
Exploring the Data Efficiency of Cross-Lingual Post-Training in Pretrained Language Models

 ,
,
Abstract
1. Introduction
2. Related Work
3. Proposed Method
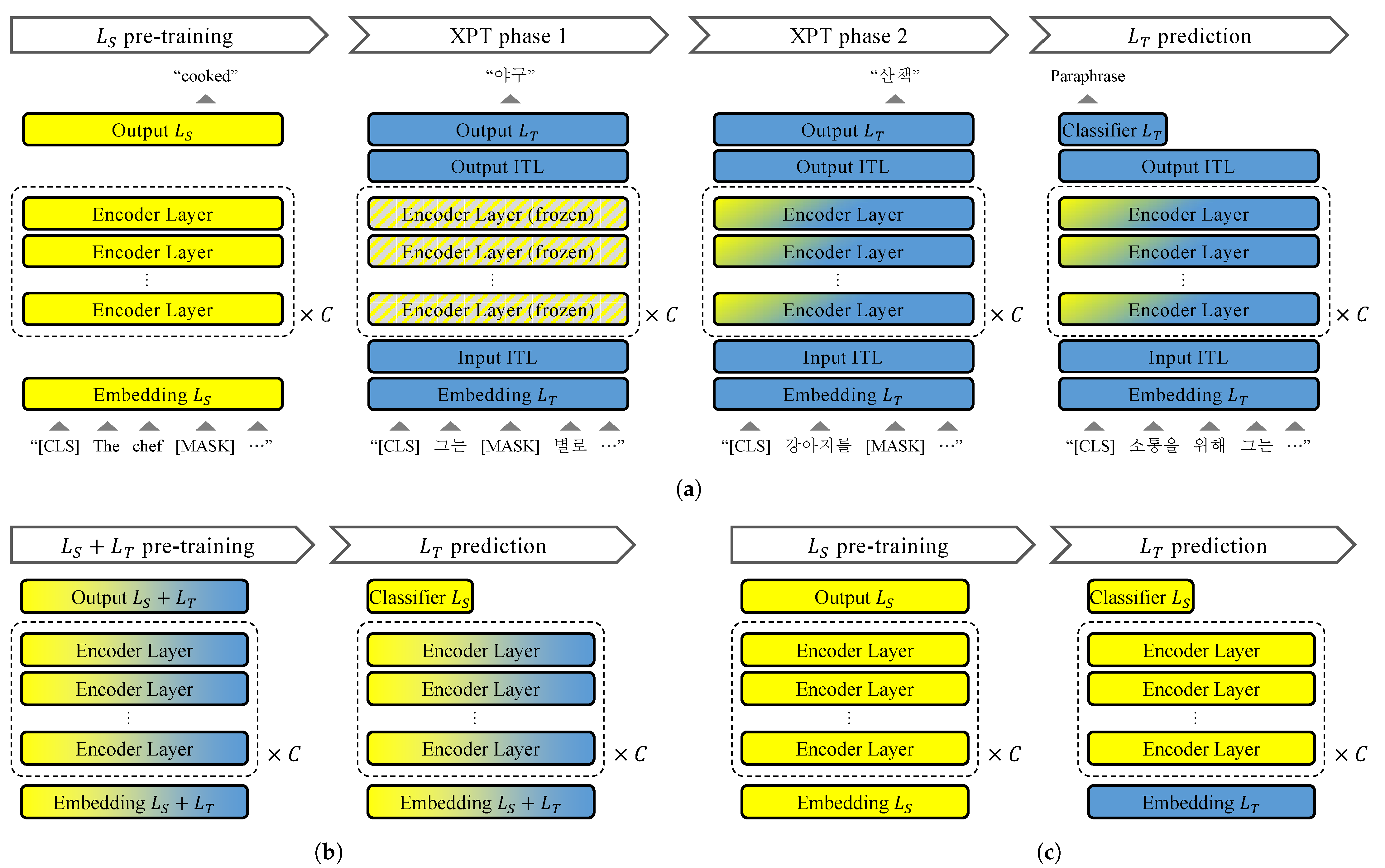
3.1. Transfer Learning as Post-Training
3.2. Selecting Parameters to Transfer
3.3. Implicit Translation Layer
3.4. Two-Phase Post-Training
4. Experimental Setup
4.1. Overview
4.2. Baselines
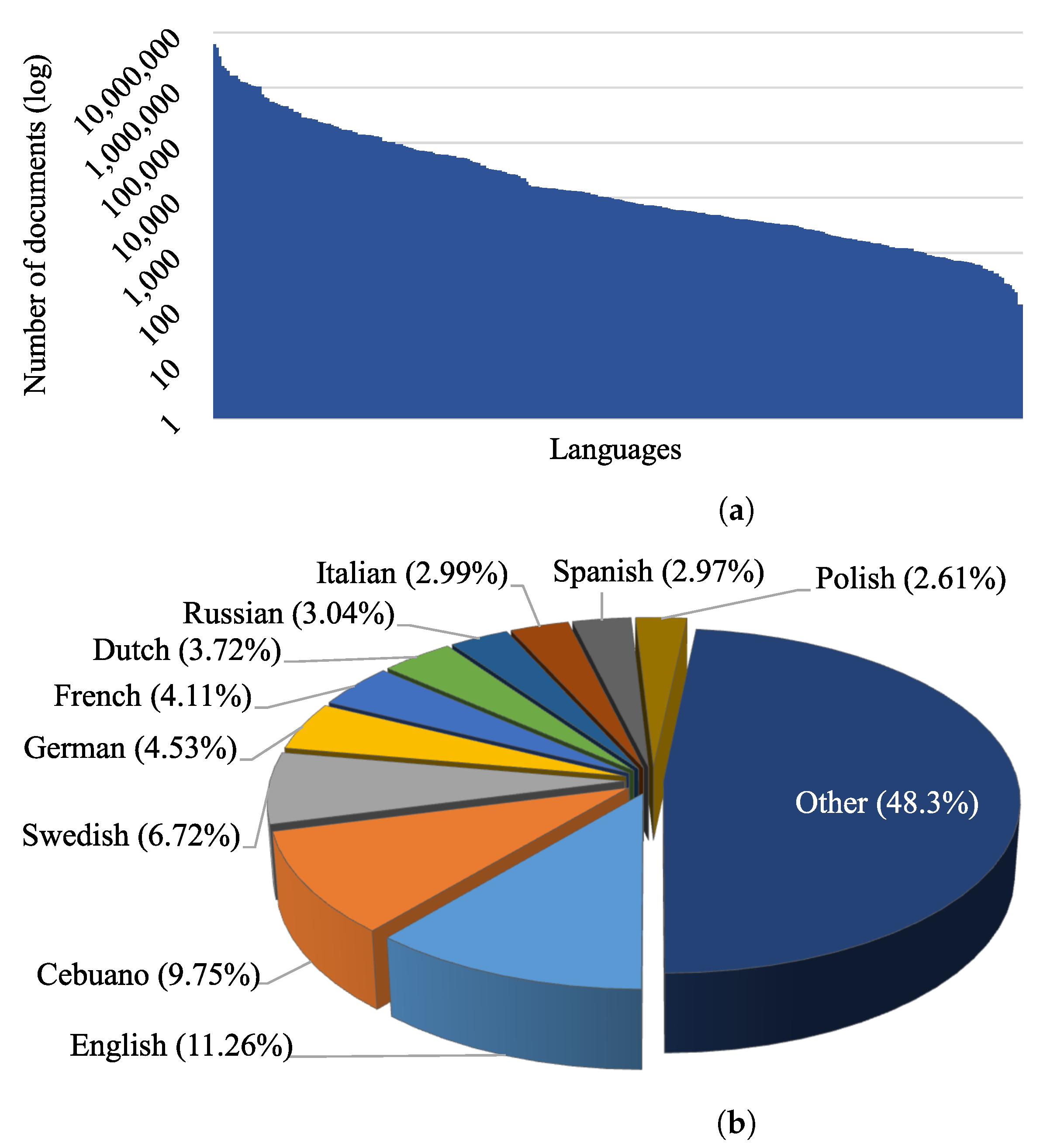
4.3. Dataset
4.4. Implementation Details
5. Results and Discussion
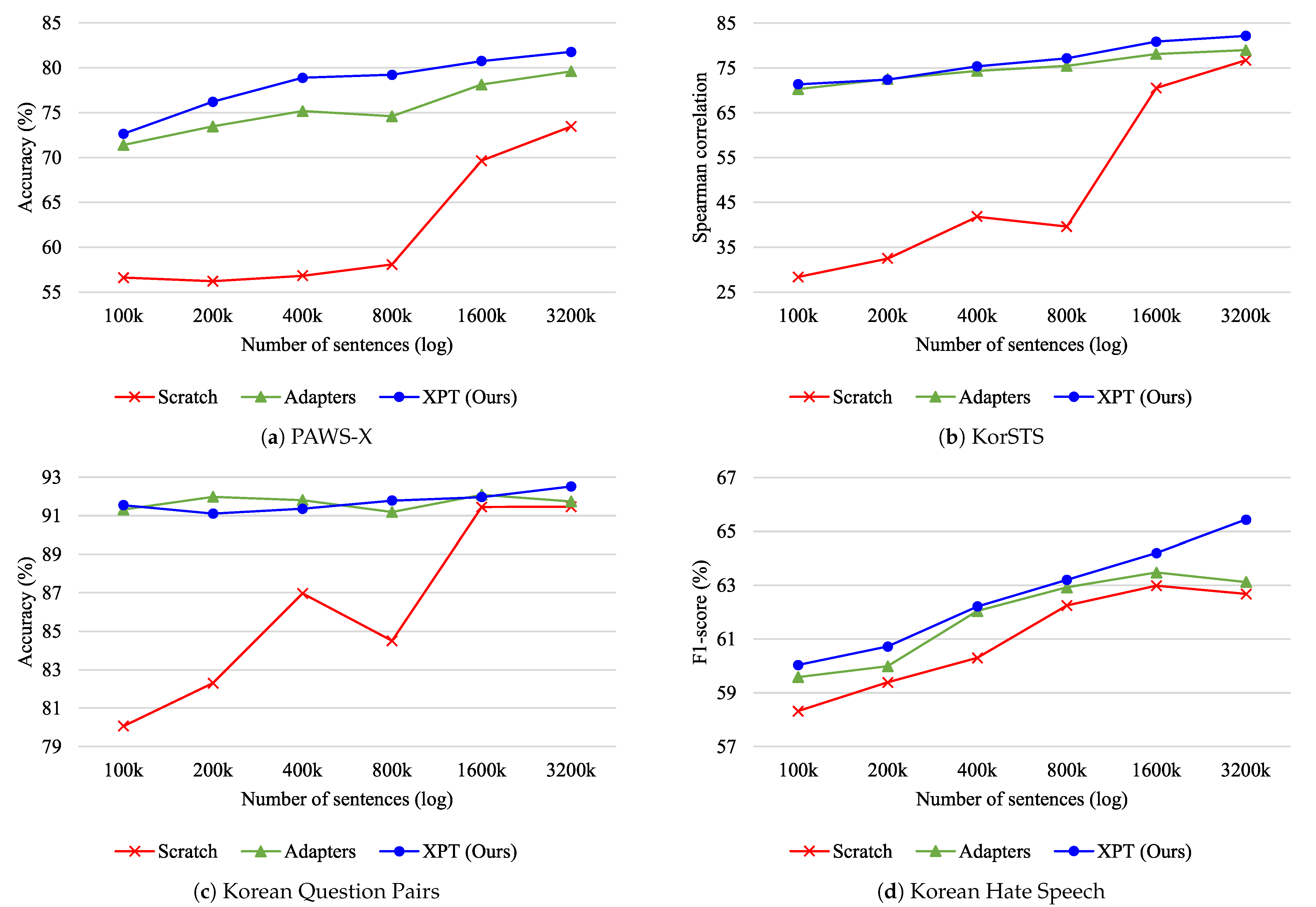
5.1. Intrinsic Evaluation
5.2. Extrinsic Evaluation
5.3. Effect of Two-Phase Training
6. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Hyperparameters

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Training Data Size | ||
|---|---|---|---|
| 100 K to 400 K | 800 K to 1.6 M | 3.2 M to 4 M | |
| Batch size | 256 | 2048 | 2048 |
| Learning rate | |||
| Total steps | 60 K | 60 K | 100 K |
| Warmup steps | 1 K | 1 K | 1 K |
| Hyperparameters | Task | |||
|---|---|---|---|---|
| PAWS-X | KorSTS | KQP | KHS | |
| Batch size | 32 | 32 | 32 | 32 |
| Learning rate | ||||
| Training epochs | 15 | 10 | 10 | 10 |
| Warpup proportion | 0.06 | 0.06 | 0.06 | 0.06 |
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 7871–7880. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-Training Text Encoders as Discriminators Rather Than Generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. DeBERTa: Decoding-Enhanced BERT with Disentangled Attention. arXiv 2020, arXiv:2006.03654. [Google Scholar]
- Ethnologue: Languages of the World. Available online: https://www.ethnologue.com (accessed on 22 February 2021).
- Lample, G.; Conneau, A. Cross-lingual language model pretraining. arXiv 2019, arXiv:1901.07291. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Artetxe, M.; Ruder, S.; Yogatama, D.; Labaka, G.; Agirre, E. A Call for More Rigor in Unsupervised Cross-lingual Learning. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 7375–7388. [Google Scholar]
- Joshi, P.; Santy, S.; Budhiraja, A.; Bali, K.; Choudhury, M. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 6282–6293. [Google Scholar]
- Kim, N.K. International Encyclopedia of Linguistics; Oxford University Press: Oxford, UK, 1992; Volume 2, pp. 282–286. [Google Scholar]
- Song, J.J. The Korean Language: Structure, Use and Context; Routledge: Oxfordshire, UK, 2006; p. 15. [Google Scholar]
- Campbell, L. Glossary of Historical Linguistics; Edinburgh University Press: Edinburgh, UK, 2007; pp. 90–91. [Google Scholar]
- Lauscher, A.; Ravishankar, V.; Vulić, I.; Glavaš, G. From Zero to Hero: On the Limitations of Zero-Shot Language Transfer with Multilingual Transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 4483–4499. [Google Scholar]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A primer in bertology: What we know about how bert works. Trans. Assoc. Comput. Linguist. 2021, 8, 842–866. [Google Scholar] [CrossRef]
- Xia, P.; Wu, S.; Van Durme, B. Which* BERT? A Survey Organizing Contextualized Encoders. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 7516–7533. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 2; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Mikolov, T.; Le, Q.V.; Sutskever, I. Exploiting similarities among languages for machine translation. arXiv 2013, arXiv:1309.4168. [Google Scholar]
- Gouws, S.; Bengio, Y.; Corrado, G. Bilbowa: Fast bilingual distributed representations without word alignments. arXiv 2014, arXiv:1410.2455. [Google Scholar]
- Lample, G.; Conneau, A.; Ranzato, M.; Denoyer, L.; Jégou, H. Word translation without parallel data. arXiv 2017, arXiv:1710.04087. [Google Scholar]
- Lample, G.; Conneau, A.; Denoyer, L.; Ranzato, M. Unsupervised Machine Translation Using Monolingual Corpora Only. arXiv 2017, arXiv:1711.00043. [Google Scholar]
- Wang, Z.; Xie, J.; Xu, R.; Yang, Y.; Neubig, G.; Carbonell, J.G. Cross-lingual Alignment vs Joint Training: A Comparative Study and A Simple Unified Framework. arXiv 2019, arXiv:1910.04708. [Google Scholar]
- Schuster, T.; Ram, O.; Barzilay, R.; Globerson, A. Cross-Lingual Alignment of Contextual Word Embeddings, with Applications to Zero-shot Dependency Parsing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 1599–1613. [Google Scholar]
- Wang, Y.; Che, W.; Guo, J.; Liu, Y.; Liu, T. Cross-Lingual BERT Transformation for Zero-Shot Dependency Parsing. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Hong Kong, China, 2019; pp. 5725–5731. [Google Scholar]
- Artetxe, M.; Schwenk, H. Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond. Trans. Assoc. Comput. Linguist. 2019, 7, 597–610. [Google Scholar] [CrossRef]
- Mulcaire, P.; Kasai, J.; Smith, N.A. Polyglot Contextual Representations Improve Crosslingual Transfer. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 3912–3918. [Google Scholar]
- Huang, H.; Liang, Y.; Duan, N.; Gong, M.; Shou, L.; Jiang, D.; Zhou, M. Unicoder: A Universal Language Encoder by Pre-Training with Multiple Cross-lingual Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Hong Kong, China, 2019; pp. 2485–2494. [Google Scholar]
- Feng, F.; Yang, Y.; Cer, D.; Arivazhagan, N.; Wang, W. Language-agnostic bert sentence embedding. arXiv 2020, arXiv:2007.01852. [Google Scholar]
- Multilingual BERT. Available online: https://github.com/google-research/bert/blob/master/multilingual.md (accessed on 22 February 2021).
- Wu, S.; Dredze, M. Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Hong Kong, China, 2019; pp. 833–844. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How Multilingual is Multilingual BERT? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Florence, Italy, 2019; pp. 4996–5001. [Google Scholar]
- Conneau, A.; Wu, S.; Li, H.; Zettlemoyer, L.; Stoyanov, V. Emerging Cross-lingual Structure in Pretrained Language Models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; 2020; pp. 6022–6034. Available online: https://www.aclweb.org/anthology/2020.acl-main.0 (accessed on 22 February 2021).
- Üstüstün, A.; Bisazza, A.; Bouma, G.; van Noord, G. UDapter: Language Adaptation for Truly Universal Dependency Parsing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 2302–2315. [Google Scholar]
- Pfeiffer, J.; Vulić, I.; Gurevych, I.; Ruder, S. MAD-X: An Adapter-based Framework for Multi-task Cross-lingual Transfer. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 7654–7673. [Google Scholar]
- Rebuffi, S.A.; Bilen, H.; Vedaldi, A. Learning multiple visual domains with residual adapters. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 506–516. [Google Scholar]
- Rebuffi, S.A.; Bilen, H.; Vedaldi, A. Efficient parametrization of multi-domain deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8119–8127. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. arXiv 2019, arXiv:1902.00751. [Google Scholar]
- Artetxe, M.; Ruder, S.; Yogatama, D. On the Cross-lingual Transferability of Monolingual Representations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 4623–4637. [Google Scholar]
- Tran, K. From english to foreign languages: Transferring pre-trained language models. arXiv 2020, arXiv:2002.07306. [Google Scholar]
- Jwa, H.; Oh, D.; Park, K.; Kang, J.M.; Lim, H. exBAKE: Automatic fake news detection model based on bidirectional encoder representations from transformers (bert). Appl. Sci. 2019, 9, 4062. [Google Scholar] [CrossRef]
- Whang, T.; Lee, D.; Lee, C.; Yang, K.; Oh, D.; Lim, H. An Effective Domain Adaptive Post-Training Method for BERT in Response Selection. arXiv 2020, arXiv:1908.04812. [Google Scholar]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 8342–8360. [Google Scholar]
- Luo, H.; Ji, L.; Li, T.; Jiang, D.; Duan, N. GRACE: Gradient Harmonized and Cascaded Labeling for Aspect-based Sentiment Analysis. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 54–64. [Google Scholar]
- Felbo, B.; Mislove, A.; Søgaard, A.; Rahwan, I.; Lehmann, S. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 1615–1625. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Melbourne, Australia, 2018; pp. 328–339. [Google Scholar]
- Published English RoBERTa model. Available online: https://dl.fbaipublicfiles.com/fairseq/models/roberta.base.tar.gz (accessed on 22 February 2021).
- Wenzek, G.; Lachaux, M.A.; Conneau, A.; Chaudhary, V.; Guzmán, F.; Joulin, A.; Grave, É. CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data. arXiv 2019, arXiv:1911.00359. [Google Scholar]
- KoBERT: Korean BERT pretrained cased. Available online: https://github.com/SKTBrain/KoBERT (accessed on 22 February 2021).
- Attardi, G. WikiExtractor. 2015. Available online: https://github.com/attardi/wikiextractor (accessed on 22 February 2021).
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 66–71. [Google Scholar]
- Yang, Y.; Zhang, Y.; Tar, C.; Baldridge, J. PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Cer, D.; Diab, M.; Agirre, E.; Lopez-Gazpio, I.; Specia, L. SemEval-2017 Task 1: Semantic Textual Similarity Multilingual and Crosslingual Focused Evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1–14. [Google Scholar]
- Ham, J.; Choe, Y.J.; Park, K.; Choi, I.; Soh, H. KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding. arXiv 2020, arXiv:2004.03289. [Google Scholar]
- Korean Question Pairs Dataset. Available online: https://github.com/songys/Question_pair (accessed on 22 February 2021).
- First Quora Dataset Release: Question Pairs. Available online: https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs (accessed on 22 February 2021).
- Moon, J.; Cho, W.I.; Lee, J. BEEP! Korean Corpus of Online News Comments for Toxic Speech Detection. In Proceedings of the Eighth International Workshop on Natural Language Processing for Social Media; Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 25–31. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the NAACL-HLT 2019: Demonstrations, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations; Association for Computational Linguistics: Minneapolis, MN, USA, 2020; pp. 38–45. [Google Scholar]




| Task | Train | Validation | Test | |||
|---|---|---|---|---|---|---|
| # Examples | # Tokens | # Examples | # Tokens | # Examples | # Tokens | |
| PAWS-X | 49,401 | 1,413,443 | 2000 | 50,292 | 2000 | 50,599 |
| KorSTS | 5749 | 86,253 | 1499 | 26,022 | 1378 | 21,066 |
| KQP | 6136 | 46,007 | 682 | 5067 | 758 | 5589 |
| KHS | 7896 | 129,422 | 471 | 7755 | N/A | N/A |
| Model | PPL | Hits@1 | Hits@3 | Hits@5 | Hits@10 | MRR | MR |
|---|---|---|---|---|---|---|---|
| Scratch | 5.88 | 63.91 | 76.18 | 80.41 | 85.18 | 0.7145 | 58.87 |
| Adapters | 5.46 | 65.05 | 77.28 | 81.40 | 86.04 | 0.7253 | 53.93 |
| XPT-SP (Ours) | 5.41 | 65.28 | 77.49 | 81.60 | 86.18 | 0.7273 | 54.03 |
| XPT (Ours) | 5.07 | 66.13 | 78.31 | 82.38 | 86.90 | 0.7354 | 50.41 |
| Model | Pre/Post-Train Data | Task | ||||
|---|---|---|---|---|---|---|
| Domain | # Tokens | PAWS-X | KorSTS | KQP | KHS | |
| mBERT | Wiki-100 | 6 B | 81.37 ± 0.63 | 77.48 ± 0.73 | 92.30 ± 0.70 | 61.66 ± 1.56 |
| XLM-R | CC-100 | 295 B | 81.54 ± 0.34 | 78.63 ± 0.63 | 93.21 ± 0.48 | 63.45 ± 1.09 |
| KoBERT | Wiki/news-ko | 324 M | 79.68 ± 0.75 | 77.67 ± 2.86 | 93.54 ± 0.75 | 64.68 ± 0.64 |
| Scratch | Wiki-ko | 61 M | 73.40 ± 0.42 | 74.38 ± 0.73 | 91.65 ± 0.55 | 65.55 ± 1.12 |
| Adapters | Wiki-ko | 61 M | 79.69 ± 0.87 | 79.78 ± 0.85 | 91.94 ± 0.34 | 62.90 ± 1.79 |
| XPT-SP (Ours) | Wiki-ko | 61 M | 80.46 ± 0.50 | 80.98 ± 0.40 | 92.22 ± 0.46 | 64.22 ± 1.24 |
| XPT (Ours) | Wiki-ko | 61 M | 81.62 ± 0.38 | 82.65 ± 0.39 | 92.88 ± 0.29 | 64.85 ± 0.53 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, C.; Yang, K.; Whang, T.; Park, C.; Matteson, A.; Lim, H. Exploring the Data Efficiency of Cross-Lingual Post-Training in Pretrained Language Models. Appl. Sci. 2021, 11, 1974. https://doi.org/10.3390/app11051974
Lee C, Yang K, Whang T, Park C, Matteson A, Lim H. Exploring the Data Efficiency of Cross-Lingual Post-Training in Pretrained Language Models. Applied Sciences. 2021; 11(5):1974. https://doi.org/10.3390/app11051974
Chicago/Turabian StyleLee, Chanhee, Kisu Yang, Taesun Whang, Chanjun Park, Andrew Matteson, and Heuiseok Lim. 2021. "Exploring the Data Efficiency of Cross-Lingual Post-Training in Pretrained Language Models" Applied Sciences 11, no. 5: 1974. https://doi.org/10.3390/app11051974
APA StyleLee, C., Yang, K., Whang, T., Park, C., Matteson, A., & Lim, H. (2021). Exploring the Data Efficiency of Cross-Lingual Post-Training in Pretrained Language Models. Applied Sciences, 11(5), 1974. https://doi.org/10.3390/app11051974