
Improved Power Normalized Cepstrum Coefficient Based on Wavelet Packet Decomposition for Trunk Borer Detection in Harsh Acoustic Environment

 , ,
, ,
Abstract
1. Introduction
2. Feasibility Analysis of Related Work
- Basic features;
- Time domain features;
- Frequency domain features;
- Time–frequency domain features;
- Other transform domain features;
3. PNCC Method Based on Wavelet Packet Transform
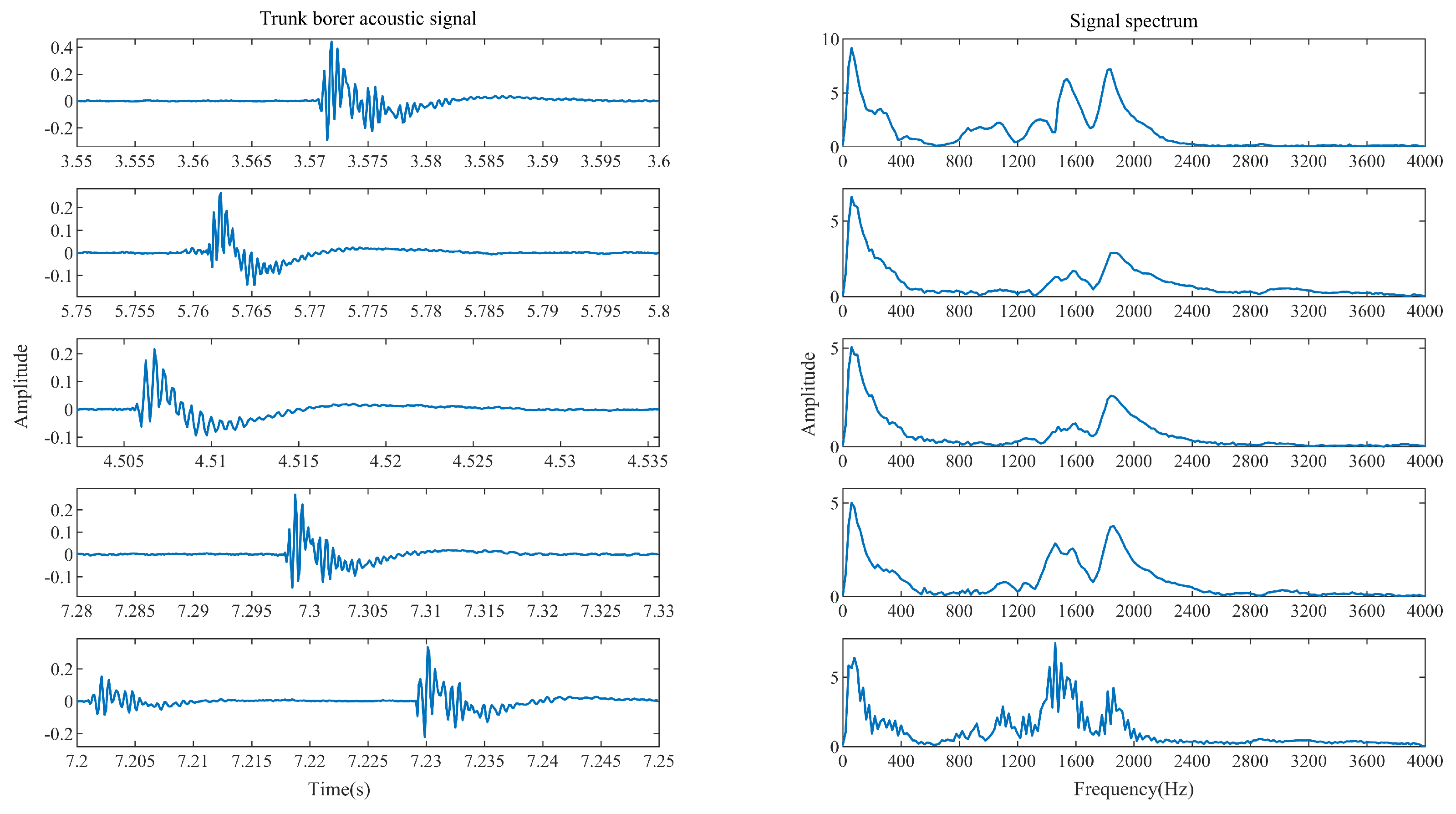
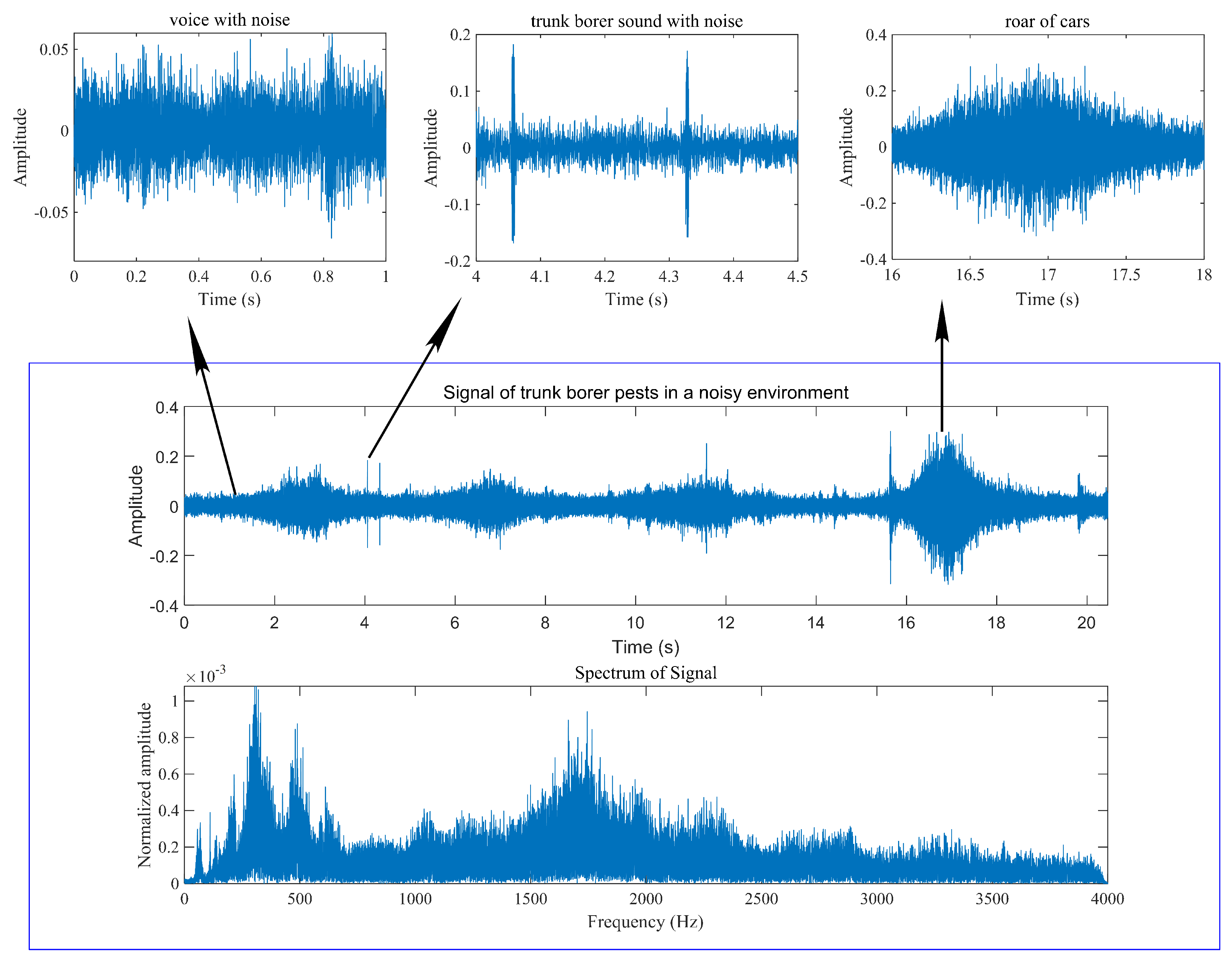
3.1. Raw Data Analysis and Preprocessing
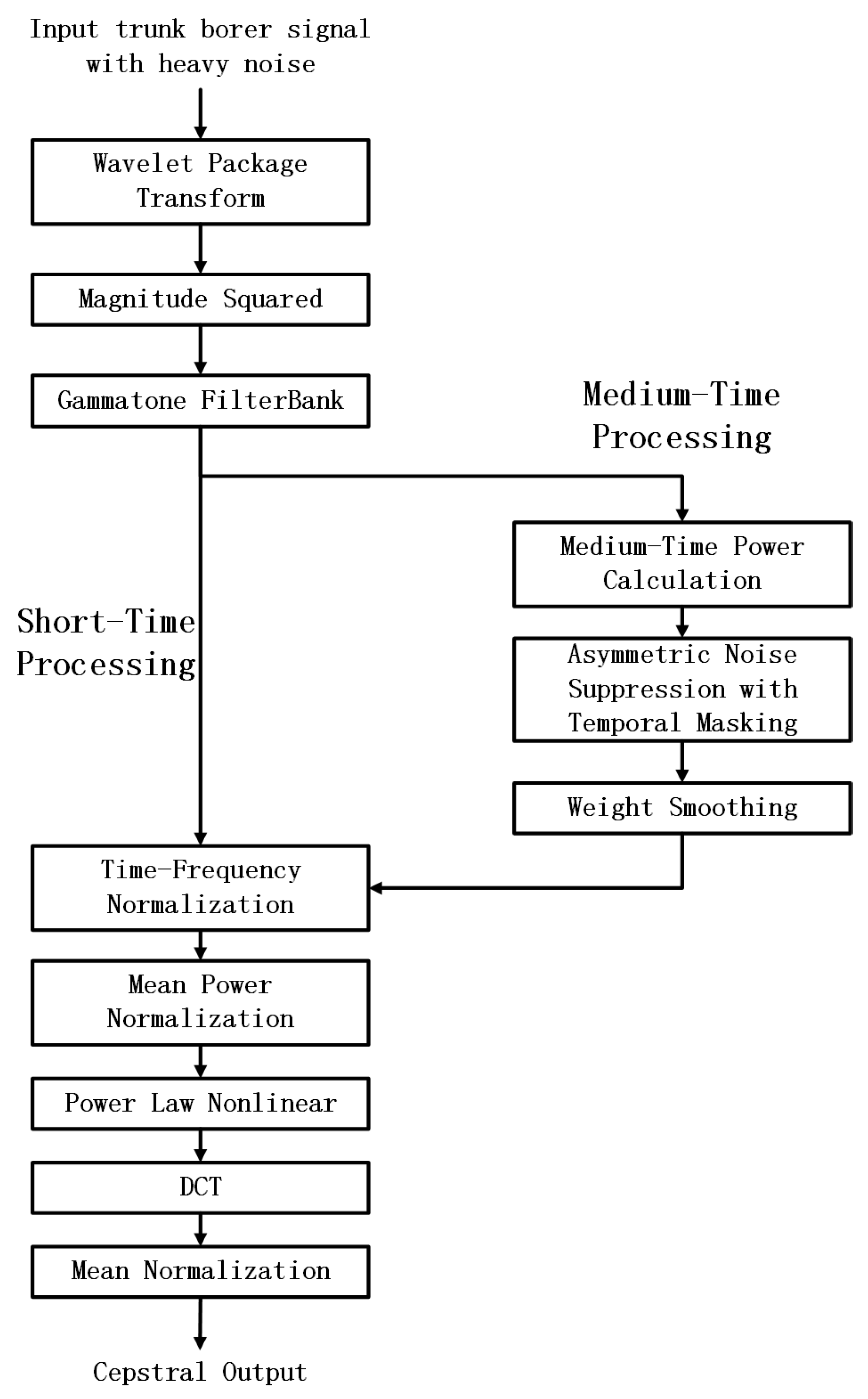
3.2. Improved PNCC Method Based on Wavlet Package
3.3. Wavelet Packet Transform
3.4. Wavelet Packet Basis Function Selection
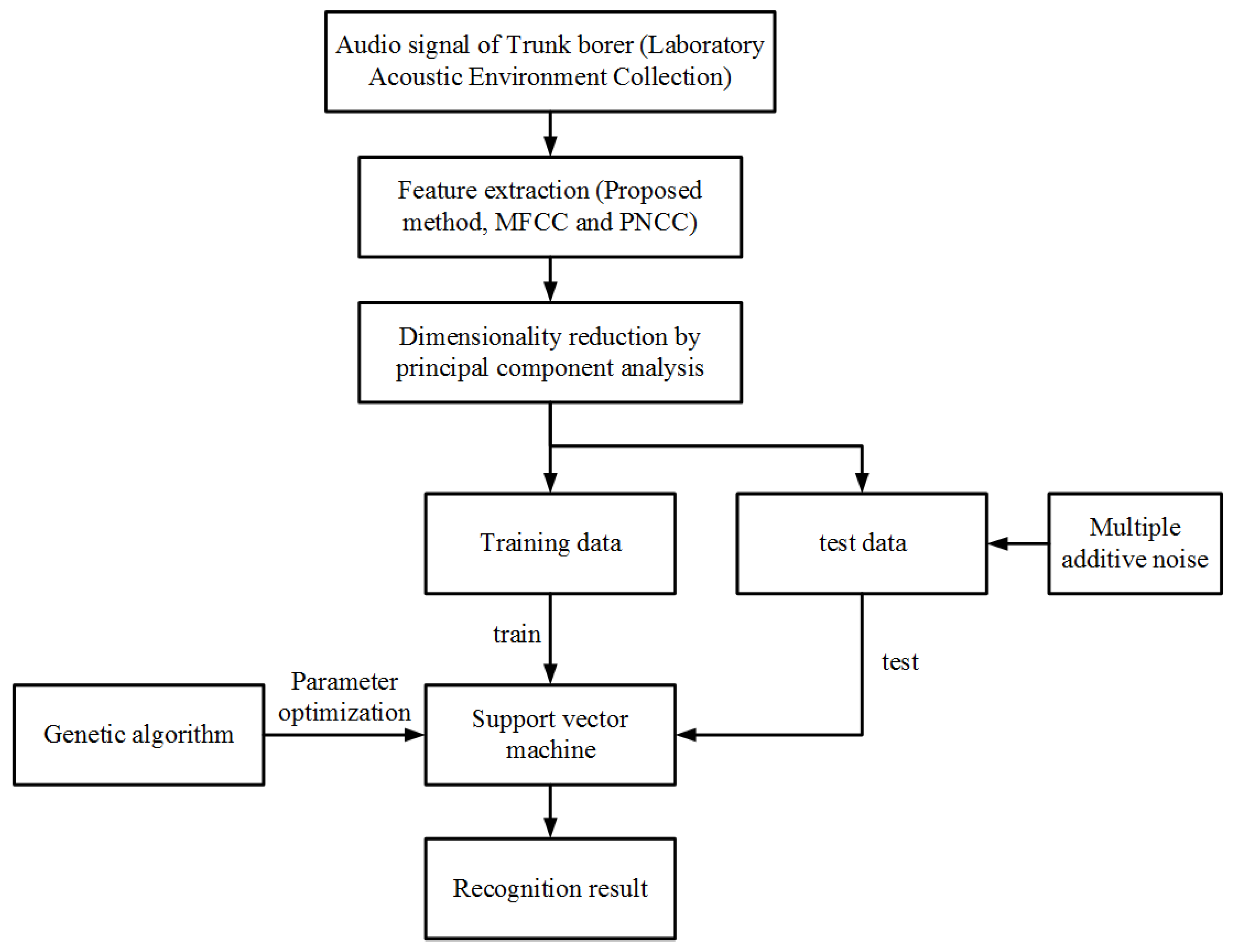
4. Sound Recognition of Trunk Borer Using SVM
- First of all, although deep neural networks and other related methods are preferred in most harsh acoustic environments, the artificial selection of features with strong robustness to noise, combined with the SVM classification model, is even better than the recognition results of the deep neural network model in some fields of sound recognition [27,28];
- Secondly, the object discussed in this paper is the sound detection of trunk borers in a noisy environment. Compared with the deep neural network, the artificial selection feature combined with machine learning classification method requires fewer data, and the model is relatively easy to train. It is easier to verify the feasibility of the method;
- Thirdly, at present, the main machine learning methods commonly used for audio signal classification are GMM, HMM and SVM. The typical application of support vector machine is to solve the problem of binary classification, that is, to judge whether the test sample belongs to a positive class or negative class. The purpose of this study is to identify the signals of trunk borer under an adverse acoustic background. In essence, it is a two-classification problem. In addition, the improved PNCC feature is a high-dimensional feature. Therefore, support vector machine is more suitable. Furthermore, SVM’s strong generalization ability makes it more suitable for solving problems in practical applications;
- Finally, in this study, when comparing the accuracy of MFCC and PNCC in the sound recognition of trunk borer under the condition of noise, background sound, channel distortion, reverberation interference, or non-synchronous training test environment, the use of SVM is more contrastive.
5. Experimental Design and Result Analysis
5.1. The Source and Composition of Sound Sample Data
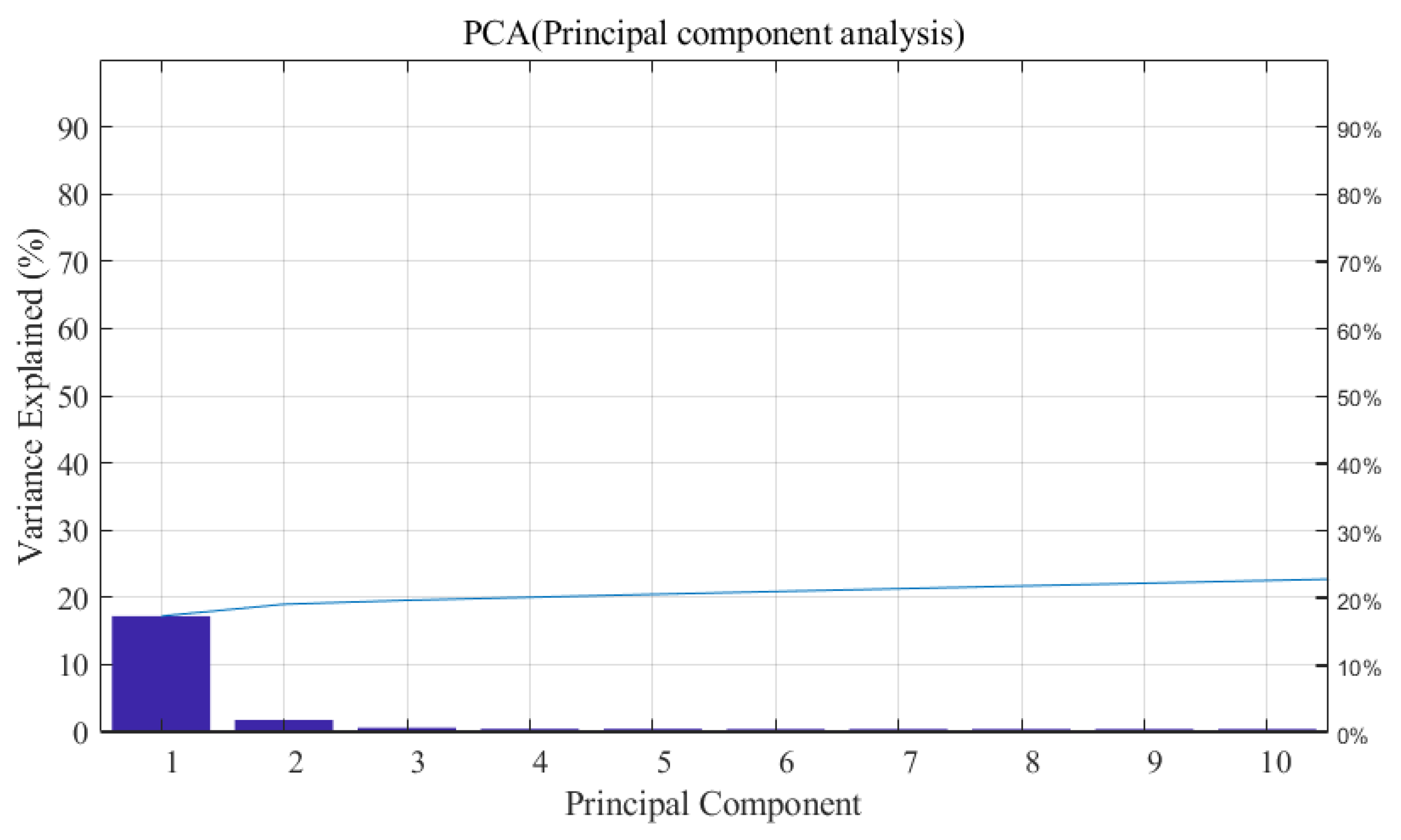
5.2. Optimizing Meta-Parameters of SVM Using GA
5.3. Experiment in Laboratory
5.4. Experiment in Field
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cao, L.; Wei, K.; Li, X.; Wang, X. Research progress in the biodiversity of oak wood and nut borers and their natural enemies in China. Acta Phytophylacica Sin. 2019, 46, 1174–1185. [Google Scholar] [CrossRef]
- Mankin, R.W.; Samson, P.R.; Chandler, K.J. Acoustic detection of melolonthine larvae in Australian sugarcane. J. Econ. Entomol. 2009, 102, 1523–1535. [Google Scholar] [CrossRef]
- Mankin, R.W.; Moore, A. Acoustic Detection of oryctes rhinoceros (Coleoptera: Scarabaeidae: Dynastinae) and Nasutitermes luzonicus (Isoptera: Termitidae) in palm trees in Urban Guam. J. Econ. Entomol. 2010, 103, 1135–1143. [Google Scholar] [CrossRef]
- Mankin, R.W.; Burman, H.; Merzocal, O.; Carrillo, D. Acoustic detection of Mallodon dasystomus (Coleoptera: Cerambycidae) in Persea americana (Laurales: Lauraceae) branch stumps. Fla Entomol. 2018, 101, 321–323. [Google Scholar] [CrossRef]
- Hetzroni, A.; Soroker, V.; Cohen, Y. Toward practical acoustic red palm weevil detection. Comput. Electron. Agric. 2016, 124, 100–106. [Google Scholar] [CrossRef]
- Lemos Escola, J.P.; Guido, R.C.; da Silva, I.N.; Cardoso, A.M.; Bottura Maccagnan, D.H.; Dezotti, A.K. Automated acoustic detection of a cicadid pest in coffee plantations. Comput. Electron. Agric. 2020, 169. [Google Scholar] [CrossRef]
- Sutin, A.; Yakubovskiy, A.; Salloum, H.R.; Flynn, T.J.; Sedunov, N.; Nadel, H. Towards an automated acoustic detection algorithm for wood-boring Beetle Larvae (Coleoptera: Cerambycidae and Buprestidae). J. Econ. Entomol. 2019, 112, 1327–1336. [Google Scholar] [CrossRef]
- Bilski, P.; Bobinski, P.; Krajewski, A.; Witomski, P. Detection of wood boring insects’ larvae based on the acoustic signal analysis and the artificial intelligence algorithm. Arch. Acoust. 2017, 42, 61–70. [Google Scholar] [CrossRef][Green Version]
- Pan, J.; Liu, X.; Shao, P.; Yan, L.; An, Y.; Wen, J. Preliminary study on the acoustic detection of larvae Heterobostrychus aequalis. J. Econ. Entomol. 2015, 37, 1237–1241. [Google Scholar] [CrossRef]
- Siriwardena, K.A.P.; Fernando, L.C.P.; Nanayakkara, N.; Perera, K.F.G.; Kumara, A.D.N.T.; Nanayakkara, T. Portable acoustic device for detection of coconut palms infested by Rynchophorus ferrugineus (Coleoptera: Curculionidae). Crop Prot. 2010, 29, 25–29. [Google Scholar] [CrossRef]
- Eliopoulos, P.A.; Potamitis, I.; Kontodimas, D.C.; Givropoulou, E.G. Detection of adult beetles inside the stored wheat mass based on their acoustic emissions. J. Econ. Entomol. 2015, 108, 2808–2814. [Google Scholar] [CrossRef]
- Zhao, Y.; Wei, X.; Wen, J.; Xu, Z. Preliminary study on the acoustic detection of larvae Semanotus bifasciatus(Motschulsky). Ecol. Sci. 2009, 28, 242–246. [Google Scholar] [CrossRef]
- Rasool, K.G.; Khan, M.A.; Aldawood, A.S.; Tufail, M.; Mukhtar, M.; Takeda, M. Identification of proteins modulated in the date palm stem infested withred palm weevil (Rhynchophorus ferrugineus Oliv.) using two dimensional differential gel electrophoresis and mass spectrometry bifasciatus (Motschulsky). Int. J. Mol. Sci. 2015, 16, 19326–19346. [Google Scholar] [CrossRef] [PubMed]
- Di Palma, A.; Pistillo, M.; Griffo, R.; Garonna, A.P.; Germinara, G.S. Scanning electron microscopy of the antennal sensilla and their secretion analysis in adults of Aromia bungii (Faldermann, 1835). (Coleoptera, Cerambycidae). Insects 2019, 10, 88. [Google Scholar] [CrossRef] [PubMed]
- Dennis, J.; Tran, H.D.; Chng, E.S. Image feature representation of the subband power distribution for robust sound event classification. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 367–377. [Google Scholar] [CrossRef]
- Ren, J.; Jiang, X.; Yuan, J.; Magnenat-Thalmann, N. Sound-event classification using robust texture features for robot hearing. IEEE Trans. Multimedia 2017, 19, 447–458. [Google Scholar] [CrossRef]
- Mulimani, M.; Koolagudi, S.G. Robust acoustic event classification using fusion fisher vector features. Appl. Acoust. 2019, 155, 130–138. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Tsai, K.; Wang, W. Blind monaural source separation on heart and lung sounds based on periodic-coded deep autoencoder. IEEE J. Biomed. Health Inform. 2020, 24, 3203–3214. [Google Scholar] [CrossRef] [PubMed]
- Hsiao, C.H.; Lin, T.W.; Lin, C.W.; Hsu, F.S.; Lin, F.Y.S.; Chen, C.W.; Chung, C.M. Breathing sound segmentation and detection using transfer learning techniques on an attention-based encoder-decoder architecture. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Montréal, QC, Canada, 20–24 July 2020; pp. 754–759. [Google Scholar] [CrossRef]
- Ren, W.; Wen, G.; Xu, B. A Novel convolutional neural network based on Timex2013; Frequency spectrogram of arc sound and its application on GTAW penetration classification. IEEE Trans. Ind. Inform. 2021, 17, 809–819. [Google Scholar] [CrossRef]
- Jiang, Y.; Peng, J.; Zhang, X. Automatic snoring sounds detection from sleep sounds based on deep learning. Physic. Eng. Sci. Med. 2020, 43, 679–689. [Google Scholar] [CrossRef]
- Tan, K.; Parascandolo, G.; Xu, B.; Kumar, A. SAGRNN: Self-attentive gated RNN for binaural speaker separation with Interaural Cue Preservation. IEEE Signal Process. Lett. 2021, 28, 26–30. [Google Scholar] [CrossRef]
- Kwak, J.Y.; Chung, Y.J. Sound event detection using derivative features in deep neural networks. Appl. Sci. 2020, 10, 4911. [Google Scholar] [CrossRef]
- Kim, C.; Stern, R.M. Power-Normalized Cepstral Coefficients (PNCC) for robust speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1315–1329. [Google Scholar] [CrossRef]
- Yu, Y.; Subhani, M. Novel hybrid method based on advanced signal processing and soft computing techniques for condition assessment of timber utility poles. J. Aerospace Eng. 2019, 32. [Google Scholar] [CrossRef]
- Grzeszick, R.; Plinge, A.; Fink, G.A. Bag-of-features methods for acoustic event detection and classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1242–1252. [Google Scholar] [CrossRef]
- Schmitt, M.; Ringeval, F.; Schuller, B.W. At the border of acoustics and linguistics: Bag-of-audio-words for the recognition of emotions in speech. Interspeech 2016, 495–499. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for support vector machines. ACM Trans Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]
- Yu, Y.; Rashidi, M.; Samali, B.; Yousefi, A. Multi-image-feature-based hierarchical concrete crack identification framework using optimized SVM multi-classifiers and D-S fusion algorithm for bridge structures. Remote Sens. 2021, 13, 240. [Google Scholar] [CrossRef]
- Guan, S.; Wang, X.; Hua, L.; Li, L. Quantitative ultrasonic testing for near-surface defects of large ring forgings using feature extraction and GA-SVM. Appl. Acoust. 2021, 173. [Google Scholar] [CrossRef]
- Glowacz, A. Recognition of acoustic signals of loaded synchronous motor using FFT, MSAF-5 and LSVM. Arch. Acoust. 2015, 40, 197–203. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Noise /Method /SNR(DB) | 10 | 5 | 2.5 | 0 | −2.5 | −5 | −7.5 | −10 | −15 | |
|---|---|---|---|---|---|---|---|---|---|---|
| NOISEX-92 white noise | MFCC original PNCC improved PNCC | 100% | 100% | / | 97.5 % | / | 90% | / | 50% | 50% |
| 100% | 100% | / | 100% | / | 100% | / | 100% | 100% | ||
| 100% | 100% | / | 100% | / | 100% | / | 100% | 99.5% | ||
| NOISEX-92 factory noise | MFCC original PNCC PNCC + PCA | 100% | 100% | / | 50 % | / | 50% | 50% | 50% | / |
| 100% | 100% | / | 98% | / | 86% | 50% | 50% | / | ||
| 100% | 100% | / | 98.5% | / | 91% | 50.5% | 50% | / | ||
| Storm reverberation | MFCC original PNCC PNCC + PCA | 100% | 100% | / | 85 % | 50.5% | 50% | / | 50% | / |
| 100% | 100% | / | 82% | 64% | 50% | / | 50% | / | ||
| 100% | 99.5% | / | 95.5% | 73% | 57.5% | / | 50% | / | ||
| Heavy rain reverberation | MFCC original PNCC PNCC + PCA | 100% | 100% | 98.5 % | 50% | / | 47.5% | / | 50% | / |
| 100% | 100% | 100% | 90.5% | / | 78% | / | 62% | / | ||
| 100% | 100% | 100% | 99% | / | 85% | / | 66.5% | / | ||
| Thunder reverberation | MFCC original PNCC PNCC + PCA | 100% | 99% | / | 97.5 % | 50% | 51.5% | / | 50% | / |
| 99.5% | 100% | / | 97% | 78% | 62% | / | 53% | / | ||
| 100% | 99.5% | / | 97% | 95% | 82% | / | 50.5% | / | ||
| Stream reverberation | MFCC original PNCC PNCC + PCA | 100% | 100% | / | 100 % | / | 98.5% | / | 50% | 50% |
| 100% | 100% | / | 100% | / | 100% | / | 99% | 100% | ||
| 100% | 100% | / | 100% | / | 100% | / | 99% | 100% | ||
| NOISEX-92 pink noise | MFCC original PNCC PNCC + PCA | 100% | 100% | / | 52.5 % | / | 50% | / | 50% | 50% |
| 100% | 100% | / | 100% | / | 100% | / | 100% | 50% | ||
| 100% | 100% | / | 100% | / | 100% | / | 100% | 50% | ||
| Train reverberation | MFCC original PNCC PNCC + PCA | 100% | 97.5% | / | 60 % | 50% | 50% | / | 50% | / |
| 97.5% | 97.5% | / | 82% | 50% | 50% | / | 50% | / | ||
| 99.5% | 97% | / | 91% | 52.5% | 50% | / | 50% | / | ||
| TDAAS | MFCC original PNCC PNCC + PCA | 100% | 99.5625% | / | 74.0625% | / | 60.9375% | / | 50% | / |
| 99.625% | 99.6875% | / | 93.6875% | / | 78.25% | / | 70.5% | / | ||
| 99.9375% | 99.5% | / | 97.625% | / | 83.1875% | / | 70.75% | / | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, H.; He, Z.; Sun, L.; Zhang, D.; Zhou, H.; Li, X. Improved Power Normalized Cepstrum Coefficient Based on Wavelet Packet Decomposition for Trunk Borer Detection in Harsh Acoustic Environment. Appl. Sci. 2021, 11, 2236. https://doi.org/10.3390/app11052236
Zhou H, He Z, Sun L, Zhang D, Zhou H, Li X. Improved Power Normalized Cepstrum Coefficient Based on Wavelet Packet Decomposition for Trunk Borer Detection in Harsh Acoustic Environment. Applied Sciences. 2021; 11(5):2236. https://doi.org/10.3390/app11052236
Chicago/Turabian StyleZhou, Huanyu, Ziqi He, Liping Sun, Dongyan Zhang, Hongwei Zhou, and Xiaodong Li. 2021. "Improved Power Normalized Cepstrum Coefficient Based on Wavelet Packet Decomposition for Trunk Borer Detection in Harsh Acoustic Environment" Applied Sciences 11, no. 5: 2236. https://doi.org/10.3390/app11052236
APA StyleZhou, H., He, Z., Sun, L., Zhang, D., Zhou, H., & Li, X. (2021). Improved Power Normalized Cepstrum Coefficient Based on Wavelet Packet Decomposition for Trunk Borer Detection in Harsh Acoustic Environment. Applied Sciences, 11(5), 2236. https://doi.org/10.3390/app11052236