Abstract
The detection and localization of faults plays a huge role in every electric power system, be it a transmission network (TN) or a distribution network (DN), as it ensures quick power restoration and thus enhances the system’s reliability and availability. In this paper, a framework that supports phasor measurement unit (PMU)-based fault detection and localization is presented. Besides making the process of fault detecting, localizing and reporting to the control center fully automated, the aim was to make the framework viable also for DNs, which normally do not have dedicated fiber-optic connectivity at their disposal. The quality of service (QoS) for PMU data transmission, using the widespread long-term evolution (LTE) technology, was evaluated and the conclusions of the evaluation were used in the development of the proposed edge-cloud framework. The main advantages of the proposed framework can be summarized as: (a) fault detection is performed at the edge nodes, thus bypassing communication delay and availability issues, (b) potential packet losses are eliminated by temporally storing data at the edge nodes, (c) since the detection of faults is no longer centralized, but rather takes place locally at the edge, the amount of data transferred to the control center during the steady-state conditions of the network can be significantly reduced.
1. Introduction
Electric power systems (EPSs) have been subject to major modifications in recent years; most notably, the production of electrical energy is shifting from large and centralized power plants (coal, hydro, nuclear based) towards numerous small and geographically dispersed renewable energy sources (RES), such as photovoltaic and wind power plants [1,2]. While such a paradigm shift affects transmission networks (TNs) in terms of lower loading and energy losses, it also imposes some radical changes to distribution networks (DNs). The gradual increase of consumers capable of locally producing energy and injecting it into the network (prosumers), together with an increasing number of installed battery energy storage systems [3], means that passive DNs are turning into active ones. Consequently, the conventionally unidirectional power flow is becoming more and more bi-directional. Another element having a significant impact on DNs is electric vehicles [4], which increase the overall consumption in low voltage grids and compromise the grid’s stability in terms of capacity. Increased consumption by the end consumer needs to be carefully counterbalanced with either a local RES or an overall reinforced infrastructure in order to avoid line congestions. All of the aforementioned changes and emerging inverter-based technologies being introduced into DNs are, on the one hand, able to contribute to the flexibility of the network [4], but can, on the other hand, adversely affect an EPS’s rotor angle, and voltage and frequency stability if integrated inappropriately [5]. In either case, the distribution system operators (DSOs) will need to enhance the infrastructure’s existing monitoring capability in order to efficiently keep track of the grid’s performance, identify possible critical areas, monitor and control two-way power flows, energy consumption and generation, grid topology, etc. [6]. An overview of measurement technologies (power sensor, smart meter, phasor measurement unit, power quality monitor, digital fault recorder etc.) used in DNs is presented in [7] together with a reporting rate of each device.
The necessity for installing additional devices with monitoring, control and protection capabilities in the context of active DNs is clear, whereas the communication solution supporting it is not that straightforward. In contrast to TNs, which are generally equipped with fiber-optic cables, DNs rarely contain any dedicated connectivity infrastructure. Installing and maintaining a wired communication infrastructure would impose a substantial financial burden on DSOs as the measurement locations are placed all the way down to the prosumer level, which is the reason why the usage of the already deployed public cellular networks, such as the widely available long-term evolution (LTE), is usually considered instead [8,9].
The distinction in the available connectivity becomes evident when schemes that are already well established and used in TNs, such as the Wide-Area Monitoring System (WAMS) and the Wide-Area Monitoring, Protection and Control (WAMPAC), are being applied to DNs [10]. It is a common approach in TNs to concentrate the entirety of the data from measuring devices in the control center and process it in a centralized fashion. However, since the backbone of the aforementioned schemes is measuring devices that produce large volumes of data, the most prominent being the phasor measurement unit (PMU), the same approach might not be the best solution for DNs. Instead, public LTE networks seem to provide the most suitable communication infrastructure at present until fifth-generation (5G) networks (currently under deployment) are sufficiently widespread to cover large-scale distributed systems such as TNs and DNs. However, as presented in this paper, the usage of the LTE network instead of fiber-optic cables presents a potential reliability issue for the transmission of data from metering devices to the remote control center and can consequently lead to either unacceptable delays or even the loss of measurements. This, in turn, adversely affects any of the corresponding decision-making or analytical schemes, such as fault detection and fault localization, which are extremely valuable to system operators. The aim of this paper is to propose a hybrid edge-cloud framework that satisfies the delay requirements of time-critical applications, such as demand response, synchro-check, adaptive relaying, out-of-step protection and fault detection, by moving them to the edge whilst leaving the monitoring applications, i.e., WAMS, and computationally demanding applications centralized. Such an approach provides several advantages over a strictly centralized approach: (a) response-critical applications are performed at the edge nodes, thus bypassing delay issues related to sending measurements from the edge device to the control center and the corresponding response back to the edge, (b) potential packet losses are eliminated by storing data at the edge nodes. Ensuring that no data are missing is of paramount importance for heavily data-reliant schemes, (c) applications that are not time-critical, such as the post-mortem investigation of faults, are executed in the cloud. This provides the ability to execute computationally demanding analysis that would have otherwise exceeded the computational capability of the edge device, (d) since the detection of events is no longer centralized, but rather takes place locally at the edge, the amount of data transferred to the control center during the steady-state conditions of the network can be significantly reduced. However, in case of an event, the full resolution of the measurements is still provided to the control center.
The structure of this paper is as follows: In Section 2, we evaluate the quality of service (QoS) for PMU data transmission over LTE and, in contrast to the strictly centralized approach used in TNs, a hybrid edge-cloud computing framework is proposed for DNs with LTE connectivity. Next, as the fault detection and localization is one of the compelling potential applications for the proposed edge-cloud-based computing framework, we provide a brief overview of the fault localization methods in Section 3. The method from [11], which served as the basis for the fault localization algorithm (FLA) applied on the proposed framework, is also presented in more detail in this Section. The distribution network where the proposed framework was implemented and the installed measuring devices required for the FLA are discussed in Section 4. Section 5 provides an in-depth explanation for each component of the proposed framework from the perspective of communication and system integration. Lastly, conclusions are drawn in Section 6.
2. Hybrid Edge-Cloud Approach
2.1. Motivation for the Edge-Cloud Approach
Metering devices that produce large volumes of data are in TNs connected to the control center with dedicated optical communication links, which is a very unrealistic scenario for the majority of DNs. Consequently, for such devices, both latency and reliability [12] of data transmission over LTE need to be tested before implementing any kind of corresponding schemes in DNs. Since the aim of this paper is to establish a functional computing framework for fault localization in DNs based on PMU measurements, the evaluation of the QoS for PMU data transmission over an LTE network is of paramount importance. The requirements for the real-time exchange of synchronized phasor measurement data between power system equipment are defined in the IEC 61850-90-5 standard. The standard specifies the acceptable time delays for communication between the PMU and the phasor data concentrator (PDC) for various applications that can be roughly divided into three categories:
- real-time (time-critical) applications
Applications that require selected signals to be available with only a small delay (order of milliseconds) are found in this category since a prompt response is of paramount importance for their proper operation. Some representatives of this group are synchro-check, adaptive relaying and out-of-step protection.
- near real-time (observability) applications
In this category, we can find applications, such as situational awareness, state estimation and on-line security assessment, which do not provide any remedial actions, but are merely used for visualization purposes. Therefore, the allowed time delay for those applications is a bit higher (order of seconds).
- archiving applications
Archiving applications do not have any time delay requirements as they serve for post-mortem analysis, which is neither real-time nor near real-time. However, those applications face a very strict requirement that the archival process be lossless, i.e., the data measured from PMUs on the system have to be exactly the same as the measurements stored in the archive.
The rest of this subsection is dedicated to the evaluation of the IEC 61850-90-5-defined QoS for an LTE network.
2.1.1. IEC 61850-90-5 Evaluation—Testbed Setup
The testbed used for the evaluation is presented in Figure 1. The PMU emulator was an experimental PMU device with the disabled PMU functionality and an installed DEKRA Performance Test Tool to emulate the network traffic of a PMU. The emulator was connected to the UXM device via a radio frequency (RF) coaxial cable, whereas a secondary data connection to the testbed PC, required for the experiment’s control, was made via the emulator’s Ethernet port and testbed network. The UXM device from Keysight is an LTE base-station emulator device that emulates custom LTE networks with configurable network conditions. For experimental control and sequencing, the Test Automation Platform from Keysight was used and dedicated scripts were written for controlling the emulated PMU and UMX as well as for data recording and the evaluation of experiment. The DEKRA Performance Tool was used as a traffic generator on the emulated PMU and as a calculator of key performance indicators, namely throughput, latency (one-way delay) and packet loss. The performance tool consists of a server and a client and can be configured to emulate various network traffic types or patterns. The Dekra server was run on a testbed PC, whereas the client was run on the simulated PMU.
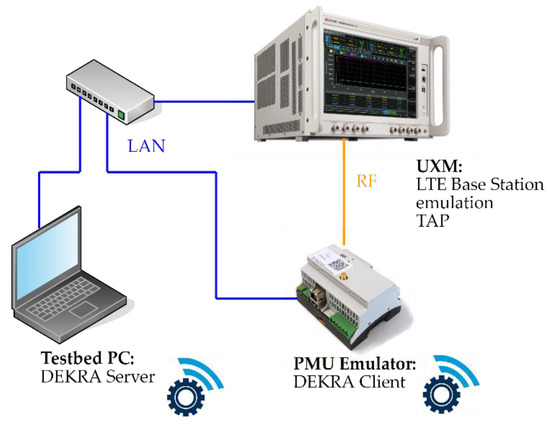
Figure 1.
IEC 61850-90-5 evaluation testbed.
2.1.2. IEC 61850-90-5 Evaluation—Use Case
An urban-pedestrian LTE network scenario was chosen for the use case as it resembles the environment of DNs the closest. The scenario was already predefined by the LTE testbed provider and was further divided into four sub-scenarios that emulated different conditions in an urban environment. The duration of each sub-scenario was set to 30 s since a steady state of the LTE network was emulated and the network stabilized within a few 100 ms after every sub-scenario switch. However, to eliminate any potential sub-scenario’s switching dependency, each of the sub-scenarios was run five times, which resulted in a total test duration of 600 s. The scenario was emulated with a DEKRA data stream of 80 kbit/s and 50 packets/s, which represents a typical PMU configuration with a reporting rate of 50 Hz.
The use case represents the PMU in a synchrophasor mode, where raw measurements of grid voltage and current are used for the calculation of synchrophasors. Those are then wrapped in IEEE C37.118-2018 packets and sent to a concentrator. Since either the transmission control protocol (TCP) or the user datagram protocol (UDP) can be used for sending the results, both protocols were tested with the aforementioned urban-pedestrian network scenario. The main difference between the protocols is that the TCP requires the authentication of the received packets, whereas the UDP does not. Therefore, some packet loss is expected for the UDP protocol, however, the upper limit is not prescribed by the standard. In contrast, no packet loss is expected for the TCP protocol as it inherently handles the loss of packets. However, each lost packet on the underlying network layers will result in increased data transmission latency.
Each of the protocols was tested in terms of packet loss and one-way delay. The C37.244-2013 standard states that the required measurements have to be provided to the time-critical applications within a short delay (between 30 ms and 40 ms). In this paper, we decided to use the lower of the two thresholds in order to give a general assessment of whether the latency requirement for real-time applications is fulfilled or not. However, for a more detailed specification of the various applications’ requirements, we refer the reader to the IEC 61850-90-5 standard.
2.1.3. IEC 61850-90-5 Evaluation—Results
No packet loss or bandwidth reduction was observed using either the TCP or the UDP protocol during the emulated scenario. However, it is worth noting that not all possible interference sources were emulated in the experiment. Therefore, the packet loss, which seemingly presented no problem in the emulation environment, can still become a severe issue for a UDP connection in a real environment since this protocol does not authenticate received packets.
The results for the one-way delay of the use case with the UDP protocol are presented in Figure 2. The solid blue line represents one-way delays for each second of the scenario, whereas the dashed red line represents the threshold for time-critical applications. The slowly increasing one-way delay is the consequence of the non-synchronised clocks in the PMU emulator and the testbed PC. The latter has a much less precise clock requiring a periodic re-synchronization with the PMU emulator indicated in Figure 2 in the period between 340 s and 380 s.
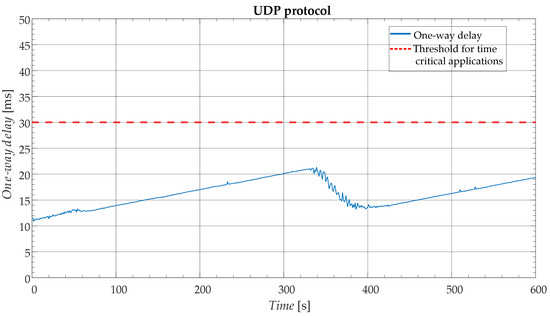
Figure 2.
One-way delay for the user datagram protocol (UDP).
In Figure 3, the results for the TCP connection type in respect to the one-way delay are presented. It is clear that the delay in this case is well above the required threshold. The reason for the much higher delays compared to the UDP connection type lies in the authentication of the received packets. In contrast to the UDP connection type, TCP packets need to be acknowledged by the TCP/IP network layer before they are forwarded to higher processing layers. Although data packets were sent only one way, the underlying TCP/IP layer sent acknowledgement packets in both ways, thus adding to the latency.
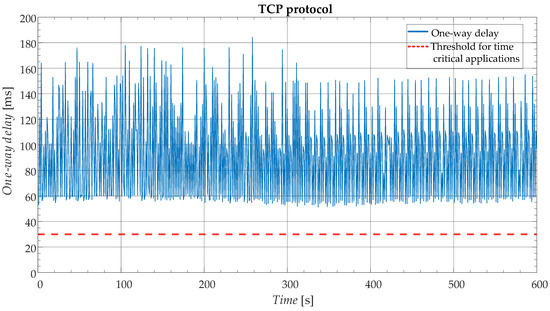
Figure 3.
One-way delay for the transmission control protocol (TCP) protocol.
2.1.4. IEC 61850-90-5 Evaluation—Conclusions
Based on the previous Subsection, it is safe to conclude that in DNs with LTE connectivity, the TCP protocol should not be used for any time-critical scheme/application as it substantially surpasses the latency threshold. In contrast, the UDP connection fulfils the latency requirement, however, it introduces another potential issue—missing data. Naturally, the reliability of applications that are heavily reliant on the corresponding PMU data becomes a great concern in such EPSs. Furthermore, the potential loss of packets contradicts the very purpose of PMUs, which is providing a higher granularity of measurements, capable of providing enhanced insight, in case of events.
We can conclude that a strictly centralized approach of data analysis and storage is not the optimal solution in DNs with LTE connectivity as we cannot simultaneously ensure both the low latency and the reliability of data transmission. An intuitive solution that comes to mind is to keep the monitoring and non-time-critical applications centralized, whilst decentralizing the analysis and decision-making processes of time-critical applications. The approach that decentralizes part of the computational power and relocates it closer to the measuring devices is not new as it was already used in the past to address a different issue, i.e., a huge amount of data that need to be transferred from devices to the control center, and was also adopted by 5G networks currently in the roll-out phase in most countries. The basics of the approach, known as edge-cloud computing, are presented in the next subsection, whereas the specifics of the proposed hybrid edge-cloud framework tailored for the purposes of automated fault localization are presented in Section 5.
2.2. Edge-Cloud Computing
Before the emergence of edge computing, the traditional cloud computing approach was to transfer the entirety of the raw data from metering devices to the cloud-based computing center and deal with computing and storage problems in a centralized manner. In recent years, the massive increase of the Internet of Things (IoT) devices caused the communication network to operate close to the bandwidth limit despite all the improvements in network technologies. This resulted in slower transfer rates and response time, which is a critical requirement for many protection and demand response applications. Consequently, edge computing technologies started to emerge [13], pushing the cloud’s computing and storage capabilities from the data centers to the proximity of data-generation devices at the edge of the network [14], thus reducing the burden on the communication network.
Given that the PMU data transmission over LTE might not be reliable, the edge-cloud approach presents an appealing alternative to the centralized approach used in TNs. The main advantage is that, since the entirety of the PMU data does not need to be sent to the data center anymore, but can rather be stored in a local manner, we completely avoid any potential issues with missing data, i.e., data are stored at the edge and can be retransmitted if necessary. As such, the edge-cloud architecture represents a perfect groundwork for the requirements of the heavily data-reliant fault localization algorithm (FLA).
Furthermore, edge computing also offers the capability to process the data locally and react accordingly. Consequently, the responsiveness of local controllability is improved since the data do not need to be uploaded and processed in the cloud anymore. This is important, since our goal is not to establish a framework capable of executing solely the FLA, but we want to provide a generic framework that will also allow the easy integration of other time-critical applications at the edge in the future when it may also leverage the shared mobile edge computing (MEC) capabilities of 5G networks as an additional intermediary computational level between edge devices and the cloud.
3. Fault Localization Methods
3.1. Introduction
Unexpected outages caused by faults or short circuits due to equipment malfunction, animal contact, weather conditions or even poor vegetation management are a frequent occurrence in EPSs and are the cause of up to 80% of all interruptions in DNs. The ability to swiftly and accurately locate a fault in an EPS can expedite the repair of faulted components, speed up power restoration and thus enhance the system’s reliability and availability. Practices such as investigating a line with a repair crew or locating a fault based on customer calls are time-consuming, outdated and inadequate for today’s demanding needs of power utilities.
Fault detection and localization is a theoretically well-known and developed field, with a variety of applicable methods [15]. Some of them have recently gained momentum due to the significant advancements made in time-precise measurements and communication infrastructure, enabling real-time processing at the edge and performing comprehensive analytics in the cloud. These methods can be roughly divided into three groups:
- impedance-based methods;
- travelling wave methods;
- pattern recognition methods.
Impedance-based methods are characterized by low complexity and offer a fairly accurate performance in the case of grounded systems. Their main disadvantage is the poor performance in isolated and Petersen-coil grounded systems. Additionally, they are highly sensitive to fault resistance and can yield multiple solutions in highly branched networks. Comparative studies of some representative methods are provided in [16,17].
Traveling wave methods offer relatively good accuracy and are not significantly affected by loads, current transformer saturation, fault type and fault resistances. However, they require measurement equipment with a high sampling frequency (in the order of MHz) along with time-precise measurements in order to detect the wave-fronts. Furthermore, most of those methods were developed for the purposes of TNs, which are usually significantly less branched and more homogenous in terms of line properties. In contrast, the heterogeneousness of DNs can manifests in the complex behaviour of the recorded traveling waves, which disables the proper localization of the events. Some representative traveling wave techniques and their application are provided in [18,19,20,21,22].
Pattern recognition methods require large training databases that contain reference fault cases for a given network. On the one hand, these methods do not need complicated formulation, but, on the other hand, very high-quality measurements and long training periods are required. Furthermore, in the case of any modification to the existing system, the entire training process and high computational burden has to be repeated [23,24,25,26,27,28].
3.2. Related Work
It is evident that each group of methods has its specifics in terms of complexity and accuracy, but it is vital to notice that the applicability of the methods also relies on the used measurement equipment. Given that PMUs already represent the backbone of the WAMS and the WAMPAC in TNs and have recently also become widely adopted in DNs in the context of smart grids, we investigated the methods that incorporate PMUs more thoroughly. Several algorithms exploiting synchronized PMU data have already been proposed and are briefly summarized in the following paragraphs.
The research in [29] presents fault detection and faulted line identification with PMU devices installed in each bus of a network. The proposed solution is suitable for both passive and active networks, with a solid-earthed or unearthed neutral, and for low and high impedance faults of any kind. Furthermore, the process was validated with a real-time simulation platform showing the identification of the faulted line, but not also the exact location.
Another approach using a real-time simulator as a means for validating results is presented in [30]. This approach combines several algorithms, depending on the type of occurring fault and network grounding. Additionally, the phasor data concentrator and geographic information system environment are introduced.
The detection of anomalies in grids using optimally placed PMUs was carried out by Jamei et al. [31]. This approach combines data-driven methods as well as criteria resulting from analysing the underlying physical model of a system. Exiting the quasi steady-state regime is exploited to design a key part of the proposed metrics. The optimal placement of PMUs with a limited number of sensors is also discussed in this work.
The generalized fault location algorithm with optimally placed PMUs, suitable for both ring and radial feeders, is presented in [32]. The integration of information available from PMU measurements with the information contained in the distribution feeder database is performed with the aim of fault location identification. The solution is based on the assumption that the network topology, line parameters and load models are all known.
In [33], multiple fault locations are first obtained using the synchro-phasors measured at one terminal. The exact location is determined after by comparing the voltage phasors in the junction nodes of terminals measured from two terminals.
A short circuit theory-based approach is presented in [34] for locating permanent and temporary faults. The refinement scheme allows finding faults not only on buses, but also on branches. In addition to the synchronised phasor approach and the approach using only magnitude measurements, unsynchronized phasors are being used for the first time for fault location purposes.
A study on a fault localization technique applicable to both legacy and modern networks with different distributed generator types is carried out in [35]. A linear least-squares estimator is utilized or a non-linear least-squares problem is solved by the trust-region-reflective algorithm if data is acquired from PMUs or smart meters (SMs), respectively.
Last but not least, the compensation theorem from circuit theory is used for the purposes of localizing events such as faults and power quality events in DNs [11]. The solution is based on measurement differences making its performance robust against constant errors in instrumentation channels, such as errors from voltage and current transformers.
It is important to emphasize that despite the extensive work that had already been undertaken in the field of fault localization, none of the papers (to the best of the authors’ knowledge) deals with the corresponding method’s data acquisition and its reliability. One of the contributions of this paper is ensuring that the premise of the methods, that the required data to perform the localization is reliable and always readily available for use, is actually met in the real environment as well.
3.3. Methodology
In order to exemplify the utility of the edge-cloud framework proposed for the operation in a real LTE-based environment, we selected the method proposed in [11] due to its robustness, low number of required PMUs and previous experience with its implementation in a laboratory environment. However, it is worth noting that any of the methods presented in Section 3.2 could be used with the proposed framework. At this point, it seems reasonable to provide a brief summary of the selected method to acquaint the reader with its main philosophy.
The goal of the method is to estimate the location of events in DNs with as few as two PMUs, utilizing the compensation theorem from circuit theory. It is worth noting that only faults, causing the de-energization of the feeder, are considered as events in this paper, whereas the method itself is sensitive enough to localize events much less severe than faults (as proven in [11]). Either way, the measurements of the networks’ pre-event and post-event steady-state synchro-phasors are used alongside known load profiles, network topology and line parameters to calculate the voltages of every bus as seen from each PMU. Those two sets of voltages are then compared and the bus where the difference is minimal is identified as a source of the event.
Optimal observability of the feeder using just two PMUs is achieved when one of them is installed at the beginning of the main feeder (primary substation) and the other is placed at the end of the feeder (secondary substation). However, it is worth pointing out that in configuration with just two installed PMUs only the faults on the main feeder can be correctly identified. When a fault occurs on a branch that is not part of the main feeder, the bus, from which the lateral stems off, will be identified as faulted instead. In DNs, such localization is usually sufficient since laterals are generally short and the exact localization does not help reduce the fault mitigation time significantly. Nevertheless, if more precise localization was needed, one could achieve it with the introduction of PMUs at the laterals’ ends. The extension of the method for the case with an arbitrary number of PMUs is presented in [36].
To summarize, the main features relevant for the implementation of the FLA on the proposed edge-cloud framework are:
- model-driven method, meaning that the topology and parameters of lines are assumed to be known;
- synchro-phasor measurements of voltages and currents acquired from as few as two PMUs are sufficient for localizing the fault on the main feeder;
- the rest of the information collected from the feeder, such as load consumption, can be in the form of pseudo-measurements from either power quality meters (PQMs) or smart meters (SMs). The term “pseudo-measurement” is used for these devices to emphasize the lower reporting rate compared to the PMU and to highlight that the measurements of PQMs and SMs are not as precisely time-stamped as in the case of a PMU.
4. Electric Power System Description
As the performance of the FLA was already extensively investigated in [11,36], the aim of this paper is not duplicating the results, but rather emphasizing how one can establish a framework capable of a reliable and automated FLA execution in a real DN with LTE connectivity. In this Section, we first present the electric power system and the position of the installed measuring devices required to meet the prerequisites of the FLA, whereas a detailed description of the proposed edge-cloud computing infrastructure implementation is presented in the next Section.
The considered distribution network is a 5.2 kV, 3-phase, low-impedance grounded network located in Spain and operated by Estabanell y Pahisa Energía S.A.U. (EyPESA). It consists of 16 buses (topology is presented in Figure 4) and is composed of both underground cables and overhead lines. The upstream grid has a short-circuit power of 54 MVA.
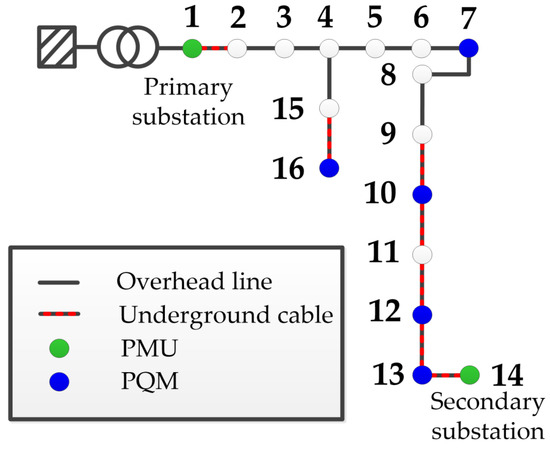
Figure 4.
Single-line diagram of a 16-bus distribution feeder located in Spain with the locations of measuring devices.
In order to fulfil the requirements of the FLA, the network has been equipped with PMUs within the context of the European Union (EU) H2020 Horizon project RESOLVD. The locations of the deployed PMUs are marked as green dots in the figure and are set, according to the methodology, to a primary substation and secondary substation at the end of the feeder. Additionally, to satisfy the FLA requirement for pseudo-measurements, all the load busses of the considered network, denoted with blue dots, have been equipped with PQMs. The latter provide information about the load’s consumed active and reactive powers, the root mean square (RMS) values of voltages and currents and the total harmonic distortion, whereas PMUs measure and report the time-tagged frequency, the rate-of-change-of-frequency (RoCoF) and the phasors of voltages and currents.
5. Proposed Edge-Cloud Framework for Automated Fault Detection and Localization
5.1. Overview and Functionalities
The main driving force behind the development of the proposed edge-cloud framework for the FLA was the concern about the reliability of the PMU data transmission over LTE (as explained in Section 2). Since missing data could adversely influence the performance of the FLA, we decided to store the full granularity (200 Hz) of the PMU measurements locally at the edge and simultaneously process them for fault detection purposes. For the observability of the grid, on the other hand, we decided to lower the reporting rate of all measuring devices down to 1 Hz in order to reduce the amount of data transfer from the edge nodes to the control center and, consequently, reduce the DSO’s bills for data transmission over LTE. The premise for doing so is that the grid is in a steady-state condition most of the time, during which it is acceptable to sacrifice some of the DSO’s resolution of the grid’s observability (WAMS for instance) on account of the reduced burden imposed on the communication infrastructure. In any case, the full resolution of data during steady state is more or less redundant and does not provide any additional information. However, this changes during the event when the full granularity of the PMU measurements is necessary in order to capture the transient nature of the event. Therefore, the full granularity of measurements (without any missing data) must still be accessible to the control center since those can help the DSO to better understand the event’s circumstances and are also crucial for the reliable operation of the FLA.
To achieve computing capability at the edge, we complemented each of the PMUs with a co-located embedded personal computer (ePC), whose importance is twofold. Firstly, the ePC serves as a temporal data storage unit for the corresponding PMU and, secondly, the ePC provides the capability for real-time analysis of the data. The latter functionality enables the detection of events on the entirety of the PMU data by comparing the obtained measurements with the pre-defined thresholds of events. Whenever an event is detected, a precise timestamp of the event’s inception moment is automatically reported and stored in the cloud’s side of the proposed framework. A query for data (the full resolution of data for a short time window around the timestamp) is then issued to the PMU and PQM databases. Once all the required data from the edge is reported back to the cloud, the FLA takes place. The algorithm’s results for the corresponding event are automatically sent to the DSO’s control center where they are visualized and stored in the events log.
The advantage of the approach described above is not only in preserving the granularity of the measurements in the case of events, but also that the detection and reporting of events to the control center is run in real-time, whereas the comprehensive analytics of events can be scheduled for later. This is not only extremely useful in the case where the second event would occur before the analysis of the first is finished, but inherently also allows the DSO to perform some other form of analysis on event measurements that is computationally more demanding than the described FLA and, therefore, cannot be carried out in real-time (e.g., machine-learning methods). The only limitation is that the analysis of the event has to be completed within the retention policy of the time-series database on ePCs (in our case set to 7 days). Another important aspect worth mentioning is that while the chance of an event in a power system coinciding with the unavailability of a communication (LTE) network is tiny, it is still not negligible. Normally in such a case, all the measurements would be lost and the DSO would have no awareness of the event. However, with the introduction of temporal data storage, we eliminate this problem as the measurements will still get transmitted as soon as the availability of the communication network is re-established.
The implementation of the edge and cloud side of the proposed framework and their interrelated communication links is presented in Figure 5. The left-hand side of the figure represents the measurement and data pre-processing infrastructure deployed in the field, whereas the middle of the figure represents an example of the application’s instantiation on the server side, hosted either in the cloud or in the control center. Lastly, the right-hand side of the figure represents the DSO’s headquarters, where the reports of the framework are gathered, visualized and stored.
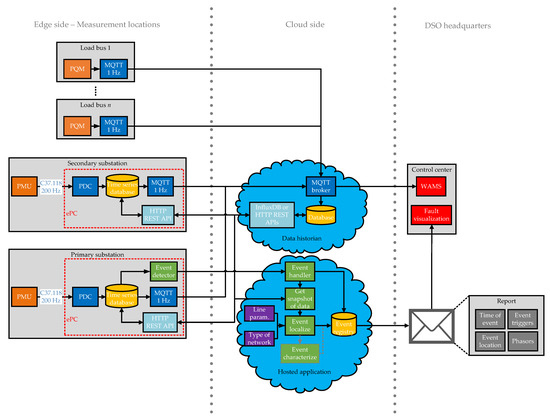
Figure 5.
Edge-cloud computing framework for automated fault localization.
In the following subsection, each of the building blocks is presented in more detail from the perspective of communication and system integration.
5.2. Building Blocks
5.2.1. Measurement Locations (Edge Nodes)
Two types of measurement device were deployed in the pilot, as already explained in Section 4. Furthermore, the PMU deployment for the primary and secondary substation differed in the sense that only the ePC of the primary substation was complemented with the Event detector module. The reason behind this decision was that the data from the primary substation are sufficient for detecting events that are narrowed down to only faults (similar to the protection scheme of the feeder, which is only implemented in the primary substation). The features of each edge node deployment are presented hereinafter.
- PQMs
One PQM is installed in each load bus, fulfilling the FLA requirements for active and reactive power measurements of loads. Each PQM is complemented with a gateway with an LTE communication interface for the transmission of data. Measurements from PQMs are pushed once a second via the message queuing telemetry transport (MQTT) protocol to the MQTT broker, which is part of the cloud-based Data historian application. Since PQMs do not require any additional edge computing capability for this particular FLA application, their measurements are not pre-processed and are pushed from the edge to the cloud side of the framework in raw format.
- PMU—secondary substation
The PMU in the secondary substation is complemented by a co-located ePC that contains a local phasor data concentrator (PDC) with a Time series database and a gateway with an LTE communication interface for the transmission of data. The gateway part is also responsible for the adaptation of the data exchange protocol from IEEE C37.118 to MQTT. Note that since the PMU and the ePC are co-located and physically connected by Ethernet cable, the entirety of the PMU data (200 Hz report rate) is transferred to the local database, whereas only 1 sample is pushed each second over the LTE gateway for the purposes of grid observability. The Time series database with a retention policy has a capacity of storing up to one week of PMU data and is accessed automatically by the Hosted application via the HTTP REST API in case of an event. On the other hand, the Control center can also request the data from this database manually in case the DSO wants more granular measurements of a particular time window. In order not to overload the figure and since this additional functionality is not required for the functioning of the FLA framework anyway, this connection is not shown in Figure 5.
- PMU—primary substation
Similarly to the PMU in the secondary substation, the PMU in the primary substation is accompanied by an ePC containing a PDC, a local short-term storage database and a gateway. However, an additional functionality of this ePC is a local application execution environment supporting a simple fault detection algorithm (Event detector in Figure 5), which is responsible for the activation of the Hosted application in the cloud.
There are currently two independent triggers of the Event detector application. The first one compares the amplitude of the phase currents to a predefined threshold (acts similar to overcurrent protection), whereas the second trigger is activated when the magnitudes of the zero-sequence current and zero-sequence voltage phasors simultaneously exceed the corresponding thresholds and the phase angle between the phasors lies in the predefined interval (acts similar to differential protection). The Event detector runs continuously, in real-time, on the entirety of the PMU data (200 Hz report rate). Once either of the triggers is activated, a notification about the event and its timestamp are pushed via the MQTT to the Event handler component in the cloud and the Hosted application is initialized.
Note that the Event detector is currently, for the purposes of the project, set to recognize only faults that trigger the breaker operation and, consequently, the de-energization of the feeder. However, it could be arbitrarily reconfigured in the future with very little effort in order to expand its functionality to also detect other kinds of event (such as power quality).
For the reader’s convenience, an example of an event from the field that triggered the Event detector is presented in Figure 6.
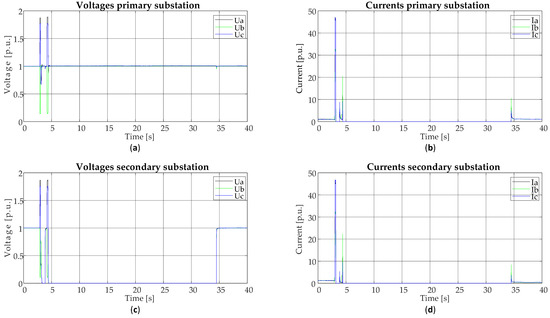
Figure 6.
A full resolution of the phasor measurement unit (PMU) measurements for an event that triggered the event detector in a real-life environment: (a) Voltage measurements of the primary substation’s PMU; (b) Current measurements of the primary substation’s PMU; (c) Voltage measurements of the secondary substation’s PMU; (d) Current measurements of the secondary substation’s PMU.
5.2.2. Cloud Side
- Data historian
The Data historian is a back-office system designed to integrate and archive processed data efficiently. Based on the InfluxDB (https://www.influxdata.com/products/influxdb-overview/, accessed on 20 February 2021) it is optimized to store and retrieve large volumes of time-series data quickly and efficiently, including high-resolution sub-second information that is measured very rapidly. The MQTT broker, based on the Eclipse Mosquitto (https://mosquitto.org/, accessed on 20 February 2021) pushes the measurements from all edge nodes to the common Database, which can be accessed by data querying the HTTP REST or InfluxDB APIs. The measurements from the data broker are in our case also used in parallel for providing the DSO with real-time grid observability (WAMS).
- Hosted application
A Hosted application is the computational heart of the FLA in the proposed edge-cloud framework and is composed of several building blocks. Once the notification of the fault is received by the Hosted application, the Event handler ensures that the event is automatically and appropriately recorded in the Event registry. Next, the block Get snapshot of data issues a query for historical data for a short time interval around the event’s timestamp. The entirety of the voltage and current phasors are extracted from the Time series databases of both PMUs, whereas the values of the active and reactive power for each load are obtained from the Database of the Data historian. Upon receiving all of the requested data, the Event localize block is run, which in its essence is the FLA presented in Section 3.3. The localization of the fault is performed according to the model of the EPS (see Section 4), where both the type of the network (grounded or isolated) and the parameters of lines are specified. The results of the Event localize block are then appended to the corresponding fault in the Event registry. Lastly, the report, containing the information about the fault location, the setting that triggered the Event detect block of the framework, the timestamp of the event’s inception moment and the entirety of the phasors from both PMUs for a predefined time window around the fault’s inception moment, is produced and sent to the Fault visualization application in the Control center.
Event characterization is part of our planned future work; therefore, the Event characterize component in Figure 5 is connected to the rest of the existing Hosted application components with a dotted arrow. The aim of the component will be to provide the DSO with further information regarding the fault, i.e., the value of fault resistance and fault type.
5.3. Bridging the Edge and Cloud Side of the Framework
For the purposes of connecting different edge nodes with the cloud side of the proposed framework, we have used the architecture as described in [37]. The main benefits of using the proposed self-sufficient architecture are:
- used components are open-sourced;
- it consists of a central system that enables the easy management and reconfiguration of all target nodes;
- it contains a service which monitors the activity and health of individual nodes in the system with orchestration functionality;
- it includes a node registry system with information about the availability of the individual node;
- by using docker technology, the framework’s functionality can be easily extended with new components.
5.4. Time Performance Indicator
In this subsection, we provide the results related to the elapsed time of the entire fault localization procedure in a real environment. According to Figure 7, the time from the fault inception moment until the moment when the FLA results are received by the DSO can be expressed as:
t = tstop − tstart = t1 + t2 + t3 + t4.
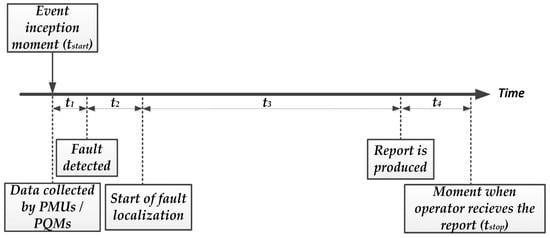
Figure 7.
Time delay of the fault localization algorithm (FLA) components.
In Equation (1), the t1 represents the time elapsed from the moment when the PMU in the primary substation reports the phasors containing the fault until the moment when the Event detector recognizes the state of a network as faulted. This time includes the time required for saving the PMU measurements to a co-located ePC and the running time of a fault detection script, which compares the phasors to the predefined thresholds. Once the fault is detected, a trigger is sent from the primary substation to the Hosted application, which is run in the cloud. This communication-induced delay is labelled as t2. Next, the processing time of the Hosted application is labelled as t3 and consists of two parts, i.e., the time required to transfer data from the Database of PQMs and the Time-series databases of PMUs to the FLA and the processing time of the FLA script itself. Finally, the report of a fault takes some time (t4) to be transferred from the cloud-based Hosted application to the Control center of the DSO, where it is displayed to the operator.
In order to evaluate the elapsed time from the event inception moment until the moment that the DSO receives the corresponding report, we manually triggered 100 artificial events. This was done by tweaking the thresholds of the Event detector application and observing the value of each individual time component. The minimum, maximum and average values for each of them are presented in Table 1. The values of t1 indicate that the Event detector application is indeed running in real-time (the 30 ms threshold is not surpassed). On the other hand, the average elapsed time of approximately 2 s places the combined fault detection and localization procedure in the category of near real-time applications.

Table 1.
Minimum, maximum and average time delay values for each component of the FLA.
6. Conclusions
Fault localization and detection are well established topics in the research literature. However, not much attention was paid to the fact that DNs, as opposed to TNs, generally lack the dedicated communication infrastructure and, consequently, how this could adversely affect the corresponding monitoring, control or analysis schemes. In this paper, the authors developed an edge-cloud computing framework specifically aimed at addressing potential issues with the reliability of the measurement data transfer, arising from using LTE communication technology. Since the proposed framework separates time-critical applications, by moving them to the edge, from near real-time applications, the reliability of schemes such as fault localization can also be ensured in DNs. Furthermore, by implementing event detection at the edge, the measurements are sent to the control center in full resolution only in case of events, which significantly reduces the amount of transferred data. With this, the DSO’s expenses are lowered, whereas the observability of the grid is not negatively affected since during the steady-state operation of the EPS, the data are generally redundant. Another important quality of the established framework is that it is completely automated; the DSO is informed about the fault and its location in near real-time, without any of the experts having to look at the data. Lastly, the proposed framework provides the capability of easy integration of other time-critical applications at the edge in the future.
Author Contributions
Conceptualization, A.Č. and D.S.; methodology, M.M. and D.S.; software, M.M. and A.Č.; validation, M.M. and D.S.; formal analysis, D.S.; investigation, A.Č. and D.S.; resources, M.S.; data curation, M.M and D.S.; writing—original draft preparation, D.S.; writing—review and editing, A.Č., U.R. and D.S.; visualization, M.M. and D.S.; supervision, U.R. and A.Č.; project administration, M.S. and D.S.; funding acquisition, M.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partly funded by the Slovenian Research Agency, grant number J2-9232, and the European Commission through the H2020 projects RESOLVD (Grant no. 773715) and PLATOON (Grant no. 872592). The authors would like to thank them for the financial support.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The authors would like to thank Ramon Gallart Fernández from EyPESA for his support and providing the access to the pilot in order to produce this work.
Conflicts of Interest
The authors declare no conflict of interest.
Nomenclature
| PMU | Phasor Measurement Unit |
| PDC | Phasor Data Concentrator |
| TN | Transmission network |
| DN | Distribution network |
| LTE | Long-Term Evolution |
| EPS | Electric power system |
| RES | Renewable energy source |
| DSO | Distribution System Operator |
| WAMS | Wide-Area Monitoring System |
| WAMPAC | Wide-Area Monitoring, Protection and Control |
| QoS | Quality of Service |
| TCP | Transmission Control Protocol |
| UDP | User Datagram Protocol |
| PQM | Power Quality Meter |
| SM | Smart Meter |
References
- Markard, J. The next Phase of the Energy Transition and Its Implications for Research and Policy. Nat. Energy 2018, 3, 628–633. [Google Scholar] [CrossRef]
- Kroposki, B.; Johnson, B.; Zhang, Y.; Gevorgian, V.; Denholm, P.; Hodge, B.-M.; Hannegan, B. Achieving a 100% Renewable Grid: Operating Electric Power Systems with Extremely High Levels of Variable Renewable Energy. IEEE Power Energy Mag. 2017, 15, 61–73. [Google Scholar] [CrossRef]
- Molina, M.G. Distributed Energy Storage Systems for Applications in Future Smart Grids. In Proceedings of the 2012 Sixth IEEE/PES Transmission and Distribution: Latin America Conference and Exposition (T D-LA), Montevideo, Uruguay, 3–5 September 2012; pp. 1–7. [Google Scholar]
- Lund, P.D.; Lindgren, J.; Mikkola, J.; Salpakari, J. Review of Energy System Flexibility Measures to Enable High Levels of Variable Renewable Electricity. Renew. Sustain. Energy Rev. 2015, 45, 785–807. [Google Scholar] [CrossRef]
- Kenyon, R.W.; Bossart, M.; Marković, M.; Doubleday, K.; Matsuda-Dunn, R.; Mitova, S.; Julien, S.A.; Hale, E.T.; Hodge, B.-M. Stability and Control of Power Systems with High Penetrations of Inverter-Based Resources: An Accessible Review of Current Knowledge and Open Questions. Sol. Energy 2020, 210, 149–168. [Google Scholar] [CrossRef]
- Ullah, Z.; Asghar, R.; Khan, I.; Ullah, K.; Waseem, A.; Wahab, F.; Haider, A.; Ali, S.M.; Jan, K.U. Renewable Energy Resources Penetration within Smart Grid: An Overview. In Proceedings of the 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, 12–13 June 2020; pp. 1–6. [Google Scholar]
- Saldaña-González, A.E.; Sumper, A.; Aragüés-Peñalba, M.; Smolnikar, M. Advanced Distribution Measurement Technologies and Data Applications for Smart Grids: A Review. Energies 2020, 13, 3730. [Google Scholar] [CrossRef]
- Gungor, V.C.; Sahin, D.; Kocak, T.; Ergut, S.; Buccella, C.; Cecati, C.; Hancke, G.P. A Survey on Smart Grid Potential Applications and Communication Requirements. IEEE Trans. Ind. Inform. 2013, 9, 28–42. [Google Scholar] [CrossRef]
- Kalalas, C.; Thrybom, L.; Alonso-Zarate, J. Cellular Communications for Smart Grid Neighborhood Area Networks: A Survey. IEEE Access 2016, 4, 1469–1493. [Google Scholar] [CrossRef]
- Ali, S.M.; Jawad, M.; Khan, B.; Mehmood, C.A.; Zeb, N.; Tanoli, A.; Farid, U.; Glower, J.; Khan, S.U. Wide Area Smart Grid Architectural Model and Control: A Survey. Renew. Sustain. Energy Rev. 2016, 64, 311–328. [Google Scholar] [CrossRef]
- Farajollahi, M.; Shahsavari, A.; Mohsenian-Rad, H. Location Identification of Distribution Network Events Using Synchrophasor Data. In Proceedings of the 2017 North American Power Symposium (NAPS), Morgantown, WV, USA, 17–19 September 2017; pp. 1–6. [Google Scholar]
- Maskey, N.; Horsmanheimo, S.; Tuomimäki, L. Analysis of Latency for Cellular Networks for Smart Grid in Suburban Area. In Proceedings of the IEEE PES Innovative Smart Grid Technologies, Europe, Istanbul, Turkey, 12–15 October 2014; pp. 1–4. [Google Scholar]
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An Overview on Edge Computing Research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Feng, C.; Wang, Y.; Chen, Q.; Ding, Y.; Strbac, G.; Kang, C. Smart Grid Encounters Edge Computing: Opportunities and Applications. Adv. Appl. Energy 2021, 1, 100006. [Google Scholar] [CrossRef]
- Gana, N.; Ab Aziz, N.F.; Ali, Z.; Hashim, H.; Yunus, B. A Comprehensive Review of Fault Location Methods for Distribution Power System. Indones. J. Electr. Eng. Comput. Sci. 2017, 6, 185. [Google Scholar] [CrossRef]
- Mora-Flòrez, J.; Meléndez, J.; Carrillo-Caicedo, G. Comparison of Impedance Based Fault Location Methods for Power Distribution Systems. Electr. Power Syst. Res. 2008, 78, 657–666. [Google Scholar] [CrossRef]
- Personal, E.; García, A.; Parejo, A.; Larios, D.F.; Biscarri, F.; León, C. A Comparison of Impedance-Based Fault Location Methods for Power Underground Distribution Systems. Energies 2016, 9, 1022. [Google Scholar] [CrossRef]
- Thomas, D.W.P.; Carvalho, R.J.O.; Pereira, E.T. Fault Location in Distribution Systems Based on Traveling Waves. In Proceedings of the 2003 IEEE Bologna Power Tech Conference Proceedings, Bologna, Italy, 23–26 June 2003; Volume 2, p. 5. [Google Scholar]
- Nouri, H.; Wang, C.; Davies, T. An Accurate Fault Location Technique for Distribution Lines with Tapped Loads Using Wavelet Transform. In Proceedings of the 2001 IEEE Porto Power Tech Proceedings (Cat. No.01EX502), Porto, Portugal, 10–13 September 2001; Volume 3, p. 4. [Google Scholar]
- Jalilzadeh Hamidi, R.; Livani, H.; Rezaiesarlak, R. Traveling-Wave Detection Technique Using Short-Time Matrix Pencil Method. IEEE Trans. Power Deliv. 2017, 32, 2565–2574. [Google Scholar] [CrossRef]
- Milioudis, A.N.; Andreou, G.T.; Labridis, D.P. Enhanced Protection Scheme for Smart Grids Using Power Line Communications Techniques—Part II: Location of High Impedance Fault Position. IEEE Trans. Smart Grid 2012, 3, 1631–1640. [Google Scholar] [CrossRef]
- Robson, S.; Haddad, A.; Griffiths, H. Fault Location on Branched Networks Using a Multiended Approach. IEEE Trans. Power Deliv. 2014, 29, 1955–1963. [Google Scholar] [CrossRef]
- Ahuja, A.; Das, S.; Pahwa, A. An AIS-ACO Hybrid Approach for Multi-Objective Distribution System Reconfiguration. IEEE Trans. Power Syst. 2007, 22, 1101–1111. [Google Scholar] [CrossRef]
- Thukaram, D.; Khincha, H.P.; Vijaynarasimha, H.P. Artificial Neural Network and Support Vector Machine Approach for Locating Faults in Radial Distribution Systems. IEEE Trans. Power Deliv. 2005, 20, 710–721. [Google Scholar] [CrossRef]
- Mora-Florez, J.; Barrera-Nunez, V.; Carrillo-Caicedo, G. Fault Location in Power Distribution Systems Using a Learning Algorithm for Multivariable Data Analysis. IEEE Trans. Power Deliv. 2007, 22, 1715–1721. [Google Scholar] [CrossRef]
- Borghetti, A.; Corsi, S.; Nucci, C.A.; Paolone, M.; Peretto, L.; Tinarelli, R. On the Use of Continuous-Wavelet Transform for Fault Location in Distribution Power Systems. Int. J. Electr. Power Energy Syst. 2006, 28, 608–617. [Google Scholar] [CrossRef]
- Lovisolo, L.; Moor Neto, J.A.; Figueiredo, K.; de Menezes Laporte, L.; dos Santos Roch, J.C. Location of Faults Generating Short-Duration Voltage Variations in Distribution Systems Regions from Records Captured at One Point and Decomposed into Damped Sinusoids. Transm. Distrib. IET Gener. 2012, 6, 1225–1234. [Google Scholar] [CrossRef]
- Mora-Flórez, J.; Cormane-Angarita, J.; Ordóñez-Plata, G. K-Means Algorithm and Mixture Distributions for Locating Faults in Power Systems. Electr. Power Syst. Res. 2009, 79, 714–721. [Google Scholar] [CrossRef]
- Pignati, M.; Zanni, L.; Romano, P.; Cherkaoui, R.; Paolone, M. Fault Detection and Faulted Line Identification in Active Distribution Networks Using Synchrophasors-Based Real-Time State Estimation. IEEE Trans. Power Deliv. 2017, 32, 381–392. [Google Scholar] [CrossRef]
- Patynowski, D.; Cardenas, J.; Menendez, D.; Zhang, Z.; Roca, J.M.; Germain, J.G.; Huete, A.Y.; Canales, M.; Martinez, A.; Rosendo, J.A.; et al. Fault Locator Approach for High-Impedance Grounded or Ungrounded Distribution Systems Using Synchrophasors. In Proceedings of the 2015 68th Annual Conference for Protective Relay Engineers, College Station, TX, USA, 30 March–2 April 2015; pp. 302–310. [Google Scholar]
- Jamei, M.; Scaglione, A.; Roberts, C.; Stewart, E.; Peisert, S.; McParland, C.; McEachern, A. Anomaly Detection Using Optimally Placed ΜPMU Sensors in Distribution Grids. IEEE Trans. Power Syst. 2018, 33, 3611–3623. [Google Scholar] [CrossRef]
- Rajeev, A.; Angel, T.S.; Khan, F.Z. Fault Location in Distribution Feeders with Optimally Placed PMU’s. In Proceedings of the 2015 International Conference on Technological Advancements in Power and Energy (TAP Energy), Kollam, India, 24–26 June 2015; pp. 438–442. [Google Scholar]
- Ren, J.; Venkata, S.S.; Sortomme, E. An Accurate Synchrophasor Based Fault Location Method for Emerging Distribution Systems. IEEE Trans. Power Deliv. 2014, 29, 297–298. [Google Scholar] [CrossRef]
- Cavalcante, P.A.H.; de Almeida, M.C. Fault Location Approach for Distribution Systems Based on Modern Monitoring Infrastructure. Transm. Distrib. IET Gener. 2018, 12, 94–103. [Google Scholar] [CrossRef]
- Majidi, M.; Etezadi-Amoli, M. A New Fault Location Technique in Smart Distribution Networks Using Synchronized/Nonsynchronized Measurements. IEEE Trans. Power Deliv. 2018, 33, 1358–1368. [Google Scholar] [CrossRef]
- Farajollahi, M.; Shahsavari, A.; Stewart, E.M.; Mohsenian-Rad, H. Locating the Source of Events in Power Distribution Systems Using Micro-PMU Data. IEEE Trans. Power Syst. 2018, 33, 6343–6354. [Google Scholar] [CrossRef]
- Vucnik, M.; Solc, T.; Gregorc, U.; Hrovat, A.; Bregar, K.; Smolnikar, M.; Mohorcic, M.; Fortuna, C. Continuous Integration in Wireless Technology Development. IEEE Commun. Mag. 2018, 56, 74–81. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).