
Investigating Health-Related Features and Their Impact on the Prediction of Diabetes Using Machine Learning

 , ,
, ,
Abstract
1. Introduction
2. Background and Related Work
2.1. Diabetes Mellitus (DM) and Risk Factors
2.2. Related Work
2.3. ML-Based Methods
2.4. Feature-Based Methods
3. Materials and Methods
3.1. Data Collection
3.2. Data Preprocessing
3.3. Subject Exclusion
3.4. Feature Engineering
3.5. Label Assignment
3.5.1. Dataset-1: HbA1c Labeling
3.5.2. Dataset-2: FPG Labeling
4. Model Development
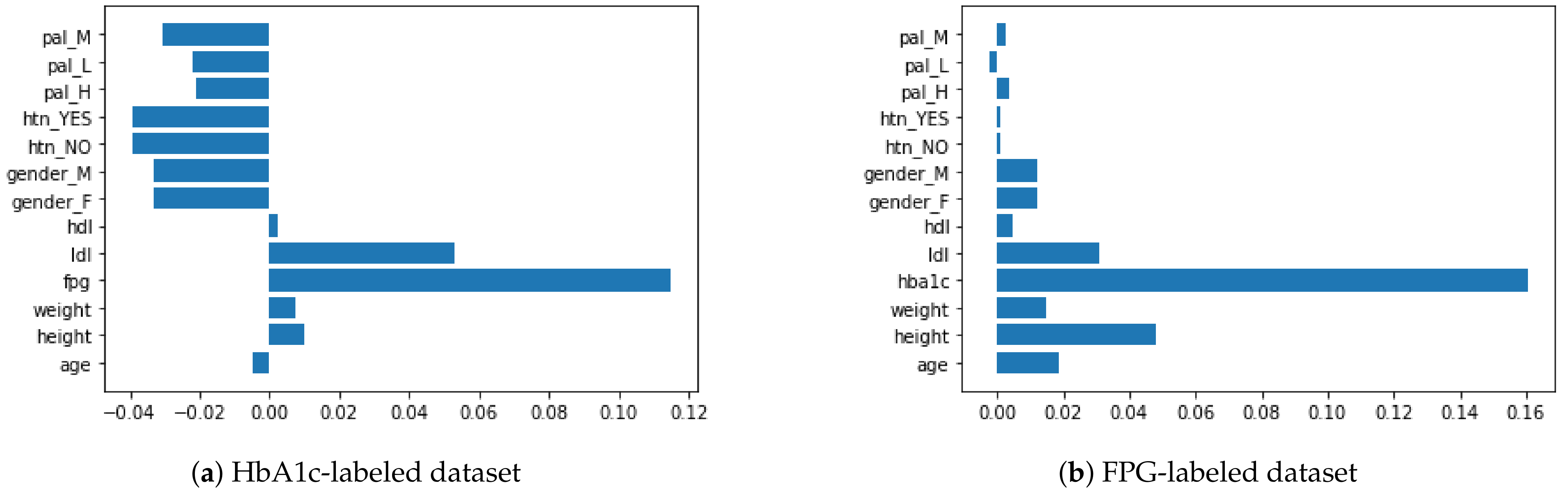
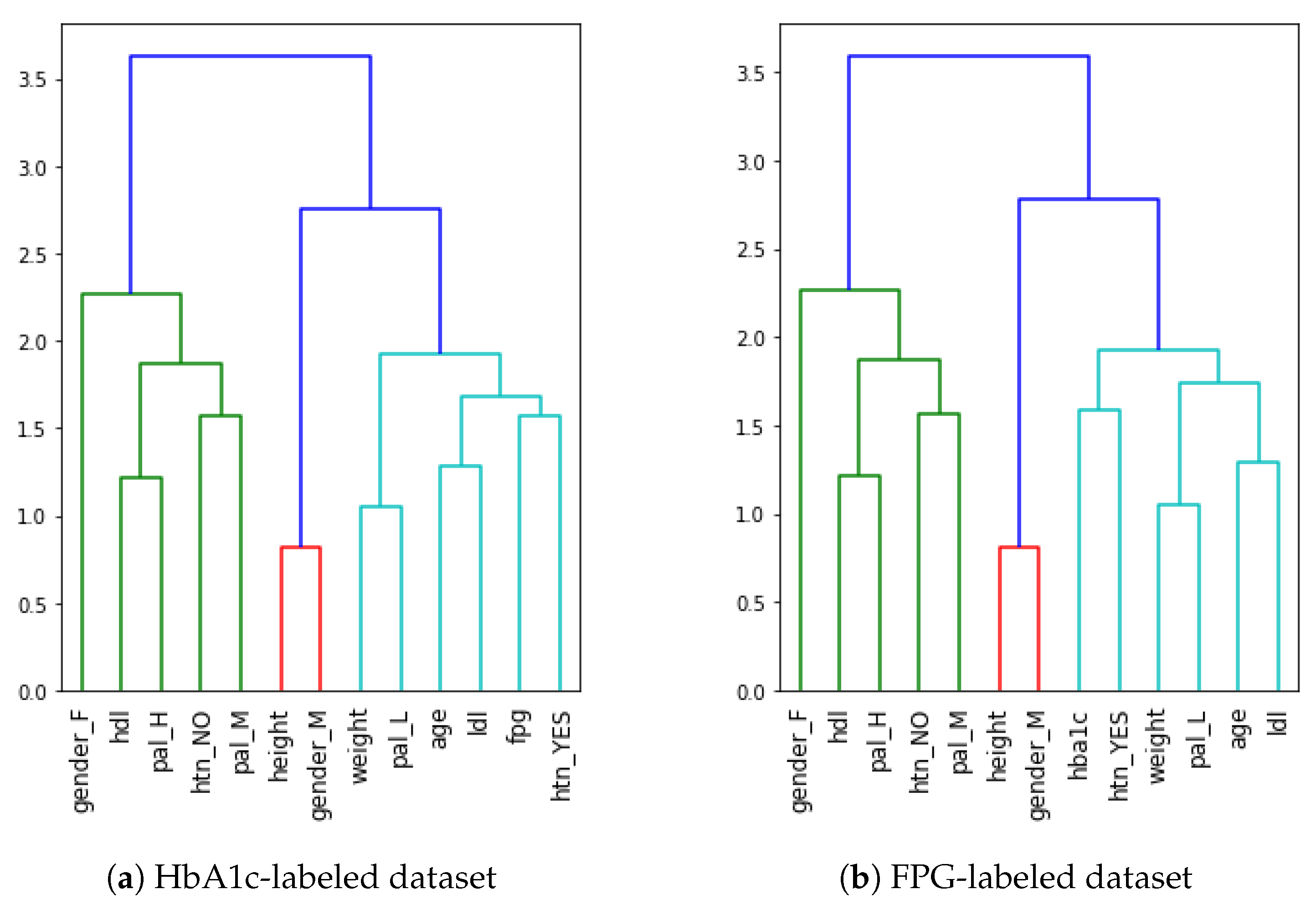
4.1. Feature Importance and Feature Elimination
4.2. Selection of Machine Learning Classifiers
5. Results
Performance of Machine Learning Classifiers
- The performance of all classifiers was better in the FPG-labeled dataset as compared to the HbA1c-labeled dataset;
- SVM performed best on the HbA1c-labeled dataset while RF performed best on the FPG-labeled dataset;
- There was no change in the performance of SVM after feature elimination in both cases, while all the other classifiers saw an improvement or a decrease in the performance after feature elimination;
- The performance of DT and EVM classifiers improved, but that of RF decreased, after feature elimination in both cases.
6. Discussion
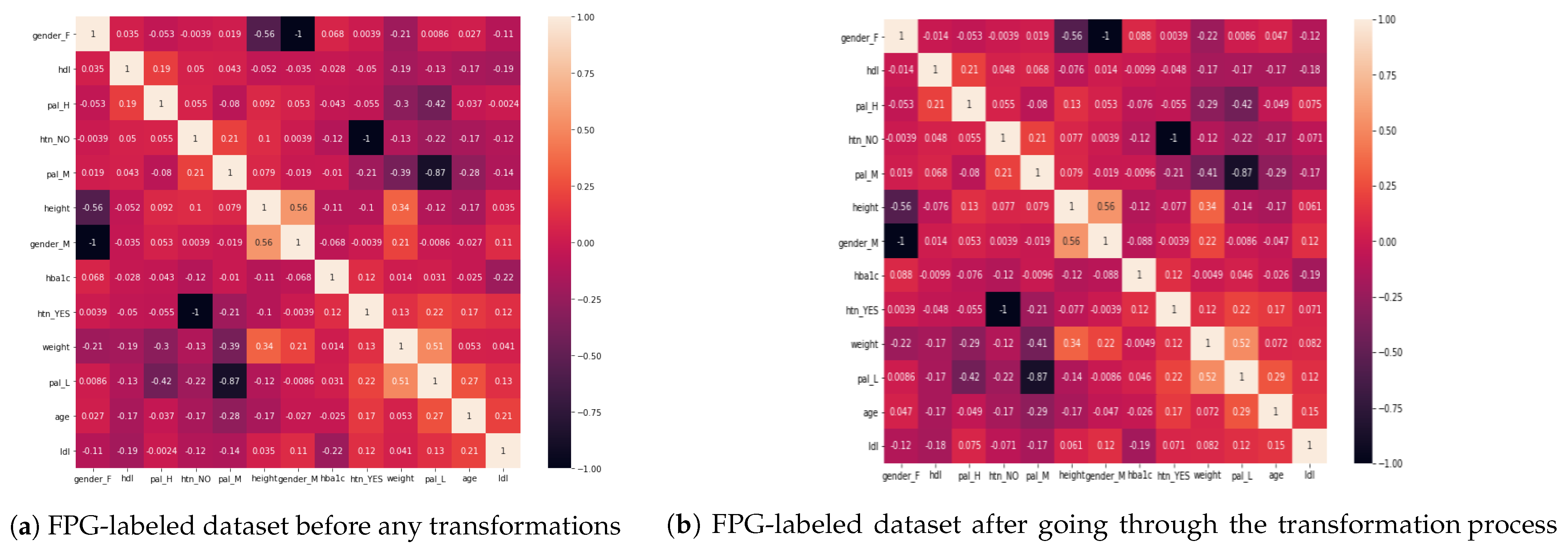
6.1. Analysis of Diabetes Risk Factors
- When we compare LDL to HbA1c and FPG, LDL is more correlated with HbA1c than FPG. On the other hand, HDL has almost no impact on HbA1c (close to 0);
- The presence of hypertension is correlated with an increase in age as well as with a lower level of physical activity. Lower PAL is associated with hypertension while medium PAL is associated with the absence of hypertension;
- Hypertension is also correlated with increasing levels of HbA1c and FPG, with an almost similar impact on both;
- A higher level of physical activity has a good impact on HDL (the “good” cholesterol), while a low level of physical activity may cause higher levels of LDL (the “bad” cholesterol);
- As the age of a person increases, so does LDL, meaning that younger people have comparatively small levels of dangerous cholesterol as compared to the older ones;
- The level of physical activity decreases with the age. Thus, older people lack physical activities;
- The level of physical activity of a person has also a strong correlation with the weight of a person, i.e., lower PAL indicates more weight while higher PAL is correlated with less weight of a person. Also, males have more weight when compared to females;
- The height of a person is negatively correlated with both HbA1c and FPG. Accordingly, shorter people may be at higher risk of diabetes. This is also in accordance with existing findings [60,61]. In comparison, when we evaluate the weight of a person against HbA1c and FPG, there is almost no correlation between them (0.01);
- There is no significant, direct relation between PAL and either HbA1c or FPG (<|0.05| in all cases of HbA1c and FPG with all PALs). Thus, we conclude that PAL has effects on weight, HTN, LDL, and HDL, which then have an impact on HbA1c and FPG levels, leading to diabetes.
6.2. Recommendations
6.3. Limitations of Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| EMR | Electronic Medical Record |
| SVM | Support Vector Machines |
| LR | Logistic Regression |
| DT | Decision Tree |
| RF | Random Forest |
| EVM | Ensemble Voting Model |
| DM | Diabetes Mellitus |
| T1D | Type 1 Diabetes |
| T2D | Type 2 Diabetes |
| HTN | Hypertenstion |
| PAL | Physical Activity Level |
References
- Saeedi, P.; Petersohn, I.; Salpea, P.; Malanda, B.; Karuranga, S.; Unwin, N.; Colagiuri, S.; Guariguata, L.; Motala, A.A.; Ogurtsova, K.; et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas. Diabetes Res. Clin. Pract. 2019, 157, 107843. [Google Scholar] [CrossRef]
- Cho, N.; Shaw, J.; Karuranga, S.; Huang, Y.; da Rocha Fernandes, J.; Ohlrogge, A.; Malanda, B. IDF Diabetes Atlas: Global estimates of diabetes prevalence for 2017 and projections for 2045. Diabetes Res. Clin. Pract. 2018, 138, 271–281. [Google Scholar] [CrossRef] [PubMed]
- Al-Rubeaan, K.; Al-Manaa, H.A.; Khoja, T.; Ahmad, N.; Alsharqawi, A.; Siddiqui, K.; Alnaqeb, D.; Aburisheh, K.; Youssef, A.; Al-Batil, A.; et al. The Saudi Abnormal Glucose Metabolism and Diabetes Impact Study (SAUDI-DM). Ann. Saudi Med. 2014, 34, 465–475. [Google Scholar] [CrossRef] [PubMed]
- AlMazroa, M. Cost of Diabetes in Saudi Arabia. Iproceedings 2018, 4, e10566. [Google Scholar] [CrossRef]
- Alotaibi, A.; Perry, L.; Gholizadeh, L.; Al-Ganmi, A. Incidence and prevalence rates of diabetes mellitus in Saudi Arabia: An overview. J. Epidemiol. Glob. Health 2017, 7, 211–218. [Google Scholar] [CrossRef] [PubMed]
- Saad, A.M.; Younes, Z.M.; Ahmed, H.; Brown, J.A.; Al Owesie, R.M.; Hassoun, A.A. Self-efficacy, self-care and glycemic control in Saudi Arabian patients with type 2 diabetes mellitus: A cross-sectional survey. Diabetes Res. Clin. Pract. 2018, 137, 28–36. [Google Scholar] [CrossRef] [PubMed]
- Alsuliman, M.A.; Alotaibi, S.A.; Zhang, Q.; Durgampudi, P.K. A systematic review of factors associated with uncontrolled diabetes and meta-analysis of its prevalence in Saudi Arabia since 2006. Diabetes/Metab. Res. Rev. 2020. [Google Scholar] [CrossRef]
- Almutairi, E.; Abbod, M.; Itagaki, T. Mathematical Modelling of Diabetes Mellitus and Associated Risk Factors in Saudi Arabia. Int. J. Simul. Sci. Technol. 2020, 21, 1–7. [Google Scholar]
- Syed, A.H.; Khan, T. Machine Learning-Based Application for Predicting Risk of Type 2 Diabetes Mellitus (T2DM) in Saudi Arabia: A Retrospective Cross-Sectional Study. IEEE Access 2020, 8, 199539–199561. [Google Scholar] [CrossRef]
- Alomar, M.J.; Al-Ansari, K.R.; Hassan, N.A. Comparison of awareness of diabetes mellitus type II with treatment’s outcome in term of direct cost in a hospital in Saudi Arabia. World J. Diabetes 2019, 10, 463. [Google Scholar] [CrossRef]
- Nathan, D.; Buse, J.; Davidson, M.; Heine, R.; Holman, R.; Sherwin, R.; Zinman, B. Management of hyperglycaemia in type 2 diabetes: A consensus algorithm for the initiation and adjustment of therapy. Diabetologia 2006, 49, 1711–1721. [Google Scholar] [CrossRef] [PubMed]
- Sacks, D. A1C Versus Glucose Testing: A Comparison. Diabetes Care 2011, 34, 518–523. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Definition and Diagnosis of Diabetes Mellitus and Intermediate Hyperglycemia: Report of a WHO/IDF Consultation. 2006. Available online: https://apps.who.int/iris/bitstream/handle/10665/43588/9241594934_eng.pdf (accessed on 26 January 2021).
- American Diabetes Association. 2. Classification and diagnosis of diabetes: Standards of medical care in diabetes—2019. Diabetes Care 2019, 42, S13–S28. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Cao, W.; Guo, J.; Ren, J.; Cheng, Y.; Davis, D.N. DMP_MI: An effective diabetes mellitus classification algorithm on imbalanced data with missing values. IEEE Access 2019, 7, 102232–102238. [Google Scholar] [CrossRef]
- Kaur, P.; Kaur, R. Comparative Analysis of Classification Techniques for Diagnosis of Diabetes. In Advances in Bioinformatics, Multimedia, and Electronics Circuits and Signals; Springer: Berlin/Heidelberg, Germany, 2020; pp. 215–221. [Google Scholar]
- Devi, R.H.; Bai, A.; Nagarajan, N. A novel hybrid approach for diagnosing diabetes mellitus using farthest first and support vector machine algorithms. Obes. Med. 2020, 17, 100152. [Google Scholar] [CrossRef]
- Abbas, H.; Alic, L.; Erraguntla, M.; Ji, J.; Abdul-Ghani, M.; Abbasi, Q.H.; Qaraqe, M. Predicting long-term Type 2 Diabetes with Support Vector Machine using Oral Glucose Tolerance Test. bioRxiv 2019. [Google Scholar] [CrossRef] [PubMed]
- Kadhm, M.S.; Ghindawi, I.W.; Mhawi, D.E. An Accurate Diabetes Prediction System Based on K-means Clustering and Proposed Classification Approach. Int. J. Appl. Eng. Res. 2018, 13, 4038–4041. [Google Scholar]
- Afzali, S.; Yildiz, O. An effective sample preparation method for diabetes prediction. Int. Arab J. Inf. Technol. 2018, 15, 968–973. [Google Scholar]
- Tuso, P. Prediabetes and lifestyle modification: Time to prevent a preventable disease. Perm. J. 2014, 18, 88–93. [Google Scholar] [CrossRef]
- Huxley, R.; James, W.; Barzi, F.; Patel, J.; Lear, S.; Suriyawongpaisal, P.; Janus, E.; Caterson, I.; Zimmet, P.; Prabhakaran, D.; et al. Ethnic comparisons of the cross-sectional relationships between measures of body size with diabetes and hypertension. Obes. Rev. 2008, 9, 53–61. [Google Scholar] [CrossRef]
- Zhu, Y.; Hedderson, M.M.; Quesenberry, C.P.; Feng, J.; Ferrara, A. Liver enzymes in early to mid-pregnancy, insulin resistance, and gestational diabetes risk: A longitudinal analysis. Front. Endocrinol. 2018, 9, 581. [Google Scholar] [CrossRef] [PubMed]
- Lomonaco, R.; Leiva, E.G.; Bril, F.; Shrestha, S.; Mansour, L.; Budd, J.; Romero, J.P.; Schmidt, S.; Chang, K.L.; Samraj, G.; et al. Advanced Liver Fibrosis Is Common in Patients With Type 2 Diabetes Followed in the Outpatient Setting: The Need for Systematic Screening. Diabetes Care 2020, 44, 399–406. [Google Scholar] [CrossRef] [PubMed]
- Jaiswal, M.; Divers, J.; Dabelea, D.; Isom, S.; Bell, R.A.; Martin, C.L.; Pettitt, D.J.; Saydah, S.; Pihoker, C.; Standiford, D.A.; et al. Prevalence of and risk factors for diabetic peripheral neuropathy in youth with type 1 and type 2 diabetes: SEARCH for Diabetes in Youth Study. Diabetes Care 2017, 40, 1226–1232. [Google Scholar] [CrossRef] [PubMed]
- Rawshani, A.; Rawshani, A.; Franzén, S.; Sattar, N.; Eliasson, B.; Svensson, A.M.; Zethelius, B.; Miftaraj, M.; McGuire, D.K.; Rosengren, A.; et al. Risk factors, mortality, and cardiovascular outcomes in patients with type 2 diabetes. N. Engl. J. Med. 2018. [Google Scholar] [CrossRef] [PubMed]
- Mendola, N.D.; Chen, T.C.; Gu, Q.; Eberhardt, M.S.; Saydah, S. Prevalence of Total, Diagnosed, and Undiagnosed Diabetes among Adults: United States, 2013–2016; NCHS Data Brief No. 319; US Department of Health and Human Services, Centers for Disease Control and Prevention, National Center for Health and Statistics: Washington, DC, USA, 2018.
- Daanouni, O.; Cherradi, B.; Tmiri, A. Type 2 diabetes mellitus prediction model based on machine learning approach. In Proceedings of the Third International Conference on Smart City Applications, Casablanca, Morocco, 2–4 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 454–469. [Google Scholar]
- Lai, H.; Huang, H.; Keshavjee, K.; Guergachi, A.; Gao, X. Predictive models for diabetes mellitus using machine learning techniques. BMC Endocr. Disord. 2019, 19, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Alić, B.; Gurbeta, L.; Badnjevic, A. Machine learning techniques for classification of diabetes and cardiovascular diseases. In Proceedings of the 2017 6th Mediterranean Conference on Embedded Computing (MECO), Bar, Montenegro, 11–15 June 2017; pp. 1–4. [Google Scholar]
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 2019, 19, 1–16. [Google Scholar] [CrossRef]
- Yu, W.; Liu, T.; Valdez, R.; Gwinn, M.; Khoury, M.J. Application of support vector machine modeling for prediction of common diseases: The case of diabetes and pre-diabetes. BMC Med. Inform. Decis. Mak. 2010, 10, 16. [Google Scholar] [CrossRef]
- Semerdjian, J.; Frank, S. An ensemble classifier for predicting the onset of type II diabetes. arXiv 2017, arXiv:1708.07480. [Google Scholar]
- Dinh, A.; Miertschin, S.; Young, A.; Mohanty, S. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning. BMC Med. Inform. Decis. Mak. 2019, 19. [Google Scholar] [CrossRef]
- Martín-González, F.; González-Robledo, J.; Sánchez-Hernández, F.; Moreno-García, M.N. Success/Failure Prediction of Noninvasive Mechanical Ventilation in Intensive Care Units. Methods Inf. Med. 2016, 55, 234–241. [Google Scholar] [CrossRef]
- Akay, M.F. Support vector machines combined with feature selection for breast cancer diagnosis. Expert Syst. Appl. 2009, 36, 3240–3247. [Google Scholar] [CrossRef]
- Chen, H.L.; Yang, B.; Liu, J.; Liu, D.Y. A support vector machine classifier with rough set-based feature selection for breast cancer diagnosis. Expert Syst. Appl. 2011, 38, 9014–9022. [Google Scholar] [CrossRef]
- Liaqat, S.; Dashtipour, K.; Zahid, A.; Assaleh, K.; Arshad, K.; Ramzan, N. Detection of atrial fibrillation using a machine learning approach. Information 2020, 11, 549. [Google Scholar] [CrossRef]
- YA Amer, A.; Vranken, J.; Wouters, F.; Mesotten, D.; Vandervoort, P.; Storms, V.; Luca, S.; Vanrumste, B.; Aerts, J.M. Feature Engineering for ICU Mortality Prediction Based on Hourly to Bi-Hourly Measurements. Appl. Sci. 2019, 9, 3525. [Google Scholar] [CrossRef]
- Tomar, D.; Agarwal, S. Hybrid feature selection based weighted least squares twin support vector machine approach for diagnosing breast cancer, hepatitis, and diabetes. Adv. Artif. Neural Syst. 2015. [Google Scholar] [CrossRef]
- Balakrishnan, S.; Narayanaswamy, R.; Savarimuthu, N.; Samikannu, R. SVM ranking with backward search for feature selection in type II diabetes databases. In Proceedings of the 2008 IEEE International Conference on Systems, Man and Cybernetics, Singapore, 12–15 October 2008; pp. 2628–2633. [Google Scholar]
- Ephzibah, E. Cost effective approach on feature selection using genetic algorithms and fuzzy logic for diabetes diagnosis. arXiv 2011, arXiv:1103.0087. [Google Scholar] [CrossRef]
- Aslam, M.W.; Zhu, Z.; Nandi, A.K. Feature generation using genetic programming with comparative partner selection for diabetes classification. Expert Syst. Appl. 2013, 40, 5402–5412. [Google Scholar] [CrossRef]
- Rodríguez-Rodríguez, I.; Rodríguez, J.V.; González-Vidal, A.; Zamora, M.Á. Feature Selection for Blood Glucose Level Prediction in Type 1 Diabetes Mellitus by Using the Sequential Input Selection Algorithm (SISAL). Symmetry 2019, 11, 1164. [Google Scholar] [CrossRef]
- Butterworth, R.; Piatetsky-Shapiro, G.; Simovici, D.A. On feature selection through clustering. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005. [Google Scholar]
- Ienco, D.; Meo, R. Exploration and reduction of the feature space by hierarchical clustering. In Proceedings of the 2008 SIAM International Conference on Data Mining, Atlanta, GA, USA, 24–26 April 2008; pp. 577–587. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Sciences 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 26 January 2021).
- American Diabetes Association. Standards of medical care in diabetes—2018 abridged for primary care providers. Clin. Diabetes A Publ. Am. Diabetes Assoc. 2018, 36, 14. [Google Scholar]
- Rodbard, H.; Jellinger, P.; Davidson, J.; Einhorn, D.; Garber, A.; Grunberger, G.; Handelsman, Y.; Horton, E.; Lebovitz, H.; Levy, P.; et al. Statement by an American Association of Clinical Endocrinologists/American College of Endocrinology consensus panel on type 2 diabetes mellitus: An algorithm for glycemic control. Endocr. Pract. 2009, 15, 540–559. [Google Scholar] [CrossRef]
- Zien, A.; Krämer, N.; Sonnenburg, S.; Rätsch, G. The feature importance ranking measure. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bled, Slovenia, September 7–11 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 694–709. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed]
- Parr, T.; Turgutlu, K.; Csiszar, C.; Howard, J. Beware Default Random Forest Importances. 26 March 2018. Available online: https://explained.ai/rf-importance/ (accessed on 26 January 2021).
- Chen, X.w.; Jeong, J.C. Enhanced recursive feature elimination. In Proceedings of the Sixth International Conference on Machine Learning and Applications (ICMLA 2007), Cincinnati, OH, USA, 13–15 December 2007; pp. 429–435. [Google Scholar]
- Parr, T.; Wilson, J.D.; Hamrick, J. Nonparametric Feature Impact and Importance. arXiv 2020, arXiv:2006.04750. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Tu, J.V. Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J. Clin. Epidemiol. 1996, 49, 1225–1231. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. Data mining in metric space: An empirical analysis of supervised learning performance criteria. In Proceedings of the tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 69–78. [Google Scholar]
- Ho-Pham, L.T.; Nguyen, U.D.; Tran, T.X.; Nguyen, T.V. Discordance in the diagnosis of diabetes: Comparison between HbA1c and fasting plasma glucose. PLoS ONE 2017, 12, e0182192. [Google Scholar] [CrossRef] [PubMed]
- Vangipurapu, J.; Stančáková, A.; Jauhiainen, R.; Kuusisto, J.; Laakso, M. Short adult stature predicts impaired β-cell function, insulin resistance, glycemia, and type 2 diabetes in Finnish men. J. Clin. Endocrinol. Metab. 2017, 102, 443–450. [Google Scholar] [CrossRef]
- Wittenbecher, C.; Kuxhaus, O.; Boeing, H.; Stefan, N.; Schulze, M.B. Associations of short stature and components of height with incidence of type 2 diabetes: Mediating effects of cardiometabolic risk factors. Diabetologia 2019, 62, 2211–2221. [Google Scholar] [CrossRef]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| No. | Feature Name | Feature Type | Feature Description |
|---|---|---|---|
| 1 | Date of birth | Date | Values in date format |
| 2 | Gender | Binominal | F: Female, M: Male |
| 3 | Height | Numerical | Values in Centimeter (cm) |
| 4 | Weight | Numerical | Values in Kilograms (kg) |
| 5 | Hypertension (HTN) | Binominal | Values as Yes, No |
| 6 | Fasting Plasma Glucose (FPG) | Numerical | Lab test results measured in mmol/L |
| 7 | Hemoglobin A1c (HbA1c) | Numerical | Lab test results measured in percentage (%). |
| 8 | High-density lipoprotein (HDL) | Numerical | Lab test results in mmol/L |
| 9 | High-density lipoprotein (LDL) | Numerical | Lab test results in mmol/L |
| 10 | Physical Activity Level | Categorical | Values in L: Low, M: Medium, H: High |
| 11 | Diagnosis start date | Date | Values in date format |
| 12 | Primary diagnosis | Categorical | Values available in ICD10 code format. |
| 13 | Secondary diagnosis | Categorical | Values available in ICD10 code format. |
| 14 | Primary diagnosis full name | Categorical | Values indicate diagnosis full name |
| 15 | Secondary diagnosis full name | Categorical | Values indicate diagnosis full name |
| 16 | Region | Categorical | Values indicate the region of the patient whether in central, |
| western or eastern region. |
| Evaluation with 9 Features | Evaluation with 8 Features | |||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| Logistic Regression | 80.86 | 80.95 | 80.86 | 80.83 | 80.86 ↔ | 80.95 ↔ | 80.86 ↔ | 80.83 ↔ |
| SVM | 82.10 | 82.30 | 82.10 | 82.05 | 82.10 ↔ | 82.30 ↔ | 82.10 ↔ | 82.05 ↔ |
| Decision Tree | 74.07 | 74.07 | 74.07 | 74.06 | 75.31 ↑ | 75.34 ↑ | 75.31 ↑ | 75.28 ↑ |
| Random Forest | 81.48 | 81.91 | 81.48 | 81.38 | 80.86 ↓ | 81.61 ↓ | 80.86 ↓ | 80.70 ↓ |
| Ensemble | 77.78 | 78.14 | 77.78 | 77.66 | 78.40 ↑ | 78.86 ↑ | 78.40 ↑ | 78.26 ↑ |
| Evaluation with 9 Features | Evaluation with 8 Features | |||||||
|---|---|---|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | |
| Logistic Regression | 83.33 | 83.31 | 83.33 | 83.04 | 82.72 ↓ | 82.62 ↓ | 82.72 ↓ | 82.45 ↓ |
| SVM | 84.57 | 84.74 | 84.57 | 84.22 | 84.57 ↔ | 84.74 ↔ | 84.57 ↔ | 84.22 ↔ |
| Decision Tree | 80.86 | 81.50 | 80.86 | 81.03 | 82.72 ↑ | 83.01 ↑ | 82.72 ↑ | 82.81 ↑ |
| Random Forest | 88.27 | 88.31 | 88.27 | 88.29 | 87.65 ↓ | 87.90 ↓ | 87.65 ↓ | 87.72 ↓ |
| Ensemble | 83.95 | 83.84 | 83.95 | 83.84 | 84.57 ↑ | 84.47 ↑ | 84.57 ↑ | 84.43 ↑ |
| LDL and HDL | Hypertension | Age, Weight, and Height | ||||||
|---|---|---|---|---|---|---|---|---|
| Feature 1 | Feature 2 | Corr | Feature 1 | Feature 2 | Corr | Feature 1 | Feature 2 | Corr |
| LDL | HbA1c | −0.19 | HTN=Yes | Age | 0.17 | Age | LDL | 0.15 |
| LDL | FPG | −0.11 | HTN=Yes | PAL=L | 0.22 | Age | PAL=L | 0.29 |
| LDL | PAL=L | 0.12 | HTN=No | PAL=M | 0.21 | Weight | PAL=L | 0.52 |
| HDL | PAL=H | 0.21 | HTN=Yes | HbA1c | 0.12 | Weight | PAL=H | −0.29 |
| HDL | FPG | −0.14 | HTN=Yes | FPG | 0.13 | Weight | Gender=M | 0.22 |
| HDL | HbA1c | −0.01 | Height | HbA1c | −0.12 | |||
| Height | FPG | −0.12 | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, H.F.; Mukhtar, H.; Alaqail, H.; Seliaman, M.; Alhumam, A. Investigating Health-Related Features and Their Impact on the Prediction of Diabetes Using Machine Learning. Appl. Sci. 2021, 11, 1173. https://doi.org/10.3390/app11031173
Ahmad HF, Mukhtar H, Alaqail H, Seliaman M, Alhumam A. Investigating Health-Related Features and Their Impact on the Prediction of Diabetes Using Machine Learning. Applied Sciences. 2021; 11(3):1173. https://doi.org/10.3390/app11031173
Chicago/Turabian StyleAhmad, Hafiz Farooq, Hamid Mukhtar, Hesham Alaqail, Mohamed Seliaman, and Abdulaziz Alhumam. 2021. "Investigating Health-Related Features and Their Impact on the Prediction of Diabetes Using Machine Learning" Applied Sciences 11, no. 3: 1173. https://doi.org/10.3390/app11031173
APA StyleAhmad, H. F., Mukhtar, H., Alaqail, H., Seliaman, M., & Alhumam, A. (2021). Investigating Health-Related Features and Their Impact on the Prediction of Diabetes Using Machine Learning. Applied Sciences, 11(3), 1173. https://doi.org/10.3390/app11031173