
Finding Effective Item Assignment Plans with Weighted Item Associations Using A Hybrid Genetic Algorithm




Abstract
1. Introduction
2. Item Assignment Model
3. Item Assignment Based on Weighted Associations
3.1. Effects of Profit and Frequency
3.2. Weighted Item Assignment Model
4. Hybrid Genetic Algorithm to Search for Effective Item Assignments
4.1. Equivalence to the TSP Problem
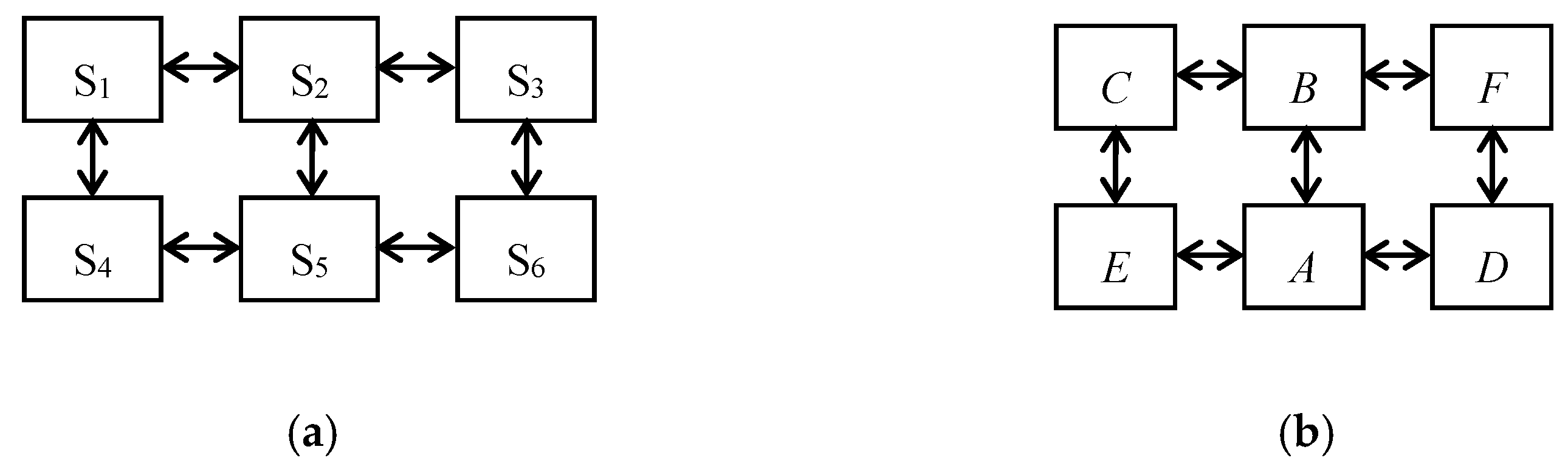
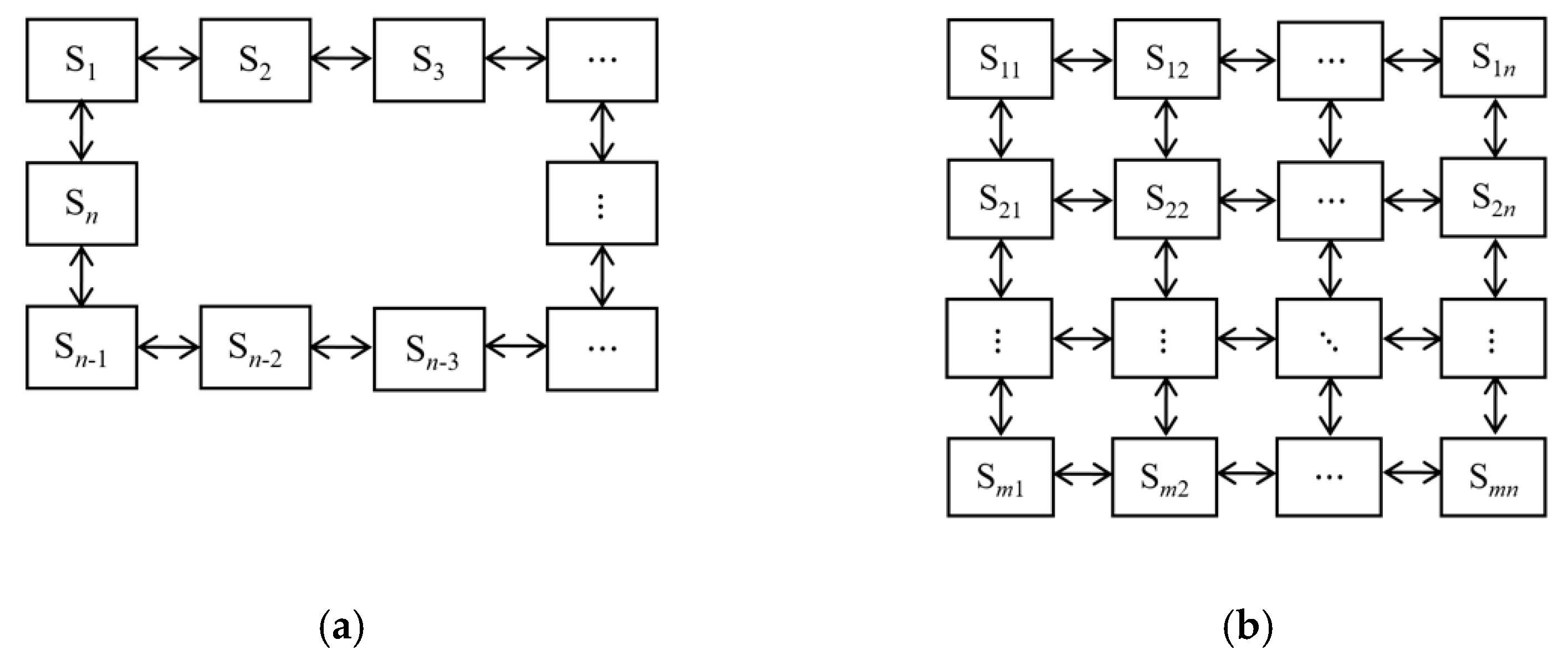
4.2. Definition of A Rectangular Chromosome
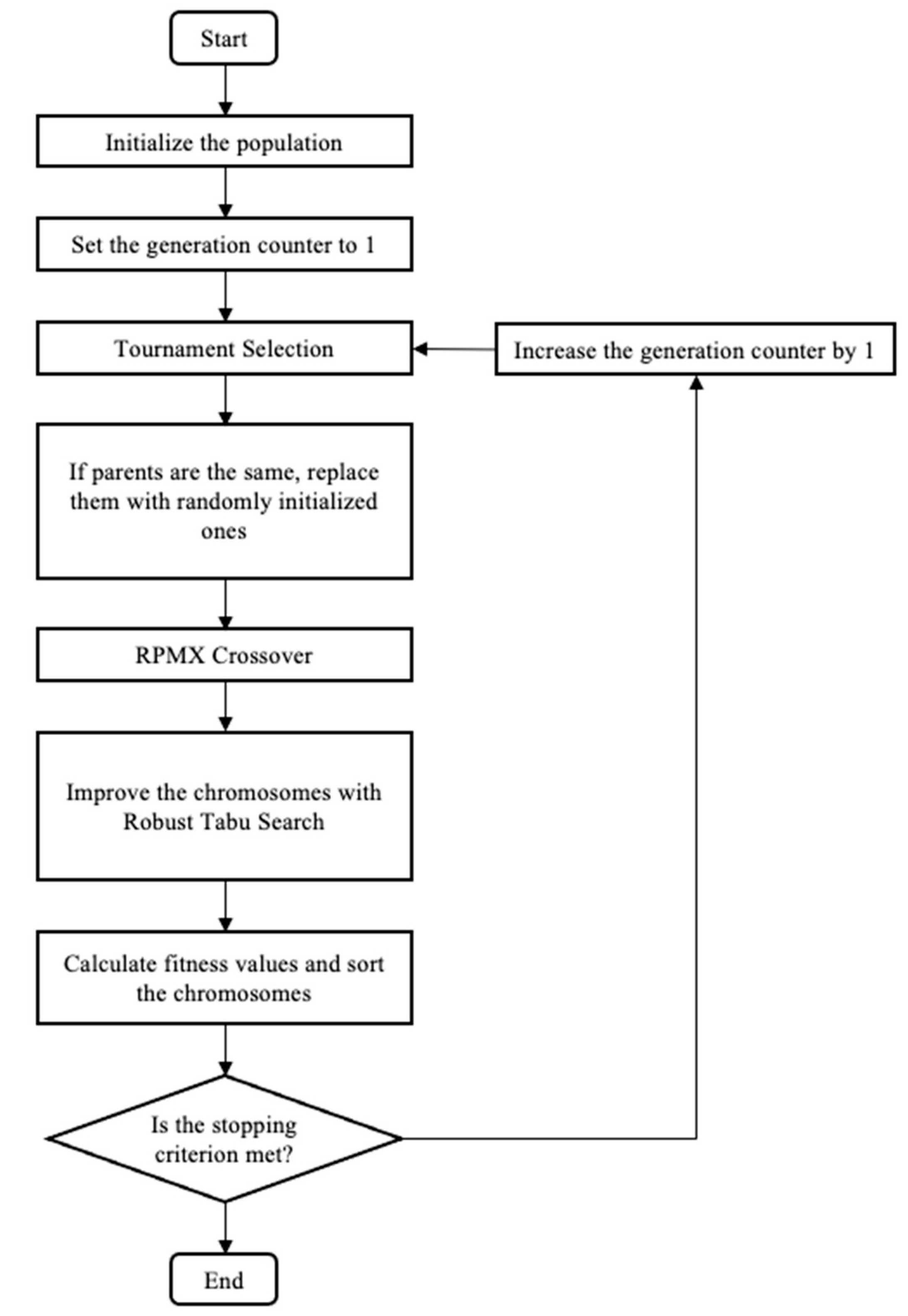
4.3. Robust Tabu Search
| Algorithm 1: Robust Tabu Search Algorithm |
|
1: authorized: if a move is not tabu, it is authorized. 2: aspired: Allow tabu moves if they are decided to be interesting. 3: tabu_list: A list to forbid reverse move. 4: Function RobustTabuSearch (bestPerm, flow, dist, minSize, maxSize, aspiration, numIters) 5: n = size of bestPerm; 6: bestCost = fitness of bestPerm; 7: curCost = bestCost; 8: curPerm = bestPerm; 9: for (I = 0; I < n; I ++) do 10: for (j = 0; j < n; j ++) do 11: tabu_list[i][j] = −(n * I + j); 12: if (I < j) then 13: delta[i][j] = compute_delta (curPerm, i, j); 14: end if 15: end for 16: end for 17: for (iter = 0; iter < numIters; iter ++) do 18: i_retained = infinite; 19: min_delta = infinite; 20: already_inspired = false; 21: for (I = 0; I < n − 1; I ++) do 22: for (j = I + 1; j < n; j ++) do 23: authorized = (tabu_list[i][j] < iter) || (tabu_list[j][curPerm[i]] < iter); 24: aspired = (tabu_list[i][p[j]] < iter-aspiration) || 25: (tabu_list[j][p[i]] < iter-aspiration) || 26: (curCost + delta[i][j] < bestCost); 27: if ((aspired &&!already_aspired) || 28: (aspired && already_aspired && (delta[i][j] < min_delta)) || 29: (!aspired &&!already_aspired && (delta[i][j] < min_delta) && authorized)) then 30: i_retained = i; 31: j_retained = j; 32: min_delta = delta[i][j]; 33: if (aspired) then 34: already_aspired = true; 35: end if 36: end if 37: end for 38: end for 39: if (i_retained! = infinite) then 40: swap(curPerm[i_retained], curPerm[j_retained]); 41: curCost = curCost + delta[i_retained][j_retained]; 42: tabu_list[i_retained][curPerm[j_retained]] = iter + unif(minSize, maxSize); 43: tabu_list[j_retained][curPerm[i_retained]] = iter + unif(minSize, maxSize); 44: if (curCost < bestCost) then 45: bestCost = curCost; 46: bestPerm = curPerm; 47: end if 48: end if 49: for (i = 0; i < n − 1; i++) do 50: for (j = i + 1; j < n; j++) do 51: if (i! = i_retained && i! = j_retained && j! = i_retained && j! = j_retained) then 52: delta[i][j] = compute_delta_part(curPerm, delta, i, j, i_retained, j_retained); 53: else 54: delta[i][j] = compute_delta(curPerm, i, j); 55: end if 56: end for 57: end for 58: end for |
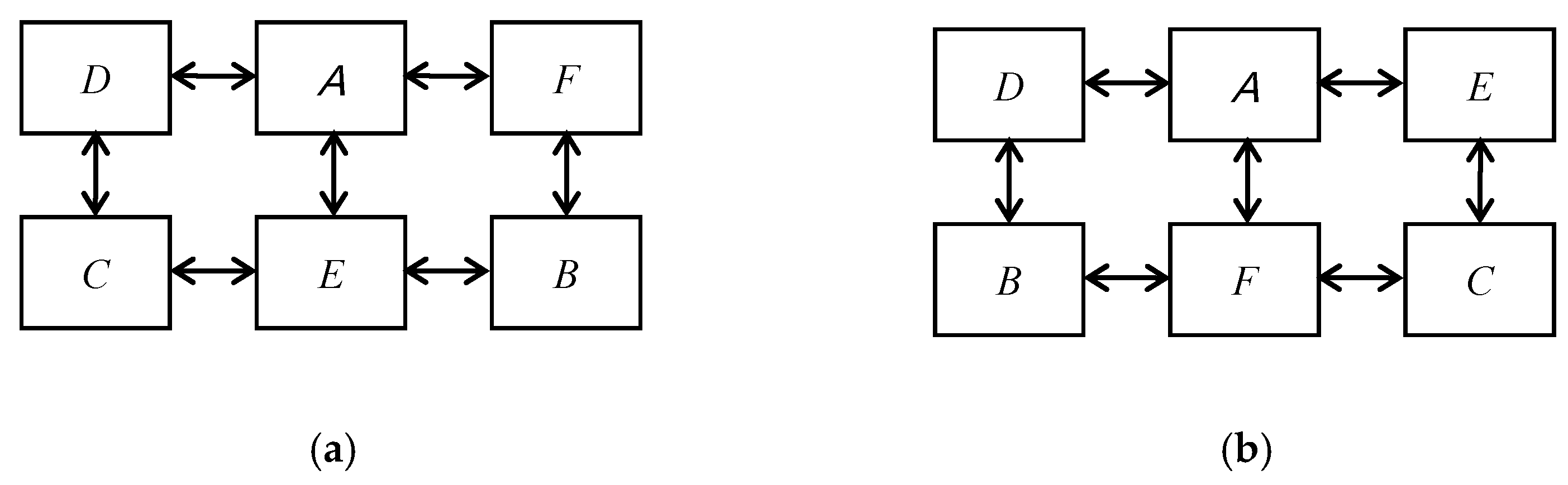
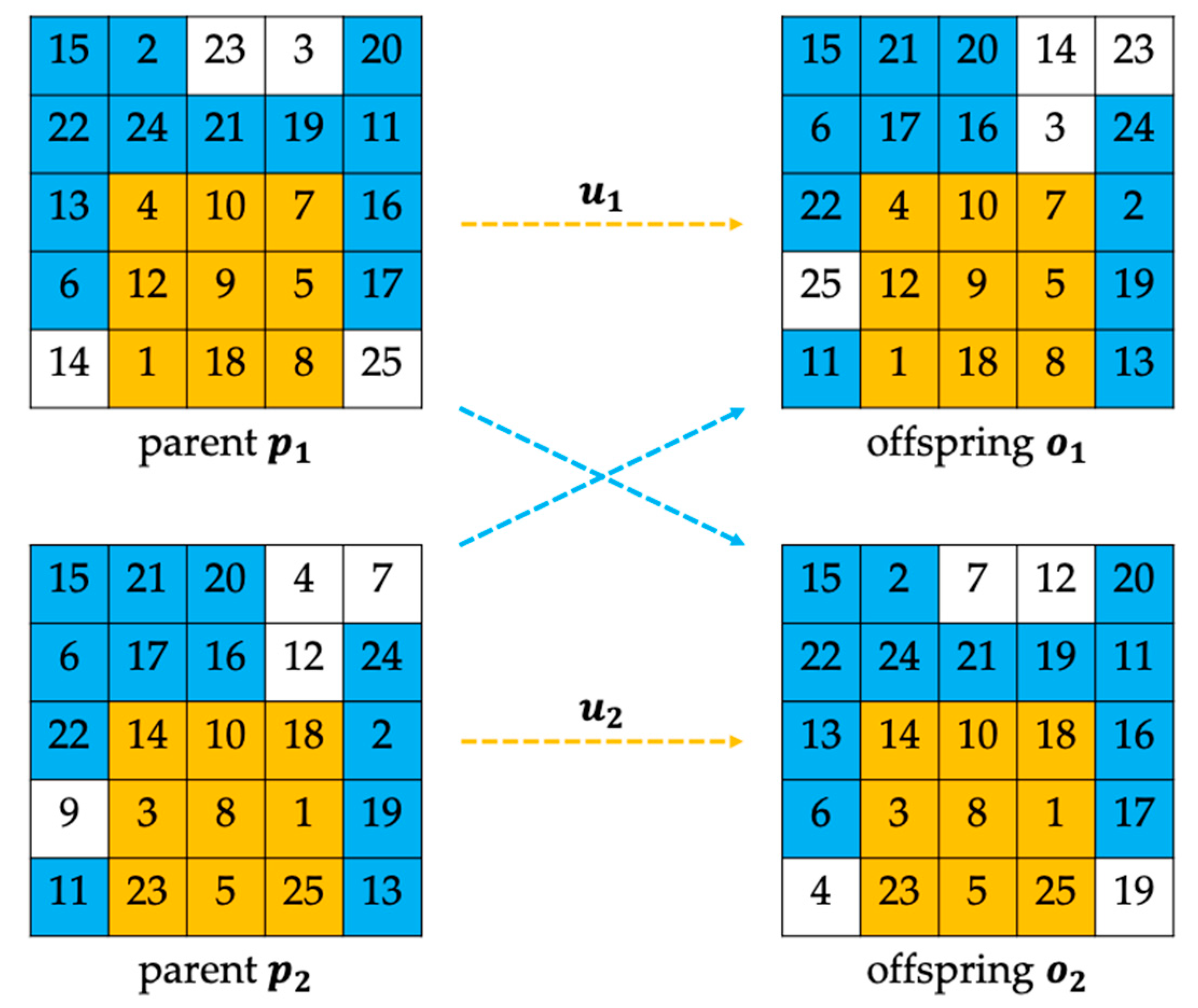
4.4. Rectangular Partially Matched Crossover
5. Experiments
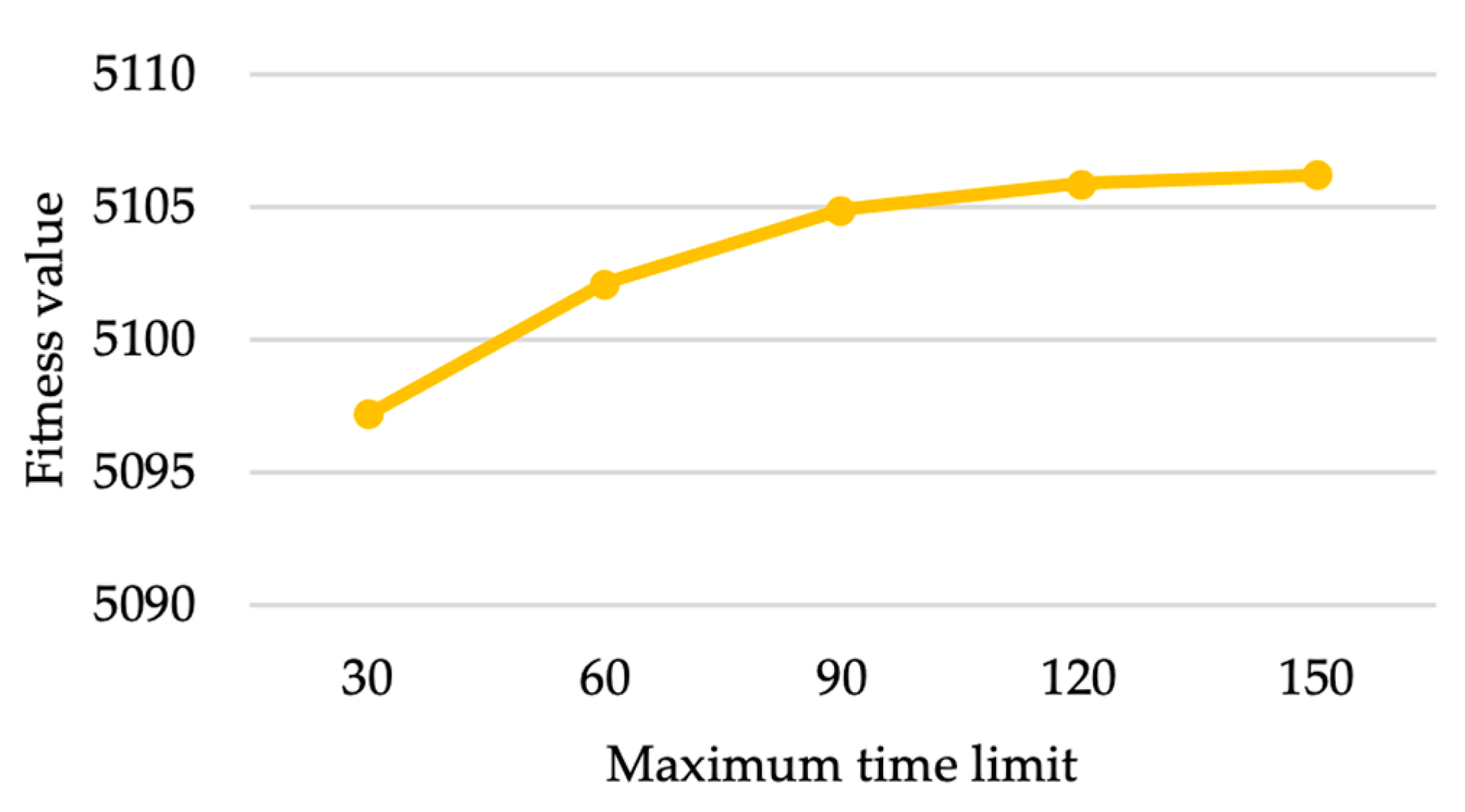
5.1. Tuning the Parameters of HGA
5.2. Experimental Results and Comparisons on the QAPLIB
5.3. Synthetic Experimental Design
5.4. Comparison of Assignment Models
5.5. Comparison of HGA Using Different Crossover
5.6. Experimental Results and Comparison on the Synthetic Data
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ahn, K.I. Effective product assignment based on association rule mining in retail. Expert Syst. Appl. 2012, 39, 12551–12556. [Google Scholar] [CrossRef]
- Yang, Z.; Tang, W.H.; Shintemirov, A.; Wu, Q.H. Association Rule Mining-Based Dissolved Gas Analysis for Fault Diagnosis of Power Transformers. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2009, 39, 597–610. [Google Scholar] [CrossRef]
- Huang, J.; Ji, S.; Xie, H.; Wang, X. Research on cross-selling in the express delivery enterprise based on data mining. In Proceedings of the 2008 International Conference on Service Systems and Service Management, Melbourne, Australia, 30 June–3 July 2008; pp. 1–6. [Google Scholar]
- Jiao, J.; Zhang, Y. Product portfolio identification based on association rule mining. Comput. Des. 2005, 37, 149–172. [Google Scholar] [CrossRef]
- Cho, Y.H.; Kim, J.K.; Kim, S.H. A personalized recommender system based on web usage mining and decision tree induction. Expert Syst. Appl. 2002, 23, 329–342. [Google Scholar] [CrossRef]
- Kang, X.; Porter, C.S.; Bohemia, E. Using the fuzzy weighted association rule mining approach to develop a customer satis-faction product form. J. Intell. Fuzzy Syst. 2020, 38, 4343–4357. [Google Scholar] [CrossRef]
- Ramasamy, S.; Nirmala, K. Disease prediction in data mining using association rule mining and keyword based clustering algorithms. Int. J. Comput. Appl. 2017, 42, 1–8. [Google Scholar] [CrossRef]
- Shao, Y.; Liu, B.; Wang, S.; Li, G. Software defect prediction based on correlation weighted class association rule mining. Knowl. Based Syst. 2020, 196, 5742. [Google Scholar] [CrossRef]
- Tuysuzoglu, G.; Birant, D. Air Pollution Monitoring in Intelligent Cities Using Weighted Association Rule Mining. In Advances in Civil and Industrial Engineering; IGI Global: Hershey, PA, USA, 2021; pp. 171–197. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mininig: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Brijs, T.; Swinnen, G.; Vanhoof, K.; Wets, G. Building an Association Rules Framework to Improve Product Assortment Decisions. Data Min. Knowl. Discov. 2004, 8, 7–23. [Google Scholar] [CrossRef]
- Chen, M.C. Configuration of cellular manufacturing systems using association rule induction. Int. J. Prod. Res. 2003, 41, 381–395. [Google Scholar] [CrossRef]
- Liu, C.; Yasuda, K.; Yin, Y.; Tanaka, K. Uncertain association rule mining algorithm for the cell formation problem in cellular manufacturing systems. Int. J. Prod. Res. 2008, 47, 667–685. [Google Scholar] [CrossRef]
- Chen, M.-C.; Huang, C.L.; Chen, K.Y.; Wu, H.P. Aggregation of orders in distribution centers using data mining. Expert Syst. Appl. 2005, 28, 453–460. [Google Scholar] [CrossRef]
- Ardakani, B.A.; Fathian, M.; Gholamian, M. A novel model for product bundling and direct marketing in e-commerce based on market segmentation. Decis. Sci. Lett. 2018, 7, 39–54. [Google Scholar] [CrossRef]
- Cai, C.; Fu, A.; Cheng, C.; Kwong, W. Mining association rules with weighted items. In Proceedings of the IDEAS’98. International Database Engineering and Applications Symposium (Cat. No.98EX156), Cardiff, UK, 10 July 2002; pp. 68–77. [Google Scholar] [CrossRef]
- Tao, F.; Murtagh, F.; Farid, M.; Coenen, F. Weighted association rule mining using weighted support and significance framework. In Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, Washington, DC, USA, 24–27 August 2003; pp. 661–666. [Google Scholar]
- Khan, M.S.; Muyeba, M.; Coenen, F. Weighted Association Rule Mining from Binary and Fuzzy Data. In Computer Vision; Springer International Publishing: New York, NY, USA, 2008; Volume 5077, pp. 200–212. [Google Scholar]
- Pears, R.; Koh, Y.S.; Dobbie, G.; Yeap, W. Weighted association rule mining via a graph based connectivity model. Inf. Sci. 2013, 218, 61–84. [Google Scholar] [CrossRef]
- Lee, D.; Park, S.H.; Moon, S. Utility-based association rule mining: A marketing solution for cross-selling. Expert Syst. Appl. 2013, 40, 2715–2725. [Google Scholar] [CrossRef]
- Heydari, M.; Yousefli, A. A new optimization model for market basket analysis with allocation considerations: A genetic al-gorithm solution approach. Manag. Mark. Chall. Knowl. Soc. 2017, 12, 1–11. [Google Scholar] [CrossRef]
- Awler, E.L. The quadratic assignment problem. Manag. Sci. 1963, 9, 586–599. [Google Scholar]
- Taillard, E. Robust taboo search for the quadratic assignment problem. Parallel Comput. 1991, 17, 443–455. [Google Scholar] [CrossRef]
- Benlic, U.; Hao, J.K. Memetic search for the quadratic assignment problem. Expert Syst. Appl. 2015, 42, 584–595. [Google Scholar] [CrossRef]
- Dokeroglu, T. Hybrid teaching–learning-based optimization algorithms for the Quadratic Assignment Problem. Comput. Ind. Eng. 2015, 85, 86–101. [Google Scholar] [CrossRef]
- Dokeroglu, T.; Sevinc, E.; Cosar, A. Artificial bee colony optimization for the quadratic assignment problem. Appl. Soft Comput. 2019, 76, 595–606. [Google Scholar] [CrossRef]
- Misevičius, A.; Verenė, D. A Hybrid Genetic-Hierarchical Algorithm for the Quadratic Assignment Problem. Entropy 2021, 23, 108. [Google Scholar] [CrossRef]
- Ma, J.; Xu, M.; Meng, Q.; Cheng, L. Ridesharing user equilibrium problem under OD-based surge pricing strategy. Transp. Res. Part B Methodol. 2020, 134, 1–24. [Google Scholar] [CrossRef]
- Dewi, S.K.; Utama, D.M. A New Hybrid Whale Optimization Algorithm for Green Vehicle Routing Problem. Syst. Sci. Control. Eng. 2021, 9, 61–72. [Google Scholar] [CrossRef]
- Hanh, N.T.; Binh, H.T.T.; Hoai, N.X.; Palaniswami, M.S. An efficient genetic algorithm for maximizing area coverage in wireless sensor networks. Inf. Sci. 2019, 488, 58–75. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Li, Y.; Li, S.; Li, H.; Wang, W. Comparative Investigation of Phenomenological Modeling for Hysteresis Responses of Magnetorheological Elastomer Devices. Int. J. Mol. Sci. 2019, 20, 3216. [Google Scholar] [CrossRef]
- Miller, B.L.; Goldberg, D.E. Genetic algorithms, tournament selection, and the effects of noise. Complex Syst. 1995, 9, 193–212. [Google Scholar]
- Oliver, I.; Smith, D.; Holland, J.R. Study of permutation crossover operators on the traveling salesman problem. In Genetic Algorithms and Their Applications, Proceedings of the Second International Conference on Genetic Algorithms; Massachusetts Institute of Technology: Cambridge, MA, USA, 1987. [Google Scholar]
- Syswerda, G. A Study of Reproduction in Generational and Steady-State Genetic Algorithms. In Foundations of Genetic Algorithms; Elsevier BV: Amsterdam, The Netherlands, 1991; Volume 1, pp. 94–101. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| A | - | 1.6 | 0 | 1.3 | 0 | 1.2 |
| B | 1.6 | - | 1.1 | 1.4 | 0 | 1.3 |
| C | 0 | 1.1 | - | 1.3 | 1.5 | 0 |
| D | 1.3 | 1.4 | 1.3 | - | 0 | 1.3 |
| E | 0 | 0 | 1.5 | 0 | - | 1.3 |
| F | 1.2 | 1.3 | 0 | 1.3 | 1.3 | - |
| (a) | A | B | C | D | E | F |
| A | - | 10 | 10 | 20 | 10 | 10 |
| B | 10 | - | 10 | 10 | 10 | 30 |
| C | 10 | 10 | - | 20 | 10 | 10 |
| D | 20 | 10 | 20 | - | 10 | 10 |
| E | 10 | 10 | 10 | 10 | - | 10 |
| F | 10 | 30 | 10 | 10 | 10 | - |
| (b) | A | B | C | D | E | F |
| A | - | 16 | 0 | 26 | 0 | 12 |
| B | 16 | - | 11 | 14 | 0 | 39 |
| C | 0 | 11 | - | 26 | 15 | 0 |
| D | 26 | 14 | 26 | - | 0 | 13 |
| E | 0 | 0 | 15 | 0 | - | 13 |
| F | 12 | 39 | 0 | 13 | 13 | - |
| (a) | A | B | C | D | E | F |
| A | - | 1000 | 1000 | 1000 | 1000 | 4000 |
| B | 1000 | - | 1000 | 4000 | 1000 | 1000 |
| C | 1000 | 1000 | - | 1000 | 3000 | 1000 |
| D | 1000 | 4000 | 1000 | - | 1000 | 1000 |
| E | - | 1000 | 1000 | 1000 | 1000 | 4000 |
| F | 1000 | - | 1000 | 4000 | 1000 | 1000 |
| (b) | A | B | C | D | E | F |
| A | - | 16,000 | 0 | 26,000 | 0 | 48,000 |
| B | 16,000 | - | 11,000 | 56,000 | 0 | 39,000 |
| C | 0 | 11,000 | - | 26,000 | 45,000 | 0 |
| D | 26,000 | 56,000 | 26,000 | - | 0 | 13,000 |
| E | - | 16,000 | 0 | 26,000 | 0 | 48,000 |
| F | 16,000 | - | 11,000 | 56,000 | 0 | 39,000 |
| A | B | C | D | E | F | |
|---|---|---|---|---|---|---|
| A | - | 1 | 1 | 2 | 1 | 1 |
| B | 1 | - | 1 | 1 | 1 | 3 |
| C | 1 | 1 | - | 1 | 1 | 1 |
| D | 21 | 1 | 1 | - | 1 | 1 |
| E | 1 | 1 | 1 | 1 | - | 1 |
| F | 1 | 3 | 1 | 1 | 1 | - |
| (a) | A | B | C | D | E | F |
| A | - | 1 | 1 | 1 | 1 | 4 |
| B | 1 | - | 1 | 4 | 1 | 1 |
| C | 1 | 1 | - | 1 | 3 | 1 |
| D | 1 | 4 | 1 | - | 1 | 1 |
| E | 1 | 1 | 3 | 1 | - | 1 |
| F | 4 | 1 | 1 | 1 | 1 | - |
| (b) | A | B | C | D | E | F |
| A | - | 1.6 | 0 | 2.6 | 0 | 4.8 |
| B | 1.6 | - | 1.1 | 5.6 | 0 | 3.9 |
| C | 0 | 1.1 | - | 2.6 | 4.5 | 0 |
| D | 2.6 | 5.6 | 2.6 | - | 0 | 1.3 |
| E | 0 | 0 | 4.5 | 0 | - | 1.3 |
| F | 4.8 | 3.9 | 0 | 1.3 | 1.3 | - |
| BASE_ASSIGN | PROFIT_ASSIGN | PROF_FRE_ASSIGN | |
|---|---|---|---|
| Objective value according to Equation (3) | 1.6 + 2.6 + 1.1 + 3.9 + 4.5 + 1.3 = 15 | 2.6 + 4.8 + 3.9 + 2.6 + 4.5 = 18.4 | 2.6 + 4.8 + 5.6 + 3.9 + 4.5 = 21.4 |
| Parameters | Value |
|---|---|
| Population size | 20 |
| Maximum generation number | Infinite |
| Maximum time limit | 2 h |
| Tabu list sizes | |
| Aspiration | |
| Number of iterations | 2000 |
| Problem | BKS | TLBO-RTS | ABC-QAP | Proposed HGA | |||
|---|---|---|---|---|---|---|---|
| APD | Min. | APD | Min. | APD | Min. | ||
| tai40a | 3,139,370 | 0.440(0) | 2.3 | 0.000(10) | 4.0 | 0.000(10) | 41.4 |
| tai50a | 4,938,796 | 0.961(0) | 4.4 | 0.312(0) | 19.8 | 0.241(1) | 58.5 |
| tai60a | 7,205,962 | 1.098(0) | 7.6 | 0.449(0) | 34.0 | * 0.335(0) | 71.8 |
| tai80a | 13,499,184 | 1.124(0) | 18.8 | 0.817(0) | 83.5 | * 0.603(0) | 52.9 |
| tai100a | 21,052,466 | 1.091(0) | 36.1 | 0.614(0) | 173.0 | 0.573(0) | 47.6 |
| tai50b | 458,821,517 | 0.000(10) | 4.2 | 0.000(10) | 1.6 | 0.000(10) | 0.8 |
| tai60b | 608,215,054 | 0.000(10) | 7.2 | 0.000(10) | 0.7 | 0.000(10) | 0.8 |
| tai80b | 818,415,043 | 0.005(0) | 17.5 | 0.000(10) | 8.0 | 0.000(10) | 10.4 |
| tai100b | 1,185,996,137 | 0.027(2) | 35.7 | 0.000(10) | 164.7 | 0.024(8) | 18.4 |
| sko72 | 48,498 | 0.024(0) | 13.2 | 0.000(10) | 7.0 | 0.000(10) | 3.3 |
| sko81 | 66,256 | - | - | 0.000(10) | 15.2 | 0.000(10) | 15.5 |
| sko90 | 90,998 | 0.049(0) | 25.2 | 0.000(10) | 14.7 | 0.000(10) | 12.9 |
| sko100a | 115,534 | 0.064(0) | 35.7 | 0.008(0) | 170.6 | * 0.003(8) | 28.1 |
| sko100b | 152,002 | 0.005(0) | 35.7 | 0.000(10) | 127.8 | 0.000(10) | 38.6 |
| sko100c | 147,862 | 0.019(0) | 35.7 | 0.000(10) | 48.3 | 0.000(7) | 41.7 |
| sko100d | 149,576 | 0.031(0) | 35.7 | 0.000(10) | 45.9 | 0.000(10) | 28.4 |
| sko100e | 149,150 | 0.023(0) | 35.7 | 0.000(10) | 42.0 | 0.000(10) | 23.1 |
| sko100f | 149,036 | 0.047(0) | 35.7 | 0.000(10) | 28.3 | 0.002(7) | 22.0 |
| wil100 | 273,038 | 0.010(0) | 36.1 | 0.000(10) | 10.4 | 0.001(6) | 31.5 |
| Average | 0.279 | 23.5 | 0.116 | 52.6 | 0.094 | 28.8 | |
| Parameters | Range |
|---|---|
| Lift | 1 to 1.4 or 0 |
| Relative profit | 1 to 4 |
| Relative frequency | 1 to 4 |
| DB1 | DB2 | DB3 | DB4 | |
|---|---|---|---|---|
| Number of items | 50 | 100 | 150 | 225 |
| Layout of sites |
| DB | (A) | (B) | (C) | (C)/(A) | (C)/(B) |
|---|---|---|---|---|---|
| DB1 | 1328.2 | 1856.8 | 2256.2 | 1.70 | 1.22 |
| DB2 | 2767.8 | 4035.6 | 4967.8 | 1.79 | 1.23 |
| DB3 | 4146.8 | 6204.4 | 7812.4 | 1.88 | 1.26 |
| DB4 | 6253.8 | 9571.4 | 12,121.0 | 1.94 | 1.27 |
| Instance | POS | UX | RPMX | |||
|---|---|---|---|---|---|---|
| Fitness | Min. | Fitness | Min. | Fitness | Min. | |
| DB1 | 2305.6 | 68.3 | 2303.2 | 53.6 | * 2306.0 | 16.2 |
| DB2 | 5033.0 | 29.6 | 5029.4 | 57.0 | * 5105.8 | 49.7 |
| DB3 | 7891.0 | 38.8 | 7894.6 | 61.8 | * 8040.4 | 69.8 |
| DB4 | 12,228.8 | 52.6 | 12,226.8 | 54.5 | * 12,464.8 | 78.7 |
| Instance | BFS | TLBO-RTS | ABC-QAP | Proposed HGA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Fitness | APD | Min. | Fitness | APD | Min. | Fitness | APD | Min. | ||
| DB1 | 2306 | 2281.6 | 1.058 | 4.5 | 2295.8 | 0.442 | 45.3 | * 2306.0 | 0.000 | 16.2 |
| DB2 | 5162 | 5027.0 | 2.615 | 29.6 | 5037.8 | 2.406 | 55.9 | * 5105.8 | 1.089 | 49.7 |
| DB3 | 8086 | 7898.8 | 2.315 | 29.0 | 7925.2 | 1.989 | 76.5 | * 8040.4 | 0.564 | 69.8 |
| DB4 | 12,554 | 12,301.6 | 2.011 | 39.3 | 12,310.0 | 1.944 | 57.5 | * 12,464.8 | 0.711 | 78.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, M.; Ahn, K.-I.; Lee, K. Finding Effective Item Assignment Plans with Weighted Item Associations Using A Hybrid Genetic Algorithm. Appl. Sci. 2021, 11, 2209. https://doi.org/10.3390/app11052209
Ryu M, Ahn K-I, Lee K. Finding Effective Item Assignment Plans with Weighted Item Associations Using A Hybrid Genetic Algorithm. Applied Sciences. 2021; 11(5):2209. https://doi.org/10.3390/app11052209
Chicago/Turabian StyleRyu, Minho, Kwang-Il Ahn, and Kichun Lee. 2021. "Finding Effective Item Assignment Plans with Weighted Item Associations Using A Hybrid Genetic Algorithm" Applied Sciences 11, no. 5: 2209. https://doi.org/10.3390/app11052209
APA StyleRyu, M., Ahn, K.-I., & Lee, K. (2021). Finding Effective Item Assignment Plans with Weighted Item Associations Using A Hybrid Genetic Algorithm. Applied Sciences, 11(5), 2209. https://doi.org/10.3390/app11052209