4.1. Discussion on the Experimental Results
The results of the first analysis for the experiments using univariate multiple linear regression found that the correlation between the differential measured weights (experimenter’s weight + heavy object weight: 5–20kg) and the corresponding sensing values (only ASUM data were used) were insufficient because the degree to which the independent variable explains the dependent variable is somewhat low. As shown in
Table 4, the
R2 values of experimenter E and experimenter C were relatively low at 24.5% and 29.3%, respectively, and the
R2 value of experimenter A was 42.2%, which almost approaches the total average of 46.4%. On the other hand, the
R2 values of experimenter D and experimenter B were relatively higher at 69.3% and 66.9%, respectively. As shown in the scatter plots in
Table 3, the reason why the regression results are not so clearly explained is due to the wide and overlapping distribution of sensor ASUM values measured for each weight. This can be said to be a result of various factors, such as the behavioral characteristics of each experimenter, their posture, shoe size, as well as the grounding status of the sensor-attached insole, all of which affect sensitive sensor values. Therefore, an effective analysis method is required to monitor the actual weight lifted by construction workers using the FSR sensing data. First, we tested the analysis method adopting logistic and linear regression classification algorithms that are conventionally used. The test results are shown in
Table 6. The accuracy of classifying weight by logistic regression analysis (77.1%) was found to be somewhat higher than that of weight classification by linear regression analysis (46.5%). However, it was confirmed that the accuracy of the analysis using these two classification algorithms was not satisfactory enough to distinguish the actual weight of the object carried by the experimenter after analyzing the FSR sensing data values.
Therefore, this research study has developed a ML-based classification analysis model using Python. This model has been tested and developed by adopting the widely used classification algorithms, which includes decision tree, random forest, GBM, and light GBM. The accuracy of the test results using the ML-based analysis model is as shown in
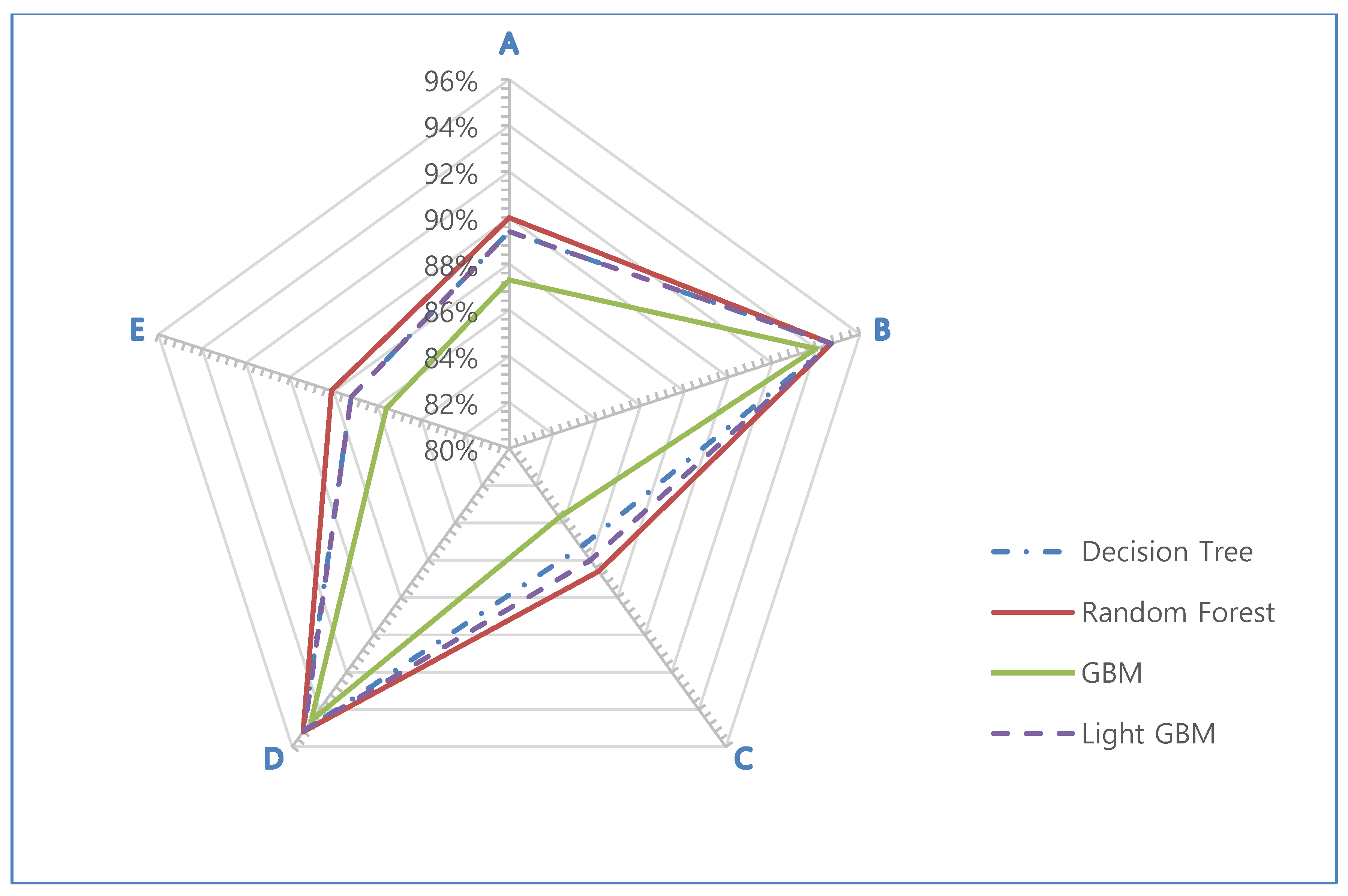
Table 7. In the case of experimenter C, who showed relatively low accuracy in weight estimation compared to the other experimenters, the average accuracy of estimation of applying the four classification algorithms was about 85.4%, and the average accuracy of experimenters B and D, which showed relatively high estimation accuracy, was 94.5% and 95.0%, respectively. In the case of experimenters A and E, who both showed medium accuracy, they had an average estimation accuracy of 89.0% and 87.0%, respectively. Therefore, the weight estimation accuracy according to all experimenters was confirmed to have an average of 90.2%, which corresponds to a relatively high and meaningful level of accuracy.
In addition, when looking at the classification accuracy of the weight lifted by each experimenter by each classification algorithm, the accuracy of the GBM classification algorithm for experimenter C is the lowest at 83.7%. On the other hand, it is found that the accuracy by decision tree and random forest for experimenter D is the highest at 95.2%. The average accuracy classifying the weight by each classification algorithm showed similar, but high accuracy in the following order as an experimental result: random forest (90.9%), light GBM (90.5%), decision tree (90.3%), and GBM (89%). This means that the developed ML-based analysis model can classify the actual weight of the object held by the experimenter with an average accuracy of 90% or more.
As described in
Section 2.3.2, this table shows the results of analysis with the sum of sensor values (LSUM, RSUM, ASUM) among the FSR sensing data measured when the experimenter is standing with a heavy object. This is the result of the experiments considering that it is common for construction workers to lift heavy objects with one or both hands while standing with their feet on the floor for a while. Of course, in some cases, pressure may not be applied evenly to both feet. Therefore, the data values measured from the left and right FSR sensors attached to both insoles may not be uniform. However, the sum of the pressure delivered to both feet can be said to be a result of direct reflection of the weight of the heavy object. Therefore, it is more reasonable to use the sum of pressure sensor values (LSUM, RSUM, or ASUM) obtained from the FSR sensors attached to both insoles to distinguish the weight the experimenter is holding.
However, it is effective to use the 14 channels of FSR sensing data values obtained from safety shoes in order to distinguish a moment when a construction worker lifts or unloads a heavy object from other moving actions.
Table 8 shows the results of classification analysis with four ML-based classification algorithms for distinguishing between the experimenter’s standing and moving act. In this analysis, all data obtained by the 14 channels of FSR sensors were utilized, since the purpose of the analysis is to classify the movement act of an experimenter from the standing act while lifting a heavy object. As shown in
Table 8, it is found that random forest has the highest accuracy, at 99%, among ML-based classification algorithms for distinguishing when an experimenter is moving and when the experimenter is standing still. It can be seen that the remaining classification algorithms also show high accuracy of over 97% on average. The result shows that it is not a problem for the algorithm to distinguish when a construction worker is lifting a heavy object.
4.2. Research Limitations and Further Studies
The result of this study shows only a prototype system that tracks the weight of heavy objects carried by construction workers using safety shoes with FSR sensors. The main scope of this study focuses mainly on determining whether construction workers lift heavy objects above the safety guidelines. In order to practically apply this system to construction sites, several limiting factors of this study should be improved through future studies from at least the following points of view. First, further research is needed on the durability of the sensor, the durability of the battery, and the convenience of wearing safety shoes under various construction work environments in order to practically use the safety shoes with FSR sensor. Second, continuous research efforts are needed to improve the accuracy of the weight tracking system. For this, experiments and analyzes need to be conducted under more diverse conditions, such as the different physical conditions of the construction workers, the grounding condition of the shoes, the use of other types of sensors, etc. Third, the experiment scenario adopted in this research was limited to 20 kg because the physical safety of the experimenter was considered. However, it may be necessary to keep analyzing the impact of various weights over 20 kg to see what those results can add to the study. Recently, the introduction of IT/ICT application technology has been newly attempted at construction sites, but the reality is that it is still insufficient. Therefore, this research result is expected to be one of the efforts to overcome this.





{kind=link}
{kind=link}
{kind=link}









