1. Introduction
The increased global competition between steel mills emphasizes the importance of the yield improvement and the quality management of products. A quality policy of the mill that answers for the requirements of the customers is mandatory for a successful manufacturer, and the costs of quality can be reduced only if the quality is taken into account already at the manufacturing stage [
1]. This kind of process control prevents the production of defective products, fault situations, waste and external failure costs which arise when the product does not meet the design quality standards or when the reduced quality is detected by the customer.
Process control is generally based on the information collected from the industrial processes. However, the amount of information can easily become overwhelming, and especially the personnel performing tasks that involve a short reaction time can become unnecessarily strained. Hence, there is a need to extract the significant knowledge from the collected data and use it to control the process, meet the demands of the quality, and find the root causes behind the problems. Zhang et al. [
2] described a typical data-involved production line that consists of three different lines: automatic, digital, and smart production lines. This kind of data-driven smart production line (SPL) consists of four common factors: integration, data-driven, service collaboration, and proactive service. SPL is one of the key elements of the smart factory. Fayyad et al. [
3] proposed that data mining is a particularly important step in the knowledge discovery process. It is an implementation of specific algorithms for extracting patterns from data. With the limited capacity of a human brain, the knowledge extraction from complex industrial data is not an easy task. Generally, it requires machine learning-enhanced data mining methods instead.
At the moment, artificial intelligence is a hot topic in scientific research. The latest ICT technology together with artificial intelligence provide new possibilities to improve the competitiveness of a company. Decision support systems (DSS) can become intelligent with AI techniques and thus give advanced support for the decision maker [
4]. The use of machine learning methods in manufacturing process development has gradually become more common, even though Braha [
5] brought together the research and application of data mining within design and manufacturing environments already in 2001. AI methods may improve both the competitiveness and the efficiency of a company. For example, Logunova et al. [
6] reported that they have obtained significant savings from quality improvements in a continuous cast billet production facility by developing an automatic system for the intelligent support of billet production control processes.
Machine learning methods are currently widely used for quality diagnosis and improvement, especially in complex manufacturing processes such as steel making. In industry, the real-time data loads easily become massive, requiring strong big data analysis skills from the user [
7]. With the help of AI methods, the knowledge behind the large amount of data is possible to determine, and with the extracted knowledge, the process outcomes can be predicted and relationships between process parameters can be utilized [
8]. For example, Wang [
9] and Tamminen et al. [
10] have demonstrated how data mining approaches have enabled intelligent tools to automatically extract useful information and knowledge from the industrial data. Hence, the workload and the cognitive load of the workers was decreased, and they were able to concentrate on improving the process when an alarm occurred, for example. AI-empowered prediction models are especially suitable for supporting decision making with their ability to predict future outcomes with different solutions after an estimated risk of failure in the process. The selection of the models should be made with care. Bustillo et al. [
11] have compared different machine learning methods in industrial applications in order to implement the most accurate model into a decision support tool. They also found out that the selection of the response variable plays a significant role when aiming for industrial standards.
For a while, the current era of Industry 4.0 has been concentrating on automation, but lately the first steps towards the Fifth Industrial Revolution (Industry 5.0) and the human-centric approach in autonomous manufacturing have been taken [
12]. Consequently, AI systems should be adequately transparent for a human managing the manufacturing process, and thus they are considered to be critically dependent on explainable machine learning models (XAI) [
13]. If the model structure does not explain the reasoning behind the results, the transparency should be increased, and the concept of XAI takes this into account with other four important aspects: causality, bias, fairness, and safety [
14]. The goal of XAI is that a human can easily understand and analyze the AI system and make decisions based on the explanation.
The surface roughness is one of the major quality issues in stainless steel strip processing, but it can be visually detected only after the surface polishing after the whole rolling process. The strip runs through two process lines: first, a hot rolling line, and then an integrated rolling, annealing and pickling line, called a RAP-line. The improvement of the yield is one of the most important goals in production, and the quality risks should be detected as early as possible in order to save the product or avoid futile work in the case of rejection. In addition, it would be essential to find the root causes behind the increased roughness, because then the failure could be prevented, the good quality of the products could be ensured, and the competitiveness of the company could be improved.
In this article, we demonstrate how data mining methods can help when a new measurement device is introduced to the process, and with this, novel information can be collected. Because the quality is measured at the end of the process, data mining and machine learning provide tools to inspect the property already during the production when process parameters can still be adjusted. However, it is not a simple task to utilize data analysis methods, explore the vast amount of collected process data, and identify all the affecting process variables that need to be controlled in order to improve the quality. Our solution is based on statistical quality predictions made with generalized boosted regression models [
15], and by using XAI methods, it finds the most probable candidates for quality deterioration and recommends the actions that could improve the quality. In addition, the process engineers and operators will learn more about the steel making process and how the process settings affect the quality property. Thus, it is possible to pinpoint the root causes behind the failure more closely and to find the process steps in which they form.
Usually, project workers have some kind of idea how certain process parameters are affected during the process, but the assumption is not evidence-based. The process should be optimized with a new quality parameter, because there is a considerable risk of using harmful settings accidentally when lacking knowledge about this quality property. With data mining methods, it is possible to explore this already before optimization and to learn the real effects of the process parameters on this particular quality property. The current data may contain useful information also from the extreme situations, which may not actually appear in the data after optimization. Thus, it would be more reliable to set good process parameter settings and find the boundaries for safe operation.
In this work, an intelligent decision support system for the manufacturing industry is developed, and the data mining methods are applied to the surface roughness of the steel strip. The article is organized as follows:
Section 2 describes the practical issues related to smart decision support.
Section 3 introduces the used data collection technique. Machine learning and XAI methods are explained in
Section 4. Training models for roughness prediction and modeling results are shown in
Section 5. The XAI empowered decision support is then presented in
Section 6. Finally, the discussion and conclusions are in
Section 7.
2. Practical Issues Related to Smart Decision Support
A system for evidence-based decision support in industry should be able to transfer the information from the manufacturing process to the end users effectively and effortlessly. This includes the handling of process data streams, the integration of prediction models and analytics to the system, and easy access to resulted decision support by end users. In a quality monitoring tool for the steel industry, the system architecture contains four levels: data acquisition, data storage, information analysis, and information delivery [
10]. The system enables timely access to the needed data sources, data preprocessing and prediction model integration, and model analytics-based decision support with a web-based user interface.
Data collection from industry, as well as the data analysis itself, are demanding tasks, because the amount of data can be extremely large and they can come from many sources and in different formats. Main challenges with big data are the volume, velocity, variety, and veracity, which are related to the amount of data, the speed of the data coming in and out, the range of data types and sources, and the uncertainty of data [
16]. Lately, the value has also been considered as a challenge; the data may be a considerable asset to an organization, but only if value can be derived [
17]. In some cases, there are no data available at all, or it is difficult to measure the property due to the challenging industrial conditions. For example, in the hot rolling mill, the conditions are extreme due to the heat, surface scaling, water, dampness, and the speed of the rolling process. In addition, measuring can be very expensive or time consuming. As a result, the relevant data sets can be too small and the data analysis methods invaluable. However, it is sometimes possible to derive new more informative variables from the measurements as well.
Reliable data are a necessity for successful modeling tasks. The accuracy of the model is dependent on the reliability of the training data, and it is possible to improve the data quality with careful preprocessing. Typically, the main data preprocessing tasks are data cleaning, such as eliminating the noise and handling the inconsistent data, data integration from different sources, data transformation, and consolidation into a suitable form for data mining methods and data reduction, including the selection and extraction of features [
18]. Missing data and data imputation are also essential topics in data preprocessing.
When prediction model-based tools are applied in the industrial environment, it has to be taken into account that the real-life process data during the operation need to be preprocessed similarly as in the training phase. Otherwise, the decision support that the tool offers is based on unreliable information that may be inherently incorrect. In practice, the full automation of the preprocessing may be impossible, but it should not be neglected either.
Co-operation between the domain experts and data analysis and modeling experts is essential in applied research. Domain experts give the need for the research, understand the industrial process, and select the data as well. Data mining experts, in turn, excel in data analysis and machine learning methods. An iterative data mining process enables the interaction between the experts during the tool development. As a result, the actual implementation process of the tool is less complicated, and the users are more motivated to use it.
5. Model Training and Results for Roughness Prediction
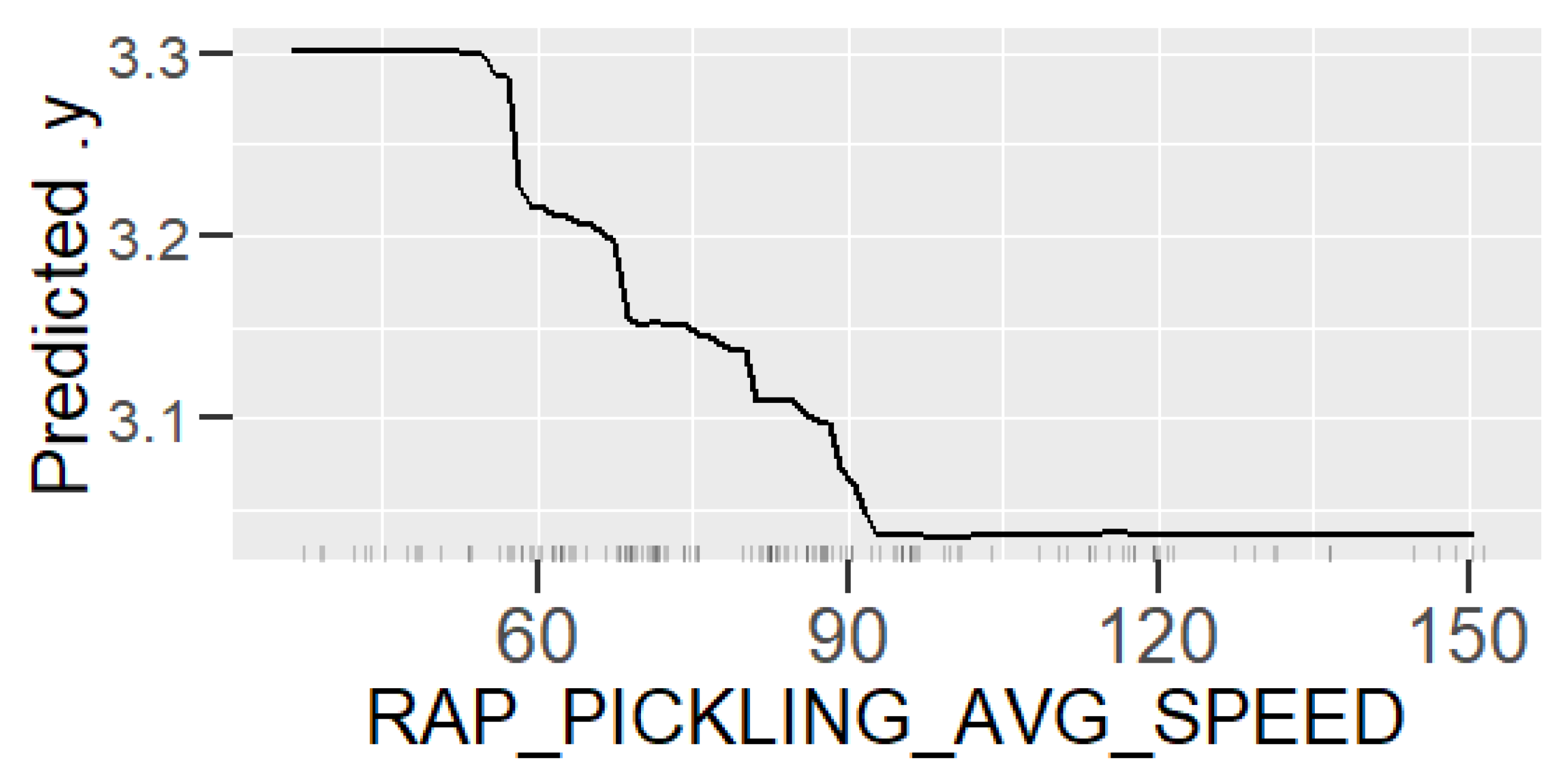
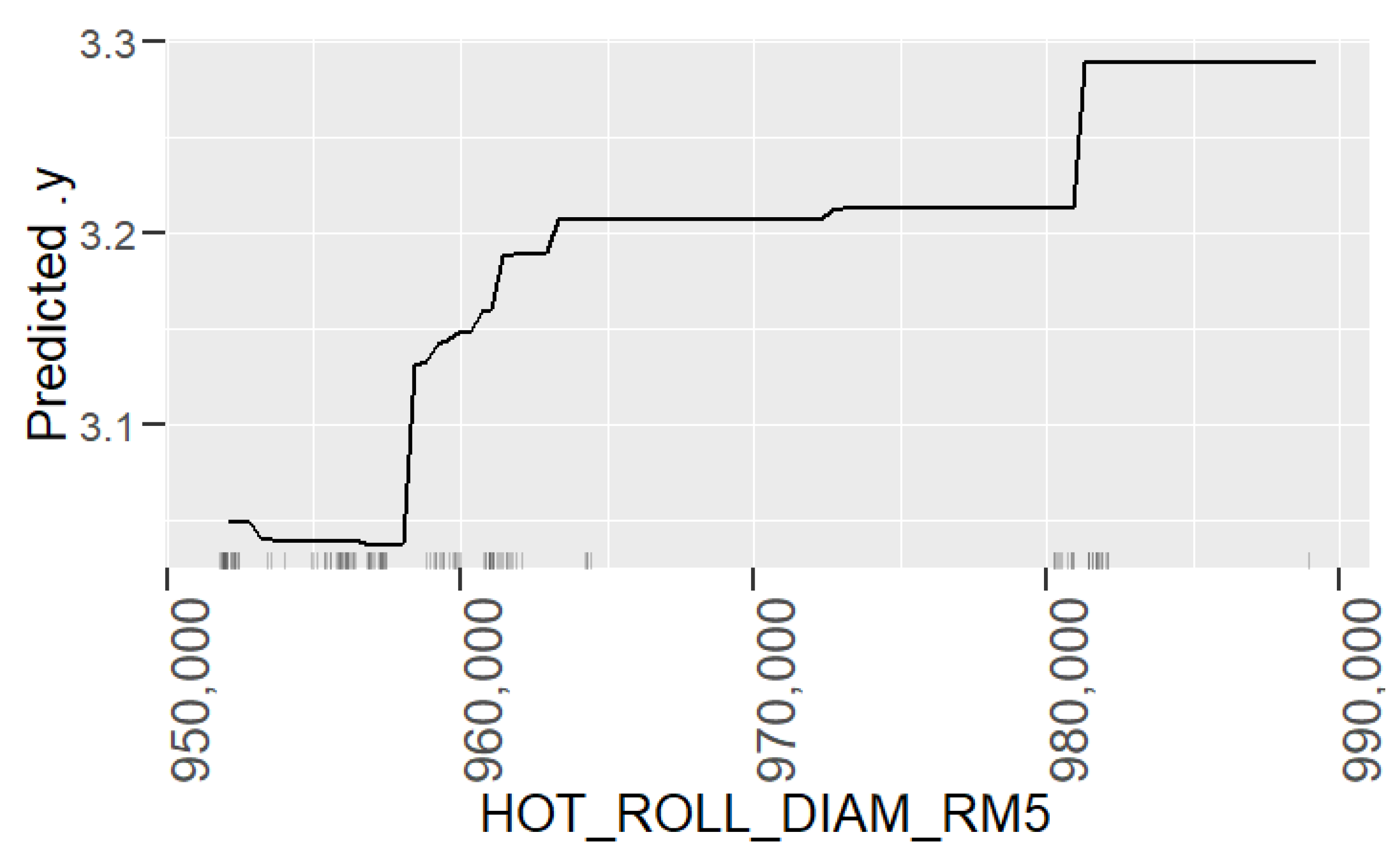
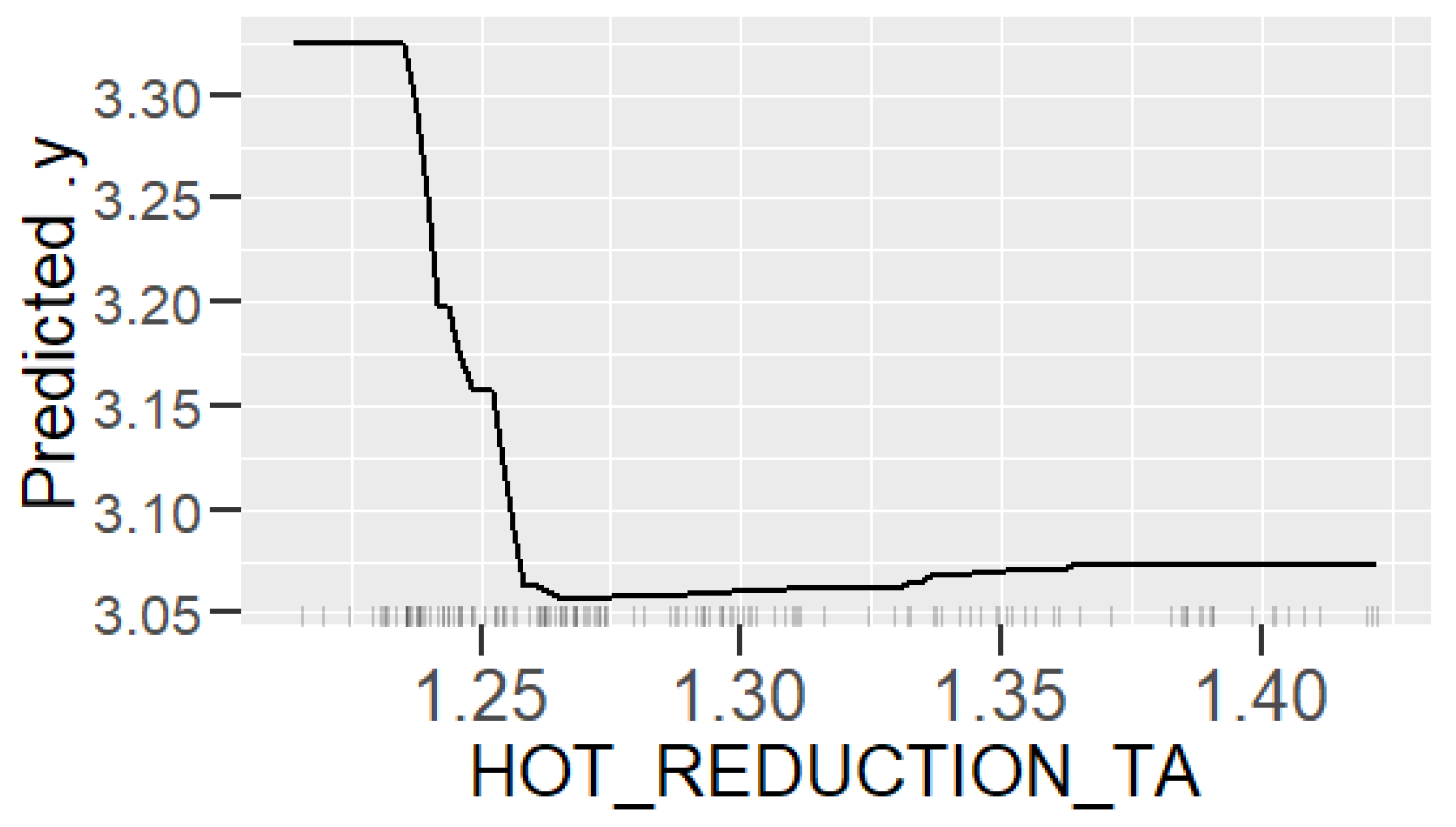
In the beginning of the project, the process engineers had a hypothesis about the quality property and the effects of the process parameters on it. They presumed that the preceding hot rolling process has a strong effect on the RAP surface quality, and process parameter corrections in that step could improve the quality of the final product. Our counter-hypothesis was that there are some specific process settings in RAP line that affect the quality, and the aim of our research was to find out how much the hot rolling actually affects the final product’s surface quality. Based on that question, we formed three GBM models for steel strip surface roughness prediction: Model_HYBRID includes both the hot rolling variables and the RAP-process variables, Model_HOT includes only the hot rolling variables, and Model_RAP includes only the RAP-process variables.
The models were implemented with R, which has been used in several industrial applications because of its flexibility and compatibility. For online use, a tool that combines the process data with the models and presents the visualizations is needed. Tamminen et al. [
10] present a quality monitoring tool (QMT) that enables the online visualization of the production line with information about the predicted quality for each product. The methods presented in this paper can be implemented in the QMT tool.
In this study, the main data preprocessing tasks were data cleaning, such as eliminating the noise and handling the inconsistent data, data integration from different sources, and data reduction, including the selection and extraction of features. The data were divided into four parts by steel type in chronological order. The first 80% from each steel type group was selected as the training set and the last 20% as the test set. Thus, each steel type is represented in both sets.
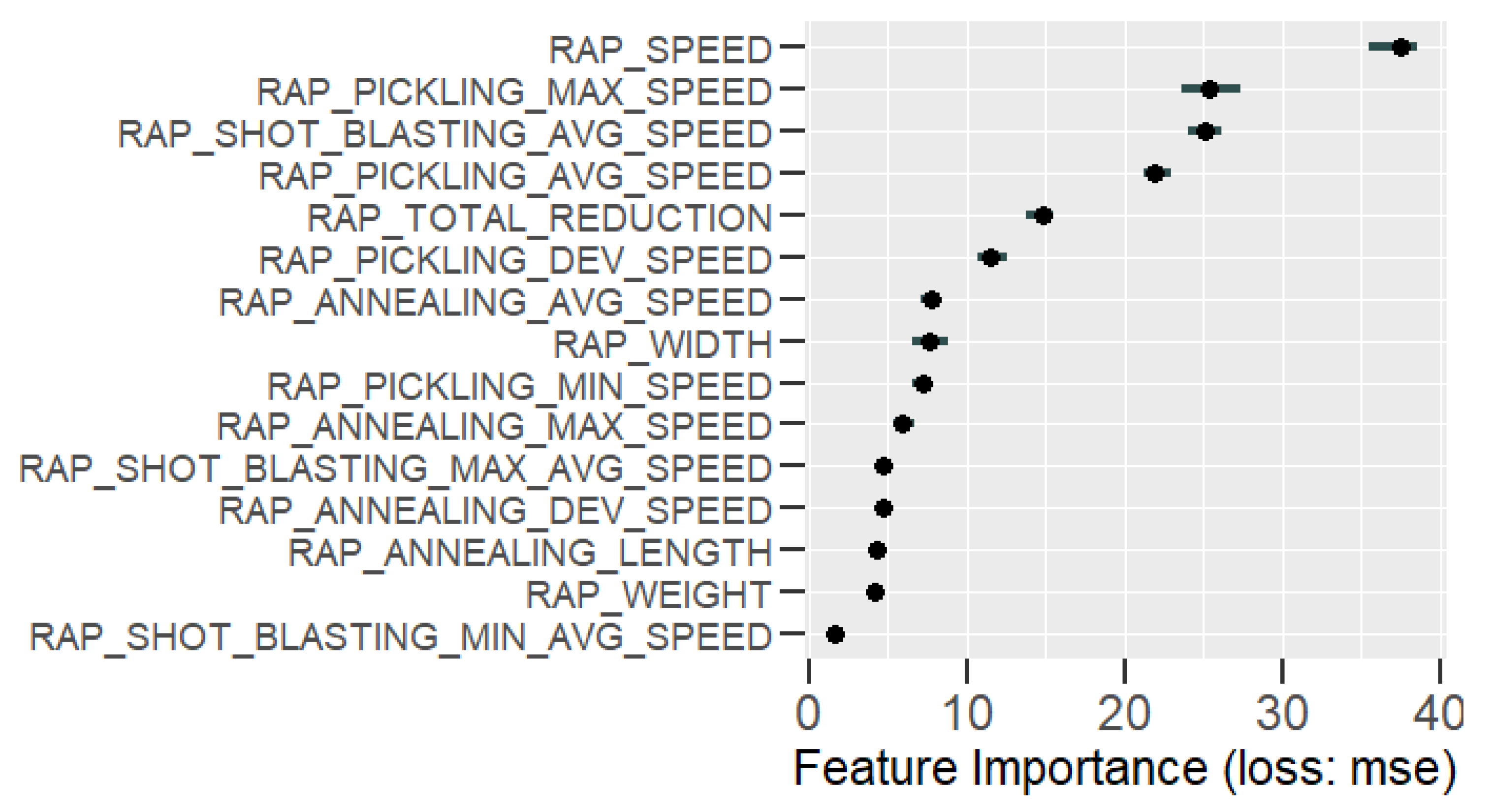
The variables used in models are measured from the hot rolling line and RAP line, and additional information about the chemical composition and the dimensions of the slab was used as well. In total, the original data set consisted of information about 128 process variables, which should be reduced significantly because the number of eligible observations was 206. After careful feature extraction and selection, there were 16 variables used in Model_HYBRID, 16 variables in Model_HOT, and 15 in Model_RAP.
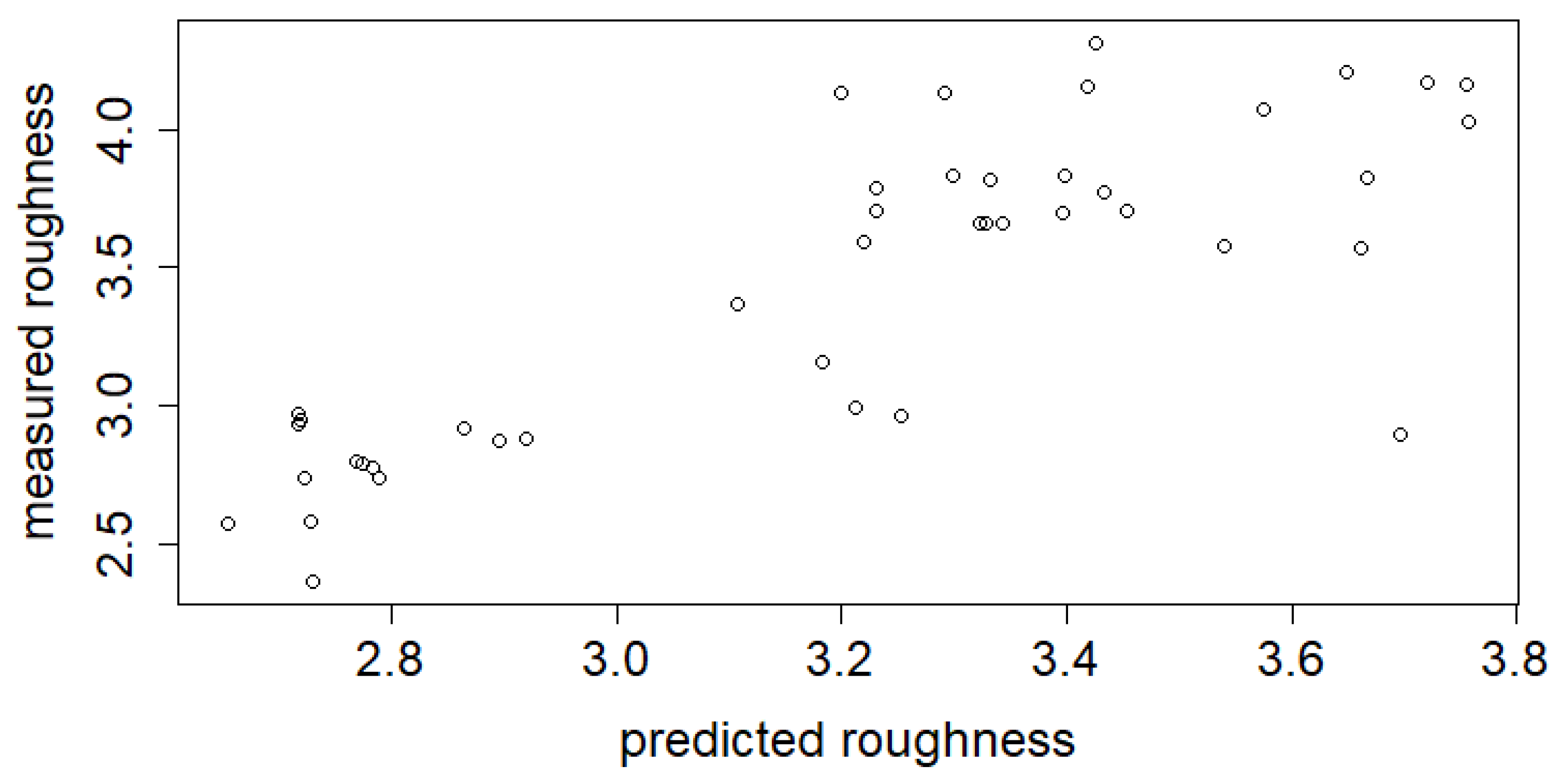
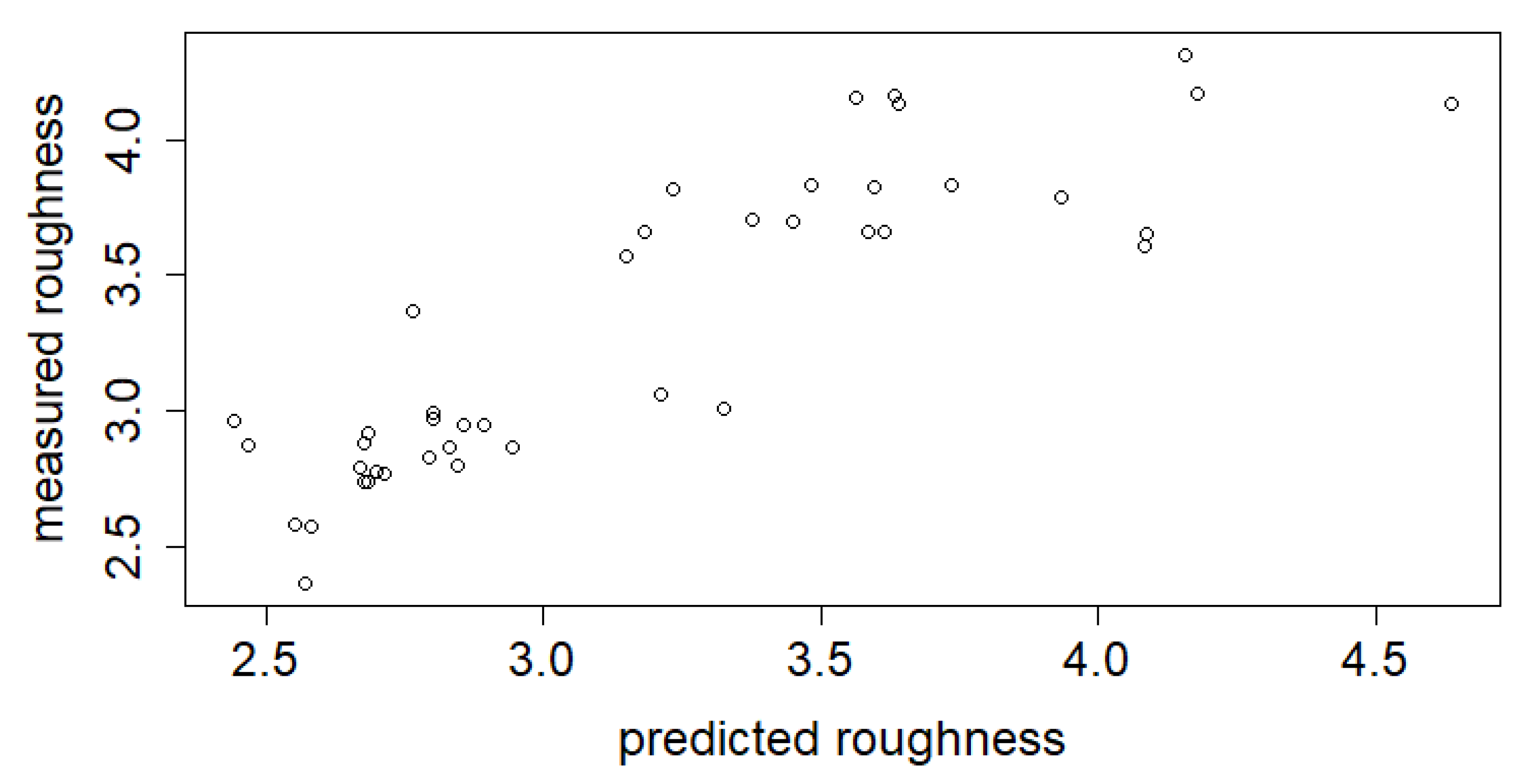
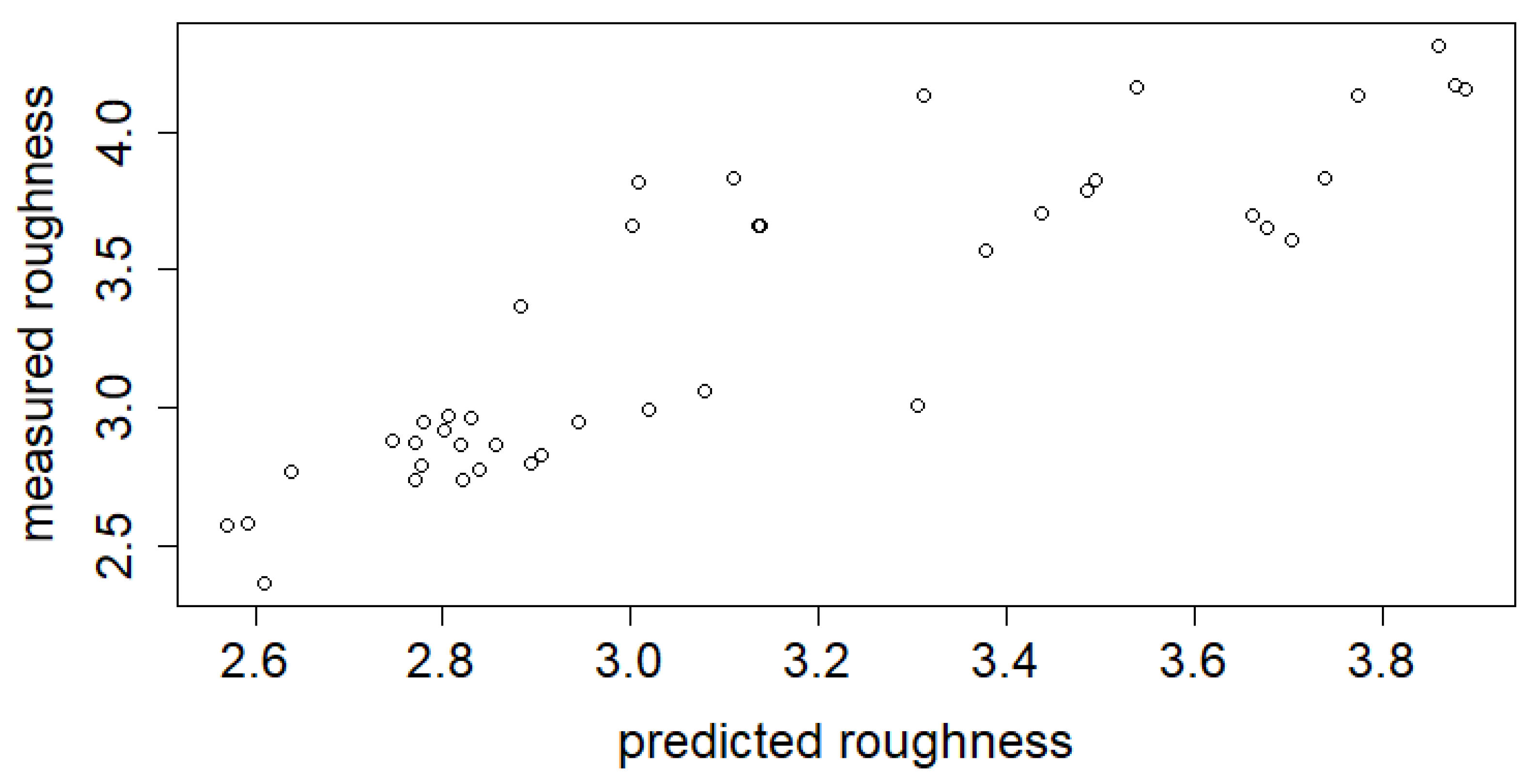
The performance and generalization based on the test set results of the GBM models are shown in
Table 1. The overall correlation between the target and estimated values of the test set was 0.87 for Model_HYBRID, 0.87 for Model_RAP, and 0.81 for Model_HOT, respectively. Scatter plots for predicted and actual values can be seen in
Figure 1,
Figure 2 and
Figure 3. The observations in Model_HOT are a bit more scattered than in Model_RAP and Model_HYBRID.
Figure 1 shows that Model_HOT cannot produce a predicted roughness greater than 3.8. In contrast, Model_RAP and Model_HYBRID perform better, as can be seen in
Figure 2 and
Figure 3. According to the root mean squared errors (RMSEs), the variables of the RAP line can actually explain the surface roughness better when compared to Model_HOT; the difference between RMSEs is 0.1. The difference between Model_RAP and Model_HYBRID is marginal. The later analysis will reveal some reasons for the weaker performance of Model_HOT.
7. Discussion and Conclusions
The need for decision support tools that are able to produce alarms for product failure risks and recommendations for preventive actions is critical for today’s manufacturing industries. This article presents a solution that utilizes machine learning prediction models and XAI methods for automated data quality monitoring and root cause analysis. Although a steel making process was selected to demonstrate the method, the concept is applicable in any manufacturing process where a product’s quality property is affected by the process variables.
7.1. Practical Aspects to Decision Support Development in Industry
The decision support tool development contained several steps from data collection and model development to model analytics and visualization based on the user’s needs. The lessons learned are generalizable to a wider audience regardless of the field. The following aspects were recognized while employing and using manufacturing data for quality improvement and decision support in industry.
Data collection. If possible, the data collection should be designed for decision support purposes. Data should contain a comprehensive set of products and production conditions with relevant parameters. In the presented application, the available data contained only a fraction of the actual repertory. In order to improve the generalizability of the model, an investment into collecting a larger data set could be made. This is advisable, especially if the model proves to be useful in product and production planning.
Surrogate model. It is possible to use model predictions as surrogates for actual measurement device. At Outokumpu, the absence of a surface roughness measurement device on site prevented the prediction of this quality property earlier. This article demonstrates that the surface roughness of the steel strip can be predicted with good accuracy, and the risk of a failure can be presented to the user already during the product planning phase, which enables the user to adjust the process parameters and minimize the risk of roughness. Even though the measurement campaign has ended, it is still possible to adjust the process based on the predicted quality and to improve the surface quality. Naturally, the model’s performance in real-time use cannot now be verified.
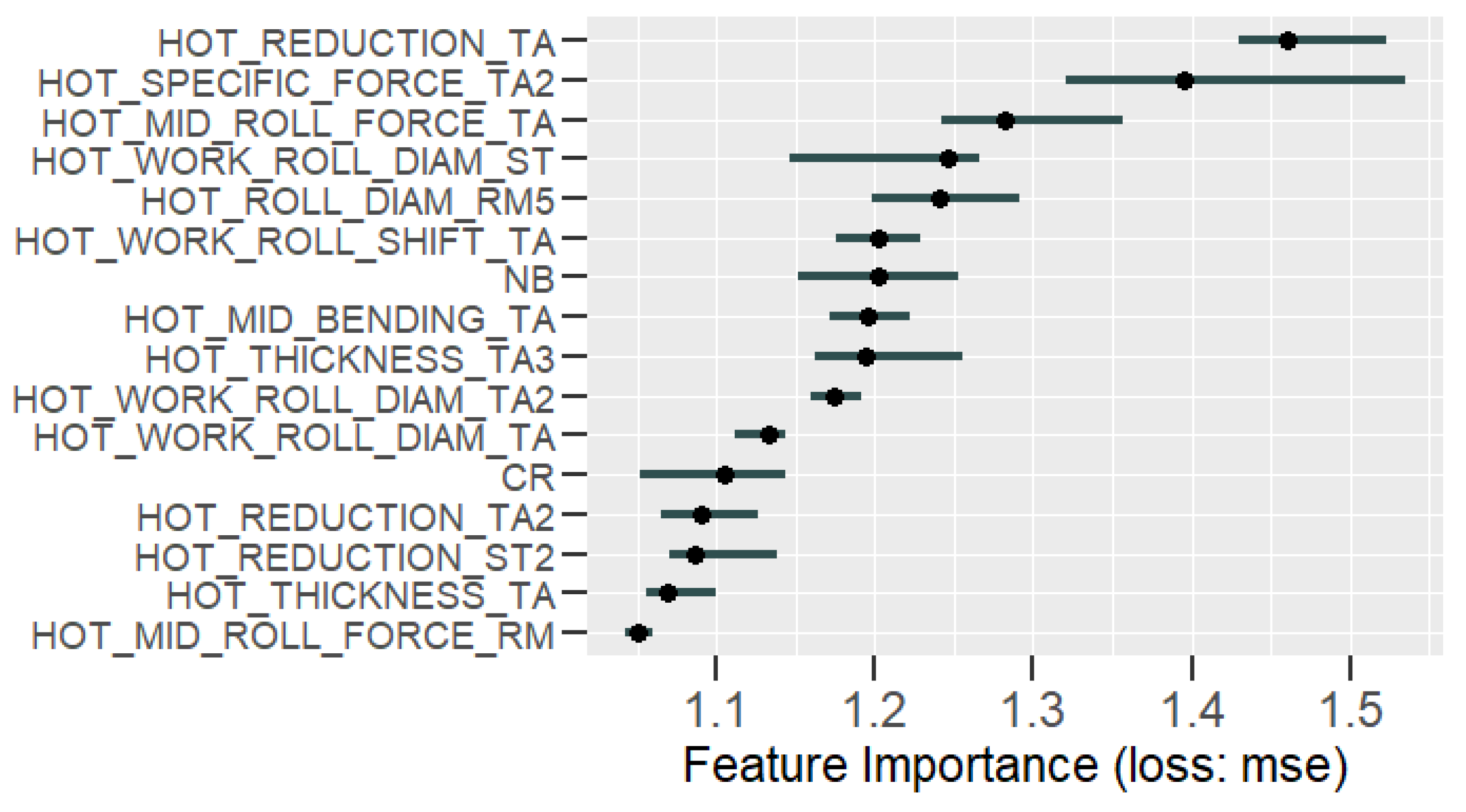
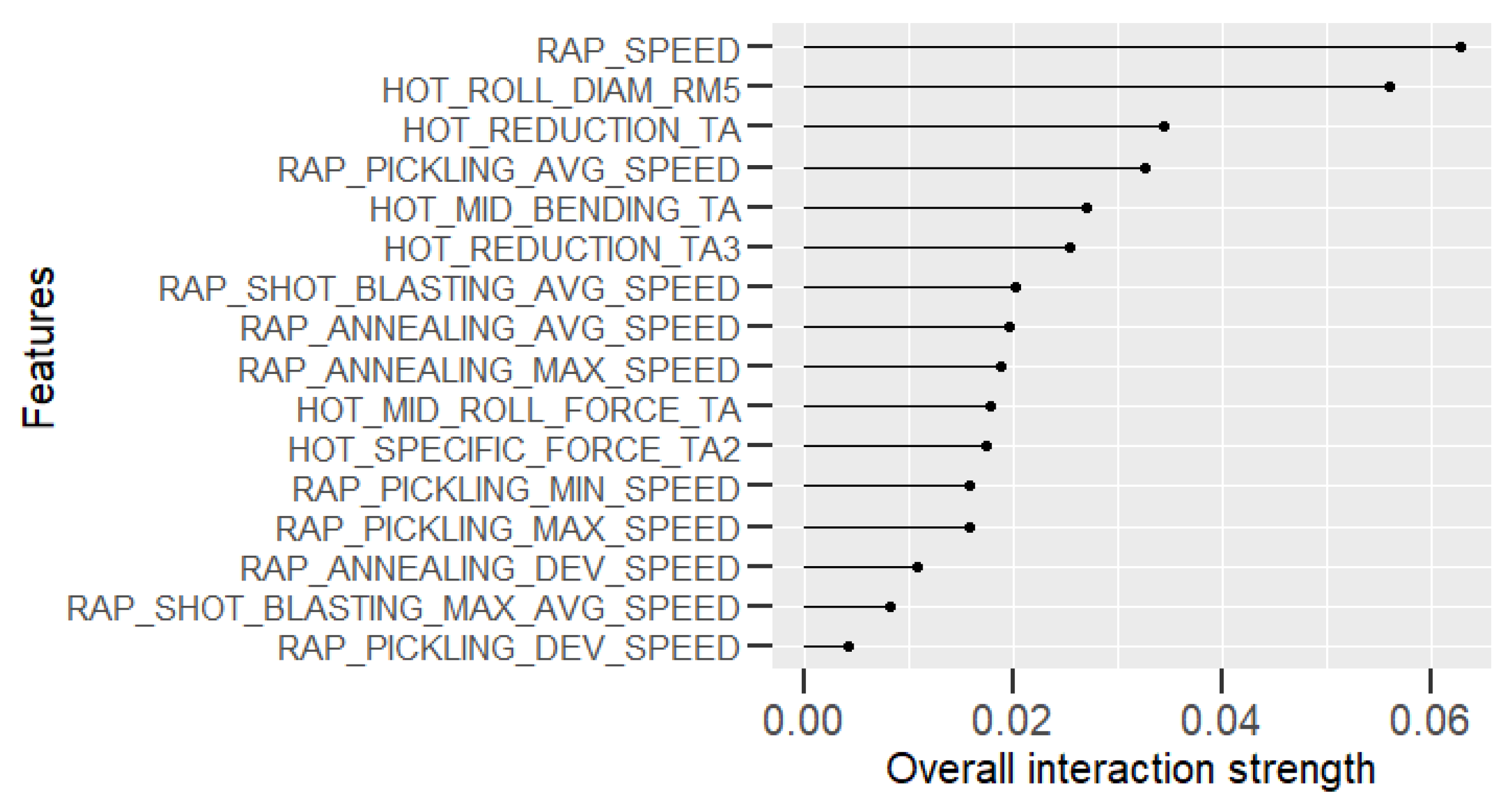
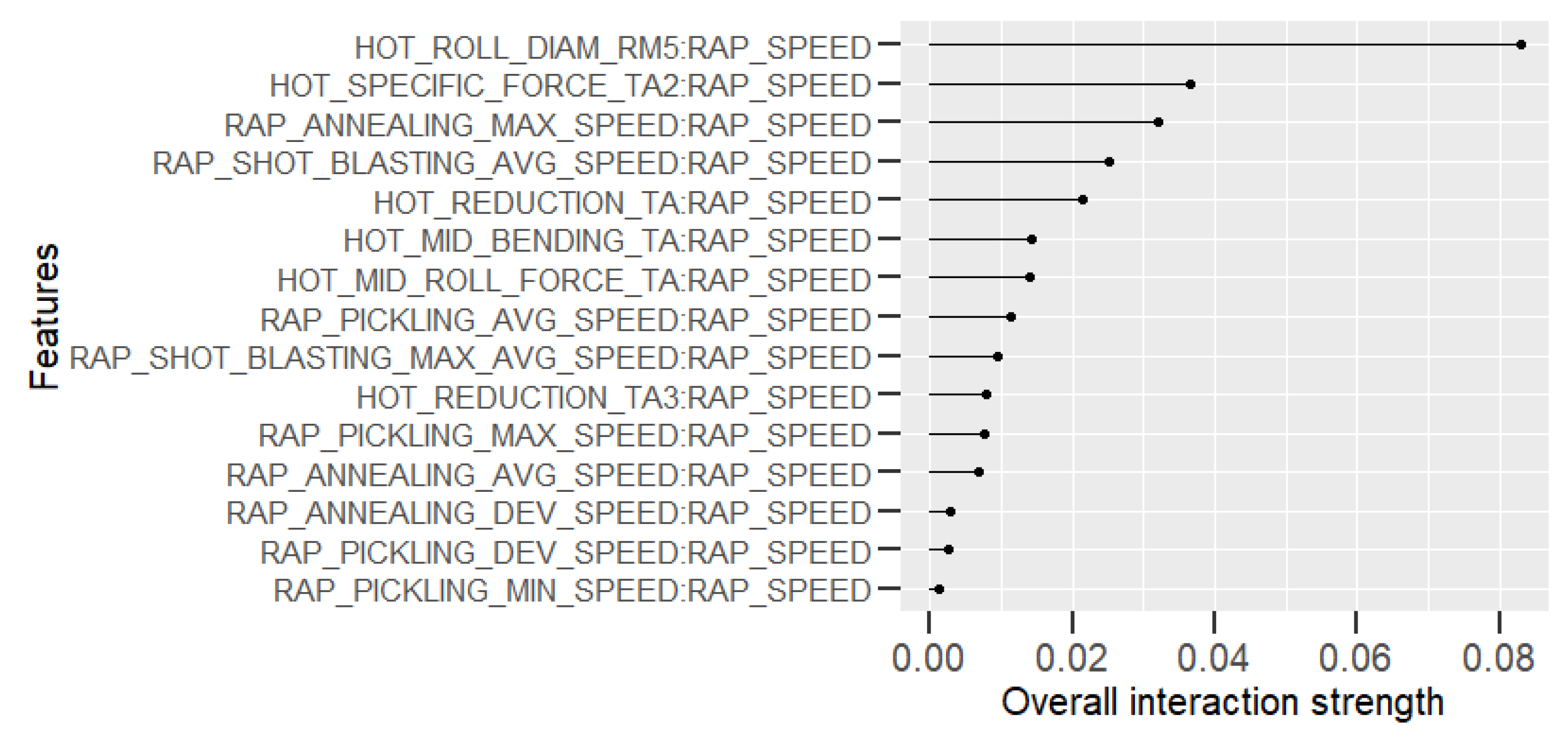
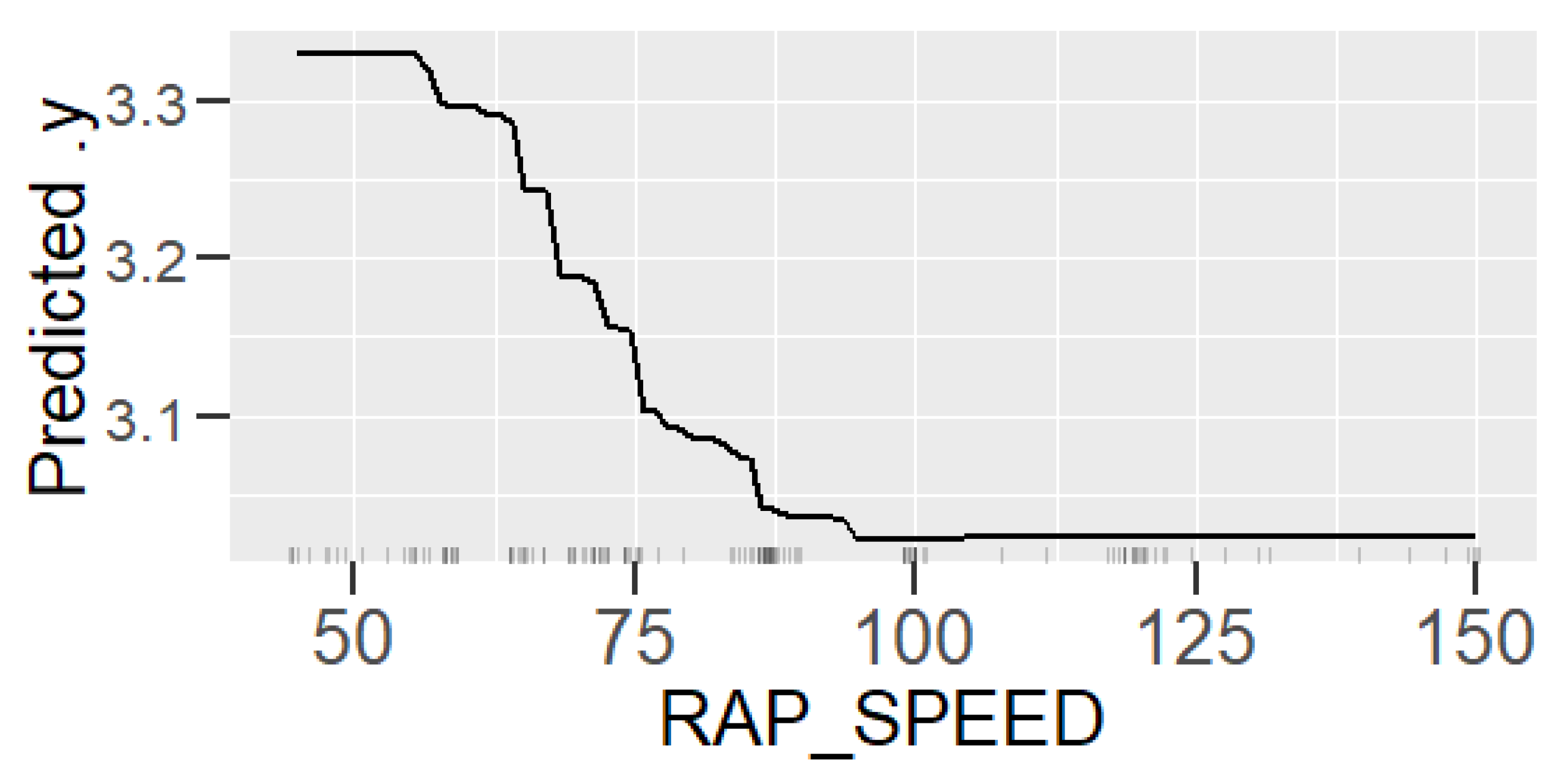
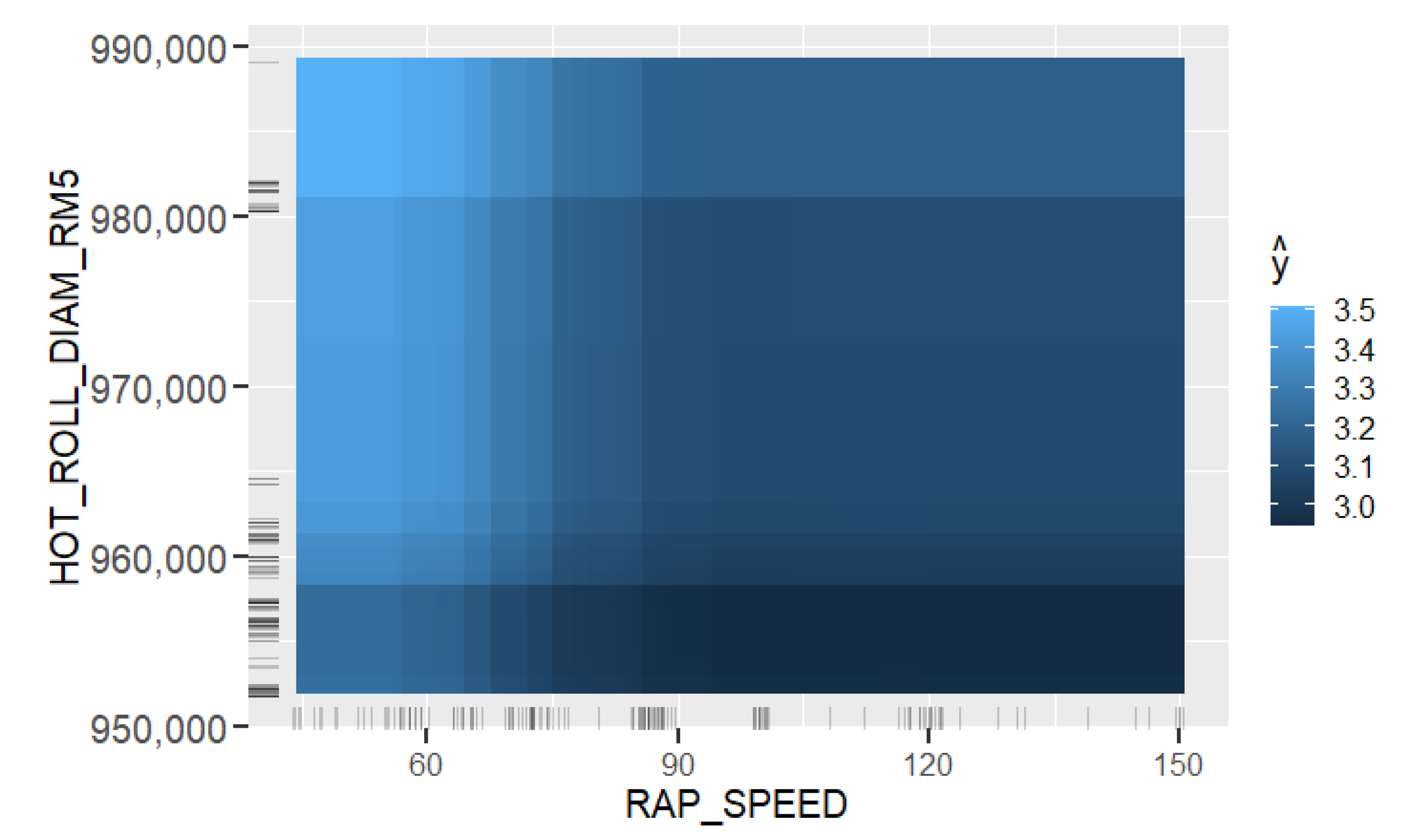
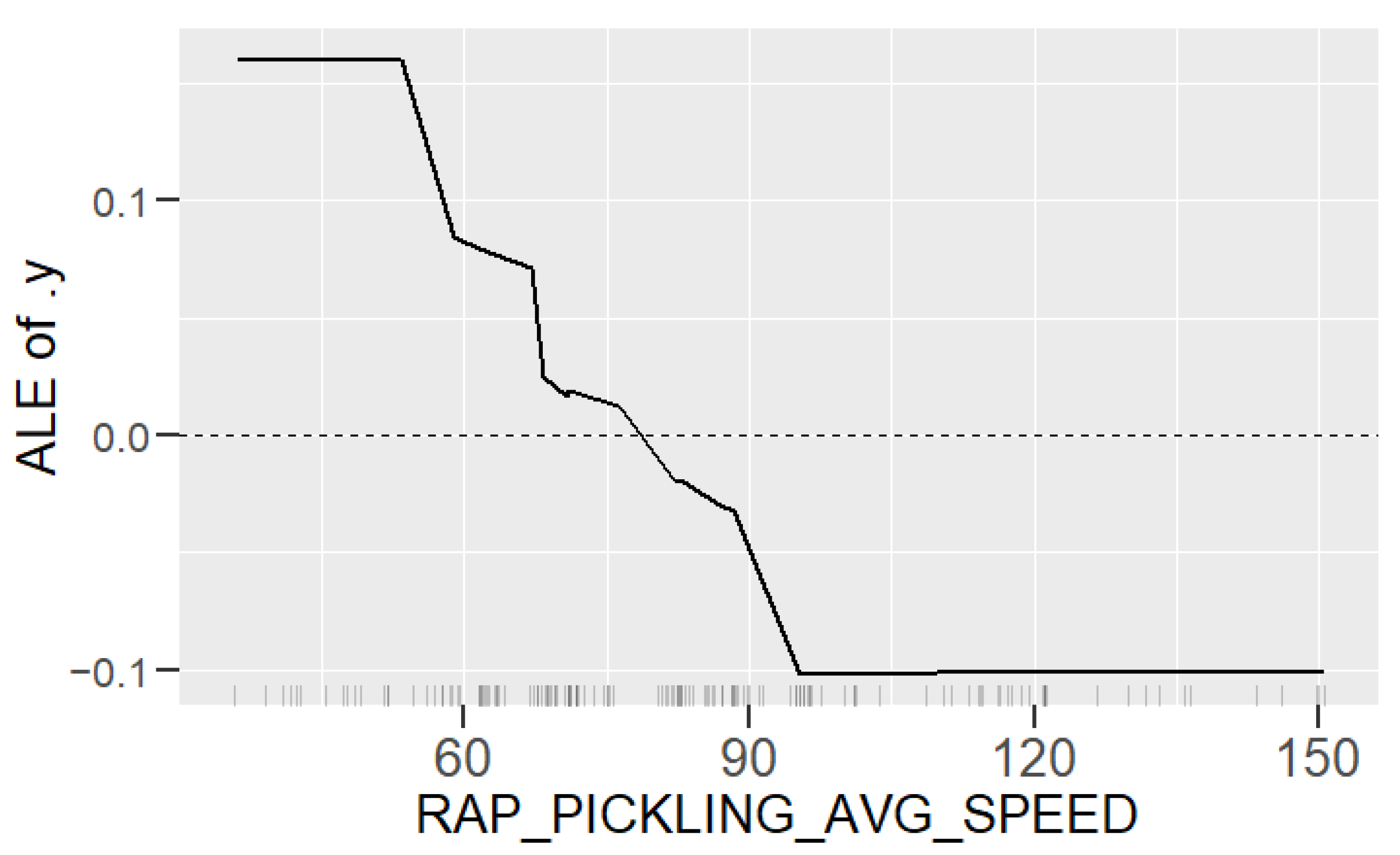
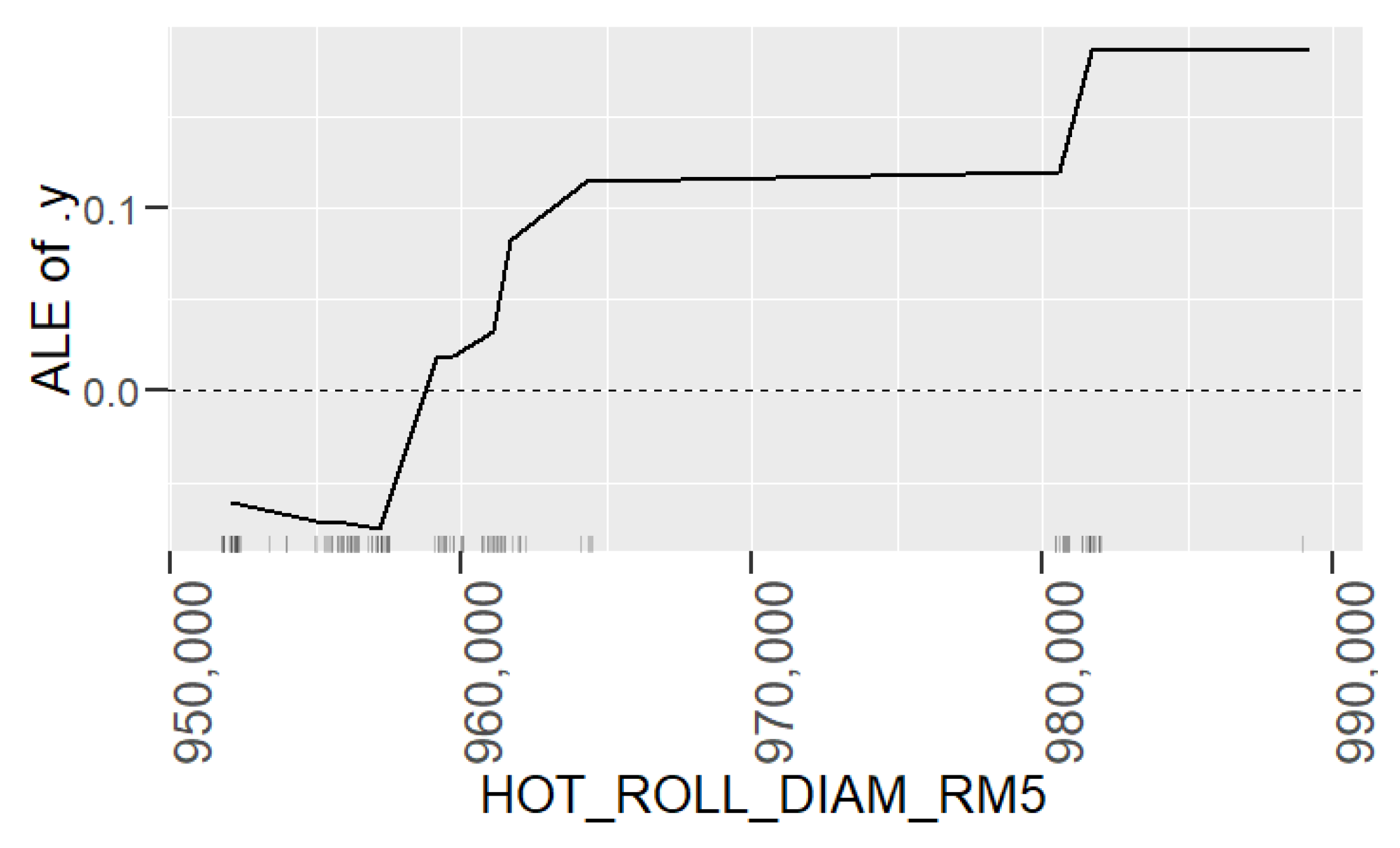
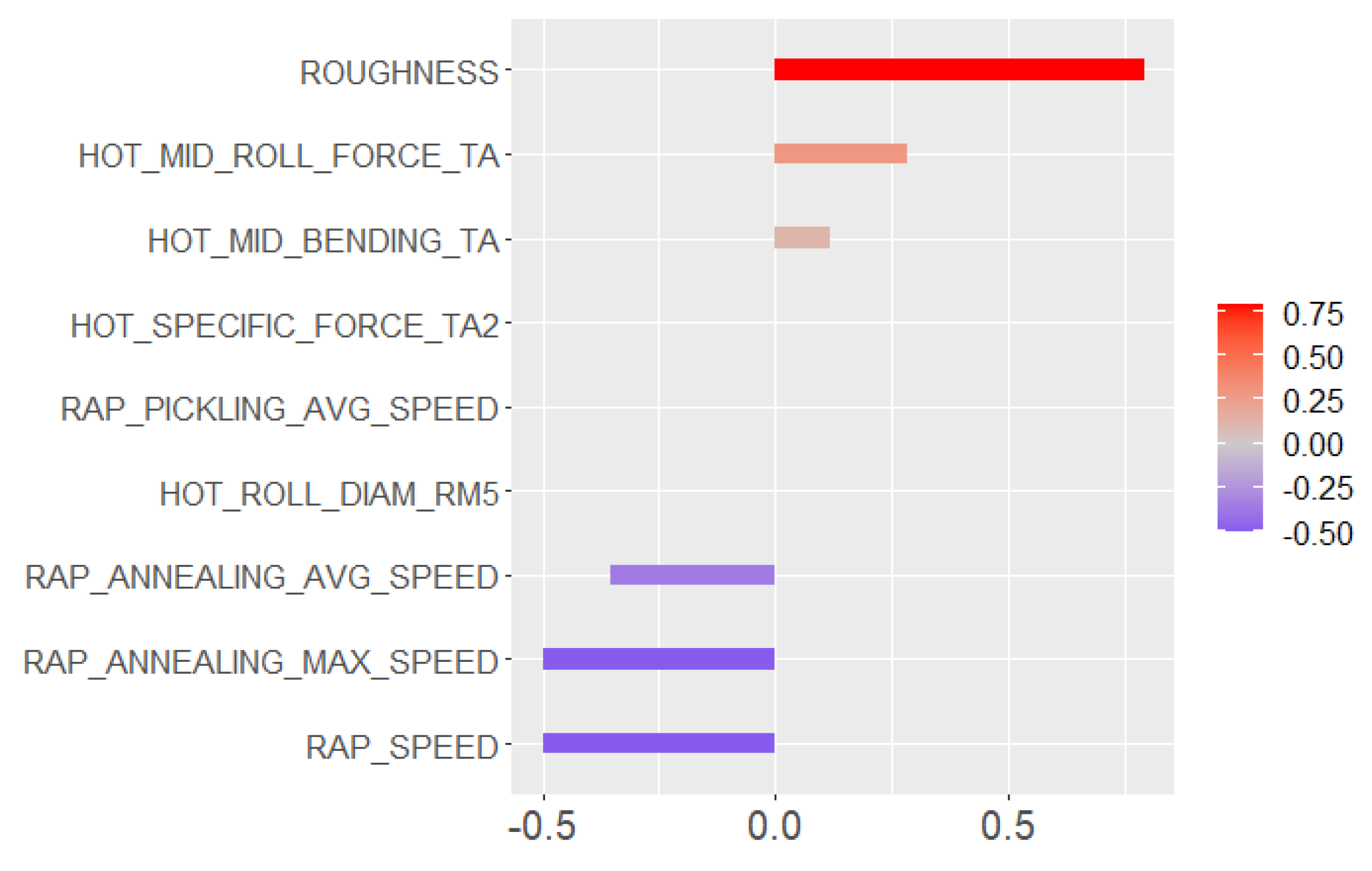
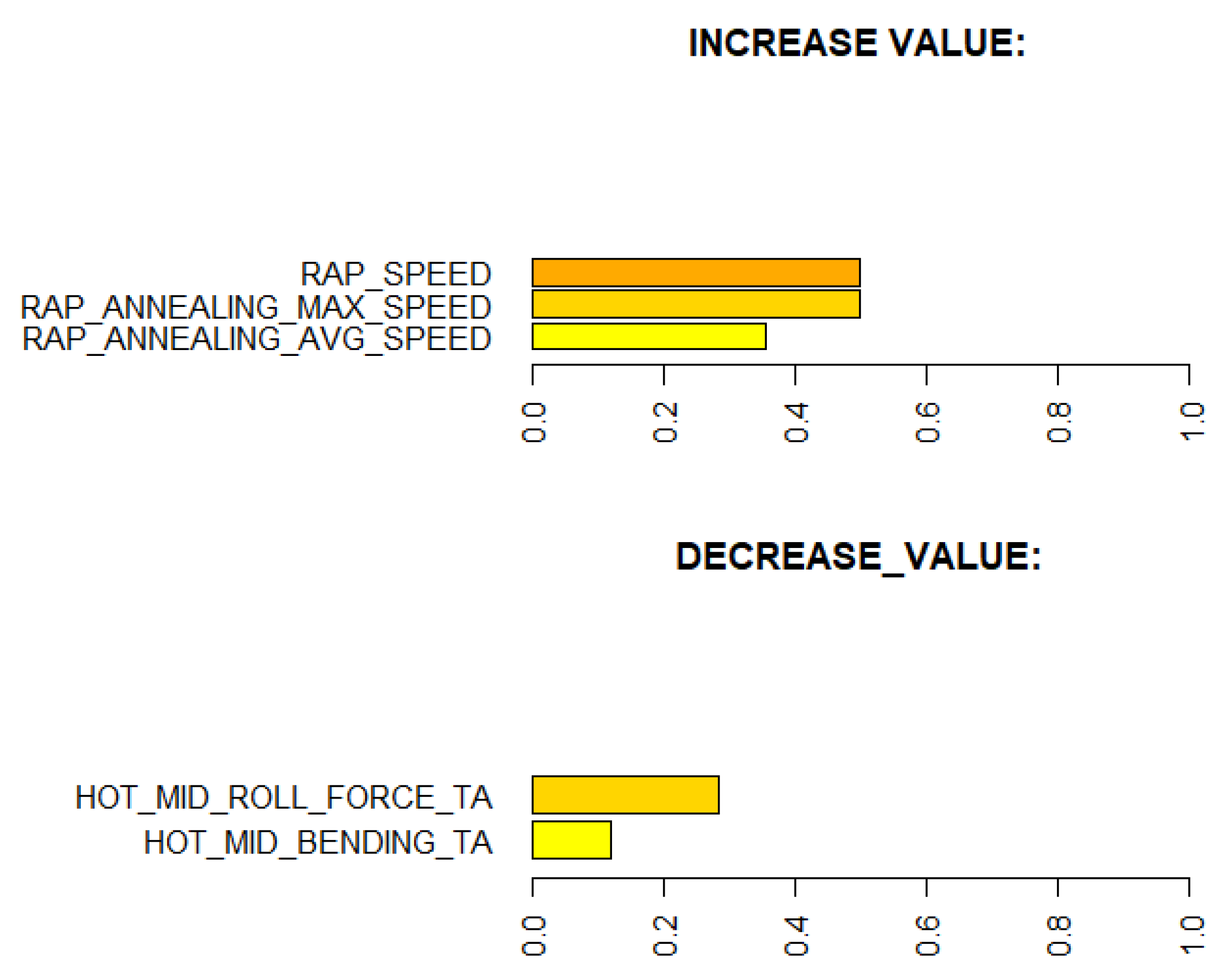
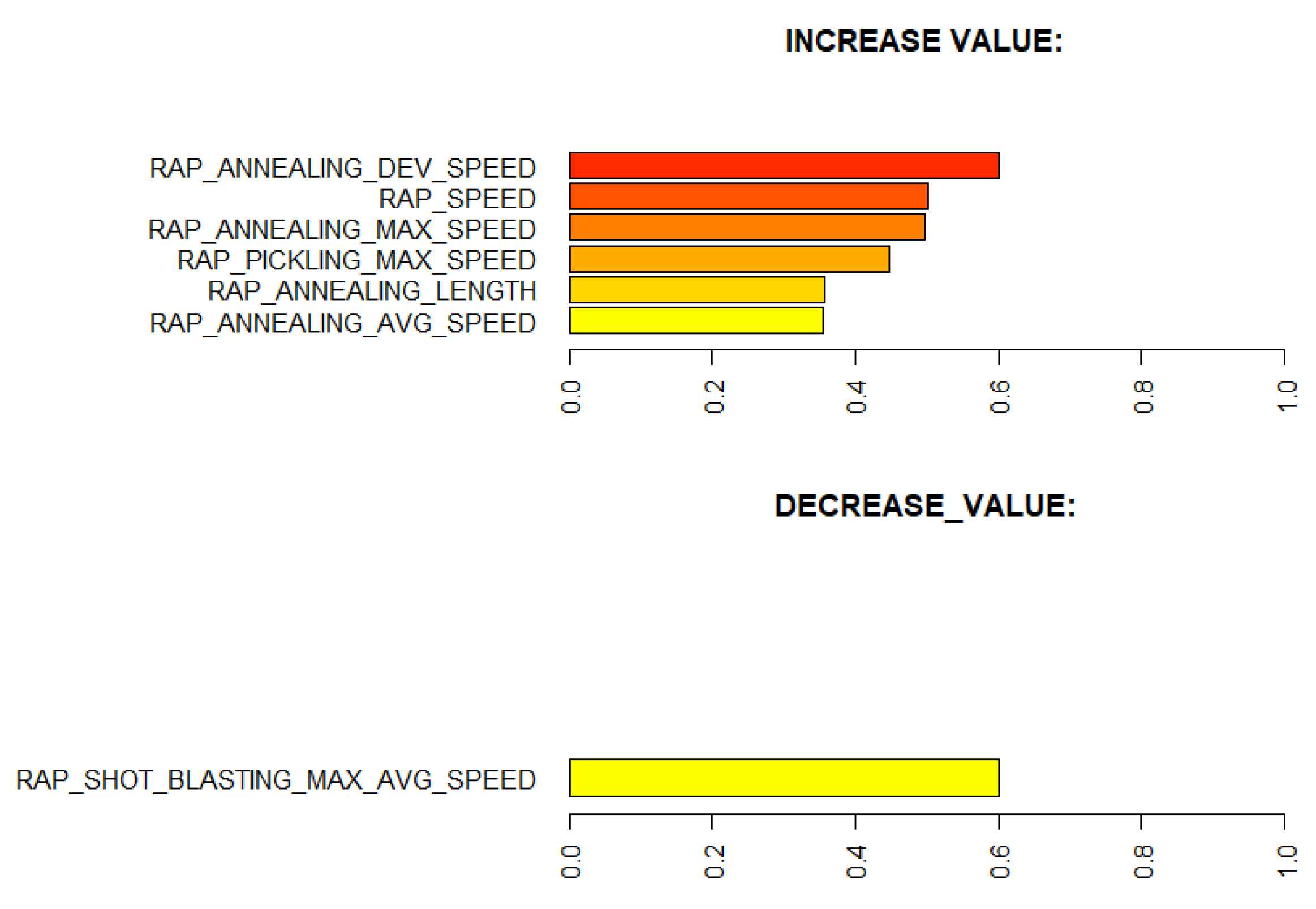
Learning the process. With prediction models, it is possible to obtain an insight into production and better understand the relationships between process parameters and the predicted property. In this case, the analysis of the roughness prediction models uncovered the parameters of the RAP-line that have the highest impact on the surface roughness. Additionally, the hypothesis for the high importance of the hot rolling process parameters on roughness formation was disproved. The hybrid model and RAP model outperformed the HOT model. Actually, the parameters in hot rolling reflected especially the mechanical properties of the product and inherently the probable surface quality. The difference in roughness appeared mainly because of the varying RAP line parameters when comparing products with similar mechanical properties. By studying the visualizations of the model’s performance, the user may learn more about the process and how the parameter settings affect the quality and how they relate to each other.
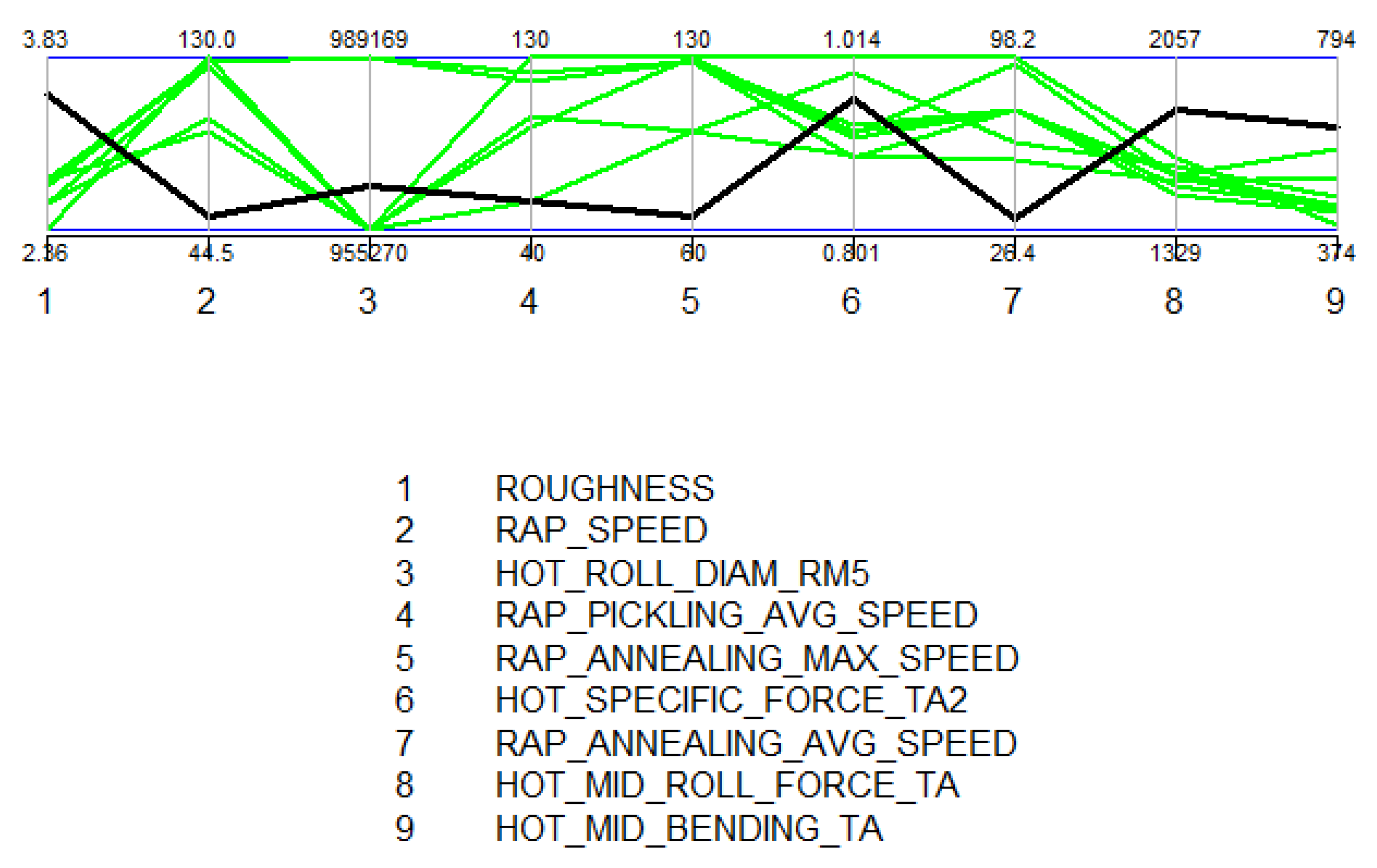
Creating new knowledge. It is important to understand the reasoning behind the predictions. This way, the user can verify the applicability of the results and evaluate the performance for individual observations. The interpretability of the models was improved with XAI methods (PDP, ALE, SHAP, parallel coordinates and its modifications) that highlight the significance of the process parameters in roughness formation individually for each observed product. The average performance of the model can be quite different for individual products as the chemical composition and mechanical properties determine how each product type responds to the process settings during the manufacturing. Thus, it is important to find out the rootncauses behind a high predicted risk of failure.
Role of domain knowledge. It is important to emphasize that the methods presented in this article cannot replace the domain knowledge; the final decision is still made by the human experts, and the strength of the proposed tool is in its capability to process large amounts of data and highlight the information in it. It is not always possible to adjust the harmful parameter to a more favorable direction, because of the product property requirements or the overall optimization of the process; the settings that guarantee high surface quality may not guarantee other quality properties that the product has. In addition, some of the parameters describe the status of the machines; the wearing of the rolls, for example. Then, the re-scheduling of the production is the only way to optimize the parameters and to find the best process conditions for the most demanding products.
Role of the user. In order to gain a large group of potential users, the tool should contain different types visualizations for different user’s needs. In a steel plant, the users of the decision support tools may have different needs based on their duties. In product design and process planning, the process engineers may want to test different settings and thus learn about the whole process, while the process operators have a different objective with a very short reaction time. In this case, the detailed visualizations of variable impacts and dependencies can be observed with time, while the simple presentation of possible actions for quality improvement works, when selecting the correct process settings for a product rapidly.
Uncertainty of models. When in actual use, if data are not complete, the user should be informed about the uncertainty of prediction when the system is extrapolating. The other possibility would be to restrict the usage of the tool to known products only. In the case of this study, the data were not collected for research purposes and were not very representative. The models could easily be improved by systematically collecting data from production.
7.2. Future Work
In this research, the practical usability was the main motivation when selecting the models and techniques. All developed tools can be integrated into an existing quality monitoring tool that has connections to process databases and the capability of running R scripts and producing the required predictions, visualizations, and decision support. This way, the potential users in the steel plant can obtain access to the tool with a web-based user interface.
After implementation, the tool can be tested by users in different roles. The need for a new measurement campaign was recognized and the data collection can be designed based on the test results. The test phase may reveal a need for systematic data collection from different product types or production periods. The model accuracy can be improved by increasing the amount of training data, and also the generalization capability of models can be verified better. In addition, the need for personnel training can be recognized with the analysis of the results. The motivation to use the tool is directly dependent on its usability and benefits.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}