Towards a Collection of Security and Privacy Patterns

 ,
,  ,
, 
Abstract
:Featured Application
Abstract
1. Introduction
- Aggregation, adaptation, and specification of patterns based on a novel pattern specification language defined for that purpose (as detailed in our previous works [9,10,11]), focusing on the core properties of Security and Privacy, while also briefly covering additional properties related to Dependability and Interoperability. These patterns include adaptations of concepts identified by surveying the relevant literature as well as original patterns developed within the SEMIoTICS project. The patterns presented in this work offer a complete coverage of all security and privacy properties and their sub-properties, also covering all data states (data in transit, data at rest, and data in processing) and all cases of platform connectivity (i.e., patterns within an IoT as well as across IoT platforms).
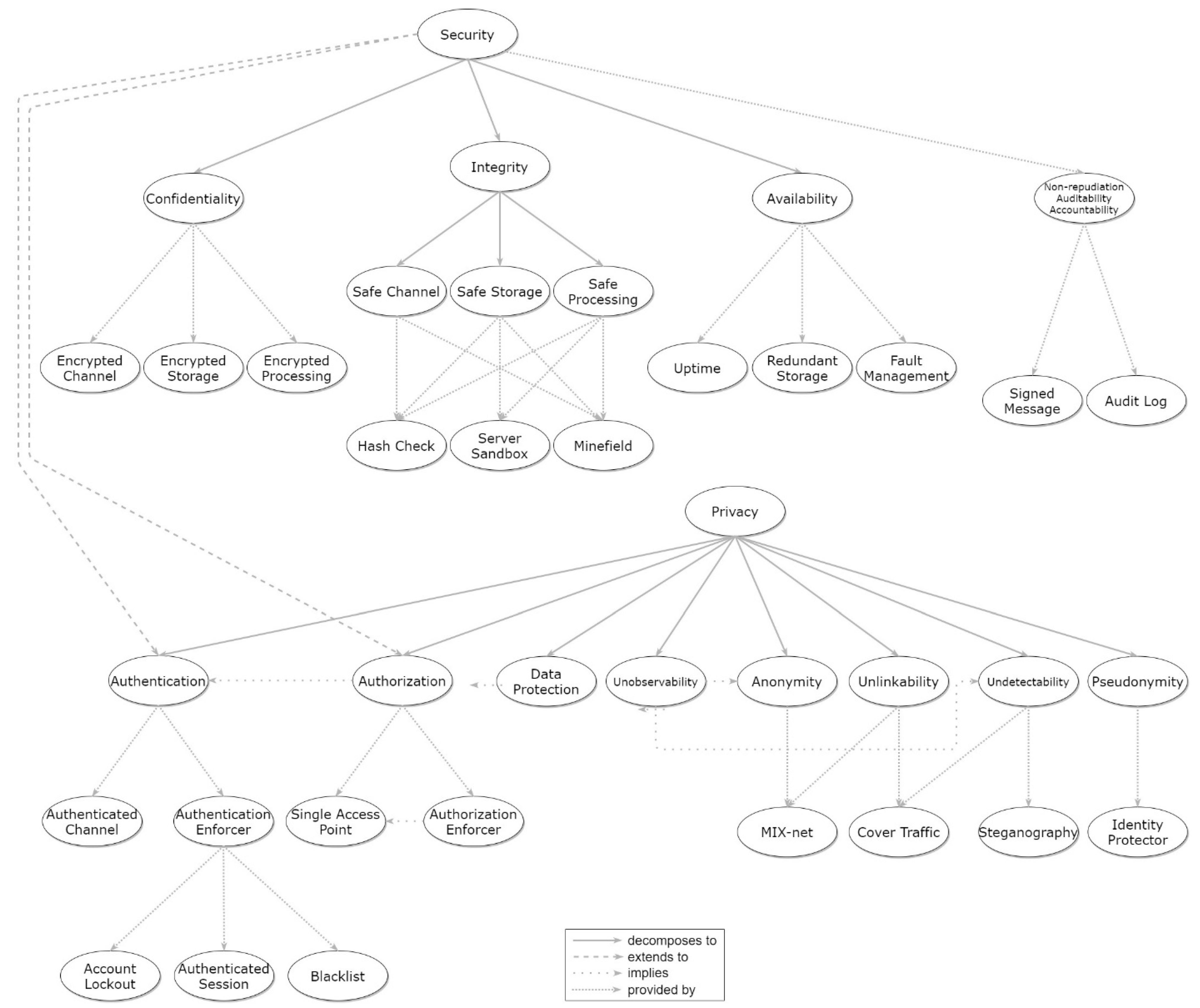
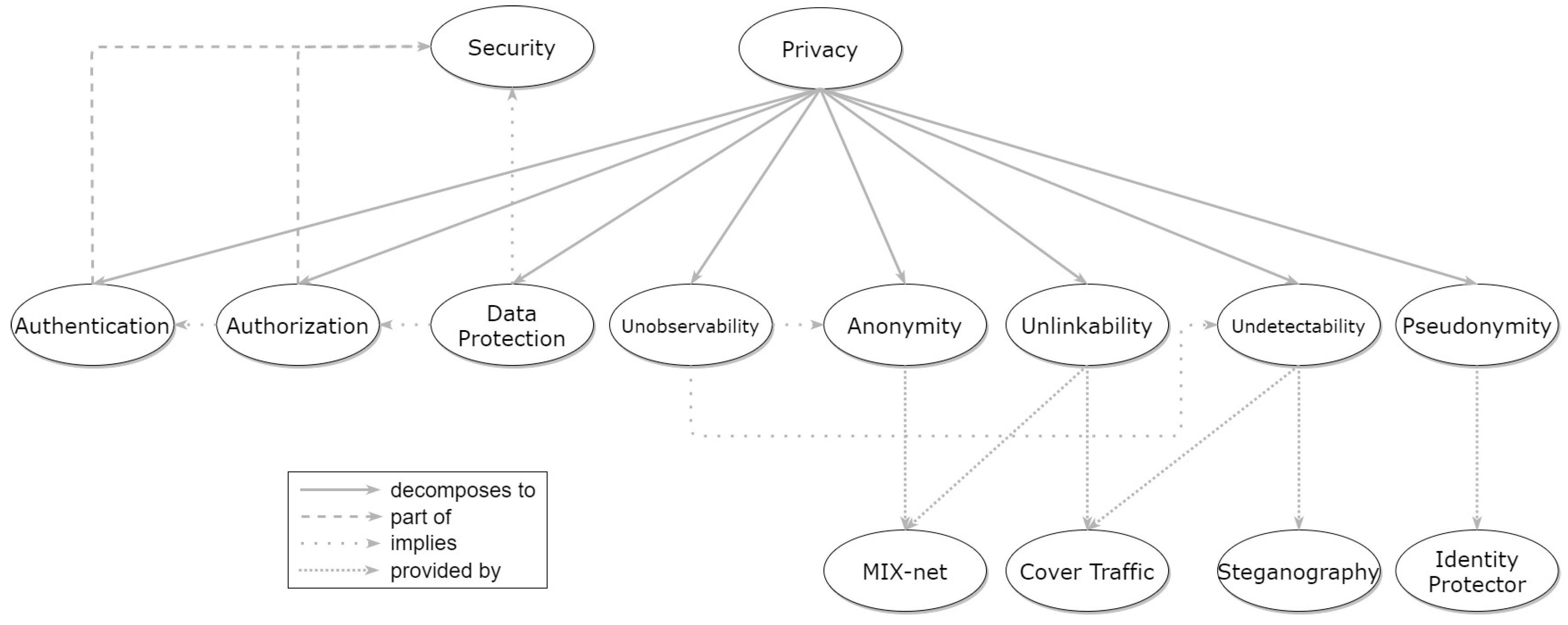
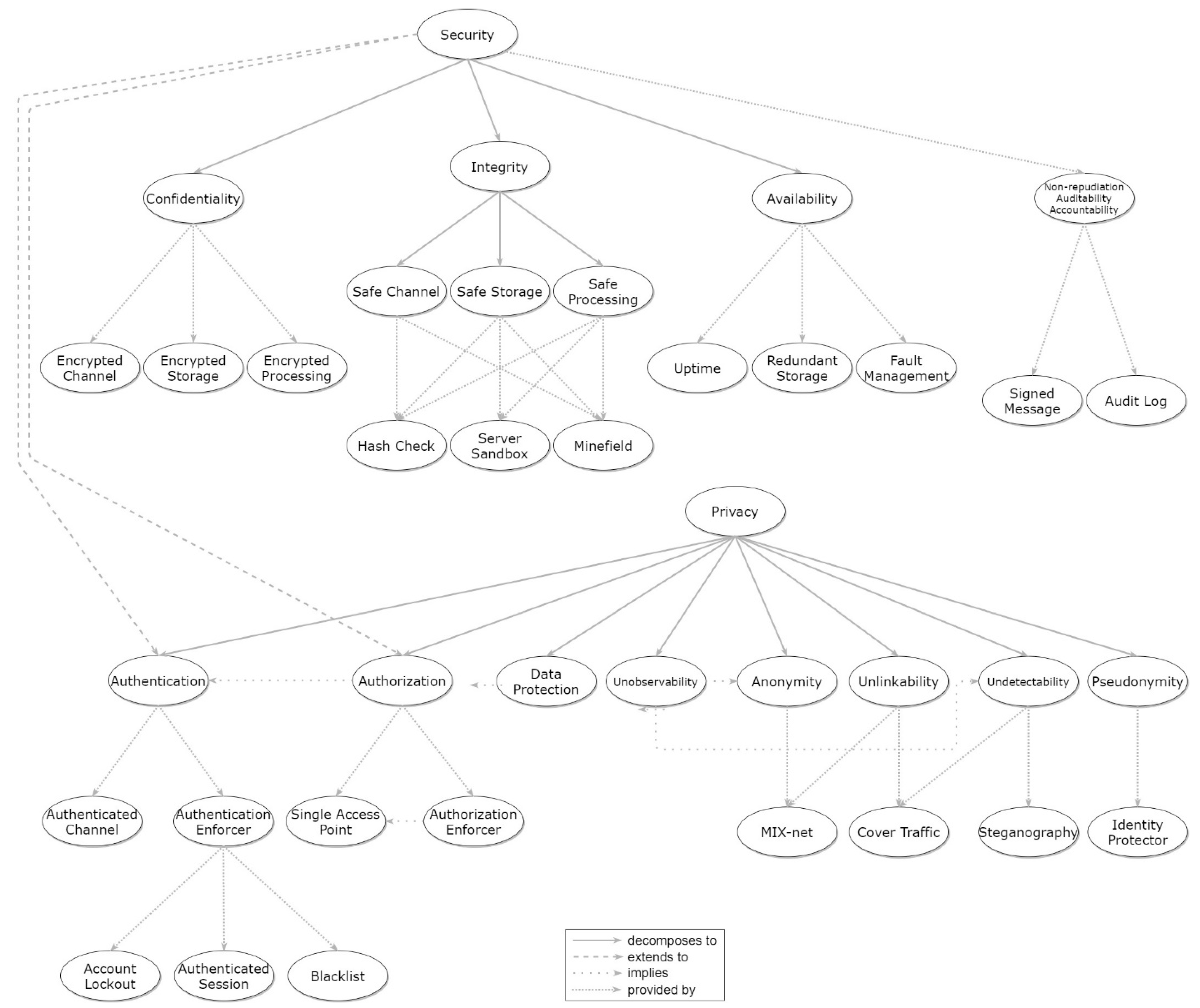
- Creation of an SP Pattern Collection featuring classification of said patterns based on the individual properties they cover, being categorized using a hierarchical taxonomy (the most widely accepted approach to tackle this issue, as shown by Hafiz et al. [12]). The proposed approach for pattern organization allows classifying patterns based on provided property, context, and generality, while also facilitating pattern relationships’ specification, the retrieval of patterns, and, consequently, the verification of the associated properties. When visualized, this results in tree-form graphs connecting the defined properties and associated patterns, as will be presented in the Sections that follow.
- Design and development of a pattern-driven approach for composing IoT orchestrations where security, privacy, dependability and interoperability (SPDI) properties are guaranteed, leveraging the presented Pattern Collection. The proposed approach is capable of defining and managing IoT applications based on patterns, allowing for design-time and run-time verification that an IoT system/orchestration satisfies certain SPDI properties, triggering adaptations (if needed) in ways that are guaranteed to satisfy said properties.
2. Related Works
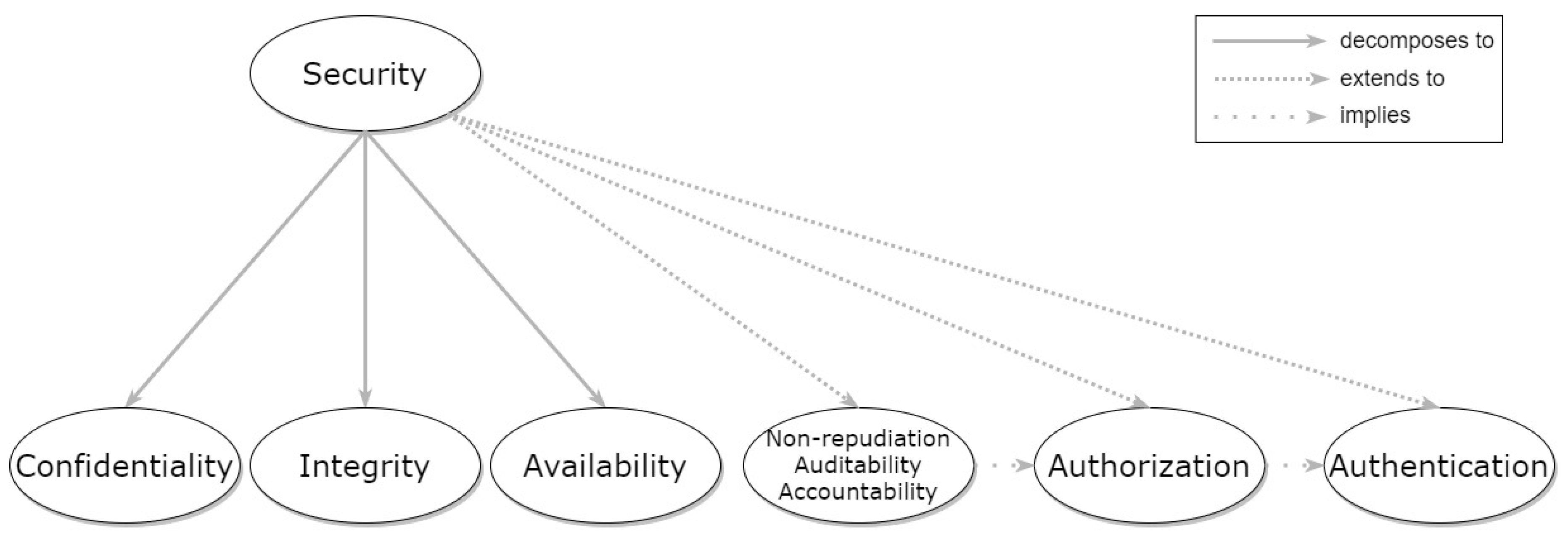
3. Security Patterns
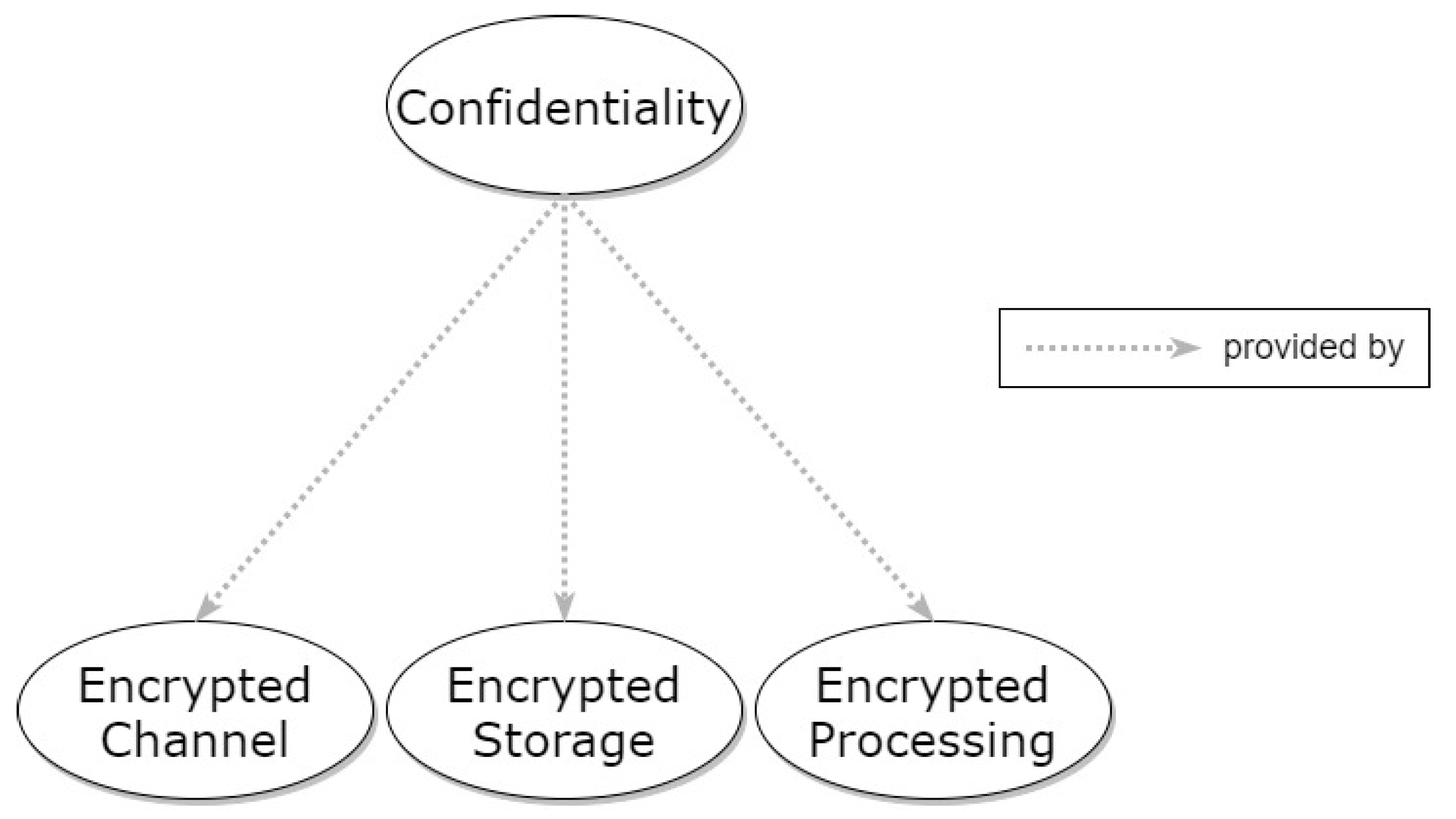
3.1. Confidentiality
3.1.1. Encrypted Storage
3.1.2. Encrypted Channel
3.1.3. Encrypted Processing
3.2. Integrity
3.2.1. Safe Channel
3.2.2. Safe Storage
3.2.3. Safe Processing
3.2.4. Hash Check
- INx and OUTx are the sets of inputs and outputs of x;
- Dx (i) are the data of x at the given time ti;
- Hash(Dx (i)) are the cryptographic hash function results applied to data Dx(i).
- The inputs of A are the inputs of the orchestration P;
- The inputs of B are the outputs of A;
- The outputs of the orchestration P are the outputs of B.
- Hash (INP) = Hash (INA);
- Hash (INB) = Hash (OUTA);
- Hash (OUTP) = Hash (OUTB).
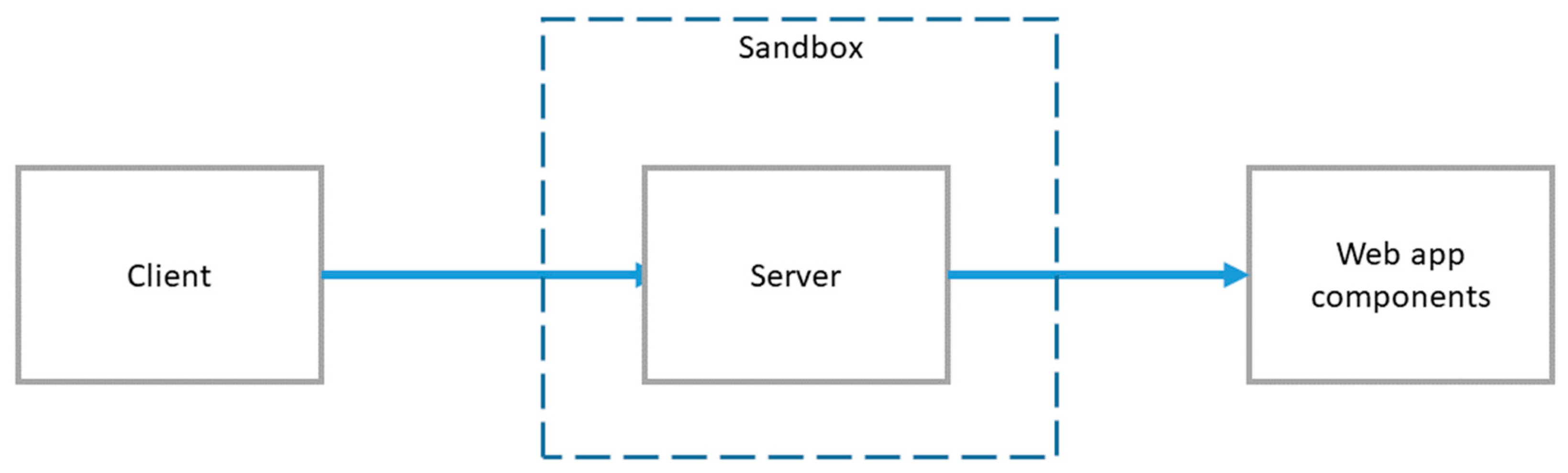
3.2.5. Server Sandbox
3.2.6. Minefield
- Rename common, exclusively administrative commands on the server and replace them with instrumented versions that alert the administrator to an intruder before executing the requested command.
- Alter the file system structure.
- Introduce controlled variations using tools such as the Deception Toolkit [35].
- Add application-specific boobytraps that will recognize tampering and prevent the application from starting.
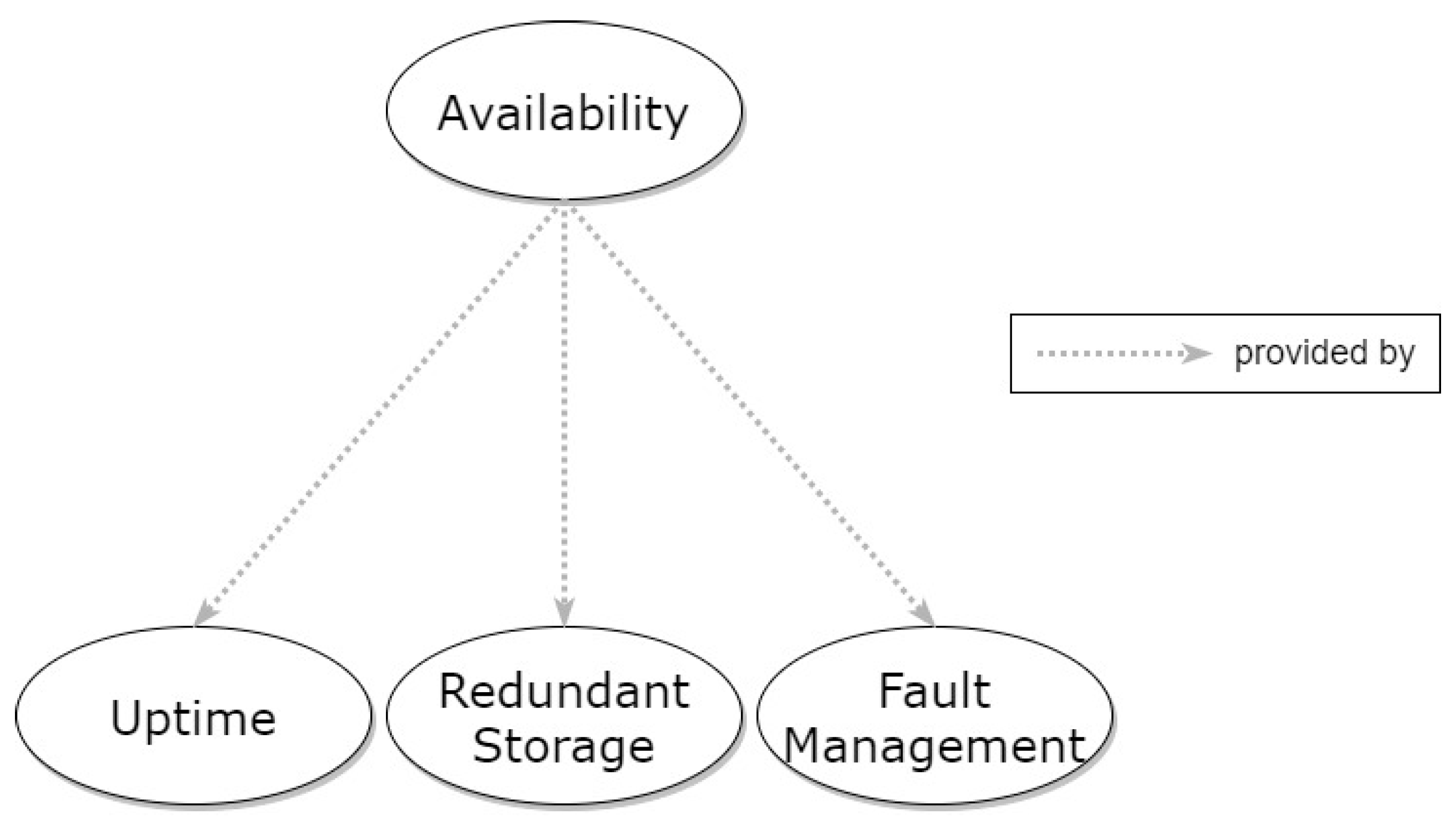
3.3. Availability
3.3.1. Uptime
3.3.2. Redundant Storage
3.3.3. Fault Management
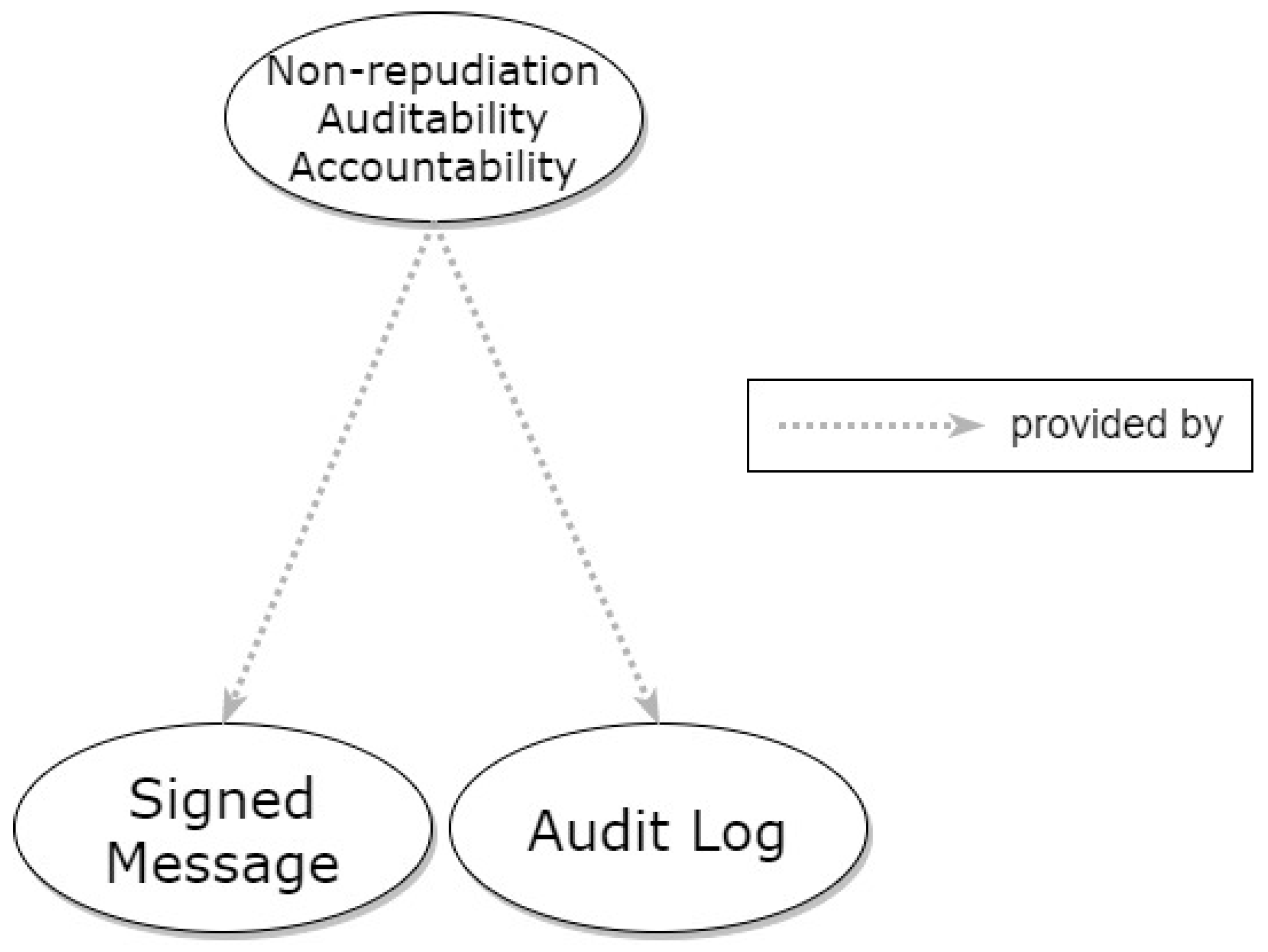
3.4. Non-Repudiation, Accountability, and Auditability
3.4.1. Signed Message
- Key generation: This algorithm provides a private key along with its corresponding public key.
- Signing: This algorithm produces a signature (typically on the digest of the message) upon receiving a private key and the message that is being signed.
- Verification: This algorithm checks the authenticity of the message by verifying it along with the signature and the public key.
3.4.2. Audit Log
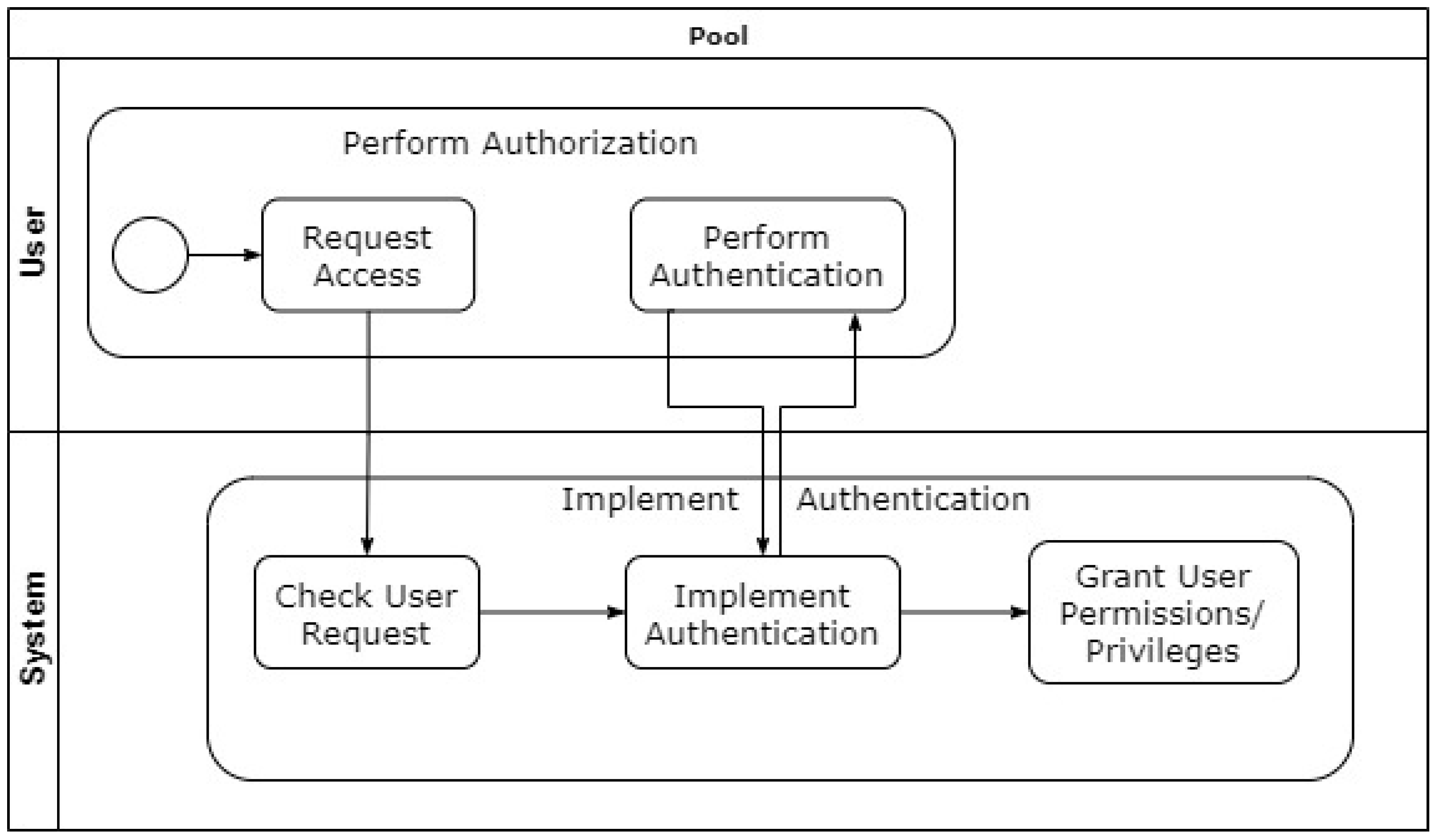
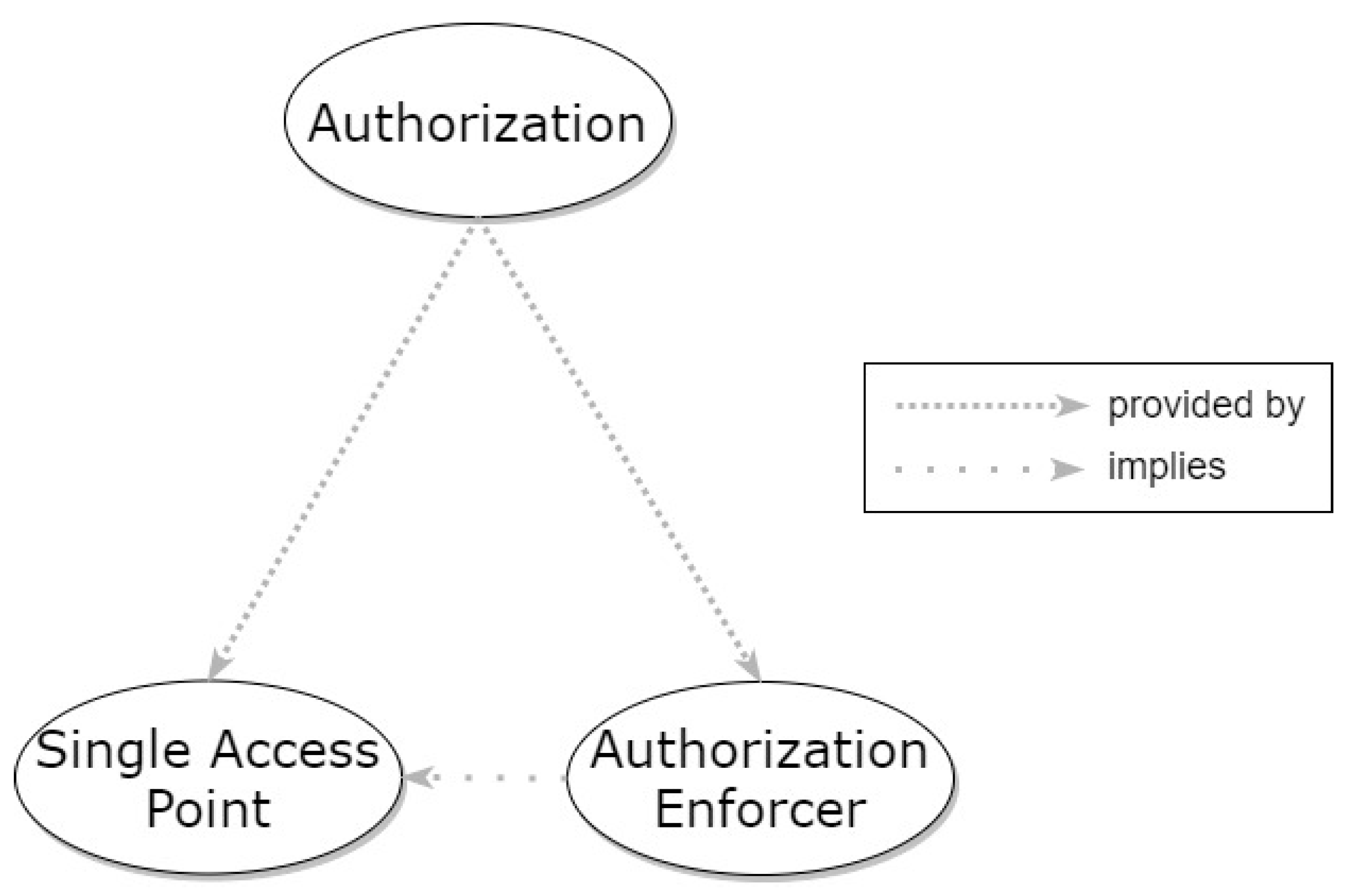
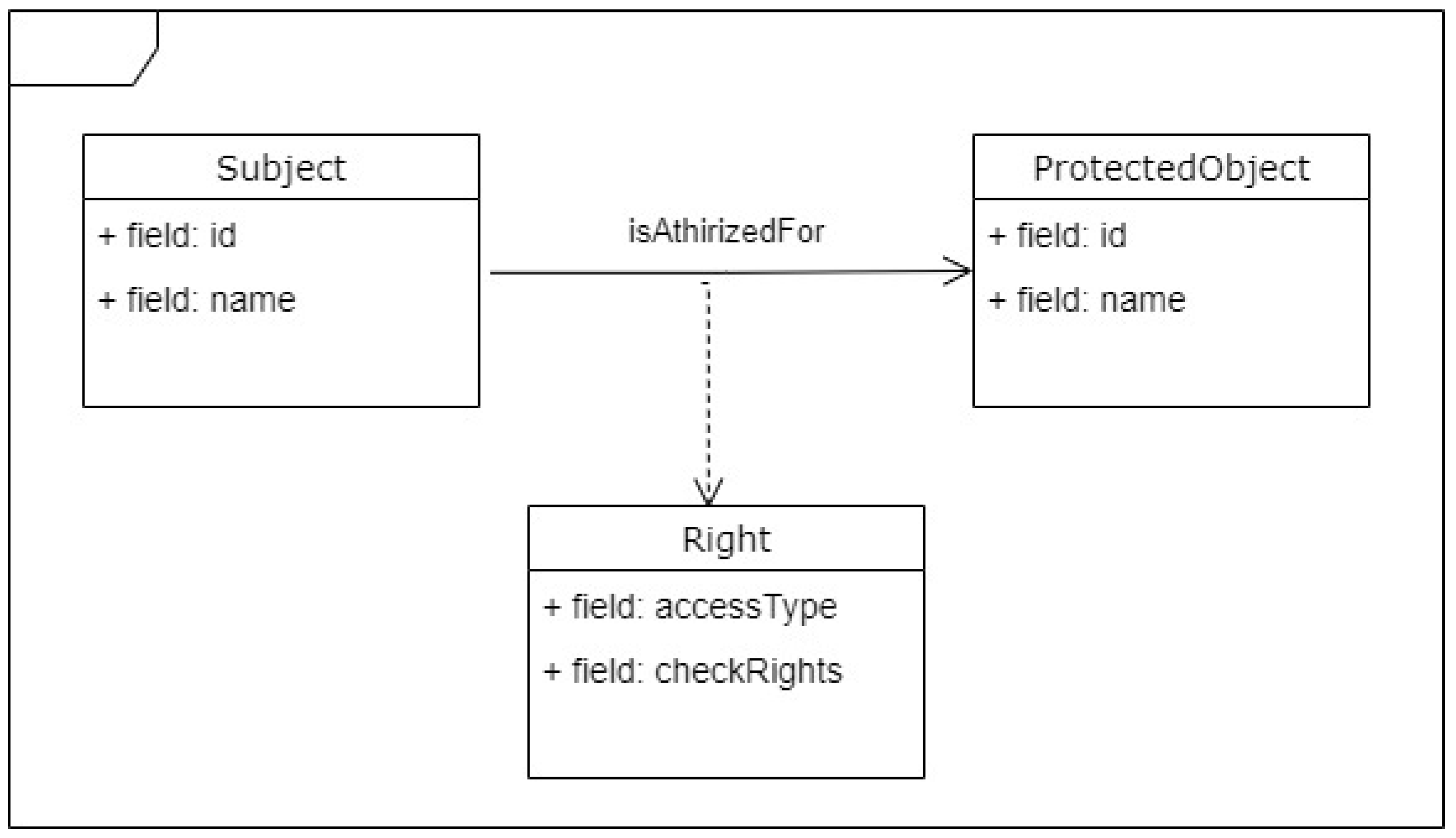
3.5. Authorization
3.5.1. Single Access Point
3.5.2. Authorization Enforcer
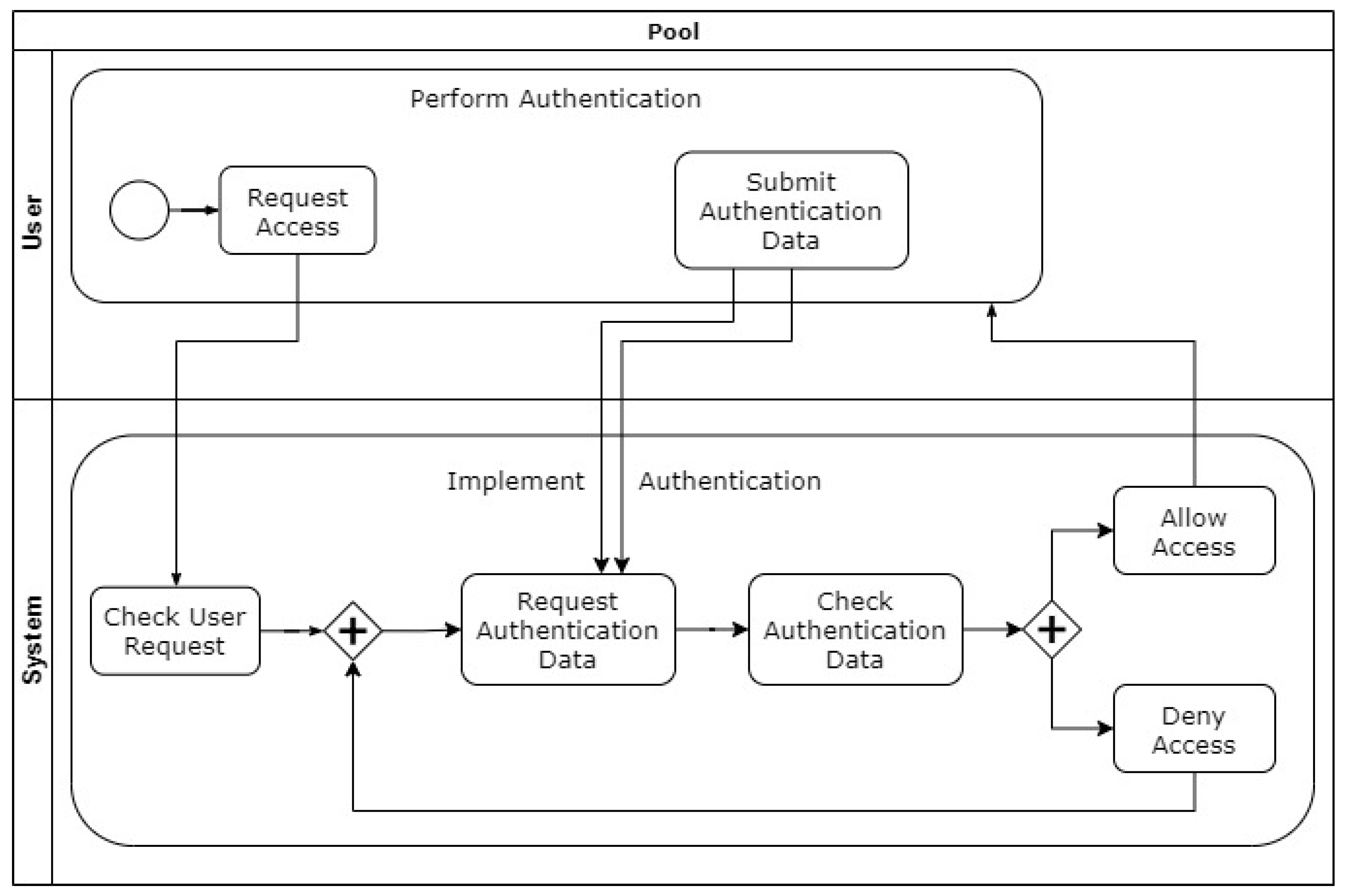
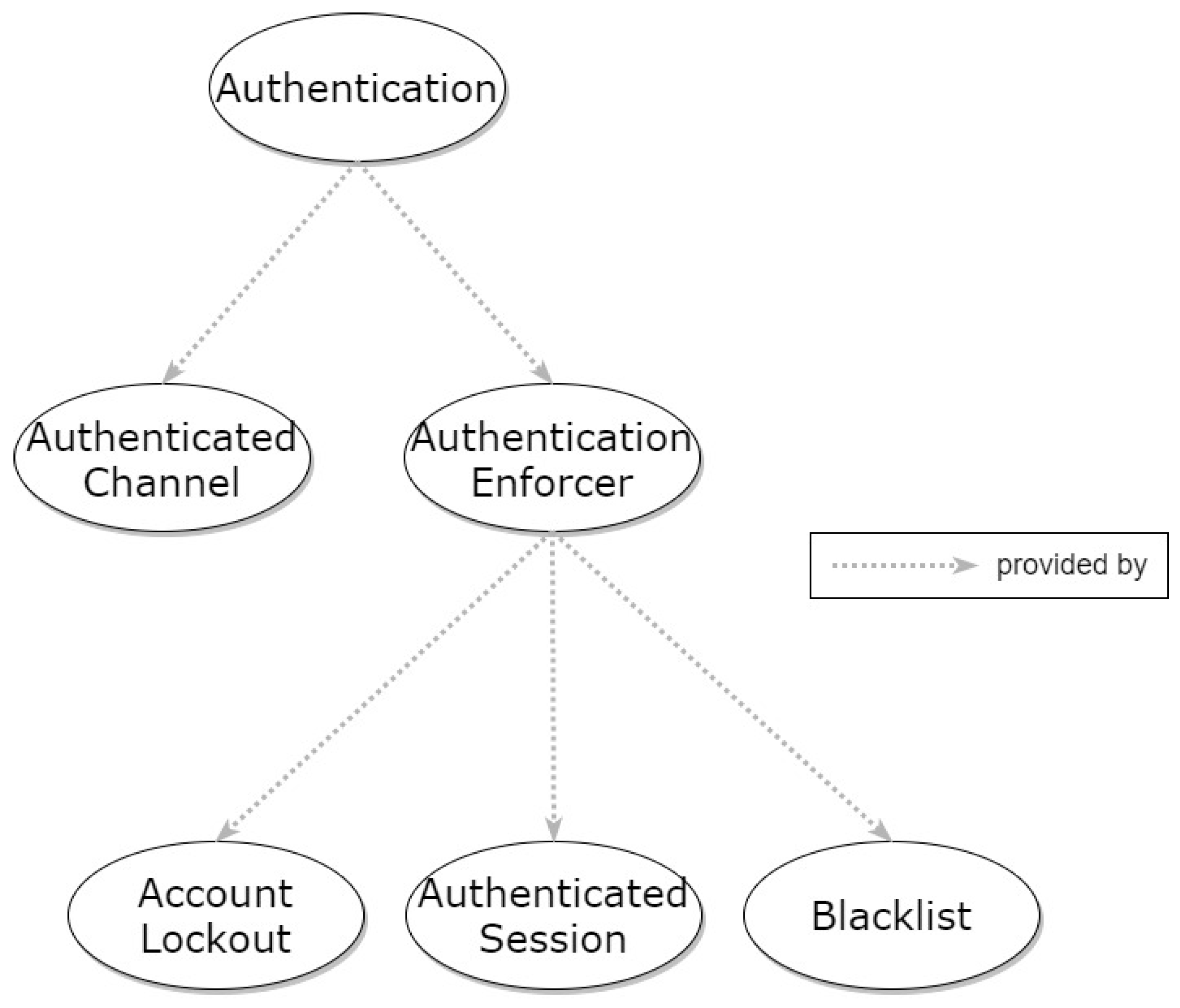
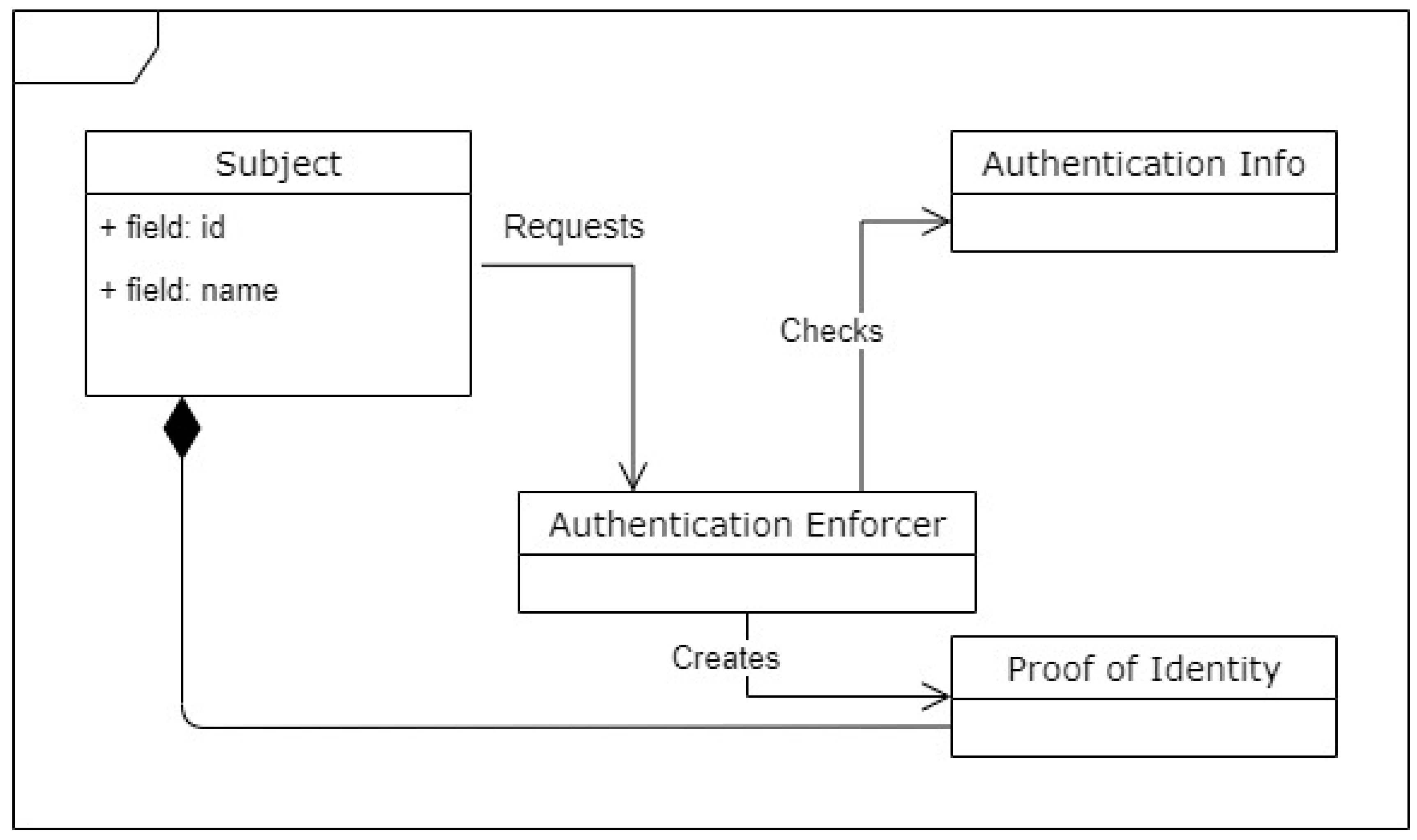
3.6. Authentication
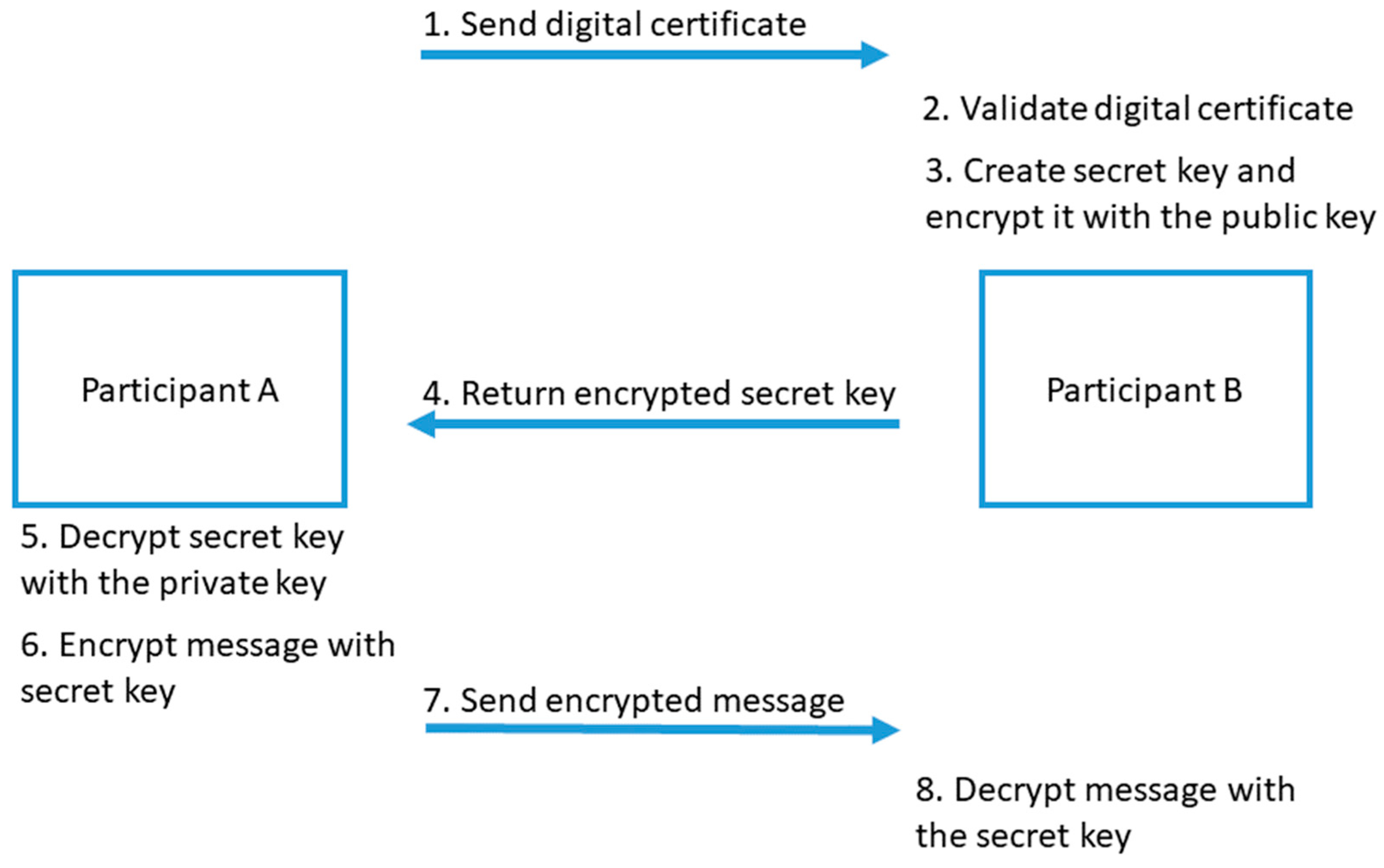
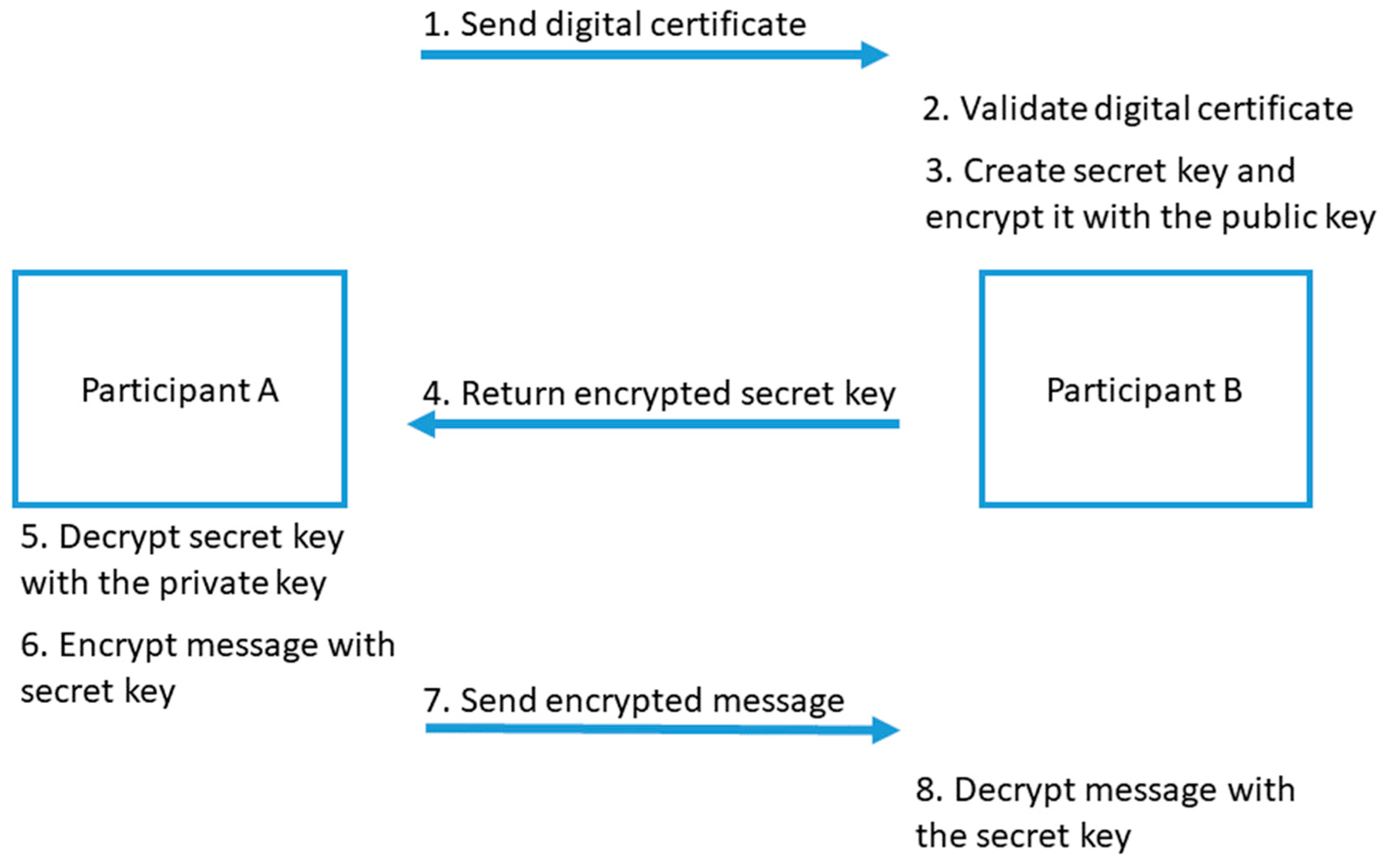
3.6.1. Authenticated Channel
- Mutual authentication of the peers;
- Key confirmation (at least one peer is able to verify that the common secret is indeed common);
- Forward secrecy (old session keys cannot be calculated even when long-term secret keys (such as certificate Secret keys are known).
3.6.2. Authentication Enforcer
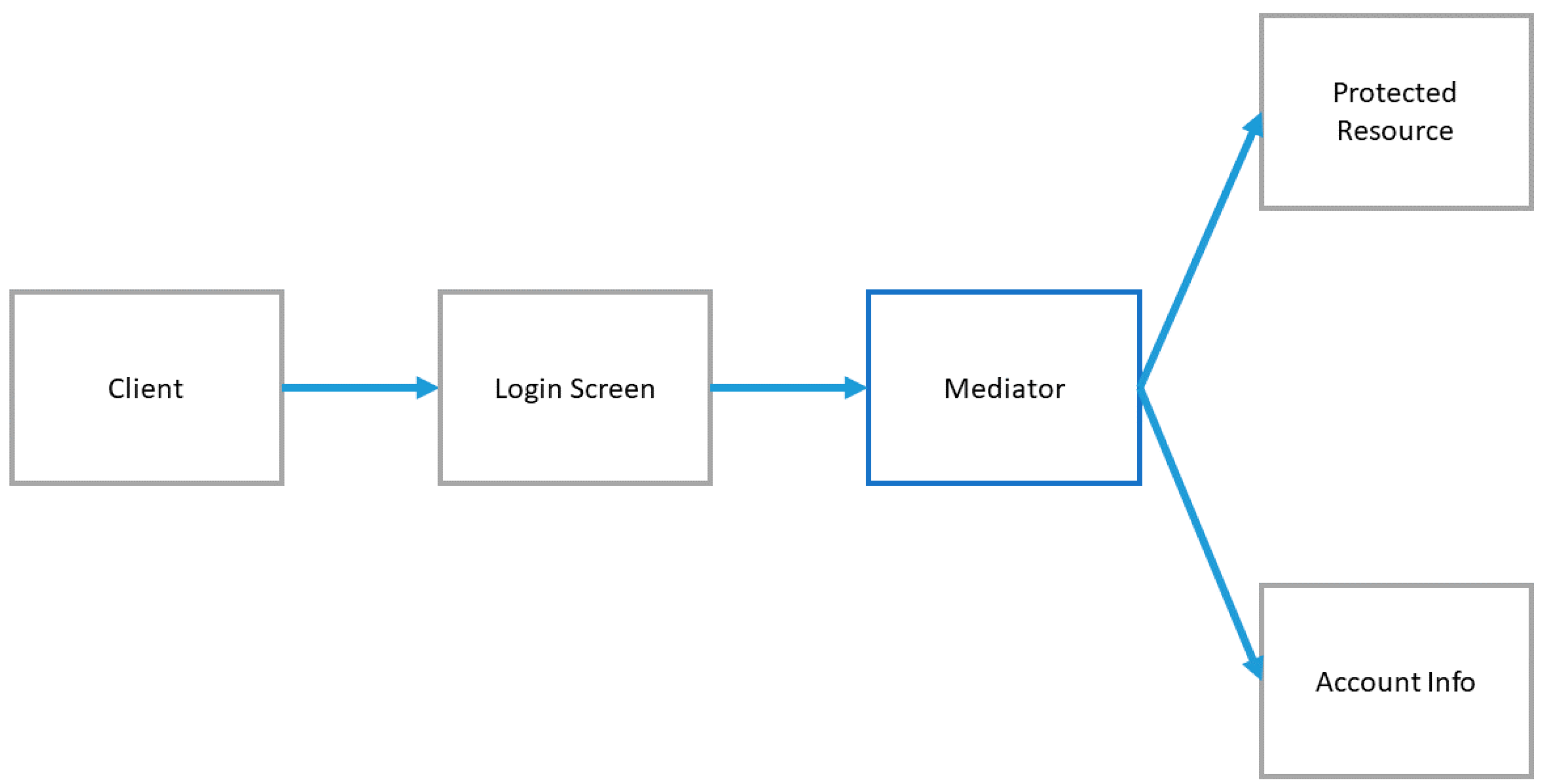
3.6.3. Account Lockout
- The client is provided with a transaction form or login screen requiring both a username and a password.
- The user provides the username and password and submits the request for a protected resource.
- The mediator checks the username and, if valid, retrieves the account information. If the username is invalid, it returns a generic failed login message.
- The mediator checks if this user’s account is locked out (number of successive failed logins exceeds the threshold) and not yet cleared (last failed login time + reset duration > current time). If locked, it returns a generic failed login message.
- If the user’s account is not locked, the mediator checks the validity of the password. If the password is not valid, it increments the number of failed login attempts against the account and sets the last failed login time to the current time. It then returns a generic failed login message.
- If the password is valid, it resets the number of failed logins to 0 and executes the request against the protected resource.
3.6.4. Authenticated Session
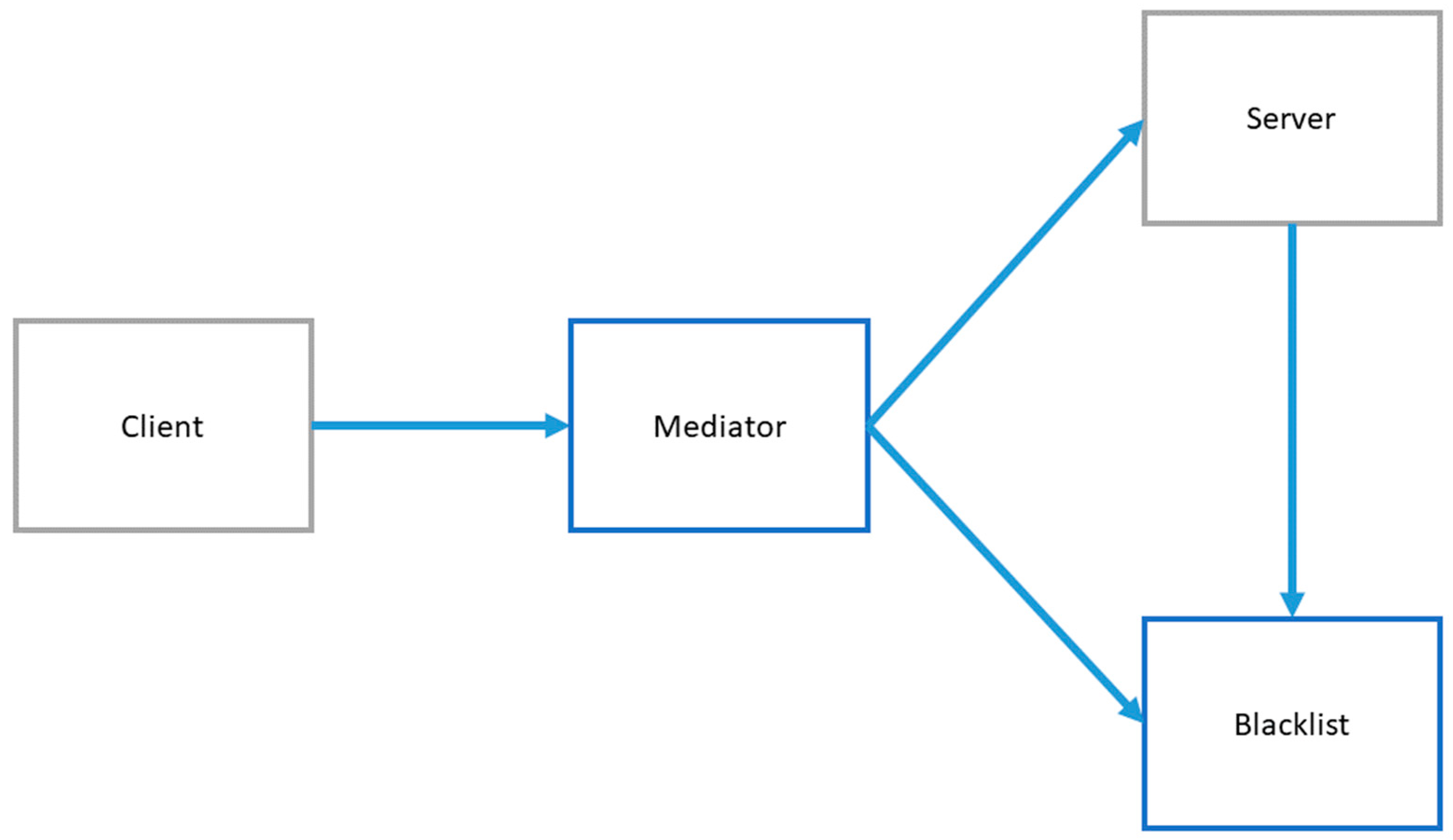
3.6.5. Blacklist
4. Privacy Patterns
4.1. Anonymity
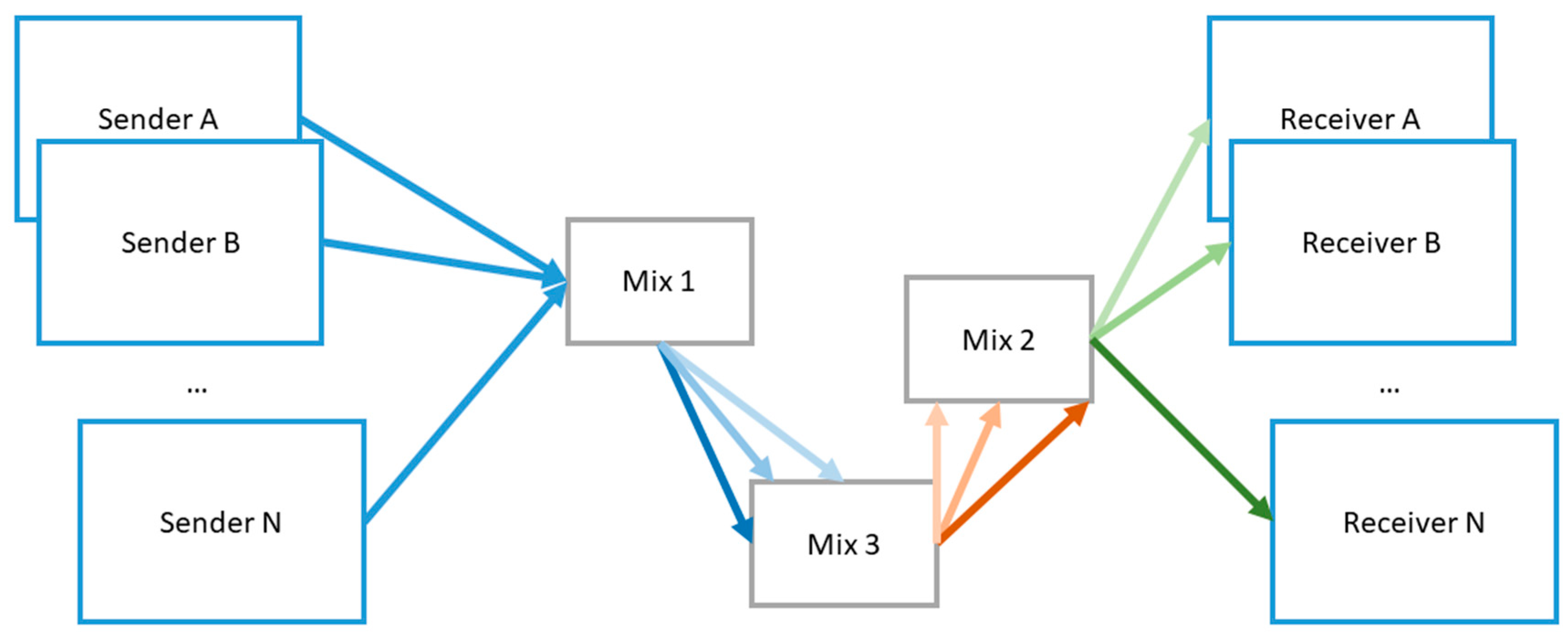
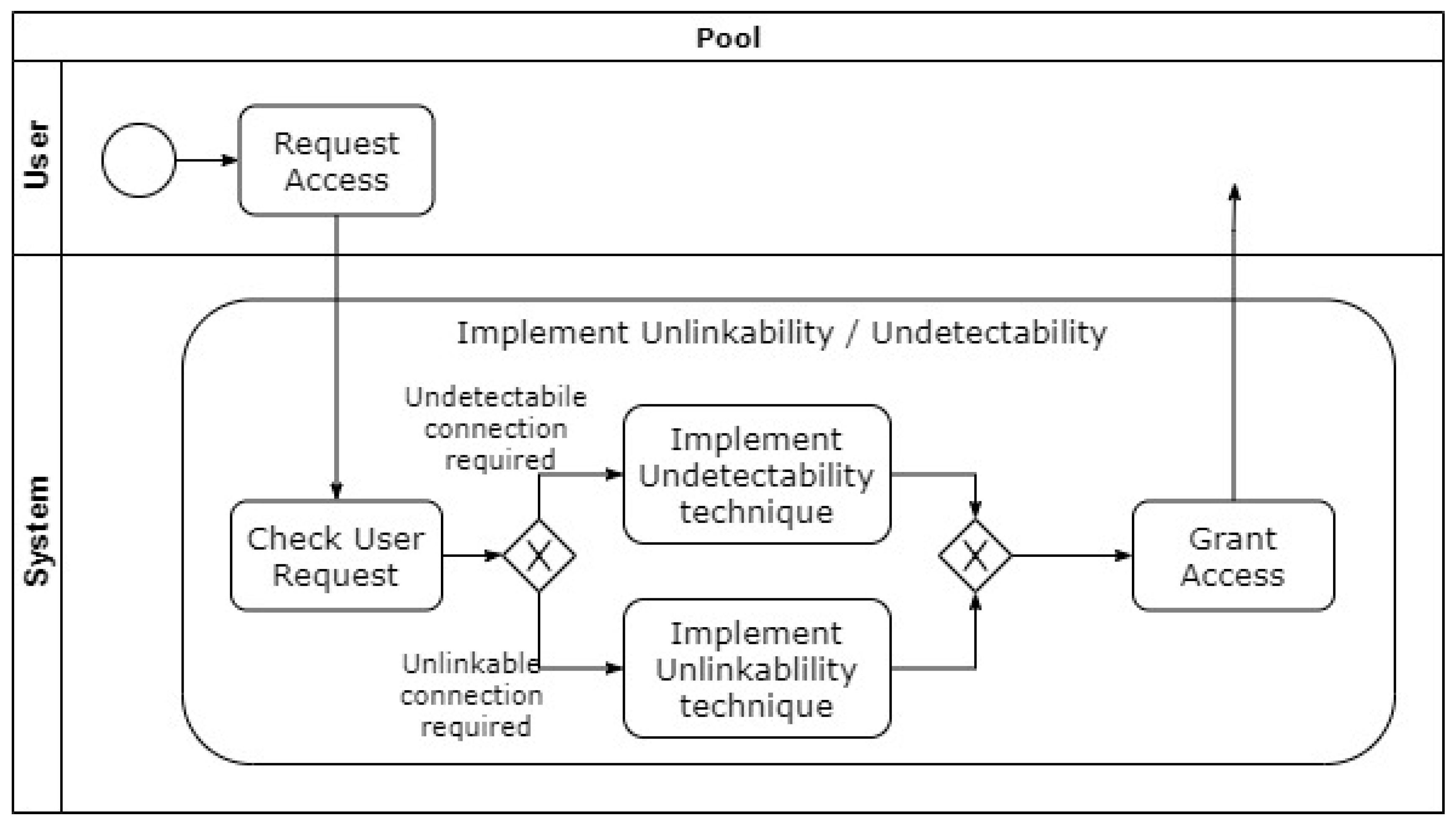
4.2. Unlinkability
Mix Network
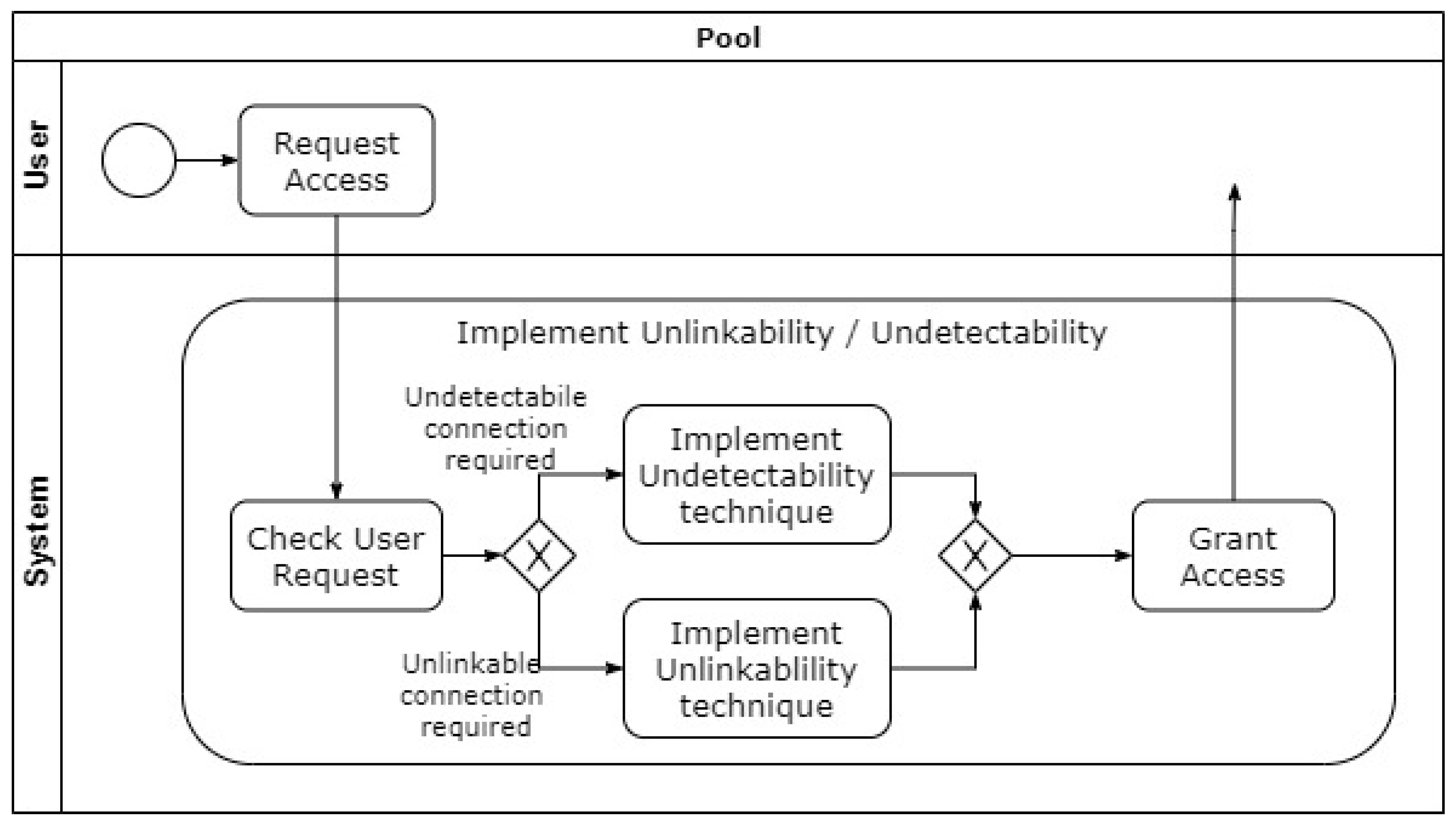
4.3. Undetectability
4.3.1. Cover Traffic
4.3.2. Steganography
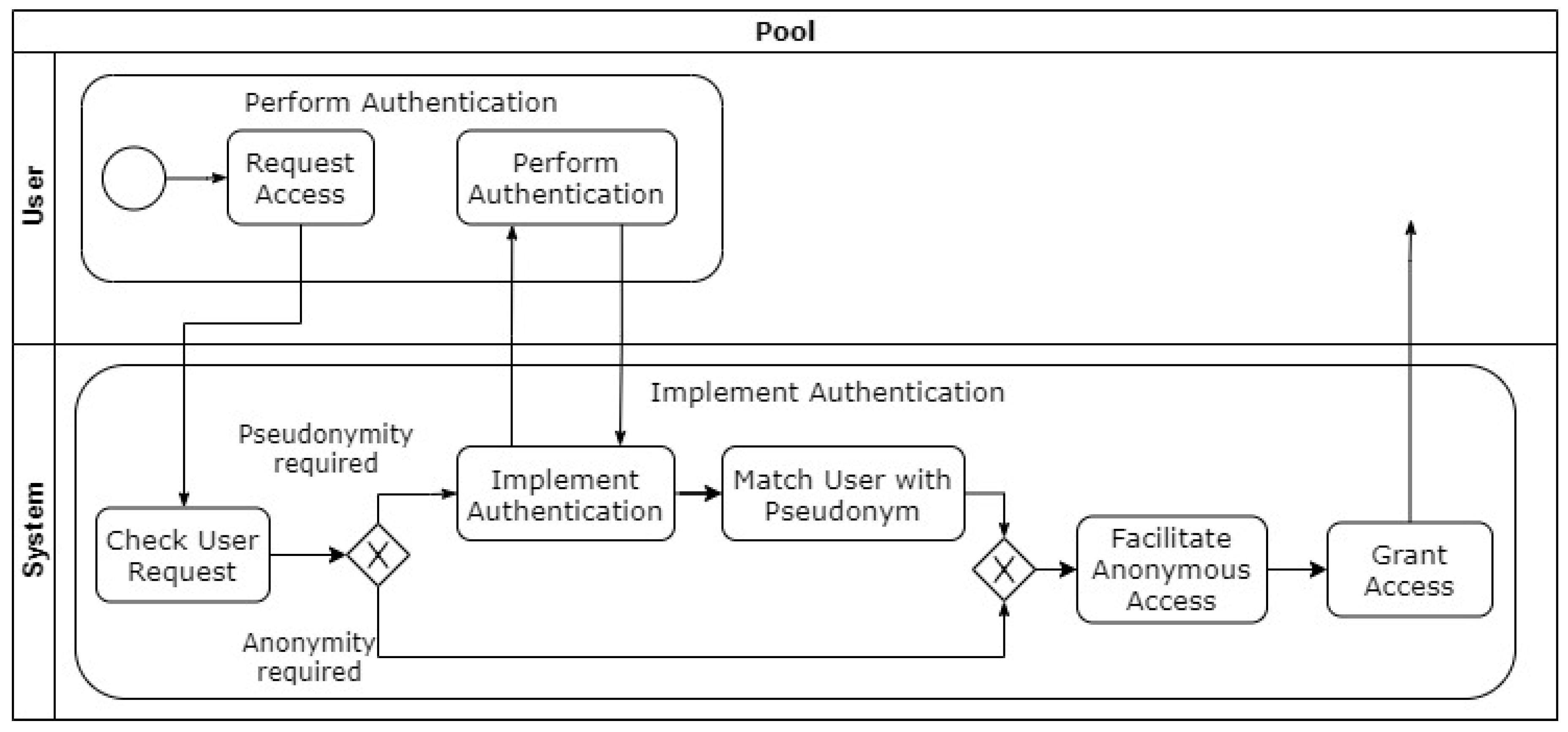
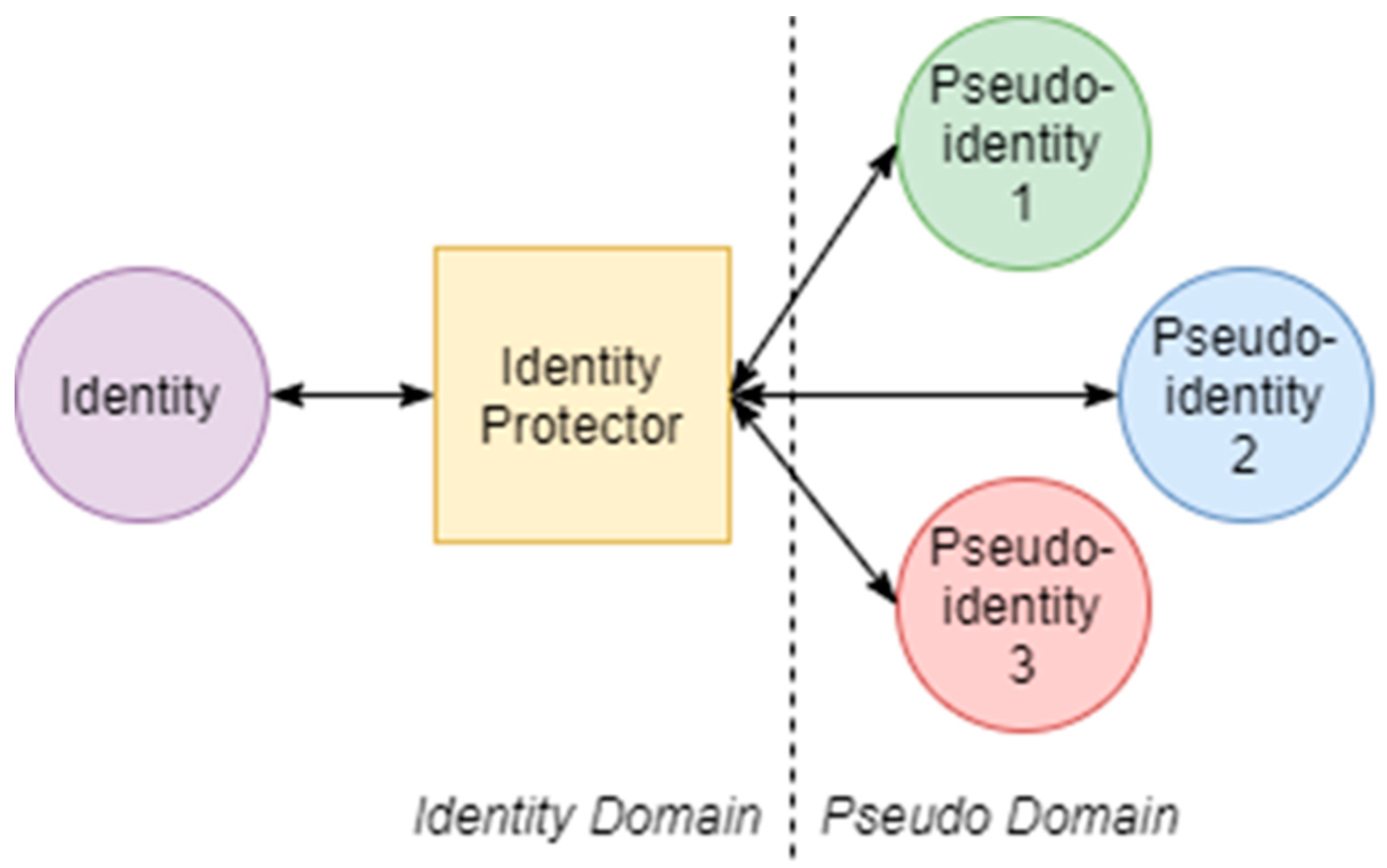
4.4. Pseudonymity
Identity Protector
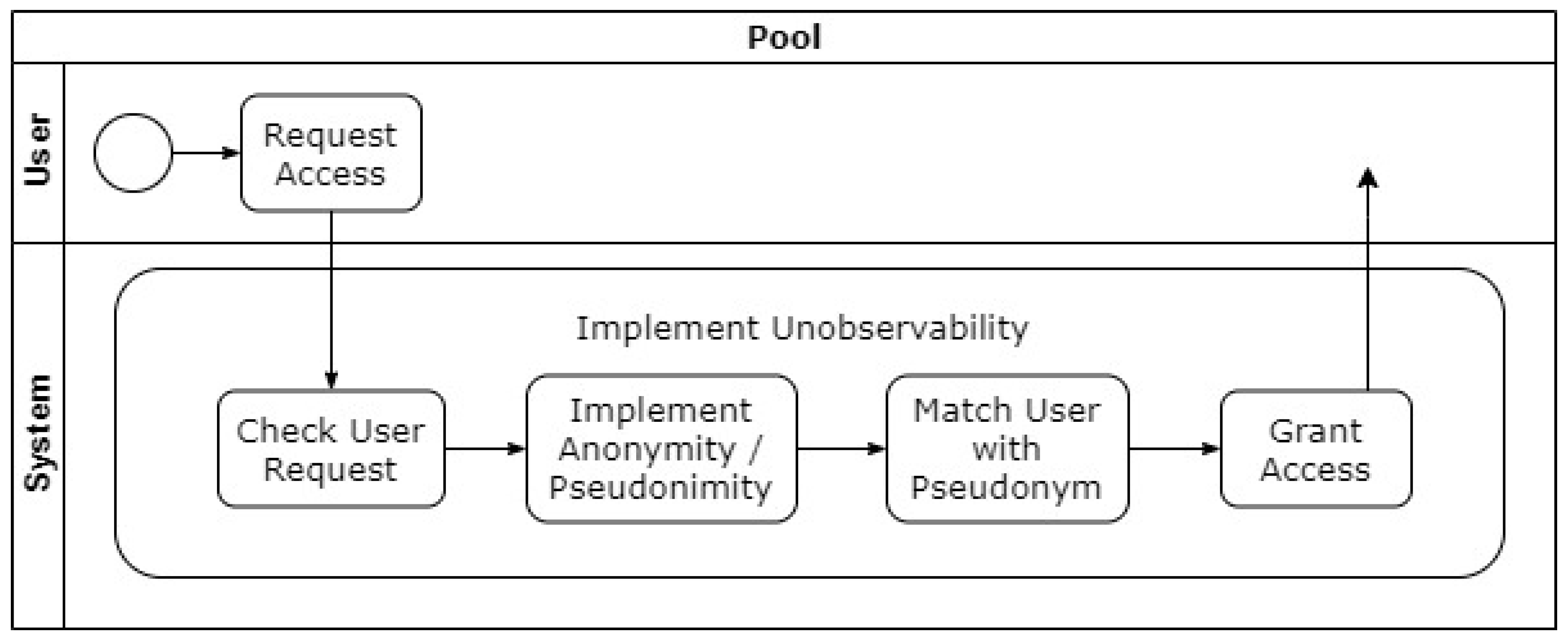
4.5. Unobservability
5. Collection Overview and Practical Application
5.1. Collection Expansion
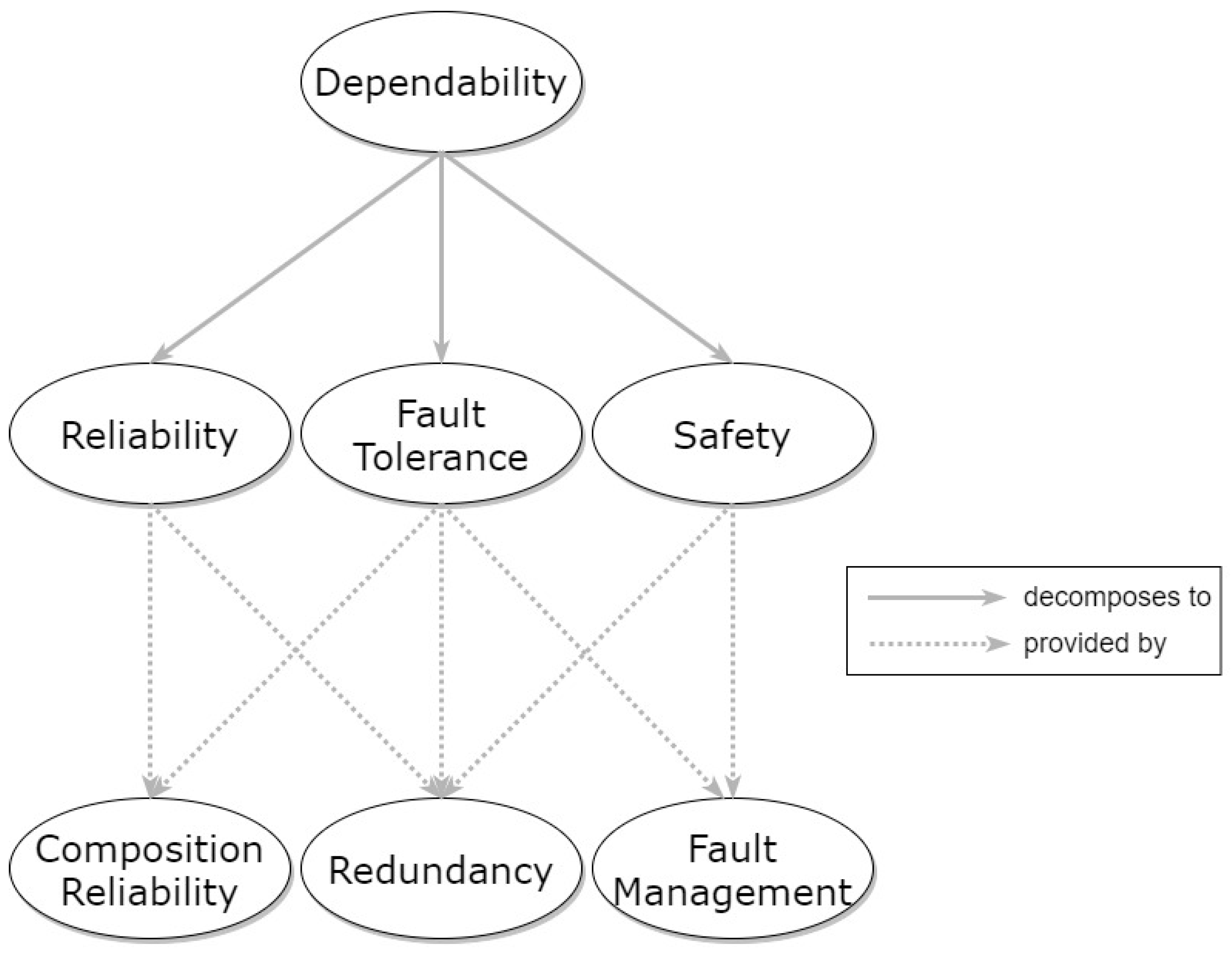
5.1.1. Dependability
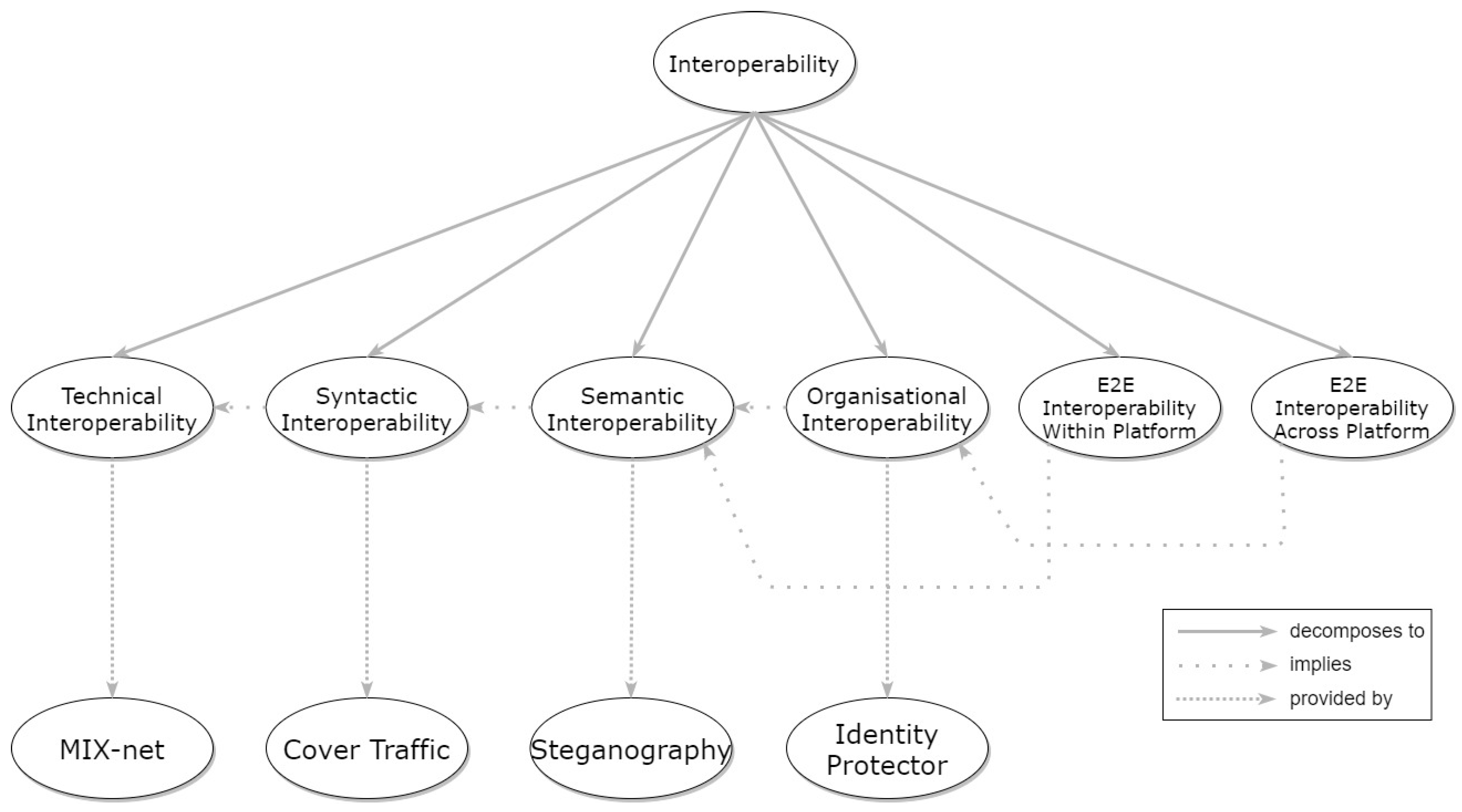
5.1.2. Interoperability
- Technical interoperability—enables seamless operation and cooperation of heterogeneous devices that utilize different communication protocols on the transmission layer.
- Syntactic interoperability—establishes clearly defined formats for data, interfaces, and encoding.
- Semantic interoperability—settles commonly agreed information models and ontologies for the used terms that are processed by the interfaces or are included in exchanged data.
- Organizational interoperability—cross-domain and cross-platform service integration and orchestration through common semantic and programming interfaces.
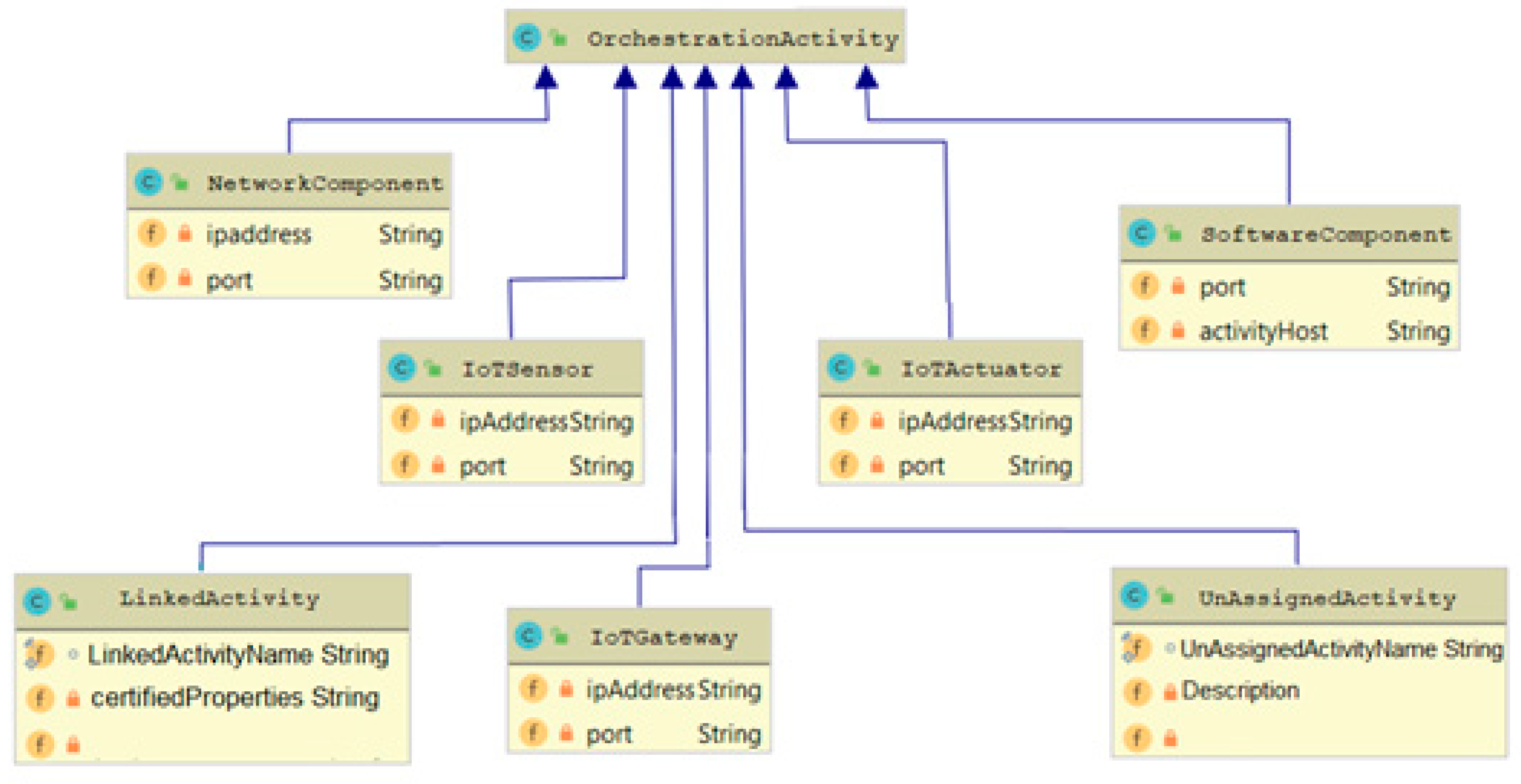
5.2. Application—The SEMIoTICS Approach to Pattern-Driven IoT/IIoT Orchestrations with SPDI Guarantees
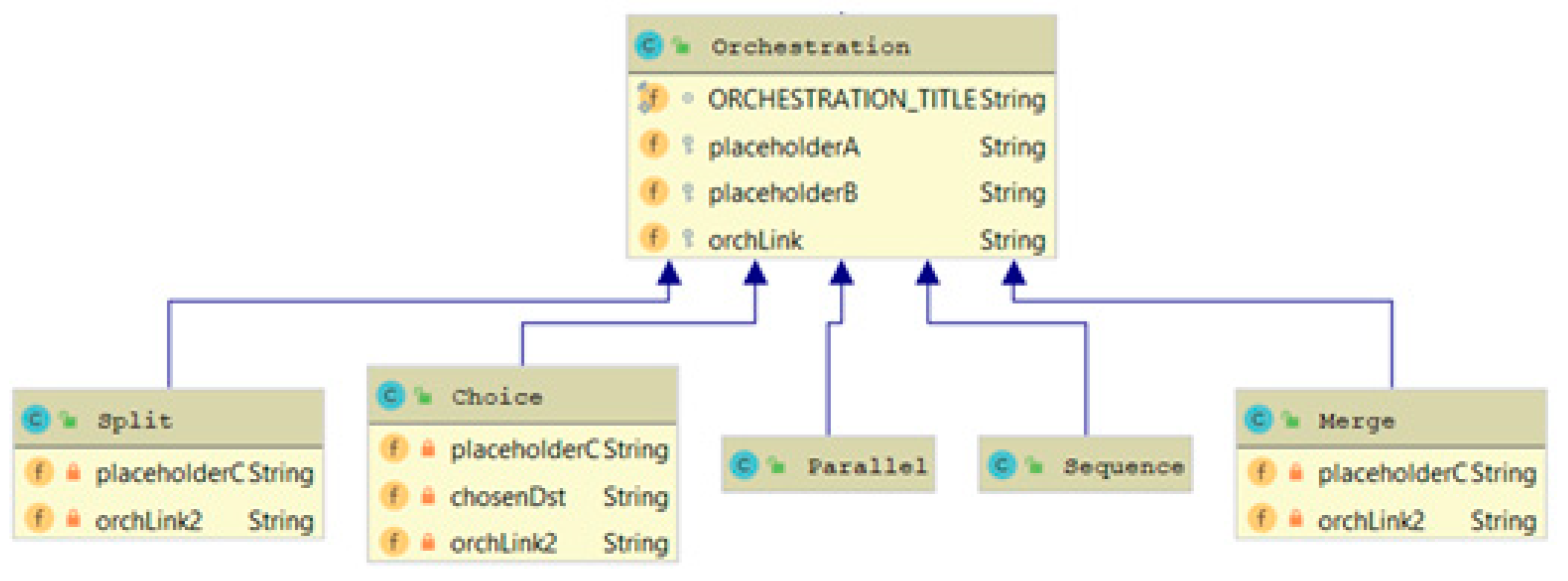
- Sequence is a segment of a process instance in which several activities are executed in sequence under a single thread of execution.
- Parallel is a segment of a process instance where two or more activity instances are executing in parallel within the workflow, giving rise to multiple threads of control.
- Merge is a point in the workflow where two or more parallel executing/alternative activities converge into a single common thread of control.
- Choice is a point within the workflow where a single thread of control makes a decision on which branch to take when encountered with multiple alternative workflow branches, based on a choice condition.
- Split is a point within the workflow where two or more branches are created and taken. After a Split, the activities of the branches that are taken are executed in parallel.
- grammar EBNF;
- …
- orchestration : sequence | parallel | choice | merge | split ;
- …
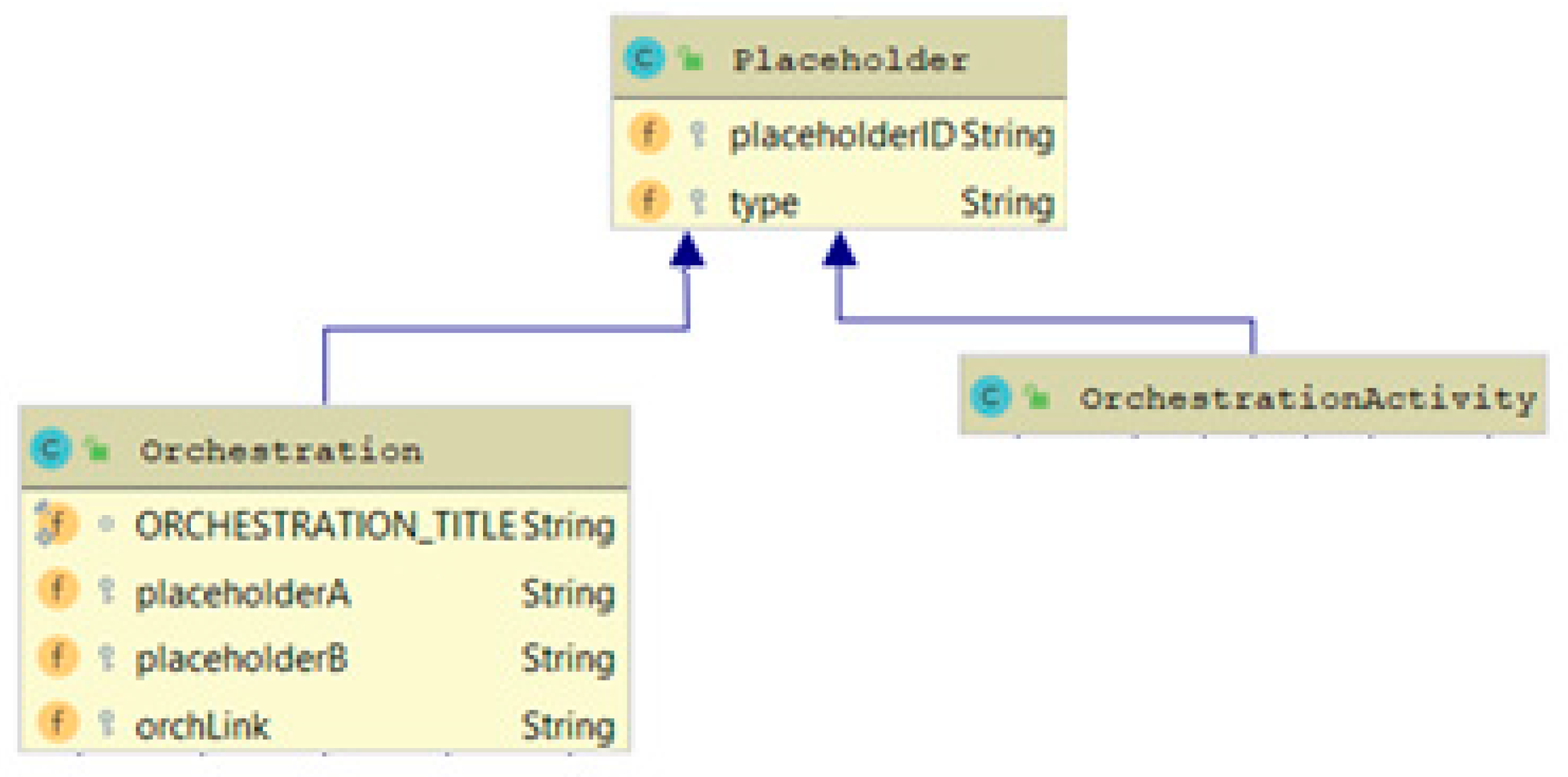
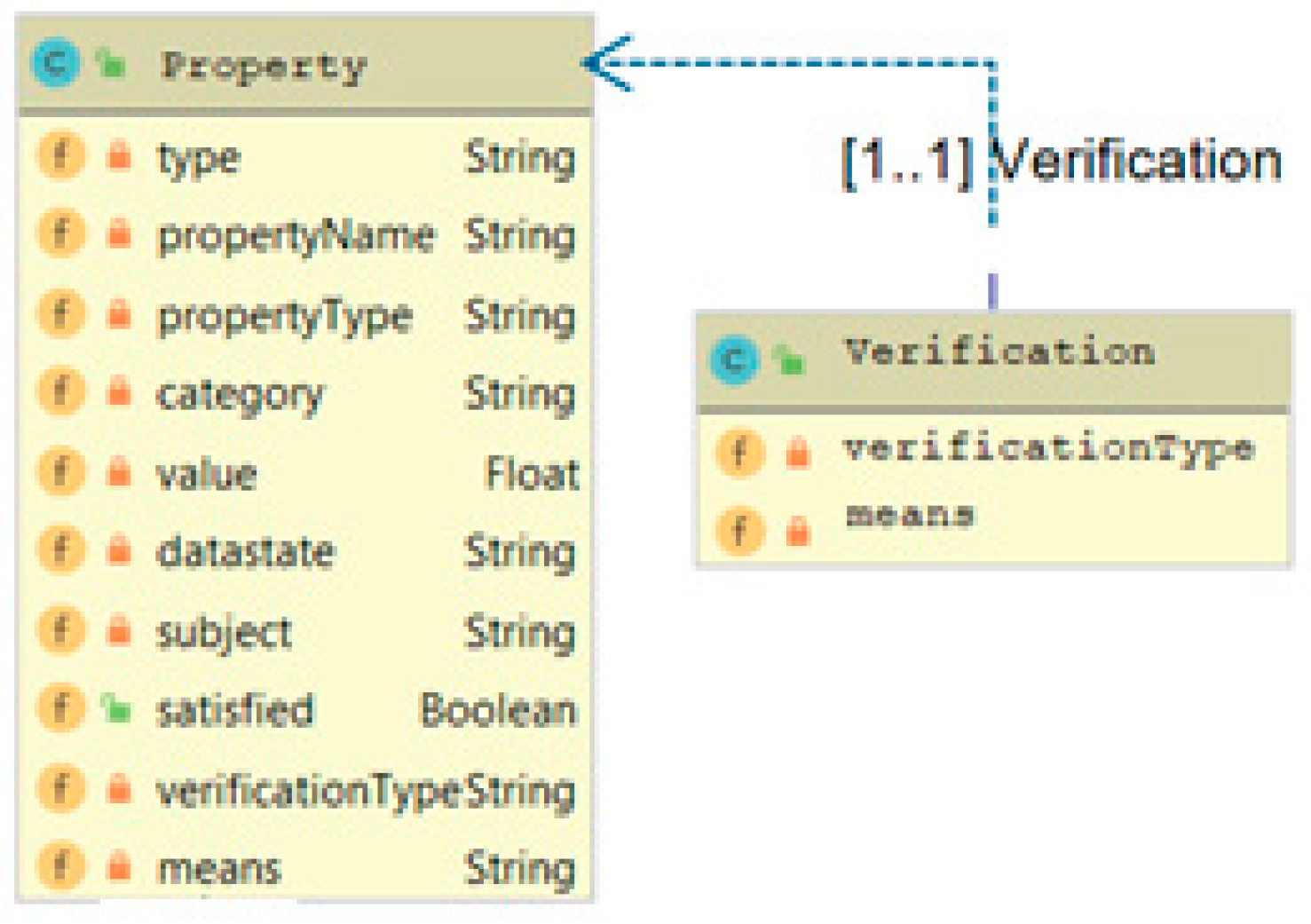
- The Activity Properties (AP) part that represents the SPDI properties of the individual placeholders of a system/orchestration.
- The Orchestration (ORCH) part that represents the abstract form of the orchestration that the pattern applies to.
- The Conditions part that describes requirements, constraints, and reactions of the system/orchestration to specific inputs.
- The Orchestration Properties (OP) part that represents the orchestration-level SPDI properties that the pattern can guarantee for the orchestration specified in the ORCH part.
- rule “Dependability Pattern”
- when
- Placeholder($sensor1:=placeholderid)
- Placeholder($sensor2:=placeholderid)
- Merge($merge1:=placeholderid,$sensor1:=placeholdera,$sensor2:=placeholderb)
- $PR: Property ($merge1:=subject, category==“Dependability”, satisfied==false)
- then
- Property s1Property = new Property();
- s1Property.setCategory(“Reliability”);
- s1Property.setSubject($merge1);
- s1Property.setSatisfied(false);
- insert(s1Property);
- Property s2Property = new Property();
- s2Property.setCategory(“FaultTolerance”);
- s2Property.setSubject($merge1);
- s2Property.setSatisfied(false);
- insert(s2Property);
- Property s3Property = new Property();
- s3Property.setCategory(“Safety”);
- s3Property.setSubject($merge1);
- s3Property.setSatisfied(false);
- insert(s3Property);
- end
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Full View of Pattern Collection Graph
References
- Tawalbeh, L.A.; Muheidat, F.; Tawalbeh, M.; Quwaider, M. IoT Privacy and security: Challenges and solutions. Appl. Sci. 2020, 10, 4102. [Google Scholar] [CrossRef]
- Botta, A.; De Donato, W.; Persico, V.; Pescapé, A. Integration of cloud computing and internet of things: A survey. In Future Generation Computer Systems; Elsevier: Amsterdam, The Netherlands, 2016; Volume 56, pp. 684–700. [Google Scholar]
- Alaba, F.A.; Othman, M.; Hashem, I.A.T.; Alotaibi, F. Internet of Things security: A survey. J. Netw. Comput. Appl. 2017, 88, 10–28. [Google Scholar] [CrossRef]
- Khan, M.A.; Salah, K. IoT security: Review, blockchain solutions, and open challenges. Future Gener. Comput. Syst. 2018, 82, 395–411. [Google Scholar] [CrossRef]
- Petroulakis, N.; Lakka, E.; Sakic, E.; Kulkarni, V.; Fysarakis, K.; Somarakis, I.; Serra, J.; Sanabria-Russo, L.; Pau, D.; Falchetto, M.; et al. SEMIoTICS Architectural Framework: End-to-end Security, Connectivity and Interoperability for Industrial IoT; Global IoT Summit (GIoTS’19): Aarhus, Denmark, 2019. [Google Scholar]
- Abowd, G.D.; Allen, R.; Garlan, D. Formalizing style to understand descriptions of software architecture. ACM Trans. Softw. Eng. Methodol. TOSEM 1995, 4, 319–364. [Google Scholar] [CrossRef]
- Schumacher, M. Security Engineering with Patterns: Origins, Theoretical Models, and New Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; p. 2754. [Google Scholar]
- Alexander, C. The Timeless Way of Building; Oxford University Press: Oxford, UK, 1979. [Google Scholar] [CrossRef]
- Fysarakis, K.; Papoutsakis, M.; Petroulakis, N.; Spanoudakis, G. Towards IoT Orchestrations with Security, Privacy, Dependability and Interoperability Guarantees. In Proceedings of the IEEE Global Communications Conference (GLOBECOM 2019), Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar]
- Fysarakis, K.; Spanoudakis, G.; Petroulakis, N.; Soultatos, O.; Bröring, A.; Marktscheffel, T. Architectural Patterns for Secure IoT Orchestrations; Global IoT Summit (GIoTS): Aarhus, Denmark, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Soultatos, O.; Papoutsakis, M.; Fysarakis, K.; Hatzivasilis, G.; Michalodimitrakis, M.; Spanoudakis, G.; Ioannidis, S. Pattern-driven Security, Privacy, Dependability and Interoperability management of IoT environments. In Proceedings of the 24th IEEE International Workshop on Computer-Aided Modeling Analysis and Design of Communication Links and Networks (CAMAD 2019), Limassol, Cyprus, 11–13 September 2019. [Google Scholar]
- Hafiz, M.; Adamczyk, P.; Johnson, R.E. Towards an Organization of Security Patterns. IEEE Softw. Spec. Issue Softw. Patterns 2007, 24, 52–60. [Google Scholar]
- Steel, C.; Nagappan, R.; Lai, R. Core Security Patterns: Best Practices and Strategies for J2EE(TM), Web Services, and Identity Management; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Schumacher, M.; Fernandez-Buglioni, E.; Hybertson, D.; Buschmann, F.; Sommerlad, P. Security Patterns: Integrating Security and Systems Engineering; John Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Kienzle, D.M.; Elder, M.C.; Tyree, D.; Edwards-Hewitt, J. Security Patterns Repository Version 1.0; DARPA: Washington, DC, USA, 2002. [Google Scholar]
- Hogg, J.; Smith, D.; Chong, F.; Taylor, D.; Wall, L.; Slater, P. Web Service Security: Scenarios, Patterns, and Implementation Guidance for Web Services Enhancements (WSE) 3.0; Microsoft Press: Redmond, WA, USA, 2006. [Google Scholar]
- Lenhard, J.; Fritsch, L.; Herold, S. A Literature Study on Privacy Patterns Research. In Proceedings of the 43rd Euromicro Conference on Software Engineering and Advanced Applications (SEAA), Vienna, Austria, 30 August–1 September 2017; pp. 194–201. [Google Scholar] [CrossRef]
- Gabel, A.; Schiering, I. Privacy Patterns for Pseudonymity. IFIP Adv. Inf. Commun. Technol. 2019, 155–172. [Google Scholar]
- Chung, E.S.; Hong, J.I.; James, L.; Prabaker, M.K.; Landay, J.A.; Liu, A.L. Development and evaluation of emerging design patterns for ubiquitous computing. In Proceedings of the 5th conference on Designing interactive systems: Processes, practices, methods, and techniques, Cambridge, MA, USA, 1–4 August 2004; pp. 233–242. [Google Scholar] [CrossRef]
- Hafiz, M. A collection of privacy design patterns. In Proceedings of the 2006 conference on Pattern languages of programs—PLoP ‘06, Portland, OR, USA, 21–23 October 2006; p. 1. [Google Scholar] [CrossRef] [Green Version]
- Hafiz, M. A pattern language for developing privacy enhancing technologies. Softw. Pract. Exp. 2013, 43, 769–787. [Google Scholar] [CrossRef]
- Drozd, O. Privacy pattern catalogue: A tool for integrating privacy principles of ISO/IEC 29100 into the software development process. In IFIP International Summer School on Privacy and Identity Management; Springer: Cham, Switzerland, 2015; pp. 129–140. [Google Scholar]
- Schümmer, T. The public privacy—Patterns for filtering personal information in collaborative systems. Proc. CHI Work Hum. Comput. Hum. Interact. Patterns 2004, 1963, 1–35. [Google Scholar]
- Schumacher, M. Security Patterns and Security Standards—With Selected Security Patterns for Anonymity and Privacy. In Proceedings of the European Conference on Pattern Languages of Programms (EuroPLoP ’2003), Irsee, Germany, 25–29 June 2003. [Google Scholar]
- Graf, C.; Wolkerstorfer, P.; Geven, A.; Tscheligi, M. A Pattern Collection for Privacy Enhancing Technology. In Proceedings of the Second International Conference on Pervasive Patterns and Applications, Lisbon, Portugal, 21–26 November 2010. [Google Scholar]
- ISO/IEC 29100:2011. Information Technology—Security Techniques—Privacy Framework. 2011. Available online: https://www.iso.org/obp/ui/#iso:std:iso-iec:29100:ed-1:v1:en (accessed on 2 December 2020).
- Stallings, W.; Brown, L.; Bauer, M.D.; Bhattacharjee, A.K. Computer security: Principles and practice. In Upper Saddle River; Pearson Education: Upper Saddle River, NJ, USA, 2012; p. 978. [Google Scholar]
- Ritter, D.; Rinderle-Ma, S. Towards a Collection of Cloud Integration Patterns. arXiv 2015, arXiv:1511.09250. [Google Scholar]
- ISO/IEC 15408-2:2008. Information Technology—Security Techniques—Evaluation Criteria for IT Security—Part 2: Security Functional Components; ISO: Geneva, Switzerland, 2008. [Google Scholar]
- Denning, D.E. A lattice model of secure information flow. Commun. ACM 1976, 19, 236–243. [Google Scholar] [CrossRef]
- Ahituv, N.; Lapid, Y.; Neumann, S. Processing encrypted data. Commun. ACM 1987, 30, 777–780. [Google Scholar] [CrossRef] [Green Version]
- Ding, W.; Yan, Z.; Deng, R.H. Encrypted data processing with Homomorphic Re-Encryption. Inf. Sci. 2017, 409–410, 35–55. [Google Scholar] [CrossRef]
- Lindell, Y. Secure multiparty computation for privacy preserving data mining. In Encyclopedia of Data Warehousing and Mining; IGI Global: Hershey, PA, USA, 2005; pp. 1005–1009. [Google Scholar]
- Bogetoft, P.; Christensen, D.L.; Damgård, I.; Geisler, M.; Jakobsen, T.; Krøigaard, M.; Toft, T. Secure multiparty computation goes live. In Proceedings of the International Conference on Financial Cryptography and Data Security; Springer: Berlin, Heidelberg; pp. 325–343.
- Cohen, F.; Lambert, D.; Preston, C.; Berry, N.; Stewart, C.; Thomas, E. A framework for deception. In National Security Issues in Science, Law, and Technology; Taylor and Francis: London, UK, 2001. [Google Scholar]
- Albanese, M.; Erbacher, R.F.; Jajodia, S.; Molinaro, C.; Persia, F.; Picariello, A.; Subrahmanian, V.S. Recognizing unexplained behavior in network traffic. In Network Science and Cybersecurity; Springer: New York, NY, USA, 2014; pp. 39–62. [Google Scholar]
- Avizienis, A.; Laprie, J.C.; Randell, B. Fundamental Concepts of Dependability. LAAS-CNRS: Tech. Rep. N01145. 2001. Available online: http://www.cs.cmu.edu/~garlan/17811/Readings/avizienis01_fund_concp_depend.pdf (accessed on 2 December 2020).
- Ahluwalia, K.S.; Jain, A. High availability design patterns. In Proceedings of the 2006 Conference on Pattern Languages of Programs—PLoP ‘06, Portland, OR, USA, 21–23 October 2006; p. 1. [Google Scholar] [CrossRef] [Green Version]
- Thatcher, J.; Flynn, D.; Aune, J.; Fillingim, J.; Inskeep, B.; Strasser, J.; Vigor, K. U.S. Patent No. 8,281,227, 2012. Available online: https://www.uspto.gov/web/offices/com/sol/og/2012/week33/TOC.htm (accessed on 2 December 2020).
- Erl, T.; Cope, R.; Naserpour, A. Cloud Computing Design Patterns; Prentice Hall Press: Upper Saddle River, NJ, USA, 2015. [Google Scholar]
- Gardiner, J.L.; Heider, G.K.; Emlich, L.W.; Luhrs, B.H.; Li, M.C.; Masters, M.R.; Seger, M.J. Apparatus, System, and Method to Increase Data Integrity in a Redundant Storage System. U.S. Patent No. 5,740,357, 2 October 2012. [Google Scholar]
- Gürer, D.W.; Khan, I.; Ogier, R.; Keffer, R. An artificial intelligence approach to network fault management. Sri Int. 1996, 86, 1–10. [Google Scholar]
- Paradis, L.; Han, Q. A survey of fault management in wireless sensor networks. J. Netw. Syst. Manag. 2007, 15, 171–190. [Google Scholar] [CrossRef]
- Dos Santos, A.L.; Duarte, E.P.; Keeni, G.M. Reliable distributed network management by replication. J. Netw. Syst. Manag. 2004, 12, 191–213. [Google Scholar] [CrossRef]
- Du, X. Identifying control and management plane poison message failure by k-nearest neighbor method. J. Netw. Syst. Manag. 2006, 14, 243–259. [Google Scholar] [CrossRef]
- Hong, J.W.; Park, S.; Kang, Y.; Park, J. Enterprise network traffic monitoring, analysis, and reporting using web technology. J. Netw. Syst. Manag. 2001, 9, 89–111. [Google Scholar] [CrossRef]
- Lutfiyya, H.L.; Bauer, M.A.; Marshall, A.D.; Stokes, D.K. Fault management in distributed systems: A policy-driven approach. J. Netw. Syst. Manag. 2000, 8, 499–525. [Google Scholar] [CrossRef]
- ISO/IEC 27000:2018. Information Technology—Security Techniques—Information Security Management Systems—Overview and Vocabulary; ISO: Geneva, Switzerland, 2018. [Google Scholar]
- Diamantopoulou, V.; Argyropoulos, N.; Kalloniatis, C.; Gritzalis, S. Supporting the design of privacy-aware business processes via privacy process patterns. In Proceedings of the International Conference on Research Challenges in Information Science, Brighton, UK, 10–12 May 2017. [Google Scholar] [CrossRef] [Green Version]
- Rantos, K.; Papanikolaou, A.; Fysarakis, K.; Manifavas, C. Secure policy-based management solutions in heterogeneous embedded systems networks. In Proceedings of the International Conference on Telecommunications and Multimedia (TEMU), Heraklion, Crete, Greece, 30 July–1 August 2012; pp. 227–232. [Google Scholar] [CrossRef]
- Zakinthinos, A.; Lee, E.S. A general theory of security properties. In Proceedings of the Proceedings. 1997 IEEE Symposium on Security and Privacy (Cat. No.97CB36097), Oakland, CA, USA, 4–7 May 1997; pp. 94–102. [Google Scholar] [CrossRef]
- X.509 Digital Certification—Microsoft. Available online: https://docs.microsoft.com/en-us/windows/win32/seccrypto/x-509-digital-certification (accessed on 10 December 2020).
- Kerberos Authentication Overview—Microsoft. Available online: https://docs.microsoft.com/en-us/windows-server/security/kerberos/kerberos-authentication-overview (accessed on 10 December 2020).
- Durand, A.; Andreaux, J.P.; Sirvent, T. Vague Feelings or An MBA Framework Fact? U.S. Patent No. 7,545,932, 9 June 2009. [Google Scholar]
- Two-Way Authentication—IBM. Available online: https://www.ibm.com/support/knowledgecenter/SSRMWJ_7.0.1/com.ibm.isim.doc/securing/cpt/cpt_ic_security_ssl_scenario.htm (accessed on 1 December 2020).
- European Union. Regulation 2016/679 of the European parliament and the Council of the European Union. Off. J. Eur. Communities 1995, 2014, 1–88. [Google Scholar]
- Maidi, M. The common fragment of CTL and LTL. Found. Comput. Sci. 2000, 643–652. [Google Scholar] [CrossRef]
- Pfitzmann, A.; Hansen, M. A terminology for talking about privacy by data minimization: Anonymity, Unlinkability, Undetectability, Unobservability, Pseudonymity, and Identity Management. Tech. Univ. Dresden 2010. [Google Scholar]
- Caiza, J.C.; Martín, Y.S.; Del Alamo, J.M.; Guamán, D.S. Organizing design patterns for privacy: A taxonomy of types of relationships. In ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Kalloniatis, C.; Kavakli, E.; Gritzalis, S. Addressing privacy requirements in system design: The PriS method. Requir. Eng. 2008, 13, 241–255. [Google Scholar] [CrossRef]
- Kuhn, C.; Beck, M.; Schiffner, S.; Jorswieck, E.; Strufe, T. On Privacy Notions in Anonymous Communication. Proc. Priv. Enhancing Technol. 2019, 2019, 105–125. [Google Scholar] [CrossRef] [Green Version]
- Van Blarkom, G.W.; Borking, J.J.; Olk, J.G.E. Handbook of Privacy and Privacy-Enhancing Technologies The case of Intelligent Software Agents. Priv. Inc. Softw. Agent PISA Consort. Hague 2003, 198, 14. [Google Scholar]
- Commission of the European Communities. Communication from the Commission to the European Parliament and the Council on Promoting Data Protection by Privacy Enhancing Technologies (PETs). COM 2007 228 Final 2007. Available online: https://eur-lex.europa.eu/legal-content/EN/LSU/?uri=CELEX%3A52007DC0228 (accessed on 2 December 2020).
- Pfitzmann, A.; Waidner, M. Networks without user observability. Comput. Secur. 1987, 6, 158–166. [Google Scholar] [CrossRef]
- Pfitzmann, A. Diensteintegrierende Kommunikationsnetze mit teilnehmerüberprüfbarem Datenschutz. In Informatik-Fachberichte 234; Springer: Berlin/Heidelberg, Germany, 1990. [Google Scholar]
- Fischer-Hübner, S. IT-Security and Privacy: Design and Use of Privacy-Enhancing Security Mechanisms; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Chaum, D.L. Untraceable electronic mail, return addresses, and digital pseudonyms. Commun. ACM 1981, 24, 84–90. [Google Scholar] [CrossRef]
- Chaum, D.L. The dining cryptographers problem: Unconditional sender and recipient untraceability. J. Cryptol. 1998, 1, 65–75. [Google Scholar] [CrossRef] [Green Version]
- Goldschlag, D.; Reed, M.; Syverson, P. Onion routing. Commun. ACM 1999, 42, 39–41. [Google Scholar] [CrossRef]
- Dingledine, R.; Mathewson, N.; Syverson, P. Tor: The second-generation onion router. In Proceedings of the 13th USENIX Security Symposium, San Diego, CA, USA, 9–13 August 2004. [Google Scholar]
- Sweeney, L. k-Anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. ℓ-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data 2007. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 11–15 April 2007; pp. 106–115. [Google Scholar] [CrossRef] [Green Version]
- Fysarakis, K.; Manifavas, C.; Papaefstathiou, I.; Adamopoulos, A. A lightweight anonymity and location privacy service. IEEE Int. Symp. Signal Process. Inf. Technol. 2013, 000124–000129. [Google Scholar] [CrossRef]
- Majeed, A. Attribute-centric anonymization scheme for improving user privacy and utility of publishing e-health data. J. King Saud Univ. Comput. Inf. Sci. 2019, 31.4, 426–435. [Google Scholar] [CrossRef]
- Majeed, A.; Sungchang, L. Anonymization Techniques for Privacy Preserving Data Publishing: A Comprehensive Survey. IEEE Access. 2020, 9, 8512–8545. [Google Scholar] [CrossRef]
- Common Criteria. Common Criteria for Information Technology Security Evaluation—Part 2: Security Functional Components. Version 3.1 Rev. 5; ISO/IEC: New York, NY, USA, 2017. [Google Scholar]
- Pfitzmann, A.; Kohntopp, M. Anonymity, unobservability, and pseudonymity—A proposal for terminology. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar] [CrossRef]
- Provos, N.; Honeyman, P. Hide and seek: An introduction to steganography. IEEE Secur. Priv. 2003, 1, 32–44. [Google Scholar] [CrossRef] [Green Version]
- Nutzinger, M.; Fabian, C.; Marschalek, M. Secure Hybrid Spread Spectrum System for Steganography in Auditive Media. In Sixth International Conference on Intelligent Information Hiding and Multimedia Signal Processing; IEEE: New York, NY, USA, 2010; pp. 78–81. [Google Scholar] [CrossRef]
- Korzhik, V.; Morales-Luna, G.; Loban, K.; Marakova-Begoc, I. Undetectable spread-time stegosystem based on noisy channels. In Proceedings of the International Multiconference on Computer Science and Information Technology, Wisła, Poland, 18–20 October 2008; pp. 723–728. [Google Scholar] [CrossRef]
- Chakraborty, T.; Jajodia, S.; Katz, J.; Picariello, A.; Sperli, G.; Subrahmanian, V.S. FORGE: A fake online repository generation engine for cyber deception. IEEE Trans. Dependable Secur. Comput. 2019. [Google Scholar] [CrossRef]
- Chaum, D. Security without identification: Transaction systems to make big brother obsolete. Commun. ACM 1985, 28, 1030–1044. [Google Scholar] [CrossRef]
- Chaum, D. Showing credentials without identification transferring signatures between unconditionally unlinkable pseudonyms. In Advances in Cryptology—AUSCRYPT; Springer: Berlin/Heidelberg, Germany, 1990; pp. 245–264. [Google Scholar]
- Danezis, G.; Dingledine, R.; Mathewson, N. Mixminion: Design of a type III anonymous remailer protocol. IEEE Symp. Secur. Priv. 2003. [Google Scholar] [CrossRef]
- Camenisch, J.; Van Herreweghen, E. Design and implementation of the idemix anonymous credential system. In Proceedings of the ACM Conference on Computer and Communications Security, Washington, DC, USA, 18–22 November 2002. [Google Scholar] [CrossRef]
- Mulvenna, M.D.; Anand, S.S.; Büchner, A.G. Personalization on the Net using Web mining: Introduction. Commun. ACM 2000, 43, 122–125. [Google Scholar] [CrossRef]
- Zöllner, J.; Federrath, H.; Pfitzmann, A.; Westfeld, A.; Wicke, G.; Wolf, G. Über die Modellierung steganographischer Systeme. In Proceedings GIFachtagung ‘Verlässliche Informationssysteme’ VIS’; Müller, G., Rannenberg, K., Reitenspieß, M., Stiegler, H., Eds.; Vieweg-Verlag: Freiburg, Germany, 1997; p. 30.9.-2.10.97. [Google Scholar]
- Fiaschetti, A.; Noll, J.; Azzoni, P.; Uribeetxeberria, R. (Eds.) Measurable and Composable Security, Privacy, and Dependability for Cyberphysical Systems: The SHIELD Methodology; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Spanoudakis, G.; Kokolakis, S. (Eds.) Security and Dependability for Ambient Intelligence; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar] [CrossRef]
- Laprie, J.C. Dependability: Basic Concepts and Terminology; Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Hatzivasilis, G.; Askoxylakis, I.; Anicic, D.; Broring, A.; Kulkarni, V.; Fysarakis, K.; Spanoudakis, G. The Interoperability of Things: Interoperable solutions as an enabler for IoT and Web 3.0. In Proceedings of the 2018 IEEE 23rd International Workshop on Computer Aided Modeling and Design of Communication Links and Networks (CAMAD), Barcelona, Spain, 17–19 September 2018; pp. 1–7. [Google Scholar]
- Papoutsakis, M.; Fysarakis, K.; Mixalodimitrakis, E.; Lakka, E.; Petroulakis, N.; Spanoudakis, G.; Ioannidis, S. A Pattern–Driven Adaptation in IoT Orchestrations to Guarantee SPDI Properties. In International Workshop on Model-Driven Simulation and Training Environments for Cybersecurity; Springer: Cham, Switzerland, 2020; pp. 143–156. [Google Scholar]
- Forgy, C. Rete: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem. Artif. Intell. 1982, 19, 17–37. [Google Scholar] [CrossRef]
- Bröring, A.; Seeger, J.; Papoutsakis, M.; Fysarakis, K.; Caracalli, A. Networking-Aware IoT Application Development. Sensors 2020, 20, 897. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pattern | Property | Data State Coverage | Platform Connectivity | Concept or Pattern Source | |||||
|---|---|---|---|---|---|---|---|---|---|
| S | P | In Transit | At Rest | In Processing | Within | Across | |||
| # | Name | ||||||||
| 1 | Overall Security | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Known concept | |
| 2 | Overall Confidentiality | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Ritter et al. [28] |
| 3 | Encrypted Storage | ✓ | ✓ | ✓ | ✓ | Kienzle et al. [15] | |||
| 4 | Encrypted Channels | ✓ | ✓ | ✓ | ✓ | ✓ | Schumacher et al. [14] | ||
| 5 | Encrypted Processing | ✓ | ✓ | ✓ | ✓ | Ahituv et al. [31] | |||
| 6 | Overall Integrity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Ritter et al. [28] |
| 7 | Safe Storage | ✓ | ✓ | ✓ | ✓ | Ritter et al. [28] | |||
| 8 | Safe Channel | ✓ | ✓ | ✓ | ✓ | ✓ | Ritter et al. [28] | ||
| 9 | Safe Processing | ✓ | ✓ | ✓ | ✓ | Ritter et al. [28] | |||
| 10 | Hash Check | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | known concept |
| 11 | Server Sandbox | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Kienzle et al. [15] | |
| 12 | Minefield | ✓ | ✓ | ✓ | ✓ | ✓ | Kienzle et al. [15] | ||
| 13 | Overall Availability | ✓ | ✓ | ✓ | ✓ | ✓ | Avizienis et al. [37] | ||
| 14 | Uptime | ✓ | ✓ | ✓ | ✓ | ✓ | Known concept | ||
| 15 | Redundant Storage | ✓ | ✓ | ✓ | ✓ | Erl et al. [40] | |||
| 16 | Fault Management | ✓ | ✓ | ✓ | ✓ | ✓ | Known concept | ||
| 17 | Non-repudiation/Auditability/Accountability | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Ritter et al. [28] |
| 18 | Signed Message | ✓ | ✓ | ✓ | ✓ | ✓ | Ritter et al. [28] | ||
| 19 | Audit Log | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Kienzle et al. [15] | |
| 20 | Overall Authorization | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Schumacher et al. [14] |
| 21 | Single Access | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Schumacher et al. [14] |
| 22 | Authorization Enforcer | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Schumacher et al. [14] | |
| 23 | Overall Authentication | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Schumacher et al. [14] |
| 24 | Authentication Enforcer | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Schumacher et al. [14] |
| 25 | Authenticated Channel | ✓ | ✓ | ✓ | ✓ | ✓ | Durand et al. [54] | ||
| 26 | Account Lockout | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Kienzle et al. [15] |
| 27 | Authenticated Session | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Kienzle et al. [15] | |
| 28 | Blacklist | ✓ | ✓ | ✓ | ✓ | ✓ | Kienzle et al. [15] | ||
| 29 | Overall Privacy | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Pfitzmann et al. [58] | |
| 30 | Mix Network | ✓ | ✓ | ✓ | M. Hafiz [21] and S. Fischer-Hübner [66] | ||||
| 31 | Pseudonymity | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Diamantopoulou et al. [49] | |
| 32 | Identity Protector | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | S. Fischer-Hübner [66] | |
| 33 | Unlinkability | ✓ | ✓ | ✓ | ✓ | S. Fischer-Hübner [66] | |||
| 34 | Cover Traffic | ✓ | ✓ | ✓ | ✓ | M. Hafiz [21] | |||
| 35 | Undetectability | ✓ | ✓ | ✓ | ✓ | Diamantopoulou et al. [49] | |||
| 36 | Steganography | ✓ | ✓ | ✓ | ✓ | Zöllner et al. [88] and S. Fischer-Hübner [66] | |||
| 37 | Unobservability | ✓ | ✓ | ✓ | ✓ | ✓ | Pfitzmann et al. [58] and Diamantopoulou et al. [49] | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papoutsakis, M.; Fysarakis, K.; Spanoudakis, G.; Ioannidis, S.; Koloutsou, K. Towards a Collection of Security and Privacy Patterns. Appl. Sci. 2021, 11, 1396. https://doi.org/10.3390/app11041396
Papoutsakis M, Fysarakis K, Spanoudakis G, Ioannidis S, Koloutsou K. Towards a Collection of Security and Privacy Patterns. Applied Sciences. 2021; 11(4):1396. https://doi.org/10.3390/app11041396
Chicago/Turabian StylePapoutsakis, Manos, Konstantinos Fysarakis, George Spanoudakis, Sotiris Ioannidis, and Konstantina Koloutsou. 2021. "Towards a Collection of Security and Privacy Patterns" Applied Sciences 11, no. 4: 1396. https://doi.org/10.3390/app11041396
APA StylePapoutsakis, M., Fysarakis, K., Spanoudakis, G., Ioannidis, S., & Koloutsou, K. (2021). Towards a Collection of Security and Privacy Patterns. Applied Sciences, 11(4), 1396. https://doi.org/10.3390/app11041396