
Multimodal Unsupervised Speech Translation for Recognizing and Evaluating Second Language Speech


Abstract
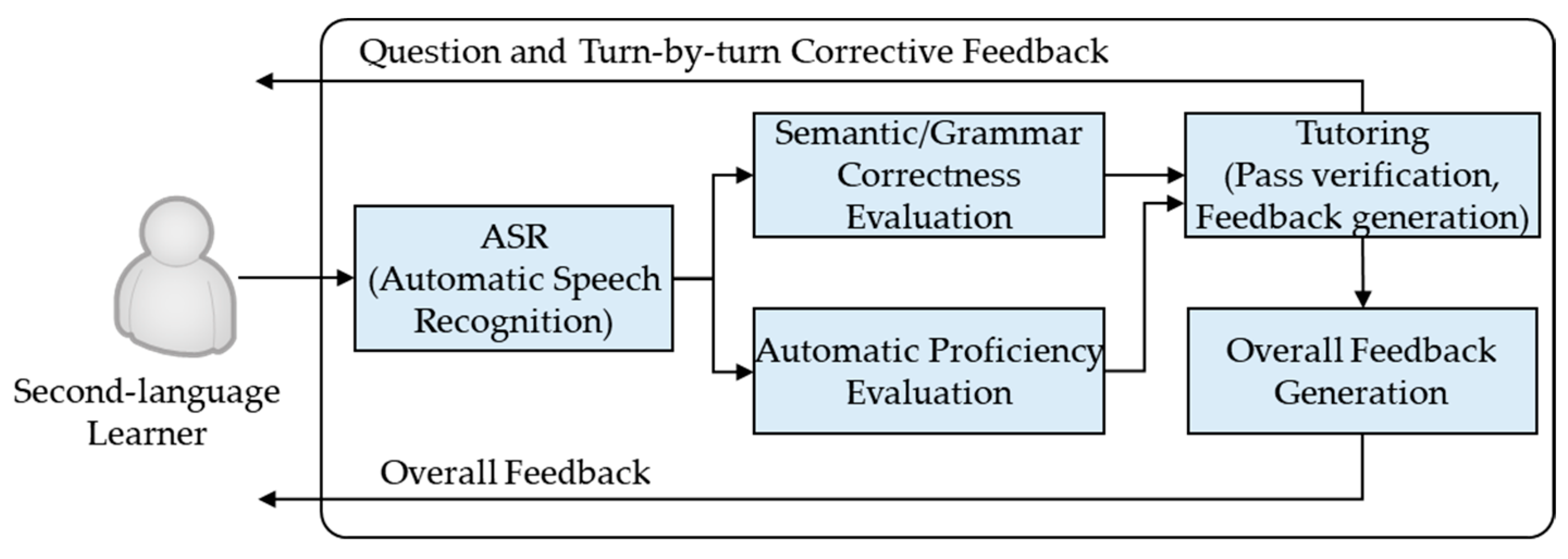
1. Introduction
2. Previous Work
3. Proposed Fluency Scoring and Automatic Proficiency Evaluation Method
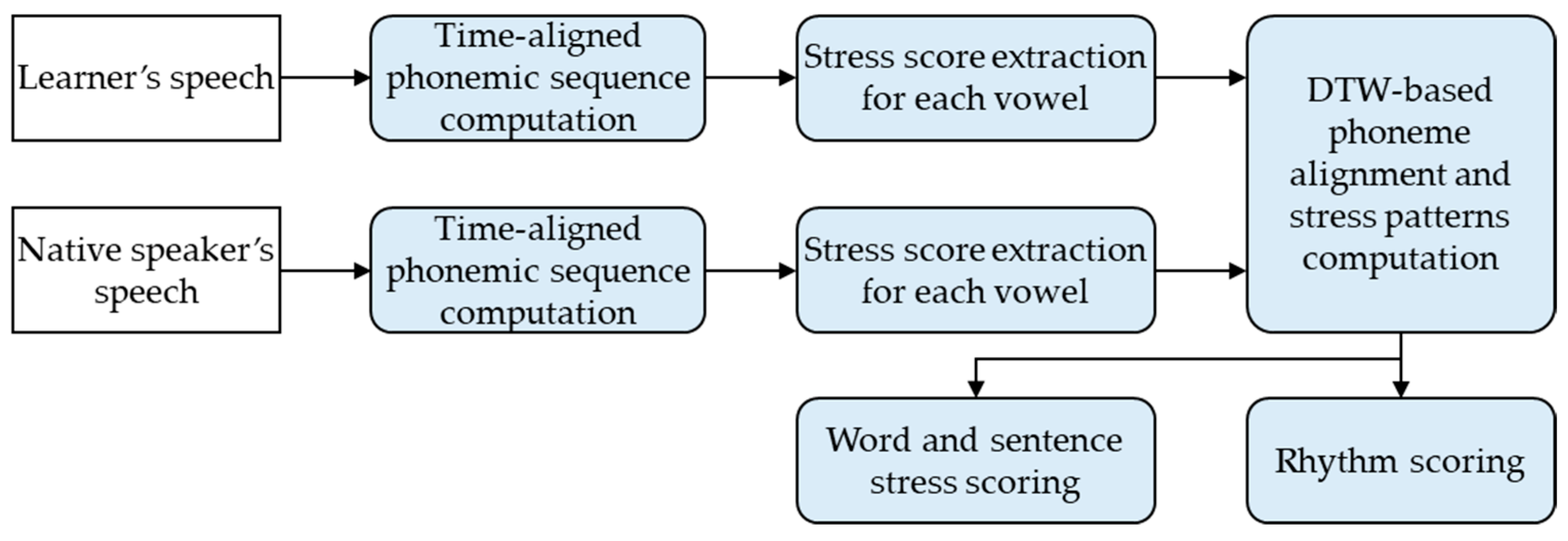
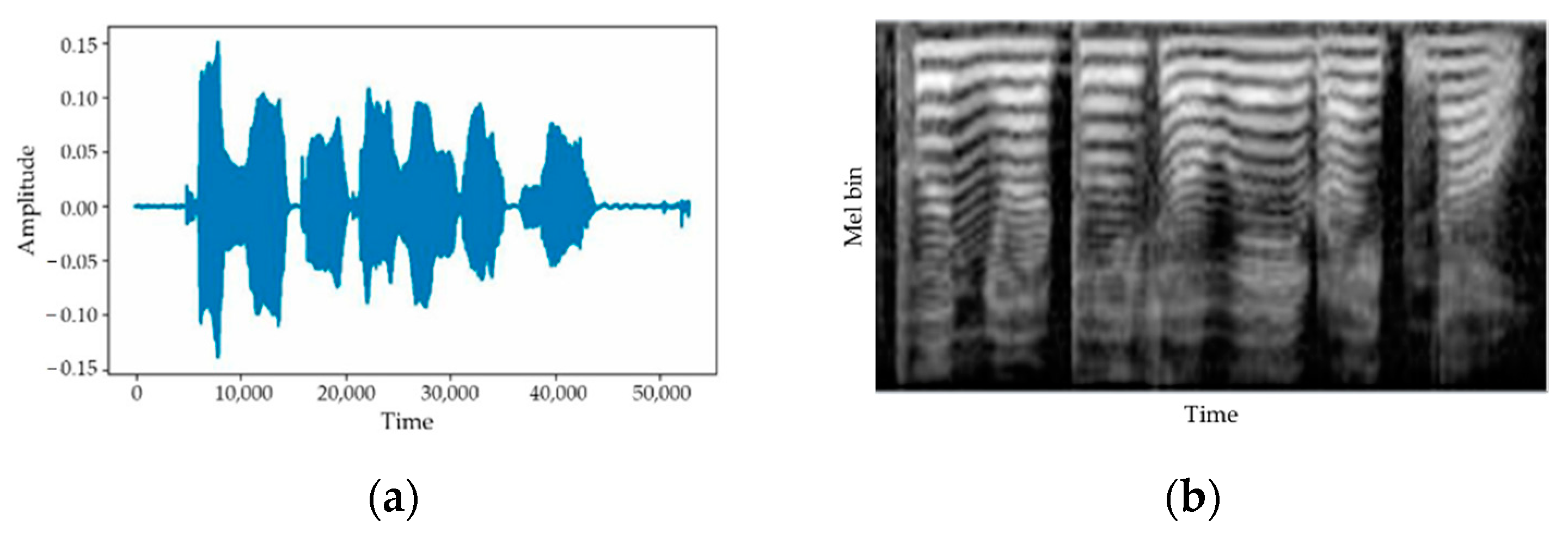
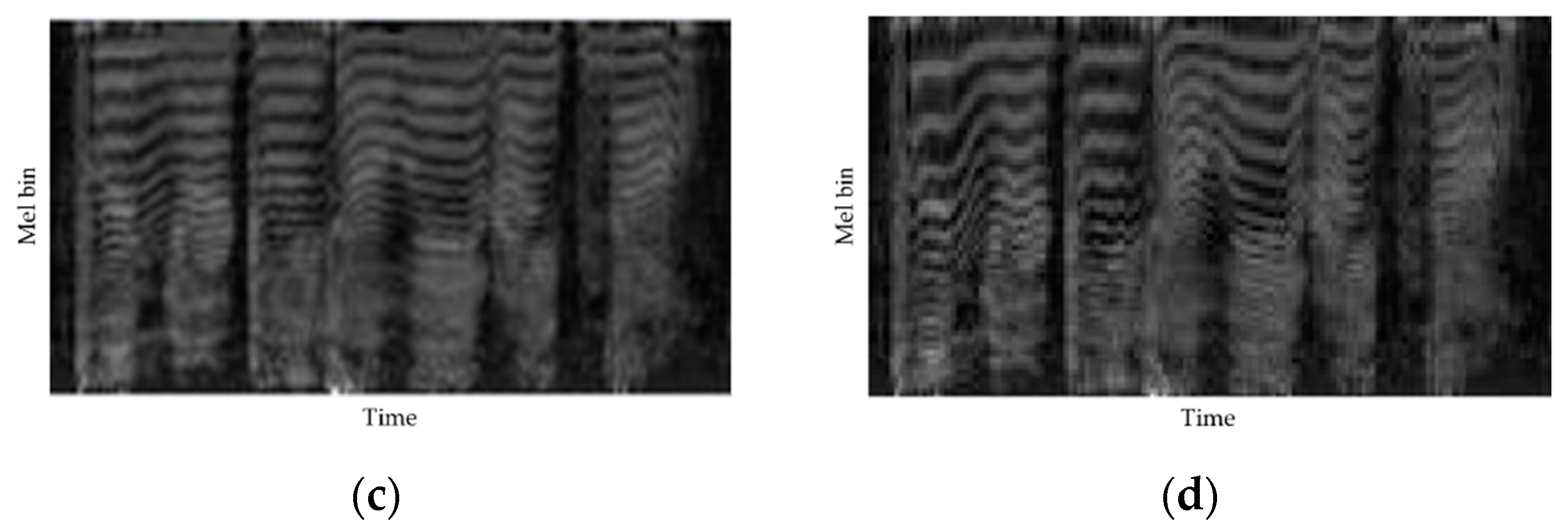
3.1. DTW-Based Feature Extraction for Fluency Scoring
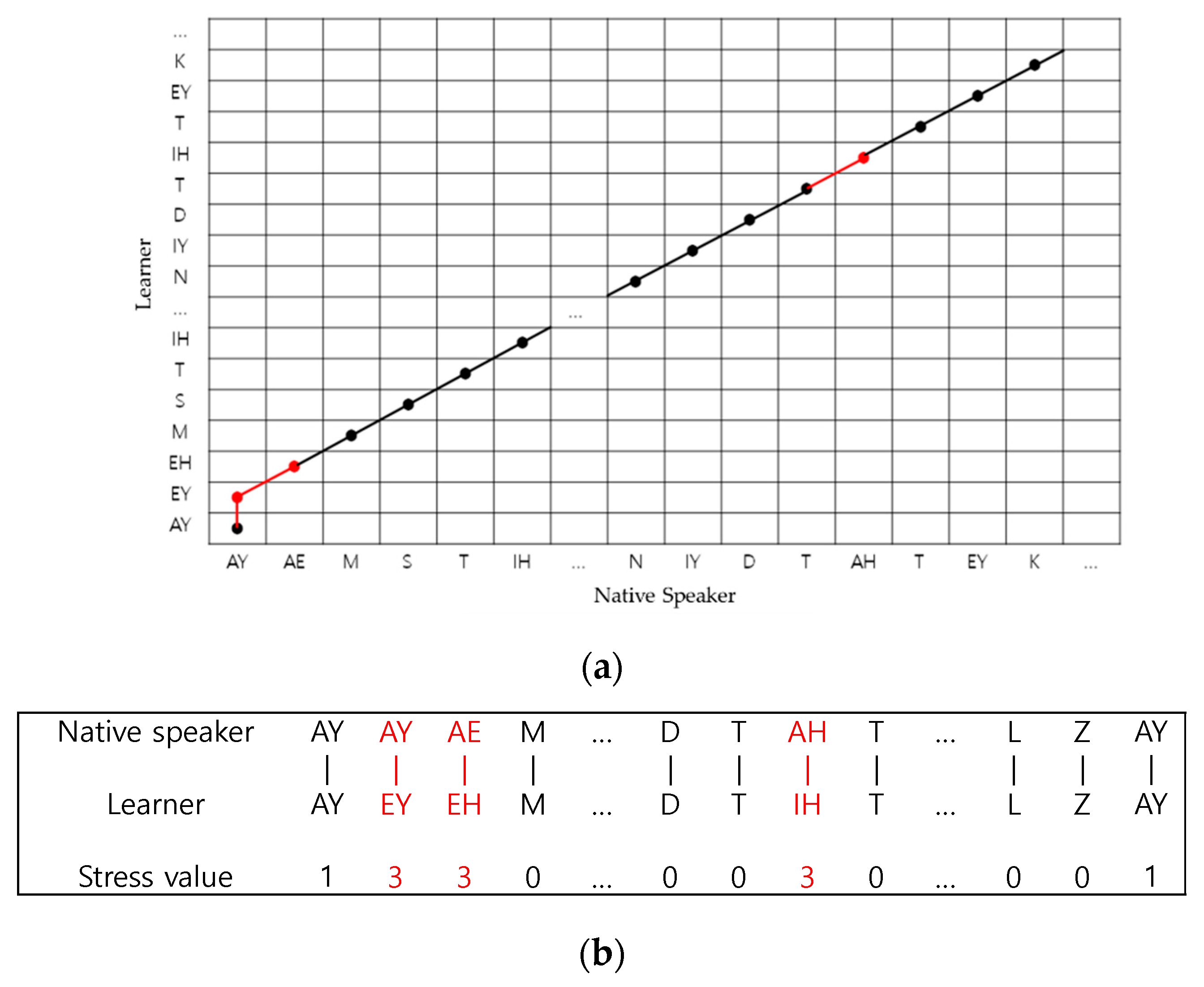
3.1.1. DTW-Based Phoneme Alignment
3.1.2. Stress and Rhythm Scoring
- Select the stressed phonemes (highlighted point in Table 1), and compute the mean and standard deviation of the time intervals between them:
- (1)
- Mean time interval:(0.2 + 0.2 + 0.6 + 0.5 + 1.5)/5 = 0.6
- (2)
- Standard deviation of the time interval:(0.16 + 0.16 + 0.0 + 0.01 + 0.81)/5 = 0.23
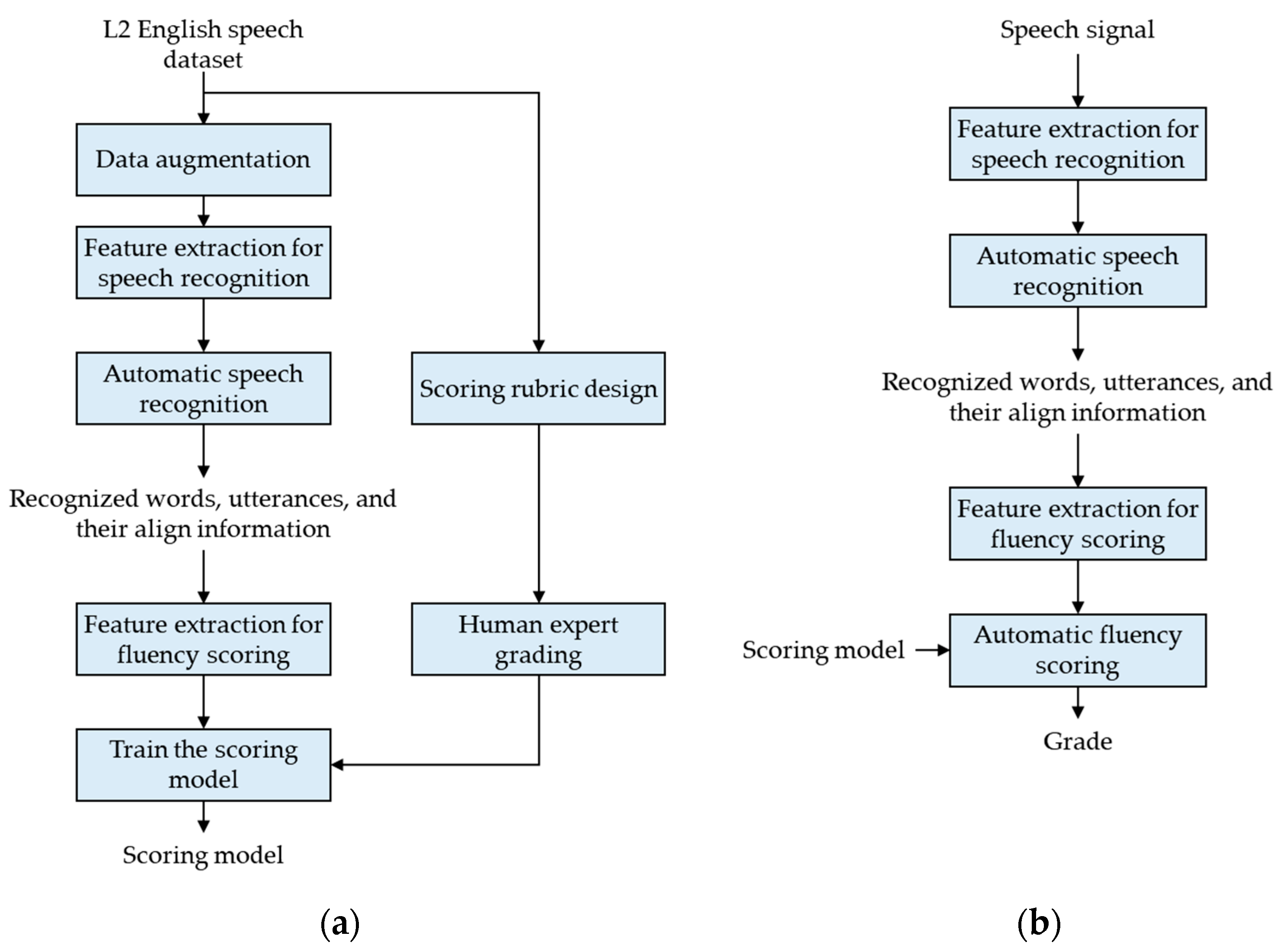
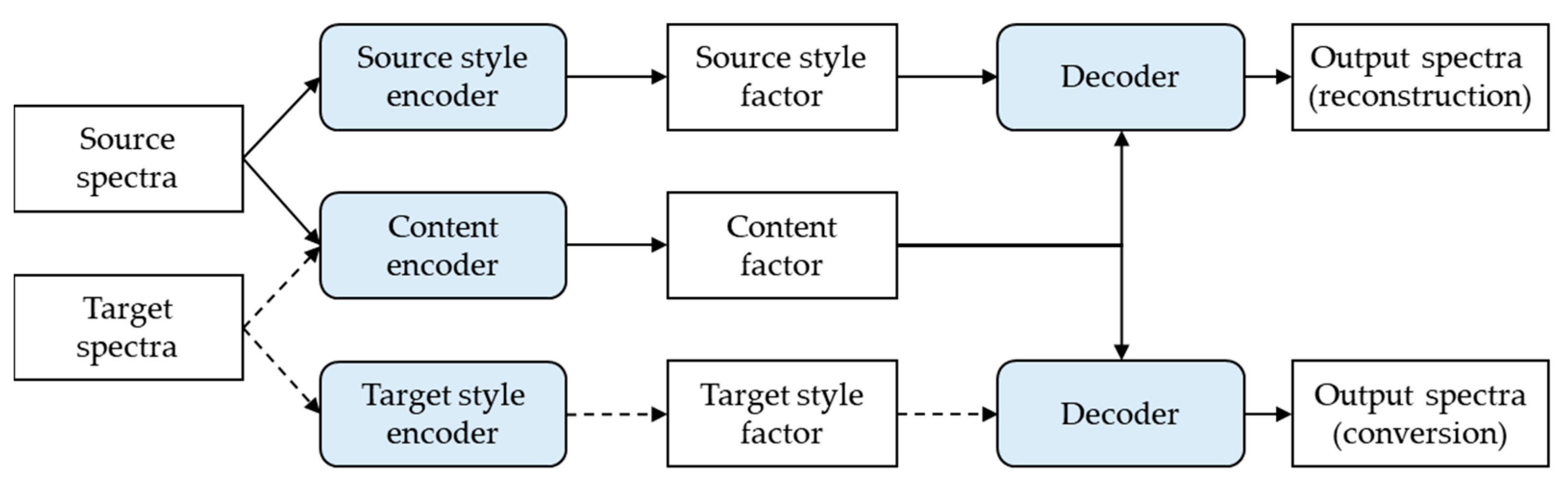
3.2. Automatic Proficiency Evaluation with Data Augmentation
4. Experimental Results
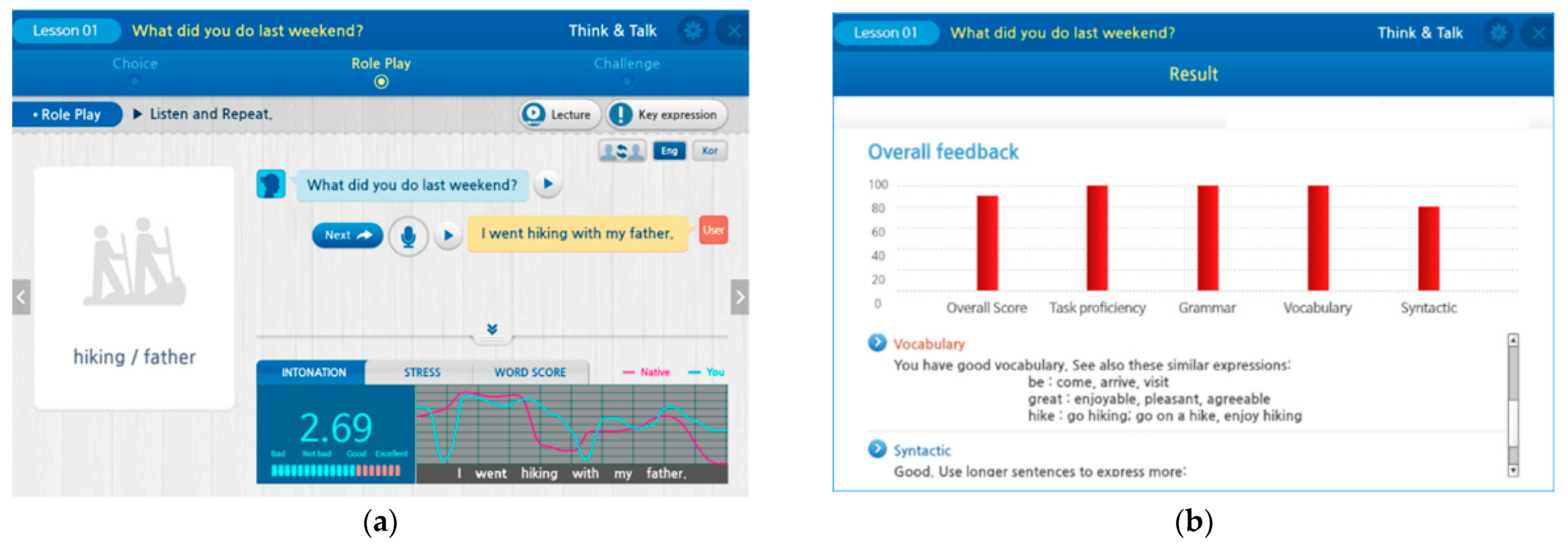
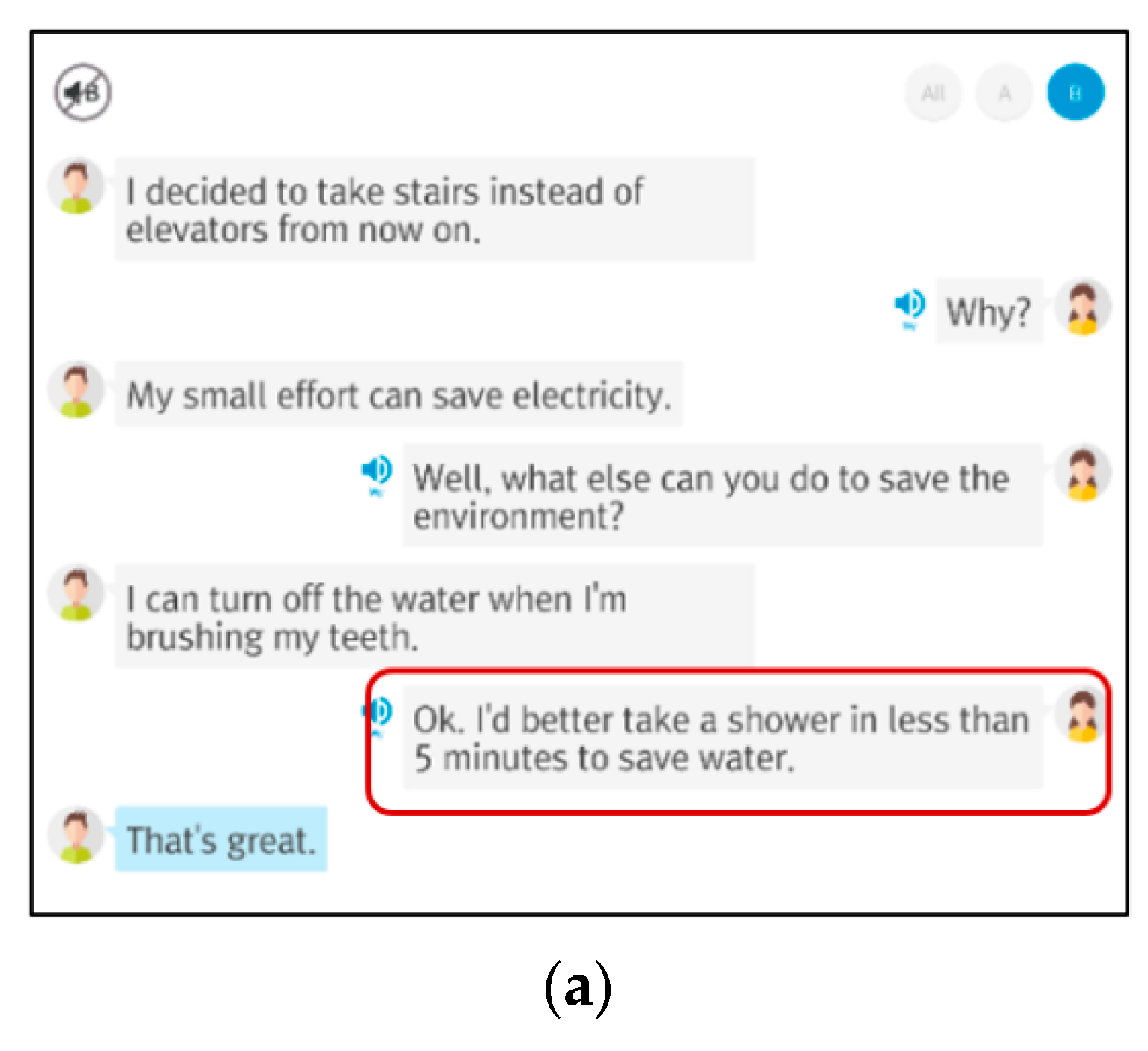
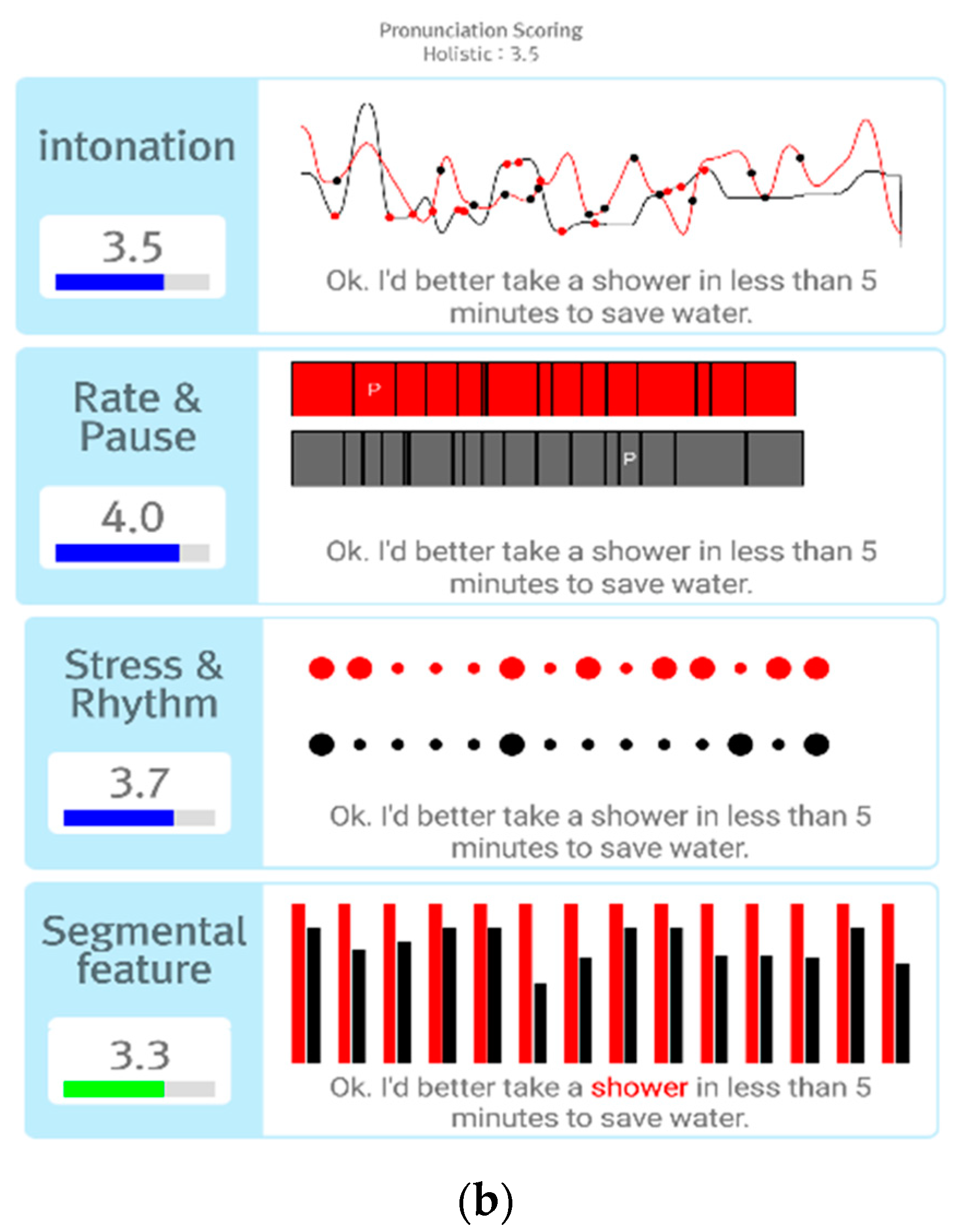
4.1. Dialogue Exercise Result
4.2. Proficiency Evaluation Test
4.2.1. Speech Database
4.2.2. Human Expert Rater
4.2.3. Data Augmentation
4.2.4. Features for Proficiency Scoring
4.2.5. Proficiency Scoring Model
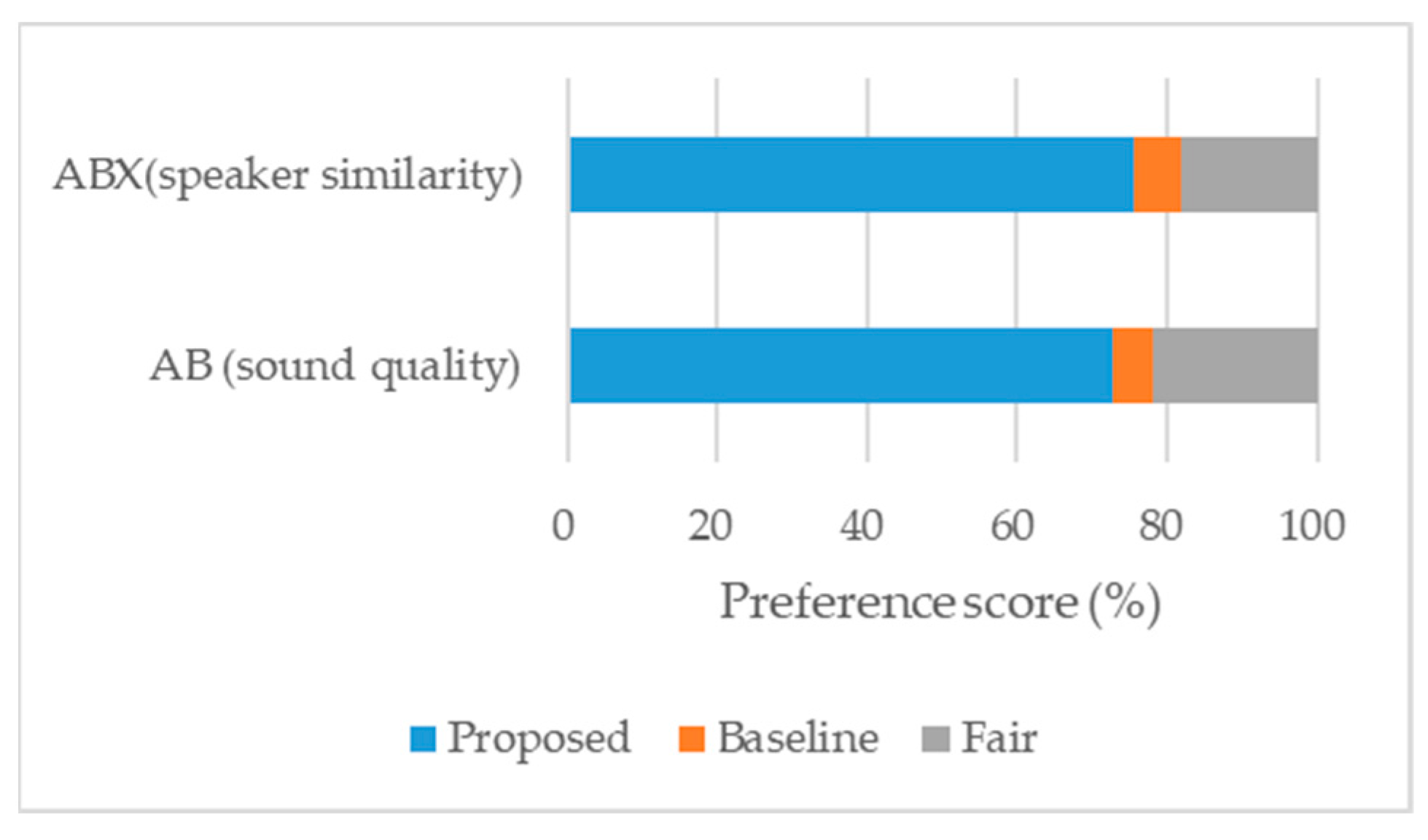
4.2.6. Proficiency Evaluation Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Eskenazi, M. An overview of spoken language technology for education. Speech Commun. 2009, 51, 832–844. [Google Scholar] [CrossRef]
- Kannan, J.; Munday, P. New Trends in Second Language Learning and Teaching through the Lens of ICT, Networked Learning, and Artificial Intelligence. Círculo de Lingüística Aplicada a la Comunicación 2018, 76, 13–30. [Google Scholar] [CrossRef]
- Gabriel, S.; Ricardo, T.; Jose, A.G. Automatic code generation for language-learning applications. IEEE Lat. Am. Trans. 2020, 18, 1433–1440. [Google Scholar]
- Chen, M.; Chen, W.; Ku, L. Application of sentiment analysis to language learning. IEEE Access 2018, 6, 24433–24442. [Google Scholar] [CrossRef]
- Song, H.J.; Lee, Y.K.; Kim, H.S. Probabilistic Bilinear Transformation Space-based Joint Maximum a Posteriori Adaptation. ETRI J. 2010, 34, 783–786. [Google Scholar] [CrossRef]
- Lee, S.J.; Kang, B.O.; Chung, H.; Lee, Y. Intra-and Inter-Frame Features for Automatic Speech Recognition. ETRI J. 2014, 36, 514–517. [Google Scholar] [CrossRef]
- Kwon, O.W.; Lee, K.; Kim, Y.-K.; Lee, Y. GenieTutor: A computer assisted second-language learning system based on semantic and grammar correctness evaluations. In Proceedings of the 2015 EUROCALL Conference, Padova, Italy, 26–29 August 2015; pp. 330–335. [Google Scholar]
- Deshmukh, O.; Kandhway, K.; Verma, A.; Audhkhasi, K. Automatic evaluation of spoken English fluency. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 4829–4832. [Google Scholar]
- Müller, M. Information Retrieval for Music and Motion; Springer: New York, NY, USA, 2007; pp. 69–84. [Google Scholar]
- Rahman, M.M.; Saha, S.K.; Hossain, M.Z.; Islam, M.B. Performance Evaluation of CMN for Mel-LPC based Speech Recognition in Different Noisy Environments. Int. J. Comput. Appl. 2012, 58, 6–10. [Google Scholar]
- Hermansky, H.; Morgan, N. RASTA Processing of Speech. IEEE Trans. Speech Audio Process. 1994, 2, 578–589. [Google Scholar] [CrossRef]
- You, H.; Alwan, A. Tenporal Modulation Processing of Speech Signals for Noise Robust ASR. In Proceedings of the Tenth Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009; pp. 36–39. [Google Scholar]
- Cadzow, J.A. Blind Deconvolution via Cumulant Extrema. IEEE Signal Process. Mag. 1993, 13, 24–42. [Google Scholar] [CrossRef]
- Chen, L.; Zechner, K.; Yoon, S.Y.; Evanini, K.; Wang, X.; Loukina, A.; Tao, J.; Davis, L.; Lee, C.M.; Ma, M.; et al. Automated scoring of nonnative speech using the SpeechRatorSM v. 5.0 Engine. ETS Res. Rep. Ser. 2018, 2018, 1–31. [Google Scholar] [CrossRef]
- Bell, A.J.; Sejnowski, T.J. An Information-Maximization Approach to Blind Separation and Blind Deconvolution. Neural Comput. 1995, 7, 1129–1159. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.H.; Amari, S. Adaptive on-Line Learning Algorithms for Blind Separation—Maximum Entropy and Minimum Mutual Information. Neural Comput. 1997, 9, 1457–1482. [Google Scholar] [CrossRef]
- Loizou, P.C. Speech Enhancement; CRC Press: Boca Raton, FL, USA, 2007; pp. 97–289. [Google Scholar]
- Papoulis, A. Probability, Random Variables, and Stochastic Processes; McGraw-Hill: New York, NY, USA, 1991. [Google Scholar]
- Oppenheim, A.V.; Schaefer, R.W. Digital Signal Processing; Prentice-Hall: Upper Saddle River, NJ, USA, 1989. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio Augmentation for Speech Recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3586–3589. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Celin, T.; Nagarajan, T.; Vijayalakshmi, P. Data Augmentation Using Virtual Microphone Array Synthesis and Multi-Resolution Feature Extraction for Isolated Word Dysarthric Speech Recognition. IEEE J. Sel. Top. Signal Process. 2020, 14, 346–354. [Google Scholar]
- Oh, Y.R.; Park, K.; Jeon, H.-B.; Park, J.G. Automatic proficiency assessment of Korean speech read aloud by non-natives using bidirectional LSTM-based speech recognition. ETRI J. 2020, 42, 761–772. [Google Scholar] [CrossRef]
- Sun, X.; Yang, Q.; Liu, S.; Yuan, X. Improving low-resource speech recognition based on improved NN-HMM structures. IEEE Access 2020, 8, 73005–73014. [Google Scholar] [CrossRef]
- Yang, S.; Wang, Y.; Xie, L. Adversarial feature learning and unsupervised clustering based speech synthesis for found data with acoustic and textual noise. IEEE Signal Process. Lett. 2020, 27, 1730–1734. [Google Scholar] [CrossRef]
- Hsu, C.; Hwang, H.; Wu, Y.; Tsao, Y.; Wang, H. Voice conversion from non-parallel corpora using variational autoencoder. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference, Jeju, Korea, 13–15 December 2016; pp. 1–6. [Google Scholar]
- Hsu, W.-N.; Zhang, Y.; Glass, J. Unsupervised learning of disentangled and interpretable representations from sequential data. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1878–1889. [Google Scholar]
- Saito, Y.; Ijima, Y.; Nishida, K.; Takamichi, S. Non-parallel voice conversion using variational autoencoders conditioned by phonetic posteriorgrams and d-vectors. In Proceedings of the ICASSP, Calgary, AB, Canada, 15–20 April 2018; pp. 5274–5278. [Google Scholar]
- Tobing, P.L.; Wu, Y.-C.; Hayashi, T.; Kobayashi, K.; Toda, T. Non-parallel voice conversion with cyclic variational autoencoder. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 674–678. [Google Scholar]
- Kang, B.O.; Jeon, H.B.; Park, J.G. Speech recognition for task domains with sparse matched training data. Appl. Sci. 2020, 10, 6155. [Google Scholar] [CrossRef]
- Wang, Y.; Dai, B.; Hua, G.; Aston, J.; Wipf, D. Recurrent variational autoencoders for learning nonlinear generative models in the presence of outliers. IEEE J. Sel. Top. Signal Process. 2018, 12, 1615–1627. [Google Scholar] [CrossRef]
- Cristovao, P.; Nakada, H.; Tanimura, Y.; Asoh, H. Generating in-between images through learned latent space representation using variational autoencoders. IEEE Access 2020, 8, 149456–149467. [Google Scholar] [CrossRef]
- Kameoka, H.; Kaneko, T.; Tanaka, K.; Hojo, N. ACVAE-VC: Non-parallel voice conversion with auxiliary classifier variational autoencoder. IEEE Acm Trans. Audio Speech Lang. Process. 2019, 27, 1432–1443. [Google Scholar] [CrossRef]
- Kameoka, H.; Kaneko, T.; Tanaka, K.; Hojo, N. Stargan-vc: Non-parallel many-to-many voice conversion using star generative adversarial networks. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 266–273. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Saito, Y.; Takamichi, S.; Saruwatari, H. Statistical parametric speech synthesis incorporating generative adversarial networks. IEEE Acm Trans. Audio Speech Lang. Process. 2018, 26, 84–96. [Google Scholar] [CrossRef]
- Oyamada, K.; Kameoka, H.; Kaneko, T.; Tanaka, K.; Hojo, N.; Ando, H. Generative adversarial network-based approach to signal reconstruction from magnitude spectrograms. In Proceedings of the EUSIPCO, Rome, Italy, 3–7 September 2018; pp. 2514–2518. [Google Scholar]
- Gu, J.; Shen, Y.; Zhou, B. Image processing using multi-code gan prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017. [Google Scholar]
- Hsu, C.-C.; Hwang, H.-T.; Wu, Y.-C.; Tsao, Y.; Wang, H.-M. Voice conversion from unaligned corpora using variational autoencoding Wasserstein generative adversarial networks. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 3164–3168. [Google Scholar]
- Liu, X.; Gherbi, A.; Wei, Z.; Li, W.; Cheriet, M. Multispectral image reconstruction from color images using enhanced variational autoencoder and generative adversarial network. IEEE Access 2021, 9, 1666–1679. [Google Scholar] [CrossRef]
- Wang, X.; Tan, K.; Du, Q.; Chen, Y.; Du, P. CVA2E: A conditional variational autoencoder with an adversarial training process for hyperspectral imagery classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5676–5692. [Google Scholar] [CrossRef]
- Weng, Z.; Zhang, W.; Dou, W. Adversarial attention-based variational graph autoencoder. IEEE Access 2020, 8, 152637–152645. [Google Scholar] [CrossRef]
- Gao, J.; Chakraborty, D.; Tembine, H.; Olaleye, O. Nonparallel emotional speech conversion. In Proceedings of the Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 2858–2862. [Google Scholar]
- Huang, X.; Liu, M.; Belongie, S.J.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Lee, Y.K.; Kim, H.W.; Park, J.G. Many-to-many unsupervised speech conversion from nonparallel corpora. IEEE Access 2021, 9, 27278–27286. [Google Scholar] [CrossRef]
- Chung, H.; Lee, Y.K.; Lee, S.J.; Park, J.G. Spoken english fluency scoring using convolutional neural networks. In Proceedings of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Korea, 1–3 November 2017; pp. 1–6. [Google Scholar]
- Huang, C.; Akagi, M. A three-layered model for expressive speech perception. Speech Commun. 2008, 50, 810–828. [Google Scholar] [CrossRef]
- Huang, X.; Belongie, S.J. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Enrique Yalta Soplin, N.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-toend speech processing toolkit. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2207–2211. [Google Scholar]
- Sisman, B.; Zhang, M.; Li, H. Group sparse representation with WaveNet Vocoder adaptation for spectrum and prosody conversion. IEEE ACM Trans. Audio Speech Lang. Process. 2019, 27, 1085–1097. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. In Noise Reduction Speech Processing; Springer: Berlin, Germany, 2009; pp. 1–4. [Google Scholar]
- Zhou, K.; Sisman, B.; Li, H. Transforming Spectrum and Prosody for Emotional Voice Conversion with Non-Parallel Training Data. In Proceedings of the Odyssey 2020 the Speaker and Language Recognition Workshop, Tokyo, Japan, 2–5 November 2020; pp. 230–237. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Word | Start Time | End Time | Stress Value |
|---|---|---|---|
| I | 0.0 | 0.2 | 1 |
| am | 0.2 | 0.4 | 1 |
| still | 0.4 | 0.8 | 2 |
| very | 0.8 | 1.0 | 0 |
| sick | 1.0 | 1.3 | 1 |
| I | 1.4 | 1.5 | 0 |
| need | 1.5 | 1.8 | 1 |
| to | 1.8 | 2.0 | 0 |
| take | 2.0 | 2.2 | 0 |
| some | 2.2 | 2.5 | 0 |
| pills | 2.5 | 3.0 | 0 |
| Proficiency Score | Mean Time Interval | Standard Deviation of the Time Interval |
|---|---|---|
| 1 | 1.12 | 0.62 |
| 2 | 0.82 | 0.42 |
| 3 | 0.68 | 0.34 |
| 4 | 058 | 0.32 |
| 5 | 0.56 | 0.31 |
| No. | Sentence |
|---|---|
| 1 | My pet bird sleeps in the cage. |
| 2 | I eat fruits when I am hungry. |
| 3 | Miss Henry drank a cup of coffee. |
| … | |
| 100 | They suspect that the suspect killed Ted. |
| Rater | 2 | 3 | 4 |
|---|---|---|---|
| 1 | 0.79 | 0.75 | 0.80 |
| 2 | - | 0.81 | 0.83 |
| 3 | - | - | 0.80 |
| Proficiency Level | Applied Method | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| Train database only | - | 57.3 | 53.4 | 30.1 | 23.4 | 22.7 |
| Augmentation | SpecAugment | 52.1 | 45.4 | 27.2 | 21.9 | 20.6 |
| Speed perturbation | 51.3 | 44.9 | 27.0 | 21.8 | 20.7 | |
| CVAE-SC | 49.3 | 43.1 | 26.0 | 21.5 | 20.4 | |
| Proposed method | 40.9 | 37.7 | 24.5 | 20.5 | 19.1 |
| Feature Name | Description |
|---|---|
| Genie_pron | Pronunciation score |
| SLLR | Sentence-level log-likelihood ratio |
| amscore0/amscore1 | Acoustic model (AM) score/anti-model-based AM score |
| Uttsegdur | Duration of entire transcribed segment but without inter-utterance pauses |
| Globsegdur | Duration of entire transcribed segment, including all pauses |
| wpsec/wpsecutt | Speech articulation rate/words per second in utterance |
| Silpwd/Silpsec | Number of silences per word/second |
| Numsil | Number of silences |
| Silmean/Silmeandev/Silstddev | Mean/mean deviation/standard deviation of silence duration in second |
| Longpfreq/Longpwd | Frequency/number of long pauses per word (0.495 s ≤ duration) |
| Longpmn/Longpmeandev/ Longpstddev | Mean/mean deviation/standard deviation of long pauses |
| Wdpchk/Secpchk | Average speech chunk length in words/seconds |
| Wdpchkmeandev/Secpchkmeandev | Mean deviation of chunks in words/seconds |
| Repfeq | Number of repetitions divided by number of words |
| Tpsec | Types (unique words) per second |
| Tpsecutt | Types normalized by speech duration |
| Wdstress/Uttstress | Word/sentence stress score |
| Rhymean/Rhystddev | Mean/standard deviation of rhythm score |
| FlucMean/Flucstddev | Mean/standard deviation of the range of fluctuation |
| propV | Vocalic segment duration ratio in sentence |
| deltaV/deltaC | Standard deviation of vocalic/consonantal segment duration |
| varcoV/varcoC | Standard deviation of vocalic/consonantal segment duration normalized by speech rate |
| Genie_amscoreK0/ Genie_amscoreK1 | AM score/anti-model AM score reflecting Korean pronunciation characteristics of English |
| Numdff | Number of disfluencies |
| Dpsec | Disfluencies per second |
| Rater | Human | MLR | Neural Network |
|---|---|---|---|
| Holistic | 0.68~0.79 | 0.78 | 0.82 |
| Intonation | 0.64~0.72 | 0.73 | 0.77 |
| Stress and rhythm | 0.71~0.74 | 0.75 | 0.78 |
| Speech rate and pause | 0.71~0.75 | 0.75 | 0.77 |
| Segmental features | 0.59~0.67 | 0.69 | 0.73 |
| Rater | Human | MLR | Neural Network |
|---|---|---|---|
| Holistic | 0.68~0.79 | 0.83 | 0.84 |
| Intonation | 0.64~0.72 | 0.78 | 0.80 |
| Stress and rhythm | 0.71~0.74 | 0.78 | 0.79 |
| Speech rate and pause | 0.71~0.75 | 0.81 | 0.82 |
| Segmental features | 0.59~0.67 | 0.73 | 0.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.K.; Park, J.G. Multimodal Unsupervised Speech Translation for Recognizing and Evaluating Second Language Speech. Appl. Sci. 2021, 11, 2642. https://doi.org/10.3390/app11062642
Lee YK, Park JG. Multimodal Unsupervised Speech Translation for Recognizing and Evaluating Second Language Speech. Applied Sciences. 2021; 11(6):2642. https://doi.org/10.3390/app11062642
Chicago/Turabian StyleLee, Yun Kyung, and Jeon Gue Park. 2021. "Multimodal Unsupervised Speech Translation for Recognizing and Evaluating Second Language Speech" Applied Sciences 11, no. 6: 2642. https://doi.org/10.3390/app11062642
APA StyleLee, Y. K., & Park, J. G. (2021). Multimodal Unsupervised Speech Translation for Recognizing and Evaluating Second Language Speech. Applied Sciences, 11(6), 2642. https://doi.org/10.3390/app11062642