
Detecting Crop Circles in Google Earth Images with Mask R-CNN and YOLOv3


 ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Proposed Methodology
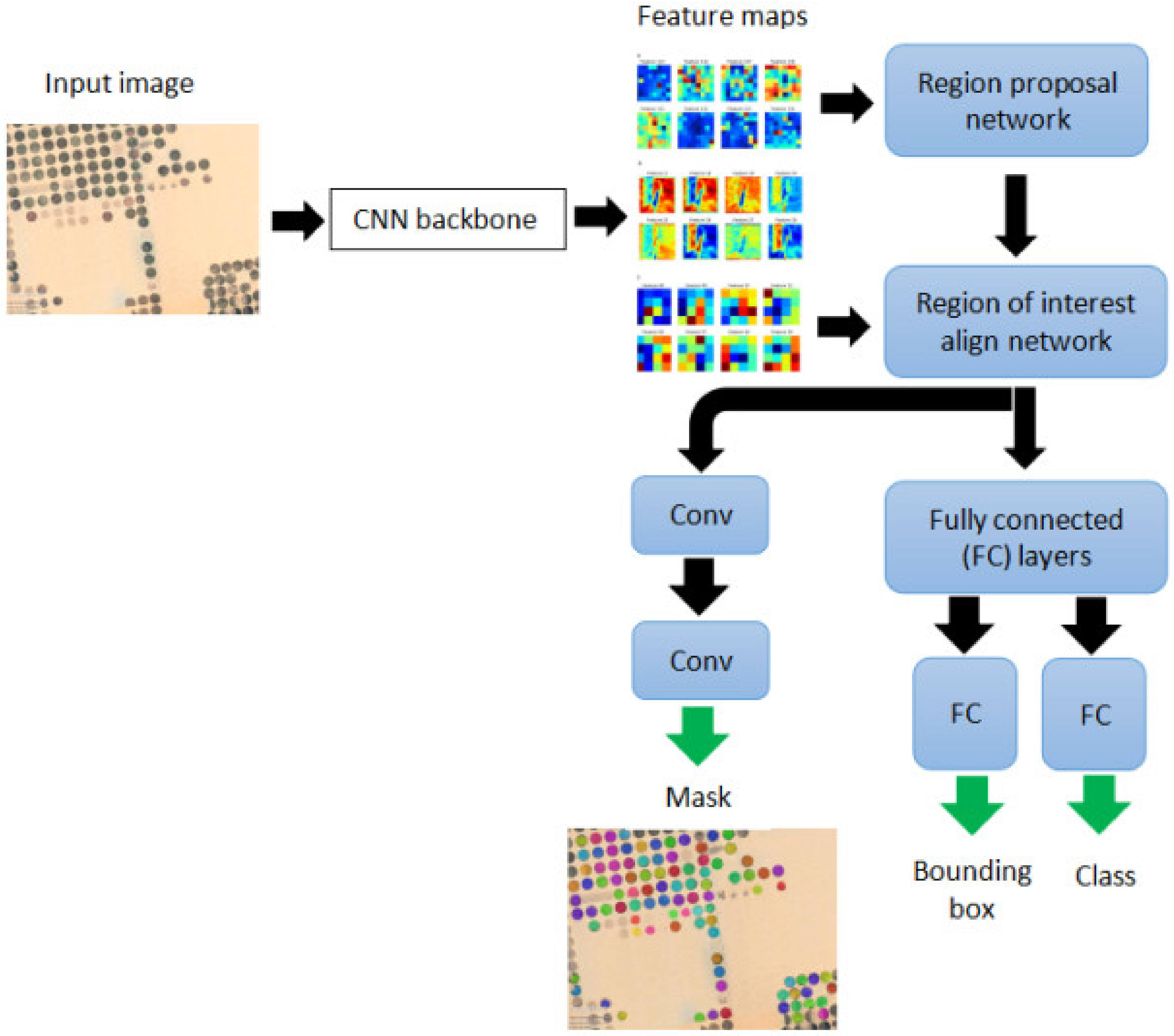
2.1. Mask R-CNN
2.2. YOLOv3
3. Experimental Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Alhawiti, H.; Bazi, Y.; Rahhal, M.M.A.; Alhichri, H.; Zuair, M.A. Deep Learning Approach for Multiple Source Classification in Remote Sensing Imagery. In Proceedings of the 2020 3rd International Conference on Computer Applications Information Security (ICCAIS), Riyadh, Saudi Arabia, 19–21 March 2020; pp. 1–4. [Google Scholar]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep Learning in Environmental Remote Sensing: Achievements and Challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of Deep-Learning Approaches for Remote Sensing Observation Enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef]
- Rahhal, M.M.A.; Bazi, Y.; Al-Hwiti, H.; Alhichri, H.; Alajlan, N. Adversarial Learning for Knowledge Adaptation from Multiple Remote Sensing Sources. IEEE Geosci. Remote Sens. Lett. 2020, 1–5. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When Deep Learning Meets Metric Learning: Remote Sensing Image Scene Classification via Learning Discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep Learning Based Feature Selection for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Das, M.; Ghosh, S.K. Deep-STEP: A Deep Learning Approach for Spatiotemporal Prediction of Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1984–1988. [Google Scholar] [CrossRef]
- Xie, F.; Shi, M.; Shi, Z.; Yin, J.; Zhao, D. Multilevel Cloud Detection in Remote Sensing Images Based on Deep Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3631–3640. [Google Scholar] [CrossRef]
- Wang, S.; Quan, D.; Liang, X.; Ning, M.; Guo, Y.; Jiao, L. A Deep Learning Framework for Remote Sensing Image Registration. ISPRS J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Gong, M.; Yang, H.; Zhang, P. Feature Learning and Change Feature Classification Based on Deep Learning for Ternary Change Detection in SAR Images. ISPRS J. Photogramm. Remote Sens. 2017, 129, 212–225. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-Scale Object Detection in Remote Sensing Imagery with Convolutional Neural Networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Zhang, S.; He, G.; Chen, H.; Jing, N.; Wang, Q. Scale Adaptive Proposal Network for Object Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 864–868. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-Insensitive and Context-Augmented Object Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2337–2348. [Google Scholar] [CrossRef]
- Diao, W.; Sun, X.; Zheng, X.; Dou, F.; Wang, H.; Fu, K. Efficient Saliency-Based Object Detection in Remote Sensing Images Using Deep Belief Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 137–141. [Google Scholar] [CrossRef]
- Coulibaly, S.; Kamsu-Foguem, B.; Kamissoko, D.; Traore, D. Deep Neural Networks with Transfer Learning in Millet Crop Images. Comput. Ind. 2019, 108, 115–120. [Google Scholar] [CrossRef]
- Zhong, L.; Hu, L.; Zhou, H. Deep Learning Based Multi-Temporal Crop Classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Chandel, N.S.; Chakraborty, S.K.; Rajwade, Y.A.; Dubey, K.; Tiwari, M.K.; Jat, D. Identifying Crop Water Stress Using Deep Learning Models. Neural Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant. Sci. 2016, 7. [Google Scholar] [CrossRef] [PubMed]
- Dyson, J.; Mancini, A.; Frontoni, E.; Zingaretti, P. Deep Learning for Soil and Crop Segmentation from Remotely Sensed Data. Remote Sens. 2019, 11, 1859. [Google Scholar] [CrossRef]
- Mekhalfi, M.L.; Nicolò, C.; Ianniello, I.; Calamita, F.; Goller, R.; Barazzuol, M.; Melgani, F. Vision System for Automatic On-Tree Kiwifruit Counting and Yield Estimation. Sensors 2020, 20, 4214. [Google Scholar] [CrossRef]
- Ashapure, A.; Jung, J.; Chang, A.; Oh, S.; Yeom, J.; Maeda, M.; Maeda, A.; Dube, N.; Landivar, J.; Hague, S.; et al. Developing a Machine Learning Based Cotton Yield Estimation Framework Using Multi-Temporal UAS Data. ISPRS J. Photogramm. Remote Sens. 2020, 169, 180–194. [Google Scholar] [CrossRef]
- Ashapure, A.; Oh, S.; Marconi, T.G.; Chang, A.; Jung, J.; Landivar, J.; Enciso, J. Unmanned Aerial System Based Tomato Yield Estimation Using Machine Learning. In Proceedings of the Autonomous Air and Ground Sensing Systems for Agricultural Optimization and Phenotyping IV, Baltimore, MD, USA, 14 May 2019; Volume 11008, p. 110080O. [Google Scholar]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine Learning in Agriculture: A Review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine Learning Approaches for Crop Yield Prediction and Nitrogen Status Estimation in Precision Agriculture: A Review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Crane-Droesch, A. Machine Learning Methods for Crop Yield Prediction and Climate Change Impact Assessment in Agriculture. Environ. Res. Lett. 2018, 13, 114003. [Google Scholar] [CrossRef]
- Mekonnen, Y.; Namuduri, S.; Burton, L.; Sarwat, A.; Bhansali, S. Review—Machine Learning Techniques in Wireless Sensor Network Based Precision Agriculture. J. Electrochem. Soc. 2019, 167, 037522. [Google Scholar] [CrossRef]
- Sharma, R.; Kamble, S.S.; Gunasekaran, A.; Kumar, V.; Kumar, A. A Systematic Literature Review on Machine Learning Applications for Sustainable Agriculture Supply Chain Performance. Comput. Oper. Res. 2020, 119, 104926. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep Learning in Agriculture: A Survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Drury, B.; Valverde-Rebaza, J.; Moura, M.-F.; de Andrade Lopes, A. A Survey of the Applications of Bayesian Networks in Agriculture. Eng. Appl. Artif. Intell. 2017, 65, 29–42. [Google Scholar] [CrossRef]
- Vuola, A.O.; Akram, S.U.; Kannala, J. Mask- and U-net ensembled for nuclei segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging, Venice, Italy, 8–11 April 2019; pp. 208–212. [Google Scholar]
- Yu, Y.; Zhang, K.; Yang, L.; Zhang, D. Fruit detection for strawberry harvesting robot in non-structural environment based on Mask-RCNN. Comput. Electron. Agric. 2019, 163, 104846. [Google Scholar] [CrossRef]
- Zhang, Q.; Chang, X.; Bian, S.B. Vehicle-damage-detection segmentation algorithm based on improved mask RCNN. IEEE Access 2020, 8, 6997–7004. [Google Scholar] [CrossRef]
- Couteaux, V.; Si-Mohamed, S.; Nempont, O.; Lefevre, T.; Popoff, A.; Pizaine, G.; Villain, N.; Bloch, I.; Cotten, A.; Boussel, L. Automatic knee meniscus tear detection and orientation classification with Mask-RCNN. Diagn. Interv. Imaging 2019, 100, 235–242. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.A.; Akram, T.; Zhang, Y.D.; Sharif, M. Attributes based skin lesion detection and recognition: A mask RCNN and transfer learning-based deep learning framework. Pattern Recognit. Lett. 2021, 143, 58–66. [Google Scholar] [CrossRef]
- Benjdira, B.; Khursheed, T.; Koubaa, A.; Ammar, A.; Ouni, K. Car detection using unmanned aerial vehicles: Comparison between faster r-cnn and yolov3. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman (UVS), Muscat, Oman, 5–7 February 2019; pp. 1–6. [Google Scholar]
- Tian, Y.; Yang, G.; Wang, Z.; Li, E.; Liang, Z. Detection of Apple Lesions in Orchards Based on Deep Learning Methods of CycleGAN and YOLOV3-Dense. J. Sens. 2019, 2019, 1–13. [Google Scholar] [CrossRef]
- Tian, Y.; Yang, G.; Wang, Z.; Wang, H.; Li, E.; Liang, Z. Apple detection during different growth stages in orchards using the improved YOLO-V3 model. Comput. Electron. Agric. 2019, 157, 417–426. [Google Scholar] [CrossRef]
- Huang, Y.Q.; Zheng, J.C.; Sun, S.D.; Yang, C.F.; Liu, J. Optimized YOLOv3 algorithm and its application in traffic flow detections. Appl. Sci. 2020, 10, 3079. [Google Scholar] [CrossRef]
- Ma, H.; Liu, Y.; Ren, Y.; Yu, J. Detection of Collapsed Buildings in Post-Earthquake Remote Sensing Images Based on the Improved YOLOv3. Remote Sens. 2019, 12, 44. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Dutta, A.; Zisserman, A. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia—ACM, Nice, France, 15 October 2019; pp. 2276–2279. [Google Scholar]
- Mirmahboub, B.; Mekhalfi, M.L.; Murino, V. Person re-identification by order-induced metric fusion. Neurocomputing 2018, 275, 667–676. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | Inference Time/Image (s) | |
|---|---|---|---|
| Mask R-CNN | 1.00 | 0.82 | 3 |
| YOLOv3 | 0.88 | 0.94 | 0.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mekhalfi, M.L.; Nicolò, C.; Bazi, Y.; Al Rahhal, M.M.; Al Maghayreh, E. Detecting Crop Circles in Google Earth Images with Mask R-CNN and YOLOv3. Appl. Sci. 2021, 11, 2238. https://doi.org/10.3390/app11052238
Mekhalfi ML, Nicolò C, Bazi Y, Al Rahhal MM, Al Maghayreh E. Detecting Crop Circles in Google Earth Images with Mask R-CNN and YOLOv3. Applied Sciences. 2021; 11(5):2238. https://doi.org/10.3390/app11052238
Chicago/Turabian StyleMekhalfi, Mohamed Lamine, Carlo Nicolò, Yakoub Bazi, Mohamad Mahmoud Al Rahhal, and Eslam Al Maghayreh. 2021. "Detecting Crop Circles in Google Earth Images with Mask R-CNN and YOLOv3" Applied Sciences 11, no. 5: 2238. https://doi.org/10.3390/app11052238
APA StyleMekhalfi, M. L., Nicolò, C., Bazi, Y., Al Rahhal, M. M., & Al Maghayreh, E. (2021). Detecting Crop Circles in Google Earth Images with Mask R-CNN and YOLOv3. Applied Sciences, 11(5), 2238. https://doi.org/10.3390/app11052238