
Leveraging Expert Knowledge for Label Noise Mitigation in Machine Learning

 ,
,
Abstract
:1. Introduction
1.1. Related Works
1.2. Contributions
- We have established a new method that leverages the experts’ knowledge for enhancing the learning model in the presence of label noise without changing the model structure. The proposed method is simple, intuitive, explainable, applicable for every learning algorithm, and can combine with other algorithms.
- The proposed method is realized as two algorithms: “Rule-Weight” algorithm weights the data sample differently to partially alleviate the bad effect in the sample; “Rule-Remove” algorithm excludes the bad sample from the training model. The performance comparison with the algorithms in [27] show that the Rule-Weight is the best even when the level of label noise in the dataset is as high as 50%.
- The experiments on image processing problem confirm that the label noise can be detected by simple pre-defined rules created from the expert knowledge.
1.3. Organization
2. Materials & Methods
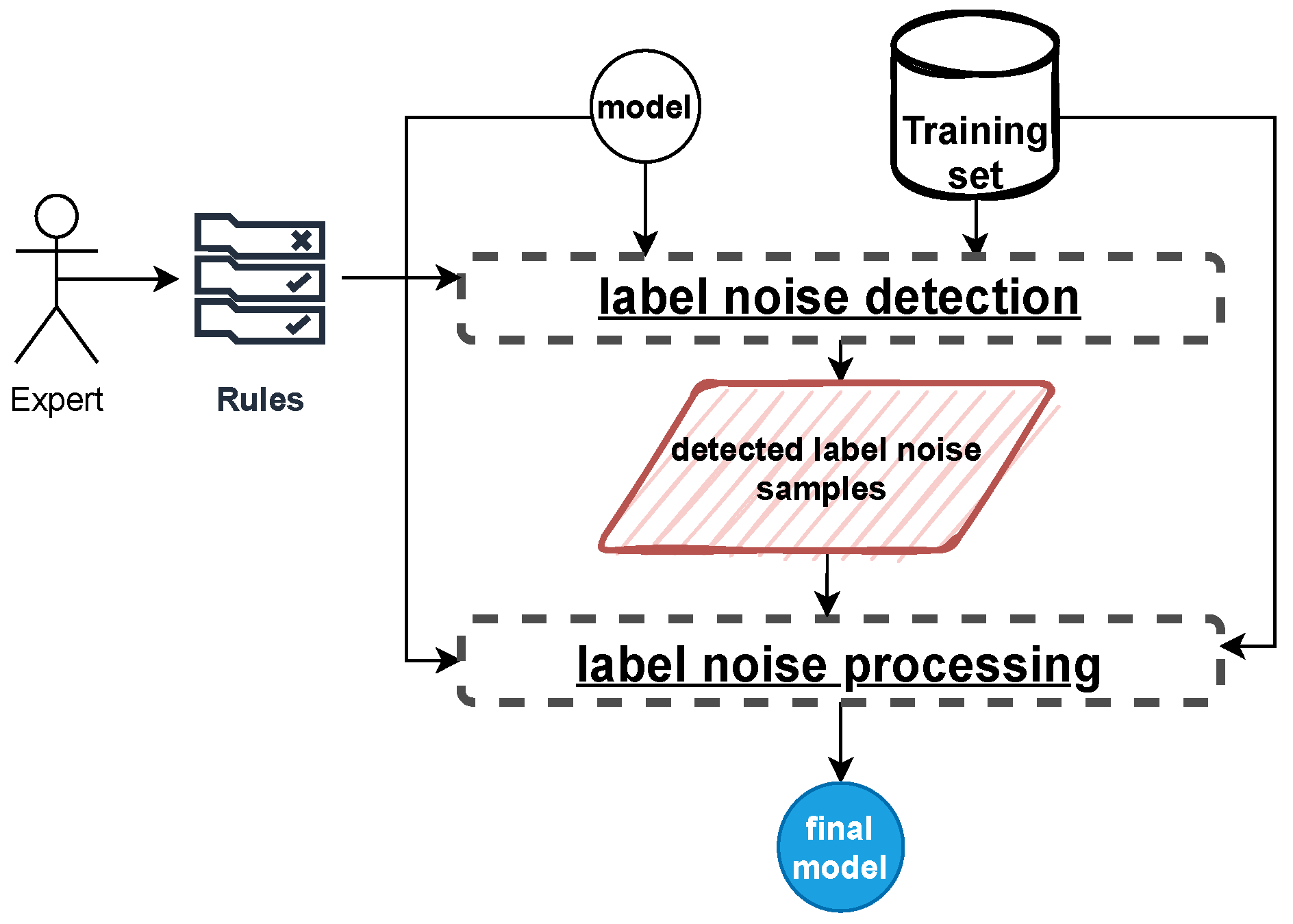
2.1. Methodology Overview
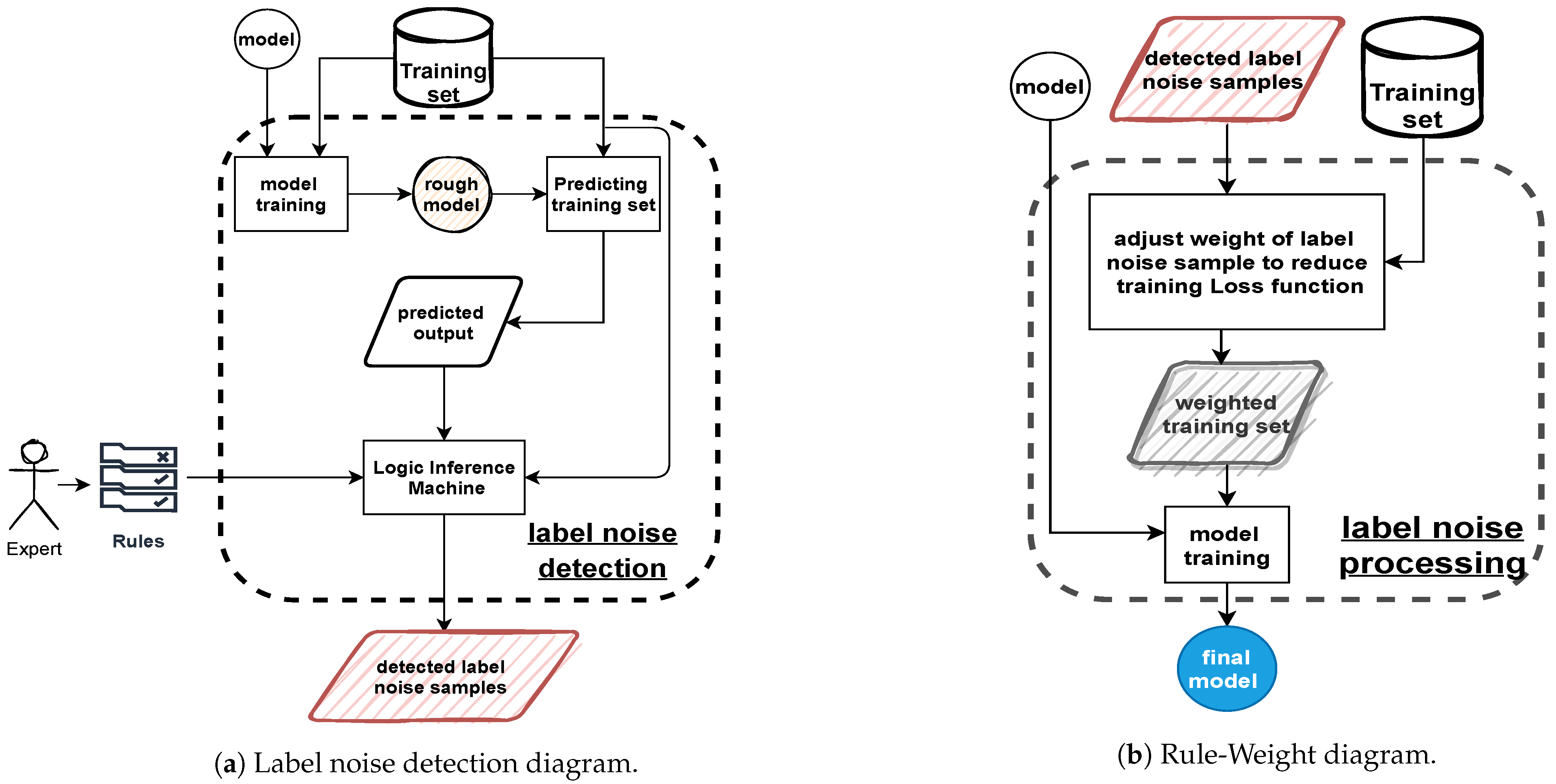
2.2. Rule-Weight Algorithm
| Algorithm 1 Rule-Weight. |
| Require:TrainingSet, trainAlgo(),model, α, T |
| Ensure:FinalModel |
| roughModel ⇐ trainAlgo(model, TrainingSet) |
| Model0 ⇐ model |
| for t = 0 to T do |
| Xt, Labelt ⇐ SampleMiniBatch(TrainingSet) |
| Yt ⇐ roughModel(Xt) |
| Dt ⇐ RuleCheck(Xt, Yt, Labelt) |
| gt ⇐ Lossj(Modelt, Yt, Labelt) |
| ϵt+1 ⇐ max(ϵt − α.gt, 0) |
| WeightedMBt ⇐ Weight(Xt, Labelt, Dt, ϵt+1) |
| Modelt+1 ⇐ trainAlgo(Modelt,WeightedMBt) |
| end for |
| FinalModel ⇐ ModelT |
2.3. Rule-Remove Algorithm
| Algorithm 2 Rule-Remove. |
| Require:TrainingSet, trainAlgo(),model, T |
| Ensure:FinalModel |
| roughModel ⇐ trainAlgo(model, TrainingSet) |
| Model0 ⇐ model |
| for t = 0 to T do |
| Xt, Labelt ⇐ SampleMiniBatch(TrainingSet) |
| Yt ⇐ roughModel(Xt) |
| Dt ⇐ RuleCheck(Xt, Yt, Labelt) |
| WeightedMBt ⇐ Weight(Xt, Labelt, Dt, ϵt+1 = 0) |
| Modelt+1 ⇐ trainAlgo(Modelt,WeightedMBt) |
| end for |
| FinalModel ⇐ ModelT |
3. Experiments
- Normal learning algorithm. The classification model is performed without removing label noise.
- Classification Filtering [29] (CF) is an algorithm on filter framework which use a model that trained from the original noisy training set to classify the training set itself, and remove samples that its predicted output differs from its label
- LC-True algorithm [27].
- LC-Est algorithm [27].
- Rule-Remove algorithm.
- Rule-Weight (RW) algorithm.
3.1. Experiment on Manga109
3.1.1. Dataset
3.1.2. Image Classification Model
3.1.3. Logical Reasoning Mechanism
- Rule one: “One author only works for one publisher”.
- Rule two: “One author only draws manga towards one target reader”.
- Rule three: “One author only draws manga towards one genre”.
3.2. Experiment on CIFAR-10
4. Evaluation and Discussion
4.1. Accuracy
4.2. Tuning Hyperparameters
4.3. Computational Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Frenay, B.; Verleysen, M. Classification in the Presence of Label Noise: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 845–869. [Google Scholar] [CrossRef] [PubMed]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Albarqouni, S.; Baur, C.; Achilles, F.; Belagiannis, V.; Demirci, S.; Navab, N. Aggnet: Deep learning from crowds for mitosis detection in breast cancer histology images. IEEE Trans. Med. Imaging 2016, 35, 1313–1321. [Google Scholar] [CrossRef] [PubMed]
- Ravì, D.; Wong, C.; Deligianni, F.; Berthelot, M.; Andreu-Perez, J.; Lo, B.; Yang, G.-Z. Deep learning for health informatics. IEEE J. Biomed. Health Inform. 2016, 21, 4–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Patrini, G.; Nielsen, F.; Nock, R.; Carioni, M. Loss factorization, weakly supervised learning and label noise robustness. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 708–717. [Google Scholar]
- Manwani, N.; Sastry, P. Noise tolerance under risk minimization. IEEE Trans. Cybern. 2013, 43, 1146–1151. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khardon, R.; Wachman, G. Noise tolerant variants of the perceptron algorithm. J. Mach. Learn. Res. 2007, 8, 227–248. [Google Scholar]
- McDonald, R.A.; Hand, D.J.; Eckley, I.A. An empirical comparison of three boosting algorithms on real data sets with artificial class noise. In Proceedings of the 4th International Workshop Multiple Classifier Systems, Guilford, UK, 11–13 June 2003; pp. 35–44. [Google Scholar]
- Melville, P.; Shah, N.; Mihalkova, L.; Mooney, R.J. Experiments on ensembles with missing and noisy data. In Proceedings of the 5th International Workshop Multi Classifier Systems, Cagliari, Italy, 9–11 June 2004; pp. 293–302. [Google Scholar]
- Dietterich, T.G. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, C.; Blanzieri, E.; Zhou, Y.; Wang, Y.; Du, W.; Liang, Y. Methods for labeling error detection in microarrays based on the effect of data perturbation on the regression model. Bioinformatics 2009, 25, 2708–2714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Malossini, A.; Blanzieri, E.; Ng, R.T. Detecting potential labeling errors in microarrays by data perturbation. Bioinformatics 2006, 22, 2114–2121. [Google Scholar] [CrossRef] [PubMed]
- Kaster, F.O.; Menze, B.H.; Weber, M.-A.; Hamprecht, F.A. Comparative validation of graphical models for learning tumor segmentations from noisy manual annotations. In Proceedings of the MICCAI Workshop on Medical Computer Vision (MICCAI-MCV’10), Beijing, China, 20 September 2010; pp. 74–85. [Google Scholar]
- Kim, H.-C.; Ghahramani, Z. Bayesian gaussian process classification with the em-ep algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1948–1959. [Google Scholar] [PubMed]
- Sun, J.-W.; Zhao, F.-Y.; Wang, C.-J.; Chen, S.-F. Identifying and correcting mislabeled training instances. In Proceedings of the Future Generation Communication and Networking, Jeju-Island, Korea, 6–8 December 2007; Volume 1, pp. 244–250. [Google Scholar]
- Zhao, Z.; Cerf, S.; Birke, R.; Robu, B.; Bouchenak, S.; Mokhtar, S.B.; Chen, L.Y. Robust Anomaly Detection on Unreliable Data. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019; pp. 630–637. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Wu, X. Class noise handling for effective cost-sensitive learning by cost-guided iterative classification filtering. IEEE Trans. Knowl. Data Eng. 2006, 18, 1435–1440. [Google Scholar]
- Khoshgoftaar, T.M.; Rebours, P. Generating multiple noise elimination filters with the ensemble-partitioning filter. In Proceedings of the 2004 IEEE International Conference on Information Reuse and Integration, Las Vegas, NV, USA, 8–10 November 2004; pp. 369–375. [Google Scholar]
- Brodley, C.E.; Friedl, M.A. Identifying mislabeled training data. J. Artif. Intell. Res. 1999, 11, 131–167. [Google Scholar] [CrossRef]
- Brodley, C.E.; Friedl, M.A. Identifying and eliminating mislabeled training instances. In Proceedings of the 13th National Conference on Artificial Intelligence, Portland, OR, USA, 4–8 August 1996; pp. 799–805. [Google Scholar]
- Ren, M.; Zeng, W.; Yang, B.; Urtasun, R. Learning to reweight examples for robust deep learning. arXiv 2018, arXiv:1803.09050. [Google Scholar]
- Shen, Y.; Sanghavi, S. Learning with bad training data via iterative trimmed loss minimization. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5739–5748. [Google Scholar]
- Roychowdhury, S.; Diligenti, M.; Gori, M. Image Classification Using Deep Learning and Prior Knowledge. In Proceedings of the Workshops at the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Ogawa, T.; Otsubo, A.; Narita, R.; Matsui, Y.; Yamasaki, T.; Aizawa, K. Object Detection for Comics Using Manga109 Annotations. March 2018. Available online: www.manga109.org/en/ (accessed on 9 November 2021).
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Patrini, G.; Rozza, A.; Krishna Menon, A.; Nock, R.; Qu, L. Making Deep Neural Networks Robust to Label Noise: A Loss Correction Approach. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Thongkam, J.; Xu, G.; Zhang, Y.; Huang, F. Support Vector Machine for Outlier Detection in Breast Cancer Survivability Prediction. In Proceedings of the APWeb 2008 International Workshops, Shenyang, China, 26–18 April 2008. [Google Scholar]
- Jeatrakul, P.; Wong, K.K.; Fung, L.C. Data Cleaning for Classification Using Misclassification Analysis. JACIII 2010, 14, 297–302. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wielemaker, J.; Anjewierden, A. SWI-Prolog. Available online: https://www.swi-prolog.org/ (accessed on 27 December 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| airplane | 0 | 0 |
| automobile | 0 | 0 |
| bird | 1 | 0 |
| cat | 1 | 1 |
| deer | 1 | 1 |
| dog | 1 | 1 |
| frog | 1 | 0 |
| horse | 1 | 1 |
| ship | 0 | 0 |
| truck | 0 | 0 |
| Noise Level | 0% | 20% | 30% | 40% | 50% | |
|---|---|---|---|---|---|---|
| Method | ||||||
| Normal | 0.678 | 0.603 | 0.553 | 0.505 | 0.324 | |
| CF | 0.679 | 0.597 | 0.422 | 0.411 | 0.303 | |
| LC-True | 0.675 | 0.600 | 0.571 | 0.529 | 0.398 | |
| LC-Est | 0.681 | 0.603 | 0.579 | 0.516 | 0.333 | |
| Rule-Remove | 0.679 | 0.618 | 0.580 | 0.568 | 0.445 | |
| RW ( = 0.02) | 0.679 | 0.619 | 0.568 | 0.551 | 0.419 | |
| RW ( = 0.1) | 0.679 | 0.627 | 0.577 | 0.565 | 0.439 | |
| RW ( = 0.4) | 0.679 | 0.616 | 0.580 | 0.568 | 0.459 | |
| Noise Level | 0% | 20% | 30% | 40% | 50% | |
|---|---|---|---|---|---|---|
| Method | ||||||
| Normal | 0.841 | 0.699 | 0.645 | 0.575 | 0.446 | |
| CF | 0.824 | 0.678 | 0.625 | 0.565 | 0.435 | |
| LC-True | 0.848 | 0.736 | 0.673 | 0.575 | 0.507 | |
| LC-Est | 0.84 | 0.725 | 0.66 | 0.57 | 0.466 | |
| Rule-Remove | 0.842 | 0.742 | 0.664 | 0.591 | 0.491 | |
| RW ( = 0.02) | 0.835 | 0.739 | 0.666 | 0.585 | 0.466 | |
| RW ( = 0.1) | 0.835 | 0.744 | 0.68 | 0.592 | 0.505 | |
| RW ( = 0.4) | 0.835 | 0.744 | 0.688 | 0.597 | 0.516 | |
| Noise Level | 20% | 30% | 40% | 50% |
|---|---|---|---|---|
| Detected label noise samples | 14,704 | 24,561 | 38,799 | 43,060 |
| Label noise samples | 21,368 | 32,052 | 42,737 | 53,421 |
| Ratio | 0.689 | 0.766 | 0.907 | 0.806 |
| Noise Level | 10% | 20% | 30% | 40% |
|---|---|---|---|---|
| Detected label noise samples | 1160 | 2357 | 4361 | 5457 |
| Label noise samples | 5000 | 10,000 | 15,000 | 20,000 |
| Ratio | 0.232 | 0.236 | 0.291 | 0.273 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, Q.; Shikina, T.; Teruya, D.; Hotta, S.; Han, H.-D.; Nakajo, H. Leveraging Expert Knowledge for Label Noise Mitigation in Machine Learning. Appl. Sci. 2021, 11, 11040. https://doi.org/10.3390/app112211040
Nguyen Q, Shikina T, Teruya D, Hotta S, Han H-D, Nakajo H. Leveraging Expert Knowledge for Label Noise Mitigation in Machine Learning. Applied Sciences. 2021; 11(22):11040. https://doi.org/10.3390/app112211040
Chicago/Turabian StyleNguyen, Quoc, Tomoaki Shikina, Daichi Teruya, Seiji Hotta, Huy-Dung Han, and Hironori Nakajo. 2021. "Leveraging Expert Knowledge for Label Noise Mitigation in Machine Learning" Applied Sciences 11, no. 22: 11040. https://doi.org/10.3390/app112211040
APA StyleNguyen, Q., Shikina, T., Teruya, D., Hotta, S., Han, H.-D., & Nakajo, H. (2021). Leveraging Expert Knowledge for Label Noise Mitigation in Machine Learning. Applied Sciences, 11(22), 11040. https://doi.org/10.3390/app112211040