
Traffic Noise Prediction Applying Multivariate Bi-Directional Recurrent Neural Network




Abstract
1. Introduction
2. Materials and Methods
2.1. General Background of Recurrent Neural Network
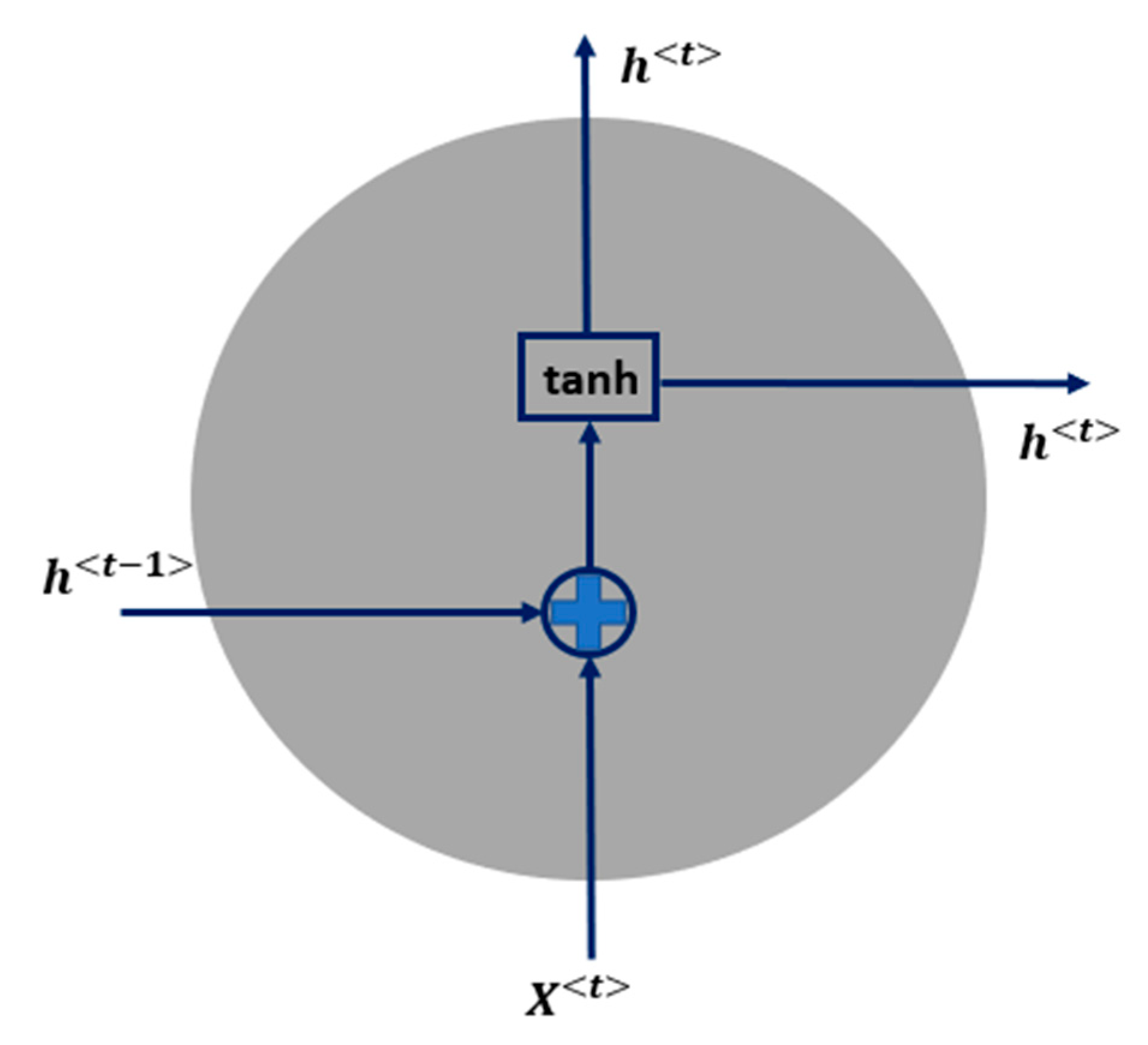
2.2. Architectures of RNN
2.3. Model Evaluation Metrics
2.4. Experiment Setup and Data Acquisition
2.5. Data Pre-Processing
2.5.1. Video Data Pre-Processing
2.5.2. Traffic Features Generation
2.5.3. Audio Data Pre-Processing
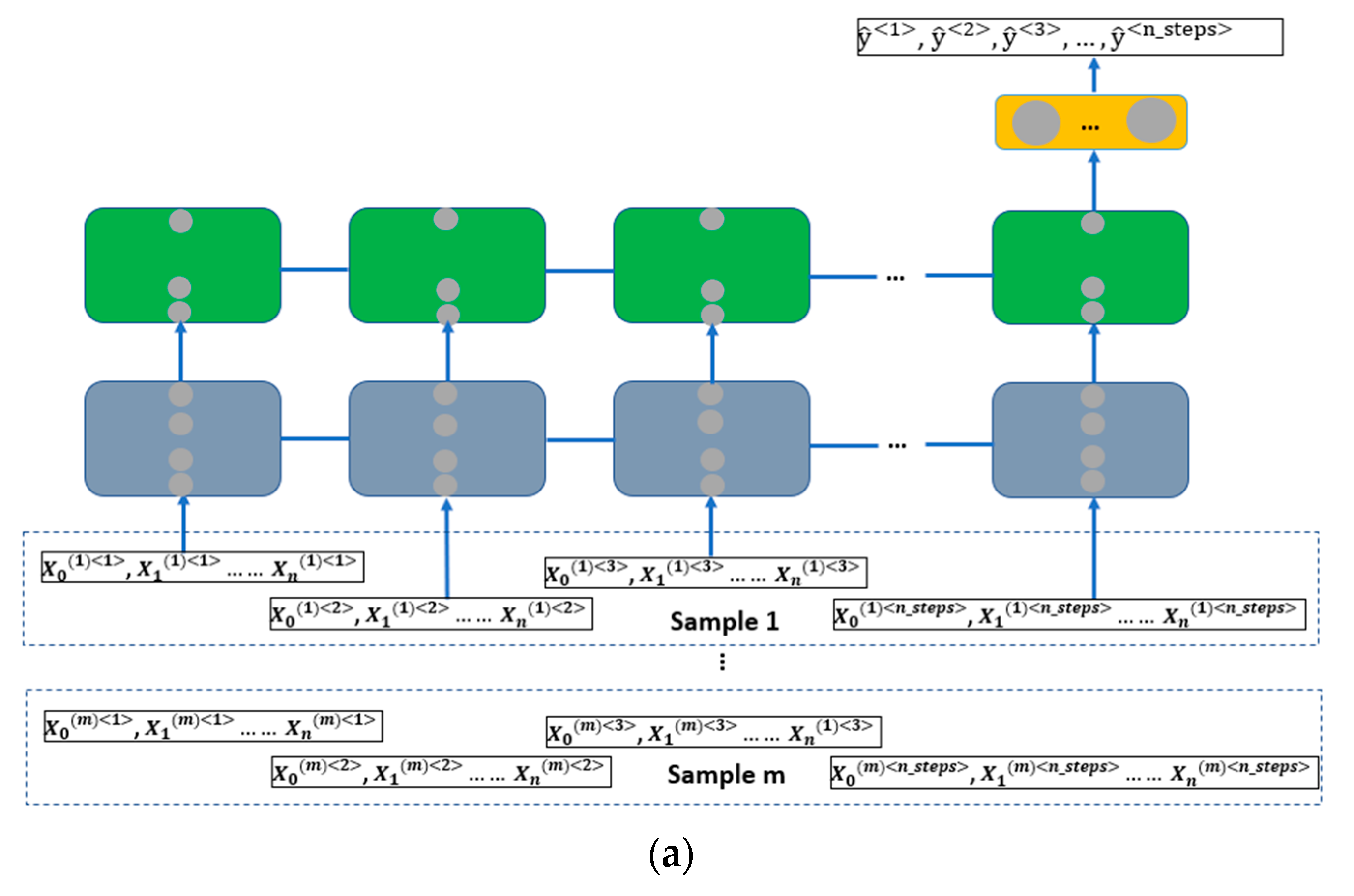
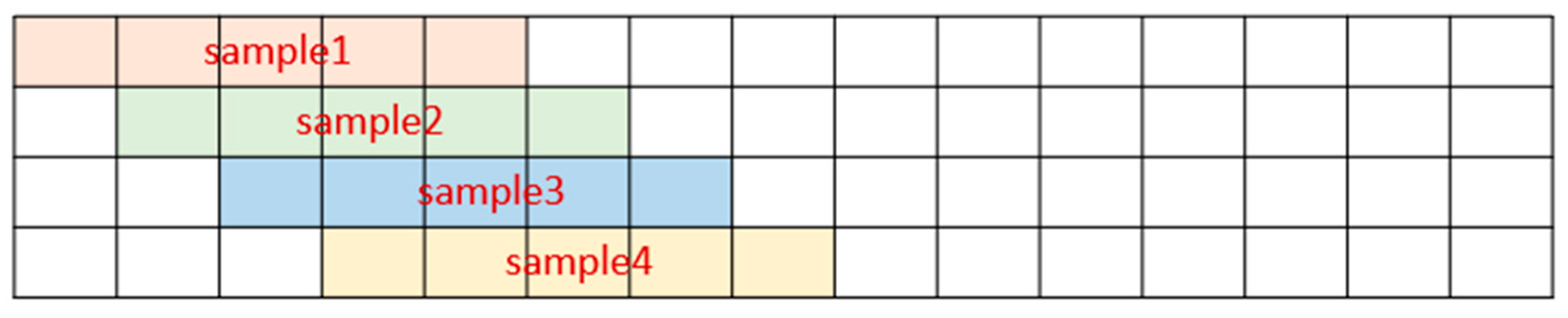
2.5.4. RNN Training Samples Generation
2.5.5. Leave One Subject out Cross-Validation
2.5.6. Data Scaling
3. Results and Discussion
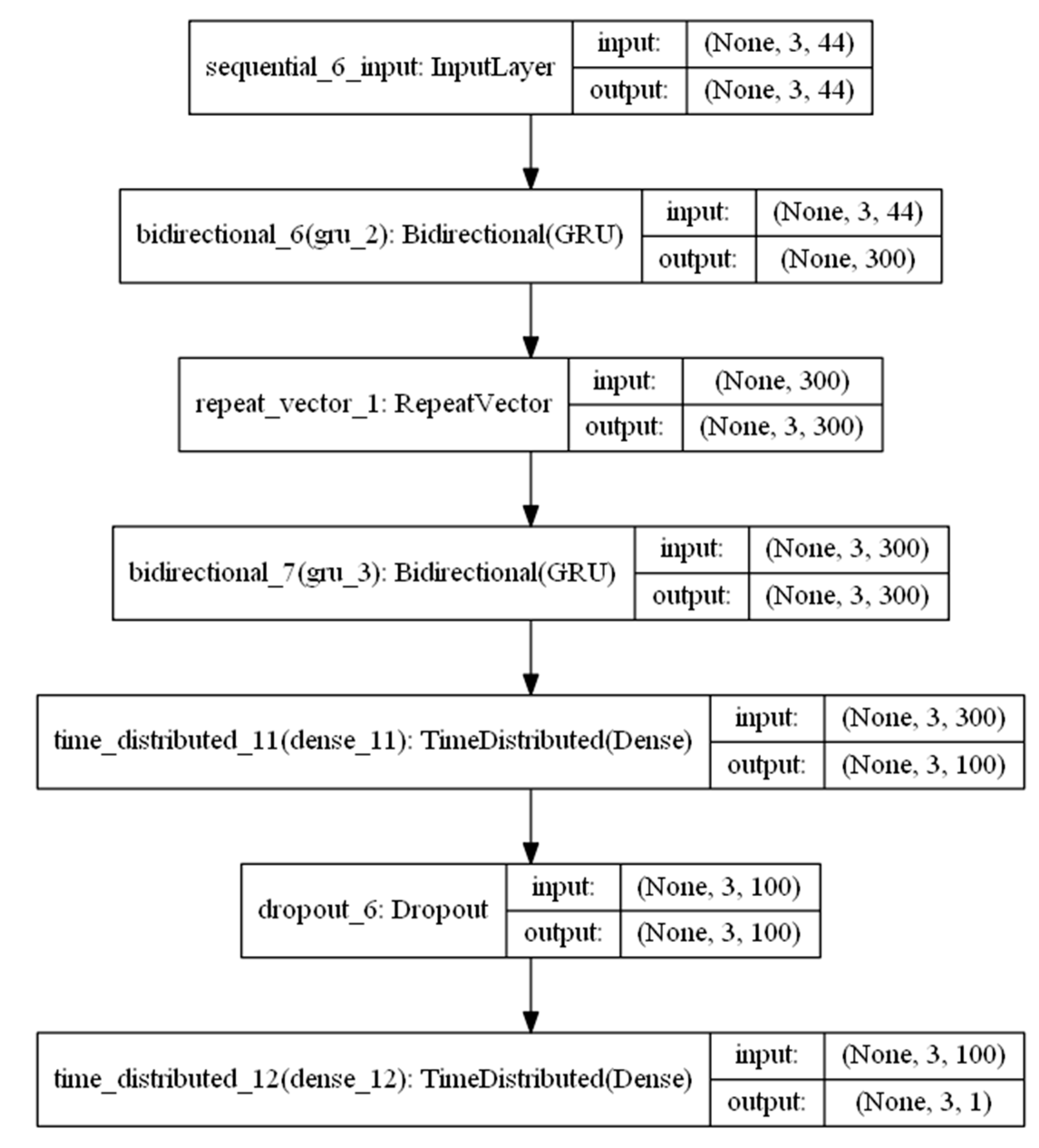
3.1. Development of RNN
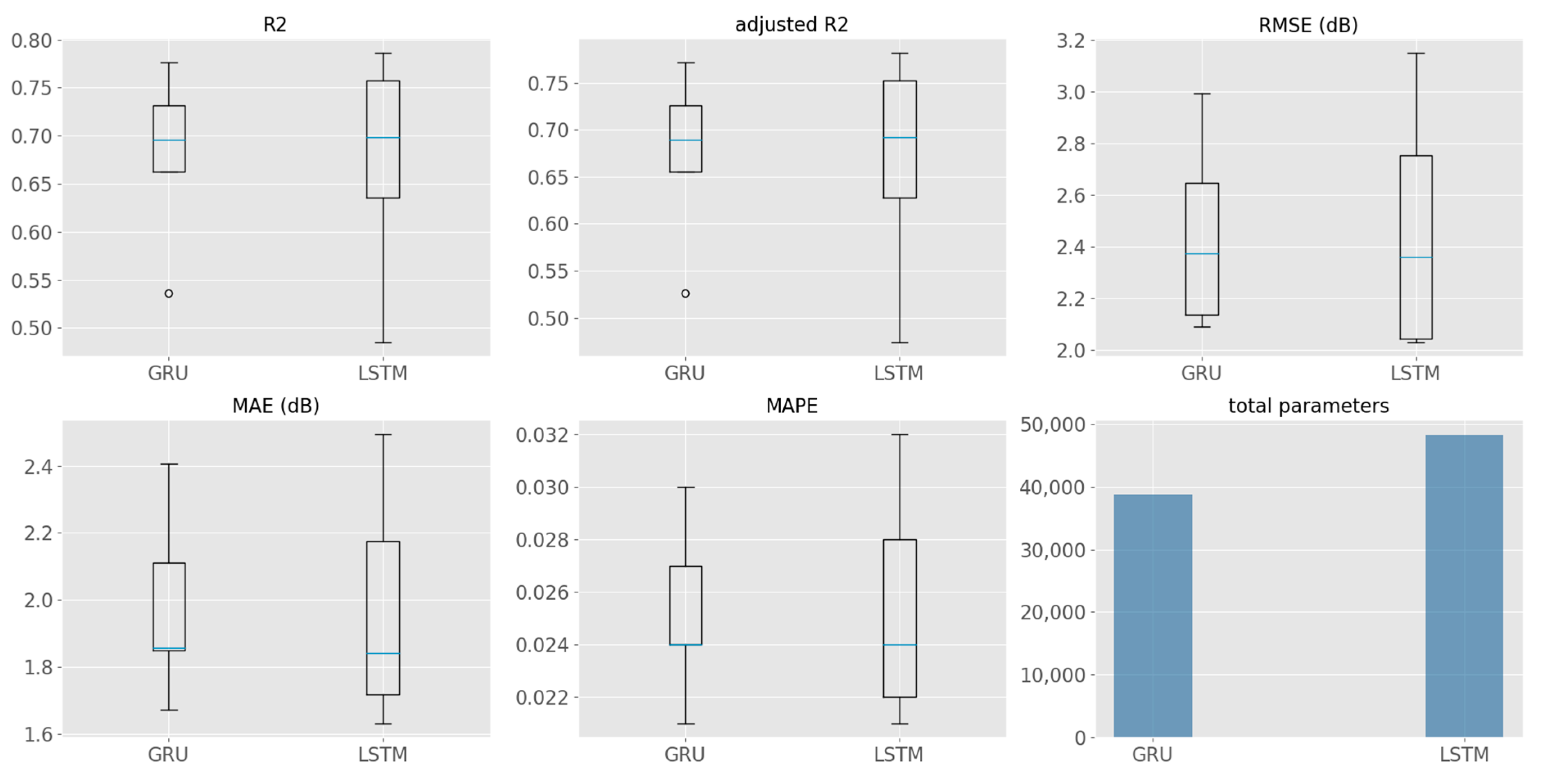
3.2. Results Comparison on Different Architectures
3.3. Results Comparison on Recurrent Units
3.4. Model Hyperparameters Tuning
3.5. Final Model Evaluation
3.6. Comparison with CNOSSOS-EU Model
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hänninen, O.; Knol, A.; Jantunen, M.; Lim, T.; Conrad, A.; Rappolder, M.; Carrer, P.; Fanetti, A.; Kim, R.; Buekers, J.; et al. Environmental Burden of Disease in Europe: Assessing Nine Risk Factors in Six Countries. Environ. Health Perspect. 2014, 122, 439–446. [Google Scholar] [CrossRef]
- Miloradović, D.; Glišović, J.; Lukić, J. Regulations on Road Vehicle Noise—Trends and Future Activities. Mob. Veh. Mech. 2017, 43, 57–72. [Google Scholar] [CrossRef]
- Guarnaccia, C. EAgLE: Equivalent acoustic level estimator proposal. Sensors (Switzerland) 2020, 20, 701. [Google Scholar] [CrossRef] [PubMed]
- Rey Gozalo, G.; Aumond, P.; Can, A. Variability in sound power levels: Implications for static and dynamic traffic models. Transp. Res. Part D Transp. Environ. 2020, 84. [Google Scholar] [CrossRef]
- Guarnaccia, C.; Bandeira, J.; Coelho, M.C.; Fernandes, P.; Teixeira, J.; Ioannidis, G.; Quartieri, J. Statistical and semi-dynamical road traffic noise models comparison with field measurements. AIP Conf. Proc. 2018, 1982. [Google Scholar] [CrossRef]
- Golmohammadi, R.; Abbaspour, M.; Nassiri, P.; Mahjub, H. Road traffic noise model. J. Res. Health Sci. 2007, 7, 13–17. [Google Scholar]
- Steele, C. Critical review of some traffic noise prediction models. Appl. Acoust. 2001, 62, 271–287. [Google Scholar] [CrossRef]
- Guarnaccia, C.; Lenza, T.L.L.; Mastorakis, N.E.; Quartieri, J. A comparison between traffic noise experimental data and predictive models results. Int. J. Mech. 2011, 5, 379–386. [Google Scholar]
- Quartieri, J.; Mastorakis, N.E.; Iannone, G.; Guarnaccia, C.; Ambrosio, S.D.; Troisi, A.; Lenza, T.L.L. A Review of Traffic Noise Predictive Noise Models. In Proceedings of the Recent Advances in Applied and Theoretical Mechanics, 5th WSEAS International Conference on Applied and Theoretical Mechanics (MECHANICS’09), Puerto De La Cruz, Tenerife, Canary Islands, Spain, 14–16 December 2009; pp. 72–80. [Google Scholar]
- Garg, N.; Maji, S. A critical review of principal traffic noise models: Strategies and implications. Environ. Impact Assess. Rev. 2014, 46, 68–81. [Google Scholar] [CrossRef]
- Petrovici, C.; Tomozei, F.; Nedeff, O. Irimia, and M. Panainte-Lehadus, A. Review on the Road Traffic Noise Assessment. J. Eng. Stud. Res. 2016, 22, 81–89. [Google Scholar]
- Bakowski, A.; Dekýš, V.; Radziszewski, L.; Skrobacki, Z. Validation of traffic noise models. AIP Conf. Proc. 2019, 2077. [Google Scholar] [CrossRef]
- Huang, K.; Fan, Y.; Dai, L. A nested ensemble filtering approach for parameter estimation and uncertainty quantification of traffic noise models. Appl. Sci. 2020, 10, 204. [Google Scholar] [CrossRef]
- Dutilleux, G.; Soldano, B. Matching directive 2015/996/EC (CNOSSOS-EU) and the French emission model for road pavements. In Proceedings of the Euronoise, Heraklion-Crete, Greece, 27–31 May 2019; pp. 1213–1218. [Google Scholar]
- Kumar, K.; Ledoux, H.; Schmidt, R.; Verheij, T.; Stoter, J. A harmonized data model for noise simulation in the EU. ISPRS Int. J. Geo-Information 2020, 9, 121. [Google Scholar] [CrossRef]
- Andrzej, B.; Leszek, R. Simulation and Assessments of Urban Traffic Noise by Statistical Measurands using mPa or dB(A) Units. Terotechnology XI 2020, 17, 108–113. [Google Scholar]
- Hamad, K.; Ali Khalil, M.; Shanableh, A. Modeling roadway traffic noise in a hot climate using artificial neural networks. Transp. Res. Part D Transp. Environ. 2017, 53, 161–177. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, M.; Dong, R. Time-series prediction of environmental noise for urban iot based on long short-term memory recurrent neural network. Appl. Sci. 2020, 10, 1144. [Google Scholar] [CrossRef]
- Navarro, J.M.; Martínez-España, R.; Bueno-Crespo, A.; Martínez, R.; Cecilia, J.M. Sound levels forecasting in an acoustic sensor network using a deep neural network. Sensors 2020, 20, 903. [Google Scholar] [CrossRef] [PubMed]
- Mansourkhaki, A.; Berangi, M.; Haghiri, M.; Haghani, M. A neural network noise prediction model for Tehran urban roads. J. Environ. Eng. Landsc. Manag. 2018, 26, 88–97. [Google Scholar] [CrossRef]
- Givargis, S.; Karimi, H. A basic neural traffic noise prediction model for Tehran’s roads. J. Environ. Manag. 2010, 91, 2529–2534. [Google Scholar] [CrossRef] [PubMed]
- Freitas, E.; Tinoco, J.; Soares, F.; Costa, J.; Cortez, P.; Pereira, P. Modelling Tyre-Road Noise with Data Mining Techniques. Arch. Acoust. 2015, 40, 547–560. [Google Scholar] [CrossRef]
- Nourani, V.; Gökçekuş, H.; Umar, I.K. Artificial intelligence based ensemble model for prediction of vehicular traffic noise. Environ. Res. 2020, 180, 108852. [Google Scholar] [CrossRef]
- Xu, D.; Wei, C.; Peng, P.; Xuan, Q.; Guo, H. GE-GAN: A novel deep learning framework for road traffic state estimation. Transp. Res. Part C Emerg. Technol. 2020, 117, 102635. [Google Scholar] [CrossRef]
- Behrendt, K.; Novak, L.; Botros, R. A deep learning approach to traffic lights: Detection, tracking, and classification. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1370–1377. [Google Scholar]
- Yu, R.; Li, Y.; Shahabi, C.; Demiryurek, U.; Liu, Y. Deep learning: A generic approach for extreme condition traffic forecasting. In Proceedings of the 2017 SIAM International Conference on Data Mining (SDM), Houston, TX, USA, 27–29 April 2017; pp. 777–785. [Google Scholar]
- Al-Qizwini, M.; Barjasteh, I.; Al-Qassab, H.; Radha, H. Deep learning algorithm for autonomous driving using googlenet. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June2017; pp. 89–96. [Google Scholar]
- Bravo-Moncayo, L.; Lucio-Naranjo, J.; Chávez, M.; Pavón-García, I.; Garzón, C. A machine learning approach for traffic-noise annoyance assessment. Appl. Acoust. 2019, 156, 262–270. [Google Scholar] [CrossRef]
- Socoró, J.C.; Alías, F.; Alsina-Pagès, R.M. An anomalous noise events detector for dynamic road traffic noise mapping in real-life urban and suburban environments. Sensors 2017, 17, 2323. [Google Scholar] [CrossRef] [PubMed]
- Shrestha, M.B.; Bhatta, G.R. Selecting appropriate methodological framework for time series data analysis. J. Financ. Data Sci. 2018, 4, 71–89. [Google Scholar] [CrossRef]
- Medsker, L.; Jain, L.C. (Eds.) Recurrent Neural Networks: Design and Applications; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance Evaluation of Deep neural networks Applied to Speech Recognition: Rnn, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- McClelland, J.L.; Rumelhart, D.E.; PDP Research Group. Parallel Distributed Processing; IEEE: Wakefield, MA, USA, 1988; Volume 1. [Google Scholar]
- Mozer, M.C. A focused backpropagation algorithm for temporal pattern recognition. In Backpropagation: Theory, Architectures, and Applications; Lawrence Erlbaum Associates: Hillsdale, NJ, USA, 1995; pp. 137–169. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the EMNLP 2014—2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Briot, J.P.; Pachet, F. Deep learning for music generation: Challenges and directions. Neural Comput. Appl. 2020, 32, 981–993. [Google Scholar] [CrossRef]
- Seo, S.; Kim, C.; Kim, H.; Mo, K.; Kang, P. Comparative Study of Deep Learning-Based Sentiment Classification. IEEE Access 2020, 8, 6861–6875. [Google Scholar] [CrossRef]
- Luong, M.T.; Le, Q.V.; Sutskever, I.; Vinyals, O.; Kaiser, L. Multi-task sequence to sequence learning. arXiv 2015, arXiv:1511.06114. [Google Scholar]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-Sequence Prediction of Vehicle Trajectory via LSTM Encoder-Decoder Architecture. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1672–1678. [Google Scholar]
- Gholamiangonabadi, D.; Kiselov, N.; Grolinger, K. Deep Neural Networks for Human Activity Recognition With Wearable Sensors: For Model Selection. IEEE Access 2020, 8, 133982–133994. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Newton, MA, USA, 2019. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012; ISBN 978-0-262-01802-9. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Everitt, B.; Skrondal, A. The Cambridge Dictionary of Statistics; Cambridge University Press: Cambridge, UK, 2002; ISBN 0-521-81099-X. [Google Scholar]
- Kephalopoulos, S.; Paviotti, M.; Ledee, F.A. Common Noise Assessment Methods in Europe (CNOSSOS-EU); Publications Office of the European Union: Luxembourg, 2012; ISBN 9789279252815. [Google Scholar]
- Kok, A.; van Beek, A. Amendments for CNOSSOS-EU. RIVM Rep. 2019, 23, 101–107. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | |||
| Device Model | Sampling Rate | Number of Channels | |
| Audio Recording | SQuadriga II | 48 KHz | 10 (6 × Line/ICP In, BHS In (2-channel), 2 × Pulse In) |
| Video Recording | Hikvision IP camera | 30 fps | N.A. |
| (b) | |||
| Microphones | Frequency Response | Sensitivity (mV/Pa) | Max. Peak SPL (dB) |
| Mic3 | 0.02–4 KHz (±0.5 dB) 4–20 KHz (±1.5 dB) | 51.3 | 130 |
| Mic5 | 51.0 | ||
| Mic6 | 51.6 | ||
| Mic7 | 51.9 | ||
| Mic8 | 52.0 | ||
| Date | Start | End | Total Duration |
|---|---|---|---|
| Day 1 (30 September 2019) | 16:43 p.m. | 20:32 p.m. | 3 h 49 min |
| Day 2 (1 October 2019) | 06:34 a.m. | 11:48 a.m. | 5 h 14 min |
| Day 1 + Day 2 | - | - | 9 h 3 min |
| Raw Data Frame | Vehicle Speed (km/h) | Vehicle Acceleration (m/s2) | Vehicle Deceleration (m/s2) | Vehicle Distance to Mic3 (m) | Vehicle Category | |
|---|---|---|---|---|---|---|
| Sample1 | Time step1 | [0.0058, 0.0034, 0.0033, 0.0043, 34.35, 31.57, 0.084, 31.61, 0.29, 8.01, 44.59, 0.0, 0.0, 27.83, 4.56, 31.02, 24.72, 31.22] | [0.0005, 0.0012, 0.0008, 0.004, 0.0, 0.0, 0.014, 0.81, 0.13, 1.89, 0.0, 0.0, 0.0, 8.42, 0.018, 3.29, 0.38, 0.0] | [0.0, 0.0, 0.0, 0.0, 3.26, 2.56, 0.0, 0.0, 0.0, 0.0, 2.12, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.26] | [39.08, 23.87, 22.70, 22.92, 68.57, 45.45, 55.99, 29.38, 46.05, 27.55, 53.53, 45.70, 22.82, 75.29, 47.44, 70.34, 94.37, 70.40] | [“car”, “car”, “car”, “car”, “car”, “car”, “car”, “car”, “car”, “heavy vehicle”, “car”, “car”, “car”, “car”, “car”, “car”, “car”, “small car”] |
| … | … | … | … | … | … | … |
| Sample800 | Time step800 | [33.61, 22.82, 17.68] | [1.44, 1.18, 1.19] | [0.0, 0.0, 0.0] | [41.69, 30.96, 30.01] | [“car”, “car”, “car”] |
| … | … | … | … | … | … | … |
| Features Representing Individual Vehicle (Raw Data) | Input Variables for Machine-Learning Model (after Preprocessing) |
|---|---|
| Vehicle category | [traffic volume, ratio of motorcycle, ratio of medium vehicle, ratio of heavy vehicle, ratio of bus, ratio of car, ratio of small car] |
| Vehicle speed | [arithmetic mean, harmonic mean, min, max, median, range, mid-point, standard deviation, skewness, kurtosis] |
| Vehicle acceleration | [arithmetic mean, min, max, median, range, mid-point, standard deviation, skewness, kurtosis] |
| Vehicle deceleration | [arithmetic mean, min, max, median, range, mid-point, standard deviation, skewness, kurtosis] |
| Vehicle distance to mics | [arithmetic mean, min, max, median, range, mid-point, standard deviation, skewness, kurtosis] |
| Samples for Model Training | Model Evaluation | ||
|---|---|---|---|
| Training Data | Validation Data | Testing Data | |
| Data Shape | (6276, 30, 44) | (2092, 30, 44) | (70, 30, 44) |
| 1st iteration | Mic3, 6, 7 | Mic5 | Mic8 |
| 2nd iteration | Mic3, 6, 8 | Mic5 | Mic7 |
| 3rd iteration | Mic3, 7, 8 | Mic5 | Mic6 |
| 4th iteration | Mic6, 7, 8 | Mic3 | Mic5 |
| 5th iteration | Mic6, 7, 8 | Mic5 | Mic3 |
| Hyperparameter | Value |
|---|---|
| Number of layers | 3 (one bidirectional GRU layer, two dense layers) |
| Number of neurons | 50, 100, 1 |
| Learning rate | 0.0001 |
| Batch size | 256 |
| Optimization algorithm | Adam |
| Dropout rate | 0.4 |
| Sequence length (n_steps) | 30 |
| Number of Epochs | 143 (controlled by Keras Early Stopping) |
| R2 | Adjusted R2 | RMSE | MAE | MAPE | |
|---|---|---|---|---|---|
| 1st iteration | 0.6953 | 0.6888 | 2.373 | 1.857 | 0.024 |
| 2nd iteration | 0.6629 | 0.6557 | 2.648 | 2.111 | 0.027 |
| 3rd iteration | 0.5359 | 0.526 | 2.993 | 2.406 | 0.030 |
| 4th iteration | 0.7766 | 0.7718 | 2.09 | 1.673 | 0.021 |
| 5th iteration | 0.7319 | 0.7262 | 2.136 | 1.848 | 0.024 |
| Average | 0.6805 | 0.6737 | 2.448 | 1.979 | 0.0252 |
| Standard dev. | 0.0816 | 0.0834 | 0.3371 | 0.2551 | 0.0031 |
| Testing Data | RMSE | MAE | MAPE |
|---|---|---|---|
| Mic3 | 6.357 | 4.902 | 0.063 |
| Mic5 | 7.706 | 6.294 | 0.079 |
| Mic6 | 7.494 | 6.121 | 0.077 |
| Mic7 | 7.189 | 5.659 | 0.072 |
| Mic8 | 6.967 | 5.539 | 0.071 |
| Average | 7.143 | 5.703 | 0.072 |
| Standard dev. | 0.467 | 0.489 | 0.006 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Kuehnelt, H.; De Roeck, W. Traffic Noise Prediction Applying Multivariate Bi-Directional Recurrent Neural Network. Appl. Sci. 2021, 11, 2714. https://doi.org/10.3390/app11062714
Zhang X, Kuehnelt H, De Roeck W. Traffic Noise Prediction Applying Multivariate Bi-Directional Recurrent Neural Network. Applied Sciences. 2021; 11(6):2714. https://doi.org/10.3390/app11062714
Chicago/Turabian StyleZhang, Xue, Helmut Kuehnelt, and Wim De Roeck. 2021. "Traffic Noise Prediction Applying Multivariate Bi-Directional Recurrent Neural Network" Applied Sciences 11, no. 6: 2714. https://doi.org/10.3390/app11062714
APA StyleZhang, X., Kuehnelt, H., & De Roeck, W. (2021). Traffic Noise Prediction Applying Multivariate Bi-Directional Recurrent Neural Network. Applied Sciences, 11(6), 2714. https://doi.org/10.3390/app11062714