
A Multilayer Data Processing and Aggregating Fog-Based Framework for Latency-Sensitive IoT Services




Abstract
1. Introduction
2. Related Work
3. Design and Implementation
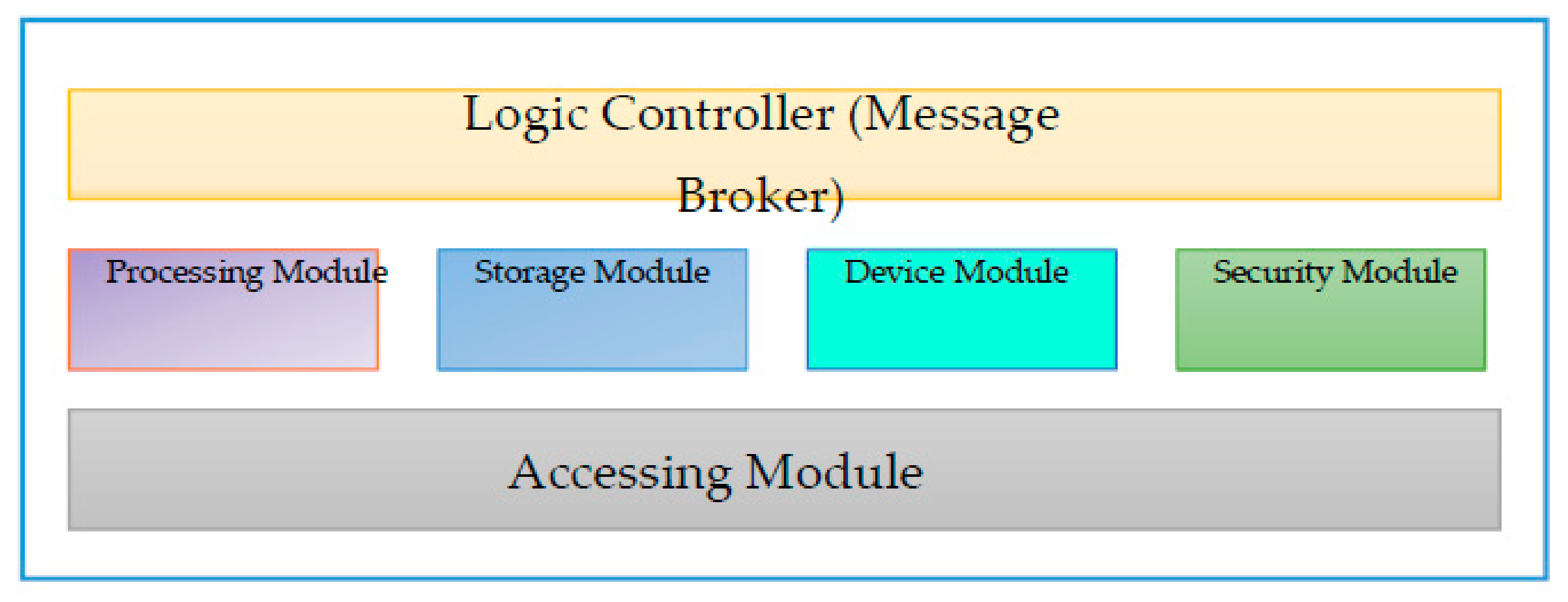
3.1. Overview
- Uploading data: data can be uploaded to the fog server and stored in the database. Data synchronization is enabled between the fog server and the cloud. Up-to-date data (i.e., newest data) will be stored in the fog server, while historical data will be stored in the cloud.
- Data query: clients can query the newest data from the fog server with a promised response time. Clients also can query the historical data from the cloud as data in the fog server will be synchronized with the cloud.
- Data Processing: the fog server supports data processing.
- Filtering data: with some configurations, data in the fog server will be synchronized with the cloud. For example, assume that the proposed CFC framework is utilized to provide a child abduction alert service (i.e., latency-sensitive and location awareness service). Users of the service have to configure and set the threshold of the fog server. The locations of parents and children will be uploaded to the fog server continuously. The fog server computes the distance between children and their parents to check whether there is a distance change or not (i.e., if distance increases over the configured threshold). An alert with the current location of the child will be sent to the parent by the fog server whenever the computed distance is over a user-defined threshold. Data will be synchronized to the cloud periodically; they will be filtered first and synchronized when the change is out of threshold to reduce the amount of data being transferred to the cloud and thus reducing the cloud overhead.
- Connection Aggregation: the fog server plays a key role in minimizing the number of concurrent cloud connections. Data from multiple clients will be aggregated and processed at the nearest fog node before being transferred to the cloud. The fog server aggregates data received from multiple clients’ nodes, usually placed on the same geographic region, in order to aggregate all data for a given geographic region before sending data to the cloud layer, which are potentially placed in a distant geographic region. Assume that there are 2000 devices connecting to the cloud directly. This situation requires 2000 concurrent cloud connections to be established. In contrast, with the proposed framework, connection aggregation is supported. The data of these 2000 devices will be aggregated and transferred to the cloud in only one connection.
- Authentication: the challenge–response protocol is employed to authenticate users by the fog server.
3.2. System Implementation
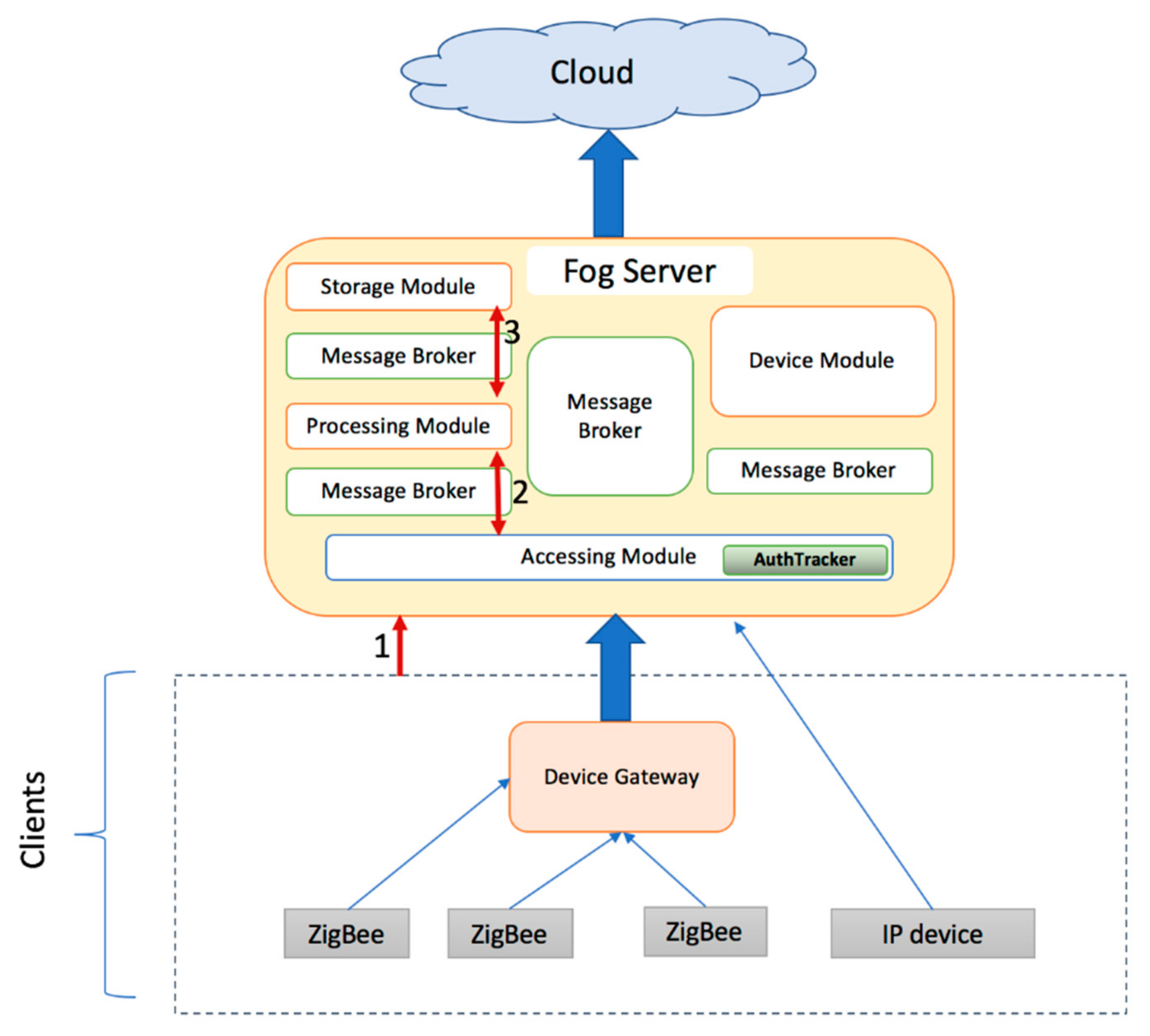
3.2.1. Device Gateway
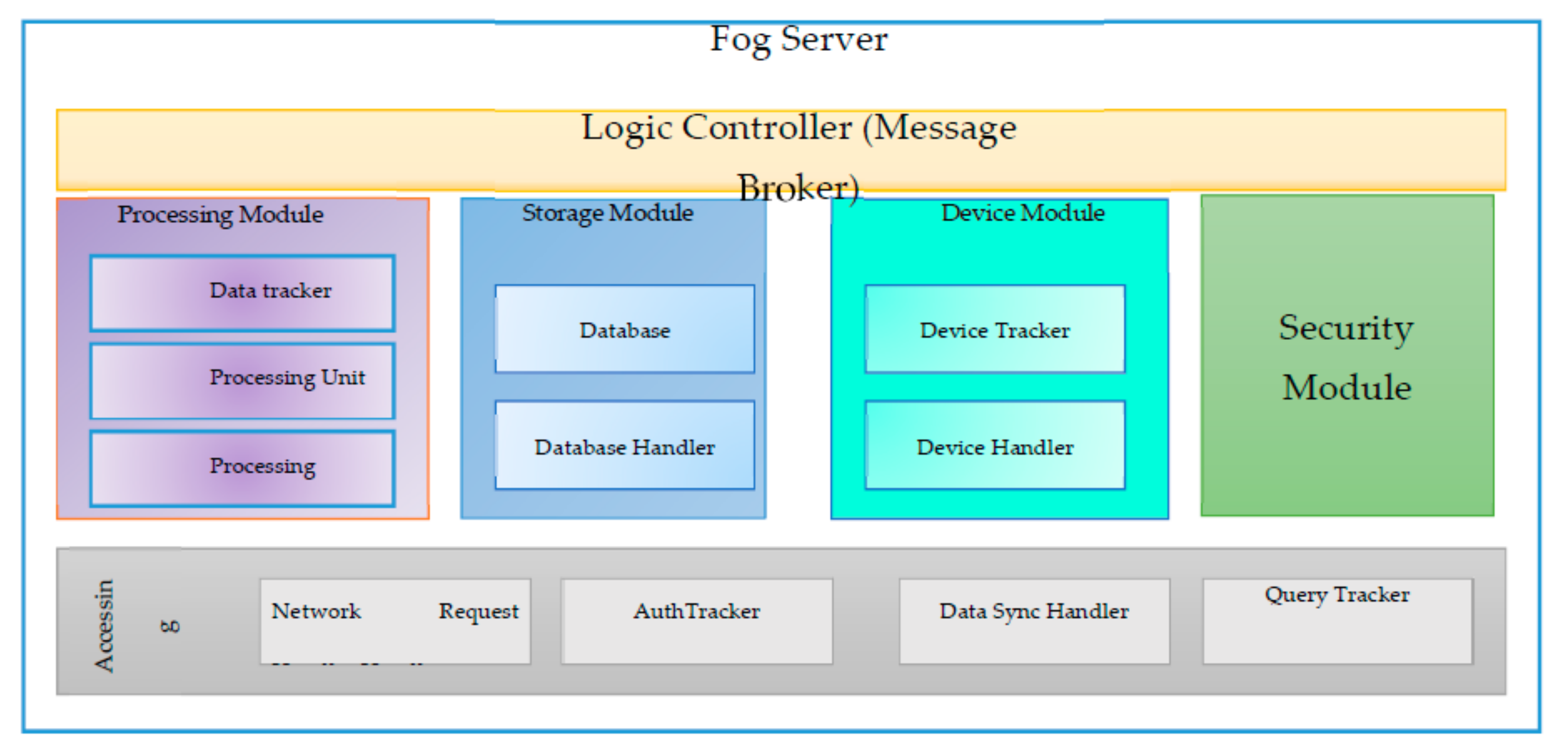
3.2.2. Fog Server
- Accessing Module
- Network Request Handler
- AuthTracker
- Data Sync Handler
- Query Tracker
- 2.
- Device Module
- Device Handler
- Device Tracker
- 3.
- Processing Module
- Processing Handler: It receives the transferred data from the accessing module.
- Processing Unit: It processes data and returns response when needed.
- Data Tracker: It filters data. Data Tracker has an in-memory object to store the newest data of every device that is connected with the fog server. Data will be relayed to the storage module periodically by a user defined period.
- 4.
- Storage Module
- DBHandler: It receives requests from the other modules and performs the corresponding operation according to the request types.
- Database: PostgreSQL is used as the database of the proposed fog server. PostgreSQL is a powerful object–relational database.
- 5.
- Security Module
- 6.
- Message broker
3.2.3. Cloud
4. Functions of the Fog Server in Details
4.1. Authentication
- A client sends a request to the fog server that will be authenticated first by the AuthTracker (quick authentication).
- As there is no authentication information stored for that client yet, the fog server sends the “need_auth” back to client.
- The authentication flow will be started in this step. The client sends the challenge that will be generated by the client to the fog server.
- After receiving the challenge, the device module of fog server will check the registration of the device first.
- If the registration information exists, the corresponding response will be calculated and sent back to the accessing module.
- While the accessing module receives the response, the device module will generate a ticket to be stored in the AuthTracker simultaneously.
- The response will be sent back to client.
- After the client receives the response, it will send the same request to fog server again and this request should be authenticated by AuthTracker as well. The quick authentication will be passed as AuthTracker already has stored the authentication information of that client.
4.2. Data Uploading
- A client sends “data upload” request to the fog server. To process the received request, the client has to pass the authentication process first (authentication steps are detailed in Section 4.1).
- Data will be sent from the accessing module to the processing module.
- The processing module will send the received data to the storage module to store.
4.3. Data Query
- A client sends a “data query” request to the fog server. To process the received request, the client has to pass the authentication process first (authentication steps are detailed in Section 4.1).
- The query tracker in the accessing module caches the newest data and sends a request to the database to retrieve all the newest data every second.
- Data are maintained in the accessing module. Consequently, when receiving a “data query” request, the response will be returned immediately without passing this through the message broker to the database.
4.4. Synchronization with Cloud
5. Experiment and Evaluation
5.1. Environment Setting
5.2. Experiment Setup
5.3. Experiment Design
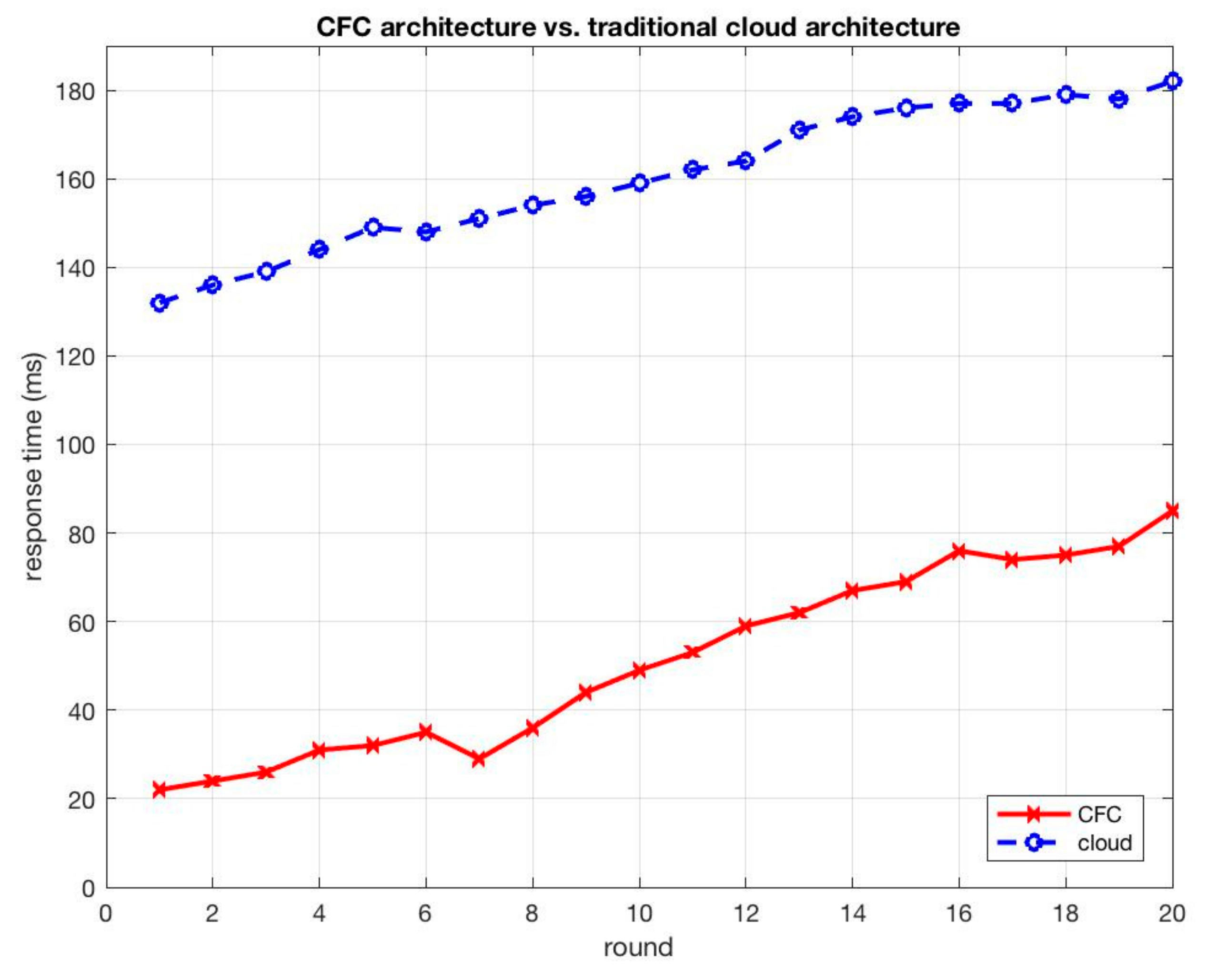
5.3.1. First Experiment: Query Newest Data
5.3.2. Second Experiment: Query Historical Data
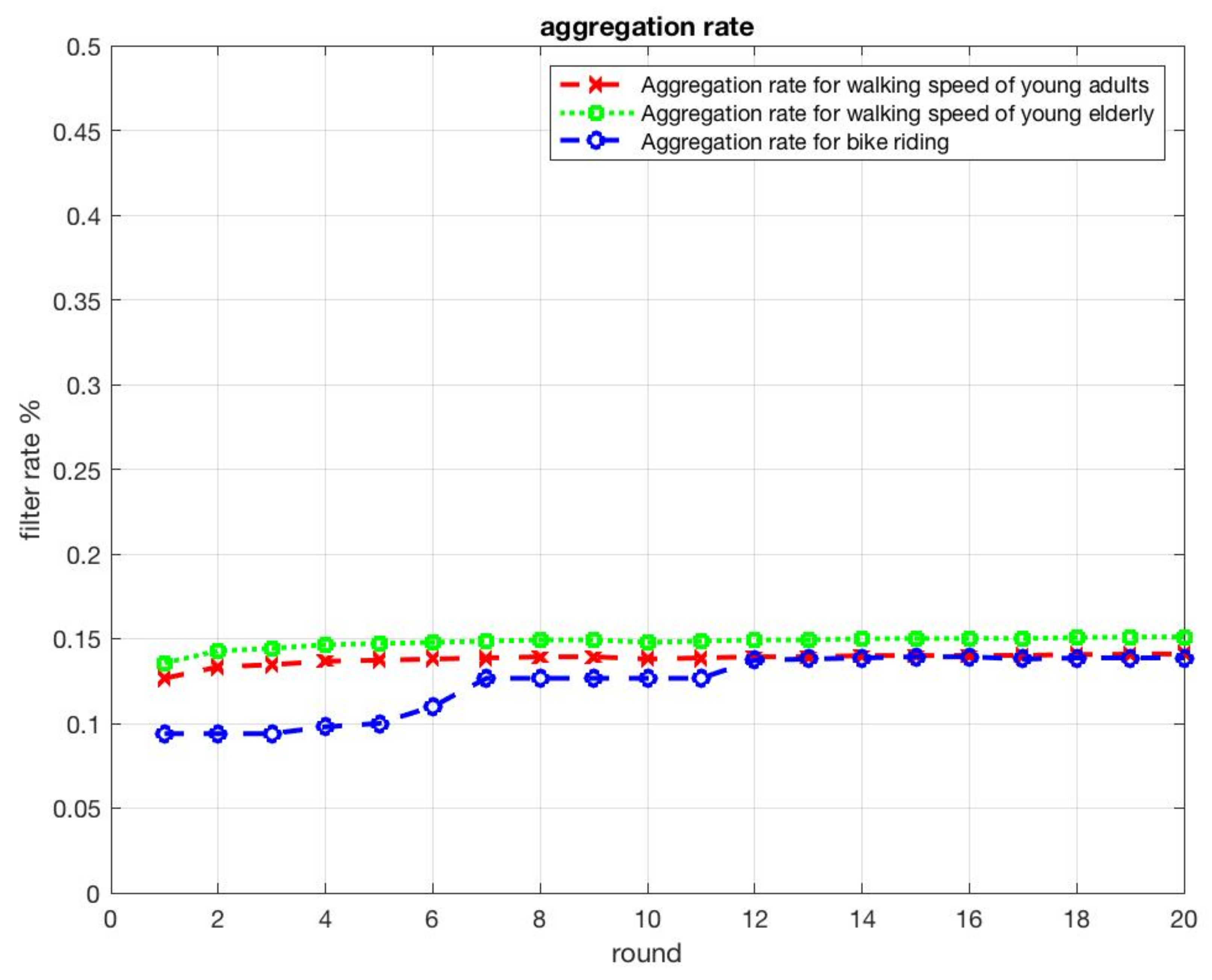
5.3.3. Third Experiment: Aggregation Rate
5.4. Results
5.4.1. First Experiment: Query Newest Data
5.4.2. Second Experiment: Query Historical Data
5.4.3. Third Experiment: Aggregation Rate
5.4.4. Additional Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hao, W.; Sun, G.; Muta, O.; Zhang, J.; Yang, S. Coordinated Hybrid Precoding Design in Millimeter Wave Fog-RAN. IEEE Syst. J. 2020, 14, 673–676. [Google Scholar] [CrossRef]
- He, J.; Wei, J.; Chen, K.; Tang, Z.; Zhou, Y.; Zhang, Y. Multitier Fog Computing With Large-Scale IoT Data Analytics for Smart Cities. IEEE Internet Things J. 2018, 5, 677–686. [Google Scholar] [CrossRef]
- Kar, P.; Misra, S.; Obaidat, M.S. RILoD: Reduction of Information Loss in a WSN System in the Presence of Dumb Nodes. IEEE Syst. J. 2019, 13, 336–344. [Google Scholar] [CrossRef]
- Kim, M.; Han, A.; Kim, T.; Lim, J. An Intelligent and Cost-Efficient Resource Consolidation Algorithm in Nanoscale Computing Environments. Appl. Sci. 2020, 10, 6494. [Google Scholar] [CrossRef]
- Montoya-Munoz, A.I.; Rendon, O.M.C. An Approach Based on Fog Computing for Providing Reliability in IoT Data Collection: A Case Study in a Colombian Coffee Smart Farm. Appl. Sci. 2020, 10, 8904. [Google Scholar] [CrossRef]
- Scarpiniti, M.; Baccarelli, E.; Momenzadeh, A. VirtFogSim: A Parallel Toolbox for Dynamic Energy-Delay Performance Testing and Optimization of 5G Mobile-Fog-Cloud Virtualized Platforms. Appl. Sci. 2019, 9, 1160. [Google Scholar] [CrossRef]
- Scarpiniti, M.; Baccarelli, E.; Momenzadeh, A.; Uncini, A. SmartFog: Training the Fog for the Energy-Saving Analytics of Smart-Meter Data. Appl. Sci. 2019, 9, 4193. [Google Scholar] [CrossRef]
- Nasir, M.; Muhammad, K.; Lloret, J.; Sangaiah, A.K.; Sajjad, M. Fog computing enabled cost-effective distributed summarization of surveillance videos for smart cities. J. Parallel Distrib. Comput. 2019, 126, 161–170. [Google Scholar] [CrossRef]
- Yousefpour, A.; Fung, C.; Nguyen, T.; Kadiyala, K.; Jalali, F.; Niakanlahiji, A.; Kong, J.; Jue, J.P. All one needs to know about fog computing and related edge computing paradigms: A complete survey. J. Syst. Archit. 2019, 98, 289–330. [Google Scholar] [CrossRef]
- Shirazi, S.N.; Gouglidis, A.; Farshad, A.; Hutchison, D. The Extended Cloud: Review and Analysis of Mobile Edge Computing and Fog From a Security and Resilience Perspective. IEEE J. Select. Areas Commun. 2017, 35, 2586–2595. [Google Scholar] [CrossRef]
- Guo, P.; Lin, B.; Li, X.; He, R.; Li, S. Optimal Deployment and Dimensioning of Fog Computing Supported Vehicular Network. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 2058–2062. [Google Scholar] [CrossRef]
- Tang, B.; Chen, Z.; Hefferman, G.; Pei, S.; Wei, T.; He, H.; Yang, Q. Incorporating Intelligence in Fog Computing for Big Data Analysis in Smart Cities. IEEE Trans. Ind. Inf. 2017, 13, 2140–2150. [Google Scholar] [CrossRef]
- Osanaiye, O.; Chen, S.; Yan, Z.; Lu, R.; Choo, K.-K.R.; Dlodlo, M. From Cloud to Fog Computing: A Review and a Conceptual Live VM Migration Framework. IEEE Access 2016, 5, 8284–8300. [Google Scholar] [CrossRef]
- Masip-Bruin, X.; Marín-Tordera, E.; Tashakor, G.; Jukan, A.; Ren, G.-J. Foggy clouds and cloudy fogs: A real need for coordinated management of fog-to-cloud computing systems. IEEE Wirel. Commun. 2016, 23, 120–128. [Google Scholar] [CrossRef]
- Sookhak, M.; Yu, F.R.; He, Y.; Talebian, H.; Safa, N.S.; Zhao, N.; Khan, M.K.; Kumar, N. Fog Vehicular Computing: Augmentation of Fog Computing Using Vehicular Cloud Computing. IEEE Veh. Technol. Mag. 2017, 12, 55–64. [Google Scholar] [CrossRef]
- Aazam, M.; Huh, E.-N. Fog Computing Micro Datacenter Based Dynamic Resource Estimation and Pricing Model for IoT. In Proceedings of the 2015 IEEE 29th International Conference on Advanced Information Networking and Applications, Gwangiu, Korea, 24–27 March 2015; pp. 687–694. [Google Scholar] [CrossRef]
- Chen, Y.-C.; Chang, Y.-C.; Chen, C.-H.; Lin, Y.-S.; Chen, J.-L.; Chang, Y.-Y. Cloud-fog computing for information-centric Internet-of-Things applications. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; pp. 637–640. [Google Scholar] [CrossRef]
- Sarkar, S.; Chatterjee, S.; Misra, S. Assessment of the Suitability of Fog Computing in the Context of Internet of Things. IEEE Trans. Cloud Comput. 2018, 6, 46–59. [Google Scholar] [CrossRef]
- Yuan, X.; He, Y.; Fang, Q.; Tong, X.; Du, C.; Ding, Y. An Improved Fast Search and Find of Density Peaks-Based Fog Node Location of Fog Computing System. In Proceedings of the 2017 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Exeter, UK, 21–23 June 2017; pp. 635–642. [Google Scholar] [CrossRef]
- Dong, Y.; Guo, S.; Liu, J.; Yang, Y. Energy-Efficient Fair Cooperation Fog Computing in Mobile Edge Networks for Smart City. IEEE Internet Things J. 2019, 6, 7543–7554. [Google Scholar] [CrossRef]
- Shah-Mansouri, H.; Wong, V.W.S. Hierarchical Fog-Cloud Computing for IoT Systems: A Computation Offloading Game. IEEE Internet Things J. 2018, 5, 3246–3257. [Google Scholar] [CrossRef]
- Mouradian, C.; Kianpisheh, S.; Abu-Lebdeh, M.; Ebrahimnezhad, F.; Jahromi, N.T.; Glitho, R.H. Application Component Placement in NFV-Based Hybrid Cloud/Fog Systems With Mobile Fog Nodes. IEEE J. Select. Areas Commun. 2015, 37, 1130–1143. [Google Scholar] [CrossRef]
- Daraghmi, E.Y.; Yuan, S.-M. A small world based overlay network for improving dynamic load-balancing. J. Syst. Softw. 2015, 107, 187–203. [Google Scholar] [CrossRef]
- MPIGate: Multi Protocol Interface Gateway. Available online: http://mpigate.loria.fr/about.html (accessed on 5 October 2020).
- Gaurav, K. iFogSim: An Open Source Simulator for Edge Computing, Fog Computing and IoT. Available online: https://www.opensourceforu.com/2018/12/ifogsim-an-open-source-simulator-for-edge-computing-fog-computing-and-iot/ (accessed on 20 December 2018).
- Fog-and-Cloud-Computing-Optimization-in-Mobile-IoT-Environments. Available online: https://github.com/JoseCVieira/Thesis---Fog-and-Cloud-Computing-Optimization-in-Mobile-IoT-Environments (accessed on 20 January 2021).
- Fog Computing. Available online: https://github.com/imrahulr/FogComputing (accessed on 20 January 2021).
- Enhancing QoS in Fog Architecture Using P2P Load Distribution. Available online: https://github.com/shashankshampi/SCloudSim (accessed on 20 January 2021).
- GitHub. Available online: https://github.com/ (accessed on 20 January 2021).
- Armbrust, M.; Fox, A.; Griffith, R.; Joseph, A.D.; Katz, R.; Konwinski, A.; Lee, G.; Patterson, D.; Rabkin, A.; Stoica, I.; et al. A view of cloud computing. Commun. ACM 2010, 53, 50–58. [Google Scholar] [CrossRef]
- Yi, S.; Li, C.; Li, Q. A Survey of Fog Computing: Concepts, Applications and Issues. In Proceedings of the 2015 Workshop on Mobile Big Data—Mobidata ’15, Hangzhou, China, 21 June 2015; pp. 37–42. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Host Machine | Guest Machine | Amazon Web Service—EC2 | |
|---|---|---|---|
| OS | VMware | CentOS 7 | CentOS 7 |
| CPU | I7-6700 core 4 | Core 2 | Core 2 |
| Memory | 40 GB | 4 GB | 4 GB |
| HDD | 2 TB | 50 GB | 30 GB |
| Location | - | - | Mumbai |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daraghmi, E.-Y.; Wu, M.-C.; Yuan, S.-M. A Multilayer Data Processing and Aggregating Fog-Based Framework for Latency-Sensitive IoT Services. Appl. Sci. 2021, 11, 1374. https://doi.org/10.3390/app11041374
Daraghmi E-Y, Wu M-C, Yuan S-M. A Multilayer Data Processing and Aggregating Fog-Based Framework for Latency-Sensitive IoT Services. Applied Sciences. 2021; 11(4):1374. https://doi.org/10.3390/app11041374
Chicago/Turabian StyleDaraghmi, Eman-Yaser, Meng-Chian Wu, and Shyan-Ming Yuan. 2021. "A Multilayer Data Processing and Aggregating Fog-Based Framework for Latency-Sensitive IoT Services" Applied Sciences 11, no. 4: 1374. https://doi.org/10.3390/app11041374
APA StyleDaraghmi, E.-Y., Wu, M.-C., & Yuan, S.-M. (2021). A Multilayer Data Processing and Aggregating Fog-Based Framework for Latency-Sensitive IoT Services. Applied Sciences, 11(4), 1374. https://doi.org/10.3390/app11041374