
Numerical and Experimental Evaluation of Structural Changes Using Sparse Auto-Encoders and SVM Applied to Dynamic Responses

 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Theoretical Background: Deep Learning, Sparse Auto-Encoder (SAE) and Support Vector Machine (SVM)
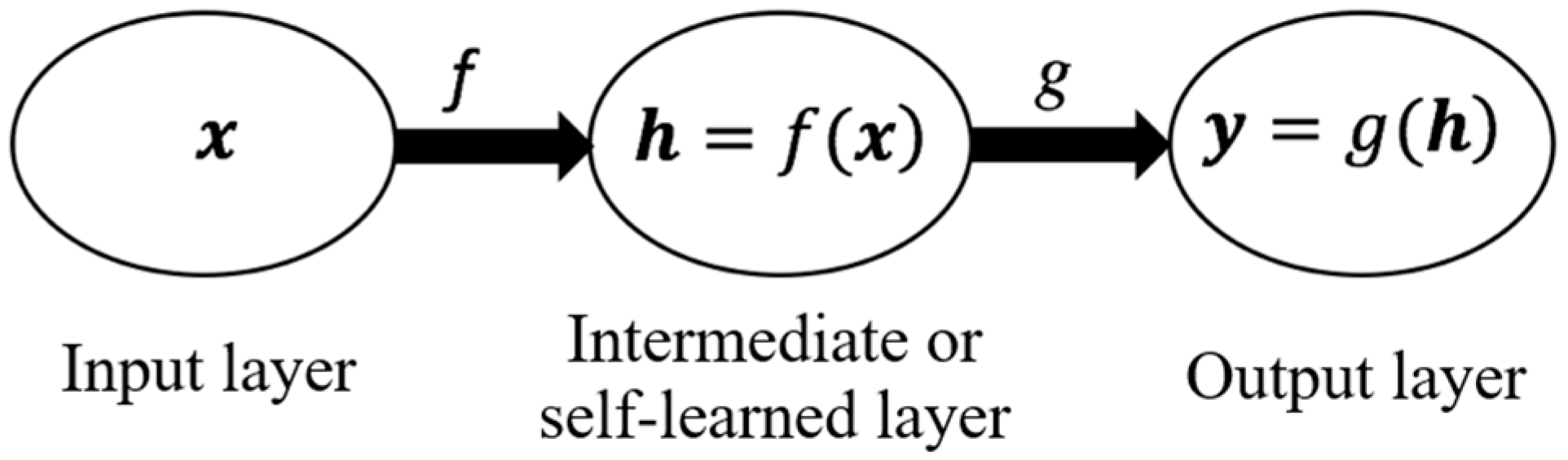
- Function f: represents the code function that operates over the input signal vector x (a single series of dynamic measurements, for instance).
- Vector h: stands for the result of a function f over a signal vector x. In other words, it is the feature vector.
- Function g: represents the code function that operates over the feature vector h. This function reconstructs an approximation of the original input signal vector x.
- Vector y: stands for the result of a function g over the feature vector h. In other words, it is the reconstruction of the auto-encoder’s input.
3. The Adopted SHM Strategy
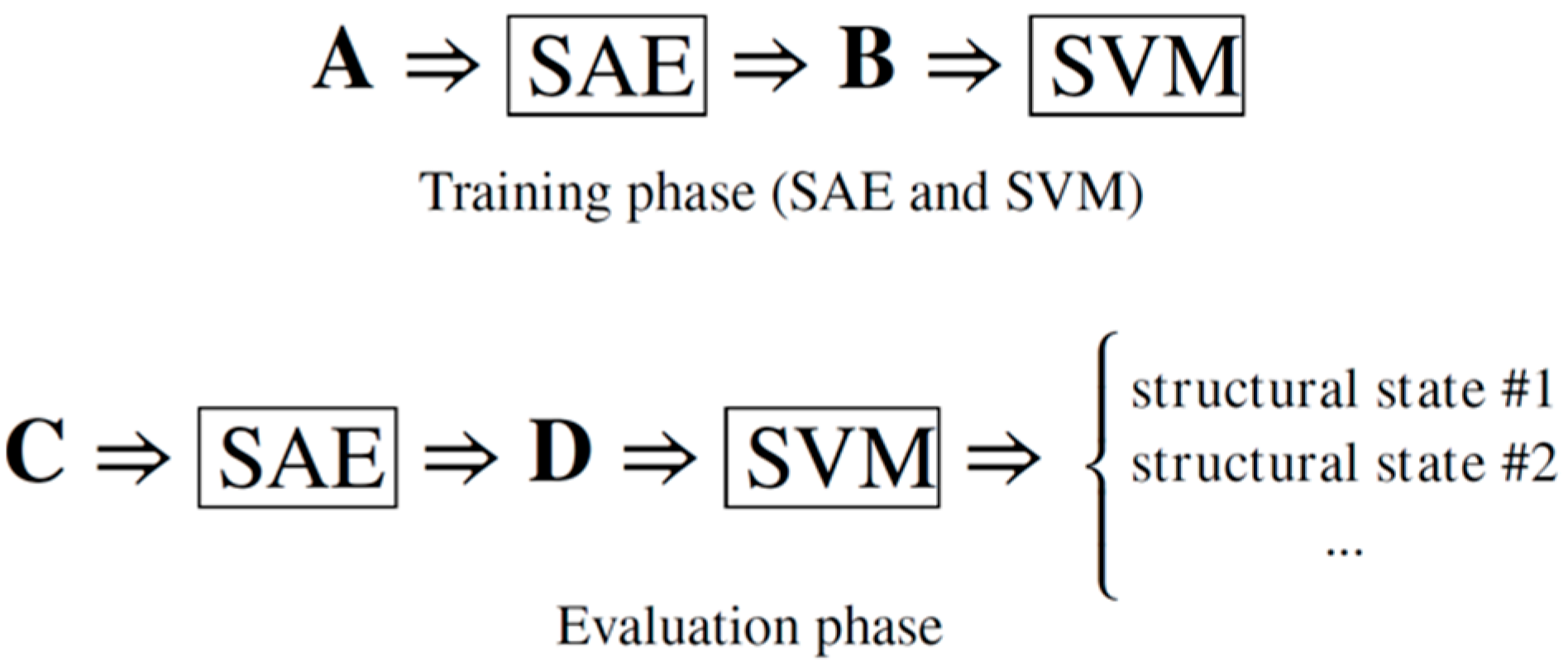
- Training phase
- (a)
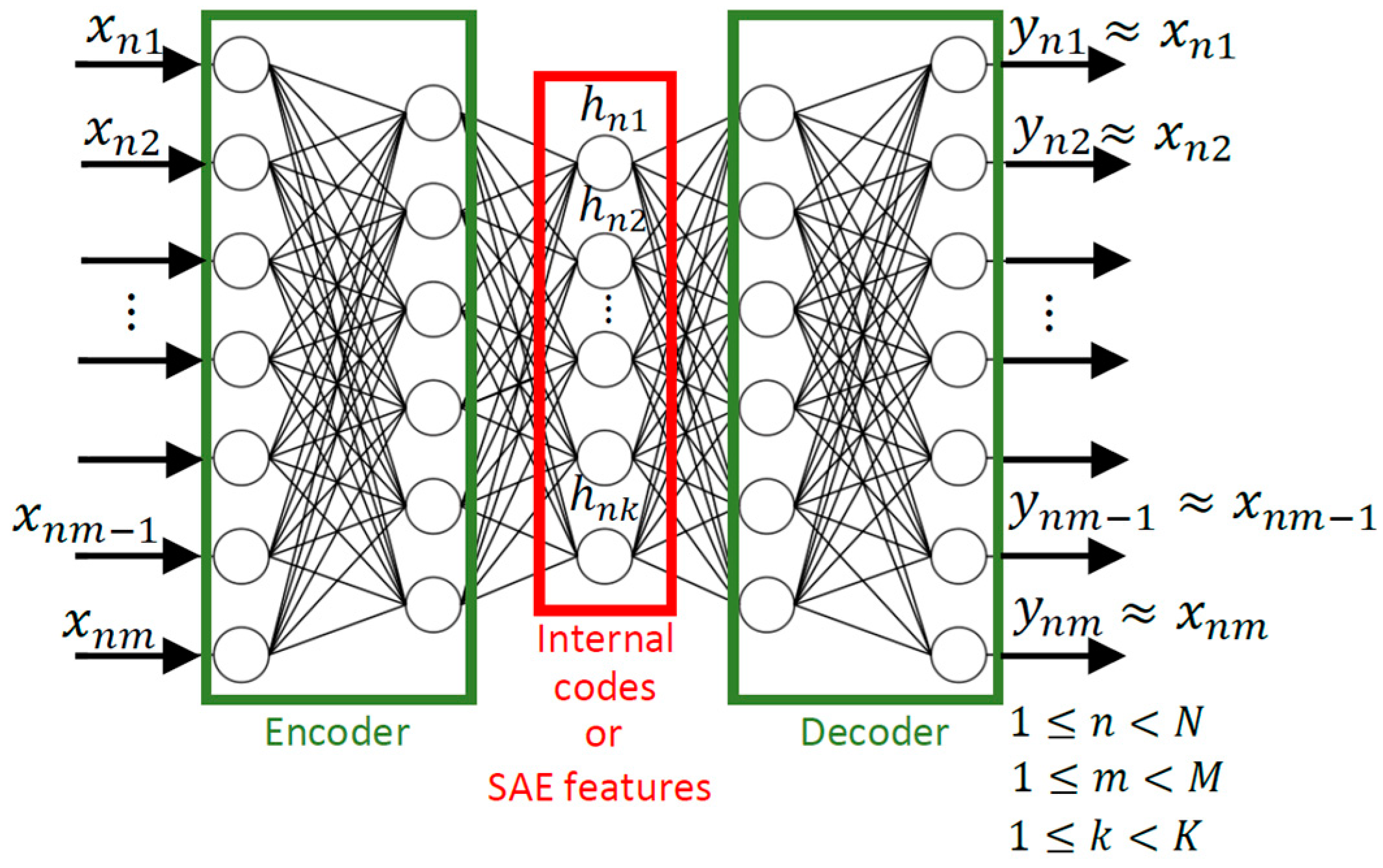
- Data organization. An input training matrix A with () elements is created, P being the number of dynamic tests randomly selected for the training phase, where M is the sampled signals’ length. Thus, matrix A is formed by arranging each selected vector x in a row of the input matrix. In other words, matrix A gathers the dynamic measurements.
- (b)
- Data characterization using SAE. This task is conducted in an unsupervised way via SAE, using matrix A. The penalization function is minimized and, for each vector x, a corresponding vector h is obtained. An SAE output matrix B with its () elements is organized with the output vectors h. It can be said that matrix B “collects” the feature vectors. The minimization is performed through a feedforward backpropagation algorithm employing the Scaled Conjugate Gradient (SCG) optimization method [41]. Furthermore, hyperparameters, such as the sparsity proportion , sparsity regularization and weight regularization , were selected empirically. These parameters are related to the sparse penalty function defined in Section 2 and assist in the determination of the best solution by the SAE [42].
- (c)
- Data classification using SVM. Although the signal characterization is unsupervised, the data classification model’s training process is supervised, since the pattern recognition herein is carried out using classical SVM. Hence, matrix B and its respective targets (referring to the structural conditions) are utilized for training the SVM. In this case, the SVM model is constructed using the Radial Basis Function (RBF) kernel and considers the one-against-one strategy to solve the multi-class problems. The parameters and (regularization terms from the RBF kernel and maximization formulation, respectively) were estimated through an exhaustive search procedure known as Grid Search [43] applying the 10-fold cross-validation [44].
- Evaluation phase. Assuming that the SVM models are well-trained and achieve acceptable classification rates, the performance of the proposed SHM strategy is directly linked to the SAE’s capability to extract features from the dynamic signals adequately. The current step is developed by evaluating the set of dynamic measurements that were not used in the previous phase, gathered in matrices and . Matrix , containing vectors (being , where is the number of available dynamic signals), is presented to the trained SAE network, resulting in a matrix with the respective vectors . Finally, matrix is presented to the trained SVM, whose output is the structural condition.
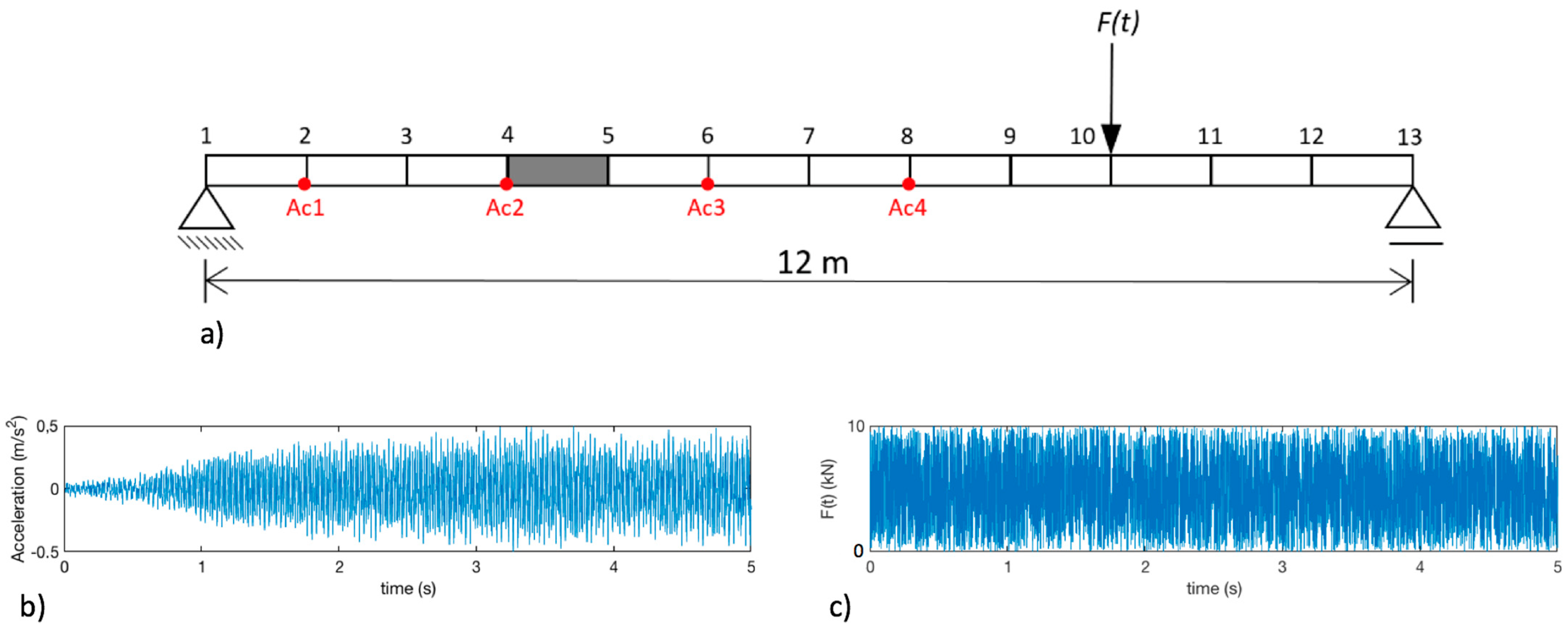
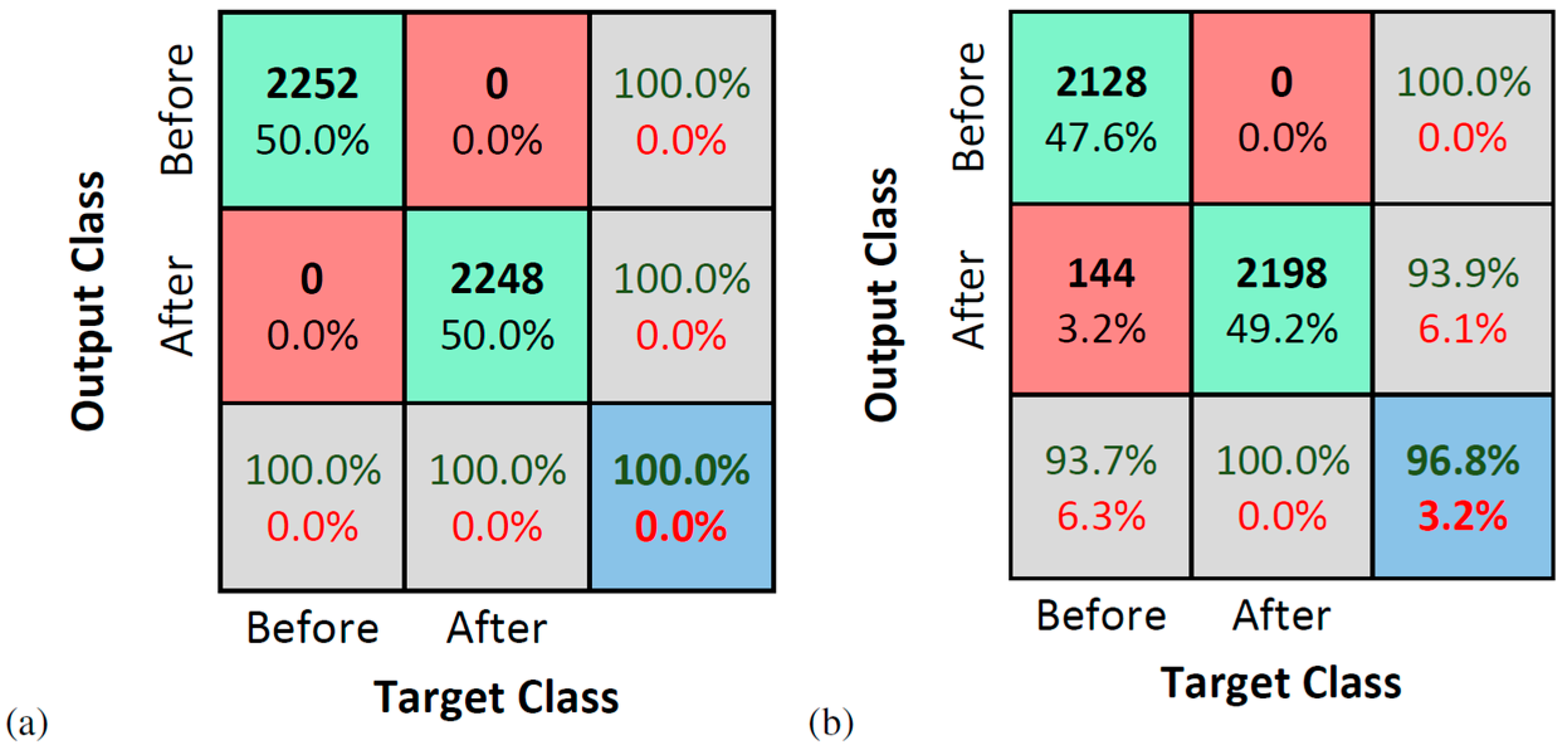
4. Numerical Application: Simply Supported Beam
Results
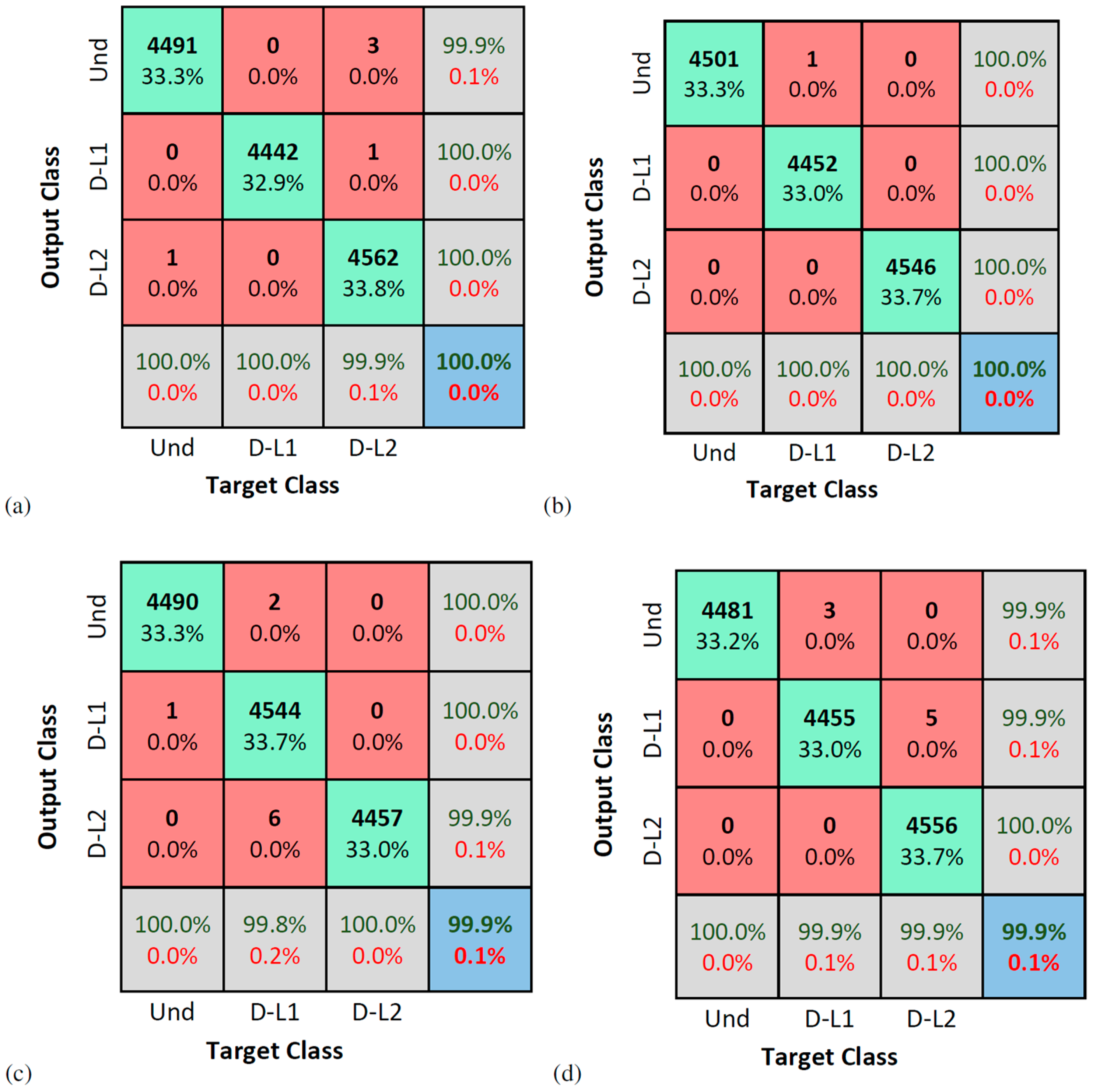
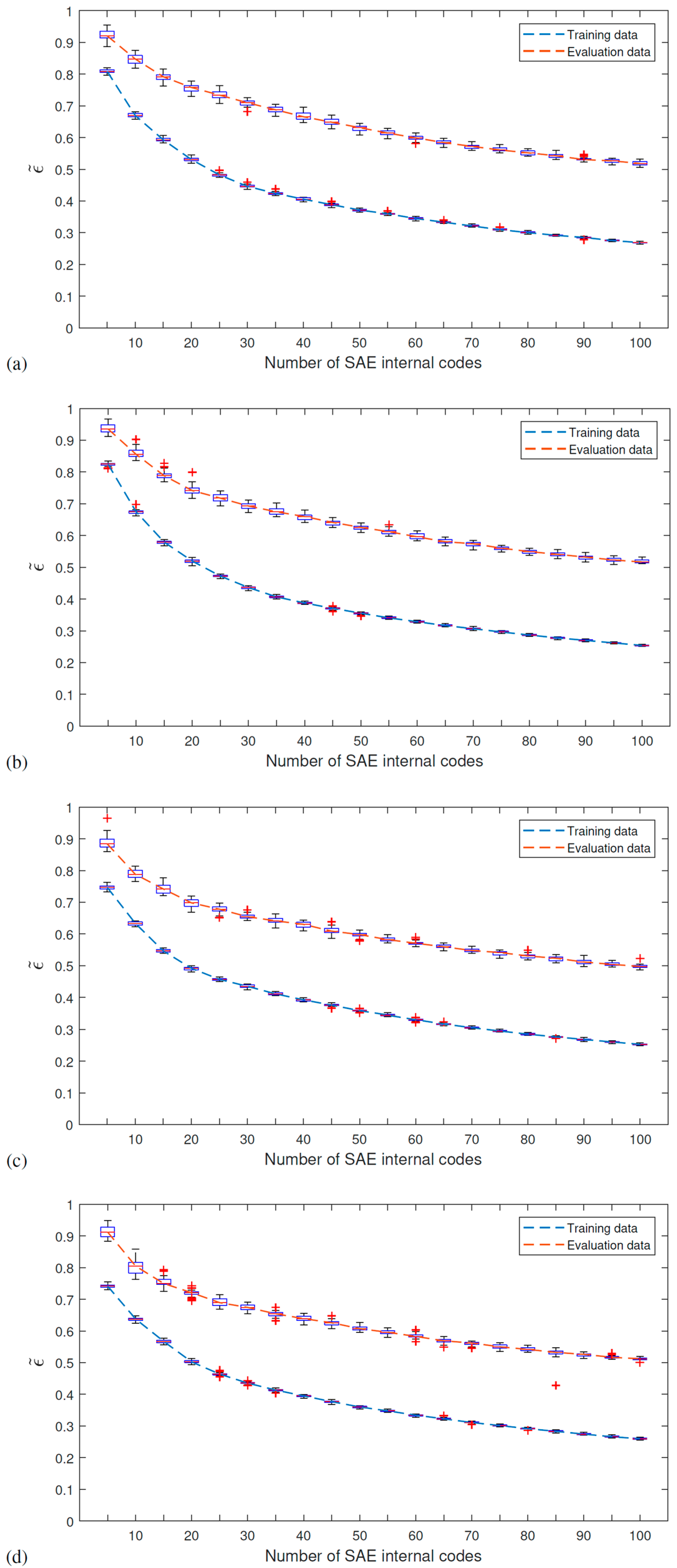
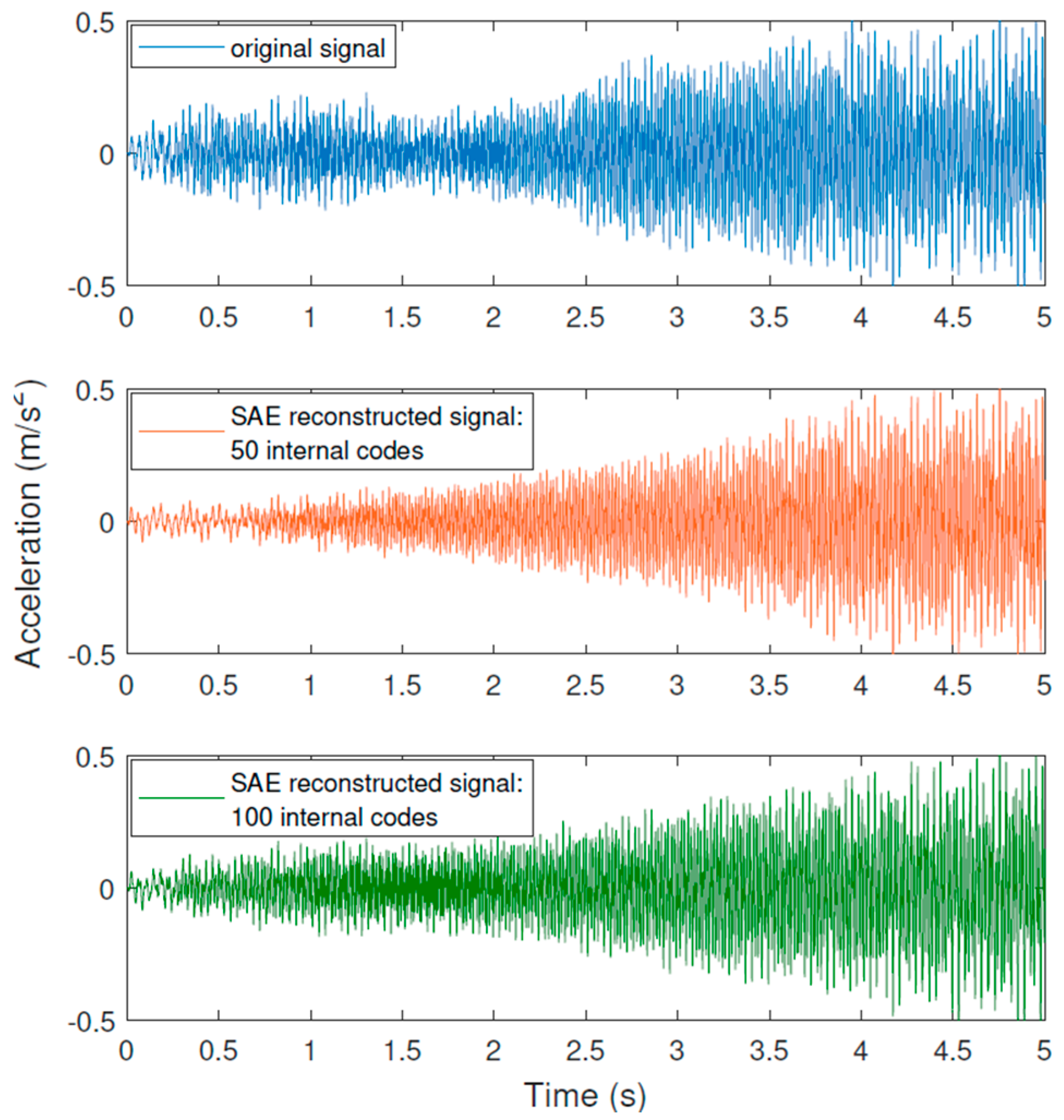
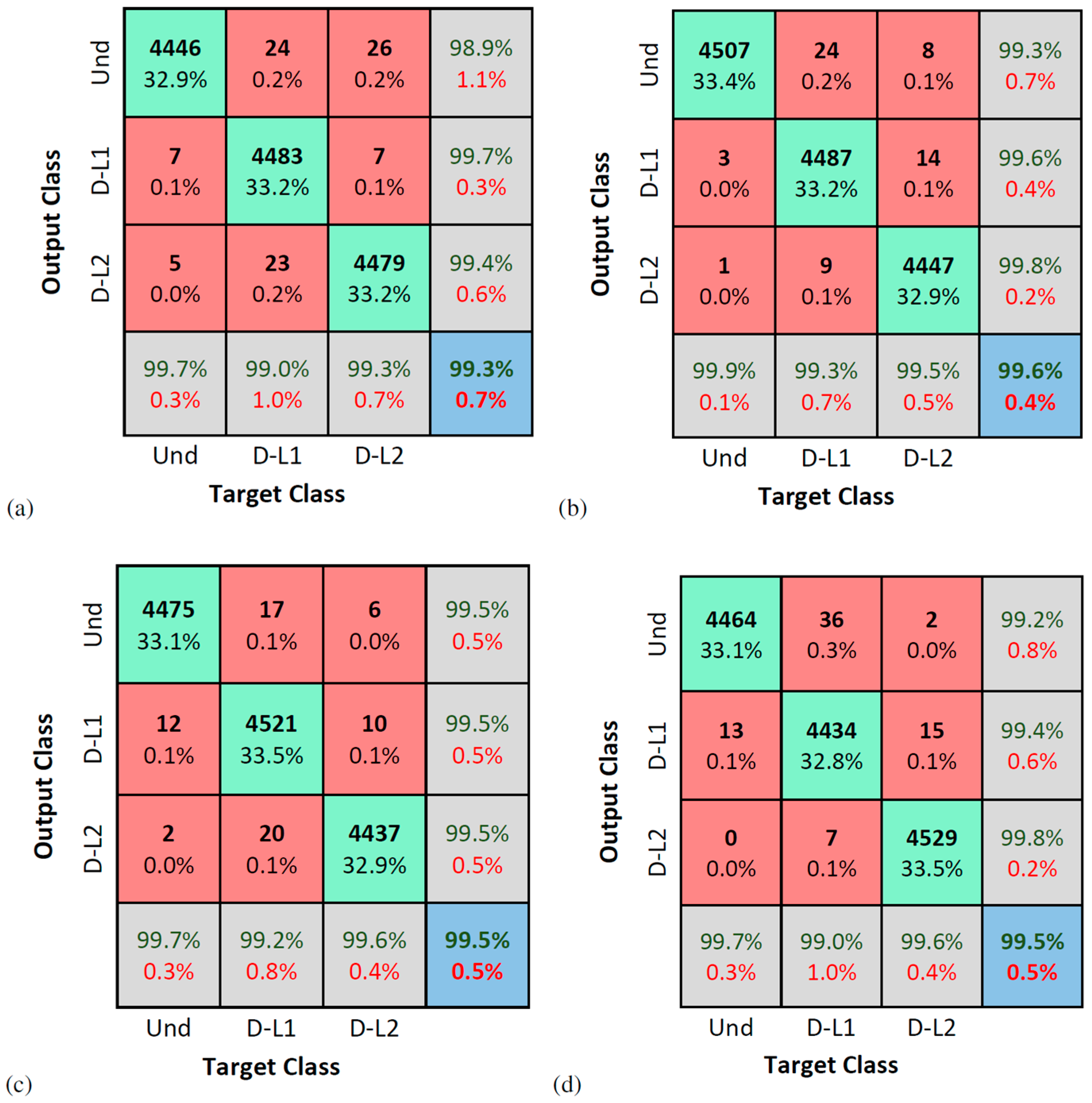
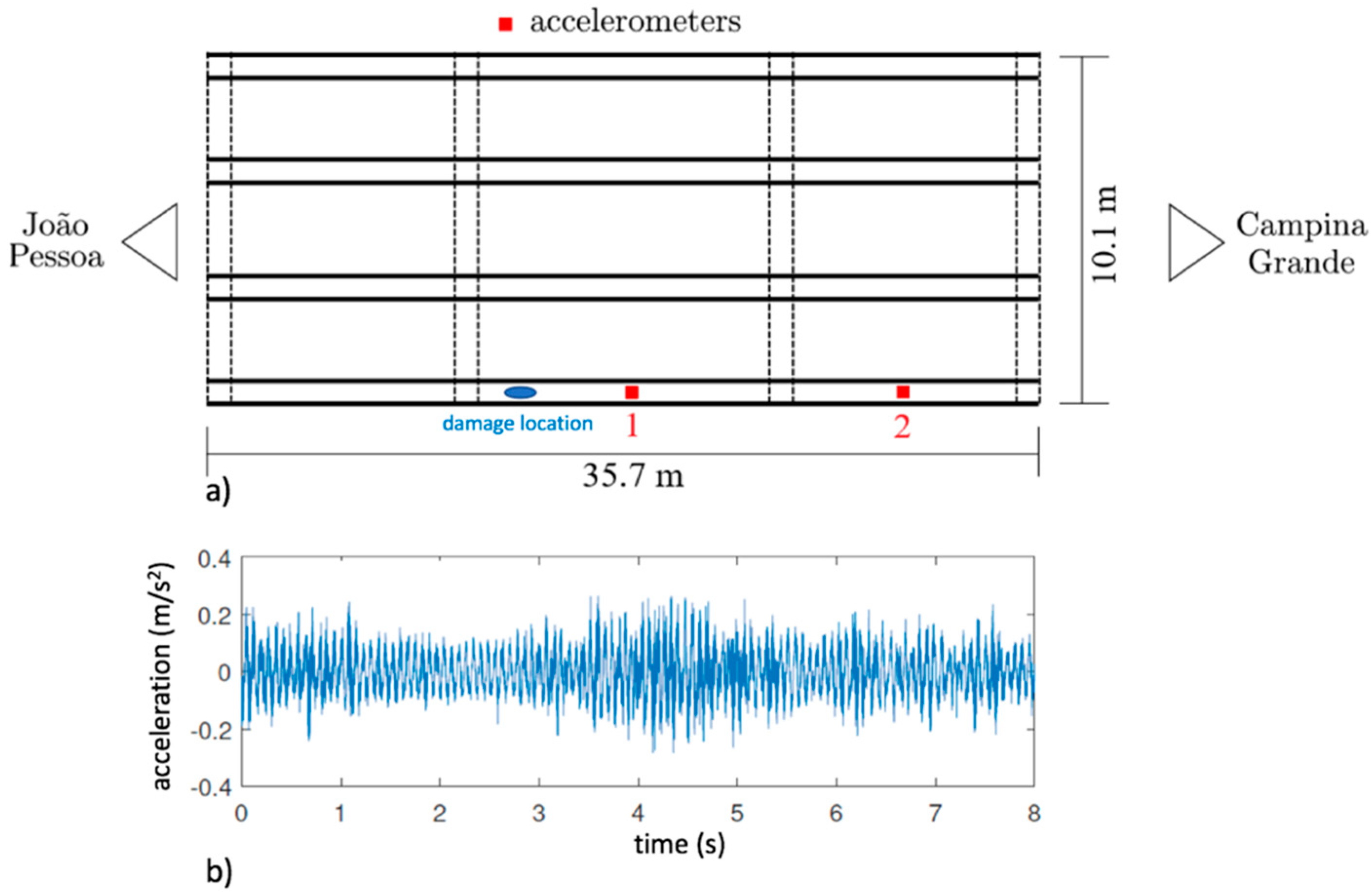
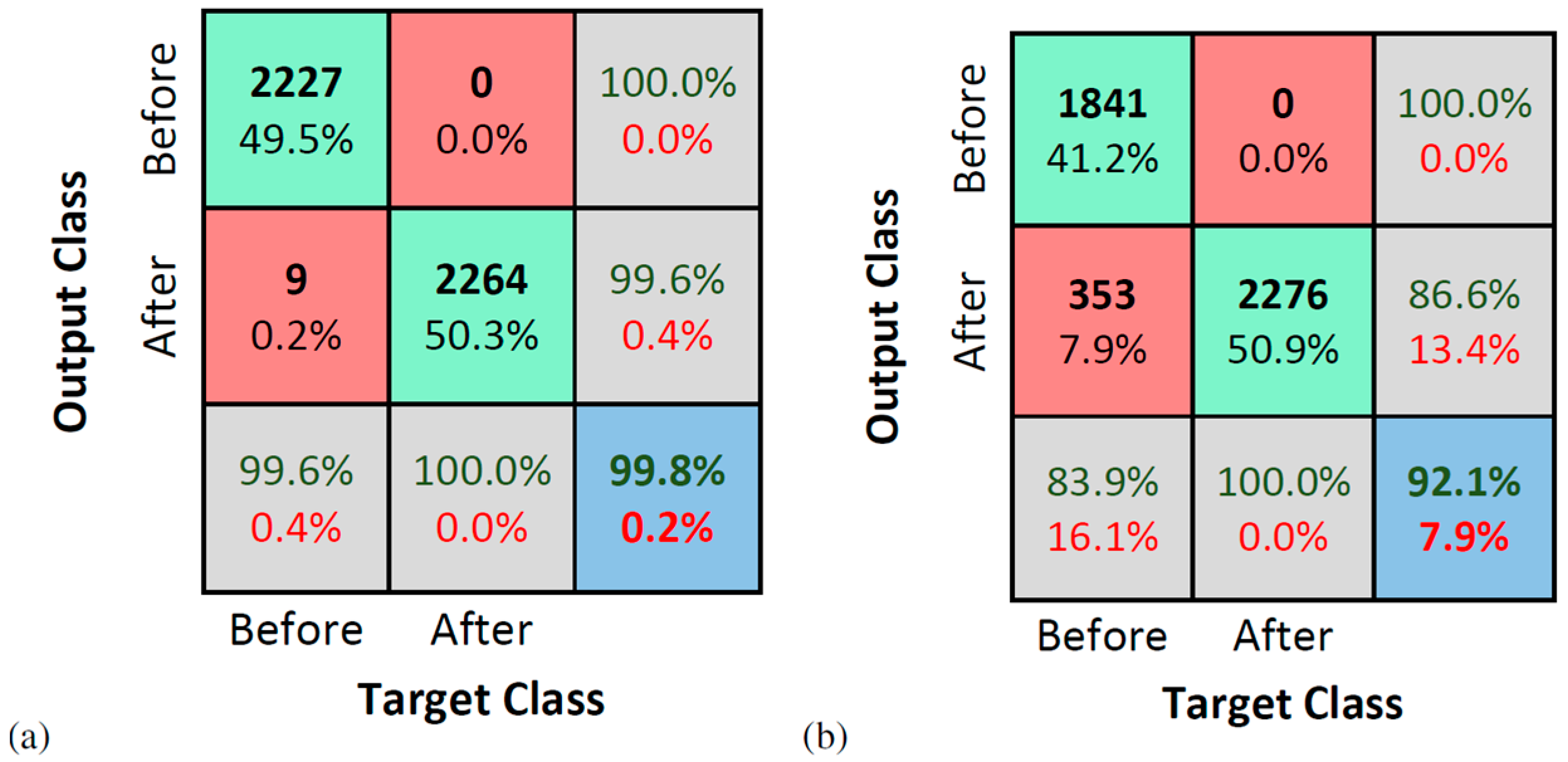
5. Experimental Application: Várzea Nova Viaduct
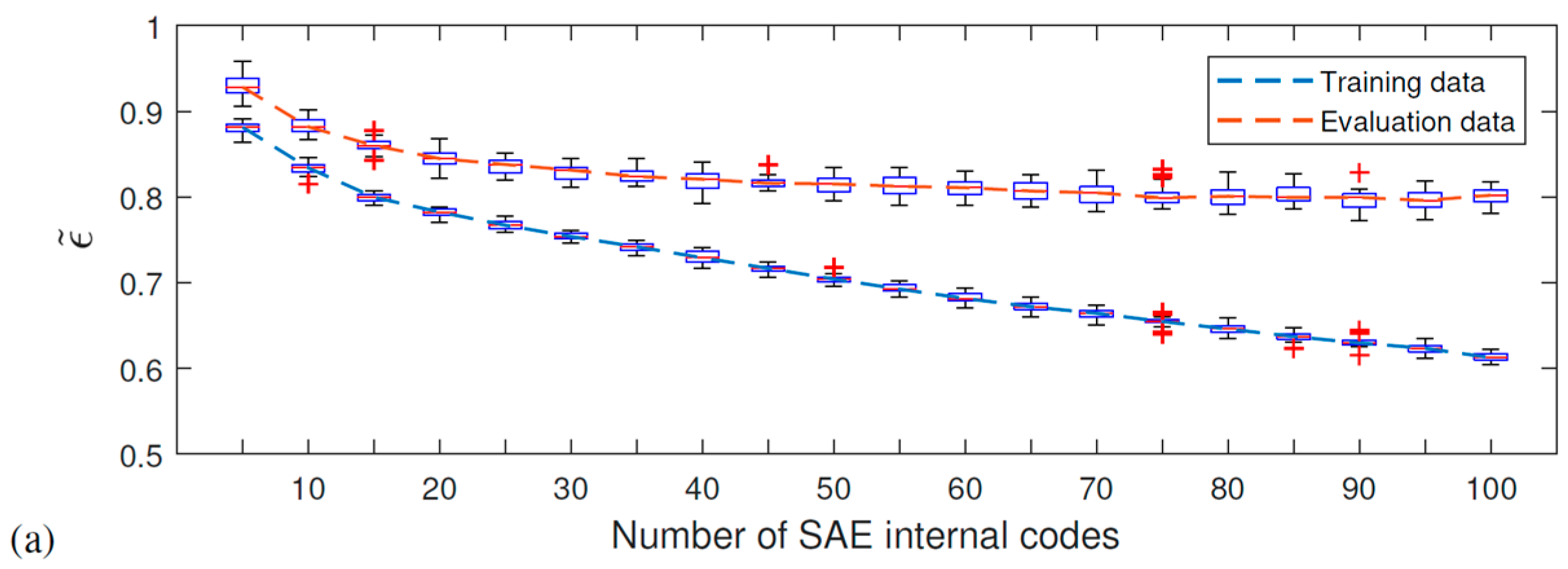
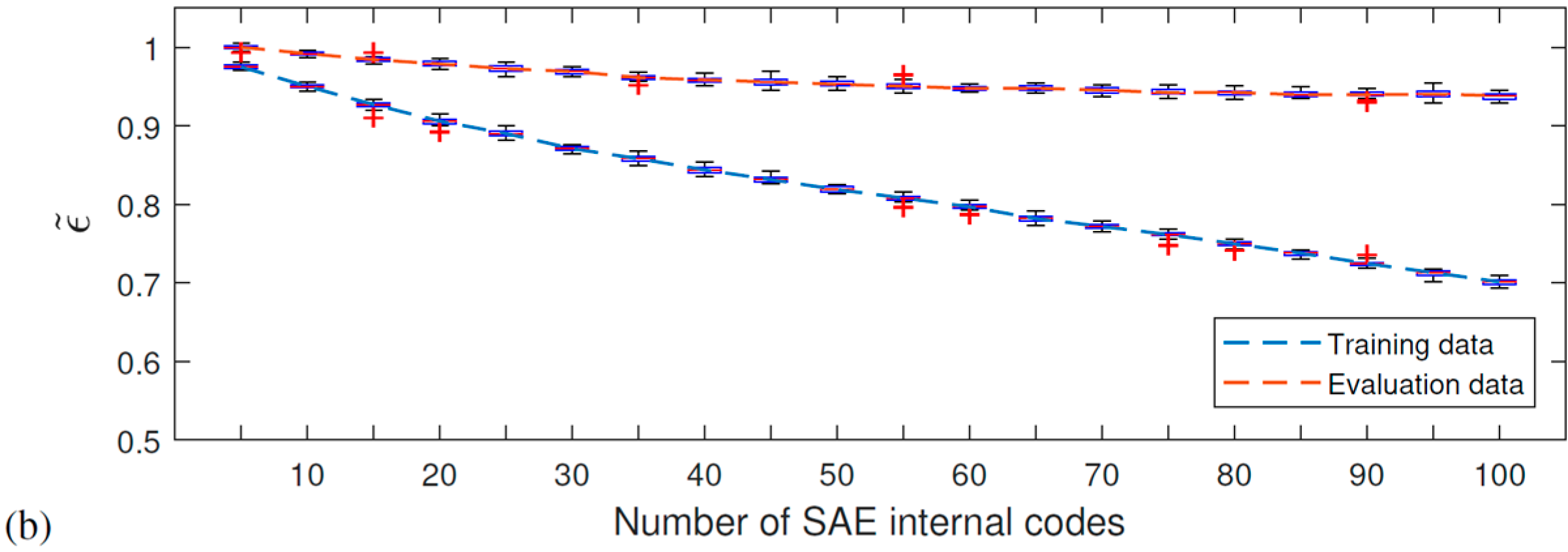
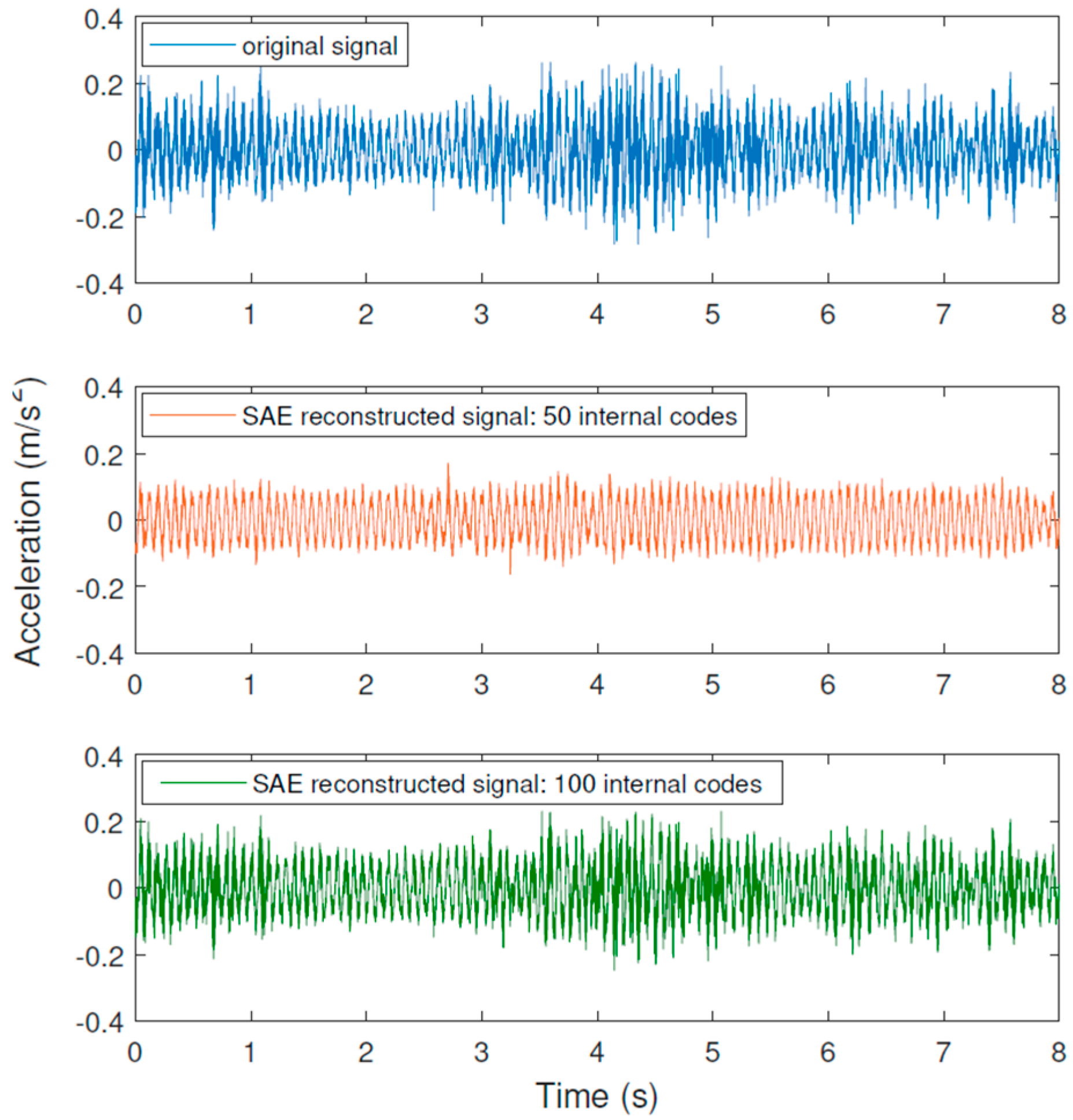
Results
6. Conclusions
- For the numerical model, the two damage scenarios were almost perfectly detected, indicating that the proposed method is sensitive to the damage level, corroborating its potential for multiple damage and damage quantification problems.
- For the Várzea Nova viaduct tests, the performance was slightly inferior due to the influence of external factors, such as noise, traffic, temperature, among others. Furthermore, even though better classification rates were obtained for signals reconstructed with 100 SAE characteristics, the results for dynamic data reconstituted with 50 features were more than reasonable. It is also important to highlight that the SAE features extracted have only 1% or 2% of the total signal’s length, for 50 or 100 internal codes, respectively. In addition, the performance of the proposed technique for the accelerometer closest to the damage was superior, which may indicate that the proposed methodology can be better explored in damage location problems.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Azim, M.R.; Gül, M. Data-driven damage identification technique for steel truss railroad bridges utilizing principal component analysis of strain response. Struct. Infrastruct. Eng. 2021, 17, 1019–1035. [Google Scholar] [CrossRef]
- Nunes, L.A.; Amaral, R.P.F.; Barbosa, F.S.; Cury, A.C. A hybrid learning strategy for structural damage detection. Struct. Health Monit. 2021, 20, 2143–2160. [Google Scholar] [CrossRef]
- Wah, W.S.L.; Chen, Y.-T.; Owen, J.S. A regression-based damage detection method for structures subjected to changing environmental and operational conditions. Eng. Struct. 2021, 228, 111462. [Google Scholar]
- Doebling, S.W.; Farrar, C.R.; Prime, M. A Summary Review of Vibration-Based Damage Identification Methods. Shock. Vib. Dig. 1998, 30, 91–105. [Google Scholar] [CrossRef] [Green Version]
- Avci, O.; Abdeljaber, O.; Kiranyaz, S.; Hussein, M.; Gabbouj, M.; Inman, D.J. A review of vibration-based damage detection in civil structures: From traditional methods to Machine Learning and Deep Learning applications. Mech. Syst. Signal Process. 2020, 147, 107077. [Google Scholar] [CrossRef]
- Yang, C.; Oyadiji, S.O. Damage detection using modal frequency curve and squared residual wavelet coefficients-based damage indicator. Mech. Syst. Signal Process. 2017, 83, 385–405. [Google Scholar] [CrossRef]
- Liu, G.; Zhai, Y.; Leng, D.; Tian, X.; Mu, W. Research on structural damage detection of offshore platforms based on grouping modal strain energy. Ocean Eng. 2017, 140, 43–49. [Google Scholar] [CrossRef]
- Marrongelli, G.; Gentile, C.; Saisi, A. Anomaly Detection Based on Automated OMA and Mode Shape Changes: Application on a Historic Arch Bridge. In Proceedings of the ARCH 2019, 9th International Conference on Arch Bridges, Porto, Portugal, 2–4 October 2019; pp. 447–455. [Google Scholar]
- Gillich, G.-R.; Furdui, H.; Wahab, M.A.; Korka, Z.-I. A robust damage detection method based on multi-modal analysis in variable temperature conditions. Mech. Syst. Signal Process. 2019, 115, 361–379. [Google Scholar] [CrossRef]
- Morales, F.A.O.; Cury, A.; Peixoto, R.A.F. Analysis of thermal and damage effects over structural modal parameters. Struct. Eng. Mech. 2019, 65, 43–51. [Google Scholar]
- Regni, M.; Arezzo, D.; Carbonari, S.; Gara, F.; Zonta, D. Effect of Environmental Conditions on the Modal Response of a 10-Story Reinforced Concrete Tower. Shock. Vib. 2018, 2018, 9476146. [Google Scholar] [CrossRef]
- Venglár, M.; Lamperová, K. Effect of the Temperature on the Modal Properties of a Steel Railroad Bridge. Slovak J. Civ. Eng. 2021, 29, 1–8. [Google Scholar] [CrossRef]
- Han, Q.; Ma, Q.; Xu, J.; Liu, M. Structural health monitoring research under varying temperature condition: A review. J. Civ. Struct. Health Monit. 2021, 11, 149–173. [Google Scholar] [CrossRef]
- Deraemaeker, A.; Worden, K. A comparison of linear approaches to filter out environmental effects in structural health monitoring. Mech. Syst. Signal Process. 2018, 105, 1–15. [Google Scholar] [CrossRef]
- Moughty, J.J.; Casas, J.R. A State of the Art Review of Modal-Based Damage Detection in Bridges: Development, Challenges, and Solutions. Appl. Sci. 2017, 7, 510. [Google Scholar] [CrossRef] [Green Version]
- Amezquita-Sanchez, J.P.; Adeli, H. Signal Processing Techniques for Vibration-Based Health Monitoring of Smart Structures. Arch. Comput. Methods Eng. 2016, 23, 1–15. [Google Scholar] [CrossRef]
- Salehi, H.; Burgueño, R. Emerging artificial intelligence methods in structural engineering. Eng. Struct. 2018, 171, 170–189. [Google Scholar] [CrossRef]
- Finotti, R.P.; Cury, A.A.; Barbosa, F.S. An SHM approach using machine learning and statistical indicators extracted from raw dynamic measurements. Lat. Am. J. Solids Struct. 2019, 16, e165. [Google Scholar] [CrossRef] [Green Version]
- Cardoso, R.D.A.; Cury, A.; Barbosa, F.; Gentile, C. Unsupervised real-time SHM technique based on novelty indexes. Struct. Control. Health Monit. 2019, 26, e2364. [Google Scholar] [CrossRef]
- Nguyen, D.H.; Bui, T.T.; De Roeck, G.; Wahab, M.A. Damage detection in Ca-Non Bridge using transmissibility and artificial neural networks. Struct. Eng. Mech. 2019, 71, 175–183. [Google Scholar]
- Umar, S.; Vafaei, M.; Alih, S.C. Sensor clustering-based approach for structural damage identification under ambient vibration. Autom. Constr. 2020, 121, 103433. [Google Scholar] [CrossRef]
- Chang, M.; Kim, J.K.; Lee, J. Hierarchical neural network for damage detection using modal parameters. Struct. Eng. Mech. 2019, 70, 457–466. [Google Scholar]
- Cremona, C.; Santos, J. Structural Health Monitoring as a Big-Data Problem. Struct. Eng. Int. 2018, 28, 243–254. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S.; Selim, B. Conceptual and empirical comparison of dimensionality reduction algorithms (PCA, KPCA, LDA, MDS, SVD, LLE, ISOMAP, LE, ICA, t-SNE). Comput. Sci. Rev. 2021, 40, 100378. [Google Scholar] [CrossRef]
- Esfandiari, A.; Nabiyan, M.-S.; Rofooei, F.R. Structural damage detection using principal component analysis of frequency response function data. Struct. Control. Health Monit. 2020, 27, e2550. [Google Scholar] [CrossRef]
- Agis, D.; Pozo, F. A Frequency-Based Approach for the Detection and Classification of Structural Changes Using t-SNE. Sensors 2019, 19, 5097. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Pathirage, C.S.N.; Li, J.; Li, L.; Hao, H.; Liu, W.; Wang, R. Development and application of a deep learning–based sparse autoencoder framework for structural damage identification. Struct. Health Monit. 2018, 18, 103–122. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Cha, Y.-J. Unsupervised deep learning approach using a deep auto-encoder with a one-class support vector machine to detect damage. Struct. Health Monit. 2021, 20, 406–425. [Google Scholar] [CrossRef]
- Bao, Y.; Tang, Z.; Li, H.; Zhang, Y. Computer vision and deep learning–based data anomaly detection method for structural health monitoring. Struct. Health Monit. 2019, 18, 401–421. [Google Scholar] [CrossRef]
- Silva, M.F.; Santos, A.; Santos, R.; Figueiredo, E.; Costa, J.C. Damage-sensitive feature extraction with stacked autoencoders for unsupervised damage detection. Struct. Control. Health Monit. 2021, 28, e2714. [Google Scholar] [CrossRef]
- Ma, X.; Lin, Y.; Nie, Z.; Ma, H. Structural damage identification based on unsupervised feature-extraction via Variational Auto-encoder. Measurement 2020, 160, 107811. [Google Scholar] [CrossRef]
- Shang, Z.; Sun, L.; Xia, Y.; Zhang, W. Vibration-based damage detection for bridges by deep convolutional de-noising autoencoder. Struct. Health Monit. 2021, 20, 1880–1903. [Google Scholar] [CrossRef]
- Cury, A.; Crémona, C. Pattern recognition of structural behaviors based on learning algorithms and symbolic data concepts. Struct. Control. Health Monit. 2012, 19, 161–186. [Google Scholar] [CrossRef]
- Finotti, R.; Bonifacio, A.; Barbosa, F.; Cury, A. Evaluation of computational intelligence methods using statistical analysis to detect structural damage. Mecánica Comput. 2016, 24, 1389–1397. [Google Scholar]
- Cardoso, R.D.A.; Cury, A.; Barbosa, F. Automated real-time damage detection strategy using raw dynamic measurements. Eng. Struct. 2019, 196, 109364. [Google Scholar] [CrossRef]
- Luo, H.; Huang, M.; Zhou, Z. A dual-tree complex wavelet enhanced convolutional LSTM neural network for structural health monitoring of automotive suspension. Measurement 2019, 137, 14–27. [Google Scholar] [CrossRef]
- Abdeljaber, O.; Avci, O.; Kiranyaz, S.; Gabbouj, M.; Inman, D.J. Real-time vibration-based structural damage detection using one-dimensional convolutional neural networks. J. Sound Vib. 2017, 388, 154–170. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 2013. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Møller, M.F. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 1993, 6, 525–533. [Google Scholar] [CrossRef]
- Ng, A. Sparse autoencoder. CS294A Lect. Notes 2011, 72, 1–19. [Google Scholar]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. 2003. Available online: https://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf (accessed on 6 November 2021).
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence—IJCAI, Montreal, QC, Canada, 20–25 August 1995; Volume 14, pp. 1137–1145. [Google Scholar]
- Singh, D.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar] [CrossRef]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study1. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structural Scenario | 1st Natural Frequency | 2nd Natural Frequency | 3rd Natural Frequency | 4th Natural Frequency |
|---|---|---|---|---|
| Healthy | 6.51 Hz | 26.06 Hz | 58.65 Hz | 104.32 Hz |
| Damage level 1 | 6.21 Hz | 25.04 Hz | 56.53 Hz | 100.30 Hz |
| Damage level 2 | 5.88 Hz | 23.92 Hz | 54.22 Hz | 96.03 Hz |
| SAE Parameters | |
| Sparsity proportion () | 0.050 |
| Sparsity regularization () | 4.000 |
| Weight regularization () | 0.001 |
| Encoder/decoder activation functions | Logarithmic sigmoid/linear |
| Optimization method | Scaled Conjugate Gradient |
| Gradient maximum value | 1.00E-6 |
| Max. of training epochs | 1000 |
| Training error metric | Mean-squared error |
| SVM Parameters | |
| Kernel function | RBF |
| Multiclass coding scheme | One-vs-one |
| —for 50 SAE internal codes | 1.0000 |
| —for 100 SAE internal codes | 1.5000 |
| —for 50 SAE internal codes | 0.3162 |
| —for 100 SAE internal codes | 0.3162 |
| Mean | Max. | Min. | Std. Deviation | |||||
|---|---|---|---|---|---|---|---|---|
| SAE Internal Codes | 50 | 100 | 50 | 100 | 50 | 100 | 50 | 100 |
| Ac1 | 99.32 | 99.96 | 100.00 | 100.00 | 98.22 | 99.78 | 0.46 | 0.08 |
| Ac2 | 99.56 | 99.99 | 100.00 | 100.00 | 98.22 | 99.78 | 0.43 | 0.04 |
| Ac3 | 99.50 | 99.93 | 100.00 | 100.00 | 98.67 | 99.56 | 0.35 | 0.12 |
| Ac4 | 99.50 | 99.94 | 100.00 | 100.00 | 98.89 | 99.56 | 0.38 | 0.13 |
| Structural Scenario | 1st Natural Frequency |
|---|---|
| Before strengthening | 13.37 Hz |
| After strengthening | 13.76 Hz |
| SAE Parameters | |
| Sparsity proportion () | 0.050 |
| Sparsity regularization () | 4.000 |
| Weight regularization () | 0.001 |
| Encoder/decoder activation functions | Logarithmic sigmoid/linear |
| Optimization method | Scaled Conjugate Gradient |
| Gradient maximum value | 1.0 × 10−6 |
| Max. of training epochs | 1000 |
| Training error metric | Mean-squared error |
| SVM Parameters | |
| Kernel function | RBF |
| Multiclass coding scheme | One-vs-one |
| —for 50 SAE internal codes | 0.3162 |
| —for 100 SAE internal codes | 0.3162 |
| —for 50 SAE internal codes | 0.3162 |
| —for 100 SAE internal codes | 0.0316 |
| Mean | Max. | Min. | Std. Deviation | |||||
|---|---|---|---|---|---|---|---|---|
| SAE Internal Codes | 50 | 100 | 50 | 100 | 50 | 100 | 50 | 100 |
| Accelerometer 1 | 99.80 | 100.00 | 100.00 | 100.00 | 98.67 | 100.00 | 0.43 | 0.00 |
| Accelerometer 2 | 92.10 | 96.78 | 97.99 | 99.33 | 87.25 | 91.95 | 2.62 | 1.87 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Finotti, R.P.; Barbosa, F.d.S.; Cury, A.A.; Pimentel, R.L. Numerical and Experimental Evaluation of Structural Changes Using Sparse Auto-Encoders and SVM Applied to Dynamic Responses. Appl. Sci. 2021, 11, 11965. https://doi.org/10.3390/app112411965
Finotti RP, Barbosa FdS, Cury AA, Pimentel RL. Numerical and Experimental Evaluation of Structural Changes Using Sparse Auto-Encoders and SVM Applied to Dynamic Responses. Applied Sciences. 2021; 11(24):11965. https://doi.org/10.3390/app112411965
Chicago/Turabian StyleFinotti, Rafaelle Piazzaroli, Flávio de Souza Barbosa, Alexandre Abrahão Cury, and Roberto Leal Pimentel. 2021. "Numerical and Experimental Evaluation of Structural Changes Using Sparse Auto-Encoders and SVM Applied to Dynamic Responses" Applied Sciences 11, no. 24: 11965. https://doi.org/10.3390/app112411965
APA StyleFinotti, R. P., Barbosa, F. d. S., Cury, A. A., & Pimentel, R. L. (2021). Numerical and Experimental Evaluation of Structural Changes Using Sparse Auto-Encoders and SVM Applied to Dynamic Responses. Applied Sciences, 11(24), 11965. https://doi.org/10.3390/app112411965