Flexible Job Shop Scheduling Problem with Sequence Dependent Setup Time and Job Splitting: Hospital Catering Case Study

Abstract
1. Introduction
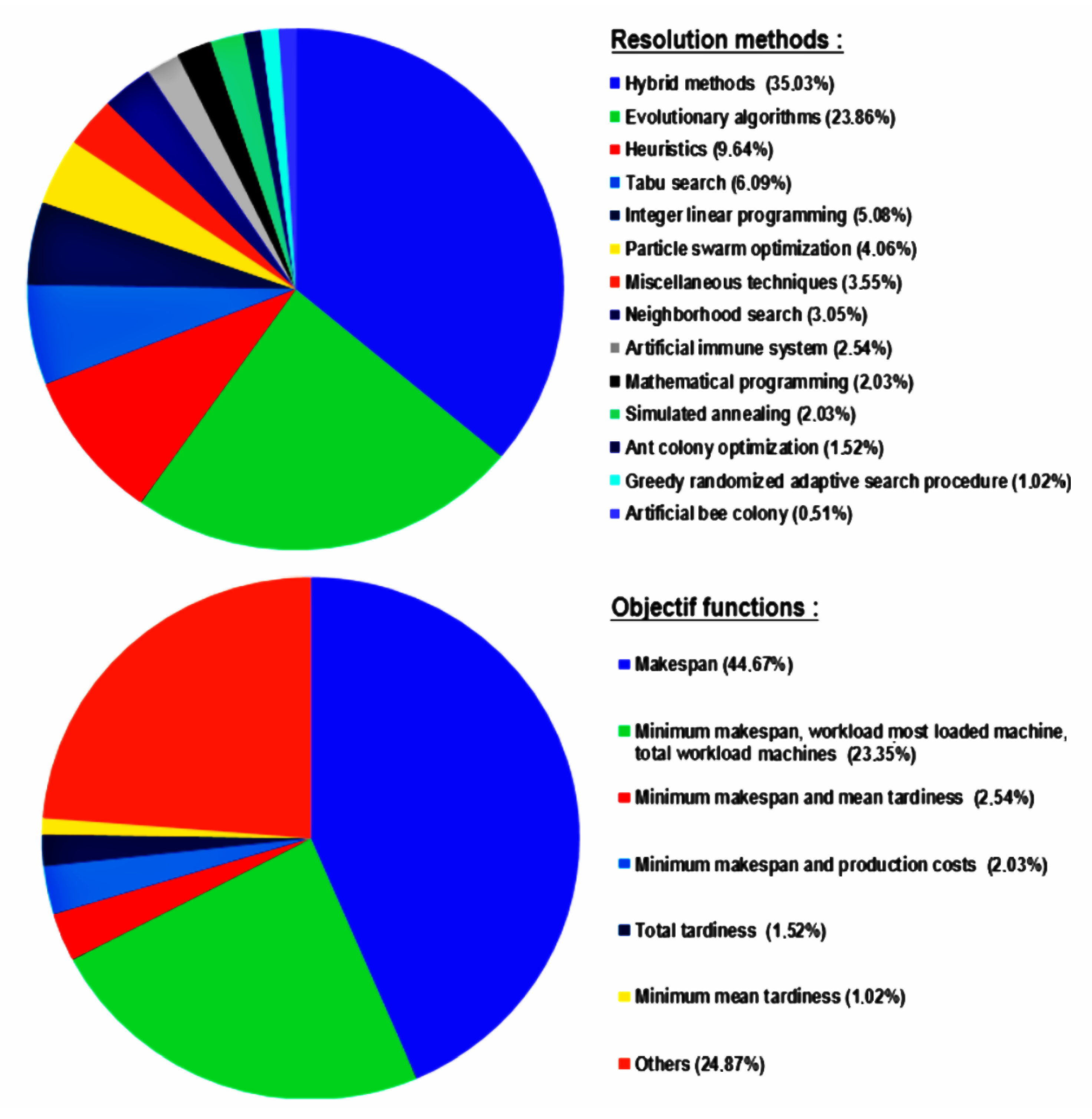
2. Literature Review
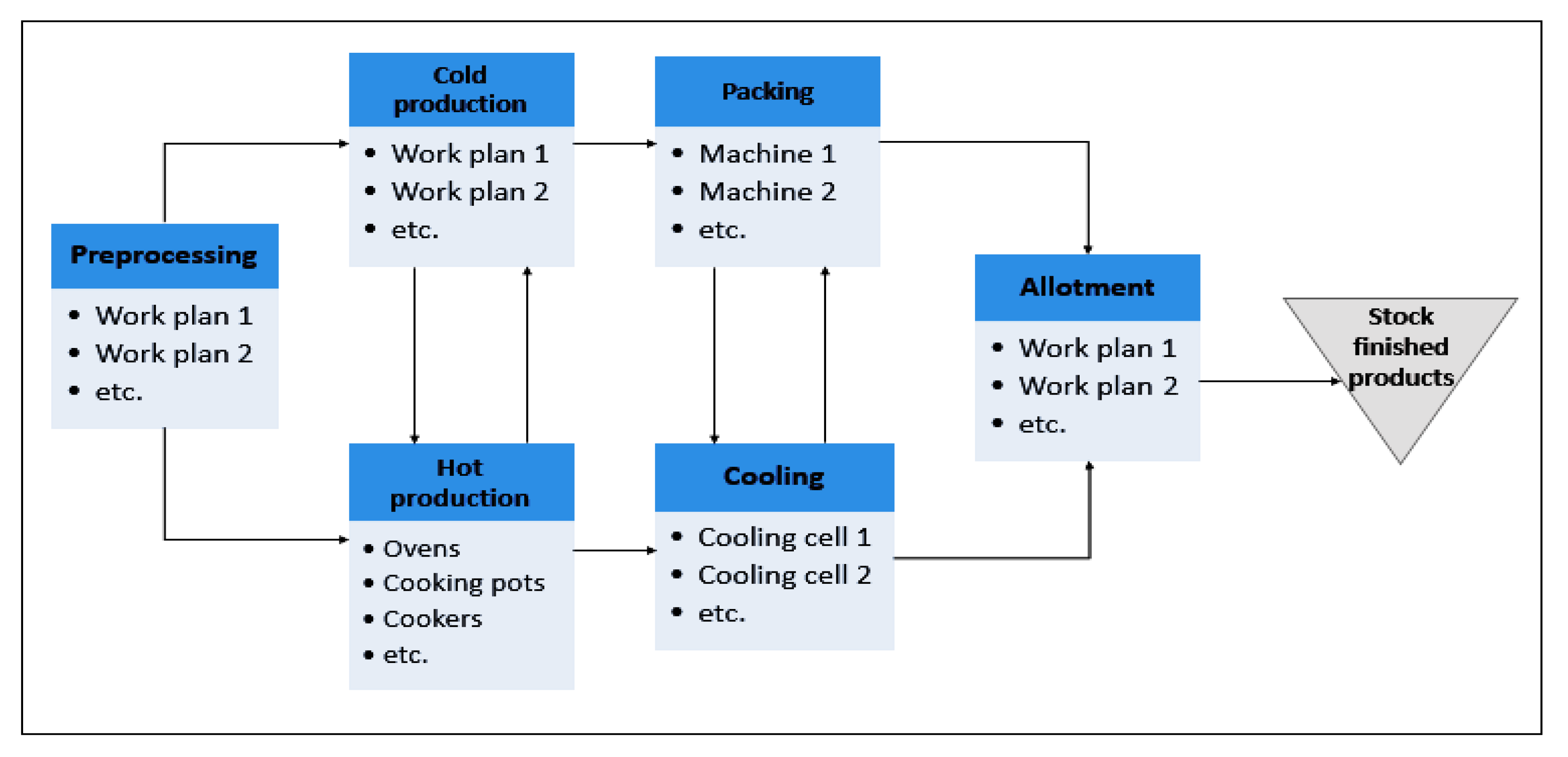
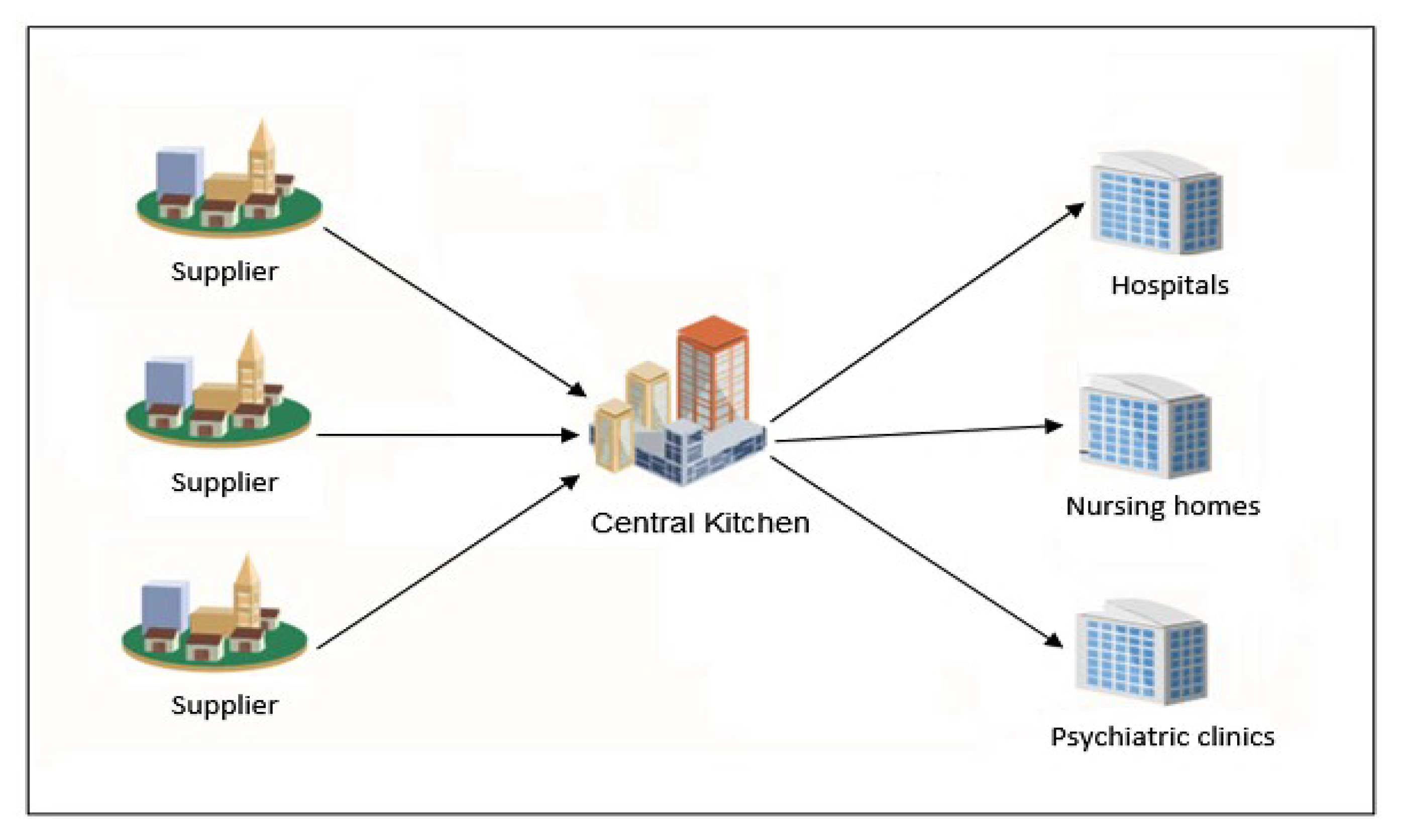
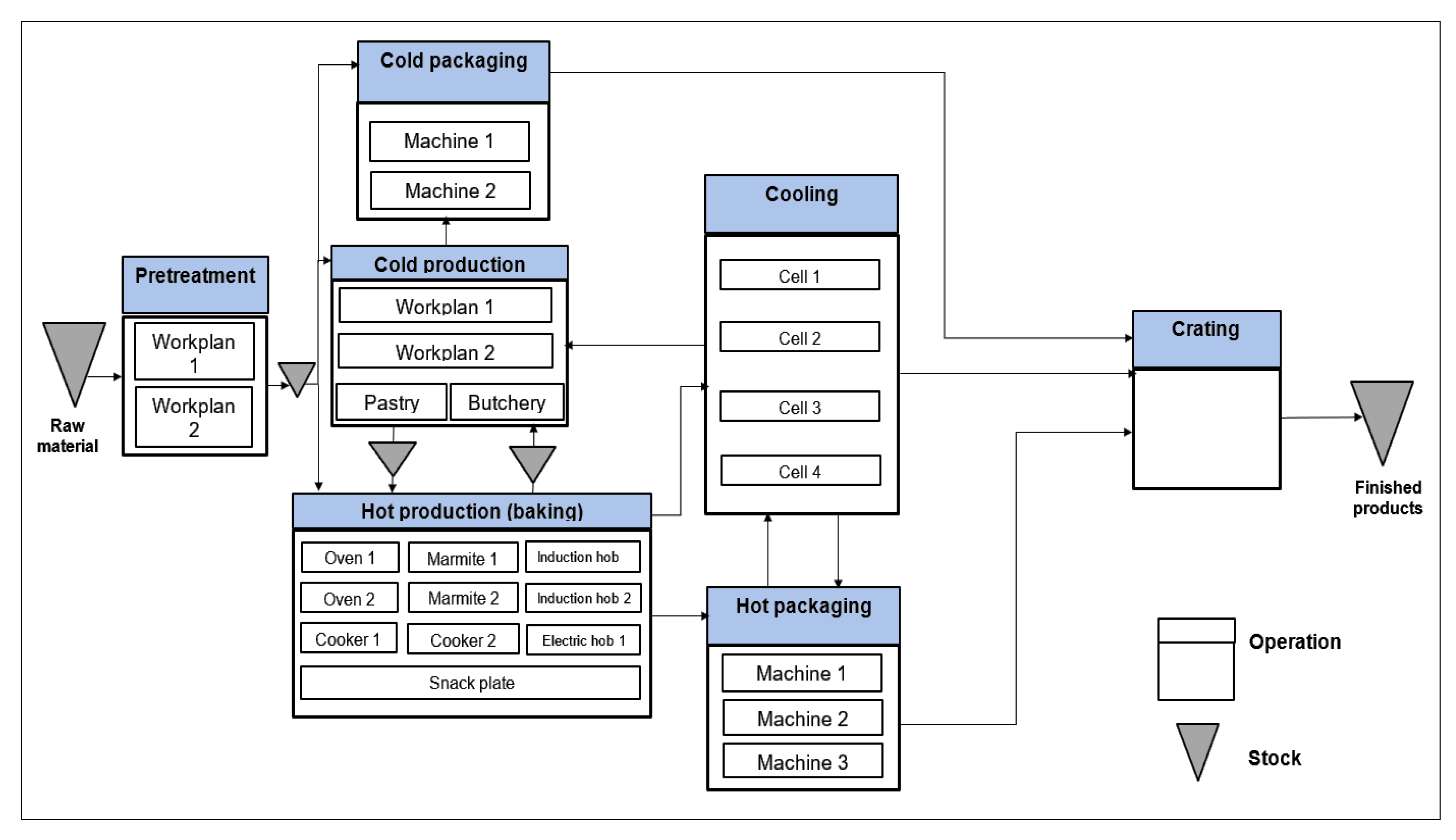
3. Problem Description
4. Mathematical Model
4.1. Assumptions
- Jobs are independent of each other,
- A job can be split into sub-lots,
- The sub-lots of a job can be grouped on the machines to be treated at the same time,
- Each sub-lot of a job consists of a set of operations that must be processed consecutively (precedence constraints between operations of sub-lots of jobs),
- Each operation of a sub-lot has a given processing time,
- The preemption of operations of sub-lots of jobs is not allowed, i.e., operation processing on a machine cannot be interrupted,
- Each job has a given due date (finish date of production at latest),
- Sub-lot sizes (number of portions) are discrete,
- Sub-lots creation is consistent throughout the processing sequence, meaning that job splitting and sub-lot sizes remain constant for all operations,
- Machines are independent,
- A machine can process, at most, one operation of a job at the same time,
- The setup times of machines are dependent on the sequence of operations of sub-lots of jobs,
- Material resources have given availability time windows that must be taken into account.
4.2. Notations
- M: set of all material resources, where .
- N: set of jobs (dishes to prepare), where and are two dummy jobs.
- : set of operations of job , such that the operation is done before the operation and .
- : number of portions (quantity) of job .
- : number of portions in each sub-lot of job .
- : set of sub-lots of job , with and such that .
- : due date of job .
- : set of material resources that can perform the operation of job .
- : maximum capacity in number of portions of the material resource .
- : unit processing time of operation of job on the material resource .
- : processing time of operation of job on the material resource .
- : setup time of material resource if the operation of job directly precedes the operation of job on the material resource .
- : preparation time of the material resource k at the beginning of scheduling.
- : cleaning time of the material resource k at the end of scheduling.
- : time window of availability of the material resource .
- B: big integer.
4.3. Decision Variables
- : binary variable that equal to 1 if operation of sub-lot of job is assigned to the material resource , and 0 otherwise.
- : binary variable that is equal to 1 if operation of sub-lot of job directly precedes operation of sub-lot of job on the material resource , and 0 otherwise.
- : binary variable that is equal to 1 if operation of sub-lot of job starts and finishes at the same time as the operation of sub-lot of job on the material resource , and 0 otherwise.
- : starting time of operation of sub-lot of job on the material resource .
- : completion time of operation of sub-lot of job on the material resource .
- : completion time of job .
4.4. Mathematical Model
4.5. Computational Results of the Mathematical Model
5. Resolution Methods
5.1. Genetic Algorithm
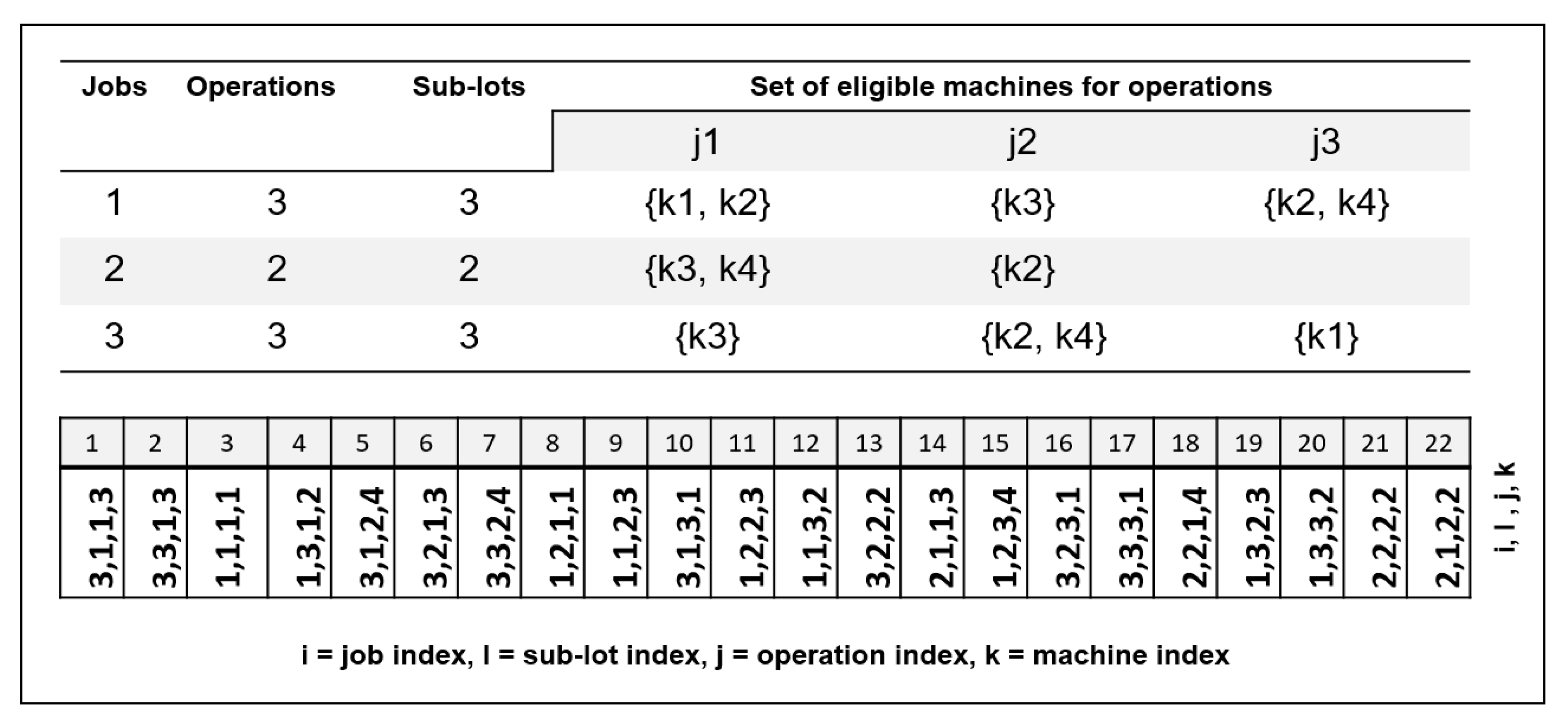
5.1.1. Solution Representation
5.1.2. Initial Population
- Random assignment (RA): The operations are randomly assigned to machines.
- SPT assignment (SPTA): For each operation, the machine with a smaller processing time is selected to perform this operation.
- LPT assignment (LPTA): For each operation, the machine with a longer processing time is selected to perform this operation.
- Minimum machine workload assignment (MMWA): The operations are iteratively assigned to machines based on their processing times and machine workloads. The workload of a machine depends on its type. For the set of machines , the workload is the sum of processing times of operations assigned to the machine. For the set of machines and , the workload is the total machine occupation time. The procedure consists in finding the machine with the minimum workload for each operation.
- Random sequence (RS): This heuristic randomly orders the operations on each machine.
- SPT sequence (SPTS): Operations with the shortest processing time will be processed first.
- Most number of operations Remaining (MNOR): This heuristic consists of processing the operations of the sub-lot of the job that has the most operations remaining as a priority.
- Most work remaining (MWR): The operations that have the most remaining processing time will be prioritized for processed.
5.1.3. Fitness Evaluation
| Algorithm 1: Evaluation steps of the fitness function of a chromosome |
|
5.1.4. Selection Operator
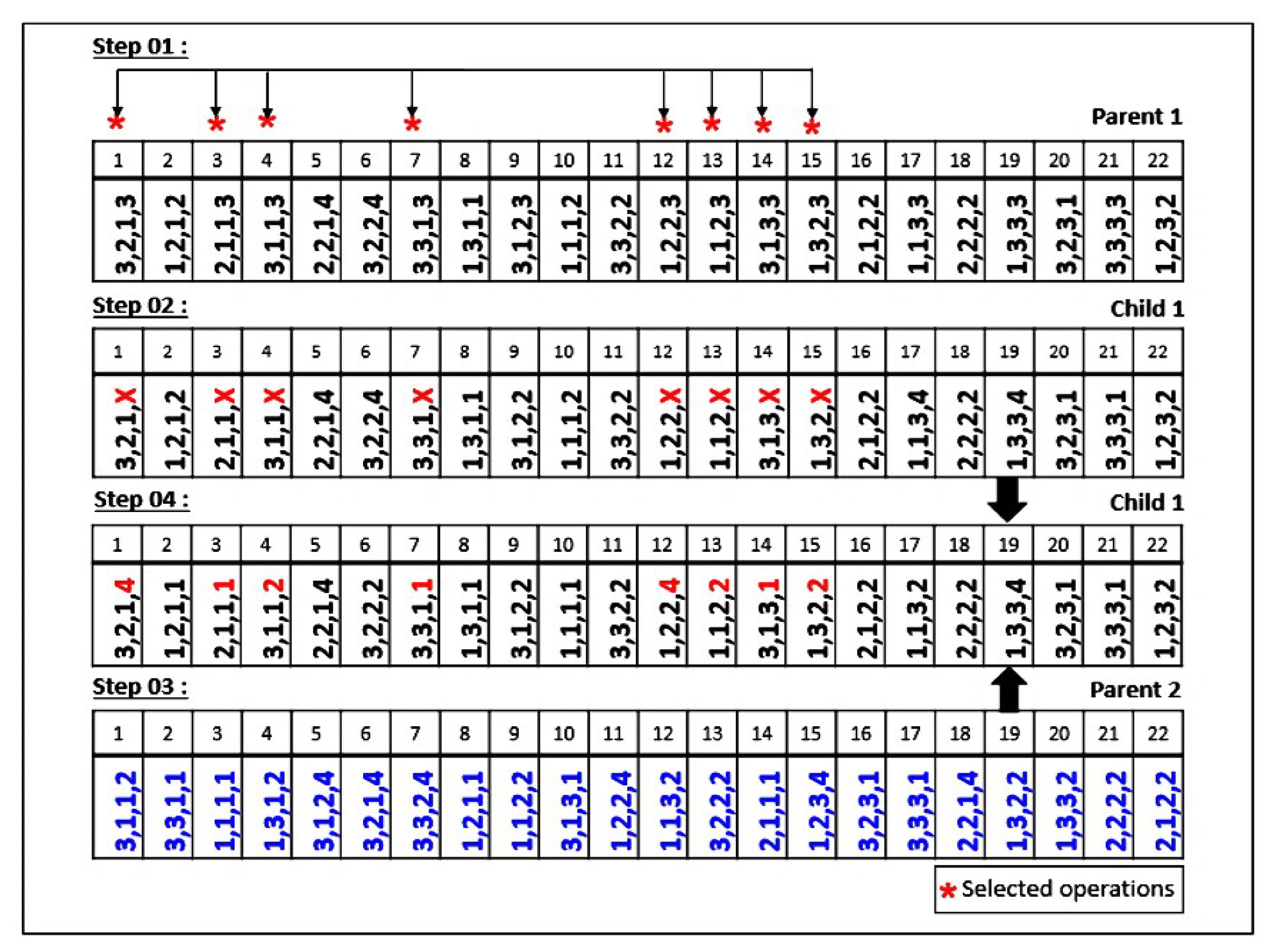
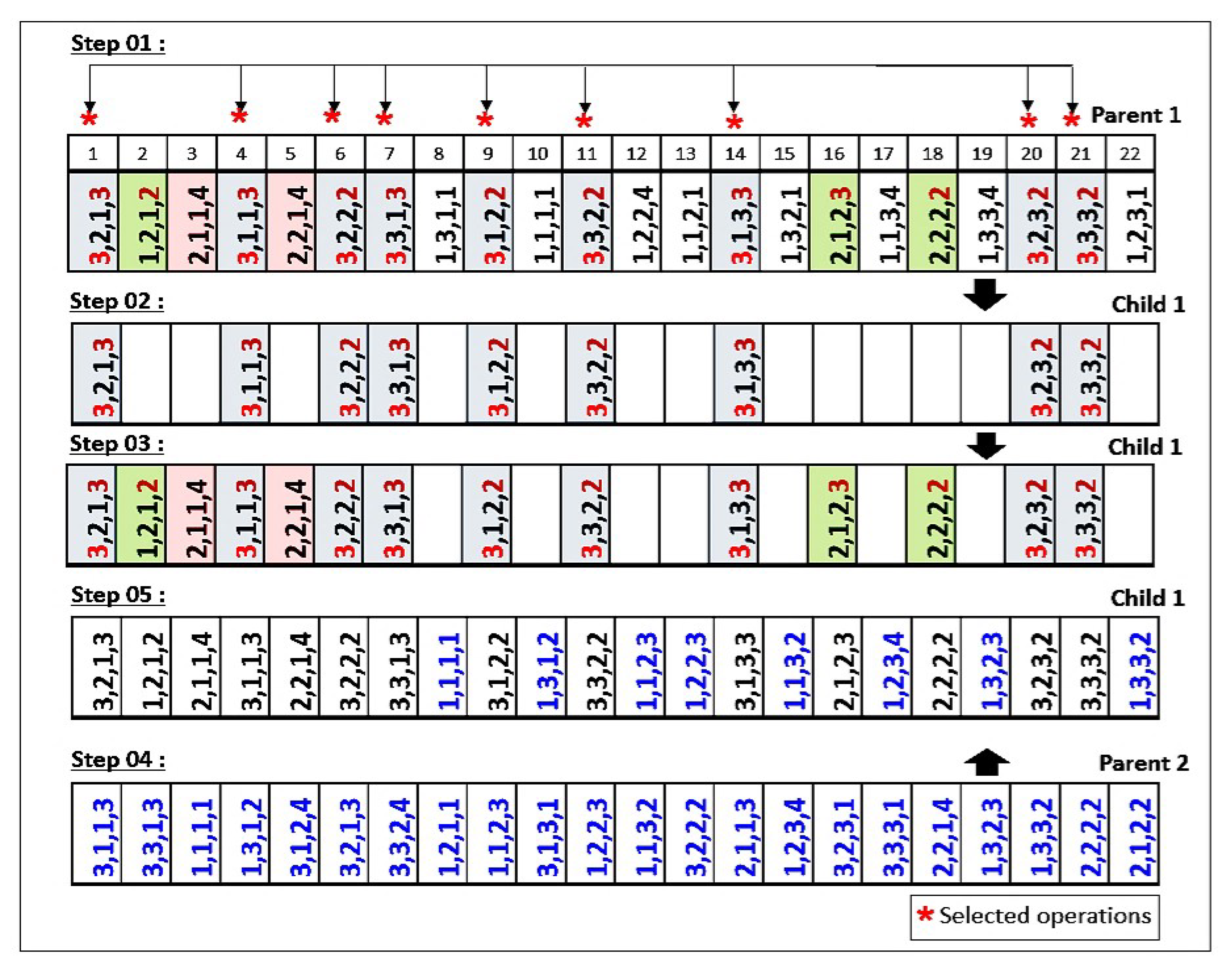
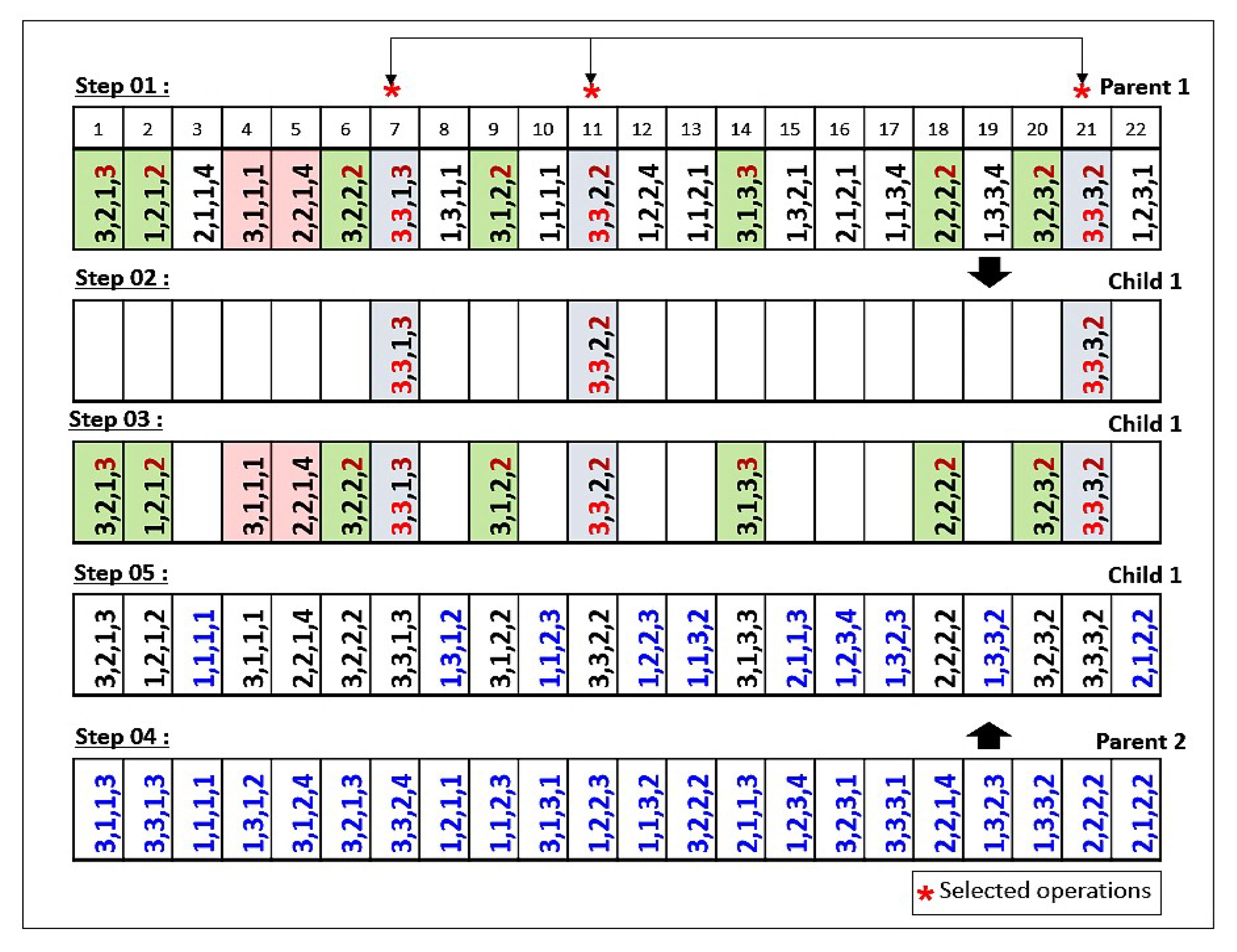
5.1.5. Crossover Operator
- OMAC 1: A set of operations of a sub-lot of jobs is chosen randomly.
- OMAC 2: A set of operations of sub-lots assigned to the loaded machines is selected.
- OMAC 3: A set of operations of sub-lots of jobs with larger completion times is chosen.
- JLOSC1 and SLOSC1: The operations are chosen randomly.
- JLOSC2 and SLOSC2: The operations are chosen according to specific rules that consist of choosing the operations of jobs with smaller completion times.
5.1.6. Mutation Operator
- ROAM (random operation assignment mutation): This operator is applied with a given probability on a set of operations of a given individual chromosome and randomly changes the assignment property of these operations to another machine.
- OSSM (operation sequence shift mutation): Whenever OSSM is applied on an individual, a set of operations is selected. Then, these operations are moved to other positions on the chromosome in such a way that no precedence constraint is violated.
5.1.7. Local Search Methods
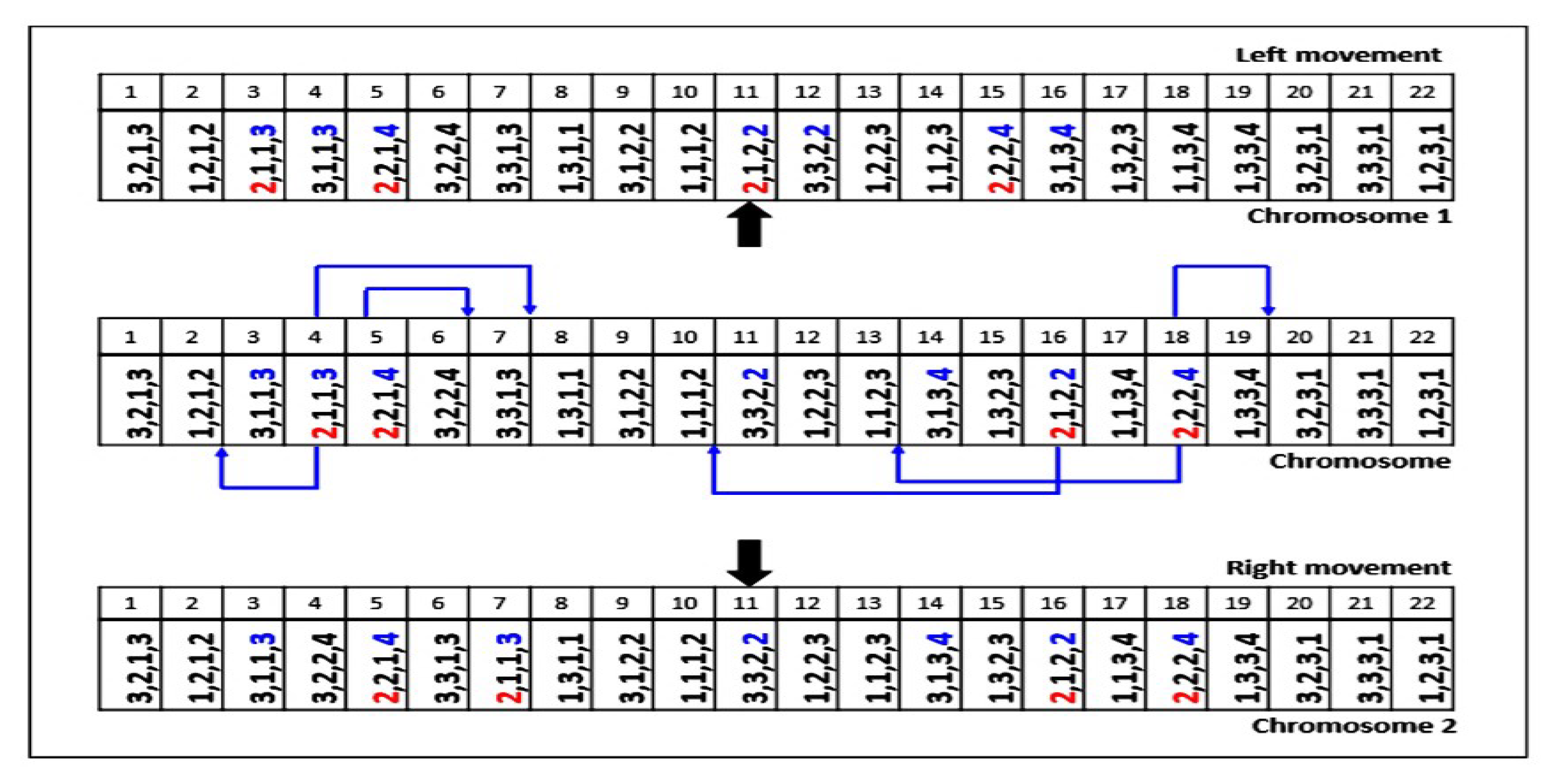
Local Search through Gene Movement
- Step 01: Choose a set of operations of jobs with larger completion times in the current chromosome.
- Step 02: Each operation chosen in Step 01 is positioned just before the previous operation assigned to the same machine (left movement) or just after (right movement) the following operation assigned to the same machine, while respecting the constraints of precedence between operations of sub-lots of jobs. This process allows one to lead research in the neighborhood of a solution by changing the sequencing of operations on the machines.
- Step 03: This process is repeated until the maximum number of iterations is not reached.
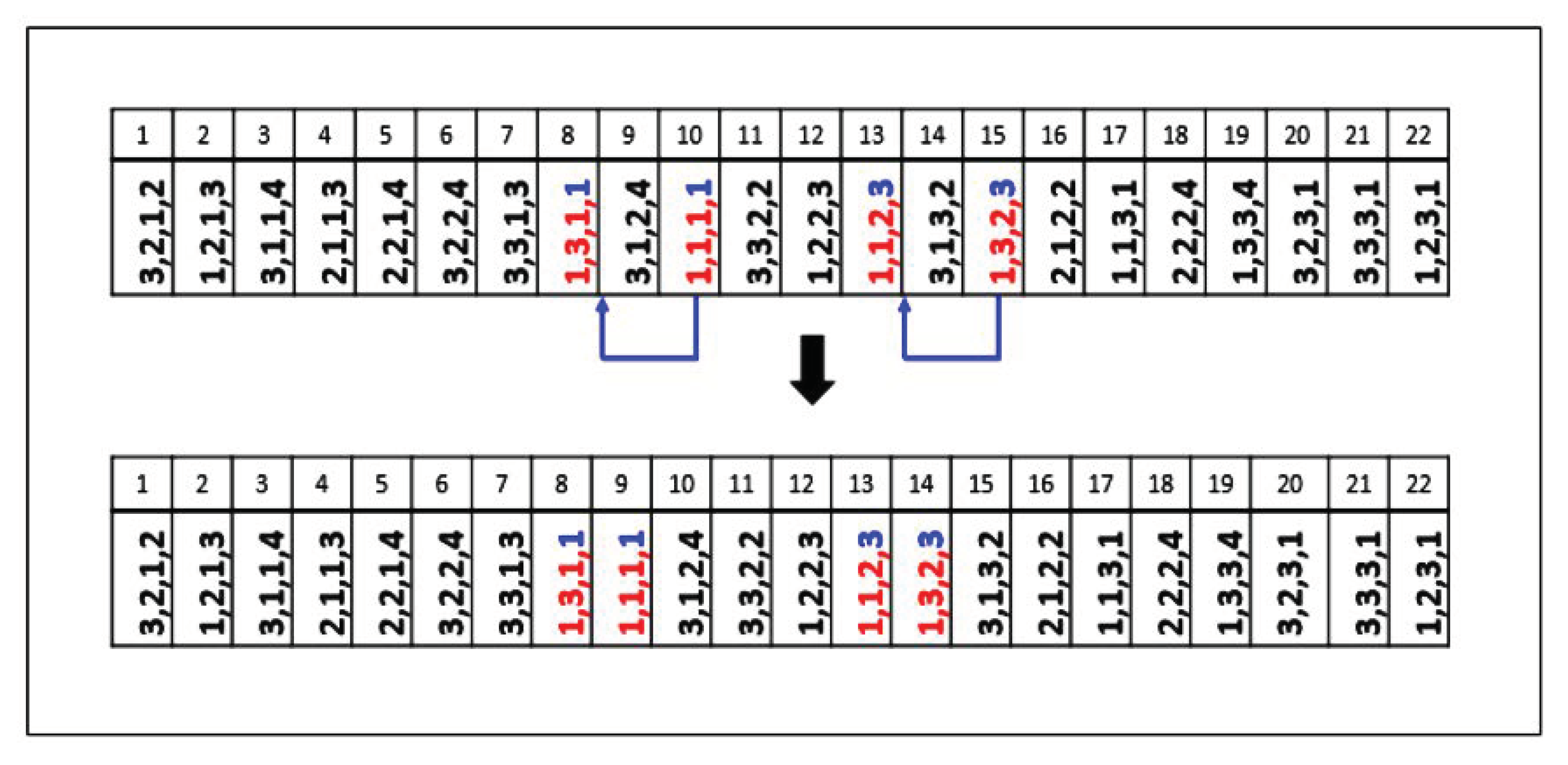
Local Search by Grouping Sub-Lots
Local Search through Intelligent Assignment of Operations
| Algorithm 2: Genetic algorithm |
| 1. Initialization: The initial solutions are chosen using the heuristics described above; 2. Evaluation: Evaluation of the initial solutions using the procedure of fitness function computation; nbIterations ← 0; nbIndividuals ← 0; 3. Application of the selection operator to choose the parent chromosomes to cross and mutate; 4. Randomly choose one of the crossover operators; 5. Application of the crossover operator chosen in 4; 6. Randomly choose one of the mutation operators; 7. Application of the mutation operator chosen in 6; 8. Application of the local search by grouping sub-lots on child chromosomes obtained after crossover and mutation; 9. nbIndividuals ← nbIndividuals + 1; 10. If the population size is reached, then go to 11, else go to 3; 11. Sorting solutions of the current population in ascending order of fitness functions; 12. Construction of the new population with solutions of the previous population; 13. Application of the local search methods through gene movement and intelligent assignment of operations on the best solutions of the new population; 14. nbIterations ← nbIterations + 1; 15. If the maximum number of iterations is not reached, then go to 3, else go to 16; 16. End of algorithm |
5.2. Iterated Local Search Algorithm
- AO1 and SO1: The operations are chosen randomly.
- AO2, AO3, SO2, and SO3: The operations are chosen according to rules developed to be specific to the studied problem.
| Algorithm 3: Iterative local search algorithm |
| 1. Initialization: The initial solution is generated by using the previously described assignment and sequencing heuristics; current solution ← initial solution; 2. Evaluation: Evaluation of the initial solution; SimilarDegree ← 0; 3. Application of the SO sequence operator; 4. If the solution is improved in 3, then; current solution ← solution obtained in 3, else go to 5; 5. Application of the AO affectation operator; 6. If the solution is improved in 5, then; current solution ← solution obtained in 5, else go to 7; 7. Application of the PO operator on the current solution; 8. Update SimilarDegree by calculating the distance between the current solution and the improved one; 9. If the degree of similarity between the solutions obtained in 8 is less than a predefined threshold; then go to 3, else go to 10; 10. End of algorithm |
6. Computational Results of the Developed Algorithms
6.1. Data Generation
6.2. Optimization of the Metaheuristics’ Parameters
6.3. Discussion of the Experimental Results
7. Application to an Industrial Case
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sun, X.; Noble, J.S.; Klein, C.M. Single-machine scheduling with sequence dependent setup to minimize total weighted squared tardiness. IIE Trans. 1999, 31, 113–124. [Google Scholar] [CrossRef]
- Lütkeentrup, M.; Günther, H.O.; Van Beek, P.; Grunow, M.; Seiler, T. Mixed-Integer Linear Programming approaches to shelf-life-integrated planning and scheduling in yoghurt production. Int. J. Prod. Res. 2005, 43, 5071–5100. [Google Scholar] [CrossRef]
- Doganis, P.; Sarimveis, H. Optimal scheduling in a yogurt production line based on mixed integer linear programming. J. Food Eng. 2007, 80, 445–453. [Google Scholar] [CrossRef]
- Doganis, P.; Sarimveis, H. Optimal production scheduling for the dairy industry. Ann. Oper. Res. 2008, 159, 315–331. [Google Scholar] [CrossRef]
- Stefansdottir, B.; Grunow, M.; Akkerman, R. Classifying and modeling setups and cleanings in lot sizing and scheduling. Eur. J. Oper. Res. 2016, 261, 849–865. [Google Scholar] [CrossRef]
- Sargut, F.Z.; Işık, G. Dynamic economic lot size model with perishable inventory and capacity constraints. Appl. Math. Model. 2017, 48, 806–820. [Google Scholar] [CrossRef]
- Akkerman, R.; van Donk, D.P. Analyzing scheduling in the food-processing industry: Structure and tasks. Cogn. Technol. Work. 2009, 11, 215–226. [Google Scholar] [CrossRef]
- Smith Daniels, V.L.; Larry, P. A Model for Lot Sizing and Sequencing in Process Industries. J. Prod. Res. 1988, 26, 647–674. [Google Scholar] [CrossRef]
- Kopanos, G.M.; Puigjaner, L.; Georgiadis, M.C. Efficient mathematical frameworks for detailed production scheduling in food processing industries. Comput. Chem. Eng. 2012, 42, 206–216. [Google Scholar] [CrossRef]
- Wauters, T.; Verbeeck, K.; Verstraete, P.V.; Berghe, G.; De Causmaecker, P. Real-world production scheduling for the food industry: An integrated approach. Eng. Appl. Artif. Intell. 2012, 25, 222–228. [Google Scholar] [CrossRef]
- Acevedo-Ojeda, A.; Contrerasa, I.; Chenb, M. Two-level lot-sizing with raw-material perishability and deterioration. J. Oper. Res. Soc. 2015, 71, 417–432. [Google Scholar] [CrossRef]
- Copil, K.; Wörbelauer, M.; Meyr, H.; Tempelmeier, H. Simultaneous lotsizing and scheduling problems: A classification and review of models. OR Spectr. 2016, 39, 1–64. [Google Scholar] [CrossRef]
- Niaki, M.K.; Nonino, F.; Komijan, A.R.; Dehghani, M. Food production in batch manufacturing systems with multiple shared-common resources: A scheduling model and its application in the yoghurt industry. Int. J. Serv. Oper. Manag. 2017, 27, 345. [Google Scholar] [CrossRef]
- Wei, W.; Amorim, P.; Guimarães, L.; Almada-Lobo, B. Tackling perishability in multi-level process industries. Int. J. Prod. Res. 2018, 57, 5604–5623. [Google Scholar] [CrossRef]
- Ahumada, O.; Villalobos, J.R. Application of planning models in the agri-food supply chain: A review. Eur. J. Oper. Res. 2009, 196, 1–20. [Google Scholar] [CrossRef]
- Sel, C.; Bilgen, B.; Bloemhof-Ruwaard, J.M.; van der Vorst, J.G.A.J. Multi-bucket optimization for integrated planning and scheduling in the perishable dairy supply chain. Comput. Chem. Eng. 2015, 77, 59–73. [Google Scholar] [CrossRef]
- Arbib, C.; Pacciarelli, D.; Smriglio, S. A three-dimensional matching model for perishable production scheduling. Discret. Appl. Math. 1999, 92, 1–15. [Google Scholar] [CrossRef]
- Basnet, C.; Foulds, L.R.; Wilson, J.M. An exact algorithm for a milk tanker scheduling and sequencing problem. Ann. Oper. Res. 1999, 86, 559–568. [Google Scholar] [CrossRef]
- Chen, S.; Berretta, R.; Clark, A.; Moscato, P. Lot Sizing and Scheduling for Perishable Food Products: A Review. Ref. Modul. Food Sci. 2019. [Google Scholar] [CrossRef]
- Liu, J.; MacCarthy, B.L. A global milp model for fms scheduling. Eur. J. Oper. Res. 1997, 100, 441–453. [Google Scholar] [CrossRef]
- Guimaraes, K.F.; Fernes, M.A. An approach for flexible job-shop scheduling with separable sequence-dependent setup time. Int. Conf. Syst. 2006, 5, 3727–3731. [Google Scholar]
- Saidi-Mehrabad, M.; Fattahi, P. Flexible job shop scheduling with tabu search algorithms. Int. J. Adv. Manuf. Technol. 2007, 32, 563–570. [Google Scholar] [CrossRef]
- Defersha, F.M.; Chen, M. A parallel genetic algorithm for a flexible job-shop scheduling problem with sequence dependent setups. Int. J. Adv. Manuf. Technol. 2010, 49, 263–279. [Google Scholar] [CrossRef]
- Mati, Y.; Lahlou, C.; Dauzère-Pérès, S. Modelling and solving a practical flexible job-shop scheduling problem with blocking constraints. Int. J. Prod. Res. 2011, 49, 2169–2182. [Google Scholar] [CrossRef]
- Bagheri, A.; Zandieh, M. Bi-criteria flexible job-shop scheduling with sequence-dependent setup times Variable neighborhood search approach. J. Manuf. Syst. 2011, 30, 8–15. [Google Scholar] [CrossRef]
- Mousakhani, M. Sequence-dependent setup time flexible job shop scheduling problem to minimize total tardiness. Int. J. Prod. Res. 2013, 51, 3476–3487. [Google Scholar] [CrossRef]
- Chaudhry, I.A.; Khan, A.A. A research survey: Review of flexible job shop scheduling techniques. Int. Trans. Oper. Res. 2015, 23, 551–591. [Google Scholar] [CrossRef]
- Rajabinasab, A.; Mansour, S. Dynamic flexible job shop scheduling with alternative process plans: An agent-based approach. Int. J. Adv. Manuf. Technol. 2010, 54, 1091–1107. [Google Scholar] [CrossRef]
- Geyik, F.; Dosdogru, A. Process plan and part routing optimization in a dynamic flexible job shop scheduling environment: An optimization via simulation approach. Neural Comput. Appl. 2013, 23, 1631–1641. [Google Scholar] [CrossRef]
- Zhou, D.; Zeng, L. A flexible job-shop scheduling method based on hybrid genetic annealing algorithm. J. Inf. Comput. Sci. 2013, 10, 5541–5549. [Google Scholar] [CrossRef]
- Buddala, R.; Mahapatra, S.S. An integrated approach for scheduling flexible job-shop using teaching–learning-based optimization method. J. Ind. Eng. Int. 2018, 15, 181–192. [Google Scholar] [CrossRef]
- Sriboonchandr, P.; Kriengkorakot, N.; Kriengkorakot, P. Improved Differential Evolution Algorithm for Flexible Job Shop Scheduling Problems. Math. Comput. Appl. 2019, 24, 80. [Google Scholar] [CrossRef]
- Nouri, H.E.; Belkahla, D.O.; Ghédira, K. Solving the flexible job shop problem by hybrid metaheuristics-based multi-agent model. J. Ind. Eng. Int. 2018, 14, 1–14. [Google Scholar] [CrossRef]
- Azzouz, A.; Ennigrou, M.; Ben Said, L. A hybrid algorithm for flexible job-shop scheduling problem with setup times. Int. J. Prod. Manag. Eng. 2017, 5, 23–30. [Google Scholar] [CrossRef]
- Lee, S.; Moon, I.; Bae, H.; Kim, J. Flexible job-shop scheduling problems with ‘AND’/‘OR’ precedence constraints. Int. J. Prod. Res. 2012, 50, 1979–2001. [Google Scholar] [CrossRef]
- Pezzella, F.; Morganti, G.; Ciaschetti, G. A genetic algorithm for the Flexible Job-shop Scheduling Problem. Comput. Oper. Res. 2008, 35, 3202–3212. [Google Scholar] [CrossRef]
- Xia, W.; Wu, Z. An effective hybrid optimization approach for multi-objective flexible job-shop scheduling problems. Comput. Ind. Eng. 2005, 48, 409–425. [Google Scholar] [CrossRef]
- Fattahi, P.; Saidi Mehrabad, M.; Jolai, F. Mathematical modeling and heuristic approaches to flexible job shop scheduling problems. J. Intell. Manuf. 2007, 18, 331–342. [Google Scholar] [CrossRef]
- Kacem, I. Genetic algorithm for the flexible jobshop scheduling problem. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics. Conference Theme-System Security and Assurance, Washington, DC, USA, 8 October 2003. [Google Scholar]
- Goldberg, D. Genetic Algorithms in Search, Optimization, and Machine Learning. Addion Wesley 1989, 1989, 36. [Google Scholar]
- Lourenço, H.R.; Martin, O.C.; Stutzle, T. Iterated local search. In Handbook of Metaheuristics; International Series in Operations Research & Management Science; Springer: Boston, MA, USA, 2003; Volume 57, pp. 320–353. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Application | Algorithm and Workshop Details | Objective Function |
|---|---|---|---|---|
| The problem considered in this paper | 2021 | Research and industry | Mathematical model and metaheuristics for a flexible job shop problem with sequence-dependent setup time and job splitting | Minimum of total flow time |
| Gao et al. | 2018 | Research | Mathematical model and discrete Jaya algorithm | Minimum of makespan, total flow time, machine workload, and total machine workload |
| Gao et al. | 2017 | Research | Resolution approaches for uncertain resource assignment and job sequence in an automated flexible job shop | Minimum of makespan, number of late jobs, total flow time, and total weighted flow time |
| Nie et al. | 2013 | Research | Gene expression programming, dynamic flexible job shop problem with job release dates | Minimum of makespan, mean flow time, and mean tardiness |
| Doh et al. | 2013 | Research | Heuristic with priority rules | Minimum of makespan, total flow time, mean tardiness, number of tardy jobs, and max tardiness |
| Lee et al. | 2012 | Research | Heuristic | Minimum of makespan and mean flow time |
| Liu et al. | 2009 | Research | Multi-swarm particle swarm optimization | Minimum makespan of total flow time |
| Tanev et al. | 2004 | Industry | Genetic algorithm and prioritydispatching rules | Minimum ratio of tardy jobs, variance of the flow time, amount of mold changes, and maximum efficiency of machines |
| Initial Population | Crossover Operators | Mutation Operators | |
|---|---|---|---|
| GA1 | MMWA, SPT | OMAC1, JLOSC1, SLOSC1 | ROAM, IOAM, OSSM |
| GA2 | MMWA, MNOR | OMAC2, OMAC3, JLOSC2, SLOSC2 | ROAM, IOAM, OSSM |
| Initial Solution | Sequence Operators | Affectation Operators | |
|---|---|---|---|
| ILS1 | SPT, MNOR | SO1 | AO1 |
| ILS2 | MMWA, MNOR | SO2, SO3 | AO2, AO3 |
| PS | MNG | NEI | NILS | Pc | Pm | DOS | MISO | MIAO | MPPO | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GA 1 | 500 | 1000 | 50 | 50 | 0.8 | 0.2 | ILS 1 | 0.05 | 100 | 100 | 50 |
| GA 2 | 800 | 1200 | 80 | 80 | 0.8 | 0.2 | ILS 2 | 0.07 | 200 | 200 | 100 |
| J | SL | O | M | F0 (h) | T0 (s) | F1 (h) | T1 (s) | F2 (h) | T2 (s) | F3 (h) | T3 (s) | F4 (h) | T4 (s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2 | 10 | 29 | 15.3 | 2 | 15.3 | 0.1 | 15.3 | 0.3 | 15.3 | 0.01 | 15.3 | 0.08 |
| 3 | 3 | 15 | 29 | 24.4 | 4 | 24.4 | 0.2 | 24.4 | 0.5 | 24.4 | 0.04 | 24.4 | 0.14 |
| 4 | 4 | 20 | 29 | 32.8 | 120 | 32.8 | 0.3 | 32.8 | 0.8 | 32.8 | 0.06 | 32.8 | 0.18 |
| 5 | 5 | 24 | 29 | 39.9 | 240 | 39.9 | 0.4 | 39.9 | 1 | 39.9 | 0.1 | 39.9 | 0.28 |
| 6 | 6 | 29 | 29 | 49.2 | 1200 | 49.2 | 0.6 | 49.2 | 1.4 | 49.2 | 0.16 | 49.2 | 0.40 |
| 7 | 7 | 34 | 29 | 57.6 | 2700 | 57.6 | 0.8 | 57.6 | 1.8 | 57.6 | 0.26 | 57.6 | 0.54 |
| 8 | 10 | 39 | 29 | 69.4 | 9000 | 69.4 | 1 | 69.4 | 2 | 69.4 | 0.46 | 69.4 | 0.3 |
| 9 | 11 | 44 | 29 | - | >10,800 | 77.7 | 1.5 | 77.7 | 3 | 77.7 | 0.71 | 77.7 | 1.2 |
| 10 | 12 | 48 | 29 | - | >10,800 | 85.0 | 2 | 85.0 | 4 | 86.4 | 0.96 | 85.9 | 1.4 |
| 20 | 22 | 93 | 29 | - | >10,800 | 162.4 | 30 | 162.4 | 60 | 166.5 | 5 | 165.8 | 11 |
| 30 | 32 | 138 | 29 | - | >10,800 | 252.9 | 60 | 252.9 | 120 | 262.3 | 15 | 260.6 | 31 |
| 40 | 42 | 179 | 29 | - | >10,800 | 339.7 | 90 | 339.7 | 180 | 354.9 | 23 | 352.3 | 49 |
| 50 | 58 | 227 | 29 | - | >10,800 | 471.6 | 138 | 478.6 | 276 | 490.6 | 30 | 485.6 | 60 |
| 60 | 68 | 271 | 29 | - | >10,800 | 590.4 | 180 | 593.9 | 360 | 624.4 | 43 | 616.7 | 87 |
| 70 | 78 | 315 | 29 | - | >10,800 | 682.8 | 228 | 677.6 | 468 | 720.7 | 51 | 715.2 | 103 |
| 82 | 92 | 370 | 29 | - | >10,800 | 798.3 | 300 | 788.6 | 600 | 846.5 | 70 | 840.8 | 141 |
| J | SL | O | M | F0 (h) | T0 (s) | F1 (h) | T1 (s) | F2 (h) | T2 (s) | F3 (h) | T3 (s) | F4 (h) | T4 (s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 110 | 110 | 402 | 29 | - | >10,800 | 986.7 | 480 | 986.2 | 720 | 1030.5 | 115 | 1018.4 | 225 |
| 100 | 100 | 342 | 29 | - | >10,800 | 696.5 | 270 | 696.5 | 480 | 732.3 | 65 | 723.5 | 126 |
| 90 | 90 | 324 | 29 | - | >10,800 | 704.7 | 240 | 705.1 | 360 | 740.2 | 58 | 732.5 | 112 |
| 80 | 80 | 286 | 29 | - | >10,800 | 525.6 | 205 | 525.5 | 356 | 556.7 | 48 | 548.7 | 94 |
| 60 | 60 | 200 | 29 | - | >10,800 | 248.8 | 140 | 248.5 | 210 | 262.4 | 34 | 258.6 | 65 |
| 50 | 50 | 173 | 29 | - | >10,800 | 318.9 | 110 | 318.3 | 198 | 336.9 | 28 | 331.5 | 54 |
| 20 | 20 | 74 | 29 | - | >10,800 | 158.6 | 60 | 158.2 | 108 | 165.3 | 15 | 163.9 | 28 |
| 15 | 15 | 59 | 29 | - | > 10,800 | 421.5 | 52 | 421.1 | 92 | 432.1 | 12 | 428.8 | 22 |
| 10 | 10 | 31 | 29 | - | >10,800 | 215.4 | 20 | 215.1 | 34 | 219.8 | 4 | 217.9 | 7 |
| 9 | 9 | 34 | 29 | - | >10,800 | 368.8 | 15 | 368.1 | 25 | 376.5 | 3 | 374.1 | 5 |
| J | SL | O | M | F0 (h) | T0 (s) | F1 (h) | T1 (s) | F2 (h) | T2 (s) | F3 (h) | T3 (s) | F4 (h) | T4 (s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 12 | 11 | 6 | 117 | 16 | 117 | 3 | 117 | 6 | 123 | 0.1 | 122 | 0.4 |
| 3 | 8 | 13 | 6 | 85 | 24 | 85 | 5 | 85 | 10 | 89 | 0.2 | 88 | 0.8 |
| 3 | 10 | 8 | 6 | 45 | 10 | 45 | 1.5 | 45 | 3 | 47 | 0.06 | 47 | 0.1 |
| 3 | 11 | 11 | 6 | 55 | 20 | 55 | 4 | 55 | 8 | 58 | 0.2 | 57 | 1.0 |
| 3 | 12 | 12 | 6 | 117 | 104 | 117 | 24 | 117 | 48 | 120 | 1.6 | 119 | 3.8 |
| 3 | 11 | 13 | 6 | 78 | 30 | 78 | 6 | 78 | 12 | 81 | 0.4 | 80 | 1.2 |
| 3 | 10 | 12 | 6 | 88 | 172 | 88 | 42 | 88 | 82 | 92 | 3.6 | 91 | 8.8 |
| 3 | 10 | 13 | 6 | 103 | 240 | 103 | 56 | 103 | 112 | 106 | 7.6 | 105 | 13.6 |
| 3 | 10 | 10 | 6 | 76 | 28 | 76 | 6 | 76 | 12 | 80 | 0.5 | 79 | 1.7 |
| 3 | 8 | 9 | 6 | 44 | 24 | 44 | 5 | 44 | 10 | 45 | 0.3 | 45 | 1.4 |
| J | SL | O | M | F0 (h) | T0 (s) | F1 (h) | T1 (s) | F2 (h) | T2 (s) | F3 (h) | T3 (s) | F4 (h) | T4 (s) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 10 | 132 | 6 | - | >10,800 | 285.8 | 20 | 285.2 | 30 | 298.2 | 5 | 294.1 | 8 |
| 15 | 15 | 168 | 7 | - | >10,800 | 302.4 | 24 | 302.0 | 35 | 312.5 | 7 | 308.7 | 12 |
| 20 | 20 | 146 | 8 | - | >10,800 | 320.5 | 30 | 320.1 | 45 | 332.8 | 9 | 328.5 | 16 |
| 25 | 25 | 154 | 9 | - | >10,800 | 332.6 | 35 | 332.0 | 52 | 345.0 | 11 | 340.2 | 20 |
| 30 | 30 | 151 | 10 | - | >10,800 | 338.2 | 42 | 337.8 | 60 | 350.8 | 13 | 346.6 | 24 |
| 35 | 35 | 149 | 11 | - | >10,800 | 354.3 | 50 | 353.8 | 75 | 368.4 | 15 | 363.1 | 28 |
| 40 | 40 | 179 | 12 | - | >10,800 | 365.1 | 58 | 364.6 | 86 | 378.9 | 18 | 375.2 | 34 |
| 45 | 45 | 221 | 13 | - | >10,800 | 381.8 | 70 | 381.0 | 102 | 396.3 | 22 | 392.7 | 42 |
| 50 | 50 | 191 | 14 | - | >10,800 | 395.0 | 85 | 398.5 | 124 | 410.1 | 28 | 406.4 | 54 |
| 55 | 55 | 205 | 15 | - | >10,800 | 412.7 | 108 | 418.2 | 158 | 428.6 | 34 | 424.5 | 65 |
| 60 | 60 | 195 | 16 | - | >10,800 | 434.2 | 120 | 439.0 | 178 | 448.0 | 40 | 446.3 | 76 |
| 65 | 65 | 201 | 17 | - | >10,800 | 454.3 | 138 | 448.5 | 202 | 472.1 | 46 | 468.9 | 88 |
| 70 | 70 | 256 | 18 | - | >10,800 | 468.5 | 160 | 460.8 | 235 | 486.8 | 52 | 482.7 | 95 |
| 75 | 75 | 258 | 19 | - | >10,800 | 485.6 | 184 | 492.1 | 272 | 504.6 | 60 | 501.4 | 116 |
| 80 | 80 | 300 | 20 | - | >10,800 | 498.0 | 215 | 510.3 | 318 | 516.5 | 68 | 512.1 | 128 |
| J | SL | O | M | F0 (h) | T0 (s) | F1 (h) | T1 (s) | F2 (h) | T2 (s) | F3 (h) | T3 (s) | F4 (h) | T4 (s) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Azzouz et al. | 3 | 3 | 11 | 3 | 74 | 8 | 74 | 2 | 74 | 4.2 | 78 | 0.5 | 76 | 1.05 |
| Bagheri et al. | 3 | 3 | 11 | 3 | 68 | 6 | 68 | 1.5 | 68 | 3.1 | 72 | 0.38 | 70 | 0.78 |
| Pezzella et al. | 3 | 3 | 10 | 4 | 33 | 7 | 33 | 1.8 | 33 | 3.8 | 35 | 0.46 | 34 | 0.95 |
| Nouri et al. | 3 | 3 | 9 | 5 | 31 | 10 | 31 | 2.8 | 31 | 5.6 | 33 | 0.82 | 32 | 1.42 |
| Lee et al. | 3 | 3 | 22 | 5 | 102 | 92 | 102 | 0.2 | 102 | 0.6 | 104 | 0.04 | 103 | 0.13 |
| Mousakhani | 4 | 4 | 12 | 3 | 101 | 9 | 101 | 2.5 | 101 | 5.2 | 106 | 0.64 | 104 | 1.35 |
| Sriboonchandr et al. | 4 | 4 | 14 | 5 | 53 | 12 | 53 | 3.2 | 53 | 6.5 | 56 | 1.2 | 55 | 1.48 |
| Instance 1 | Instance 2 | Instance 3 | Instance 4 | |
|---|---|---|---|---|
| - Number of dishes | 82 | 110 | 62 | 72 |
| - Number of sub-lots of dishes | 92 | 115 | 68 | 80 |
| - Number of operations | 370 | 392 | 218 | 328 |
| - Number of material resources | 29 | 29 | 29 | 29 |
| - Average number of meals produced | 4800 | 4800 | 4800 | 4800 |
| - Real solutions | 901.97 h | 1062.66 h | 278.23 h | 784.84 h |
| - Genetic algorithm solutions | 788.64 h | 952.48 h | 226.12 h | 705.96 h |
| - Gaps between real and genetic algorithm solutions | −12.56% | −10.36% | −18.72% | −11.18% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abderrabi, F.; Godichaud, M.; Yalaoui, A.; Yalaoui, F.; Amodeo, L.; Qerimi, A.; Thivet, E. Flexible Job Shop Scheduling Problem with Sequence Dependent Setup Time and Job Splitting: Hospital Catering Case Study. Appl. Sci. 2021, 11, 1504. https://doi.org/10.3390/app11041504
Abderrabi F, Godichaud M, Yalaoui A, Yalaoui F, Amodeo L, Qerimi A, Thivet E. Flexible Job Shop Scheduling Problem with Sequence Dependent Setup Time and Job Splitting: Hospital Catering Case Study. Applied Sciences. 2021; 11(4):1504. https://doi.org/10.3390/app11041504
Chicago/Turabian StyleAbderrabi, Fatima, Matthieu Godichaud, Alice Yalaoui, Farouk Yalaoui, Lionel Amodeo, Ardian Qerimi, and Eric Thivet. 2021. "Flexible Job Shop Scheduling Problem with Sequence Dependent Setup Time and Job Splitting: Hospital Catering Case Study" Applied Sciences 11, no. 4: 1504. https://doi.org/10.3390/app11041504
APA StyleAbderrabi, F., Godichaud, M., Yalaoui, A., Yalaoui, F., Amodeo, L., Qerimi, A., & Thivet, E. (2021). Flexible Job Shop Scheduling Problem with Sequence Dependent Setup Time and Job Splitting: Hospital Catering Case Study. Applied Sciences, 11(4), 1504. https://doi.org/10.3390/app11041504