
Data-Dependent Feature Extraction Method Based on Non-Negative Matrix Factorization for Weakly Supervised Domestic Sound Event Detection


Abstract
1. Introduction
2. Background
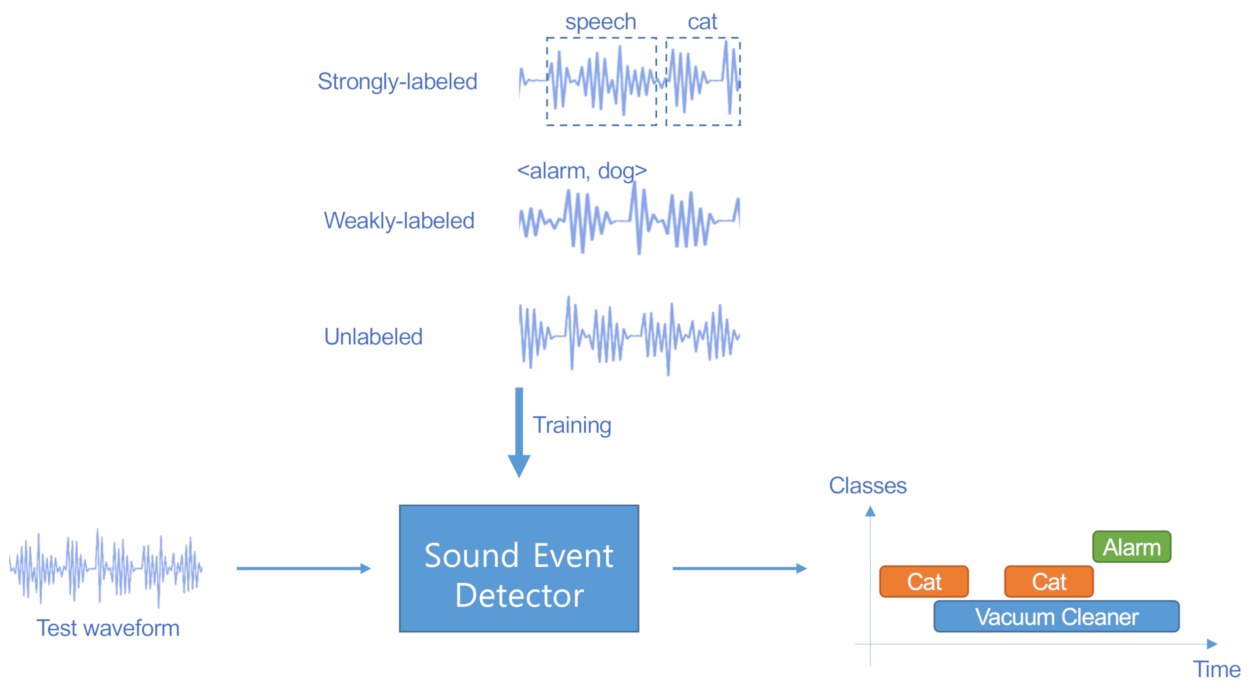
2.1. Problem Description
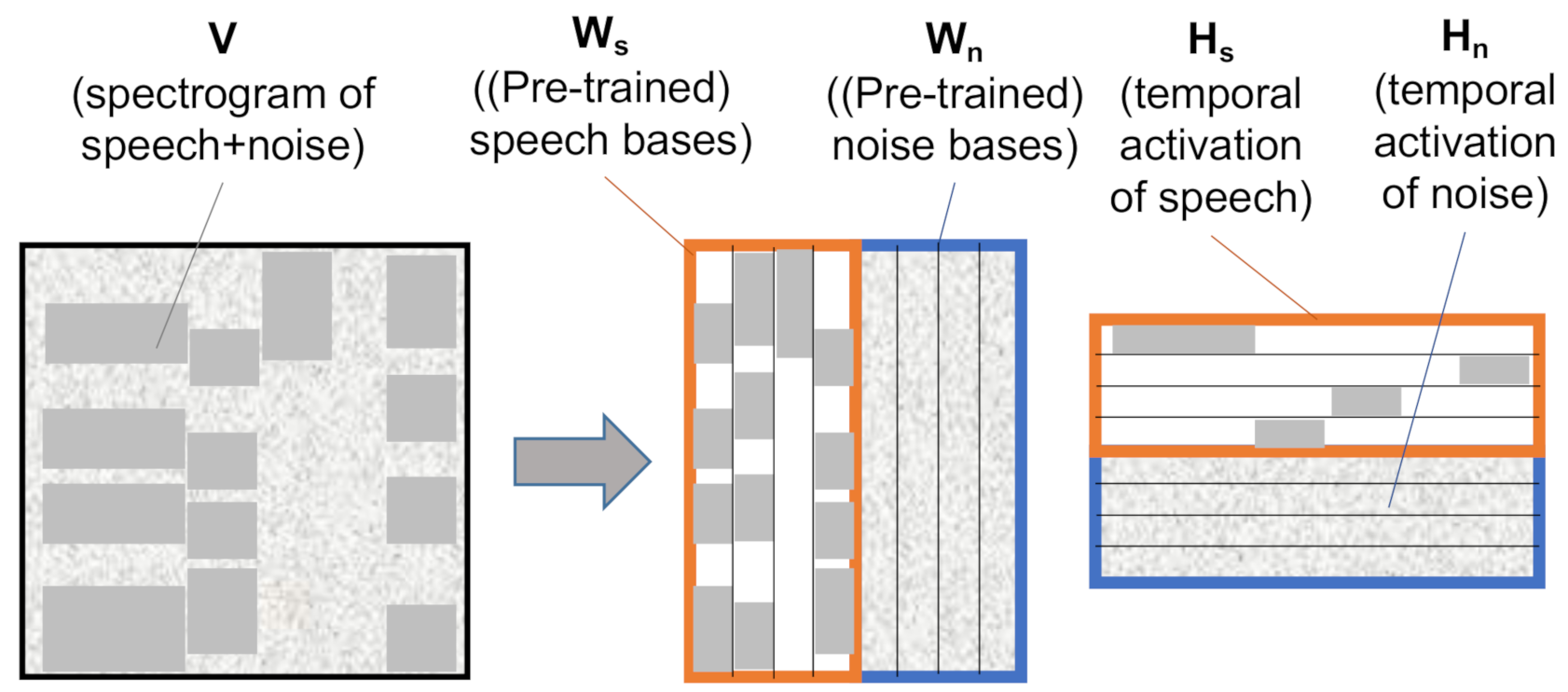
2.2. Non-Negative Matrix Factorization
3. Proposed System
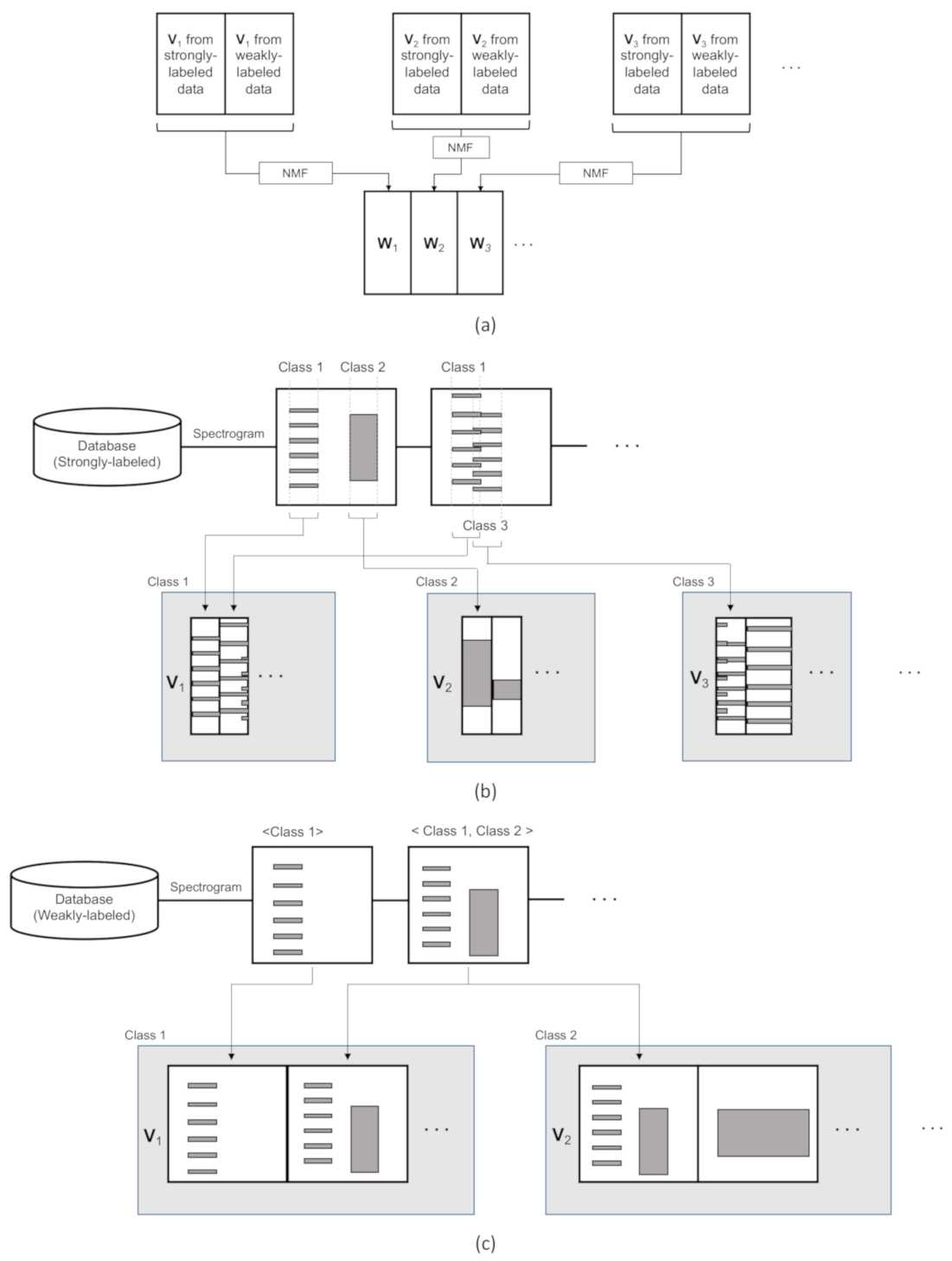
3.1. Strategy for the Frequency Basis Learning
3.2. Iterative and Non-Iterative Feature Extraction Methods
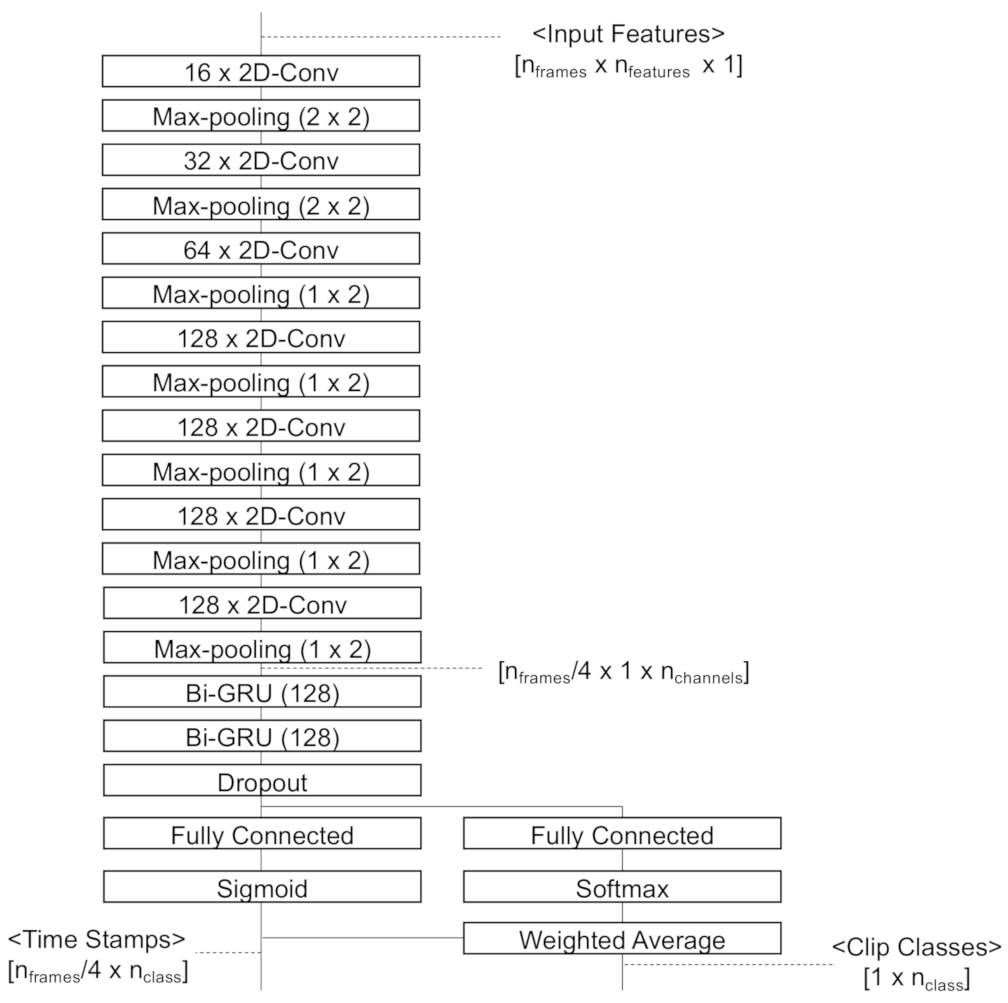
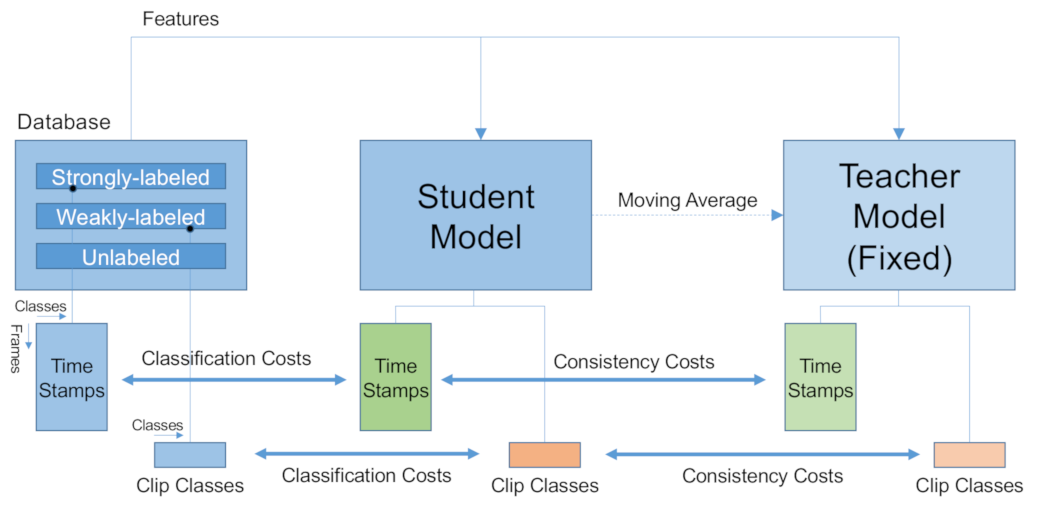
3.3. Classifier
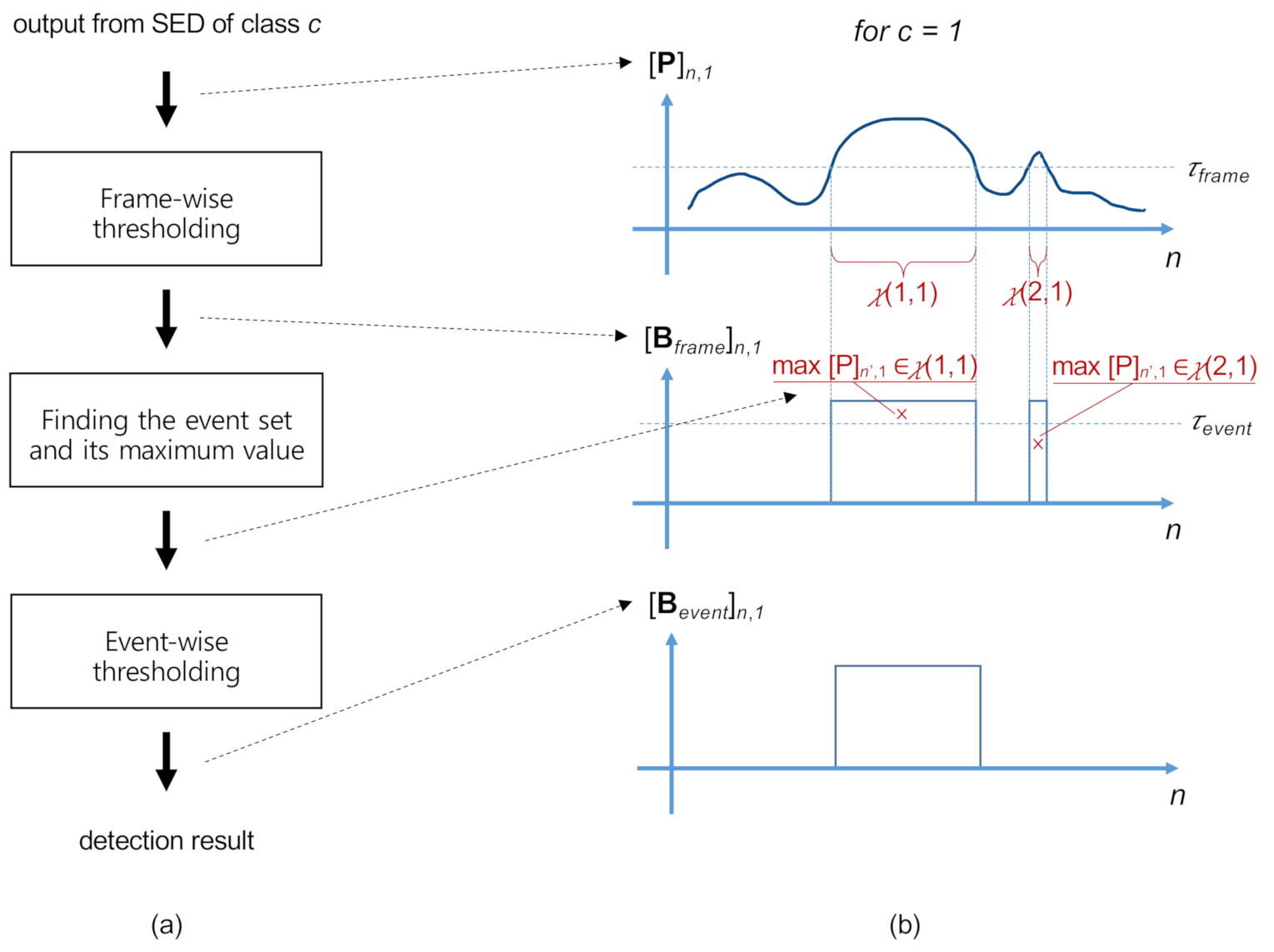
3.4. Post-Processing
4. Evaluation
4.1. Evaluation Settings
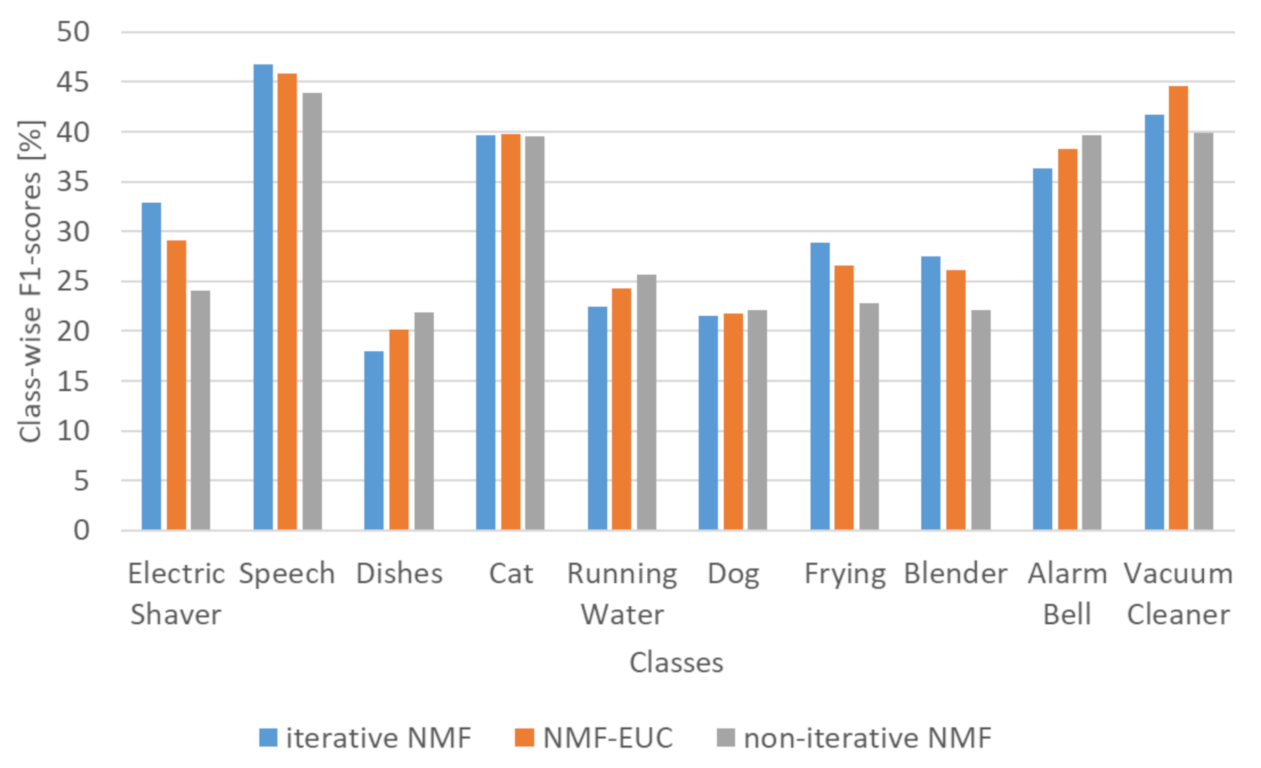
4.2. Comparison of Various Features
4.3. Effect of the Training Data on the Frequency Basis Learning
4.4. Thresholding Singular Values for Calculating the Pseudo-Inverse Matrix
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chu, S.; Narayanan, S.; Kuo, C.C.J.; Mataric, M.J. Where am I? Scene recognition for mobile robots using audio features. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, Canada, 9–12 July 2006; pp. 885–888. [Google Scholar]
- Ellis, D.P.; Lee, K. Minimal-impact audio-based personal archives. In Proceedings of the the 1st ACM Workshop on Continuous Archival and Retrieval of Personal Experiences, New York, NY, USA, 15 October 2004; pp. 39–47. [Google Scholar]
- Barchiesi, D.; Giannoulis, D.; Stowell, D.; Plumbley, M.D. Acoustic scene classification: Classifying environments from the sounds they produce. IEEE Signal Process. Mag. 2015, 32, 16–34. [Google Scholar] [CrossRef]
- Mesaros, A.; Heittola, T.; Virtanen, T. A multi-device dataset for urban acoustic scene classification. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2018 Workshop (DCASE2018), Surrey, UK, 19–20 November 2018; pp. 9–13. [Google Scholar]
- Bisot, V.; Serizel, R.; Essid, S.; Richard, G. Feature learning with matrix factorization applied to acoustic scene classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1216–1229. [Google Scholar] [CrossRef]
- Cakır, E.; Parascandolo, G.; Heittola, T.; Huttunen, H.; Virtanen, T. Convolutional recurrent neural networks for polyphonic sound event detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1291–1303. [Google Scholar] [CrossRef]
- Huang, Z.; Jiang, D. Acoustic Scene Classification Based on Deep Convolutional Neuralnetwork with Spatial-Temporal Attention Pooling; Technical Report; DCASE2019 Challenge; DCASE Community: Washington, DC, USA, 2019. [Google Scholar]
- Liu, H.; Wang, F.; Liu, X.; Guo, D. An Ensemble System for Domestic Activity Recognition; Technical Report; DCASE2018 Challenge; DCASE Community: Washington, DC, USA, 2018. [Google Scholar]
- Chen, H.; Liu, Z.; Liu, Z.; Zhang, P.; Yan, Y. Integrating the Data Augmentation Scheme with Various Classifiers for Acoustic Scene Modeling; Technical Report; DCASE2019 Challenge; DCASE Community: Washington, DC, USA, 2019. [Google Scholar]
- Inoue, T.; Vinayavekhin, P.; Wang, S.; Wood, D.; Greco, N.; Tachibana, R. Domestic Activities Classification Based on CNN Using Shuffling and Mixing Data Augmentation; Technical Report; DCASE2018 Challenge; DCASE Community: Washington, DC, USA, 2018. [Google Scholar]
- Valenti, M.; Squartini, S.; Diment, A.; Parascandolo, G.; Virtanen, T. A convolutional neural network approach for acoustic scene classification. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1547–1554. [Google Scholar]
- Moore, B.C. An Introduction to the Psychology of Hearing; Brill Academy Press: Leiden, The Netherlands, 2012. [Google Scholar]
- Bisot, V.; Essid, S.; Richard, G. HOG and subband power distribution image features for acoustic scene classification. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 719–723. [Google Scholar]
- Roma, G.; Nogueira, W.; Herrera, P.; De Boronat, R. Recurrence quantification analysis features for auditory scene classification. IEEE Aasp Chall. Detect. Classif. Acoust. Scenes Events 2013. [Google Scholar] [CrossRef]
- Gowdy, J.N.; Tufekci, Z. Mel-scaled discrete wavelet coefficients for speech recognition. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing, (Cat. No. 00CH37100), Istanbul, Turkey, 5–9 June 2000; Volume 3, pp. 1351–1354. [Google Scholar]
- Waldekar, S.; Saha, G. Wavelet Transform Based Mel-scaled Features for Acoustic Scene Classification. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 3323–3327. [Google Scholar]
- Waldekar, S.; Kumar A, K.; Saha, G. Mel-Scaled Wavelet-Based Features for Sub-Task A and Texture Features for Sub-Task B of DCASE 2020 Task 1; Technical Report; DCASE2020 Challenge; DCASE Community: Washington, DC, USA, 2020. [Google Scholar]
- Phan, H.; Koch, P.; Katzberg, F.; Maass, M.; Mazur, R.; Mertins, A. Audio scene classification with deep recurrent neural networks. arXiv 2017, arXiv:1703.04770. [Google Scholar]
- Valero, X.; Alias, F. Gammatone cepstral coefficients: Biologically inspired features for non-speech audio classification. IEEE Trans. Multimed. 2012, 14, 1684–1689. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Smaragdis, P.; Brown, J.C. Non-negative matrix factorization for polyphonic music transcription. In Proceedings of the 2003 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 19–22 October 2003; pp. 177–180. [Google Scholar]
- Bertin, N.; Badeau, R.; Vincent, E. Enforcing harmonicity and smoothness in Bayesian non-negative matrix factorization applied to polyphonic music transcription. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 538–549. [Google Scholar] [CrossRef]
- Benetos, E.; Dixon, S.; Giannoulis, D.; Kirchhoff, H.; Klapuri, A. Automatic music transcription: Challenges and future directions. J. Intell. Inf. Syst. 2013, 41, 407–434. [Google Scholar] [CrossRef]
- Wilson, K.W.; Raj, B.; Smaragdis, P.; Divakaran, A. Speech denoising using nonnegative matrix factorization with priors. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 30 March–4 April 2008; pp. 4029–4032. [Google Scholar]
- Kwon, K.; Shin, J.W.; Kim, N.S. NMF-based speech enhancement using bases update. IEEE Signal Process. Lett. 2014, 22, 450–454. [Google Scholar] [CrossRef]
- Fan, H.T.; Hung, J.w.; Lu, X.; Wang, S.S.; Tsao, Y. Speech enhancement using segmental nonnegative matrix factorization. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4483–4487. [Google Scholar]
- Cauchi, B. Non-Negative Matrix Factorisation Applied to Auditory Scenes Classification. Master’s Thesis, Master ATIAM, Université Pierre et Marie Curie, Paris, France, 2011. [Google Scholar]
- Bisot, V.; Serizel, R.; Essid, S.; Richard, G. Acoustic scene classification with matrix factorization for unsupervised feature learning. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6445–6449. [Google Scholar]
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef]
- Lee, S.; Pang, H.S. Feature Extraction Based on the Non-Negative Matrix Factorization of Convolutional Neural Networks for Monitoring Domestic Activity With Acoustic Signals. IEEE Access 2020, 8, 122384–122395. [Google Scholar] [CrossRef]
- Choi, K.; Joo, D.; Kim, J. Kapre: On-gpu audio preprocessing layers for a quick implementation of deep neural network models with keras. arXiv 2017, arXiv:1706.05781. [Google Scholar]
- Cheuk, K.W.; Anderson, H.; Agres, K.; Herremans, D. nnAudio: An on-the-Fly GPU Audio to Spectrogram Conversion Toolbox Using 1D Convolutional Neural Networks. IEEE Access 2020, 8, 161981–162003. [Google Scholar] [CrossRef]
- Turpault, N.; Serizel, R.; Parag Shah, A.; Salamon, J. Sound event detection in domestic environments with weakly labeled data and soundscape synthesis. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop, New York, NY, USA, 25–26 October 2019. [Google Scholar]
- Lee, D.D.; Seung, H.S. Algorithms for non-negative matrix factorization. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2001; pp. 556–562. [Google Scholar]
- Cichocki, A.; Zdunek, R.; Phan, A.H.; Amari, S.I. Nonnegative Matrix and Tensor Factorizations: Applications to Exploratory Multi-Way Data Analysis and Blind Source Separation; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Lee, S.; Lim, J.S. Reverberation suppression using non-negative matrix factorization to detect low-Doppler target with continuous wave active sonar. EURASIP J. Adv. Signal Process. 2019, 2019, 11. [Google Scholar] [CrossRef]
- Févotte, C.; Bertin, N.; Durrieu, J.L. Nonnegative matrix factorization with the Itakura-Saito divergence: With application to music analysis. Neural Comput. 2009, 21, 793–830. [Google Scholar] [CrossRef] [PubMed]
- Ben-Israel, A.; Greville, T.N. Generalized Inverses: Theory and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 15. [Google Scholar]
- Delphin-Poulat, L.; Plapous, C. Mean Teacher with Data Augmentation for Dcase 2019 Task 4; Technical Report; Orange Labs: Lannion, France, 2019. [Google Scholar]
- Jiakai, L. Mean Teacher Convolution System for Dcase 2018 Task 4; Technical Report; DCASE2018 Challenge; DCASE Community: Washington, DC, USA, 2018. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv 2017, arXiv:1703.01780. [Google Scholar]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. Proc. IEEE ICASSP 2017. [Google Scholar] [CrossRef]
- Fonseca, E.; Pons, J.; Favory, X.; Font, F.; Bogdanov, D.; Ferraro, A.; Oramas, S.; Porter, A.; Serra, X. Freesound Datasets: A platform for the creation of open audio datasets. In Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR 2017), Suzhou, China, 23–27 October 2017; pp. 486–493. [Google Scholar]
- Dekkers, G.; Lauwereins, S.; Thoen, B.; Adhana, M.W.; Brouckxon, H.; Van Waterschoot, T.; Vanrumste, B.; Verhelst, M.; Karsmakers, P. The SINS Database for Detection of Daily Activities in a Home Environment Using an Acoustic Sensor Network. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 Workshop (DCASE2017), Munich, Germany, 16–17 November 2017; pp. 32–36. [Google Scholar]
- Cornell, S.C.; Pepe, G.; Principi, E.; Pariente, M.; Olvera, M.; Gabrielli, L.; Squartini, S. The UNIVPM-INRIA Systems for The DCASE 2020 Task 4; Technical Report; DCASE2020 Challenge; DCASE Community: Washington, DC, USA, 2020. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| w/o Event-Wise Post-Processing | w/ Event-Wise Post-Processing | |||
|---|---|---|---|---|
| F1-Score [%] (Micro) | F1-Score [%] (Macro) | F1-Score [%] (Micro) | F1-Score [%] (Macro) | |
| NMF(iterative) | 35.06 | 31.58 | 40.12 | 39.23 |
| NMF (non-iterative) | 34.87 | 30.16 | 40.02 | 38.45 |
| MelSpec | 34.41 | 32.31 | 40.41 | 39.72 |
| Log-Mel | 30.27 | 29.88 | 35.11 | 36.60 |
| GAM | 32.15 | 33.09 | 37.23 | 39.81 |
| CQT | 32.25 | 28.76 | 37.28 | 35.36 |
| Cornell et al. [46] | - | - | (with own post-processing) | |
| 42.48 | 39.56 | |||
| Electric Shaver | Speech | Dishes | Cat | Running Water | Dog | Frying | Blender | Alarm Bell | Vacuum Cleaner | |
|---|---|---|---|---|---|---|---|---|---|---|
| ine NMF (iterative) | 32.9 | 46.8 | 18.0 | 39.7 | 22.4 | 21.5 | 28.9 | 27.5 | 36.3 | 41.7 |
| ine NMF (non-iterative) | 24.1 | 43.9 | 21.9 | 39.5 | 25.7 | 22.1 | 22.8 | 22.1 | 39.6 | 39.9 |
| ine MelSpec | 35.7 | 45.0 | 18.0 | 39.1 | 30.9 | 17.4 | 24.0 | 32.0 | 32.0 | 49.0 |
| ine Log-Mel | 38.3 | 37.3 | 14.2 | 36.7 | 27.4 | 13.7 | 23.5 | 23.0 | 35.8 | 49.0 |
| ine GAM | 29.5 | 34.2 | 24.6 | 41.7 | 28.3 | 19.7 | 31.4 | 33.9 | 39.4 | 48.2 |
| ine CQT | 34.6 | 46.7 | 18.4 | 35.9 | 21.7 | 16.5 | 9.1 | 24.8 | 24.1 | 55.6 |
| NMF (Iterative) | NMF (Non-Iterative) | |||
|---|---|---|---|---|
| F1-Score [%] (Micro) | F1-Score [%] (Macro) | F1-Score [%] (Micro) | F1-Score [%] (Macro) | |
| STR | 40.12 | 39.23 | 40.02 | 38.45 |
| WEAK(U) | 40.02 | 38.89 | 38.98 | 37.65 |
| WEAK | 41.53 | 38.28 | 39.01 | 37.76 |
| STR + WEAK(U) | 38.91 | 37.50 | 38.39 | 38.79 |
| STR + WEAK | 38.51 | 37.39 | 39.97 | 38.40 |
| w/o Event-Wise Post-Processing | w/ Event-Wise Post-Processing | |||
|---|---|---|---|---|
| F1-Score [%] (Micro) | F1-Score [%] (Macro) | F1-Score [%] (Micro) | F1-Score [%] (Macro) | |
| 27.26 | 24.56 | 35.16 | 34.24 | |
| 33.59 | 29.95 | 39.59 | 37.94 | |
| 34.87 | 30.16 | 40.02 | 38.45 | |
| 32.52 | 28.35 | 38.51 | 36.23 | |
| 21.45 | 10.88 | 26.45 | 17.39 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Kim, M.; Shin, S.; Park, S.; Jeong, Y. Data-Dependent Feature Extraction Method Based on Non-Negative Matrix Factorization for Weakly Supervised Domestic Sound Event Detection. Appl. Sci. 2021, 11, 1040. https://doi.org/10.3390/app11031040
Lee S, Kim M, Shin S, Park S, Jeong Y. Data-Dependent Feature Extraction Method Based on Non-Negative Matrix Factorization for Weakly Supervised Domestic Sound Event Detection. Applied Sciences. 2021; 11(3):1040. https://doi.org/10.3390/app11031040
Chicago/Turabian StyleLee, Seokjin, Minhan Kim, Seunghyeon Shin, Sooyoung Park, and Youngho Jeong. 2021. "Data-Dependent Feature Extraction Method Based on Non-Negative Matrix Factorization for Weakly Supervised Domestic Sound Event Detection" Applied Sciences 11, no. 3: 1040. https://doi.org/10.3390/app11031040
APA StyleLee, S., Kim, M., Shin, S., Park, S., & Jeong, Y. (2021). Data-Dependent Feature Extraction Method Based on Non-Negative Matrix Factorization for Weakly Supervised Domestic Sound Event Detection. Applied Sciences, 11(3), 1040. https://doi.org/10.3390/app11031040