1. Introduction
Drowsiness and distraction are the two most significant reasons for fatal car accidents in the last two decades [
1]. In 2017, the US Department of Transportation’s National Highway Traffic Safety Administration (NHTSA) reported that 795 causalities in vehicle crashes were the result of driver drowsiness, which was 2.3–2.5% of the total fatal crashes in the US. According to NHSTA reports, 2841 lives were claimed in the accidents due to distracted drivers in 2018, which was 6–9% of the total fatal crashes in the US [
2]. At the time of a crash, 13% of distracted drivers were using their cell phones, indicating that cell phone usage was a major cause of these crashes [
2]. Some signs that indicate the drowsiness of a driver include the inability to keep eyes open, frequent yawning, leaning the head forward, and face complexion change [
3].
There are various metrics to determine the level of a driver’s drowsiness: physiological, vehicle-based, and behavioral measures [
4,
5]. In behavioral measures, information is based on the camera to detect slight changes in the driver’s facial expression. Facial expression analysis uses a combination of multiple facial features to predict various characteristics of the face, such as attractiveness [
6] or disease [
7]. It also can be used to evaluate driver drowsiness, such as extreme head poses and wrinkles in the forehead [
8,
9,
10], and facial landmarks [
11]. Eye blink rate and eye closure rate are other drowsiness detection measures [
12,
13,
14], along with the physiological signal registered using wearable (on-body) sensors, such as electroencephalography (EEG) [
15,
16], respiratory signals [
17], electrocardiogram/photoplethysmogram (ECG/PPG) signals [
18,
19], and heart rate variability (HRV) [
20]. Finally, the sitting posture of the human body can be recognized and evaluated using motion sensors [
21,
22] or video recordings [
23,
24] as well as hand gestures [
25].
Distraction is mainly a result of the driver’s in-attention that may be due to cell phone usage, eating, talking to other passengers, texting, or adjusting the radio or climate controls. In terms of the driver’s functionality, the NHTSA characterizes distraction as auditory, biomechanical, visual, or cognitive [
26]. Various approaches for detecting driver distraction have been developed, which can be classified based on the parameters being measured as driving performance, subjective, physical, biological, and hybrid measures. Driving performance measurements, such as braking, steering, and other relevant driving behaviors, are among these that can be used to detect visual distraction [
27]. Eye gaze is a useful distraction measuring tool, while subjective measures cannot be obtained in real-time in an uncontrolled driving environment. The drivers’ biological measures also affect the driving operation.
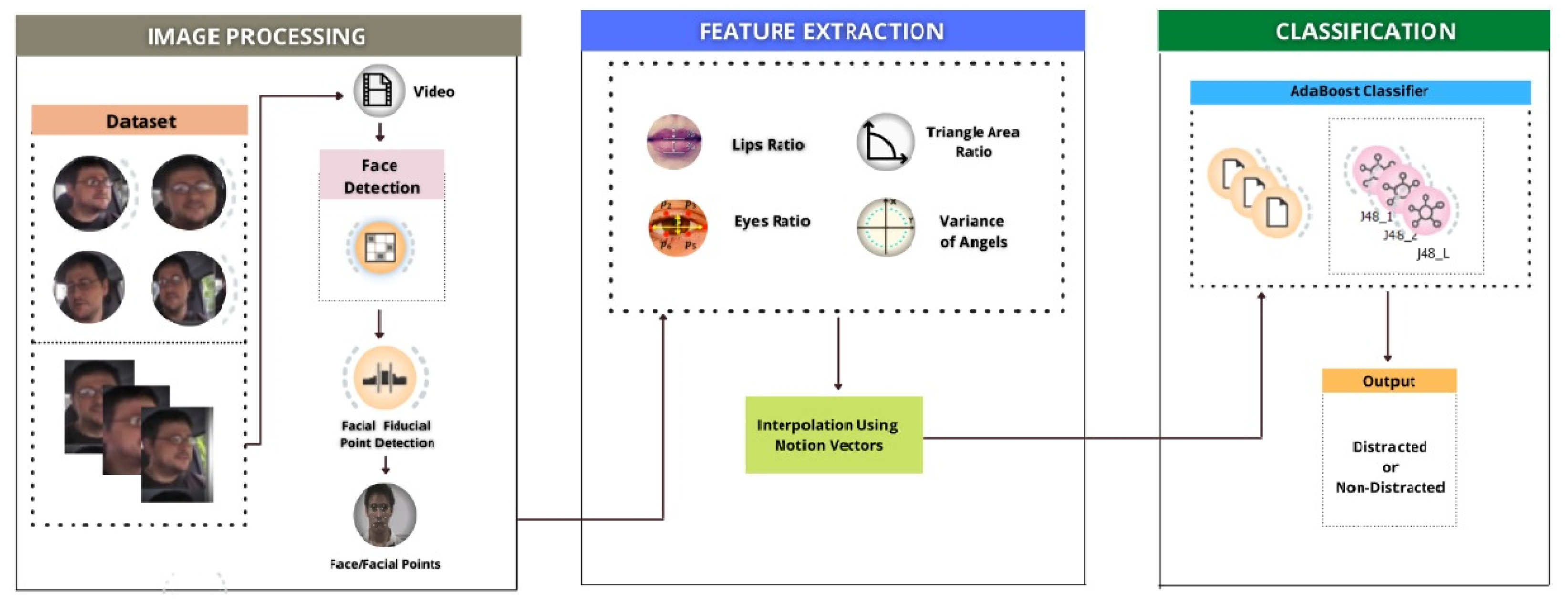
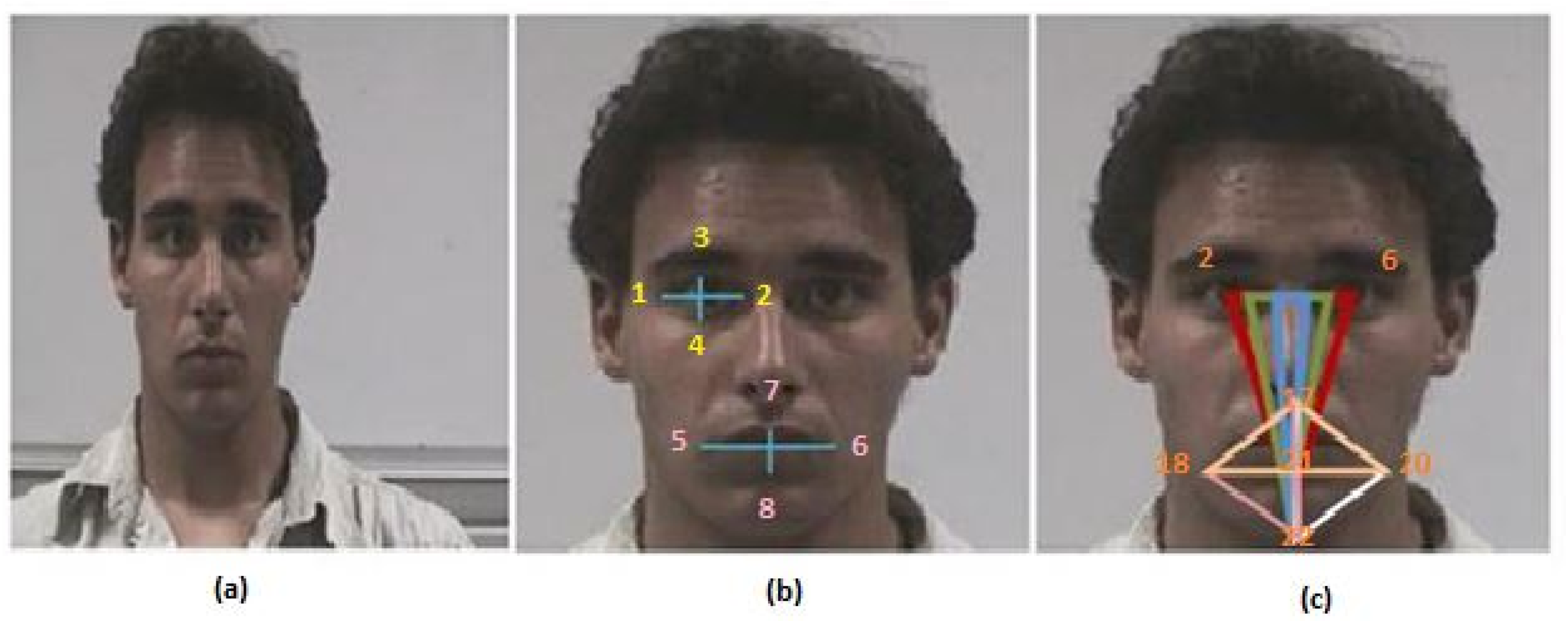
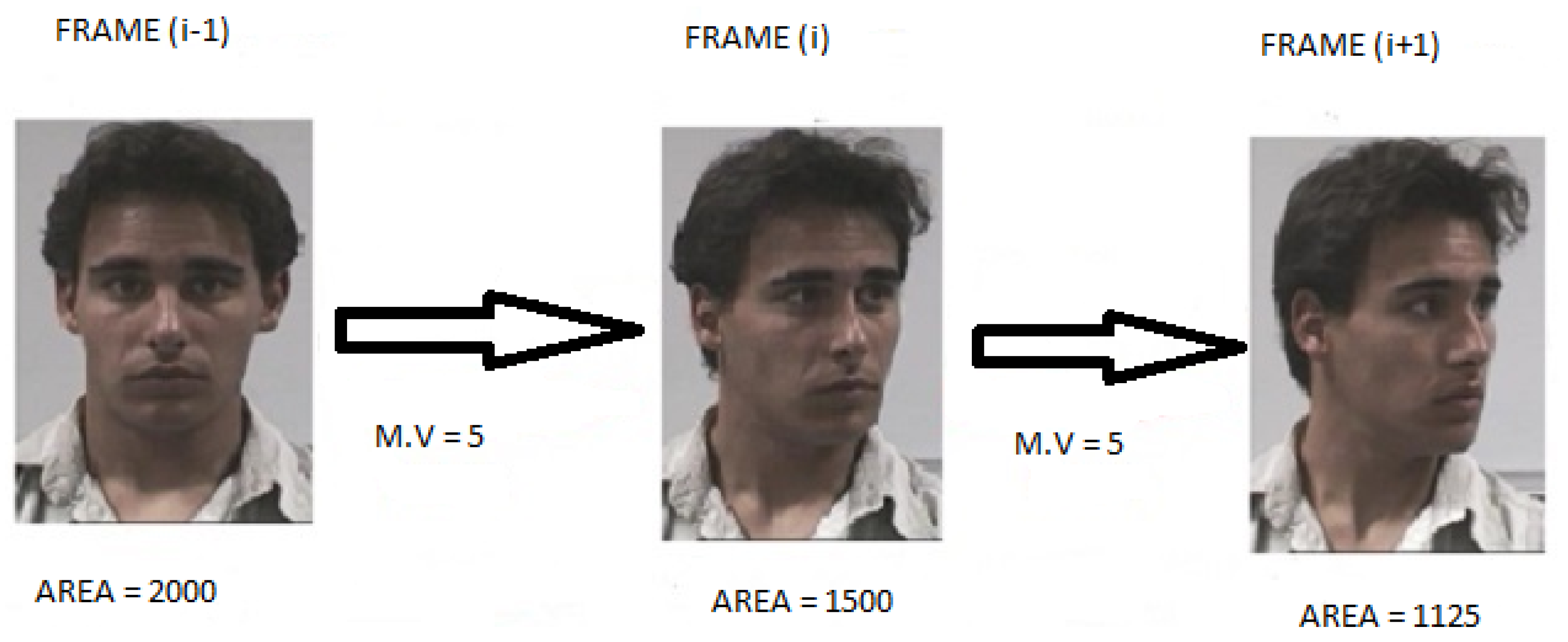
Human lives can be saved by using effective automatic distraction detection technologies. One way for detecting driver distraction is to detect the driver’s 3D head rotation, which can be classified into three types: changes in the yaw angle produce spinning (rotation in the horizontal plane), rotation caused due to the changes in pitch angle (rotation in the vertical plane), and rotation caused due to the changes in roll angle (back and forth rotation). The paper proposes a scale-invariant system under a boosting framework that can detect the driver’s head rotation due to a change in the yaw angle more accurately than the existing state-of-the-art methods. The work also proposes spatial and temporal variance-based features that estimate the geometric orientation of a driver’s head.
The structure of this paper is as follows.
Section 2 discusses related work on the drivers’ distraction.
Section 3 describes the proposed methodology for distraction detection due to drivers’ head panning, while the results and discussion are explained in
Section 4.
Section 5 presents the conclusion and discusses future work.
2. Related Work
Typically, head pose estimation is the first step in many driving safety applications. The head pose estimation methods can be categorized into visual methods, which monitor the position of face, its expression, and various movements of its parts, such as blinking or yawning. On the other hand, multimodal methods combine information from driver videos or images with additional data obtained from physiological or embedded car sensors.
An example of a visual method is the study of Nikolaidis et al., which calculated head yaw from the distortion of the isosceles triangle made by the mouth and the two eyes [
28]. They make use of the facial feature point locations and head shape to estimate the head pose. Another work proposed geometric models that only used the location of the center of the face and face boundaries for head yaw estimation [
29]. The geometric methods for head yaw estimation are invariant to facial expressions, support large head rotations, and work with or without glasses. Ji et al. proposed a similar approach for estimating and tracking the 3D pose of a face obtained from a single monocular camera [
30]. The shape of the 3D face was estimated by the ellipse and its aspect ratio. The detected face ellipse was then tracked in subsequent frames, which allowed tracking the 3D face pose. The authors claimed that their approach was more robust than existing feature-based approaches based on synthetic and real datasets. Zhang et al. proposed a system for estimating a head pose based on multi-view face detectors using a Naive Bayesian classifier [
31]. The temporal variation of the head pose was modeled by HMM that predicted the optimal head pose. Ohue et al. developed a driver’s facial pose recognition system that alarms if the face was distracted [
32]. Wang utilized the mouth and eye corner points for vanishing point and head pose estimation [
33]. The authors reported the mean error in head pose estimation of 2.56
, 1.67
, and 3.54
around the X-axis, Y-axis, and Z-axis, respectively, over eight video sequences. Balasubramanian et al. proposed a framework called Biased-Manifold Embedding for obtaining performance improvement in head pose estimation [
34]. The experimental results obtained an average pose angle estimation error up to 2
on the FacePix dataset, which contained 5430 face images with pose variations at a granularity of 1
. Wang et al. developed an approach that combined non-linear techniques of dimensionality reduction with a learned distance metric transformation [
35]. The experimental results showed that their method achieved accuracy in the range of 97% to 98% for facial images with varying poses and 96–97% accuracy on images with both pose and illumination variations. Fu et al. demonstrated that discriminating power can be sufficiently boosted by applying the local manner in sample space, feature space, and learning space via linear subspace learning [
36]. Experiments demonstrated that the local approach had around a 20% estimation error in head pose and 30% error in pitch.
Morency et al. presented a probabilistic framework that integrated the three approaches: the user independence and relative precision of differential registration, the stability and automatic initialization of static head pose estimation, and bounded drift of frame tracking [
37]. Ji et al. proposed a novel regression method for learning the regression between pose angles and image features and noise removal and outlier detection from the training data [
38]. Experiments on real data with outliers demonstrated an MAR of 9.1
in yaw estimation and 12.6
in pitch estimation. Hu et al. proposed a method for improving the accuracy of head pose estimation [
39]. The symmetry of the face image and the head pose resulted in the use of Gabor filters and Local Binary Pattern operators in one-dimension. The experiments on two different datasets resulted in a mean yaw estimation error of 7.33
.
Some visual methods used three-dimensional (3D) tracking. For example, Yan et al. proposed a novel manifold embedding algorithm supervised by both identity and pose information, called synchronized sub-manifold embedding (SSE), for precise 3D pose estimation [
40]. The experiments on the 3D pose estimation dataset, CHIL data for CLEAR07 evaluation, showed 6.60
mean pan estimation error and 8.25
mean tilt estimation error. Murphy-Chutorian et al. presented a new method for static head pose estimation and a new algorithm for visual 3D tracking [
41]. The system consisted of three interconnected modules that detected the driver’s head, provided initial estimates of the head pose, and continuously tracked its position and orientation with six degrees of freedom. Experimental results showed the mean estimation error of 3.62
in yaw, and 9.28
in pitch during the day driving. For night driving, the yaw estimation error of 5.18
and pitch estimation error of 7.74
was reported. Narayanan et al. proposed the head yaw angle estimation, with the advantages of real-time performance, ability to work with low-resolution images, and tolerable to partial occlusions [
42]. The proposed model achieved an MAR of 6.65
in head yaw estimation. Tran et al. proposed a vision-based distraction detection system that used four deep network architectures [
43]. Residual Network, VGG-16, AlexNet, and GoogleNet architectures resulted in a performance of frequency in the range of (8–14 Hz) and an accuracy in the range of (86–92%). The GoogleNet outpeformed the other network, yielding frequency of 11 Hz at an accuracy of 89%. Ruiz et al. presented a robust method to determine a head pose by using a multi-loss convolutional neural network to predict the intrinsic yaw angle, pitch angle, and roll angle directly from the image intensity through pose classification and regression [
44]. The authors claimed promising results on common pose benchmark datasets. Eraqi et al. proposed a genetically weighted ensemble of convolutional neural networks on a publicly available dataset with a great variety of distraction postures, reporting an accuracy of 90% [
45].
Minaee et al. surveyed the face detection techniques and summarized five important models, cascade-CNN-based models, R-CNN-based models, single-shot detector models, feature pyramid network-based models, and transformers-based models [
46]. The authors reported an accuracy of 34.5% to 96.5% on the Wider-Face dataset. The authors discussed major challenges in face detection, such as robustness on tiny faces, face occlusion, accurate lightweight models, few-shot face detection, interpretable deep models, and face detection bias reduction. Alotaibi et al. proposed a posture recognition system for drivers’ distraction based on a deep recurrent neural network (RNN) that yielded an accuracy of 96.23% and 92.36% on the StateFarm and AUC datasets, respectively, [
47]. Yang et al. proposed head pose estimation from a single image [
48]. The authors proposed a fine-grained structure mapping for spatially grouping features before aggregation. The fine-grained structure provides part-based information and pooled values. The authors claimed to have results comparable to the most recent methods. Torres et al. explored the machine learning algorithms to detect driver distraction due to smartphone usage [
49]. The authors reported that more than 95% accuracy can be obtained using CNN and gradient boosting methods. Ye et al. proposed a driver fatigue detection system based on the residual channel attention network and head pose estimation [
50]. The authors reported 98.62% accuracy of detecting eye state and 98.56% of detecting mouth state. The authors also proposed the perspective-n-point method to estimate excessive deflection of head. Xing et al. proposed a driver activity recognition system based on deep convolutional neural networks and reported to achieve an accuracy of 81.6% using AlexNet, 78.6% using GoogleNet, and 74.90% using ResNet50 neural networks [
51]. Chen et al. proposed a two-stream CNN model to estimate the spatial and temporal parameters of driver behavior [
52]. The authors reported an increase in accuracy of 30% compared to the score-level fusion neural network model.
In multimodal head pose estimation, gaze tracking is often used to improve the head pose estimation result. For example, Valenti et al. proposed a hybrid scheme to combine eye location and head pose information to yield better gaze estimation [
53]. The information obtained from the head pose was utilized for normalizing the eye regions, while the information generated by the eye location was used for correcting the pose estimation procedure. The experimental results indicated that the combined gaze estimation system was accurate with a mean error of 2–5
. Fu et al. studied a gaze tracking system that was important for monitoring driver’s attention, detecting fatigue, and providing better driver’s assistance systems, but it was difficult to deploy due to large head movements and highly variable illumination [
54]. The authors proposed a calibration method for determining the head orientation of the driver that utilized the rear-view mirror, the side mirrors, and the instrument board as calibration points. The system categorized the head pose in twelve gaze zones based on facial features using a self-learning algorithm. Experimental results showed that the automatic calibration method achieved an MAR of 2.44
in yaw estimation and an MAR of 4.73
in pitch estimation during day and night driving. Vicente et al. described a vision-based system to detect Eyes Off the Road (EOR) distraction [
55]. The system had three components: head pose and gaze estimation, robust facial feature tracking, and 3D geometric reasoning to detect EOR distraction. Experimental evaluation under a wide variety of illumination conditions, facial expressions, and individuals showed that the system achieved above 90% EOR accuracy for all tested scenarios. Hirayama et al. proposed a data mining approach for comparing the neutral driving state with the cognitive distracted state by monitoring the vehicle behavior and driver’s gaze variations [
56]. The proposed method achieved a classification accuracy of 96.2% under the distracted condition and 76.6% under neutral condition. Fridman et al. investigated the question: How much better could the driver gaze be classified using both eye and head pose versus only head pose [
57]? The experimental results showed that eye pose increased the average accuracy from 89.2% to 94.6%. Lee et al. proposed a method that relied on fuzzy-system for detecting a driver’s corneal and pupil specular reflection (SR) that could track the gaze in a vehicle environment [
58]. Based on the fuzzy output, the proposed method excluded the eye region that had a high error rate. Experimental results on 20,654 images showed that the method achieved a mean pupil detection error of 4.06 pixels and a mean corneal SR detection error of 2.48 pixels across different gaze regions.
Additionally, information obtained from external car monitoring can be used. For example, Loce et al. emphasized that major advancements in driver distraction could be achieved by jointly analyzing and fusing the internal state of the vehicle and the external state of the vehicle [
59]. The authors pointed out that in the CARSAFE mobile application, 83% precision and 75% recall rate for dangerous driving situations were achieved by combining both the internal video monitoring of vehicle and external video monitoring. Streiffer et al. proposed using deep learning-based classification (DarNet) on driver image data and inertial measurement unit data, attaining an accuracy of 87.02% [
60]. Hssayeni et al. reported an accuracy of 85% with ResNet deep convolutional network on a dataset that incorporates drivers engaging in seven different distracting behaviors [
61]. Peng et al. established a platform in which unexpected lane changing of cars was used as typical risky driving behavior [
62]. The authors established a neural network identification model based on a Bayesian filter using data samples to identify risky driving behaviors. The experimental results indicated an identification accuracy of 83.6% with the neural network model only, but this could be increased to 92.46% if the Bayesian filter was also used.
The previous works, including the features and the methods used alongside their limitations, are summarized in
Table 1. Note that none of the distraction detection measures are accurate enough for detecting distraction in all scenarios, so hybrid measures are used.
5. Conclusions and Future Work
Distraction detection is an important feature in modern semi-assisted vehicles, but it is difficult to detect it accurately due to the large number of factors involved. Numerous research works attempted to detect the distraction of a driver while driving, but most of them failed to achieve all the objectives of accuracy, simplicity, cost-effectiveness, and timeliness.
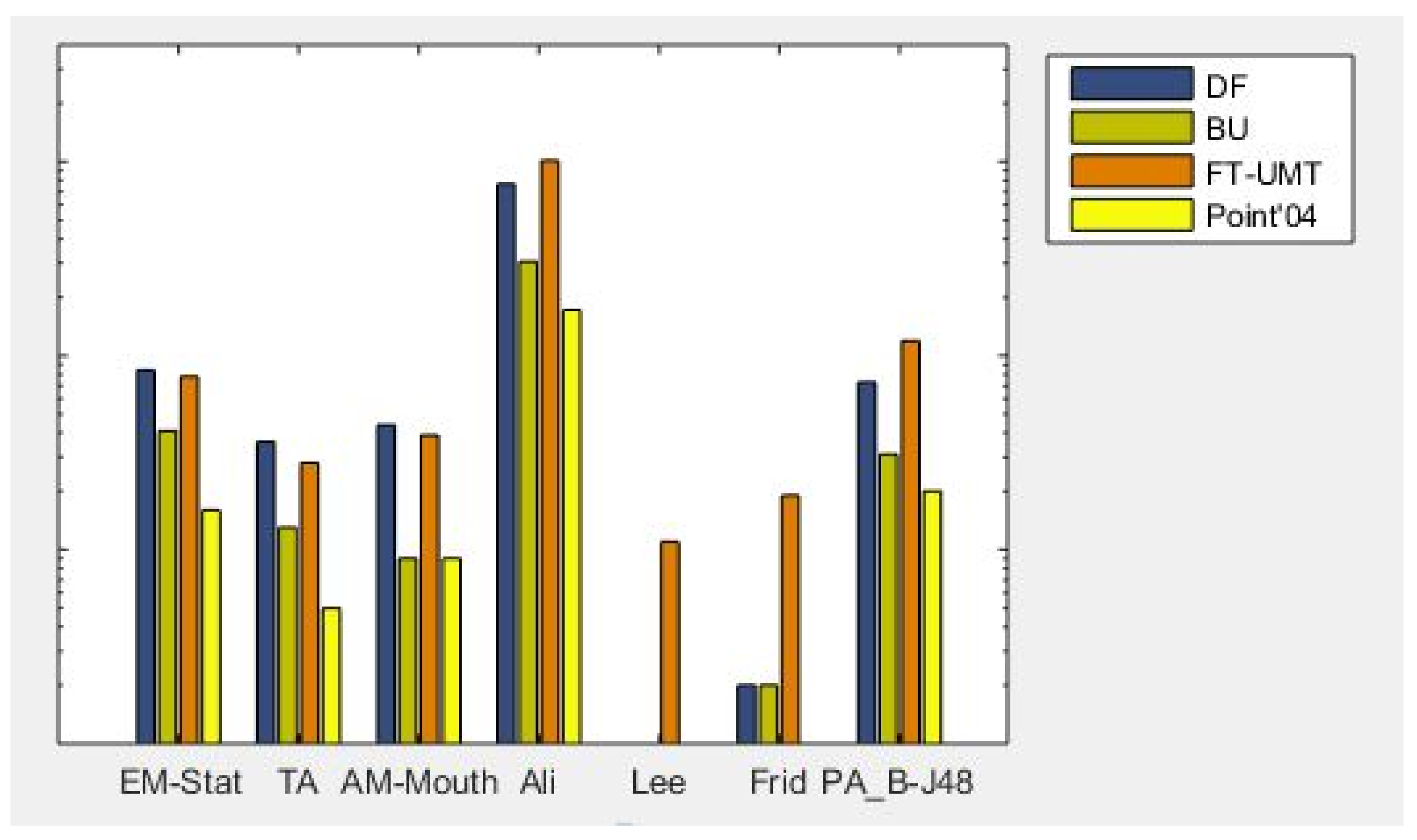
This paper proposes a feature-based approach that outperforms state-of-the-art methods, including EM-Stat, TA, AM-Mouth, Ali, Lee, and Frid on the DrivFace, Boston University, FT-UMT, and Pointing’04 datasets. The proposed approach also yields better percentage accuracy than the deep learning models, namely: ResNet-50, ResNet-101, VGG-19, Inception-V3, MobileNet, and Xception. The proposed approach is compared with its variants and gives better results. The deep learning models are end to end and provide better accuracy compared to the approach of hand-crafted features. However, deep learning approaches also come with a cost and require high processing power, large datasets for training, and long training time. On the contrary, the classical approach works better than deep networks on smaller datasets. Our proposed approach requires computationally cheaper hardware and fewer data. Our technique is simple, accurate, and fast enough to be implemented in the real world to detect a driver’s distraction from head panning.
As an extension of this work, the factors such as eye gaze movement, driver behavior while driving, driver’s facial expressions, driver actions, and vehicle movement can be considered. Distraction detection of a driver in night driving or dim light also needs to be investigated. A distraction detection system should be invariant to various factors, including camera distortion, projective geometry, multi-source non-Lambertian lighting, as well as the movement of facial muscles, biological appearance, facial expression, use of cell phone, hats, and glasses.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}