
Generalization-Based Acquisition of Training Data for Motor Primitive Learning by Neural Networks



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Problem Statement
1.2. Related Work
2. Methods and Data Acquisition for Learning
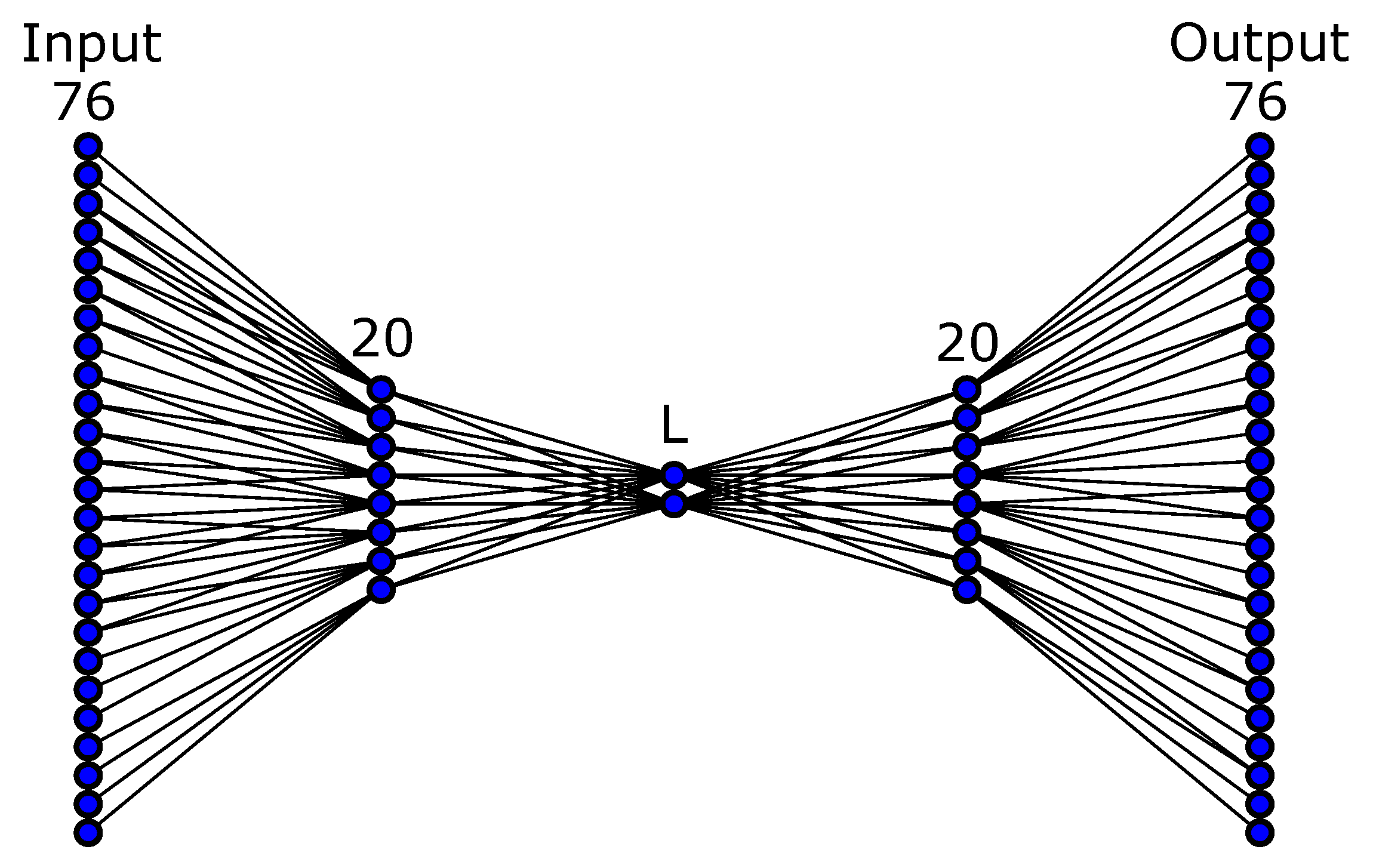
2.1. Dimensionality Reduction of Policy Parameter Space with Autoencoders
2.2. Database Acquisition by Generalization
3. Experimental Setup and Protocol
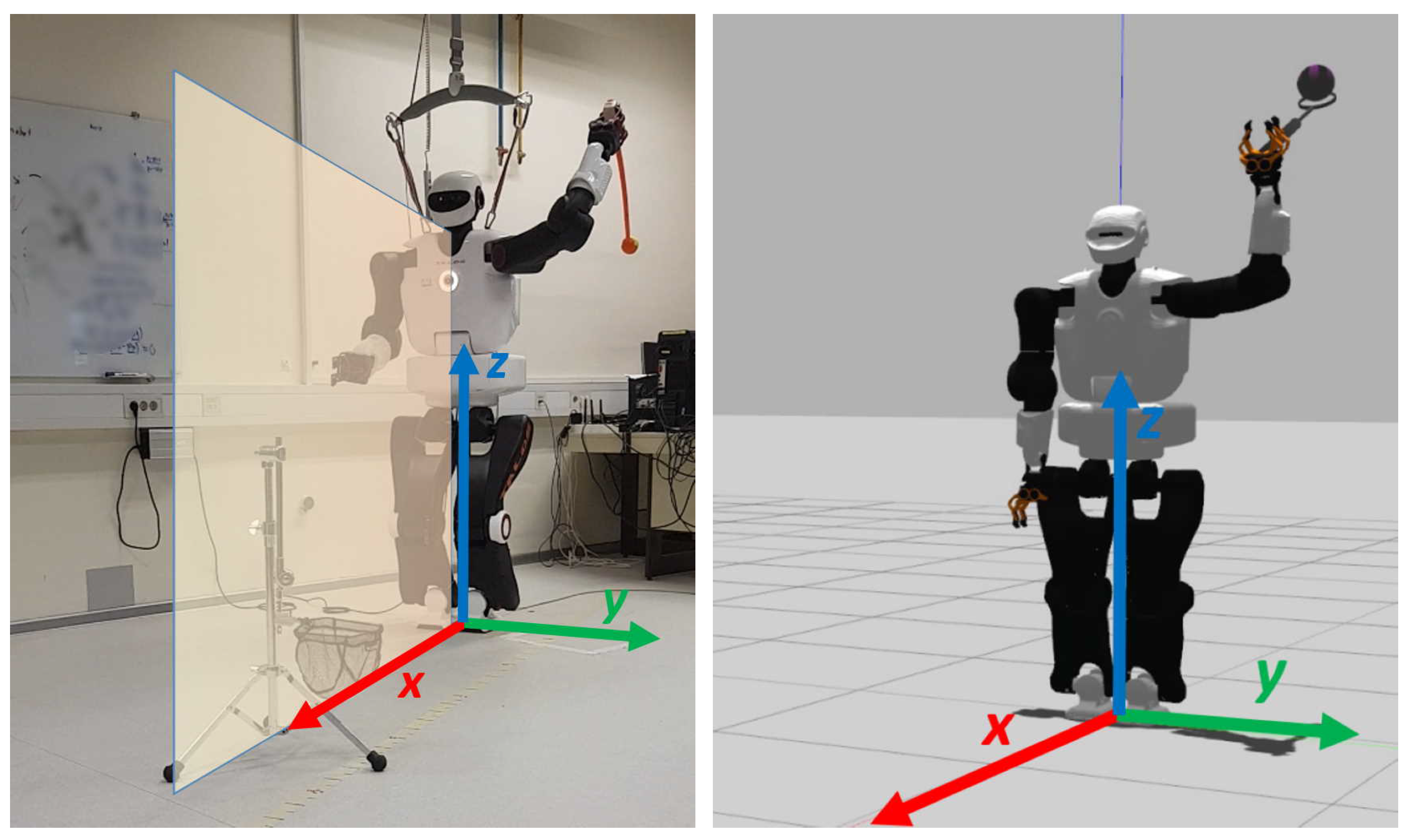
3.1. Task and Robot
3.2. Policy Parameter Space and Latent Space
3.3. Database for AE Training
3.4. Evaluation Metrics
4. Results
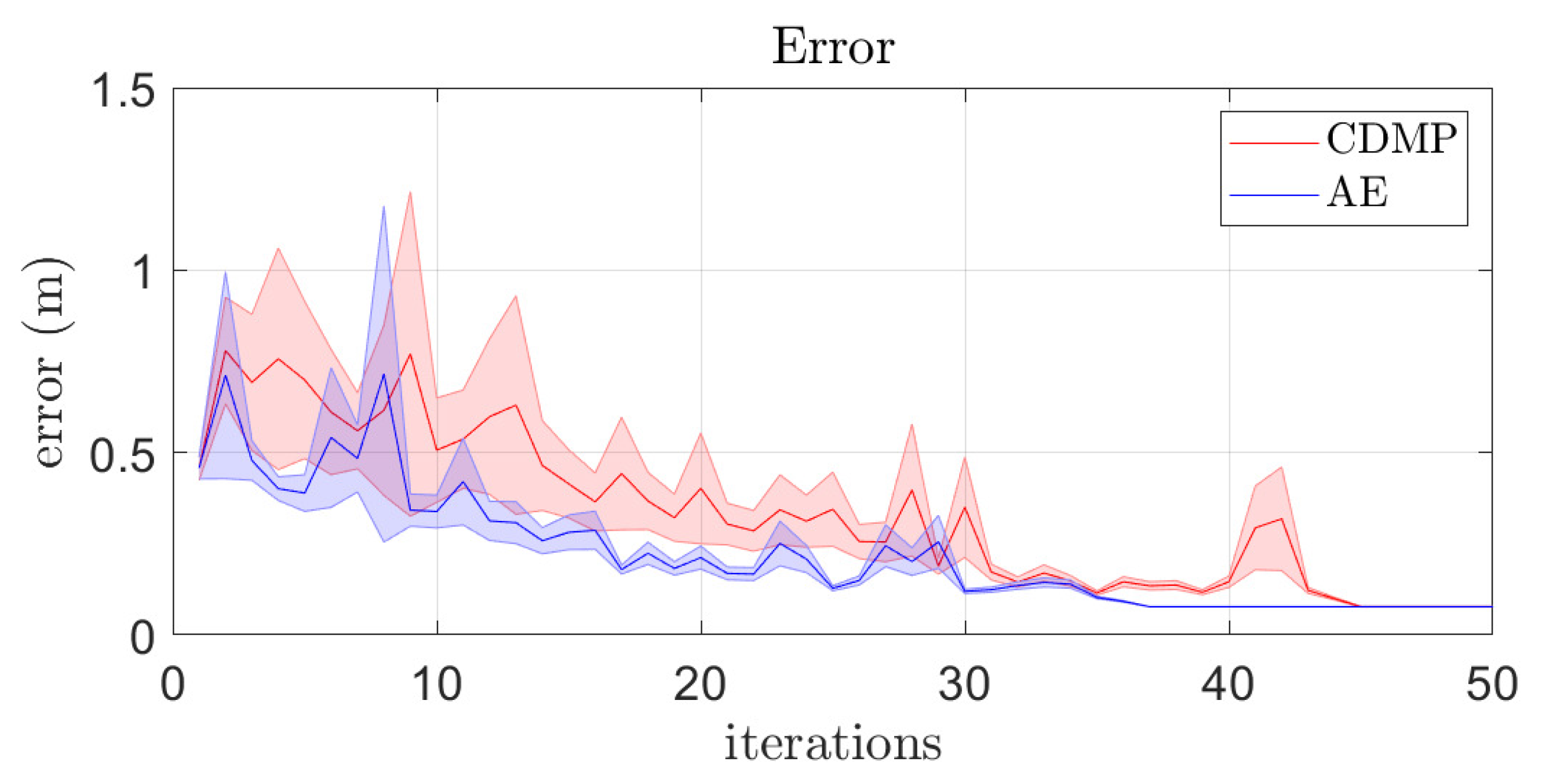
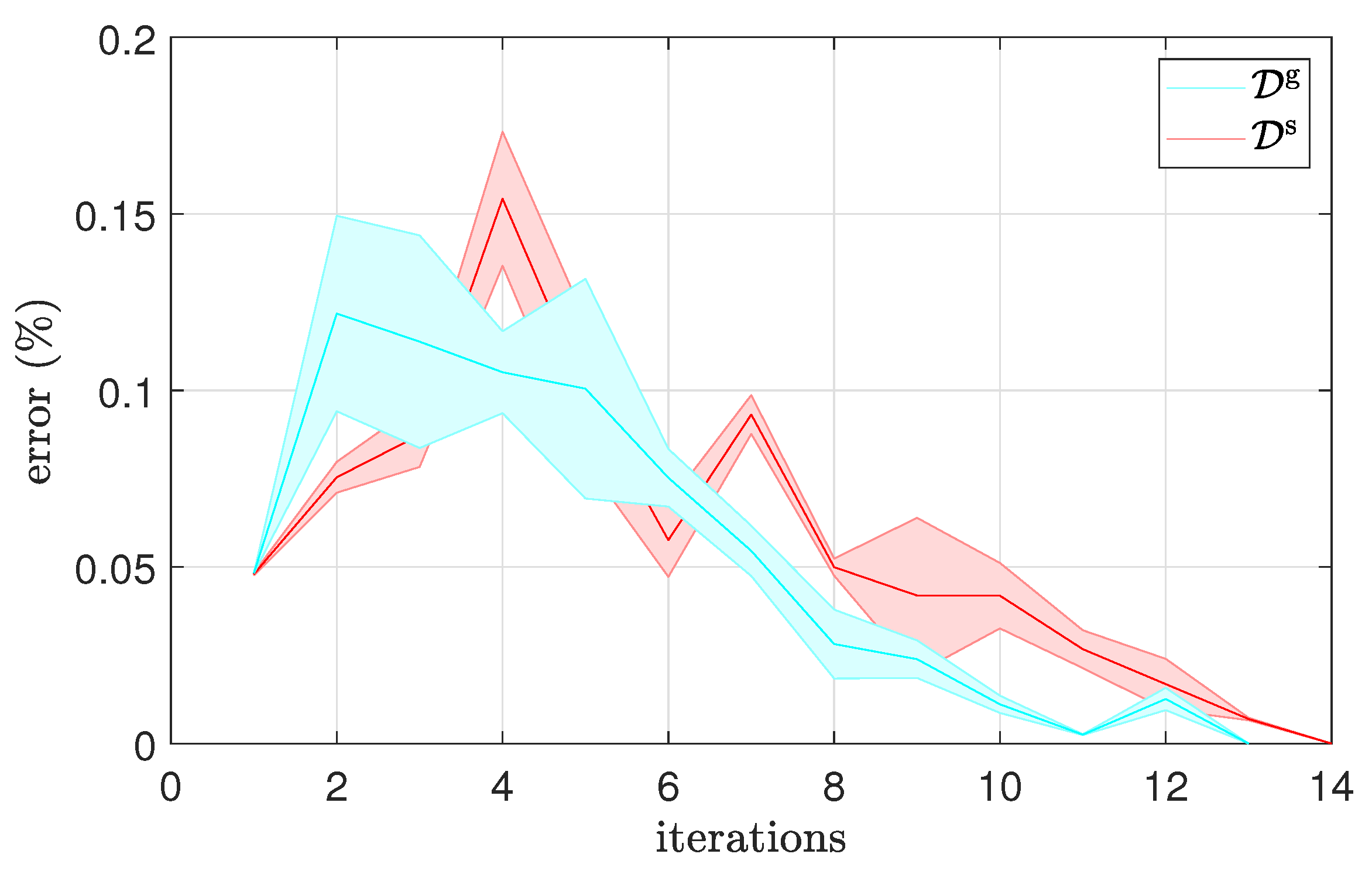
4.1. Effect of Database Size and Latent Space Dimension on the Quality of AE Approximation
4.2. RL in AE Latent Spaces
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Cartesian Dynamic Movement Primitives—CDMPs
Appendix B. Gaussian Process Regression
References
- Kroemer, O.; Niekum, S.; Konidaris, G.D. A review of robot learning for manipulation: Challenges, representations, and algorithms. arXiv 2019, arXiv:1907.03146. [Google Scholar]
- Peters, J.; Kober, J.; Muelling, K.; Kroemer, O.; Neumann, G. Towards Robot Skill Learning: From Simple Skills to Table Tennis. In Proceedings of the European Conference on Machine Learning (ECML), Prague, Czech Republic, 23–27 September 2013; pp. 627–631. [Google Scholar]
- Schaal, S. Is Imitation Learning the Route to Humanoid Robots? Trends Cogn. Sci. 1999, 3, 233–242. [Google Scholar] [CrossRef]
- Kaelbling, L.P. The foundation of efficient robot learning. Science 2020, 369, 915–916. [Google Scholar] [CrossRef] [PubMed]
- Pahič, R.; Lončarević, Z.; Ude, A.; Nemec, B.; Gams, A. User Feedback in Latent Space Robotic Skill Learning. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots (Humanoids), Beijing, China, 6–9 November 2018; pp. 270–276. [Google Scholar]
- Dillmann, R. Teaching and learning of robot tasks via observation of human performance. Robot. Auton. Syst. 2004, 47, 109–116. [Google Scholar] [CrossRef]
- Nemec, B.; Vuga, R.; Ude, A. Efficient sensorimotor learning from multiple demonstrations. Adv. Robot. 2013, 27, 1023–1031. [Google Scholar] [CrossRef]
- Matsubara, T.; Hyon, S.H.; Morimoto, J. Learning parametric dynamic movement primitives from multiple demonstrations. Neural Netw. 2011, 24, 493–500. [Google Scholar] [CrossRef]
- Ude, A.; Gams, A.; Asfour, T.; Morimoto, J. Task-specific generalization of discrete and periodic dynamic movement primitives. IEEE Trans. Robot. 2010, 26, 800–815. [Google Scholar] [CrossRef]
- Zhou, Y.; Gao, J.; Asfour, T. Movement primitive learning and generalization: Using mixture density networks. IEEE Robot. Autom. Mag. 2020, 27, 22–32. [Google Scholar] [CrossRef]
- Forte, D.; Gams, A.; Morimoto, J.; Ude, A. On-line motion synthesis and adaptation using a trajectory database. Robot. Auton. Syst. 2012, 60, 1327–1339. [Google Scholar] [CrossRef]
- Kober, J.; Bagnell, D.; Peters, J. Reinforcement Learning in Robotics: A Survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Deisenroth, M.P.; Neumann, G.; Peters, J. A Survey on Policy Search for Robotics. Found. Trends Robot. 2013, 2, 388–403. [Google Scholar]
- Sigaud, O.; Stulp, F. Policy search in continuous action domains: An overview. Neural Netw. 2019, 113, 28–40. [Google Scholar] [CrossRef] [PubMed]
- Kober, J.; Peters, J. Policy Search for Motor Primitives in Robotics. Mach. Learn. 2011, 84, 171–203. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Pahič, R.; Lončarević, Z.; Gams, A.; Ude, A. Robot skill learning in latent space of a deep autoencoder neural network. Robot. Auton. Syst. 2021, 135, 103690. [Google Scholar] [CrossRef]
- Stasse, O.; Flayols, T.; Budhiraja, R.; Giraud-Esclasse, K.; Carpentier, J.; Mirabel, J.; Del Prete, A.; Souères, P.; Mansard, N.; Lamiraux, F.; et al. TALOS: A new humanoid research platform targeted for industrial applications. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots (Humanoids), Birmingham, UK, 15–17 November 2017; pp. 689–695. [Google Scholar]
- Jiang, X.; Motai, Y. Learning by observation of robotic tasks using on-line PCA-based Eigen behavior. In Proceedings of the IEEE International Symposium on Computational Intelligence in Robotics and Automation (CIRA), Espoo, Finland, 27–30 June 2005; pp. 391–396. [Google Scholar]
- Kim, S.; Park, F.C. Fast Robot Motion Generation Using Principal Components: Framework and Algorithms. IEEE Trans. Ind. Electron. 2008, 55, 2506–2516. [Google Scholar]
- Martinez, A.M.; Kak, A.C. PCA versus LDA. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 228–233. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In Proceedings of the International Conference on Artificial Neural Networks, Lausanne, Switzerland, 8–10 October 1997; pp. 583–588. [Google Scholar]
- Mi, J.; Takahashi, Y. Humanoid Robot Motion Modeling Based on Time-Series Data Using Kernel PCA and Gaussian Process Dynamical Models. J. Adv. Comput. Intell. Intell. Inform. 2018, 22, 965–977. [Google Scholar] [CrossRef]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Petrič, T.; Gams, A. Effect of Sequence Order on Autonomous Robotic Database Expansion. Advances in Robot Design and Intelligent Control. In Proceedings of the 25th Conference on Robotics in Alpe-Adria-Danube Region (RAAD16), Torino, Italy, 21–23 June 2017; pp. 405–412. [Google Scholar]
- Muelling, K.; Kober, J.; Kroemer, O.; Peters, J. Learning to Select and Generalize Striking Movements in Robot Table Tennis. Int. J. Robot. Res. 2013, 32, 263–279. [Google Scholar] [CrossRef]
- Petrič, T.; Gams, A.; Colasanto, L.; Ijspeert, A.J.; Ude, A. Accelerated Sensorimotor Learning of Compliant Movement Primitives. IEEE Trans. Robot. 2018, 34, 1636–1642. [Google Scholar] [CrossRef]
- Calinon, S.; Alizadeh, T.; Caldwell, D.G. On improving the extrapolation capability of task-parameterized movement models. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 610–616. [Google Scholar]
- Chen, N.; Bayer, J.; Urban, S.; van der Smagt, P. Efficient movement representation by embedding Dynamic Movement Primitives in deep autoencoders. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots (Humanoids), Seoul, Korea, 3–5 November 2015; pp. 434–440. [Google Scholar]
- Chen, N.; Karl, M.; van der Smagt, P. Dynamic movement primitives in latent space of time-dependent variational autoencoders. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 629–636. [Google Scholar]
- Yamamoto, H.; Kim, S.; Ishii, Y.; Ikemoto, Y. Generalization of movements in quadruped robot locomotion by learning specialized motion data. ROBOMECH J. 2020, 7, 29. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Babuschkin, I.; Czarnecki, W.; Mathieu, M.; Dudzik, A.; Chung, J.; Choi, D.; Powell, R.; Ewalds, T.; Georgiev, P.; et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 2019, 575, 350–354. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Cai, Y.; Lu, T.; Wang, R.; Wang, S. Real–Sim–Real Transfer for Real-World Robot Control Policy Learning with Deep Reinforcement Learning. Appl. Sci. 2020, 10, 1555. [Google Scholar] [CrossRef]
- Zhang, J.; Tai, L.; Yun, P.; Xiong, Y.; Liu, M.; Boedecker, J.; Burgard, W. VR-Goggles for Robots: Real-to-Sim Domain Adaptation for Visual Control. IEEE Robot. Autom. Lett. 2019, 4, 1148–1155. [Google Scholar] [CrossRef]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar]
- Hahnloser, R.; Sarpeshkar, R.; Mahowald, M.; Douglas, R.; Seung, H. Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit. Nature 2000, 405, 947–951. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Williams, C.; Klanke, S.; Vijayakumar, S.; Chai, K. Multi-task Gaussian Process Learning of Robot Inverse Dynamics. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 265–272. [Google Scholar]
- Aguero, C.; Koenig, N.; Chen, I.; Boyer, H.; Peters, S.; Hsu, J.; Gerkey, B.; Paepcke, S.; Rivero, J.; Manzo, J.; et al. Inside the Virtual Robotics Challenge: Simulating Real-Time Robotic Disaster Response. Autom. Sci. Eng. 2015, 12, 494–506. [Google Scholar] [CrossRef]
- Ude, A.; Nemec, B.; Petrič, T.; Morimoto, J. Orientation in Cartesian space dynamic movement primitives. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2997–3004. [Google Scholar]
- Ijspeert, A.; Nakanishi, J.; Pastor, P.; Hoffmann, H.; Schaal, S. Dynamical Movement Primitives: Learning Attractor Models for Motor Behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef]
- Pahič, R.; Ridge, B.; Gams, A.; Morimoto, J.; Ude, A. Training of deep neural networks for the generation of dynamic movement primitives. Neural Netw. 2020, 127, 121–131. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 3 December 2020).
- Gams, A.; Mason, S.A.; Ude, A.; Schaal, S.; Righetti, L. Learning Task-Specific Dynamics to Improve Whole-Body Control. In Proceedings of the IEEE-RAS International Conference on Humanoid Robots (Humanoids), Beijing, China, 6–9 November 2018; pp. 280–283. [Google Scholar]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lončarević, Z.; Pahič, R.; Ude, A.; Gams, A. Generalization-Based Acquisition of Training Data for Motor Primitive Learning by Neural Networks. Appl. Sci. 2021, 11, 1013. https://doi.org/10.3390/app11031013
Lončarević Z, Pahič R, Ude A, Gams A. Generalization-Based Acquisition of Training Data for Motor Primitive Learning by Neural Networks. Applied Sciences. 2021; 11(3):1013. https://doi.org/10.3390/app11031013
Chicago/Turabian StyleLončarević, Zvezdan, Rok Pahič, Aleš Ude, and Andrej Gams. 2021. "Generalization-Based Acquisition of Training Data for Motor Primitive Learning by Neural Networks" Applied Sciences 11, no. 3: 1013. https://doi.org/10.3390/app11031013
APA StyleLončarević, Z., Pahič, R., Ude, A., & Gams, A. (2021). Generalization-Based Acquisition of Training Data for Motor Primitive Learning by Neural Networks. Applied Sciences, 11(3), 1013. https://doi.org/10.3390/app11031013