
A Biologically Inspired Sound Localisation System Using a Silicon Cochlea Pair

 ,
,  , ,
, ,  and
and
Abstract
1. Introduction
2. Materials and Methods
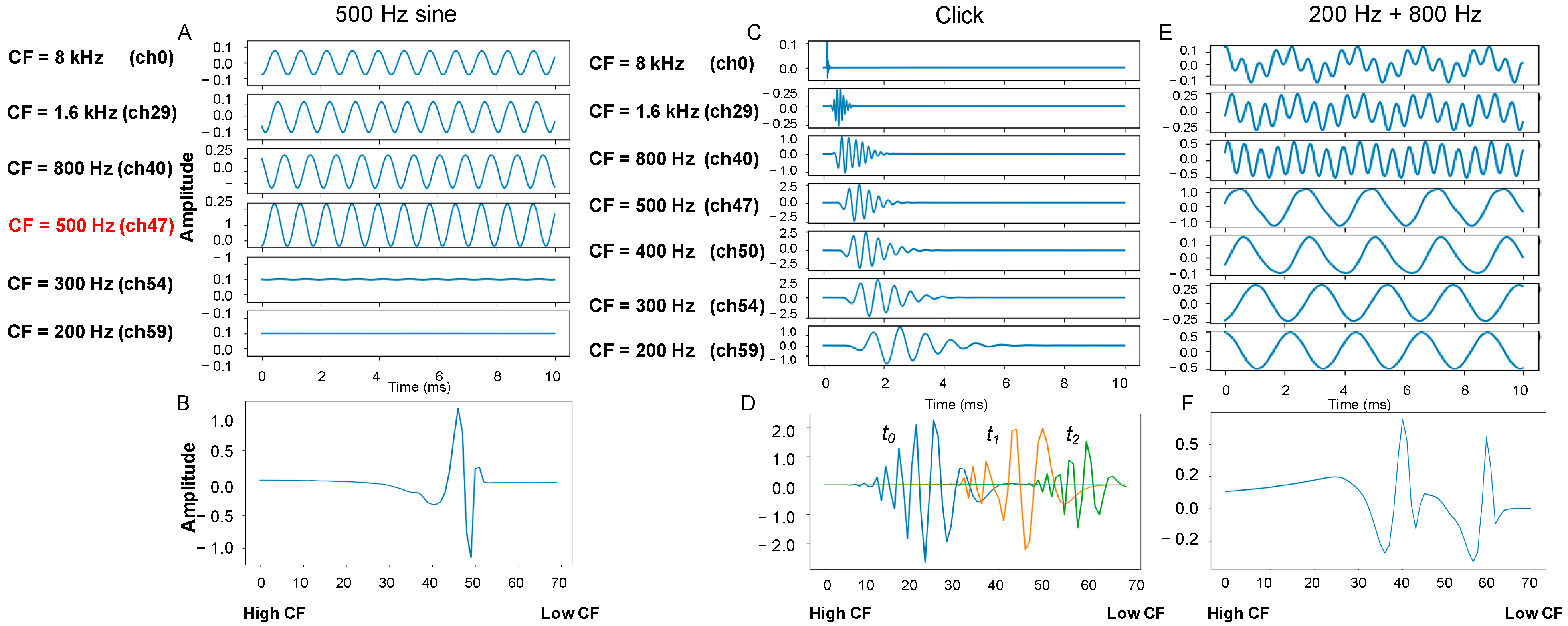
2.1. Binaural CAR-FAC Pre-Processing
2.2. Modelling the Medial Superior Olive Using Coincidence Detection
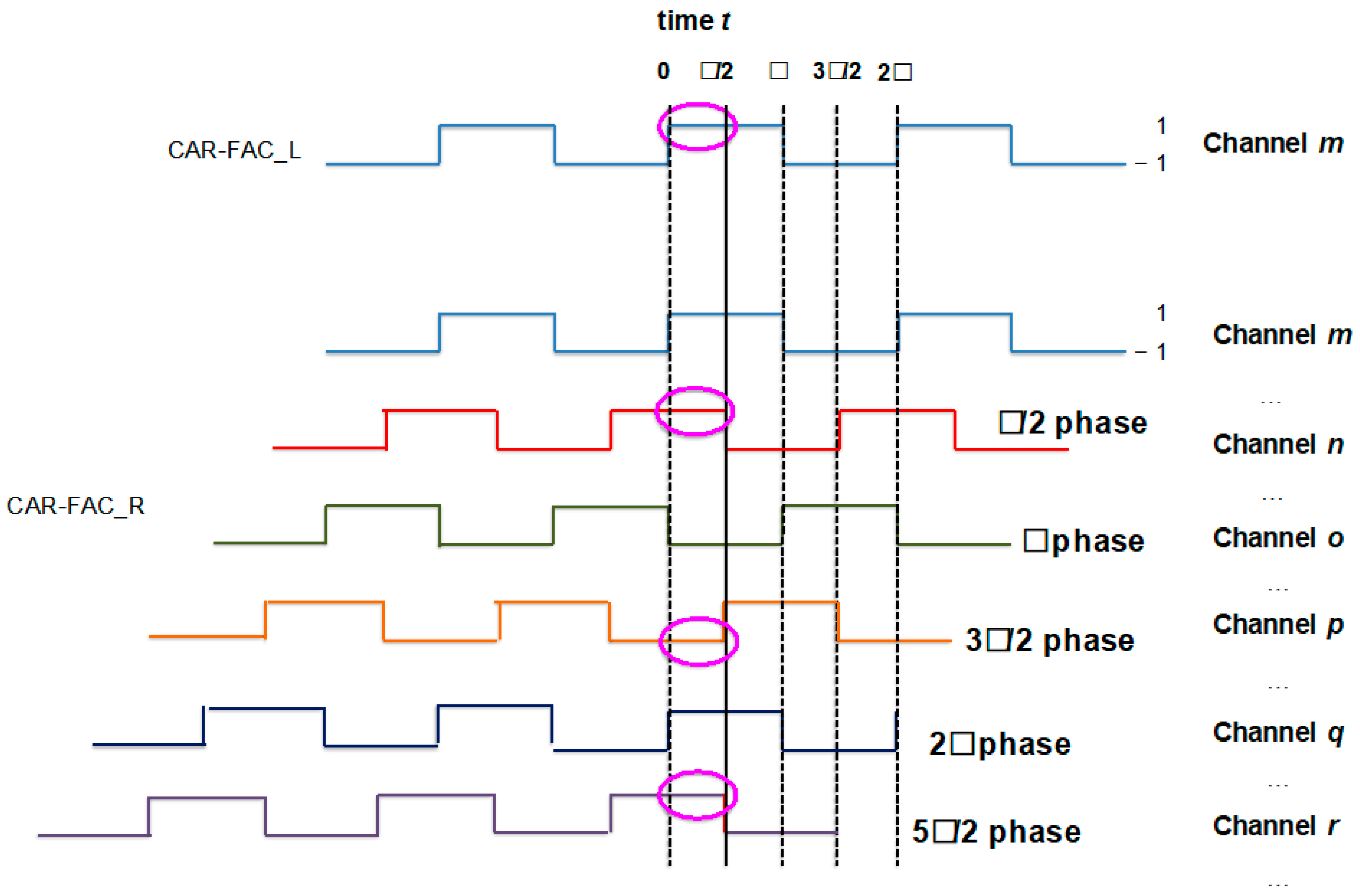
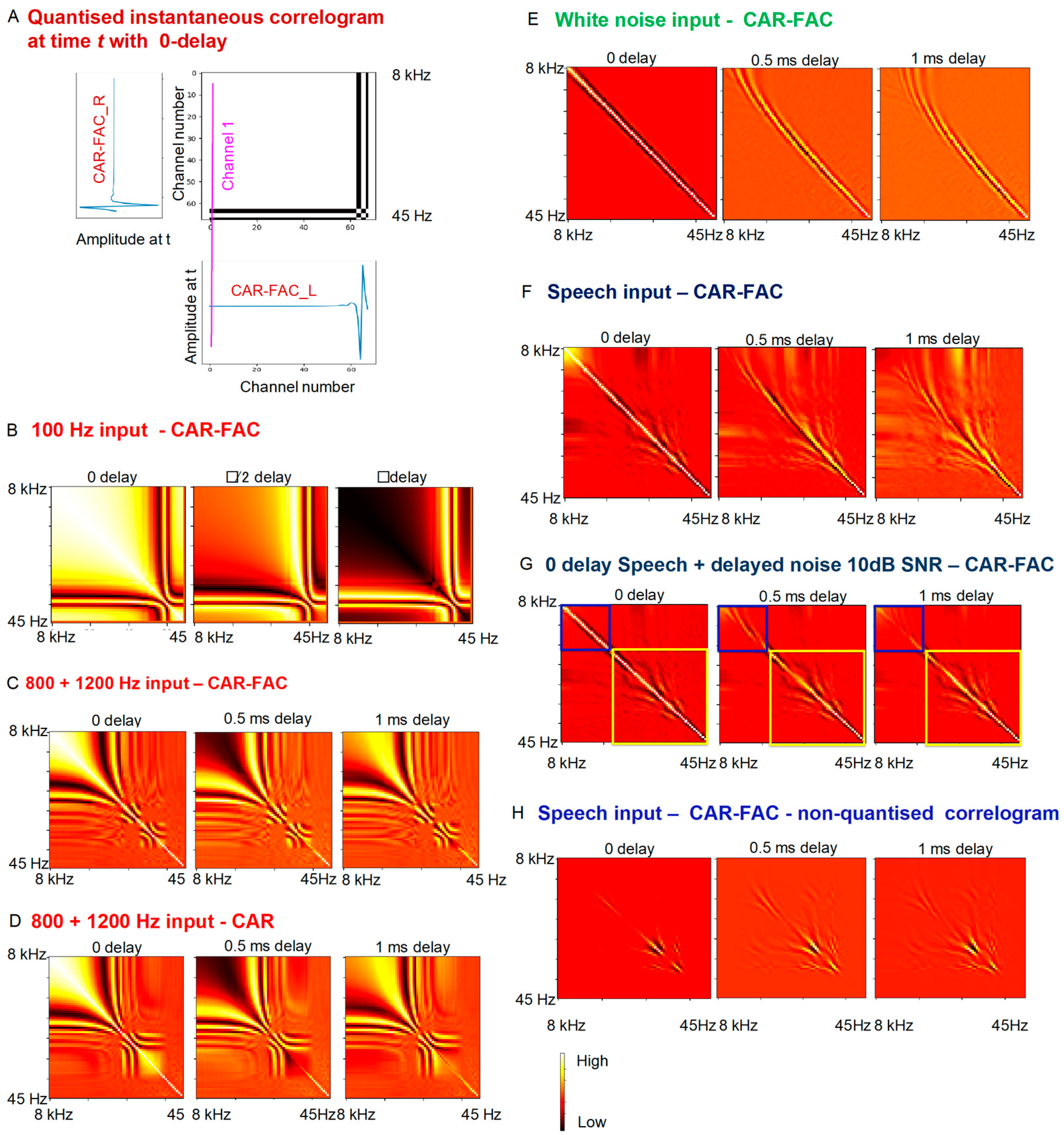
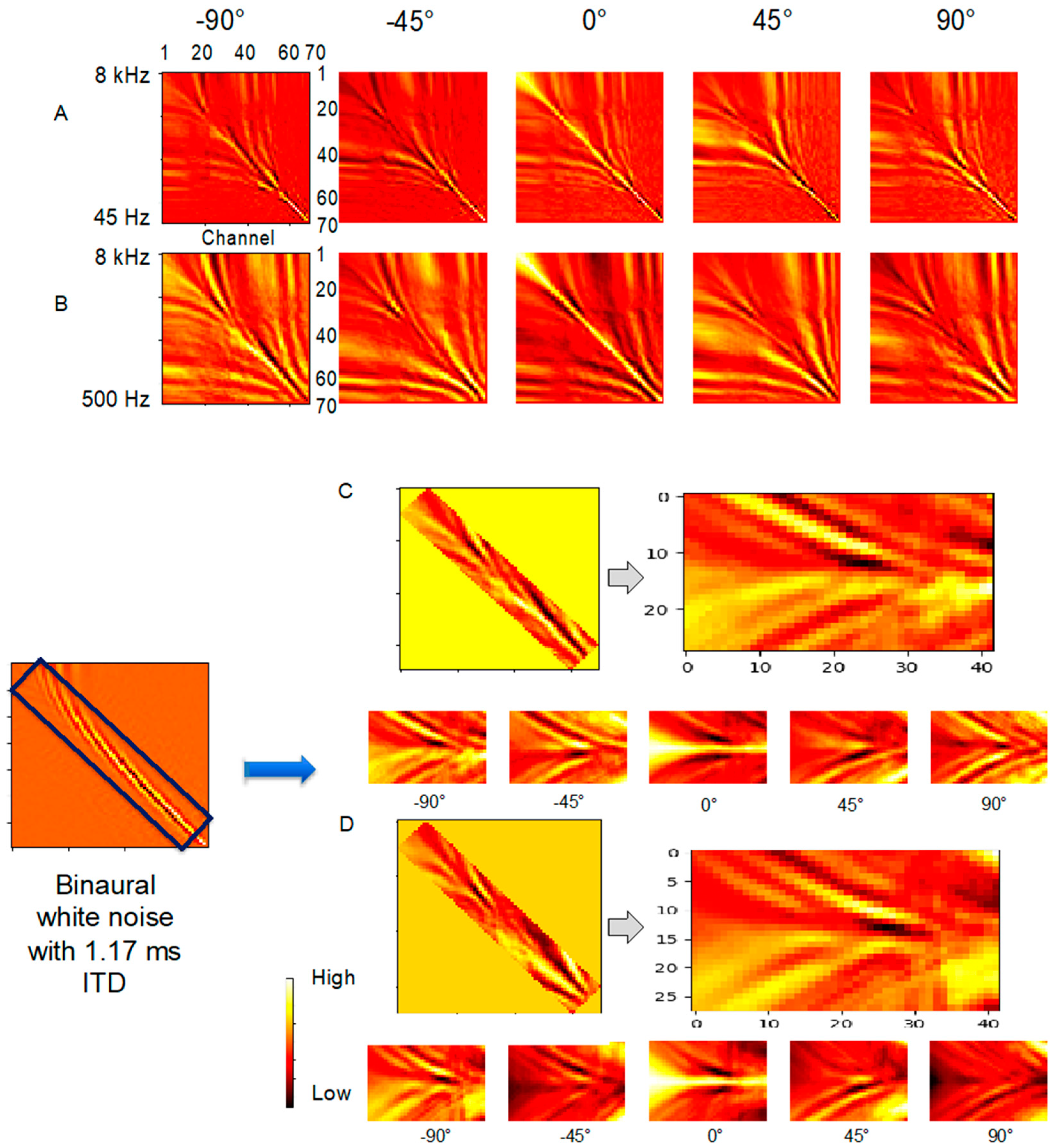
2.3. Onset Detection and Onset Correlogram
2.4. Regression Neural Network
3. Experiment and Evaluation
3.1. Experimental Setup
3.2. Results and Comparisons
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Grothe, B.; Neuweiler, G. The function of the medial superior olive in small mammals: Temporal receptive fields in auditory analysis. J. Comp. Physiol. A Sens. Neural Behav. Physiol. 2000, 186, 413–423. [Google Scholar] [CrossRef] [PubMed]
- Yin, T.C.T. Neural mechanisms of encoding Binaural localization cues in the auditory brainstem. In Integrative Functions in the Mammalian Auditory Pathway; Springer: Berlin, Germany, 2002; Volume 15, pp. 99–159. [Google Scholar]
- Park, T.J.; Klug, A.; Holinstat, M.; Grothe, B. Interaural level difference processing in the lateral superior olive and the inferior colliculus. J. Neurophysiol. 2004, 92. [Google Scholar] [CrossRef][Green Version]
- Rayleigh, L. On our perception of sound direction. Philos. Mag. 1907, 13, 214–232. [Google Scholar] [CrossRef]
- Zwislocki, J.; Feldman, R.S. Just noticeable differences in dichotic phase. J. Acoust. Soc. Am. 1956, 28, 860–864. [Google Scholar] [CrossRef]
- Casseday, J.H.; Neff, W.D. Localization of pure tones. J. Acoust. Soc. Am. 1973, 54, 365–372. [Google Scholar] [CrossRef]
- Henning, G.B. Detectability of interaural delay in high-frequency complex waveforms. J. Acoust. Soc. Am. 1974, 55, 84–90. [Google Scholar] [CrossRef]
- Batra, R.; Kuwada, S.; Stanford, T.R. Temporal coding of envelopes and their interaural delays in the inferior colliculus of the unanesthetized rabbit. J. Neurophysiol. 1989, 61, 257–268. [Google Scholar] [CrossRef] [PubMed]
- Joris, P.X. Envelope coding in the lateral superior olive. II. Characteristic delays and comparison with responses in the medial superior olive. J. Neurophysiol. 1996, 76, 2137–2156. [Google Scholar] [CrossRef]
- Grothe, B.; Pecka, M.; McAlpine, D. Mechanisms of Sound localization in mammals. Physiol. Rev. 2010, 90, 983–1012. [Google Scholar] [CrossRef] [PubMed]
- Yin, T.C.T.; Kuwada, S. Binaural localization cues. In The Oxford Handbook of Auditory Science: The Auditory Brain; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Lyon, R.F. A computational model of binaural localization and separation. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Boston, MA, USA, 14–16 April 1983. [Google Scholar]
- Shamma, S.A.; Shen, N.; Gopalaswamy, P. Stereausis: Binaural processing without neural delays. J. Acoust. Soc. Am. 1989, 86. [Google Scholar] [CrossRef]
- Jeffress, L.A. A place theory of sound localization. J. Comp. Physiol. 1948, 41, 35–39. [Google Scholar] [CrossRef]
- Heckmann, M.; Rodemann, T.; Joublin, F.; Goerick, C.; Schölling, B. Auditory inspired binaural robust sound source localization in echoic and noisy environments. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006. [Google Scholar]
- Joris, P.X.; van Der Heijden, M. Early Binaural hearing: The Comparison of temporal differences at the two ears. Annu. Rev. Neurosci. 2019, 42, 433–457. [Google Scholar] [CrossRef] [PubMed]
- Lazzaro, J.; Mead, C. A silicon model of auditory localization. Neural Comput. 1989, 1, 47–57. [Google Scholar] [CrossRef]
- Ashida, G.; Carr, C.E. Sound localization: Jeffress and beyond. Curr. Opin. Neurobiol. 2011, 21, 745–751. [Google Scholar] [CrossRef]
- Bhadkamkar, N.; Fowler, B. A sound localization system based on biological analogy. In Proceedings of the 1993 IEEE International Conference on Neural Networks, San Francisco, CA, USA, 28 March–1 April 1993; pp. 1902–1907. [Google Scholar]
- Grech, I.; Micallef, J.; Vladimirova, T. Analog CMOS chipset for a 2-D sound localization system. Analog. Integr. Circuits Signal. Process. 2004, 41, 167–184. [Google Scholar] [CrossRef]
- Mead, C.; Arreguit, X.; Lazzaro, J. Analog VLSI model of binaural hearing. IEEE Trans. Neural Netw. 1991, 2, 230–236. [Google Scholar] [CrossRef] [PubMed][Green Version]
- van Schaik, A.; Shamma, S. A neuromorphic sound localizer for a smart MEMS system. Analog Integr. Circuits Signal. Process 2004, 39, 267–273. [Google Scholar] [CrossRef]
- Ponca, M.; Schauer, C. FPGA implementation of a spike-based sound localization system. In Artificial Neural Networks and Genetic Algorithms; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Finger, H.; Liu, S.C. Estimating the location of a sound source with a spike-timing localization algorithm. In Proceedings of the IEEE International Symposium on Circuits and Systems, Rio de Janeiro, Brazil, 15–18 May 2011. [Google Scholar]
- Iwasa, K.; Kugler, M.; Kuroyanagi, S.; Iwata, A. A sound localization and recognition system using pulsed neural networks on FPGA. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Orlando, FL, USA, 12–17 August 2007; pp. 902–907. [Google Scholar]
- Kugler, M.; Iwasa, K.; Benso, V.A.; Kuroyanagi, S.; Iwata, A. A complete hardware implementation of an integrated sound localization and classification system based on spiking neural networks. Neural Inf. Process. 2008, 4985, 577–587. [Google Scholar]
- Chan, V.Y.S.; Jin, C.T.; van Schaik, A. Adaptive sound localization with a silicon cochlea pair. Front. Neurosci. 2010, 4, 1–31. [Google Scholar] [CrossRef] [PubMed]
- Schauer, C.; Zahn, T.; Paschke, P.; Gross, H.M. Binaural sound localization in an artificial neural network. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Istanbul, Turkey, 5–9 June 2000. [Google Scholar]
- Youssef, K.; Argentieri, S.; Zarader, J.L. A learning-based approach to robust binaural sound localization. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- Ma, N.; May, T.; Brown, G.J. Exploiting deep neural networks and head movements for robust binaural localization of multiple sources in reverberant environments. IEEE ACM Trans. Audio Speech Lang. Process. 2017, 25, 2444–2453. [Google Scholar] [CrossRef]
- Wang, J.; Wang, J.; Qian, K.; Xie, X.; Kuang, J. Binaural sound localization based on deep neural network and affinity propagation clustering in mismatched HRTF condition. Eurasip J. Audio Speech Music Process. 2020. [Google Scholar] [CrossRef]
- Jiang, S.; Wu, L.; Yuan, P.; Sun, Y.; Liu, H. Deep and CNN fusion method for binaural sound source localisation. J. Eng. 2020, 2020, 511–516. [Google Scholar] [CrossRef]
- Xu, Y.; Afshar, S.; Singh, R.K.; Hamilton, T.J.; Wang, R.; van Schaik, A. A machine hearing system for binaural sound localization based on instantaneous correlation. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018. [Google Scholar]
- Wallach, H.; Newman, E.B.; Rosenzweig, M.R. The precedence effect in sound localization. Am. J. Psychol. 1949, 62, 315–336. [Google Scholar] [CrossRef] [PubMed]
- Wühle, T.; Merchel, S.; Altinsoy, M.E. The precedence effect in scenarios with projected sound. AES J. Audio Eng. Soc. 2019, 67, 92–100. [Google Scholar]
- Xu, Y.; Afshar, S.; Singh, R.K.; Wang, R.; van Schaik, A.; Hamilton, T.J. A binaural sound localization system using deep convolutional neural networks. In Proceedings of the IEEE International Symposium on Circuits and Systems, Sapporo, Japan, 26–29 May 2019. [Google Scholar]
- Lyon, R.F. Human and Machine Hearing—Extracting Meaning from Sound; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Xu, Y.; Singh, R.K.; Thakur, C.S.; Wang, R.; van Schaik, A. CAR-FAC Model of the cochlea on the FPGA. In Proceedings of the BioMedical Circuits and Systems Conference (BIOCAS), Shanghai, China, 17–19 October 2016; pp. 1–4. [Google Scholar]
- Xu, Y.; Thakur, C.S.; Singh, R.K.; Hamilton, T.J.; Wang, R.M.; van Schaik, A. A FPGA implementation of the CAR-FAC cochlear model. Front. Neurosci. 2018, 12, 1–14. [Google Scholar] [CrossRef]
- Greenwood, D.D. A cochlear frequency-position function for several species—29 years later. J. Acoust. Soc. Am. 1990, 87, 2592–2605. [Google Scholar] [CrossRef]
- Singh, R.K.; Xu, Y.; Wang, R.; Hamilton, T.J.; van Schaik, A.; Denham, S.L. CAR-lite: A Multi-rate cochlear model on FPGA for Spike-based sound encoding. IEEE Trans. Circuits Syst. I Regul. Pap. 2018, 66, 1805–1817. [Google Scholar] [CrossRef]
- Singh, R.K.; Xu, Y.; Wang, R.; Hamilton, T.J.; van Schaik, A.; Denham, S.L. CAR-lite: A Multi-rate cochlea model on FPGA. In Proceedings of the IEEE International Symposium on Circuits and Systems, Florence, Italy, 27–30 May 2018. [Google Scholar]
- Katsiamis, A.G.; Drakakis, E.M.; Lyon, R.F. Practical gammatone-like filters for auditory processing. Eurasip J. Audio Speech Music Process. 2007. [Google Scholar] [CrossRef]
- Chi, T.; Ru, P.; Shamma, S.A. Multiresolution spectrotemporal analysis of complex sounds. J. Acoust. Soc. Am. 2005, 118. [Google Scholar] [CrossRef]
- Seidner, D. Efficient implementation of log10 lookup table in FPGA. In Proceedings of the IEEE International Conference on Microwaves, Communications, Antennas and Electronic Systems, Tel-Aviv, Israel, 13–14 May 2008; pp. 1–9. [Google Scholar]
- Bangqiang, L.; Ling, H.; Xiao, Y. Base-N logarithm implementation on FPGA for the data with random decimal point positions. In Proceedings of the IEEE 9th International Colloquium on Signal Processing and Its Applications (CSPA), Kuala Lumpur, Malaysia, 8–10 March 2013. [Google Scholar]
- Huang, G.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- McDonnell, M.D.; Tissera, M.D.; Vladusich, T.; van Schaik, A.; Tapson, J. Fast, simple and accurate handwritten digit classification by training shallow neural network classifiers with the ‘extreme learning machine’ algorithm. PLoS ONE 2015, 10, 1–18. [Google Scholar] [CrossRef] [PubMed]
- van Schaik, A.; Tapson, J. Online and adaptive pseudoinverse solutions for ELM weights. Neurocomputing 2015, 149, 233–238. [Google Scholar] [CrossRef][Green Version]
- Wang, R.; Cohen, G.; Thakur, C.S.; Tapson, J.; van Schaik, A. An SRAM-based implementation of a convolutional neural network. In Proceedings of the IEEE Biomedical Circuits and Systems Conference, Shanghai, China, 17–19 October 2016; pp. 1–4. [Google Scholar]
- Kala, S.; Jose, B.R.; Mathew, J.; Nalesh, S. High-performance CNN accelerator on FPGA using unified winograd-GEMM architecture. IEEE Trans. Very Large Scale Integr. Syst. 2019, 27, 2816–2828. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Nguyen, T.N.; Kim, H.; Lee, H.J. A high-throughput and power-efficient fpga implementation of yolo CNN for object detection. IEEE Trans. Very Large Scale Integr. Syst. 2019, 27, 1861–1873. [Google Scholar] [CrossRef]
- Lian, X.; Liu, Z.; Song, Z.; Dai, J.; Zhou, W.; Ji, X. High-performance FPGA-based CNN accelerator with block-floating-point arithmetic. IEEE Trans. Very Large Scale Integr. Syst. 2019, 27, 1874–1885. [Google Scholar] [CrossRef]
- Al-Rfou, R. Theano: A Python Framework for Fast Computation of Mathematical Expressions; Cornell University: Ithaca, NY, USA, 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms; Cornell University: Ithaca, NY, USA, 2016; pp. 1–14. [Google Scholar]
- Theano Development Team. Theano: A Python Framework for Fast Computation of Mathematical Expressions; Cornell University: Ithaca, NY, USA, 2016. [Google Scholar]
- Zhou, J.; Hong, X.; Su, F.; Zhao, G. Recurrent convolutional neural network regression for continuous pain intensity estimation in video. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 Jun–1 July 2016. [Google Scholar]
- Burnham, D.; Ambikairajah, E.; Arciuli, J.; Bennamoun, M.; Best, C.T.; Bird, S.; Butcher, A.R.; Cassidy, S.; Chetty, G.; Cox, F.M.; et al. A blueprint for a comprehensive Australian English auditory-visual speech corpus. In Selected Proceedings of the 2008 HCSNet Workshop on Designing the Australian National Corpus; Cascadilla Proceedings Project: Somerville, MA, USA; pp. 96–107.
- Burnham, D.; Estival, D.; Fazio, S.; Viethen, J.; Cox, F.; Dale, R.; Cassidy, S.; Epps, J.; Togneri, R.; Wagner, M. Building an audio-visual corpus of Australian English: Large corpus collection with an economical portable and replicable black box. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Florence, Italy, 27–31 August 2011; pp. 841–844. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Lyon, R.F. Cascades of two-pole-two-zero asymmetric resonators are good models of peripheral auditory function. J. Acoust. Soc. Am. 2011, 130, 3893–3904. [Google Scholar] [CrossRef] [PubMed]
- Julian, P.; Andreou, A.G.; Goldberg, D.H. A low-power correlation-derivative CMOS VLSI circuit for bearing estimation. IEEE Trans. Very Large Scale Integr. Syst. 2006, 14, 207–212. [Google Scholar] [CrossRef]
- Escudero, E.C.; Peña, F.P.; Vicente, R.P.; Jimenez-Fernandez, A.; Moreno, G.J.; Morgado-Estevez, A. Real-time neuro-inspired sound source localization and tracking architecture applied to a robotic platform. Neurocomputing 2018, 283, 129–139. [Google Scholar] [CrossRef]
- Middlebrooks, J.C.; Green, D.M. Sound localization by human listeners. Annu. Rev. Psychol. 1991, 42, 135–159. [Google Scholar] [CrossRef]
- Carlile, S.; Leong, P.; Hyams, S. The nature and distribution of errors in sound localization by human listeners. Hear. Res. 1997, 114, 179–196. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Used | Available | Utilisation | |
|---|---|---|---|
| ALM | 15,122 | 29,080 | 52% |
| Memory (bits) | 1,826,816 | 4,567,040 | 40% |
| DSPs | 138 | 150 | 92% |
| Standard Deviation | Avg. Unsigned Error (°) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | |||||||||||||||
| CAR-FAC Non Quantised Correlation | Linear | 33.65 | 29.16 | 18.12 | 18.30 | 18.88 | 17.67 | 15.66 | 19.57 | 19.42 | 21.28 | 22.86 | 27.04 | 24.50 | 19.05 |
| ELM | 22.90 | 17.12 | 11.64 | 13.24 | 12.11 | 11.81 | 11.75 | 11.87 | 14.50 | 12.34 | 12.87 | 18.92 | 15.41 | 13.34 | |
| CNN | 6.03 | 5.35 | 4.82 | 4.04 | 3.19 | 1.92 | 0.50 | 1.26 | 1.00 | 0.60 | 0.45 | 3.03 | 4.32 | 2.87 | |
| CAR-FAC Quantised Correlation | Linear | 29.00 | 24.90 | 23.13 | 24.64 | 19.63 | 17.00 | 15.81 | 27.56 | 17.70 | 19.59 | 20.24 | 27.62 | 27.10 | 18.76 |
| ELM | 17.58 | 15.67 | 10.87 | 10.21 | 11.07 | 10.99 | 8.05 | 10.52 | 10.68 | 11.88 | 14.51 | 16.40 | 13.30 | 13.06 | |
| CNN | 11.37 | 3.03 | 4.96 | 3.86 | 1.04 | 2.79 | 2.02 | 1.92 | 1.16 | 1.94 | 0.61 | 2.32 | 5.22 | 3.11 | |
| CAR Non Quantised Correlation | Linear | 16.98 | 16.70 | 19.18 | 18.44 | 19.39 | 19.61 | 13.66 | 17.83 | 27.81 | 20.99 | 17.83 | 26.00 | 28.10 | 16.84 |
| ELM | 11.53 | 11.23 | 9.10 | 11.10 | 12.15 | 8.92 | 9.51 | 9.9 | 11.55 | 9.87 | 10.92 | 18.96 | 11.40 | 9.35 | |
| CNN | 2.76 | 0.99 | 4.21 | 4.80 | 0.84 | 2.66 | 0.38 | 0.58 | 0.39 | 0.16 | 0.31 | 1.91 | 0.33 | 1.25 | |
| CAR Quantised Correlation | Linear | 24.05 | 20.30 | 23.38 | 16.50 | 14.01 | 17.41 | 14.06 | 17.79 | 17.00 | 20.61 | 19.41 | 21.20 | 20.86 | 16.52 |
| ELM | 12.45 | 10.36 | 9.92 | 8.69 | 8.21 | 7.53 | 5.46 | 7.84 | 7.04 | 11.28 | 8.81 | 11.80 | 10.32 | 8.34 | |
| CNN | 6.96 | 4.04 | 3.90 | 2.64 | 0.17 | 0.45 | 0.00 | 0.26 | 0.16 | 0.16 | 0.22 | 3.95 | 1.40 | 2.74 | |
| CF Range/Damping | Diagonal Correlogram | Max-Pooling Correlogram | |
|---|---|---|---|
| RMS Error (°) 0–45°/45–90° | RMS Error (°) 0–45°/45–90° | ||
| CAR-FAC Non-quantised Correlation | 45 Hz–8 kHz | 2.78/5.60 | 4.88/9.15 |
| 500 Hz–8 kHz | 4.48/6.86 | 3.02/6.22 | |
| CAR-FAC Quantised Correlation | 45 Hz–8 kHz | 2.92/7.12 | 3.51/7.62 |
| 500 Hz–8 kHz | 2.21/6.88 | 2.44/6.62 | |
| CAR Non-quantised Correlation | 45 Hz–8 kHz | 2.55/3.28 | 4.39/5.41 |
| 500 Hz–8 kHz | 1.92/3.79 | 2.72/4.83 | |
| CAR Quantised Correlation | 45 Hz–8 kHz | 1.82/5.97 | 2.82/4.26 |
| 500 Hz–8 kHz | 3.18/3.70 | 3.46/4.21 | |
| System | Mic | Cues | Stimulus | Accuracy | Approach |
|---|---|---|---|---|---|
| 0–45°/45–90° | |||||
| [17] | 2 | ITD | Periodic clicks (475 Hz) | N/A | Two silicon cochlear models and the Jeffress model on chip |
| [21] | 2 | ITD | Sine tones, white noises, and vowels | N/A | Instantaneous cross correlation with two silicon cochlear models on chip |
| [23] | 2 | ITD | N/A | N/A | Propose FPGA implementation of the cochlear model, LIF neuron model and WTA network |
| [20] | 4 | IPD, IED, IID, Spectral cues | Impulse | 5° RMS error (azimuth and elevation) | Three-chip system; One for onset detection, one for BPF bank and IED/IID cue extraction, and one for cross-correlation, IPD |
| [22] | 2 | ITD | (50–300 Hz) sounds | 3°/12° RMS error | Two silicon cochleae, zero-crossing |
| [63] | 4 | ITD | <300 Hz | 3°/8° RMS error | Digital delay line on chip |
| [26] | 2 | ITD | FM Noise, Alarm Bell | FM Noise * RMS error 9.27°/12.48° Alarm Bell * 42.7°/54.76° | Delay line and CONP on FPGA |
| [64] | 2 | IID | Pure tones | 1.09°/0.70° RMS error | Event-based cochleae, IID, “head” movement |
| [27] | 2 | ITD | Noise, Sine tones | 2.7°/5.5° RMS error | Two silicon cochleae (AER-EAR) |
| This work | 2 | ITD(IPD) | Spoken digits in office | 2.82°/4.26° RMS error Or 1.32°/2.93° unsigned average error | CAR pair CNN |
| Human [62] | 2 ears | Binaural processing | Broadband sound sources | 4.03°/7.03° azimuth ** unsigned average error | Brief (150 ms) sound presented in front of 6 subjects in a free field |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Afshar, S.; Wang, R.; Cohen, G.; Singh Thakur, C.; Hamilton, T.J.; van Schaik, A. A Biologically Inspired Sound Localisation System Using a Silicon Cochlea Pair. Appl. Sci. 2021, 11, 1519. https://doi.org/10.3390/app11041519
Xu Y, Afshar S, Wang R, Cohen G, Singh Thakur C, Hamilton TJ, van Schaik A. A Biologically Inspired Sound Localisation System Using a Silicon Cochlea Pair. Applied Sciences. 2021; 11(4):1519. https://doi.org/10.3390/app11041519
Chicago/Turabian StyleXu, Ying, Saeed Afshar, Runchun Wang, Gregory Cohen, Chetan Singh Thakur, Tara Julia Hamilton, and André van Schaik. 2021. "A Biologically Inspired Sound Localisation System Using a Silicon Cochlea Pair" Applied Sciences 11, no. 4: 1519. https://doi.org/10.3390/app11041519
APA StyleXu, Y., Afshar, S., Wang, R., Cohen, G., Singh Thakur, C., Hamilton, T. J., & van Schaik, A. (2021). A Biologically Inspired Sound Localisation System Using a Silicon Cochlea Pair. Applied Sciences, 11(4), 1519. https://doi.org/10.3390/app11041519