1. Introduction
Particle physics experiments, and especially those at particle colliders, have to deal with vast amounts of data where, very often, an elusive signal must be found against a much larger background. This has naturally paved the way for the usage of Machine Learning (ML) in the field. As in other problems where ML applies, the separation between signal and background relies on several variables (features) that behave differently in both categories. ML algorithms are able to statistically combine the separation power of different features, making the best of them all, and using the correlations between them in its favor. The resulting discrimination power is usually superior to anything a “manual” selection of requirements would achieve, and can be obtained in a more efficient way. The use of ML in particle physics is an emerging area, which is extending to more and more fields, as we shall see. A very complete (and live) review of this wide range of uses can be found in Reference [
1].
To better understand the implementation of ML as a way of improving the discrimination between signal and background, we chose the LHCb experiment [
2,
3] at CERN as a benchmark. LHCb is one of the large collaborations in the Large Hadron Collider (LHC) project, where protons are accelerated to ultrarelativistic energies (∼14 TeV) and then made to collide against each other, allowing for the study of the smallest pieces of matter. These collisions happen at an incredibly high rate (∼40 million times per second), giving rise to hundreds of other particles whose interaction is then recorded by detectors (such as LHCb), which act as gigantic photographic cameras that collect 90 petabytes of data per year [
4]. From these vast datasets, scientists try to extract interesting and rare phenomena, such as undiscovered particles or very infrequent particle decays, whose characteristics help to understand the properties of the smallest pieces of matter.
The usual pipeline in analyses at a LHC experiment is as follows. Particles produced by collisions leave different types of electronic signals at the different components of the detectors (or subdetectors). These subdetectors are specialized in different aspects, from tracking to particle identification (PID). Their final goal is to provide as realistic a picture as possible of what happened after the collision. This picture involves knowing the energy, identity and position of the particles produced, and is usually referred to as “reconstruction”. To reconstruct each collision, different algorithms help to interpret the electronic signals grouping the particle “hits” into tracks or understanding which type of particle left those hits. Another type of object that is often reconstructed at particle colliders are jets, which are groups of particles flying very close to each other and usually originating from a single energetic particle of interest. Determining the nature of this particle from the properties of jets (known as tagging) is also a frequent task in the reconstruction of collisions. Although they are not the goal of this study, all these aspects have recently led to surge in the use of ML. Recent examples are the use of graph neural networks (aspects of some of these ML algorithms are discussed later in the paper) for PID [
5], reinforcement learning for jet reconstruction [
6] or deep learning for track reconstruction [
7] or tagging of jets [
8]. We refer one more time to Reference [
1] for a more complete compendium of examples.
Once particle collisions are reconstructed, analysts are faced with a list of objects they must use to conduct measurements of interest (to perform what particle physicists denote “analyses”). Note that this reconstruction is not perfect, but instead limited by the resolution of the detectors. Although efforts can be made to improve this resolution, such as improving the calibration of detectors by means of convolutional neural networks [
9], the reconstructed objects will always be different to their “original” counterparts, which limits what experiments can do with them. One of the main consequences of this is that, very often, it becomes very hard to distinguish the target signals that experiments look for from backgrounds composed of other particles with similar properties. For instance, if one looks for an exotic new particle decaying into a pair of hadrons, this could be faked by situations in which each hadron originates from a different standard particle, although they are located close to each other in space. This all fits very nicely with the use of ML algorithms, particularly with classifiers that are able to separate scarce signals hiding behind much larger amounts of background. Finding the best of these classifiers has been the subject of many studies in particle physics, using algorithms of very different kind, ranging from boosted decision trees [
10] to deep learning [
11]. Alternative involves unsupervised [
12] or semi-supervised [
13] algorithms, with the goal of optimizing searches for rare phenomena for which more traditional methods have failed to date. Despite the many efforts being conducted in this area of signal-background discrimination by means of ML, as we shall see, most analysts either still rely on more traditional approaches or do not use the latest, best-performing, tools available in terms of libraries and algorithms. Assessing this question in detail is one the main goals of this paper.
To some extent, the LHCb experiment has pioneered the application of ML at the LHC. This involves, for instance, the use of Multi-Variate Analysis (MVA) classification libraries in some of their first analyses [
14] or the introduction of ML in the online trigger system of the detector [
15,
16], which runs automatically at every LHC proton collision. Even if LHCb is, in many ways, an example of good use of ML in particle physics, in this paper we first assess the extent to which ML is used in their analyses and then what kind of libraries and algorithms are currently being used in the experiment. We also compare these aspects to those of other experiments. We then contrast the performance of some of the most frequent ML libraries and those used in particle physics with simulated LHCb data, to find out the extent to which there is room for improvement in the signal-background discrimination achieved in standard analyses. Note this is a novelty, since many other comparisons of this kind rely on existing High-Energy Physics (HEP) datasets designed for benchmarking, but corresponding to other topologies, kinematic ranges and experiments [
17,
18,
19]. Next, we extend these tests to other libraries and algorithms. We quantify the overall margin of improvement and provide guidelines on how to use the latest libraries available in ML to improve the sensitivity of particle physics experiments. The conclusions of this study can mostly be expanded to experiments beyond LHCb. Therefore, instead of testing a specific algorithm to solve a specific problem, we try to provide a more global perspective, based on the actual popularity of algorithms and libraries in experiments and their potential performance. In summary, our main goals are:
Finding out the popularity of different algorithms and libraries at LHC experiments.
Determining whether the most popular methods are those that provide the best performance.
Providing examples of potential alternatives, which might have a better performance.
Describing how these alternatives might depend on the conditions of the analysis, such as the amount of statistics that are available for training.
This article is divided as follows. In
Section 2 we present the main libraries and tools one can use for signal-background discrimination and check their use in different LHC experiments.
Section 3 introduces the datasets we simulated to perform the comparisons in the rest of the paper, as well as the main features that we used to discriminate signal against the background.
Section 4 presents a first comparison of the performance of different ML libraries for classification, out of those presented in
Section 2, when facing simulated data. This comparison is extended in
Section 5 to more libraries and algorithms. We then discuss our results in
Section 6. Finally, we conclude in
Section 7.
2. Main Ml Algorithms for Signal and Background Discrimination and Their Use at Particle Colliders
When tackling signal-background discrimination by means of ML, most analysts in LHC experiments automatically limit themselves to one library, TMVA [
20], and one algorithm, BDTs with AdaBoost. In this section, we describe both of these and discuss other convenient options on the market, in terms of libraries and methods.
The Toolkit for Multivariate Data Analysis (TMVA) used with ROOT [
21], is an open-source data analysis framework that provides all the necessary functionalities for processing large volumes of data, statistic analysis, visualization and information storage. ROOT was created at CERN and, although it was designed for HEP, it is currently used in many other areas such as biology, chemistry, astronomy, etc. As ROOT is specifically designed for HEP, the library is very popular and well-known for LHC experiments. The same is true for TVMA. As both ROOT and TMVA were developed some time ago, some of the latest techniques and innovations concerning data analysis are not yet available using just these tools. In this regard, several different TMVA interfaces have been recently created to solve this issue, with many framework options developed to integrate TMVA with more sophisticated libraries, such as Keras and PyTorch (described below). Thanks to this expansion, the use of ML for particle physicists is becoming easier, wider and more common. TMVA can be convenient for Python users, providing easy interfaces to examine data correlations, overtraining checks and a simpler event weighting management. Even though these characteristics are available in other Python libraries, TMVA offers the possibility of integrating every step of the process without the need for additional ones. Moreover, it offers suitable pre-processing possibilities for the data before feeding them into any of the classifiers. Thiese data must be given in form of either ROOT
TTrees or ASCII text files. The first is the usual format in which scientists at CERN deal with their datasets. The analyses in this paper are based on ROOT v6.22/08.
Sklearn [
22] is a native open-source library for Python, and is currently an essential tool for modern data analysis. It includes a large range of tools and algorithms, which allow for the appropriate statistical modeling of systems. It incorporates algorithms for classification, regression, clustering, and dimensionality reduction, and supports a wide variety of algorithms [
23] such as KNNs, boosted decision trees, random forests and SVMs among others. Furthermore, it is compatible with other Python libraries such as matplotlib [
24], pandas [
25], SciPy [
26] or NumPy [
27]. Contrary to TMVA, Sklearn was originally designed for Python. This means that the library provides a variety of modules and algorithms that facilitate the learning and work of the data scientist in the early stages of its development. For TMVA users, Sklearn can provide a versatile and simple interface for ML, with very simple applications for the trained classifier in new datasets. In this paper, we use Sklearn version 0.20.4.
Other popular types of libraries were designed to better deal with Neural Networks (NNs), which are introduced below. PyTorch [
28] created by Adam Paszke, is object-oriented, which allows for dealing with NNs in a natural and convenient way. An NN in PyTorch is an object, so each NN is an instance of the class through which the network is defined, all of which are inherited from the torch NNs Module. The torch NNs Module provides the main tools for creating, training, testing and deploying an NN. In our analyses, we use PyTorch 1.8.0. Keras [
29] is an open-source software library that provides a Python interface for artificial NNs. It is capable of running on top of Tensorflow [
30], Theano [
31] and CNTK [
32]. Keras has wide compatibility between platforms for the developed models and excellent support for multiple GPUs. For this paper, we use Keras Release 2.6.0.
Moving on to the methodologies, as explained above, BDTs are among the most popular at LHC experiments. BDT stands for “Boosted Decision Tree”, and is currently one of the most popular algorithms for classification in ML. BDTs are based on the combination of weak predictive models (decision trees or DTs) to create a stronger one. These DTs are generated sequentially, with each tree being created to correct the errors in the previous one. This process of sequencing is known as “Boosting”, and can be of different types. The usual trees in BDTs are typically “shallow”, which means they have just one, two, or three levels of deepness. BDTs were designed to improve the disadvantages of the regular DTs, such as as a tendency to overfit and their sensitivity to unbalanced training data. When boosting DTs, a very common choice is Adaptive Boosting (AdaBoost). This boosting technique is one of the canonical examples of ensemble learning in ML. In this method, the weights that are assigned to the classified instances are re-assigned at each step of the process. AdaBoost gives higher values to the more incorrectly classified instances in order to reduce bias and the variance. With this, one can can make weak learners, such as DTs, stronger. The main difference between other types of boosting and AdaBoost relates to the use of particular loss functions. BDTs boosted with AdaBoost are the most frequent algorithm used at the LHC for signal-background discrimination by means of ML. Due to this, in the first part of the paper, we focus on how the performance obtained by this algorithm depend on the library used (namely, TMVA vs. Sklearn).
A very popular alternative in ML is NNs. This is a type of model that can try to emulate the behaviour of the human brain, whose potential for HEP was first introduced decades ago [
33]. In NNs, nodes, usually denominated “artificial neurons”, are connected to each other to transmit signals. The main goal is to transmit these signals from the input to the end in order to generate an output. The neurons of a network can be arranged in layers to form the NN. Each of the neurons in the network is given a weight, which modifies the received input. This weight changes the values that come through, to later continue on their way through the network. Once the end of the network has been reached, the final prediction calculated by the network is shown as the output. In general, it can be said that an NN is more complex the more layers and neurons it has.
Although they are not directly part of this study, for reference, we now briefly review some of the algorithms that data scientists have developed more recently. Even though some of these are slowly being incorporated into HEP, they are beyond the scope of our analysis. One example of these new developments is that of Extreme Gradient Boosting (XGBoost) [
34], which is yet another type of boosting. XGBoost modifies the more traditional BDT algorithms by using a different objective function, so that a convex loss function is combined with a penalty term that accounts for the model complexity. XGBoost can be used together with different types of techniques, such as independent component analysis, gray wolf optimization or the whale optimization algorithm, to improve the general BDT results [
35,
36]. Going beyond this, we should now mention “liquid learning”. Liquid Learning [
37] is a new type of ML algorithm that continuously adjusts depending on new data inputs. This means that the algorithm is able to modify its internal equations do that it can always adapt to changes in the incoming data stream. The fluidity of this new type of learning makes the algorithms more robust against noise or unforeseen changes in the data. Finally, one of the most expected developments these days concerns quantum technologies, and, with these, quantum ML (QML) [
38]. QML algorithms and models try to use the advantages of quantum technologies to improve classical ML, for instance, by developing efficient implementations of slow classical algorithms using quantum computing.
In the process of analyzing how to make the most of ML in analyses at particle colliders, as mentioned above, we first compare the two best-known libraries in particle physics, TMVA and Sklearn, to quantify which one is more effective for the same problem, i.e., using the same data with the same characteristics and the same algorithm: a BDT with AdaBoost. For the second part of the paper, we increase the range of methodologies beyond the usual BDTs with AdaBoost to include NNs, and enlarge the range of libraries to PyTorch and Keras. The goal is to determine how all of these methods and libraries perform in terms of signal-background discrimination.
To compare the performance of different classifiers, the usual methodology in ML involves the use of the so-called ROC curve. A Receiver Operating Characteristic (ROC) curve is a representation of a classifying model, built to show the discrimination power of the classifier at different thresholds. The two parameters represented in the curve are the rate of true positives vs. the rate of false positives. We built ROC curves for all the classifiers of interest in this paper. For each classifier, one can also integrate the area under the corresponding ROC curve (AUC). The AUC turns out to be a very useful benchmark when one wants to compare the performance of different classifiers, providing a metric to quantify the separation power between different classes. In general, the higher the AUC score, the better the model, i.e., the more often it correctly assigns each instance to the class to which it belongs. This parameter is taken into account to compare the different classifiers. Moreover, we also account for the learning time needed for the algorithms to process the data, as well as the correlations with some key independent or “spectator” variables, such as the invariant mass.
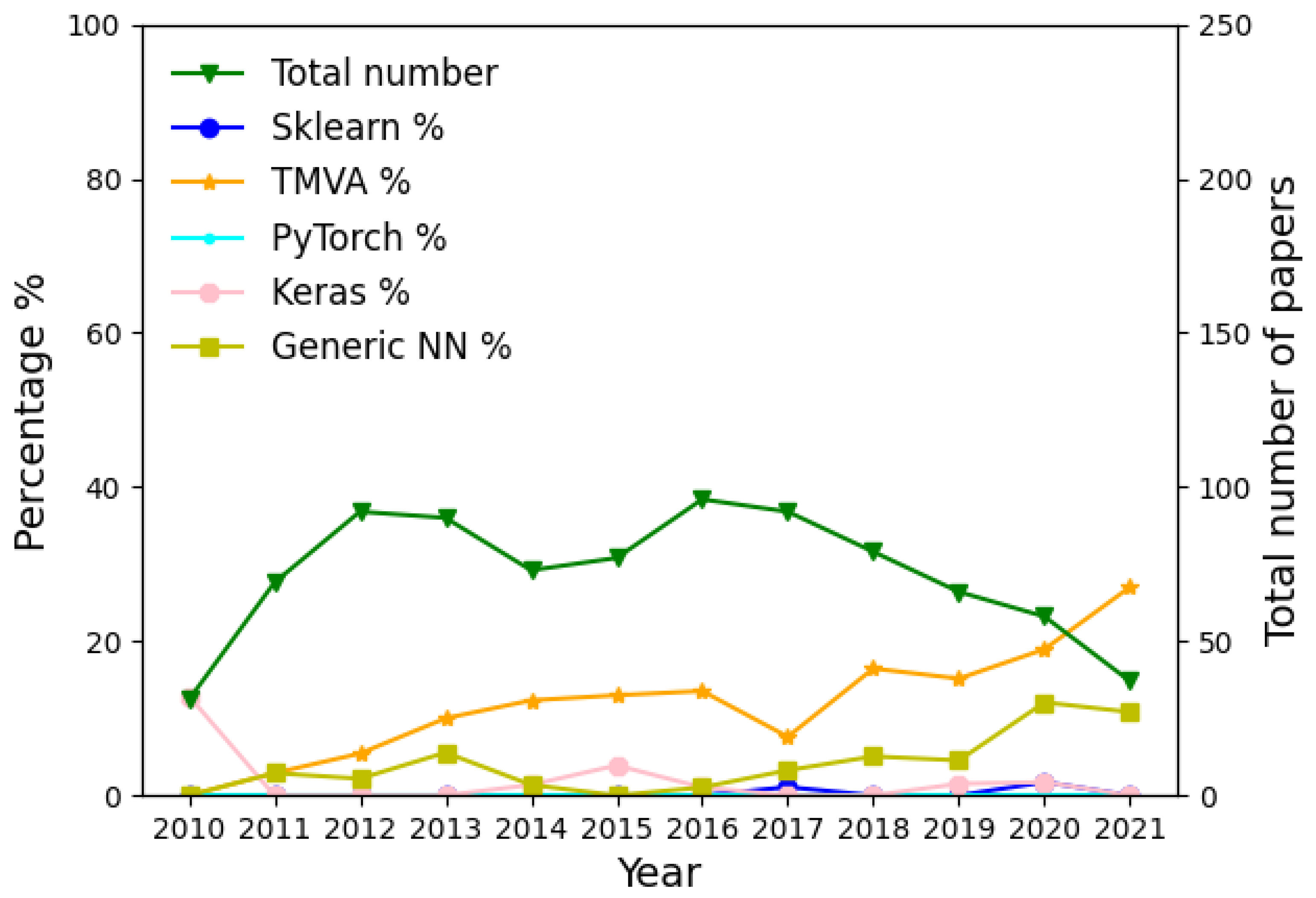
Before moving to the problem of creating the models, let us examine how different LHC experiments have been using ML in recent years. This is a counting exercise, with which we intend to evaluate the popularity of different ML algorithms and libraries, without directly comparing their performance, which will be performed in the following sections. After looking into all LHCb publications from 2010 to August 2021, we calculated the percentage of papers per year that use TMVA and the percentage of papers that use Sklearn or other popular libraries that deal with NNs, such as Keras and PyTorch. We also generated a label, which we named “Generic NN” for those papers in which the use of a Neural Network is implied but the library used is not mentioned. The result can be seen in
Figure 1, which shows how the use of TMVA is higher than Sklearn. In
Figure 2 and
Figure 3, we repeated this for ATLAS [
39] and CMS [
40], respectively. We observed a similar behaviour to LHCb, where the use of TMVA was preferred to the other libraries. In ATLAS, even though TMVA is still the most used tool, we can appreciate an increase in the use of Keras in the last two years. Note than, in all three experiments, the use of Keras, PyTorch or other types of general NNs usually was not focused on direct signal-background discrimination at the analysis level, but instead on other tasks related to the reconstruction of events at the LHC, such as jet reconstruction and tagging, PID or track reconstruction.
3. The Data
As we mentioned before, the data we used to compare all the classifiers were the same. The main characteristics of the data are described in this section.
The data were generated using the simulation tool Pythia [
41]. Pythia is a toolkit for the generation of high-energy physics events, simulating, for instance, the proton collisions that occur at the LHC. Given that we use LHCb as the benchmark for our studies, we focused on several
B meson decay modes that were studied in the experiment. These correspond to different generic topologies and final-state particles. Note that we based our studies on the topology of the final states, and ignored any PID variable. LHCb has excellent libraries for PID, many of which rely on ML [
42]. We generated the following decays:
The procedure to generate the signal samples is as follows. We enabled the
HardQCD: gg2bbbard and
HardQCD:qqbar2bbbar processes (which correspond to the production of a
pair of quarks at the LHC) in Pythia at a collision energy of 14 TeV, and looked for
B mesons. We then redecayed these to our desired final state using the
TGenPhaseSpace tool from ROOT.
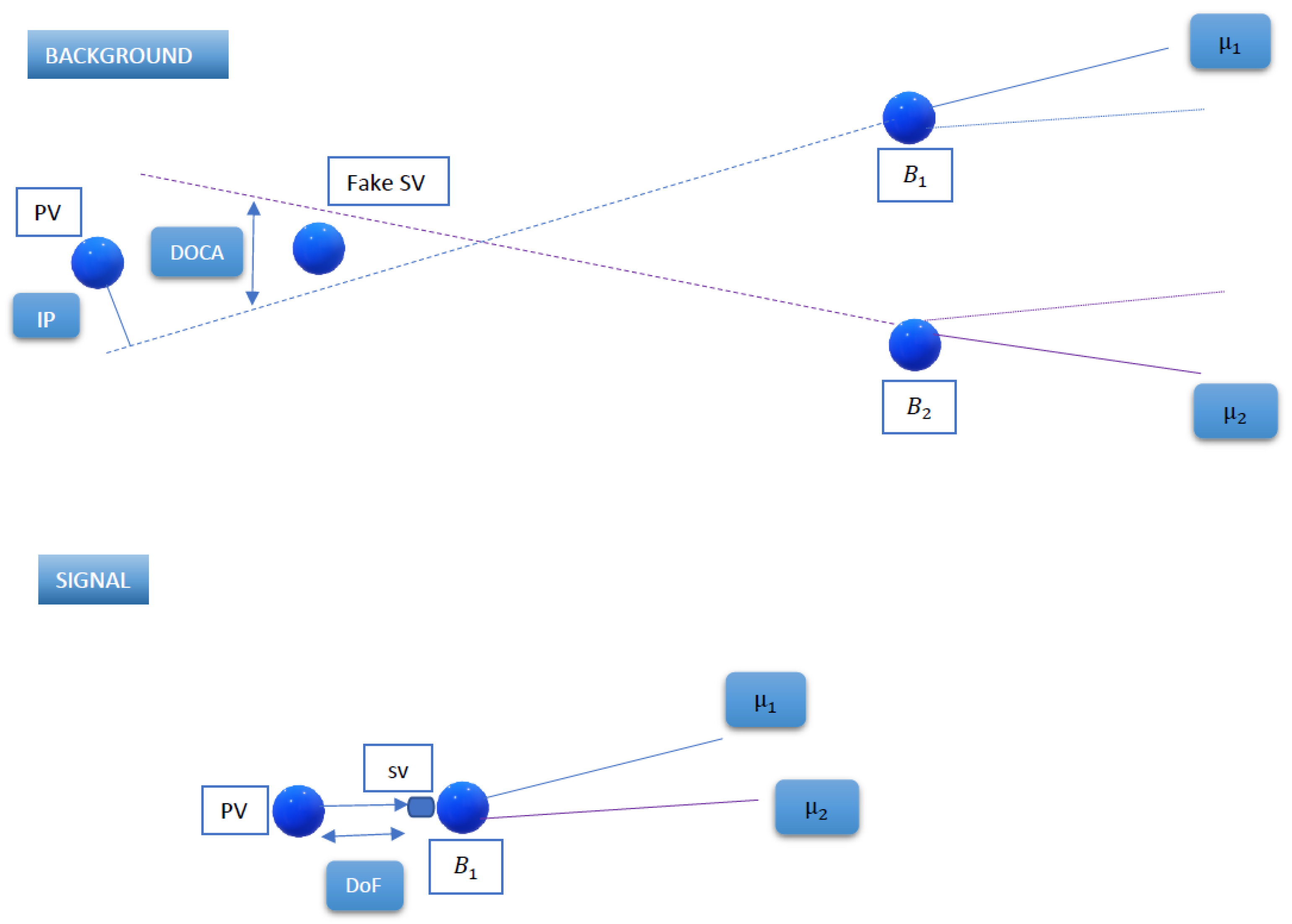
Figure 4 characterizes the usual signal topology, with a
B meson that flights a few mm and then decays to charged particles (such as pions or muons) whose trajectory and momentum can be fully reconstructed. We then applied the set of selection requirements included in
Table 1. These are based on the quantities explained on
Table 2 and
Figure 4. On top of these quantities, we also applied selection requirements based on the pseudo-rapidity (
) of the final state particles. This relates to the angular acceptance of the detector, so that particles not falling in a specific
range fall outside the detector and therefore cannot be reconstructed.
Figure 4 also explains the characterization of background events. We used the same type of Pythia processes to generate
events, but there is no redecay at all this time, taking the event as it was originally fully simulated. We selected the charged pions and muons appearing in the event, grouped them, and applied the same cuts indicated in
Table 1. For some of the cuts, we needed to generate a fake
B meson decay vertex, which we used as the point in space minimizing the sum of distances to all the daughter particles.
In order to train the classifiers, we selected a list of variables (features) that was similar to those used to select the signal and background samples. These features are coherent between different types of classifiers to make the comparison fair. Note that some of the features chosen depend on the decay channel that was chosen. For instance, the
decay has four particles in the final state, which means the
of two more particles is included compared to, e.g.,
. As explained below, different sub-selections of features were also tried to provide as complete a picture as possible. The full list of features that were used can be found in
Table A1. An additional aspect we have accounted for is the detector resolution. Our simulation provides the “true” value of features, but real-life detectors have some inherent inaccuracies due to their resolutions, as discussed in the introduction, so what they measure differs from this; for instance, the resolution damages the discrimination power of some of the features we work with. While, in principle, this would be only be a problem when trying to find a realistic performance of the classifiers, our goal here is only to compare their performance. In any case, to use a dataset that is as close as possible to that used by LHCb analysts, we conducted a Gaussian smear of the variables that are most affected by resolution effects. These are the momenta of the particles, the DOCAs and
. To determine the associated resolutions, we based ourselves in References [
44,
45].
Apart from the features introduced above, for the
case we added an additional variable, the isolation, which is known to provide excellent signal-background discrimination in analyses of this kind [
14]. The isolation exploits the fact that the usual
decays have nothing “around” other than the muons, while the background contains additional objects produced in
hadron decays (see
Figure 4). To quantify this isolation, we calculated it as the minimum DOCA between our selected muons and every other charged particle in the event. These other particles were selected by applying the cuts in
Table 3. Defined in this way, the isolation peaks at lower values for background and has larger peaks for the signal.
The simulated data consist of around 3000 samples of both signal and background events, generated as explained above. A normal LHC analysis may face difficulties in finding enough signal or background events to train a classifier, for instance, due to the very small selection efficiencies that require the simulation of an unreasonable amount of events. Additionally, analysts often face the choice between computing “low”- or “high”-level features. The former are those that were directly measured by the detector (for instance, the position or momentum or charged tracks), while the latter are combinations of those that are known to behave differently for the signal and backgrounds (such as the DOCA or , introduced above). While the usual classifiers typically rely on high-level features, a smart enough algorithm should be as effective only by using the low-level ones. To make all of this more concrete, we create six different training combinations between features and the number of samples. These are all features–high stats, all features–low stats, low-level features–high stats, low-level features–low stats, high-level features–high stats, high-level features–low stats. The meaning of these categories is as follows:
High stats: In this category, we use all the 3000 samples for both signal and background.
Low stats: In this category, we use 30% of the 3000 samples available for both signal and background.
All features: In this category, we use all the features we have available for the data.
High-level features: In this category, we only use high-level features.
Low-level features: In this category, we only use low-level features.
With these categories, we aim to provide guidelines to analysts, helping them with different future analyses to choose the best tool to treat their data. All of the features used for each of the options mentioned above are shown in
Appendix A.
One important last aspect to discuss, before moving on to the final analyses, is how the classifiers that we build must be uncorrelated with the invariant mass. In particle physics, one typically builds the invariant mass (the name “invariant” arises from special relativity, since this mass is the same for any reference frame) out of the properties of the final state particles. For instance, for the
decay, if we know the four-momenta of the muons, we can determine the invariant mass of the
B mother. Since the value of the
B meson mass is known a priori, the invariant mass is an excellent way to separate signal from background events, since, for signal, the distribution of this variable peaks at that known value. Another advantage of the invariant mass is that its distribution can be parameterized in an analytical way, which allows “counting” the amount of signal and background events by performing statistical fits to data. Since the invariant mass is a common and widely used feature in analyses in particle physics, as a rule of thumb, it is very important that any classifier we build is not correlated with the invariant mass, since the final count of signal events is performed based on this variable. This is so much the case that efforts have been made to develop classifiers that are explicitly trained so that no correlation is produced with the invariant mass (or other designed external variable) [
46,
47]. This is tricky, since a classifier might be able to learn the discrimination achieved by the invariant mass, provide an excellent AUC score and still not be useful for an actual analysis in particle physics. Accordingly, we followed a simple approach and ensured all our classifiers were not correlated with the invariant mass, which guarantees a fair comparison.
4. Scikit Learn vs. Tmva
As seen in
Section 2, TMVA is the dominant reference tool for signal-background discrimination at LHC experiments. Therefore, in this section we check, using the generic data presented above, whether TMVA provides the optimal discrimination when compared to Sklearn, assuming that one is using the same datasets and the same algorithm. The exercises below are intended to show the same analysis being carried out with both TMVA and Sklearn libraries, with the goal of helping scientists to switch between the two according to their needs.
The main difference between Sklearn and TMVA is the way the data are processed. In Sklearn, we have to transform the ROOT
TTrees to a numpy array or a pandas dataframe in order to work with them. At present, libraries such as uproot [
48] or rootnumpy [
49] allow us to make this change in the data format without extra effort. This option allows for theuse of other libraries, instead of TMVA, even for the usual datasets in LHC experiments, which tend to be ROOT
TTrees.
Both TMVA and Sklearn offer a simple way of handling algorithms, allowing for easy changes to their hyperparameters and providing useful information about the training time or even the ranking of features. To analyse and explain how the use of different libraries could be advantageous to the users, in
Figure 5 and
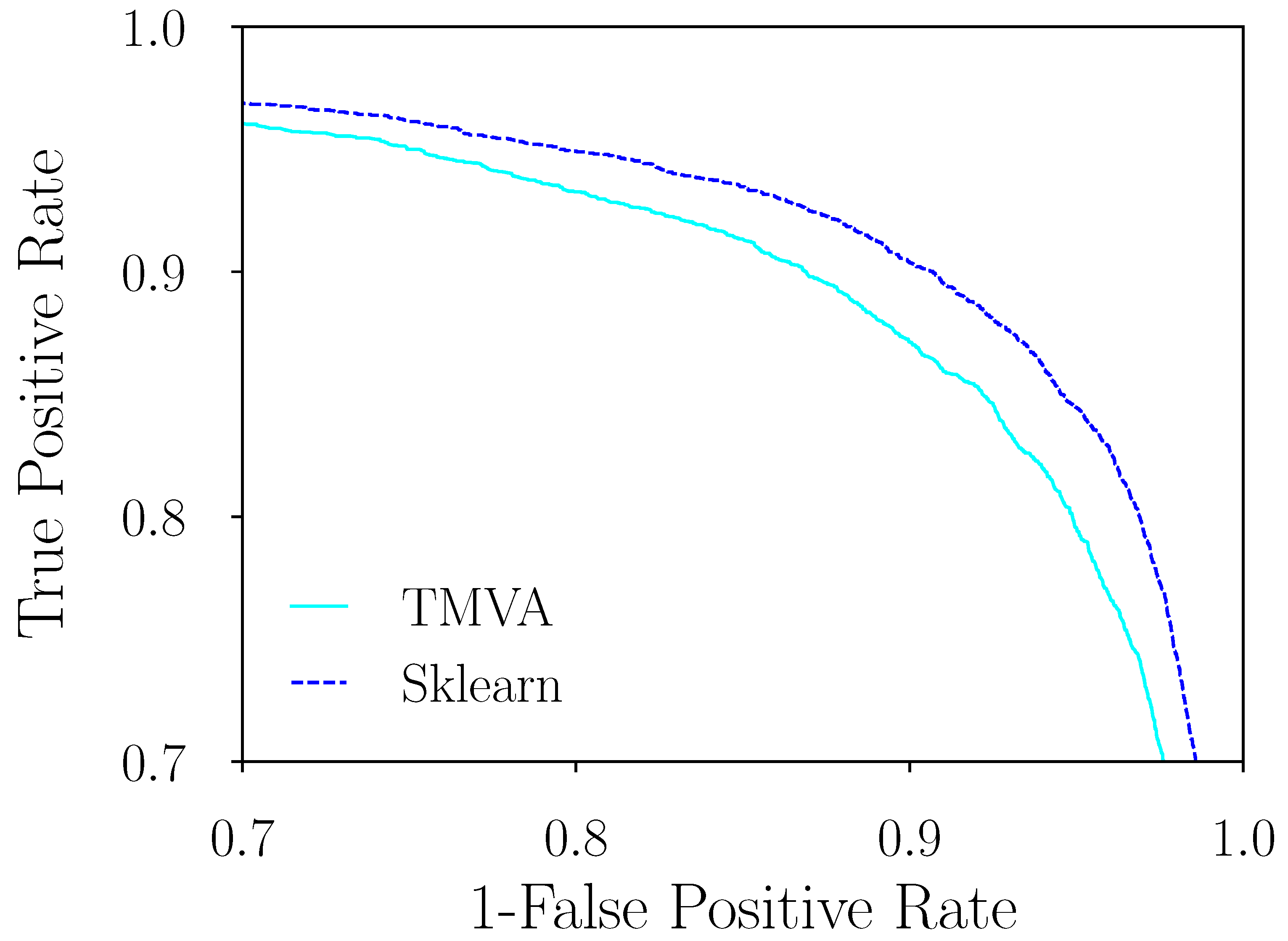
Table 4, we compare both libraries using BDT with AdaBoost for the
decay. In this case, we focus in the high-level features and high stats option for training. The comparison was made with the same hyperparameters and the same data for both libraries. This means that all the tunable parameters had the same value and the samples used for training and testing were the same for both cases. These hyperparameters were chosen as the best after performing a grid search, i.e., running through a range of the best score was reached. The results of the classifiers can be seen in
Figure 5, where Sklearn is shown to have better results. This is also shown in
Table 4, where the AUC scores for
and the rest of the decays can be found.
In
Table 4, we show all the results for the analyses that we defined in the previous section. For all these cases, Sklearn performs better than TMVA. This difference is small and not large enough to make a stronger statement, but it is still noticeable. To obtain a feeling of the statistical significance of the difference, we perform the DeLong test [
50,
51], which allows for the AUCs of pairs of classifiers to be compared. This test provides a z score that helps to quantify the probability that the two classifiers perform differently when looking at the same test data. The larger the z score, the more significant the separation between both AUCs. When comparing Sklearn and TMVA, we find that, for all decay channels, the AUC scores are statistically significantly different. Note that this statistical test is limited to pairs of classifiers, so we do not apply it further in the paper, given the large amount of comparisons being performed in
Section 5.
One of the reasons that we think could explain the differences we observe between libraries relates to how these are designed and have evolved. Sklearn was released in 2007, and TMVA in 2009. Through the years, both libraries have changed and improved their performance until becoming those available at present. Still, as is shown in the tables and figures in this section, Sklearn always performs slightly better than TMVA. This means that even though both libraries a priori use the same algorithm, there are differences in the way these two frameworks operate. Different versions of these algorithms provide slightly different results, so one would be tempted to claim that Sklearn is able to provide a better optimization of the BDTs when compared to TMVA. This might be related to the application of the loss function or computational reasons.
6. Results and Discussion
Once we have calculated the ROC curves and obtained the AUC scores for each of the algorithms, we proceed to compare them all for each channel. In the following tables, the results are shown for each tool and each training option.
Table 5,
Table 6,
Table 7 and
Table 8 follow the results for each analysis. For reference, some of the training times, which are comparable in all cases, can be found in
Appendix C. As shown in these tables, the AUC scores are similar for all of the options and most of the decays behave in a similar way, even when these scores are also subject to statistical fluctuations. The best results tend to be those obtained using PyTorch as the library, high-level features and all the available stats. This conclusion can be seen in
Table 9 and
Table 10. Here, we can appreciate how PyTorch is the dominant library for most of the options, as it is the
decay, with all features and low stats and the
decay low-level features and high stats serving as the two exceptions. In these cases, Keras worked better. However, the result for high-level features and high stats is still the best option for all the decays, as shown in
Table 10. We note again that most of the results are consistent across different decay channels, which correspond to different topologies, different types of background and even slightly different features (e.g., the use of isolation for the
decay).
When using the same decay and the same classification features, we can compare how differently the low-stat and high-stat options behave. In some cases, as in , we see how the result improves for all options when using high stats. This is the type of behaviour we would generally expect to achieve when using ML. However, this is not something that happens in every case. For example, in the decay, we see that when using all features the AUC score does not improve, with more statistics, for Keras. The same occurs with Sklearn and high-level features and PyTorch and all features in the same channel. We observe that PyTorch and Sklearn tend to improve, with high stats, while Keras is more robust against a change. We also see a tendency to have a higher dependence on the statistics for the and decays, which present more final state particles and, therefore, have more features to account for.
To check how the selection of features affects the performance of these algorithms, we note there are no large differences between different decay channels and between the low- and high-stats categories. We then count how often the best AUC score is obtained for the different libraries depending on the feature selection. One would a priori expect that the addition of information from secondary features at the “all features” option would benefit the discrimination, especially for NNs. This must be balanced by the fact that adding too many or redundant variables can damage the overall performance in some cases. When looking at the global picture, we see that PyTorch performs better with the high-level features, while for Keras, the results tend to be better when choosing all features. The situation is slightly more balanced for Sklearn, although all features tend to provide a worse performance. Additionally, the use of low-level features does not provide the best performance in every library, but this still does not dramatically affect the power of discrimination, which indicates that the algorithms we use are robust. For reference, all the features used in this study can be found in
Appendix A. Note that, as an additional element to judge the best choice, fewer features and smaller datasets can help to train the models faster and is more manageable in terms of, e.g., grid searches.
The convenience of using BDTs or NNs has long been a subject of discussion in the particle physics literature. For instance, Reference [
52] discusses how BDTs can improve the performance of NNs for PID in neutrino detectors. Note that these results do not include some of the latest progress concerning the training of NNs, which provided essential improvements in the last decade [
53]. It is is remarkable how these improvements recover NNs as the best solution in the same dataset [
54]. Other examples, which are more related to the type of analysis we present here, look into different algorithms in datasets that are often used by the ATLAS and CMS experiments, finding consistently better or similar results when comparing NNs to BDTs with different types of boosting, such as XGBoost [
55,
56]. One of the first attempts to apply QML in a data sample comparable to ours, composed of
B meson decays [
57], is also notable. The AUC achieved in this study manages to improve on those of other classical methods, although no NNs are included. Reference [
58] compares QML algorithms to NNs in a different HEP dataset, achieving better or similar AUC scores, although this depends on the size of the training sample. Another interesting example concerns the use of these algorithms for the simulation of HEP data [
59], where, again, NNs beat BDTs in terms of regression. Regarding the libraries used, the advantages of using PyTorch to deal with NNs are becoming well known, and several toolkits based on it have recently been developed for different HEP applications. Examples include Lumin [
60,
61] and Ariadne [
7]. The first is a wrapper that includes some of the newest techniques that facilitate the training of NNs, while the second, as mentioned in the introduction, is used for tracking. As a final remark, the benefits NNs can bring over other methods, such as BDTs, not only concern physics, but also appear in fields such as medicine [
62,
63], finance [
64], marketing [
65], biology [
66] or engineering [
67]. As a general trend, NNs tend to perform better in these references, although the present developments in, e.g., BDTs, make these very competitive. We note the interest in looking at other sources, beyond particle physics, to find inspiration and discover better models for signal classification.
7. Conclusions
In this paper, we review the most frequent ML libraries used in HEP, checking their popularity and comparing their performance in terms of signal-background discrimination in an independent simulated dataset. These datasets are generated and selected using the LHCb detector at CERN as a benchmark.
In the first part of the paper, we observe that, even though TMVA is one of the most popular libraries, and by far the more frequently used for this type of analyses, there are other options that can work as well or even better. In fact, Sklearn performs better than TMVA in all the decays analysed in this paper when using BDTs boosted with AdaBoost. This can be a way to prompt scientists in HEP collaborations to try new alternatives and generate new content using the most modern libraries that are available according to Python and other languages. Thanks to the wide range of new libraries, the conversion between the ROOT files and Python-friendly data structures is growing easier over time, and this can result in the popularization of these modern ML libraries for particle physicists.
In the second part of the paper, we compared the obtained results with some of the most popular ML libraries in data science, namely, Keras, PyTorch and Sklearn, and showed how NNs can improve the results obtained by BDTs. Even if the results are similar between the three of them, PyTorch tends to provide the best scores. In any case, the final choice might depend on other aspects, such as the amount of statistics available, since, for instance, Keras appears to be more robust for lower training statistics. Regarding the selection of features, this depends on the library, but, as a rule of thumb, we recommend not enlarging the list unnecessarily, focusing on high-level libraries that are known to provide excellent signal-background discrimination. To our knowledge, this is the first time that a detailed study of the dependence of algorithms and libraries on the training statistics and number of features has been performed with an HEP dataset.
We should highlight that, even though we are able to see some differences among the libraries, algorithms and decays, all AUC scores are in the range of 0.95–0.96, and subject to statistical fluctuations. This means that the results we have obtained are indicative, but must still be made with caution. Therefore, even if our findings can be used as a guideline, we still advise analysts to check for the best classifier for their specific case, depending on aspects such as available statistics or the available CPU for training.
As a final note, we emphasize the need for particle physicists to enrich their perspective by looking at what is being carried out in other fields in terms of classification by means of ML. This not only concerns other areas of physics [
68], but also fields that look far away, such as medicine [
69], chemistry [
70], industrial applications [
71,
72] or the interface with users [
73].




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






