
Time-Domain Sound Field Reproduction with Pressure and Particle Velocity Jointly Controlled


Abstract
:1. Introduction
2. Review: Frequency-Domain Velocity-Assisted Sound Field Reproduction
3. Proposed: Time-Domain Sound Field Reproduction with Joint Control of Sound Pressure and Particle Velocity
3.1. System Formulation
3.2. EVD-Based Approach with Conjugate Gradient Algorithm
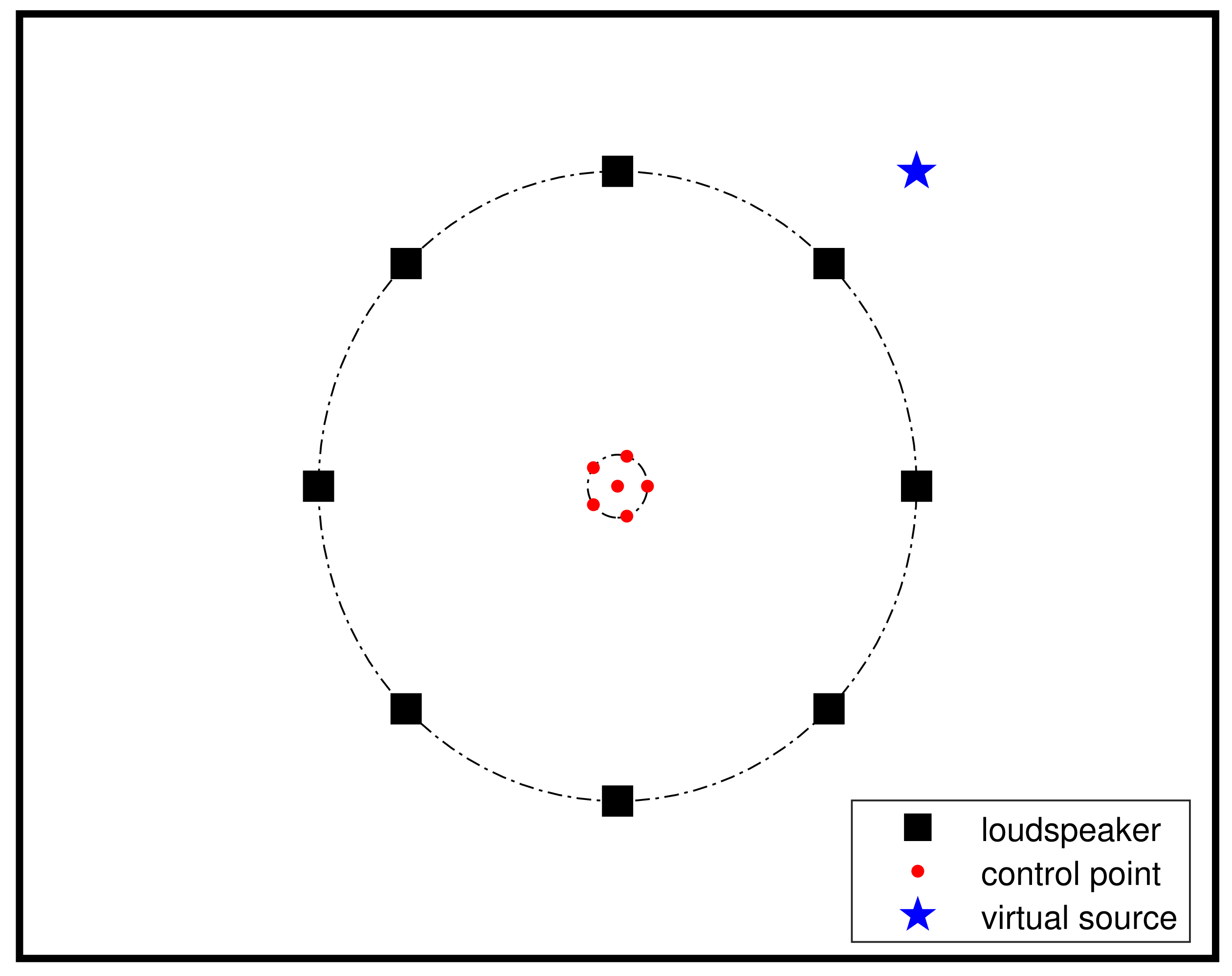
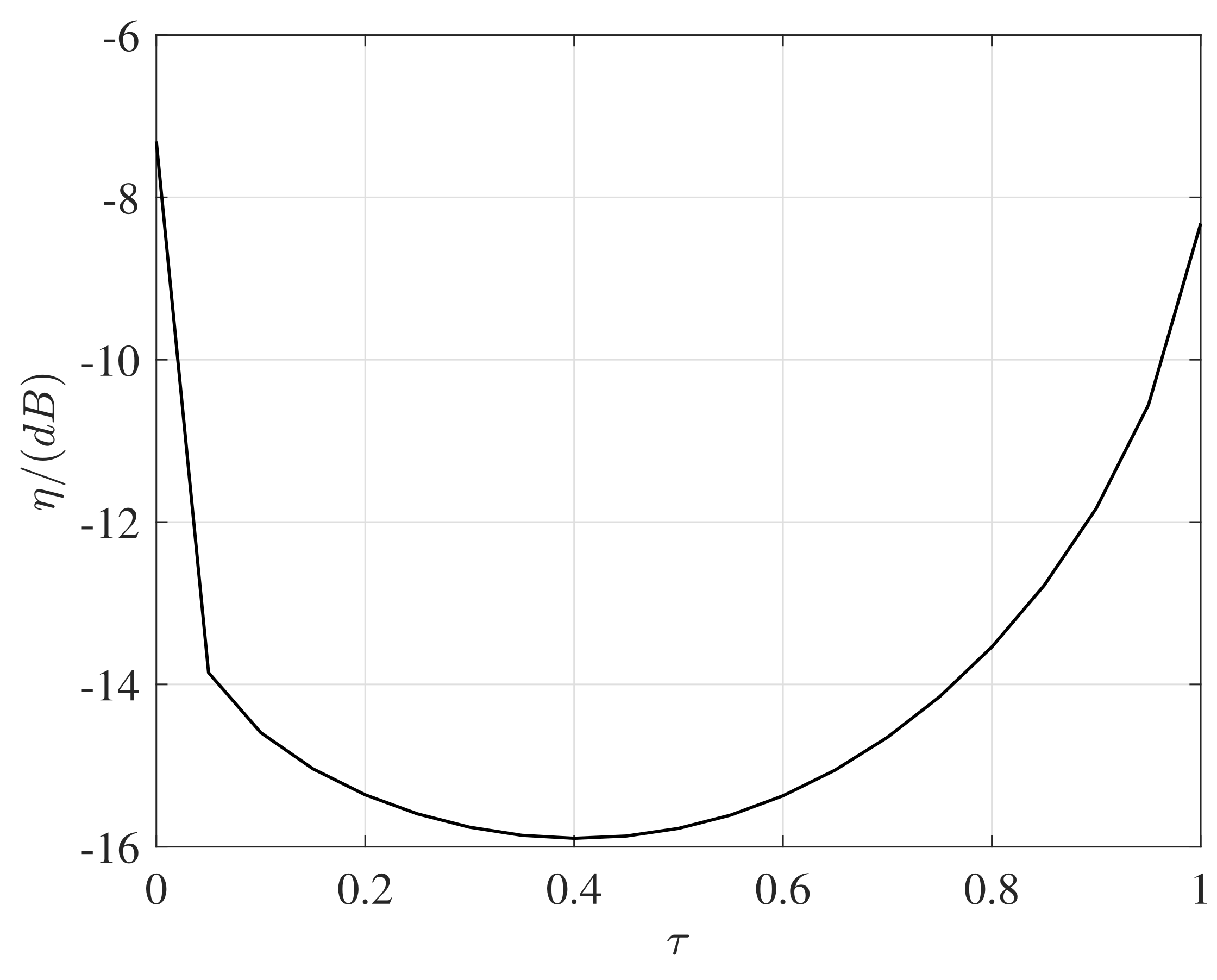
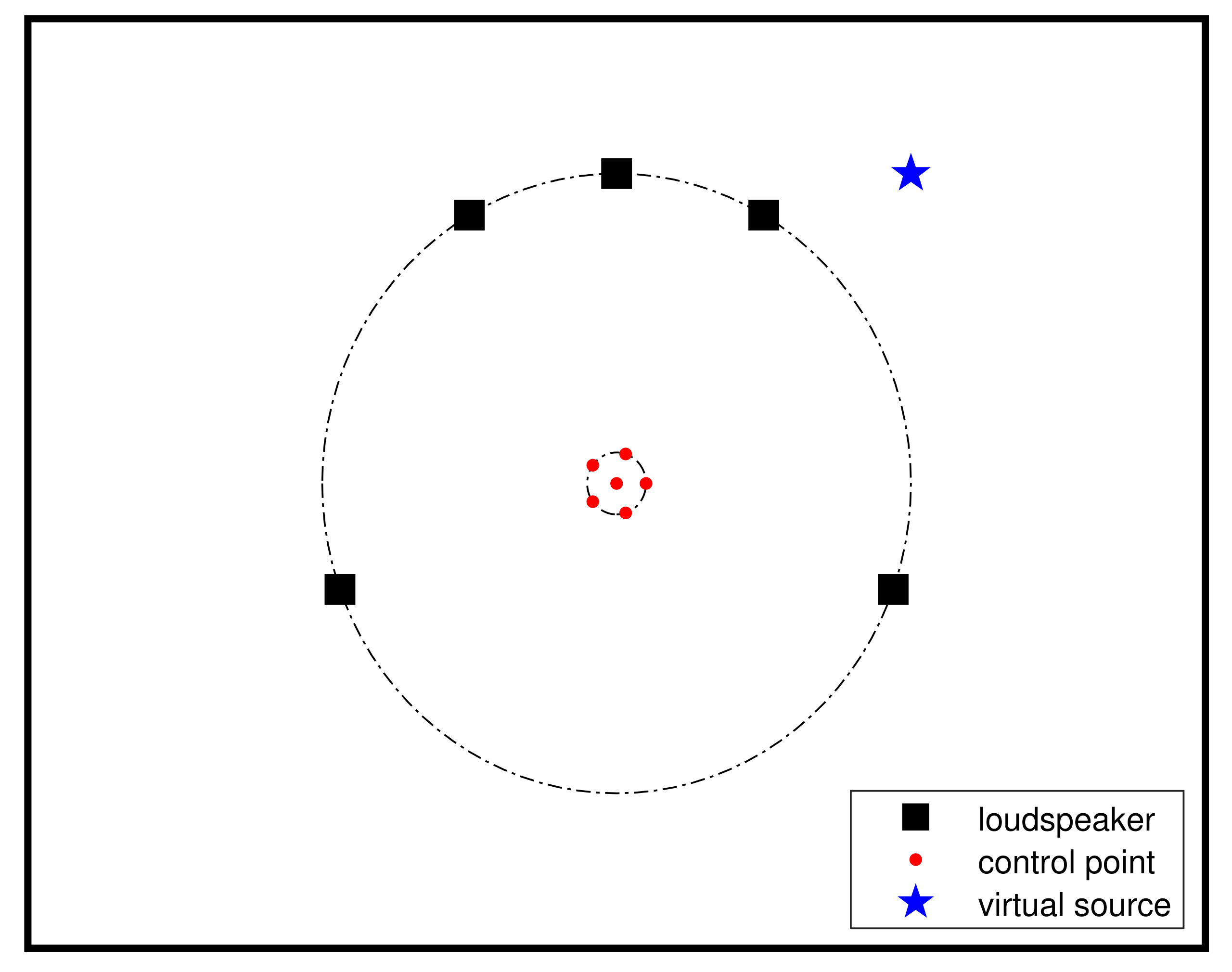
4. Simulation
4.1. Performance Evaluation Metrics
- The normalized mean squared error (NMSE) of reproduced sound intensity, which is defined aswith the sound intensity vector calculated as follows [23]:Here, and denote the reproduced and desired sound intensity at the point , respectively. The results over N time samples and M points are averaged in Equation (20).Specially, the intensity reproduction NMSE along c () axis is investigated separately, that is,Note that as proved in psycho-acoustic experiments, the sound intensity measure is closely linked with human perception of sound locations [24].
- The NMSE of the reproduced sound pressure, which defined aswhere and denote the reproduced and desired sound pressure at the point , respectively. This measure is commonly used for evaluating the accuracy of sound field reproduction systems.
4.2. Regular Loudspeaker Array
4.3. Irregular Loudspeaker Array
4.4. Computation Complexity Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, W.; Parasanga, N.S.; Chen, H.; Abhayapala, T.D. Surround by sound: A review of spatial audio recording and reproduction. Appl. Sci. 2017, 7, 532. [Google Scholar] [CrossRef]
- Berkhout, A.J. A holographic approach to acoustic control. J. Audio Eng. Soc. 1988, 36, 977–995. [Google Scholar]
- Berkhout, A.J.; de Vries, D.; Vogel, P. Acoustic control by wave field synthesis. J. Acoust. Soc. Am. 1993, 93, 2764–2778. [Google Scholar] [CrossRef]
- Spors, S.; Rabenstein, R. Spatial aliasing aritifacts produced by linear and circular loudspeaker arrays used for wave field synthesis. In Proceedings of the 120th Audio Engineering Society Convention, Paris, France, 20–23 May 2006. [Google Scholar]
- Gerzon, M.A. Periphony: With-height sound reproduction. J. Audio Eng. Soc. 1973, 21, 2–10. [Google Scholar]
- Gerzon, M.A. Ambisonics in multichannel broadcasting video. J. Audio Eng. Soc. 1985, 33, 859–871. [Google Scholar]
- Poletti, M.A. Three-dimensional surround sound systems based on spherical harmonics. J. Audio Eng. Soc. 2005, 53, 1004–1025. [Google Scholar]
- Daniel, J. Spatial sound encoding including near field effect: Introducing distance coding filters and a viable, new ambisonic format. In Proceedings of the 23rd AES International Conference: Signal Processing in Audio Recording and Reproduction, Copenhagen, Denmark, 23–25 May 2003. [Google Scholar]
- Ahrens, J.; Spors, S. Applying the ambisonics approach to planar and linear distributions of secondary sources and combinations thereof. Acta Acust. United Acust. 2012, 98, 28–36. [Google Scholar] [CrossRef] [Green Version]
- Ward, D.B.; Abhayapala, T.D. Reproduction of a plane-wave sound field using an array of loudspeakers. IEEE Trans. Speech Audio Process. 2001, 9, 697–707. [Google Scholar] [CrossRef] [Green Version]
- Kirkeby, O.; Nelson, P.A. Reproduction of plane wave sound fields. J. Acoust. Soc. Am. 1993, 94, 2992–3000. [Google Scholar] [CrossRef]
- Koyama, S.; Chardon, G.; Daudet, L. Optimizing source and sensor placement for sound field control: An Overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 696–714. [Google Scholar] [CrossRef] [Green Version]
- Bianco, F.; Teti, L.; Licitra, G.; Cerchiai, M. Loudspeaker FEM modelling: Characterisation of critical aspects in acoustic impedance measure through electrical impedance. Appl. Acoust. 2017, 124, 20–29. [Google Scholar] [CrossRef]
- Shin, M.; Nelson, P.A.; Fazi, F.M.; Seo, J. Velocity controlled sound field reproduction by non-uniformly spaced loudspeakers. J. Sound Vib. 2016, 370, 444–464. [Google Scholar] [CrossRef] [Green Version]
- Zuo, H.; Abhayapala, T.D.; Samarasinghe, P.N. Particle velocity assisted three dimensional sound field reproduction using a modal-domain approach. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2119–2133. [Google Scholar] [CrossRef]
- Buerger, M.; Hofmann, C.; Kellermann, W. Broadband multizone sound rendering by jointly optimizing the sound pressure and particle velocity. J. Acoust. Soc. Am. 2018, 143, 1477–1490. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zuo, H.; Abhayapala, T.D.; Samarasinghe, P.N. Intensity based spatial soundfield reproduction using an irregular loudspeaker array. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1356–1369. [Google Scholar] [CrossRef]
- Zuo, H.; Abhayapala, T.D.; Samarasinghe, P.N. 3D multizone soundfield reproduction in a reverberant room using intensity matching method. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Feng, Q.; Yang, F.; Yang, J. Time-domain sound field reproduction using the group Lasso. J. Acoust. Soc. Am. 2018, 143, EL55–EL60. [Google Scholar] [CrossRef] [PubMed]
- Molés-Cases, V.; Piñero, G.; de-Diego, M.; Gonzale, A. Personal sound zones by subband filtering and time domain optimization. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2684–2696. [Google Scholar] [CrossRef]
- Lee, T.; Shi, L.M.; Nielsen, J.K.; Christensen, M.D. Fast generation of sound zones using variable span trade-off filters in the DFT-domain. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 363–378. [Google Scholar] [CrossRef]
- Shi, L.M.; Lee, T.; Zhang, L.; Nielsen, J.K.; Christensen, M.D. Generation of personal sound zones with physical meaningful constraints and conjugate gradient method. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 823–837. [Google Scholar] [CrossRef]
- Williams, E.G. Fourier Acoustics: Sound Radiation and Nearfield Acoustical Holography; Academic Press: London, UK, 1999. [Google Scholar]
- Gerzon, M.A. General metatheory of auditory localisation. In Proceedings of the 92nd Convention of the Audio Engineering Society, Vienna, Austria, 24–27 March 1992. [Google Scholar]
- Habets, E.A.P. Room Impulse Response Generator. 2010. Available online: http://home.tiscali.nl/ehabets/rir_generator.html (accessed on 20 September 2010).
- Allen, J.B.; Berkley, D.A. Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| INITIALIZATION: |
|---|
| 1. Calculate the spatial autocorrelation matrix and the spatial cross-correlation vector using (16) and (17) |
| 2. Set the initial value of the filter , the initial search direction vector , and the initial residual error |
| 3. Set the number of iterations I |
| LOOP: for |
| 1. Determine the step of the ith iteration according to |
| 2. Update the estimates of the control filter and the residual error |
| 3. Calculate the factor that satisfies the conjugation condition, that is, |
| 4. Calculate the th search direction vector |
| Uncontrolled Point No. | x (m) | y (m) | z (m) |
|---|---|---|---|
| 1 | 4.0492 | 3.0087 | 2.0000 |
| 2 | 4.0070 | 3.0495 | 2.0000 |
| 3 | 3.9551 | 3.0219 | 2.0000 |
| 4 | 3.9653 | 2.9640 | 2.0000 |
| 5 | 4.0235 | 2.9559 | 2.0000 |
| 6 | 4.0693 | 3.0400 | 2.0000 |
| 7 | 3.9834 | 3.0783 | 2.0000 |
| 8 | 3.9204 | 3.0084 | 2.0000 |
| 9 | 3.9675 | 2.9269 | 2.0000 |
| 10 | 4.0595 | 2.9465 | 2.0000 |
| 11 | 4.0376 | 3.1034 | 2.0000 |
| 12 | 3.9133 | 3.0677 | 2.0000 |
| 13 | 3.9088 | 2.9385 | 2.0000 |
| 14 | 4.0303 | 2.8943 | 2.0000 |
| 15 | 4.1099 | 2.9962 | 2.0000 |
| 16 | 4.0900 | 3.1072 | 2.0000 |
| 17 | 3.9258 | 3.1187 | 2.0000 |
| 18 | 3.8642 | 2.9661 | 2.0000 |
| 19 | 3.9902 | 2.8603 | 2.0000 |
| 20 | 4.1298 | 2.9476 | 2.0000 |
| Method | Inverse | I = 100 | I = 200 | I = 400 | I = 800 |
|---|---|---|---|---|---|
| Time(s) | 203.97 | 25.53 | 29.90 | 39.02 | 70.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Wang, J.; Zhang, W.; Zhang, L. Time-Domain Sound Field Reproduction with Pressure and Particle Velocity Jointly Controlled. Appl. Sci. 2021, 11, 10880. https://doi.org/10.3390/app112210880
Hu X, Wang J, Zhang W, Zhang L. Time-Domain Sound Field Reproduction with Pressure and Particle Velocity Jointly Controlled. Applied Sciences. 2021; 11(22):10880. https://doi.org/10.3390/app112210880
Chicago/Turabian StyleHu, Xuanqi, Jiale Wang, Wen Zhang, and Lijun Zhang. 2021. "Time-Domain Sound Field Reproduction with Pressure and Particle Velocity Jointly Controlled" Applied Sciences 11, no. 22: 10880. https://doi.org/10.3390/app112210880
APA StyleHu, X., Wang, J., Zhang, W., & Zhang, L. (2021). Time-Domain Sound Field Reproduction with Pressure and Particle Velocity Jointly Controlled. Applied Sciences, 11(22), 10880. https://doi.org/10.3390/app112210880