto based multi-objective feature selection for software defect prediction. J. Syst. Softw. 2019, 152, 215–238. [Google Scholar] [CrossRef]
- Ríos, M.Á.D.; Chicano, F.; Alba, E.; del Águila, I.; del Sagrado, J. Efficient anytime algorithms to solve the bi-objective Next Release Problem. J. Syst. Softw. 2019, 156, 217–231. [Google Scholar]
- Parejo, J.A.; Sánchez, A.B.; Segura, S.; Cortés, A.R.; Herrejon, R.E.L.; Egyed, A. Multi-objective test case prioritization in highly configurable systems: A case study. J. Syst. Softw. 2016, 122, 287–310. [Google Scholar] [CrossRef]
- Zhang, M.; Ali, S.; Yue, T. Uncertainty-wise test case generation and minimization for cyber-physical systems. J. Syst. Softw. 2019, 153, 1–21. [Google Scholar] [CrossRef]
- Pradhan, D.; Wang, S.; Yue, T.; Ali, S.; Liaaen, M. Search-based test case implantation for testing untested configurations. Inf. Softw. Technol. 2019, 111, 22–36. [Google Scholar] [CrossRef]
- Ferreira, T.D.N.; Kuk, J.N.; Pozo, A.; Vergilio, S.R. Product Selection Based on Upper Confidence Bound MOEA/D-DRA for Testing Software Product Lines. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 4135–4142. [Google Scholar]
- Li, R.; Etemaadi, R.; Emmerich, M.T.; Chaudron, M.R. An Evolutionary Multiobjective Optimization Approach to Compo-nent-Based Software Architecture Design. In Proceedings of the 2011 IEEE Congress of Evolutionary Computation (CEC), New Orleans, LA, USA, 5–8 June 2011; pp. 432–439. [Google Scholar]
- Xue, Y.; Li, M.; Shepperd, M.; Lauria, S.; Liu, X. A novel aggregation-based dominance for Pareto-based evolutionary algorithms to configure software product lines. Neurocomputing 2019, 364, 32–48. [Google Scholar] [CrossRef]
- Strickler, A.; Lima JA, P.; Vergilio, S.R.; Pozo, A.T. Deriving products for variability test of feature models with a hy-per-heuristic approach. Appl. Soft Comput. 2016, 49, 1232–1242. [Google Scholar] [CrossRef]
- Chhabra, J.K. FP-ABC: Fuzzy-Pareto dominance driven artificial bee colony algorithm for many-objective software module clustering. Comput. Lang. Syst. Struct. 2018, 51, 1–21. [Google Scholar]
- Bouaziz, R.; Lemarchand, L.; Singhoff, F.; Zalila, B.; Jmaiel, M. Efficient Parallel Multi-Objective Optimization for Real-Time Systems Software Design Exploration. In Proceedings of the 27th International Symposium on Rapid System Prototyping: Shortening the Path from Specification to Prototype, Pittsburgh, PA, USA, 6–7 October 2016; pp. 58–64. [Google Scholar]
- Ferrer, J.; Chicano, F.; Alba, E. Evolutionary algorithms for the multi-objective test data generation problem. Softw. Pract. Exp. 2012, 42, 1331–1362. [Google Scholar] [CrossRef]
- Xue, Y.; Zhong, J.; Tan, T.H.; Liu, Y.; Cai, W.; Chen, M.; Sun, J. IBED: Combining IBEA and DE for optimal feature selection in software product line engineering. Appl. Soft Comput. 2016, 49, 1215–1231. [Google Scholar] [CrossRef]
- Krall, J.; Menzies, T.; Davies, M. Gale: Geometric active learning for search-based software engineering. IEEE Trans. Softw. Eng. 2015, 41, 1001–1018. [Google Scholar] [CrossRef]
- Ouni, A.; Kessentini, M.; Sahraoui, H.; Inoue, K.; Hamdi, M.S. Improving multi-objective code-smells correction using de-velopment history. J. Syst. Softw. 2015, 105, 18–39. [Google Scholar] [CrossRef]
- Durillo, J.J.; Zhang, Y.; Alba, E.; Harman, M.; Nebro, A.J. A study of the bi-objective next release problem. Empir. Softw. Eng. 2011, 16, 29–60. [Google Scholar] [CrossRef]
- Amaral, A.; Elias, G. A risk-driven multi-objective evolutionary approach for selecting software requirements. Evol. Intell. 2019, 12, 421–444. [Google Scholar] [CrossRef]
- Kumari, A.C.; Srinivas, K.; Gupta, M.P. Software Requirements Optimization Using Multi-Objective Quantum-Inspired Hy-brid Differential Evolution. In EVOLVE—A Bridge between Probability, Set Oriented Numerics, and Evolutionary Computation II; Springer: Berlin, Germany, 2013; pp. 107–120. [Google Scholar]
- Brasil MM, A.; da Silva TG, N.; de Freitas, F.G.; de Souza, J.T.; Cortes, M.I. A Multiobjective Optimization Approach to the Software Release Planning with Undefined Number of Releases and Interdependent Requirements. In Proceedings of the International Conference on Enterprise Information Systems, Beijing, China, 8–11 June 2011; pp. 300–314. [Google Scholar]
- Guizzo, G.; Vergilio, S.R.; Pozo, A.T.; Fritsche, G.M. A multi-objective and evolutionary hyper-heuristic applied to the inte-gration and test order problem. Appl. Soft Comput. 2017, 56, 331–344. [Google Scholar] [CrossRef]
- Bill, R.; Fleck, M.; Troya, J.; Mayerhofer, T.; Wimmer, M. A local and global tour on MOMoT. Softw. Syst. Model. 2019, 18, 1017–1046. [Google Scholar] [CrossRef]
- Ramirez, A.; Romero, J.R.; Ventura, S. Interactive multi-objective evolutionary optimization of software architectures. Inf. Sci. 2018, 463, 92–109. [Google Scholar] [CrossRef]
- Ramírez, A.; Parejo, J.A.; Romero, J.R.; Segura, S.; Cortés, A.R. Evolutionary composition of QoS-aware web services: A many-objective perspective. Expert Syst. Appl. 2017, 72, 357–370. [Google Scholar] [CrossRef]
- Ramírez, A.; Romero, J.R.; Ventura, S. A comparative study of many-objective evolutionary algorithms for the discovery of software architectures. Empir. Softw. Eng. 2016, 21, 2546–2600. [Google Scholar] [CrossRef]
- Colanzi, T.E.; Vergilio, S.R. A feature-driven crossover operator for multi-objective and evolutionary optimization of product line architectures. J. Syst. Softw. 2016, 121, 126–143. [Google Scholar] [CrossRef]
- Chen, T.; Li, K.; Bahsoon, R.; Yao, X. FEMOSAA: Feature-guided and knee-driven multi-objective optimization for self-adaptive software. ACM Trans. Softw. Eng. Methodol. (TOSEM) 2018, 27, 1–50. [Google Scholar] [CrossRef]
- Mariani, T.; Colanzi, T.E.; Vergilio, S.R. Preserving architectural styles in the search based design of software product line architectures. J. Syst. Softw. 2016, 115, 157–173. [Google Scholar] [CrossRef]
- Pascual, G.G.; Herrejon, R.E.L.; Pinto, M.; Fuentes, L.; Egyed, A. Applying multiobjective evolutionary algorithms to dynamic software product lines for reconfiguring mobile applications. J. Syst. Softw. 2015, 103, 392–411. [Google Scholar] [CrossRef]
- Ferreira, T.N.; Lima, J.A.P.; Strickler, A.; Kuk, J.N.; Vergilio, S.R.; Pozo, A. Hyper-heuristic based product selection for soft-ware product line testing. IEEE Comput. Intell. Mag. 2017, 12, 34–45. [Google Scholar] [CrossRef]
- Pietrantuono, R.; Potena, P.; Pecchia, A.; Rodriguez, D.; Russo, S.; Sanz, L.F. Multiobjective testing resource allocation under uncertainty. IEEE Trans. Evol. Comput. 2017, 22, 347–362. [Google Scholar] [CrossRef]
- Calinescu, R.; Češka, M.; Gerasimou, S.; Kwiatkowska, M.; Paoletti, N. Efficient synthesis of robust models for stochastic systems. J. Syst. Softw. 2018, 143, 140–158. [Google Scholar] [CrossRef]
- Wu, H.; Nie, C.; Kuo, F.C. The optimal testing order in the presence of switching cost. Inf. Softw. Technol. 2016, 80, 57–72. [Google Scholar] [CrossRef]
- Cai, X.; Wei, O.; Huang, Z. Evolutionary approaches for multi-objective next release problem. Comput. Inform. 2012, 31, 847–875. [Google Scholar]
- Chen, J.; Nair, V.; Menzies, T. Beyond evolutionary algorithms for search-based software engineering. Inf. Softw. Technol. 2018, 95, 281–294. [Google Scholar] [CrossRef]
- Assunção, W.K.; Vergilio, S.R.; Herrejon, R.E.L. Automatic extraction of product line architecture and feature models from UML class diagram variants. Inf. Softw. Technol. 2020, 117, 106198. [Google Scholar]
- Jakubovski Filho, H.L.; Ferreira, T.N.; Vergilio, S.R. Preference based multi-objective algorithms applied to the variability testing of software product lines. J. Syst. Softw. 2019, 151, 194–209. [Google Scholar] [CrossRef]
- Panichella, A.; Oliveto, R.; di Penta, M.; de Lucia, A. Improving multi-objective test case selection by injecting diversity in genetic algorithms. IEEE Trans. Softw. Eng. 2014, 41, 358–383. [Google Scholar] [CrossRef]
- Zhang, Y.; Harman, M.; Lim, S.L. Empirical evaluation of search based requirements interaction management. Inf. Softw. Technol. 2013, 55, 126–152. [Google Scholar] [CrossRef]
- Zhang, G.; Su, Z.; Li, M.; Yue, F.; Jiang, J.; Yao, X. Constraint handling in NSGA-II for solving optimal testing resource allocation problems. IEEE Trans. Reliab. 2017, 66, 1193–1212. [Google Scholar] [CrossRef]
- Ouni, A.; Kula, R.G.; Kessentini, M.; Ishio, T.; German, D.M.; Inoue, K. Search-based software library recommendation using multi-objective optimization. Inf. Softw. Technol. 2017, 83, 55–75. [Google Scholar] [CrossRef]
- Sarro, F.; Ferrucci, F.; Harman, M.; Manna, A.; Ren, J. Adaptive multi-objective evolutionary algorithms for overtime planning in software projects. IEEE Trans. Softw. Eng. 2017, 43, 898–917. [Google Scholar] [CrossRef]
- González, J.M.C.; Toledano, M.A.P. Differential evolution with Pareto tournament for the multi-objective next release problem. Appl. Math. Comput. 2015, 252, 1–13. [Google Scholar]
- González, J.M.C.; Toledano, M.A.P.; Navasa, A. Teaching learning based optimization with Pareto tournament for the mul-tiobjective software requirements selection. Eng. Appl. Artif. Intell. 2015, 43, 89–101. [Google Scholar] [CrossRef]
- Mansoor, U.; Kessentini, M.; Langer, P.; Wimmer, M.; Bechikh, S.; Deb, K. MOMM: Multi-objective model merging. J. Syst. Softw. 2015, 103, 423–439. [Google Scholar] [CrossRef]
- Zhang, Y.; Harman, M.; Finkelstein, A.; Mansouri, S.A. Comparing the performance of metaheuristics for the analysis of multi-stakeholder tradeoffs in requirements optimisation. Inf. Softw. Technol. 2011, 53, 761–773. [Google Scholar] [CrossRef]
- Gonzalez, J.M.C.; Toledano, M.A.P.; Navasa, A. Software requirement optimization using a multiobjective swarm intelligence evolutionary algorithm. Knowl. Based Syst. 2015, 83, 105–115. [Google Scholar] [CrossRef]
- Shen, X.N.; Minku, L.L.; Marturi, N.; Guo, Y.N.; Han, Y. A Q-learning-based memetic algorithm for multi-objective dynamic software project scheduling. Inf. Sci. 2018, 428, 1–29. [Google Scholar] [CrossRef]
- Chen, T.; Li, M.; Yao, X. Standing on the shoulders of giants: Seeding search-based multi-objective optimization with prior knowledge for software service composition. Inf. Softw. Technol. 2019, 114, 155–175. [Google Scholar] [CrossRef]
- Kumari, A.C.; Srinivas, K. Comparing the performance of quantum-inspired evolutionary algorithms for the solution of software requirements selection problem. Inf. Softw. Technol. 2016, 76, 31–64. [Google Scholar] [CrossRef]
- Assunção WK, G.; Colanzi, T.E.; Vergilio, S.R.; Pozo, A. A multi-objective optimization approach for the integration and test order problem. Inf. Sci. 2014, 267, 119–139. [Google Scholar] [CrossRef]
- De Souza, L.S.; Prudêncio, R.B.; Barros FD, A. A Hybrid Binary Multi-Objective Particle Swarm Optimization with Local Search for Test Case Selection. In Proceedings of the 2014 Brazilian Conference on Intelligent Systems, Sao Paulo, Brazil, 18–22 October 2014; pp. 414–419. [Google Scholar]
- De Souza, L.S.; Prudêncio, R.B.; Barros, F.D.A. A Comparison Study of Binary Multi-Objective Particle Swarm Optimization Approaches for Test Case Selection. In Proceedings of the 2014 IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 2164–2171. [Google Scholar]
- Shen, X.; Minku, L.L.; Bahsoon, R.; Yao, X. Dynamic software project scheduling through a proactive-rescheduling method. IEEE Trans. Softw. Eng. 2015, 42, 658–686. [Google Scholar] [CrossRef]
- Črepinšek, M.; Ravber, M.; Mernik, M.; Kosar, T. Tuning Multi-Objective Evolutionary Algorithms on Different Sized Problem Sets. Mathematics 2019, 7, 824. [Google Scholar]
- Guo, J.; Liang, J.H.; Shi, K.; Yang, D.; Zhang, J.; Czarnecki, K.; Yu, H. SMTIBEA: A hybrid multi-objective optimization algorithm for configuring large constrained software product lines. Softw. Syst. Model. 2019, 18, 1447–1466. [Google Scholar] [CrossRef]
- De Souza, L.S.; de Miranda, P.B.; Prudencio, R.B.; Barros, F.D.A. A Multi-Objective Particle Swarm Optimization for Test Case Selection Based on Functional Requirements Coverage and Execution Effort. In Proceedings of the 2011 IEEE 23rd Interna-tional Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 7–9 November 2011; pp. 245–252. [Google Scholar]
- Almarimi, N.; Ouni, A.; Bouktif, S.; Mkaouer, M.W.; Kula, R.G.; Saied, M.A. Web service API recommendation for automat-ed mashup creation using multi-objective evolutionary search. Appl. Soft Comput. 2019, 85, 105830. [Google Scholar] [CrossRef]
- Shi, K.; Yu, H.; Guo, J.; Fan, G.; Chen, L.; Yang, X. A Parallel Framework of Combining Satisfiability Modulo Theory with Indicator-Based Evolutionary Algorithm for Configuring Large and Real Software Product Lines. Int. J. Softw. Eng. Knowl. Eng. 2019, 29, 489–513. [Google Scholar] [CrossRef]
- Shi, K.; Yu, H.; Guo, J.; Fan, G.; Yang, X. A parallel portfolio approach to configuration optimization for large software product lines. Softw. Pract. Exp. 2018, 48, 1588–1606. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Query String | Keyword |
|---|---|---|
| Software Engineering | General terms | Software engineering OR software development |
| Software engineering (SE) related terms | Software requirement OR software design OR software modeling OR quality attributes OR software component OR reusable components OR software testing OR test cases OR test cases generation OR test case prioritization OR test specification OR test suite OR software specifications OR software verifications OR model checking OR fault tolerance OR fault localization OR refactoring OR reverse engineering OR object-oriented design OR software development methodology | |
| Search-Based Software Engineering | Multi-objective evolutionary related terms | Multi-criteria optimization OR multi-objective optimization OR multi-objective optimization OR multi-objective optimization algorithms OR multi-objective evolutionary algorithms OR many-objective optimization OR many-objective optimization OR many-objective optimization algorithms OR many-objective evolutionary algorithms OR bi-objective evolutionary algorithm OR bi-objective optimization OR MOEA |
| Performance Metric | General terms | Performance indicator OR performance metrics OR quality indicator |
| No. | Metric | Symbol |
|---|---|---|
| 1 | Hypervolume | HV |
| 2 | Hypervolume ratio | HVR |
| 3 | Hypervolume with R-metric | R-HV |
| 4 | Pareto front size | PFS |
| 5 | Number of non-dominated solutions | NDS |
| 6 | Generalized spread | GS |
| 7 | Error ratio | ER |
| 8 | Inverted generational distance | IGD |
| 9 | Generational distance | GD |
| 10 | R-metric | R2 |
| 11 | Maximum spread | MS |
| 12 | Contribution metric | - |
| 13 | Maximum Pareto front error | MPFE |
| 14 | Hypercube-based diversity metric | - |
| 15 | Spread: Delta measure | ∆ |
| 16 | Convergence metric | CM |
| 17 | Coverage difference | D |
| 18 | Two set coverage | C |
| 19 | Euclidean distance | ED |
| 20 | Epsilon family | ϵ |
| 21 | Spacing | S |
| 22 | Inverted generational distance | IGD+ |
| 23 | Overall nondominated vector generation | ONVG |
| 24 | Percentage | P |
| 25 | Lp-norm-based diversity | Lp-norm |
| 26 | Number of solutions in the region of interest | Proi |
| 27 | Convergence measure | ρ |
| Metrics | Frequency | % |
|---|---|---|
| HV | 54 | 32.1 |
| IGD | 17 | 10.1 |
| GD | 12 | 7.1 |
| Hypercube-based diversity metric | 10 | 6.0 |
| ∆, ϵ, S | 8 | 4.8 |
| NDS, ED | 6 | 3.6 |
| PFS, GS, C | 5 | 3.0 |
| HVR, ER, Contribution metric, CM | 3 | 1.8 |
| MS | 2 | 1.2 |
| R-HV, R2, MPFE, D, IGD+, ONVG, Norm-based, Proi, ρ, γ | 1 | 0.6 |
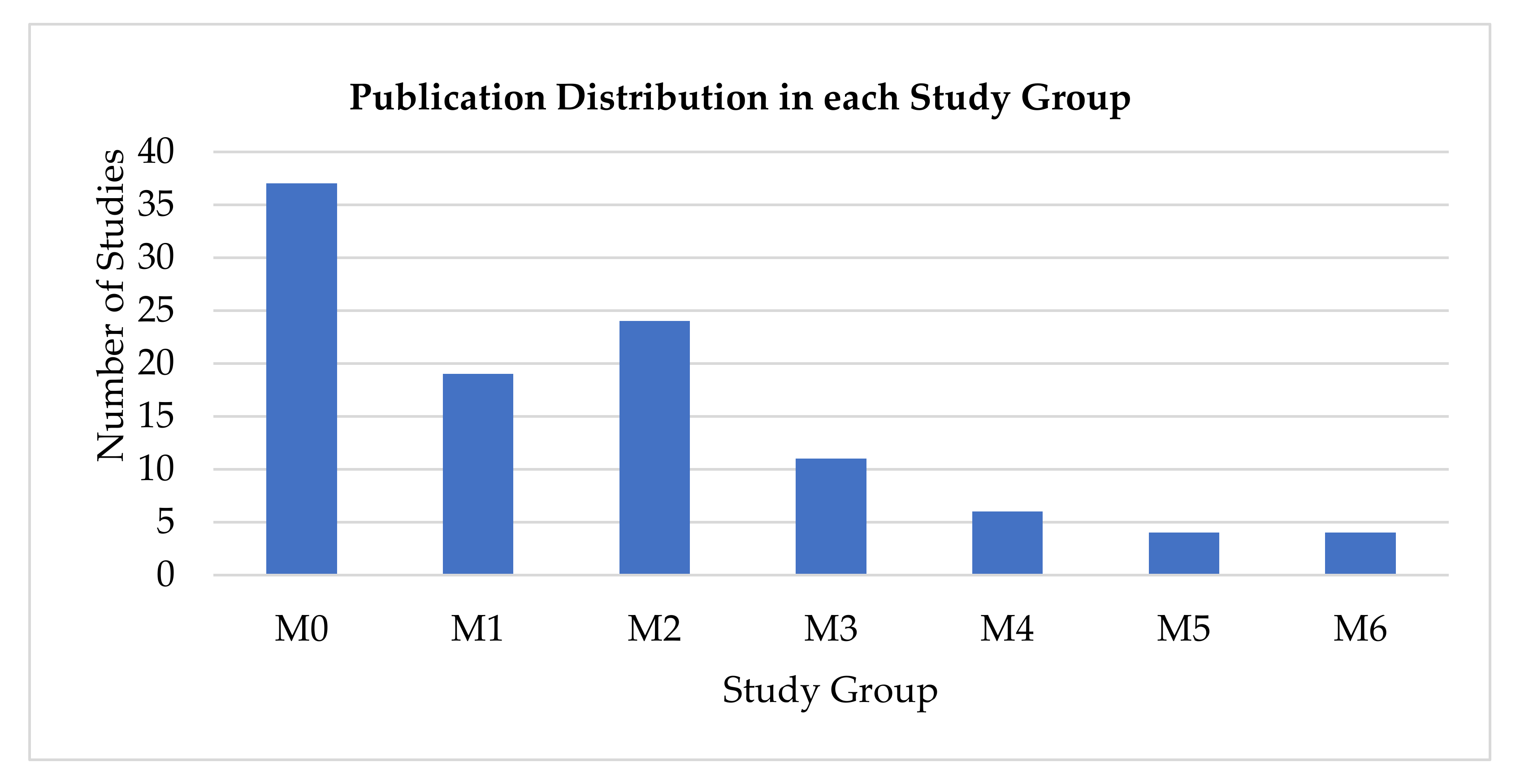
| Study Group | Reference | Total |
|---|---|---|
| M0 | [7,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82] | 37 |
| M1 | [83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101] | 19 |
| M2 | [3,46,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123] | 24 |
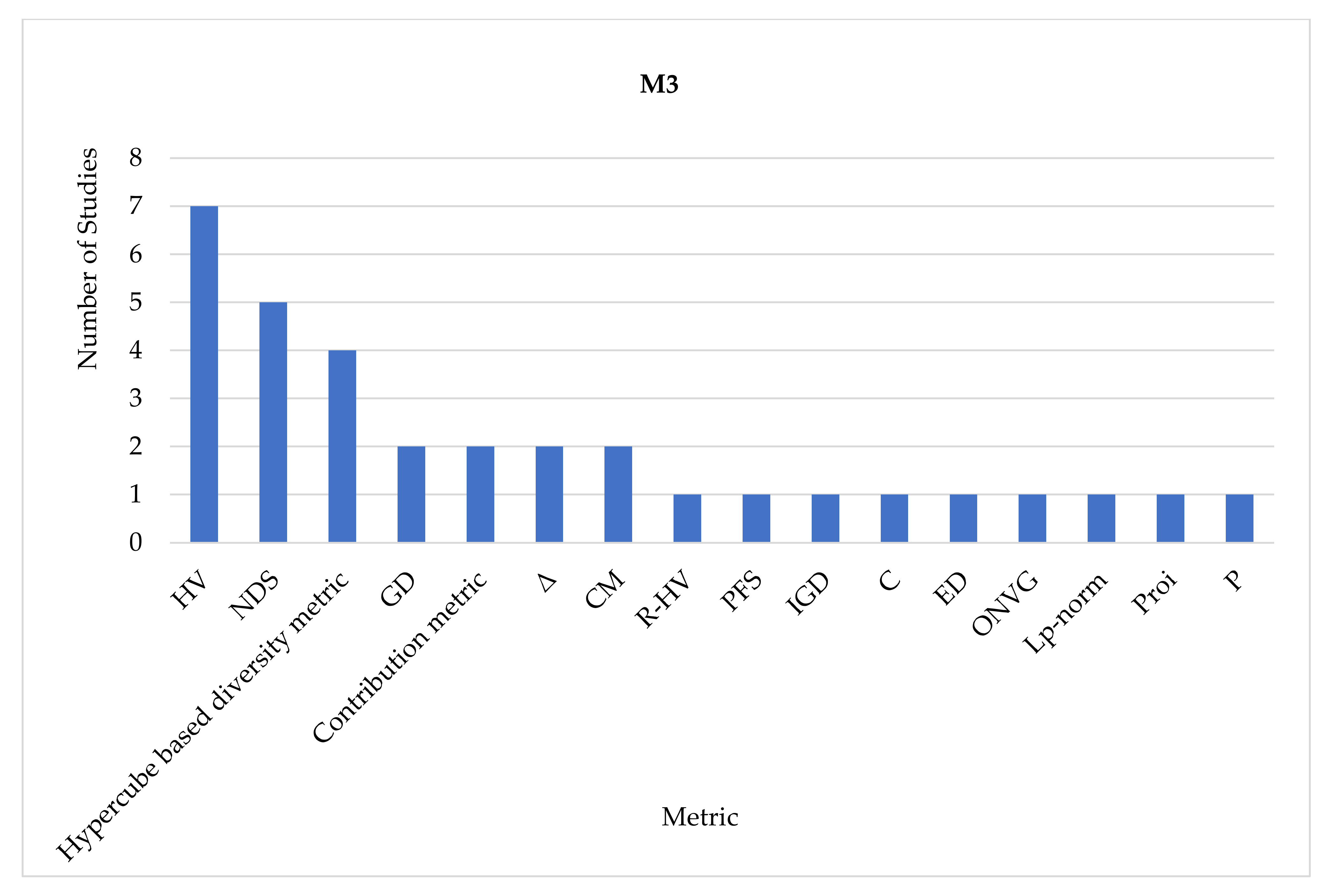
| M3 | [124,125,126,127,128,129,130,131,132,133,134] | 11 |
| M4 | [135,136,137,138,139,140] | 6 |
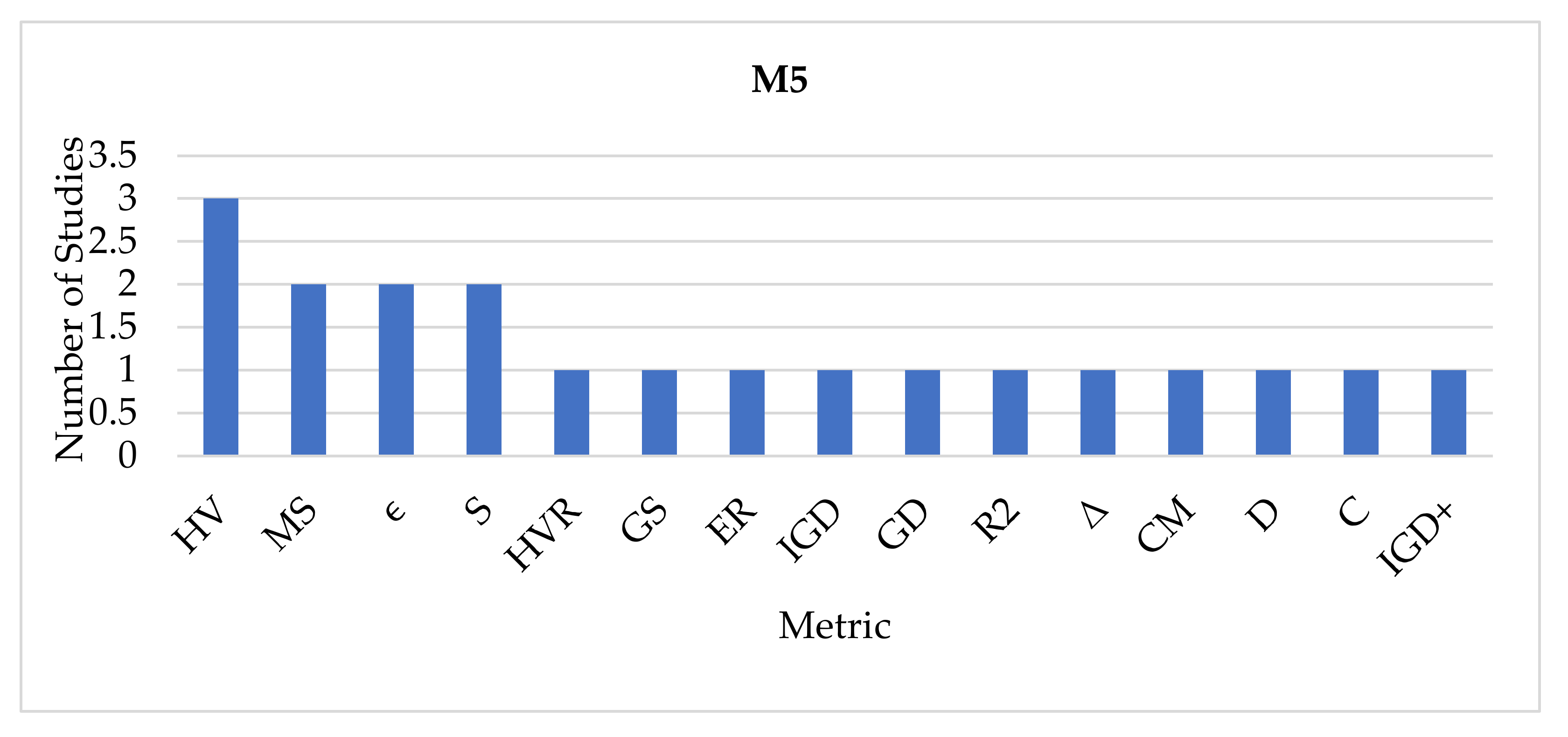
| M5 | [141,142,143,144] | 4 |
| M6 | [6,145,146,147] | 4 |
| Number of Objective | Reference |
|---|---|
| Two Objectives | [7,46,47,50,51,56,57,62,63,64,67,69,72,73,74,76,80,81,84,86,88,89,90,91,95,99,100,104,106,108,109,113,114,115,119,120,121,123,124,125,126,130,131,132,134,137,138,139,140,142,144] |
| Three Objectives | [49,53,55,66,68,70,71,75,76,77,78,82,83,85,86,87,91,94,95,97,102,103,105,107,109,110,116,117,118,122,123,124,125,127,128,129,136,145] |
| Four Objectives | [3,48,52,54,58,60,65,75,79,96,102,108,117,122,133,138,141,146,147] |
| Five Objectives | [6,59,61,93,98,101,109,133,135,143,146,147] |
| Six Objectives | [92] |
| Seven Objectives | [96] |
| Nine Objectives | [111,112] |
| Metrics | References |
|---|---|
| Management | [7,49,56,71,78,89,102,122,128,129,135,141] |
| Requirements | [6,69,88,90,96,101,104,105,106,107,116,121,126,130,131,133,134,137,143,146,147] |
| Design | [3,47,48,51,52,53,54,55,58,59,61,62,63,65,67,68,77,79,87,95,98,99,103,109,110,111,112,113,114,115,123,132,136,145] |
| Testing | [46,50,57,60,64,66,70,72,73,74,75,76,80,81,82,83,84,85,86,91,92,93,94,97,100,108,117,118,120,124,125,127,138,139,140,142,144] |
| Verification | [119] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nuh, J.A.; Koh, T.W.; Baharom, S.; Osman, M.H.; Kew, S.N. Performance Evaluation Metrics for Multi-Objective Evolutionary Algorithms in Search-Based Software Engineering: Systematic Literature Review. Appl. Sci. 2021, 11, 3117. https://doi.org/10.3390/app11073117
Nuh JA, Koh TW, Baharom S, Osman MH, Kew SN. Performance Evaluation Metrics for Multi-Objective Evolutionary Algorithms in Search-Based Software Engineering: Systematic Literature Review. Applied Sciences. 2021; 11(7):3117. https://doi.org/10.3390/app11073117
Chicago/Turabian StyleNuh, Jamal Abdullahi, Tieng Wei Koh, Salmi Baharom, Mohd Hafeez Osman, and Si Na Kew. 2021. "Performance Evaluation Metrics for Multi-Objective Evolutionary Algorithms in Search-Based Software Engineering: Systematic Literature Review" Applied Sciences 11, no. 7: 3117. https://doi.org/10.3390/app11073117
APA StyleNuh, J. A., Koh, T. W., Baharom, S., Osman, M. H., & Kew, S. N. (2021). Performance Evaluation Metrics for Multi-Objective Evolutionary Algorithms in Search-Based Software Engineering: Systematic Literature Review. Applied Sciences, 11(7), 3117. https://doi.org/10.3390/app11073117