
Neuroscope: An Explainable AI Toolbox for Semantic Segmentation and Image Classification of Convolutional Neural Nets


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Explainable Artificial Intelligence (AI) Methods for Convolutional Neural Networks
2.2. Semantic Segmentation Using Deep Learning
2.3. State-of-the-Art Visualization Tools for Convolutional Neural Networks
2.4. Adaption of Image Classification Explanation Algorithms to Semantic Segmentation
2.5. Activation Maps
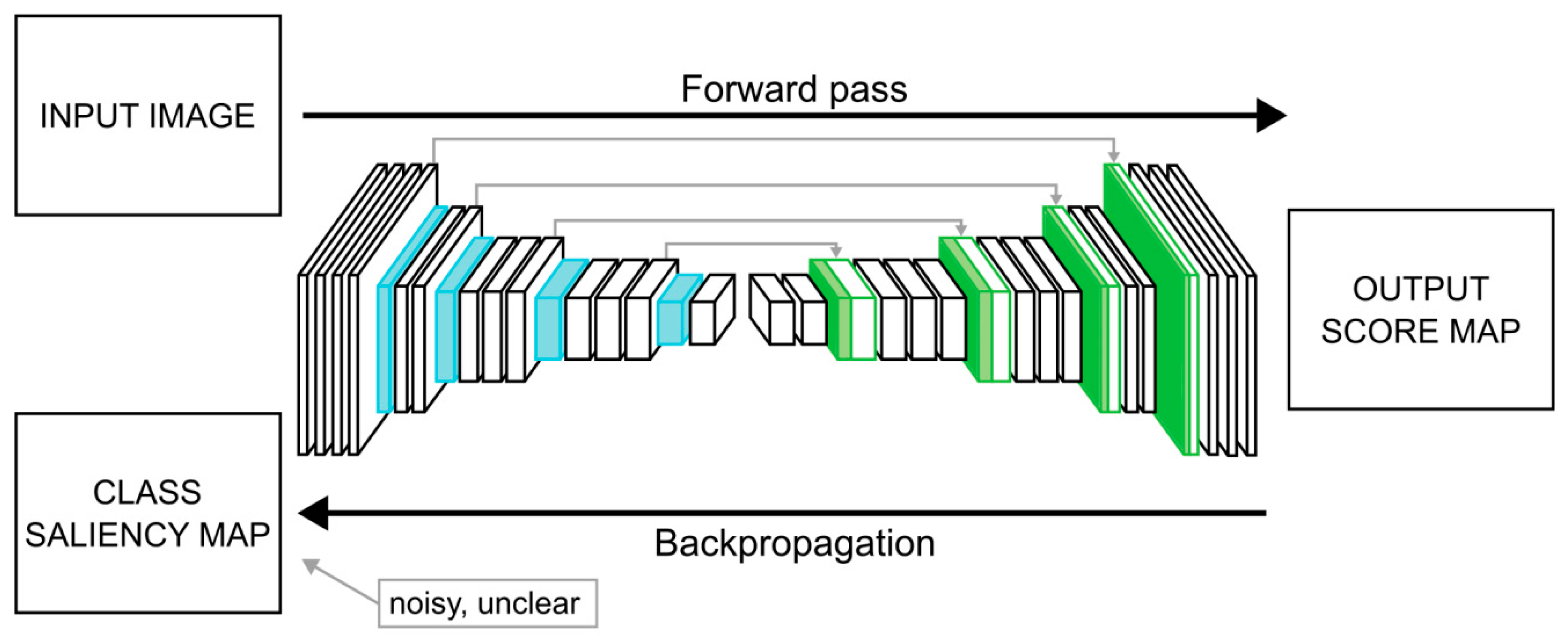
2.6. Class Saliency
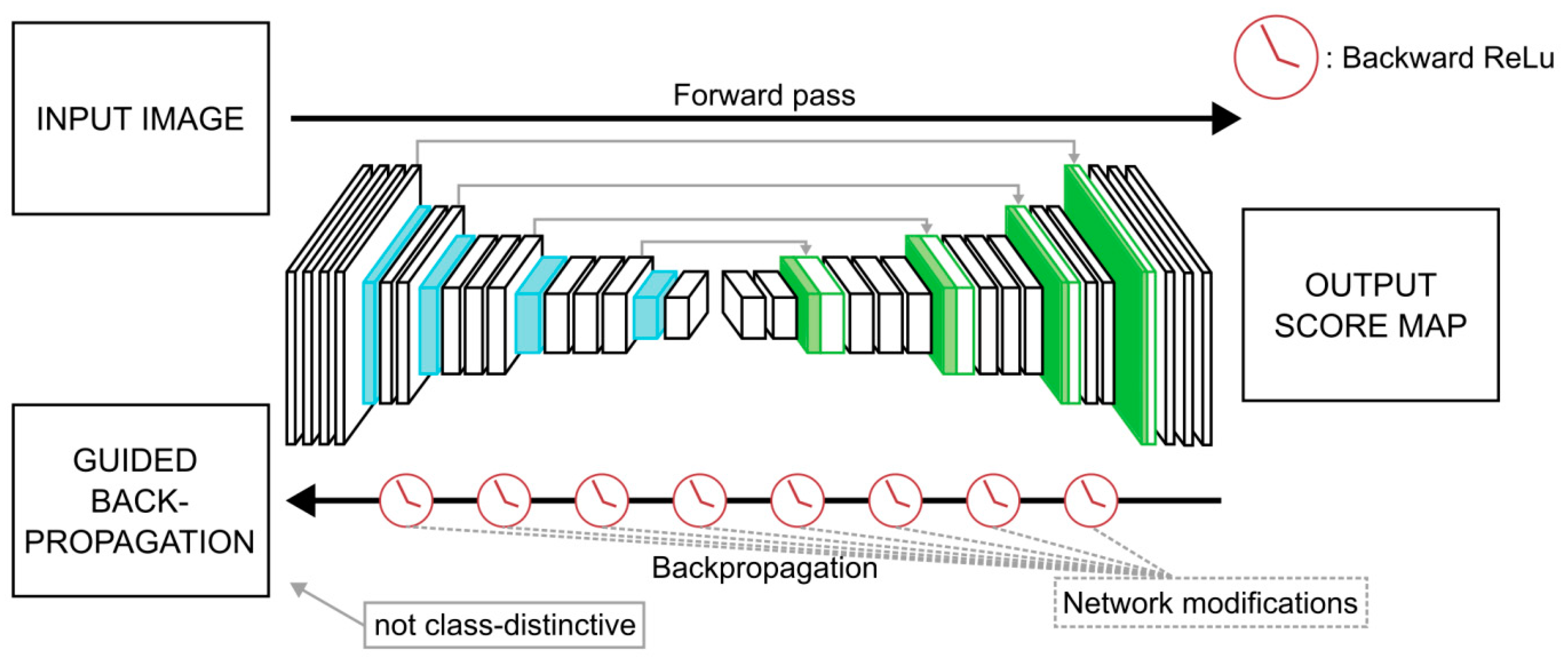
2.7. Guided Back-Propagation
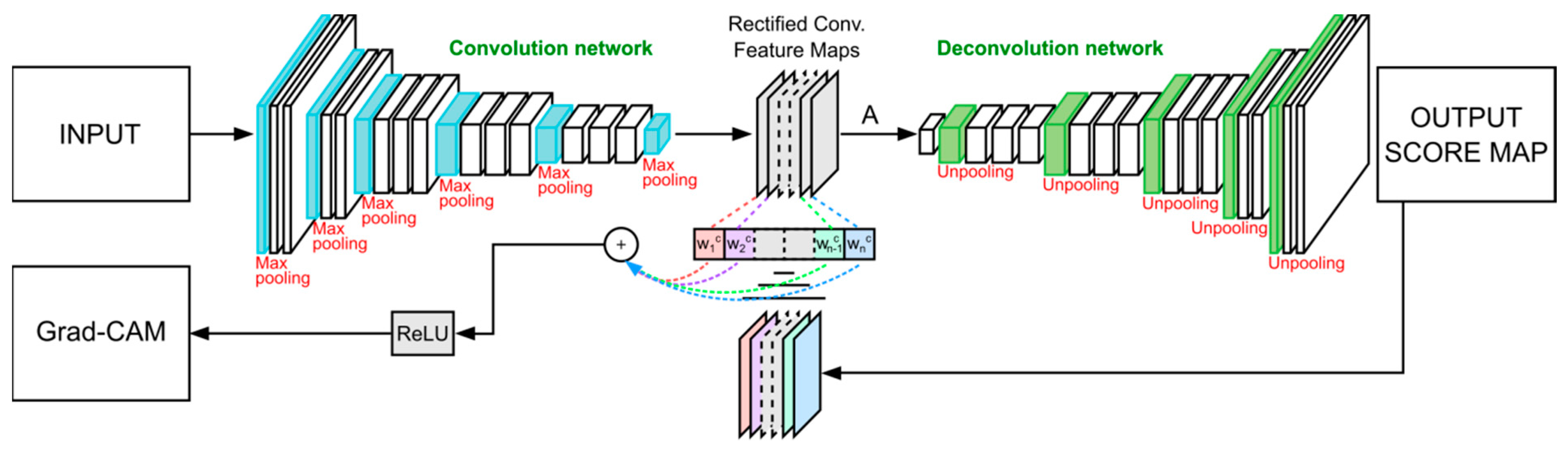
2.8. Grad-CAM
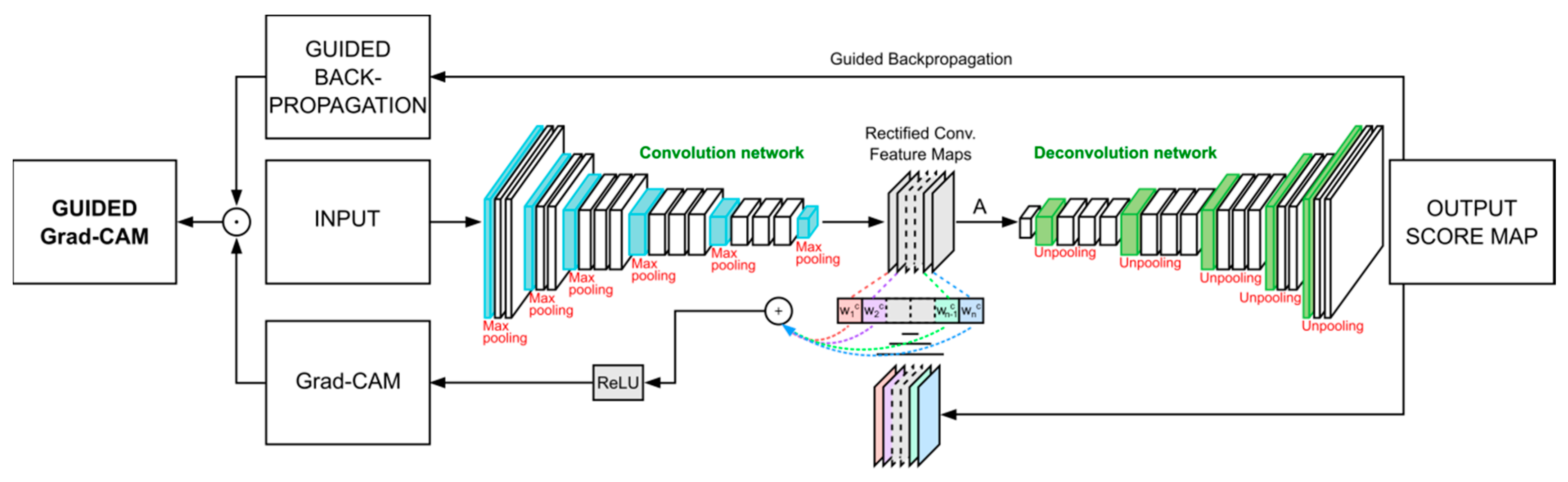
2.9. Guided Grad-CAM
2.10. Segmentation Score Maps
2.11. Segmented Score Mapping
2.12. Guided Segmented Score Mapping
2.13. Similarity Mapping
2.14. Fusion Score Mapping
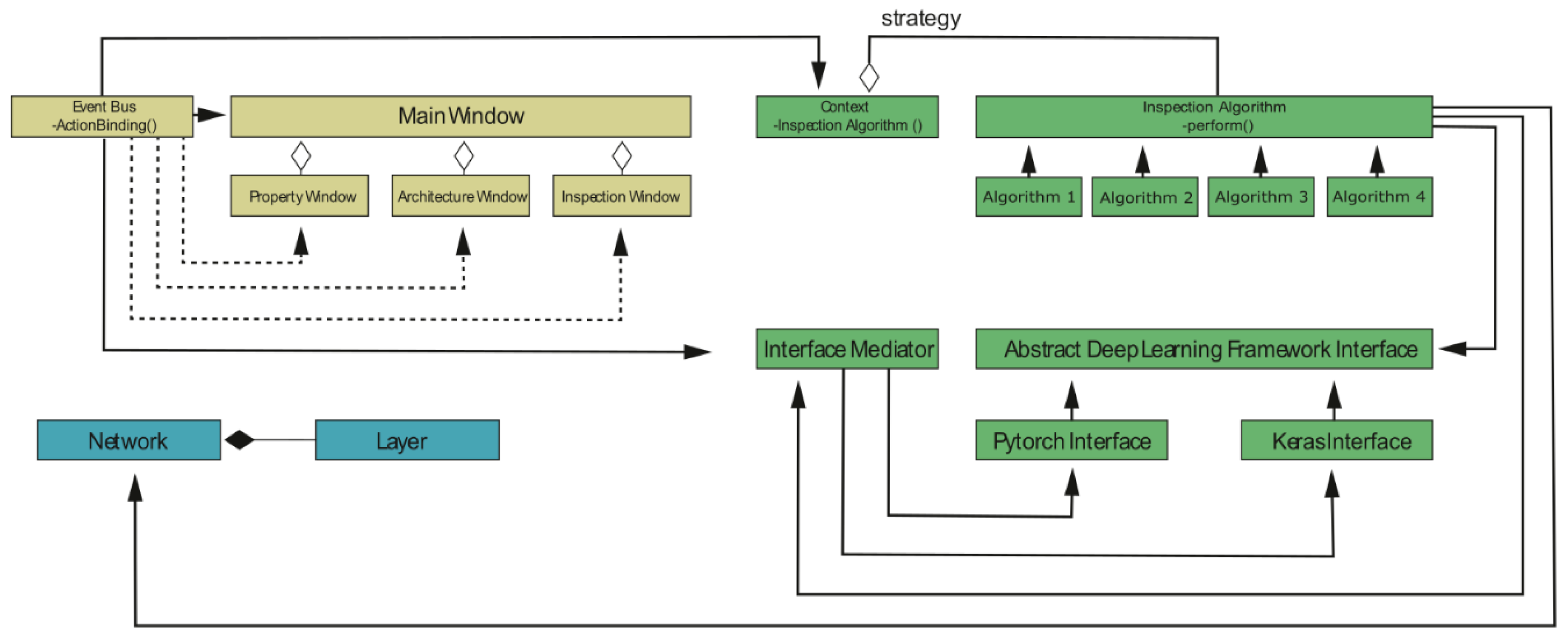
2.15. Integration into Neuroscope
3. Results
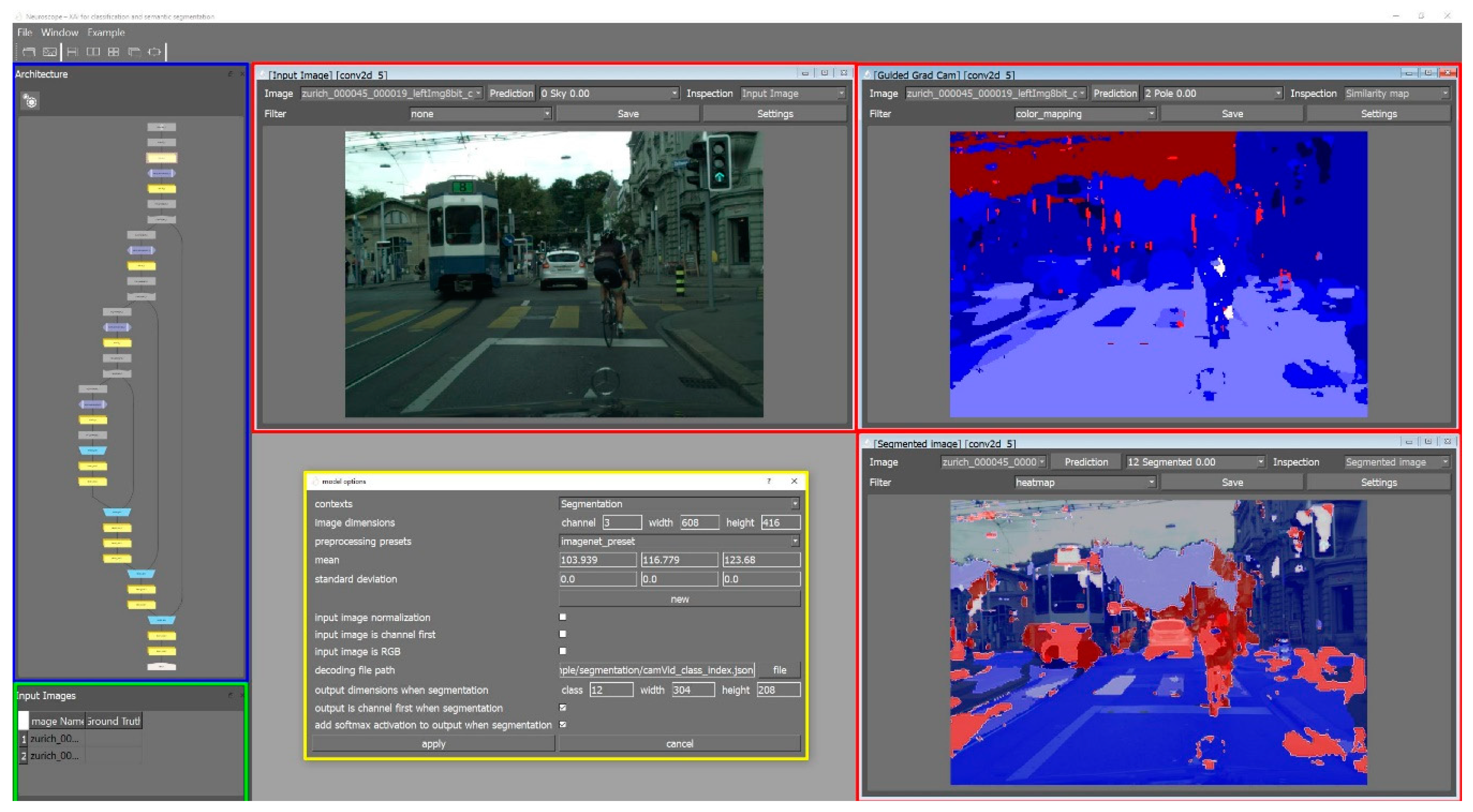
3.1. Neuroscope Components
3.1.1. Architecture View
3.1.2. Model Options
3.1.3. Image List
3.1.4. Inspection Window
3.2. Application of Neuroscope to Real World Data
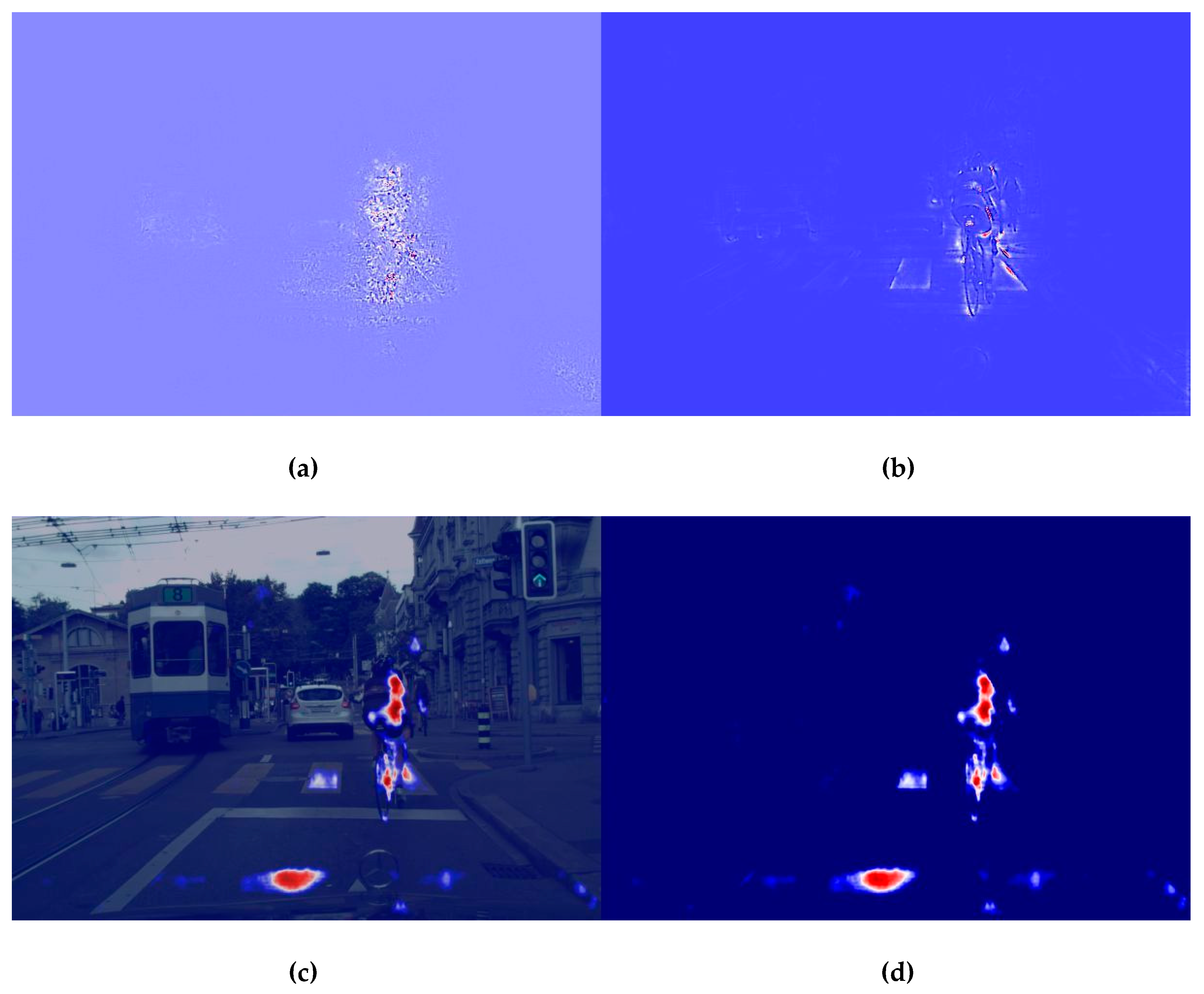
3.2.1. Comparing Different Visualization Methods
3.2.2. Guided Grad-CAM for Different Model Layers
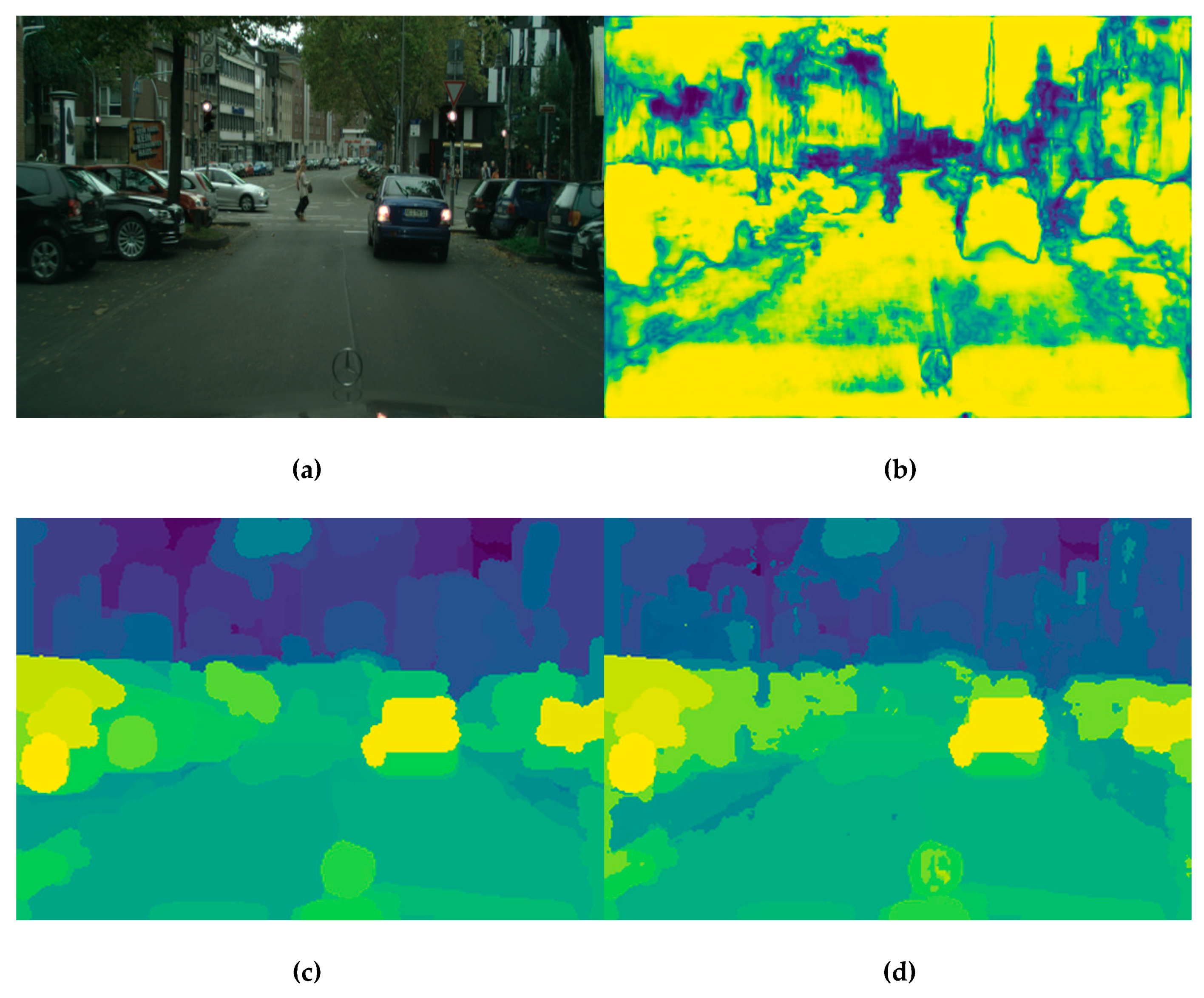
3.2.3. Score Maps for Semantic Segmentation
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 4th ed.; Pearson: New York City, NY, USA, 2018. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Computer Vision–ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2014; Volume 8689, pp. 818–833. [Google Scholar] [CrossRef]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for Simplicity: The All Convolutional Net. In Proceedings of the Workshop Track Proceedings, 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Olah, C.; Satyanarayan, A.; Johnson, I.; Carter, S.; Schubert, L.; Ye, K.; Mordvintsev, A.R. The Building Blocks of Interpretability. Distill 2018, 3. [Google Scholar] [CrossRef]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning Research (PMLR), Sydney, NSW, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.-R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10. [Google Scholar] [CrossRef] [PubMed]
- Fong, R.; Vedaldi, A. Interpretable Explanations of Black Boxes by Meaningful Perturbation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3429–3437. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar] [CrossRef]
- Bau, D.; Zhou, B.; Khosla, A.; Oliva, A.; Torralba, A. Network Dissection: Quantifying Interpretability of Deep Visual Representations. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3319–3327. [Google Scholar] [CrossRef]
- Dhamdhere, K.; Sundararajan, M.; Yan, Q. How Important Is a Neuron? arXiv 2018, arXiv:1805.12233. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. DeepInside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2014, arXiv:1312.6034v2. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. ‘Why Should I Trust You?’: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. arXiv 2015, arXiv:1505.04366v1. [Google Scholar] [CrossRef]
- Mahendran, A.; Vedaldi, A. Visualizing Deep Convolutional Neural Networks Using Natural Pre-images. Int. J. Comput. Vis. 2016, 120, 233–255. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Tensorflow. Available online: https://wwwtensorflow.org (accessed on 11 December 2020).
- Tensorboard. Available online: https://www.tensorflow.org/tensorboard (accessed on 11 December 2020).
- Tensorflow Playground. Available online: https://playground.tensorflow.org (accessed on 11 December 2020).
- Wongsuphasawat, K.; Smilkov, D.; Wexler, J.; Wilson, J.; Mane, D.; Fritz, D.; Krishnan, D.; Viegas, F.; Wattenberg, M. Visualizing Dataflow Graphs of Deep Learning Models in TensorFlow. Trans. Vis. Comput. Graph. 2018, 24, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Hohman, F.; Hodas, N.N.; Chau, D.H. ShapeShop: Towards Understanding Deep Learning Representations via Interactive Experimentation. Ext. Abstr. Hum. Factors. Comput. Syst. 2017. [Google Scholar] [CrossRef]
- Hohman, F.; Park, H.; Robinson, C.; Chau, D.H. SUMMIT: Scaling Deep Learning Interpretability by Visualizing Activation and Attribution Summarizations. Trans. Vis. Comput. Graph. 2019, 26, 1096–1106. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.J.; Turko, R.; Shaikh, O.; Park, H.; Das, N.; Hohman, F.; Kahng, M.; Chau, D.H. CNN EXPLAINER: Learning Convolutional Neural Networks with Interactive Visualization. Trans. Vis. Comput. Graph. 2020. [Google Scholar] [CrossRef]
- Park, H.; Hohman, F.; Chau, D.H. NeuralDivergence-Exploring and Understanding Neural Networks by Comparing Activation Distributions. arXiv 2019, arXiv:1906.00332v1. [Google Scholar]
- Kahng, M.; Andrews, P.; Kalro, A.; Chau, D.H. ActiVis: Visual Exploration of Industry-Scale Deep Neural Network Models. Trans. Vis. Comput. Graph. 2017, 24, 88–97. [Google Scholar] [CrossRef]
- Goodarzi, P. Visualizing and Understanding Convolutional Networks for Semantic Segmentation. Master’s Thesis, Saarland University, Saarbrücken, Germany, 2020. [Google Scholar]
- Vinogradova, K.; Dibrov, A.; Myers, G. Towards Interpretable Semantic Segmentation via Gradient-weighted Class Activation Mapping. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; AAAI Press: Palo Alto, CA, USA, 2020; pp. 13943–13944. [Google Scholar] [CrossRef]
- Adebayo, J.; Gilmer, J.; Muelly, M.; Goodfellow, I.; Hardt, M.; Kim, B. Sanity Checks for Saliency Maps. In Proceedings of the Advances in Neural Information Processing Systems 31, Annual Conference on Neural Information Processing Systems 2018 (NeurIPS), Montréal, QC, Canada, 3–8 December 2018; pp. 9505–9515. [Google Scholar]
- Kapishnikov, A.; Bolukbasi, T.; Viégas, F.; Terry, M. Segment Integrated Gradients: Better attributions through regions. CoRR 2019. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Gamma, J.V.E.; Helm, R.; Johnson, R.E. Design Patterns. In Elements of Reusable Object-Oriented Software, 1st ed.; Addison-Wesley Publishing Company: Upper Saddle River, NJ, 1995. [Google Scholar]
- Chen, F. A Visual Explanation Tool on Multiple Deep Learning Frameworks for Classification Tasks. Master’s Thesis, Saarland University, Saarbrücken, Germany, 2019. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11618–11628. [Google Scholar] [CrossRef]
- Simonyan, K.; Zissermann, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar]
- Roscher, R.; Bohn, B.; Duarte, M.F.; Garcke, J. Explainable Machine Learning for Scientific Insights and Discoveries. IEEE Access 2020. [Google Scholar] [CrossRef]
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–2015. [Google Scholar] [CrossRef]
- Chen, C.; Lin, K.; Rudin, C.; Shaposhnik, Y.; Wang, S.; Wang, T. An Interpretable Model with Globally Consistent Explanations for Credit Risk. In Proceedings of the NeurIPS 2018 Workshop on Challenges and Opportunities for AI in Financial Services: The Impact of Fairness, Explainability, Accuracy, and Privacy, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Ancona, M.; Ceolini, E.; Öztireli, C.; Gross, M. A unified view of gradient-based attribution methods for Deep Neural Networks. CoRR 2017. [Google Scholar]










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schorr, C.; Goodarzi, P.; Chen, F.; Dahmen, T. Neuroscope: An Explainable AI Toolbox for Semantic Segmentation and Image Classification of Convolutional Neural Nets. Appl. Sci. 2021, 11, 2199. https://doi.org/10.3390/app11052199
Schorr C, Goodarzi P, Chen F, Dahmen T. Neuroscope: An Explainable AI Toolbox for Semantic Segmentation and Image Classification of Convolutional Neural Nets. Applied Sciences. 2021; 11(5):2199. https://doi.org/10.3390/app11052199
Chicago/Turabian StyleSchorr, Christian, Payman Goodarzi, Fei Chen, and Tim Dahmen. 2021. "Neuroscope: An Explainable AI Toolbox for Semantic Segmentation and Image Classification of Convolutional Neural Nets" Applied Sciences 11, no. 5: 2199. https://doi.org/10.3390/app11052199
APA StyleSchorr, C., Goodarzi, P., Chen, F., & Dahmen, T. (2021). Neuroscope: An Explainable AI Toolbox for Semantic Segmentation and Image Classification of Convolutional Neural Nets. Applied Sciences, 11(5), 2199. https://doi.org/10.3390/app11052199